







第二节课 轻松玩转书生·浦语大模型趣味 Demo
读前感:
之前参加过书生浦语的实战营,所以这部分严格按照文档走就行。 由于是第二次学习,重点理解代码的执行过程和核心功能。
这次Demo的内容还是比较全面的, 把大模型的主流应用都展示了一下。
读后感:
不同的DEMO对显存的需求不同,所以需要及时调整开发机的配置。重启动开发机后,别忘了启动虚拟环境。
感谢74班的助教 “白菜炖豆腐”的大力支持,有个好助教,效率提升很多。
1 InternLM 模型简介
InternLM
是一个开源的轻量级训练框架,旨在支持大模型训练而无需大量的依赖。通过单一的代码库,它支持在拥有数千个 GPU 的大型集群上进行预训练,并在单个 GPU 上进行微调,同时实现了卓越的性能优化。在 1024 个 GPU 上训练时,InternLM 可以实现近 90% 的加速效率。
预训练模型(开源)
- InternLM-7B
- InternLM-20B
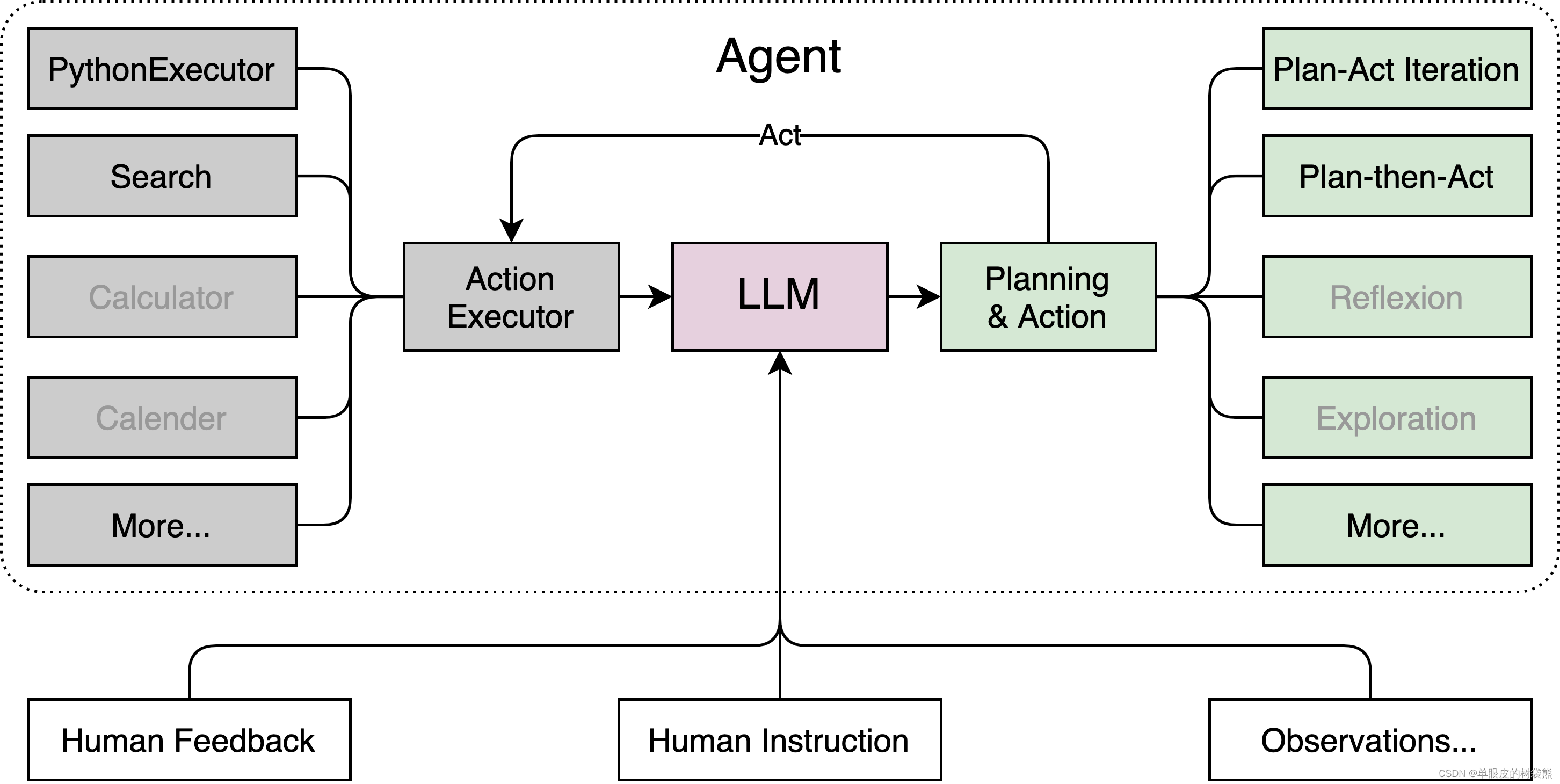
Lagent
Lagent 是一个轻量级、开源的基于大语言模型的智能体(agent)框架,支持用户快速地将一个大语言模型转变为多种类型的智能体,并提供了一些典型工具为大语言模型赋能。通过 Lagent 框架可以更好的发挥 InternLM 的全部性能。
浦语·灵笔
浦语·灵笔是基于书生·浦语大语言模型研发的视觉-语言大模型,提供出色的图文理解和创作能力,结合了视觉和语言的先进技术,能够实现图像到文本、文本到图像的双向转换。使用浦语·灵笔大模型可以轻松的创作一篇图文推文,也能够轻松识别一张图片中的物体,并生成对应的文本描述。
2 InternLM-Chat-7B 智能对话 Demo
2.1环境准备
# 在InternStudio创建开发机, 这里面可以先随便选一个GPU配置, 后期开发机停机后可以调整。这里注意基础镜像要选择Cuda11.7。
# 启动开发机后选择SSH连接, 我是通过VS Code(VSC)的远程连接功能。 不会的可以网上查询一下如何设置SSH.
# VSC连接到远程后在终端里面输入命令,安装虚拟环境和必要的安装包
bash /root/share/install_conda_env_internlm_base.sh internlm-demo #这里要等待一段时间, 系统自动安装,大约20分钟
#终端显示如下:
Finised!
Now you can use your environment by typing:
conda activate internlm-demo
(base) root@intern-studio-50012385:~# 激活虚拟环境
conda activate internlm-demo #启动虚拟环境
#终端显示如下:前面括号内里面的描述变为“internlm-demo”
(base) root@intern-studio-50012385:~# conda activate internlm-demo
(internlm-demo) root@intern-studio-50012385:~# 安装依赖,继续等待===, 大概10分钟。
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.12.2模型下载
mkdir -p /root/model/Shanghai_AI_Laboratory #创建目录
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/model/Shanghai_AI_Laboratory #拷贝共享的模型到开发机拷贝的目录下包括如下文件:
drwxr-xr-x 2 root root 4096 May 30 19:26 ./ # 当前目录
drwxr-xr-x 3 root root 4096 May 30 19:24 ../ # 上一级目录
-rw-r--r-- 1 root root 62 May 30 19:24 .mdl # 可能是模型的元数据文件,包含模型的基本信息
-rw------- 1 root root 1528 May 30 19:24 .msc # NLP模型相关的配置文件或脚本,可能是特定于某个框架或库的
-rw------- 1 root root 12053 May 30 19:26 README.md # 项目说明文件,包含NLP大模型的介绍、使用说明、依赖关系等
-rw------- 1 root root 731 May 30 19:25 config.json # NLP模型的配置文件,包含训练参数、模型架构设置等
-rw------- 1 root root 62 May 30 19:24 configuration.json # 另一个配置文件,可能与config.json具有不同的配置或用途,比如用于特定的应用场景
-rw------- 1 root root 5183 May 30 19:25 configuration_internlm.py # 内部语言模型(InternLM)的Python配置文件,包含模型架构和训练过程的特定参数
-rw------- 1 root root 132 May 30 19:25 generation_config.json # 文本生成相关的配置文件,包含生成文本时的参数设置
-rw------- 1 root root 43576 May 30 19:25 modeling_internlm.py # 内部语言模型的Python脚本,定义模型架构和训练逻辑
-rw------- 1 root root 1969371359 May 30 19:24 pytorch_model-00001-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第1部分),包含模型权重
-rw------- 1 root root 1933845097 May 30 19:25 pytorch_model-00002-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第2部分)
-rw------- 1 root root 1933845161 May 30 19:25 pytorch_model-00003-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第3部分)
-rw------- 1 root root 1990459141 May 30 19:26 pytorch_model-00004-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第4部分)
-rw------- 1 root root 1990459735 May 30 19:25 pytorch_model-00005-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第5部分)
-rw------- 1 root root 1990459735 May 30 19:25 pytorch_model-00006-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第6部分)
-rw------- 1 root root 1990468265 May 30 19:25 pytorch_model-00007-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第7部分)
-rw------- 1 root root 845153194 May 30 19:25 pytorch_model-00008-of-00008.bin # PyTorch格式的NLP大模型的分片文件(第8部分)
-rw------- 1 root root 37116 May 30 19:24 pytorch_model.bin.index.json # PyTorch模型分片的索引文件,用于加载模型时定位各个分片
-rw------- 1 root root 95 May 30 19:25 special_tokens_map.json # 特殊标记的映射文件,用于分词或标记处理时识别特定的词汇或符号
-rw------- 1 root root 8954 May 30 19:25 tokenization_internlm.py # 内部语言模型的tokenization脚本,可能定义了分词逻辑和词汇表的使用
-rw------- 1 root root 1658691 May 30 19:26 tokenizer.model # 可能是预训练的tokenizer模型文件,包含词汇表信息和分词规则
-rw------- 1 root root 343 May 30 19:24 tokenizer_config.json # tokenizer的配置文件,包含tokenizer的设置和参数2.3 代码准备
开发机默认进入的是root权限和根目录,这里新建一个code目录,然后复制开源的代码。
mkdir code
cd /root/code
git clone https://gitee.com/internlm/InternLM.git
cd InternLM
git checkout 3028f07cb79e5b1d7342f4ad8d11efad3fd13d17 #切换 commit 版本,与教程 commit 版本保持一致,可以让大家更好的复现。
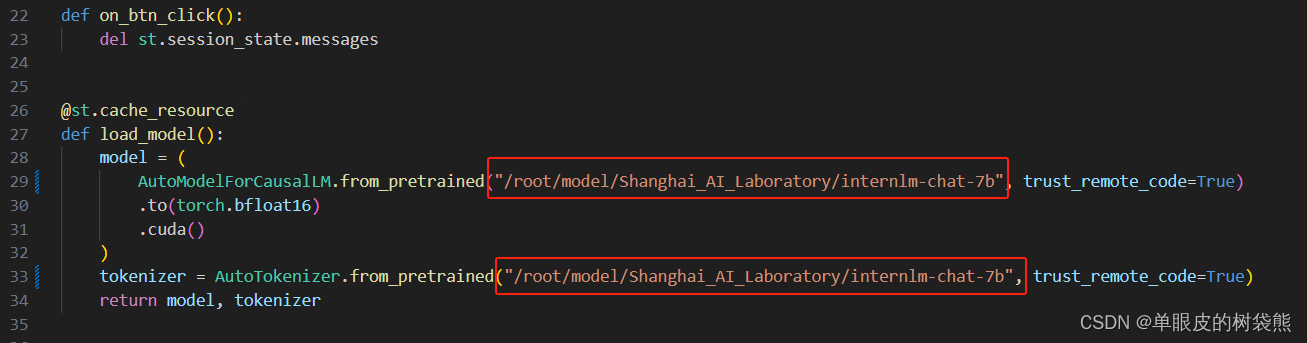
修改 /root/code/InternLM/web_demo.py 中 29 行和 33 行的模型的目录位置,更换为本地的 /root/model/Shanghai_AI_Laboratory/internlm-chat-7b。
2.4 终端运行
我们可以在 /root/code/InternLM 目录下新建一个 cli_demo.py 文件,将以下代码填入其中:
# 导入PyTorch库,PyTorch是一个用于深度学习的库
import torch
# 从transformers库中导入AutoTokenizer和AutoModelForCausalLM,用于自动加载预训练的模型和分词器
from transformers import AutoTokenizer, AutoModelForCausalLM
# 设置模型的路径,这里指定为一个本地的模型路径
model_name_or_path = "/root/model/Shanghai_AI_Laboratory/internlm-chat-7b"
# 使用预训练的模型路径加载分词器,trust_remote_code=True允许从远程源加载模型(这里可能不是最佳实践,除非确实需要)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=True)
# 使用预训练的模型路径加载因果语言模型,并设置一些参数。torch_dtype=torch.bfloat16表示使用bfloat16数据类型,device_map='auto'让库自动选择设备
model = AutoModelForCausalLM.from_pretrained(model_name_or_path, trust_remote_code=True, torch_dtype=torch.bfloat16, device_map='auto')
# 将模型设置为评估模式,这样在前向传播时就不会进行梯度计算和更新模型权重
model = model.eval()
# 定义一个系统提示,用于告知用户这是一个名为InternLM的AI助手,由上海人工智能实验室开发
system_prompt = """You are an AI assistant whose name is InternLM (书生·浦语).
- InternLM (书生·浦语) is a conversational language model that is developed by Shanghai AI Laboratory (上海人工智能实验室). It is designed to be helpful, honest, and harmless.
- InternLM (书生·浦语) can understand and communicate fluently in the language chosen by the user such as English and 中文.
"""
# 初始化对话历史,包含一个系统提示和空的用户输入
messages = [(system_prompt, '')]
# 打印欢迎信息
print("=============Welcome to InternLM chatbot, type 'exit' to exit.=============")
# 进入无限循环,等待用户输入
while True:
# 获取用户输入
input_text = input("User >>> ")
# 移除用户输入中的空格(这可能不是最佳实践,因为空格在文本中可能有意义)
input_text = input_text.replace(' ', '')
# 如果用户输入是"exit",则退出循环
if input_text == "exit":
break
# 使用模型进行对话,并获取响应和更新历史记录
# 注意:这里的model.chat方法不是Hugging Face Transformers库的标准方法,可能是一个自定义方法或来自其他库
response, history = model.chat(tokenizer, input_text, history=messages)
# 将新的用户输入和响应添加到历史记录中
messages.append((input_text, response))
# 打印机器人的响应
print(f"robot >>> {response}")然后运行这段程序, 这段程序运行的有点慢,大概~10分钟。
python /root/code/InternLM/cli_demo.py我使用的是10%A100, 在开发机里面的“资源监控”的情况如下, 显存基本用满。
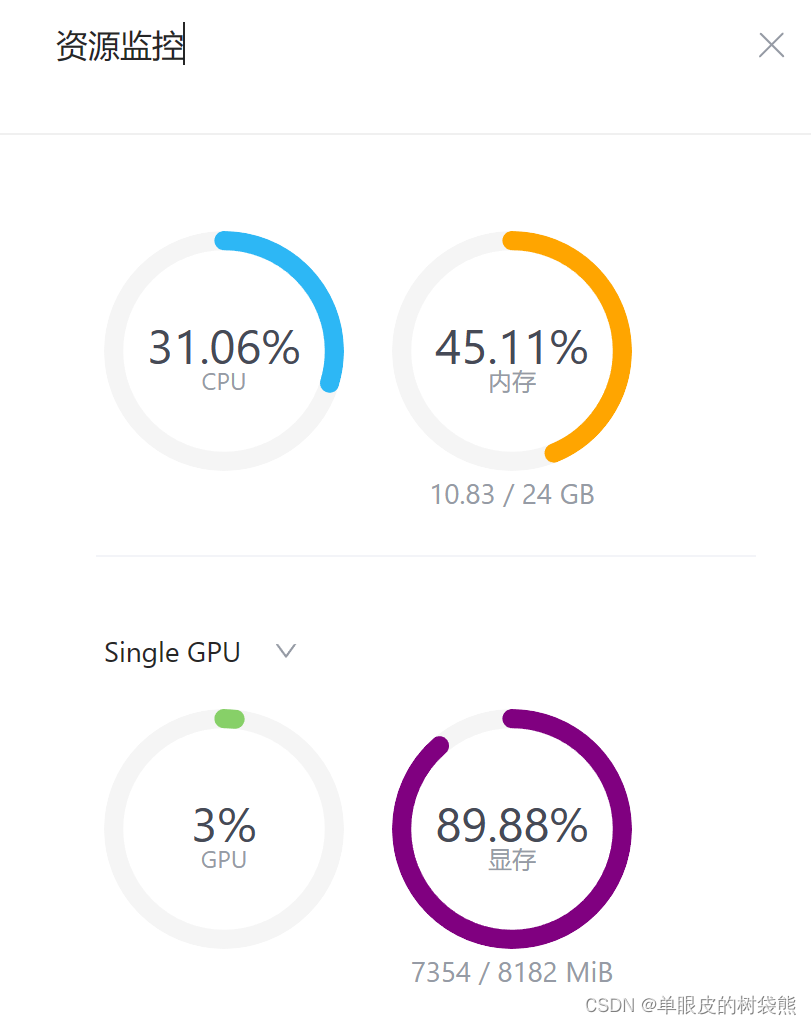
我提问模型“你是谁”,结果它5分总都没有回答我,显存偶尔达到99%,显然跑不动了。
果断停机调整开发机位30%A100。提醒一下, 重新启动开发机后别忘了重新进入虚拟环境。
conda activate internlm-demo
python /root/code/InternLM/cli_demo.py这次启动用了4分钟,资源消耗如下:
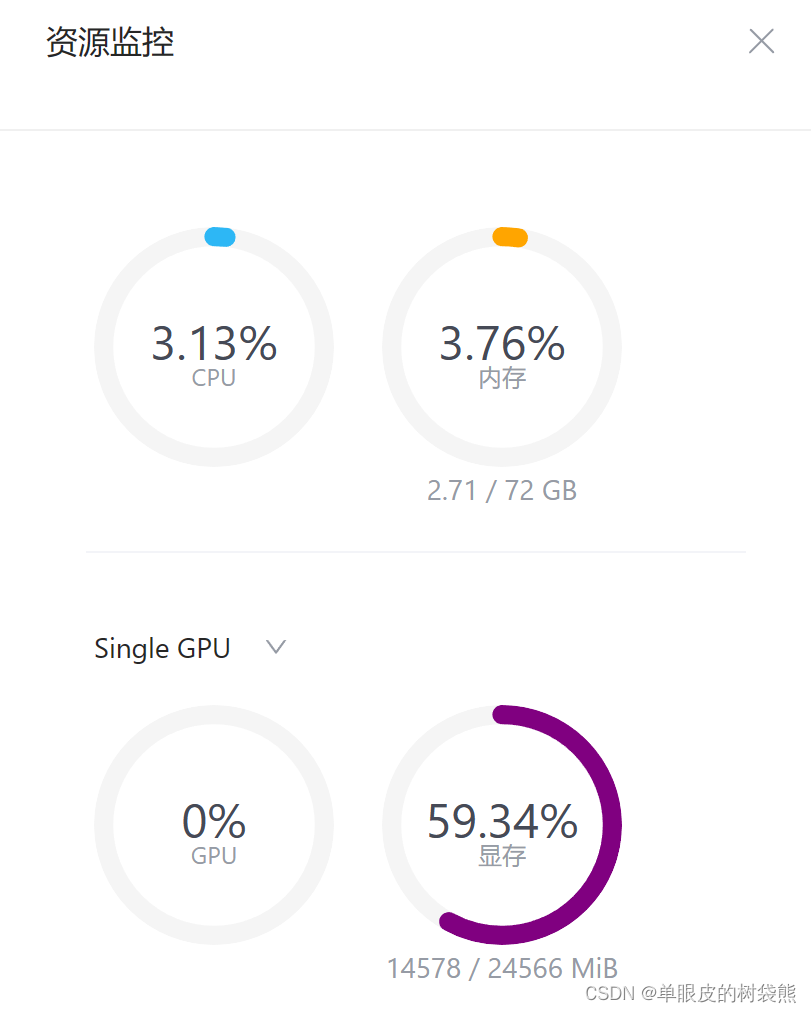
运行效果如下, 这次响应速度快很多,但感觉大模型有点不耐烦了。

2.5 WEB DEMO运行
前面的程序可以输入“eixt”退出, 然后运行另外一个python程序web_demo.py
cd /root/code/InternLM
streamlit run web_demo.py --server.address 127.0.0.1 --server.port 6006我使用的是vscode,这里面需要到“端口”,然后点击转发地址连接的网址即可。


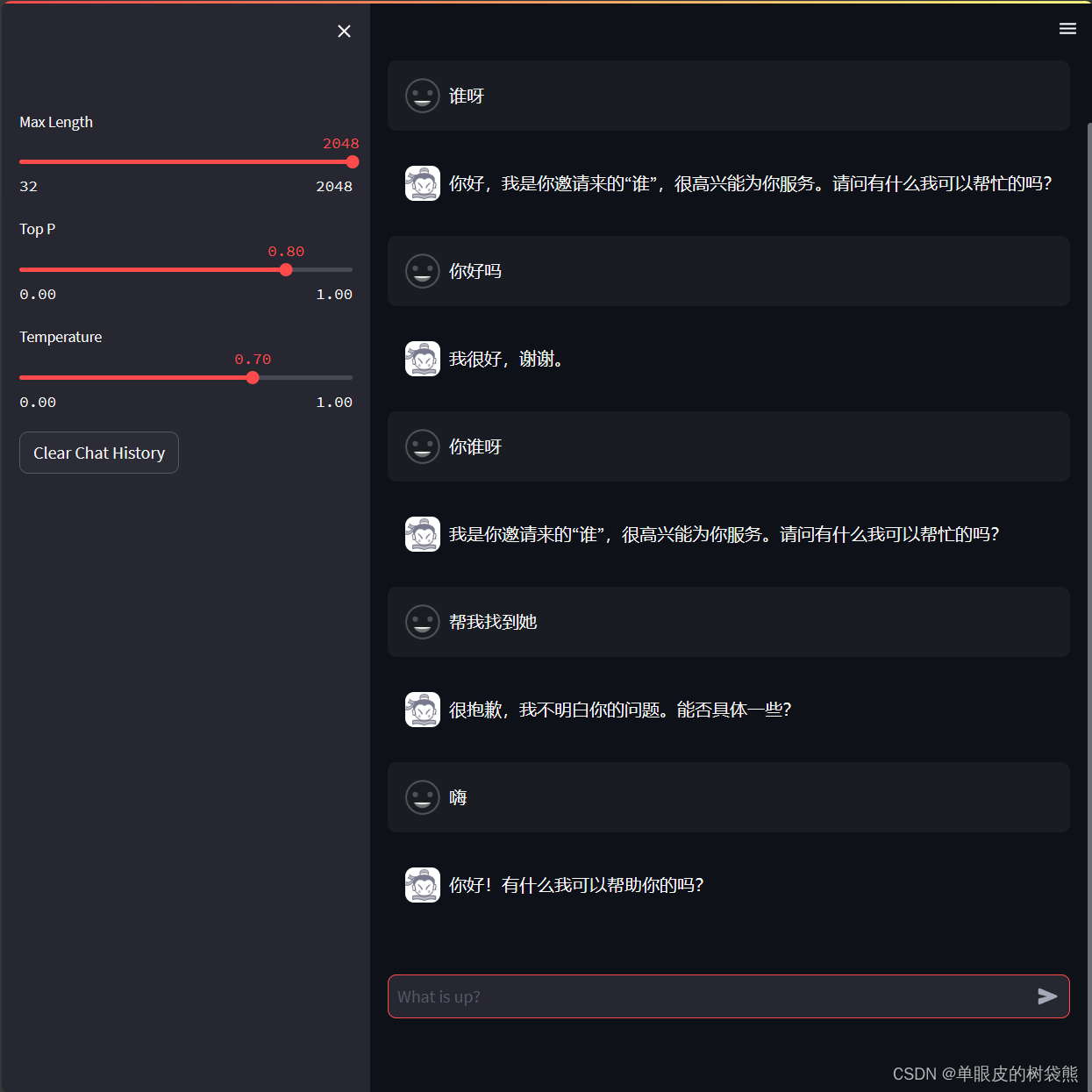
学习一下web_demo.py的内容。
程序过程描述:
- 初始化
- main()函数是程序入口,首先尝试清理GPU缓存,然后加载模型和分词器到GPU。
- 初始化聊天应用界面,设置标题,并配置生成对话的参数滑块于侧边栏。
- 如果session状态中没有聊天历史,则初始化为空列表。
- 展示历史消息
- 遍历st.session_state.messages,通过st.chat_message展示历史消息,包括用户和机器人的消息,每个消息使用相应的头像。
- 接受用户输入
- 用户通过st.chat_input输入问题,触发新的对话回合。
- 生成响应
- 调用combine_history(prompt)组合历史消息和当前用户输入形成完整prompt。
- 使用generate_interactive函数,传入模型、分词器、prompt和生成配置,交互式生成机器人的响应。
- 每个中间响应通过message_placeholder.markdown(cur_response + "▌")实时显示,最后的响应则无"▌"。
- 更新聊天历史
- 用户的输入和机器人的响应都会被追加到st.session_state.messages中,以便后续重新加载时显示。
- 资源管理
- 每次对话结束,清理GPU缓存。
资源库:
代码及备注:
# 导入dataclasses的asdict函数,用于将dataclass实例转换为字典
from dataclasses import asdict
# 导入streamlit库,用于构建交互式Web应用
import streamlit as st
# 导入torch库,用于深度学习和模型推理
import torch
# 从transformers库导入AutoModelForCausalLM和AutoTokenizer,用于加载和使用预训练模型
from transformers import AutoModelForCausalLM, AutoTokenizer
# 导入transformers的日志工具
from transformers.utils import logging
# 从自定义的tools.transformers.interface模块中导入GenerationConfig和generate_interactive函数
from tools.transformers.interface import GenerationConfig, generate_interactive
# 创建一个日志记录器
logger = logging.get_logger(__name__)
# 定义一个按钮点击事件处理函数,用于清空会话状态中的消息
def on_btn_click():
"""
清空streamlit会话状态中的messages列表
"""
del st.session_state.messages
# 使用streamlit的cache_resource装饰器,确保模型只加载一次
@st.cache_resource
def load_model():
"""
加载预训练的chatglm2模型和分词器
Args:
无
Returns:
model: 加载的预训练模型
tokenizer: 加载的分词器
"""
model = (
AutoModelForCausalLM.from_pretrained("/root/model/Shanghai_AI_Laboratory/internlm-chat-7b", trust_remote_code=True)
.to(torch.bfloat16) # 将模型转换为bfloat16类型
.cuda() # 将模型移至GPU
)
tokenizer = AutoTokenizer.from_pretrained("/root/model/Shanghai_AI_Laboratory/internlm-chat-7b", trust_remote_code=True)
return model, tokenizer
# 准备生成配置的函数
def prepare_generation_config():
"""
在侧边栏中设置生成配置参数,并返回GenerationConfig实例
Args:
无
Returns:
generation_config: 生成的GenerationConfig实例
"""
with st.sidebar:
max_length = st.slider("Max Length", min_value=32, max_value=2048, value=2048) # 设置最大生成长度滑块
top_p = st.slider("Top P", 0.0, 1.0, 0.8, step=0.01) # 设置Top P值滑块
temperature = st.slider("Temperature", 0.0, 1.0, 0.7, step=0.01) # 设置温度值滑块
st.button("Clear Chat History", on_click=on_btn_click) # 添加一个按钮用于清空聊天历史
generation_config = GenerationConfig(max_length=max_length, top_p=top_p, temperature=temperature) # 创建GenerationConfig实例
return generation_config
# 定义用户输入和机器人回复的模板字符串
user_prompt = "<|User|>:{user}\n"
robot_prompt = "<|Bot|>:{robot}<eoa>\n"
cur_query_prompt = "<|User|>:{user}<eoh>\n<|Bot|>:"
# 将聊天历史记录结合成完整的提示字符串
def combine_history(prompt):
# 获取会话状态中的消息列表
messages = st.session_state.messages
total_prompt = ""
for message in messages:
# 获取当前消息的内容
cur_content = message["content"]
# 根据消息的角色(用户或机器人)来构建提示字符串
if message["role"] == "user":
cur_prompt = user_prompt.replace("{user}", cur_content)
elif message["role"] == "robot":
cur_prompt = robot_prompt.replace("{robot}", cur_content)
else:
# 如果角色不是用户也不是机器人,则抛出运行时错误
raise RuntimeError("Unknown role in message.")
# 将当前提示字符串添加到总提示字符串中
total_prompt += cur_prompt
# 添加当前查询的提示到总提示字符串中
total_prompt = total_prompt + cur_query_prompt.replace("{user}", prompt)
return total_prompt
#主函数
def main():
# 不执行清除CUDA缓存的操作(可能为了性能考虑)
# torch.cuda.empty_cache()
# 打印开始加载模型的消息
print("load model begin.")
# 调用load_model函数加载模型和分词器
model, tokenizer = load_model()
# 打印结束加载模型的消息
print("load model end.")
# 设置用户头像的文件路径
user_avator = "doc/imgs/user.png"
# 设置机器人头像的文件路径
robot_avator = "doc/imgs/robot.png"
# 设置Streamlit应用的标题
st.title("InternLM-Chat-7B")
# 准备生成文本的配置
generation_config = prepare_generation_config()
# 初始化聊天历史记录(如果会话状态中没有'messages'键)
# Initialize chat history
if "messages" not in st.session_state:
st.session_state.messages = []
# 在应用重新运行时显示历史聊天消息
# Display chat messages from history on app rerun
for message in st.session_state.messages:
# 在聊天消息容器中显示消息,包括角色和头像
with st.chat_message(message["role"], avatar=message.get("avatar")):
st.markdown(message["content"])
# 接受用户输入 Accept user input 用户通过 st.chat_input("What is up?")输入消息,这里的st.chat_input是一个阻塞调用,意味着程序会在这里等待用户输入一些内容。一旦用户输入了文本并提交,prompt变量就会被赋值,程序继续往下执行。
if prompt := st.chat_input("What is up?"):
# 在聊天消息容器中显示用户消息和头像 Display user message in chat message container
with st.chat_message("user", avatar=user_avator):
st.markdown(prompt)
# 组合用户输入的历史(可能是将当前输入与之前的输入合并)
real_prompt = combine_history(prompt)
# 将用户消息添加到聊天历史记录中 Add user message to chat history
st.session_state.messages.append({"role": "user", "content": prompt, "avatar": user_avator})
# 在聊天消息容器中显示机器人的响应,包括头像
with st.chat_message("robot", avatar=robot_avator):
# 创建一个空白的消息占位符
message_placeholder = st.empty()
# 调用generate_interactive函数生成机器人的响应
for cur_response in generate_interactive(
model=model, # 加载的模型
tokenizer=tokenizer, # 加载的分词器
prompt=real_prompt, # 合并后的提示
additional_eos_token_id=103028, # 可能是结束符号的token ID
**asdict(generation_config), # 展开配置字典作为关键字参数,**asdict(generation_config) 是一个常见的模式,它涉及到函数参数的解包(unpacking)和dataclasses模块中的asdict函数。asdict(generation_config)会返回一个字典,例如generation_config={'max_length': 200, 'temperature': 0.7},然后**操作符会将这个字典解包为命名参数 max_length=200, temperature=0.7,并将它们传递给generate_interactive函数。
):
# 在聊天消息容器中逐步显示机器人的响应(带有一个占位符字符)
# Display robot response in chat message container
message_placeholder.markdown(cur_response + "▌")
# 显示完整的机器人响应(不再带占位符)
message_placeholder.markdown(cur_response)
# 将机器人的响应添加到聊天历史记录中
# Add robot response to chat history
st.session_state.messages.append({"role": "robot", "content": cur_response, "avatar": robot_avator})
# 清除CUDA缓存(可能为了释放GPU内存)
torch.cuda.empty_cache()
if __name__ == "__main__":
main()3 Lagent 智能体工具调用 Demo
3.1环境准备
继续使用之前的环境。 相关的包基本都装过了, 不放心可以再试一下。
conda activate internlm-demo #启动虚拟环境
# 升级pip
python -m pip install --upgrade pip
pip install modelscope==1.9.5
pip install transformers==4.35.2
pip install streamlit==1.24.0
pip install sentencepiece==0.1.99
pip install accelerate==0.24.13.2 模型下载
这部分其实是不需要的,之前已经做过了这个操作。 跨过前面章节直接调到这里的可以操作一下。
mkdir -p /root/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-chat-7b /root/model/Shanghai_AI_Laboratory3.3 Lagent 安装
首先切换路径到 /root/code 克隆 lagent 仓库,并通过 pip install -e . 源码安装 Lagent
cd /root/code
git clone https://gitee.com/internlm/lagent.git
cd /root/code/lagent
git checkout 511b03889010c4811b1701abb153e02b8e94fb5e # 尽量保证和教程commit版本一致
pip install -e . # 源码安装3.4 修改代码
由于代码修改的地方比较多,大家直接将 /root/code/lagent/examples/react_web_demo.py 内容替换为以下代码。 简化记录,代码不再复述。下面简介一下代码的功能。
UML类图
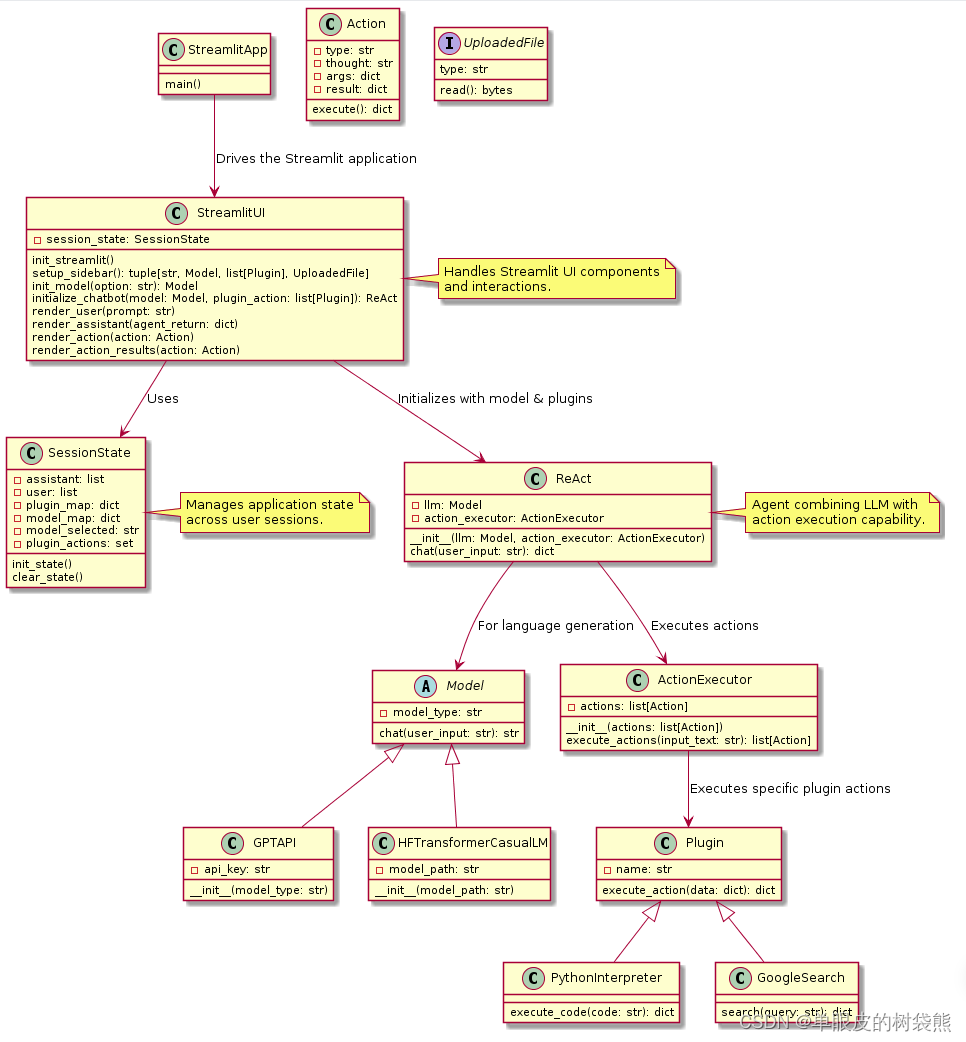
类与接口
- SessionState
- 属性:
- assistant: 存储AI助手的回复信息列表。
- user: 存储用户的输入信息列表。
- plugin_map: 插件映射,键为插件名,值为插件实例。
- model_map: 模型映射,键为模型名,值为模型实例。
- model_selected: 当前选中的模型名称。
- plugin_actions: 已选择的插件动作集合。
- 方法:
- init_state(): 初始化会话状态变量。
- clear_state(): 清空会话状态。
- 属性:
- StreamlitUI
- 构造函数: 接受一个SessionState实例作为参数。
- 属性:
- 继承自SessionState的属性间接访问。
- 方法:
- init_streamlit(): 初始化Streamlit界面设置。
- setup_sidebar(): 设置侧边栏,包含模型和插件选择。
- init_model(option): 根据选项初始化模型实例。
- initialize_chatbot(model, plugin_action): 使用指定模型和插件动作初始化聊天机器人。
- render_user(prompt), render_assistant(agent_return), render_action(action), render_action_results(action): 分别用于渲染用户消息、助手回复、动作详情及动作结果。
- ActionExecutor
- (未直接展示类定义,但通过使用推断)
- 职责: 执行一组动作,并可能与插件交互。
- ReAct
- 构造函数: 接收语言模型(llm)和动作执行器(action_executor)。
- 职责: 实现基于React模式的对话系统,结合推理与行动。
- GPTAPI
- , HFTransformerCasualLM
- 分别代表GPT相关的API模型和基于HuggingFace的Transformer模型。
- 职责: 提供语言模型功能,生成文本回复。
- 其他类与组件
- GoogleSearch, PythonInterpreter: 动作插件示例,执行具体任务。
关系
- 依赖关系(Dependency): StreamlitUI依赖于SessionState来管理状态;StreamlitUI也使用GPTAPI, HFTransformerCasualLM等模型;依赖ReAct实现对话逻辑;使用ActionExecutor执行动作。
- 关联(Association): SessionState持有assistant, user, plugin_map, model_map等属性,与具体模型实例和插件实例关联。
- 聚合(Aggregation): ActionExecutor聚合多个动作实例,如PythonInterpreter, GoogleSearch实例。
- 组合(Composition): StreamlitUI内部组合了SessionState实例,紧密合作以驱动应用流程。
控制流
- 应用启动时,main()函数初始化Streamlit应用环境,创建或复用StreamlitUI实例。
- StreamlitUI通过setup_sidebar()设置模型选择和插件选择,根据用户选择初始化或更新聊天机器人(ReAct)。
- 用户通过界面输入或上传文件,触发对话流程,StreamlitUI捕获用户输入,调用ReAct的chat()方法进行对话处理。
- 对话过程中,可能触发ActionExecutor执行外部插件动作,如执行Python代码或网络搜索。
- 执行结果被整合进AI回复中,通过render_assistant()展示给用户,同时维护对话历史。
此描述虽非直接的UML图,但勾勒出了代码结构和关键交互流程,帮助理解代码的核心功能和组件间的关系。
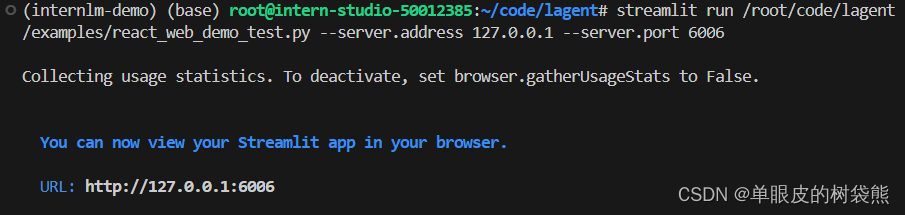
3.5 Demo 运行
streamlit run /root/code/lagent/examples/react_web_demo.py --server.address 127.0.0.1 --server.port 6006正常运行显示如下:
这里运行的显存不够,所以报错了
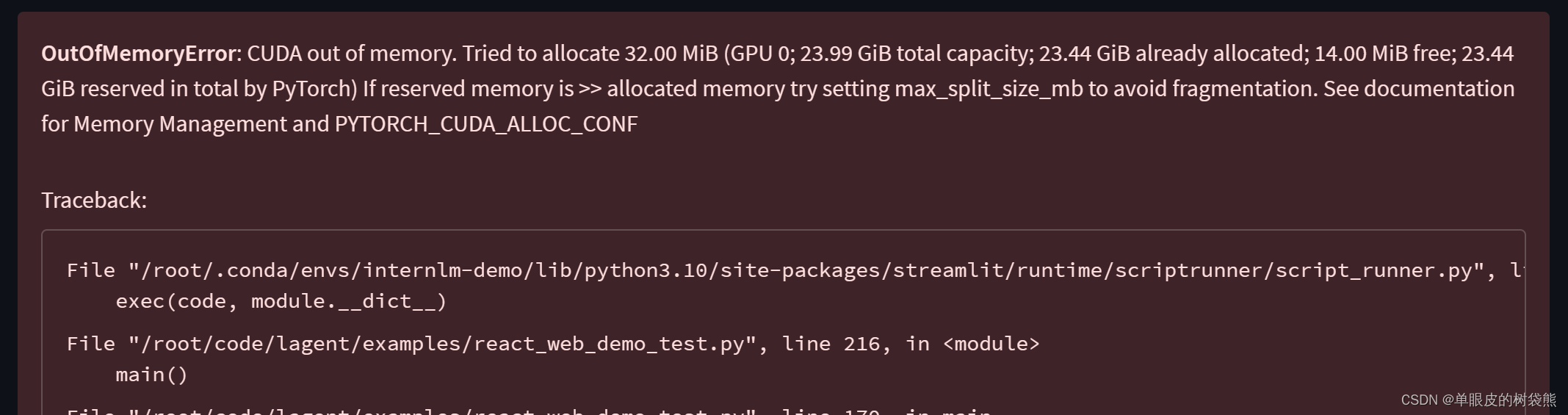
调整开发机的配置到50%A100,可以正常运行了。
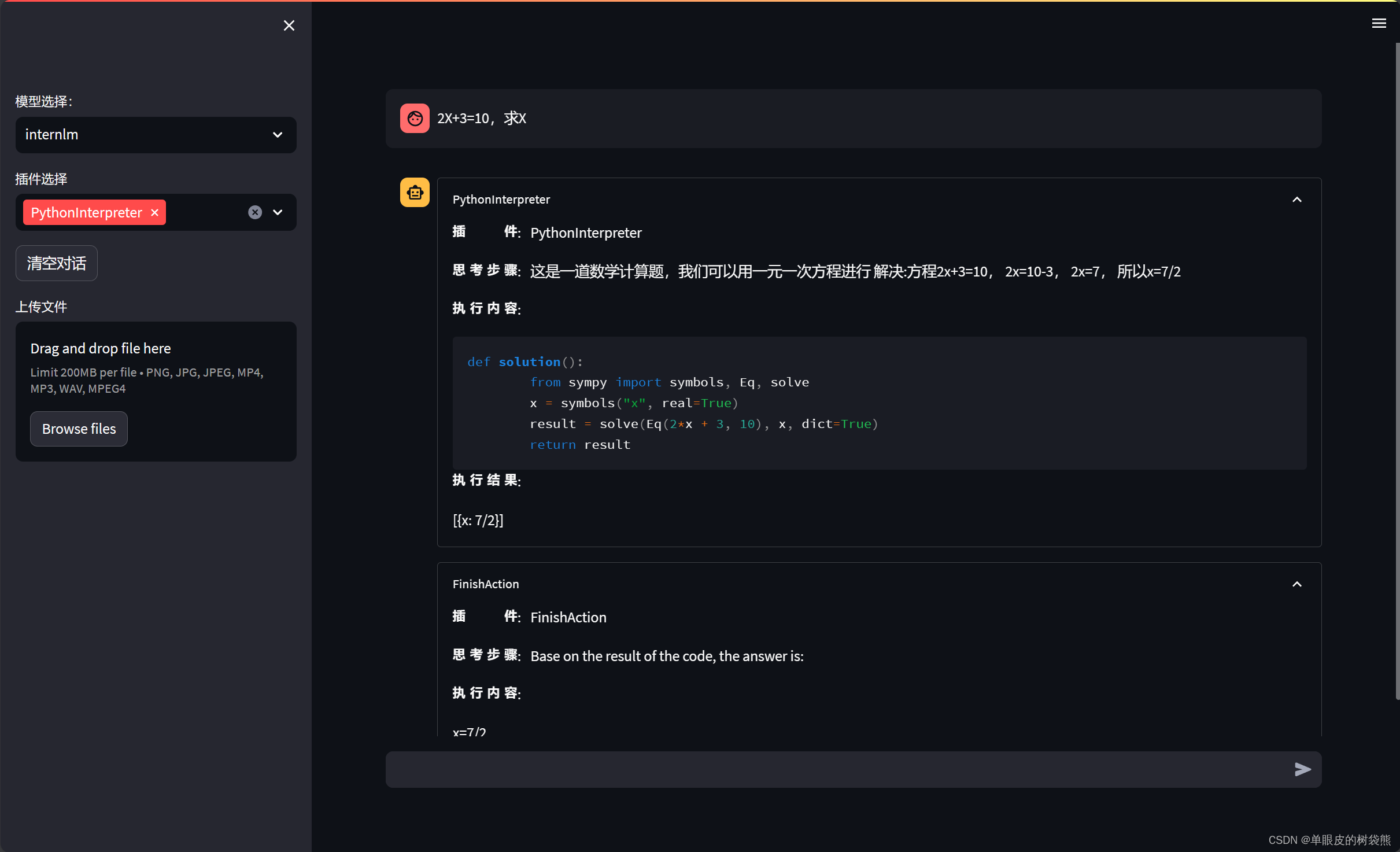
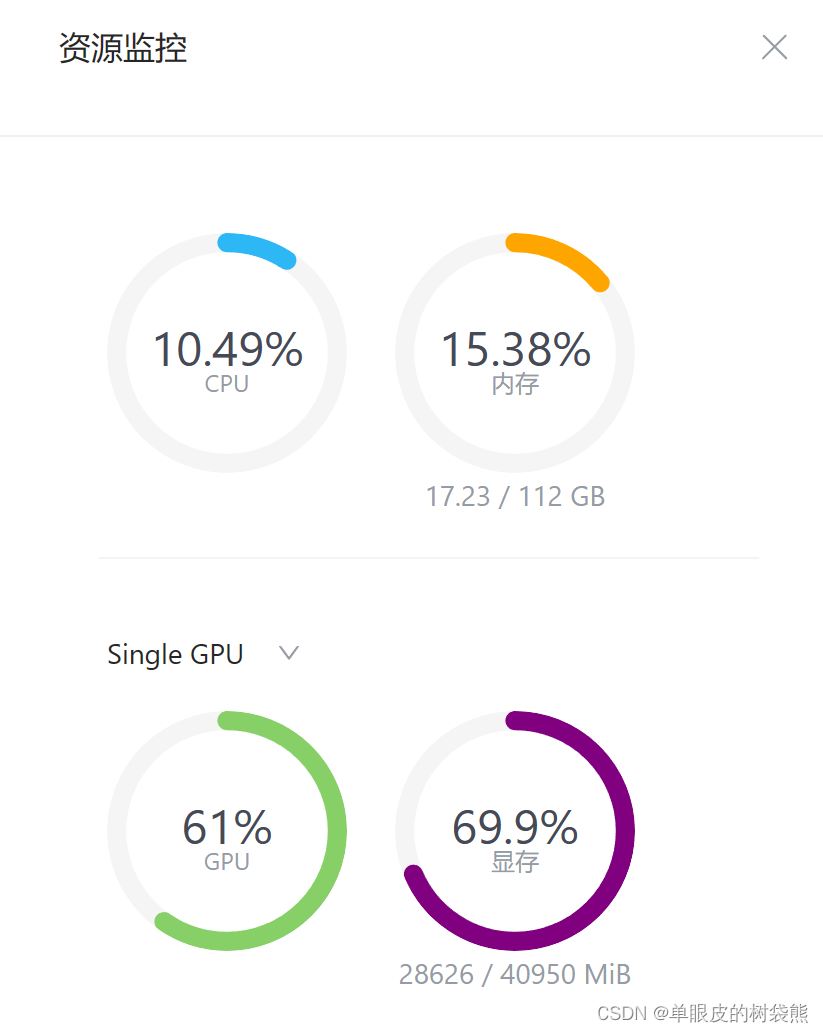
资源监控情况:
总体上讲, 复杂计算、多元、多次,三角函数计算不太准确。
4 浦语·灵笔图文理解创作 Demo
4.1 环境准备
进入 conda 环境之后,使用以下命令从本地克隆一个已有的pytorch 2.0.1 的环境
/root/share/install_conda_env_internlm_base.sh xcomposer-demo #需要等待20分钟左右。
conda activate xcomposer-demo #命令激活环境
pip install transformers==4.33.1 timm==0.4.12 sentencepiece==0.1.99 gradio==3.44.4 markdown2==2.4.10 xlsxwriter==3.1.2 einops accelerate #安装
transformers、gradio 等依赖包。请严格安装以下版本安装!4.2 模型下载
这里需要重新下载模型, 不能用 /root/model/Shanghai_AI_Laboratory/internlm-chat-7b这个模型。
mkdir -p /root/model/Shanghai_AI_Laboratory
cp -r /root/share/temp/model_repos/internlm-xcomposer-7b /root/model/Shanghai_AI_Laboratory4.3 代码准备
在 /root/code git clone InternLM-XComposer 仓库的代码
cd /root/code
git clone https://gitee.com/internlm/InternLM-XComposer.git
cd /root/code/InternLM-XComposer
git checkout 3e8c79051a1356b9c388a6447867355c0634932d # 最好保证和教程的 commit 版本一致4.4 Demo 运行
在终端运行以下代码,启动时间比较长,慢慢等待吧。
cd /root/code/InternLM-XComposer
python examples/web_demo.py \
--folder /root/model/Shanghai_AI_Laboratory/internlm-xcomposer-7b \
--num_gpus 1 \
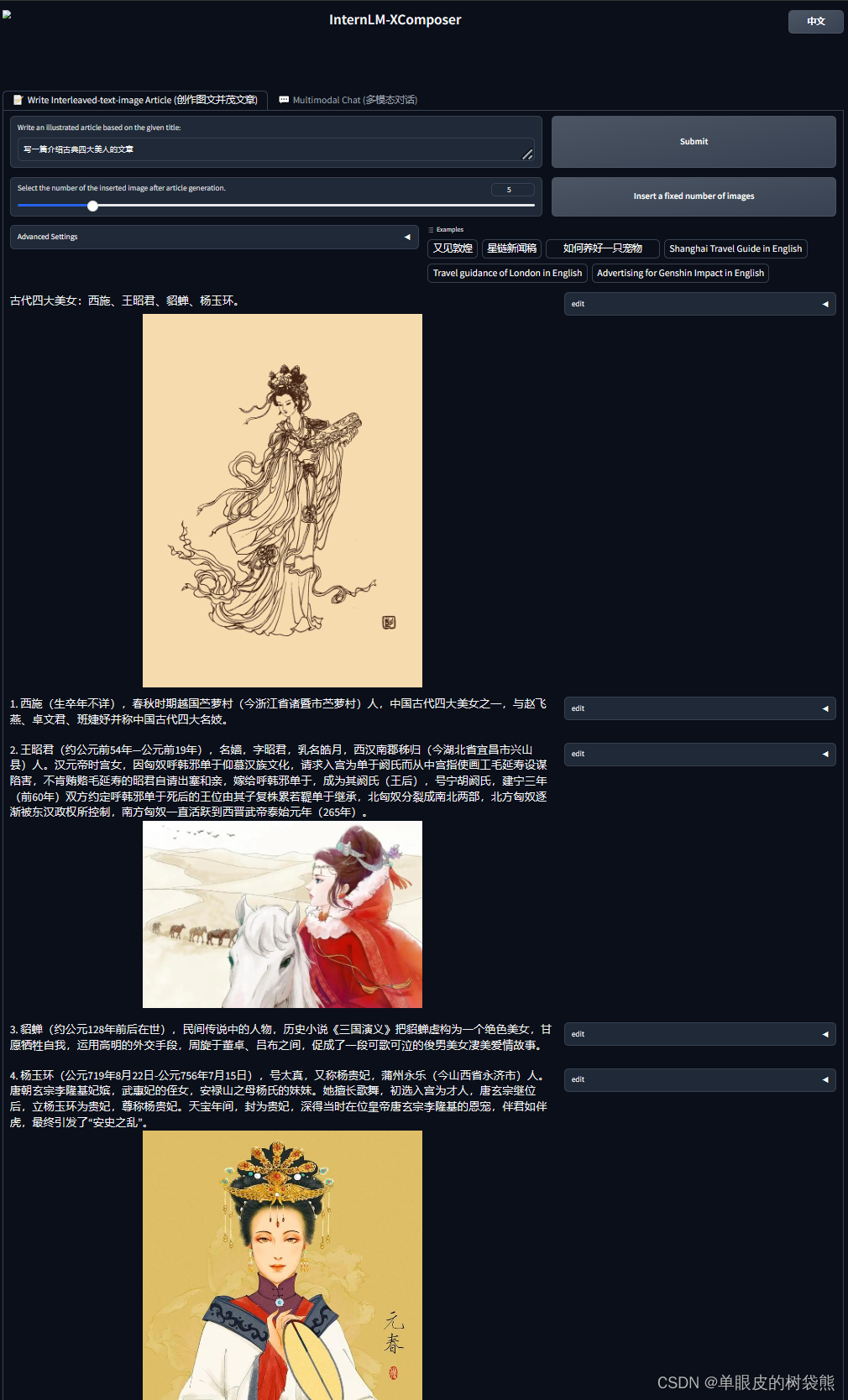
--port 6006图文创作:
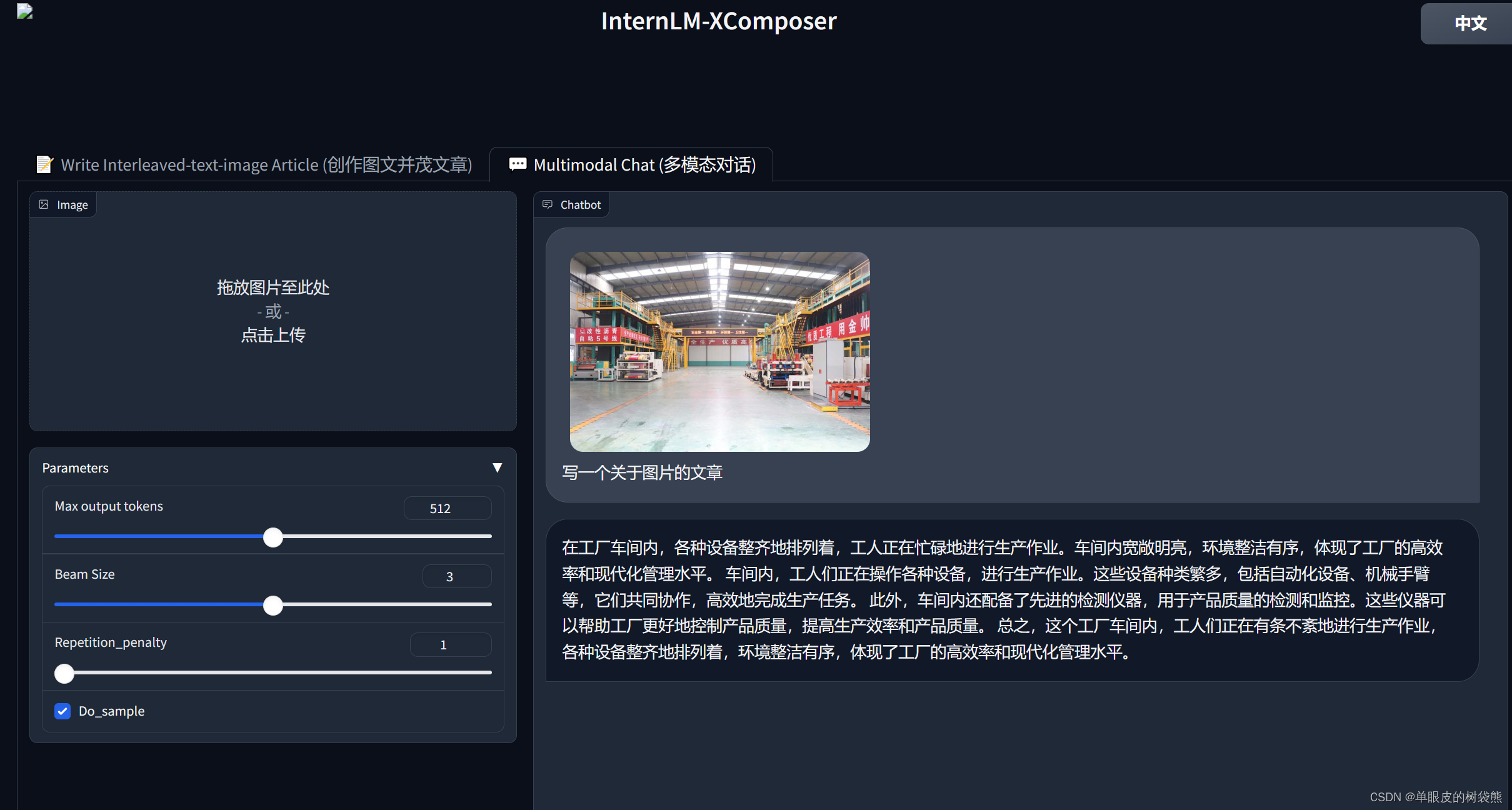
多模态对话:
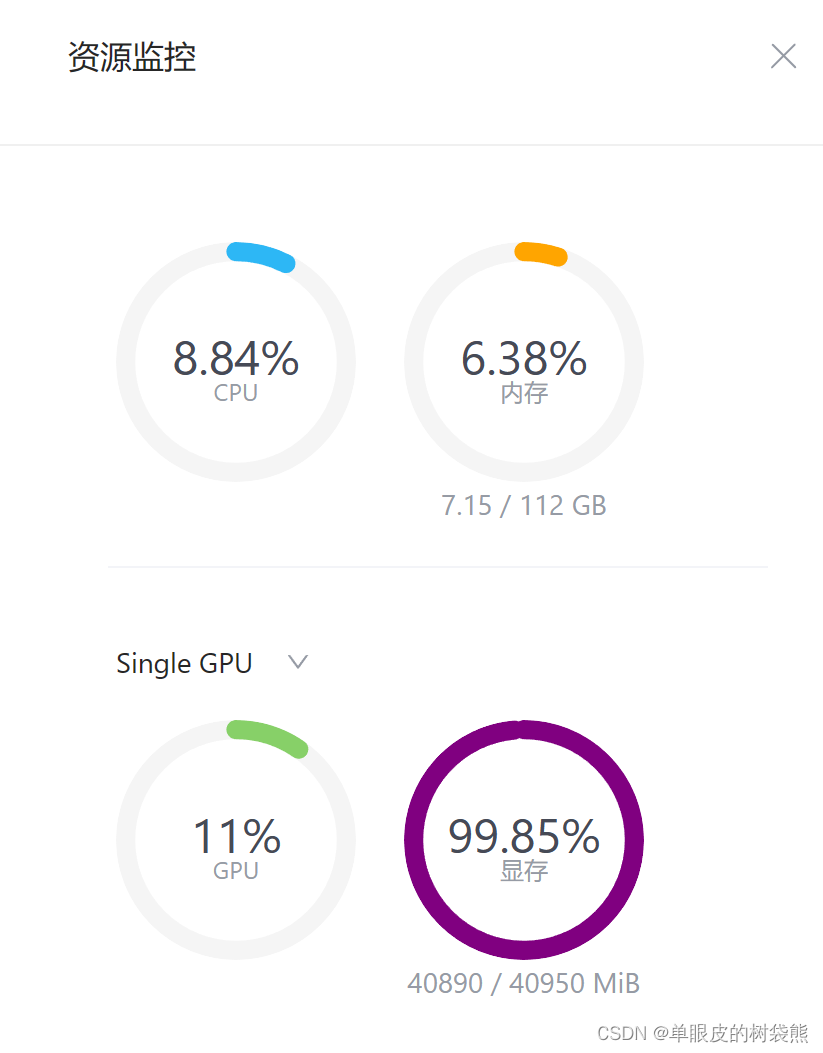
资源监控: 生成内容的时候40G显存跑满了!
5. 通用环境配置
之前已经有描述, 这里略过。

















 1398
1398

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









