







14 隐马尔可夫模型HMM(Hidden Markov Model)
1 背景
机器学习大致可以分为两个派别,也就是频率派和贝叶斯派的方法,这个之前,我们都有过详细的说明。这里再大致的回顾一下。
- 频率派的思想就衍生出了统计学习方法,说白了统计学习方法的重点在于优化,找 loss function。 频率派的方法可以分成三步:
- 定义 Model, 比如 f ( w ) = w T x + b f(w)=w^{T} x+b f(w)=wTx+b;
- 寻找策略 strategy,也就是定义 Loss function;
- 求解,也就是优化的方法,比如梯度下降 (GD),随机梯度下降 (SGD),牛顿法, 拟牛顿法等等。
- 贝叶斯派的思想也就衍生出了概率图模型。概率图模型重点研究的是一个 Inference 的问题,我们要求的是一个后验概率分布 P ( Z ∣ X ) P(Z | X) P(Z∣X) , 其中 X X X 为观测变量, Z Z Z 为隐变量。实际上就是一个积分问题, 为什么呢?因为贝叶斯框架中的归一化因子需要对整个状态空间进行积分,非常的复杂。代表性的有前面讲到的 MCMC,MCMC 的提出才是彻底的把贝叶斯理论代入到实际的运用中。
1.1 概率图模型回顾

概率图模型,如果不考虑时序的关系,我们可以大致的分为:有向图的Bayesian Network 和无向图的Markov Random Field (Markov Network)。这样,我们根据分布获得的样本之间都是
i
i
d
iid
iid (独立同分布) 的。比如Gaussian Mixture Model (GMM),我们从
P
(
X
∣
θ
)
P(X | \theta)
P(X∣θ) 的分布中采出 N 个样本
{
x
1
,
x
2
,
⋯
,
x
n
}
\left\{x_{1}, x_{2}, \cdots, x_{n}\right\}
{x1,x2,⋯,xn} N 个样本之间都是独立同分布的。也就是对于隐变量
Z
Z
Z, 观测变量
X
X
X 之间,我们可以假设
P
(
X
∣
Z
)
=
N
(
μ
,
Σ
)
P(X | Z)=\mathcal{N}(\mu, \Sigma)
P(X∣Z)=N(μ,Σ) , 这样就可以引入我们的先验信息,从而简化
X
X
X 的复杂分布。 如果引入了时间的信息,也就是
x
i
x_{i}
xi 之间不再是
i
i
d
iid
iid 的了,我们称之为 Dynamic Model。模型如下 所示:
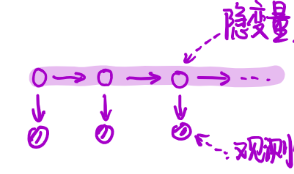
Dynamic Model 可以从两个层面来看,横着看就是 time 的角度,如果是竖着看就可以表达为
P
(
X
j
,
Z
)
P(X_j,Z)
P(Xj,Z) 的形式,也就是 Mixture 的形式。概率系统根据状态与状态之间的关系,可以分为两类。
- 如果是离散的则有HMM 算法。
- 如果是连续的,按照线性和非线性可以分为 Kalman Filter 和 Paricle Filter。
1.2 HMM 算法简介
Hidden Markov Model 的拓扑结构图如下所示:
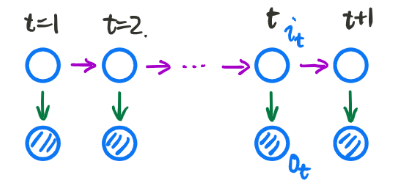
大家看到这个模型就会觉得和上一讲提到的,MCMC 模型方法有点类似。HMM 可以看做一个三元组
λ
=
(
π
,
A
,
B
)
\lambda=(\pi, \mathcal{A}, \mathcal{B})
λ=(π,A,B) 。其中:
π :
π
\pi
π: 是初始概率分布。
A :
A
\mathcal{A}
A: 状态转移矩阵。
B :
B
\mathcal{B}
B: 发射矩阵。
拓扑结构图的第二行为观测变量,观测变量 O : o 1 , o 2 , ⋯ , o t , ⋯ ← V = v 1 , v 2 , ⋯ , v M O: o_{1}, o_{2}, \cdots, o_{t}, \cdots \leftarrow \mathcal{V}=v_{1}, v_{2}, \cdots, v_{M} O:o1,o2,⋯,ot,⋯←V=v1,v2,⋯,vM 。其中 V \mathcal{V} V 是观察变量 o o o 的值域,代表每一个观测变量 o i o_{i} oi 可能有 M 个状态。
拓扑结构图的第一行为状态变量,状态变量 I : i 1 , i 2 , ⋯ , i t , ⋯ ← Q = q 1 , q 2 , ⋯ , q N I: i_{1}, i_{2}, \cdots, i_{t}, \cdots \leftarrow \mathcal{Q}=q_{1}, q_{2}, \cdots, q_{N} I:i1,i2,⋯,it,⋯←Q=q1,q2,⋯,qN。其中 Q \mathcal{Q} Q 是状态变量 i i i 的值域,代表每一个状态变量 i i i 可能有 N 个状态。
A
=
[
a
i
j
]
\mathcal{A}=\left[a_{i j}\right]
A=[aij] 表示状态转移矩阵,
a
i
j
=
P
(
i
i
+
1
=
q
j
∣
i
t
=
q
i
)
a_{ij}=P\left(i_{i+1}=q_{j} | i_{t}=q_{i}\right)
aij=P(ii+1=qj∣it=qi)
B
=
[
b
j
(
k
)
]
\mathcal{B}=\left[b_{j}(k)\right]
B=[bj(k)] 表示发射矩阵,
b
j
(
k
)
=
P
(
o
t
=
V
k
∣
i
t
=
q
j
)
b_{j}(k)=P\left(o_{t}=V_{k} | i_{t}=q_{j}\right)
bj(k)=P(ot=Vk∣it=qj)
而
π
\pi
π 是什么意思呢?假设当
t
t
t 时刻的隐变量
i
t
i_{t}
it , 可能有
{
q
1
,
q
2
,
⋯
,
q
N
}
\left\{q_{1}, q_{2}, \cdots, q_{N}\right\}
{q1,q2,⋯,qN} 个状态,而这些状态出现的概率分别为
{
p
1
,
p
2
,
⋯
,
p
N
}
\left\{p_{1}, p_{2}, \cdots, p_{N}\right\}
{p1,p2,⋯,pN} 。这就是一个关于
i
t
i_{t}
it 隐变量的离散随机分布。

A
\mathcal{A}
A 表示为各个状态转移之间的概率。
B
\mathcal{B}
B 表示为观测变量和隐变量之间的关系。
1.2.1 两个假设
这是有关 Hidden Markov Model 的两个假设:
- 齐次 Markov 假设 (无后向性):2. 观察独立假设。
1. 齐次马尔可夫假设:未来与过去无关,只依赖与当前的状态。也就是:
P
(
i
t
+
1
∣
i
t
,
i
t
−
1
,
⋯
,
i
1
,
o
t
,
⋯
,
o
1
)
=
P
(
i
t
+
1
∣
i
t
)
P\left(i_{t+1} | i_{t}, i_{t-1}, \cdots, i_{1}, o_{t}, \cdots, o_{1}\right)=P\left(i_{t+1} | i_{t}\right)
P(it+1∣it,it−1,⋯,i1,ot,⋯,o1)=P(it+1∣it)2. 观测独立假设:
P
(
o
t
∣
i
t
,
i
t
−
1
,
⋯
,
i
1
,
o
t
,
⋯
,
o
1
)
=
P
(
o
t
∣
i
t
)
P\left(o_{t} | i_{t}, i_{t-1}, \cdots, i_{1}, o_{t}, \cdots, o_{1}\right)=P\left(o_{t} | i_{t}\right)
P(ot∣it,it−1,⋯,i1,ot,⋯,o1)=P(ot∣it)
1.2.2 三个问题
- Evaluation 的问题,我们要求的问题就是 P ( O ∣ λ ) P(O | \lambda) P(O∣λ) 。也就是前向后向算法,给定一个模型 λ \lambda λ, 求出观测变量的概率分布。
- Learning 的问题, λ \lambda λ 如何求的问题。也就是 λ M L E = arg max λ P ( O ∣ λ ) \lambda_{M L E}=\arg \max _{\lambda} P(O | \lambda) λMLE=argmaxλP(O∣λ) 。求解的方法是 E M \mathrm{EM} EM 算 法和 Baum Welch 算法。
- Decoding 的问题,状态序列为
I
I
I,也就是隐变量序列,
I
^
=
arg
max
I
P
(
I
∣
O
,
λ
)
\hat{I}=\arg \max _{I} P(I | O, \lambda)
I^=argmaxIP(I∣O,λ) 。也就是在观测变量 O 和
λ
\lambda
λ 的情况下使隐变量序列
I
I
I 出现的概率最大。而这个问题大致被分为预测和滤波。
预测问题为: P ( i t + 1 ∣ o 1 , ⋯ , o t ) P\left(i_{t+1} | o_{1}, \cdots, o_{t}\right) P(it+1∣o1,⋯,ot); 也就是在已知当前观测变量的情况下预测下一个状态,也就是 Viterbi 算法。
滤波问题为: P ( i t ∣ o 1 , ⋯ , o t ) P\left(i_{t} | o_{1}, \cdots, o_{t}\right) P(it∣o1,⋯,ot); 也就是求 t t t 时刻的隐变量。即Kalman or Particle Filter
Hidden Markov Model,可以被我们总结成一个模型 λ = ( π , A , B ) \lambda=(\pi, \mathcal{A}, \mathcal{B}) λ=(π,A,B), 两个假设,三个问题。而其中我们关注得最多的就是 Decoding 的问题。
1.3 什么样的问题需要HMM模型
首先我们来看看什么样的问题解决可以用HMM模型。使用HMM模型时我们的问题一般有这两个特征:
- 我们的问题是基于序列的,比如时间序列,或者状态序列。
- 我们的问题中有两类数据,一类序列数据是可以观测到的,即观测序列;而另一类数据是不能观察到的,即隐藏状态序列,简称状态序列。
有了这两个特征,那么这个问题一般可以用HMM模型来尝试解决。这样的问题在实际生活中是很多的。比如:我现在在打字写博客,我在键盘上敲出来的一系列字符就是观测序列,而我实际想写的一段话就是隐藏序列,输入法的任务就是从敲入的一系列字符尽可能的猜测我要写的一段话,并把最可能的词语放在最前面让我选择,这就可以看做一个HMM模型了。再举一个,我在和你说话,我发出的一串连续的声音就是观测序列,而我实际要表达的一段话就是状态序列,你大脑的任务,就是从这一串连续的声音中判断出我最可能要表达的话的内容。
从这些例子中,我们可以发现,HMM模型可以无处不在。但是上面的描述还不精确,下面我们用精确的数学符号来表述我们的HMM模型。
2 Evaluation

Evaluation 的问题可以被我们描述为:给定一个
λ
\lambda
λ,如何求得
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ)。也就是在给定模型
λ
\lambda
λ 的情况下,求某个观测序列出现的概率。
2.1 模型求解
对于
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ) 我们利用概率的基础知识进行化简可以得到:
P
(
O
∣
λ
)
=
∑
I
P
(
O
,
I
∣
λ
)
=
∑
I
P
(
O
∣
I
,
λ
)
P
(
I
∣
λ
)
P(O | \lambda)=\sum_{I} P(O, I | \lambda)=\sum_{I} P(O | I, \lambda) P(I | \lambda)
P(O∣λ)=I∑P(O,I∣λ)=I∑P(O∣I,λ)P(I∣λ)其中
∑
I
\sum_I
∑I 表示所有可能出现的隐状态序列 ;
∑
I
P
(
O
∣
I
,
λ
)
\sum_{I} P(O | I, \lambda)
∑IP(O∣I,λ) 表示在某个隐状态下,产生某个观测序列的概率;
P
(
I
∣
λ
)
P(I|\lambda)
P(I∣λ) 表示某个隐状态出现的概率。
那么:
P
(
I
∣
λ
)
=
P
(
i
1
,
⋯
,
i
T
∣
λ
)
=
P
(
i
T
∣
i
1
,
⋯
,
i
T
−
1
,
λ
)
⋅
P
(
i
1
,
⋯
,
i
T
−
1
∣
λ
)
\begin{aligned} P(I | \lambda) &=P\left(i_{1}, \cdots, i_{T} | \lambda\right) \\ &=P\left(i_{T} | i_{1}, \cdots, i_{T-1}, \lambda\right) \cdot P\left(i_{1}, \cdots, i_{T-1} | \lambda\right) \end{aligned}
P(I∣λ)=P(i1,⋯,iT∣λ)=P(iT∣i1,⋯,iT−1,λ)⋅P(i1,⋯,iT−1∣λ)
根据 Hidden Markov Model 两个假设中的,齐次马尔可夫假设,我们可以得到:
P
(
i
T
∣
i
1
,
⋯
,
i
T
−
1
,
λ
)
=
P
(
i
T
∣
i
T
−
1
)
=
a
i
T
−
1
,
i
T
P\left(i_{T} | i_{1}, \cdots, i_{T-1}, \lambda\right)=P\left(i_{T} | i_{T-1}\right)=a_{i_{T-1}, i_{T}}
P(iT∣i1,⋯,iT−1,λ)=P(iT∣iT−1)=aiT−1,iT。 后面按照一样的思路进行迭代就可以了。那么我们继续对上式进行化简可以得到:
P
(
i
T
∣
i
1
,
⋯
,
i
T
−
1
,
λ
)
⋅
P
(
i
1
,
⋯
,
i
T
−
1
∣
λ
)
=
P
(
i
T
∣
i
T
−
1
)
⋅
P
(
i
1
,
⋯
,
i
T
−
1
∣
λ
)
=
a
i
T
−
1
,
i
T
⋅
a
i
T
−
2
,
i
T
−
1
⋯
a
i
1
,
i
2
⋅
π
(
a
i
1
)
=
π
(
a
i
1
)
∏
t
=
2
T
a
i
i
−
1
,
i
t
\begin{aligned} P\left(i_{T} | i_{1}, \cdots, i_{T-1}, \lambda\right) \cdot P\left(i_{1}, \cdots, i_{T-1} | \lambda\right) &=P\left(i_{T} | i_{T-1}\right) \cdot P\left(i_{1}, \cdots, i_{T-1} | \lambda\right) \\ &=a_{i_{T-1}, i_{T}} \cdot a_{i_{T-2}, i_{T-1}} \cdots a_{i_{1}, i_{2}} \cdot \pi\left(a_{i_{1}}\right) \\ &=\pi\left(a_{i_{1}}\right) \prod_{t=2}^{T} a_{i_{i-1}, i_{t}} \end{aligned}
P(iT∣i1,⋯,iT−1,λ)⋅P(i1,⋯,iT−1∣λ)=P(iT∣iT−1)⋅P(i1,⋯,iT−1∣λ)=aiT−1,iT⋅aiT−2,iT−1⋯ai1,i2⋅π(ai1)=π(ai1)t=2∏Taii−1,it然后,运用观察独立假设,我们可以知道:
P
(
O
∣
I
,
λ
)
=
P
(
o
1
,
o
2
,
⋯
,
o
T
∣
I
,
λ
)
=
∏
t
=
1
T
P
(
o
t
∣
I
,
λ
)
=
∏
t
=
1
T
b
i
t
(
o
t
)
\begin{aligned} P(O | I, \lambda) &=P\left(o_{1}, o_{2}, \cdots, o_{T} | I, \lambda\right) \\ &=\prod_{t=1}^{T} P\left(o_{t} | I, \lambda\right) \\ &=\prod_{t=1}^{T} b_{i_{t}}\left(o_{t}\right) \end{aligned}
P(O∣I,λ)=P(o1,o2,⋯,oT∣I,λ)=t=1∏TP(ot∣I,λ)=t=1∏Tbit(ot)
那么,结合公式 (2-5),我们可以得到:
P
(
O
∣
λ
)
=
∑
I
π
(
a
i
1
)
∏
t
=
2
T
a
i
t
−
1
,
i
t
∏
t
=
1
T
b
i
t
(
o
t
)
=
∑
i
1
⋅
∑
i
2
⋯
∑
i
T
π
(
a
i
1
)
∏
t
=
2
T
a
i
t
−
1
,
i
t
∏
t
=
1
T
b
i
t
(
o
t
)
\begin{aligned} P(O | \lambda) &=\sum_{I} \pi\left(a_{i_{1}}\right) \prod_{t=2}^{T} a_{i_{t-1}, i_{t}} \prod_{t=1}^{T} b_{i_{t}}\left(o_{t}\right) \\ &=\sum_{i_{1}} \cdot \sum_{i_{2}} \cdots \sum_{i_{T}} \pi\left(a_{i_{1}}\right) \prod_{t=2}^{T} a_{i_{t-1}, i_{t}} \prod_{t=1}^{T} b_{i_{t}}\left(o_{t}\right) \end{aligned}
P(O∣λ)=I∑π(ai1)t=2∏Tait−1,itt=1∏Tbit(ot)=i1∑⋅i2∑⋯iT∑π(ai1)t=2∏Tait−1,itt=1∏Tbit(ot)因为一共有
T
T
T 个状态,每个状态有
N
N
N 种可能,所以算法复杂度为
O
(
N
T
)
O\left(N^{T}\right)
O(NT)。 题然这样直接求太困难了,我们就需要另外想办法。
2.2 Forward Algorithm
⽤前向算法来解决复杂度⼤的问题。下面,我们首先展示一下Hidden Markov Model 的拓扑结构图:

我们记,
α
t
(
i
)
=
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
∣
λ
)
\alpha_{t}(i)=P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i} | \lambda\right)
αt(i)=P(o1,⋯,ot,it=qi∣λ), 这个公式表示的是在之前所有的观测变量的前提下求出当前时刻的隐变量的概率。那么:
P
(
O
∣
λ
)
=
∑
i
=
1
N
P
(
O
,
i
t
=
q
i
∣
λ
)
=
∑
i
=
1
N
α
t
(
i
)
P(O | \lambda)=\sum_{i=1}^{N} P\left(O, i_{t}=q_{i} | \lambda\right)=\sum_{i=1}^{N} \alpha_{t}(i)
P(O∣λ)=i=1∑NP(O,it=qi∣λ)=i=1∑Nαt(i)其中,
∑
i
=
1
N
\sum_{i=1}^{N}
∑i=1N 表示对所有可能出现的隐状态情形求和,而
α
t
(
i
)
\alpha_{t}(i)
αt(i) 表示对所有可能出现的隐状态情形。我们的想法自然就是寻找
α
t
(
i
)
\alpha_{t}(i)
αt(i) 和
α
t
(
i
+
1
)
\alpha_{t}(i+1)
αt(i+1) 之间的关系,这样通过递推,我们就可以得到整个观测序列出现的概率。
那么,下面我们来进行推导:
α
t
(
i
+
1
)
=
P
(
o
1
,
⋯
,
o
t
,
o
t
+
1
,
i
t
+
1
=
q
j
∣
λ
)
\alpha_{t}(i+1)=P\left(o_{1}, \cdots, o_{t}, o_{t+1}, i_{t+1}=q_{j} | \lambda\right)
αt(i+1)=P(o1,⋯,ot,ot+1,it+1=qj∣λ)因为
α
t
(
i
)
\alpha_{t}(i)
αt(i) 里面有
i
t
=
q
j
i_{t}=q_{j}
it=qj, 我们就要想办法把
i
t
i_{t}
it 给塞进去,所以:
α
t
(
i
+
1
)
=
P
(
o
1
,
⋯
,
o
t
,
o
t
+
1
,
i
t
+
1
=
q
j
∣
λ
)
=
∑
i
=
1
N
P
(
o
1
,
⋯
,
o
t
,
o
t
+
1
,
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
λ
)
=
∑
i
=
1
N
P
(
o
t
+
1
∣
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
,
λ
)
⋅
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
λ
)
\begin{aligned} \alpha_{t}(i+1) &=P\left(o_{1}, \cdots, o_{t}, o_{t+1}, i_{t+1}=q_{j} | \lambda\right) \\ &=\sum_{i=1}^{N} P\left(o_{1}, \cdots, o_{t}, o_{t+1}, i_{t}=q_{i}, i_{t+1}=q_{j} | \lambda\right) \\ &=\sum_{i=1}^{N} P\left(o_{t+1} | o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j}, \lambda\right) \cdot P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j} | \lambda\right) \end{aligned}
αt(i+1)=P(o1,⋯,ot,ot+1,it+1=qj∣λ)=i=1∑NP(o1,⋯,ot,ot+1,it=qi,it+1=qj∣λ)=i=1∑NP(ot+1∣o1,⋯,ot,it=qi,it+1=qj,λ)⋅P(o1,⋯,ot,it=qi,it+1=qj∣λ)又根据观测独立性假设, 我们可以很显然的得到
P
(
o
t
+
1
∣
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
,
λ
)
=
P
(
o
t
+
1
∣
i
t
+
1
=
q
j
)
P\left(o_{t+1} | o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j}, \lambda\right)=P\left(o_{t+1} | i_{t+1}=q_{j}\right)
P(ot+1∣o1,⋯,ot,it=qi,it+1=qj,λ)=P(ot+1∣it+1=qj) 所以:
α
t
(
i
+
1
)
=
∑
i
=
1
N
P
(
o
t
+
1
∣
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
,
λ
)
⋅
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
λ
)
=
∑
i
=
1
N
P
(
o
t
+
1
∣
i
t
+
1
=
q
j
)
⋅
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
λ
)
\begin{aligned} \alpha_{t}(i+1) &=\sum_{i=1}^{N} P\left(o_{t+1} | o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j}, \lambda\right) \cdot P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j} | \lambda\right) \\ &=\sum_{i=1}^{N} P\left(o_{t+1} | i_{t+1}=q_{j}\right) \cdot P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j} | \lambda\right) \end{aligned}
αt(i+1)=i=1∑NP(ot+1∣o1,⋯,ot,it=qi,it+1=qj,λ)⋅P(o1,⋯,ot,it=qi,it+1=qj∣λ)=i=1∑NP(ot+1∣it+1=qj)⋅P(o1,⋯,ot,it=qi,it+1=qj∣λ)
看到这个化简后的公式,我们关注一下和
α
t
(
i
)
\alpha_{t}(i)
αt(i) 相比,好像还多了一项
i
t
+
1
=
q
j
i_{t+1}=q_{j}
it+1=qj, 我们下一步的工作就是消去它。所以:
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
i
t
+
1
=
q
j
∣
λ
)
=
P
(
i
t
+
1
=
q
j
∣
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
λ
)
⋅
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
∣
λ
)
P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i}, i_{t+1}=q_{j} | \lambda\right)=P\left(i_{t+1}=q_{j} | o_{1}, \cdots, o_{t}, i_{t}=q_{i}, \lambda\right) \cdot P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i} | \lambda\right)
P(o1,⋯,ot,it=qi,it+1=qj∣λ)=P(it+1=qj∣o1,⋯,ot,it=qi,λ)⋅P(o1,⋯,ot,it=qi∣λ)
根据齐次马尔可夫性质,我们可以得到
P
(
i
t
+
1
=
q
j
∣
o
1
,
⋯
,
o
t
,
i
t
=
q
i
,
λ
)
=
P
(
i
t
+
1
=
q
j
∣
i
t
=
q
i
)
P\left(i_{t+1}=q_{j} | o_{1}, \cdots, o_{t}, i_{t}=q_{i}, \lambda\right)=P\left(i_{t+1}=q_{j}|i_{t}=q_{i}\right)
P(it+1=qj∣o1,⋯,ot,it=qi,λ)=P(it+1=qj∣it=qi)
所以根据以上的推导,我们可以得到:
α
t
+
1
(
j
)
=
∑
i
=
1
N
P
(
o
t
+
1
∣
i
t
+
1
=
q
j
)
⋅
P
(
i
t
+
1
=
q
j
∣
i
t
=
q
i
)
⋅
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
∣
λ
)
=
∑
i
=
1
N
b
j
(
o
t
+
1
)
⋅
a
i
j
⋅
α
t
(
i
)
\begin{aligned} \alpha_{t+1}(j) &=\sum_{i=1}^{N} P\left(o_{t+1} | i_{t+1}=q_{j}\right) \cdot P\left(i_{t+1}=q_{j} | i_{t}=q_{i}\right) \cdot P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i} | \lambda\right) \\ &=\sum_{i=1}^{N} b_{j}\left(o_{t+1}\right) \cdot a_{i j} \cdot \alpha_{t}(i) \end{aligned}
αt+1(j)=i=1∑NP(ot+1∣it+1=qj)⋅P(it+1=qj∣it=qi)⋅P(o1,⋯,ot,it=qi∣λ)=i=1∑Nbj(ot+1)⋅aij⋅αt(i)经过上述的推导,我们就成功的得到了
α
t
+
1
(
j
)
\alpha_{t+1}(j)
αt+1(j) 和
α
t
(
i
)
\alpha_{t}(i)
αt(i) 之间的关系。通过这个递推关系,就可以遍历整个 Markov Model 了。这个公式是什么意思呢?它可以被我们表达为,所有可能出现的隐变量状态乘以转移到状态
j
j
j 的概率,乘以根据隐变量
i
t
+
1
i_{t+1}
it+1 观察到
o
t
+
1
o_{t+1}
ot+1 的概率,乘上根据上一个隐状态观察到的观察变量的序列的概率。 我们可以用一个图来进行表示:

其实读神经网络了解的同学就会发现,这实际上和前向传播神经网络非常的像,实际上就是状态的值乘以权重。也就是对于上一个隐状态的不同取值分别计算概率之后再求和。这样每次计算,有隐状态的状态空间数为N,序列的长度为T,那么总的时间复杂度为
O
(
T
N
2
)
O(TN^2)
O(TN2) 。
时间复杂度是怎么算出来的?
算法小结

2.3 Backward Algorithm
后向概率的推导实际上比前向概率的理解要难一些,前向算法实际上是一个联合概率,而后向算法则是一个条件概率,所以后向的概率实际上比前向难求很多。

我们设
β
t
(
i
)
=
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
=
q
i
,
λ
)
\beta_{t}(i)=P\left(o_{t+1}, \cdots, o_{T} | i_{t}=q_{i}, \lambda\right)
βt(i)=P(ot+1,⋯,oT∣it=qi,λ), 以此类推 ,
β
t
(
1
)
=
P
(
o
2
,
⋯
,
o
T
∣
i
1
=
q
i
,
λ
)
\beta_{t}(1)=P\left(o_{2}, \cdots, o_{T} | i_{1}=q_{i}, \lambda\right)
βt(1)=P(o2,⋯,oT∣i1=qi,λ) 。我们的目标是计算
P
(
O
∣
λ
)
P(O | \lambda)
P(O∣λ) 的概率,我们首先来推导一下这个公式:
P
(
O
∣
λ
)
=
P
(
o
1
,
o
2
,
⋯
,
o
N
∣
λ
)
=
∑
i
=
1
N
P
(
o
1
,
o
2
,
⋯
,
o
N
,
i
1
=
q
i
∣
λ
)
=
∑
i
=
1
N
P
(
o
1
,
o
2
,
⋯
,
o
N
∣
i
1
=
q
i
,
λ
)
P
(
i
1
=
q
i
∣
λ
)
=
∑
i
=
1
N
P
(
o
1
∣
o
2
,
⋯
,
o
N
,
i
1
=
q
i
,
λ
)
⋅
P
(
o
2
,
⋯
,
N
,
i
1
=
q
i
∣
λ
)
⋅
π
i
=
∑
i
=
1
N
P
(
o
1
∣
i
1
=
q
i
,
λ
)
⋅
β
1
(
i
)
⋅
π
i
=
∑
i
=
1
N
b
i
(
o
1
)
⋅
π
i
⋅
β
1
(
i
)
\begin{aligned} P(O | \lambda) &=P\left(o_{1}, o_{2}, \cdots, o_{N} | \lambda \right) \\ &=\sum_{i=1}^{N} P\left(o_{1}, o_{2}, \cdots, o_{N}, i_{1}=q_{i} | \lambda\right) \\ &=\sum_{i=1}^{N} P\left(o_{1}, o_{2}, \cdots, o_{N} | i_{1}=q_{i}, \lambda\right) P\left(i_{1}=q_{i} | \lambda\right) \\ &=\sum_{i=1}^{N} P\left(o_{1} | o_{2}, \cdots, o_{N}, i_{1}=q_{i}, \lambda\right) \cdot P\left(o_{2}, \cdots,_{N}, i_{1}=q_{i} | \lambda\right) \cdot \pi_{i} \\ &=\sum_{i=1}^{N} P\left(o_{1} | i_{1}=q_{i}, \lambda\right) \cdot \beta_{1}(i) \cdot \pi_{i} \\ &=\sum_{i=1}^{N} b_{i}\left(o_{1}\right) \cdot \pi_{i} \cdot \beta_{1}(i) \end{aligned}
P(O∣λ)=P(o1,o2,⋯,oN∣λ)=i=1∑NP(o1,o2,⋯,oN,i1=qi∣λ)=i=1∑NP(o1,o2,⋯,oN∣i1=qi,λ)P(i1=qi∣λ)=i=1∑NP(o1∣o2,⋯,oN,i1=qi,λ)⋅P(o2,⋯,N,i1=qi∣λ)⋅πi=i=1∑NP(o1∣i1=qi,λ)⋅β1(i)⋅πi=i=1∑Nbi(o1)⋅πi⋅β1(i)
现在我们已经成功的找到了
P
(
O
∣
λ
)
P(O|\lambda)
P(O∣λ) 和第一个状态之间的关系。其中,
π
i
\pi_{i}
πi 为某个状态的初始状态的概率,
b
i
(
o
1
)
b_{i}\left(o_{1}\right)
bi(o1)表示为第
i
i
i 个隐变量产生第 1 个观测变量的概率,
β
1
(
i
)
\beta_{1}(i)
β1(i) 表示为第一个观测状态确定以后生成后面观测状态序列的概率。结构图如下所示:

那么,我们下一步要通过递推,找到最后一个状态与第一个状态之间的关系。下面做如下的推导:
β
t
(
i
)
=
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
=
q
i
)
=
∑
j
=
1
N
P
(
o
t
+
1
,
⋯
,
o
T
,
i
t
+
1
=
q
j
∣
i
t
=
q
i
)
=
∑
j
=
1
N
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
+
1
=
q
j
,
i
t
=
q
i
)
⋅
P
(
i
t
+
1
=
q
j
∣
i
t
=
q
i
)
⏟
a
i
j
=
∑
j
=
1
N
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
+
1
=
q
j
)
⋅
a
i
j
=
∑
j
=
1
N
P
(
o
t
+
1
∣
o
t
+
2
⋯
,
o
T
,
i
t
+
1
=
q
j
)
⋅
P
(
o
t
+
2
⋯
,
o
T
∣
i
t
+
1
)
⏟
β
t
+
1
(
j
)
⋅
a
i
j
=
∑
j
=
1
N
P
(
o
t
+
1
∣
i
t
+
1
=
q
j
)
⋅
β
t
+
1
(
j
)
⋅
a
i
j
=
∑
j
=
1
N
b
j
(
o
t
+
1
)
⋅
β
t
+
1
(
j
)
⋅
a
i
j
\begin{aligned} \beta_{t}(i) &=P\left(o_{t+1}, \cdots, o_{T} | i_{t}=q_{i}\right) \\ &=\sum_{j=1}^{N} P\left(o_{t+1}, \cdots, o_{T}, i_{t+1}=q_{j} | i_{t}=q_{i}\right) \\ &=\sum_{j=1}^{N} P\left(o_{t+1}, \cdots, o_{T} | i_{t+1}=q_{j}, i_{t}=q_{i}\right) \cdot \underbrace{P\left(i_{t+1}=q_{j} | i_{t}=q_{i}\right)}_{a_{i j}} \\ &=\sum_{j=1}^{N} P\left(o_{t+1}, \cdots, o_{T} | i_{t+1}=q_{j}\right) \cdot a_{i j} \\ &=\sum_{j=1}^{N} P\left(o_{t+1} | o_{t+2} \cdots, o_{T}, i_{t+1}=q_{j}\right) \cdot \underbrace{P\left(o_{t+2} \cdots, o_{T} | i_{t+1}\right)}_{\beta_{t+1}(j)} \cdot a_{i j} \\ &=\sum_{j=1}^{N} P\left(o_{t+1} | i_{t+1}=q_{j}\right) \cdot \beta_{t+1}(j) \cdot a_{i j} \\ &=\sum_{j=1}^{N} b_{j}\left(o_{t+1}\right) \cdot \beta_{t+1}(j) \cdot a_{i j} \end{aligned}
βt(i)=P(ot+1,⋯,oT∣it=qi)=j=1∑NP(ot+1,⋯,oT,it+1=qj∣it=qi)=j=1∑NP(ot+1,⋯,oT∣it+1=qj,it=qi)⋅aij
P(it+1=qj∣it=qi)=j=1∑NP(ot+1,⋯,oT∣it+1=qj)⋅aij=j=1∑NP(ot+1∣ot+2⋯,oT,it+1=qj)⋅βt+1(j)
P(ot+2⋯,oT∣it+1)⋅aij=j=1∑NP(ot+1∣it+1=qj)⋅βt+1(j)⋅aij=j=1∑Nbj(ot+1)⋅βt+1(j)⋅aij
其中第三行到第四行的推导
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
+
1
=
q
j
,
i
t
=
q
i
)
=
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
+
1
=
q
j
)
P\left(o_{t+1}, \cdots, o_{T} | i_{t+1}=q_{j}, i_{t}=q_{i}\right)=P\left(o_{t+1}, \cdots, o_{T} | i_{t+1}=q_{j}\right)
P(ot+1,⋯,oT∣it+1=qj,it=qi)=P(ot+1,⋯,oT∣it+1=qj) 使用的马尔可夫链的性质,每一个状态都是后面状态的充分统计量,与之前的状态无关。通过这样的迭代从后往前推,我们就可以得到 β
β
i
(
1
)
\beta_{i}(1)
βi(1) 的概率,从而推断出
P
(
O
∣
λ
)
P(O | \lambda)
P(O∣λ) 。整体的推断流程图如下图所示:

所以,可以通过求
β
t
(
i
)
\beta_{t}(i)
βt(i) 进而求得
P
(
O
∣
λ
)
P(O | \lambda)
P(O∣λ)
后推导没看懂?
3 Learning
首先我们回顾一下,上一节讲的有关 Evaluation 的问题。Evaluation 可以被我们描述为在已知模型
λ
\lambda
λ 的情况下,求观察序列的概率。也就是:
P
(
O
∣
λ
)
=
∑
I
P
(
O
,
I
∣
λ
)
=
∑
i
1
⋯
∑
i
T
π
i
i
∏
t
=
2
T
a
i
i
−
1
,
i
i
∏
t
=
1
T
b
i
1
(
o
t
)
P(O | \lambda)=\sum_{I} P(O, I | \lambda)=\sum_{i_{1}} \cdots \sum_{i_{T}} \pi_{i_{i}} \prod_{t=2}^{T} a_{i_{i-1}, i_{i}} \prod_{t=1}^{T} b_{i_{1}}\left(o_{t}\right)
P(O∣λ)=I∑P(O,I∣λ)=i1∑⋯iT∑πiit=2∏Taii−1,iit=1∏Tbi1(ot)此时的算法复杂度为
O
(
N
T
)
O(N^{T})
O(NT) 。算法的复杂度太高了,所以,就有了后来的 forward 和 backward 算法。那么就有如下定义:
α
t
(
i
)
=
P
(
o
1
,
⋯
,
o
t
,
i
t
=
q
i
∣
λ
)
β
t
(
i
)
=
P
(
o
t
+
1
,
⋯
,
o
T
∣
i
t
=
q
i
,
λ
)
α
T
(
i
)
=
P
(
O
,
i
T
=
q
i
)
→
P
(
O
∣
λ
)
=
∑
i
=
1
N
α
T
(
i
)
β
1
(
i
)
=
P
(
o
2
,
⋯
,
o
T
∣
i
1
=
q
i
,
λ
)
→
P
(
O
∣
λ
)
=
∑
i
=
1
N
π
i
b
i
(
o
1
)
β
1
(
i
)
\begin{array}{l} \alpha_{t}(i)=P\left(o_{1}, \cdots, o_{t}, i_{t}=q_{i} | \lambda\right) \\ \\ \beta_{t}(i)=P\left(o_{t+1}, \cdots, o_{T} | i_{t}=q_{i}, \lambda\right) \\ \\ \alpha_{T}(i)=P\left(O, i_{T}=q_{i}\right) \rightarrow P(O | \lambda)=\sum_{i=1}^{N} \alpha_{T}(i) \\ \\ \beta_{1}(i)=P\left(o_{2}, \cdots, o_{T} | i_{1}=q_{i}, \lambda\right) \rightarrow P(O | \lambda)=\sum_{i=1}^{N} \pi_{i} b_{i}\left(o_{1}\right) \beta_{1}(i) \end{array}
αt(i)=P(o1,⋯,ot,it=qi∣λ)βt(i)=P(ot+1,⋯,oT∣it=qi,λ)αT(i)=P(O,iT=qi)→P(O∣λ)=∑i=1NαT(i)β1(i)=P(o2,⋯,oT∣i1=qi,λ)→P(O∣λ)=∑i=1Nπibi(o1)β1(i)
而使用 forward 和 backward 算法的复杂度为
O
(
T
N
2
)
O(TN^{2})
O(TN2) 。这一节,我们就要分析 Learning 的部分, Learning 就是要在已知观测数据的情况下求参数
λ
\lambda
λ, 也就是:
λ
M
L
E
=
arg
max
λ
P
(
O
∣
λ
)
\lambda_{M L E}=\arg \max _{\lambda} P(O∣λ)
λMLE=argλmaxP(O∣λ)
3.1 Learning:已知 O O O,求 λ \lambda λ
问题描述:我们有D个观测序列
i
1
,
i
2
,
⋯
,
i
D
i_1,i_2,\cdots,i_D
i1,i2,⋯,iD,每个序列长度是T,需要求出初始分布
π
\pi
π,状态转移矩阵A,和发射矩阵B。
Baum-Welch算法是使用EM方法解决这个问题的算法。
我们需要计算的目标是:
λ
M
L
E
=
arg
max
λ
P
(
O
∣
λ
)
\lambda_{M L E}=\arg \max _{\lambda} P(O | \lambda)
λMLE=argλmaxP(O∣λ)又因为:
P
(
O
∣
λ
)
=
∑
i
1
⋯
∑
i
T
π
i
1
∏
t
=
2
T
a
i
t
−
1
,
i
t
∏
t
=
1
T
b
i
1
(
o
t
)
P(O | \lambda)=\sum_{i_{1}} \cdots \sum_{i_{T}} \pi_{i_{1}} \prod_{t=2}^{T} a_{i_{t-1}, i_{t}} \prod_{t=1}^{T} b_{i_{1}}\left(o_{t}\right)
P(O∣λ)=i1∑⋯iT∑πi1t=2∏Tait−1,itt=1∏Tbi1(ot)对这个方程的
λ
\lambda
λ 求偏导,实在是太难算了。所以,我们考虑使用 EM 算法。我们先来同顾一下 EM 算法:
θ
(
t
+
1
)
=
arg
max
θ
∫
z
log
P
(
X
,
Z
∣
θ
)
⋅
P
(
Z
∣
X
,
θ
(
t
)
)
d
Z
\theta^{(t+1)}=\arg \max _{\theta} \int_{z} \log P(X, Z | \theta) \cdot P\left(Z | X, \theta^{(t)}\right) d Z
θ(t+1)=argθmax∫zlogP(X,Z∣θ)⋅P(Z∣X,θ(t))dZ而
X
→
O
X \rightarrow O
X→O 为观测变量 ;
Z
→
I
Z \rightarrow I
Z→I 为隐变量,其中
I
I
I 为离散变量;
θ
→
λ
\theta \rightarrow \lambda
θ→λ 为参数。那么,我们可以将公式改写为:
λ
(
t
+
1
)
=
arg
max
λ
∑
I
log
P
(
O
,
I
∣
λ
)
⋅
P
(
I
∣
O
,
λ
(
t
)
)
\lambda^{(t+1)}=\arg \max _{\lambda} \sum_{I} \log P(O, I | \lambda) \cdot P\left(I | O, \lambda^{(t)}\right)
λ(t+1)=argλmaxI∑logP(O,I∣λ)⋅P(I∣O,λ(t))这里的
λ
(
t
)
\lambda^{(t)}
λ(t) 是一个常数,而
P
(
I
∣
O
,
λ
(
t
)
)
=
P
(
I
,
O
∣
λ
(
t
)
)
P
(
O
∣
λ
(
t
)
)
P\left(I | O, \lambda^{(t)}\right)=\frac{P\left(I, O | \lambda^{(t)}\right)}{P\left(O | \lambda^{(t)}\right)}
P(I∣O,λ(t))=P(O∣λ(t))P(I,O∣λ(t))并且
P
(
O
∣
λ
(
t
)
)
P\left(O | \lambda^{(t)}\right)
P(O∣λ(t)) 中
λ
(
t
)
\lambda^{(t)}
λ(t) 是常数,所以这项是个定量,与
λ
\lambda
λ 无关, 所以
P
(
I
,
O
∣
λ
(
t
)
)
P
(
O
∣
λ
(
t
)
)
∝
P
(
I
,
O
∣
λ
(
t
)
)
\frac{P\left(I, O | \lambda^{(t)}\right)}{P(O | \lambda(t))} \propto P\left(I, O | \lambda^{(t)}\right)
P(O∣λ(t))P(I,O∣λ(t))∝P(I,O∣λ(t)) 。所以,我们可以将
λ
(
t
+
1
)
\lambda^{(t+1)}
λ(t+1) 改写为:
λ
(
t
+
1
)
=
arg
max
λ
∑
I
log
P
(
O
,
I
∣
λ
)
⋅
P
(
I
,
O
∣
λ
(
t
)
)
\lambda^{(t+1)}=\arg \max _{\lambda} \sum_{I} \log P(O, I | \lambda) \cdot P\left(I, O | \lambda^{(t)}\right)
λ(t+1)=argλmaxI∑logP(O,I∣λ)⋅P(I,O∣λ(t))这样做有什么目的呢?很显然这样可以把
log
P
(
O
,
I
∣
λ
)
\log P(O, I | \lambda)
logP(O,I∣λ) 和
P
(
I
,
O
∣
λ
(
t
)
)
P\left(I, O | \lambda^{(t)}\right)
P(I,O∣λ(t)) 变成一种形式。其中,
λ
(
t
)
=
(
π
(
t
)
,
A
(
t
)
,
B
(
t
)
)
\lambda^{(t)}=\left(\pi^{(t)}, \mathcal{A}^{(t)}, \mathcal{B}^{(t)}\right)
λ(t)=(π(t),A(t),B(t)) , 而
λ
(
t
+
1
)
=
(
π
(
t
+
1
)
,
A
(
t
+
1
)
,
B
(
t
+
1
)
)
\lambda^{(t+1)}=\left(\pi^{(t+1)}, \mathcal{A}^{(t+1)}, \mathcal{B}^{(t+1)}\right)
λ(t+1)=(π(t+1),A(t+1),B(t+1))
我们定义:
Q
(
λ
,
λ
(
t
)
)
=
∑
I
log
P
(
O
,
I
∣
λ
)
⋅
P
(
O
,
I
∣
λ
(
t
)
)
Q\left(\lambda, \lambda^{(t)}\right)=\sum_{I} \log P(O, I | \lambda) \cdot P\left(O, I | \lambda^{(t)}\right)
Q(λ,λ(t))=I∑logP(O,I∣λ)⋅P(O,I∣λ(t))而其中,
P
(
O
∣
λ
)
=
∑
i
1
⋯
∑
i
T
π
i
1
∏
t
=
2
T
a
i
i
−
1
,
i
t
∏
t
=
1
T
b
i
1
(
o
t
)
P(O | \lambda)=\sum_{i_{1}} \cdots \sum_{i_{T}} \pi_{i_{1}} \prod_{t=2}^{T} a_{i_{i-1}, i_{t}} \prod_{t=1}^{T} b_{i_{1}}\left(o_{t}\right)
P(O∣λ)=i1∑⋯iT∑πi1t=2∏Taii−1,itt=1∏Tbi1(ot)所以,
Q
(
λ
,
λ
(
t
)
)
=
∑
I
[
(
log
π
i
1
+
∑
t
=
2
T
log
a
i
i
−
1
,
i
t
+
∑
t
=
1
T
log
b
i
t
(
o
t
)
)
⋅
P
(
O
,
I
∣
λ
(
t
)
)
]
Q\left(\lambda, \lambda^{(t)}\right)=\sum_{I}\left[\left(\log \pi_{i_{1}}+\sum_{t=2}^{T} \log a_{i_{i-1}, i_{t}}+\sum_{t=1}^{T} \log b_{i_{t}}\left(o_{t}\right)\right) \cdot P\left(O, I | \lambda^{(t)}\right)\right]
Q(λ,λ(t))=I∑[(logπi1+t=2∑Tlogaii−1,it+t=1∑Tlogbit(ot))⋅P(O,I∣λ(t))]
3.2 求 π ( t + 1 ) \pi^{(t+1)} π(t+1)
这小节中我们以
π
(
t
+
1
)
\pi^{(t+1)}
π(t+1) 为例,在公式
Q
(
λ
,
λ
(
t
)
)
Q\left(\lambda, \lambda^{(t)}\right)
Q(λ,λ(t)) 中 ,
∑
t
=
2
T
log
a
i
l
−
1
,
i
c
\sum_{t=2}^{T} \log a_{i_{l-1}, i_{c}}
∑t=2Tlogail−1,ic 与
∑
t
=
1
T
log
b
i
i
(
o
t
)
\sum_{t=1}^{T} \log b_{i_{i}}\left(o_{t}\right)
∑t=1Tlogbii(ot) 与
π
\pi
π 无关,
所以,
π
(
t
+
1
)
=
arg
max
π
Q
(
λ
,
λ
(
t
)
)
=
arg
max
π
∑
I
[
log
π
i
1
⋅
P
(
O
,
I
∣
λ
(
t
)
)
]
=
arg
max
π
∑
i
1
⋯
∑
i
T
[
log
π
i
1
⋅
P
(
O
,
i
1
,
⋯
,
i
T
∣
λ
(
t
)
)
]
\begin{aligned} \pi^{(t+1)} &=\arg \max _{\pi} Q\left(\lambda, \lambda^{(t)}\right) \\ &=\arg \max _{\pi} \sum_{I}\left[\log \pi_{i_{1}} \cdot P\left(O, I | \lambda^{(t)}\right)\right] \\ &=\arg \max _{\pi} \sum_{i_{1}} \cdots \sum_{i_{T}}\left[\log \pi_{i_{1}} \cdot P\left(O, i_{1}, \cdots, i_{T} | \lambda^{(t)}\right)\right] \end{aligned}
π(t+1)=argπmaxQ(λ,λ(t))=argπmaxI∑[logπi1⋅P(O,I∣λ(t))]=argπmaxi1∑⋯iT∑[logπi1⋅P(O,i1,⋯,iT∣λ(t))]我们观察
{
i
2
,
⋯
,
i
T
}
\left\{i_{2}, \cdots, i_{T}\right\}
{i2,⋯,iT} 就可以知道,联合概率分布求和可以得到边缘概率。所以:
π
(
t
+
1
)
=
arg
max
π
∑
i
1
[
log
π
i
1
⋅
P
(
O
,
i
1
∣
λ
(
t
)
)
]
=
arg
max
π
∑
i
=
1
N
[
log
π
i
⋅
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
]
(
s.t.
∑
i
=
1
N
π
i
=
1
)
\begin{aligned} \pi^{(t+1)} &=\arg \max _{\pi} \sum_{i_{1}}\left[\log \pi_{i_{1}} \cdot P\left(O, i_{1} | \lambda^{(t)}\right)\right] \\ &=\arg \max _{\pi} \sum_{i=1}^{N}\left[\log \pi_{i} \cdot P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)\right] \quad\left(\text {s.t.} \sum_{i=1}^{N} \pi_{i}=1\right) \end{aligned}
π(t+1)=argπmaxi1∑[logπi1⋅P(O,i1∣λ(t))]=argπmaxi=1∑N[logπi⋅P(O,i1=qi∣λ(t))](s.t.i=1∑Nπi=1)
3.2.1 拉格朗日乘子法求解
根据拉格朗日乘子法,我们可以将损失函数写成:
L
(
π
,
η
)
=
∑
i
=
1
N
log
π
i
⋅
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
+
η
(
∑
i
=
1
N
π
i
−
1
)
\mathcal{L}(\pi, \eta)=\sum_{i=1}^{N} \log \pi_{i} \cdot P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)+\eta\left(\sum_{i=1}^{N} \pi_{i}-1\right)
L(π,η)=i=1∑Nlogπi⋅P(O,i1=qi∣λ(t))+η(i=1∑Nπi−1)使似然函数最大化,则是对损失函数
L
(
π
,
η
)
\mathcal{L}(\pi, \eta)
L(π,η) 求偏导,则为:
L
π
i
=
1
π
i
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
+
η
=
0
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
+
π
i
η
=
0
\begin{array}{l} \frac{\mathcal{L}}{\pi_{i}}=\frac{1}{\pi_{i}} P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)+\eta=0 \\ \\ P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)+\pi_{i} \eta=0 \end{array}
πiL=πi1P(O,i1=qi∣λ(t))+η=0P(O,i1=qi∣λ(t))+πiη=0又因为
∑
i
=
1
N
π
i
=
1
\sum_{i=1}^{N} \pi_{i}=1
∑i=1Nπi=1, 所以,我们将公式 (17) 进行求和,可以得到:
∑
i
=
1
N
(
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
+
π
i
η
)
=
0
⇒
P
(
O
∣
λ
(
t
)
)
+
η
=
0
\sum_{i=1}^{N} \left(P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)+\pi_{i} \eta\right)=0 \Rightarrow P\left(O | \lambda^{(t)}\right)+\eta=0
i=1∑N(P(O,i1=qi∣λ(t))+πiη)=0⇒P(O∣λ(t))+η=0所以,我们解得
η
=
−
P
(
O
∣
λ
(
t
)
)
\eta=-P\left(O | \lambda^{(t)}\right)
η=−P(O∣λ(t)), 由
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
+
π
i
η
=
0
P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)+\pi_{i} \eta=0
P(O,i1=qi∣λ(t))+πiη=0 从而推出:
π
i
(
t
+
1
)
=
P
(
O
,
i
1
=
q
i
∣
λ
(
t
)
)
P
(
O
∣
λ
(
t
)
)
\pi_{i}^{(t+1)}=\frac{P\left(O, i_{1}=q_{i} | \lambda^{(t)}\right)}{P\left(O | \lambda^{(t)}\right)}
πi(t+1)=P(O∣λ(t))P(O,i1=qi∣λ(t))进而,我们就可以推导出
π
(
t
+
1
)
=
(
π
1
(
t
+
1
)
,
π
2
(
t
+
1
)
,
⋯
,
π
N
(
t
+
1
)
)
\pi^{(t+1)}=\left(\pi_{1}^{(t+1)}, \pi_{2}^{(t+1)}, \cdots, \pi_{N}^{(t+1)} \right.)
π(t+1)=(π1(t+1),π2(t+1),⋯,πN(t+1)) 而
A
(
t
+
1
)
\mathcal{A}^{(t+1)}
A(t+1) 和
B
(
t
+
1
)
\mathcal{B}^{(t+1)}
B(t+1) 也都是同样的求法。这就是大名鼎鼎的 Baum Welch 算法,实际上思路和 EM 算法一致。不过在 Baum Welch 算法诞生之前,还没有系统的出现 EM 算法的归纳。所以,这个作者还是很厉害的。
3.3 求 A ( t + 1 ) A ^{(t+1)} A(t+1)

3.4 求 B ( t + 1 ) B ^{(t+1)} B(t+1)

4 Decoding:已知 O , λ O,\lambda O,λ,求 I I I
Vertibi算法的思想:Vertibi是一种动态规划算法,将序列 i 1 , i 2 , ⋯ , i T i_1,i_2,\cdots,i_T i1,i2,⋯,iT 看作是路径的选择,总共有 N T N^T NT 条路径,我们需要找出概率最大的路径。
具体的说,Decoding 问题可被我们描述为:
I
^
=
arg
max
I
P
(
I
∣
O
,
λ
)
\hat{I}=\arg \max _{I} P(I | O, \lambda)
I^=argImaxP(I∣O,λ)也就是在给定观察序列的情况下,寻找最大概率可能出现的隐概率状态序列。也有人说 Decoding 问题是预测问题,但是实际上这样说是并不合适的。预测问题应该是 ,
P
(
o
t
+
1
∣
o
1
,
⋯
,
o
t
)
P\left(o_{t+1} | o_{1}, \cdots, o_{t}\right)
P(ot+1∣o1,⋯,ot) 和
P
(
i
t
+
1
∣
o
1
,
⋯
,
o
t
)
P\left(i_{t+1} | o_{1}, \cdots, o_{t}\right)
P(it+1∣o1,⋯,ot) 这里的
P
(
i
1
,
⋯
,
i
t
∣
o
1
,
⋯
,
o
t
)
P\left(i_{1}, \cdots, i_{t} | o_{1}, \cdots, o_{t}\right)
P(i1,⋯,it∣o1,⋯,ot) 看成是预测问题显然是不合适的。
4.1 Decoding Problem
下面我们展示一下Hidden Markov Model 的拓扑模型:

这里实际上就是一个动态规划问题,这里的动态规划问题实际上就是最大概率问题,只不过将平时提到的最大距离问题等价于最大概率问题,理论上都是一样的。每个时刻都有 N 个状态,所有也就是从
N
T
N^T
NT 个可能的序列中找出概率最大的一个序列,实际上就是一个动态规划问题,如下图所示:

我们假设:
δ
t
(
i
)
=
max
i
1
,
⋯
,
i
t
−
1
P
(
o
1
,
⋯
,
o
t
,
i
1
,
⋯
,
i
t
−
1
,
i
t
=
q
i
)
\delta_{t}(i)=\max _{i_{1}, \cdots, i_{t-1}} P\left(o_{1}, \cdots, o_{t}, i_{1}, \cdots, i_{t-1}, i_{t}=q_{i}\right)
δt(i)=i1,⋯,it−1maxP(o1,⋯,ot,i1,⋯,it−1,it=qi)

这个等式是什么意思呢? 也就是当
t
t
t 个时刻是
q
i
q_{i}
qi, 前面
t
−
1
t-1
t−1 个随便走,只要可以到达
q
i
q_{i}
qi 这个状态就行,而从中选取概率最大的序列。我们下一步的目标就是在知道
δ
t
(
i
)
\delta_{t}(i)
δt(i) 的情况下如何求
δ
t
(
i
+
1
)
\delta_{t}(i+1)
δt(i+1) 那么这样就能通过递推来求得知道最后一个状态下概率最大的序列。
δ
t
(
i
+
1
)
\delta_{t}(i+1)
δt(i+1) 的求解方法如下所示:

所以,
δ
t
+
1
(
j
)
=
max
i
1
,
⋯
,
i
t
P
(
o
1
,
⋯
,
o
t
+
1
,
i
1
,
⋯
,
i
t
,
i
t
+
1
=
q
j
)
=
max
i
1
,
⋯
,
i
t
δ
t
(
i
)
⋅
a
i
j
⋅
b
j
(
o
t
+
1
)
\begin{aligned} \delta_{t+1}(j) &=\max _{i_{1}, \cdots, i_{t}} P\left(o_{1}, \cdots, o_{t+1}, i_{1}, \cdots, i_{t}, i_{t+1}=q_{j}\right) \\ &=\max _{i_{1}, \cdots, i_{t}} \delta_{t}(i) \cdot a_{i j} \cdot b_{j}\left(o_{t+1}\right) \end{aligned}
δt+1(j)=i1,⋯,itmaxP(o1,⋯,ot+1,i1,⋯,it,it+1=qj)=i1,⋯,itmaxδt(i)⋅aij⋅bj(ot+1)这就是 Viterbi 算法,但是这个算法最后求得的是一个值,没有办法求得路径,如果要想求得路径,我们需要引入一个变量:
φ
t
+
1
(
j
)
=
arg
max
1
≤
i
≤
N
δ
t
(
i
)
⋅
a
i
j
⋅
b
j
(
o
t
+
1
)
\varphi_{t+1}(j)=\arg \max _{1 \leq i \leq N} \delta_{t}(i) \cdot a_{i j} \cdot b_{j}\left(o_{t+1}\right)
φt+1(j)=arg1≤i≤Nmaxδt(i)⋅aij⋅bj(ot+1)这个函数用来干嘛的呢?他是来记录每一次迭代过程中经过的状态的 index。这样我们最终得到的
{
φ
1
,
φ
2
,
⋯
,
φ
T
}
\left\{\varphi_{1}, \varphi_{2}, \cdots, \varphi_{T}\right\}
{φ1,φ2,⋯,φT}, 就可以得到整个路径了。
5 小结
Hidden Markov Model 实际上是一个 Dynamic Model。我们以 Guassian Mixture Model (GMM)为例。对于一个观测状态,在隐变量状态给定的情况下,是符合一个 Gaussian Distribution,也就是
D
(
O
∣
i
1
)
∼
N
(
μ
,
Σ
)
D\left(O | i_{1}\right) \sim \mathcal{N}(\mu, \Sigma)
D(O∣i1)∼N(μ,Σ) 。如果加入了
time
\operatorname{time}
time 的因素就是 Hidden Markov Model,而其中
{
i
1
,
i
2
,
⋯
,
i
T
}
\left\{i_{1}, i_{2}, \cdots, i_{T}\right\}
{i1,i2,⋯,iT} 是离散的就行,这些我们在第一章的背景部分有过讨论。而观测变量
o
1
o_{1}
o1 是离散的还是连续的都不重要。

5.1 Hidden Markov| Model 简介
Hidden Markov Model,可以用一个模型,两个假设和是三个问题来描述。
- 一个模型就是指 λ = ( π , A , B ) \lambda=(\pi, \mathcal{A}, \mathcal{B}) λ=(π,A,B) 。其中, π \pi π: 指的是初始概率分布 ; A \mathcal{A} A: 指的是状态转移矩阵 ; B \mathcal{B} B: 指的是发射矩阵,也就是在已知隐变量的情况下,得到观测变量的概率分布。
- 两个假设:
- 齐次马尔可夫模型,马尔科夫性质中非常重要的一条。
- 观测独立假设,也就是观测变量只和当前的隐变量状态有关。
- 三个问题:
- Evaluation: P ( O ∣ λ ) P(O | \lambda) P(O∣λ), 也就是在在已知模型的情况下,求观测变量出现的概率。
- 2 Learning: λ ^ = arg max λ P ( O ∣ λ ) \hat{\lambda}=\arg \max _{\lambda} P(O | \lambda) λ^=argmaxλP(O∣λ), 在已知观测变量的情况下求解隐马尔可夫模型的参数。
- Decoding: P ( I ∣ O ) = P ( i 1 , ⋯ , i t ∣ o 1 , ⋯ , o t ) P(I | O)=P\left(i_{1}, \cdots, i_{t} | o_{1}, \cdots, o_{t}\right) P(I∣O)=P(i1,⋯,it∣o1,⋯,ot), 用公式的语言描述就是 I ^ = arg max I P ( I , O ∣ λ ) \hat{I}=\arg \max _{I} P(I, O | \lambda) I^=argmaxIP(I,O∣λ)
5.2 Dynamic Model
Dynamic Model 实际上就是一个State Space Model,通常我们可以将Dynamic Model 的问题分成两类。
- 第一类为Learning 问题,即为,参数 λ \lambda λ 是未知的,通过数据来知道参数是什么;
- 第二类就是Inference 问题,也就是在
λ
\lambda
λ 未知的情况下,推断后验概率。实际上,我们需要求的就是
P
(
Z
∣
X
)
P(Z|X)
P(Z∣X),其中
X
=
{
x
1
,
x
2
,
⋯
,
x
T
}
X = \left\{x_{1}, x_{2}, \cdots, x_{T}\right\}
X={x1,x2,⋯,xT} 数据之间不是i.i.d 的。
Inference 问题大概可以被分成:

5.3 整体框架

5.3.1 Learning
Learing 问题中 λ \lambda λ 是已知的, λ M L E = a r g m a x λ P ( X ∣ λ ) \lambda_{MLE} = arg max_\lambda P(X|\lambda) λMLE=argmaxλP(X∣λ)。我们采用的是Baum Welch Algorithm,算法思想上和EM 算法类似,实际上也是Forward-Backward 算法。
5.3.2 Inference
5.3.2.1 Decoding
这里前面已经做出过详细的描述了,这里就不再展开进行描述了,主要可以概括为:在已知观测数据序列的情况下,求得出现概率最大的隐变量序列, 被我们描述为:
Z
=
arg
max
z
P
(
z
1
,
⋯
,
z
t
∣
x
1
,
⋯
,
x
t
)
Z=\arg \max _{z} P\left(z_{1}, \cdots, z_{t} | x_{1}, \cdots, x_{t}\right)
Z=argmaxzP(z1,⋯,zt∣x1,⋯,xt)
我们使用的一种动态规划的算法,被称为 Viterbi Algorithm|。
5.3.2.2 Prob of Evidence
在还有大家应该见得比较多的 Prob of Evidence 问题,也就是: P ( X ∣ θ ) = P ( x 1 , ⋯ , x t ∣ θ ) P(X | \theta)=P\left(x_{1}, \cdots, x_{t} |\theta\right) P(X∣θ)=P(x1,⋯,xt∣θ) 。我们通俗的称之为证据分布,实际上就是我们前面讲到的 Evaluation 方法。也就是在已知参数的情况下, 求观测数据序列出现的概率,用公式描述即为: P ( X ∣ θ ) = P ( x 1 , x 2 , ⋯ , x t ∣ θ ) P(X | \theta)=P\left(x_{1}, x_{2}, \cdots, x_{t} | \theta\right) P(X∣θ)=P(x1,x2,⋯,xt∣θ)
5.3.2.3 Filtering
实际上是一个 Online-Learning 的过程,也就是如果不停的往模型里面喂数据,我们可以得到概率分布为:
P
(
z
t
∣
x
1
,
⋯
,
x
t
)
P\left(z_{t} | x_{1}, \cdots, x_{t}\right)
P(zt∣x1,⋯,xt) 。所以 Filtering 非常的适合与 online update。我们要求的这个就是隐变量的边缘后验分布。为什么叫滤波呢?这是由于我们求的后验是
P
(
z
t
∣
x
1
,
⋯
,
x
t
)
P\left(z_{t} | x_{1}, \cdots, x_{t}\right)
P(zt∣x1,⋯,xt), 运用到了大量的历史信息,比
P
(
z
t
∣
x
t
)
P\left(z_{t} | x_{t}\right)
P(zt∣xt) 的推断更加的精确,可以过滤掉更多的噪声,所以被我们称为“过滤”。求解过程如下所示:
P
(
z
t
∣
x
1
:
t
)
=
P
(
z
t
,
x
1
,
⋯
,
x
t
)
P
(
x
1
,
⋯
,
x
t
)
=
P
(
z
t
,
x
1
:
x
t
)
∑
z
t
P
(
z
t
,
x
1
:
x
t
)
∝
P
(
z
t
,
x
1
:
x
t
)
P\left(z_{t} | x_{1: t}\right)=\frac{P\left(z_{t}, x_{1}, \cdots, x_{t}\right)}{P\left(x_{1}, \cdots, x_{t}\right)}=\frac{P\left(z_{t}, x_{1}: x_{t}\right)}{\sum_{z_{t}} P\left(z_{t}, x_{1}: x_{t}\right)} \propto P\left(z_{t}, x_{1}: x_{t}\right)
P(zt∣x1:t)=P(x1,⋯,xt)P(zt,x1,⋯,xt)=∑ztP(zt,x1:xt)P(zt,x1:xt)∝P(zt,x1:xt)
5.3.3.4 Smoothing
Smoothing 问题和 Filtering 问题的性质非常的像,不同的是,Smoothing 问题需要观测的是一个不变的完整序列。对于 Smoothing 问题的计算,前面的过程和 Filtering 一样,都是:
P
(
z
t
∣
x
1
:
T
)
=
P
(
z
t
,
x
1
,
⋯
,
x
T
)
P
(
x
1
,
⋯
,
x
T
)
=
P
(
z
t
,
x
1
:
x
T
)
∑
z
t
P
(
z
t
,
x
1
:
x
T
)
∝
P
(
z
t
,
x
1
:
x
T
)
P\left(z_{t} | x_{1: T}\right)=\frac{P\left(z_{t}, x_{1}, \cdots, x_{T}\right)}{P\left(x_{1}, \cdots, x_{T}\right)}=\frac{P\left(z_{t}, x_{1}: x_{T}\right)}{\sum_{z_{t}} P\left(z_{t}, x_{1}: x_{T}\right)} \propto P\left(z_{t}, x_{1}: x_{T}\right)
P(zt∣x1:T)=P(x1,⋯,xT)P(zt,x1,⋯,xT)=∑ztP(zt,x1:xT)P(zt,x1:xT)∝P(zt,x1:xT)同样因为
∑
z
t
P
(
z
t
,
x
1
:
x
T
)
\sum_{z_{t}} P\left(z_{t}, x_{1}: x_{T}\right)
∑ztP(zt,x1:xT) 是一个归一化常数, 我们这里不予考虑。下面的主要问题是关于
P
(
z
t
,
x
1
)
P(z_{t}, x_{1})
P(zt,x1) 如何计算,我们来进行推导:
P
(
x
1
:
T
,
z
t
)
=
P
(
x
1
:
t
,
x
t
+
1
:
T
,
z
t
)
=
P
(
x
t
+
1
:
T
∣
x
1
:
t
,
z
t
)
⋅
P
(
x
1
:
t
,
z
t
)
⏟
α
t
\begin{aligned} P\left(x_{1: T}, z_{t}\right) &=P\left(x_{1: t}, x_{t+1: T}, z_{t}\right) \\ &=P\left(x_{t+1: T} | x_{1: t}, z_{t}\right) \cdot \underbrace{P\left(x_{1: t}, z_{t}\right)}_{\alpha_{t}} \end{aligned}
P(x1:T,zt)=P(x1:t,xt+1:T,zt)=P(xt+1:T∣x1:t,zt)⋅αt
P(x1:t,zt)推导到了这里就是要对
P
(
x
t
+
1
:
T
⏟
C
∣
x
1
:
t
⏟
A
,
z
t
⏟
B
)
P(\underbrace{x_{t+1: T}}_{C} | \underbrace{x_{1: t}}_{A}, \underbrace{z_{t}}_{B})
P(C
xt+1:T∣A
x1:t,B
zt) 进行分析,在这个概率图模型中,符合如下结构:
根据概率图模型中提到 D-Separation 中,如下图

我们可以很简单的得出,
A
⊥
C
∣
B
A \perp C | B
A⊥C∣B 。所以,
P
(
x
t
+
1
:
T
∣
x
1
:
t
,
z
t
)
=
P
(
x
t
+
1
:
T
∣
z
t
)
=
β
t
P\left(x_{t+1: T} | x_{1: t}, z_{t}\right)=P\left(x_{t+1: T} | z_{t}\right)=\beta_{t}
P(xt+1:T∣x1:t,zt)=P(xt+1:T∣zt)=βt 。所以,我们可以得到:
P
(
x
1
:
T
,
z
t
)
=
α
t
⋅
β
t
P\left(x_{1: T}, z_{t}\right)=\alpha_{t} \cdot \beta_{t}
P(x1:T,zt)=αt⋅βt那么,最终得到的就是:
P
(
z
t
∣
x
1
:
T
)
∝
P
(
x
1
:
T
,
z
t
)
=
α
t
β
t
P\left(z_{t} | x_{1: T}\right) \propto P\left(x_{1: T}, z_{t}\right)=\alpha_{t} \beta_{t}
P(zt∣x1:T)∝P(x1:T,zt)=αtβt所以, 我们需要同时用到 Forward Algorithm 和 Backward Algorithm, 所以,被我们称为 Forward Backward Algorithm

5.3.3.5 Prediction
预测问题,大体上被我们分成两个方面:
公
式
1
:
P
(
z
t
+
1
∣
x
1
,
⋯
,
x
t
)
=
∑
z
t
P
(
z
t
+
1
,
z
t
∣
x
1
,
⋯
,
x
t
)
=
∑
z
t
P
(
z
t
+
1
∣
z
t
,
x
1
,
⋯
,
x
t
)
⏟
P
(
z
t
+
1
∣
z
t
)
P
(
z
t
,
x
1
,
⋯
,
x
t
)
⏟
Filtering
公
式
2
:
P
(
x
t
+
1
∣
x
1
,
⋯
,
x
t
)
=
∑
z
t
+
1
P
(
x
t
+
1
,
z
t
+
1
∣
x
1
,
⋯
,
x
t
)
=
P
(
x
t
+
1
∣
z
t
+
1
,
x
1
,
⋯
,
x
t
)
⏟
P
(
x
t
+
1
∣
z
t
+
1
)
⋅
P
(
z
t
+
1
∣
x
1
,
⋯
,
x
t
)
⏟
F
o
r
mula
(
1
)
\begin{aligned} 公式1:P\left(z_{t+1} | x_{1}, \cdots, x_{t}\right) &=\sum_{z_{t}} P\left(z_{t+1}, z_{t} | x_{1}, \cdots, x_{t}\right) \\ &=\sum_{z_{t}} \underbrace{P\left(z_{t+1} | z_{t}, x_{1}, \cdots, x_{t}\right)}_{P\left(z_{t+1} | z_{t}\right)} \underbrace{P\left( z_{t}, x_{1}, \cdots, x_{t}\right)}_{\text {Filtering }} \\ 公式2:P\left(x_{t+1} | x_{1}, \cdots, x_{t}\right) &=\sum_{z_{t+1}} P\left(x_{t+1}, z_{t+1} | x_{1}, \cdots, x_{t}\right) \\ &=\underbrace{P\left(x_{t+1} | z_{t+1}, x_{1}, \cdots, x_{t}\right)}_{P\left(x_{t+1} | z_{t+1}\right)} \cdot \underbrace{P\left(z_{t+1} | x_{1}, \cdots, x_{t}\right)}_{F o r \operatorname{mula}(1)} \end{aligned}
公式1:P(zt+1∣x1,⋯,xt)公式2:P(xt+1∣x1,⋯,xt)=zt∑P(zt+1,zt∣x1,⋯,xt)=zt∑P(zt+1∣zt)
P(zt+1∣zt,x1,⋯,xt)Filtering
P(zt,x1,⋯,xt)=zt+1∑P(xt+1,zt+1∣x1,⋯,xt)=P(xt+1∣zt+1)
P(xt+1∣zt+1,x1,⋯,xt)⋅Formula(1)
P(zt+1∣x1,⋯,xt)
公式 (2) 选择从
z
t
+
1
z_{t+1}
zt+1 进行积分的原因是因为想利用齐次马尔科夫性质。实际上求解的过程大同小异都是缺什么就补什么。
其实,我们已经大致的介绍了 Dynamic Model 的几种主要模型,后面我们会详细的来解释线性动态系统。
6 可参考
版权声明:本文为CSDN博主「AI路上的小白」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/cengjing12/article/details/106592894















 4358
4358











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









