






这篇论文《Why Do Multi-Agent LLM Systems Fail?》对多代理大型语言模型(LLM)系统中的失败模式进行了开创性的研究。作者通过系统地分析多个流行的多代理框架,识别出14种独特的失败模式,并提出了一个适用于各种多代理框架的全面分类法(MASFT)。这项工作不仅为理解多代理系统的失败提供了结构化的框架,还为未来的研究指明了方向。
论文中提出的MASFT分类法通过专家注释和一致性验证,确保了其可靠性和有效性。此外,作者还开发了一个可扩展的LLM评估管道,用于分析新多代理系统的性能并诊断失败模式。尽管在某些干预措施上取得了一定的成功,但论文也强调了需要更复杂的解决方案来彻底解决多代理系统中的失败问题。
总体而言,这篇论文为多代理系统的设计和改进提供了宝贵的见解,具有重要的理论和实践意义。它不仅揭示了当前多代理系统面临的挑战,还为研究人员和开发者提供了一个有用的工具来识别和改进这些系统。
核心速览
研究背景
- 研究问题:这篇文章旨在解决多智能体系统(Multi-Agent Systems, MAS)在任务执行过程中表现不佳的问题。尽管单个大型语言模型(LLM)代理在基准测试中表现出色,但多个LLM代理协作的系统在性能提升上仍然有限。
- 研究难点:该问题的研究难点包括:多智能体系统中的代理之间可能存在对齐问题、任务验证和终止机制不足、系统设计和规范不明确等。
- 相关工作:该问题的研究相关工作包括Agent Workflow Memory、DSPy、Agora、StateFlow等,这些工作分别解决了长时导航、通信流程、状态控制和任务解决能力等问题,但没有全面理解多智能体系统失败的原因或提出广泛适用的策略。
研究方法
这篇论文提出了第一个系统的多智能体系统失败模式分类体系(Multi-Agent System Failure Taxonomy, MASFT),用于理解和缓解多智能体系统的失败问题。具体来说,
-
扎根理论(Grounded Theory):首先,采用扎根理论方法对多智能体系统的执行轨迹进行系统性分析。扎根理论通过归纳分析实证数据来构建理论,避免了预设假设的测试。

-
数据收集与分析:收集并分析了超过150个多智能体系统执行轨迹,每个轨迹平均包含15,000行文本。通过开放编码方法对轨迹进行分析,识别出代理之间以及代理与环境之间的交互失败模式。
-
迭代细化分类体系:通过专家标注者的交叉验证,迭代调整失败模式和失败类别,直到达成共识。初始分类体系通过Cohen's Kappa评分验证其可靠性,最终达到了0.88的一致性。
-
自动化评估管道:开发了基于LLM的标注器,并通过交叉验证验证了其可靠性。LLM标注器的准确率为94%,Cohen's Kappa值为0.77,证明了其在自动化评估中的有效性。
实验设计
- 数据收集:选择了五个流行的开源多智能体系统(MetaGPT、ChatDev、HyperAgent、AppWorld、AG2),并从这些系统中收集了超过150个执行轨迹。
- 样本选择:每个多智能体系统的任务选择代表了其预期能力,而不是人为制造的挑战场景。例如,如果系统在特定基准或数据集上报告了性能,则直接从这些基准中选择任务。
- 参数配置:在案例研究中,使用了两种不同的LLM(GPT-4和GPT-4o)进行基准测试,并进行了六次重复实验以评估结果的一致性。
结果与分析
-
失败模式分类:通过扎根理论和专家标注,识别出14种细粒度的失败模式,并将这些模式归类为三类主要失败类别:系统设计与规范失败、代理间对齐失败、任务验证与终止失败。
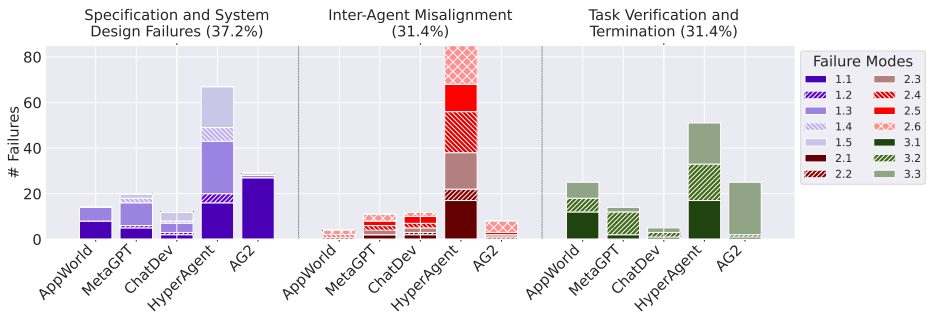
-
失败模式分布:不同多智能体系统表现出不同的失败模式分布。例如,AG2在代理间对齐失败方面较少,而ChatDev在系统设计与规范失败方面面临更多挑战。
-
验证与终止问题:许多失败模式可以追溯到缺乏适当的验证或验证过程不正确。验证作为最后一道防线,但并非所有问题都能仅归因于验证不足。
-
高可靠性组织特征:MASFT发现的失败模式与复杂人类组织的常见失败模式一致,表明MASFT具有适用性,并需要非平凡的干预措施。
总体结论
这篇论文通过系统的分析和分类,揭示了多智能体系统失败的多种原因,并提出了相应的解决方案。研究表明,尽管改进提示和优化代理组织可以带来一定的性能提升,但仍需更全面的结构性策略来实现更可靠的系统。论文的贡献包括:
- 提出了第一个系统的多智能体系统失败模式分类体系(MASFT)。
- 开发了一个可扩展的基于LLM的自动评估管道,用于分析新多智能体系统的性能和诊断失败模式。
- 通过案例研究验证了部分策略的有效性,但发现这些策略在解决所有失败模式方面仍存在局限性,强调了结构性策略的必要性。
- 开源了所有标注的多智能体系统对话轨迹、评估管道和专家标注,为未来的研究提供了丰富的资源。
论文评价
优点与创新
- 首次系统研究:本文首次系统地研究了多智能体(MAS)系统的失败模式,填补了现有研究的空白。
- 综合分类体系:提出了多智能体系统失败分类体系(MASFT),涵盖了14种细粒度的失败模式,并分为三大类:规范和系统设计失败、智能体间对齐失败、任务验证和终止失败。
- 可扩展的评估管道:开发了基于大型语言模型(LLM)的判官(LLM-as-a-judge)评估管道,实现了对新MAS性能的可扩展自动化分析。
- 专家标注与验证:通过六名专家标注者的独立标注,确保了失败模式的定义一致性,最终Cohen's Kappa评分为0.88。
- 开源数据集:全面开源了所有150多个标注的多智能体对话轨迹、可扩展的LLM判官评估管道以及150多个轨迹的LLM标注。
- 干预措施研究:进行了针对代理规范、对话管理和验证策略的最佳努力干预措施研究,尽管取得了14%的任务完成率提升,但仍不足以满足实际部署需求。
不足与反思
- 干预措施的局限性:尽管改进了提示工程和增强的代理拓扑编排,但发现这些干预措施并不能完全解决所有失败案例,表明需要更结构化的MAS重新设计。
- 未来研究方向:本文指出,MASFT不仅仅是现有多智能体框架的问题,而是反映了MAS的基本设计缺陷。未来的研究需要更深入地探讨强验证、增强的通信协议、不确定性量化以及记忆和状态管理等结构性策略。
关键问题及回答
问题1:论文中提出的“多智能体系统失败模式分类体系(MASFT)”具体包括哪些失败模式?这些模式是如何分类的?
- 系统设计与规范失败(FC1):
- FM-1.1:违反任务规范:未能遵守任务的特定约束或要求,导致次优或错误的结果。
- FM-1.2:违反角色规范:未能遵守分配角色的责任和约束,可能导致代理行为类似于其他角色。
- FM-1.3:步骤重复:在过程中不必要地重复已完成步骤,可能导致延迟或错误。
- FM-1.4:丢失对话历史:意外的上下文截断,忽略最近的交互历史并回到之前的对话状态。
- FM-1.5:未意识到终止条件:缺乏对应触发代理交互终止的标准或理解,可能导致不必要的继续。
- 代理间对齐失败(FC2):
- FM-2.1:对话重置:意外或无故地重新开始对话,可能丢失上下文和进展。
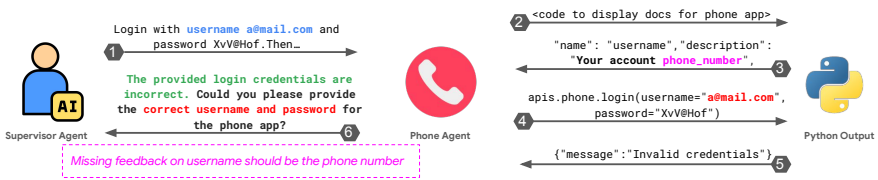
- FM-2.2:未能请求澄清:在面对不清晰或不完整数据时,无法请求额外信息,可能导致错误行动。
- FM-2.3:任务偏离:偏离预定目标或关注点,可能导致无关或无效的行动。
- FM-2.4:信息隐瞒:未能共享或传达重要数据或见解,可能影响其他代理的决策。
- FM-2.5:忽视其他代理的输入:忽视或未能充分考虑系统内其他代理提供的输入或建议,可能导致次优决策或错过合作机会。
- FM-2.6:推理-行动不匹配:逻辑推理过程与实际采取的行动之间的差异,可能导致意外或不良行为。
- 任务验证与终止失败(FC3):
- FM-3.1:过早终止:在交换所有必要信息或实现目标之前结束对话、交互或任务,可能导致不完整或错误的结果。
- FM-3.2:无或不完全验证:部分或完全省略适当的检查或确认任务结果或系统输出,可能导致错误或不一致的传播。
- FM-3.3:错误的验证:在迭代过程中未能充分验证或交叉检查关键信息或决策,可能导致系统中的错误或漏洞。
这些失败模式被归类为三类主要失败类别,帮助理解和缓解多智能体系统的失败问题。
问题2:论文中提到的“扎根理论(Grounded Theory)”方法是如何用于分析多智能体系统执行轨迹的?
- 数据收集:首先,收集了超过150个多智能体系统执行轨迹,每个轨迹平均包含15,000行文本。
- 开放编码:使用开放编码方法对轨迹进行分析,将定性数据分解为标记段,允许标注者创建新代码并记录观察结果。
- 理论抽样:通过理论抽样确保识别的失败模式具有多样性,选择的系统和任务反映了其目标和实现方法的变化。
- 常量比较分析:标注者不断将新创建的代码与现有代码进行比较,识别出新的失败模式并进行迭代反思和协作。
- 迭代细化:通过专家标注者的交叉验证,迭代调整失败模式和失败类别,直到达成共识。初始分类体系通过Cohen's Kappa评分验证其可靠性,最终达到了0.88的一致性。
通过这一过程,扎根理论方法帮助从实证数据中自然构建理论,识别出多智能体系统中的各种失败模式。
问题3:论文中提到的“基于LLM的标注器”是如何开发和验证的?其性能如何?
- 开发:开发了基于LLM的标注器,通过提供包含失败模式及其详细解释的系统提示,使用OpenAI的o1模型进行训练。为了提高准确性,还提供了示例。
- 验证:通过交叉验证验证了标注器的可靠性,使用了三轮讨论和标注,每轮选择不同的轨迹集进行标注和一致性检查。第一轮的Cohen's Kappa评分为0.24,经过迭代调整后,第二轮和第三轮的评分分别为0.92和0.84,表明标注器具有较高的可靠性。
- 性能:最终,基于LLM的标注器的准确率为94%,Cohen's Kappa值为0.77,证明了其在自动化评估中的有效性。
通过这一开发和验证过程,论文展示了如何利用LLM进行自动化的多智能体系统失败模式标注,提高了评估的效率和准确性。

















 1582
1582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









