






weakly superviesd person search
L. Yan, W. Zheng, F.
文章目录
abstract
虽然现有的人员搜索方法已经取得了很好的性能,但它们要求用于训练的图像包含关于每个人的身份和包围框位置的标签。然而,在大规模场景中手动注释这些标签是昂贵且困难的。为了克服这个问题,我们考虑了弱监督人搜索。弱监督设置是指在训练过程中,
- 我们只知道哪些身份出现在图像集中,以及每个图像中有多少个人出现,没有任何身份或位置信息在图像上。
- 面对这一挑战,我们提出一个基于clustering and patch based weakly supervised learning聚类和补丁弱监督学习(CPBWSL)框架,两个子任务包括行人检测和识别。
- 特别地,我们引入多个探测器提供更多的检测结果以及fuzzy c-means模糊c均值聚类算法。
- 另外,设计了一种基于patch的学习网络,用于生成不同的patch,学习区分性的patch特征。在两个基准上的大量实验表明,所提出的弱监督设置是可行的,并且我们的方法可以达到与一些完全监督的人搜索方法相当的性能。
1 intro

(a) Fully supervised setting: images in gallery set are manually labeled and each image has bounding boxes and corresponding identity labels. Note that the pale yellow bounding boxes in the figure represent unknown identities.
(b) Weakly supervised setting: every picture in gallery set has a label describing the number of people in the picture, and the gallery set has a label suggesting which identities present in the set, while the annotations regarding pixel-level bounding box and which picture the identity arise in are not given
(a)全监督设置:图片库中的图片都是人工标注的,每张图片都有边框和相应的标识。注意,图中浅白色的框表示未知的身份。
(b)弱监督设置:每个图片画廊组都有一个标签描述的人数,和画廊有一个标签显示的身份出现在集合, 而注释进行像素级边界框和哪一幅出现不再标出
in the gallery set, the first image is annotated by “2 Persons” indicating that number of pedestrians is two in this image. The gallery set is tagged with a label “{Person 1, Person 2, Person 3, Person 4}” implying that Person 1, Person 2, Person 3 and Person 4 are present in this set. Obviously, these annotations are weak
在图库集合中,第一张图标注了“2个人”,表示该图中的行人数量为2人。图库集合被标记为“{Person 1, Person 2, Person 3, Person 4}”,这意味着Person 1, Person 2, Person 3和Person 4存在于该集合中。显然,这些注释是弱的
detection和reid区别
前者把所有的人都看成一个阶级,目的是区分不同背景的人;后者把不同的人看成不同的类别,目的是对这些不同的类别进行识别。因此,在这两个子任务之间共享表示是不合适的,我们单独解决它们
多个检测器
fuzzy c-means
fuzzy c-means (FCM) clustering algorithm [15] to remove the false detection results
patch feature
we design a patch based learning network that is able to generate different patches and learn discriminative patch features
2相关工作
1 reid
2 person search
3 方法

Overview
1检测,提升了检测的准确性,设置聚类数为全景图像中标记的人数(监督信息)
给定一个完整的场景图像输入,首先将其输入到M个检测器中,获得若干个包围框。然后,我们将聚类的数量设置为全景图像中的人数(在图2中具体值为3),并使用FCM聚类算法对这些包围框进行聚类。在此之后,如果一个边界框对任何类的隶属度较低,则该边界框将被丢弃
1reid
在行人的再识别阶段,在两个损失函数的指导下,主要由特征提取器和patch 生成网络组成的基于patch的学习网络学习判别特征
详细 检测和聚类
it is impractical to learn a great detection model from scratch, instead of designing a pedestrian detector specially, we apply the existing excellent detection model as our pedestrian detector
从零开始学习一个好的检测模型是不现实的,我们不是专门设计一个行人检测器,而是应用现有的优秀的检测模型作为我们的行人检测器
FCM:fuzzy c-means clustering 模糊c均值聚类
得到每个簇成员的隶属度级别: obtain the degree of membership of each bounding box sample to each cluster
删除隶属度低的成员 low membership samples
按如下公式表示
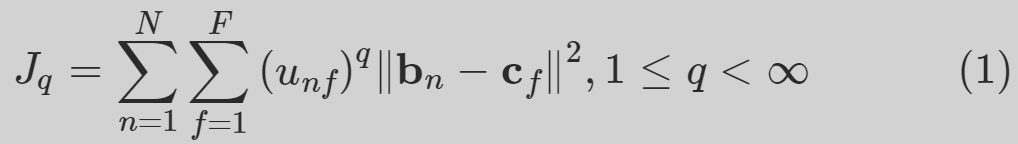

这是设置q = 2;
最小化损失 Jq
当隶属矩阵U满足U(k+1) - U(k) < ε。其中k为迭代次数,ε为迭代终止参数,在实验中我们设ε= 10^6
聚类簇数是监督信息,N是多个检测器检测出的bbox
迭代后,我们得到最终的隶属度矩阵U。然后,我们找到包围盒样本bn在矩阵U中的最大隶属度,用unf∗表示。如果最大隶属度unf∗低于给定的阈值,我们将删除边界框bn。我们将每幅图像的检测结果分别聚类,并通过给定的阈值将低隶属度检测结果切断。再识别网络只应用剩下的边界框
2 详细reid of patch based基于小块local feature more discriminative than global f
Patch based learning network for REID: feature extractor and the patch generation network
The localization network consists of a convolutional layer and two fully connected layers: 定位网络是两个全连接网络

==patch-based discriminative feature learning loss (PEDAL) ==
推远不相似的patch,拉近相似的块
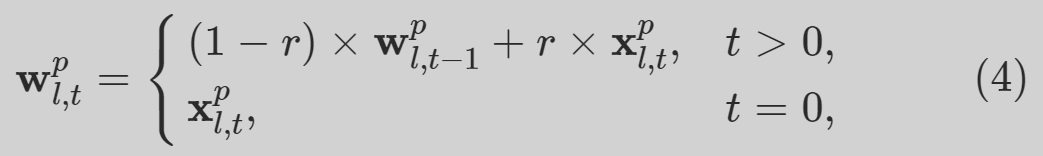
we store the patch features and maintain a memory bank Wp, L is the number of the cropped images. During training, we update wpl (4)
patch-based discriminative feature learning loss (PEDAL) [43]

进一步挖掘难样本,引入度量学习
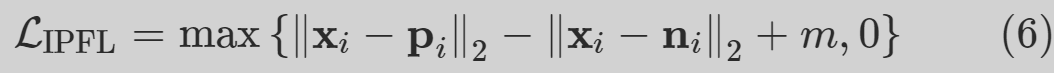
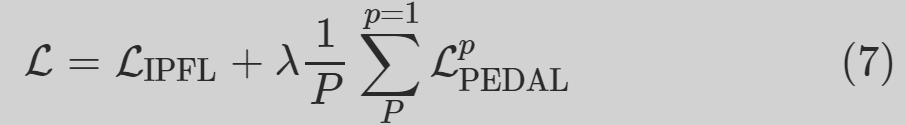
3 推理阶段

实验
ssm、prw
Pytorch
Two TITAN XP GPUs
Detector: off-the-shelf detector from the open source object detection toolbox mmdetection[45] Pretrained on MS COCO dataset with Resnet101 FPN as backbone and frozen 0.8阈值IOU
- Faster rcnn
- RetinaNet
- Cascade R-CNN
[45] MMDetection: Open mmlab detection toolbox and benchmark
reid
ImageNet-pretrained ResNet-50 [50] and remove the fully connected layer along with set the stride of last residual unit as 1
We pre-train the batch based learning network with the MSMT17 dataset [51] and fix the patch generation network during training on other datasets. As for the loss functions, we follow the setting of [43]patch-based discriminative feature learning for unreid and the update rate r in Eq.(4) is set to 0.1, the scaling factor s is set to 5, the margin m and the weight λ are set to 2. During the person re-identification model training process, the cropped images are resized to 384 × 128. We use SGD [52] optimizer for training, with a batch size of 40 and the momentum of 0.9. The learning rate is initialized at 1×10−4 and decayed by 0.1 every 40 epochs. We train the re-identification model on the unlabeled cropped images for 50 epochs.















 632
632











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









