







一、IP核配置
使用非实时模式配置如下
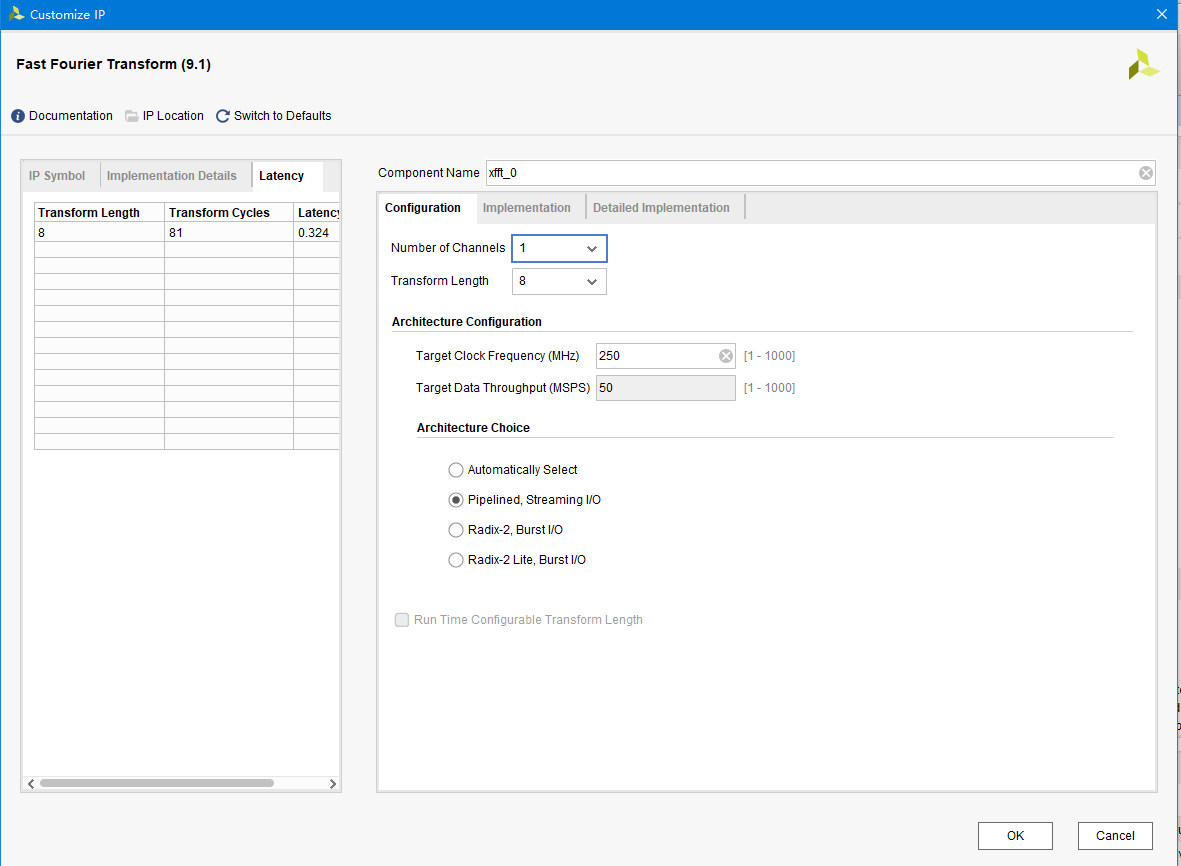
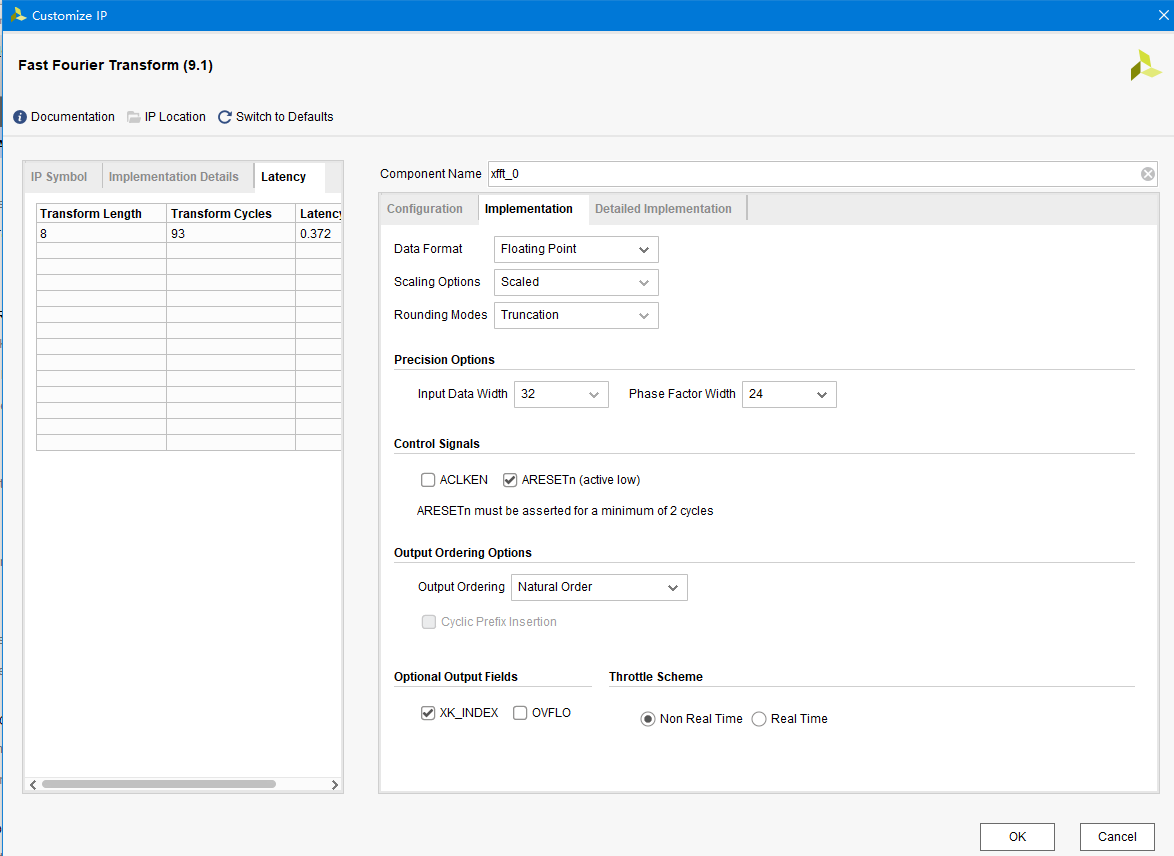
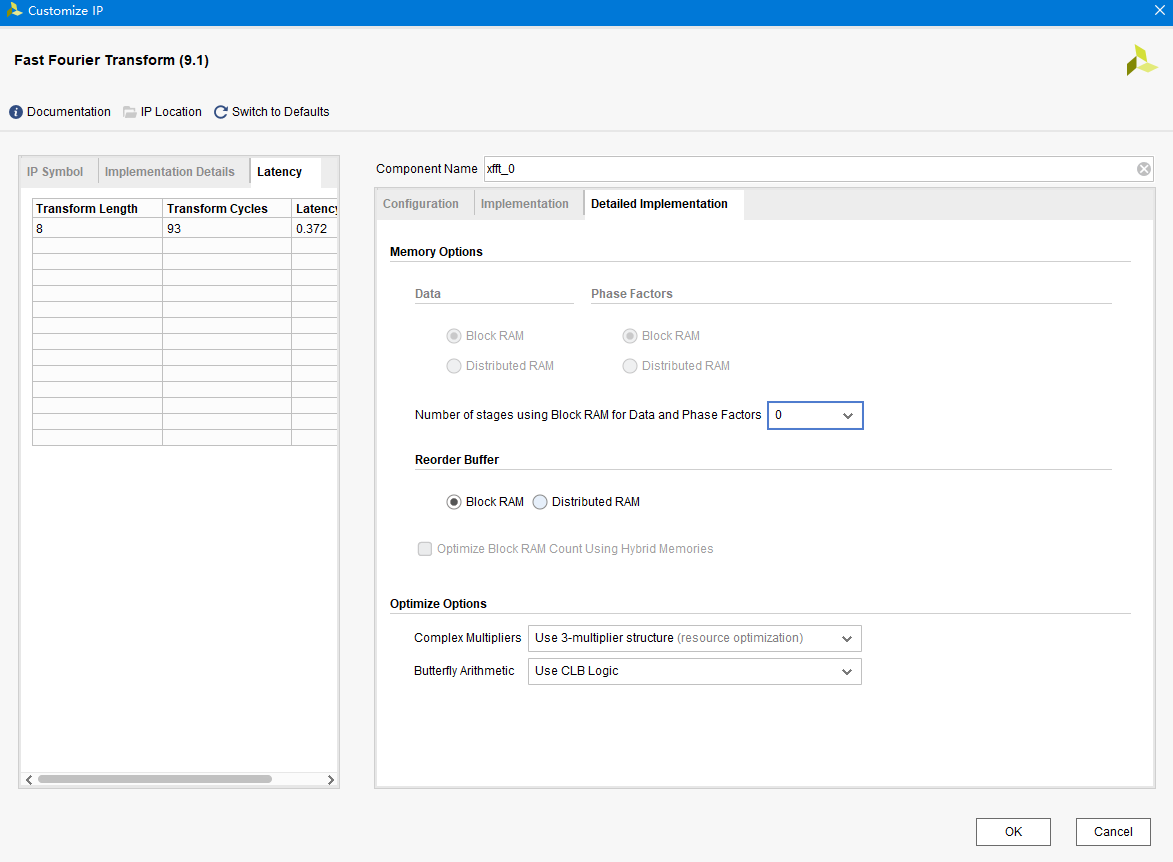
二、时序
是遵守AXIS协议的,不像real time mode,一旦开始吭哧吭哧的读数据,根本不管s_axis_data_tvalid信号了。


三、资源消耗
在implement查看两者的资源消耗差不多
四、仿真
4.1 中间不停顿
输入

结果

4.2 中间停顿4拍再写最后一位
信号整体情况
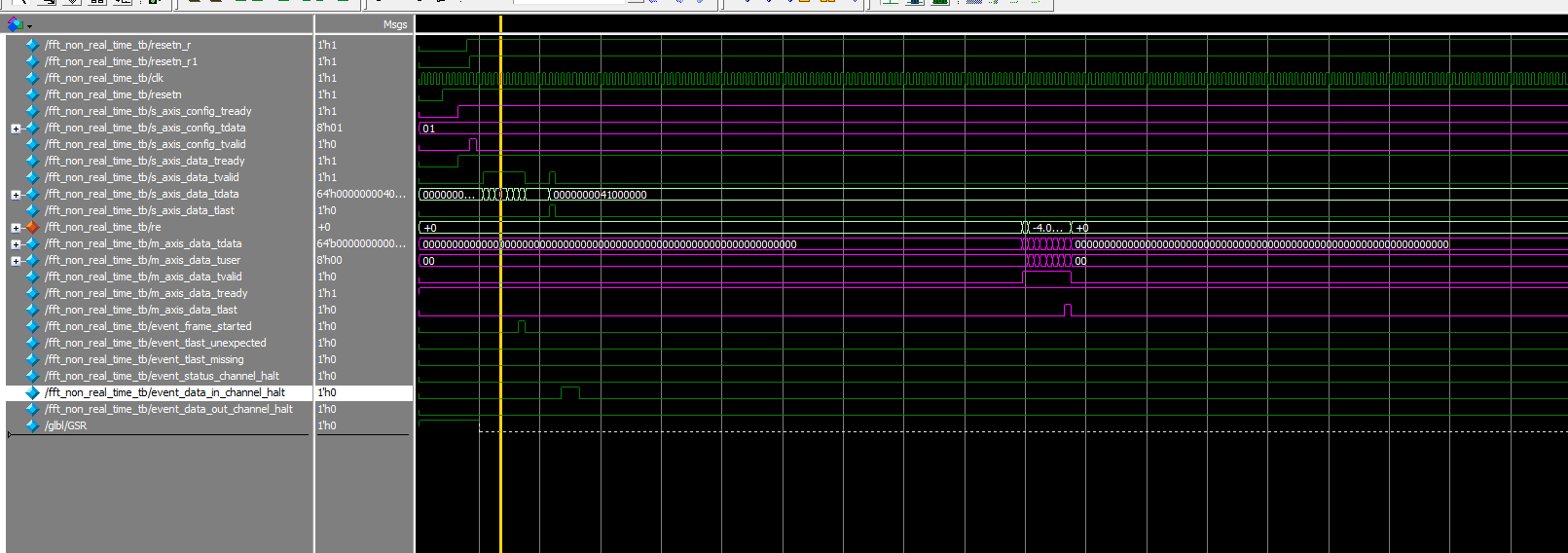
event_data_in_channel_halt
有个有意思的点是event_data_in_channel_halt信号拉高了。查了手册,原因是表明在IP核在non-realtime的情况下需要数据,但是现在没有有效的数据可以给IP核消耗。
但是在real time的情况下,就意味着会读取之前的数据,出现错误。

输入

输出
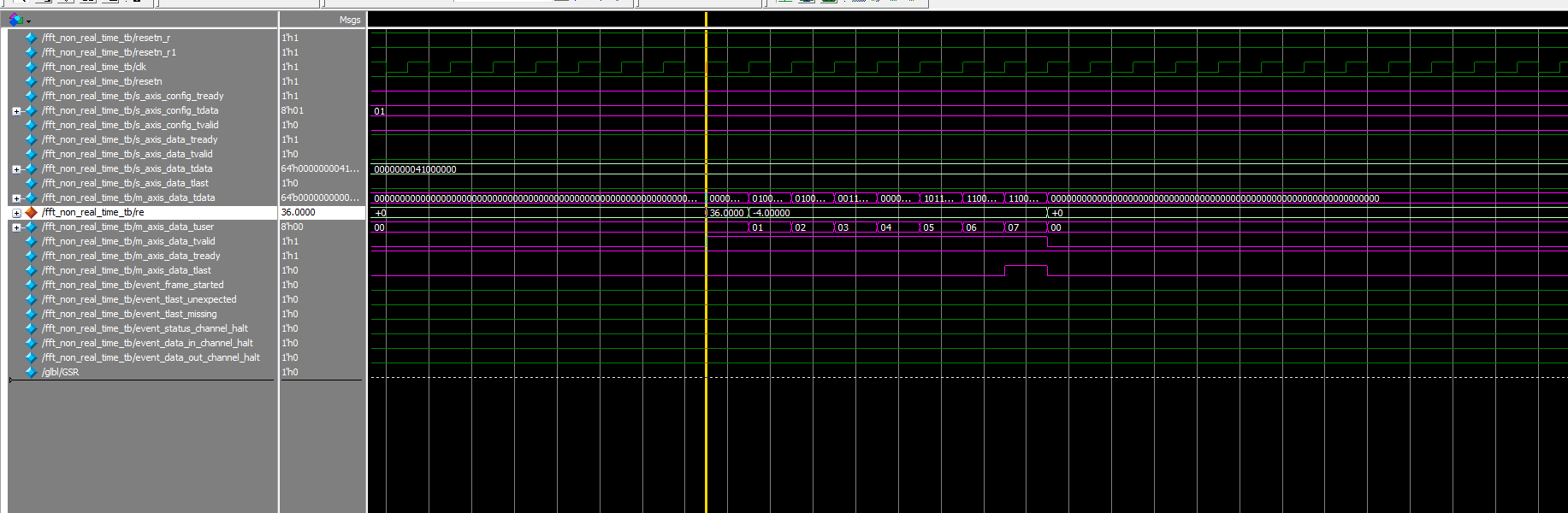
4.3 back-to-back的(上一个8点数据输入完毕,立马输入下一个8点数据)
信号整体情况
输入
输出

唯一有点奇怪的就是最后的多算了一个36,但是输出valid也没有把它那一块拉高。
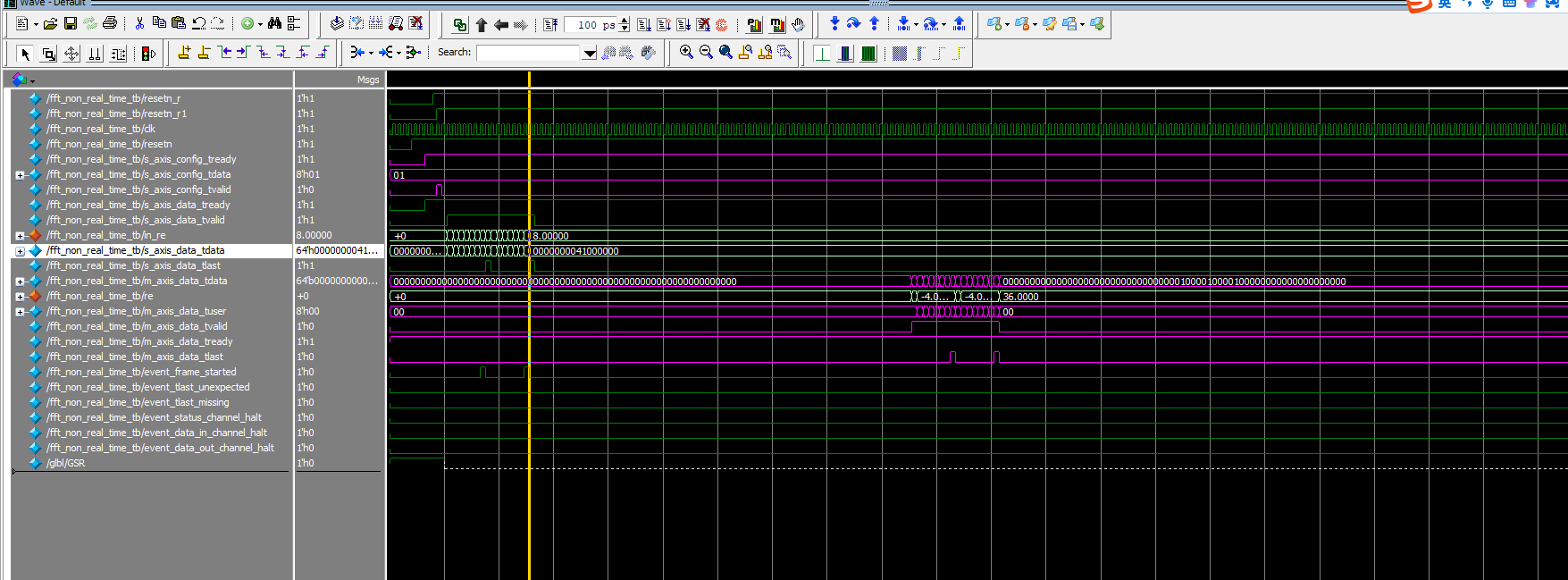
4.4 在4.3 back-to-back的基础上,输入7个数据之后,停10个时钟周期,然后输入第八个数据,然后接着输入7个数据,再停10个时钟周期,输入第二组数据的第八个数据,考虑到之前数据过于简单,可能会出现问题,从这里开始切换更复杂的数据
更改输入数据
FFT的输入是99, 100, 78, 76, 82, 98, 10000, 555
输出是

整体信号
输入信号

输出信号

4.5 目的:上一次FFT结束之后,过了很久再次重新输入数据会不会有问题
在4.3 back-to-back的基础上,输入7个数据之后,停10个时钟周期,然后输入第八个数据,然后停16个时钟周期,接着输入7个数据,再停10个时钟周期,输入第二组数据的第八个数据,
整体信号

输入信号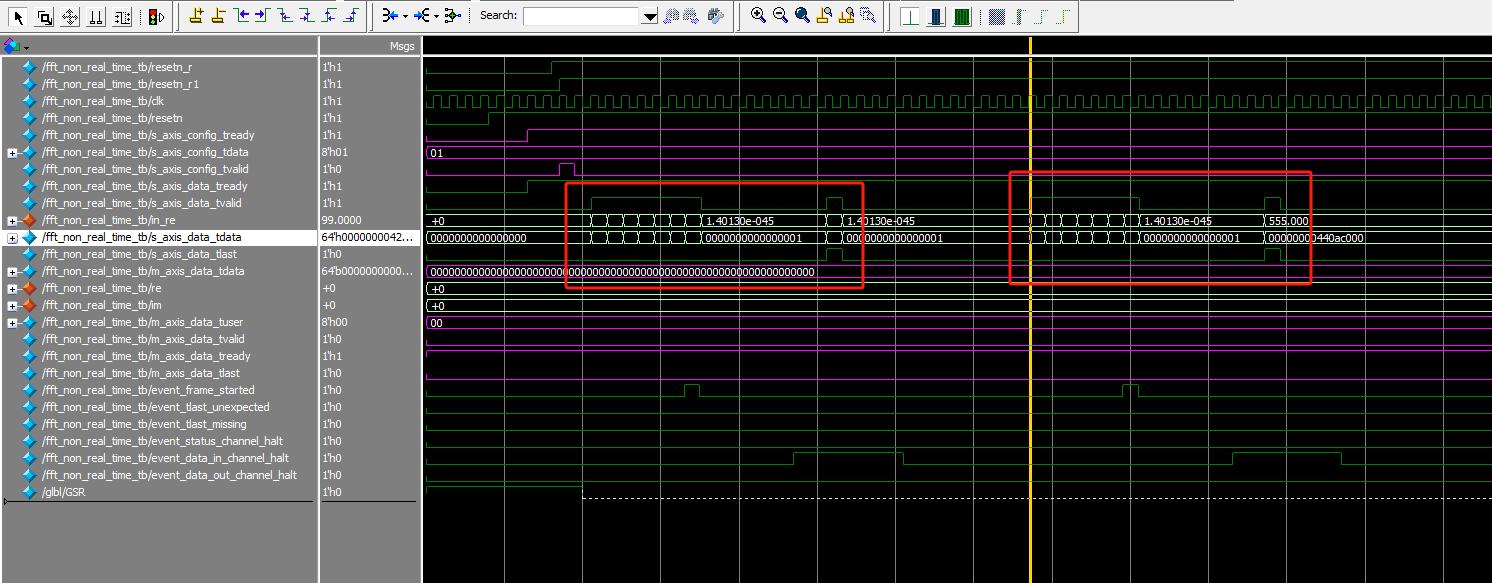
输出信号

整体信号分析
可以看到输出和之前不一样,没有像之前一样连起来,这个我记得文档上面有写明这个情况,如果输入数据是连在一起的,那么输出数据也是连在一起的。测试的时候两个FFT的输入相差12个是时钟周期,那么前一帧的最后一位输出和下一帧的第一位输出就是相差12个时钟周期。
4.6 上一个实验,将两帧之间的延迟降低到4个时钟周期
输出信号
确实输出结果也相差4个时钟周期。

五、关于m_axis_data_tready的实验
具体行为描述在手册里面有,被红框框住的部分

5.1 如果m_axis_data_tready一直不拉高,是不是结果也不会正常输出
m_axis_data_tready不拉高,确实是没有结果输出
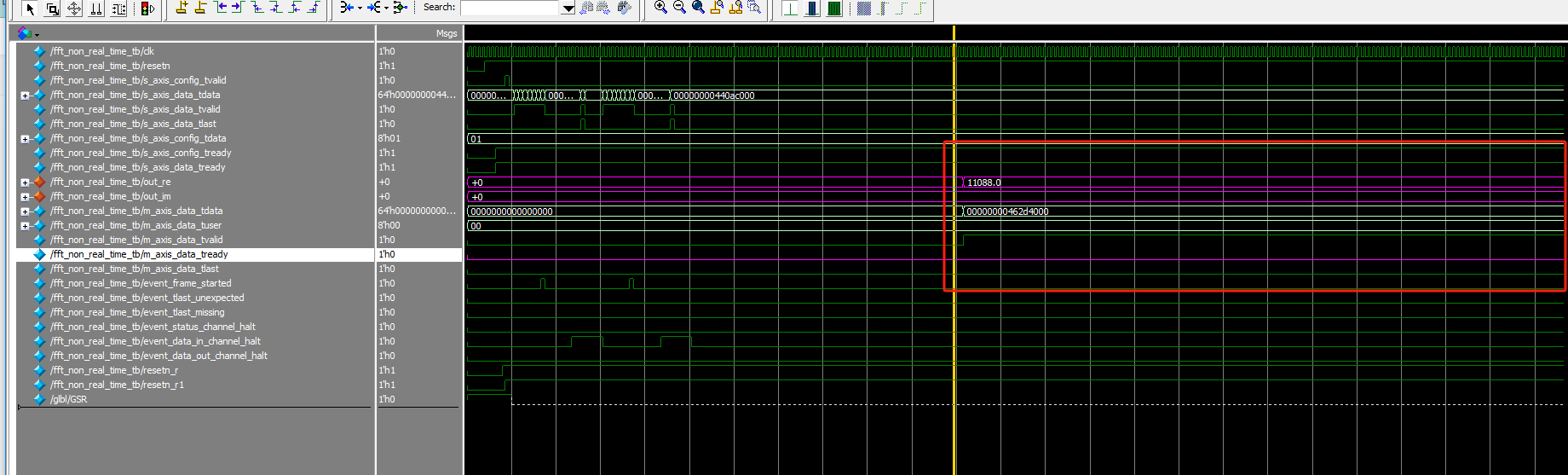
5.2 如果m_axis_data_tready一直不拉高,但是很久了之后会把m_axis_data_tready拉高
可以看到结果IP核的valid信号一直是拉高的,但是m_axis_data_tready不拉高,结果就不会输出。 对照结果也是对的。
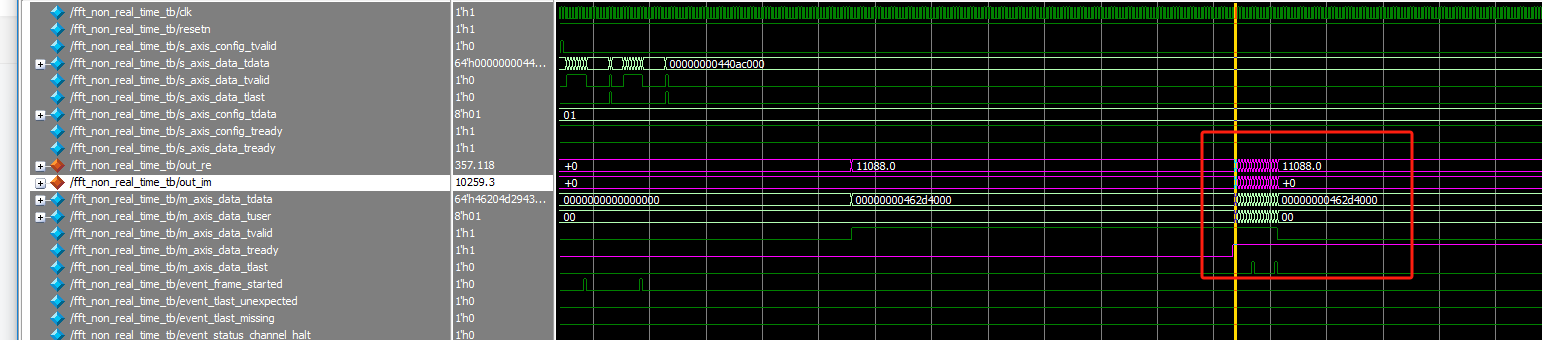

5.3 什么时候m_axis_data_tready会影响到IP核的s_axis_data_tready
如图所示,s_axis_data_tready拉低了一段时间,这会导致一个问题,数据开开心心的输入进来,但是IP核不接收,就会出现错误。

产生原因猜测如下:
m_axis_data_tready的拉低确实是会影响到s_axis_data_tready信号的,原因是FFT的结果已经能输出了,但是太久 m_axis_data_tready没有完成和 m_axis_data_tvalid的握手,FFT的输出一直卡着不出来,然后FFT部件的buffer都满了,这样IP核就会停止工作,s_axis_data_tready就会拉低,不接收数据,下图是手册的说明。

测试,把m_axis_data_tready一直拉高,如果上述猜测正确,那么m_axis_data_tready一直拉高,buffer没有堵住,就不会出现s_axis_data_tready拉低,IP核不接收数据的情况。
测试结果如下,光标位置在和上图一样的位置,让仿真多进行了一段时间。如果m_axis_data_tready一直为1,FFT部件的输出端不需要缓冲数据,

六、测试一下,从FFT的最后一位输入,到FFT开始输出第一个数据,中间的时间是不是FFT点数的定值
FFT的TLAST信号时间

FFT的帧输出时间
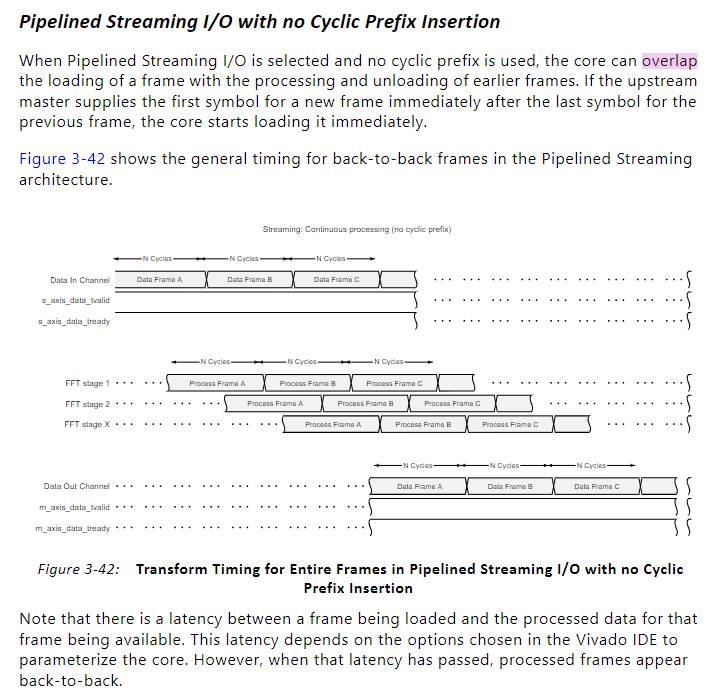
文档说明,理想情况下,输入数据的第一帧的第一个符号,到数据输出帧的最后一个符号,就是Latency,是一个定值。在8点FFT的情况下,是93个时钟周期。
帧内有wait states
实际上,帧内如果有间隔,插了80ns,也就是8个wait states,现在我们暂且给出公式:
real_latency(真正的延迟)= latency(vivao给出的时钟周期)+ wait_states(等待状态的个数)
图中计算两个帧的差值的时候,差了80ns,刚刚好是8个wait_states的个数。

帧内没有wait states,帧间有间隔
这种情况和back to back一样,都没有问题

师兄有空了看看就行,我测试了,和event_frame_start没关系,详见文档第七点。
已知1、FFT输出的两帧之间的间隔值等于输入的两帧之间的间隔。
2、一个数据的tlast信号不论拉的多远,IP核需要数据但是没有数据输入,IP核的数据处理就会中止,如图中的显示event_data_in_channel_halt拉高,(总结,任何IP核的event和异常信号能连上就一定要连上,不要嫌麻烦),文档如图
3、这么一来,其实之前的那张图(如下)就能解释了,IP核给出8点FFT的处理时间周期是93个时钟周期(输入帧的第一个符号到输出帧的最后一个符号),之前的图如下图所示,93*10(一个时钟周期的时间)=930,1195-106-(305-235)-(505-435)=929(tsetbench写的懒,用的阻塞赋值,所以#1,保证时钟上升沿的值是确定的),其实公式就已经出来了,实际延迟=FFT的IP核给的延迟+ event_data_in_channel_halt拉高的时钟周期

4、用这个验算结果是959,不知道误差在哪里,有可能是第一个 帧开始后的第一个event_data_in_channel_halt不算,但是基本逻辑是这样了 
七、event_frame_started的行为

是在每个数据帧的第一个输入之后,过固定的几个时钟周期后,event_frame_started会拉高。可以看到和中间是否有wait states没有关系。附一张对比图和文档截图。
















 7803
7803











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









