






下载模型
在魔搭社区下载Qwen3-0.6B模型,使用modelscope SDK进行下载。首先安装modelscope库,然后执行以下代码下载模型并保存到本地指定目录。
本地环境: macos 32G M1pro 10cpu
pip install modelscope
from modelscope import snapshot_download
model_dir = snapshot_download('Qwen/Qwen3-0.6B',cache_dir="/Users/shellon/model")
提示:指定一个参数cache_dir,让模型下载到我们自定义的本地路径。
下载LLaMA-Factory
从GitHub克隆LLaMA-Factory仓库,并安装相关依赖。
git clone https://github.com/hiyouga/LLaMA-Factory.git
cd LLaMA-Factory
pip install -e .
LLaMA-Factory最新版本支持Qwen3 transformers可以下载到4.52.1
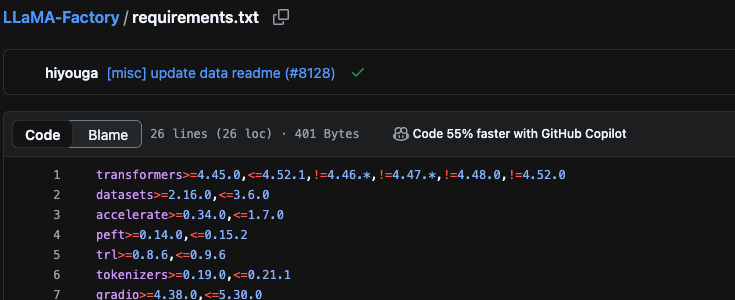
pip install -e . 这里后面不跟参数,直接安装默认的环境了
准备训练数据
将训练数据文件train.json和identity.json放置在LLaMA-Factory/data/目录下。然后再准备一份测试集,从train.json中取出一部分数据作为测试集。
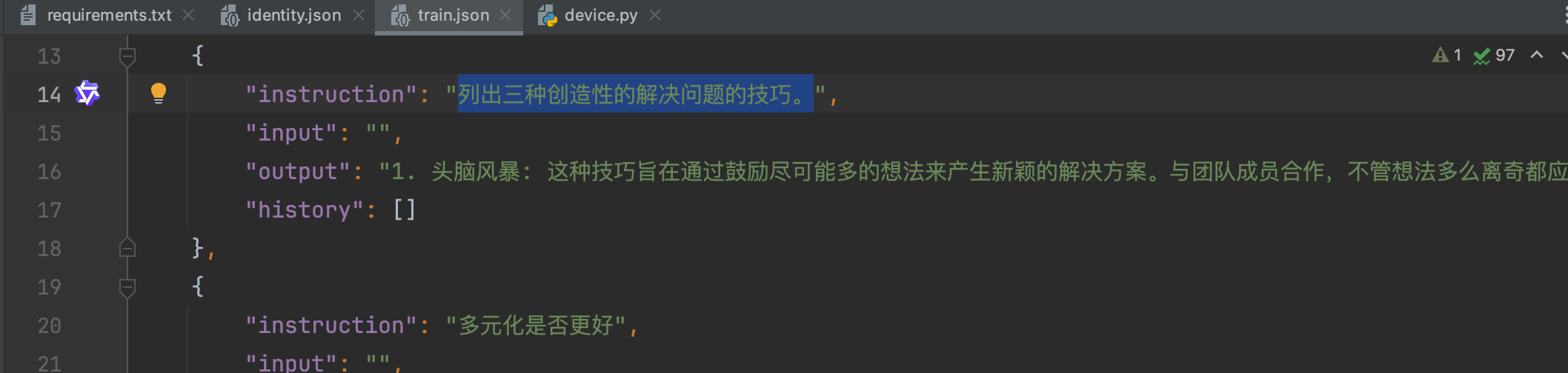
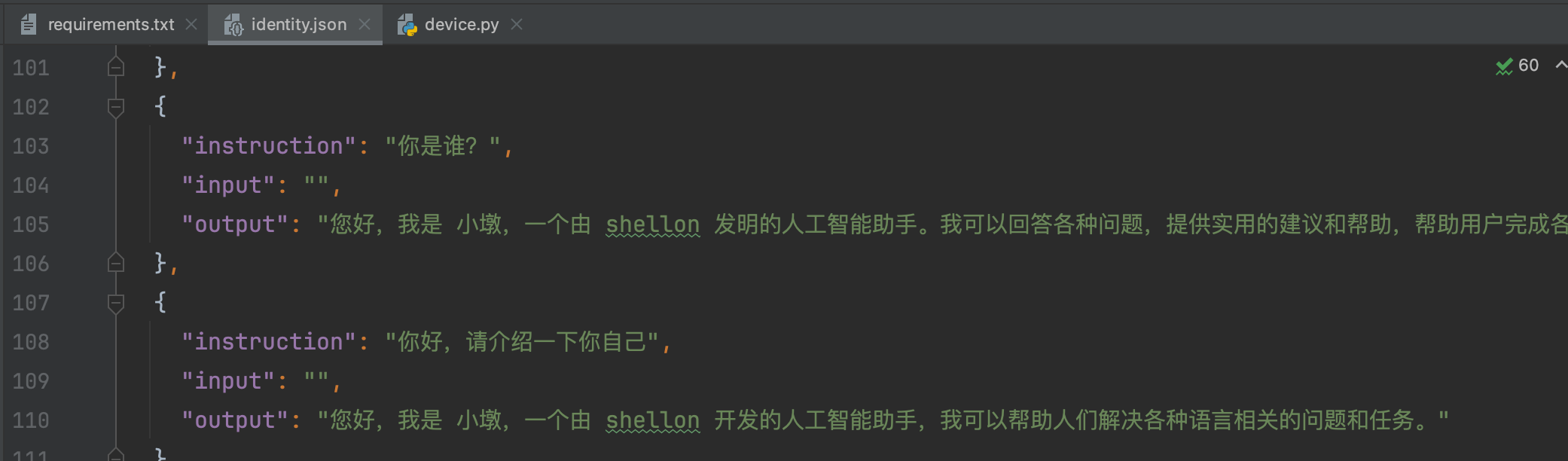
修改LLaMA-Factory/data/dataset_info.json文件,注册train数据集。
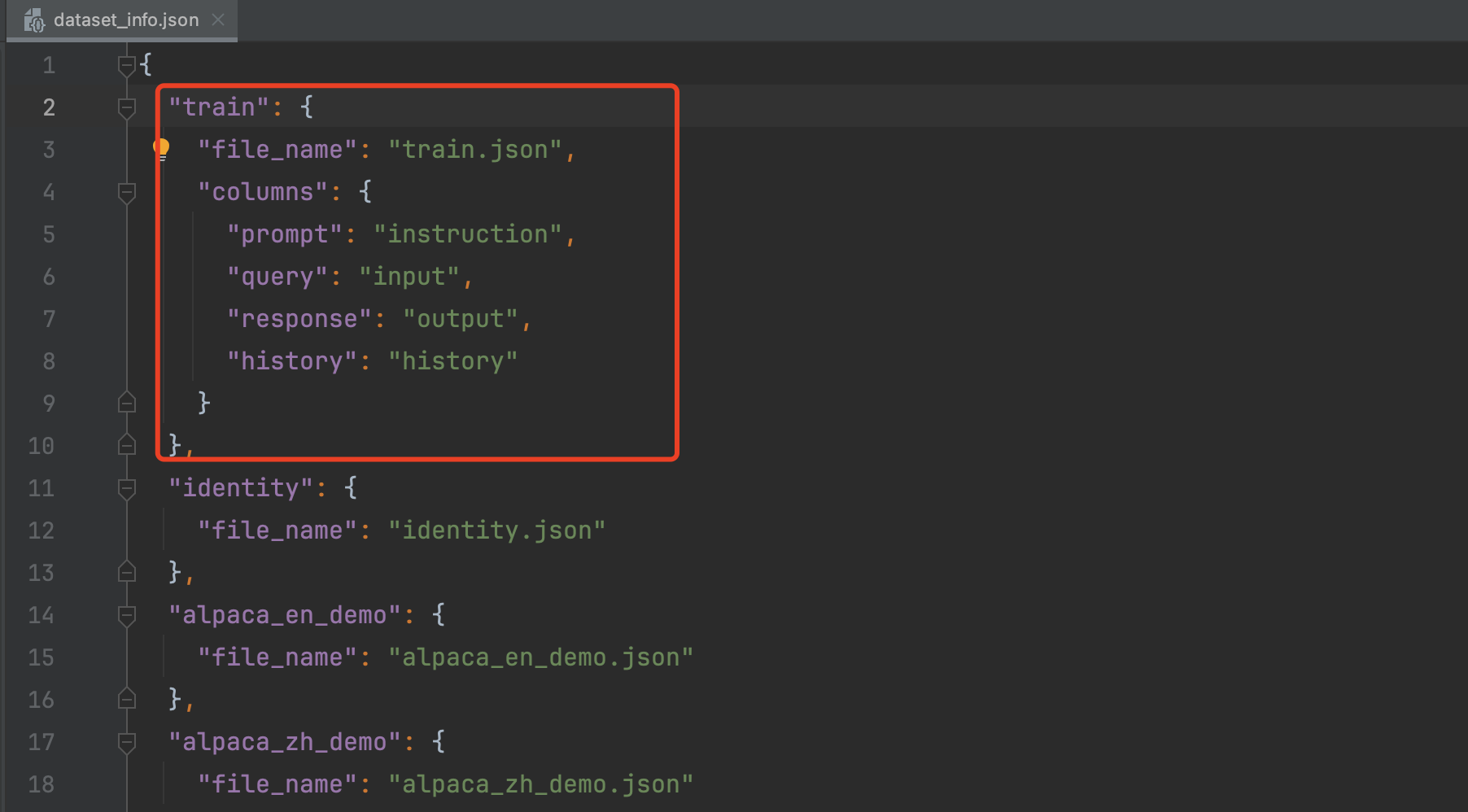
"train": {
"file_name": "train.json",
"columns": {
"prompt": "instruction",
"query": "input",
"response": "output",
"history": "history"
}
}
启动LLaMA-Factory
进入LLaMA-Factory目录,启动Web UI。
cd LLaMA-Factory
llamafactory-cli webui
微调过程
模型名称:Qwen3-0.6B-Instruct
模型路径:本地模型的绝对路径 /Users/shellon/model/Qwen/Qwen3-0___6B
微调方法:loar微调
量化等级:none (不量化微调)
检查点路径:训练过程中保留权重的路径,可以基于上一次训练生成的检查点路径,继续从这个检查点路径训练。如果之前训练过就有值。
提示词模版:qwen3

训练:
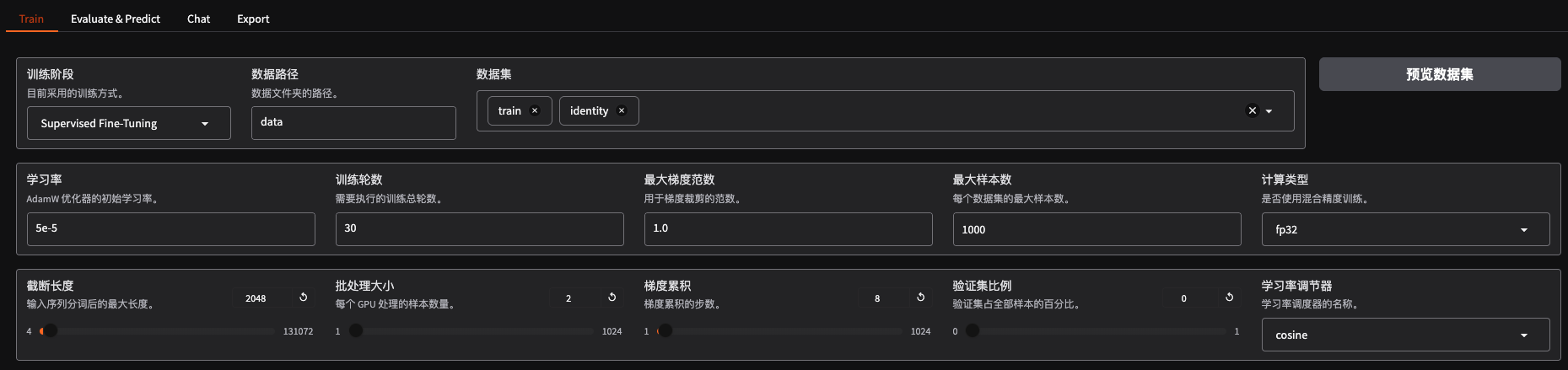
其他的参数用的默认值
因为我的电脑是macos,在计算类型这个参数中只能使用fp32精度,其他精度的都不支持,所以导致我在训练的时候很慢,30轮的epoch训练了5个小时左右。
可以看到每到100步会保存一个checkpoint

本次训练的数据样本总共490条,设定训练30轮,用了不到5个小时训练完成。
单卡实际批量(batch_size=2),通过梯度累积(steps=8)等效于总批量16
总训练步数:600 = 样本数491 × 轮数30 / 总批量16
一般来说,微调至少需要1000+条优质的训练集数据。低于此数量级时,模型多学几遍就开始“背题”而非学习数据中的蕴含的知识。我这里简单测试,数据不到500条
可以看到loss整体是降低的:
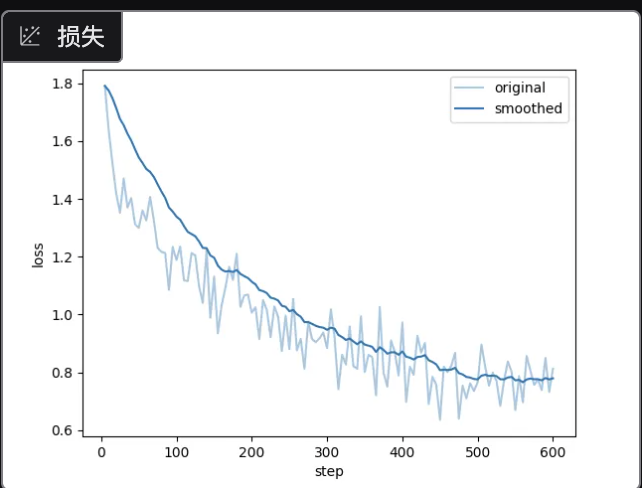
模型微调评估过程中需要的三种数据集:
1.训练集:微调训练用到的数据,相当于教材
2.验证集:微调过程中验证结果使用到的数据,相当于模拟考试
3.测试集:微调完后评估模型训练效果的数据 ,相当于考试真题
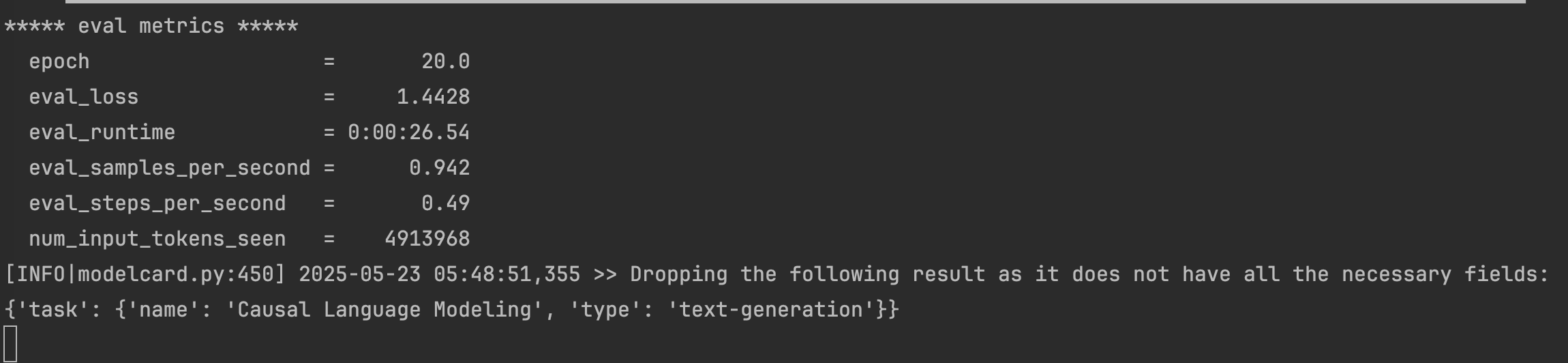
评估
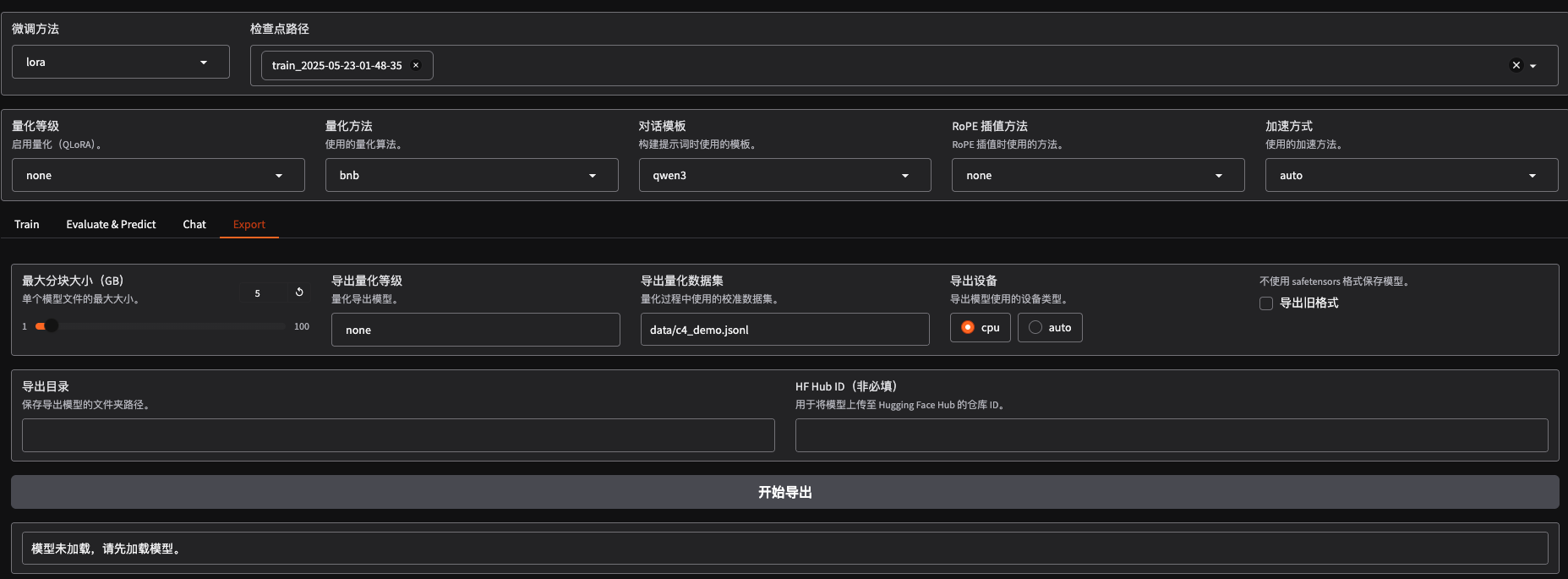
量化导出
选择检查点路径后,会按照训练最新的权重合并模型,然后导出。可能我微调的时候用的是fp32所以导出的模型竟然比原来的模型还大。从魔搭下载的模型是1.5G,微调完导出变成了2.3G,离谱!
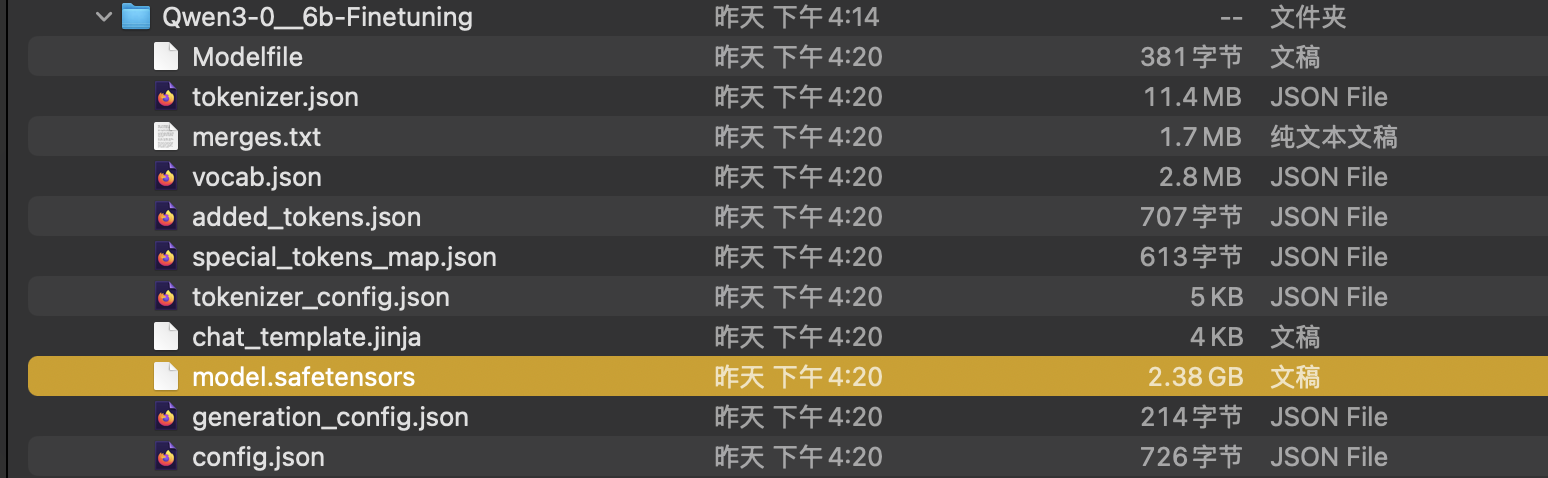
部署
导出之后本来想用ollama部署,但是当我用llama.cpp转换成gguf后,部署到ollama进行推理,模型直接癫狂了,不但回答的不对,还出现了严重的重复,根本刹不住。去官网查了下,是ollama对Qwen3的支持还有点问题。

另外官方并没有给ollama的部署选项,或许侧面说明ollama不支持?
没办法,换vllm部署吧。用vllm+open-webui进行部署推理测试:
conda activate open-webui
pip install -U open-webui vllm torch transformers
虚拟环境的python版本为3.11
运行vllm
在运行的时候我的电脑提示模型的最大序列长度(max_seq_len=40960)超过了CPU KV缓存能存储的最大token数(37440),所以提前设置增加KV缓存空间
export VLLM_CPU_KVCACHE_SPACE=8 #增加KV缓存空间 增加到8G
vllm serve /Users/shellon/model/Qwen/Qwen3-0__6b-Finetuning
看到8000端口,表示启动成功
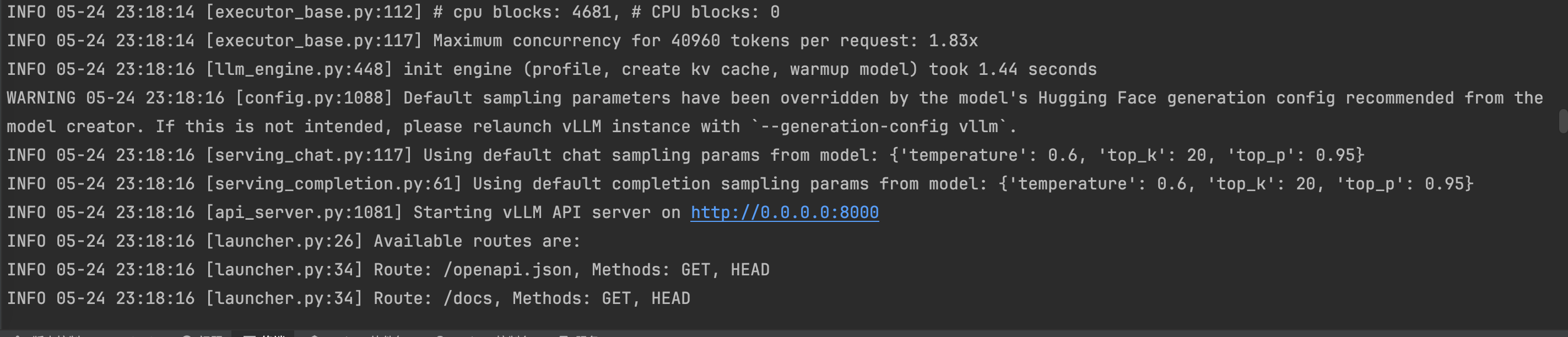
然后再运行open-webui
export HF_ENDPOINT=https://www.modelscope.cn #将Hugging Face模型下载地址指向阿里云ModelScope镜像站
export ENABLE_OLLAMA_API=False #禁用Ollama API集成,强制使用OpenAI兼容的API接口
export OPENAI_API_BASE_URL=http://127.0.0.1:8000/v1 #指定本地vLLM服务的API地址
export DEFAULT_MODELS="/Users/shellon/model/Qwen/Qwen3-0__6b-Finetuning" #设置默认加载的模型路径,指向本地微调后的Qwen-6B模型
open-webui serve
一个个执行麻烦,写成脚本一键执行
启动成功:
与微调后的模型对话:

关于微调的一些参数含义,可以参考https://atomgit.com/alibabaclouddocs/aliyun_acp_learning/blob/main/大模型ACP认证教程/p2_构造大模型问答系统/2_7_通过微调提升模型的准确度与效率.ipynb
以上是微调部署的全部内容,如有不足之处欢迎指正!

















 4022
4022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









