






1、 Introduction
概述
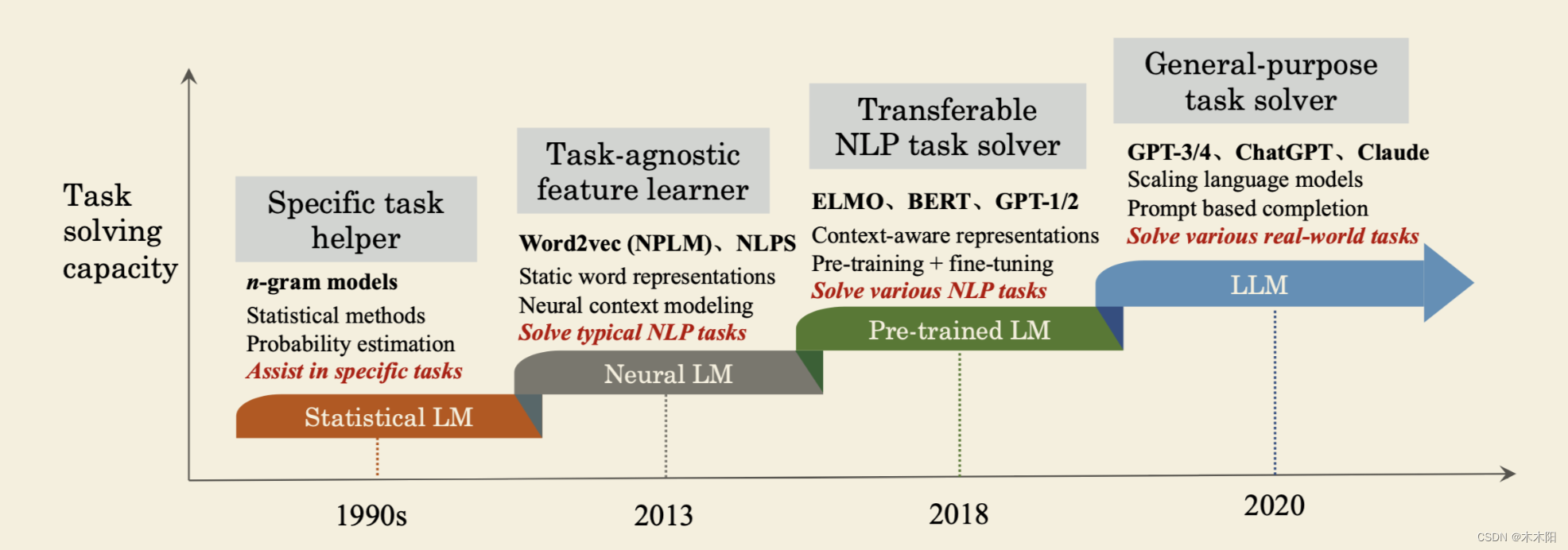
本章介绍了大语言模型(LLM)的背景和发展历程。
A. Statistical Language Models (SLM)
统计语言模型(SLM)基于统计学习方法,通过马尔可夫假设构建词预测模型,但面临数据稀疏性问题。
统计语言模型(SLM)是基于统计学习方法开发的,主要在1990年代兴起。其基本思想是基于马尔可夫假设构建词预测模型,例如基于最近上下文预测下一个词。SLM常被用于信息检索(IR)和自然语言处理(NLP)任务。然而,SLM面临维数灾难的问题,即难以准确估计高阶语言模型的转移概率,因此引入了回退估计和Good-Turing估计等平滑策略来缓解数据稀疏性问题。
B. Neural Language Models (NLM)
神经语言模型(NLM)使用神经网络进行词序列概率建模,引入了分布式表示的概念,提高了词预测的效果。
神经语言模型(NLM)通过神经网络表征词序列的概率,例如多层感知器(MLP)和循环神经网络(RNN)。NLM引入了分布式表示的概念,通过聚合上下文特征进行词预测。这些研究开创了使用语言模型进行表示学习的先河,对NLP领域产生了重要影响。
C. Pre-trained Language Models (PLM)
预训练语言模型(PLM)通过大规模未标注语料上的预训练和特定下游任务的微调,显著提高了NLP任务的性能。
预训练语言模型(PLM)首先通过预训练双向LSTM网络来捕捉上下文相关的词表示,然后根据特定下游任务进行微调。基于Transformer架构和自注意力机制,BERT通过在大规模未标注语料上进行预训练显著提高了NLP任务的性能。这一学习范式激发了大量后续研究,引入了不同的架构和改进的预训练策略。
D. Large Language Models (LLM)
大语言模型(LLM)通过增加参数规模,不仅在性能上有显著提升,还表现出一些小型模型没有的特殊能力。
随着研究人员发现模型扩展可以提高模型容量,他们进一步通过增加参数规模来研究扩展效应。当参数规模超过一定水平时,这些大型语言模型不仅在性能上有显著提升,还表现出一些小型模型没有的特殊能力(例如上下文学习)。LLM在学术界和工业界得到了广泛关注,特别是ChatGPT的推出引起了社会的广泛关注。LLM的发展对整个AI社区产生了重要影响,可能会彻底改变AI算法的开发和使用方式。
整体梳理 (Summary)
第一章详细介绍了大语言模型的发展历程,从统计语言模型到神经语言模型,再到预训练语言模型和大语言模型,展示了每一代模型在任务解决能力上的进步。本文还强调了LLM与PLM的三个主要区别,包括LLM的突现能力、LLM对AI算法开发方式的革命性影响以及LLM的研究与工程一体化特点。
2、Overview
概述
本节概述了大语言模型(LLM)的背景,并总结了GPT系列模型的技术演变。
A. Background for LLMs
Formulation of Scaling Laws for LLMs (LLM缩放定律的制定)
LLM主要基于Transformer架构,通过扩展模型规模、数据规模和总计算量,显著提高模型容量。
KM Scaling Law (KM缩放定律)
提出参数数量、数据量和计算量之间的关系,指导模型训练的资源分配。
Chinchilla Scaling Law (Chinchilla缩放定律)
提出了在固定计算预算下,模型规模和训练数据量的最佳平衡点。
Discussion on Scaling Laws (缩放定律讨论)
Predictable Scaling (可预测的缩放)
缩放定律可以用于指导LLM的训练,通过小模型的表现来可靠地估计大模型的性能。
Task-Level Predictability (任务级可预测性)
探讨语言模型损失的减少如何转化为任务性能的提升,尽管某些任务可能出现逆缩放现象,即模型性能随损失减少而下降。
Emergent Abilities of LLMs (LLM的突现能力)
LLM在达到一定规模时会表现出一些小模型没有的特殊能力,例如上下文学习和指令跟随能力。
In-Context Learning (上下文学习)
LLM能够在给定自然语言指令和示例的情况下,在不需要额外训练或梯度更新的情况下生成预期输出。
Instruction Following (指令跟随)
通过混合微调提升LLM理解和执行自然语言指令的能力,这一能力在GPT-3模型中得到了显著表现。
Step-by-step Reasoning (逐步推理)
利用提示机制引导模型进行中间推理步骤,从而解决需要多步推理的复杂任务。
How Emergent Abilities Relate to Scaling Laws (突现能力与缩放定律的关系)
探讨LLM的突现能力如何随着模型规模的增加而出现和增强,说明了缩放定律在解释和预测这些能力方面的重要性。
Key Techniques for LLMs (LLM的关键技术)
LLM的发展过程中引入了许多重要技术,如模型扩展、分布式训练、能力引出和对齐微调等,这些技术极大地提高了LLM的能力。
Scaling (扩展)
通过增加模型参数和计算资源来提高模型的性能。
Training (训练)
使用大规模数据集和高效的训练方法来优化模型参数。
Ability Eliciting (能力引出)
设计策略和提示来引出和增强模型的特定能力。
Alignment Tuning (对齐微调)
通过微调和人类反馈对齐模型的输出,使其更加符合预期。
Tools Manipulation (工具操作)
使模型能够使用外部工具和资源来完成复杂任务。
B. Technical Evolution of GPT-series Models
Early Explorations (早期探索)
GPT-1
首次引入了Transformer架构,展示了生成式预训练的潜力。
GPT-2
增加了模型参数数量,显著提升了文本生成的质量。
Capacity Leap (容量飞跃)
GPT-3
通过1750亿参数的模型规模,展示了强大的零样本、少样本学习能力。
Capacity Enhancement (容量增强)
Training on Code Data (代码数据训练)
通过在大规模代码数据上进行训练,提升了模型在代码生成和理解方面的能力。
Human Alignment (人类对齐)
通过人类反馈和微调,提高了模型输出的相关性和安全性。
The Milestones of Language Models (语言模型的里程碑)
ChatGPT
展示了强大的对话能力,并引起了广泛的社会关注。
GPT-4
进一步提升了模型的能力,增加了参数数量和多模态输入能力。
GPT-4v
在GPT-4基础上,进一步增强了视觉和文本的多模态处理能力。
整体梳理 (Summary)
第二章概述了大语言模型的背景信息和GPT系列模型的技术演变。通过总结这些信息,可以更好地理解LLM的发展历程及其在自然语言处理中的应用潜力。


















 3014
3014

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









