










本文将围绕以下问题展开:1、什么是需求优先级排序,目的是什么?2、优先级排序的8大依据;3、需求优先级排序面临的挑战;4、一些优秀的需求优先级排序工具。
一、什么是需求优先级排序,目的是什么?
排列优先级是对需求进行排序以确定它们对于相关方的相对重要性。当一项需求经过优先级排序,它会被赋予或高、或低的优先级。优先级可以指需求的相对价值,或是它将会被实施的顺序。优先级排序是一个持续进行的过程,优先级会随情境的变化而改变。
需要识别需求间的相互依赖关系,并可将其作为优先级排序的依据。优先级排序是确保价值得以最大化的关键性活动。
优先级排序的目的:排列需求优先级的目的是根据相对重要性对需求进行排序。
二、优先级排序的依据
排列需求优先级的依据由所涉及的相关方商定,并在商业分析规划与监督知识领域中定义。影响优先级排序的常见因素包括:
1、收益
针对变革的宗旨和目标进行衡量的实施需求能够为相关方所带来的好处。所提供的收益可以指一项具体功能、期望质量,或是战略宗旨或业务目标。如果存在多个相关方,每个群体考察收益的方式可能不同。可能需要运用冲突化解和谈判来达成针对总体收益的共识。
2、惩罚
不实施特定需求所造成的后果。这包括为满足施加于组织的监管或政策要求而排列需求优先级,这可能比其他相关方利益更优先。惩罚也可以指不实施一项改进客户体验的需求所带来的负面后果。
3、成本
实施需求所需的工作量与资源。有关成本的信息通常来自实施团队或卖方。客户在了解成本后可能改变一项需求的优先级。成本常常与其他标准结合使用,例如成本收益分析。
4、风险
需求无法带来潜在价值,或根本无法实现的可能。这可以包括得多因素,诸如实施一项需求的难度,或是相关方不能接受一个解决方案部件的可能。如果存在解决方案技术上不可行的风险,最难实施的需求可能会被列为最高优先级,从而将了解到拟议解决方案无法交付前所花费的资源最小化。可以开发概念验证以确定高风险选择是可行的。
5、依赖关系
需求之间的关联关系,其中一项需求只有在另一项需求被实现后才有可能实现。在某些情况下,将相关需求同时进行实施可能可以达成更高效率。依赖关系也可能超越当前行动,包括(但不限于)其他团队的决定、资金投入承诺与资源可用情况。依赖关系在跟踪需求任务中进行识别。
6、时间敏感性
需求的“最佳实现期限”,在此之后实施需求将丧失重要价值。这包括上市时间方案,其中某项功能如果可以先于竞争对手交付,所取得的收益将会极大增加。它也可以指仅在一年中的特定时间具有价值的季节性功能。
7、稳定性
需求将会发生改变的可能性,改变的原因可以是由于需要对它做进一步分析,或是由于相关方未就其达成共识。如果一项需求不稳定,则它的优先级可能较低,以减少无法预计的返工与工作量损失。
8、监管或政策合规
为满足施加于组织的监管或政策要求而必须实施的需求,它们可能比其他相关方利益更加优先。
三、优先级排序面临的挑战
优先级排序是对相对价值的评估,每个相关方对某事物可能有不同的价值衡量。出现这种情况时,相关方之间可能产生冲突。相关方也可能不愿将任何需求设为较低优先级,这可能会导致无法作出必要的取舍。此外,相关方可能(有意或无意地)在表明优先级时使其偏向他们所期望的结果。不同类别的需求对于排序标准的适用可能不尽相同,也可能出现冲突。相关方可能需要在优先级排序中作出取舍。
四、持续性的优先级排序
随着情境的演变以及更多信息的获取,优先级可能发生改变。初始的优先级排序在较高抽象层次进行。当需求被进一步提炼,优先级排序会在颗粒度更细的层次进行,并在需要时加入更多优先级排序依据。在变革的各个阶段,优先级排序的依据可能会有所不同。例如,相关方可能在刚开始时依据收益排列优先级。随后实施团队可能由于技术约束而依据必需的实施顺序重新排列优先级。当实施团队给出每项需求的成本时,相关方可以重新排列优先级。
五、好用的需求排序软件有哪些?
根据 PMI 进行的多项需求管理调查得出:糟糕的需求管理流程常常被认为是项目失败的首要原因。
建立标准化、规范化需求管理流程的方法有很多工具也有很多,就比如最简单的 Excel。用什么样的方法或工具都是取决于你能否通过该工具解决问题,提升效率。比如很多公司在十多个人的时候 Excel 或者Office 几乎是万能的,但随着人数规模的逐渐扩大,PingCode、Jira 这样的专业化工具就开始变得不可或缺。
1、最适合中小企业的需求管理工具:Pingcode
它是国内首款实现产品管理与研发过程管理全面打通的工具,曾在2021年曾获得36氪企服点评-国内研发管理工具榜单的TOP1。
在产品管理方面,PingCode 被广泛用于工单收集、需求管理、需求评审(支持定义评审因素指标及权重)、需求优先级排序、产品路线图绘制等。
除此以外,它还被广泛用于项目管理(含敏捷/kanban/瀑布)、测试管理、缺陷追踪、文档管理、效能度量等领域。并且集成了github、gitlab、jinkens、企微、飞书等主流工具,也就是说我们能在需求下面关联代码,关联集成信息,在飞书查看通知等。
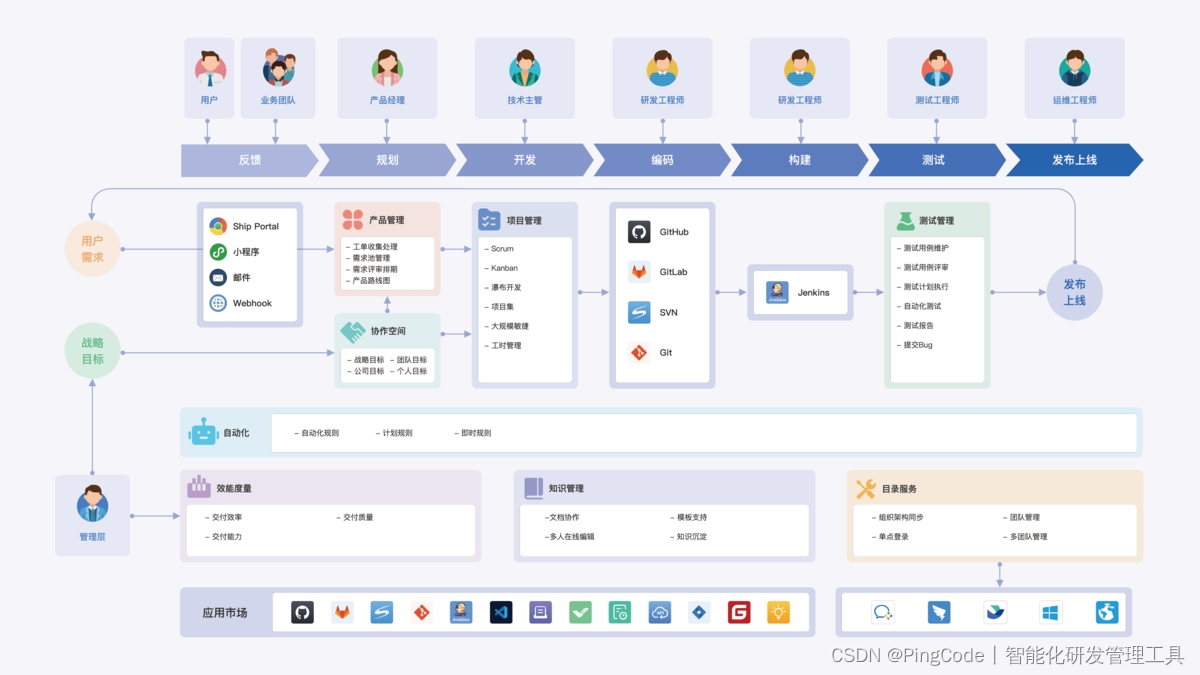
对比其他产品它具有简单易上手、开箱即用的特点,避免了Jira、禅道等使用上的辅助配置流程。且为25人以下团队提供了免费版本。
2、国内顶级项目管理工具:Worktile
Worktile 虽然是一个项目管理工具,但却有非常多的中小型团队用其满足了需求管理的需求,比如需求收集、需求关联缺陷、跟踪进度等等。
因为它是一个工具集合,除了需求管理之外,中小型团队的绝大部分需求都能在这一工具得到满足。这既能为创业型的公司节省一大笔钱,又能满足安全等方面的需求。
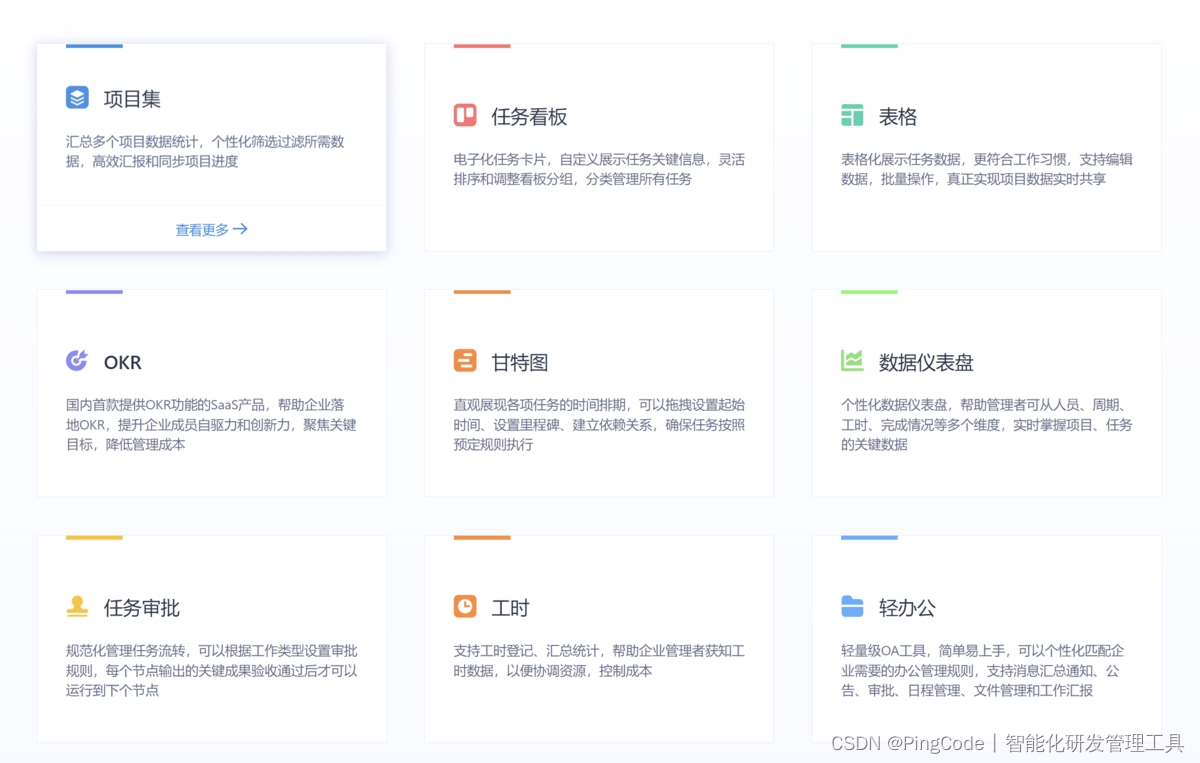
核心能力:
- 有标准的需求模板,可显示详细的需求流转过程。
- 明确的优先级分类、标签分类、状态情况等,让整个需求规划更有序。
- 对应的责任人分布,事情对应到个人。
- 详细的需求步骤流程,一眼看清需求所在进度。
- 方便的排期工具,有利于团队成员把握进度。
- 详细的可跟踪动态列表,对于后续的复盘起到很大作用。
- 各类文件的共享,文档、导图、文件等。
3、国外需求管理工具:Jama Software
Jama Software 是一家面向复杂产品和关键任务软件系统的公司的产品开发平台,能够帮助团队缩短周期,提高质量,减少返工并最大程度地减少证明合规性的工作。该平台的强大功能加上易于采用的界面将人员、流程和工具集中在一个地方,以提供对端到端产品、系统和软件开发流程的可见性和可操作的洞察力。
核心能力:
- 在整个开发过程中准确地捕捉和沟通需求、目标、进展,以及建立之间的依赖关系
- 人员、数据和流程的端到端实时跟踪
- 实时影响分析,显示与上游和下游需求有关的变化的影响
- 与ALM、PLM、QA、MBSE整合
- 定义、组织和执行基于需求的测试计划和测试案例
- 重用经过验证的需求,以便在不同产品间快速复制功能
官网: https://www.jamasoftware.com/
4、全面的需求管理工具-Visure
Visure 是一种易于使用且全面的需求管理工具。 它集成了同一环境中的其他流程,例如风险管理、测试管理、问题和缺陷跟踪以及变更管理。比较可惜的是不支持在国内使用。

核心能力:
- 支持各种开发流程,敏捷、V-模型、瀑布等
- 与MS Word/Excel的集成
- 流程审批
- 从系统需求一直到测试的全部可追溯性
- 风险管理,测试管理,错误跟踪等
- 可定制的ISO26262、IEC62304、IEC61508、CENELEC50128、DO178/C、FMEA、SPICE、CMMI等标准合规模板。
- 与多个工具集成的开放环境,如DOORS、Jama、Siemens Polarion、PTC、Perforce、JIRA、Enterprise Architect、HP ALM、Microfocus ALM、PTC、TFS、Word、Excel、Test RT、RTRT、VectorCAST、LDRA和其他工具
官网: https://visuresolutions.com/
以上就是关于需求优先级排序的方法、工具以及最佳实践的一些内容,希望对大家有所帮助。

















 995
995

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









