







我自己的原文哦~ https://blog.51cto.com/whaosoft/11566532
# 语言模型是否会规划未来 token
Transformer本可以深谋远虑,但就是不做,语言模型是否会规划未来 token?这篇论文给你答案。
「别让 Yann LeCun 看见了。」
Yann LeCun 表示太迟了,他已经看到了。今天要介绍的这篇 「LeCun 非要看」的论文探讨的问题是:Transformer 是深谋远虑的语言模型吗?当它在某个位置执行推理时,它会预先考虑后面的位置吗?
这项研究得出的结论是:Transformer 有能力这样做,但在实践中不会这样做。
我们都知道,人类会思而后言。数十年的语言学研究表明:人类在使用语言时,内心会预测即将出现的语言输入、词或句子。
不同于人类,现在的语言模型在「说话」时会为每个 token 分配固定的计算量。那么我们不禁要问:语言模型会和人类一样预先性地思考吗?
近期的一些研究已经表明:可以通过探查语言模型的隐藏状态来预测下一 token 之后的更多 token。有趣的是,通过在模型隐藏状态上使用线性探针,可以在一定程度上预测模型在未来 token 上的输出,而干扰隐藏状态则可以对未来输出进行可预测的修改。
这些发现表明在给定时间步骤的模型激活至少在一定程度上可以预测未来输出。
但是,我们还不清楚其原因:这只是数据的偶然属性,还是因为模型会刻意为未来时间步骤准备信息(但这会影响模型在当前位置的性能)?
为了解答这一问题,近日科罗拉多大学博尔德分校和康奈尔大学的三位研究者发布了一篇题为《语言模型是否会规划未来 token?》的论文。
论文标题:Do Language Models Plan for Future Tokens?
论文地址:https://arxiv.org/pdf/2404.00859.pdf
研究概览
他们观察到,在训练期间的梯度既会为当前 token 位置的损失优化权重,也会为该序列后面的 token 进行优化。他们又进一步问:当前的 transformer 权重会以怎样的比例为当前 token 和未来 token 分配资源?
他们考虑了两种可能性:预缓存假设(pre-caching hypothesis)和面包屑假设(breadcrumbs hypothesis)。

预缓存假设是指 transformer 会在时间步骤 t 计算与当前时间步骤的推理任务无关但可能对未来时间步骤 t + τ 有用的特征,而面包屑假设是指与时间步骤 t 最相关的特征已经等同于将在时间步骤 t + τ 最有用的特征。
为了评估哪种假设是正确的,该团队提出了一种短视型训练方案(myopic training scheme),该方案不会将当前位置的损失的梯度传播给之前位置的隐藏状态。
对上述假设和方案的数学定义和理论描述请参阅原论文。
实验结果
为了了解语言模型是否可能直接实现预缓存,他们设计了一种合成场景,其中只能通过显式的预缓存完成任务。他们配置了一种任务,其中模型必须为下一 token 预先计算信息,否则就无法在一次单向通过中准确计算出正确答案。

该团队构建的合成数据集定义。
在这个合成场景中,该团队发现了明显的证据可以说明 transformer 可以学习预缓存。当基于 transformer 的序列模型必须预计算信息来最小化损失时,它们就会这样做。
之后,他们又探究了自然语言模型(预训练的 GPT-2 变体)是会展现出面包屑假设还是会展现出预缓存假设。他们的短视型训练方案实验表明在这种设置中,预缓存出现的情况少得多,因此结果更偏向于面包屑假设。
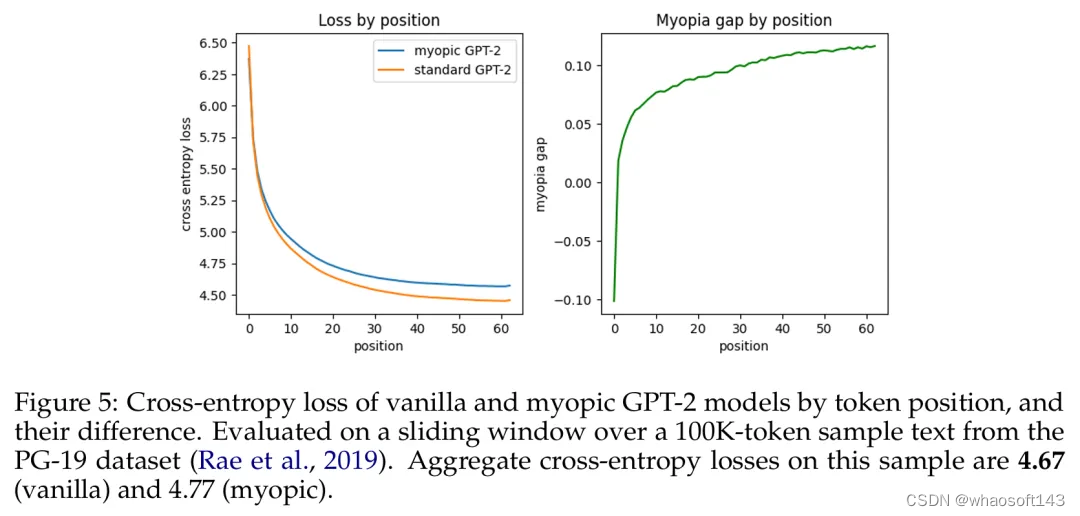
基于 token 位置的原始 GPT-2 模型与短视型 GPT-2 模型的交叉熵损失及其差异。
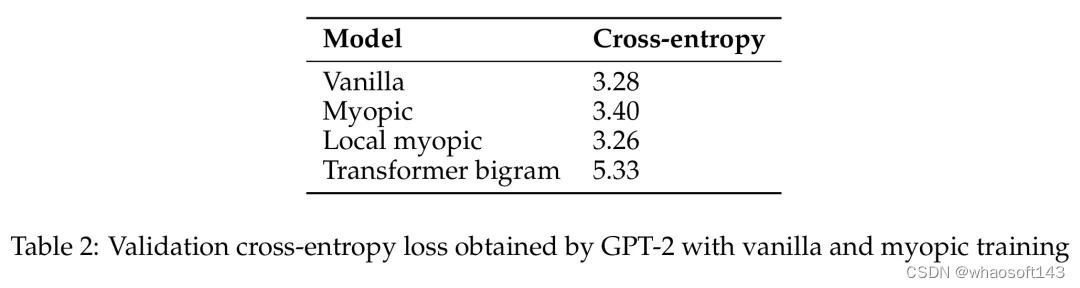
GPT-2 通过原始和短视型训练获得的验证交叉熵损失。
于是该团队声称:在真实语言数据上,语言模型并不会在显著程度上准备用于未来的信息。相反,它们是计算对预测下一个 token 有用的特征 —— 事实证明这对未来的步骤也很有用。
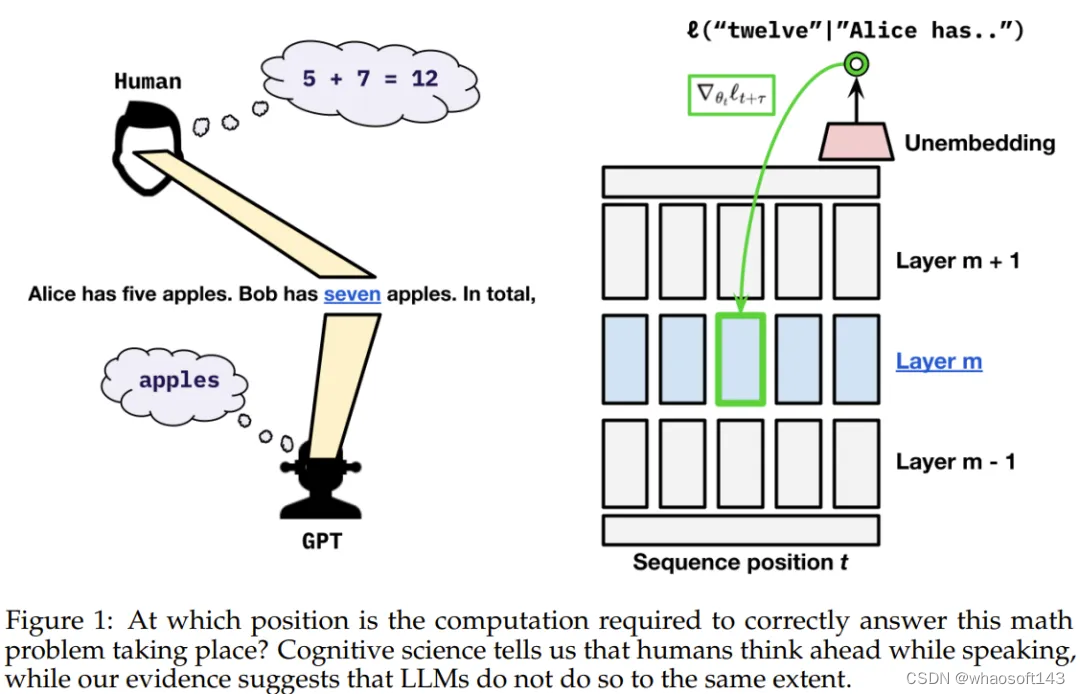
该团队表示:「在语言数据中,我们观察到贪婪地针对下一 token 损失进行优化与确保未来预测性能之间并不存在显著的权衡。」
因此我们大概可以看出来,Transformer 能否深谋远虑的问题似乎本质上是一个数据问题。
# Bigger is not Always Better
大模型一定就比小模型好?谷歌的这项研究说不一定, 在这个大模型不断创造新成就的时代,我们通常对机器学习模型有一个直观认知:越大越好。但事实果真如此吗?
近日,Google Research 一个团队基于隐扩散模型(LDM)进行了大量实验研究,得出了一个结论:更大并不总是更好(Bigger is not Always Better),尤其是在预算有限时。
- 论文标题:Bigger is not Always Better: Scaling Properties of Latent Diffusion Models
- 论文地址:https://arxiv.org/pdf/2404.01367.pdf
近段时间,隐扩散模型和广义上的扩散模型取得的成就不可谓不耀眼。这些模型在处理了大规模高质量数据之后,可以非常出色地完成多种不同任务,包括图像合成与编辑、视频创建、音频生成和 3D 合成。
尽管这些模型可以解决多种多样的问题,但要想在真实世界应用中大规模使用它们,还需要克服一大障碍:采样效率低。
这一难题的本质在于,为了生成高质量输出,LDM 需要依赖多步采样,而我们知道:采样总成本 = 采样步骤数 × 每一步的成本。
具体来说,目前人们首选的方法需要使用 50 步 DDIM 采样。这个过程虽能确保输出质量,但在具备后量化(post-quantization)功能的现代移动设备上却需要相当长的延迟才能完成。因此,为了促进 LDM 的实际应用,就需要优化其效率。
事实上,这一领域已经出现了一些优化技术,但对于更小型、冗余更少的模型的采样效率,研究社区还未给予适当关注。在这一领域,一个重大障碍是缺少可用的现代加速器集群,因为从头开始训练高质量文生图 LDM 的时间和资金成本都很高 —— 往往需要几周时间和数十万美元资金。
该团队通过实验研究了规模大小的变化对 LDM 的性能和效率的影响,其中关注重点是理解 LDM 的规模扩展性质对采样效率的影响。他们使用有限的预算从头开始训练了 12 个文生图 LDM,参数量从 39M 到 5B 不等。whaosoft开发板商城测试设备www.143ai.com
图 1 给出了一些结果示例。所有模型都是在 TPUv5 上训练的,使用了他们的内部数据源,其中包含大约 6 亿对已过滤的文本 - 图像。

他们的研究发现,LDM 中确实存在一个随模型规模变化的趋势:在同等的采样预算下,较小模型可能有能力超越较大模型。
此外,他们还研究了预训练文生图 LDM 的大小会如何影响其在不同下游任务上的采样效率,比如真实世界超分辨率、主题驱动的文生图( 即 Dreambooth)。
对于隐扩散模型在文生图和其它多种下游任务上的规模扩展性质,该团队得到了以下重要发现:
- 预训练的性能会随训练计算量而扩展。通过将模型的参数量从 39M 扩展到 5B,该团队发现计算资源和 LDM 性能之间存在明显联系。这表明随着模型增大,还有潜力实现进一步提升。
- 下游性能会随预训练而扩展。该团队的实验表明:预训练性能与在下游任务上的成功之间存在很强的关联。较小模型即使使用额外的训练也无法完全赶上较大模型的预训练质量所带来的优势。
- 较小模型的采样效率更高。当给定了采样预算时,较小模型的图像质量一开始会优于较大模型,而当放松计算限制时,较大模型会在细节生成上胜过较小模型。
- 采样器并不会改变规模扩展效率。无论使用哪种扩散采样器,较小模型的采样效率总是会更好一点。这对确定性 DDIM、随机性 DDPM 和高阶 DPM-Solver++ 而言都成立。
- 在步数更少的下游任务上,较小模型的采样效率更高。当采样步数少于 20 步时,较小模型在采样效率上的优势会延伸到下游任务。
- 扩散蒸馏不会改变规模扩展趋势。即使使用扩散蒸馏,当采样预算有限时,较小模型的性能依然能与较大蒸馏模型竞争。这说明蒸馏并不会从根本上改变规模扩展趋势。
LDM 的规模扩展
该团队基于广被使用的 866M Stable Diffusion v1.5 标准,开发了一系列强大的隐扩散模型(LDM)。这些模型的去噪 UNet 具有不同的规模,参数数量从 39M 到 5B 不等。该团队通过逐渐增大残差模块中过滤器的数量,同时维持其它架构元素不变,实现了可预测的受控式规模扩展。表 1 展示了这些不同大小模型的架构差异。其中也提供了每个模型相较于基线模型的相对成本。
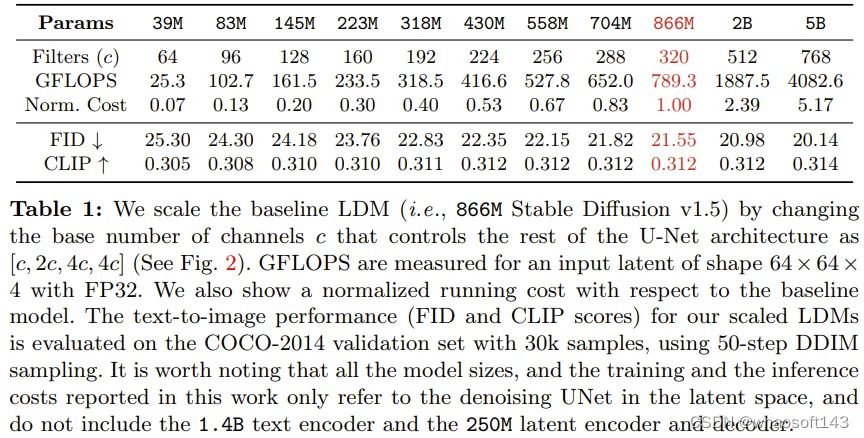
图 2 展示了规模扩展过程中的架构差异。这些模型的训练使用了他们的内部数据源,其中有 6 亿对经过过滤的文本 - 图像。所有模型都训练了 50 万步,批量大小为 2048,学习率为 1e-4。这让所有模型都能到达收益递减的程度。
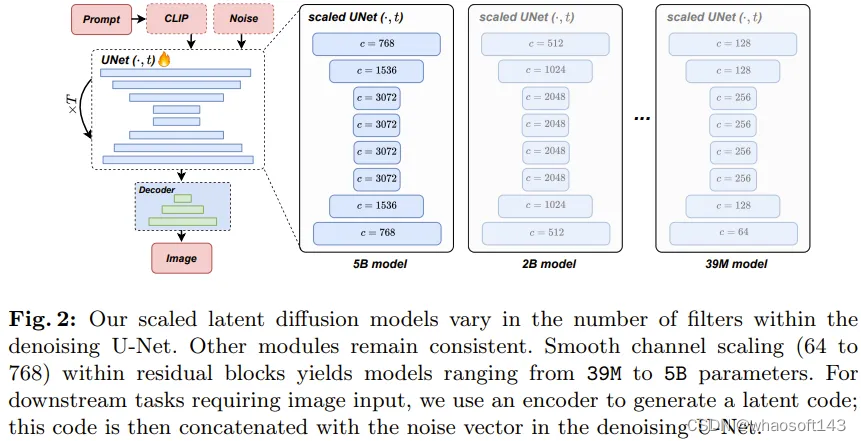
图 1 表明这些不同大小的模型都具有稳定一致的生成能力。
对于文生图任务,他们设置的采样步数为常用的 50 步,采样器为 DDIM,无分类器指导率为 7.5。可以看到,随着模型规模增大,所得结果的视觉质量明显提升。
文生图性能随训练计算量的扩展规律
实验中,各种大小的 LDM 的生成性能相对于训练计算成本都有类似的趋势,尤其是在训练稳定之后 —— 通常是在 20 万次迭代之后。这些趋势表明不同大小的模型的学习能力具备明显的扩展趋势。
具体来看,图 3 展示了参数量从 39M 到 5B 的不同模型的运行情况,其中的训练计算成本是表 1 中给出的相对成本和训练迭代次数的积。评估时,使用了相同的采样步数和采样参数。
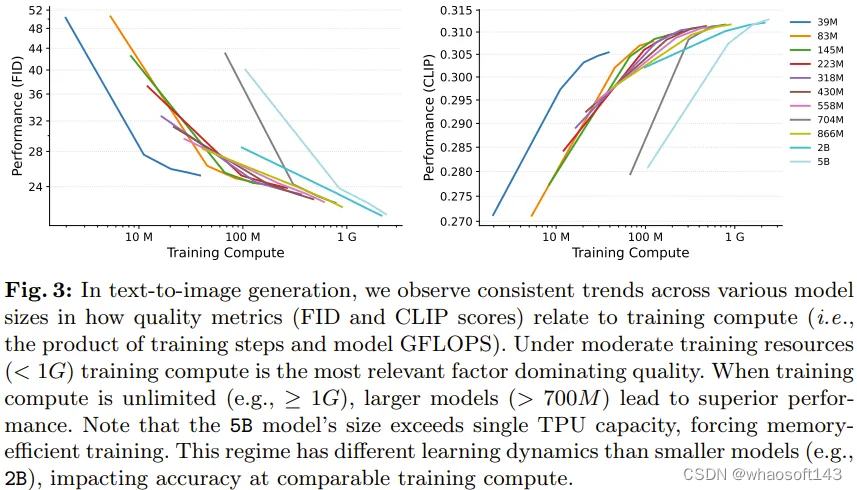
在训练计算量适中(即 < 1G,见图 3)的场景中,文生图模型的生成性能可在额外计算资源的帮助下很好地扩展。
预训练能扩展下游任务的性能
基于在文本 - 图像数据上预训练的模型,该团队又针对真实世界超分辨率和 DreamBooth 这两个下游任务进行了微调。表 1 给出了这些预训练模型的性能。
图 4 左图给出了在超分辨率(SR)任务上的生成性能 FID 与训练计算量的对应情况。
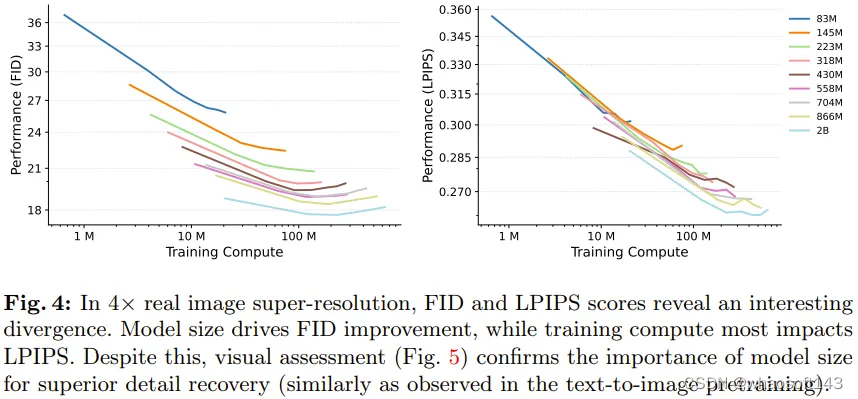
可以看出来,相比于训练计算量,超分辨率的性能更依赖模型大小。实验结果表明较小模型有一个明显的局限性:不管训练计算量如何,它们都无法达到与较大模型同等的性能。
图 4 右图给出了失真度指标 LPIPS 的情况,可以看到其与生成指标 FID 有一些不一致。虽如此,还是可以从图 5 明显看出:较大模型比较小模型更擅长恢复细粒度的细节。

基于图 4 能得到一个关键见解:相比于较小的超分辨率模型,较大模型即使微调时间更短,也能取得更好的结果。这说明预训练性能(由预训练模型大小主导)对超分辨率 FID 分数的影响比对微调的持续时间(即用于微调的计算量)的影响大。
此外,图 6 比较了不同模型上 DreamBooth 微调的视觉结果。可以看到视觉质量和模型大小之间也有相似的趋势。

扩展采样效率
分析 CFG 率的影响。文生图生成模型需要超过单一指标的细致评估。采样参数对定制化来说非常重要,而无分类器引导(CFG)率可以直接影响视觉保真度以及与文本 prompt 的语义对齐之间的平衡。
Rombach 等人的论文《High-resolution image synthesis with latent diffusion models》通过实验表明:不同的 CFG 率会得到不同的 CLIP 和 FID 分数。
而这项新研究发现 CFG 率(一个采样参数)会在不同的模型大小上得到不一致的结果。因此,使用 FID 或 CLIP 分数以定量方式确定每个模型大小和采样步骤的最佳 CFG 率是很有趣的。
该团队使用不同的 CFG 率(即 1.5、2.0、3.0、4.0、5.0、6.0、7.0、8.0)对不同规模的模型进行了采样,并以定量和定性方式比较了它们的结果。
图 7 便是两个模型在不同的 CFG 率下的视觉结果,从中可以看出其对视觉质量的影响。

该团队观察到,相比于 prompt 语义准确度,CFG 率的变化对视觉质量的影响更大,因此为了确定最佳 CFG 率,他们选取的评估指标是 FID 分数。
图 8 给出了不同的 CFG 率对文生图任务的 FID 分数的影响。
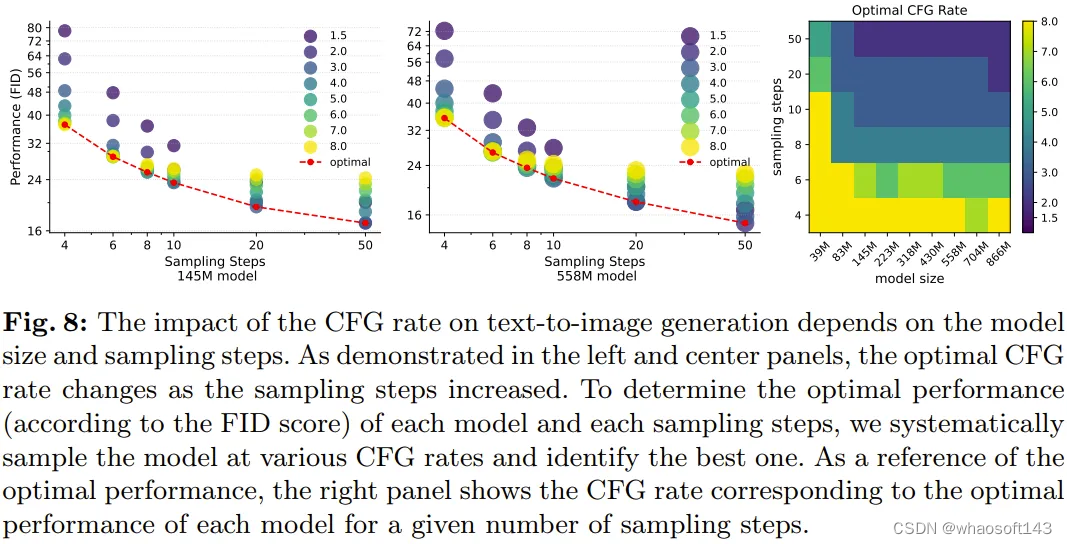
规模扩展效率趋势。使用每个模型在不同采样步骤下的最佳 CFG 率,该团队分析了最优性能表现,以理解不同 LDM 大小的采样效率。
具体来说,图 9 比较了不同采样成本下(归一化成本 × 采样步数)的不同模型及其最优性能。通过追踪不同采样成本下的最优性能点(竖虚线),可以看到一个趋势:在一个采样成本范围内,较小模型的 FID 分数通常优于较大模型。
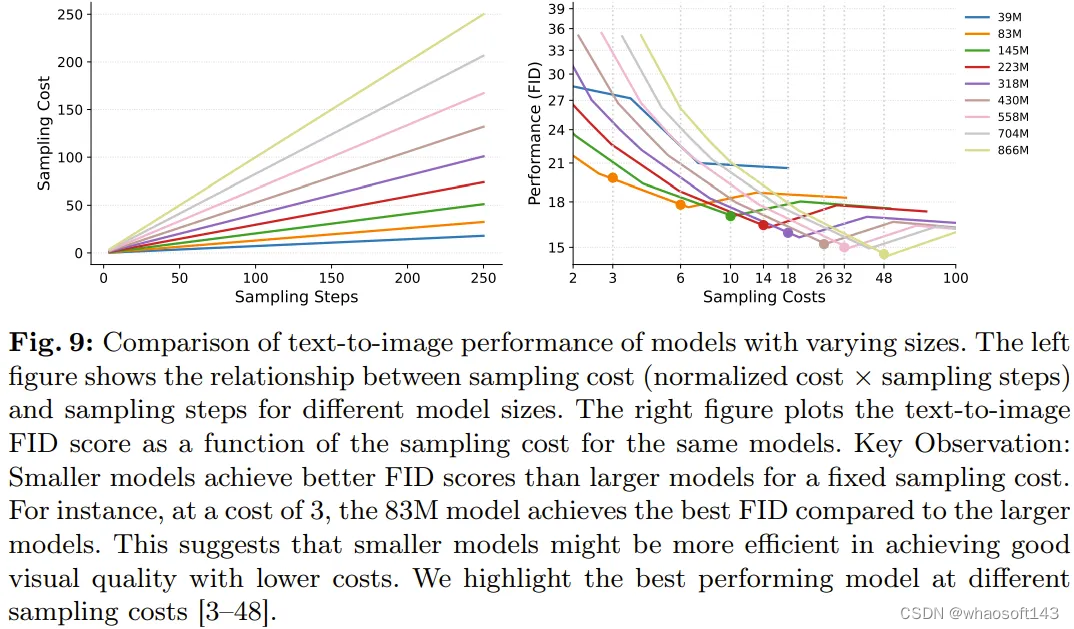
图 10 则给出了较小和较大模型结果的定性比较,从中可以看到在相似的采样成本条件下,较小模型是可以匹敌较大模型的。

不同大小的模型使用不同采样器的采样效率
为了评估采样效率趋势在不同模型规模下的普遍性,该团队评估了不同大小的 LDM 使用不同扩散采样器的性能。
他们使用的采样器有三种:DDIM、随机性 DDPM、高阶 DPM-Solver++。
图 11 给出了实验结果。
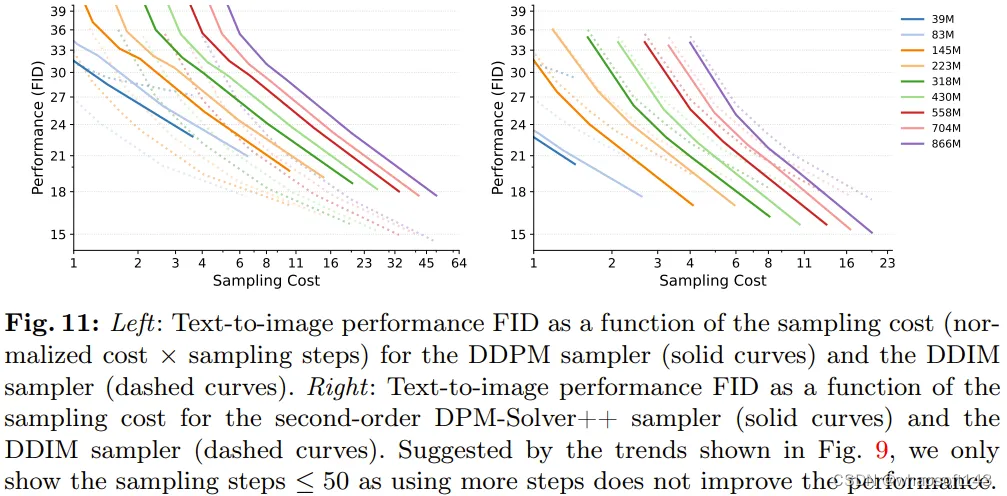
可以看出,当采样步数较少时,DDPM 采样器得到的质量通常低于 DDIM,而 DPM-Solver++ 则在图像质量上胜过 DDIM。
另一个发现也很重要,即三种采样器都有一致的采样效率趋势:采样成本一样时,较小模型的性能会优于较大模型。由于 DPM-Solver++ 采样器的设计并不适合用于超过 20 步的采样,因此这也是其采样范围。
结果表明:不管使用什么采样器,LDM 的规模扩展性质始终保持一致。
不同大小的模型在不同下游任务上的采样效率
这里关注的重点下游任务是超分辨率。这里是直接使用超分辨率采样结果,而不使用 CFG。受图 4 启发(在下游任务上,不同大小的 LDM 在采样 50 步时性能差距较大),该团队从两个方面调查了采样效率:较少采样步数和较多采样步数。
如图 12 左图所示,当采样步数不超过 20 步时,不同大小模型的采样效率趋势在超分辨率任务上依然成立。但图 12 右图又表明,一旦超过这个范围,较大模型的采样效率就会超过较小模型。
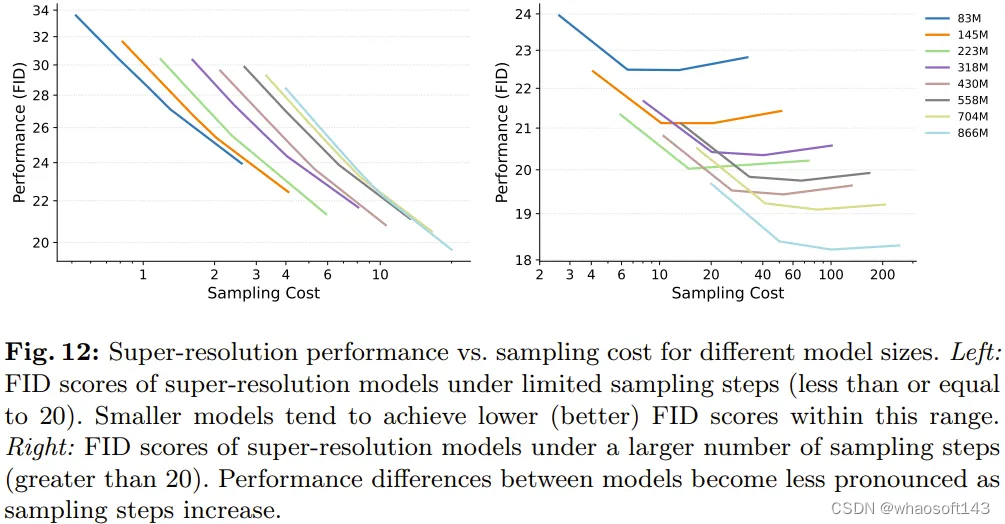
这一观察结果说明,在文生图和超分辨率等任务上,不同大小模型在采样步数较少时的采样效率趋势是一致的。
不同大小的已蒸馏 LDM 的采样效率
虽然之前的实验结果说明较小模型的采样效率往往更高,但需要指出,较小模型的建模能力也往往更差一些。对于近期那些严重依赖建模能力的扩散蒸馏方法来说,这就成了一大难题。人们可能会预测出一个矛盾的结论:经过蒸馏的大模型的采样速度快于经过蒸馏的小模型。
为了展示经过蒸馏的不同大小模型的采样效率,该团队使用条件一致性蒸馏方法在文生图数据上对之前的不同大小模型进行了蒸馏操作,然后比较了这些已蒸馏模型的最佳性能。
详细来说,该团队在采样步数 = 4(这已被证明可以实现最优的采样性能)的设定下测试了所有已蒸馏模型;然后在归一化的采样成本上比较了每个已蒸馏和未蒸馏模型。
图 13 左图表明,在采样步数 = 4 时,蒸馏可以提升所有模型的生成性能,并且 FID 全面提升。而在右图中,可以看到在同等的采样成本下,已蒸馏模型的表现优于未蒸馏模型。
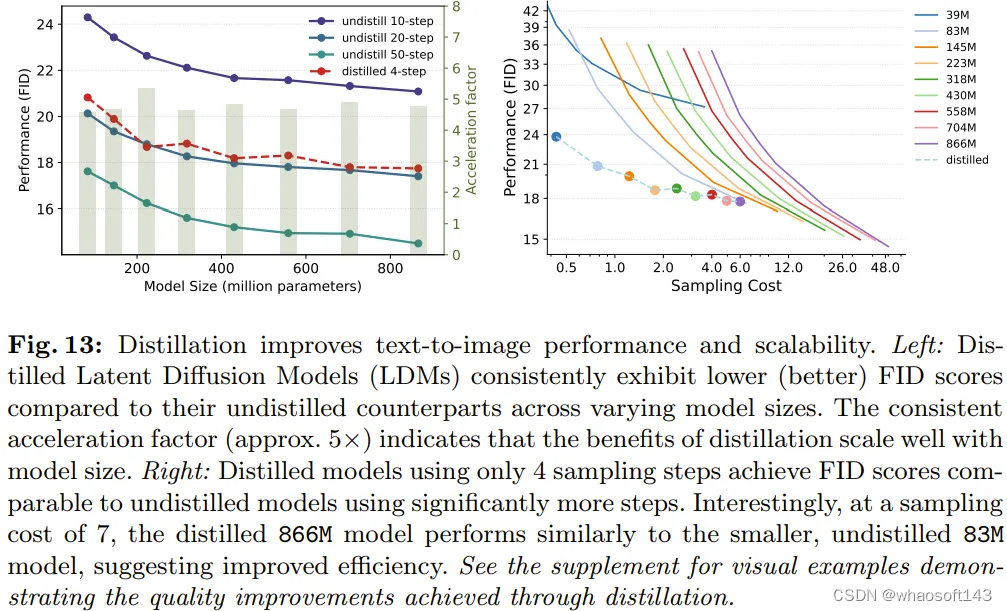
但是,在特定的采样成本下(即采样成本≈8),较小的未蒸馏 83M 模型依然能取得与较大已蒸馏 866M 模型相近的性能。这一观察进一步支持了该团队提出的不同大小 LDM 的采样效率趋势,其在使用蒸馏时也依然成立。
# AI重建粒子轨迹,发现新物理学
电子学在核物理领域从来都不是一帆风顺的。大型强子对撞机作为全球最强大的加速器,所产生的数据如此之多,使得全部记录这些数据从来都不是一个可行的选择。
因此,处理来自探测器的信号波的系统擅长于「遗忘」——它们在不到一秒的时间内重建次级粒子的轨迹,并评估刚刚观察到的碰撞是否可以被忽略,或者是否值得保存以供进一步分析。然而,当前重建粒子轨迹的方法很快将不再足够。
波兰科学院核物理研究所 (IFJ PAN) 的科学家通过研究表明,使用人工智能构建的工具可能是当前快速重建粒子轨迹方法的有效替代方法。它们的首次亮相可能会在未来两到三年内出现,或许是在支持寻找新物理的 MUonE 实验中。
该研究以《Machine Learning based Reconstruction for the MUonE Experiment》为题,于 2024 年 3 月 10 日发布在《Computer Science》上。
论文链接:https://doi.org/10.7494/csci.2024.25.1.5690
过去几十年来,包括计算技术在内的高能物理(HEP)实验领域取得了重大进展。对新物理现象的探索是对所谓的标准模型的扩展,即当前关于自然界基本成分的基本行为及其相互作用的不完整的理论知识,导致在不断增加的能量下进行实验研究。
两个粒子相互作用(碰撞事件)产生的粒子数量通常随着碰撞能量的增加而增加。因此,必须重建大量带电粒子(例如在质子-质子碰撞中),从而导致更复杂的事件模式。

图示:高能物理实验中的事件示例,显示多个粒子穿过探测器的轨迹。(来源:论文)
粒子在加速器中碰撞产生大量次级粒子级联(cascade)。然后,处理从探测器传来的信号的电子设备,有不到一秒的时间来评估某个事件是否值得保存以供以后分析。
在不久的将来,这项艰巨的任务可能会使用基于 AI 的算法来完成。
在现代高能物理实验中,从碰撞点发散的粒子穿过探测器的连续层,在每一层中沉积一点能量。实际上,这意味着如果探测器由十层组成,并且二次粒子穿过所有这些层,则必须基于十个点来重建其路径。任务看似简单。
「探测器内部通常有一个磁场。带电粒子在其中沿着曲线移动,这也是由它们激活的探测器元件(称之为撞击)相对于彼此定位的方式。」IFJ PAN 的 Marcin Kucharczyk 教授解释道。
「实际上,所谓的探测器占用率,即每个探测器元件的命中次数,可能非常高,这在尝试正确重建粒子轨迹时会导致许多问题。特别是,重建彼此靠近的轨道是一个很大的问题。」
旨在寻找新物理学的实验将以比以前更高的能量碰撞粒子,这意味着每次碰撞都会产生更多的次级粒子。光束的亮度也必须更高,这反过来又会增加单位时间的碰撞次数。在这种情况下,重建粒子轨迹的经典方法已经无法应对。AI 在需要快速识别某些普遍模式的领域表现出色,可以伸出援手。
用于轨迹重建的深度神经网络
「我们设计的 AI 是一个深度型神经网络,包括 20 个神经元组成的输入层、4 个各 1000 个神经元的隐藏层,以及 8 个神经元的输出层。每层的所有神经元都是相连的。该网络总共有 200 万个配置参数,这些参数的值是在学习过程中设置的。」IFJ PAN Milosz Zdybal 博士说道。
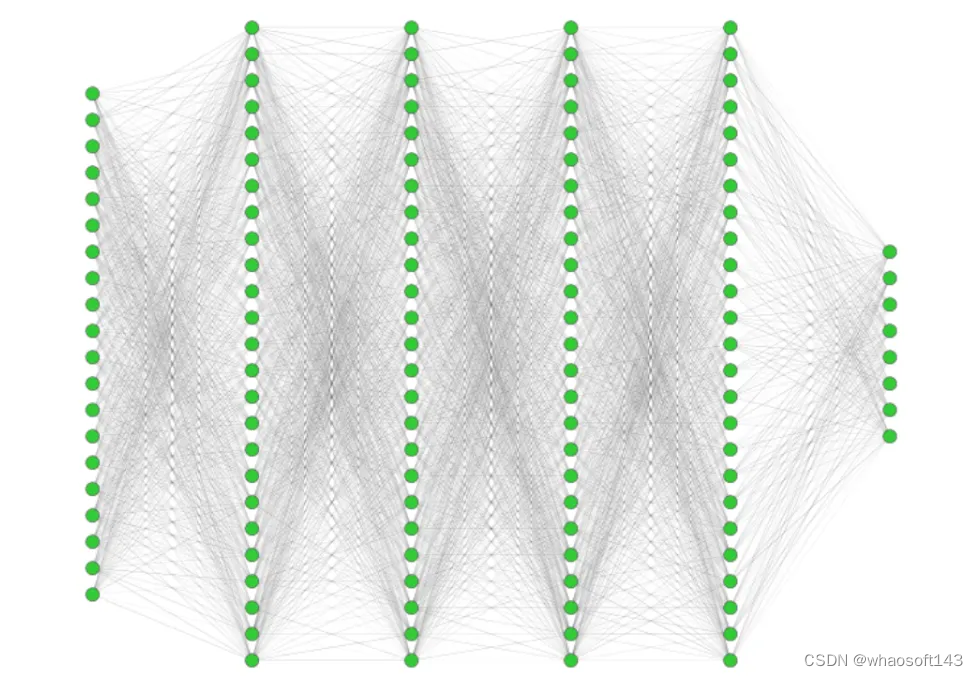
图示:用于轨迹重建的神经网络架构。(来源:论文)
由此制备的深度神经网络使用 40,000 次模拟粒子碰撞进行训练,并辅以人工生成的噪声。在测试阶段,只有命中信息被输入网络。由于这些来自计算机模拟,因此可以准确地了解负责粒子的原始轨迹,并且可以与 AI 提供的重建进行比较。在此基础上,AI 学会了正确重建粒子轨迹。
Kucharczyk 教授强调说:「在我们的论文中,我们表明,在适当准备的数据库上训练的深度神经网络能够像经典算法一样准确地重建二次粒子轨迹。这对于检测技术的发展非常重要。虽然训练一个深度神经网络是一个漫长且计算要求很高的过程,但训练后的网络会立即做出反应。由于它的精度也令人满意,因此我们可以乐观地考虑在实际碰撞的情况下使用它。」
MUonE 实验
基于机器学习技术的概念验证解决方案已在 MUonE(MUon ON Electron 弹性散射) 实验中实施和测试,该实验旨在寻找 μ 子反常磁矩领域的新物理。这检验了与 μ 子(质量大约是电子的 200 倍)有关的某个物理量的测量值与标准模型(即用于描述基本粒子世界的模型)的预测之间的有趣差异。
美国加速器中心费米实验室(American accelerator center Fermilab)进行的测量表明,所谓的 μ 子反常磁矩与标准模型的预测存在高达 4.2 个标准差(简称 sigma)的确定性差异。同时,物理学界普遍认为,高于 5 sigma 的显著性(对应于 99.99995% 的确定性)是宣布一项发现可接受的值。
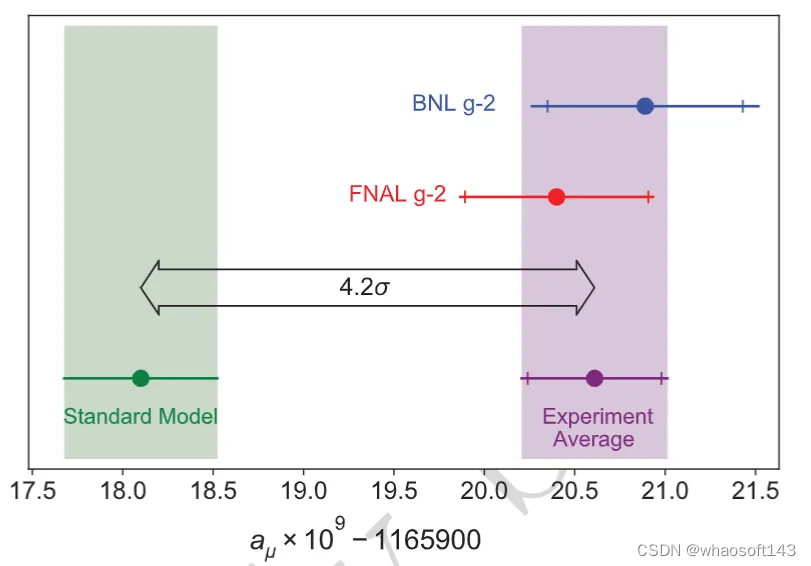
图示:反常 μ 子磁矩测量值与标准模型预测的比较。(来源:论文)
如果标准模型预测的精度能够提高,则表明新物理学的差异的重要性可能会显著增加。然而,为了更好地确定 μ 介子的反常磁矩,有必要知道一个更精确的参数值,即强子校正。不幸的是,无法对该参数进行数学计算。
至此,MUonE 实验的作用就变得清晰起来。其中,科学家们打算研究 μ 子在低原子序数原子(例如碳或铍)的电子上的散射。结果将允许更精确地确定直接取决于强子校正的某些物理参数。
如果一切按照物理学家的计划进行,以这种方式确定的强子校正将增加测量 μ 子反常磁矩的理论值和测量值之间高达 7 sigma 的差异的信心,迄今为止未知的物理学的存在可能会成为现实。
MUonE 实验最早将于明年在欧洲 CERN 核设施开始,但目标阶段已计划在 2027 年,届时克拉科夫物理学家可能有机会看到他们创造的人工智能是否能在重建粒子轨迹方面发挥作用。在真实实验条件下确认其有效性可能标志着粒子检测技术新时代的开始。
参考内容:https://phys.org/news/2024-03-team-ai-reconstruct-particle-paths.html















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









