






Model Globally, Match Locally
参考资料
1、论文
Model Globally, Match Locally: Efficient and Robust 3D Object Recognition.
算法原理介绍
1.voxel体素滤波精简
2.所有点循环每个点建立4维度的特征集合(训练与场景一起)
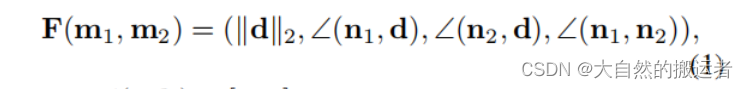
给定指定距离步长,角度步长建立hashmap 其中hashmap的键由四个数据组成 (组成算法没有在源码看懂)猜测是每一个维度因为取整的因素其总数量都固定,那么总数量就固定了,加入点(2,2,2,2) 键为:2*(后三个总和)+2*(后两个总和)+2*(后一个总和)+2
3.因此场景点云来了以后相同的体素后去hashmap查找相同的值,找到匹配点对以后进入下一步
4.根据匹配模板点计算一个点的法向量与(1,0,0)之间差的角度并求出旋转轴组成旋转矩阵,场景点做同同的处理,并保留两者的角度信息 就会得到(mr,a) mr为找到的模板和算出来的角度。
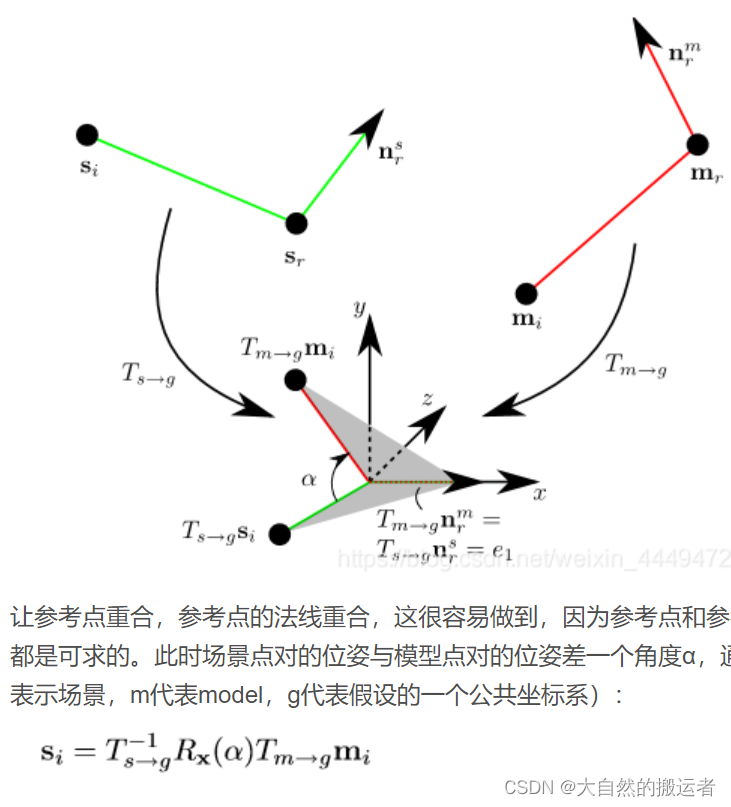 对于根据上述描述:一个场景参考点sr,他有大量的点对srsi(i∈scene cloud),对所有的srsi求PPF,由此找到哈希表对应的mr’mi’,同时得到一个α’。那么,我们就在建立的二维矩阵上,投一个票。
对于根据上述描述:一个场景参考点sr,他有大量的点对srsi(i∈scene cloud),对所有的srsi求PPF,由此找到哈希表对应的mr’mi’,同时得到一个α’。那么,我们就在建立的二维矩阵上,投一个票。
我们对这一个场景参考点sr的所有点对srsi都进行这个操作,最后就得到了一个投票表。(注意:这个投票表示针对这个特定的参考点sr的 (二维矩阵投票表)),表一定有一个峰值,这个峰值对应的mr’’,α‘’便是这个场景参考点sr的最佳局部坐标系,由mr’’,α‘’算出的来的位姿,视为最理想位姿(假设这个场景参考点sr一开始就在场景目标中,而不是在场景中其他的物体上)
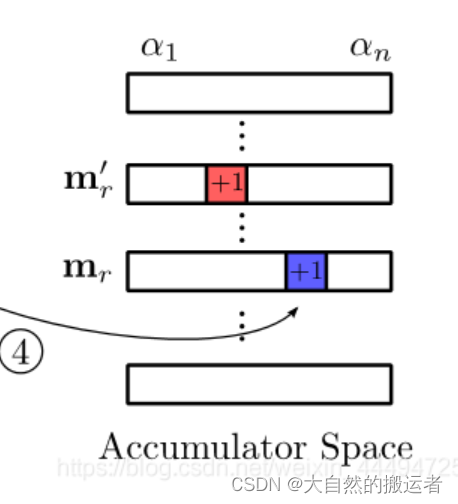 多说一句,投票矩阵怎么建立?
多说一句,投票矩阵怎么建立?
纵坐标是模型点数,因为我们在线下阶段对模型中的所有点对都求取了PPF,所以任何一个模型点都可以是mr;
横坐标是α,其值是(2π/△angle),并上取整。(△angle仍取π/15)
5 因此对于没一个场景点云Sr 都存在一个投票表和一个最高票数的姿态 .我们把相近的位姿放到一起作为一类(这些位姿在旋转和平移上不超过一个既定阈值),这个类有一个分数(分数=类中所有位姿在上一阶段的投票数之和),分数最高的类,我们将类中的pose取平均,认定为最终的pose。
同时,scene中可能有不止一个的目标,我们去分数最高的两个类,作为结果。
原文链接:https://blog.csdn.net/weixin_44494725/article/details/102984750















 1445
1445











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









