






UCIE 是一种 “分层合作” 的协议,就像搭建积木塔,每一层(组件)都有独特功能。三个主要组件(协议层、芯片到芯片适配器层、物理层),每层分工明确(如物理层负责底层信号传输,适配器层处理数据转发规则,协议层对接具体通信协议)。
UCIE 要求每个组件都得 “胜任工作”,即能支持宣传的功能和带宽。同时,为确保组件间交互正常,对不同 “互动环节”(握手)和状态变化设定了超时机制与错误规则。除非特别说明,超时时间允许在规定值基础上 “上下浮动”(下限 0%,上限 + 50%)。而且,当系统 “重启归零”(域复位)后,所有超时值和计数器值都得恢复到规定状态,保证每次启动都有统一的 “起跑线”。
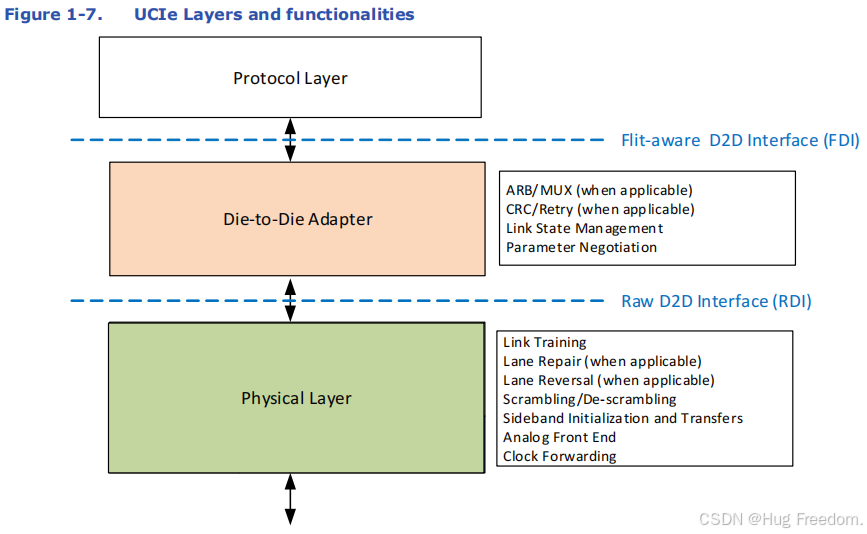
1.1.1 协议层(Protocol Layer)
协议层如同 “翻译官”,其工作会随应用场景变化。UCIE 规范举例了通过 UCIE 链路传输 CXL 或 PCIe 协议的情况,它支持以下几种协议:
- PCIe:即 PCIe 基础规范中的协议。
- CXL:源自 CXL 规范,但不支持 RCD/RCH/eRCD/eRCH。
- 流协议:为用户自定义协议提供通用传输模式,方便各类自定义协议借助 UCIE 传输数据。
每种协议在 UCIE 上传输时,都有不同的优化方式和数据单元(Flit)传输规则。
1.1.2 Die-to-Die (D2D) Adapter
D2D Adapter 如同 “协调员”,在协议层和物理层之间协调,确保数据在 UCIE 链路上成功传输。它尽量简化主数据路径的逻辑,为协议数据单元(Flit)打造低延迟的优化通道。
例如,传输 CXL 协议且需同时处理多个协议时,D2D Adapter 会执行 ARB/MUX 功能(类似 “交通指挥”,安排不同协议数据的传输顺序)。当原始误码率(Raw BER,衡量数据传输出错概率,数值越高越易出错)高于 1e - 27 时,UCIE 规范针对 PCIe、CXL 或流协议提供的 CRC(循环冗余校验,用于检查数据错误)和重试方案,会在 D2D Adapter 中实现。此外,D2D Adapter 还负责协调高层链路状态机的启动、与远程链路伙伴交换协议相关参数,若支持,还会协调电源管理。
1.1.3 Physical Layer
UCIE 的主数据传输路径在芯片接口焊点上被 “打包” 成一个个 “小组”,每个小组称为一个 模块(Module)。模块是 UCIE 物理前端(AFE)结构设计的最小单元,就像建造房屋时的 “标准组件”。标准封装和高级封装中每个模块包含的 “数据通道(Lanes)” 数量在第 4 章有具体规定。当协议层或D2D Adapter需要更大带宽(比如要传输更多数据)时,就可以通过多个模块同时发送数据,如同从 “单车道” 变为 “多车道” 并行运输。
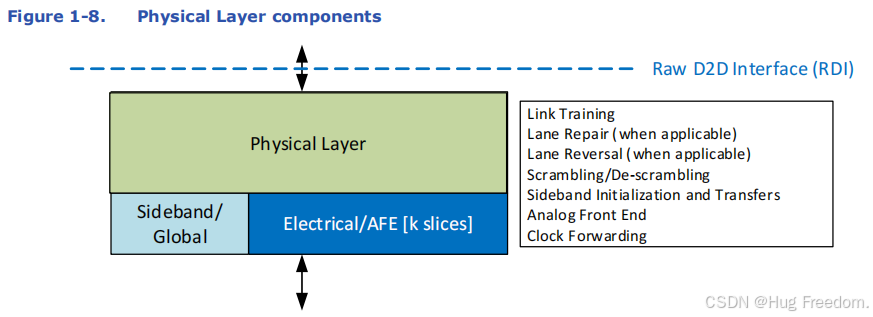
UCIE 的物理链路包含两种 “通道”:
-
边带(Sideband):
这是一条 “辅助通道”,专门用于传输 “控制信息”,比如模块间参数交换、调试时访问寄存器、协调链路训练与管理。它每个方向有一根转发时钟引脚(固定频率为 800MHz)和一根数据引脚。边带逻辑必须由辅助电源供电,且处于 “始终开启” 状态,每个模块都有自己独立的边带引脚。对于高级封装,为防止边带损坏影响系统,每个方向还额外提供一对冗余的时钟和数据引脚。 -
主带(Mainband):
这是 “主数据通道”,承担 UCIE 的主要数据传输任务。每个模块包含转发时钟、数据有效引脚(告知数据是否有效)、跟踪引脚(追踪数据路径)和 N 条数据通道。- 高级封装中,N = 64(也叫 x64)或 N = 32(也叫 x32),并且在凸点布局中提供四条额外引脚用于数据通道修复。
- 标准封装中,N = 16(也叫 x16),不提供额外修复引脚(结构更简单,成本更低)。
最后,逻辑物理层如同 “交通总指挥”,负责协调边带传输、主带训练与修复等不同功能及其执行顺序,确保整个物理链路正常启动和管理。
简单总结:UCIE 通过模块组织数据通道,边带负责 “指挥控制”,主带负责 “运输数据”,高级封装更复杂高级(通道多、有备用修复引脚),标准封装更简单,逻辑物理层则确保整个物理链路有序运行。
1.1.4 Interfaces
UCIE 定义了两个关键接口:
- Raw D2D 接口(物理层 ↔ D2D 适配器):
类似 “硬件插头与插座” 的规则,规定物理层(负责信号传输的硬件)如何与 D2D 适配器(数据转发的 “中转站”)连接,比如电压、时序、数据格式等。 - Flit-aware D2D 接口(D2D 适配器 ↔ 协议层):
类似 “软件 API 接口”,规定 D2D 适配器如何与协议层(负责处理 PCIe/CXL 等协议的软件逻辑)交互,比如数据单元(Flit)的封装、传输控制指令等。
定义接口的两大动机
① 降低集成成本,加速产品落地
- 场景:
芯片设计公司(如高通)想使用 A 公司的物理层 IP、B 公司的 D2D 适配器 IP、C 公司的协议层 IP,无需自行设计接口,只需按 UCIE 标准对接,像 “组装电脑” 一样混搭不同厂商的组件。 - 好处:
- 避免重复开发接口,缩短研发周期(比如原本需要 1 年开发接口,现在直接用标准接口,3 个月完成)。
- 降低技术门槛,小公司也能使用成熟 IP,快速推出产品(类似用现成的 USB 接口芯片开发外设)。
② 简化硅后测试,统一开发模型
- 硅后测试痛点:
芯片制造完成后(硅后),发现接口不兼容,修改成本极高(可能需要重新流片,花费数百万美元)。 - 解决方案:
UCIE 定义了统一的总线功能模型(BFM),类似 “接口说明书”,所有厂商按同一标准开发 IP,确保:- 开发阶段:用 BFM 模拟接口交互,提前发现问题(好比按图纸组装零件,先检查尺寸是否匹配)。
- 测试阶段:无需复杂适配,直接验证互操作性(比如不同品牌的 U 盘都能在电脑上识别)。
1.2 UCIE configurations
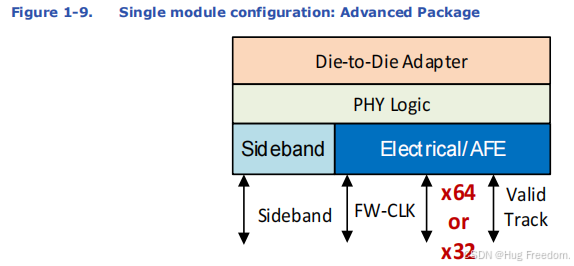
1.2.1 单模块配置
- 高级封装:单模块配置是一个 x64 或 x32 的数据接口,就像一条有 64 或 32 条 “车道” 的数据通道。
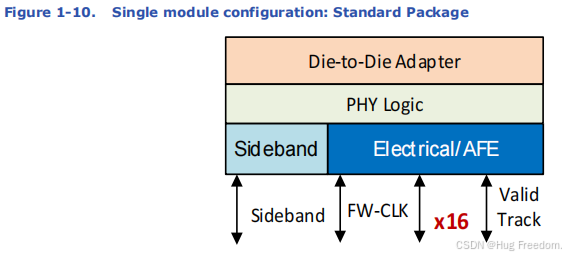
- 标准封装:单模块配置是一个 x16 的数据接口,即数据通道有 16 条 “车道”。
- 多实例独立运行:如果有多个单模块配置的实例,且每个模块都有自己专用的适配器(Die - to - Die Adapter),它们可以独立运行。例如,不同模块可以以不同的数据速率和宽度传输数据,就像多条独立的道路,每辆车(数据)的行驶速度(速率)和车道数量(宽度)可以不同。
1.2.2 多模块配置
- 配置类型:规范允许 两模块 和 四模块 配置。
- 共同适配器下的要求:当这些模块使用一个共同的适配器时,两模块和四模块配置中的模块必须以 相同的数据速率和宽度 运行。例如,两模块配置就像两条并行的道路,每辆车的行驶速度和车道数量必须一致;四模块配置同理。
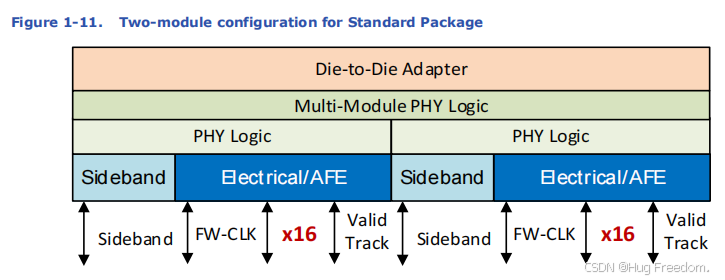

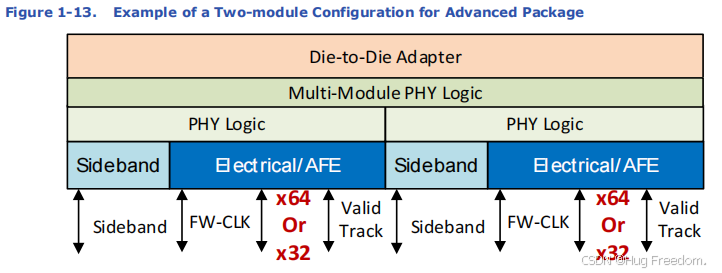
简单来说,单模块配置灵活,可独立运行;多模块配置在使用共同适配器时,需保持数据速率和宽度一致,以确保协同工作。
1.3 UCIE Retimers
UCIe Retimers 用于实现不同类型的封装外互连,扩展不同封装上两个 UCIe 芯片(UCIe Die)之间的通道连接。每个 UCIe Retimer 有一个本地 UCIe 链路连接到封装内的 UCIe Die,还有一个外部连接用于长距离传输。例如图中,UCIe Retimer 0 与 UCIe Die 0 通过package 0 内的 UCIe Link 0 连接,UCIe Retimer 1 与 UCIe Die 1 通过package1 内的 UCIe Link 1 连接,“remote Retimer partner” 指封装外互连另一端的 UCIe Retimer 芯片。
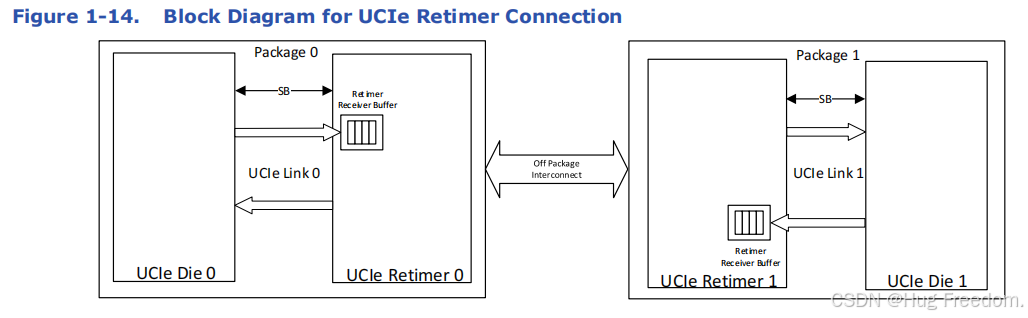
UCIe Retimer 的责任
- 可靠的 Flit 传输:有三种实现方式
- 方式一:Retimer 可使用承载协议(如 PCIe 或 CXL)底层规范定义的 FEC(前向纠错)和 CRC(循环冗余校验),但外部互连需符合该协议的错误模型(如误码率 BER 和错误相关性)。UCIe 链路通过 Raw Format 传输协议原生位(如 PCIe 或 CXL Flits),此时需调整 UCIe Die 上的队列大小(协议层缓冲区)以适应往返延迟。
- 方式二:Retimer 自身提供 FEC、CRC 和重试能力处理封装外互连的 BER。Flits 经历三个独立链路,每个 UCIe Retimer 与封装内 UCIe Die、远程 Retimer 伙伴分别进行独立的 ACK/NAK(确认 / 否定确认)重试。此场景下,协议可使用任何适用的 Flit 格式通过 UCIe 链路传输。
- 方式三:Retimer 用自己的 FEC 替换或补充原生 PCIe/CXL 定义的 FEC,但利用底层协议的内置 CRC 和重放机制。此时,需调整 UCIe Die 上的队列大小(协议层缓冲区、重试缓冲区)以匹配往返延迟。
- 解析链路和协议参数:与远程 Retimer 伙伴确保 UCIe Die 端到端(E2E)互操作性。例如,强制封装 0 和封装 1 使用相同的链路宽度、速度、协议(含特定参数)和 Flit 格式。具体解析机制(如跨封装外互连的参数交换消息传输)因 Retimers 实现而异,但需考虑自身及两端 UCIe Die 的能力,确保一致操作模式。为避免 UCIe 链路因外部互连链路建立或参数解析时间长而超时,UCIe 规范定义了 “Stall” 响应。Retimers 必须按规范规则响应 “Stall”,避免不必要超时,且确保链路不会无限期停顿。
- 解析链路状态:与远程 Retimer 伙伴解析适配器链路状态机(LSM)或 RDI 状态,确保端到端正确操作。
流量控制和背压
- UCIe Die 到 UCIe Retimer:使用信用(credits)流量控制,该信用在底层协议信用机制(如 PCIe 的 PH、PD 信用)之上。UCIe D2D 信用用于两个 UCIe Retimers 间的流量控制,确保数据最终被远程 UCIe Die 消耗。每个 UCIe Retimer 需为接收的 Flits 实现接收缓冲区,初始参数交换时向 UCIe Die 通告接收缓冲区信用,无信用时 UCIe Die 不能发送数据(1 信用对应 256B 数据,含 FEC、CRC 等)。信用返回通过有效成帧(Valid framing)重载。当 RDI 状态从 Active 转换时,UCIe Die 的信用计数器重置为初始值;UCIe Retimer 重新进入 Active 状态前,需排空或转储接收缓冲区数据。
- UCIe Retimer 到 UCIe Die:在 D2D 适配器级别不进行流量控制,UCIe Retimer 若需与其他 UCIe Retimer 进行独立流量控制,超出本规范范围。
简言之,UCIe Retimers 在扩展 UCIe 连接、确保数据可靠传输、协调参数及流量控制等方面发挥关键作用,通过多种机制保障不同封装下 UCIe 系统的互操作性和稳定性。
1.4 UCIE Key Performance Targets
这张表格展示了 UCIe(通用芯片互联 Express)的关键性能目标,包含芯片边缘带宽密度、能效和延迟目标三个指标,对比了高级封装(x64)和标准封装在不同链路速度及电压下的表现,具体如下:
芯片边缘带宽密度(Die Edge Bandwidth Density)
单位为 GB/s per mm,反映单位长度芯片边缘的带宽传输能力。
- 随着链路速度(4 GT/s 至 32 GT/s)提升,高级封装(x64)和标准封装的带宽密度均增加。例如,4 GT/s 时,高级封装为 165 GB/s per mm,标准封装为 28 GB/s per mm;32 GT/s 时,高级封装达 1317 GB/s per mm,标准封装为 224 GB/s per mm。
- 高级封装的带宽密度显著高于标准封装,体现其更强的高速数据传输能力。
能效(Energy Efficiency)
单位为 pJ/bit,衡量每比特数据传输消耗的能量。
- 0.7 V 供电电压:
- 高级封装:≤12 GT/s 时为 0.5 pJ/bit,≥16 GT/s 时为 0.6 pJ/bit。
- 标准封装:≤16 GT/s 时为 1.0 pJ/bit,32 GT/s 时为 1.25 pJ/bit。
- 0.5 V 供电电压:
- 高级封装:≤12 GT/s 时为 0.25 pJ/bit,≥16 GT/s 时为 0.3 pJ/bit。
- 标准封装:≤16 GT/s 时为 0.5 pJ/bit,32 GT/s 时为 0.75 pJ/bit。
- 总体上,高级封装在相同速度下能效更优,且低电压时优势更明显。
延迟目标(Latency Target)
基于 16 GT/s,高级封装延迟 < 2 ns;标准封装在不同速度下有不同目标(如 32 GT/s 时为 0.75 ns)。其他速度下延迟会因物理层特性变化,但目标不包括处理比特的累积时间,仅关注适配器和物理层(从 FDI 到凸点再返回 FDI)的延迟。
注释补充:
- 芯片边缘带宽密度的定义与凸点间距有关(高级封装 45 - um,标准封装 110 - um),x32 高级封装模块的带宽密度是 x64 的 50%。
- 能效计算包含适配器和物理层相关电路(如发送、接收、锁相环、时钟分配等)的能耗。
- 延迟包含发送和接收方向上适配器和物理层的延迟。
1.5 Interoperability
-
互操作的基本要求:
封装设计者需确保同一封装上连接的芯片(Dies)能够互操作,这涉及兼容的封装互连(如高级封装与标准封装的差异)、协议、电压水平等。强烈建议芯片采用低于 0.85 V 的发射极电压,以便在未来可预见的时间内,能与广泛的工艺节点实现互操作。 -
高级封装的凸点间距与互操作性:
该规范涵盖了高级封装选项中广泛的凸点间距(bump pitch)的互操作性。随着时间推移,预计更小的凸点间距将成为主流。采用更小凸点间距时,设计会降低最大宣传频率(即便可达到 32G),以优化面积,并应对高带宽下因面积减小带来的电源传输和热约束问题。 -
性能目标的凸点间距基础:
表 中的性能目标基于 45 - um 凸点间距,这是依据 UCIe 1.0 和 UCIe 1.1 规范发布时(2022 - 2023 年)广泛部署的技术确定的。
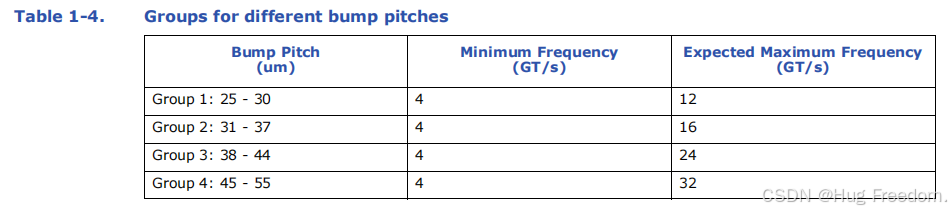
简言之,这段话强调了封装设计中互操作性的关键要素,包括电压、凸点间距等,以及这些要素如何影响芯片的兼容性、性能优化和实际应用。

















 769
769

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









