







学习目标:
看论文
学习内容:
一、TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
二、TACKLING THE GENERATIVE LEARNING TRILEMMAWITH DENOISING DIFFUSION GANS
学习时间:
7.15-7.21
学习产出:
一、TransGAN: Two Pure Transformers Can Make One Strong GAN, and That Can Scale Up
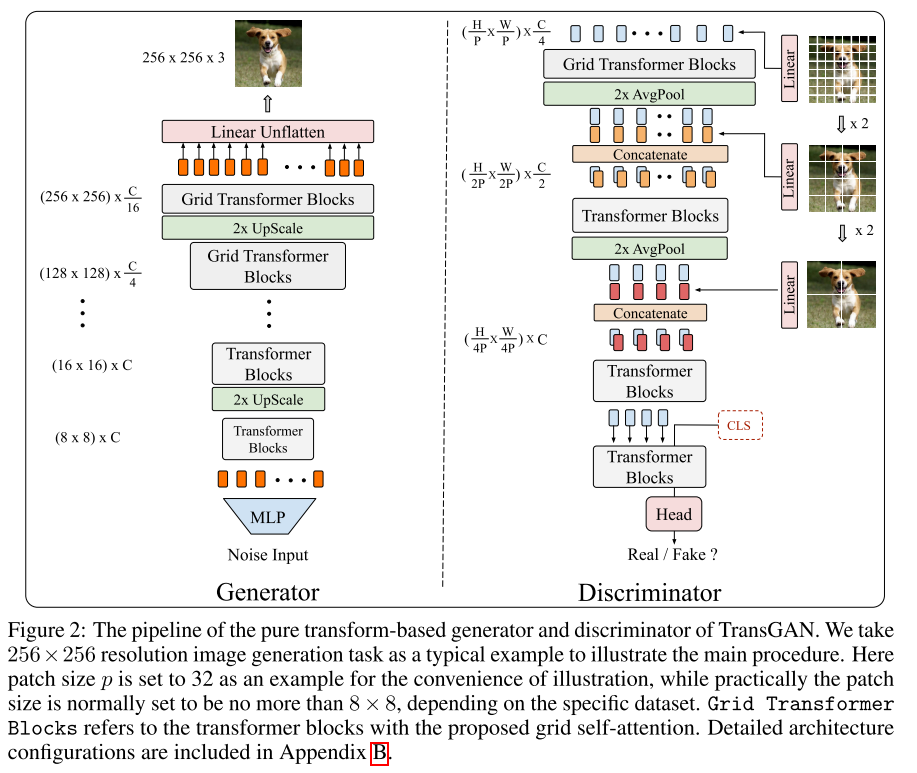
一、方法:
构建一个纯Transformer架构的GAN,从一个基于Transformer的生成器开始,逐渐增加每个阶段的特征图分辨率。使用多尺度结构改进鉴别器,以不同大小的patch作为输入,平衡了全局上下文和局部细节的捕捉,并进一步提高了内存效率。
1、内存友好的生成器:生成器由多个阶段组成,每个阶段堆叠几个Transformer Block,每个阶段逐渐增加特征图分辨率,直到达到目标分辨率H×W。具体而言,生成器以随机噪声作为输入,并将其通过多层感知机传递到长度为H0×W0×C的向量中,然后将其重塑为H0×W0分辨率,维度为C的特征图(默认情况下H0=W0=8),这个特征图随后被视为一个长度为64,维度为C的token序列,并与位置编码相结合。并在每个阶段后插入一个上采样模块,包括一个reshape和上采样层。对于低分辨率阶段(低于64×64),上采样模块首先将嵌入token的1D序列重新塑造为2D特征图,然后采用双三次插值对其分辨率进行上采样,同时保持嵌入维度不变,得到输出。之后,2D特征图再次被重塑为嵌入token的1D序列。对于更高分辨率的阶段,使用pixelshuffle模块替换双三次插值,该模块将特征映射的分辨率上采样2倍,并将嵌入维度缩小为输入的四分之一。
2、多尺度鉴别器:多尺度鉴别器被设计为在不同阶段将不同大小的patch作为输入。首先将输入图像Y的序列分成三个不同的补丁大小(P、2P、4P)。最长序列(H/P×W/P)×3被线性转换为(H/P×W/P)×C/4,然后与可学习的位置编码结合在一起作为第一阶段的输入。类似地,第二个和第三个序列分别被线性转换为(H/2P×W/2P)×C/2和(H/4P×W/4P)×C,然后分别连接到第二个和第三个阶段。因此,这三个不同的序列能够提取语义结构和纹理细节。跟生成器类似,鉴别器也会将1D序列重塑为2D特征图,并在每个阶段之间采用平均池化层对特征图分辨率进行下采样。通过在每个阶段中递归地形成Transformer Block,获得了一个金字塔结构,提取多尺度表示。在这些Block的末端,将cls令牌附加在1D序列的开头,然后由分类头提取并输出真实/伪造预测。
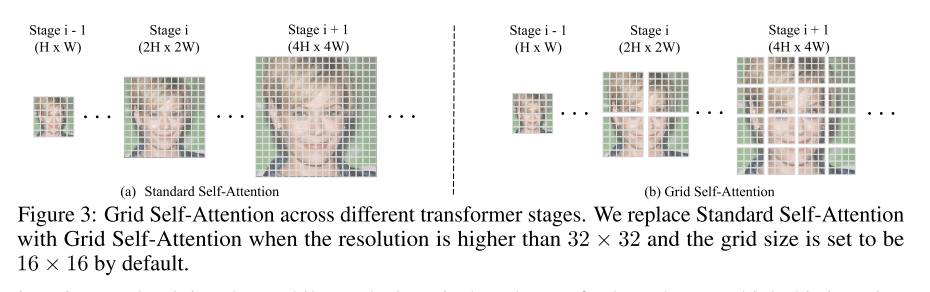
3、Grid Self-Attention:为了将自注意力适应于更高分辨率的生成任务,提出了Grid Self-Attention,专门针对高分辨率图像生成。Grid Self-Attention将全尺寸特征图分成几个非重叠的网格,并在每个局部网格内计算token的关系(不是计算给定token与所有其他token之间的对应关系)。低分辨率使用标准子注意力,在高分辨率阶段(分辨率高于32×32)添加Grid Self-Attention,以便平衡局部细节和全局感知。
二、实验
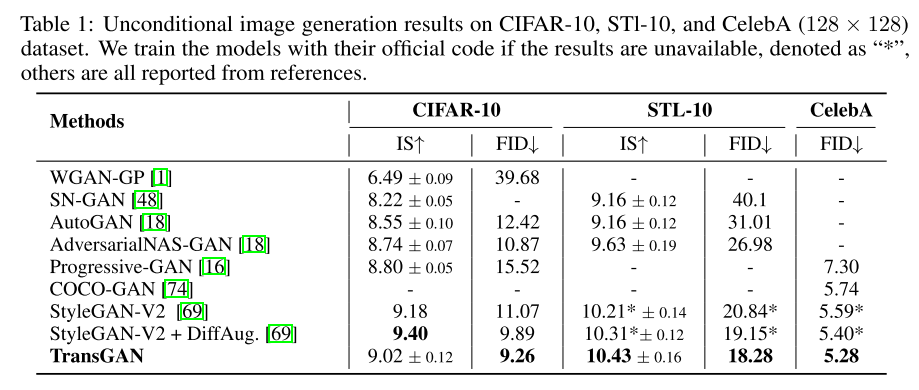
三、结论
提出了第一个GAN与纯Transformer结合的架构,并在多个流行的数据集上达到了最先进的性能,可以扩展到更高分辨率的生成任务
二、TACKLING THE GENERATIVE LEARNING TRILEMMA WITH DENOISING DIFFUSION GANS
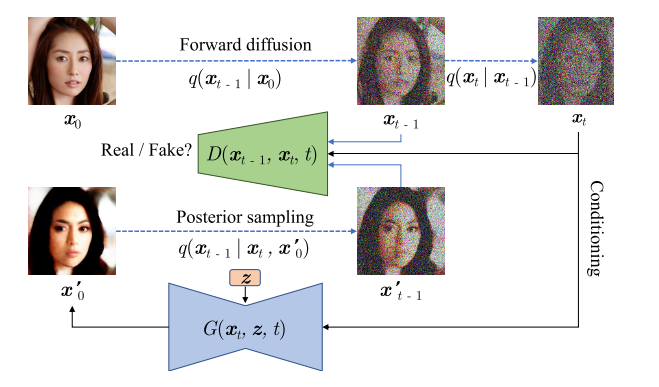
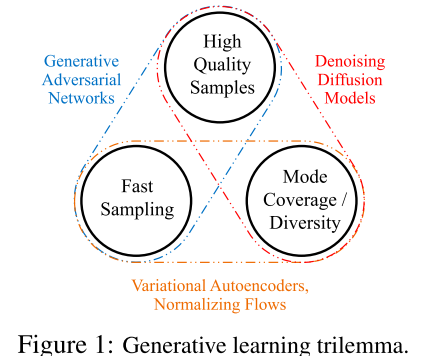
当前的生成学习框架仍无法同时满足三个关键要求:1、高质量采样;2、模式覆盖和样本多样性;3、快速且计算成本低廉的采样。
一、方法
1、使用条件 GAN 建模去噪分布:为了减少扩散模型的反向过程中所需的去噪扩散步骤T的数量,提出使用一个具有表达力的多模态分布来建模去噪分布。由于条件 GAN(conditional GANs)已被证明可以在图像领域中建模复杂的条件分布,本文采用它来近似真实的去噪分布q(xt−1|xt)。具体来说,前向扩散设置类似于扩散模型,主要假设是 T 被假定为小的扩散步骤(T ≤ 8),每个扩散步骤具有更大的 βt。模型的训练是通过使用对抗损失将条件 GAN 生成器 pθ(xt−1|xt) 与 q(xt−1|xt) 匹配,每个去噪步骤都会最小化一个散度Dadv(Dadv可以是Wasserstein距离、Jenson-Shannon散度或取决于对抗训练设置的f散度)。修改鉴别器,将N维xt−1和xt作为输入,来自 pθ(xt−1|xt) 的假样本与来自 q(xt−1|xt) 的真样本进行对比,鉴别器决定xt−1是否是xt的合理去噪版本。
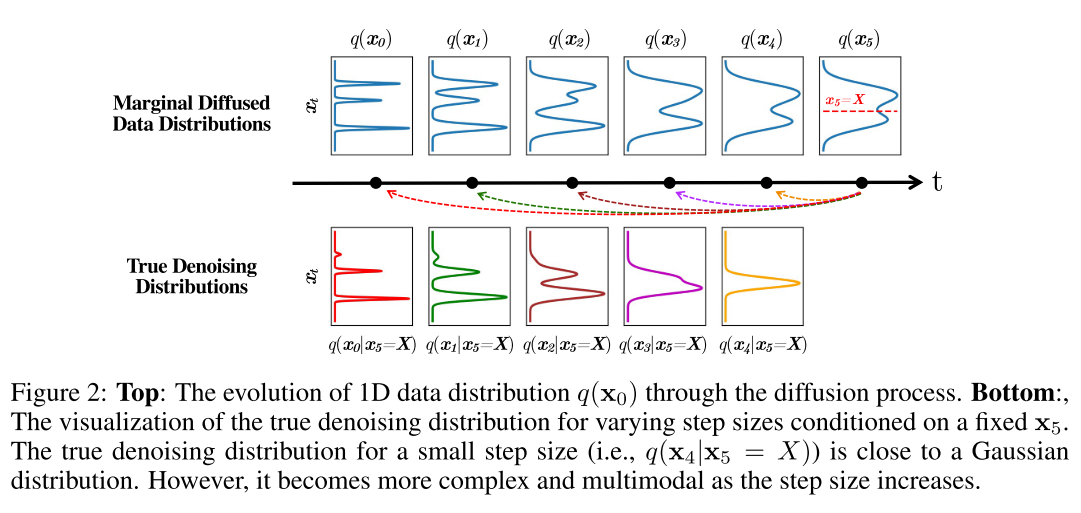
2、参数化隐式去噪模型:扩散模型使用去噪模型 fθ(xt, t) 预测 x0,然后使用给定 xt 和预测的 x0 的后验分布 q(xt−1|xt, x0) 对 xt−1 进行采样,当从 xt 向 x0 进行去噪时,分布 q(xt−1|x0, xt) 直观上是 xt−1 的分布,并且对于式1中的扩散过程,无论步长和数据分布的复杂性如何,它始终具有高斯形式。同样,作者按照DDPM的方式使用隐式的模型定义了他们模型的去噪过程pθ(xt−1|xt)。优点:可以从 DDPM 中借鉴一些归纳偏差,例如网络结构设计。与DDPM的区别:1、在 DDPM 中,x0 被预测为 xt 的确定性映射,而本模型x0 是由带有随机潜变量 z 的生成器产生的。2、对于不同的 t,xt 具有不同程度的扰动,因此在不同的 t 上直接使用单个网络直接预测 xt−1 可能会很困难。然而本模型的生成器只需要预测未扰动的 x0,然后使用 q(xt−1|xt, x0) 加回扰动。
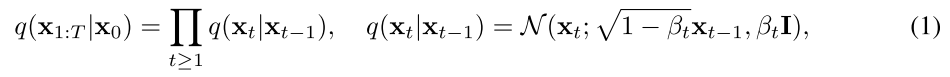
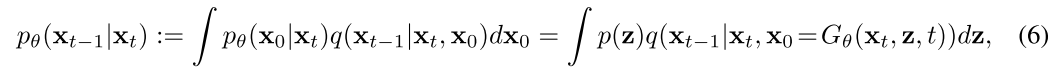
其中pθ(x0|xt)是由生成器强加的隐式分布。
二、实验
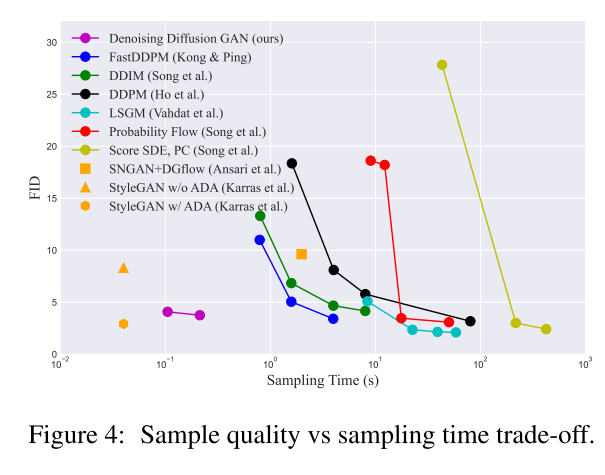
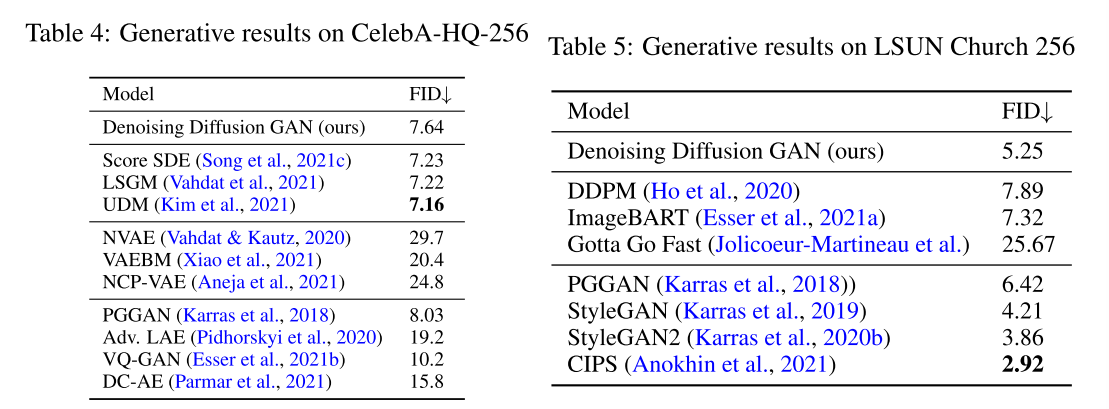
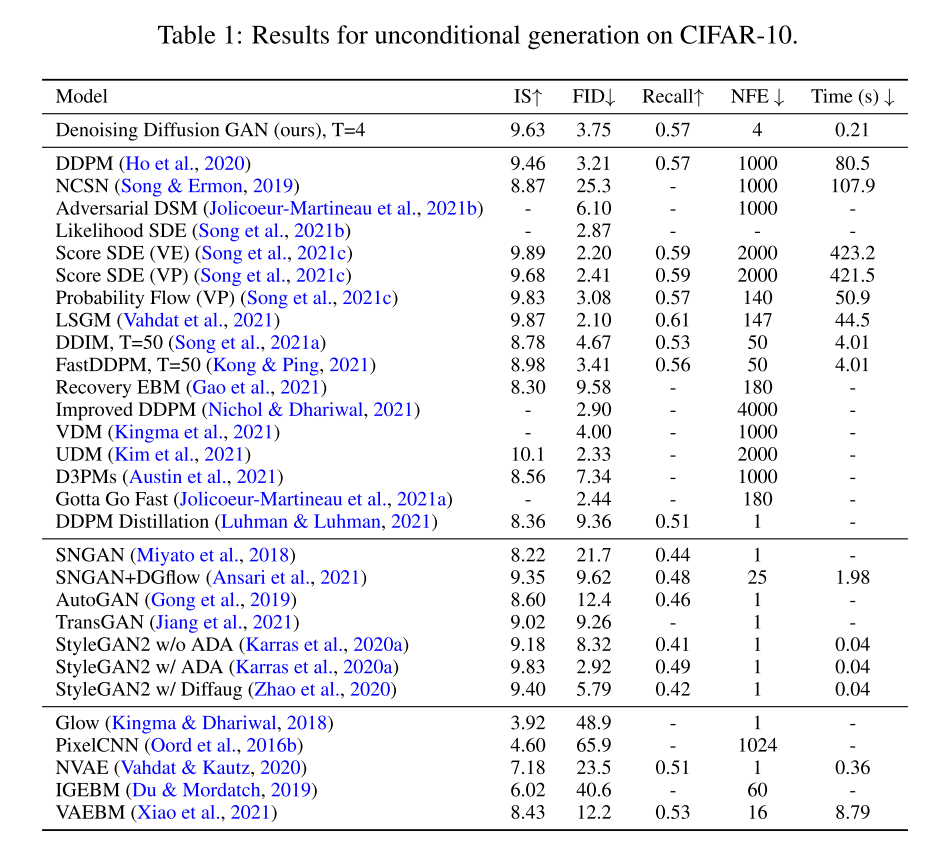
三、结论
在本文认为,扩散模型的慢采样主要原因之一是高斯假设的去噪分布,为了解决这个问题,提出了去噪扩散GAN,它使用复杂的多模态分布对每个去噪步骤进行建模,从而使去噪过程能够采取大的去噪步骤。在高样本质量和多样性方面,去噪扩散GAN可以与原始扩散模型进行竞争,但在采样速度比原始扩散模型快几个数量级。与传统的GANs相比,本文提出的模型具有更好的模式覆盖率和样本多样性并在很大程度上克服了生成学习三元悖论,使扩散模型能够以较低的计算成本应用于现实世界的问题。















 1520
1520











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









