







 本文介绍了概率预测评估的方法,包括概率积分变换(PIT)及其可视化分析,连续概率排位分数(CRPS)与交叉熵、对数分数作为数值评分规则的详细解释,以及在真实分布未知情况下的应用和注意事项。通过这些方法可以评估模型预测的校准度(calibration)和集中度(sharpness),并判断预测的相对优劣。
本文介绍了概率预测评估的方法,包括概率积分变换(PIT)及其可视化分析,连续概率排位分数(CRPS)与交叉熵、对数分数作为数值评分规则的详细解释,以及在真实分布未知情况下的应用和注意事项。通过这些方法可以评估模型预测的校准度(calibration)和集中度(sharpness),并判断预测的相对优劣。
本文链接:个人站 | 简书 | CSDN
版权声明:除特别声明外,本博客文章均采用 BY-NC-SA 许可协议。转载请注明出处。
概率预测的目标是在满足 calibration 的前提下尽可能提高预测的 sharpness。所谓的 calibration 指的是预测分布和观测值在统计上的一致性,而 sharpness 则是指预测分布的集中程度。下面介绍一些常见的概率预测的评估方法。
1. 概率积分变换(Probability Integral Transform,PIT)
对于观测值 ξ 1 , ⋯ , ξ n \xi_1, \cdots, \xi_n ξ1,⋯,ξn ,假设模型预测的累积分布函数分别为 F 1 , ⋯ , F n F_1, \cdots, F_n F1,⋯,Fn。如果模型预测准确,则概率积分变换 { F i ( ξ i ) } i = 1 n \{F_i(\xi_i)\}_{i=1}^n { Fi(ξi)}i=1n 应当服从标准的均匀分布 U ( 0 , 1 ) U(0,1) U(0,1)。
PIT 的优势之一是便于可视化。最简单的做法是画直方图。 ∪ \cup ∪ 形的直方图意味着预测的分布过于集中; ∩ \cap ∩ 形的直方图意味着预测的分布过于分散;明显不对称的直方图则意味着预测的分布整体偏离真实值。
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from scipy.stats import norm
sns.set()
obs = np.random.normal(loc=0, scale=1, size=1000) # 观测值
pit_1 = norm.cdf(x=obs, loc=0, scale=1) # 准确的预测
pit_2 = norm.cdf(x=obs, loc=0, scale=0.5) # 预测过于集中
pit_3 = norm.cdf(x=obs, loc=0, scale=2) # 预测过于分散
pit_4 = norm.cdf(x=obs, loc=1, scale=1) # 均值偏离
plt.figure(figsize=(10, 8))
ax1 = plt.subplot(221)
sns.distplot(pit_1, bins=20, kde=False, color='g')
ax1.set_title('Histogram of PIT_1')
ax2 = plt.subplot(222)
sns.distplot(pit_2, bins=20, kde=False, color='g')
ax2.set_title('Histogram of PIT_2')
ax3 = plt.subplot(223)
sns.distplot(pit_3, bins=20, kde=False, color='g')
ax3.set_title('Histogram of PIT_3')
ax4 = plt.subplot(224)
sns.distplot(pit_4, bins=20, kde=False, color='g')
ax4.set_title('Histogram of PIT_4')
plt.tight_layout()
plt.show()
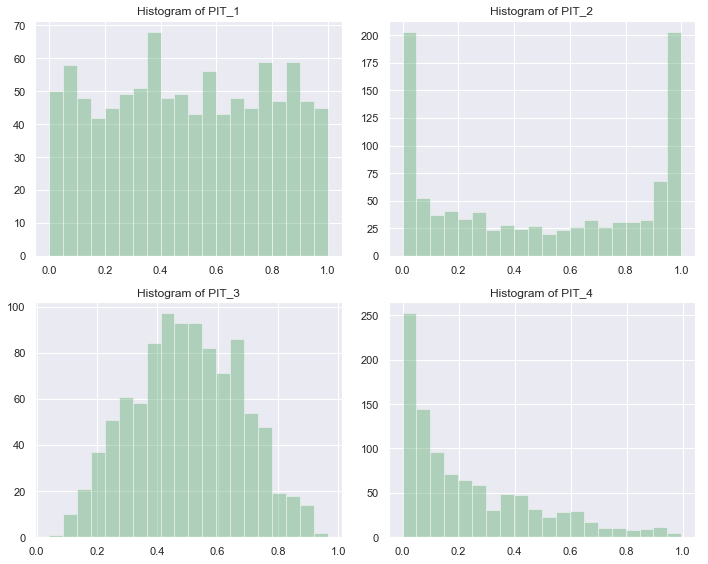
PIT 还可
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2514
2514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









