







Follow the Rules: Reasoning for Video Anomaly Detection with Large Language Models 论文阅读
文章信息:

发表于:2024ECCV
原文链接:https://arxiv.org/abs/2407.10299
源码:https://github.com/Yuchen413/AnomalyRuler
Abstract.
视频异常检测(VAD)在安全监控和自动驾驶等应用中至关重要。然而,现有的VAD方法提供的检测依据有限,这阻碍了公众对实际部署的信任。本文采用了一种推理框架来处理VAD。尽管大语言模型(LLMs)展现出了革命性的推理能力,但我们发现其直接应用于VAD时效果不佳。具体而言,LLMs中隐含的知识主要关注一般背景,因此可能无法适用于每一个特定的实际VAD场景,导致灵活性和准确性不足。
为了解决这个问题,我们提出了AnomalyRuler,这是一种结合LLMs的基于规则的推理框架。AnomalyRuler包括两个主要阶段:归纳和演绎。在归纳阶段,LLM接收少量正常参考样本,并总结这些正常模式,从而归纳出一组用于检测异常的规则。演绎阶段则根据归纳的规则在测试视频中识别异常帧。此外,我们还设计了规则聚合、感知平滑和鲁棒推理策略,以进一步增强AnomalyRuler的鲁棒性。AnomalyRuler是首个针对单类VAD任务的推理方法,只需少量正常样本提示,无需全样本训练,从而实现对各种VAD场景的快速适应。我们在四个VAD基准上的综合实验展示了AnomalyRuler在检测性能和推理能力方面的领先表现。
1 Introduction

图1:单类VAD方法的比较。在这个具体的安全应用示例中,只有“走路”是正常的。测试帧包含“滑板”,因此它是异常的。(a) 传统方法需要全样本训练,仅输出异常分数,缺乏推理。(b) 直接使用LLM可能无法满足特定的VAD需求。在这里,GPT-4V错误地将“滑板”视为正常。© 我们的AnomalyRuler具有归纳和演绎阶段。它从少量正常参考帧中推导规则以检测异常,正确识别“滑板”为异常。
视频异常检测(VAD)旨在识别监控视频中不频繁或意外的异常活动。它有广泛的实际应用,包括安全(例如,暴力事件)、自动驾驶(例如,交通事故)等。VAD是一个具有挑战性的问题,因为现实生活中异常事件稀少且呈长尾分布,这导致缺乏大规模具有代表性的异常数据。因此,单类VAD(即无监督VAD)范式被优先考虑,因为它假设只有更易获得的正常数据可用于训练。大多数现有的单类VAD方法通过自监督的前置任务学习建模正常模式,如帧重建和帧顺序分类。尽管这些传统方法表现良好,但它们只能输出异常分数,几乎没有提供检测结果背后的理由。这在实际产品部署时阻碍了它们赢得公众信任。
我们通过推理框架来处理VAD任务,以构建一个值得信赖的系统,这在文献中尚未得到充分探索。一个直观的方法是结合新兴的大语言模型(LLMs),这些模型在各种推理任务中展现出了革命性的能力。然而,我们发现它们的直接使用在执行VAD时效果不佳。具体来说,LLMs中隐含的知识主要关注一般背景,这意味着它可能并不总是与特定的实际VAD应用对齐。换句话说,LLM对异常的理解与某些场景所需的异常定义之间存在不匹配。例如,GPT-4V通常将“滑板”视为一种正常活动,而某些安全应用需要将其定义为异常,例如在限制区域内(见图1b)。然而,通过对每个应用进行微调以注入如此特定的知识是成本高昂的。这突显了需要一种灵活的提示方法,以引导LLM的推理能力适应不同的VAD应用。
为了找到这样的解决方案,我们重新审视科学方法的基本过程,强调推理,这涉及以严谨的方式得出结论。我们的动机源于两种推理方式:归纳推理,它从给定观察中推断出一般原则;演绎推理,它基于给定前提得出结论。本文提出了AnomalyRuler,这是一种基于LLMs推理的新型VAD框架。AnomalyRuler包括一个归纳阶段和一个演绎阶段,如图1c所示。在归纳阶段,LLM接收少量正常样本的视觉描述作为参考,以推导出一套判断正常性的规则。在这里,我们使用视觉-语言模型(VLM)为每个输入视频帧生成描述。接下来,LLM通过对比正常性的规则,推导出一套用于检测异常的规则。演绎阶段也是推理阶段,它根据归纳的规则识别测试视频序列中的异常帧。此外,针对VLM和LLM可能出现的感知和推理错误,我们设计了一些策略,包括通过随机平滑进行的规则聚合以减轻规则归纳错误,通过所提的指数多数平滑进行的感知平滑以减少感知错误并增强时间一致性,以及通过重检机制进行的鲁棒推理以确保可靠的推理输出。这些策略集成到AnomalyRuler的流程中,以进一步增强其检测的鲁棒性。
除了为VAD赋予推理能力外,AnomalyRuler还提供了几个优势。首先,AnomalyRuler是一种新颖的少量正常样本提示方法,仅利用训练集中少量正常样本作为参考来推导VAD规则。这避免了传统单类VAD方法所需的昂贵的全样本训练或对整个训练集的微调。重要的是,它通过仅使用少量正常参考样本,实现了将LLM的隐含知识高效重定向到不同特定VAD应用的能力。其次,AnomalyRuler在数据集之间表现出强大的领域适应性,因为语言在不同视觉领域中提供了一致的描述,例如,在视觉数据变异中仍然能描述“走路”。这使得归纳出的规则能够应用于具有相似场景但视觉外观不同的数据集。此外,AnomalyRuler是一个通用框架,能够与VLM和LLM基础模型互补。它适用于封闭源模型,如GPT系列,以及开源替代品,如Mistral。根据我们所知,所提出的AnomalyRuler是针对单类VAD问题的首个推理方法。对四个VAD数据集的广泛实验展示了AnomalyRuler在性能、推理能力和领域适应性方面的领先表现。
总之,本文有三个主要贡献。(1) 我们提出了一种新的基于规则的推理框架,用于结合大语言模型(LLMs)进行视频异常检测(VAD),即AnomalyRuler。根据我们所知,这是针对单类VAD的首个推理方法。(2) 所提出的AnomalyRuler是一种新颖的少量正常样本提示方法,消除了昂贵的全样本微调的需求,并实现了对各种VAD场景的快速适应。(3) 我们为AnomalyRuler提出了规则聚合、感知平滑和鲁棒推理策略,以增强其鲁棒性,从而实现了领先的检测性能、推理能力和领域适应性。
2 Related Work
Video Anomaly Detection.VAD是一项具有挑战性的任务,因为异常数据稀缺且呈长尾分布。因此,研究人员通常关注单类VAD(即无监督VAD)范式[14, 16, 18, 25, 27, 36, 43, 45, 49, 53, 54],该范式仅在训练中使用正常数据。大多数单类方法通过自监督的前置任务来学习建模正常模式,基于模型在异常数据上表现不佳的假设。重建方法[16, 25, 27, 36, 45, 53, 54]使用生成模型,如自编码器和扩散模型,执行帧重建或帧预测作为前置任务。基于距离的方法[14, 43, 49]则使用分类器执行帧顺序分类等前置任务。这些传统方法只能输出异常分数,几乎没有提供检测背后的理由。最近的几项研究探索了在异常检测中利用视觉-语言模型(VLMs)或大语言模型(LLMs)。Elhafsi等人[12]分析了驾驶场景中的语义异常,结合了对象检测器和LLM[7]。然而,该方法依赖于预定义的正常性和异常性概念,限制了其对不同场景的适应能力,且无法处理长尾未定义异常。此外,该方法尚未在标准VAD基准上进行评估[2, 22, 24, 28]。Cao等人[8]探索了使用GPT-4V进行异常检测,但其直接应用可能面临GPT-4V隐含知识与特定VAD需求之间的不对齐问题,正如前文所述。Gu等人[15]采用大型VLM进行异常检测,但该方法专注于工业图像。尽管支持对话,该方法只能描述异常,而无法解释检测背后的理由。Lv等人[31]将基于视频的LLMs引入VAD框架,以提供检测解释。该方法涉及三阶段训练以微调重量较大的基于视频的LLMs。此外,该方法关注的是弱监督VAD,这是一种需要使用异常数据和标签进行训练的放宽范式。与这些研究不同,我们的AnomalyRuler通过高效的少量正常样本提示提供基于规则的推理,并实现对不同VAD场景的快速适应。
Large Language Models.大语言模型(LLMs)[1, 7, 19, 38, 39, 46, 47]在自然语言处理领域取得了显著成功,最近也开始被探索用于计算机视觉问题。最近的进展,如GPT系列[1, 7, 38, 39]、LLaMA系列[46, 47]和Mistral[19],展示了在理解和生成自然语言方面的卓越能力。另一方面,大型视觉-语言模型(VLMs)[1, 21, 23, 34, 44, 51, 57, 58, 60]在桥接视觉和语言领域方面展现了潜力。BLIP-2[21]利用Q-Former将视觉特征集成到语言模型中。LLaVA[23]引入了一种视觉指令调优方法,用于视觉和语言理解。CogVLM[51]训练一个视觉专家模块,以提高大型VLM的视觉能力。Video-LLaMA[57]扩展了LLMs,以理解视频数据。这些模型的参数化知识是为一般目的训练的,因此可能不适用于每个VAD应用。最近的研究探索了提示方法,以利用LLMs的推理能力。链式思维(Chain-of-Thought, CoT)[11, 52]引导LLMs通过多个较小且可管理的中间步骤来解决复杂问题。由简单到复杂(Least-to-Most, LtM)[20, 59]将复杂问题分解为多个简单的子问题,并按顺序解决。假设到理论(Hypotheses-to-Theories, HtT)[61]通过有标签的训练数据以监督方式学习推理的规则库。然而,对于单类范式下的VAD任务,推理方法尚未得到充分探索。
3 Induction(归纳)
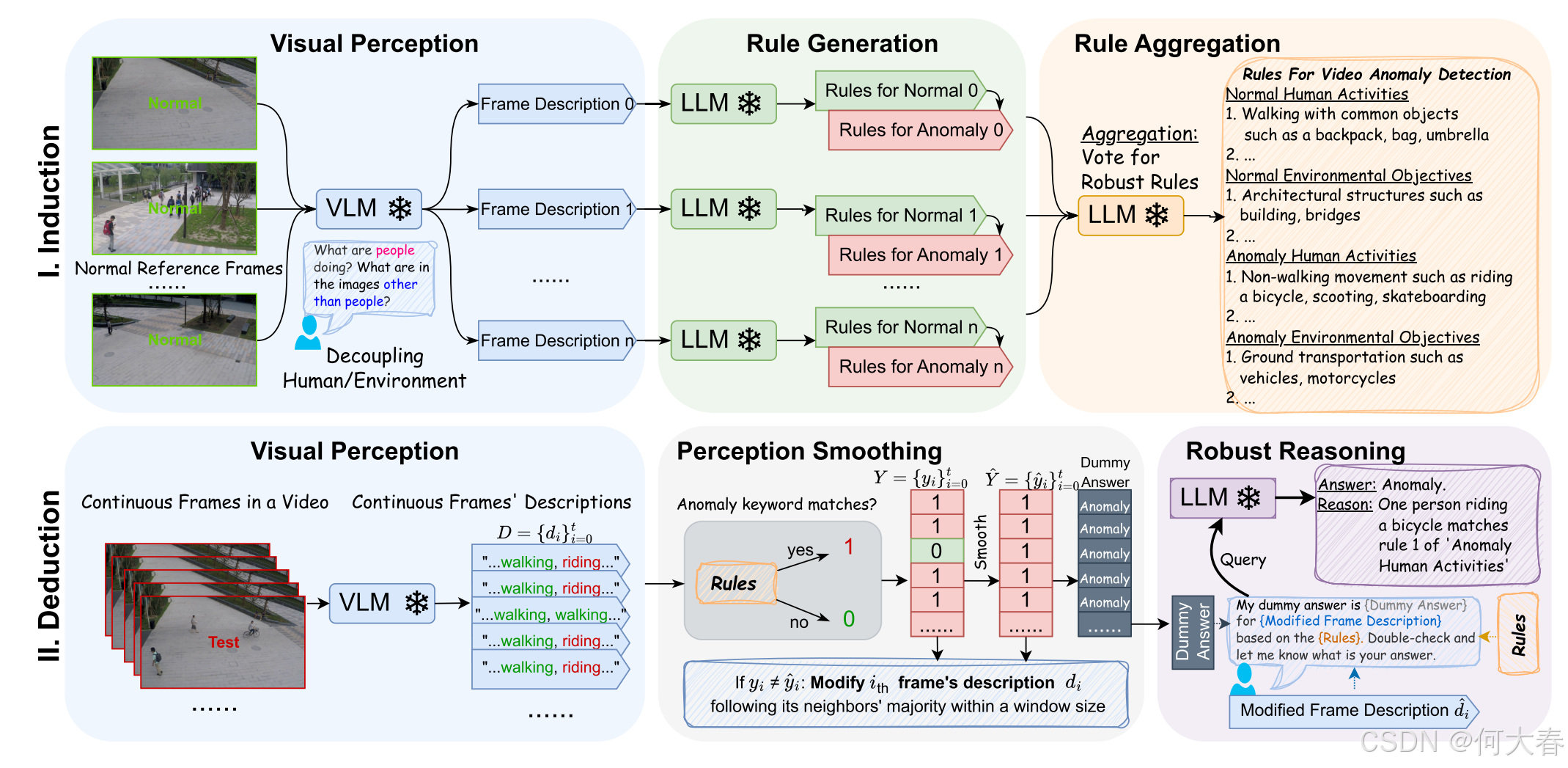
图2:AnomalyRuler管道由两个主要阶段组成:归纳和演绎。归纳阶段包括:i)视觉感知将正常参考帧转换为文本描述;ii)规则生成根据这些描述推导规则,以确定正常性和异常性;iii)规则聚合采用投票机制以减轻规则中的错误。演绎阶段包括:i)视觉感知将连续帧转换为描述;ii)感知平滑调整这些描述,以考虑时间一致性,确保相邻帧具有相似特征;iii)鲁棒推理对先前的虚假答案进行复查并输出推理结果。
归纳阶段的目标是从少量正常参考帧中推导出一套规则,以进行视频异常检测(VAD)。图2的上部分展示了归纳流程中的三个模块。视觉感知模块利用视觉-语言模型(VLM),该模型以少量正常参考帧作为输入,并输出帧描述。规则生成模块使用大语言模型(LLM)根据这些描述生成规则。规则聚合模块采用投票机制来减轻规则生成中的错误。在接下来的部分中,我们将详细讨论每个模块及其应用的策略。
3.1 Visual Perception
我们将视觉感知模块设计为管道中的初始步骤。该模块利用视觉-语言模型(VLM)将视频帧转换为文本描述。我们定义 F n o r m a l = { f n o r m a l 0 , . . . , f n o r m a l n } F_{normal} = \{f_{normal_0}, ..., f_{normal_n}\} Fnormal={fnormal0,...,fnormaln} 为少量正常参考帧,每个帧 f n o r m a l i f_{normal_i} fnormali ∈ F n o r m a l F_{normal} Fnormal从训练集中随机选择。该模块输出每个正常参考帧的文本描述:
D n o r m a l D_{normal} Dnormal = { V L M ( f n o r m a l i \{VLM(f_{normal_i} {VLM(fnormali, p v p_v pv) | f n o r m a l i f_{normal_i} fnormali ∈ F n o r m a l } F_{normal}\} Fnormal},其中 p v p_v pv 是提示“人们在做什么?图像中除了人还有什么?”我们并没有直接询问“图像中有什么?”,而是设计了 p v p_v pv 来区分人类与环境,具有以下优点。首先,它通过引导模型关注场景的特定方面来增强感知精度,确保没有细节被忽视。其次,它通过将任务分为两个子问题[20],即人类活动的规则和环境对象的规则,简化了后续的规则生成模块。我们将这一策略称为“人类与环境”。
3.2 Rule Generation
利用来自正常参考帧的文本描述 D n o r m a l D_{normal} Dnormal,我们设计了规则生成模块,该模块使用一个固定的 LLM 来生成规则(记为 R)。形式上, R = { L L M ( d n o r m a l i , p g ) ∣ d n o r m a l i ∈ D n o r m a l } R = \{LLM(d_{normal_i}, p_g) | d_{normal_i} ∈ D_{normal}\} R={LLM(dnormali,pg)∣dnormali∈Dnormal},其中 p g p_g pg是附录 A.2 中详细说明的提示。我们通过三种策略来设计 p g p_g pg,以引导 LLM 从观察到的正常模式中逐步推导规则:
Normal and Anomaly.提示 p g p_g pg引导 LLM 执行对比,首先基于 D n o r m a l D_{normal} Dnormal 推导正常的规则,这些规则被假设为真实的正常状态。然后,通过将这些规则与正常规则进行对比,生成异常的规则。例如,如果“走路”是 D n o r m a l D_{normal} Dnormal中的常见模式,它就成为一个正常规则,而“非走路动作”将被纳入异常规则。这一策略在没有访问异常帧的情况下,清晰地划定了正常与异常之间的界限。
Abstract and Concrete.提示 p g p_g pg 帮助 LLM 执行类比,从一个抽象概念出发,然后有效地推广到更具体的例子。以“走路”为例,正常规则的定义现在扩展为“走路,无论是独自还是与他人一起”。因此,异常规则也随之演变,包含具体的非走路动作,即“非走路动作,例如骑自行车、滑行或滑板”。这一策略通过详细的例子明确了规则,使 LLM 能够利用类比进行推理,而无需穷尽每一个潜在场景。
Human and Environment.这一策略继承自视觉感知模块。提示 p g p_g pg 引导 LLM 分别关注环境元素(如车辆或场景因素)和人类活动。这丰富了 VAD 任务的规则集,因为异常往往源于人类与其环境之间的互动。
这些策略与链式思维(CoT)[52] 的精神相一致,但在 VAD 任务中进行了进一步的细化。第五章第 4 节的消融实验展示了它们的有效性。
3.3 Rule Aggregation
规则聚合模块使用 LLM 作为聚合器,
通过投票机制将从 n 个随机选择的正常参考帧独立生成的 n 组规则(即 R)合并为一组稳健的规则 R r o b u s t R_{robust} Rrobust = LLM(R, p a p_a pa)。该模块旨在减轻前面阶段的错误,例如视觉感知模块可能将“走路”错误解读为“滑板”,导致错误规则的产生。聚合过程通过保留在 n 组规则中始终存在的规则元素,过滤掉不常见的元素。
用于 LLM 实现这一点的提示 p a p_a pa 在附录 A.2 中详细说明。该策略基于随机平滑的假设[10],即错误可能发生在单个输入上,但在多个随机抽样输入中一致发生的可能性较小。因此,通过聚合这些输出,AnomalyRuler 生成的规则对个别错误更具弹性。超参数 n 可以视为批次数。为简便起见,之前的讨论假设每个批次只有一个帧,即 m = 1。在这里,我们将 m 定义为每批次的正常参考帧数量,即批次大小。我们展示了规则聚合的有效性,并在第五章第 4 节中提供了不同 n 和 m 值的消融实验。
4 Deduction
在归纳阶段推导出一组稳健的规则后,推理阶段依据这些规则进行视频异常检测(VAD)。图2的底部展示了推理阶段,其目标是精确感知视频的每一帧,并利用大语言模型(LLM)根据规则推理这些帧是正常还是异常。为了实现这一目标,我们设计了三个模块。首先,视觉感知模块的工作方式与归纳阶段类似。然而,推理阶段并不是使用少量正常参考帧,而是处理每个测试视频中的连续帧,并输出一系列帧描述 D = { d 0 , d 1 , … , d t } D=\{d_0,d_1,\ldots,d_t\} D={d0,d1,…,dt}。其次,感知平滑模块通过提出的指数多数平滑方法减少误差。仅此步骤即可提供初步的检测结果,称为 AnomalyRuler-base。第三,稳健推理模块利用大语言模型(LLM)对初步检测结果进行规则核对并进行推理。感知平滑和稳健推理模块将在后续章节中详细介绍。
4.1 Perception Smoothing
正如我们在第3.3节中讨论的那样,视觉感知错误可能会在归纳阶段发生,而这种问题同样会延续到推理阶段。为了解决这一挑战,我们提出了一种新的机制,称为指数多数平滑(Exponential Majority Smoothing)。该机制通过考虑视频中的时间一致性来减少错误,即运动是连续的,应该呈现出一致的模式。我们利用这种平滑结果来指导帧描述的修正,从而增强 AnomalyRuler 对错误的鲁棒性。该过程包括以下四个关键步骤:
Initial Anomaly Matching. 对于连续的帧描述 D = { d 0 , d 1 , … , d t } D = \{d_0, d_1, \ldots, d_t\} D={d0,d1,…,dt},AnomalyRuler 首先从归纳阶段的异常规则中匹配找到的异常关键词 K K K(详细内容见附录 A.2),并为每个帧描述 d i d_i di 分配一个标签 y i y_i yi,其中 i ∈ [ 0 , t ] i \in [0, t] i∈[0,t],表示预测的标签。形式化表达为:如果 ∃ k ∈ K ⊆ d i \exists k \in K \subseteq d_i ∃k∈K⊆di,即帧描述 d i d_i di 中包含异常关键词(如动词“riding”或“running”),则我们有 y i = 1 y_i = 1 yi=1,表示触发了异常。否则, y i = 0 y_i = 0 yi=0 表示正常。我们将初始匹配的预测结果表示为 Y = { y 0 , y 1 , … , y t } Y = \{y_0, y_1, \ldots, y_t\} Y={y0,y1,…,yt}。
Exponential Majority Smoothing. 我们提出了一种结合指数移动平均(EMA)和多数投票的方法。该方法旨在通过调整预测结果,以反映指定窗口内最常见的状态,从而增强人体或物体运动的连续性。最终的平滑预测结果表示为
Y
^
=
{
y
^
0
,
y
^
1
,
…
,
y
^
t
}
\hat{Y} = \{\hat{y}_0, \hat{y}_1, \ldots, \hat{y}_t\}
Y^={y^0,y^1,…,y^t},其中每个
y
^
i
\hat{y}_i
y^i 取值为 1 或 0。形式化表达为:
∙
\bullet
∙ 步骤 I: EMA。对于原始预测
y
t
y_t
yt,EMA 值
s
t
s_t
st 计算为:
s
t
=
∑
i
=
0
t
(
1
−
α
)
t
−
i
y
i
∑
i
=
0
t
(
1
−
α
)
i
s_t = \frac{\sum_{i=0}^t(1-\alpha)^{t-i} y_i}{\sum_{i=0}^t(1-\alpha)^i}
st=∑i=0t(1−α)i∑i=0t(1−α)t−iyi.
我们将 α \alpha α 定义为影响 EMA 计算中数据点权重的参数。
∙
\bullet
∙ 步骤 II: 多数投票。该步骤的思路是对每个 EMA 值
s
i
s_i
si 周围一个窗口内的预测进行多数投票平滑。窗口的大小为
p
p
p。具体而言,对于每个
s
i
s_i
si,我们考虑其邻近的 EMA 值,并根据这些值中大于或小于阈值
τ
\tau
τ 的多数决定平滑后的预测
y
^
i
\hat{y}_i
y^i。我们将该阈值定义为所有 EMA 值的平均值:
τ
=
1
t
∑
i
=
1
t
s
i
\tau = \frac{1}{t} \sum_{i=1}^t s_i
τ=t1∑i=1tsi.
形式化地,平滑后的预测
y
^
i
\hat{y}_i
y^i 由以下公式确定:
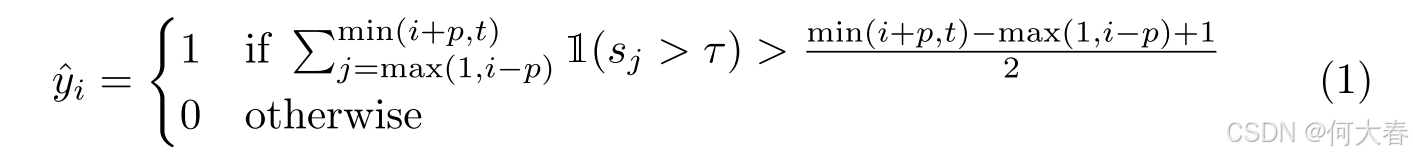
其中 1
(
⋅
)
(\cdot)
(⋅) 表示指示函数,窗口大小自适应定义为
min
(
i
+
p
,
t
)
−
max
(
1
,
i
−
p
)
+
1
\min(i+p,t) - \max(1,i-p) + 1
min(i+p,t)−max(1,i−p)+1,确保窗口不会超出由范围
max
(
1
,
i
−
p
)
\max(1,i-p)
max(1,i−p) 到
min
(
i
+
p
,
t
)
\min(i+p,t)
min(i+p,t) 所确定的边界。
Anomaly Score. 给定
Y
Y
Y 表示 AnomalyRuler 的初始检测结果,我们可以通过二次 EMA 进一步评估这些结果,从而计算出异常分数。具体而言,异常分数记为
A
=
{
a
0
,
a
1
,
…
,
a
t
}
A = \{a_0, a_1, \ldots, a_t\}
A={a0,a1,…,at},其中
a
t
a_t
at 计算为:
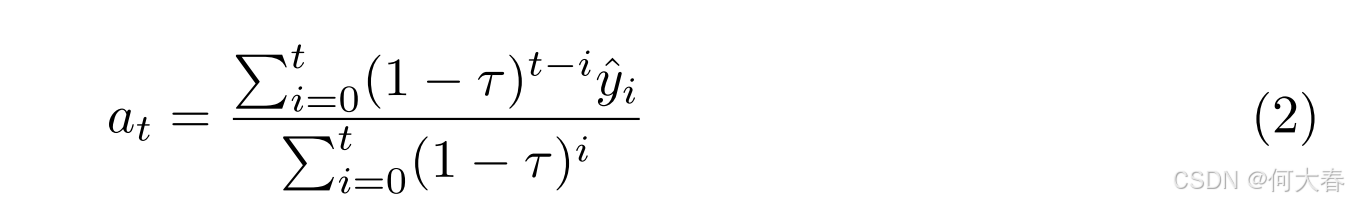
我们将上述过程称为 AnomalyRuler-base,作为我们方法的基准,它提供一个“虚拟”答案,即当
y
^
i
=
1
\hat{y}_i = 1
y^i=1 时为“异常”,否则为“正常”,并且其异常分数与当前最先进的 VAD 方法 [3, 25, 35, 43] 相当。随后,AnomalyRuler 在稳健推理模块中利用该“虚拟”答案进行进一步分析。
Description Modification. 在这一步中,AnomalyRuler 通过比较 Y Y Y 和 Y ^ \hat{Y} Y^ 来修改描述 D D D,并输出修改后的 D ^ \hat{D} D^。如果 y i = 0 y_i = 0 yi=0 而 y ^ i = 1 \hat{y}_i = 1 y^i=1,即感知模块中的假阴性,AnomalyRuler 通过添加 “There is a person { k } \{k\} {k}.” 来修正 d i d_i di,其中 k ∈ K k \in K k∈K 是窗口大小 w w w 内最频繁的异常关键词。相反,如果 y i = 1 y_i = 1 yi=1 而 y ^ i = 0 \hat{y}_i = 0 y^i=0,即感知模块中的假阳性,AnomalyRuler 会通过移除包含异常关键词 k k k 的部分描述来修改 d i d_i di。
4.2 Robust Reasoning
在稳健推理模块中,AnomalyRuler 利用大语言模型(LLM)进行 VAD 的推理任务,并将从归纳阶段得出的稳健规则 R robust R_\text{robust} Rrobust 作为上下文。LLM 输入的是每一帧的修改后的描述 d ^ i \hat{d}_i d^i 和其虚拟答案,即从 AnomalyRuler-base 生成的“异常”或“正常”。我们将稳健推理的输出表示为 Y ∗ = { LLM ( d ^ i , y ^ i , R robust , p r ) ∣ d ^ i ∈ D ^ , y ^ i ∈ Y ^ } Y^* = \{\text{LLM}(\hat{d}_i, \hat{y}_i, R_\text{robust}, p_r) \mid \hat{d}_i \in \hat{D}, \hat{y}_i \in \hat{Y}\} Y∗={LLM(d^i,y^i,Rrobust,pr)∣d^i∈D^,y^i∈Y^}。为了确保结果的可靠性,提示词 p r p_r pr(详见附录 A.2)引导 LLM 根据 R robust R_\text{robust} Rrobust 核对虚拟答案 y ^ i \hat{y}_i y^i 是否与描述 d ^ i \hat{d}_i d^i 匹配。这个验证步骤通过使用虚拟答案作为提示,而不是直接让 LLM 分析 d ^ i \hat{d}_i d^i,从而改进决策过程。这种方法帮助 AnomalyRuler 减少漏检的异常(假阴性),并确保其推理更符合规则。此外,为了将 AnomalyRuler 与基于阈值的最先进方法进行比较,我们使用公式(2),将 y ^ i \hat{y}_i y^i 替换为 y i ∗ ∈ Y ∗ y_i^* \in Y^* yi∗∈Y∗ 来输出异常分数。
5 Experiments
本节将从检测和推理能力两个方面,将AnomalyRuler与基于大型语言模型(LLM)的基线方法和最先进的方法进行比较。我们还对AnomalyRuler中的每个模块进行了消融研究,以评估它们的贡献。完整的提示示例、推导出的规则和输出结果见附录A.2。
5.1 Experimental Setup
Datasets. 我们在四个视频异常检测(VAD)基准数据集上评估了我们的方法。(1) UCSD Ped2(Ped2)[22]:一个在行人步道上拍摄的单场景数据集,包含超过4,500帧的视频,其中包括滑冰、骑车等异常行为。(2) CUHK Avenue(Ave)[28]:在香港中文大学(CUHK)校园大道上拍摄的单场景数据集,包含超过30,000帧的视频,其中包括跑步、骑车等异常行为。(3) ShanghaiTech(ShT)[24]:一个具有挑战性的数据集,包含13个校园场景,超过317,000帧的视频,其中包括骑车、打架以及行人区域的车辆等异常行为。(4) UBnormal(UB)[2]:一个由Cinema4D软件生成的开放集虚拟数据集,包含29个场景,超过236,000帧的视频。对于每个数据集,我们使用默认的训练集和测试集,这些集合遵循单类设置。AnomalyRuler使用的正常参考帧是从正常训练集中随机抽取的。除非另有说明,否则这些方法将在整个测试集上进行评估。
Evaluation Metrics.按照惯例,我们使用接收者操作特征曲线(ROC)下的面积(AUC)作为主要检测性能指标。为了与无法输出异常分数的基于大型语言模型(LLM)的方法进行比较,我们还使用了准确率、精确率和召回率等指标。此外,我们采用DoubleRight指标[32]来评估推理能力。所有这些指标都是基于帧级别的真实标签计算得出的。
Implementation Details.我们使用PyTorch[37]实现了我们的方法AnomalyRuler。除非另有说明,我们采用CogVLM-17B[51]作为视觉感知的视觉大型语言模型(VLM),采用GPT-4-1106-Preview[1]作为归纳推理的大型语言模型(LLM),而采用开源的Mistral-7B-Instruct-v0.2[19]作为演绎推理(即推断)的LLM,因为在整个测试集上使用GPT的成本太高。我们在附录A.4中讨论了其他VLM/LLM的选择。AnomalyRuler的默认超参数设置如下:规则聚合中的批次数量n=10,每批次中的正常参考帧数m=1,多数投票中的填充大小p=5,以及指数移动平均(EMA)中的加权参数α=0.33。
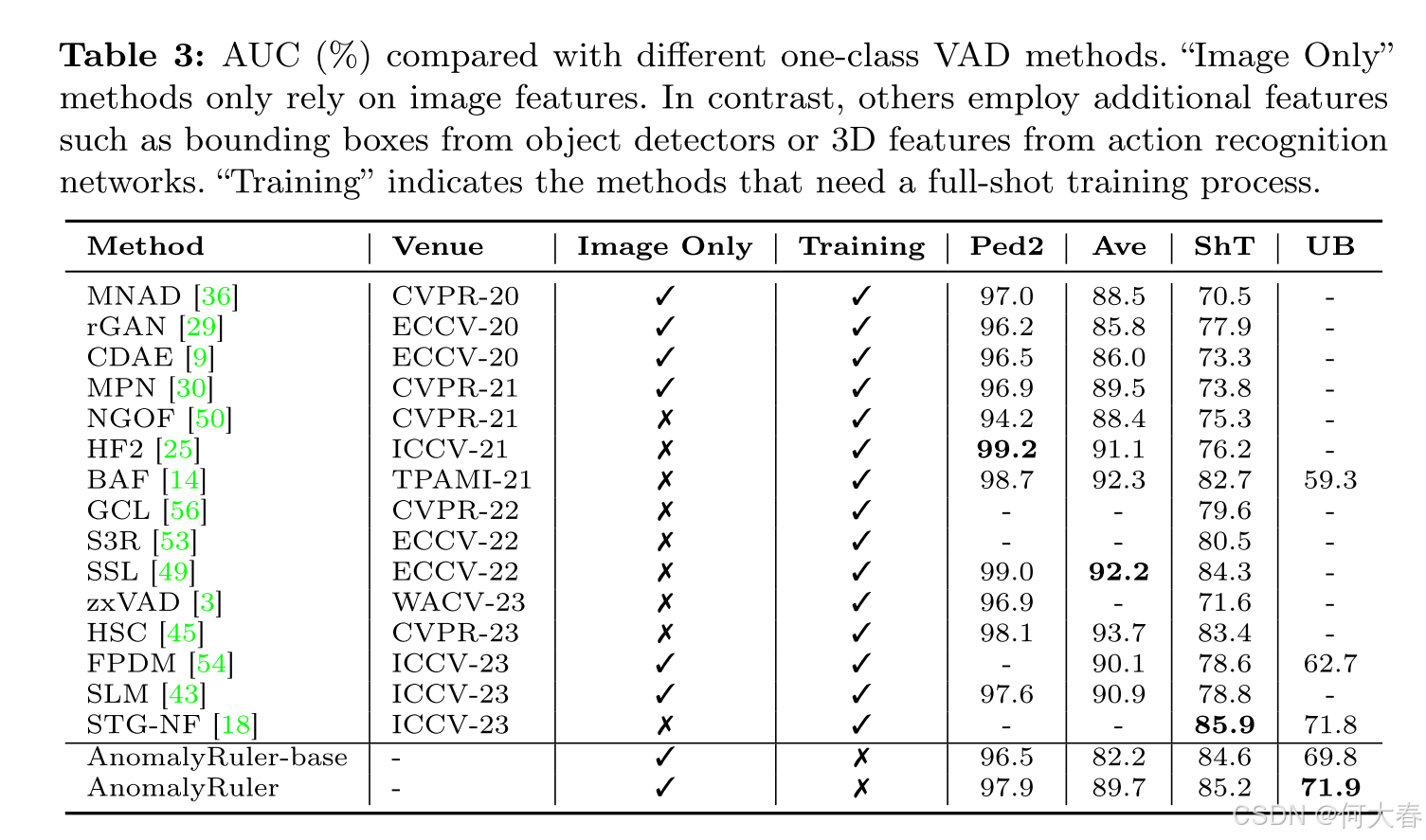
6 Conclusion
在本文中,我们提出了AnomalyRuler,这是一个基于大型语言模型(LLM)的视频异常检测(VAD)的新型基于规则的推理框架。通过归纳和演绎阶段,AnomalyRuler仅需要少量正常样本的提示,而无需昂贵的全样本调优,从而能够快速引导LLM的推理优势应用于各种特定的VAD场景。据我们所知,AnomalyRuler是首个针对单类VAD的推理方法。大量实验证明了AnomalyRuler的先进性能、推理能力和领域适应性。本文在附录A.1中讨论了该工作的局限性以及可能产生的负面社会影响。在未来的研究中,我们期望这项工作能够推动更广泛的单类问题及相关任务的发展,如工业异常检测[6, 55]、开放集识别[5, 40]和分布外检测[17, 42]。
阅读总结
感觉包装了太多复杂的概念,其实没看起来那么高级。
完全问gpt得到结果,也是一个方向吧。感觉现在的论文已经很少单纯靠堆叠模型能有新的提升了。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









