







原文链接:https://arxiv.org/abs/2407.04049
简介:现有方法多采用密集体素表达,难以关注特殊区域或感知范围外的区域。本文提出多视图图像3D占用预测的点表达,使用感兴趣点(PoI)来表达场景,并提出基于点的3D占用预测网络OSP。由于点表达的灵活性,其性能和训练/推断适应性均很强大,且可以无缝整合到体素方法中以提高性能。
1. 引言
现有的3D占用预测方法多基于密集BEV,存在一些共有的问题:均匀采样(平等地对待每一区域,而不能区分);推断灵活性有限(只能一次处理整个场景,不能根据下游任务或实际需要推断场景的不同部分)。
本文提出感兴趣点(PoI),将场景视为点集,有助于在训练和推断阶段灵活采样场景。其优势在于:可接收任意尺度的输入和位置信息来预测占用;可关注部分区域而非同等对待所有区域。
基于PoI,本文提出OSP。
3. 准备知识
问题设置:假设已知每帧各相机的内外参 { K i } , { [ R i ∣ t i ] } \{K_i\},\{[R_i|t_i]\} { Ki},{[Ri∣ti]}以及相机可视性掩膜(可知道任意位置的可视性)。则3D占用预测的输入为 N N N视图图像 I i = { I 1 , ⋯ , I N } I_i=\{I_1,\cdots,I_N\} Ii={ I1,⋯,IN},输出占用预测 Y i ∈ { c 0 , ⋯ , c M } H × W × Z Y_i\in\{c_0,\cdots,c_M\}^{H\times W\times Z} Yi∈{ c0,⋯,cM}H×W×Z,其中 c 0 c_0 c0为空, c j ( j = 1 , ⋯ , N ) c_j(j=1,\cdots,N) cj(j=1,⋯,N)为语义类别。
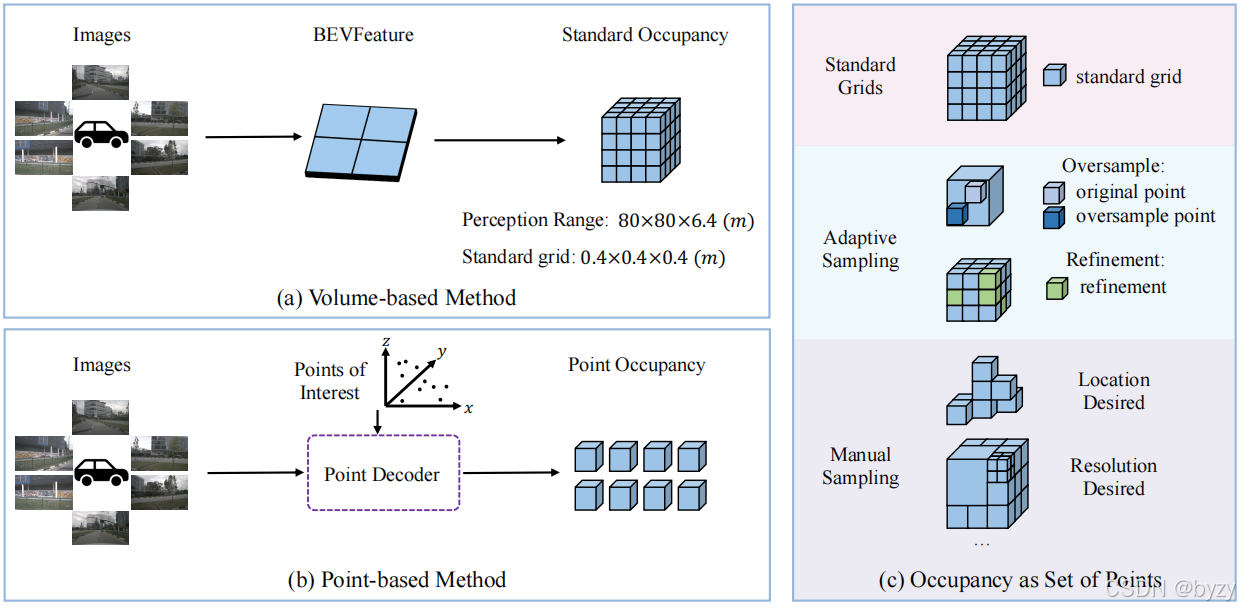
感兴趣点:PoI是表达3D场景的点集,可在训练或推断时灵活调整,以表达需要关注的区域或物体。本文定义3类PoI:
(1)标准网格:PoI即传统方法中的体素中心;可和体素方法公平比较。
(2)自适应采样:训练时可自适应采样点并在其周围过采样以提高性能;此外,还可插入基于体素的方法中,在关注区域或难学习的区域进行重采样,以增强性能。
(3)手工采样:可通过设置PoI在场景外部,进行超范围的占用预测(评估方法:仅在较小范围内训练,推断时设置范围外的PoI)。
4. 方法
4.1 整体结构
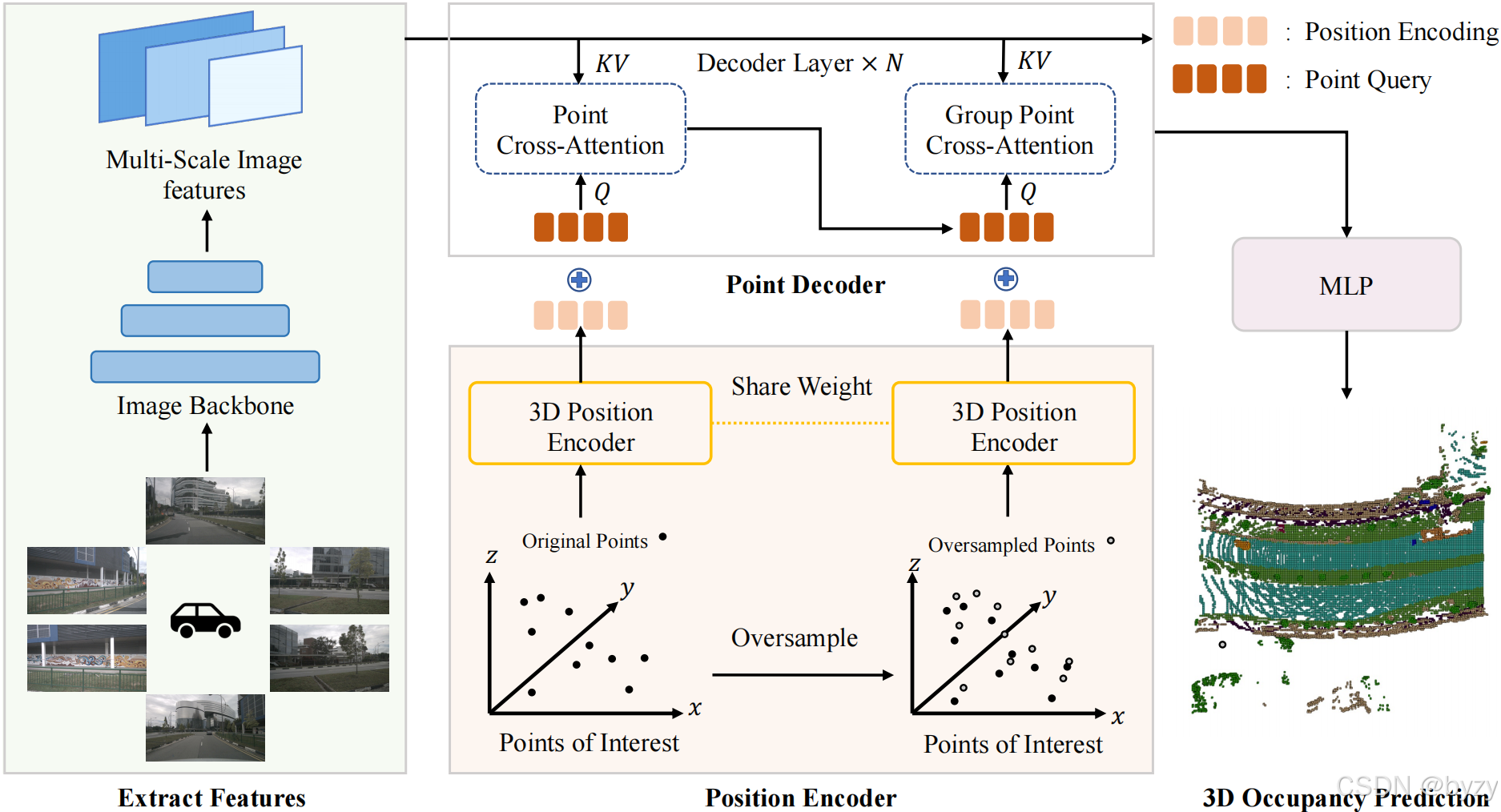
OSP包括图像主干、3D位置编码器和解码器。获取图像特征后,首先在相机可视区域内采样 K K K个3D点作为初始PoI(本文使用标准网格以和体素方法比较,并作为基准方案)并添加扰动。
随后,归一化3D点,并进行正余弦位置编码,建立查询位置嵌入。训练阶段,每个查询的查询位置是不变的,其3D坐标会使用相机内外参投影到图像上,产生键值对,并使用交叉注意力生成输出。随后,过采样 M M M个点(位置由线性层计算),并使用组点交叉注意力融合额外采样点的特征。
4.2 3D位置编码器
得到PoI后,使用下式归一化坐标:
x = x − x min x max − x min , y = y − y min y max − y min , z = z − z min z max − z min x=\frac{x-x_{\min}}{x_{\max}-x_{\min}}, y=\frac{y-y_{\min}}{y_{\max}-y_{\min}}, z=\frac{z-z_{\min}}{z_{\max}-z_{\min}} x=xmax
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











