







 针对多模态行为识别中数据标注成本高昂的问题,Cosmo框架采用云-边协同架构,利用对比融合学习处理无标注数据,并结合有监督学习在边缘端进行微调,有效提升了模型在少量标注数据下的性能。
针对多模态行为识别中数据标注成本高昂的问题,Cosmo框架采用云-边协同架构,利用对比融合学习处理无标注数据,并结合有监督学习在边缘端进行微调,有效提升了模型在少量标注数据下的性能。
文章目录
精读笔记 - Cosmo: Contrastive Fusion Learning with Small Data for Multimodal Human Activity Recognition
1. 基本信息
| 论文标题 | Cosmo: Contrastive Fusion Learning with Small Data for Multimodal Human Activity Recognition |
|---|---|
| 论文作者 | Xiaomin Ouyang, Xian Shuai, Jiayu Zhou, Ivy Wang Shi, Zhiyuan Xie, Guoliang Xing, Jianwei Huang |
| 科研机构 | The Chinese University of Hong Kong, Michigan State University, Li Po Chun United World College, Hong Kong, The Chinese University of Hong Kong, Shenzhen, Shenzhen Institute of Artificial Intelligence and Robotics for Society |
| 会议年份 | Mobicom 2022 |
| 开源代码 | https://github.com/xmouyang/Cosmo |
| 摘要概括 | 面对多模态行为识别数据集来源于各种传感器,传感器采集的数据人工标注需要昂贵的成本的挑战,作者提出了 Cosmo 框架,这是对比融合学习在多模态行为识别数据集中的首次应用;作者采用云-边协同的系统架构,在云端采用对比融合的方法以无标注的数据集作为训练集,训练不同模态数据的特征提取器,在边缘端基于云端训练好的特征提取器,引入质量导向和注意力机制的方法以有标注的数据作为训练集训练下游任务;(3)作者采用两个经典的多模态行为识别数据集以及自主采集的多模态行为识别数据集,并模拟云边协同系统平台验证Cosmo,通过对比其他经典的多模态对比融合方法,证明了Cosmo的可靠性以及模型收敛性 |
2. 设计动机
2.1 分析多模态融合
- 多模态信息融合的目的是实现对齐不同模态的一致信息以及补全不同模态的互补信息;
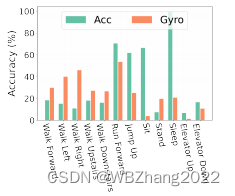
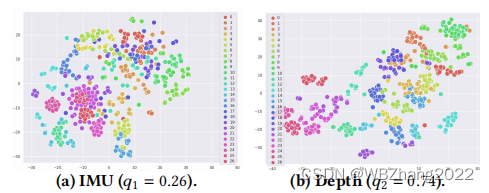
- 互补信息:如下图所示,不同模态的传感器数据,面对不同类别标签数据,使用Acc传感器对特定的某些类别分类准确,对某些类别分类准确度较低,而Gryo传感器恰恰与Acc的结果相反,体现了在不同类别数据的分类准确度的优势互补;
- 一致性信息:不同模态信息一致性的衡量标准 - 将所有的数据样本点通过t-SNE的降维方法映射至二维空间中,对于同一个样本的不同模态,得到两个点,分别连接原点,得到两个向量。计算余弦距离,可知同一个样本不同模态的信息一致性,总体而言所有样本的平均余弦距离越大说明信息越趋于一致性。
- 作者比较了DeepSense,DeepAttn两种经典的多模态融合的方法,分析DeepSense仅实现了多模态数据的一致性信息对齐,而DeepAttn同时实现了多模态数据的一致性信息对齐和互补信息补全;
2.2 有限的标注数据问题
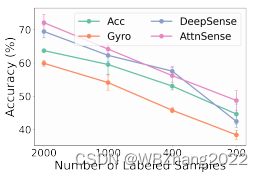
如下图所示,无论是使用单模态还是多模态融合方法,有标注的样本数量的减少,都会造成模型性能的下降;
3. 系统架构
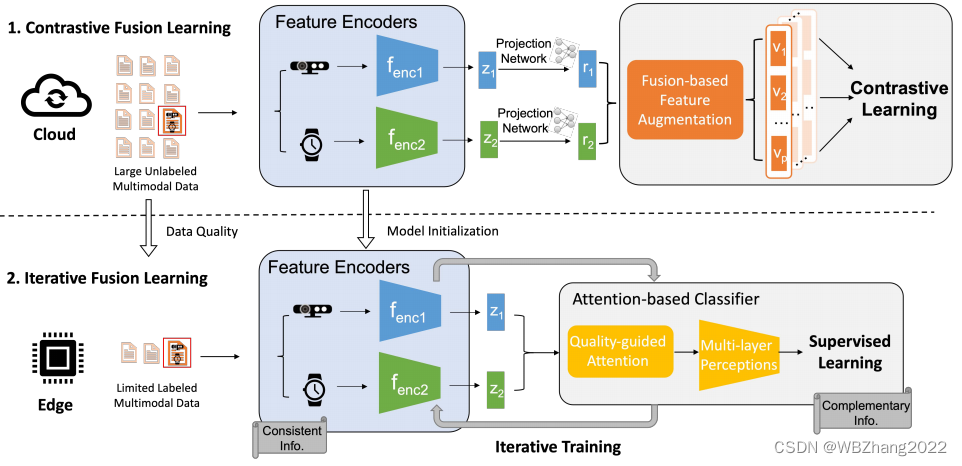
围绕着上述的动机作者提出了一种以云-边协同为系统架构的对比多模态融合的框架。在云端,有大量的无标注数据,采用对比融合的方法训练不同模态的特征提取器,并将训练好的特征提取器分发给边缘端的下游任务;在边缘端,有少量的标注数据,基于云端训练好的特征提取器,在采用传统的有监督学习方法的同时引入了质量导向和注意力机制,训练下游任务的分类器。
3.1 第一阶段:云端对比融合
3.1.1 不同模态的特征提取器
- 如系统结构图所示,假设有 N N N 个无标注的多模态数据 x = { x i , ∀ i = 1 , 2 , . . . , N } x=\{x^i, \forall i=1,2,...,N\} x={xi,∀i=1,2,...,N},每一个样本都有 M M M 个模态 x = { x 1 i , x 2 i , . . . , x M i } x=\{x_1^i, x_2^i,...,x_M^i\} x={x1i,x2i,...,xMi},每一个模态对应一个特征提取器 ( f e n c 1 ( ⋅ ) , f e n c 2 ( ⋅ ) , . . . , f e n c M ( ⋅ ) ) (f_{enc1}(\cdot),f_{enc2}(\cdot),...,f_{encM}(\cdot)) (fenc1(⋅),fenc2(⋅),...,fencM(⋅)); z j i = F l a t t e n ( f e n c j ( x j i ) ) z^i_j=Flatten(f_{encj}(x_j^i)) zji=Flatten(fencj(xji)) 表示第 i i i 个样本的 第 j j j 个模态的特征向量;
- 将同一数据的不同模态,映射到一个低维空间 r j i = N o r m ( h j ( z j i ) ) r^i_j=Norm(h_j(z^i_j)) rji=Norm(hj(zji))
3.1.2 云端特征融合
- 对(每一个样本的每一个模态)第 i i i 个样本的第 j j j 个模态数据特征向量 r j i r^i_j rji;
- 对
r
j
i
r^i_j
rji 进行特征增强,其类似图像增强,区别在于图像增强是通过裁剪,旋转等方式生成
P
P
P 张 图片,实现数据增广;而特征增强首先对每一个数据的特征向量
r
i
r^i
ri 复制
P
P
P 份,随后对于每一份
r
i
r^{i}
ri 的每一个模态
r
j
i
r^{i}_j
rji 我们分别给一个权重
α
j
k
\alpha_{jk}
αjk,并且每一份
r
i
r^{i}
ri 的每一个模态
r
j
i
r^{i}_j
rji 的权重
α
j
k
\alpha_{jk}
αjk 满足
∑
j
=
1
M
α
j
k
=
1
\sum^{M}_{j=1}\alpha_{jk}=1
∑j=1Mαjk=1,对每一个模态进行加权求和得到融合后的特征
v
k
i
v_k^{i}
vki
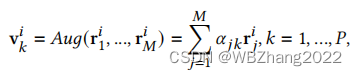
3.1.3 对比损失
- 对于每一个样本而言都需要生成
P
P
P 个增强后的融合特征,在云端训练的过程中,作者采用基于 SimCLR 的经典对比学习来训练特征提取器,其目标优化函数如下;
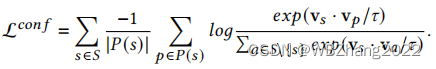
- 上述表达式是以一个batch为例子的,一个batch样本集 S S S 有 N × P N×P N×P 个样本,先看外面一层的求和,对于 S S S 中的每一个样本 s s s ,而 P ( s ) P(s) P(s) 表示的是与 s s s 同源的其它增强特征融合样本集;里层的求和,看分母 v s v_s vs 表示的是样本 s s s 的特征向量, v p v_p vp 表示的是与 s s s 同源的其它增强特征融合样本集的特征向量,得到正样本的相似度量值,分母表示的是除了 s s s 的本身其它所有样本特征向量与 s s s 的特征向量相似度量之和,对于同源的增强特征融合样本的求和结果取算术平均;回到最外层求和就是对每一个样本平均求和的结果;
- 实际意义:采用对比损失的目的是让正样本的特征向量更加相近,让负样本的特征向量更加远。进而实现了多模态特征的一致性信息的对齐;
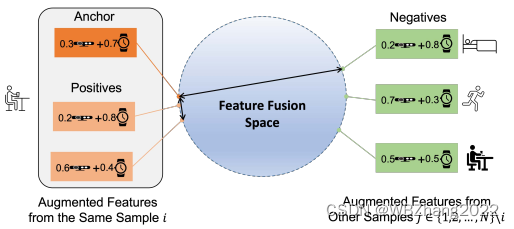
3.2 第二阶段:边缘端迭代融合
边缘端的特征编码器是采用云端基于对比融合学习训练的特征提取器的模型参数;将边缘端有标注的不同模态数据的经过特征提取器得到的特征向量,放入以质量-注意力机制的分类器,进行有监督训练,其基本步骤如下:
- 【第1步】:将云端基于对比学习训练好的特征提取器参数下载,加载到边缘端的特征提取器上,然后固定特征提取参数不变,随机初始化基于质量-注意力机制的分类器参数;
- 【第2步】:固定分类器,用边缘端有标注的数据集微调特征提取器的模型参数;
- 【第3步】:固定特征提取器,用边缘端有标注的数据集微调分类器的模型参数;
3.2.1 基于注意力机制的权重设置
如系统架构图所示,系统的边缘端的分类器有一个Attention模块,通过Attention模块得到第一个权重 β ( A t t n ) \beta(Attn) β(Attn)
- 同样对于模态的数据的特征向量
z
j
z_j
zj 先放入Attention模块进行线性变换+tanh激活 得到
μ
j
\mu_j
μj,每一个模态将
z
j
z_j
zj 和
μ
j
\mu_j
μj 作点积的结果作softmax得到每一个模态的权重
β
(
A
t
t
n
)
j
\beta(Attn)_j
β(Attn)j
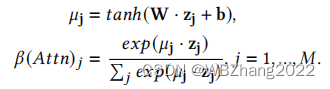
3.2.2 基于质量导向的权重设置
对于不同模态的数据现将其每一个样本进行t-SNE降维映射到二维空间,再聚类;
- 对于每一个模态降维后的数据计算其霍普金斯统计量
H
(
x
j
)
H(x_j)
H(xj),然后选择不同的类别数进行聚类,选取最高轮廓系数对应的类别数同真实的类别数相减的绝对值的倒数
1
/
c
j
1/c_j
1/cj与霍普金斯统计量相乘得到
q
j
q_j
qj,随后对每一个模态的
q
j
q_j
qj 作归一化 得到
β
(
Q
o
M
)
j
=
q
j
/
∑
j
=
1
M
q
j
\beta(QoM)_j=q_j/\sum^{M}_{j=1}q_j
β(QoM)j=qj/∑j=1Mqj
- 每一个模态的最终的权重是 β ( A t t n ) j \beta(Attn)_j β(Attn)j 和 β ( Q o M ) j \beta(QoM)_j β(QoM)j 加权得到的,即 β j = ( 1 − λ ) ⋅ β ( A t t n ) + λ ⋅ β ( Q o M ) j \beta_j=(1-\lambda)\cdot\beta(Attn)+\lambda \cdot \beta(QoM)_j βj=(1−λ)⋅β(Attn)+λ⋅β(QoM)j;同样进行归一化,得到了每一个模态最终的权重 β j = β j / ∑ j = 1 M β j \beta_j=\beta_j/\sum^{M}_{j=1}\beta_j βj=βj/∑j=1Mβj
3.2.3 迭代融合的方法
融合多模态特征的方法存在两种方法:
- 其一:如果不同模态的特征向量 z j z_j zj 维度是相同的,则 融合的特征 v = ∑ j = 1 M β j ⋅ z j v=\sum^{M}_{j=1}\beta_j\cdot z_j v=∑j=1Mβj⋅zj
- 其二:如果不同模态的特征向量 z j z_j zj 维度是不同的,则 融合的特征乘以对应的权重后直接拼接起来 v = c o n c a t ( β 1 ⋅ z j , . . . , β M ⋅ z M ) v=concat(\beta_1 \cdot z_j,...,\beta_M \cdot z_M) v=concat(β1⋅zj,...,βM⋅zM)
4. 实验验证
4.1 实验设置
4.1.1 实验数据集

4.1.2 对比模型
- SingleModal
- DeepSense
- AttnSense
- Contrastive Predictive Coding
- Contrastive Multi-view Learning
4.2 实验结果(在不同数据集下准确度)
4.2.1 在有限的标注数据下的总体性能
- 本组实验评估在三组标注数据有限的数据集(USC,UTD,self-collected)上使用不同的训练方法比较最终模型的准确率;
- 如下表所示,数据集USC,UTD,Self-collected有标注的训练集占所有训练集比率分别是 1 % , 5 % , 2 % 1\%,5\%,2\% 1%,5%,2% ,作者模拟了现实中多模态行为识别标注难度大的场景;
- 通过比较SingleModal对应单模态数据的预测准确率,DeepSense,AttnSense,CMC和Cosmo不同模态数据预测准确率的平均值,验证Cosmo在有限的标注数据下总体性能的优越;
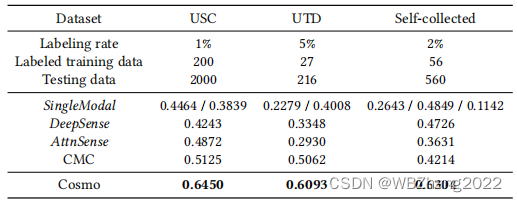
4.2.2 标注数据数量
- 本组实验作者保持训练数据的总量不变,改变标注数据占训练数据的比率,评估不同训练方法最终模型的准确率;
- 如下图所示,模型的预测准确率随着有标注的数据占所有训练数据的比重增大而增大;在USC,UTD,Self-collected数据集中Cosmo的表现最佳,甚至Cosmo使用小部分标注数据的模型性能可以达到AttnSense
100
%
100\%
100%的标注性能;
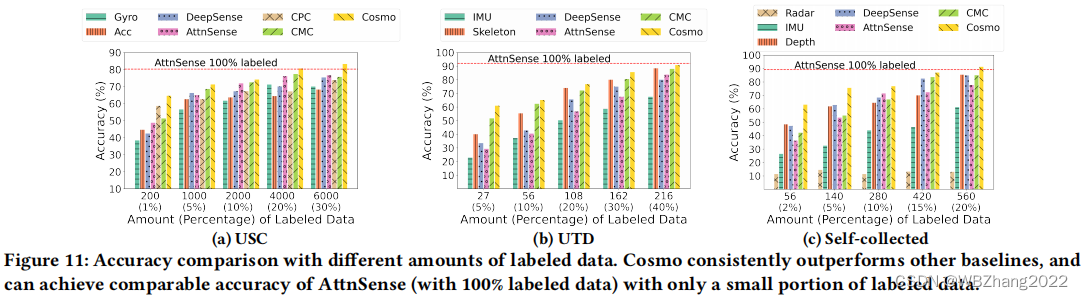
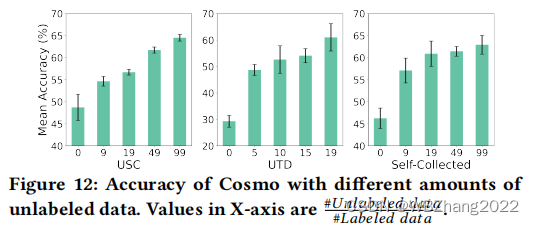
4.2.3 未标注数据数量
- 本组实验我们保持标注样本的数量不变,改变无标注训练样本的数量,评估Cosmo方法在不同无标注数据数量下,最终模型的预测准确率;
- 如下表所示,不同的数据集Cosmo训练的模型预测准确率,随无标注的样本的比率增大而增大;
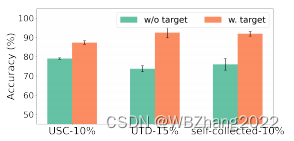
4.2.4 标注数据是来自目标测试对象的情况下模型的性能
- 本组实验是评估,标注的数据来自目标测试对象与不来自目标测试对象的情况是模型性能;
- 如下图所示,当标注数据来自目标测试对象时,模型的性能得到了显著的提高;
4.2.5 模型的收敛性
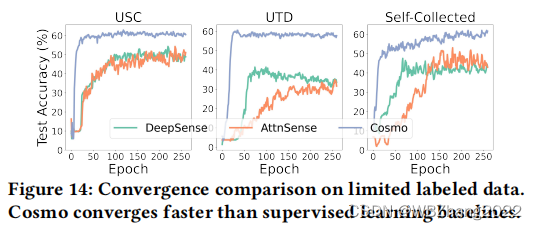
5. 结论
- 本篇论文提出了Cosmo训练框架,采用云-边协同的系统架构;
- 在云端基于对比融合的方法以大量无标注的数据作为训练集得到不同模态数据的特征提取器实现了不同模态数据一致性信息的对齐;
- 在边缘端采用质量-注意力机制为导向的有监督学习以少量标注的多模态行为识别实现微调,实现了不同模态信息互补信息的补全;

















 772
772

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









