







目录
2.5基于随机森林学习与二值描述子学习相融合的并行搜索SLAM重定位
4 SLAM with Event-based Vision Sensors:Past, Present, and Future——周易
4.1 Neuromorphic Event-based Camera Introduction
4.2 Past: A Review on Event-based VO/SLAM
4.4 Future: Bottlenecks and Promising Directions
5 SLAM在自动驾驶中的应用&非惯性系下VIO探索——秦通
7 When Machine Learning Meets DynamicVision: SLAM Research for Mobile Sensors——查红彬
7.2 Online Learning Paradigm for SLAM
像衍科技提问环节——基于深度学习的三维重建与位姿估计系统设计
前言
有幸在搜索SLAM会议的时候,看到了这个全国SLAM技术论坛,论坛中来了很多大佬分享了自己的工作、成果以及对前沿技术的一些看法让我受益匪浅。但是如果光听的话,据我的经验,后面就会淡忘,所以就做了一下粗糙的记录,后面如果想翻阅论坛的内容也能够及时找到。由于会议内容很多,所以本文很长,且记录粗糙,如果对这个论坛感兴趣,可以去深蓝学院观看这个会议记录,或者在B站上看回放。
1 端-云协同的视觉定位与重建及应用——章国锋
章国锋,浙江大学CAD&CG国家重点实验室的老师。章老师重点讲了云和端的配合以及slam在AR中的实际应用。云和手机端结合,可以解决手机算力不足的问题,在特征提取中可以选择更复杂的特征进行提取实现精准的视觉定位以及环境重建。有了云的配合,在特定应用场景下,可以让云端保留环境地图,使得手机端在建图时具有环境先验,提高建图的准确性。章老师还提出了许多问题,并给出了一些解决办法,如下。
在视觉slam中存在两大关键挑战,一是精度和稳定性:①动态变化、快速运动②弱纹理、重复纹理③优化计算不稳定。二是实时性:①场景规模大②计算维度高③低功耗设备计算能力有限。
1.1 如何提升前端稳定性?
提升稳定性可以从约束的正确性(高效准确的匹配:分布先验,剔除外点:变化检测)和约束的充分性(运动先验约束、结构先验约束、多传感器融合)入手。章老师提出了惯性神经网络辅助下的视觉惯性里程计:RNIN-VIO: Robust Neural Inertial Navigation Aided Visual-Inertial Odometry in Challenging Scenes. ISMAR 2021.且代码开源https://github.com/zju3dv/rnin-vio,主要优势有①降低系统对视觉的依赖,纯IMU也可以长时间进行鲁棒跟踪,提升极端场景鲁棒性②禁耦合视觉信息,正常场景下维持高精度跟踪。
1.2 如何提高全局优化效率?
全局优化一般采用集束调整BA,高效求解一般为分治求解和增量式计算。集束调整BA计算复杂度随着帧数急剧增长,使用增量集束调整的方式可提高优化的效率。关键思路①增量更新和求解:尽可能利用之前计算的结果来加速,仅重新计算新加入或更新的变量对应矩阵元素②将长特征轨迹分裂成短轨迹,降低苏尔补矩阵的稠密度,从而显著减少计算时间。https://github.com/baidu/ICE-BA
1.3 关于端-云协同的应用课题如下:
端-云协同突破计算和空间瓶颈:
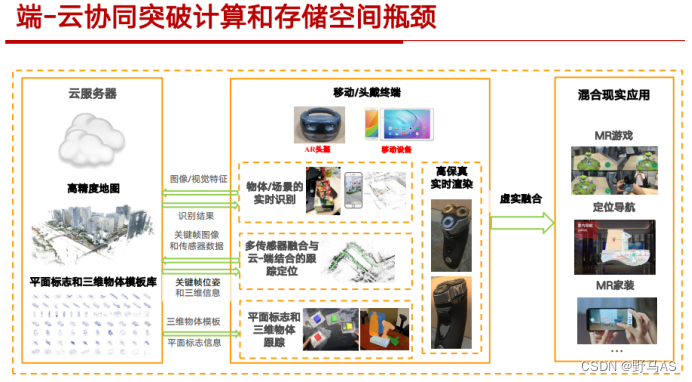
基于多机器人的协同场景重建:Best Paper Finalist Award on Safety, Security, and Rescue Robotics in memory of Motohiro Kisoi。机器人端:①视觉SLAM模块:实现定位②三维重建模块:建立SDF地图③信息压缩模块:将SDF地图进行精简表达并发送。服务器端:①回环检测模块:匹配多机器人产生的关键帧,确定回环。②通信处理模块:将机器人端传输的信息恢复为SDF地图③优化模块:根据相关约束优化得到全局一致的稠密地图。
 容忍高时延的高精度地图与VIO紧耦合框架:Robust Tightly-Coupled Visual-Inertial Odometry with Pre-built Maps in High Latency Situations. TVCG 2022.设计了一整套将高精度地图点与VIO窗口点生成匹配的流程,对不同的地图点设计不同的优化约束项,还设计了异常处理机制。主要优势:①能够平滑地印制住误差累积②能够容忍高时延和低定位请求频次③能够较好地容忍定位噪声和地图噪声。
容忍高时延的高精度地图与VIO紧耦合框架:Robust Tightly-Coupled Visual-Inertial Odometry with Pre-built Maps in High Latency Situations. TVCG 2022.设计了一整套将高精度地图点与VIO窗口点生成匹配的流程,对不同的地图点设计不同的优化约束项,还设计了异常处理机制。主要优势:①能够平滑地印制住误差累积②能够容忍高时延和低定位请求频次③能够较好地容忍定位噪声和地图噪声。
基于分割投票的视觉定位:VS-Net: Voting with Segmentation for Visual Localization. CVPR 2021.用CNNs检测二维特征点,用PnP算法求解位姿。难点:遮挡和截断导致部分关键点不可见。关键思路:①使用superVoxel对三维点云进行预先的聚类,每个块的几何中心作为关键点②构造一个可学习的类别coding数据库,通过最近邻查找每个像素的1关键点在类别数据库的正样本和负样本,组成三元组损失。
基于特征匹配的视觉定位:Learning Bipartite Graph Matching for Robust Visual Localization. ISMAR 2020.在描述子空间寻找最近邻再使用手工设计的方法剔除错误匹配。难点在有重复纹理、光照变化或大视角变化等复杂场景中正确不在最近邻的匹配当中。关键思路:首先根据局部特征相似度为每个2D点寻找多个3D点作为候选匹配,然后再利用几何信息从所有候选匹配中找到几何上全局最优的一对一匹配,并预测正确匹配的概率。
1.4 提问环节:
1,关于稀疏地图和稠密地图他们的应用场景分别是什么?
稀疏地图用来进行传统的定位应用。如果做其他的应用如碰撞检测可能就不够了,需要稠密地图来进行,更复杂的需求,如动态规划什么的。
2,现在新的技术transform和NeRF,他们在slam上有没有新的应用或者进展?
之后肯定会有,如渲染地图,未来slam会不断融合现有好的技术。
3,slam对实时性要求很高,现在有很多深度学习结合的slam算法,深度学习如何与slam结合,以及算法的实时性如何保证?
看应用场景,在手机或者一般的嵌入式平台,可能会比较吃紧。通过加速算法可以实现一定的实时效果,但还无法和orb等特征的速度相比。
4,除了深度学习方法的发展,传统方法如PnP和优化等,这些算法是否还有优化的空间?
PnP的问题是比较老的问题了,传统方法已经比较成熟了,可以拿来和现有的新技术进行结合。有时候设备会有限制,无法用复杂的特征去表示,虽然可以结合云端,但是实际应用中,还是要做移动端上做一些任务,可以采用传统方法进行加速。
2 多模态信息感知的SLAM——吴毅红
吴毅红,中科院自动化所、模式识别国家重点实验室的老师。吴老师和章老师讲解实际应用场景的知识不一样,吴老师更侧重理论分析、数学分析。遗憾的是吴老师并没有像章老师一样将论文以及代码索引放在文中,而是将论文中的数据推导放在了PPT里面。吴老师主要从多模态信息(①不同的几何元素:点、线、面、边缘②不同的传感器:相机、IMU、激光)融合入手,进行slam优化。
2.1特征点优化的相机与激光外参数标定
激光雷达在测量过程中会存在测距误差、光斑分散误差。吴老师使用几何约束消除了激光测距和光斑分散误差,恢复了标定板的真实形状,使用位姿约束,在优化过程中,保持了空间中四个顶点的位置。吴老师设计的方法优点①误差更小②使用一个标定板数据即可进行标定。
2.2两阶段视角不变匹配的激光SLAM
吴老师提出了基于PCA特征提取算法和两步匹配的激光SLAM。在特征提取阶段对点云中每个点,计算这个点集的质心,然后计算协方差矩阵。这周基于PCA的特征提取与匹配的关键帧法具有视角不变性和距离不变性。还优化了帧到局部地图的跟踪以及帧到稀疏局部地图的跟踪,使得在数据集中实现了更好的效果。
2.3结构信息辅助的SLAM
SLAM特征跟踪中存在弱纹理、重复纹理、运动模糊以及光照变化下、鲁棒性和精度较低,基于线的跟踪较慢。解决思路:提出了①点线特征混合的策略②提出了基于L1-范数图优化的线段跟踪。吴老师提出了基于凸优化与IMU-KLT的线段跟踪, PL SLAM。实验效果优于VINS-Mono,PL-VINS,OpenVINS,在运动模糊和弱纹理条件下,实验效果优于ORB-SLAM3。
2.4 基于深度哈希学习的SLAM闭环检测与位姿误差纠正
深度学习融入SLAM存在着速度慢、数据标注难、动态遮挡、相似场景的问题。解决思路①自监督②哈希分层③全局CNN特征+局部特征④视频多关键帧。在地点识别中:自监督深度哈希学习,不需要标注数据,CPU实时;在闭环检测中:深度学习特征与传统特征相融合,可以解决实时、运动遮挡、视角、相似场景问题;误差抑制采用图优化。
2.5基于随机森林学习与二值描述子学习相融合的并行搜索SLAM重定位
现有SLAM重定位存在的问题①基于图像检索的方法:鲁棒性高;但视角大、图像相似占比大则会失败②基于2D-3D匹配的方法:传统局部描述子鲁棒性较低;大视角、图像相似也可区分③深度学习局部描述子,速度较慢,浮点型直接二值化,精度下降严重④图像检索与2D-3D匹配结合的方法:串行,限定在有限范围内。
解决思路:①深度学习:整幅全局、局部描述子。解决速度较慢的问题:随机森林,二值。解决精度下降的问题:cotrain局部浮点+二值,浮点与二值混合。解决光照的问题:融入小波的全局CNN低光增强
2.6提问环节
1,目前提取线特征有没有什么快的方法,还有旋转、尺度的不变性怎么样?
我们用的还是已有的线性特征提取方法,之后考虑结合深度学习做一下线特征提取方法。
2,商城、办公建筑的幕墙玻璃,对于slam有什么好的解决办法吗?
用深度学习,采用数据驱动,深度学习最大的好处就是不管有没有严谨的数学推导和几何推理过程,都能采用数据驱动的方式较好的解决问题。
3,PPT演示种隧道里的视觉slam几公里的距离,怎样处理这种情况下的漂移和累计误差?
采用特征融合以及多个激光配合,保证在一个激光处理不了的情况下,另一个激光能够照到这个视点,采用软硬协同的方式解决,而不是单靠算法去解决这个问题。
4,户外不是街区、街道,而是农田这种场景,缺少结构性的建筑作为参考,有什么好的方法解决?
关于野外的场景,比较难处理,因为野外植物存在大量的重复纹理。解决植物的特征非常具有挑战。目前还没有良好的解决方法。
3 Visual-Inertial Systems:Sensing, Estimation, Perception & Navigation——黄国权
黄国权,美国特拉华大学终身副教授、美团资深科学家。黄老师可能是在国外当副教授的原因,PPT全英文。在会议上,黄老师主要讲了惯导系统在视觉slam种的应用。惯导传感器可以弥补相机的许多缺陷,等于是两种传感器融合,因此外参的获取很重要,便于后期数据对齐。
3.1提问环节
1,对VIO系统的效率和鲁棒性是很重要的,如果考虑精度和效率的平衡,对视觉分类以及涉及到的视觉特征数量有什么建议没有?
几何特征还是有优越性的,可以深入了解一下,利用先验信息。视觉特征多一点可以提高识别准确率,但是达到一定的平衡之后,就不用增加特征数量。
2,最近有很多深度学习和IMU结合的论文,您对深度学习和IMU结合怎么看?
深度学习是一个方向,在可以借助先验信息的运动场景下,借助深度学习还是很好的,综合应用场景来看,这是值得尝试的方向。
3,在落地应用中,我们基于滤波的算法和基于凸优化的算法,那种会好一点?
本质上没有差异,实际应用中会有一点差别。最大的不同可能是资源上分配的差异。
4 SLAM with Event-based Vision Sensors:Past, Present, and Future——周易
周易,湖南大学机器人学院教授。周老师也有留学经历,PPT也是全英文的,不过周老师讲的事件相机令人深刻,还是想详细记录一下。普通的RGB相机或者RGB-D相机在高速和转向的时候会产生运动模糊,无法捕捉周围事物的特征。而事件相机,有亮度变化,图像才会有变化,为相机大大减少了捕捉信息量,使得事件相机具有超低时延的特性,这个特性在高速和转向的时候不会产生运动模糊。
4.1 Neuromorphic Event-based Camera Introduction
机器人大脑的关键内容是感知、导航、控制,解决,解决where I from,where I am,where I go。传统相机暂时无法从本质上解决高速和较高速度转向时的运动模糊问题、以及进隧道、出隧道产生的高亮度变化的问题。而事件相机理论上可以达到1us的时延,可以在极端场景下依旧能捕捉变化的信息。
4.2 Past: A Review on Event-based VO/SLAM
传统相机在SLAM的任务中主要是跟踪和建图,这两个问题又和状态估计、深度估计密切相关,事件相机也能进行深度深度估计,相关论文在PPT中。最早的事件相机用于机器人定位在2012年论文也在PPT中。
4.3 Present: State of the Art
这节周老师也是重点介绍当前发的比较重要的事件相机论文,在Mapping和Tracking都取得了一定的成果。事件相机记录的是事件,基于事件相机的VO核心问题是确定事件摄像机获得的数据之间的关联。周老师提出了一种双目事件相机的解决方案。
4.4 Future: Bottlenecks and Promising Directions
这节介绍了事件相机的瓶颈①不令人满意的信噪比②有限的空间分辨率③延迟和计算复杂度的权衡④计算资源和功耗问题。未来的方向:①为什么需要事件相机是由于HDR和Aggressive Motion问题,目前HDR得到了较好的解决,但剧烈运动还是没有解决②统一的数学建模方案③深度学习在事件相机上的探索。
4.5 提问环节
1,事件相机的成本大概是什么量级,市面上有那些好的厂商?
。。。。听不清英文厂商,做研究的话,事件相机还是很贵的,进口要几万,不过以后能普及开来,进行量产,成本就会降低很多。
2,事件相机标定的流程和普通的相机标定有什么区别?
标定就是确定内参和外参,内参数可以通过加工工艺使得RGB的内参数作为事件相机的内参数。如果是单一的事件相机则可以用led序列。外参数的话。。。
3,事件相机,室内外表现差异大吗?静止的情况下是否无法进行跟踪?
隧道那种情况没什么问题,但如果玻璃有反光可能会产生影响,要保证光照的问题。可以跟踪运动的物体,低速机器人可能没有什么用武之地,事件相机主要还是处理高速运动。
5 SLAM在自动驾驶中的应用&非惯性系下VIO探索——秦通
秦通,香港科技大学博士、华为智能驾驶SLAM专家。秦老师主要讲了APV自动泊车、众包构建地图以及令人印象深刻的非惯性体系下的探索,而且这些成果仅靠相机以及IMU等低成本传感器实现,非常具有应用价值,也可能已经在应用了(膜拜大佬)。
5.1 自动代客泊车(AVP)
自动泊车的任务主要是在司机下车或者不操作的情况下,车辆能够自动驶入停车场,导航至指定车位泊车;司机需要用车时,车辆能够召回至指定位置。完成这些任务需要高精度地图+定位,难点①地库无GPS信号②地库场景狭窄复杂、纹理重复③量产车、低成本方案。秦老师使用的解决方案采用低成本摄像头完成视觉构图+视觉定位。
视觉构图部分,视觉预处理采用鱼眼摄像头获取图像——>鸟瞰图投影拼接(IPM)——>语义分割,语义元素为:车位线、车位角点、减速带、车道线、地面标识、建筑物、轮挡....。(不知道怎么标注语义元素的,车位线,角点都能标注太强了,这样精细的标注效果也很强,能清晰的看到车位及其间距)预处理完后就开始建图①局部语义元素——>投影到车体坐标系——>多帧累积②回环检测优化——>全局一致地图,然后语义构图。
视觉定位部分,采用局部语义元素ICP匹配,EKF估计①轮速计+IMU递推②视觉更新——6DoF。
最终实现精准的定位导航、自动泊车,效果很好。
5.2 城区众包构图
任务背景城区道路复杂,依赖高精度地图。高精度地图以往由带有高精度雷达的导航车到实地去构建地图,但这样的效率缓慢,耗费人力资源,而且不是实时更新。于是提出了一个问题能否采用轻量级地图和低成本传感器方案,秦老师提出了,采用视觉构建的众包地图以及采用相机作为传感器。众包地图所依赖的平台很普通,许多的汽车都有这样的配置,利用这些车上手机到的信息就可以实现众包构图。
总结起来就是将部署了众包平台的车上的数据进行融合、实时更新、然后将更新的最新数据传到众包构建的地图上,由于采用摄像头实现,成本低廉。
5.3非惯性系下的VIO探索
首先是问题为什么要使用非惯性系下的VIO,目前大多数开发的slam算法都是基于惯性系统下,如果到了非惯性系下,会产生较大的误差,比如电梯升降、在汽车或变速移动的物体内,IMU感应的数据和实际有偏差。如果不解决这个问题,会使得以后的AR不能在这些场景下使用,不过秦老师在Facebook实习时的工作解决了这个问题,采用的方法是将惯性系和非惯性下IMU的数据分开处理,处理过程详见PPT,非常不错的工作,效果也很棒。
5.4提问环节
1,AVP SLAM是否支持跨层,如果跨层应该怎么去做?
跨层是可以支持的,思路是相对定位要比较准确,对这个汽车的配视角有一个比较好的估计,Z方向的估计再加上零速估计引入到系统中,这样楼层的估计会比较准确。
2,分享的非惯性工作中,怎么触发进入非惯性系统的条件呢,就是怎么判断进入电梯?
我们做的工作假设是电梯一直存在,我们一直非惯性系统中,只不过零速更新有没有发生,在没有进入电梯时有零速更新,进入了电梯就没有零速更新。所以判断条件是什么时候启动零速更新,我们采用的方法是看速度与加速度噪声模型来判断是否进入电梯,是针对电梯做的工作。这方面可以结合更多的方法如自动化、机器学习等,判断什么时候进入非惯性系统中。
3,有关AVP SLAM当面,如果遇到减速带,车辆加减速导致IPM图严重变形有什么好的解决思路吗?
这种语义特征,如果做了多帧的累积、多帧的滤波、多帧的统计,效果就会
还可以,因为这种非常差的只会有一两帧,通过滤波、估计等方式可以将这些帧去除掉,从而实现较好的效果。
4,如何处理点云地图数据量大,导致后端优化处理量大,导致耗时过多的问题?
可以做一些trick的工作,比如停车库非常的大,但地图优化可以不用在用户使用的时候进行,可以在用户不使用车辆的时候运行,并不一定要实时的完成优化。
5,如果众包地图,构建、探测不完整怎么办,如何形成一个完整的方案?
对于构建不完整的图,可以先mask掉,将完整的图才上传给用户,残缺的先保留,等完整了再拖入闭环应用。
6,自动驾驶对高精度有什么要求?
当前还没遇到这个瓶颈,高精度地图虽然精度高,但是现实经过合规之后,质量会有偏差。但根本问题是保证地图与定位匹配起来就可以了,可以忽略绝对精度,保证相对精度能完成自动驾驶任务就可以了。
7,众包建图有什么技术架构可以从哪方面进行学习?
主要的技术栈还是SLAM,还有一些深度学习进行特征的方法.在学校很难开展这项工作,没有数据支持。
8,初学SLAM这个方向有什么建议?
这次主讲嘉宾有很多大牛,可以看看他们的履历,看看他们是怎么成长起来的。
6 LIO系统的改进及其在自动驾驶定位模块中的应用——高翔
高翔,清华大学博士、慕尼黑工业大学博士后。高翔老师YYDS,还是熟悉的感觉,会议讲解跟唠家常一样,吐槽论文审稿人喜欢“花活”。唯一的遗憾是视觉十四讲的开拓者,转行弄雷达了,这应该和他现在从事自动驾驶有关,会议中多次提到VIO不适合复杂的自动驾驶场景,用LIO更具有普适性和鲁棒性。结尾还透露了在写新书《自动驾驶中的SLAM技术》,看样子视觉十四讲第三版是很长时间内都不会出了。
在会议中,高老师主要分析了LIO系统,以及低成本也就是线数较少的雷达如何在实际场景中应用,研究的目的也是想以后做出的成果能够进行量产,而不会因为成本昂贵导致,只能做研究。主要分析了目前做的工作iVOX和最快的fast-lio2的区别以及与其他经典LIO框架的比较。
6.1 什么是LIO,为什么要用LIO
经典自动驾驶定位系统中,以IMU+轮速作为Odom,以GNSS/点云定位作为全局观测,使用ESKF进行融合,输出融合结果。特点是①基于ESKF,效率快、平滑、计算简单②精度高③点云和RTK至少应该有一个有效。④通过卡方检测剔除异常值,需要一定工程调试⑤难以处理极端场景(隧道)。高老师认为实现自动驾驶不能依赖于高精度地图,过分依赖高精度地图的L4,相比人类系统比较脆弱。影响L4量产的技术问题①城区HD遥遥无期,生产和更新成问题②对高精度地图和高精度定位的依赖,使L4方案变得脆弱。高老师提出了一种不依赖离线高精度地图的方式①原本的HD地图信息实时由感知实时生成②控制和导航必须忍受地图的不确定性③控制依赖实时地图中的定位,导航则使用低精度的全局定位。
LIO(lidar-inertial odemetry),特点①在DR上添加点云输入②可以输出相对定位结果,还可以输出实时点云地图,描述三维结构③于RTK和点云定位组合后可输入传统高精度定位结果④可基于ESKF或优化框架。常见开源:LIO-SAM,FastLIO,LiLi-OM等。
6.2 LIO系统的典型实现方式及其改进
LIO的目的①准确的相对点位②点云地图③尽可能快速,占用资源少。FastLIO实现框架优点①后端是基于ESKF的,快,相对容易理解②相比Loam类算法,不用提取特征,位姿估计在EKF内部计算③整个计算量从优化问题变成了最近邻问题。
对FastLIO的改进,iVOX:Incremental voxels增量式模型①可以增量构建的体素方法,支持近似的最近邻②每个点首先被存放在体素当中,体素由Hash表索引,同体素内的点按照一定结构存放。
6.3以LIO为核心的实时定位系统
该系统于传统融合定位的特性:①LIO保持相对定位精度,且在局部空间内不随时间发散②相对定位和绝对定位分开输出,相对定位保持精度和平滑性,绝对定位有优先保证正确性③PGO四合一融合,允许输出的跳变等等特性。
LIO系统在自动驾驶中的一些应用要点:①纯LIO系统虽然会估计重力方向,但与IMU加计零偏耦合。长时间运行可能出现全局姿态不稳定情况②加入RTK观测后会使LIO更稳定。
6.4提问环节
1,fastlio对于上台阶问题,怎么增加Z轴约束减少Z轴抖动?
Lidar具有3D结构,通过迭代上台阶一般没什么问题。
2,LIO退化场景有什么好的办法吗?
点面残差,关键帧可以解决一部分。
3,LIO关于IMU有什么好的选择吗,六轴还是九轴?
都可以,没什么特别的要求。
4,SLAM在生成地图的过程中,如果某一帧的位姿估计出现了较大的误差可能会影响后面的数据配准,这种情况怎么处理?是否可以自动剔除?
做一些check,还可以加关键帧,加轮速等辅助来判断筛选错误的帧。
5,iVox对于远处的近邻点,召查找回率比较低,这样在LIO的初始化情况下会比较稀疏,关键点距离比较远,比如说像环状雷达的地面点,这时候会不会对定位的性能影响比较大,有什么好的解决办法吗?
降采样不要下降太多,前几帧可以处理一下,增加采集到的点,或者加RTK进行完善。
6,lidar slam在自动驾驶场景下还有什么通点需要解决的吗?
今后大的发展方向,我感觉是实时地图。其中的语义信息如何与点云地图匹配在一起,这是给比较好的点
7,点云地图有什么轻量化的存储方法吗?
不太好做,压缩一般压不了多少。
8,2D Lidar SLAM 还有什么好的改进方向吗?
理论上已经比较成熟了,实际应用由于遮挡,所以应用比较有限。
9,可以解释一下2.5D地图是什么吗?然后2.5D的分层定位有什么好的方法吗?
2.5D地图指中将X,Y,Z空间拟合几个高斯分布或者一个高斯分布和几个协方差。分层定位没听懂,高老师采用的是单高斯定位的方法。
10,上坡和不平整场景对LIO影响大吗?
不大,有IMU和点云控制的很好。
11,在自动驾驶中,VIO是不是比LIO效果差?
是的,因为VIO获取的纹理信息较差,由于引用场景为动态的,以及运动模糊问题导致相机并不好用。
12,LIO框架中优化和滤波哪个更好
滤波好一些。
7 When Machine Learning Meets DynamicVision: SLAM Research for Mobile Sensors——查红彬
查红彬,北京大学教授、机器感知与智能教育重点实验室主任。查老师语速比较快,但铿锵有力。查老师讲了动态视觉和SLAM的关系,以及机器学习在动态视觉,实时SLAM的作用。
7.1 Dynamic Vision
动态视觉解决的问题是从视频中实时理解场景:①捕捉3D场景和移动摄像机的相关性②利用连续图像帧之间的时空信息③实时处理流数据。基于学习的动态视觉方法存在一下缺点①需要费力的数据预采集和批量培训②不能推广到复杂的环境③不能满足实际在线使用的需求。SLAM是动态视觉的一个典型例子,它会在线估计设备运动状态、增量式建设环境、本地化和映射的紧密耦合。
最近的进展①充分利用多视图几何背后的理论和算法②通过融合不同种类的传感器来提高性能③在有限的环境中完成特定的任务。剩余的挑战还是要注意时间的连续性、以及缺乏系统的制定、泛化能力较差。
7.2 Online Learning Paradigm for SLAM
SLAM在线学习范式①通过不断提取的知识构建动态更新的预测器②将知识和先验存储在概率地图表示中作为全局约束,周期性地对预测器进行自监督在线学习,以适应环境变化。
流程制定,将SLAM作为一个学习如何通过提取和利用数据流来构造预测器的过程,会面临这些挑战①SLAM中固有的时间连续性被忽略了②冗余计算会降低系统的效率③要实现长期的一致性绝非易事。查老师提的解决方案①用顺序学习的方式来阐述问题②明确利用时间的连续性来预测传感器数据的变化模式③增量计算,提高效率。具体解决方法采用层次化的Conv-LSTM体系结构提炼出长期的顺序相关性、自我监督学习是生成对抗网络(GAN)范式中表述的、贝叶斯学习框架下的线流描述了结构信息的时间相干性。
内存和细化,使系统能够有效地提取和利用长期知识,提高SLAM的准确性。面临的挑战:现有的在线处理方法存在严重的灾难性遗忘、局部观测的优化缺乏全局约束、当前的预测不能用来改进以前学到的估计。查老师提的解决方案①逐步存储长期依赖项②使用全局内存信息优化结果③特征选择的时空注意力。
7.3 Online Adaptation
在线自适应指提高不同环境和任务下的自我适应能力,以便更好地泛化。面临的挑战①深度VO在看不见的环境中表现不佳②范围转移需要在线学习的重新规划③原始的在线学习导致灾难性的遗忘和缓慢的收敛。查老师提的解决方案①在线适应的元学习和自我监督②时空聚合的Conv-LSTM③非平稳数据分布的在线特征对齐。在线自适应框架在范围漂移下具有良好的泛化能力,元学习和特征对齐可以缓解灾难性遗忘问题,自我监督避免了非琐碎的地面真相数据收集过程。
概率地图表示,为一个地图为中心的SLAM范式增强地图表示的不确定性感知表达能力。面临的挑战①存储在地图中的信息是有限的,并且在逐渐增加②嘈杂的观测结果导致不准确的地图描述③现有的方法缺乏一个系统和概率的公式。查老师提的解决方案①使用好的概率地图的表示②在增量贝叶斯框架下更新③显式不确定性推理和异常值拒绝。增量贝叶斯框架得到干净、紧凑的场景几何图形,摒弃了噪声和异常值。显式空间分布建模使得地图置信度表示可以用于进一步的探索,统一的概率地图表示允许方便的转换到普遍的几何输出中。
7.4 提问环节
1,LSTM方法需要利用的资源为多少,位姿输出的频率为多少?
用的资源不是很多,但还是有完善空间,将LSTM分层处理,原本只有2、3帧,层次化处理之后有十几帧。
2,您提到的SLAM论文在机器人领域好发表,视觉领域不好发表,但您在视觉领域发表了很多,这有什么秘诀吗?
之前投过几次都被拒绝了,但后面发现视觉领域的审稿人喜欢一下系统化的研究,加入深度学习,使得研究更具有鲁棒性。有了系统化的研究,得到了同行的认可,才发表了一些文章。
3,关于动态和静态场景,如果构建地图,怎么进行更好的管理?比如在动态场景中,看到了动态的物体,如果看不到之后就感知不到了,那我们该怎么储存这些动态物体的信息?
动态场景,需要制作具有动态数据结构的地图,这种数据结构是柔性的,随着时间的改变,数据结构相应改变。
8 融合人与环境的激光雷达三维动态场景感知——王程
王程,厦门大学南强重点岗位教授福建省智慧城市感知与计算重点实验室主任。王老师主要讲了激光雷达在大场景的应用以及人体动态捕捉上面的应用。在此次会议上展示了很多成果,很多都发表在了顶会上。不过对激光雷达,点云数据还不是很了解,听得有点迷迷糊糊,就是感觉吴老师做的工作很强,在激光雷达应用上面深入得非常厉害。
8.1 激光雷达车辆行人目标检测与跟踪
这个课题下,有个疑问是如何得到点云帧间的运动场景流,王老师提了采用连续踪片(小轨迹)的方式。于是演变成了基于踪片候选生成与优化的多目标跟踪,这个课题难点在于①目标运动复杂,运动状态难预测②点云稀疏,目标相似度难以衡量③目标遮挡,目标易漏检。王老师采用的方法基于踪偏优化的多目标跟踪。这个方法有着这些优势①连续踪片(小轨迹)内优化检测结果②构建端对端的踪片候选、优化卷积神经网络③提高踪片准确性和跟踪精度。
然后就是成果展示,在多个数据集上性能榜单第一,第二。
8.2 激光雷达人体动作捕捉
人体动捕目前有许多需求,比如动画制作、虚拟现实、体育训练、机器人、虚拟主播等。目前主要方法为①基于标记的动捕方法②基于图像的动捕方法。动捕面临的挑战①增大作用距离②融合真实环境③降低使用门槛④个人隐私保护。成像雷达相对于相机的优势①覆盖距离可达两百米②三维分辨率高③光照等环境因素不敏感④无面部细节。
王老师提了一种雷达的动捕方式,LiDARCap:无标记远距离人体动作捕捉。它的特点是远距离且无标记,多模态综合了激光雷达点云、RGB图像、IMU采集真实人体动作。采用了多阶段框架动态点云时空编码器、逆动力学求解器、SMPL优化器。
8.3 激光雷达多任务场景捕捉
这个工作的需求是协作SLAM和人体动作捕捉任务。为了解决这个任务,王老师的团队设计了可穿戴的采集系统,提出了大尺度空间下基于可穿戴IMU和LiDAR的四维场景捕捉,并将采集到的数据制作了数据集并且进行了开源:Http://www.lidarhumanmotion.net。
针对这个任务,王老师提出了基于深度学习的三维建图:LO-Net。在这个课题的难点在于①关键点需要手工设计②点云稀疏难找到点准确对应。使用的方法为LO-Net-平台自身姿态估计深度神经网络,采用了①球坐标投影点云编码为输入的神经网络②构建平滑区域的时空一致性约束③掩码预测网络补偿动态点的扰动。
8.4 激光雷达三维视觉定位
疑问:如何仅用基于激光雷达大范围视觉定位?常用定位方案为全球定位系统GPS、惯性导航系统INS、基于视觉(激光点云/图像)的定位技术。定位目标:在已有城市级别高精度三维地图、再次进入场景中时,通过运动过程中获取的激光点云数据进行定位定姿。
王老师提出基于激光雷达的三维视觉定位针对有地图的城市场景的课题,难点①场景范围大,结构复杂②兼顾速度与精度。使用的方法为基于深度回归的城市激光扫描定位①多级(检索与配准)定位解决大场景下的定位问题②多任务训练提升不同任务的性能③自动平衡不同任务尺度的损失函数。
王老师提出基于激光雷达的三维视觉定位针对无地图的城市场景的课题,难点①场景范围大,结构复杂②神经网络的记忆与泛化。使用的方法为基于通用编码和记忆感知回归的激光雷达定位①通过神经网络模拟整个定位流程②绝对位姿回归网络直接输出点云的6-DoF位姿③编码器的通用性和回归器的记忆能力。
8.5 提问环节
1,动作捕捉的话,多人互相遮挡时,有没有比较好的处理策略。
采用三维雷达,可以获得比较好的三维信息,可以通过训练获得较好的姿态估计。
2,您演示捕捉的动作姿态非常平滑,是不是捕捉到姿态之后,再进行一些处理,就是怎么让捕捉的姿态变为平滑,是不是有什么关键的技术?
我们融合了许多图像领域的技术,比如动作的连续性、人体抖动估计。我们做的比较特殊的点是如何将环境与人融合起来。
3,测试人员穿戴激光位置有什么要求,佩戴了几个激光?
之前做的工作在髋关节上有一个,正在做的工作头上有一个。采用端的方式,计算方法为深度方法。
4,关于行人是用激光来检测,它这个是带有深度的,对姿态进行估计进行处理或者拟合,这样是不是很准确了?之后又用网络来识别,网络对姿态提升的作用?
激光对于人体的位置是很好获取的,姿态的话需要求解,目前精确到关节点了,所以姿态是比较准确的。
9 面向自主移动机器人感知和规划前沿进展——刘勇
刘勇,浙江大学教授、浙江大学控制学院智能驾驶与未来交通中心主任。老师主要介绍了自主移动机器人,介绍了它的发展以及多源融合感知在移动机器人上的应用,还将了自主移动机器人的规划问题。
9.1 自主移动机器人背景
近年来,传感器技术和SLAM理论的突破,自主移动机器人已广泛应用于各领域如无人驾驶、智慧城市、火星车,国内外许多巨头也开始投入这方面的研究。感知、规划、控制是自主移动机器人的三大核心环节。感知涉及内容为估计自身姿态、建立环境地图、传感器标定。规划涉及内容为搜索最优路径、运动模型约束、多机协同、躲避障碍物。
9.2 多源融合SLAM感知
机器人感知主要面临这些挑战:①单一传感器无法处理复杂环境,如纹理少、四季天气变化、空旷场地②SLAM是软硬件结合系统,硬件带来的问题(算力、同步、精度)软件无法解决。这些挑战可以建立多源融合SLAM系统克服多种挑战(多传感器、多特征基元、几何语义融合)。以下难点解决方法在原PPT中都给出了具体的论文索引。
多传感器融合难点:①传感器准确的时空标定是多传感器融合的前提②激光与IMU间数据关联较为困难,激光数据的连续采集特性进一步加剧难度③传感器内参的出厂标定进度受限,影响多传感器数据融合④各传感器间存在时间偏置,若忽略会影响标定精度⑤车载情况下运动受限、导致激励不充分,部分外参不客观。刘老师提的解决思路是将激光传感器轨迹连续化,点云数据确定轨迹形状,IMU测量值约束轨迹平滑度。
多特征基元融合:点、线、面的难点:①现有的点云特征基元只有点特征,特征匹配内点率低,需要大量RANSAC②线特征是高级特征基元,而点云是离散的,无法通过相邻点直接提取线段③点云特征人工标注工作量大,尚无公开的标注数据集。刘老师提的方法是参考SuperPoint,简单点云训练模型来标注激光点云。但这种方法难点:生成的简单标注点云与真实点云尺度不同。解决思路:采用尺度不变特征编码方法,消除Sim(3)变换中的尺度因子。
语义辅助的激光雷达里程计的难点:①现有的SLAM系统大都使用低层次的几何信息,很少系统的利用语义信息来提升其效果②对于SLAM系统来说闭环检测十分重要,可以帮助消除累积误差并建立全局一致的地图,对于基于激光雷达的SLAM系统来说闭环检测仍然是一个巨大的挑战。刘老师提的解决思路①实现一个完整的基于语义的SLAM系统,建立全局一致的语义地图②使用语义信息来辅助点云配准算法以提高里程计精度③设计一种基于语义地图的闭环检测模块,有效消除里程计的累计误差。
基于语义扫描上下文的大场景位置识别难点:①位置识别可以帮助SLAM系统消除里程计的累积误差,建立全局一致的地图②现有位置识别方法大都使用坐标、法线、反射强度等低层次信息③当闭环发生是机器人并不是严格的处于相同位置,一般来说会有旋转以及一定程度的平移,大部分现有方法只考虑了旋转却忽略了平移。刘老师提的解决思路:①使用一种新的描述子semantic scan context,它结合语义信息和几何信息实现对场景的充分描述②构建一种两阶段全局ICP算法,可以在没有初始信息的情况下快速计算点云间的相对位姿(x,y,yaw)③在公开数据集上的测试表面我们的方法在闭环检测和位姿估计上都取得了远超其他方法的效果。
点云地图压缩网络难点:①3D点云地图几何信息丰富,但大范围点云体积巨大,重定位时消耗大量计算资源②地图中每个点在重定位中的重要性不同,存在大量无用点③可用统计学方法计算每个点的优先级,设计网络筛选保留高优先级点。刘老师提的解决思路:①统计点的观测次数,作为点云优先级评价标准②序列内观测次数统计。
核回归引导的稀疏激光深度恢复难点:①单目深度估计具有二义性②激光与RGB图像不同源,难以融合③卷积网络直接学习,稀疏特征,存在的无效值导致网络性能下降③传统插值难以适应多样化的稀疏观测模式。刘老师提的解决思路:①引入稀疏观测:将极稀疏的激光引入网络,消除二义性②对稀疏观测重构:将稀疏观测投影到相机坐标系,统一表现形式③重构的稠密参考深度:将稀疏观测插值,引入残差学习④自适应插值:提出基于RGB图像的可学习集成可微核回归层。
从粗糙到精细的特征融合补全难点:①稀疏观测点有助于恢复场景深度的尺度,得到更精确的深度图②现有的基于图像引导的深度补全方法主要大多数为一阶段方法。提的解决思路①将深度补全问题表示为一个二阶段任务②提出一个用特征融合的通道混合操作③提出一个基于能量的融合操作④在KITTI排行榜上达到SoTA结果
域分离的全天自监督单目深度估计难点:①大多数估计方法仅能处理白天或者晚上的单一图像②晚上的图像由于低能见度核不均匀光照,图像整体并不稳定③现有的解决晚上图像深度估计的方法效果仍然受限。解决方法:①一个全天深度估计的domain-separated框架②新的损失函数③在数据上提高了全天深度估计的效果。
高分辨率自监督单目深度估计难点①深度是机器人感知环境的重要信息之一②现有室外深度传感器成本昂贵③现有网络参数量大,分辨率低,精度不够。解决方法①提出高分辨率高精度深度估计的网络结构②提出全连接的跳跃联接结构③提出基于SE block的特征融合模块④在公开数据集上取得最好结果。
实时稠密重建的视觉惯导里程计难点:①单目视觉惯性里程计无法实现实时稠密重建②在某些应用中深度传感器缺失,如何进行有尺度的稠密重建③如何高效地表示核优化稠密的深度。解决方法轻量的CVAE稠密深度预测与编码①压缩稠密深度②快速的有尺度的稠密深度预测③输入为图像+VIO估计的有尺度的稀疏深度④预测稠密深度的不确定性。
消费级无人机大尺度在线稠密重建难点:①传统基于无人机的重建方法采集存在难度大、成本高、建模效率低等问题②基于消费级无人机稠密重建受传感器的限制,往往难以进行精确的稠密重建③输入为无人机对地航拍图片,构建一张稠密的点云地图。④无人机飞行的高度高,整个场景尺度较大,容易发生尺度漂移问题②传统的视觉里程可以达到实时,建图结果较为稀疏,基于MVS的方法建图结果较为稠密但是耗时巨大。解决思路:①结合基于高航空航拍图片的视觉里程计、基于深度学习的深度恢复②前端:以DSO为基础,利用GPS给予DSO真实尺度②后端:融合GPS,带回环的后端优化③SCCVA-MVSNet:输入滑动窗口中所有帧的信息,得到当前最新关键帧的深度④融合:利用位姿融合多帧深度图。
9.3 自主移动机器人规划
自主移动机器人规划指:①为每个智能体规划出从起点到终点的路径②路径需要避开环境内障碍物③需要避免与其他智能体发生碰撞。规划问题面临的挑战①运动学模型复杂②挑战性环境③多智能体。规划层面的机器人系统应用:足式机器人、水面机器人平台,多机器人规划问题:时空约束、姿态约束多智能体规划,强化学习智能规划等。
针对行人跟随任务的四足机器人高效运动方法难点①行人跟随任务多采用轮式机器人平台,但其移动能力有限,难以处理狭窄或复杂的地形②为全向移动机器人设计的规划器能够在SE(2)中规划轨迹,但运动模型复杂,须考虑四足机器人更加详细的运动力学约束③基于复杂的四足动力学模型无法实现在线规划,但是过于简单的足迹描述又不能保证生成运动轨迹的可执行性。解决思路:①四足机器人相比传统机器人拥有更优越的地形适应能力以及灵活的运动能力②提出一种简化的运动动力学模型在线运动规划方案,满足在复杂环境中人员跟随任务的需求。
融合2D-3D感知的无人船感知和规划难点①环境监测、抢险救援等不同任务对水面无人艇需求迫切②目前针对无人艇结构化、系统化问题深入研究工作较少亟需一套安全可靠、可供实际运行的无人艇避障航行系统方案③环境感知:无人艇实际应用的特殊场景要求更高的数据获取能力④船体自身运动特性:控制精度低、水面扰动大。解决思路①定位模块:无人艇采用NDT匹配算法,根据事先建立的全局地图与感知雷达点云数据进行配准,从而实现精准实时定位②环境感知模块:算法采用相机二维数据与激光雷达三维数据融合的方式提取环境中障碍物信息。主要通过二维数据确定ROI区域,在对雷达数据进行聚类分析。主要通过二维数据确定ROI区域,在对雷达进行聚类分析。规划模块:无人艇根据环境信息和目标位置,采用A*局部规划实现实时动态避障。
基于时空约束的多智能体路径规划方法难点:①多智能体寻路(MAPF)问题大多为基于冲突的搜索或基于优先级的方法②现有求解器大多缺乏完整性保证或基于一定的假设,比如忽略机器人的运动学约束并使用离散网格地图③CL-CBS基于连续的空间,考虑Ackermann底盘机器人的路径规划问题。解决思路针对阿克曼模型的基于冲突搜索算法:分层搜索框架①上层搜索:车身约束树②下层搜索:时空混合A*算法③顺序规划版本:牺牲了少许求解质量,换取程序运行时间。
姿态约束的多车辆运动规划方法难点:①集中式多智能体规划算法随着智能体数量的增加,计算代价呈指数增长,且要求智能体具有完美的感知能力②分布式多智能体规划算法大多驾驶智能体可全向移动,而固定翼无人机等智能体只能前向运动或者小幅转弯③多智能体规划问题不仅要求智能体从起点到终点,还需要考虑智能体在起点和重点的姿态。解决思路:①运动规划部分基于传统的RVO算法提出了一种对称情况下的分流策略,为智能体选择最优速度②姿态约束部分:针对多智能体到达指定航迹点时需要满足指定的姿态,以及航迹点之间需要考虑智能体的姿态约束,以及航迹点之间需要考虑智能体的姿态约束,在运动规划工作的基础上引入Dubins曲线解决智能体的姿态约束问题,提出了一种姿态避碰算法。
在动态数量场景中学习通信以促进合作难点:①目前大多数智能体强化学习算法都局限于固定的网络难度,并且在训练阶段使用先验知识来预设智能体的数量这导致算法的泛化性较差②传统大规模多智能体强化学习算法集中训练会导致网络维度的爆炸式增长,进而导致集中学习算法的可扩展性非常有限。解决思路:①所有智能体使用注意力机制构建动态通信数组,智能体只关注值得交流的智能体,并给出注意力网络训练方法②在Mixing Network对所有组进行分值操作,使用mask屏蔽不存在的分组,有效地在动态代理数量上训练。大量智能体场景与分组情况类似,每个智能体不必关注远处智能体行为,所以每个智能体组周围智能体进行分值分解操作即可,即值分解操作具有上限③动态智能体合作网络采用组内集中训练和分散执行,故此算法可扩展性极强,泛化能力得到大大提高。
基于局部视野的多智能体编队规划方法难点①移动机器人部署于现实应用时,往往要求避开障碍物的同时以特定的队形移动,如仓库机器人需要维持特定队形来运输大件货物②现有路径规划算法不考虑移动中的编队队形③现有的规划方法集中在全局规划,需要场景全局信息④全局规划搜索时间长,无法适应大规模场景⑤基于强化学习的方法可学习分布式方法,但并行学习多个任务时会因训练冲突而效果不佳。解决思路提出一种分层强化学习结构,将多目标任务解耦①底层策略:分别单独利用路径规划任务奖励与编队任务奖励训练,保证不同任务的策略训练之间不存在冲突②高层策略:训练Meta Policy在每个时间步绝对调用哪个底层策略,保证整体策略可以平衡规划性能与编队性能。
9.4 提问环节
1,在标定的时候,能观的方向的标准判断能介绍一下吗?能观方向的判断标准和阈值能否出现在在线标定当中?
在这个方向没有激励就是不能观。目前能观是一种经验性的判断,暂时没有固定的阈值。
2,在激光点云上提取直线,直线的精度比点云配准精度高,其中一个原因会不会是因为直线比较稀疏,可区分性更强?
外点率特别高,外点率要降下来,肯定要RANSCK。直线确实比点更稀疏而且更容易区分,外线率比较低,所以不用RANSCK,误匹配率比较低。提取直线的时间虽然耗费的比较多,但是后端没有RANSCK,总体来说时间节约了不少。
3,在闭环检测中,用到了语义信息,语义信息具体有哪些,检测语义信息是不是很耗时?
语义还好,两阶段语义方法可以实现在线跑。前端提取完信息后,后面匹配不是很费时间,而且闭环检测并不是一直做。
4,核回归激光点深度恢复,激光点有没有可能切入到网络中?
关键是图像核点云结合,将两个数据耦合然后放到网络里面去。
5,全天候自监督单目深度估计,这个自监督体现在哪里?
自监督很简单,白天和夜晚的场景具有一定的关系,通过对白天的学习可以监督晚上和白天。。
6,单个机器人路径规划比较成熟,多个机器人路径规划不太成熟,是不是因为有可能碰撞,还是因为其他问题?
这个问题很多,碰撞是其中一个,调度不好容易死锁。还有就是架构是分布式还是集中式,这个对规划都有影响,而且规划要求实时性,需要快速的计算出路径。
Neal提问环节-AR与计算机视觉技术
1,可以介绍一下SLAM在AR应用当中的技术难度吗?
SLAM在AR行业,主要挑战是算力和传感器的质量以及传感器的数量是十分受限的。一般XR设备要求算力小、续航高,所以对SLAM算法计算效率要求很高。
2,前端和后端优化时,会发生跳变,XR要求稳定,那这种情况该怎么处理?
这个没有什么特别好的方法,需要根据情况来看,如果变化小则通过时间的宽度来延缓跳变,如果变化大则立刻纠正更新。
3,滤波和优化时,重新线性化时机和处理方式能介绍一下吗?
还是看具体情况而定,好的pose,重新线性化少一些,差的或者说是新的pose重新线性化多一些。
4,分析一下XR发展趋势,VR眼镜发展情况?
要保持续航,以及相应生态需要累积,尽量找到一些近年可以落地的点。未来三年内,air这样的眼镜会比较多,后面全功能的眼镜才会慢慢出来。
5,SLAM在工程领域,有哪些加速的模块或者技术?
要先将前端确定下来,然后在硬件层面进行加速,然后在VIO或者VINS模块进行剪裁,保证实时性。后端的大矩阵进行一下拆分,然后做一下算法的加速。
灵犀微光提问环节—AR光波导的应用与发展
。。。。光学在AR的应用,做XR眼镜可以了解一下。
像衍科技提问环节——基于深度学习的三维重建与位姿估计系统设计
1,关于onepose方面的工作,每一个新的物体需要新的mapping吗?需要的话需要采集那些角度或者范围的数据量?
需要新的mapping,采集的数据量,看设计,需要从那些角度看,就采集那些数据。
2,onepose都在做小物体,如果换在大场景的定位会怎么样?
定位的主要问题,还是随机的点太多了,可以尝试深入研究一下。
3,neural跟lidar相比,重建一个楼或者商城,有过实际的测试结果吗,对比起来怎么样?
如果能用lidar还是用lidar,没用测试过,如果放到大场景应该还可以。
4,后面做空间采样的时候,有没有尝试油腻sef的尝试?
做完发现比较相似,就没有继续测试。
5,你做的重建和colmap对比了一下,有overfast这样的模式,这样的模式和别的模式有区别吗?
没有,只是减少了训练时间。
6,insdand dp修改起来速度怎么样?对Nerf的看法
不好做。NeRF很好,公司也在使用,值得投入学习。
7,做研究的心路里程怎么样,给一下做科研的建议
我们在一个很好的时代,有很多工具来解决难点。要有开拓的想法,而不是只想着发paper。有很好的机会做很好的工作,需要静下心来,尽量少水一些paper。找一个好的,世界级的团队会很很多
8,你是怎么找到好的平台的呢?
开始我是在大疆工作,工作了一年之后,想换一个学术氛围很好的地方。之后看到zhouxiaobo老师回国就去联系他了。
9,NeRF后面有什么好的应用方向吗?
室外光照变化剧烈的情况,处理好。


















 1688
1688

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









