







人工智能咨询培训老师叶梓 转载标明出处
在自然语言处理领域,大模型(LLMs)如ChatGPT等已经展现出了处理多种语言任务的卓越能力。然而大模型在面对复杂问题时,往往受限于其固化的知识库,难以提供准确和及时的信息。为了突破这一局限,工具学习(Tool Learning)作为一种新兴的范式应运而生,它通过使LLMs能够动态地与外部工具互动,从而增强其解决问题的能力。本文《Tool Learning with Large Language Models: A Survey》由屈长乐等人撰写,系统回顾了工具学习领域的现有研究,探讨了工具学习对LLMs的益处,并详细介绍了工具学习的实施方法。
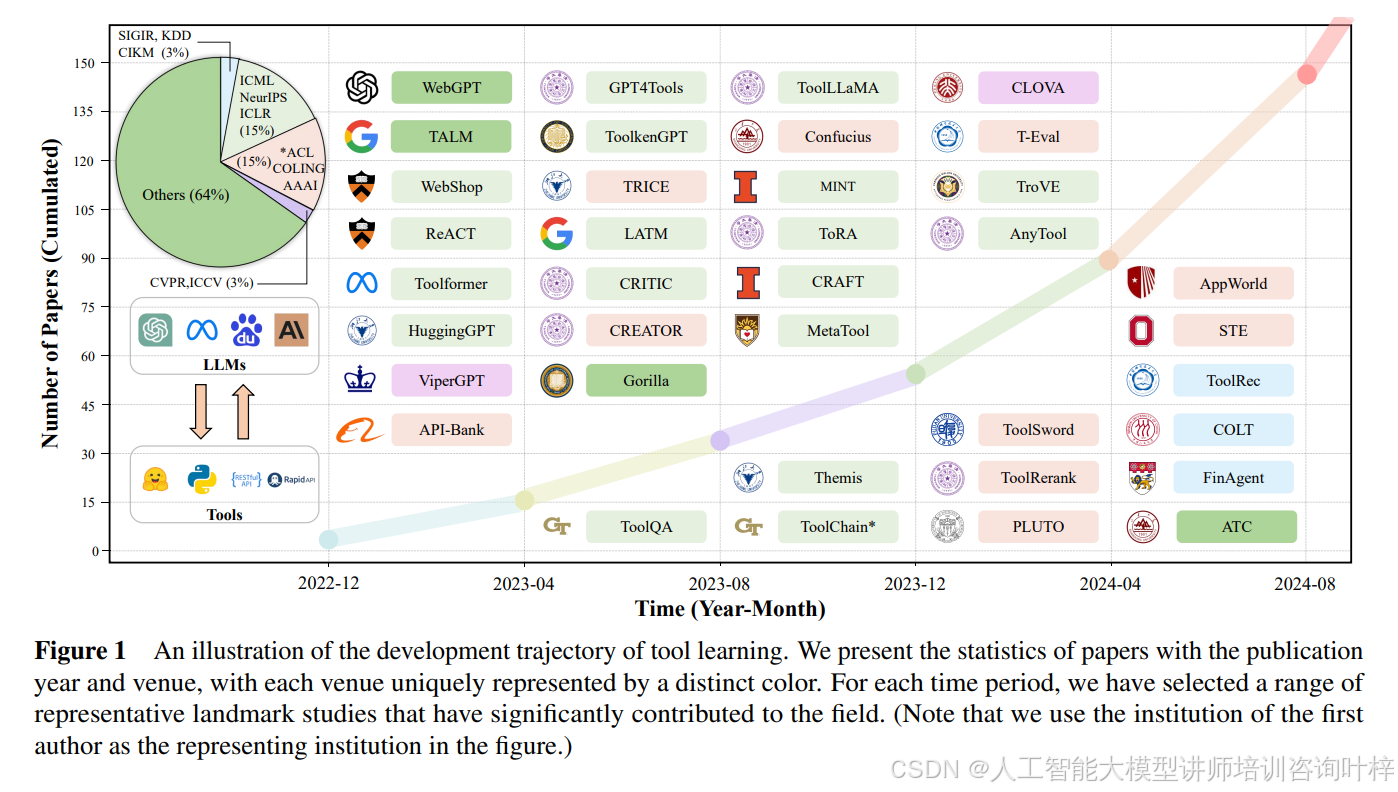
图1展示了工具学习领域的发展轨迹,图中显示了从2023年4月到2024年4月的时间轴,以及在这段时间内不同会议(如NeurIPS、ICLR、AAAI等)上发表的相关论文数量。
想要掌握如何将大模型的力量发挥到极致吗?叶老师带您深入了解 Llama Factory —— 一款革命性的大模型微调工具(限时免费)。
1小时实战课程,您将学习到如何轻松上手并有效利用 Llama Factory 来微调您的模型,以发挥其最大潜力。
CSDN教学平台录播地址:https://edu.csdn.net/course/detail/39987
工具学习的重要性及其对大模型的多方面影响
工具学习(Tool Learning)对大模型的重要性主要有两个方面:工具集成的好处和工具学习范式本身的好处。一方面,将工具集成到大模型中可以增强多个领域的能力,包括知识获取、专业能力提升、自动化与效率、以及交互增强。另一方面,采用工具学习范式增强了响应的鲁棒性和生成过程的透明度,从而提高了可解释性和用户信任度,同时也改善了系统的鲁棒性和适应性。
-
知识获取:大模型通过集成外部工具,例如搜索引擎和数据库,能够动态获取和更新知识,突破了预训练知识的限制,从而提供更准确、更相关的信息。
-
专业能力提升:大模型在特定领域,如数学计算和编程,通过使用专业工具来增强其解决问题的能力,弥补了在复杂任务上的不足。
-
自动化与效率:大模型结合任务自动化工具,可以自动执行日常任务,如安排日程和过滤电子邮件,提高了工作效率和用户体验。
-
交互增强:面对多语言和多模态的输入,大模型可以利用语音识别、图像分析等工具来增强对用户意图的理解,改善人机交互。
-
提高可解释性:工具学习使大模型的决策过程更加透明,用户能够看到模型的每一步操作,这有助于建立用户对模型决策的信任。
-
增强鲁棒性和适应性:通过集成外部工具,大模型在面对不同的输入和新环境时,能够更加稳定地执行任务,减少了输入错误的风险。
工具学习的过程和范式
工具学习是大模型(Large Language Models, LLMs)领域的一个重要进展,它通过将模型与外部工具相结合,增强了模型处理复杂任务的能力。工具学习的过程可以分为四个阶段:任务规划(Task Planning)、工具选择(Tool Selection)、工具调用(Tool Calling)和响应生成(Response Generation)。工具学习还可以分为两种范式:一步任务解决(One-step Task Solving)和迭代任务解决(Iterative Task Solving)。如图3所示。
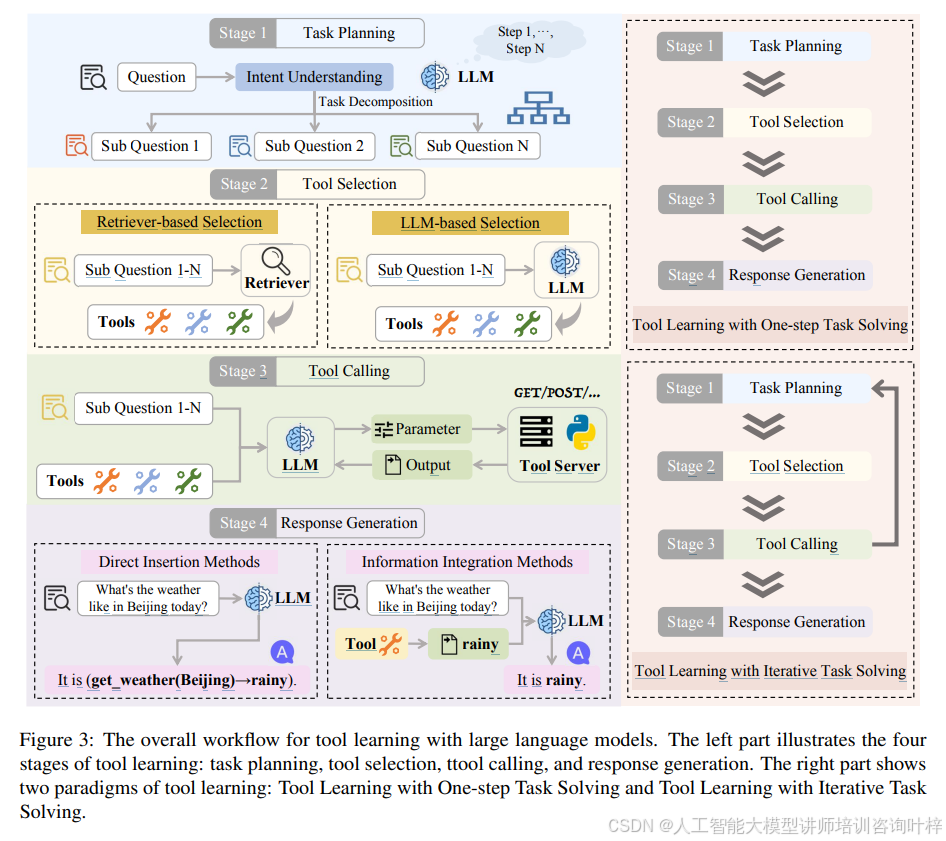
图3左侧部分:工具学习的四个阶段
- 任务规划(Task PlanningTask Planning): 任务规划是工具学习的起始阶段,大模型在此阶段需要理解用户的查询意图,并将复杂的问题分解为多个可解的子问题。例如,对于用户查询“5盎司黄金加1百万AMZN股票的人民币价值”,大模型会将其分解为三个子问题:查询黄金的实时价格、查询亚马逊股票的实时价格以及查询美元对人民币的实时汇率。
- 工具选择(Tool SelectionTool Selection): 在工具选择阶段,大模型需要从众多可用工具中选择最适合解决每个子问题的工具。这一阶段可以进一步分为基于检索器的工具选择(Retriever-based Tool Selection)和基于大模型的工具选择(LLM-based Tool Selection)。基于检索器的工具选择首先使用检索器从大量工具中筛选出最相关的几个工具,然后由大模型进行最终选择。例如,对于查询黄金价格的子问题,大模型可能会从候选工具中选择“金属价格率API”,因为它能提供实时的黄金价格数据。
- 工具调用(Tool CallingTool Calling): 在选择了合适的工具后,大模型需要调用这些工具以获取必要的信息。这要求大模型能够根据工具的描述提取出正确的参数,并按照工具的要求格式化这些参数,然后向工具服务器发送请求。例如,如果需要调用一个提供金属价格的API,大模型需要知道如何正确地提取和格式化参数,如“symbols”和“base”,以便获取实时的金属价格数据。
- 响应生成(Response GenerationResponse Generation): 最后,在响应生成阶段,大模型需要将从工具调用中获得的信息与自身的知识相结合,生成对用户原始查询的全面回答。这一阶段的挑战在于如何有效地整合来自不同工具的多样化输出,并生成一个准确、连贯且有用的回答。例如,大模型可能会结合实时的黄金价格、股票价格和汇率数据,计算并告诉用户5盎司黄金和1百万AMZN股票的总价值。
右侧部分:工具学习的两种范式
- 一步任务解决(One-step Task Solving):在这种范式中,大模型在接收到用户查询后,会立即规划所有需要解决的子任务,并直接基于选定工具的返回结果生成回答,而不根据工具的反馈调整计划。
- 迭代任务解决(Iterative Task Solving):这种范式不预先承诺一个完整的任务计划,而是允许大模型与工具进行迭代交互,根据工具的反馈逐步调整子任务。这使得大模型能够逐步解决问题,并根据工具返回的结果不断完善计划,从而提高问题解决能力。
工具学习的基准测试与评估
在工具学习的研究进展中,已经开发并提供了大量的基准测试(benchmarks),以评估大模型在工具学习不同阶段的能力。这些基准测试为验证工具学习方法的有效性和效率提供了结构化的评估协议。
目前,已经为工具学习建立了多个基准测试,以评估大模型在不同阶段的工具学习能力。这些基准测试主要分为两类:通用基准测试和其他基准测试。表格1列出了不同的基准测试(benchmarks)及其具体配置。
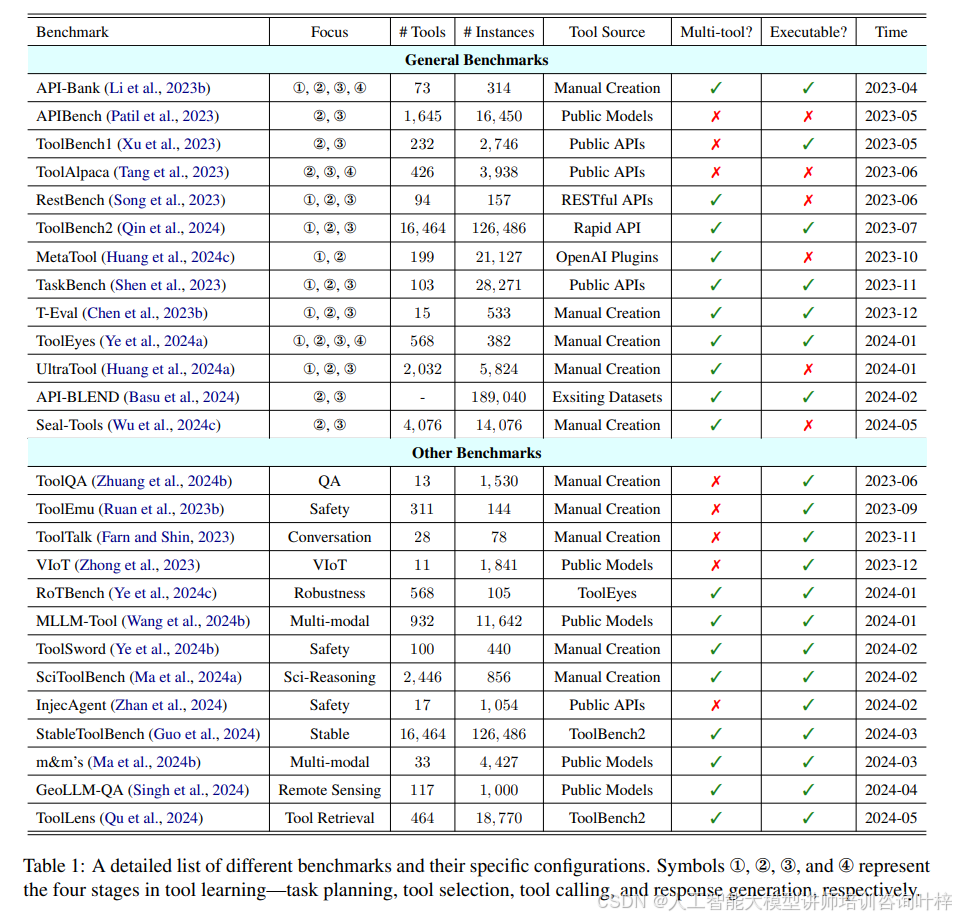
通用基准测试(General Benchmarks):
- API-Bank:评估大模型在任务规划、工具选择、工具调用和响应生成等四个阶段的能力。
- APIBench 和 ToolBench1:专注于工具选择和工具调用阶段,评估大模型准确选择合适工具及其参数配置的能力。
- ToolBench2:目前最大的工具学习数据集,包含16,464个工具和126,486个实例,涵盖了任务规划、工具选择和工具调用三个阶段。
- MetaTool:专注于任务规划和工具选择阶段,评估大模型是否能够识别使用工具的必要性,并选择最合适的工具来满足用户需求。
其他基准测试(Other Benchmarks):
- ToolQA:专注于提升大模型通过使用外部工具的问题回答能力。
- ToolTalk:集中于大模型在多轮对话中使用工具的能力。
- VIoT:关注与大模型一起使用的VIoT工具的能力。
- RoTBench、ToolSword 和 ToolEmu:强调工具学习中的鲁棒性和安全性问题。
- MLLM-Tool 和 m&m’s:将工具学习扩展到多模态领域,评估大模型在多模态环境中使用工具的能力。
- StableToolBench:倡导创建一个大规模且稳定的工具学习基准测试。
- ToolLens:专注于工具检索阶段,考虑真实世界中用户查询通常简洁但意图复杂和模糊。
工具学习的评估方法对应于工具学习的四个阶段:
-
任务规划评估:评估大模型是否正确识别给定查询是否需要外部工具,测量工具使用意识的准确性。可以使用ChatGPT提供的通过率或人类评估来评估任务规划的有效性。
-
工具选择评估:使用多种指标从不同角度评估工具选择的有效性,包括Recall、NDCG 和 COMP。这些指标不仅考虑了选定工具的准确性,还考虑了它们在列表中的位置。
-
工具调用评估:评估大模型在执行工具调用功能时输入的参数是否与工具文档中的规定一致。这包括验证提供的参数是否与特定工具所需的参数匹配,以及输出参数是否满足所需的范围和格式。
-
响应生成评估:工具学习的最终目标是提高大模型有效处理下游任务的能力。因此,通常基于解决这些下游任务的性能来评估工具利用的有效性。这需要大模型整合整个过程中收集的信息,为用户提供直接的响应。可以使用ROUGE-L、exact match、F1等指标来评估最终响应的质量。
https://arxiv.org/pdf/2405.17935
https://github.com/quchangle1/LLM-Tool-Survey



















 560
560

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











