






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
⛳️赠与读者
👨💻做科研,涉及到一个深在的思想系统,需要科研者逻辑缜密,踏实认真,但是不能只是努力,很多时候借力比努力更重要,然后还要有仰望星空的创新点和启发点。建议读者按目录次序逐一浏览,免得骤然跌入幽暗的迷宫找不到来时的路,它不足为你揭示全部问题的答案,但若能解答你胸中升起的一朵朵疑云,也未尝不会酿成晚霞斑斓的别一番景致,万一它给你带来了一场精神世界的苦雨,那就借机洗刷一下原来存放在那儿的“躺平”上的尘埃吧。
或许,雨过云收,神驰的天地更清朗.......🔎🔎🔎
💥1 概述
基于DQN算法的无人机路径规划研究
一、DQN算法的基本原理与核心创新
DQN(Deep Q-Network)是深度强化学习领域的里程碑算法,通过深度神经网络对Q值函数进行近似,解决了传统Q-learning在高维状态空间下的维度灾难问题。其核心创新包括:
- 双网络架构
- 评估网络(Evaluate Network) :负责实时更新Q值并选择动作。
- 目标网络(Target Network) :周期性同步评估网络的参数,用于计算TD Target的Q值,减少目标值波动,提升训练稳定性。
- 经验回放(Experience Replay)
- 将状态转移序列(s, a, r, s')存储在固定容量的记忆库中,训练时随机采样小批量数据,打破样本间的相关性,提升泛化能力。
- 探索与利用平衡
- 采用ε-贪婪策略,以概率ε随机选择动作(探索),否则选择当前Q值最大的动作(利用),逐步衰减ε以优化收敛过程。
公式表示:
Q值的更新公式为:

(τ为软更新系数)。
二、无人机路径规划的技术挑战
无人机路径规划需应对以下核心问题:
- 动态环境复杂性
- 障碍物分布、地形变化及气象条件(如风速、温度)的动态性要求算法具备实时适应能力。
- 计算资源限制
- 无人机机载设备的计算能力有限,传统算法(如A*、RRT)在复杂环境中计算效率低下。
- 运动约束
- 包括最大转弯角(水平/垂直)、爬升速度、最小转弯半径等物理限制,需在路径规划中严格满足。
- 传感器不确定性
- 传感器噪声或通信中断可能导致环境感知误差,影响规划可靠性。
案例:
在峡谷环境中,传统Roadmap算法因无法处理连续障碍物而失效,而可变分辨率八叉树(Octo-tree)通过局部精细化分析实现实时规划。
三、DQN在无人机路径规划中的应用案例
- 复杂地形避障
- 实验设计:在虚拟地形中,DQN通过设计奖励函数(如碰撞惩罚、接近目标奖励)引导无人机避开障碍物,成功率显著高于传统方法。
- 未知环境探索
- E-DQN算法:结合事件驱动机制(Event-Driven DQN),利用事件流数据减少冗余信息,在AirSim模拟器中实现快速路径规划,较传统方法效率提升30%。
- 多无人机协同
- DCDQN算法:分布式协作DQN通过扩展状态空间(融合环境信息与协作信号),优化多无人机覆盖路径,降低通信中断率80%。
- 三维路径优化
- NDQN算法:引入差值增长机制,缓解Q值过估计问题,在三维环境中路径长度缩短15%,收敛速度提升40%。
对比实验:
在船舶全局路径规划中,改进DQN(优先经验回放)相比传统A*算法,路径长度减少1.9%,拐点数量减少62.5%。
四、DQN与传统路径规划算法的对比
| 指标 | 传统算法(如A、RRT)* | DQN及其改进算法 |
|---|---|---|
| 环境适应性 | 依赖静态地图,动态环境下需频繁重规划 | 通过在线学习适应动态变化,支持实时调整 |
| 计算效率 | 高维环境下搜索复杂度呈指数增长 | 神经网络推理速度快,适合实时场景 |
| 全局最优性 | 易陷入局部最优(如人工势场法) | 通过经验回放和探索策略逼近全局最优 |
| 硬件需求 | 需高精度传感器和完整环境信息 | 可处理部分观测状态,鲁棒性更强 |
实验数据:
- 在移动机器人避障任务中,改进DQN的训练时间缩短40.25%,成功率提升79.8%。
- 分层DQN在仿真环境中仅需1000回合收敛,而传统DQN需4200回合。
五、研究现状与未来方向
- 当前进展
- 算法优化:优先经验回放(PER)、竞争架构(Dueling DQN)、噪声网络(Noisy DQN)等改进显著提升性能。
- 多模态融合:结合LSTM处理时序决策问题,增强动态环境下的路径重规划能力。
- 未来挑战
- 稀疏奖励问题:复杂环境中奖励信号稀疏,需设计内在激励机制。
- 多智能体协同:通信受限下的分布式DQN优化仍需突破。
- 硬件部署:轻量化网络结构设计以适应机载计算资源。
六、标准研究文档框架建议
- 引言:研究背景、意义及无人机路径规划的难点。
- 相关技术:DQN原理、路径规划算法分类(传统方法、DRL方法)。
- 方法设计:状态/动作空间定义、奖励函数设计、网络结构优化。
- 实验验证:仿真环境搭建(如AirSim、Gazebo)、评价指标(成功率、路径长度、收敛速度)。
- 结果分析:与传统算法对比、消融实验、多场景鲁棒性测试。
- 结论与展望:总结创新点,提出未来研究方向(如多目标优化、异构无人机协同)。
示例结构:
- 状态空间:无人机位置、速度、障碍物距离、目标方向。
- 动作空间:前进、转向(水平/垂直)、爬升/下降。
- 奖励函数:路径长度奖励、碰撞惩罚、能量消耗惩罚。
📚2 运行结果
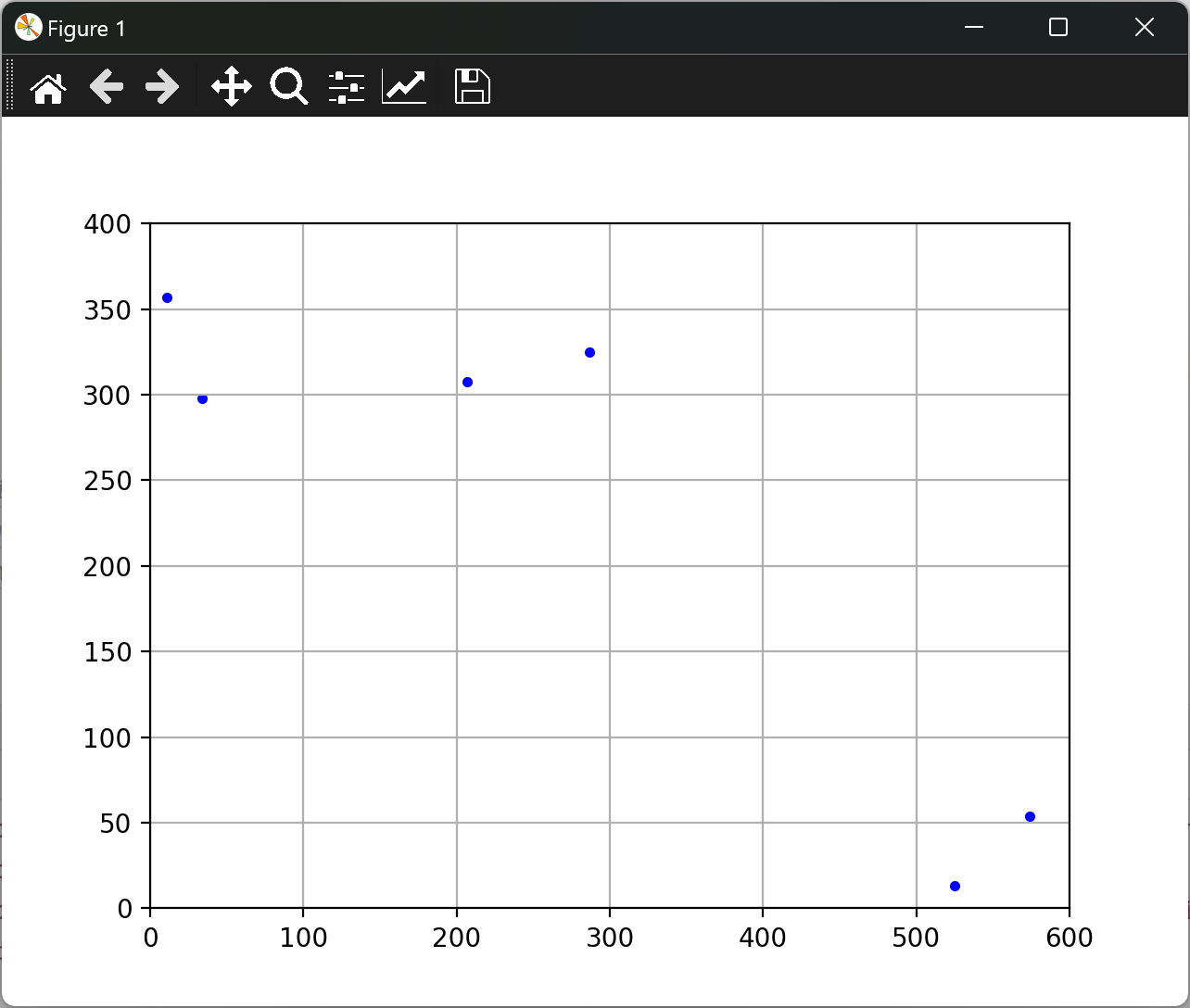
部分代码:
#init plt
plt.close() #clf() # 清图 cla() # 清坐标轴 close() # 关窗口
fig=plt.figure()
ax=fig.add_subplot(1,1,1)
plt.xlim((0,600))
plt.ylim((0,400))
plt.grid(True) #添加网格
plt.ion() #interactive mode on
X=np.zeros([num_UAV])
Y=np.zeros([num_UAV])
fg=1
for t in range(Ed): #move first, get the data, offload collected data
gp.gen_datarate(averate,region_rate)
# print(t)
if t%T==0 and t>0:
Center.epsilon=ep0
Center.save("./save/center-dqn.h5")
if t%pl_step==0:
pre_feature=[]
aft_feature=[]
act_note=[]
for i in range(num_UAV):
pre_feature.append(UAVlist[i].map_feature(region_rate,UAVlist,E_wait)) #record former feature
act=Center.act(pre_feature[i],fg) # get the action V
act_note.append(act) #record the taken action
for i in range(num_UAV):
OUT[i]=UAVlist[i].fresh_position(vlist[act_note[i]],region_obstacle) #execute the action
UAVlist[i].cal_hight()
X[i]=UAVlist[i].position[0]
Y[i]=UAVlist[i].position[1]
UAVlist[i].fresh_buf()
prebuf[i]=UAVlist[i].data_buf #the buf after fresh by server
gp.list_gama(g0,d0,the,UAVlist,P_cen)
for i in range(num_sensor): #fresh buf send data to UAV
sensorlist[i].data_rate=region_rate[sensorlist[i].rNo]
sensorlist[i].fresh_buf(UAVlist)
cover[t]=cover[t]+sensorlist[i].wait
cover[t]=cover[t]/num_sensor
print(cover[t])
for i in range(num_UAV):
reward[i]=reward[i]+UAVlist[i].data_buf-prebuf[i]
Mentrd[i,t]=reward[i]
# if sum(OUT)>=num_UAV/2:
# fg=0
# if np.random.rand()>0.82 and fg==0:
# fg=1
if t%pl_step==0:
E_wait=gp.W_wait(600,400,sensorlist)
rdw=sum(sum(E_wait))
print(t)
for i in range(num_UAV): #calculate the reward : need the modify
# aft_feature.append(UAVlist[i].map_feature(region_rate,UAVlist,E_wait)) #recode the current feature
rd=reward[i]/1000
reward[i]=0
# UAVlist[i].reward=reward
# reward=get_data/(pre_data[i]+1)
# if OUT[i]>0:
# rd=-200000
# if get_data<700:
# reward=-1
# pre_data[i]=get_data
UAVlist[i].reward=rd
# l_queue[t]=l_queue[t]+UAVlist[i].data_buf
# print("%f, %f, %f, %f"%(rd,UAVlist[i].data_buf,UAVlist[i].D_l,UAVlist[i].D_tr))
# if UAVlist[i].data_buf>jud:
# reward=reward/(reward-jud)
# if t>0:
# Center.remember(pre_feature[i],act_note[i],rd,aft_feature[i],i) #record the training data
# if t>1000:
# Center.epsilon=ep0
# Center.epsilon_decay=1
# if t>batch_size*pl_step and t%pl_step==0:
# for turn in range(num_UAV):
## Center.replay(batch_size,turn,t%reset_p_T)
# Center.replay(batch_size,turn,t-batch_size*pl_step)
if t>0:
ax.clear()
plt.xlim((0,600))
plt.ylim((0,400))
plt.grid(True) #添加网格
ax.scatter(X,Y,c='b',marker='.') #散点图
# if t>0:
plt.pause(0.1)
#np.save("record_rd3",Mentrd)
np.save("cover_hungry_10",cover)
fig=plt.figure()
plt.plot(cover)
plt.show()
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。(文章内容仅供参考,具体效果以运行结果为准)
[1]王杰,王高攀,孙天杨.基于DQN算法的无人机校园安全监控路径自动规划模型[J].自动化与仪器仪表, 2024(4):193-196.
[2]赵恬恬,孔建国,梁海军,等.未知环境下基于Dueling DQN的无人机路径规划研究[J].现代计算机, 2024, 30(5):37-43.
[3]李延儒,左铁东,王婧.基于DQN深度强化学习的无人机智能航路规划方法研究[J].电子技术与软件工程, 2022(18):5-8.
🌈4 Python代码实现
资料获取,更多粉丝福利,MATLAB|Simulink|Python资源获取




















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











