







Enhancing Autonomous Driving: A Low-Cost Monocular End-to-End Framework with Multi-Task Integration and Temporal Fusion
原文链接:https://ieeexplore.ieee.org/document/10438033
I. 引言
目前常用的自动驾驶模型采用模块化部署,有信息损失和误差积累的问题。因此,端到端自动驾驶被提出,并取得了重大进展。
早期方法使用模仿学习,通过运动预测的标签监督模型,有不错的性能。但其缺乏环境的表达,无法处理复杂导航任务。随着BEV表达和多任务学习(MTL)的提出,感知、预测和规划在BEV下被整合,可节省计算并利用多任务知识提高泛化能力和性能。但是,目前多数MTL方法仅共享特征,可能导致负迁移或不充分交互;且仅考虑当前帧。
本文提出以单目图像为输入的、基于查询的端到端多任务学习自动驾驶框架,带有基于流的时间模块。其包含的任务包括BEV建图、BEV目标检测、语义分割、深度估计、目标速度预测和路径点预测。使用基于Transformer的模型,利用交叉注意力增强模块之间的联系,即使用深度感知的和语义感知的嵌入指导BEV感知。此外,还提出运动解码器生成运动规划结果,从BEV感知的特征中分离智能体特征,输入基于Transformer的解码器指导路径点预测和目标速度预测。流式时间处理模块能通过时间解码器高效地融合历史特征。
III. 方法
本文方法以单目图像、车辆测量、导航目标点和指令为输入,输出运动规划结果。模型包括三部分:感知模块、时间处理模块和规划模块,如图所示。
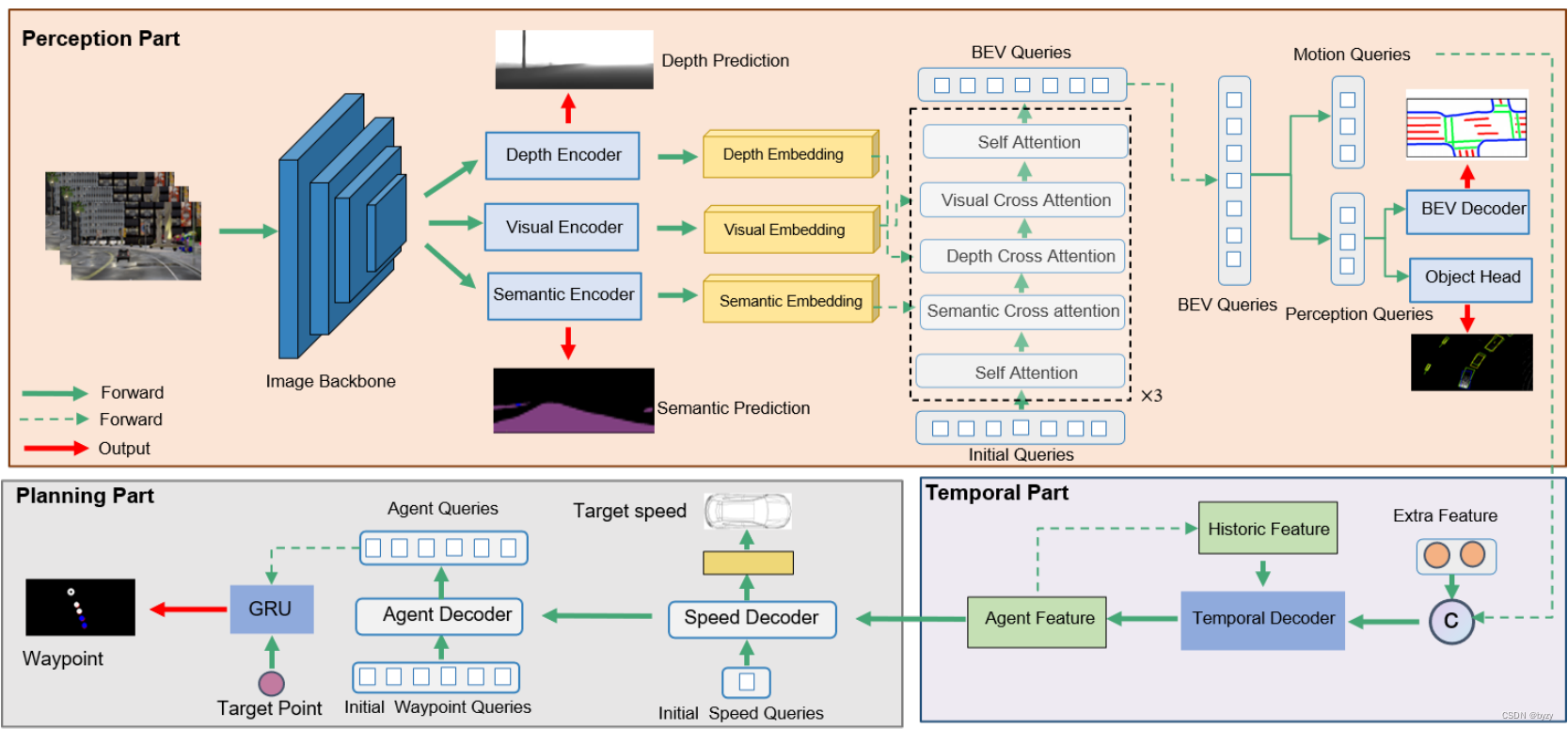
A. 感知部分
本文的感知模块包含四个任务:深度监督、语义分割、BEV地图生成和BEV目标检测,其中后两者为主要任务,而前两者用于生成深度感知的和语义感知的嵌入,以指导PV到BEV的视图变换。
设输入单目图像为
X
∈
R
h
×
w
×
3
X\in\mathbb R^{h\times w\times3}
X∈Rh×w×3,使用RegNety-32作为主干并使用FPN聚合多尺度图像特征,得到中间特征图
f
m
f_m
fm,输入到编码器得到语义嵌入
f
s
f_s
fs和深度嵌入
f
d
f_d
fd。如图所示,编码器为
3
×
3
3\times3
3×3卷积,且
f
s
f_s
fs与
f
d
f_d
fd会送入
1
×
1
1\times1
1×1卷积得到语义分割和深度估计结果,被相应的真值监督。
f
m
f_m
fm,
f
s
f_s
fs与
f
d
f_d
fd会加入可学习位置嵌入,输入到不同的全局自注意力和FFN层中,得到视觉嵌入特征
f
v
e
f_{ve}
fve、深度嵌入
f
d
e
f_{de}
fde和语义嵌入
f
s
e
f_{se}
fse。

语义-深度感知的解码器会进一步交互这些特征,该模块由自注意力、深度注意力、语义交叉注意力、视觉交叉注意力、自注意力和FFN组成。首先初始化可学习BEV查询
q
∈
R
N
×
C
q\in\mathbb R^{N\times C}
q∈RN×C,并输入自注意力进行交互。然后应用深度交叉注意力聚合深度嵌入
f
d
e
f_{de}
fde:
Q
1
=
w
q
′
,
K
1
=
w
k
′
f
d
e
,
V
1
=
w
v
′
f
d
e
,
A
1
=
S
o
f
t
m
a
x
(
Q
1
K
1
T
/
C
/
h
)
,
Q
2
=
w
2
(
A
1
V
1
)
Q_1=w'_q,K_1=w'_kf_{de},V_1=w'_vf_{de},\\A_1=Softmax(Q_1K^T_1/\sqrt{C/h}),\\Q_2=w_2(A_1V_1)
Q1=wq′,K1=wk′fde,V1=wv′fde,A1=Softmax(Q1K1T/C/h),Q2=w2(A1V1)
其中
w
q
′
,
w
k
′
,
w
v
′
,
w
2
w'_q,w'_k,w'_v,w_2
wq′,wk′,wv′,w2分别表示可学习参数,
A
1
A_1
A1为注意力图,
h
h
h为注意力头数。类似地,将
Q
2
Q_2
Q2输入语义交叉注意力生成语义感知的查询
Q
3
Q_3
Q3:
Q
2
′
=
w
q
′
′
,
K
2
=
w
k
′
′
f
s
e
,
V
2
=
w
v
′
′
f
s
e
,
A
2
=
S
o
f
t
m
a
x
(
Q
2
′
K
2
T
/
C
/
h
)
,
Q
3
=
w
3
(
A
2
V
2
)
Q'_2=w''_q,K_2=w''_kf_{se},V_2=w''_vf_{se},\\A_2=Softmax(Q'_2K^T_2/\sqrt{C/h}),\\Q_3=w_3(A_2V_2)
Q2′=wq′′,K2=wk′′fse,V2=wv′′fse,A2=Softmax(Q2′K2T/C/h),Q3=w3(A2V2)
其中 w q ′ ′ , w k ′ ′ , w v ′ ′ , w 3 w''_q,w''_k,w''_v,w_3 wq′′,wk′′,wv′′,w3分别表示可学习参数, A 2 A_2 A2为注意力图。
然后,将查询输入视觉交叉注意力模块,类似得到 Q 4 Q_4 Q4。并输入自注意力得到最终查询 Q f Q_f Qf。
为减轻负迁移,本文将 Q f ∈ R ( N 1 + N 2 2 ) × C Q_f\in\mathbb R^{(N_1+N_2^2)\times C} Qf∈R(N1+N22)×C分为两部分:运动查询 Q m ∈ R N 1 × C Q_m\in\mathbb R^{N_1\times C} Qm∈RN1×C和感知查询 Q b ∈ R N 2 2 × C Q_b\in\mathbb R^{N_2^2\times C} Qb∈RN22×C。将感知查询输入BEV解码器和检测头获得感知结果;运动查询输入运动预测模块得到最终的运动预测。
为得到BEV感知结果,首先将 Q b ∈ R N 2 2 × C Q_b\in\mathbb R^{N_2^2\times C} Qb∈RN22×C变形为 Q b ∈ R N 2 × N 2 × C Q_b\in\mathbb R^{N_2\times N_2\times C} Qb∈RN2×N2×C。BEV地图生成时,将其输入上采样模块(卷积+双线性插值)得到输出 o b ∈ R N × N × c b o_b\in\mathbb R^{N\times N\times c_b} ob∈RN×N×cb,其中 c b c_b cb为类别数。BEV目标检测任务中则预测位置热图 f p ∈ [ 0 , 1 ] N ′ × N ′ f_p\in[0,1]^{N'\times N'} fp∈[0,1]N′×N′、朝向图 f o ∈ R N ′ × N ′ × 12 f_o\in\mathbb R^{N'\times N'\times 12} fo∈RN′×N′×12和回归图 f r ∈ R N ′ × N ′ × 5 f_r\in\mathbb R^{N'\times N'\times5} fr∈RN′×N′×5(含BEV大小、位置偏移量和朝向角偏移量)。
B. 时间存储体
许多端到端自动驾驶模型仅关注当前帧信息或简单拼接历史特征。有方法使用时间存储体存储和融合历史特征,但其空间消耗较高。本文提出流式时间解码器融合历史特征,如图所示。

本文仅将运动查询输入,并引入额外信息(将速度和独热编码的指令通过MLP得到额外特征
f
e
∈
R
1
×
C
f_e\in\mathbb R^{1\times C}
fe∈R1×C),与运动查询组合得到
f
a
c
∈
R
(
N
1
+
1
×
C
)
f_a^c\in\mathbb R^{(N_1+1\times C)}
fac∈R(N1+1×C)。将其输入时间处理模块,通过Transformer解码器融合历史特征。具体来说,设历史智能体特征为
f
a
h
∈
R
(
N
1
+
1
×
C
)
f_a^h\in\mathbb R^{(N_1+1\times C)}
fah∈R(N1+1×C)(对于第一帧而言,
f
a
h
=
f
c
h
f_a^h=f_c^h
fah=fch),并以其作为键与值,当前帧特征作为查询,输入交叉注意力,将输出通过自注意力和FFN得到最终的智能体特征
F
a
F_a
Fa。
f
1
=
C
r
o
s
s
A
t
t
n
(
Q
t
′
=
l
i
n
e
a
r
(
f
a
c
)
,
K
t
′
V
t
′
=
l
i
n
e
a
r
(
f
a
h
)
)
,
f
2
=
S
e
l
t
A
t
t
n
(
f
1
)
,
F
a
=
F
F
N
(
f
2
)
f_1=CrossAttn(Q'_t=linear(f_a^c),K'_tV'_t=linear(f_a^h)),\\f_2=SeltAttn(f_1),\\F_a=FFN(f_2)
f1=CrossAttn(Qt′=linear(fac),Kt′Vt′=linear(fah)),f2=SeltAttn(f1),Fa=FFN(f2)
最终,时间融合的智能体特征 F a F_a Fa会作为下一帧的历史智能体特征。
C. 规划部分
运动规划通常是预测路径点和未来速度。本文参考前人的工作,预测固定距离的路径点和目标速度。
智能体特征会输入到如图所示的速度解码器和路径点解码器。

速度解码器由交叉注意力和FFN组成。首先初始化速度查询
Q
s
∈
R
c
×
1
Q_s\in\mathbb R^{c\times1}
Qs∈Rc×1,与
F
a
F_a
Fa通过交叉注意力交互后,通过FFN得到最终的目标速度查询
Q
t
s
Q_{ts}
Qts。最后使用2层MLP解码得到目标速度预测
p
v
∈
R
4
p_v\in\mathbb R^4
pv∈R4,对应4种预定义速度概率。
路径点解码器由交叉注意力、自注意力和FFN组成。首先初始化路径点查询
Q
w
∈
R
c
×
T
s
Q_w\in\mathbb R^{c\times T_s}
Qw∈Rc×Ts,其中
T
s
T_s
Ts为运动预测的时间范围。首先使用智能体特征
F
a
F_a
Fa通过交叉注意力与
Q
w
Q_w
Qw交互,并输入自注意力和FFN得到更新的路径点查询。这些查询会和当前位置、目标位置一起输入基于GRU的时间模块,其中
Q
w
Q_w
Qw为初始隐特征。

记
t
t
t时刻的隐特征为
Z
t
Z_t
Zt,输出为
x
t
x_t
xt。隐特征会输入MLP得到
Δ
t
\Delta t
Δt内的路径点偏移量
Δ
x
t
\Delta x_t
Δxt,完整过程如下:
Δ
x
t
=
M
L
P
(
G
R
U
(
c
o
n
c
a
t
[
x
t
,
x
t
a
]
,
Z
t
)
)
,
x
t
=
x
t
−
1
+
Δ
x
t
\Delta x_t=MLP(GRU(concat[x_t,x_{ta}],Z_t)),\\x_{t}=x_{t-1}+\Delta x_t
Δxt=MLP(GRU(concat[xt,xta],Zt)),xt=xt−1+Δxt
其中 x t a x_{ta} xta为目标位置(初始位置为 x 0 = ( 0 , 0 ) x_0=(0,0) x0=(0,0))。
D. 控制部分

给定规划模块的路径点输出 { w t } t = 1 T s \{w_t\}_{t=1}^{T_s} {wt}t=1Ts和速度预测 v p v_p vp,控制部分会生成控制信号(转向、油门和刹车)。控制器分为横向控制器和纵向控制器。
计算两个路径点的朝向角差,输入横向PID控制器计算转向信号。纵向控制器使用预测速度
p
v
p_v
pv计算最终速度
v
t
v_t
vt:
{
v
t
=
0
,
p
v
[
0
]
≥
V
T
v
t
=
∑
i
=
0
3
V
[
i
]
×
p
v
[
i
]
p
v
[
0
]
<
V
T
\begin{cases}v_t=0,&p_v[0]\geq V^T\\v_t=\sum_{i=0}^3V[i]\times p_v[i]&p_v[0]<V^T\end{cases}
{vt=0,vt=∑i=03V[i]×pv[i]pv[0]≥VTpv[0]<VT
其中 V = [ 0 , 7 , 19 , 29 ] V=[0,7,19,29] V=[0,7,19,29]为预定义速度, V T V^T VT为停止速度阈值。 v t v_t vt会被送入纵向PID控制器,控制油门与刹车。
E. 损失函数
语义分割和BEV地图生成任务使用交叉熵损失。深度估计任务使用 L 1 L_1 L1损失。BEV目标检测任务中,位置热图、朝向图和回归图分别使用focal损失、交叉熵损失和 L 1 L_1 L1损失。规划任务中的路径点预测使用 L 1 L_1 L1损失。速度预测任务为分类任务,使用交叉熵损失监督。
IV. 实验
A. 数据集与基准
本文使用三种评估指标:
(1)路线完成度(RC):完成路线距离占总距离的百分比。
R
C
=
1
N
∑
i
=
1
N
R
i
R
i
r
RC=\frac1N\sum_{i=1}^N\frac{R_i}{R_i^r}
RC=N1i=1∑NRirRi
其中 N N N为路线数量; R i R_i Ri为路线 i i i的完成距离, R i r R_i^r Rir为路线 i i i的总距离。
(2)违规分数(IS):惩罚系数之积。
I
=
∏
j
P
e
d
,
V
e
h
,
S
t
a
t
,
R
e
d
(
p
j
)
#
i
n
f
r
a
c
t
i
o
n
s
j
I
S
=
1
N
∑
i
=
1
N
I
(
i
)
I=\prod_{j}^{Ped,Veh,Stat,Red}(p^j)^{\#infractions^j}\\IS=\frac1N\sum_{i=1}^NI(i)
I=j∏Ped,Veh,Stat,Red(pj)#infractionsjIS=N1i=1∑NI(i)
其中 I ( i ) I(i) I(i)为路线 i i i的违规分数,Ped,Veh,Stat,Red为不同违规类型(与行人、车辆、静物碰撞以及闯红灯),#infractions为各类违规的数量, p j p^j pj为惩罚系数。
(3)驾驶分数(DS):路线完成度与违规分数之积。
D
S
=
1
N
∑
i
=
1
N
R
i
R
i
r
I
(
i
)
DS=\frac1N\sum_{i=1}^N\frac{R_i}{R_i^r}I(i)
DS=N1i=1∑NRirRiI(i)
B. 实施细节
使用两阶段训练策略,先训练感知部分,再训练完整模型。
C. 与SotA比较
实验表明,本文方法在DS指标下能超过单一模态和多模态方法的性能(或达到多模态相当水平)。
D. 运行时间
实验表明,本文方法(40ms)比多模态方法有更快的速度。
E. 消融研究
首先,评估深度嵌入和语义嵌入的作用。去掉其中一种或同时去掉两种嵌入后,性能大幅下降。这说明深度和语义嵌入对提高模型性能的重要性。可视化特征图表明,主干输出特征图的注意力分布非常分散,而深度嵌入和语义嵌入的注意力更加集中,其中前者关注物体,后者关注车道线和交通灯。BEV特征图则最关注物体、车道线和交通灯。这说明深度嵌入与语义嵌入能指导模型关注关键信息,进行视图变换。
为评估时间存储体的有效性,去掉时间存储体进行实验,性能大幅下降,这说明历史信息对安全驾驶来说是关键的。
若运动解码器以整个BEV特征而非从BEV特征中分离的智能体特征为输入,性能会有下降。此外,为路径点预测和速度预测使用相同的Transformer解码器也会导致性能下降。
G. 结果解析
比较不同场景(城镇、天气、时间)下的性能发现,很多结果偏离预期。例如大雨时的性能最好,而小雨时的性能最差;日落时的性能比夜晚差。这可能是影响因素(如城镇大小、天气在城镇之间的分布等等)之间的相互依赖性。实验表明,与时间和天气相比,路线和城镇对性能的影响更大。
为分析失效情况,可视化失效(碰撞、阻塞、闯红灯)位置表明,碰撞为最主要的失效情况。
















 1135
1135

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











