







2024年5月10日发表在Nature上
摘要
药物分子是一种改变生物体精神或身体状态的物质。每种获批药物都有适应症,即该药物用于治疗特定疾病的治疗用途。虽然大型语言模型 (LLM),一种生成式人工智能 (AI) 技术,最近已证明在分子和其文本描述之间进行翻译方面非常有效,但在促进药物分子和适应症(描述使用该药物治疗的疾病、病症或症状)或反之亦然之间的翻译应用方面,研究仍然存在差距。解决这一挑战可以极大地促进药物发现过程。根据给定的适应症生成药物的能力将允许发现针对特定疾病或靶标的药物,并最终为患者提供更好的治疗。在本文中,我们首先提出一项新任务,即药物分子和相应适应症之间的翻译,然后在这项新任务上测试现有的 LLM。具体来说,我们考虑了 T5 LLM 的九种变体,并在从 ChEMBL 和 DrugBank 获得的两个公共数据集上对它们进行了评估。我们的实验展示了使用 LLM 完成这项任务的早期结果,并提供了对最新技术的展望。我们还强调了当前的局限性,并讨论了未来有可能提高这项任务性能的工作。根据适应症创建分子,反之亦然,将允许更有效地针对疾病并显著降低药物发现的成本,并有可能在生成 AI 时代彻底改变药物发现领域。
“翻译”解释:
虽然已经有研究证明在药物分子和其文字描述之间进行“翻译”非常有效,但是在“翻译”药物分子与其适应症之间的关系,或者反过来,从适应症来找出对应的药物分子,在这方面的研究仍然比较不足。这里的“翻译”是指利用某种模型或者算法将一种表现形式转换为另一种表现形式,比如从药物分子的化学结构得出其功能的文字描述,或者从具体的疾病、症状推出适合治疗的药物分子。
一、介绍
药物研发是一个成本高昂的过程1,需要识别出有潜力成为治疗药物的化学实体2。由于药物研发对健康具有明显的益处和意义,已成为一个活跃的研究领域,研究人员正试图实现药物研发的自动化和简化3、4。获批的药物都有适应症,即使用该药物治疗某种特定的疾病、病症或症状5 。适应症会具体说明该药物是用于治疗、预防、缓解、治愈、缓解还是诊断该特定疾病。根据适应症创建分子,或反之亦然,将能够更有效地针对疾病,并显著降低药物研发的成本,有可能彻底改变该领域。
大型语言模型 (LLM) 已成为生成式人工智能 (AI) 研究的主要方向之一,近年来开发出了GPT-3 6、GPT-4 7、LLaMA 8和 Mixtral 9等高性能模型,而ChatGPT 等服务则覆盖超过1亿用户10、11。LLM利用深度学习方法执行各种自然语言处理 (NLP) 任务,例如文本生成12、13和神经机器翻译14、15。LLM的能力部分归功于它们在大规模文本数据上的训练,这使得模型熟悉各种各样的主题。LLM 还在不同科学领域的各种任务中表现出色16、17、18、19 。由于LLM 处理文本数据,因此第一步通常是找到一种用文本或语言表达问题的方法。
图像或图表是呈现分子的典型方式,但也存在获取分子文本表示的方法。其中一种方法是简化分子输入行输入系统 (SMILES) 20,它通常被视为描述分子的语言。由于 SMILES 字符串以文本形式表示药物,我们可以评估 LLM 在药物分子及其适应症之间翻译的可行性。在本文中,我们考虑两个任务:药物到适应症和适应症到药物,其中我们分别试图从药物的 SMILES 字符串中生成适应症,以及从可能的适应症中生成 SMILES 字符串。药物和相应适应症之间的翻译将允许找到治疗目前无治疗方法的疾病的方法。
研究人员尝试通过使用人工智能来从头发现药物,包括图神经网络21、22以及最近的生成式人工智能23。目前有许多使用人工智能进行分子设计和药物发现的研究,例如基于 GPT 的模型,使用支架 SMILES 字符串并伴随输出分子的所需特性24。其他人已使用 T5 架构执行各种任务,例如反应预测25和分子标题与 SMILES 字符串之间的转换26。该领域的其他工作主要集中在使用生成对抗网络从基因表达特征生成新分子27,对已知化合物及其 SMILES 字符串训练循环神经网络,然后针对某些受体的特定激动剂进行微调28,或使用图神经网络从 SMILES 预测药物及其相应的适应症29。因此,使用人工智能进行药物发现和分子设计有着既定的前景。为了让数据更适合人工智能药物生成,我们还开发了自引用嵌入字符串 (SELFIES) 30,它可以表示每个有效分子。理由是,这种格式将允许生成式人工智能构建有效分子,同时在字符串中保留关键的结构信息。这些努力的集合为我们尝试从分子生成药物适应症奠定了基础。
随着药物化学的进步导致越来越多的药物用于复杂的过程,理解每种药物的独特特性和细微差别变得至关重要。在这方面,研究人员发布了许多资源,包括连接药物和化学成分的数据集(如 TCMBank)31、32 、用于生成高质量分子表征以促进计算机辅助药物设计(CADD)的模型33,以及药物 - 药物相互作用的模型34、35。这也导致了分子指纹的发展,例如 Morgan 指纹36和 MAP4 指纹37 ,它们使用独特的算法将分子的特征矢量化。指纹表征的计算速度很快,并且它们保留了分子的大部分特征38。分子指纹识别方法通常以 SMILES 字符串的形式接收输入,SMILES 字符串是一种线性符号,用于表示分子的结构形式,同时考虑到存在的不同原子、原子之间的键以及其他关键特征,如分支、环状结构和芳香性20。由于 SMILES 是一种传达不同分子结构的通用方法,因此使用 SMILES 字符串生成指纹是合适的。Mol2vec 39通过将分子转换为文本表示,将 Morgan 指纹提供给 Word2vec 40算法。基于 Transformer 的双向编码器表示 (BERT) 41的模型也已用于获取分子表示,包括 MolBERT 42和 ChemBERTa 43等模型,它们是预训练的 BERT 实例,以 SMILES 字符串作为输入并分别执行分子表示和分子属性预测的下游任务。其他利用人工智能进行分子表征的努力包括通过强化学习、分解和重组生成新型分子图44,以及基于小分子的二维图形对应物预测其三维表征45。
在本文中,我们使用 DrugBank 和 ChEMBL 中的药物数据,通过药物到适应症和适应症到药物这两项任务,评估基于 T5 的模型 MolT5 在药物及其适应症之间进行转换的能力。药物到适应症任务利用现有药物的 SMILES 字符串作为输入,以药物的匹配适应症作为目标输出。适应症到药物任务将药物的适应症集作为输入,并试图为治疗所列疾病的药物生成相应的 SMILES 字符串。
我们在实验中采用了所有可用的 MolT5 模型大小,并在两个数据集上分别对其进行评估。此外,我们在三种不同的配置下进行实验:
1.对整个可用数据集上的基线模型进行评估
2.对 20% 数据集的基线模型进行评估
3.在 80% 的数据集上对模型进行微调,然后对 20% 的子集进行评估
我们发现,在所有配置和任务中,较大的 MolT5 模型表现优于较小的模型。还应注意,微调 MolT5 模型会对性能产生负面影响。
在这些初步实验之后,我们使用自定义标记器从头开始训练最小的可用 MolT5 模型。在药物到适应症任务中,此自定义模型在 DrugBank 数据上的表现优于在 ChEMBL 数据上的表现,这可能是因为其数据集中的药物适应症和 SMILES 字符串之间的信号更强,这要归功于其适应症描述的细节水平。在 80% 的数据集上对自定义模型进行微调不会降低任何一项任务的模型性能,并且一些指标由于微调而有所改善。总体而言,对适应症到药物任务的微调并没有持续提高性能,这对 ChEMBL 和 DrugBank 数据集都是如此。
虽然自定义标记器方法的性能仍然不令人满意,但使用更大的模型并获取更多数据是有希望的。如果我们拥有大量高质量数据来训练药物及其适应症之间的转换模型,那么使用 LLM 可能可以提高性能并促进新药的发现。
在本文中,我们做出以下贡献:
1.我们引入了一项新任务:药物分子和适应症之间的转换。
2.我们使用基于 T5 的 LLM 和两个数据集(DrugBank 和 ChEMBL)进行了各种实验。我们的实验考虑了所有实验中的 16 个评估指标。此外,我们讨论了当前的瓶颈,如果解决这些瓶颈,则有可能显著提高任务的性能。
二、MolT5 模型评估
我们使用 HuggingFace 的 MolT5 模型进行了初步实验(GitHub 链接:https 😕/huggingface.co/laituan245/molt5-small/tree/main、https : //huggingface.co/laituan245/molt5-base/tree/main、https : //huggingface.co/laituan245/molt5-large/tree/main)。MolT5 提供三种模型尺寸和每种尺寸的微调模型,以支持我们实验的每项任务。对于从药物适应症(药物到适应症)生成 SMILES 字符串的实验,我们使用了微调模型 MolT5-smiles-to-caption,对于从药物适应症(适应症到药物)生成 SMILES 字符串,我们使用了模型 MolT5-caption-to-smiles。对于每个表,我们使用以下标志:FT(表示在 80% 的数据集上对模型进行微调并在剩余 20% 的测试子集上进行评估的实验)、SUB(表示仅在 20% 的测试子集上对模型进行评估的实验)和 FULL(用于在每个数据集的整体上评估模型的实验)。
这个表格名为 “Evaluation metrics used in the experiments”,它详细列出了在实验中使用的评估指标,每个指标的介绍,可能的值,以及趋势。
各指标解释:
-
BLEU:测量两个文本的相似性,值范围在0到1之间,值越大越好。
-
Exact:判断字符串匹配是否完全一样,值只有0或1,1代表完全匹配,越大越好。
-
Levenshtein:衡量两个字符串之间的Levenshtein编辑距离,值可以是0到无限大,越小越好。
-
MACCS,RDK,Morgan:使用Tanimoto算法计算两个分子指纹的相似性,值范围在0到1之间,越大越好。
-
FCD:测量真实样本和模型生成样本的分布间的距离,值可以是0到无限大,越大越好。
-
Text2Mol:使用预训练模型计算SMILES字符串和文本之间的相似性,值范围在0到1之间,越大越好。
-
Validity:判断生成的SMILES字符串是否语法正确,值只有0或1,1代表完全正确,越大越好。
-
BLEU-2和BLEU-4:分别计算累积的2-gram和4-gram BLEU评分,值范围在0到1之间,越大越好。
-
ROUGE-1,ROUGE-2和ROUGE-L:计算候选字符串和参考字符串之间的一元,二元及最长公共子序列的重叠情况,值范围在0到1之间,越大越好。
-
METEOR:通过加权一元F分数,计算两个字符串之间的相似性,值范围在0到1之间,越大越好。
这些指标主要应用于自然语言处理,化学信息学及机器学习领域,用于评估模型性能的准确性和有效性。大部分指标的理想趋势都是向上的,也就是说分数越高,模型的性能越好。唯一的例外是Levenshtein编辑距离,其理想趋势是向下的,也就是说,值越低,模型的性能越好。
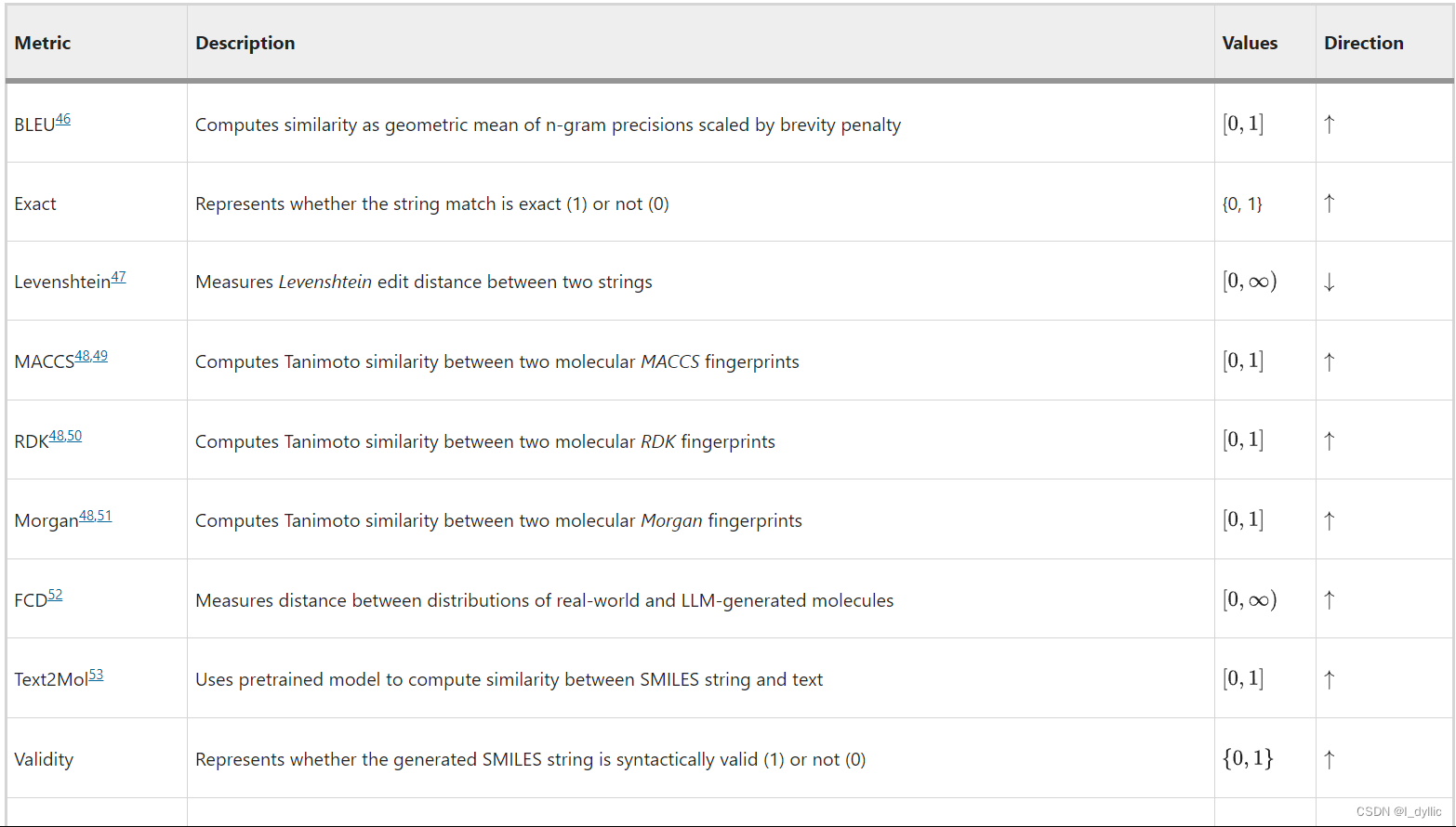
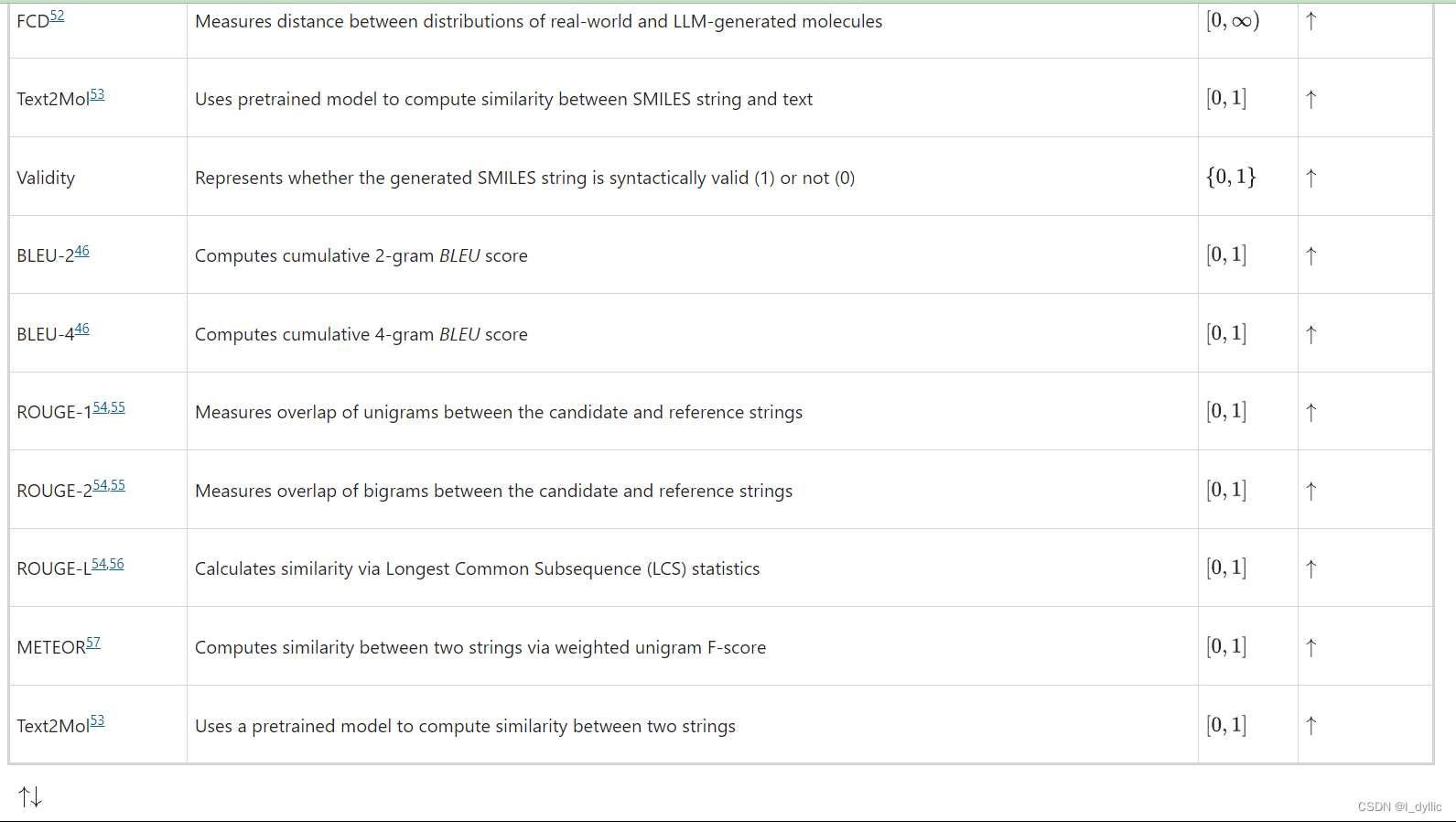
为了评估药物与适应症的对应关系,我们采用了自然语言生成指标 BLEU 46、ROUGE 54、55、56和 METEOR 57,以及 Text2Mol 53指标,该指标可生成 SMILES-适应症对的相似度。对于适应症与药物的对应关系的评估,我们测量 SMILES 字符串的精确匹配度、Levenshtein 距离47、SMILES BLEU 分数、Text2Mol 相似度指标,以及三种不同的分子指纹指标:MACCS 48、49、RDK 48、50和 Morgan FTS 48、51,其中 FTS 代表指纹 Tanimoto 相似度48,以及返回的有效分子 SMILES 字符串的比例。评估 SMILES 生成的最终指标是 FCD,即 Fréchet ChemNet Distance,它测量两个分子分布与其 SMILES 字符串52之间的距离。表 1列出了药物与适应症和适应症与药物的指标,包括它们的描述、值和支持的区间。
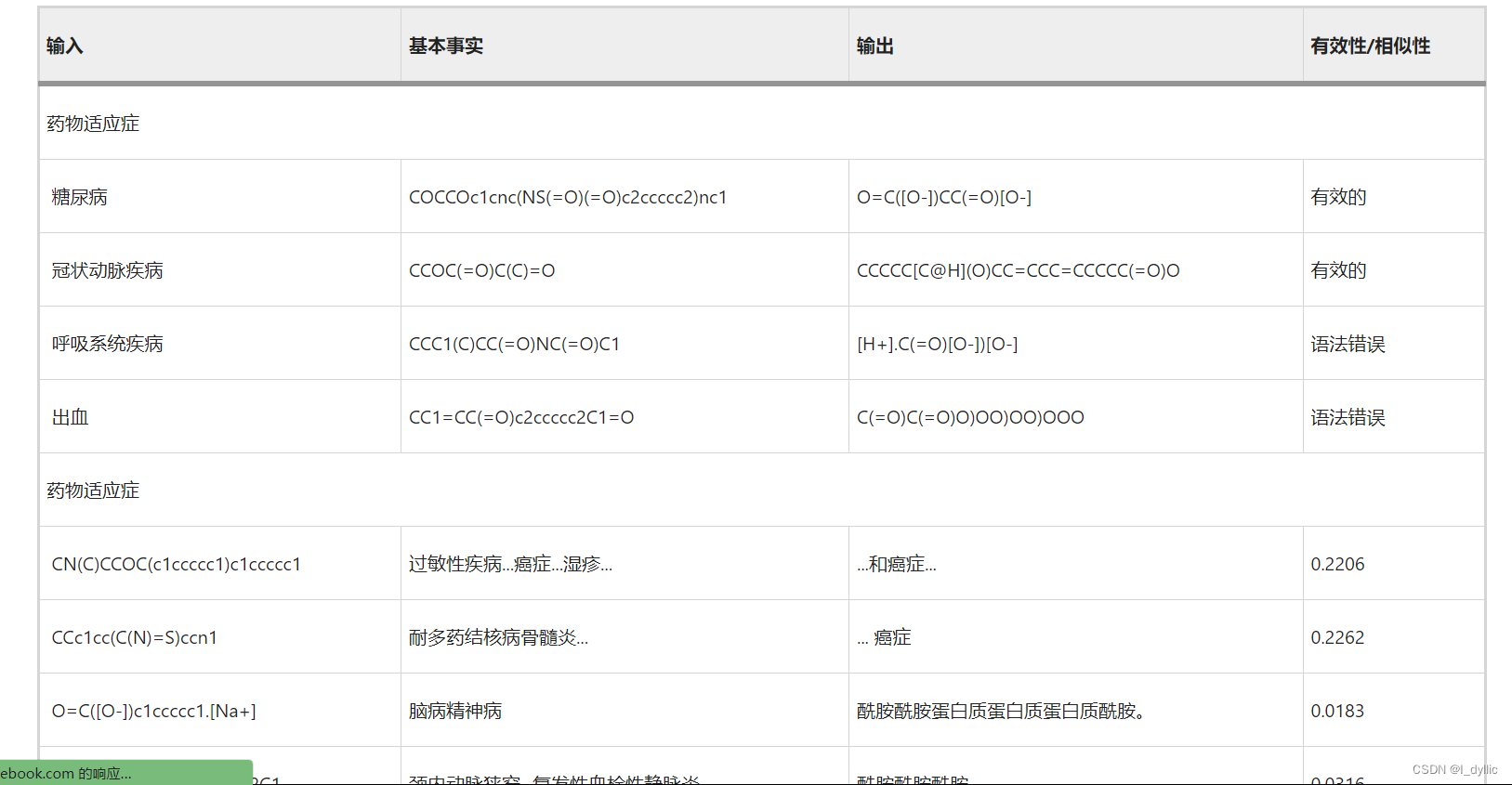
下表和表4分别显示了 MolT5 在 DrugBank 和 ChEMBL 数据上进行的药物到适应症实验的结果。模型规模越大,在每次实验的所有指标上都表现得越好。在 DrugBank 和 ChEMBL 数据集上,在药物到适应症任务的几乎所有指标上,该模型在 20% 子集数据上的表现最佳。同时,子集和完整数据集评估都比微调实验取得了更好的结果。由于 MolT5 模型是在分子标题上进行训练的,因此使用适应症进行微调可能会引入噪音并削弱输入文本和目标文本之间的信号。这些模型在 DrugBank 数据上的表现优于 ChEMBL 数据,这可能是由于 DrugBank 为其药物适应症提供的细节水平。
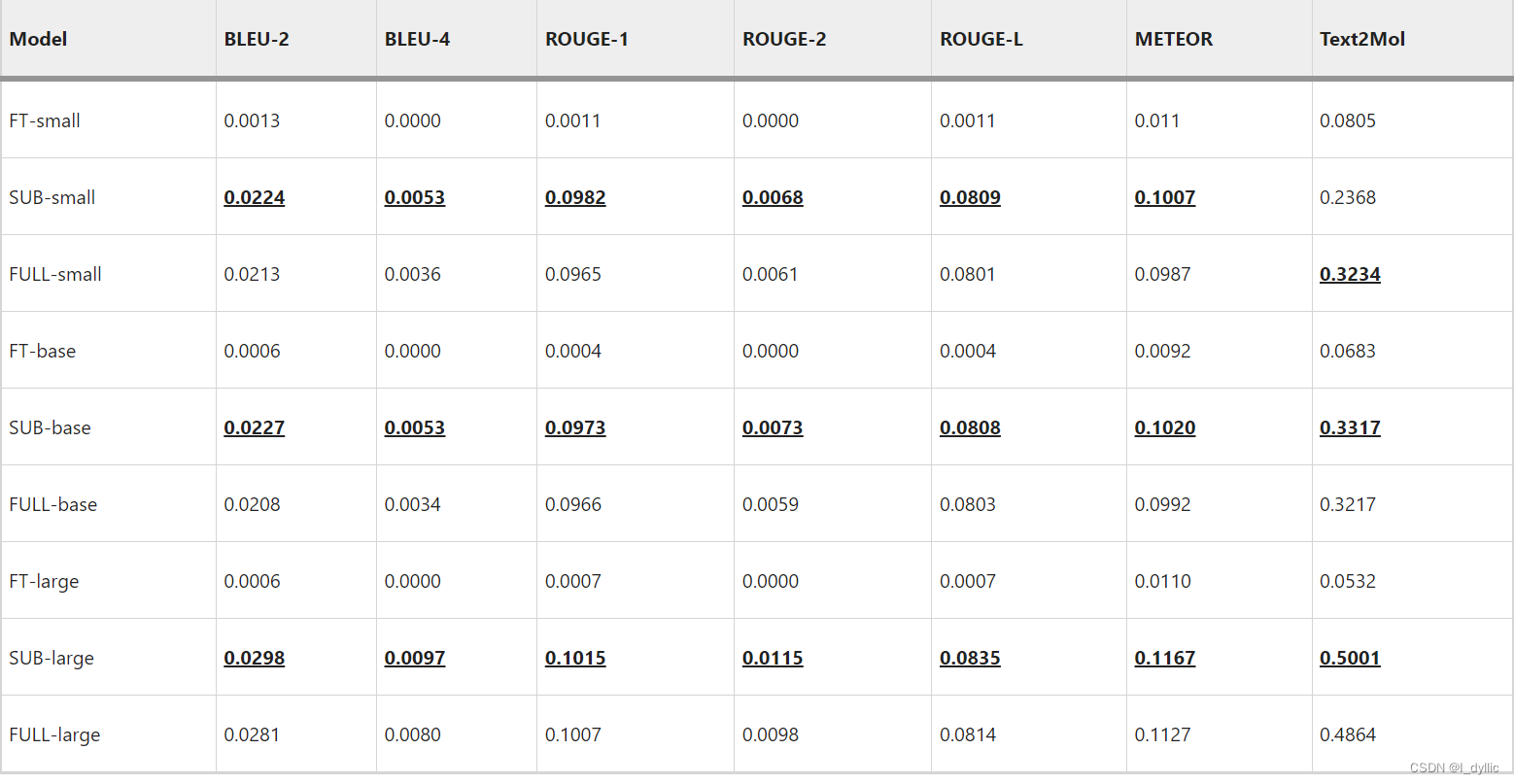
表5和表6分别显示了 MolT5 在 DrugBank 和 ChEMBL 数据上针对药物的实验结果。表格表明,在新数据上微调模型会降低性能,这反映在 FT 实验产生的结果比 SUB 或 FULL 实验更差。此外,较大的模型往往在每次实验的所有指标上表现更好。
在我们的药物到适应症和适应症到药物的实验中,我们发现微调模型会导致模型在所有指标上的表现变差。此外,较大的模型在我们的任务上表现更好。然而,在我们的自定义标记器实验中,我们对 MolT5-Small 进行了预训练,没有添加 SMILES 到字幕和字幕到 SMILES 的层。通过在我们的数据上微调自定义预训练模型以完成药物到适应症和适应症到药物的任务,我们的目标是看到更好的结果。
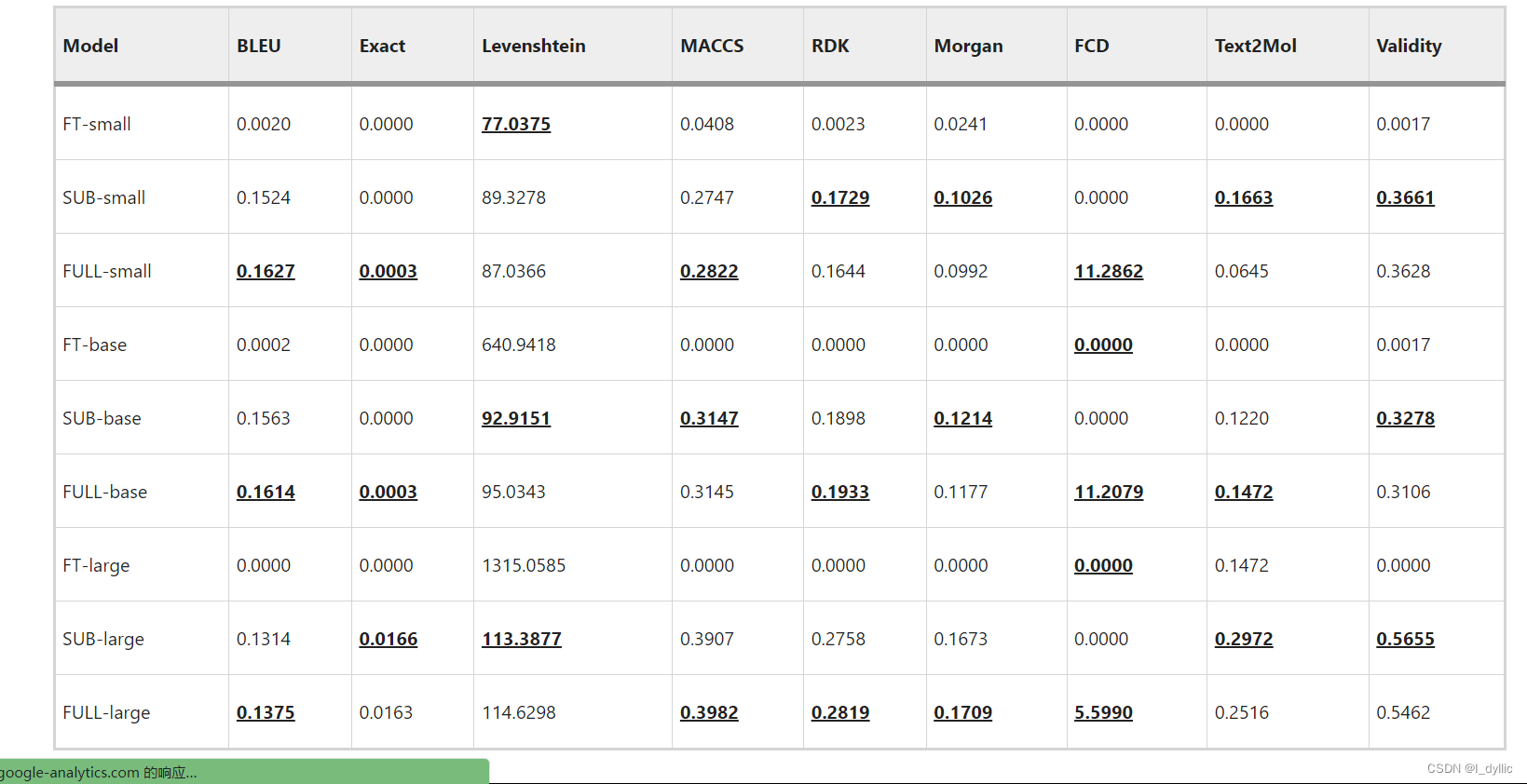
这个表格是名为 “DrugBank indication-to-drug results” 的数据分析结果。它展示了在不同模型下(如FT-small,SUB-small,FULL-small,FT-base,SUB-base,FULL-base,FT-large,SUB-large,FULL-large)效果的比较。对于每种模型,都有对应的BLEU,Exact,Levenshtein,MACCS,RDK,Morgan,FCD,Text2Mol,Validity等指标的分数。
指标说明:
- BLEU:这是一种用于评估机器翻译的算法的分数。
- Exact:这可能是一个精确匹配指标,即模型预测结果和真实结果的完全一致程度。
- Levenshtein:这是一种字符串对比的测量方法,即两个字符串之间通过修改(插入、删除或替换)字符达到一致所需的最少步骤数量。
- MACCS,RDK,Morgan:这些可能是化学信息学相关的指标,用于评估模型预测化合物结构的准确性。
- FCD:可能是一种用于衡量模型性能的指数。
- Text2Mol:这可能是一个针对特定文本到分子转换模型的评估指标。
- Validity:这可能是一个衡量模型预测结果在实际应用中的可用性或合理性的指标。
每行的数据都对应了特定模型在每个指标下的表现分数,而粗体下划线的数值代表了在对应指标下表现显著的模型。
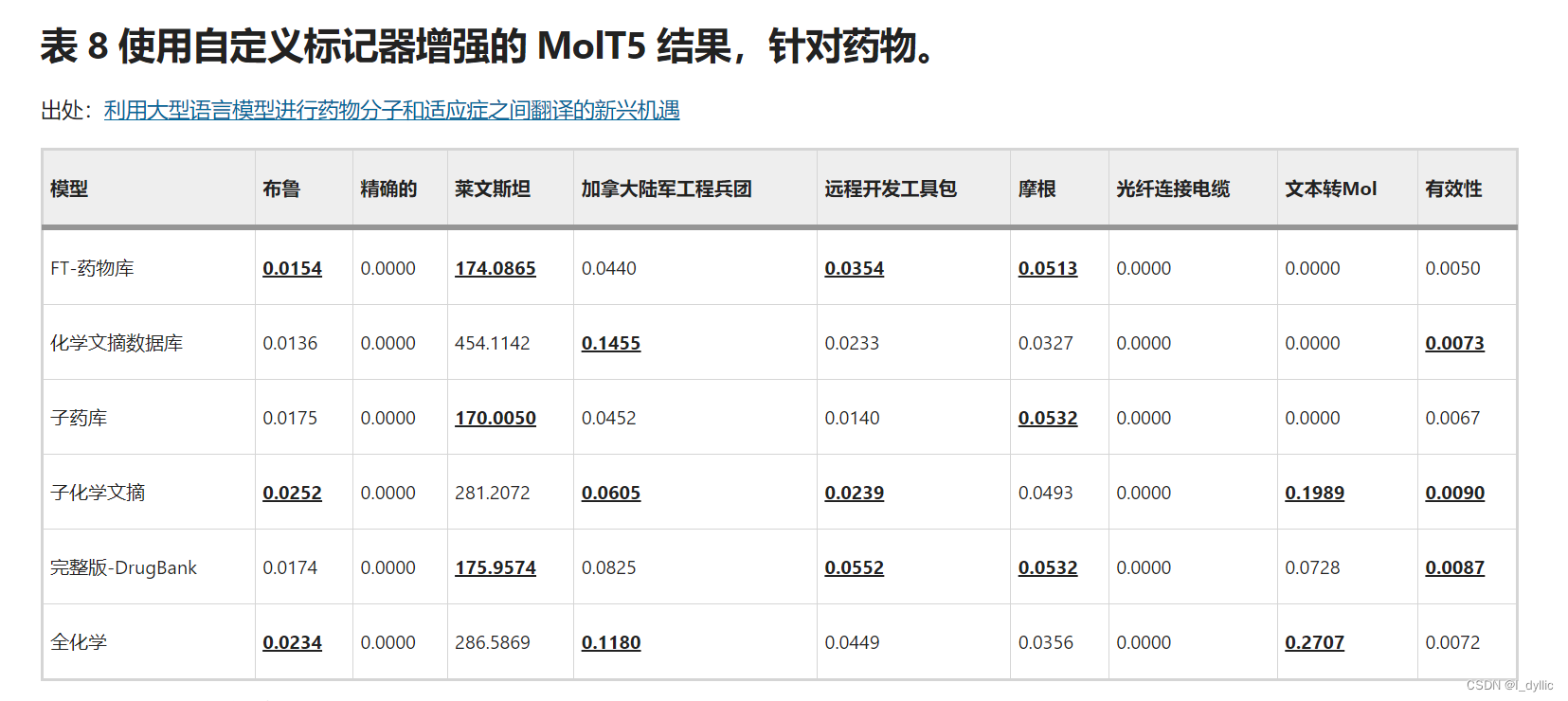
表7和表8分别展示了使用自定义标记器预训练的 MolT5 在药物到适应症和适应症到药物任务上的评估结果。对于药物到适应症,该模型在 DrugBank 数据集上的表现更好,这反映在所有指标上。这种性能差异可能是由于 DrugBank 数据集中药物适应症和 SMILES 字符串之间的信号更强,因为药物适应症包含更多细节。在 80% 的数据集上对模型进行微调并没有像在基线结果中那样降低药物到适应症的性能,并且一些指标显示出更好的结果。适应症到药物的结果更加复杂。该模型在两个数据集上的表现并非始终更好,并且对模型进行微调会对评估指标产生不一致的影响。
三、讨论
在本文中,我们提出了一种在药物和适应症之间进行转换的新任务,同时考虑了药物到适应症和适应症到药物的子任务。我们专注于从现有药物的 SMILES 字符串生成适应症,并从适应症集合中生成 SMILES 字符串。我们的实验是解决这个问题的首次尝试。在使用各种模型配置和两个数据集进行实验后,我们假设了需要进一步研究的潜在问题。我们相信,正确解决这些问题可以显著提高所提任务的性能。
SMILES 字符串和适应症之间的信号较弱。在原始 MolT5 任务(分子与其文本描述之间的翻译)中,“相似”的 SMILES 字符串通常具有相似的文本描述。在药物到适应症和适应症到药物任务中,相似的 SMILES 字符串可能有完全不同的文本描述,因为它们是不同的药物,而且它们的适应症也不同。人们也可以对不同的 SMILES 字符串做出类似的观察:药物适应症可能相似。药物和适应症之间没有直接关系,很难在提议的任务上取得高性能。我们假设,拥有药物(或适应症)映射到的中间表示可能会提高性能。例如,将 SMILES 字符串映射到其标题(MolT5 任务),然后将标题映射到适应症可能是未来潜在的研究方向。
药物和适应症之间的信号并不是唯一的问题:数据也很稀缺。由于我们不考虑随机分子及其文本描述,而是考虑药物及其适应症,因此可用数据受到药物数量的限制。在 ChEMBL 和 DrugBank 数据集中,药物适应症对的数量均低于 10,000,总规模也低于 10,000。寻找丰富数据的方法可能有助于在 SMILES 字符串和适应症之间建立信号,并可能成为未来探索的潜在途径。
总体而言,从我们的实验中得出的结论是,模型越大,表现越好。通过使用更大的模型和更多的数据(或药物适应症和 SMILES 字符串之间信号更强的数据),我们可能能够成功地在药物适应症和分子(即 SMILES 字符串)之间进行转换,并最终促进新药的发现。
我们注意到,我们的实验不涉及对生成的指示进行人工评估,而是完全依赖于自动化指标。我们承认,这些指标可能与人类判断没有很好的相关性58、59、60。同时,手动审查数千个指示会非常昂贵,并且会涉及大量人力。未来的工作可能会考虑将人类纳入其中或使用 LLM 来评估生成的指示的质量。
尝试其他模型和模型架构可以成为另一种探索途径。一些潜在的好处可能包括更好的性能、更低的延迟和改进的计算复杂度。例如,我们当前的方法使用 Transformer 架构,其总体时间复杂度为
(其中
是序列长度,
是嵌入维度),其中
是注意层本身的时间复杂度。另一方面,状态空间模型 (SSM),例如 Mamba 61,与序列长度成线性比例。
实验方法概述:药物数据来自 ChEMBL 和 DrugBank,并用作 MolT5 的输入。我们的实验涉及两个任务:药物到适应症和适应症到药物。对于药物到适应症任务,现有药物的 SMILES 字符串被用作输入,产生药物适应症作为输出。相反,对于适应症到药物任务,同一组药物的药物适应症是输入,产生 SMILES 字符串作为输出。此外,我们在预训练中使用自定义标记器增强了 MolT5,并在相同任务上评估了生成的模型。
本节介绍本研究中使用的数据集、分析方法、ML 模型和特征提取技术。图 1显示了该过程的流程图。我们调整了现有生成分子标题模型的工作流程,改为生成药物适应症。通过训练 LLM 进行 SMILES 字符串和药物适应症之间的转换,我们致力于有朝一日能够创造出治疗疾病的新药。
数据
我们的数据来自两个数据库,DrugBank 62和 ChEMBL 63,我们之所以选择这两个数据库,是因为它们表示药物适应症的方式不同。DrugBank 详细描述了每种药物如何治疗患者,而 ChEMBL 则提供了每种药物治疗的疾病列表。表9概述了每个数据集的大小,以及 SMILES 和适应症数据的长度。对于 DrugBank,我们必须请求访问权限才能使用药物适应症和 SMILES 数据。ChEMBL 数据无需请求即可获得,但需要在本地建立数据库来查询和解析药物适应症和 SMILES 字符串以转换为可行的格式。最后,我们为这两个数据库准备了一个 pickle 文件,以便按照 MolT5 26中介绍的步骤进行度量计算。
我们使用基于 T5 架构26的 MolT5 模型进行了初步实验。该模型的 T5 基础通过在自然语言文本数据集 Colossal Clean Crawled Corpus (C4) 64上进行预训练而获得文本模态,而在 ZINC-15 数据集65上的 1 亿个 SMILES 字符串上进行预训练而获得分子模态。
在我们的实验中,我们使用了现有 MolT5 模型的微调版本:SMILES-to-caption,微调后可从 SMILES 字符串生成分子标题,caption-to-SMILES,微调后可从分子标题生成 SMILES 字符串。然而,我们试图评估模型在药物适应症和 SMILES 字符串之间进行转换的能力。因此,我们使用药物适应症代替分子标题,从而产生两个任务:药物到适应症和适应症到药物。
我们的实验过程首先在全部可用数据(DrugBank 3004 对,ChEMBL 6127 对)和 20% 的数据子集(DrugBank 601 对,ChEMBL 1225 对)上评估每个任务的基线 MolT5 模型,然后对 80%(DrugBank 2403 对,ChEMBL 4902 对)的数据对模型进行微调,并对相同的 20% 子集进行评估。
在汇总初步实验结果后,我们决定在 MolT5 模型架构中使用自定义标记器。虽然默认标记器利用了 T5 预训练,但原因是将 SMILES 字符串视为自然语言的一种形式,并相应地将其标记为其组成键和分子,可以提高模型对 SMILES 字符串的理解,从而提高性能。
我们选择的用于 MolT5 自定义预训练的标记器来自之前关于调整 SMILES 字符串转换器的工作66。该标记器将 SMILES 字符串分离为单个键和分子。图 2说明了 MolT5 和自定义标记器的行为。由于计算限制,我们仅对最小的可用 MolT5 模型进行了自定义预训练,该模型包含 7700 万个参数。我们的预训练方法利用 MolT5 和 JAX(https://jax.readthedocs.io/en/latest/index.html)/ Flax(https://github.com/google/flax )的模型配置在 ZINC 数据集64上执行跨度掩码语言模型目标。预训练后,我们评估了模型在两个数据集上的性能。实验包含三种条件:对 80%(DrugBank 2403 对,ChEMBL 4902 对)的数据进行微调并对剩余 20%(DrugBank 601 对,ChEMBL 1225 对)的数据进行评估;对 20% 的数据进行评估而不进行微调;对 100%(DrugBank 3004 对,ChEMBL 6127 对)的数据进行评估。
1.引入库
代码如下(示例):
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings
warnings.filterwarnings('ignore')
import ssl
ssl._create_default_https_context = ssl._create_unverified_context
2.读入数据
代码如下(示例):
data = pd.read_csv(
'https://labfile.oss.aliyuncs.com/courses/1283/adult.data.csv')
print(data.head())
该处使用的url网络请求的数据。
总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。















 1047
1047

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









