







 本文概述了多项旨在提升人类中心感知、通用模型和多任务学习效率的研究,包括共享与任务特定组件的设计、Transformer架构的应用、模态融合与自监督学习方法,以及针对梯度平衡和动态优先级的解决方案。
本文概述了多项旨在提升人类中心感知、通用模型和多任务学习效率的研究,包括共享与任务特定组件的设计、Transformer架构的应用、模态融合与自监督学习方法,以及针对梯度平衡和动态优先级的解决方案。
humanbench
- HumanBench: Towards General Human-centric Perception with Projector Assisted Pretraining;
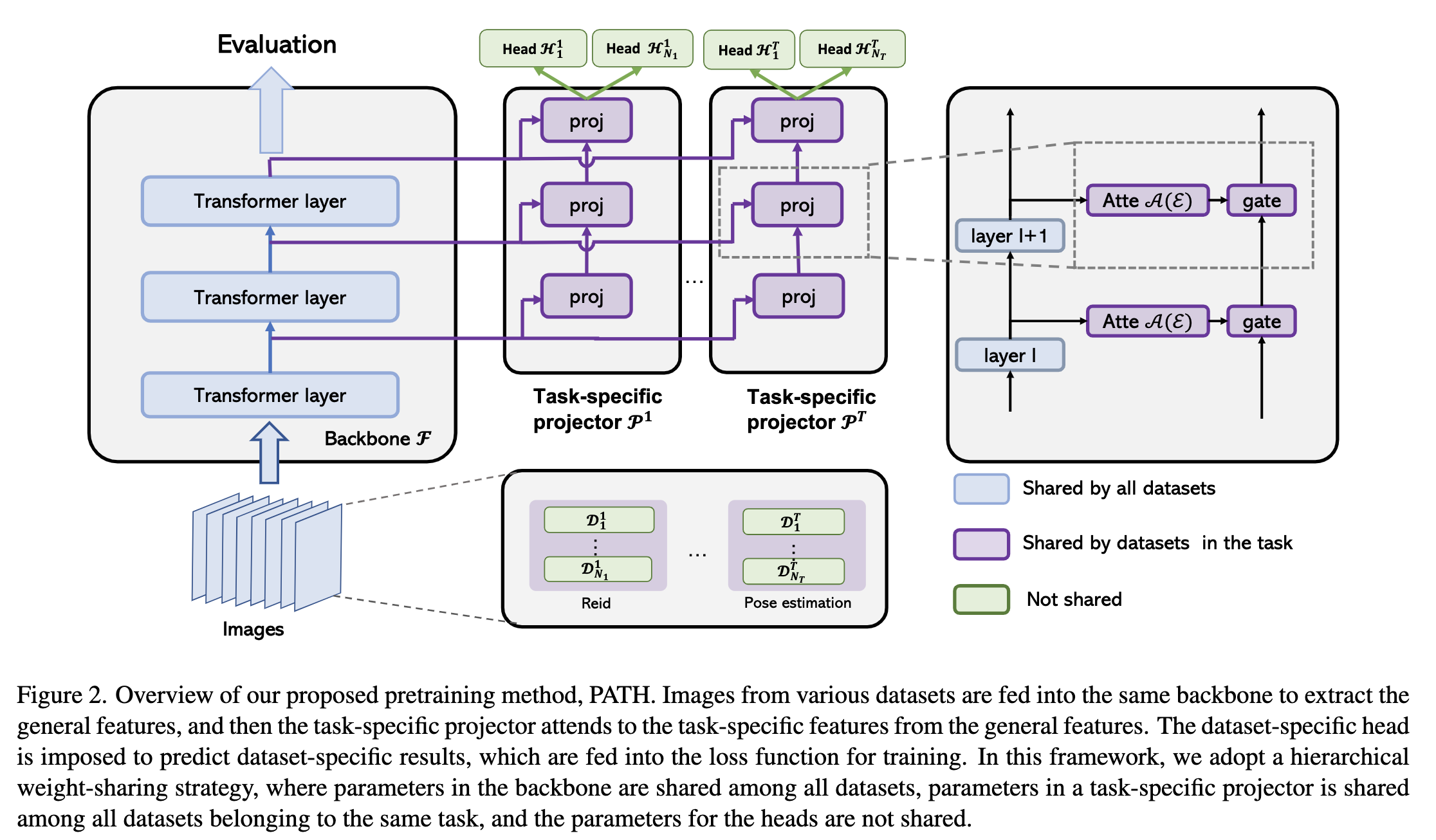
- 为了解决不同任务之间的conflict以及不同dataset之间的差异(相同任务),提出PATH,backbone是所有任务共享、projector是任务级别共享的、head是dataset级别共享的,也就是普通多任务+task specific projector+dataset specific head;
- projector: attention module(channel atten(senet) + spatial atten(self atten))(atten feature of specific task) + gate module(fuse featrue of different layer);
UniHCP
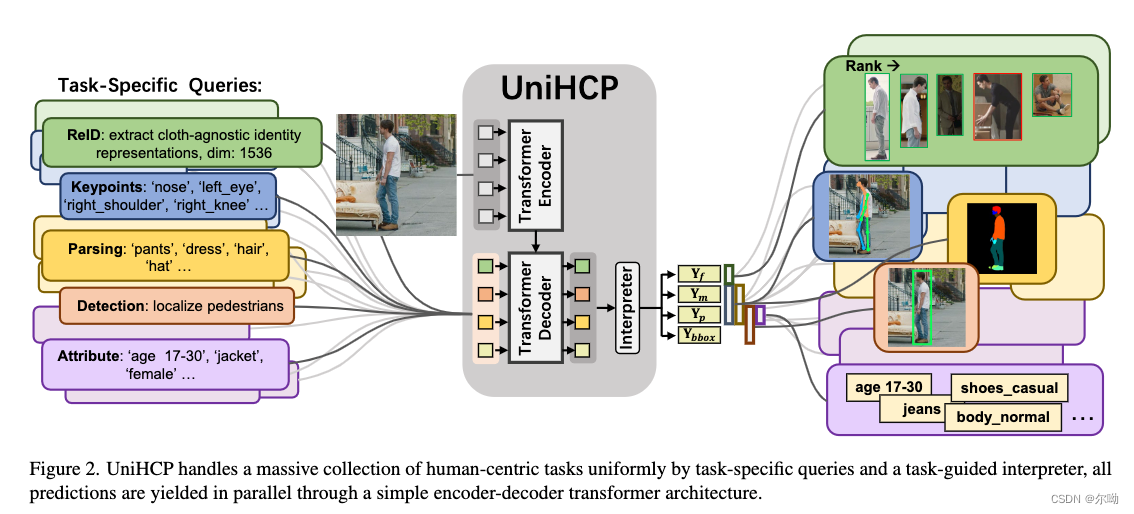
- UniHCP: A Unified Model for Human-Centric Perceptions
- transformer encoder不分任务提取特征
- transformer decoder + task-specific query关注特定任务的特征
- task guided interpreter
Uni-Perceiver
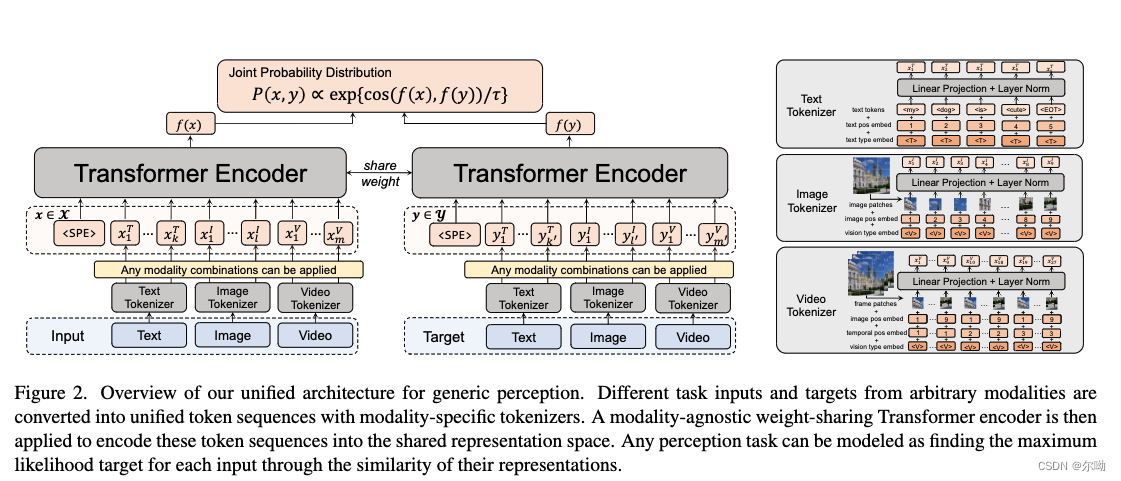
- Uni-Perceiver: Pre-training Unified Architecture for Generic Perception for Zero-shot and Few-shot Tasks;
- 人类通过同时处理多模态的数据来感知这个世界,这个过程是多任务的,但是当前的机器学习方法关注于一个任务,本文建立了一个统一的框架,将输入和target经过task-agnostic transformer encoder和task-specific tokenizer来将不同任务不同模态的表示统一到一个空间,之后再训练的过程中使用寻找最大相似的目标的准则进行
- 主要解决的问题是当前的大模型针对每一个任务都有自己的head,随着任务的增加都要为其定制head以及获取对应的训练数据;
- 整体思路是将所有的任务共性抽象出来,将输入和目标都统一到同一个空间,寻求输入和对应输出匹配的最大似然概率,此处使用余弦相似度来计算;
- 首先将不同模态的输入数据和目标使用modality-specific tokenizer来产生token sequence,之后input token seq和target token seq都送到transformer encoder中转换到同一个空间,目标是寻求匹配的最大似然概率;
- 针对不同数据有不同的tokenizer;
Uni-Perceiver-MoE
- Uni-Perceiver-MoE: Learning Sparse Generalist Models with Conditional MoEs
- 主要解决的问题是不同的任务在general model的训练过程中会相互产生不好的影响,使用conditional MoEs来解决
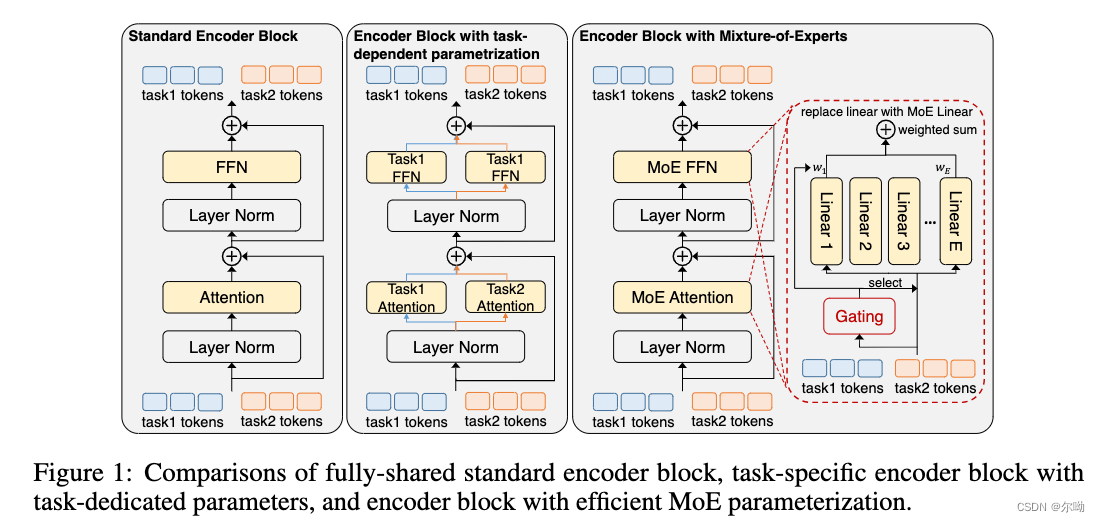
- transformer原来的FFN层和linear projection层被MoEs取代,主要是一个gate操作,将部分的输出变为0,相当于选择了特定的子网络,但是是自适应的;
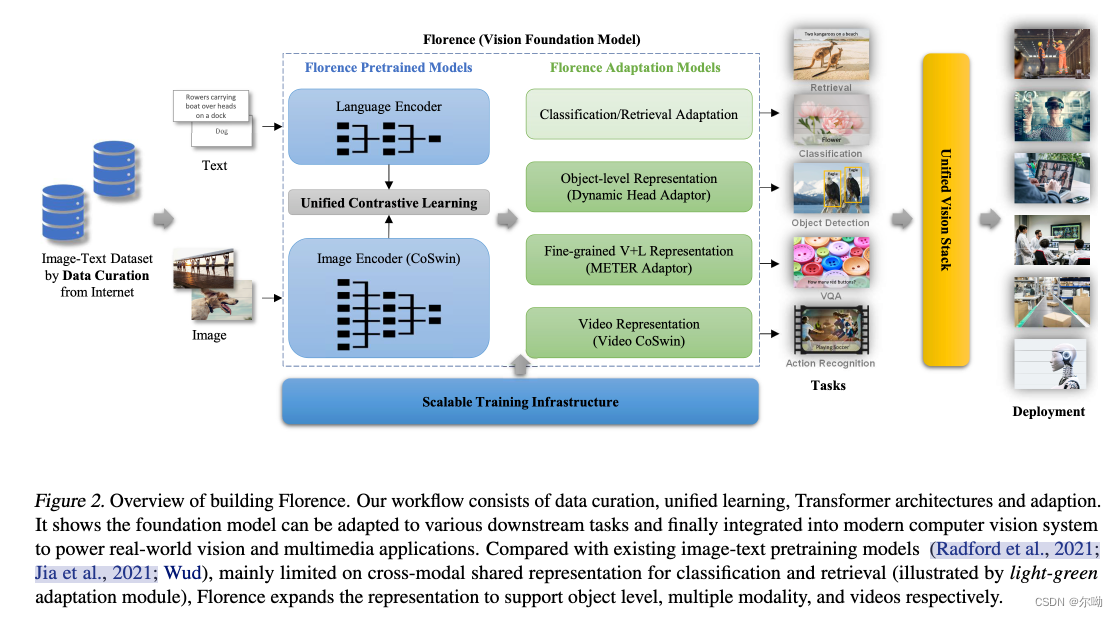
Florence
- Florence: A New Foundation Model for Computer Vision
- 主要解决的问题针对当时视觉基础模型的模态仅仅是text和image(CLIP等),扩展了模态,从小物体到大场景,从静态到动态,从单图像到加上深度图等等;由此针对增加的模态增加了新的模块来利用,以利于下游任务;
FLAVA
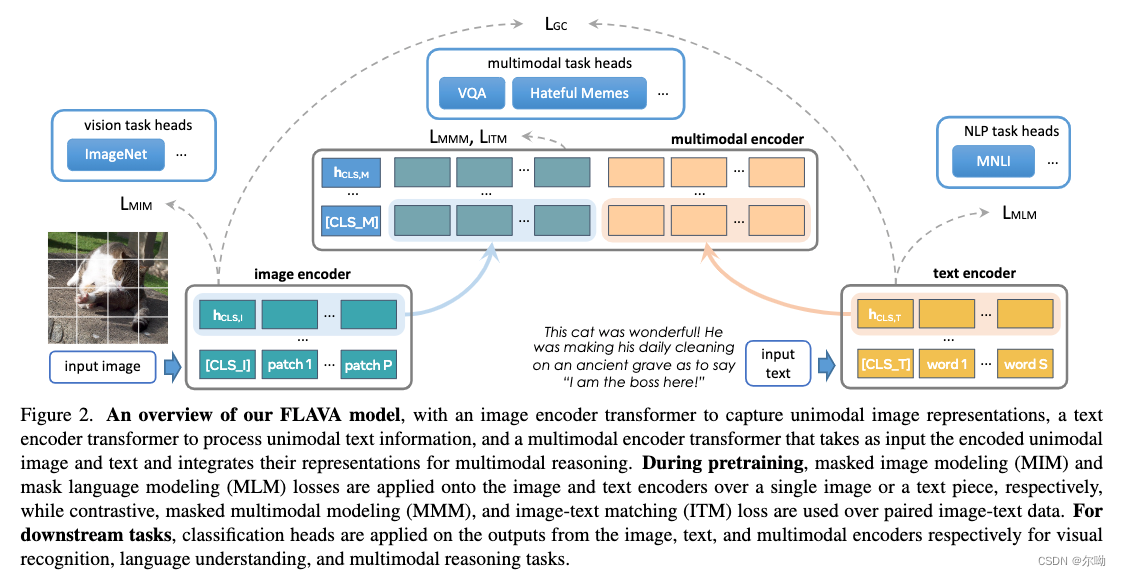
- FLAVA: A Foundational Language And Vision Alignment Model
- 主要解决CLIP等cross modal模型数据不开源,现有模型单使用使用cross model或者modal fuse,无法同时应对unimoal,cross modal和multi modal的情况,在image-text对数据上提出新的训练策略
- 分为三个部分,针对图片uni modal的transformer+针对text uni-modal的transformer+针对multimodal的损失,这样就可以同时处理单模态以及多模态任务
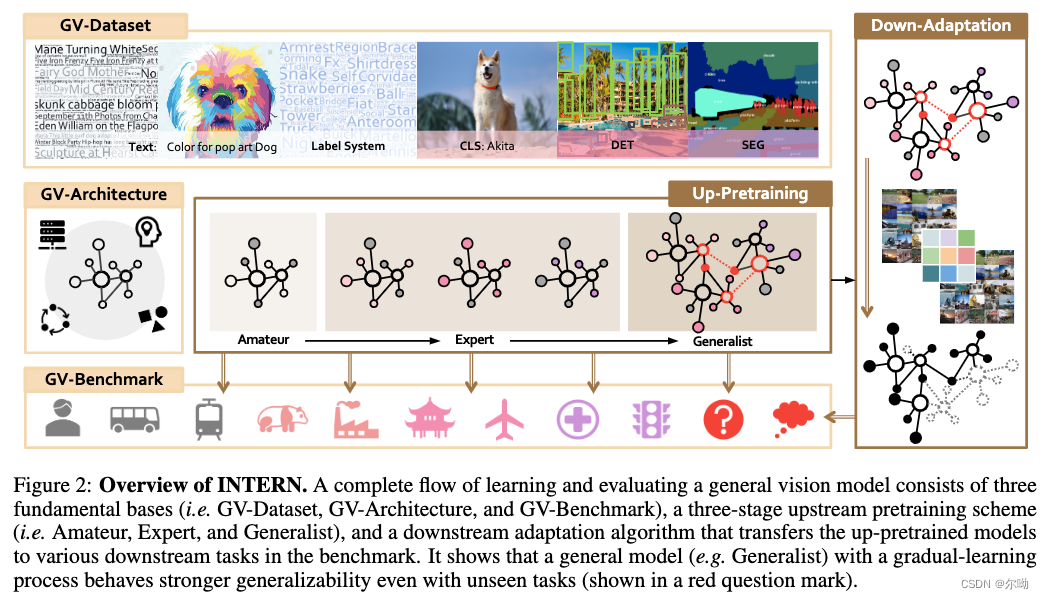
INTERN
- INTERN: A New Learning Paradigm Towards General Vision
- 主要解决之前的通用模型不够通用的问题,提出了新的训练范式
- 分为数据、网络结构以及下游任务三个部分,有down adaptation来使得任务更好的应对下游任务,主体网络部分分为三个阶段,amateur+expert+generalist
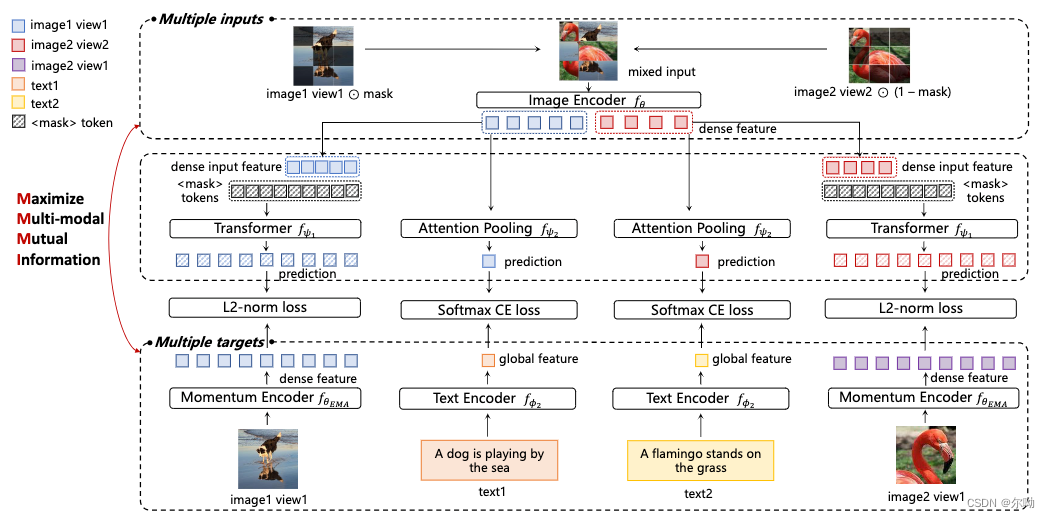
M3I-pretraining
- Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information
- 主要针对的问题是现在有很多种训练方法,例如全监督、弱监督、自监督,有很好的效果,有一些方法通过多阶段的方式结合使用这些方法,但是这种结合使用的方式有一个问题是当整个训练流程走完以后假如结果不好,无法确定是哪一个stage的问题,提出的解决方法就是只用一个统一的stage
GRADNORM
- GRADNORM: GRADIENT NORMALIZATION FORADAPTIVE LOSS BALANCING IN DEEP MULTITASKNETWORKS
- 主要解决的是多任务训练不好收敛的问题,可以一个损失量级大的任务占了主导地位,gradnorm调和了不同任务的损失,使不同损失的量级相同
- 通过增加一个新的gradiant loss,这个损失的定义是每个任务的梯度和总的梯度的l1正则之和,最终得到的效果是不同任务的梯度量级相同,降低损失降低快的下降速度,提高损失降低慢的下降速度,达到调和的目的https://zhuanlan.zhihu.com/p/378533888,https://zhuanlan.zhihu.com/p/570751177 ,其中第一项是单任务的损失带权梯度,第二项是不同任务的损失带权梯度,r表示的值和学习速度成反比https://zhuanlan.zhihu.com/p/470955143
- 实现https://github.com/brianlan/pytorch-grad-norm
- 两个损失,多任务损失和梯度损失独立更新,梯度损失是权重的函数,达到对权重更新的目的
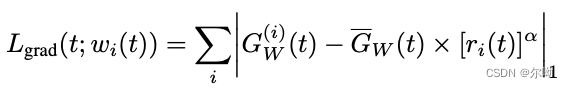
Dynamic Task Prioritization for Multitask Learning
- 针对多任务训练,主要是动态的关注于更加困难的任务,分为两个级别,一个是样本级别,类似于focal loss,另一个是任务级别,关注于困难任务,通过指定kpi开完成,kpi取值0-1,和任务的困难程度成反比,任务的困难程度和损失的权重成正比https://zhuanlan.zhihu.com/p/71012037 ;
Multi-Task Learning Using Uncertainty to Weigh Losses for Scene Geometry and Semantics
- 针对多任务训练,根据不确定性来确定损失的权重http://www.liuxiao.org/2020/07/multi-task-learning-using-uncertainty-to-weigh-losses-for-scene-geometry-and-semantics/
- 一种正则化方法
- 两个回归问题多任务
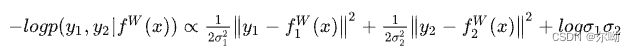
- 回归+分类
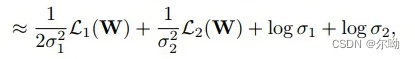
- 两个sigma都是可学习的参数
- 代码https://github.com/yaringal/multi-task-learning-example/blob/master/multi-task-learning-example.ipynb
End-to-End Multi-Task Learning with Attention
- https://zhuanlan.zhihu.com/p/82234448
- 实现https://github.com/lorenmt/mtan
- humanbench和这个很像,在共享特征之后加上了task spetial的attention模块来聚焦任务相关的特征
- 采用dynamic weight average来决定损失的权重,和gradnorm的思路很像
Multi-Task Learning as Multi-Objective Optimization
- 将多任务转变为多目标优化问题,Pareto optimality是指一组参数,没有另一组不同的参数会使损失值更小,非劣解是指不存在一个最优解的情况下所有的可能解,Pareto最优解——无法在改进任何目标函数的同时不削弱至少一个其他目标函数。这种解称作非支配解或Pareto最优解。
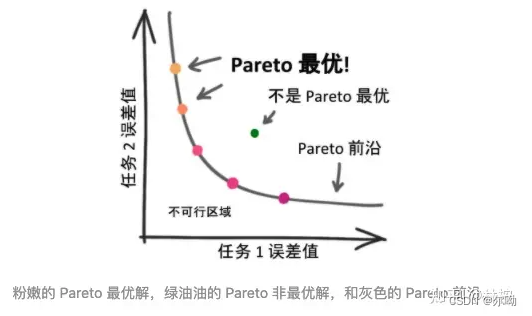
- Multiple Gradient Descent Algorithm(MGDA)来解决MTL Parato optimality
Gradient Surgery for Multi-Task Learning
- 当不同任务的梯度方向相反的时候,将梯度更新为处理之后的梯度
MOE, MMOE, SNR, PLE, MOSE, MTDNN, ESSM
- 工业界多任务学习

















 1523
1523

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









