







背景介绍
现有的知识图谱大多是以单一的文本的形式表示,而多模态知识图谱会将文本信息和图像等其他模态的信息综合起来。
多模态知识图谱主要分为两种表现形式,其一是将多模态信息作为实体的属性,另一种是将多模态信息作为单独的实体。
多模态知识图谱目前也有较多的应用,针对知识图谱本身而言,它可以提供额外的多模态信息,以便进行连接预测等任务,而针对下游任务而言,可以据此进行视觉问答、图文匹配等。
本文将介绍四篇多模态知识图谱构建的相关论文,涉及到的方法主要分为两类,即根据多模态文档构建(GAIA、RESIN)和根据搜索引擎获取的图像构建(MMKG、Richpedia)。
GAIA
GAIA系统的结构如下,主要由文本知识抽取分支、视觉知识抽取分支和跨媒体知识融合模块构成。两个分支由相同的多模态文档集(比如有图片或视频又有文本的新闻)作为输入、都使用了DARPA AIDA本体中的相同类型,以便在跨媒体知识融合模块进行合并。
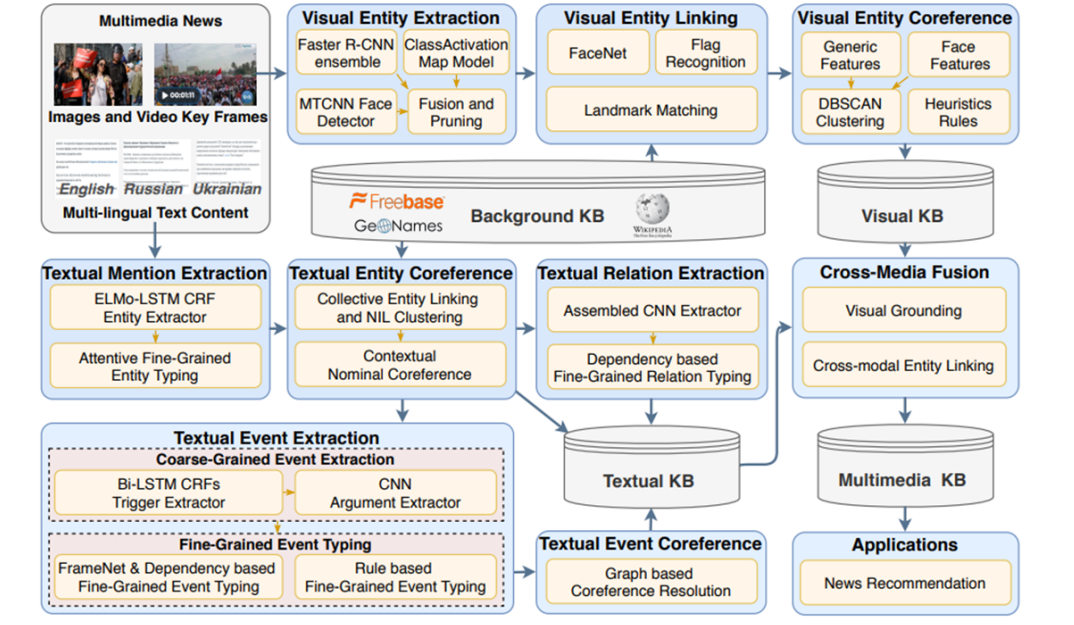
文本知识抽取分支
文本知识抽取分支由常规的文本实体抽取、关系抽取、事件抽取等模块构成。
对于可链接到同一背景知识图谱实体的提及,会添加共指信息。对于无法链接到知识图谱的提及,会使用启发式的规则将其聚成NIL簇(NIL簇是指提及同一实体但没有相应知识图谱条目的实体提及簇)。
此外,GAIA为每篇文档中的每个实体分配了一个显著性得分。如果该实体以名称的形式提及,则显著性会更高,以名词或代词的形式提及,则显著性会变低。每个文档中的所有实体的显著性得分会进行归一化处理。
视觉知识抽取分支
视觉知识抽取分支通过目标检测等模型生成检测框,以此进行实体抽取。特别地,GAIA单独使用人脸检测器MTCNN,并将结果作为额外的人物实体。
视觉实体连接过程中,模型尝试将每个实体与背景知识图谱中的实体联系起来。为每种粗粒度实体类型开发了不同的模型。对于人类型的实体,训练了一个FaceNet模型。对于位置、设施和组织实体,使用了预训练好的DELF模型。为了识别地缘政治实体,训练了CNN识别国旗,并将其归入预定的国家实体列表。如果在图像中检测到了国旗,会应用一套启发式规则,在知识图谱中创建某些实体与
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 5038
5038

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









