





系列文章目录
基于注意力共享的时间序列预测领域自适应 ICML2022
文章目录
前言
近年来,深度神经网络在时间序列预测领域得到了越来越广泛的应用。它们成功的一个主要原因是它们能够有效地捕获跨多个相关时间序列的复杂时间动态。只有在有足够数据的情况下,这些深度预测者的优势才开始显现。这对实践中的典型预测问题提出了挑战,其中每个时间序列或观察值的数量有限,或两者兼而有之。为了解决这一数据稀缺性问题,我们提出了一种新的领域自适应框架——领域自适应预测器(DAF)。DAF利用来自具有丰富数据样本(源)的相关领域的统计优势,以有限数据(目标)提高感兴趣领域的性能。特别地,我们使用了一个基于注意力的共享模块,该模块具有跨域的域鉴别器和单个域的私有模块。我们同时引入领域不变的潜在特征(查询和键)并重新训练领域特定的特征(值),以实现源和目标领域预测者的联合训练。一个主要的见解是,我们的对齐键的设计允许目标域利用源时间序列,即使具有不同的特征。在不同领域的大量实验表明,我们提出的方法在合成和现实世界数据集上的性能优于最先进的基线,并且消融研究验证了我们设计选择的有效性。
提示:以下是本篇文章正文内容,下面案例可供参考
一、引言
与其他具有预测任务的领域类似,时间序列预测最近受益于深度神经网络的发展(Flunkert et al., 2020;Borovykh等人,2017;Oreshkin等人,2020b),最终走向零售(B¨ose等人,2017)、云计算资源规划(Park等人,2019)和最优控制车辆(Kim等人,2020;Park et al., 2022)。特别是,基于Transformer模型在自然语言处理中的成功(Vaswani et al., 2017),注意力模型也被有效地应用于预测(Li et al., 2019;Lim等人,2019;Zhou et al., 2021;Xu等人,2021)。虽然这些深度预测模型擅长从足够大的时间序列数据集中捕获复杂的时间动态,但在实践中收集足够的数据往往具有挑战性。
数据稀缺问题的一个常见解决方案是引入另一个数据集,其中包含来自与感兴趣的数据集相关的所谓源域(称为目标域)的大量数据样本。例如,来自具有大量传感器的区域(源域)的交通数据可用于训练模型,以预测监控记录不足的区域(目标域)的交通流量。然而,由于域转移问题,即域之间的分布差异,在一个域上训练的深度神经网络在泛化到另一个域时可能会很差(Wang et al., 2021)。
领域自适应(DA)方法试图通过对齐源域和目标域之间提取的特征来减轻领域移动的有害影响(Ganin等人,2016;Bousmalis et al., 2016;Hoffman等人,2018;Bartunov & Vetrov, 2018;Wang et al., 2020)。现有的方法主要集中在分类任务上,其中分类器使用源数据学习从学习到的域不变潜在空间到固定标签空间的映射。因此,分类器仅依赖于跨域的共同特征,并且可以应用于目标域(Wilson & Cook, 2020)。
将现有的数据分析方法直接应用于时间序列预测有两个主要的挑战。首先,由于时间序列的时间性质,时间序列中的演变模式不太可能被整个历史的表示所捕获。未来的预测可能取决于不同时间段内的本地模式,而本地表示的序列可能比使用大多数传统方法所做的整个历史更合适。其次,预测任务中的输出空间通常不是跨域固定的,因为预测器在输入之后生成时间序列,这是依赖于域的,例如电源数据中的kW与库存目标数据中的单位计数。需要提取领域不变和领域特定的特征,并将其合并到预测中,以建模领域相关的属性,以便适当地近似各自领域的数据分布。因此,我们需要仔细设计不同领域共享或非共享的特征类型,并为我们的时间序列预测模型选择合适的体系结构。
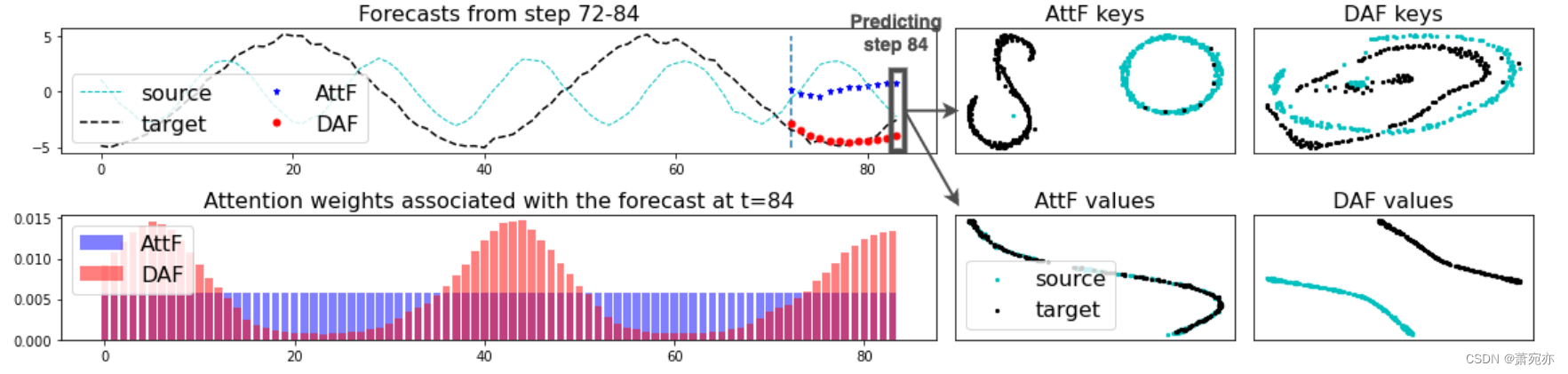
图1。基于注意力的单领域预测器(AttF)和我们的跨领域预测器(DAF)在综合数据上的预测。步骤72-84在目标域上的样本预测,我们的DAF也在源域上训练(左上角)。与预测步骤84相关的AttF和DAF的注意力分布的上下文历史权重的条形图(左下)。降维后AttF和DAF的注意键(右上)和值(右下)。通过简单地将目标数据上训练的AttF模型应用于源数据,可以生成源域中AttF的键和值。在我们的DAF中,在源域和目标域之间对齐键而不是值的策略捕获了正确的注意力权重,正如与AttF相比的准确预测所示(参见步骤72-84中的红点与蓝点)。
我们建议使用基于注意力的模型(Vaswani et al., 2017)来解决这两个挑战,该模型配备了领域自适应功能。首先,对于不断变化的模式,注意模型可以根据时间相关的查询键对齐加权值的组合进行动态预测。其次,由于注意力模块中的对齐与特定模式无关,因此查询和键可以被诱导为领域不变的,而值可以保持特定于领域的,以便模型进行领域相关的预测。图1展示了传统的基于注意力的预测器(AttF)与我们的领域自适应策略(DAF)在具有正弦信号的合成数据集上的对比示例。AttF是使用有限的目标数据训练的,而DAF是在两个领域上联合训练的。通过跨域对齐键(如右上方面板所示),在源域中学习到的上下文匹配帮助DAF生成更合理的关注权重,这些关注权重关注目标数据前一阶段的相同阶段,而不是由左下方面板中的AttF生成的统一权重。右下角的面板说明,由于输入高度重叠,单域AttF为两个域生成相同的值,而DAF能够为每个域生成不同的值。因此,左上角的面板显示DAF比AttF产生更准确的特定于领域的预测。
本文提出了一种新的方法——领域自适应预测器(DAF),该方法通过关注共享的方式应用领域自适应技术,有效地解决了时间序列预测特定任务中的数据稀缺性问题。本文的主要贡献有:
- 在DAF中,我们提出了一种新的体系结构,该体系结构适当地归纳和结合了领域不变和领域特定的特征,通过共享关注模块对源域和目标域进行多水平预测。据我们所知,我们的工作为具有对抗性训练的多视界预测任务提供了第一个端到端数据处理解决方案。
- 我们通过广泛的合成实验和现实世界的实验证明,DAF在数据稀缺的目标领域的准确性方面优于最先进的单领域预测和领域自适应基线,这些实验解决了冷启动和少射预测问题。
- 我们进行了广泛的研究,以证明由鉴别器引起的领域不变特征和在我们的DAF模型中重新训练的领域特定特征的重要性,并且我们设计的与鉴别器的共享策略比其他潜在变体产生更好的性能。
二、 相关工作
深度神经网络已被引入到时间序列预测中,并取得了相当大的成功(Flunkert et al., 2020;Borovykh等人,2017;Oreshkin et al., 2020b;Wen et al., 2017;Wang et al., 2019;Sen等人,2019;Rangapuram等人,2018;Park et al., 2022;Kan et al., 2022)。特别是,基于注意力的类变压器模型(Vaswani等人,2017)已经实现了最先进的性能(Li等人,2019;Lim等人,2019;Wu et al., 2020;周等人,2021)。这些复杂模型的一个缺点是它们依赖于具有同质时间序列的大型数据集进行训练。一旦经过训练,由于领域移位问题,深度学习模型可能无法很好地推广到外生数据的新领域(Wang等人,2005;Purushotham et al., 2017;Wang等人,2021)。在防御对抗性攻击方面,有几种强大的预测方法(Yoon et al., 2022),但没有明确涵盖对抗性攻击之外的一般领域转移。
为了解决领域转移问题,已经提出了领域自适应,将从具有足够数据的源领域捕获的知识转移到具有未标记或标记不足数据的目标领域,用于各种任务(Motiian et al., 2017;Wilson & Cook, 2020;Ramponi & Plank, 2020)。特别是,自然语言处理中的序列建模任务主要采用一种范式,即在一般域上依次对大型变压器进行预训练,并在任务域上进行微调(Devlin等人,2019;Han & Eisenstein, 2019;Gururangan et al., 2020;Rietzler et al., 2020;姚等人,2020)。由于一些挑战,不能立即将这些方法直接应用于预测情景。首先,在时间序列预测中很难找到一个通用的源数据集来预训练一个大型的预测模型。其次,为每个目标域预训练不同的模型是昂贵的。第三,预测值不受固定词汇的约束,严重依赖外推。最后,有许多领域特定的混杂因素无法通过预训练模型进行编码。
预训练和微调领域适应的另一种方法是从原始数据中提取领域不变表示(Ben-David et al., 2010;Cortes & Mohri, 2011)。然后,利用源数据学习预测标签的识别模型可以应用于目标数据。在他们的开创性作品中,加宁和莱姆皮茨基(2015);Ganin等人(2016)提出DANN通过混淆经过训练以区分不同域表示的域鉴别器来获得域不变性。一系列作品遵循这种对抗性训练范式(Tzeng et al., 2017;Zhao et al., 2018;Alam等人,2018;Wright & Augenstein, 2020;Wang et al., 2020;Xu et al., 2022),并且优于传统的基于度量的方法(Long et al., 2015;Chen et al., 2020;Guo等,2020)在领域自适应的各种应用中。然而,这些工作并没有考虑时间序列预测的任务,并相应地解决了引言中的挑战。
鉴于相关领域的成功,领域自适应技术已被引入到时间序列任务中(Purushotham等人,2017;Wilson et al., 2020)。Cai et al.(2021)旨在通过最小化域间时间序列变量关联结构的差异来解决分类和回归任务中的域转移问题。这种基于度量的方法的一个限制是,它不能处理多水平预测任务,因为标签与输入相关联,而不是预定义的。Hu等人(2020)建议DATSING采用对抗性训练来微调预训练的预测模型,方法是根据预定义的指标用选定的源数据增强目标数据集。由于这种方法的两阶段性质,它缺乏端到端解决方案的效率。此外,它不考虑特定于领域的特征来进行依赖于领域的预测。最后,Ghifary等人(2016);Bousmalis et al. (2016);Shi等人(2018)在自适应中使用了领域不变和领域特定的表示。然而,由于这些方法不能适应时间序列的顺序性质,它们不能直接应用于预测。
三、 预测中的领域自适应
假设一组N个时间序列,每个时间序列由观测值 z i , t ∈ R , z_{i,t}\in\mathbb{R}, zi,t∈R,组成,与可选的输入协变量 ξ i , t ∈ R d ˇ \xi_{i,t}\in\mathbb{R}^{\check{d}} ξi,t∈Rdˇ(如价格和促销)相关联。在时间序列预测中,给定t个过去的观测值和所有未来的输入协变量,我们希望通过模型F对时刻T的τ多视界未来进行预测:
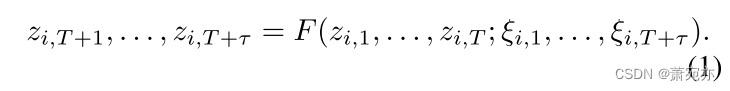
在本文中,我们关注的场景是,对于感兴趣的问题,只有很少的数据可用,而从其他来源提供了足够的数据。例如,一个或两个时间序列的数量N和长度T是有限的。为了简化符号,我们在下面去掉协变量 { ξ i , t } t = 1 T + τ \{\xi_{i,t}\}_{t=1}^{T+\tau} {ξi,t}t=1T+τ。我们表示数据集 D = { ( X i , Y i ) } i = 1 N \mathcal{D}=\{(\mathbf{X}_{i},\mathbf{Y}_{i})\}_{i=1}^{N} D={(Xi,Yi)}i=1N,过去的观测值 X i = [ z i , t ] t = 1 T \mathbf{X}_i=[z_{i,t}]_{t=1}^T Xi=[zi,t]t=1T,未来的基本事实 Y i = [ z i , t ] t = T + 1 T + τ \mathbf{Y}_{i}=[z_{i,t}]_{t=T+1}^{T+\tau} Yi=[zi,t]t=T+1T+τ。当上下文明确时,我们也省略了索引i。
为了在数据稀缺的时间序列数据集上找到合适的预测模型F(1),我们将问题转换为领域适应问题,假设另一个“相关”数据集是可访问的。在域适应设置中,我们有两种类型的数据:样本丰富的源数据 D S \mathcal{D}_{\mathcal{S}} DS和样本有限的目标数据 D T \mathcal{D}_{\mathcal{T}} DT。我们的目标是利用源域s中的数据,在数据很少的目标域T上产生准确的预测。由于我们的目标是在目标域中提供预测,因此在文本的其余部分中,我们分别使用T和τ来表示目标历史长度和目标预测长度。源数据 D S \mathcal{D}_{\mathcal{S}} DS中对应的量用下标S表示,T也是如此。
要计算期望的目标预测,
Y
^
i
=
[
z
^
i
,
t
]
t
=
T
+
1
T
+
τ
\hat{\mathbf{Y}}_{i}=[\hat{z}_{i,t}]_{t=T+1}^{T+\tau}
Y^i=[z^i,t]t=T+1T+τ, i = 1,…,N,我们以对抗性的方式联合优化两个域上的训练误差,下面是极大极小问题:
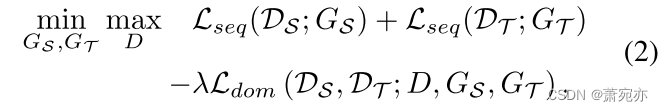
其中参数λ≥0在估计误差
L
s
e
q
\mathcal{L}_{seq}
Lseq和领域分类误差
L
d
o
m
\mathcal{L}_{dom}
Ldom之间取得平衡。其中,
G
S
G_{\mathcal{S}}
GS、
G
T
G_{\mathcal{T}}
GT分别表示估计每个域中序列的序列生成器,D表示在源和目标之间进行域分类的判别器。
我们首先定义由序列生成器G引起的估计误差
L
s
e
q
L_{seq}
Lseq如下:
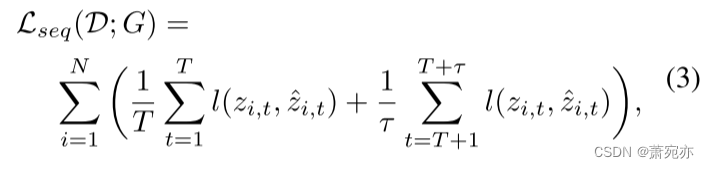
式中,l为损失函数,估计为
z
^
i
,
t
\hat{z}_{i,t}
z^i,t为发生器G的输出,式(3)中的每一项分别表示输入重构误差和未来预测误差。然后设
H
=
{
h
i
,
t
}
i
=
1
,
t
=
1
N
,
T
+
τ
\mathcal{H}=\{h_{i,t}\}_{i=1,t=1}^{N,T+\tau}
H={hi,t}i=1,t=1N,T+τ是由生成器g诱导的某个潜在特征
h
i
.
t
h_{i.t}
hi.t的集合,则式(2)中的域分类误差
L
d
o
m
\mathcal{L}_{dom}
Ldom表示潜在空间中的交叉熵损失如下:
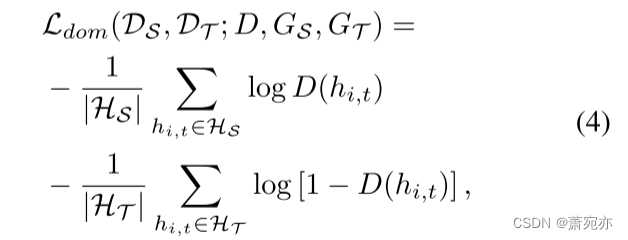
其中
H
S
\mathcal{H}_{\mathcal{S}}
HS和
H
T
\mathcal{H}_{\mathcal{T}}
HT为源
D
S
\mathcal{D}_{\mathcal{S}}
DS和目标
D
T
\mathcal{D}_{\mathcal{T}}
DT相关的潜在特征集,
∣
H
∣
\left|\mathcal{H}\right|
∣H∣表示集合H的基数。通过对抗性训练交替优化极大极小目标方程(2)。在接下来的小节中,我们提出了DAF模型中
G
S
,
G
T
G_{\mathcal{S}},G_{\mathcal{T}}
GS,GT(见4.1小节)和潜在特征
H
S
,
H
T
H_{\mathcal{S}},H_{\mathcal{T}}
HS,HT(见4.2小节)的具体设计选择。
四、 领域适应预测器(DAF)
提出了一种基于注意机制的预测领域自适应策略。提出的解决方案,领域自适应预报器(DAF),使用一个序列生成器来处理来自每个领域的时间序列。每个序列发生器由一个编码器、一个注意模块和一个解码器组成。由于每个领域提供的数据具有来自不同空间的不同模式,因此我们将编码器和解码器保留在各自的领域私有。核心注意模块由两个领域共享以适应。除了计算未来预测外,生成器还重建输入,以进一步保证学习表征的有效性。图2展示了所建议的体系结构的概述。
4.1. Sequence Generators
在本小节中,我们将讨论方程(2)中序列生成器 G S , G T G_{\mathcal{S}},G_{\mathcal{T}} GS,GT的设计。由于两个域中的生成器具有相同的结构,因此我们省略所有量的域索引,并在以下段落中默认用G表示任一生成器。每个域的生成器G对输入的时间序列 X = [ z t ] t = 1 T \mathbf{X}=[z_t]_{t=1}^T X=[zt]t=1T进行处理,生成重构序列 X ^ \hat{\mathbf{X}} X^和预测未来 Y ^ \hat{\mathbf{Y}} Y^。
Private Encoders 私有编码器将原始输入X转换为模式嵌入 P = [ p t ] t = 1 T \mathbf{P}=[\mathbf{p}_t]_{t=1}^T P=[pt]t=1T和值嵌入 V = [ v t ] t = 1 T . \mathbf{V}=[\mathbf{v}_t]_{t=1}^{T}. V=[vt]t=1T.。我们应用参数为 θ v \theta_{v} θv的位置MLP对输入 X = [ z t ] t = 1 T \mathbf{X}=[z_{t}]_{t=1}^{T} X=[zt]t=1T进行编码,用于值嵌入 v t = M L P ( z t ; θ v ) \mathbf{v}_t=\mathrm{MLP}(z_t;\boldsymbol{\theta}_v) vt=MLP(zt;θv)。同时,我们采用不同核大小的M个独立的时间卷积来提取不同尺度的短期模式。具体来说,对于j = 1,…,M,每次参数为 θ p \theta_{p} θp的卷积取输入X,给出一个局部表示序列, p j = C o n v ( X ; θ p j ) \mathbf{p}^{j}=\mathrm{Conv}(\mathbf{X};\boldsymbol{\theta}_{p}^{j}) pj=Conv(X;θpj);然后,我们将每个 p j \mathbf{p}^{j} pj连接起来,构建一个多尺度模式,将 P = [ p j ] j = 1 M \mathbf{P}=[\mathbf{p}^{j}]_{j=1}^{M} P=[pj]j=1M嵌入参数 θ p = [ θ p j ] j = 1 M \boldsymbol{\theta}_p=[\boldsymbol{\theta}_p^j]_{j=1}^M θp=[θpj]j=1M。为了避免连接带来的维度问题,我们保持P和V的维度相同。提取的模式P和值V被输入到共享注意力模块中。
我们将注意力模块设计为两个域共享,因为它的主要任务是从源域和目标域的模式嵌入P中生成域不变查询Q和键K。形式上,我们通过位置MLP将P投影到d维查询 Q = [ q t ] t = 1 T \mathbf{Q}=[\mathbf{q}_{t}]_{t=1}^{T} Q=[qt]t=1T和键 K = [ k t ] t = 1 T \mathbf{K}=[\mathbf{k}_t]_{t=1}^T K=[kt]t=1T中
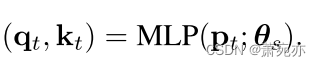
结果,来自两个域的模式被投射到一个公共空间,然后通过对抗性训练诱导为域不变。在时刻t,使用正半定核 K ( ⋅ , ⋅ ) \mathcal{K}(\cdot,\cdot) K(⋅,⋅)计算注意分数α为查询 q t q_t qt和键 k t ′ \mathrm{k}_{t^{\prime}} kt′邻近位置 t ′ ∈ N ( t ) t^{\prime}\in \mathcal{N}(t) t′∈N(t)之间的归一化对齐。
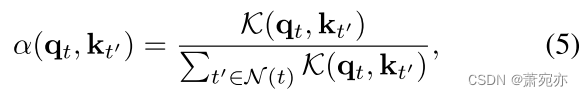
例如,指数比例的点积
K
(
q
,
k
)
=
exp
(
q
T
k
d
)
\mathcal{K}(\mathbf{q},\mathbf{k})\quad=\exp\left(\frac{\mathbf{q}^{T}\mathbf{k}}{\sqrt{d}}\right)
K(q,k)=exp(dqTk)。然后,用注意力得分
α
(
q
t
,
k
t
′
)
\alpha(\mathbf{q}_t,\mathbf{k}_{t^{\prime}})
α(qt,kt′)在邻域
N
(
t
)
\mathcal{N}(t)
N(t)上加权的值
v
μ
(
t
′
)
\mathbf{v}_{\mu(t^{\prime})}
vμ(t′)的平均值表示t,然后得到参数为
θ
o
\theta_{o}
θo的MLP:
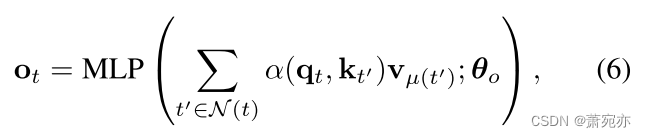
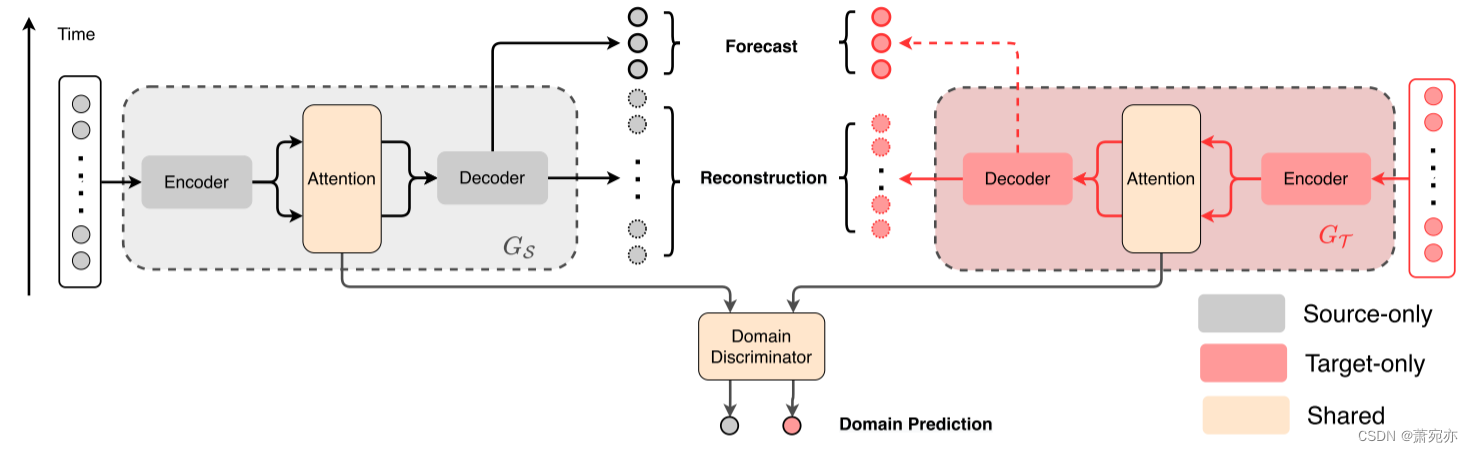
图2。DAF的体系结构概述。灰色模块属于源域,红色模块属于目标域。以米色表示的注意模块和领域鉴别器由两个领域共享。该模型将时间序列的历史部分作为输入,并产生输入的重建和对未来时间步长的预测。领域鉴别器是一个二元分类器,它预测注意力模块中一个中间表示的起源,要么是源,要么是目标。

图3。在DAF中,共享注意模块处理来自任一领域的模式和值嵌入。核函数将模式嵌入编码到一个共享的潜在空间中进行权值计算。我们结合不同权重组的值嵌入,得到重构
X
^
\hat{\mathbf{X}}
X^的插值t≤T和预测
Y
^
\hat{\mathbf{Y}}
Y^的外推
t
=
T
+
1
t=T+1
t=T+1。
我们利用在其他时间点的观测值,通过插值 z ^ t \hat{z}_{t} z^t来重建输入。图4(b)的上面板说明了一个示例,其中我们希望使用 { z 1 , z 2 , … , z T − 2 , z T } \{z_{1},z_{2},\ldots,z_{T-2},z_{T}\} {z1,z2,…,zT−2,zT}来估计 z ^ T − 1 \hat{z}_{T-1} z^T−1。我们将 q T − 1 \mathbf{q}_{T-1} qT−1作为查询, q T − 1 \mathbf{q}_{T-1} qT−1依赖于以目标步骤T−1为中心的本地窗口,如图4(a)所示,并将其与键 { k 1 , k 2 , … , k T − 2 , k T } \{\mathbf{k}_1,\mathbf{k}_2,\ldots,\mathbf{k}_{T-2},\mathbf{k}_T\} {k1,k2,…,kT−2,kT}。与查询类似,参与的键依赖于以各自步骤为中心的本地窗口。因此,由式(5)计算并由图4(b)中箭头的厚度表示的分数 α ( q T − 1 , k t ′ ) \alpha(\mathbf{q}_{T-1},\mathbf{k}_{t'}) α(qT−1,kt′)描述了值 z ^ T − 1 \hat{z}_{T-1} z^T−1与所关注的值 z t ′ z_{t^{\prime}} zt′的相似性,输出 o T − 1 \mathbf{o}_{T-1} oT−1是由式(5)中 α ( q T − 1 , k t ′ ) \alpha(\mathbf{q}_{T-1},\mathbf{k}_{t^{\prime}}) α(qT−1,kt′)加权 v t ′ \mathbf{v}_{t^{\prime}} vt′后的结果。
通过将上面的例子在时间T−1推广到所有时间步长,我们设置
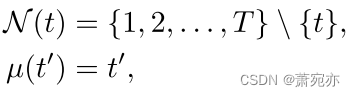
为式(6)。由于输出ot取决于N(T)处的值,并且不访问基本真值
z
t
z_t
zt,因此重建任务并不简单。
外推:未来预测由于DAF是一个自回归预测器,它提前一步生成预测。在每一步中,我们通过从给定的历史值外推来预测下一个值。图4(b)的下面板说明了一个例子,在这个例子中,我们希望根据过去的T观测值和期望值来估计(T+1)-th值。预测 z ^ T + 1 \hat z_{T+1} z^T+1随着最后一个局部窗口 { z T − s + 1 , z T − s + 2 , … , z T } \{z_{T-s+1},z_{T-s+2},\ldots,z_{T}\} {zT−s+1,zT−s+2,…,zT}是查询 q T − s ˉ \mathbf{q}_{T-\bar{s}} qT−sˉ所依赖的,其中 s ˉ = ⌈ s − 1 2 ⌉ \bar{s}=\lceil\frac{s-1}{2}\rceil sˉ=⌈2s−1⌉, ⌈ ⋅ ⌉ \left\lceil\cdot\right\rceil ⌈⋅⌉表示最高算子。我们将 q T − s ˉ \mathbf{q}_{T-\bar{s}} qT−sˉ作为T+1的查询,即我们设置 q T + 1 = q T − s ˉ \mathbf{q}_{T+1}=\mathbf{q}_{T-\bar{s}} qT+1=qT−sˉ,并注意之前不编码填充零的键,即我们设置:

在这种情况下,方程(5)中的注意力得分
α
(
q
T
+
1
,
k
t
′
)
\alpha(\mathbf{q}_{T+1},\mathbf{k}_{t'})
α(qT+1,kt′)描述了未知的
z
^
T
+
1
\hat{z}_{T+1}
z^T+1, 局部窗口
{
z
t
′
−
s
ˉ
,
…
,
z
t
′
,
…
,
z
t
′
+
s
ˉ
}
\{z_{t'-\bar{s}},\ldots,z_{t'},\ldots,z_{t'+\bar{s}}\}
{zt′−sˉ,…,zt′,…,zt′+sˉ}之后的值
z
t
′
+
s
ˉ
+
1
z_{t^{\prime}+\bar{s}+1}
zt′+sˉ+1的相似性,对应出席键
k
t
′
\mathrm{k}_{t^{\prime}}
kt′。因此,我们设
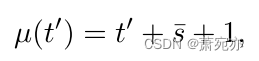
在式(6)中估计
o
T
+
1
\mathbf{o}_{T+1}
oT+1
图4展示了一个未来预测的示例,其中编码器模块中的s = 3和M = 1。详细的演练可以在标题中找到。
私有解码器:私有解码器通过另一个基于位置的MLP从 o t o_t ot中产生预测 z ^ t \hat{z}_{t} z^t: z ^ t = \hat{z}_{t}= z^t= M L P ( o t ; θ d ) \mathrm{MLP}(\mathbf{o}_t;\boldsymbol{\theta}_d) MLP(ot;θd)。通过这样做,我们可以生成重建 X ^ = [ z ^ t ] t = 1 T \hat{\mathbf{X}}=[\hat{z}_t]_{t=1}^T X^=[z^t]t=1T和一步预测 z ^ T + 1 \hat{z}_{T+1} z^T+1。这个预测 z ^ T + 1 \hat{z}_{T+1} z^T+1被反馈到编码器和注意模型中,以预测下一步的预测。我们递归地输入先前的预测以生成预测 Y ^ = [ z ^ t ] t = T + 1 T + τ \hat{\mathbf{Y}}=[\hat{z}_{t}]_{t=T+1}^{T+\tau} Y^=[z^t]t=T+1T+τ时间步长τ。
4.2. Domain Discriminator
为了使关注模块的查询和关键字是域不变的,引入了域鉴别符来识别给定查询或关键字的来源。基于位置的mlp二元分类器 D : R d → [ 0 , 1 ] : D:\mathbb{R}^{d}\to[0,1]{:} D:Rd→[0,1]:
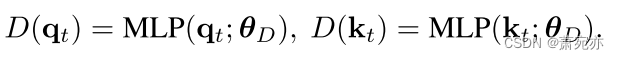
通过最小化式(4)中
L
d
o
m
\mathcal{L}_{dom}
Ldom的交叉熵损失来训练。我们将式(4)中的潜在特征
H
S
,
H
T
\mathcal{H_{S}},\mathcal{H_{T}}
HS,HT分别设计为源域和目标域的键
K
=
[
k
t
]
t
=
1
T
+
τ
\mathbf{K}=[\mathbf{k}_t]_{t=1}^{T+\tau}
K=[kt]t=1T+τ和查询Q =
[
q
t
]
t
=
1
T
+
τ
[\mathbf{q}_t]_{t=1}^{T+\tau}
[qt]t=1T+τ。

4.3. 对抗性训练
回想一下,我们已经定义了基于私有编码器/解码器和共享注意力模块的生成器 G S G_S GS, G T G_T GT。鉴别器D诱导潜在特征键K和查询Q跨域的不变性。当D试图对源和目标之间的域进行分类时, G S G_S GS, G T G_T GT被训练来混淆D。通过选择l的MSE损失,方程(2)中的极大极小目标现在正式定义为生成器GS、GT(参数 Θ G = { θ p S , θ v S , θ d S , θ p T , θ v T , θ d T , θ s , θ o } \Theta_G=\{\boldsymbol{\theta}_p^\mathcal{S},\boldsymbol{\theta}_v^\mathcal{S},\boldsymbol{\theta}_d^\mathcal{S},\boldsymbol{\theta}_p^\mathcal{T},\boldsymbol{\theta}_v^\mathcal{T},\boldsymbol{\theta}_d^\mathcal{T},\boldsymbol{\theta}_s,\boldsymbol{\theta}_o\} ΘG={θpS,θvS,θdS,θpT,θvT,θdT,θs,θo}和域鉴别器D(参数为 θ D θ_D θD)。算法1总结了DAF的训练程序。我们交替地在相反的方向上更新 Θ G a n d θ D \Theta_G\mathrm{~and~}\boldsymbol{\theta}_D ΘG and θD,以便G = { G S G_S GS, G T G_T GT}和D被对抗性地训练。这里,我们对X、Y使用标准的预处理,对X、Y使用标准的后处理。在我们的实验中,方程(2)中的系数λ固定为1。
五、 实验
我们进行了大量的实验来证明所提出的DAF在从源域到目标域的适应方面的有效性,从而提高了最先进的预测器和现有的DA精神的准确性。此外,我们还进行烧蚀研究,以检验我们的设计对显著性能改进的贡献。
5.1. 基线及评估
在实验中,我们将DAF与以下单域和跨域基线进行比较。仅在目标域上训练的传统单域预测器包括:
•DAR: DeepAR (Flunkert et al., 2020);•VT: Vanilla Transformer (Vaswani et al., 2017);•AttF:通过最小化Lseq(DT)来训练目标域的序列生成器GT;式(2)中的GT)。
在源域和目标域上训练的跨域预测者包括:
•DATSING:预训练和微调的预测器(Hu et al., 2020);•SASA:时间序列数据的基于度量的域自适应(Cai et al., 2021),从回归任务扩展到多水平预测;•RDA:将DAF中的注意力模块替换为LSTM模块,并引入LSTM编码的域不变性,从而获得基于rnn的DA预测器。具体来说,我们考虑了三种变体:
- RDA-DANN:通过梯度逆转的对抗性数据处理(Ganin等人,2016);- RDA-ADDA:通过类gan优化的对抗性数据处理(Tzeng et al., 2017);- RDA-MMD:通过最小化LSTM编码之间的MMD,基于度量的数据分析(Li et al., 2017)。
我们使用PyTorch (Paszke等人,2019)实现这些模型,并在AWS Sagemaker (Liberty等人,2020)上训练它们。对于DAR,我们将其称为Sagemaker上的公开可用版本。在大多数实验中,DAF和基线都是在固定验证集上进行调优的。关于模型配置和超参数选择的详细信息,请参见附录B.2。
我们用归一化偏差(ND)来评估预测误差(Yu et al., 2016):
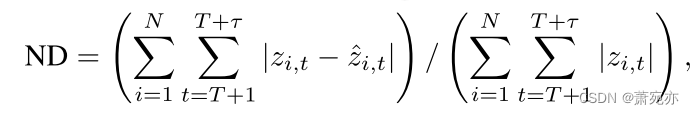
其中,
Y
i
=
[
z
i
,
t
]
t
=
T
+
1
T
+
τ
a
n
d
Y
^
i
=
[
z
^
i
,
t
]
t
=
T
+
1
T
+
τ
\mathbf{Y}_{i}=[z_{i,t}]_{t=T+1}^{T+\tau}\mathrm{~and~}\hat{\mathbf{Y}}_{i}=[\hat{z}_{i,t}]_{t=T+1}^{T+\tau}
Yi=[zi,t]t=T+1T+τ and Y^i=[z^i,t]t=T+1T+τ分别表示基础真理和预测。在随后的表格中,平均ND度量值在平均ND度量值最低的方法的一个标准差内的方法以粗体显示。
5.2. 合成数据集
我们首先模拟适合领域自适应的场景,即冷启动和少镜头预测。在这两种情况下,我们都考虑源数据集 D S \mathcal{D}_{\mathcal{S}} DS和目标数据集 D T \mathcal{D}_{\mathcal{T}} DT,这些数据集由时间指数正弦信号组成,这些信号具有随机参数,包括幅度、频率和相位,从不同的均匀分布中采样。有关数据生成的详细信息,请参见附录A。在这两种情况下,目标数据集中的总观测值都受到时间序列长度或数量的限制。
冷启动预测的目的是在目标领域进行预测,其中信号相当短,并且用于未来预测的历史信息有限。为了模拟解决冷启动问题,我们将源数据中的时间序列历史长度设为 T S T_S TS = 144,并在{36,45,54}内改变目标数据T中的历史长度。目标域中正弦波的周期固定为36,因此历史观测覆盖1 ~ 1.5个周期。我们还固定了时间序列的个数 N S N_S NS = N = 5000。
对于训练有素的预测者来说,当目标域中的时间序列数量不足时,就会出现少量预测。为了模拟这个问题,我们设置源数据NS中的时间序列个数为5000,目标数据N中的时间序列个数在{20,50,100}内变化。我们还固定了历史长度 T S T_S TS = T = 144。将源数据集和目标数据集的预测长度设置为相等,即 τ S = τ \tau_{\mathcal{S}}=\tau τS=τ = 18。
表1中冷启动和少弹问题的综合实验结果表明,在所有实验中,DAF的性能都优于或等于基线。我们还注意到以下观察结果,以便更好地理解领域适应方法。首先,我们看到使用源数据和目标数据端到端联合训练的跨域预测器RDA和DAF总体上比单域预测器更准确。这一发现表明源数据有助于预测目标数据。其次,在跨领域预测中,DATSING的表现优于RDA和DAF,这表明在两个领域进行联合训练的重要性。第三,在大多数实验中,我们基于注意力的DAF模型比基于rnn的DA (RDA)方法更准确或更具竞争力。我们展示了RDA-ADDA的结果,因为其他DA变体,DANN和MMD具有类似的性能。在接下来的实际实验中(见表2)考虑了它们。最后,我们在图5中观察到,随着训练样本数量的减少,DAF的提高更加显著。
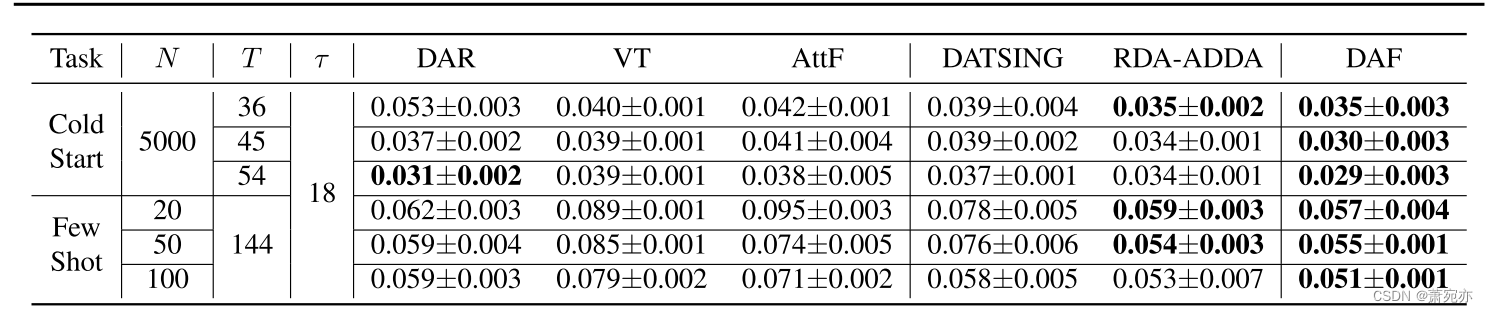
表1。不同历史长度T (cold-start)、不同时间序列N (few-shot)和预测长度τ (mean +/- standard deviation ND metric)的合成数据集上DAF的性能比较。获胜者和竞争的追随者(差距小于5次运行的标准差)被保留以供参考。
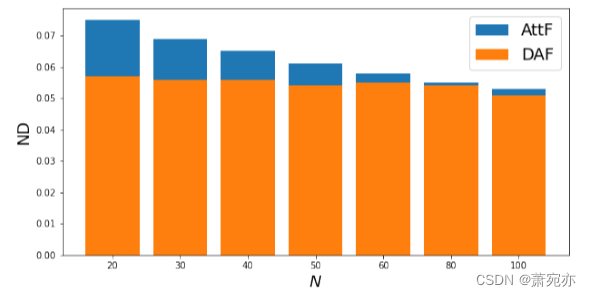
图5。AttF和DAF方法在不同目标数据集大小的合成few-shot实验中的预测精度。
5.3. 真实世界数据集
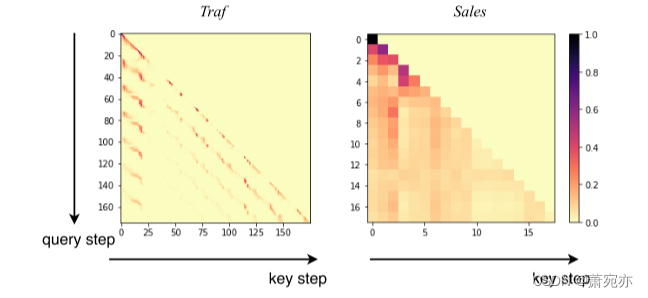
图6。由
D
S
=
t
r
a
f
(
l
e
f
t
)
a
n
d
D
T
=
s
a
l
e
s
(
r
i
g
h
t
)
.
\mathcal{D}_{\mathcal{S}}=traf(\mathrm{left})\mathrm{and}\mathcal{D}_{\mathcal{T}}=sales(\mathrm{right}).
DS=traf(left)andDT=sales(right).的DAF注意头产生的注意分布。
我们在预测文献中广泛使用的四个真实基准数据集上进行了实验:来自UCI数据存储库的elec和traffic (Dua & Graff, 2017),来自Kaggle的sales (Kar, 2019)和wiki (Lai, 2017)。值得注意的是,电动和交通数据集呈现出清晰的每日和每周模式,而销售和wiki则不那么规律,更具挑战性。我们使用以下时间特征ξt∈R2作为协变量:每小时数据集elec和traffic是星期几和星期几,每天数据集sales和wiki是星期几和星期几。有关更多数据集的详细信息,请参见附录A。
为了评估DAF的性能,我们考虑了跨数据集自适应,即在一对数据集之间传输。由于原始数据集足够大,可以训练出一个相当好的预测器,因此我们只取每个数据集的一个子集作为目标域来模拟数据稀缺的情况。具体来说,我们从每小时数据集elec和traffic中获取每个时间序列的最近30天,从每日数据集sales和wiki中获取最近60天。我们将目标数据集平均划分为训练/验证/测试部分,即每小时数据集为10/10/10天,每天数据集为20/20/20天。采用完整的数据集作为自适应的源域。我们遵循Flunkert等人(2020)的滚动窗口策略,并将每个窗口分别拆分为长度为T和T + τ的历史和预测时间序列。在我们的实验中,我们设置每小时数据集的T = 168, τ = 24,以及每天数据集的T = 28, τ = 7。对于数据处理方法,源数据的分割也类似地进行。
表2显示,从表1中得出的关于合成实验的结论一般适用于真实世界的数据集。特别是,我们看到DAF在基线上的精度提高比在合成实验中更显着。实际实验也表明,DAF的成功与源域无关,甚至在源域与目标域频率不同的情况下也是有效的。此外,跨域预测、DATSING、RDA变量和我们的DAF在大多数情况下都优于三个单域基线。与合成情况一样,DATSING的性能相对较RDA和DAF差。另一方面,另一个跨域预测器SASA最初是为回归任务设计的,其中固定大小的窗口用于预测单个外源数字标签。虽然它可以通过将标签替换为下一步值并进行自回归预测来扩展到多水平预测任务,但在某些情况下,其性能明显不如其他跨领域竞争对手,甚至不如一些单领域对手。DAF与RDA的精度差异大于综合情况下的差值,有利于DAF。这一发现进一步表明,我们选择的基于注意力的架构非常适合于实际的领域适应问题。
值得注意的是,在我们的设置下,DAF设法学习源域和目标域之间的不同模式。例如,图6说明了DAF可以成功地学习交通数据集中清晰的日常模式,并在销售数据集中发现不规则模式。其成功的一个原因是私有编码器捕获不同领域的不同尺度的特征,而注意力模块通过使用领域不变查询和键通过上下文匹配捕获领域相关模式。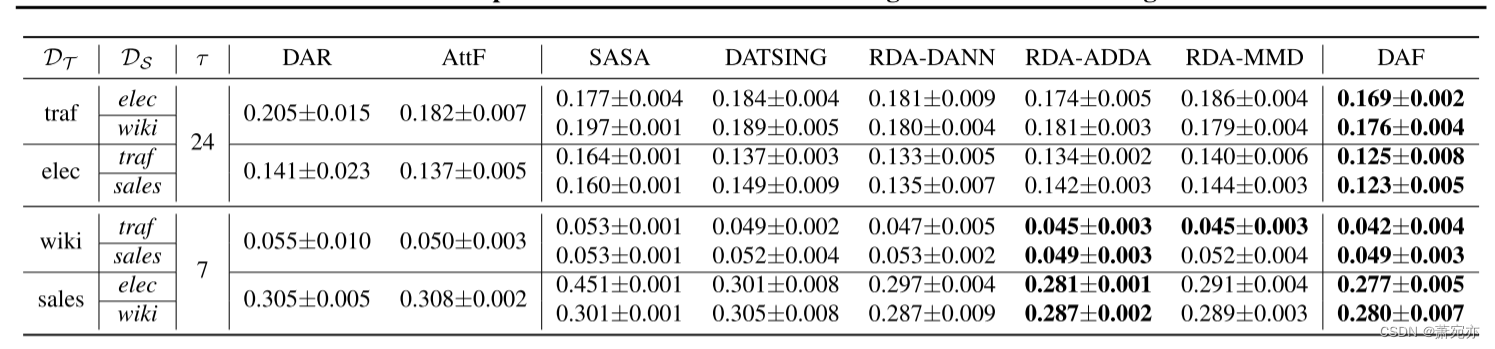 表2。根据平均+/-标准差ND度量,DAF在目标域预测长度为τ的实际基准数据集上的性能比较。获胜者和竞争的追随者(差距小于5次运行的标准差)被保留以供参考。
表2。根据平均+/-标准差ND度量,DAF在目标域预测长度为τ的实际基准数据集上的性能比较。获胜者和竞争的追随者(差距小于5次运行的标准差)被保留以供参考。
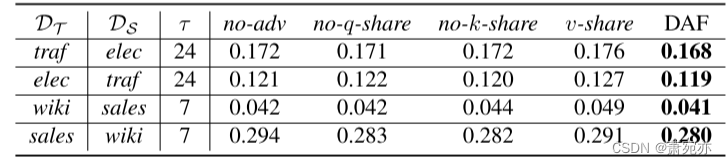
表3。真实世界数据集上四种适应任务的DAF变异消融研究结果。
5.4. 附加实验
除了5.1节中列出的基线之外,我们还将DAF与其他单域预测器进行了比较,例如ConvTrans (Li et al., 2019)、N-BEATS (Oreshkin et al., 2020b)以及时间序列任务上的域自适应方法,例如MetaF (Oreshkin et al., 2020a)。这些方法要么类似于表2中的基线,要么设计用于不同的设置。在附录C的表6-7中,我们仍然对它们进行了调整,以提供额外的结果。
5.5. 消融研究
为了检验我们设计的有效性,我们通过连续调整每个关键部件来进行烧蚀研究。表3显示了DAF在目标域的四个自适应任务上相对于其变体的改进性能。与非对抗性变体(no-adv)相比,DAF配备了域鉴别器,提高了其自适应效率。我们看到,在DAF中共享键和查询比不共享(无k-share和无q-share)更能提高性能。此外,很明显,对于依赖于领域的预测,我们的设计选择是特定于领域的值,而不是共享(v-share),这对性能有最大的积极影响。
图7可视化了DAF和no-adv学习到的查询和键的分布,其中目标数据DT =传输和源数据DS = elec通过TSNE嵌入传输。根据经验,我们看到潜在分布在DAF中很好地对齐,而不是在no-adv中。这可以解释DAF优于其变体的性能。它还进一步验证了我们的直觉,即DAF受益于跨域查询和键的对齐潜在空间。

图7。查询对齐(DAF:右)和没有对抗性训练(no-adv:左),其中
D
S
=
e
l
e
c
a
n
d
D
T
=
t
r
a
f
.
\mathcal{D}_{\mathcal{S}}=elec\mathrm{~and~}\mathcal{D}_{\mathcal{T}}=traf.
DS=elec and DT=traf.
六、结论
本文旨在将领域自适应应用于时间序列预测,以解决数据稀缺问题。识别了预测任务与常见领域适应场景的差异,提出了基于注意力共享的领域适应预测器(DAF)。通过实证实验,我们证明DAF在合成和现实世界数据集上优于最先进的单域预测器和各种域自适应基线。我们通过广泛的消融研究进一步证明了我们设计的有效性。尽管有经验证据,但在注意模型中具有领域不变特征的理论证明仍然是一个悬而未决的问题。推广到多变量时间序列预测实验是今后工作的另一个方向。

















 998
998

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









