









 本文介绍了一种结合元学习和在线学习的新方法,即在线元学习。该方法允许模型在连续的任务流中快速适应新任务,同时保持高效的学习能力。通过提出的Follow the Meta Leader (FTML)算法,实现在高阶光滑假设下的对数级后悔界限。
本文介绍了一种结合元学习和在线学习的新方法,即在线元学习。该方法允许模型在连续的任务流中快速适应新任务,同时保持高效的学习能力。通过提出的Follow the Meta Leader (FTML)算法,实现在高阶光滑假设下的对数级后悔界限。
论文信息
题目:
- Online Meta-Learning
作者:
- Chelsea Finn * 1 Aravind Rajeswaran * 2 Sham Kakade 2 Sergey Levine 1
1 University of California, Berkeley
2University of Washington. Correspondence to: Chelsea Finn cbfinn@cs.stanford.edu, Aravind Rajeswaran aravraj@cs.washington.edu.
期刊会议:
年份:
- 2019
论文地址:
代码:
摘要
元学习能够通过对先验任务的学习实现在新任务上的快速适应,但是是在假设任务作为batch一起使用(任务分布可以随时获得). 而online learning考虑的是有序的设定,在这种设置中任务是一个接一个的被revealed. 基于这些工作,这篇论文引入online meta-Learning setting,融合meta learning思想到 online learning. 提出follow the meta leader learning,拓展meta learning到这种setting. 保证一个高阶光滑假设下理论证明有一个 O ( log T ) \mathcal{O}(\log T) O(logT)regret保证. 通过实验证明了提出的算法性能significantly超过传统online learning方法.
基础补充
online learning
在线学习算法的特点是:每来一个训练样本,就用该样本产生的loss和梯度对模型迭代一次,一个一个数据地进行训练,因此可以处理大数据量训练和在线训练。常用的有在线梯度下降(OGD)和随机梯度下降(SGD)等
准确地说,Online Learning并不是一种模型,而是一种模型的训练方法,Online Learning能够根据线上反馈数据,实时快速地进行模型调整,使得模型及时反映线上的变化,提高线上预测的准确率。Online Learning的流程包括:将模型的预测结果展现给用户,然后收集用户的反馈数据,再用来训练模型,形成闭环的系统。
Online Learning训练过程也需要优化一个目标函数(红框标注的),但是和其他的训练方法不同,Online Learning要求快速求出目标函数的最优解,最好是能有解析解。
在online learning setting中,agent面临的是一系列的损失函数,
{
f
t
}
t
=
1
∞
\left\{f_{t}\right\}_{t=1}^{\infty}
{ft}t=1∞,在每个round
t
t
t 有一个,而这些函数不需要从一个固定的分布中获得,学习者的目标是按顺序确定模型参数
{
w
t
}
t
=
1
∞
\left\{\mathbf{w}_{t}\right\}_{t=1}^{\infty}
{wt}t=1∞,这些模型参数能够在在损失序列上表现很好。其中,最standard 目标是最小化regret的notion,这些是定义我们的学习者的loss,
∑
t
=
1
T
f
t
(
w
t
)
\sum_{t=1}^{T} f_{t}\left(\mathbf{w}_{t}\right)
∑t=1Tft(wt)与一些方法族(比较器类)可以实现的最佳性能的差距。最标准的regret的notion是在事后将其与最佳固定模型的累积损失进行比较:
Regret
T
=
∑
t
=
1
T
f
t
(
w
t
)
−
min
w
∑
t
=
1
T
f
t
(
w
)
\operatorname{Regret}_{T}=\sum_{t=1}^{T} f_{t}\left(\mathbf{w}_{t}\right)-\min _{\mathbf{w}} \sum_{t=1}^{T} f_{t}(\mathbf{w})
RegretT=t=1∑Tft(wt)−wmint=1∑Tft(w)
这种设置中最简单的算法之一是follow the leader (FTL),通过如下方式更新参数:
w
t
+
1
=
arg
min
w
∑
k
=
1
t
f
k
(
w
)
\mathbf{w}_{t+1}=\arg \min _{\mathbf{w}} \sum_{k=1}^{t} f_{k}(\mathbf{w})
wt+1=argwmink=1∑tfk(w)
对于少镜头监督学习的例子,FTL将把之前任务流中的所有数据合并到一个大数据集中,并为这个数据集匹配一个单一的模型。
meta-learning与MAML
- meta learning: 假设任务能从一个固定分布中获得 T ∼ P ( T ) \mathcal{T} \sim \mathbb{P}(\mathcal{T}) T∼P(T)。在meta-training time,采了M个task { T i } i = 1 M \left\{\mathcal{T}_{i}\right\}_{i=1}^{M} {Ti}i=1M,对于的数据集agent能够获得。At deployment time,会遇到一个新的task T j ∼ P ( T ) \mathcal{T}_{j} \sim \mathbb{P}(\mathcal{T}) Tj∼P(T),这个新task是由一个small的labeled dataset D j : = { x j , y j } \mathcal{D}_{j}:=\left\{\mathbf{x}_{j}, \mathbf{y}_{j}\right\} Dj:={xj,yj}。meta-learning做的是使用M个task训练模型,这样当从测试任务中发现 D j \mathcal{D}_{j} Dj时,可以快速更新模型以最小化 f j ( w ) f_{j}(\mathbf{w}) fj(w)
- MAML是学习一个初始值
W
M
A
M
L
\mathbf{W}_{\mathrm{MAML}}
WMAML,实现meta-test time,利用
D
j
\mathcal{D}_{j}
Dj进行几步梯度更新
W
M
A
M
L
\mathbf{W}_{\mathrm{MAML}}
WMAML,就能实现最小化
f
j
(
⋅
)
f_{j}(\mathbf{\cdot})
fj(⋅),MAMl主要解决的是一个优化问题
w M A M L : = arg min w 1 M ∑ i = 1 M f i ( w − α ∇ f ^ i ( w ) ) \mathbf{w}_{\mathrm{MAML}}:=\arg \min _{\mathbf{w}} \frac{1}{M} \sum_{i=1}^{M} f_{i}\left(\mathbf{w}-\alpha \nabla \hat{f}_{i}(\mathbf{w})\right) wMAML:=argwminM1i=1∑Mfi(w−α∇f^i(w))
其中,inner gradient ∇ f ^ i ( w ) \nabla \hat{f}_{i}(\mathbf{w}) ∇f^i(w)是基于small min-batch of data from D i \mathcal{D}_{i} Di
梯度更新为
w
j
←
w
M
A
M
L
−
α
∇
f
^
j
(
w
M
A
M
L
)
\mathbf{w}_{j} \leftarrow \mathbf{w}_{\mathrm{MAML}}-\alpha \nabla \hat{f}_{j}\left(\mathbf{w}_{\mathrm{MAML}}\right)
wj←wMAML−α∇f^j(wMAML)
- 特点是:需要大量的数据集,而数据集从一个固定分布中获得,但是真实世界,任务可能只是按顺序可用的,就像agent在世界中学习一样,而且是从非平稳分布中学习的。通过在顺序或在线环境中重新定义元学习,我们可以在新任务出现时更快地进行学习
内容
算法
online meta learning setting
先利用已有的数据对
w
\mathbf{w}
w进行一次梯度更新
U
t
(
w
)
=
w
−
α
∇
f
^
t
(
w
)
\boldsymbol{U}_{t}(\mathbf{w})=\mathbf{w}-\alpha \nabla \hat{f}_{t}(\mathbf{w})
Ut(w)=w−α∇f^t(w)
Regret
T
=
∑
t
=
1
T
f
t
(
U
t
(
w
t
)
)
−
min
w
∑
t
=
1
T
f
t
(
U
t
(
w
)
)
\operatorname{Regret}_{T}=\sum_{t=1}^{T} f_{t}\left(\boldsymbol{U}_{t}\left(\mathbf{w}_{t}\right)\right)-\min _{\mathbf{w}} \sum_{t=1}^{T} f_{t}\left(\boldsymbol{U}_{t}(\mathbf{w})\right)
RegretT=t=1∑Tft(Ut(wt))−wmint=1∑Tft(Ut(w))


实验
使用FTML方法与其他三种方法对比:
- TOE,在所有可用数据上进行训练
- From Scratch,(随机初始化 w t w_{t} wt,然后再 D t 上 微 调 D_{t}上微调 Dt上微调)
- FTL,使用微调联合训练(joint training)
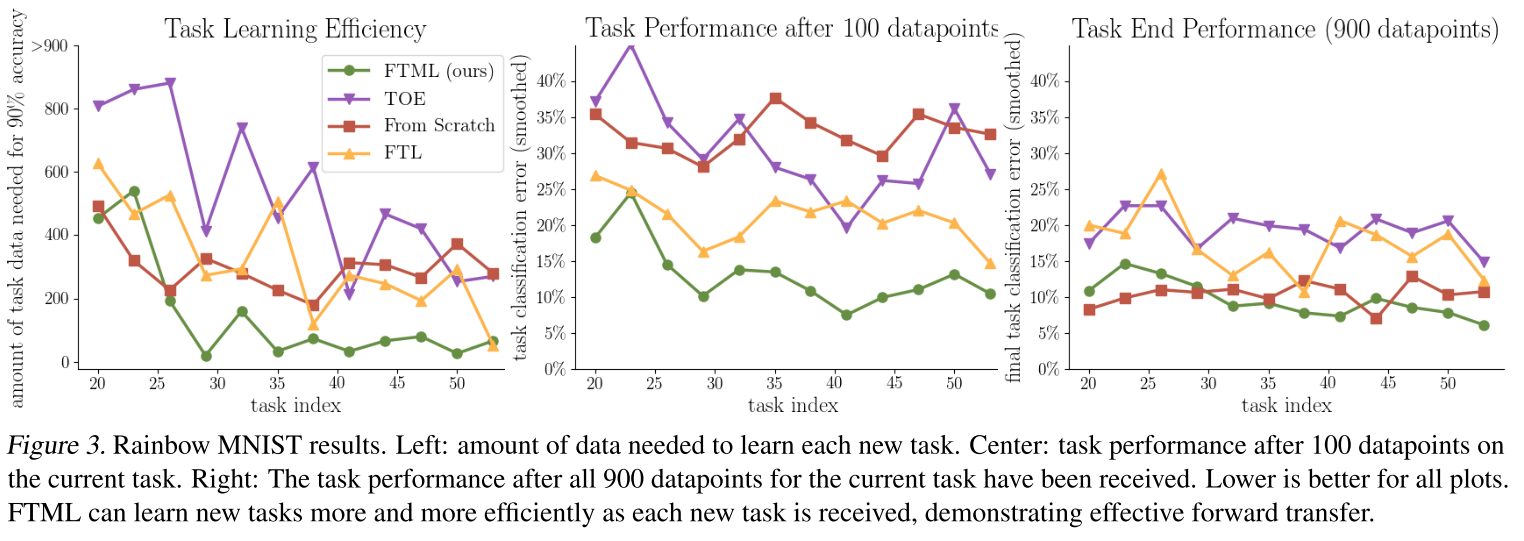
- 图3中的学习曲线显示,随着每个新任务的添加,FTML学习任务的速度越来越快。我们还观察到,FTML在效率和最终性能方面大大优于其他方法。
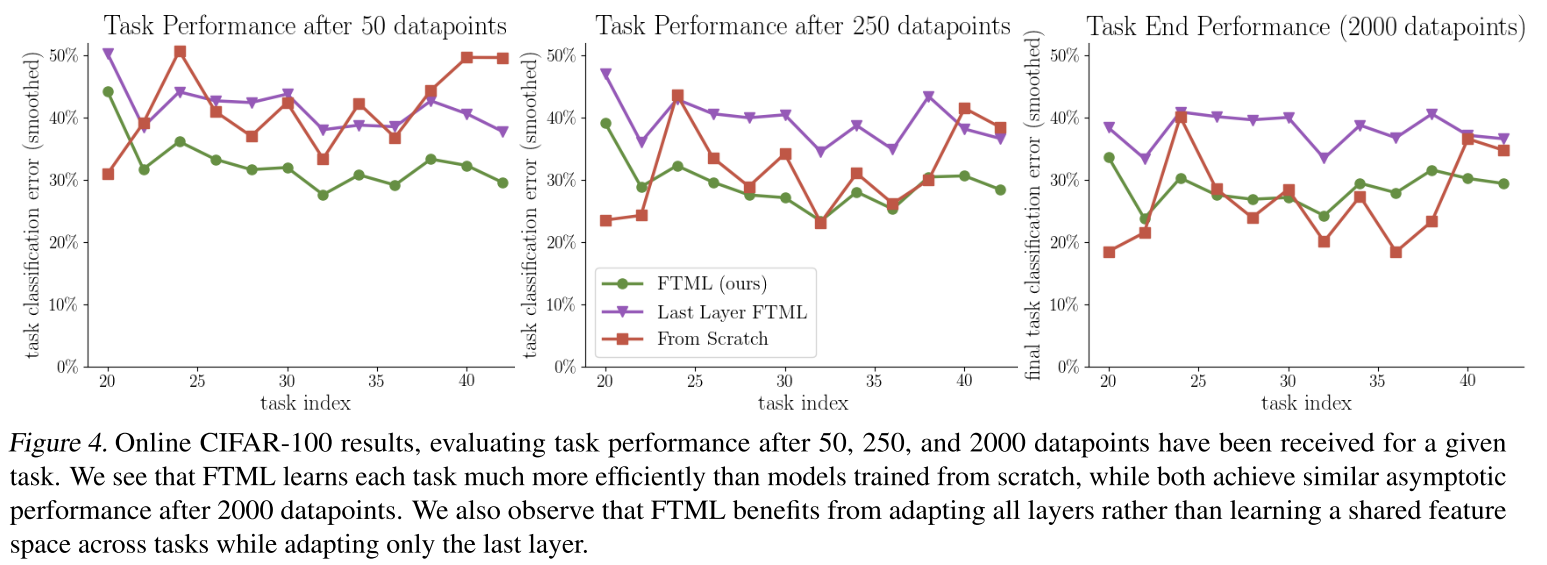
- 图4表明,FTML比独立的模型和具有,共享的特性空间。从右边的结果可以看出,在2000个数据点的情况下,从零开始的训练取得了很好的性能,达到了与FTML相似的性能。然而,FTML的最后一层变体似乎不能在所有任务上都达到良好的性能。还可以观察到,FTML受益于调整所有层,而不是在只调整最后一层的情况下学习跨任务的共享特性空间。说明这是所有层共同作用的结果
结论
在本文中,我们引入了在线元学习问题陈述,旨在将元学习和在线学习领域联系起来。在线元学习在某种意义上为理想的现实学习过程提供了一个更自然的视角:一个与不断变化的环境交互的智能代理应该利用流体验来掌握手头的任务,并在未来更加熟练地学习新的任务。对提出的FTML算法进行了分析,结果表明该算法达到了对数后悔。然后,我们演示了如何将FTML应用于实际算法。实验结果表明,提出的算法性能优于已有的算法。在本节的其余部分中,我们将重申在线元学习设置的一些显著特性(第3节),并概述未来工作的途径。
更强大的更新过程。在这项工作中,我们集中分析的情况下,更新程序Ut,由MAML的启发,对应于梯度下降的一个步骤。然而,在实践中,许多使用MAML的工作(包括我们的实验评估)在更新过程中使用多个梯度步骤,并通过这些多个梯度步骤所采取的整个路径进行反向传播。分析这种情况,以及潜在的更高顺序的更新规则,也将使未来的工作更加令人兴奋。
内存和计算限制。在这项工作中,我们的主要目的是了解是否可以在顺序设置中进行元学习。为此,我们提出了基于FTML模板的在线学习算法。正如第7节所讨论的,众所周知,FTL具有较差的计算性能,因为随着新的损失函数的累积,FTL的计算成本会随着时间增长。此外,在许多实际的在线学习问题中,存储以前任务的所有数据点是具有挑战性的(有时是不可能的)。虽然我们展示了我们的方法可以有效地按顺序学习近100个任务,而不需要大量的计算或内存负担,但是可伸缩性仍然是一个问题。像镜像下降这样不存储所有过去经验的流化算法也能成功吗?我们的主要理论结果(第4.3节)表明,存在大量在线元学习算法享受次线性遗憾。利用在线学习的大量工作,特别是镜像下降,来开发计算上更便宜的算法,将使未来的工作令人兴奋
可借鉴地方
- 将元学习应用于online learning中,算是个应用,同时也extend元学习的setting
https://blog.csdn.net/weixin_41803874/article/details/90480329


















 926
926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











