









 YOLOv1算法将目标检测问题转化为回归问题,通过单个卷积神经网络直接预测边界框位置及类别概率,实现了实时检测。网络结构借鉴GoogLeNet,输出7×7×30的tensor,每个网格单元预测2个边界框及其置信度。
YOLOv1算法将目标检测问题转化为回归问题,通过单个卷积神经网络直接预测边界框位置及类别概率,实现了实时检测。网络结构借鉴GoogLeNet,输出7×7×30的tensor,每个网格单元预测2个边界框及其置信度。
从R-CNN到Faster R-CNN一直采用的思路是proposal+分类 (proposal 提供位置信息, 分类提供类别信息)精度已经很高,但由于two-stage(proposal耗费时间过多)处理速度不行达不到real-time效果。
(R-CNN use region proposal methods to first generate potential bounding boxes in an image and then run a classifier on these proposed boxes.)
YOLO提供了另一种更为直接的思路: 直接在输出层回归bounding box的位置和bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)。
YOLO v1
网络结构借鉴了 GoogLeNet 。24个卷积层,2个全链接层。(用1×1 reduction layers 紧跟 3×3 convolutional layers 取代GoogleNet的 inception modules )。
 The final output of our network is the 7 × 7 × 30 tensor of predictions.
The final output of our network is the 7 × 7 × 30 tensor of predictions.
优点
1.由于整个检测管道是单个网络,因此可以直接根据检测性能进行端到端优化。
2.与基于滑动窗口和基于区域提案的技术不同,YOLO在训练和测试期间可以看到整个图像,因此它可以隐式地编码有关类及其外观的上下文信息。
算法原理
1.在YOLOv1中作者将一幅图片分成7x7个网格(grid cell),由网络的最后一层输出7×7×30的tensor,也就是说每个格子输出1×1×30的tensor。30里面包括了2个bounding box的x,y,w,h,confidengce以及针对格子而言的20个类别概率,输出就是 7x7x(5x2 + 20) 。(通用公式: SxS个网格,每个网格要预测B个bounding box还要预测C个categories,输出就是S x S x (5×B+C)的一个tensor。 注意:class信息是针对每个网格的,confidence信息是针对每个bounding box的),如Figure 2: The Model所示。
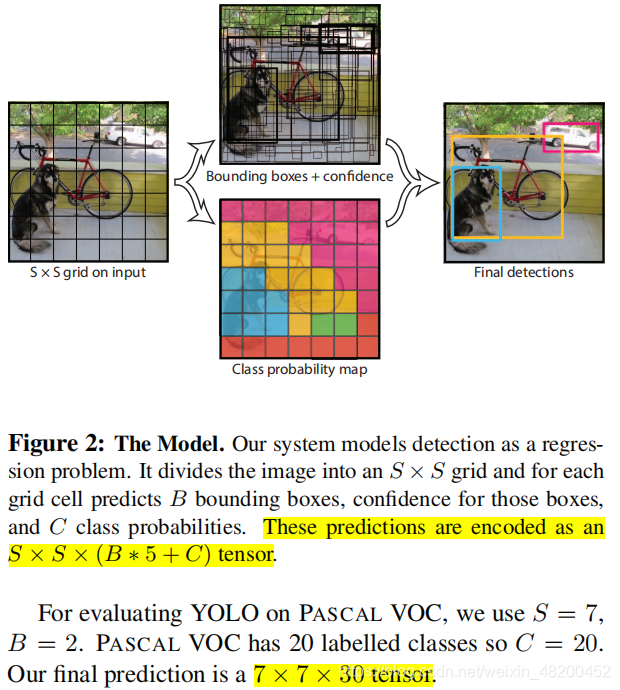
2.我们的系统将输入图像划分为一个S×S网格。如果对象的中心落入一个网格单元格中,则该网格单元格负责检测该对象。
算法首先把输入图像划分成S×S的格子,然后对每个格子都预测B个bounding boxes,每个bounding box都包含5个预测值:x,y,w,h和confidence。x,y就是bounding box的中心坐标,与grid cell对齐(即相对于当前grid cell的偏移值),使得范围变成0到1;w,h进行归一化(分别除以图像的w和h,这样最后的w和h就在0到1范围)。confidence代表了所预测的box中 【含有object的置信度】 和 【这个box预测的有多准】 两重信息。
3.损失函数如下图所示:
注:损失函数只有在该网格单元格中存在一个对象时,才能惩罚分类错误。

4. 我们根据图像的宽度和高度来规范化边界框的宽度和高度,使它们落在0和1之间。我们将边界框x和y坐标参数化为特定网格单元位置的偏移,因此它们也在0和1之间有界(We normalize the bounding box width and height by the image width and height so that they fall between 0 and 1. We parametrize the bounding box x and y coordinates to be offsets of a particular grid cell location so they are also bounded between 0 and 1.)。
专业词汇解释:
作者在YOLO算法中把物体检测(object detection)问题处理成回归问题,用一个卷积神经网络结构就可以从输入图像直接预测bounding box和类别概率。
( Instead, we frame object detection as a regression problem to spatially separated bounding boxes and associated class probabilities.我们将对象检测框架做为一个回归问题,以实现空间分离的边界框和相关的类概率。)
1.置信度(confidence)
置信度(confidence)=类概率*IoU
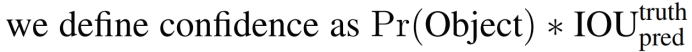 Pr(Object)是边界框内存在对象的概率,若存在对象,Pr(Object)=1,否则Pr(Object)=0;IOU是真实框(ground truth)与预测框(predicted box)的交并比
Pr(Object)是边界框内存在对象的概率,若存在对象,Pr(Object)=1,否则Pr(Object)=0;IOU是真实框(ground truth)与预测框(predicted box)的交并比
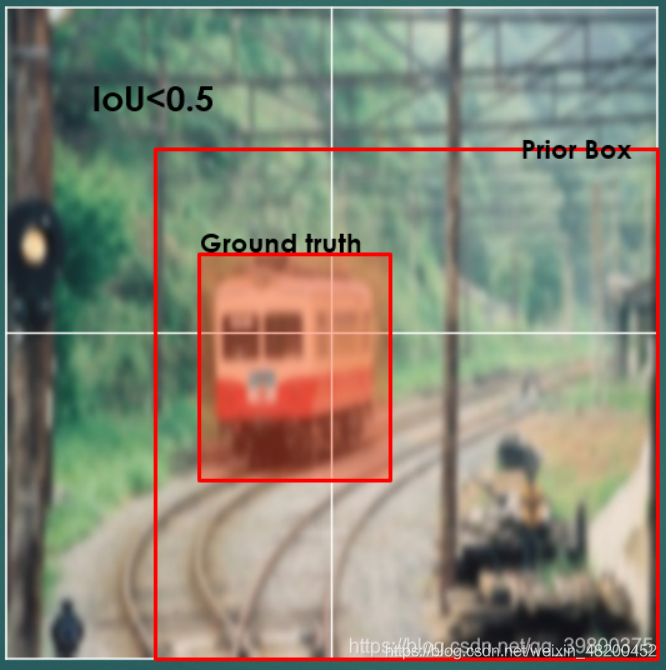
2.IoU(Intersection over Union ratio)
实际上就是预测框和真实框面积的交集与并集的比值(两边界框相交部分面积与相并部分面积之比)。我们认为只有IoU>0.5的priorbox才是有价值的。

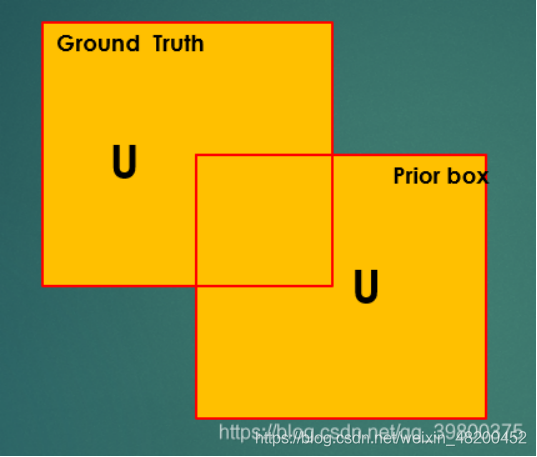

下面看一组图:
原图

卷积后

(1)9*9feature map

(2)5*5feature map
(3)2*2feature map
(Each bounding box consists of 5 predictions: x, y, w, h, and confidence. The (x, y) coordinates represent the center of the box relative to the bounds of the grid cell. The width and height are predicted relative to the whole image. Finally the confidence prediction represents the IOU between the predicted box and any ground truth box.每个边界框由5个预测组成:x、y、w、h和置信度。(x、y)坐标表示相对于网格单元格边界的框的中心。相对于整个图像预测宽度和高度。最后,置信度预测表示预测盒与任何地面真盒之间的IOU。)
训练步骤
1.我们的系统将输入图像划分为一个S×S网格。如果对象的中心进入网格单元,则该网格单元负责检测该对象。
2.每个网格单元格都预测B个边界框和这些框的confidence scroe置信度分数
1.测试

公式如下:

对每一个网格的每一个bbox执行同样操作: 7x7x2 = 98 bbox (每个bbox既有对应的class信息又有坐标信息)。
得到98bbox的信息后,首先对阈值小于0.2的score清零,然后重新排序,最后再用NMS算法去掉重复率较大的bounding box(NMS:针对某一类别,选择得分最大的bounding box,然后计算它和其它bounding box的IOU值,如果IOU大于0.5,说明重复率较大,该得分设为0,如果不大于0.5,则不改;这样一轮后,再选择剩下的score里面最大的那个bounding box,然后计算该bounding box和其它bounding box的IOU,重复以上过程直到最后)。最后每个bounding box的20个score取最大的score,如果这个score大于0,那么这个bounding box就是这个socre对应的类别(矩阵的行),如果小于0,说明这个bounding box里面没有物体,跳过即可。
参考文章:
https://blog.csdn.net/litt1e/article/details/88814417
https://blog.csdn.net/qq_39800375/article/details/107721015
You Only Look Once: Unified, Real-Time Object Detection


















 2498
2498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











