







AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
paper:https://arxiv.org/abs/2010.11929
code:https://github.com/google-research/vision_transformer
pytorch_code:https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/vision_transformer
本篇包含了模型讲解-模型代码解析/代码微调-原文阅读~
1.Vision Transformer的由来
Vision Transformer(ViT)是一种基于注意力机制的深度学习模型,它是由 Google 提出的,旨在将Transformer架构应用到计算机视觉任务中。它的提出证明了:
- Transformer 在CV领域的可行性:在过去,卷积神经网络一直是CV的主流模型,而 Transformer 被广泛应用于NLP任务,如机器翻译和文本生成。因此,人们开始探索是否可以将Transformer 及其多头自注意力机制应用于计算机视觉任务中,从而避免传统卷积神经网络在处理长距离依赖关系时的局限性。研究人员通过提出 Vision Transformer,并将其成功应用于图像分类、目标检测和分割等任务,证明了 Transformer 在计算机视觉领域的可行性。这种方法的优势在于能够有效处理不同尺度和分辨率的图像,接捕捉图像中的全局信息和像素之间的长程依赖关系,从而实现端到端的图像处理。
因此,Vision Transformer的提出为图像处理领域带来新的思路和方法。
2.Vision Transformer模型
Vision Transformer(ViT)模型架构是一种基于 Transformer 架构的深度学习模型,用于处理计算机视觉任务。下面是 Vision Transformer 的模型框架,主要划分为3个模块:
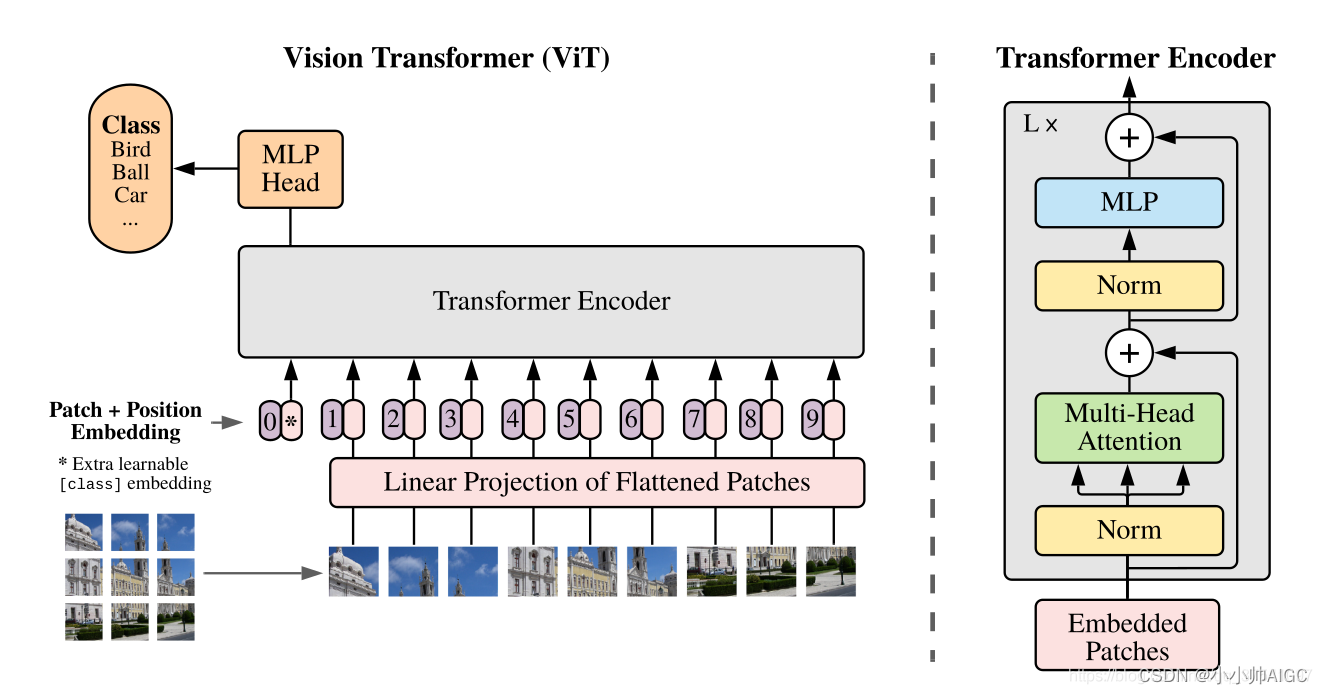
-
Linear Projection of Flattened Patches模块(Embedding层):将输入的图像数据转换为可以输入到 Transformer 编码器中的序列化表示,其中包括了patch+position+learnable embedding。
-
Transformer encoder (Transformer编码层):向量表示被输入到 Transformer 编码器中。每个 Transformer 编码器包含多头自注意力机制和前馈神经网络,用于捕捉全局信息和学习特征表示。这一部分是 Vision Transformer 中最关键的组件。
-
MLP Head(用于分类的全连接层):在经过一系列 Transformer 编码器之后,模型的输出会被送入一个包含多层感知机(MLP)的输出层中,用于最终的分类或其他计算机视觉任务。
2.1.Vision Transformer处理流程
ViT模型的主要流程:
-
输入阶段: 首先将输入的原始图像按照给定大小切分成固定大小的图像块(patches),每个图像块包含图像中的局部信息。 每个图像块通过一个线性变换(通常是一个卷积层)映射到一个低维的特征空间,得到Patch Embeddings。同时,为每个Patch Embedding加入位置编码(Positional Embedding)和可学习嵌入(learnable Embedding) 以综合考虑图像的空间位置和全局信息。
-
输入到Transformer: 将经过嵌入层处理的序列化表示作为输入,传入到多层Transformer Encoder来对序列化表示进行处理。
-
输出分类结果: 经过一系列Transformer编码器的处理后,模型的最后一层输出向量经过全连接层或其他分类层进行分类任务。
总的来说,ViT模型将传统的图像数据处理模式转换为序列数据处理,借助Transformer的强大表达能力和自注意力机制处理图像数据,同时充分利用位置编码和类别嵌入等信息,实现对图像数据的高效学习和处理。ViT模型可以用于图像分类、目标检测等各种视觉任务。下图是ViT的动态流程图:

2.2 Embedding Layer
对于标准的Transformer模块,要求输入的是token序列,即二维矩阵[num_token, token_dim],对于图像而言,其数据格式为[H, W, C]是三维矩阵,不符合Transformer的输入要求。所以需要先通过一个Embedding层来对数据做个变换。
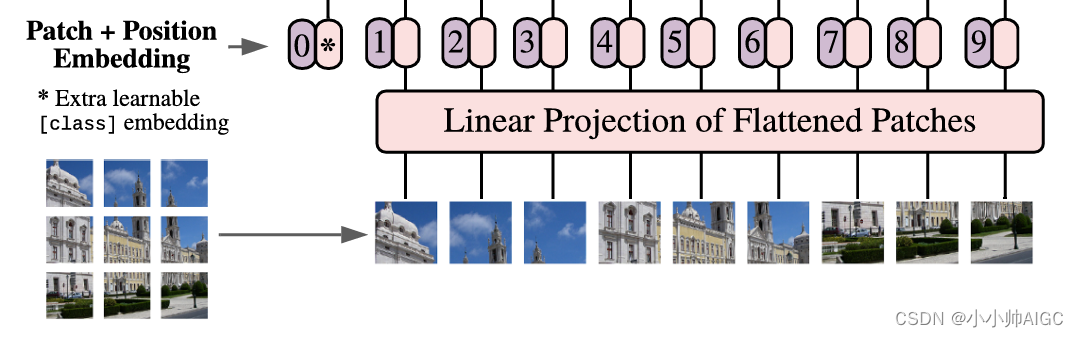
2.2.1 Patch Embedding
Patch Embedding 是指将输入的图像划分为固定大小的图像块(patches)后,将每个图像块映射成一个向量表示,最终所有的图像块被变换成满足transformer输入的一维表示。
具体来说,Patch Embedding 的过程如下:
- 图像划分为图像块: 输入的原始图像被切分成大小相同的图像块,每个图像块通常是不重叠的固定大小的方形区域。这样做的目的是为了将图像信息分割为局部区域,使得模型能够处理不同尺寸的图像。
例:以ViT-B/16为例,将输入图片(224x224)按照16x16大小的Patch进行划分,划分后会得到 ( 224 / 16 ) 2 = 196 ( 224 / 16 )^2 = 196 (224/16)2=196个Patches,每个Patche数据shape为[16, 16, 3]。 - 映射为向量表示: 对于每个图像块,通过一个线性变换(一个卷积层)将其映射成一个一维特征向量,也称为 Patch Embedding。这个过程可以理解为将图像块中的像素信息转换为一个固定维度的向量,以表示该图像块的特征。
例:每个Patche数据通过映射得到一个长度为768的向量,即[16, 16, 3] -> [768] - 串联所有 Patch Embedding: 将所有图像块经过 Patch Embedding 后得到的向量表示串联在一起,形成一个序列化的特征矩阵。这个矩阵作为Transformer的输入,传入Transformer编码器进行处理。
例:将196个Patchs串联起来,最终组成[196,768]的二维token向量,token的个数是196,token维度是768。
在实际代码中,直接通过一个卷积层来实现。例如:
在ViT-B/16中,直接使用一个卷积核大小为16x16,步距为16,卷积核个数为768的卷积来实现。通过卷积[224, 224, 3] -> [14, 14, 768],然后把H以及W两个维度展平即可[14, 14, 768] -> [196, 768]。
通过Patch Embedding的过程,ViT模型将复杂的图像数据转换成序列化的表示形式,使得Transformer可以处理序列数据而不需要训练额外的卷积神经网络结构。
2.2.2.Learnable Embedding
除了将图像块映射为向量表示的 Patch Embedding 外,还存在一种额外的可学习的嵌入 Learnable Embedding: 它是一个可学习的向量,它用来表示整个输入图像的信息。
在ViT模型的原论文中,作者模仿BERT模型,为ViT 模型中引入一个专门用于分类的
[
c
l
a
s
s
]
[class]
[class] token。这个
[
c
l
a
s
s
]
[class]
[class] 是一个可训练的参数,其数据格式和其他 token 一样都是一个向量,例如在 ViT-B/16 模型中,这个向量的长度是 768。
具体步骤如下:
-
生成 [ c l a s s ] [class] [class] token: 在取得一堆 tokens(图像块经过 Patch Embedding 后得到的表示)之后,作者在其中插入一个特殊的 [ c l a s s ] [class] [class] token。这个 [ c l a s s ] [class] [class] token 是用于表示整个输入图像的信息,用于分类任务的输出预测,其是一个可学习的向量
[1, 768] -
向量拼接: 将 [ c l a s s ] [class] [class] token 的向量与之前从图片中生成的 tokens 拼接在一起。例如,原先有
196个 tokens,每个 token 长度为768,则token embeddding变为Cat([1, 768], [196, 768]) -> [197, 768],注意, [ c l a s s ] [class] [class] token插在开头。
通过引入这种特殊的 [ c l a s s ] [class] [class] token,ViT 模型可以使用这个用于分类的 token来捕捉整个图像的全局信息,并帮助模型更好地为分类任务做出预测。这个机制类似于 BERT 模型中使用 [ C L S ] [CLS] [CLS] token 来表示整个输入序列的信息。
2.2.3.Position Embedding
在 ViT 模型中,由于输入的图像经过 Patch Embedding 转换为一系列的图像块,这些 Patch 之间的相对位置是重要的。因此,位置编码以帮助模型理解图像路径中各个 Patch 之间的位置关系。另外,不同于 CNN,Transformer 需要位置嵌入来编码 patch tokens 的位置信息,这主要是由于 自注意力的扰动不变性 (Permutation-invariant),即打乱 Sequence 中 tokens 的顺序并不会改变结果。相反,若不给模型提供图像块的位置信息,那么模型就需要通过图像块的语义来学习拼图,这就额外增加了学习成本。
ViT的Position Embedding采用的是一个可学习/训练的 1-D 位置编码嵌入,是直接叠加在tokens上的(add),
例: position embedding的shape应该是[197,768],直接position embedding +
[
c
l
a
s
s
]
[class]
[class] token embedding=[197,768]
最终输入到Transformer的嵌入为:
Cat[learnable Embedding,patch Embedding] +position Embedding
2.3.Transformer encoder
Transformer Encoder 是用来处理输入序列的部分,它由多个 Transformer Block 组成。每个 Transformer Block 都包括两个主要组件:多头自注意力层和前馈神经网络。Transformer Encoder 的结构:
Multi-head Self-Attention Layer: 在每个 Transformer Block 中,输入特征首先被送入一个多头自注意力层。这个层用来计算输入序列中每个位置对应的注意力权重,以捕捉不同位置之间的关系。
Feed-Forward Neural Network: 在经过多头自注意力层后,每个位置的特征会通过一个前馈神经网络进行处理。这个前馈神经网络通常由两个全连接层和激活函数组成,用来对每个位置的特征进行非线性变换和映射。
Residual Connection & Layer Normalization: 在每个 Transformer Block 的多头自注意力层和前馈神经网络中都会包含残差连接和层归一化操作,这有助于缓解梯度消失问题和加速训练过程。
在 ViT 模型中,多个 Transformer Block 会串联在一起,构成整个 Transformer Encoder。输入特征会经过多个 Transformer Block 的处理,每个块产生一系列更具语义信息的特征表示。通过反复堆叠和叠加多个 Transformer Block,ViT 模型能够有效地学习输入图像的复杂特征和结构信息。
每个 Transformer Block的处理步骤:
输入特征序列会分别通过多个注意力头进行注意力计算,以捕捉不同位置之间的依赖关系。
在每个注意力层之后都会应用残差连接和层归一化操作,有助于梯度传播和模型训练的稳定性。
经过自注意力机制后的特征会传入一个全连接前馈神经网络,以进行非线性转换和映射。
在前馈神经网络之后同样会使用残差连接和层归一化操作。
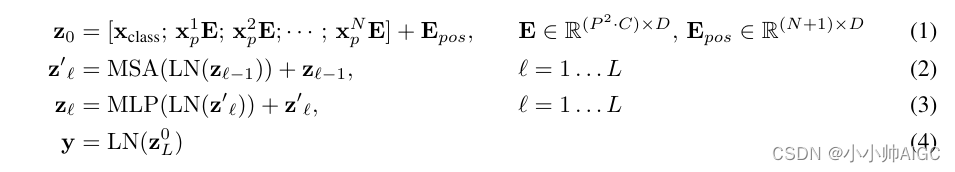
等式 1:由 图像块嵌入 x p i E x_p^iE xpiE,类别向量 x c l a s s x_{class} xclass,位置编码 E p o s E_{pos} Epos构成 输入向量 z 0 z_0 z0
等式 2:由 多头注意力机制、层归一化和跳跃连接构成的 MSA Block,可重复L个,最后一个输出为 z l ‘ z_l^{‘} zl‘
等式 3:由 前馈网络、层归一化 和 跳跃连接构成的 MLP Block,可重复L个,最后一个输出为 z l z_l zl
等式 4:由 层归一化 和 分类头 (MLP or FC) 输出 图像表示 y y y
2.4. MLP Head
MLP Head 是指位于模型顶部的全连接前馈神经网络模块,用于将提取的图像特征表示转换为最终的分类结果或其他预测任务输出。MLP Head 通常跟在 Transformer Encoder 的输出之后,作为整个模型的最后一层。
具体来说,当我们只需要分类信息时,只需要提取出
[
c
l
a
s
s
]
[class]
[class]token生成的对应结果就行,即[197, 768]中抽取出
[
c
l
a
s
s
]
[class]
[class]token对应的[1, 768]。接着我们通过MLP Head得到我们最终的分类结果。MLP Head原论文中说在训练ImageNet21K时是由Linear+tanh激活函数+Linear组成。但是迁移到ImageNet1K上或者你自己的数据上时,只用一个Linear即可。
2.5.归纳偏置与混合架构
归纳偏置:Vision Transformer 的图像特定归纳偏置比 CNN 少得多。在 CNN 中,局部性、二维邻域结构和平移等效性存在于整个模型的每一层中。而在ViT中,只有MLP层是局部和平移等变的,因为自注意力层都是全局的。
混合架构:Hybrid 模型是一种结合传统卷积神经网络(CNN)和Transformer的方法,旨在兼顾两种模型的优势,从而更好地处理图像数据。论文通过对比发现,在训练epoch较少时Hybrid优于ViT,但当epoch增大后ViT优于Hybrid
2.6.Vision Transformer维度变换
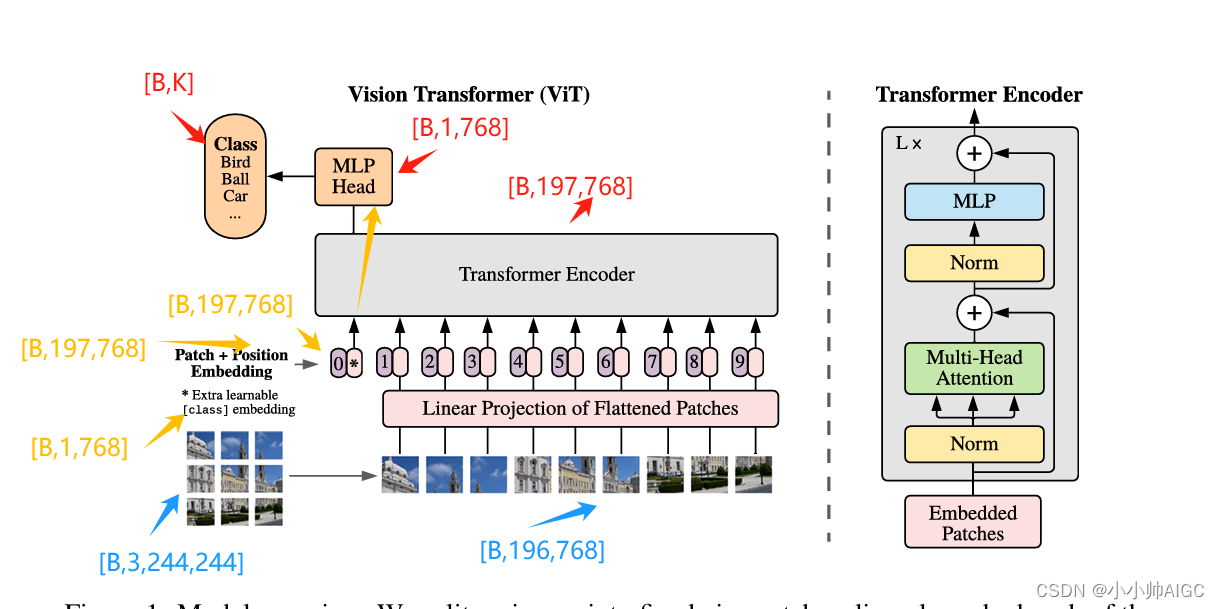
- 输入图像的input shape=
[1,3,224,224],1是batch_size,3是通道数,224是高和宽 - 输入图像经过patch Embedding,其中Patch大小是14,卷积核是768,则经过分块后,获得的块数量是
(
224
)
2
/
1
4
2
=
196
(224)^2/14^2=196
(224)2/142=196,每个块的维度被转换为
768,即得到的patch embedding的shape=[1,196,768] - 将可学习的[class] token embedding拼接到patch embedding前,得到shape=
[1,197,768] - 将position embedding加入到拼接后的embedding中,组成最终的输入嵌入,最终的输入shape=
[1,197,768] - 输入嵌入送入到Transformer encoder中,shape并不发生变化
- 最后transformer的输出被送入到MLP或FC中执行分类预测,选取[class] token作为分类器的输入,以表示整个图像的全局信息,假设分类的类目为
K
K
K,最终的shape=
[1,768]*[768,K]=[1,K]
2.7.微调及更高分辨率
微调:通常,在大型数据集上预训练 ViT,并对 (更小的) 下游任务进行微调。为此,在微调时,移除了预训练的预测头部,换为一个前馈层 / 全连接层。
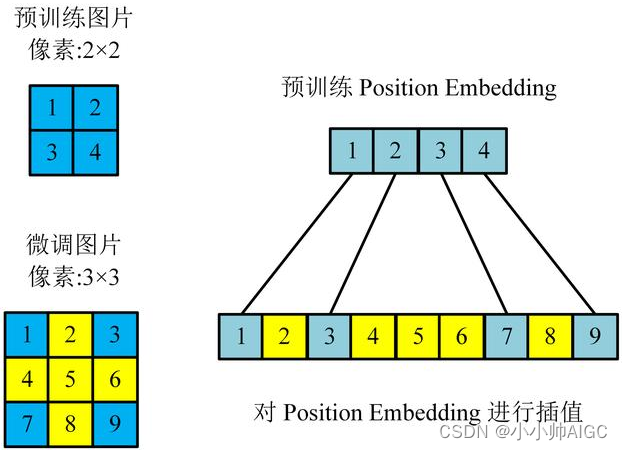
更高分辨率:当提供更高分辨率的图像时,有效图像 patchs 数变多,使得有效序列长度会变长。Vision Transformer 可处理任意序列长度,但预训练的位置嵌入 (position embedding) 可能不再有意义,因为当前的位置嵌入无法与之一一对应了。因此,根据它们在原图中的位置,对预训练的位置嵌入执行 2D 插值,以扩展到微调尺寸。
3.ViT源码
3.1.ViT源码解析
我们按照ViT处理数据的流程来一步步解刨源码,首先对于整体的框架源码如下:
class VisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_c=3, num_classes=1000,
embed_dim=768, depth=12, num_heads=12, mlp_ratio=4.0, qkv_bias=True,
qk_scale=None, representation_size=None, distilled=False, drop_ratio=0.,
attn_drop_ratio=0., drop_path_ratio=0., embed_layer=PatchEmbed, norm_layer=None,act_layer=None):
super(VisionTransformer, self).__init__()
self.num_classes = num_classes
self.num_features = self.embed_dim = embed_dim
self.num_tokens = 2 if distilled else 1
norm_layer = norm_layer or partial(nn.LayerNorm, eps=1e-6)
act_layer = act_layer or nn.GELU
self.patch_embed = embed_layer(img_size=img_size, patch_size=patch_size, in_c=in_c, embed_dim=embed_dim)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim))
self.dist_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) if distilled else None
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim))
self.pos_drop = nn.Dropout(p=drop_ratio)
dpr = [x.item() for x in torch.linspace(0, drop_path_ratio, depth)]
self.blocks = nn.Sequential(*[
Block(dim=embed_dim, num_heads=num_heads, mlp_ratio=mlp_ratio, qkv_bias=qkv_bias, qk_scale=qk_scale,
drop_ratio=drop_ratio, attn_drop_ratio=attn_drop_ratio, drop_path_ratio=dpr[i],
norm_layer=norm_layer, act_layer=act_layer)
for i in range(depth)
])
self.norm = norm_layer(embed_dim)
# Representation layer
if representation_size and not distilled:
self.has_logits = True
self.num_features = representation_size
self.pre_logits = nn.Sequential(OrderedDict([
("fc", nn.Linear(embed_dim, representation_size)),
("act", nn.Tanh())
]))
else:
self.has_logits = False
self.pre_logits = nn.Identity()
# Classifier head(s)
self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity()
self.head_dist = None
if distilled:
self.head_dist = nn.Linear(self.embed_dim, self.num_classes) if num_classes > 0 else nn.Identity()
# Weight init
nn.init.trunc_normal_(self.pos_embed, std=0.02)
if self.dist_token is not None:
nn.init.trunc_normal_(self.dist_token, std=0.02)
nn.init.trunc_normal_(self.cls_token, std=0.02)
self.apply(_init_vit_weights)
def forward_features(self, x):
# [B, C, H, W] -> [B, num_patches, embed_dim]
x = self.patch_embed(x) # [B, 196, 768]
# [1, 1, 768] -> [B, 1, 768]
cls_token = self.cls_token.expand(x.shape[0], -1, -1)
if self.dist_token is None:
x = torch.cat((cls_token, x), dim=1) # [B, 197, 768]
else:
x = torch.cat((cls_token, self.dist_token.expand(x.shape[0], -1, -1), x), dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.blocks(x)
x = self.norm(x)
if self.dist_token is None:
return self.pre_logits(x[:, 0])
else:
return x[:, 0], x[:, 1]
def forward(self, x):
x = self.forward_features(x)
if self.head_dist is not None:
x, x_dist = self.head(x[0]), self.head_dist(x[1])
if self.training and not torch.jit.is_scripting():
# during inference, return the average of both classifier predictions
return x, x_dist
else:
return (x + x_dist) / 2
else:
x = self.head(x)
return x
假设我们输入的图像大小是[3,800,800],经过batch构造最终的输入为[1,3,800,800],使用ViT-B/16_224预训练权重,下面按照2.1中的流程开始执行:
-
Image预处理:
-
在训练阶段:首先,随机裁剪输入图像,并将裁剪后的图像调整大小为 224x224 像素,然后,以一定的概率对图像进行水平翻转,最后,将图像数据转换为 PyTorch 的 Tensor 格式并对图像进行标准化处理。
transforms.Compose([transforms.RandomResizedCrop(224),transforms.RandomHorizontalFlip(),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])]) -
在预测阶段:首先,将输入图像调整大小为 256x256 像素,然后,对调整大小后的图像进行中心裁剪,保留图像中心区域 224x224 像素,最后,将图像数据转换为 PyTorch 的 Tensor 格式并对图像进行标准化处理。
transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5])])
维度:Image:
[3,800,800]经过预处理变换为[3,224,224] -
-
执行patch embedding操作,即
def forward_features(self, x):中的x = self.patch_embed(x):-
首先,检查输入图像的尺寸是否与模型期望的图像大小一致。
-
然后通过卷积层 self.proj 对输入图像进行卷积操作,将图像转换为嵌入向量形式,
-
将转换后的嵌入向量进行扁平化(flatten)和转置(transpose),以便最终得到形状为
[B, C, HW]的输出。 -
最后,通过规范化层 self.norm 对嵌入向量进行规范化处理,并返回处理后的结果。
维度:Image:
[1,3,224,224]经过patch embedding变换为[1,196,768]
完整代码如下:
class PatchEmbed(nn.Module): def __init__(self, img_size=224, patch_size=16, in_c=3, embed_dim=768, norm_layer=None): super().__init__() img_size = (img_size, img_size) patch_size = (patch_size, patch_size) self.img_size = img_size self.patch_size = patch_size self.grid_size = (img_size[0] // patch_size[0], img_size[1] // patch_size[1]) self.num_patches = self.grid_size[0] * self.grid_size[1] self.proj = nn.Conv2d(in_c, embed_dim, kernel_size=patch_size, stride=patch_size) self.norm = norm_layer(embed_dim) if norm_layer else nn.Identity() def forward(self, x): B, C, H, W = x.shape assert H == self.img_size[0] and W == self.img_size[1], f"Input image size ({H}*{W}) doesn't match model ({self.img_size[0]}*{self.img_size[1]})." x = self.proj(x).flatten(2).transpose(1, 2) x = self.norm(x) return x -
-
执行learnable embedding&position embedding操作:
- 通过
self.cls_token.expand(x.shape[0], -1, -1)创建一个与输入x 相同 Batch Size 的类别标记向量,并将其与 x 进行拼接操作,形成新的张量 x,即learnable embedding拼接到patch embedding前。 - 将位置编码(pos_embed)添加到 x 中,并使用位置 Dropout(pos_drop)来对位置信息进行随机丢弃。即
x = self.pos_drop(x + self.pos_embed)
维度:
[1,196,768]经过cls_token变换为[1,197,768],在经过pos_embed变换为[1,197,768]Note: position&learnable embedding都是可学习参数,随机初始化由模型训练学习得到:
self.cls_token = nn.Parameter(torch.zeros(1, 1, embed_dim)) self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + self.num_tokens, embed_dim)) nn.init.trunc_normal_(self.pos_embed, std=0.02) nn.init.trunc_normal_(self.cls_token, std=0.02) - 通过
-
执行Transformer encoder操作:
在获取Transformer的输入嵌入后(
cat[class embed,patch embed]+pos embed)执行Transformer流程,这里不做讲解。(使用了12层的Transformer encoder block)维度:
[1,197,768]经过transformer后不变,还是[1,197,768]。具体代码如下:class Block(nn.Module): def __init__(self,dim,num_heads,mlp_ratio=4.,qkv_bias=False,qk_scale=None,drop_ratio=0.,attn_drop_ratio=0.,drop_path_ratio=0.,act_layer=nn.GELU,norm_layer=nn.LayerNorm): super(Block, self).__init__() self.norm1 = norm_layer(dim) self.attn = Attention(dim, num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,attn_drop_ratio=attn_drop_ratio, proj_drop_ratio=drop_ratio) self.drop_path = DropPath(drop_path_ratio) if drop_path_ratio > 0. else nn.Identity() self.norm2 = norm_layer(dim) mlp_hidden_dim = int(dim * mlp_ratio) self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop_ratio) def forward(self, x): x = x + self.drop_path(self.attn(self.norm1(x))) x = x + self.drop_path(self.mlp(self.norm2(x))) return x -
执行MLP head操作执行分类:
分类通过全连接将其转换为对应类别的维度,即
维度:假设分类的类目数是10,则最终的维度变换为
[1,197,768]->[1,10]self.head = nn.Linear(self.num_features, num_classes) if num_classes > 0 else nn.Identity() x = self.head(x)
3.2.ViT微调
参考https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/vision_transformer 中的代码,执行微调,这里我跳跃式讲解一下代码即可。具体流程:
-
加载数据:
-
读取和拆分数据:函数从指定路径读取数据,标签分别赋值给
train_images_path、train_images_label、val_images_path、val_images_labeltrain_images_path, train_images_label, val_images_path, val_images_label = read_split_data(args.data_path) -
实例化数据集类:使用自定义的数据集类
MyDataSet分别实例化了训练数据集train_dataset和验证数据集val_dataset,并传入对应的图像路径、标签和数据转换方式。train_dataset = MyDataSet(images_path=train_images_path,images_class=train_images_label,transform=data_transform["train"]) val_dataset = MyDataSet(images_path=val_images_path,images_class=val_images_label,transform=data_transform["val"]) -
数据加载器设置:实例化了训练数据加载器
train_loader和验证数据加载器val_loadertrain_loader = torch.utils.data.DataLoader(train_dataset,batch_size=batch_size,shuffle=True,pin_memory=True,num_workers=nw,collate_fn=train_dataset.collate_fn) ...
-
-
加载模型:
-
创建模型:调用
create_model函数创建模型,其中传入了分类类别数目num_classes和一个布尔值参数has_logitsmodel = create_model(num_classes=args.num_classes, has_logits=False).to(device) -
加载预训练权重:读取该权重文件,然后通过
torch.load函数加载权重参数字典,并对字典中的一些不需要的参数进行删除。删除的参数包括了模型中的某些层的权重参数,根据模型是否具有 logits 层来确定删除哪些参数。最后使用model.load_state_dict方法加载剩下的权重参数到模型中weights_dict = torch.load(args.weights, map_location=device) # 删除不需要的权重 del_keys = ['head.weight', 'head.bias'] if model.has_logits \ else ['pre_logits.fc.weight', 'pre_logits.fc.bias', 'head.weight', 'head.bias'] for k in del_keys: del weights_dict[k] print(model.load_state_dict(weights_dict, strict=False)) -
冻结部分层权重:如果命令行参数中指定了
freeze_layers,则会对模型的参数进行冻结操作,只有特定的层权重需要进行训练。遍历模型的参数,对除了指定的几个层(‘head’ 和 ‘pre_logits’)外的所有其他层的参数进行冻结,设置为不需要梯度更新if args.freeze_layers: for name, para in model.named_parameters(): # 除head, pre_logits外,其他权重全部冻结 if "head" not in name and "pre_logits" not in name: para.requires_grad_(False)
-
-
执行模型的Train:
for epoch in range(args.epochs): # train train_loss, train_acc = train_one_epoch(model=model,optimizer=optimizer,data_loader=train_loader,device=device,epoch=epoch) def train_one_epoch(model, optimizer, data_loader, device, epoch): model.train() loss_function = torch.nn.CrossEntropyLoss() accu_loss = torch.zeros(1).to(device) # 累计损失 accu_num = torch.zeros(1).to(device) # 累计预测正确的样本数 optimizer.zero_grad() sample_num = 0 data_loader = tqdm(data_loader, file=sys.stdout) for step, data in enumerate(data_loader): images, labels = data sample_num += images.shape[0] pred = model(images.to(device)) pred_classes = torch.max(pred, dim=1)[1] accu_num += torch.eq(pred_classes, labels.to(device)).sum() loss = loss_function(pred, labels.to(device)) loss.backward() accu_loss += loss.detach() optimizer.step() optimizer.zero_grad() return accu_loss.item() / (step + 1), accu_num.item() / sample_num
最后,注意,如何想要改变微调图像的分辨率大小,需要对预训练的位置嵌入执行 2D 插值,以扩展到微调尺寸,具体的步骤如下:
- 首先,获取新的位置嵌入的 token 数目
ntok_new,并从原始位置嵌入中分离出类别[class] token 的位置嵌入posemb_tok和patches位置嵌入posemb_grid。 - 计算原始位置嵌入的patches大小
gs_old和新位置嵌入的patches大小gs_new。 - 将patches位置嵌入
posemb_grid转换为 2D 维度的形式,然后使用双线性插值(bilinear interpolation)对其进行调整,将其修改为新的patches大小gs_new。 - 最后,将调整后的[class] token 位置嵌入和调整后的patches位置嵌入合并,并返回调整后的完整位置嵌入
posemb。
def resize_pos_embed(posemb, posemb_new):
_logger.info('Resized position embedding: %s to %s', posemb.shape, posemb_new.shape)
ntok_new = posemb_new.shape[1]
# 除去 class token 的 pos_embed
posemb_tok, posemb_grid = posemb[:, :1], posemb[0, 1:]
ntok_new -= 1
gs_old = int(math.sqrt(len(posemb_grid)))
gs_new = int(math.sqrt(ntok_new))
_logger.info('Position embedding grid-size from %s to %s', gs_old, gs_new)
# 把 pos_embed 变换到 2-D 维度再进行插值
posemb_grid = posemb_grid.reshape(1, gs_old, gs_old, -1).permute(0, 3, 1, 2)
posemb_grid = F.interpolate(posemb_grid, size=(gs_new, gs_new), mode='bilinear')
posemb_grid = posemb_grid.permute(0, 2, 3, 1).reshape(1, gs_new * gs_new, -1)
posemb = torch.cat([posemb_tok, posemb_grid], dim=1)
return posemb
4.原文阅读
ABSTRACT
虽然 Transformer 架构已成为自然语言处理任务的事实标准,但它在计算机视觉领域的应用仍然有限。在视觉领域,注意力要么与卷积网络结合使用,要么用来替代卷积网络的某些组件,同时保持其整体结构不变。我们的研究表明,这种对卷积网络的依赖并非必要,直接应用于图像斑块序列的纯净变换器可以在图像分类任务中表现出色。在对大量数据进行预训练并将其应用于多个中型或小型图像识别基准(ImageNet、CIFAR-100、VTAB 等)时,Vision Transformer(ViT)与最先进的卷积网络相比取得了优异的成绩,而训练所需的计算资源却大大减少。
4.1 INTRODUCTION
基于自我注意的架构,尤其是 Transformers,已成为自然语言处理(NLP)领域的首选模型。主流方法是在大型文本语料库上进行预训练,然后在较小的特定任务数据集上进行微调。得益于 Transformers 的计算效率和可扩展性,训练出的模型规模空前,参数超过 100B。随着模型和数据集的不断增长,其性能仍然没有饱和的迹象。
然而,在计算机视觉领域,卷积架构仍然占据主导地位。受 NLP 成功的启发,多项研究尝试将类似 CNN 的架构与自注意相结合,有些研究甚至完全取代了卷积。后一种模型虽然理论上高效,但由于使用了专门的注意力模式,尚未在现代硬件加速器上有效扩展。因此,在大规模图像识别中,类似 ResNet 的经典架构仍然是最先进的。
受 NLP 中 Transformer 扩展成功的启发,我们尝试将标准 Transformer 直接应用于图像,并尽可能减少修改。为此,我们将图像分割成多个片段,并提供这些片段的线性嵌入序列作为 Transformer 的输入。图像补丁的处理方式与 NLP 应用中的标记(单词)相同。我们以监督的方式对模型进行图像分类训练。
在中等规模的数据集(如 ImageNet)上进行训练时,如果不进行强正则化,这些模式的准确率会适度降低,比同等规模的 ResNets 低几个百分点。这种看似令人沮丧的结果可能是意料之中的:Transformers缺乏 CNN 固有的一些归纳偏差,如翻译等差性和定位性,因此在数据量不足的情况下进行训练时无法很好地泛化。然而,如果在更大的数据集(1400万至3亿张图像)上对模型进行训练,情况就会发生变化。我们认为,大规模训练战胜了归纳偏差。
我们的视觉转换器(Vision Transformer,ViT)在进行足够规模的预训练并将其应用于数据点较少的任务时,取得了优异的成绩。当在公共 ImageNet-21k 数据集或内部 JFT-300M 数据集上进行预训练时,ViT 在多个图像识别基准上接近或超越了技术水平。其中,最佳模型在 ImageNet 上的准确率为 88.55%,在 ImageNet-ReaL 上的准确率为 90.72%,在 CIFAR-100 上的准确率为 94.55%,在包含 19 项任务的 VTAB 套件上的准确率为 77.63%。
4.2. RELATED WORK
4.3 METHOD
在模型设计中,我们尽可能地沿用了最初的 Transformer。 这种有意简单设置的优势在于,可扩展的 NLP Transformer 架构及其高效实现几乎可以开箱即用。
4.3.1 VISION TRANSFORMER (VIT)
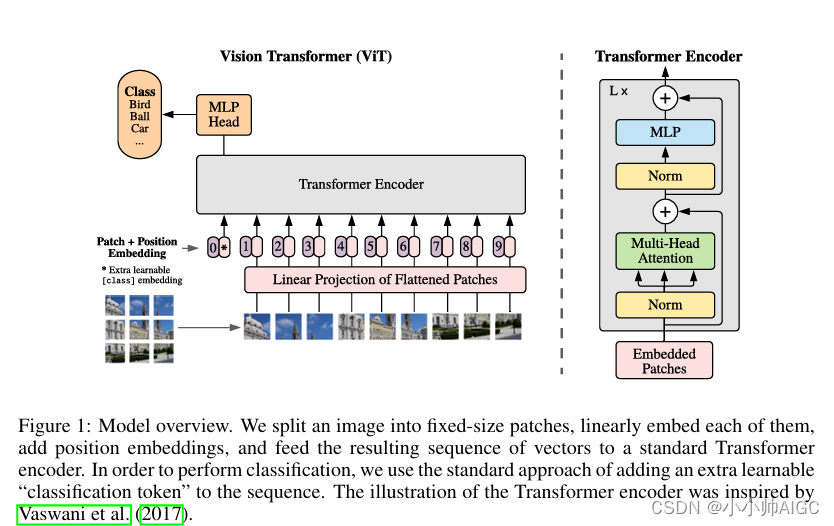
图 1 是该模型的概览。标准Transformer的输入是一维标记嵌入序列。为了处理二维图像,我们将图像 x ∈ R H × W × C x\in R^{H \times W\times C} x∈RH×W×C重塑为扁平化的二维patchs序列 x p ∈ R N × ( P 2 × C ) x_p\in R^{N \times (P^2\times C)} xp∈RN×(P2×C),其中 ( H , W ) (H,W) (H,W) 是原始图像的分辨率, C C C 是通道数, ( P , P ) (P,P) (P,P) 是每个图像补丁的分辨率, N = H W / P 2 N = HW/P^2 N=HW/P2 是生成的patches数,这也是Transformer的有效输入序列长度。Transformer在其所有层中使用恒定的潜在向量大小 D D D,因此我们用一个可训练的线性投影(公式 1)将patch网格化并映射到 D D D维。我们将此投影的输出称为patch嵌入。
与 BERT 的 [ c l a s s ] [class] [class]标记类似,我们在此处为图像 patch 嵌入序列预设一个可学习的嵌入( z 0 0 = x c l a s s z_0^0=x_{class} z00=xclass),该嵌入在 Vision Transformer 编码器输出的状态/特征( z L 0 z_L^0 zL0)作为图像表示 y(公式 4)。在预训练和微调过程中,都有一个 分类头 (Classification Head)附加在 z L 0 z_L^0 zL0之后,从而用于图像分类。在预训练时,分类头由一个带有一个隐藏层的 MLP 实现,而在微调时,则由一个线性层实现。(多层感知机与线性模型类似,区别在于 MLP 相对于 FC 层数增加且引入了非线性激活函数,例如 FC + GELU + FC 形式的 MLP)
position embeddings被添加到patch embeddings中,以保留位置信息。我们使用标准的可学习一维位置嵌入,因为我们没有观察到使用更先进的二维感知位置嵌入能显著提高性能。由此产生的嵌入向量序列将作为编码器的输入。
Transformer 编码器由多头自我注意和 MLP 块交替层组成。在每个区块之前应用 Layernorm(LN),在每个区块之后应用残差连接。
MLP 包含两层,具有 GELU 非线性特性:
z
0
=
[
x
c
l
a
s
s
;
x
p
1
E
;
x
p
2
E
;
.
.
.
,
x
p
N
E
]
+
E
p
o
s
z
ℓ
′
=
M
S
A
(
L
N
(
z
ℓ
−
1
)
)
+
z
ℓ
−
1
z
ℓ
=
M
L
P
(
L
N
(
z
ℓ
′
)
)
+
z
ℓ
′
y
=
L
N
(
z
L
0
)
\begin{aligned} z_0&=[x_{class};x_p^1E;x_p^2E;...,x_p^NE]+E_{pos} \\ z^{'}_{\ell}&=MSA(LN(z_{\ell -1}))+z_{\ell -1} \\ z_{\ell}&=MLP(LN(z^{'}_{\ell}))+z^{'}_{\ell} \\ y&=LN(z_L^0) \\ \end{aligned}
z0zℓ′zℓy=[xclass;xp1E;xp2E;...,xpNE]+Epos=MSA(LN(zℓ−1))+zℓ−1=MLP(LN(zℓ′))+zℓ′=LN(zL0)
Inductive bias. 我们注意到,与 CNN 相比,Vision Transformer 的图像特定归纳偏差要小得多。在 CNNs 中,局部性、二维邻域结构和平移等差性被嵌入到整个模型的每一层中。在 ViT 中,只有 MLP 层具有局部性和平移等差性,而自我注意层则具有全局性。二维邻域结构只在极少数情况下使用:在模型开始时,将图像切割成斑块;在微调时,针对不同分辨率的图像调整位置嵌入(如下文所述)。除此以,初始化时的位置嵌入不携带有关图像块的 2D 位置的信息,图像块之间的所有空间关系都必须从头开始学习。
Hybrid Architecture. 作为原始图像patches的替代方法,输入序列可以由 CNN 的特征图形成。在这种混合模型中,图像块嵌入投影 E E E(公式 1)应用于从 CNN 特征图中提取的patch。作为一种特例,补丁的空间尺寸可以是 1 × 1 1\times 1 1×1,这意味着输入序列是通过 简单地将特征图的空间维度展平并投影到 Transformer 维度 获得的。然后,如上所述添加了分类输入嵌入和位置嵌入,再将三者组成的整体馈入 Transformer 编码器。就是先用 CNN 提取图像特征,然后由 CNN 提取的特征图构成图像块嵌入。由于 CNN 已经将图像降采样了,所以块尺寸可为 1×1。
4.3.2 FINE-TUNING AND HIGHER RESOLUTION
通常,我们在大型数据集上对 ViT 进行预训练,然后根据(较小的)下游任务进行微调。为此,我们会移除预训练的预测头,并附加一个零初始化的 D × K D\times K D×K 前馈层,其中 $K $是下游类的数量。与预训练相比,在更高分辨率下进行微调通常是有益的。当输入更高分辨率的图像时,我们会保持补丁大小不变,这样就会增加有效序列长度。视觉转换器可以处理任意长度的序列(受内存限制),但是,预训练的位置嵌入可能不再有意义。因此,我们根据预训练位置嵌入在原始图像中的位置,对其进行二维插值。需要注意的是,只有在调整分辨率和提取图像patches时,才会手动向Vision Transformer注入有关图像二维结构的归纳偏差。
4.4 EXPERIMENTS
我们评估了 ResNet、Vision Transformer (ViT) 和混合模型的表征学习能力。为了了解每个模型对数据的要求,我们在不同规模的数据集上进行了预训练,并对许多基准任务进行了评估。考虑到预训练模型的计算成本,ViT 的表现非常出色,它以较低的预训练成本在大多数识别基准上达到了最先进的水平。最后,我们使用自监督技术进行了一项小型实验,结果表明自监督 ViT 在未来大有可为。
4.4.1 SETUP
Datasets. 为了探索模型的可扩展性,我们使用了 ILSVRC-2012 ImageNet 数据集(包含 1k 个类别和 1.3M 张图像)(以下简称 ImageNet)、其超集 ImageNet-21k (包含 21k 个类别和 14M 张图像)以及 JFT(包含 18k 个类别和 303M 张高分辨率图像)。我们按照 Kolesnikov 等人的方法,将预训练数据集与下游任务的测试集去重复。我们将在这些数据集上训练的模型转移到几个基准任务中:原始验证标签和经过清理的 ReaL 标签上的 ImageNet、CIFAR-10/100、Oxford-IIIT Pets和 Oxford Flowers-102。对于这些数据集,预处理遵循 Kolesnikov 等人的方法。
我们还在 19 个任务的 VTAB 分类套件上进行了评估。VTAB 评估了低数据传输到不同任务的情况,每个任务使用 1000 个训练示例。任务分为三组:自然任务–如上述任务、宠物、CIFAR 等。专业任务–医疗和卫星图像,以及结构化任务–需要几何理解的任务,如定位。
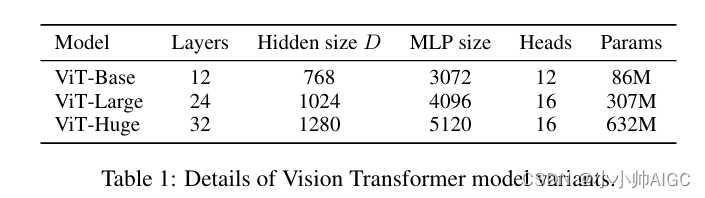
Model Variants. 我们以 BERT使用的 ViT 配置为基础,如表 1 所示。基础 "和 "大型 "模型直接采用 BERT 模型,我们还增加了更大的 "巨大 "模型。在下文中,我们使用简短的符号来表示模型大小和输入patch大小:例如,ViT-L/16 表示输入补丁大小为 16 × 16 16\times 16 16×16 的 "大型 "变体。 请注意,Transformer的序列长度与patch大小的平方成反比,因此patch大小较小的模型计算成本较高。
对于基线 CNN,我们使用 ResNet,但用组归一化替换了批归一化铺设器,并使用了标准化卷积)。这些修改提高了传输效率,我们将修改后的模型称为 “ResNet (BiT)”。对于混合模型,我们将中间特征图输入 ViT,patch大小为一个 “像素”。为了试验不同的序列长度,我们要么 (i) 采用常规 ResNet50 第 4 阶段的输出,要么 (ii) 删除第 4 阶段,将相同层数的层放入第 3 阶段(保持总层数不变),然后采用扩展后的第 3 阶段的输出。方案 (ii) 会导致序列长度增加 4 倍,ViT 模型的成本也会增加。
Training & Fine-tuning. 我们使用 Adam训练包括 ResNets 在内的所有模型, β 1 = 0.9 , β 2 = 0.999 \beta_1 = 0.9,\beta_2 = 0.999 β1=0.9,β2=0.999,批处理大小为 4096,并应用高权重衰减 0.1,我们发现这对所有模型的转移都很有用(与常见做法不同,在我们的设置中,Adam 对 ResNets 的效果略好于 SGD)。我们使用线性学习率预热和衰减。为了进行微调,我们对所有模型都使用了带动量的 SGD,批量大小为 512。对于表 2 中的 ImageNet 结果,我们使用了更高的分辨率进行微调:对于表 2 中的 ImageNet 结果,我们使用了更高的分辨率进行微调:ViT-L/16 为 512 分辨率,ViT-H/14 为 518 分辨率,同时还使用了 Polyak & Juditsky的平均值,系数为 0.9999。
Metrics. 微调精度反映了每个模型在相应数据集上微调后的性能。少量拍摄精度是通过解决正则化最小二乘回归问题获得的,该问题将训练图像子集的(冻结)表示映射到 11K 个目标向量。这种表述方式使我们能够以封闭形式恢复精确解。虽然我们主要关注的是微调性能,但在微调成本过高的情况下,我们有时也会使用线性几发精确度进行快速即时评估。
4.4.6 SELF-SUPERVISION
Transformer在 NLP 任务中表现出令人印象深刻的性能。然而,它们的成功不仅源于其出色的可扩展性,还源于大规模的自我监督预训练。通过自我监督预训练,我们的小型 ViT-B/16 模型在图像网络上实现了 79.9% 的准确率,比从零开始训练显著提高了 2%,但仍比监督预训练落后 4%。
4.5 CONCLUSION
我们探索了将变换器直接应用于图像识别的方法。与之前在计算机视觉中使用自我关注的工作不同,我们没有在最初的片段提取步骤之外,在架构中引入特定于图像的诱导偏差。因此,VisionTransform 在许多图像分类数据集上都达到或超过了最先进的水平,同时在预训练方面也相对简单。
虽然这些初步结果令人鼓舞,但仍存在许多挑战。其中一个挑战是将 ViT 应用于其他计算视觉任务,如检测和分割,我们的结果以及卡里翁等人(2020)的结果都表明这种方法大有可为。我们的初步实验表明,自我监督预训练的效果有所改善,但自我监督预训练与大规模监督预训练之间仍有很大差距。


















 1463
1463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









