






来源:AI缝合术


一、论文信息

1
论文题目:MobileMamba: Lightweight Multi-Receptive Visual Mamba Network中文题目:MobileMamba:轻量级多感受野视觉Mamba网络论文链接:https://arxiv.org/pdf/2411.15941
所属单位:浙江大学,腾讯优图实验室,华中科技大学
核心速览:本文介绍了一种名为MobileMamba的轻量级多感受野视觉网络,旨在解决现有轻量级模型在效率和性能之间的平衡问题。MobileMamba不仅在图像分类任务中表现出色,而且在目标检测和实例分割任务中也具有竞争力,并且在GPU上的效率非常高。即插即用,可以直接替换现有的基于CNN、Transformer或者Mamba的骨干网络Backbone!

二、论文概要

Highlight
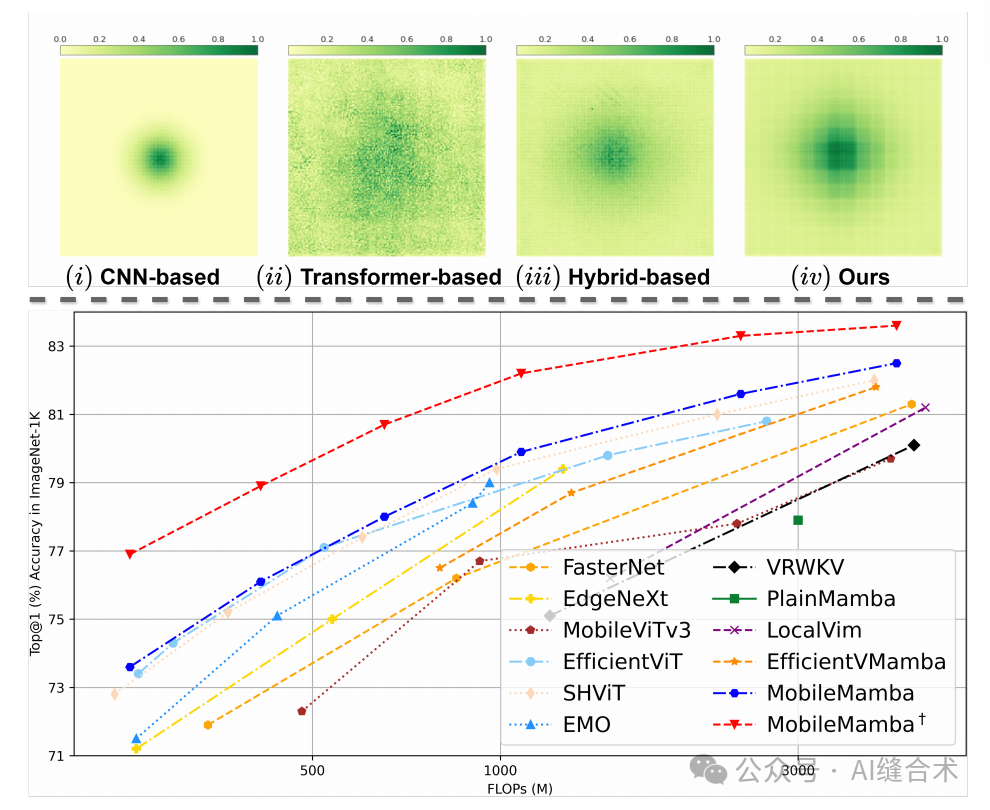
图1. 上:不同架构的有效感受野(ERF)可视化。下:基于最近的CNN/Transformer/Mamba方法的性能与FLOPs对比。
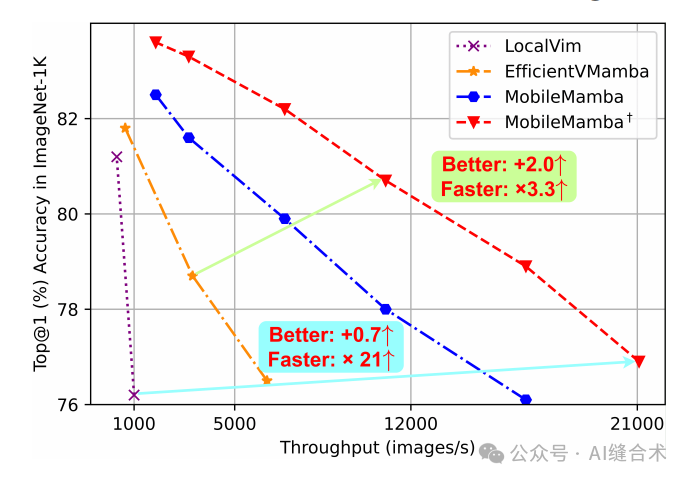
图2. 基于Mamba方法的准确率与速度对比。
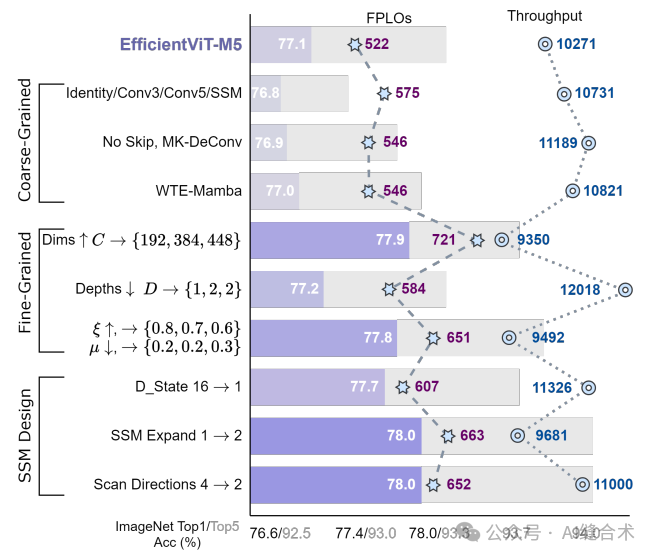
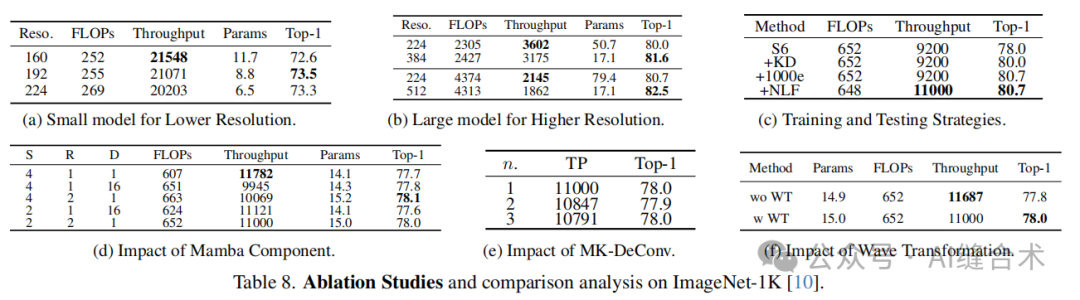
图5. 在ImageNet-1K上对MobileMamba进行增量实验,比较Top1/Top5准确率、FLOPs和吞吐量。
1. 研究背景:
研究问题:随着移动设备的普及,对资源受限环境下的高效准确视觉处理需求日益增长。现有的轻量级模型主要分为基于CNN和基于Transformer的结构,但它们在捕捉长距离依赖关系和处理高分辨率输入时存在局限性。CNN模型虽然计算复杂度较低,但其局部感受野限制了其捕捉长距离相关性的能力;而Transformer模型虽然具有全局感受野和长距离建模能力,但其二次方的计算复杂度在高分辨率场景下成为瓶颈。因此,研究者们寻求一种新的模型结构,以在保持低计算复杂度的同时,提高模型的性能和效率。
研究难点:设计一种新的轻量级网络结构,使其在保持低计算复杂度的同时,能够有效捕捉长距离依赖关系,并在高分辨率输入下保持高性能。此外,还需要考虑如何通过训练和测试策略进一步提升模型的性能和效率。
文献综述:文章提到了当前轻量级模型的研究进展,包括基于CNN的MobileNets和基于Transformer的Vision Transformers (ViTs)。这些模型在降低计算复杂度和提高推理速度方面取得了一定的成果,但仍然存在局限性。例如,CNN模型难以捕捉长距离依赖关系,而ViT模型在高分辨率输入下计算复杂度过高。此外,还提到了最近流行的基于Mamba的模型,这些模型虽然具有线性的计算复杂度,但在实际应用中仍然存在推理速度慢和性能不佳的问题。
2. 本文贡献:MobileMamba框架
三阶段网络结构:MobileMamba框架采用三阶段网络结构,以提高推理速度和准确性。与四阶段网络相比,三阶段网络在相同的吞吐量下能够达到更高的准确率,在相同的性能下具有更高的吞吐量。
多感受野特征交互模块(MRFFI):设计了MRFFI模块,该模块包含长距离小波变换增强的Mamba(WTE-Mamba)、高效多核深度卷积(MK-DeConv)和消除冗余身份组件。MRFFI模块整合了多感受野信息,增强了高频细节的提取。
训练和测试策略:通过知识蒸馏和扩展训练周期等训练策略,以及测试阶段的归一化层融合策略,进一步提升了模型的性能和效率。

三、创新方法

1
一、 MobileMamba的粗粒度设计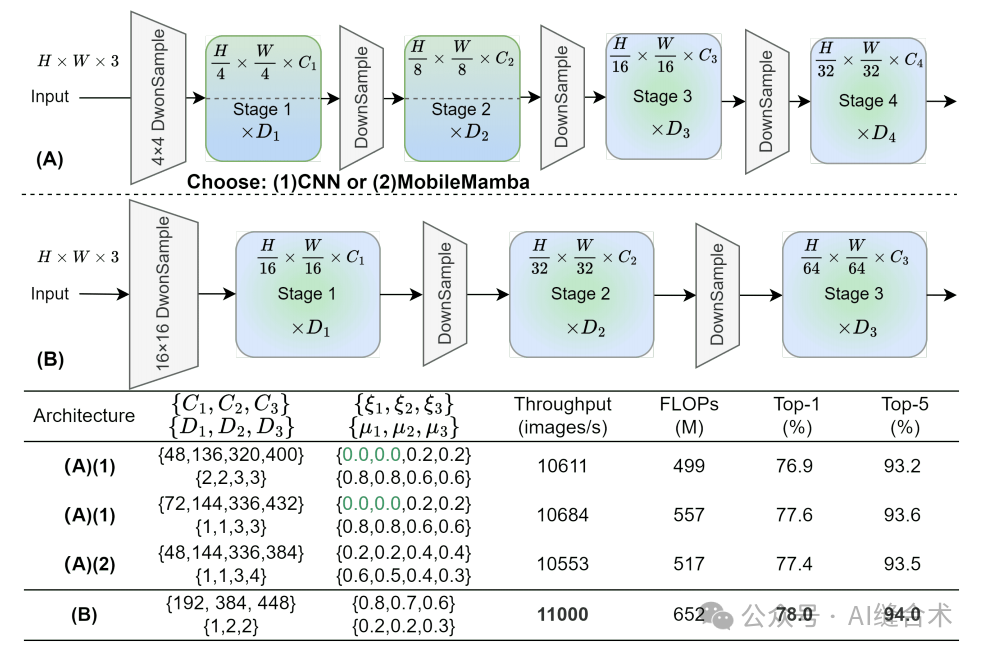
图3. 粗粒度设计。(A) 描述了一种常用的四阶段网络结构,其中前两个阶段可以配置为 (1) 纯粹基于CNN的结构 或 (2) MobileMamba结构。(B) 描绘了本研究中采用的三阶段网络结构。下表展示了不同结构的模型参数以及在等效吞吐量下的ImageNet-1K Top-1和Top-5结果。图4. MobileMamba概述。
四阶段网络:在第一阶段下采样时,将输入图像从H×W×3降低到C1,最终输出为C4。由于四阶段网络的特征图尺寸较大,因此需要更多的计算,导致速度较慢。
三阶段网络:在第一阶段下采样时,特征图尺寸较小,因此计算量减少,速度更快。在相同的吞吐量条件下,三阶段网络在Top-1和Top-5准确率上都有所提高。
实验比较:在实验中,首先使用纯CNN架构设计了四阶段网络的前两个阶段,以提高推理速度。然后,使用MobileMamba块替换四阶段网络的所有四个阶段。结果表明,尽管四阶段网络在前两个阶段使用纯CNN结构时显示出更快的推理速度和更好的性能,但三阶段网络在推理速度和分类结果上都有所提升。
选择三阶段网络:最终选择了三阶段网络结构,以提高推理速度并改善分类结果。
二、MobileMamba的细粒度设计
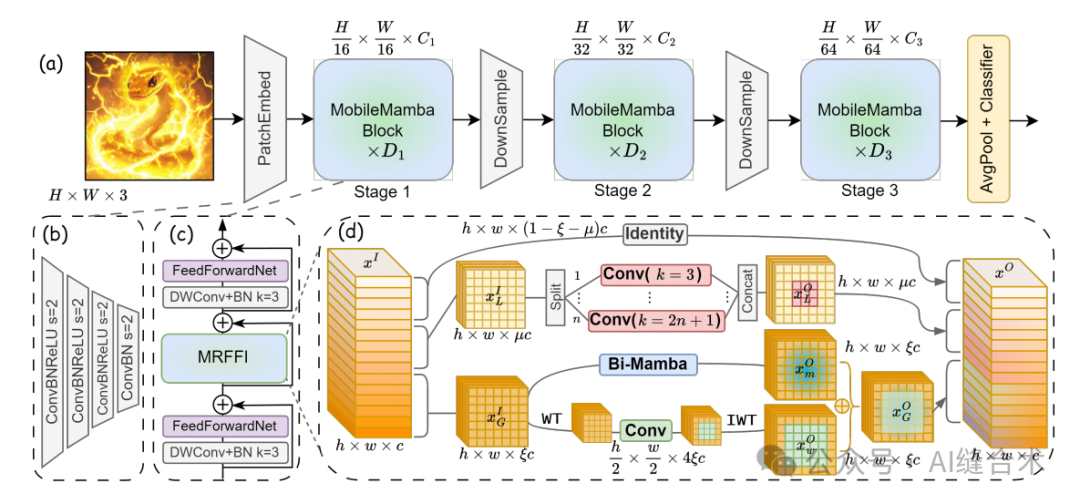
(a) MobileMamba的架构。(b) 16 ×16下采样PatchEmbed。(c) MobileMamba块的结构。(d) 细粒度设计。提出的高效多感受野特征交互(MRFFI)模块。
MRFFI模块的组成:MRFFI模块位于MobileMamba块中对称的局部信息感知和FFN之间。它将特征沿通道维度分为三部分:
第一部分通过长距离小波变换增强的Mamba(WTE-Mamba)模块处理,以增强高频边缘信息的提取并进行全局建模。
第二部分通过多核深度卷积(MK-DeConv)操作处理,以增强不同感受野的感知能力。
第三部分通过恒等映射减少高维空间中的特征冗余,降低计算复杂度,提高处理速度。
长距离WTE-Mamba:目的是基于全局建模增强提取细粒度信息,如高频边缘细节。通过双向扫描Mamba模块学习全局信息,然后通过Haar小波变换获得不同频率尺度的特征表示,并通过逆小波变换恢复原始特征图大小。
高效MK-DeConv:通过不同大小的卷积核提取局部信息,实现多感受野交互。对于剩余特征,选择局部通道比例,并将这些通道分为n部分,每部分通过不同大小的卷积核进行处理,最后将不同卷积操作的结果拼接形成输出特征。
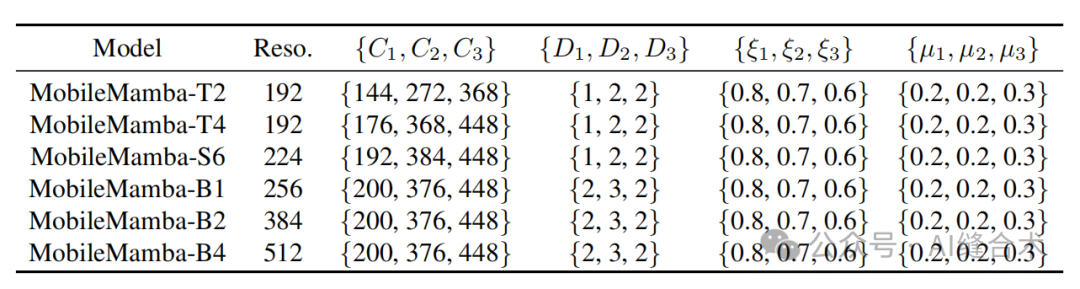
模型变体的架构细节:MobileMamba设计了六种结构,通过调整输入分辨率来平衡计算效率和性能之间的权衡。不同模型保持相同的全局和局部通道比例,小模型使用较小的输入分辨率以实现较低的计算复杂度和更快的运行时间,而大模型使用较大的输入分辨率以获得更好的性能。

四、实验分析

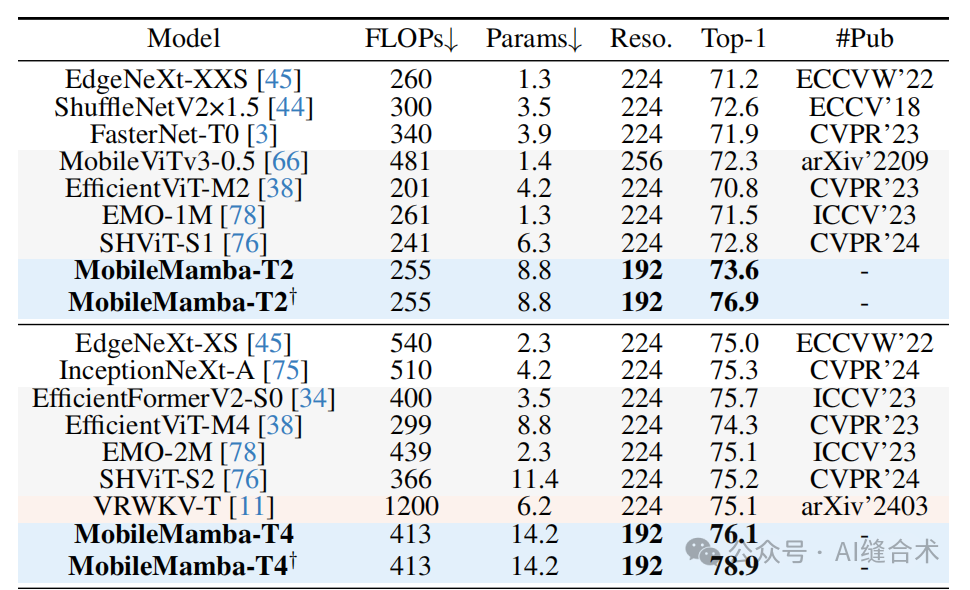
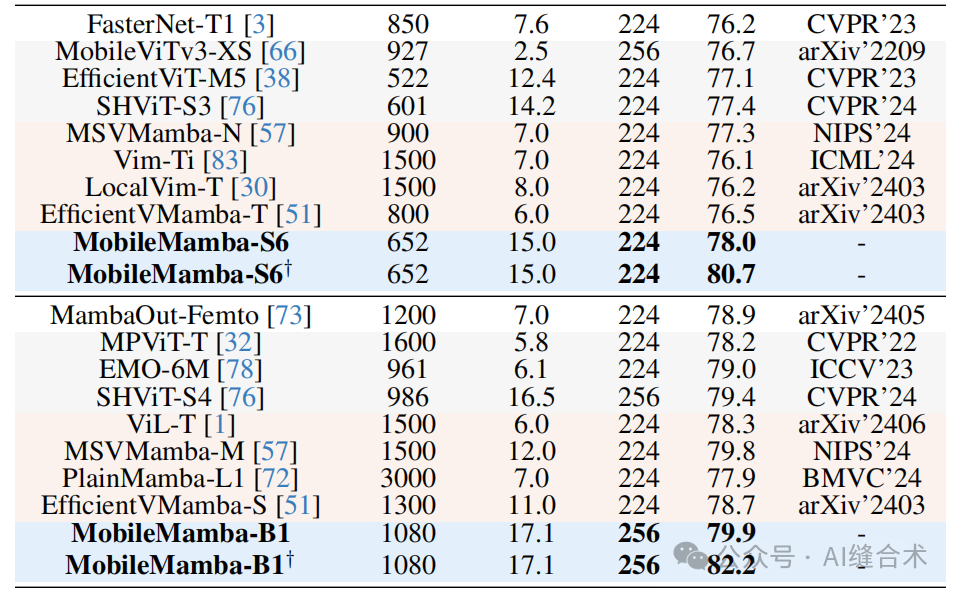
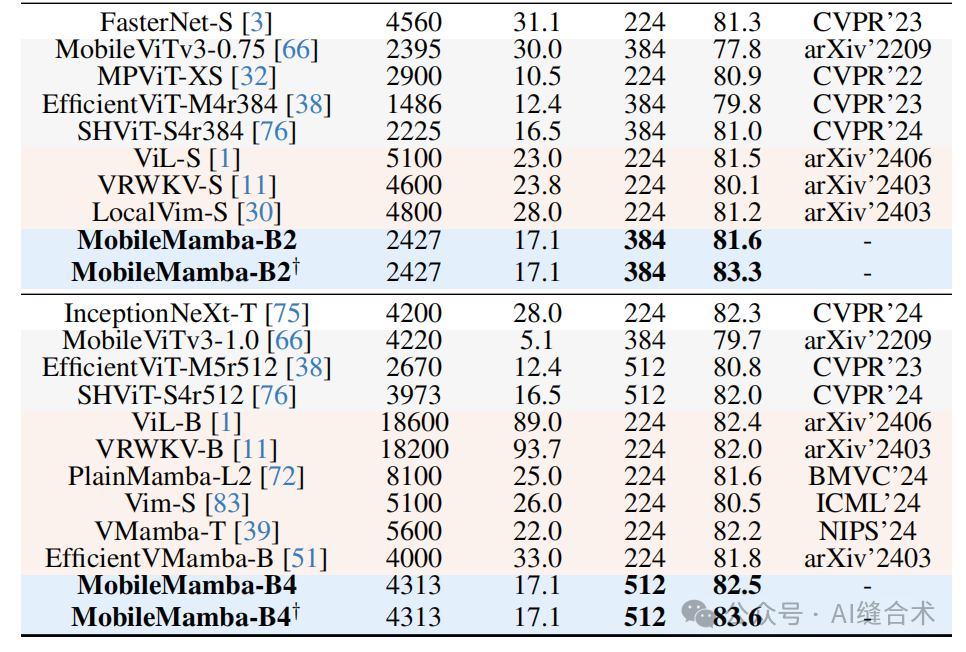
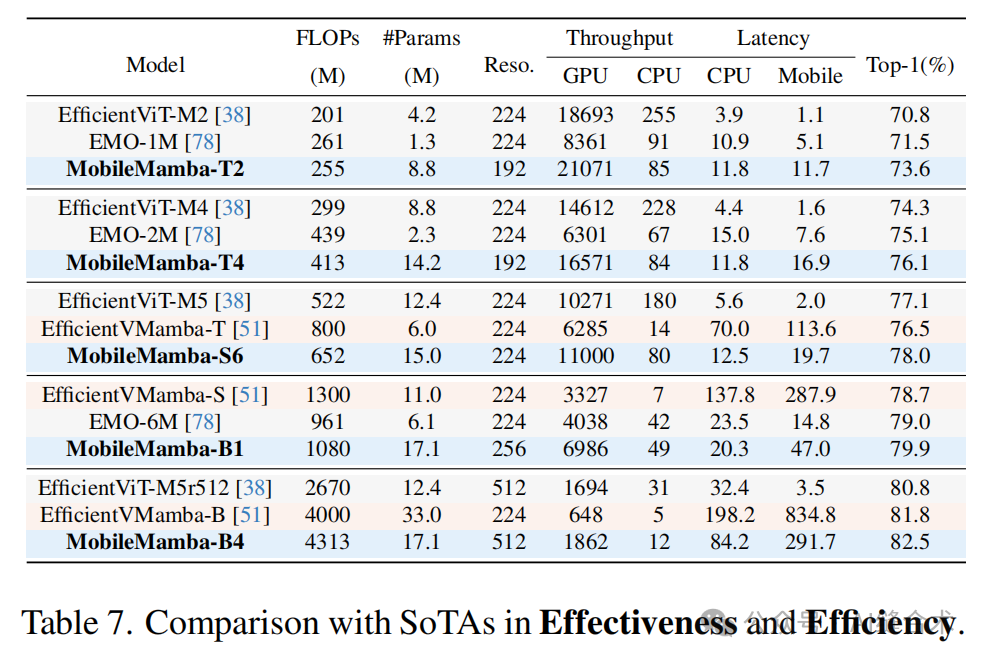
1. ImageNet-1K分类任务:MobileMamba在ImageNet-1K数据集上的Top-1准确率达到了83.6%,超过了现有的最先进方法,并且在GPU上的速度是LocalVim的21倍以上。
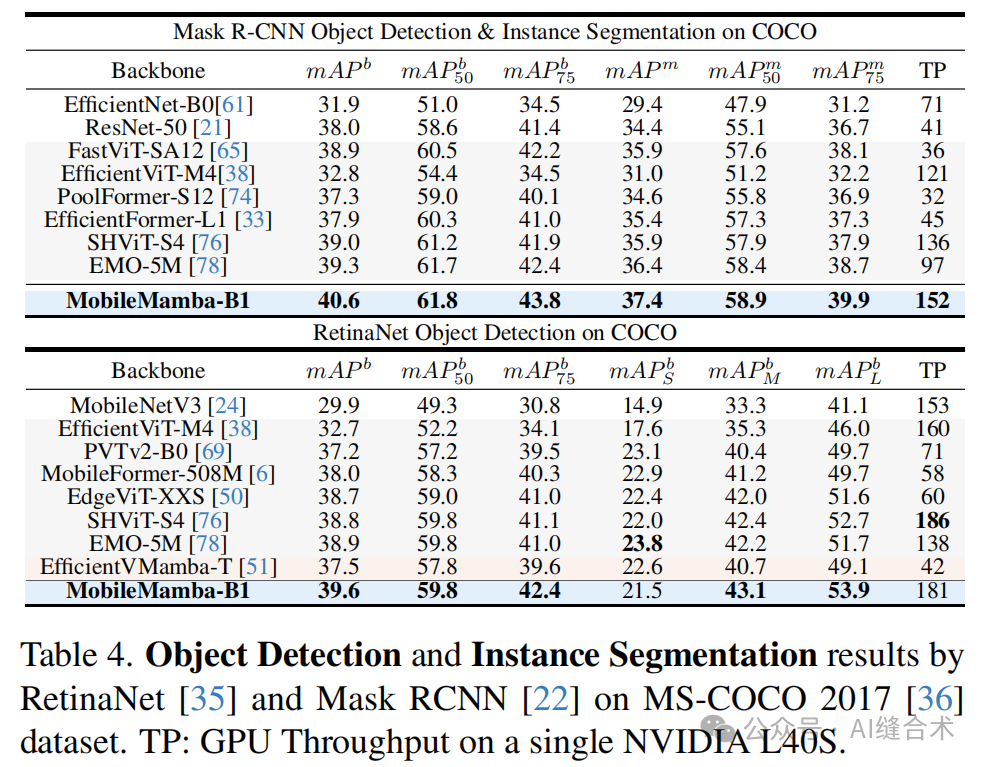
2. 下游任务性能:在高分辨率的下游任务中,MobileMamba超越了当前的高效模型,实现了速度和准确性的最佳平衡。例如,在Mask RCNN上,MobileMamba提高了mAPb和mAPm,并且吞吐量增加了56%;在RetinaNet上,提高了mAPb和吞吐量。
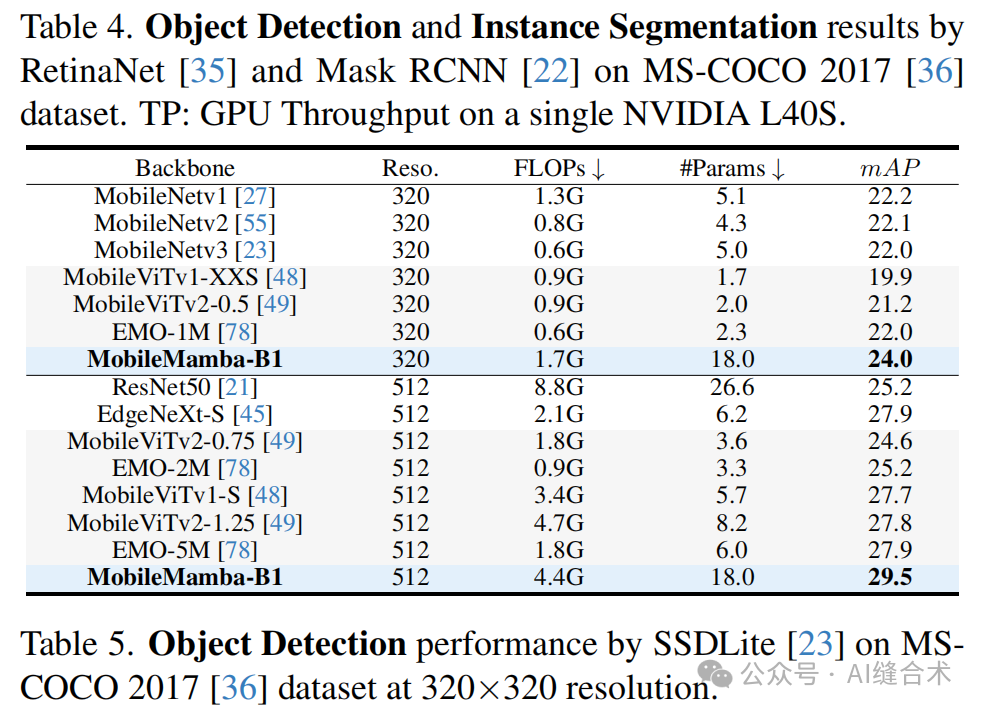
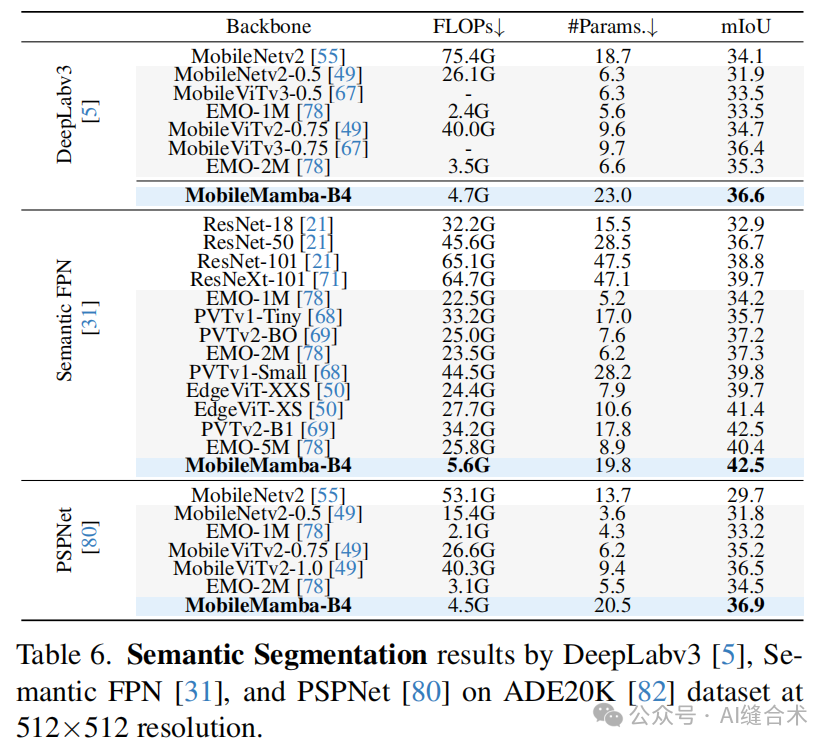
3. 效率比较:MobileMamba在GPU吞吐量上超过了所有现有方法,平均速度是EfficientVMamba的3.5倍以上。尽管在CPU吞吐量和移动设备上的延迟方面落后于基于Transformer的模型,但MobileMamba在Top-1准确率上平均提高了1.5以上。

五、结论

1
1. 结论:MobileMamba框架通过平衡性能和效率,解决了现有Mamba模型的局限性。MRFFI模块增强了不同感受野的感知能力,同时保留了高频特征和推理效率。训练和测试策略进一步提升了性能和效率。
2. 未来工作:尽管Mamba模型取得了进展,但在CPU加速和边缘设备加速方面仍存在工程实现的不足。未来将专注于提升Mamba模型在各种设备上的推理能力,特别是关注效率的提升。
推荐阅读
欢迎大家加入DLer-大模型技术交流群!

👆 长按识别,邀请您进群!


















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









