







 本文详细介绍了PID控制器的基本原理,包括其传递函数和不同变种形式。重点讨论了位置式PID和增量式PID的差异,以及如何将连续系统转换为离散化形式以适应单片机编程。作者还提及了其他高级控制策略如MPC-PID和复矢量PI在复杂控制场景的应用。
本文详细介绍了PID控制器的基本原理,包括其传递函数和不同变种形式。重点讨论了位置式PID和增量式PID的差异,以及如何将连续系统转换为离散化形式以适应单片机编程。作者还提及了其他高级控制策略如MPC-PID和复矢量PI在复杂控制场景的应用。
目录:
1、前引
上篇《电机控制杂记篇—浅谈FOC》中有简单提到PID原理,对其进行拆分来看:P所代表的就是产生偏差的比例,而I是积分,D就是微分,三者结合起来即为PID自动控制器,其实就是一种线性求解的过程。

敢想象吗?这玩意儿已被使用快一个世纪,过程中不断被优化衍生出了多"变种",比如有:抗饱和/抗干扰(ADRC)PID、模糊PID、神经网络PID...
从不同(行业应用背景不同下)口中说出的PID名字也不同。有对积分I环节改进后得到积分分离、遇限削弱积分的PID控制等,也有对微分环节改进得到不完全微分、微分先行、带死区的PID控制等。
工程使用时较难规定以特定的一种形式来规定PlD控制器,不同的算法应用在不同的被控对象身上,每种都有其缺点和优点。虽如此,但各个“变种”形式在本质上是基于PID的。
接下来回顾一下传递函数。
什么是传递函数?
描述系统输入和输出关系的一种数学表示。对于连续时间输入信号X(t)和和输出信号Y(t)来说,传递函数G(s)反映的就是零状态条件下输入信号的拉普拉斯变换和输出信号拉普拉斯变换之间的关系。即为:
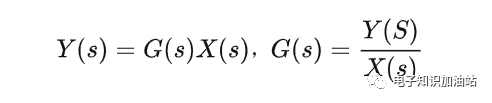
------公式0
那么,
再来回顾一下PID调节器的传递函数:
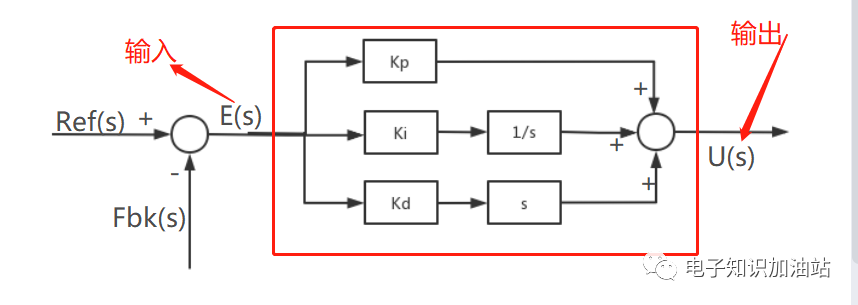
图1 PID框图
根据图1可写出传递函数:
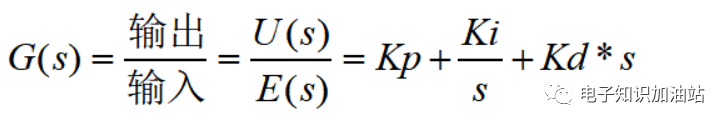
------公式1
再根据公式1稍微做下变形:
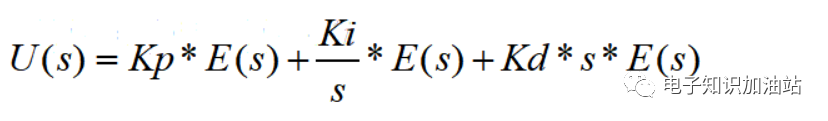
------公式2
公式2可变成时域微分方程,等同于:
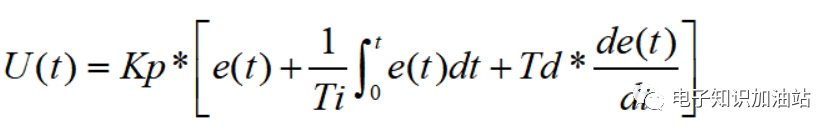
------公式3
其中公式3有:
-
U(t):输出
-
e(t) :偏差,等同于设定值和反馈值的差值
-
Kp、Ti、Td :分别代表比例系数、积分时间常数、微分时间常数
-
Ki : 积分系数,等于Kp/Ti
-
Kd:微分系数,等于Kp*Td
到此为止的时域表达式还是连续系统,为了最终方便单片机顺利编程,需要将时域的公式离散化处理。今天就要介绍适合控制器以离散化为目标模拟连续信号的PID算法,其分为两种类型:增量式PID算法和位置式PID算法。
2、位置式PID
位置式PID将当前系统实际位置与期望位置的偏差进行控制。
位置式PID时域微分方程表达式为:
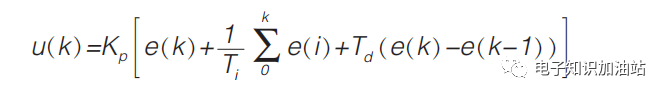
------公式4
其中公式4:
u(k):为控制器的输出;
e(k):为控制器的偏差;
Kp:为控制器的比例放大系数;
Ti:为积分时间;
Td:为微分时间;
看得出来,位置式PID的每次运算的输出都与过去的状态有关,积分项的误差会进行累加。这个时候如果偏差一直都是正的或者是负的,位置式PID在积分项就会一直累积,当偏差开始反向变化的时候,位置式PID需要调节一阵子才能从最大值减下来,这样会造成控制输出的滞后。
例:当前输出是15,位置式PID算出20,最终输出:20。
%简单写下代码(demo)Err = ValRef - ValCurrent; % 设定 - 当前反馈SumErr += Err;dError = LastErr - PrevErr;PrevErr = LastErr;LastErr = Err;result = kp * Err + ki * SumErr + kd * dErr;
所以需要对积分项进行限幅,同时也要对输出进行限幅。
3、增量式PID
改进 PID 控制算法为增量式 PID 控制算法,其表达式为:
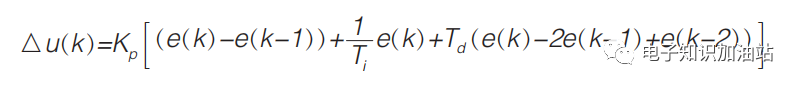
------公式5
其公式5中:
Kp:为控制器比例放大系数;
e(k):为控制器的偏差;
Ti:为积分时间;
Td:为微分时间。
对于增量式PID来说,给定一个输入量,反馈量与设定量的偏差为e(k),系统中保存上一次的偏差e(k-1)和上上次的偏差e(k-2),这三个输入量经过增量式PID计算得到控制增量ΔU(k),没有误差累加。即在上一次的控制量的基础上需要增加控制量。
例:当前输出是15,增量式PID算出5,最终输出:15+5=20。
%简单写下代码(demo)Err = ValRef - ValCurrent; % 设定 - 当前反馈result= kp * (Err - LastErr) + ki * Err + kd * (Err - 2*LastErr + PrevErr);PrevErr = LastErr;LastErr = Err;SumErr = SumErr + result;
增量式 PID 算法适用于自身带有积分记忆元件的执行器。这类执行器的动作终点位置和之前每次输入信号的累加值相关。即每次输入的信号决定相邻两次执行器动作终点位置的增量。因为增量式PID没有积分功能,因此该方法适用于带有积分部分的对象,在步进电机的控制和步进电机驱动阀门有着较广泛的运用。

增量式算法很好地避免了积分饱和现象,因此在增量式 PID 控制算法中只需要对输出限幅,而无需积分限幅。
4、两者的差别
由增量式PI:
U(k) = U(k - 1) + ΔU(k)
= U(k - 1) + Kp*[e(k) - e(k - 1)] + Ki*Ts*e(k)
------公式6
可得到:
U(k - 1) = U(k - 2) + ΔU(k - 1)
= U(k - 2) + Kp*[e(k - 1) - e(k - 2)] + Ki*Ts*e(k - 1)
-------公式7
从公式的角度:将公式7中U(k - 1) 代入到公式6中,不断迭代,由于e(0) = 0,可发现最终位置式PI和增量式PI在未超出限幅的前提下一模一样,但用起来稍有不同。
在现有的工程PI应用上有些人习惯叫做串联型PI、并联型PI、标准型PI,这种区分就很有意思,因为串联型PI又有位置式和增量式,并联型/标准型也一样有位置式/增量式之分(这个只是我自己喜欢这么区分,和PID类型别搞混,只关注实现的手段哈)。
所以,拿位置式和增量式来讲PI也没毛病。

位置式PI:
优点:
1、是一种非递推式算法,可以直接控制对象,输出值与反馈对应,所以在不带积分的控制对象中可以很好应用,例如电动液压伺服阀,这个也是目前伺服、工控电机用的最多的一种。
缺点:
1、计算每次输出都与之前的状态有关,并且还要对误差值err进行累加,计算量大。
2、一旦误差开始反向变化或者上述说的误差一直为正或负,系统就会进入饱和区,并且需要较长时间才能从饱和区退出。
增量式PI:
优点:
1、算法采用加权处理,而不需要累加,控制增量 Δu(k)仅仅与最近 3 次的采样值有关;计算机每次只会输出控制增量 Δu(k),发生故障的几率较小;
2、手动切换和自动切换时的冲击小,可以做到无扰动切换。
缺点:
1、积分截断效应大,有稳态误差,溢出的影响大。
附:
什么是积分截断效应大?
积分截断效应是将具有不连续点的周期函数进行傅立叶级数展开后,选取有限项进行合成。积分截断效应当选取的项数越多,在所合成的波形中出现的峰起越靠近原信号的不连续点。当选取的项数很大时,该峰起值趋于一个常数,大约等于总跳变值的9%。这种现象称为截断效应,又叫吉布斯效应。
5、拓展
有很多大佬觉得只在PID的三个参数上做手脚太有局限性,好用还行,但有的复杂场合并不是那么好用,毕竟各个控制参数回路之间存在着明显的耦合关系,这样也使PID三个参数的整定过程变得尤为困难。于是大佬们不断精进,推出了不少可以代替PID(内模控制器IMC、模型预测器MPC)或者结合PID的方法,其中就有MPC-PID,如下图2。
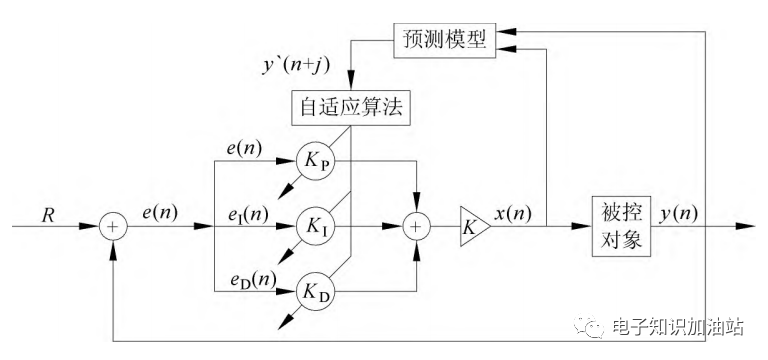
图2 复合控制策略MPC-PID
还有复矢量PI,其也在慢慢工程化。
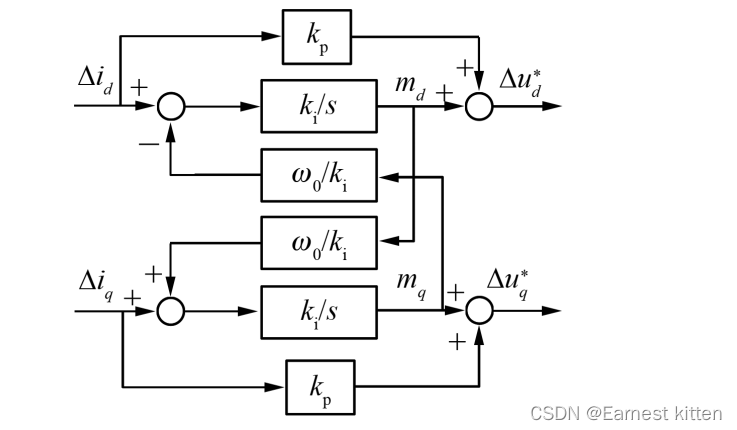
图3 复矢量PI控制框图
目前汽车行业有一部分大师已经在产品中使用了模型预测控制结合的PI或者复矢量PI,有兴趣的可以了解一下。
串联型PI和并联型PI的区别:
串联型PI:
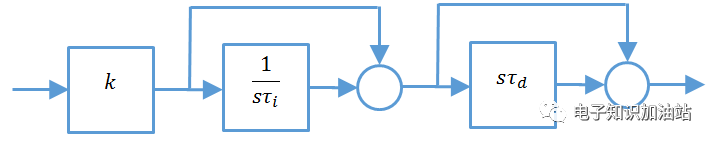
图4 串联型PI
并联型PI:
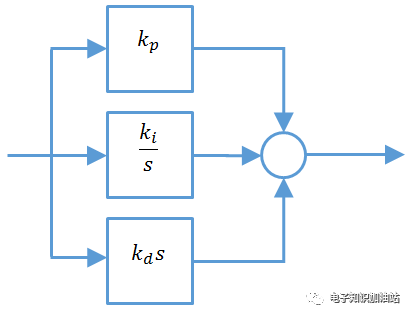
图5 串联型PI
从图3和图4可以看出:
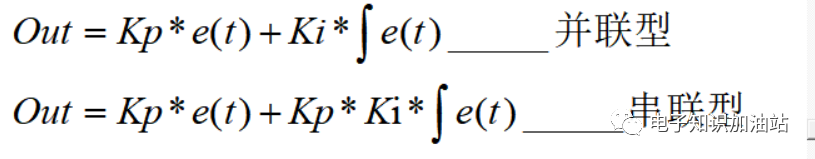
------公式8
串联型PI最典型的就是TI用的方案了,并联型ST用的多些。在并联中Kp和Ki并不解耦,都影响着系统的零点,串联型PI,Kp影响增益,Ki影响系统带宽。
参考资料:Serial or parallel PID, which structure to pick?

看到这里了,点个赞呗,你的支持就是我们的动力,biu~biu~biu~
另外,不对的地方请指正~

















 5001
5001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









