








常见的数据合并函数有rbind,cbind,left_join, right_join, full_join, inner_join等。
接下来我一一为大家介绍这些不同函数的使用及限制
1. 使用 rbind()
rbind() 函数用于将数据框垂直堆叠在一起。这意味着你可以在一个数据框的底部添加另一个数据框的行。所有数据框必须具有相同的列名和相同数量的列。
例如:
假设我们有两个数据框 df1 和 df2,它们有相同的列名和列数。
df1 <- data.frame(id = c(1, 2, 3), value1 = c("A", "B", "C"))
df2 <- data.frame(id = c(4, 5, 6), value1 = c("D", "E", "F"))
# 使用 rbind 合并数据框
df_combined <- rbind(df1, df2)
print(df_combined)在这里,df1如下图所示:

df2如下图所示:
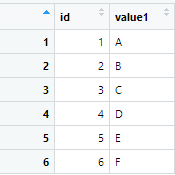
而合并后的df_combind如下图所示,可以看到这里我们把df1和df2合并成了1个数据。在GBD中,我们可以按这个方法,读取但不同csv文件但格式相同的数据,使用rbind()进行合并。
2. 使用 cbind()
cbind() 函数用于将数据框水平堆叠在一起。这意味着你可以在一个数据框的右侧添加另一个数据框的列。所
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1697
1697

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









