







之前我们认识了 一般的注意力模型。本文将介绍自注意力和多头注意力,为后续介绍Transformer做铺垫。
自注意力
如果注意力模型中注意力是完全基于特征向量计算的,那么称这种注意力为自注意力:
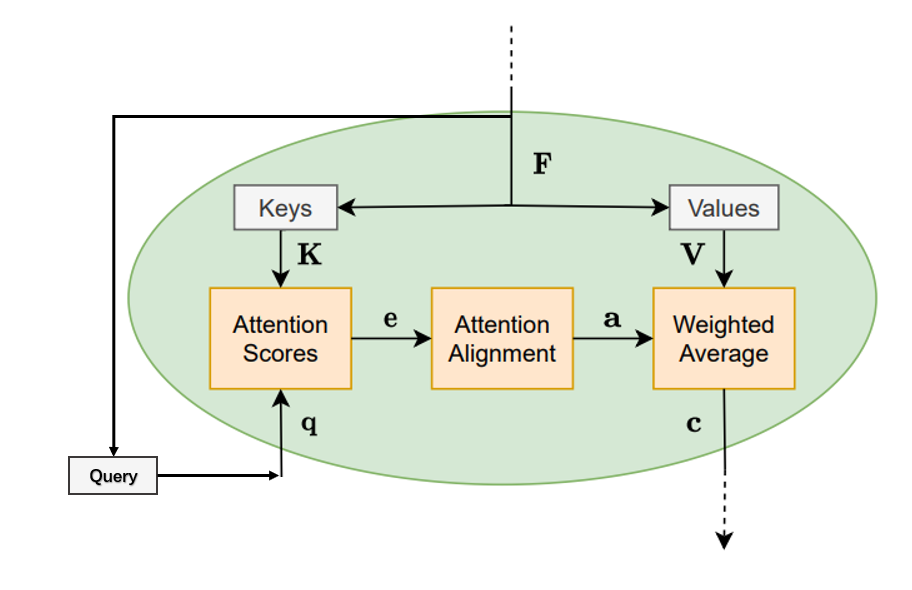
图片改自:[1]
例如,我们可以使用权重矩阵 W K ∈ R d k × d f \boldsymbol{W}_K∈\mathbb{R}^{d_k×d_f} WK∈Rdk×df、 W V ∈ R d v × d f \boldsymbol{W}_V∈\mathbb{R}^{d_v×d_f} WV∈Rdv×df和 W Q ∈ R d q × d f \boldsymbol{W}_{Q} \in \mathbb{R}^{d_{q} \times d_{f}} WQ∈Rdq×df对特征矩阵 F = [ f 1 , … , f n f ] ∈ R d f × n f \boldsymbol{F}=[\boldsymbol{f}_{1}, \ldots, \boldsymbol{f}_{n_{f}}] \in \mathbb{R}^{d_{f}\times n_f} F=[f1,…,fnf]∈Rdf×nf进行线性变换,得到
键(Key)矩阵
K
=
W
K
F
=
W
K
[
f
1
,
…
,
f
n
f
]
=
[
k
1
,
…
,
k
n
f
]
∈
R
d
k
×
n
f
\begin{aligned} \boldsymbol{K}&=\boldsymbol{W}_{K}\boldsymbol{F}\\ &=\boldsymbol{W}_{K}[\boldsymbol{f}_{1}, \ldots, \boldsymbol{f}_{n_{f}}]\\ &=\left[\boldsymbol{k}_{1}, \ldots, \boldsymbol{k}_{n_{f}}\right] \in \mathbb{R}^{d_{k} \times n_{f}} \end{aligned}
K=WKF=WK[f1,…,fnf]=[k1,…,knf]∈Rdk×nf
值(Value)矩阵
V
=
W
V
F
=
W
V
[
f
1
,
…
,
f
n
f
]
=
[
v
1
,
…
,
v
n
f
]
∈
R
d
v
×
n
f
\begin{aligned} \boldsymbol{V}&=\boldsymbol{W}_{V}\boldsymbol{F}\\ &=\boldsymbol{W}_{V}[\boldsymbol{f}_{1}, \ldots, \boldsymbol{f}_{n_{f}}]\\ &=\left[\boldsymbol{v}_{1}, \ldots, \boldsymbol{v}_{n_{f}}\right] \in \mathbb{R}^{d_{v} \times n_{f}} \end{aligned}
V=WVF=WV[f1,…,fnf]=[v1,…,vnf]∈Rdv×nf
查询(Query)矩阵
Q
=
W
Q
F
=
W
Q
[
f
1
,
…
,
f
n
f
]
=
[
q
1
,
…
,
q
n
f
]
∈
R
d
q
×
n
f
\begin{aligned} \boldsymbol{Q}&=\boldsymbol{W}_{Q}\boldsymbol{F}\\ &=\boldsymbol{W}_{Q}[\boldsymbol{f}_{1}, \ldots, \boldsymbol{f}_{n_{f}}]\\ &=\left[\boldsymbol{q}_{1}, \ldots, \boldsymbol{q}_{n_{f}}\right] \in \mathbb{R}^{d_{q} \times n_{f}} \end{aligned}
Q=WQF=WQ[f1,…,fnf]=[q1,…,qnf]∈Rdq×nf
Q \boldsymbol{Q} Q的每一列 q i \boldsymbol{q}_i qi都用作注意力模型的查询。当使用查询向量 q i \boldsymbol{q}_i qi计算注意力时,生成的上下文向量 c i \boldsymbol{c}_i ci将汇总特征向量中对查询 q i \boldsymbol{q}_i qi来说重要的的信息。
首先,对查询 q i , i = 1 , 2 , . . . , n f \boldsymbol{q}_i,i=1,2,...,n_f qi,i=1,2,...,nf计算键向量 k j \boldsymbol{k}_{j} kj的注意力得分:
e i , j 1 × 1 = score ( q i d q × 1 , k j d k × 1 ) , j = 1 , 2 , . . . , n f \underset{1 \times 1}{e_{i,j}}=\operatorname{score}\left(\underset{d_{q} \times 1}{\boldsymbol{q}_i}, \underset{d_{k} \times 1}{\boldsymbol{k}_{j}}\right),j=1,2,...,n_f 1×1ei,j=score(dq×1qi,dk×1kj),j=1,2,...,nf
查询 q i \boldsymbol{q}_i qi表示对信息的请求。注意得分 e i , j e_{i,j} ei,j表示根据查询 q i \boldsymbol{q}_i qi,键向量 k j \boldsymbol{k}_j kj中包含的信息有多重要。计算每个值向量的得分,得到关于查询 q i \boldsymbol{q}_i qi的注意力得分向量:
e i = [ e i 1 , e i 2 , . . . , e i , n f ] T \boldsymbol{e_i}=[e_{i1},e_{i2},...,e_{i,n_f}]^T ei=[ei1,ei2,...,ei,nf]T
然后,使用对齐函数
align
(
)
\operatorname{align}()
align()进行对齐:
a
i
,
j
1
×
1
=
align
(
e
i
,
j
;
1
×
1
e
i
n
f
×
1
)
,
j
=
1
,
2
,
.
.
.
,
n
f
\underset{1 \times 1}{a_{i,j}}=\operatorname{align}\left(\underset{1 \times 1}{e_{i,j} ;} \underset{n_{f} \times 1}{\boldsymbol{e_i}}\right),j=1,2,...,n_f
1×1ai,j=align(1×1ei,j;nf×1ei),j=1,2,...,nf
得到注意力权重向量: a i = [ a i , 1 , a i , 2 , . . . , a i , n f ] T \boldsymbol{a}_i=[a_{i,1},a_{i,2},...,a_{i,n_f}]^T ai=[ai,1,ai,2,...,ai,nf]T。
最后计算上下文向量:
c
i
d
v
×
1
=
∑
j
=
1
n
f
a
i
,
j
1
×
1
×
v
j
d
v
×
1
\underset{d_{v} \times 1}{\boldsymbol{c}_i}=\sum_{j=1}^{n_{f}}\underset{1\times 1} {a_{i,j}} \times \underset{d_v\times 1}{\boldsymbol{v}_{j}}
dv×1ci=j=1∑nf1×1ai,j×dv×1vj
总结以上步骤,自注意力计算表达式为:
c
i
=
self-att
(
q
i
,
K
,
V
)
∈
R
d
v
\boldsymbol{c}_i=\text { self-att }(\boldsymbol{q}_i, \boldsymbol{K}, \boldsymbol{V})\in \mathbb{R}^{d_v}
ci= self-att (qi,K,V)∈Rdv
由于
q
i
=
W
Q
f
i
\boldsymbol{q}_i=\boldsymbol{W}_Q\boldsymbol{f}_i
qi=WQfi,因此可以说上下文向量
c
i
\boldsymbol{c}_i
ci包含所有特征向量中(包括
f
i
\boldsymbol{f}_i
fi)对特定特征向量
f
i
\boldsymbol{f}_i
fi来说重要的的信息。例如,对于语言,这意味着自注意力可以提取单词特征之间的关系(动词与名词;代词与名词等等),如果
f
i
\boldsymbol{f}_i
fi是一个词的特征向量,那么自注意力可以计算得到其他词对于
f
i
\boldsymbol{f}_i
fi来说重要的信息。对于图像,自注意力则可以得到各个图像区域特征之间的关系。
计算
Q
\boldsymbol{Q}
Q中所有查询向量的上下文向量,得到自注意力层的输出:
C
=
self-att
(
Q
,
K
,
V
)
=
[
c
1
,
c
2
,
.
.
.
,
c
n
f
]
∈
R
d
v
×
n
f
\boldsymbol{C}=\text { self-att }(\boldsymbol{Q}, \boldsymbol{K}, \boldsymbol{V})=[\boldsymbol{c}_1,\boldsymbol{c}_2,...,\boldsymbol{c}_{n_f}]\in \mathbb{R}^{d_{v}\times n_f}
C= self-att (Q,K,V)=[c1,c2,...,cnf]∈Rdv×nf
多头注意力
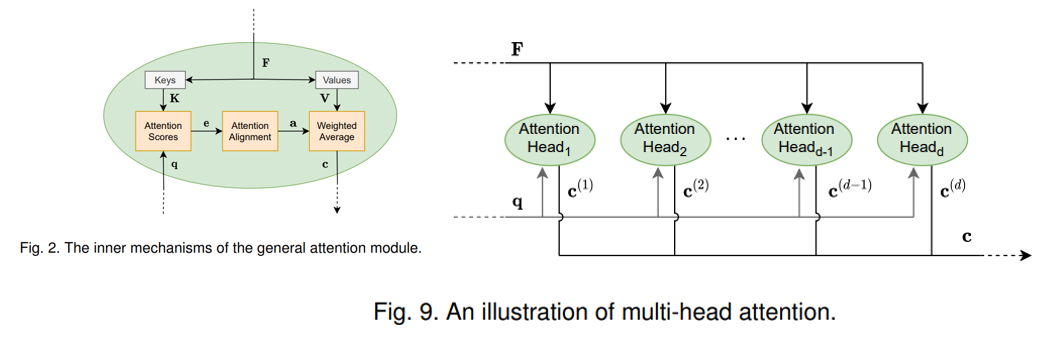
多头注意力通过利用同一查询的多个不同版本并行实现多个注意力模块来工作。其思想是使用不同的权重矩阵对查询 q \boldsymbol{q} q进行线性变换得到多个查询。每个新形成的查询本质上都需要不同类型的相关信息,从而允许注意模型在上下文向量计算中引入更多信息。
多头注意力的 d d d个头部都有自己的多个查询向量、键矩阵和值矩阵: q ( l ) , K ( l ) \boldsymbol{q}^{(l)}, \boldsymbol{K}^{(l)} q(l),K(l)和 V ( l ) \boldsymbol{V}^{(l)} V(l), l = 1 , … , d l=1, \ldots, d l=1,…,d。
查询 q ( l ) \boldsymbol{q}^{(l)} q(l)由原始查询 q \boldsymbol{q} q经过线性变换得到,而 K ( l ) \boldsymbol{K}^{(l)} K(l)和 V ( l ) \boldsymbol{V}^{(l)} V(l)则是 F \boldsymbol{F} F经过线性变换得到。每个注意力头都有自己的可学习权重矩阵 W q ( l ) 、 W K ( l ) 和 W V ( l ) \boldsymbol{W}^{(l)}_q、\boldsymbol{W}^{(l)}_K和\boldsymbol{W}^{(l)}_V Wq(l)、WK(l)和WV(l)。第 l l l个头的查询、键和值的计算如下:
q ( l ) d q × 1 = W q ( l ) d q × d q × q d q × 1 , \underset{d_{q} \times 1}{\boldsymbol{q}^{(l)}}=\underset{d_{q} \times d_{q}}{\boldsymbol{W}_{q}^{(l)}} \times \underset{d_{q} \times 1}{\boldsymbol{q}}, dq×1q(l)=dq×dqWq(l)×dq×1q,
K ( l ) d k × n f = W K ( l ) d k × d f × F d f × n f \underset{d_{k} \times n_{f}}{\boldsymbol{K}^{(l)}}=\underset{d_{k} \times d_{f}}{\boldsymbol{W}_K^{(l)}} \times \underset{d_{f} \times n_{f}}{\boldsymbol{F}} dk×nfK(l)=dk×dfWK(l)×df×nfF
V ( l ) d v × n f = W V ( l ) d v × d f × F d f × n f \underset{d_{v} \times n_{f}}{\boldsymbol{V}^{(l)}}=\underset{d_{v} \times d_{f}}{\boldsymbol{W}_V^{(l)}} \times \underset{d_{f} \times n_{f}}{\boldsymbol{F}} dv×nfV(l)=dv×dfWV(l)×df×nfF
每个头都创建了自己对查询 q \boldsymbol{q} q和输入矩阵 F \boldsymbol{F} F的表示,从而允许模型学习更多的信息。例如,在训练语言模型时,一个注意力头可以学习关注某些动词(例如行走、驾驶、购买)与名词(例如,学生、汽车、苹果)的关系,而另一个注意力头部则学习关注代词(例如,他、她、it)与名词的关系。
每个头还将创建自己的注意力得分向量 e i ( l ) = [ e i , 1 ( l ) , … , e i , n f ( l ) ] T ∈ R n f \boldsymbol{e}_i^{(l)}=\left[e_{i,1}^{(l)}, \ldots, e_{i,n_{f}}^{(l)}\right]^T \in \mathbb{R}^{n_{f}} ei(l)=[ei,1(l),…,ei,nf(l)]T∈Rnf,以及相应的注意力权重向量 a i ( l ) = [ a i , 1 ( l ) , … , a i , n f ( l ) ] T ∈ R n f \boldsymbol{a}_i^{(l)}=\left[a_{i,1}^{(l)}, \ldots, a_{i,n_{f}}^{(l)}\right]^T \in \mathbb{R}^{n_{f}} ai(l)=[ai,1(l),…,ai,nf(l)]T∈Rnf
然后,每个头都会产生自己的上下文向量 c i ( l ) ∈ R d v \boldsymbol{c}_i^{(l)}\in \mathbb{R}^{d_{v}} ci(l)∈Rdv,如下所示:
c i ( l ) d v × 1 = ∑ j = 1 n f a i , j ( l ) 1 × 1 × v j ( l ) d v × 1 \underset{d_{v} \times 1}{\boldsymbol{c}_i^{(l)}}=\sum_{j=1}^{n_f} \underset{1\times 1}{a_{i,j}^{(l)}}\times \underset{d_{v}\times 1}{\boldsymbol{v}_j^{(l)}} dv×1ci(l)=j=1∑nf1×1ai,j(l)×dv×1vj(l)
我们的目标仍然是创建一个上下文向量作为注意力模型的输出。因此,要将各个注意力头产生的上下文向量被连接成一个向量。然后,使用权重矩阵
W
O
∈
R
d
c
×
d
v
d
\boldsymbol{W}_{O} \in \mathbb{R}^{d_{c} \times d_{v} d}
WO∈Rdc×dvd对其进行线性变换:
c
i
d
c
×
1
=
W
O
d
c
×
d
v
d
×
concat
(
c
i
(
1
)
d
v
×
1
;
…
;
c
i
(
d
)
d
v
×
1
)
\underset{d_{c} \times 1}{\boldsymbol{c}_i}=\underset{d_{c} \times d_{v} d}{\boldsymbol{W}_{O}} \times \operatorname{concat}\left(\underset{d_v \times 1}{\boldsymbol{c}_i^{(1)}} ; \ldots; \underset{d_v \times 1}{\boldsymbol{c}_i^{(d)}} \right)
dc×1ci=dc×dvdWO×concat(dv×1ci(1);…;dv×1ci(d))
这保证最终的上下文向量 c i ∈ R d c \boldsymbol{c}_i\in\mathbb{R}^{d_c} ci∈Rdc符合目标维度
参考:
[1] A General Survey on Attention Mechanisms in Deep Learning https://arxiv.org/pdf/2203.14263v1.pdf



















 2659
2659

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











