







我自己的原文哦~ https://blog.51cto.com/whaosoft/12413878
#MCTrack
迈驰&旷视最新MCTrack:KITTI/nuScenes/Waymo三榜单SOTA
paper:MCTrack: A Unified 3D Multi-Object Tracking Framework for Autonomous Driving
code:https://github.com/megvii-research/MCTrack
机构:迈驰智行、旷视、国防科大、川大、中科大
1. 写在前面&出发点
自2016年SORT[1]算法提出以来,多目标跟踪任务已经经历了多年的发展,从最初的TBD(Tracking-By-Detection)范式发展到TBA(Tracking-By-Attention), JDT(Joint-Detection-Tracking)等范式,从单模态到多模态跟踪,从2D跟踪发展到3D跟踪,可谓百花齐放,百家争鸣。在3D跟踪领域,KITTI、nuScenes和Waymo是常用的数据集,它们各有特点,数据格式差异显著,采集场景和帧率也尽不相同。迄今为止,几乎没有一种方法能够在这三个数据集上都达到SOTA性能。
而对于评价指标而言,目前主流的包含MOTA, AMOTA, HOTA等,这些指标均是在评价一条轨迹是否能够正确、稳定匹配上,但是对于匹配之后,跟踪这个任务所需要对下游预测规划输出的关键信息(如速度、加速度、角速度)是否合理、是否能满足需求依然打个问号?这也就意味着我们缺乏对运动信息的评测指标。
基于上述问题:
我们的目标是首先提供一种统一的感知结果格式,以便在不同数据集上刷榜时,无需担心数据格式的差异。
其次,我们希望提供一个统一的跟踪框架,能够在KITTI、nuScenes和Waymo这三个常用数据集上都达到SOTA性能。
最后,我们希望建立一套“运动指标”,用以评估跟踪任务输出给下游任务的运动信息(如速度、加速度等)的正确性,这其实在实际工程应用中至关重要。
2. 领域背景
3D多目标跟踪在自动驾驶领域作为感知与预测规划任务之间的桥梁,扮演着至关重要的角色。学术界已经提出了多种跟踪范式,包括基于检测的跟踪(TBD)、基于注意力的跟踪(TBA)和联合检测跟踪(JDT)等。通常情况下,TBD范式在各方面的性能都优于其他范式,并且由于其不需要GPU资源,这极大地推动了该范式在工程中的应用。总体来看,TBD范式的方法主要分为两个步骤:首先是目标检测,然后是数据关联,具体流程如图1所示。

图1
- 检测:通常利用现有的检测器得到感知结果
- 数据关联:利用感知结果与历史轨迹进行多对多的匹配,通常会涉及到代价函数的计算、匹配函数的选择、卡尔曼滤波预测等等。
很显然,这种范式下,跟踪结果很大程度上依赖于感知模块的性能。通常来说,感知性能越出色,跟踪效果也越好。这种范式在某种程度上既有优势也有劣势。其优势在于结构简单明了,不需要复杂的处理步骤,工程落地非常容易。劣势一在于由于跟踪过程基于检测结果而非原始数据(如外观特征等),一旦检测性能下降,跟踪性能也会随之受到影响。劣势二在于这种方式很难处理密集场景,一旦场景中目标数量过多,仅通过空间位置关系来计算相似度会非常困难,但对于自驾场景而言,无论是高速还是城区,障碍物并不会过多,即通过空间位置关系通常是可以hold住的(当然,引入特征是更好的)。尽管目前在各大3D MOT榜单上基于TBD范式的性能已经比较好了,但我们认为依旧没有达到这类范式的上限,可靠稳定的代价函数依然待发掘。
另一方面,在学术研究中,大家对跟踪任务的关注点通常集中在轨迹连接的准确性,而连接后的进一步处理往往被忽视。然而,在工业界,跟踪任务作为感知的最下游,负责汇总和优化各类信息,并将结果传递给预测和规划模块。这其中包括了诸如速度、加速度等重要的运动信息,而这些信息在学术界的跟踪任务中几乎没有涉及。这在一定程度上反映了学术界与工业界的某种脱节。
在以上背景下,诞生了MCTrack(MC--迈驰智行),提供了一套统一的pipeline,一套评估速度的运动指标。
3. MCTrack
3.1 统一数据格式
我们对KITTI、nuScenes和Waymo三大数据集的感知结果格式进行了统一整合,这意味着只要采用TBD范式的方法,便可以直接使用这一统一格式,通过一套pipeline运行三个数据集,无需编写多个预处理脚本来适配不同数据集。我们将按照场景、帧、障碍物、全局信息等维度进行存储,整体格式包含以下内容:
image2024-10-18_19-38-6.png
3.2 整体框架
整体框架遵循简单直接的TBD范式,先进行检测,再进行匹配,并通过不同维度的信息接入卡尔曼滤波器,以确保输出给下游模块的信息稳定性。值得注意的是,在匹配阶段,我们采用了多视角相似度计算方法,首先在BEV平面上进行第一次匹配,然后在RV平面(图像2D平面)上进行第二次匹配。相似度计算过程中,我们提出了更为鲁棒的Ro_GDIoU。

https://picx.zhimg.com/80/v2-436883a9be383d7fb17ad978b7f6ffd9_1440w.png
3.3 Ro_GDIoU
在3D多目标跟踪中,常用的代价矩阵包括IoU、GIoU、DIoU和欧式距离等。在3D空间中,交并比和距离是两种不同的度量方式:交并比及其变体侧重于从体积上衡量两个3D框的相似度,而距离则用于描述两个框之间的相对接近程度。在跟踪任务中,仅使用其中一种度量方式进行匹配,无法确保在各类场景中都取得理想效果。DIoU在某种程度上结合了交并比和欧氏距离,但当两个框之间没有交集时,DIoU退化为纯距离度量,无法同时兼顾体积相似度和中心点接近度。一个显而易见的改进是将GIoU和DIoU融合在一起。

基于此,我们提出了Ro_GDIoU,这是一种融合了旋转角、交并比与中心距离的更强相似度计算方法。旋转角的引入如图所示:当将3D框投影到BEV平面时,这些框通常会呈现不同的角度。如果像在2D检测任务中那样将其“掰正”,将无法准确衡量两个框的真实相似度。因此,需要按照它们的实际朝向来计算交并比,以更准确地反映它们的相似性。

Ro_GDIoU具体计算方式如下面的伪代码所示:

3.4 不同维度的匹配方式
二次匹配其实并非是一个新颖的操作,诸多SOTA方法都有涉及。我们在实验中发现,之所以需要二次匹配,是因为所使用的代价函数无法自调节以适应感知框的抖动,导致无法采用统一相似度阈值来度量,所以自然而然就诞生了二次匹配。通常而言,这些方法都会选择在第二次匹配时使用更加宽松的匹配阈值,但问题在于感知的抖动能通过放大匹配阈值来消除掉吗?在工程中我们发现一个非常有意思的现象,基于图像的3D感知在深度上时常会出现抖动,尤其是对于远距离的小目标而言,有时抖动会达到10m以上。这种情况下,仅通过调整匹配阈值无法完全解决问题,依然会出现frag和idsw。我们尝试将3D框投影到前视平面上(即压缩深度),虽然在一定程度上缓解了问题,但也导致后视目标与前视目标出现错误匹配,这显然是不可接受的。于是,我们进一步尝试在不同相机视角下进行投影,以确保不同视角的目标不会相互匹配,从而形成了本文中的二次匹配模块。整体的匹配流程如下图的伪代码所示:

4. 运动指标
为了解决当前多目标跟踪(MOT)评估指标未能充分考虑运动属性的问题,我们提出了一系列新的运动指标,包括速度角度误差(VAE)、速度范数误差(VNE)、速度角度倒数误差(VAIE)、速度反转比(VIR)、速度平滑度误差(VSE)和速度延迟误差(VDE)。这些运动指标旨在全面评估跟踪系统处理运动特征的性能,涵盖速度、角度及速度平滑度等运动信息的准确性和稳定性。在这里我们主要介绍速度平滑度误差(VSE)和速度延迟误差(VDE)两大指标,这两个指标在自驾工程应用中至关重要。什么样的速度对于下游控制是可接受的?答案是既要响应快速,又需要足够平稳。当前方障碍物急剧减速或加速时,跟踪系统应能迅速响应,并提供准确的速度预测。显然,雷达传感器依赖多普勒效应能够生成相对完美的速度曲线,但实际上,雷达的FP较多,并且并不总是能在每一时刻都匹配上。因此,跟踪模块仍需通过位置采用滤波器来提供一套速度预测。然而,如何衡量速度的优劣便成了一个关键问题。
- 速度延迟误差(VDE)
首先,计算真实速度(gt)的峰值点,并设定窗口大小为 w。在峰值点的前后各取 w/2个点。同时,基于 gt 的峰值点,在计算滤波速度的时候取 w个点,并设定一个滑动窗口 tau。这样可以提取出tau组滤波速度,并计算这tau组数据与 gt 的差值。接着,通过计算差值的均值和方差,选择均值和方差最小的那组tau×帧率,这就是对应的延迟误差(单位:秒)。具体计算过程如下:

借助论文的一幅图来说明该指标的重要性:该图展示了两辆以每小时100公里速度行驶的车辆:红色车辆表示自动驾驶车辆,白色车辆表示前方障碍物。两车之间的初始安全距离设定为100米。假设在时间点 t_m 时,前车开始紧急减速,并在时间点 t_n 时将速度降至每小时60公里。如果自动驾驶车辆在感知前车速度上存在延迟,则可能会错误地认为前车仍然以每小时100公里的速度行驶,这会导致两车之间的安全距离在不知不觉中缩短。直到时间点 t_n 时,自动驾驶车辆才最终感知到前车的减速,但此时安全距离可能已经非常接近极限。

- 速度平滑度误差(VSE)
平滑性误差不涉及到gt,首先对原始dt使用SG滤波器进行平滑,将平滑后的dt与原始dt计算差值并求和,理论上,如果一条曲线足够平滑,那么将该条曲线送到滤波器再次进行平滑其效果并不大,即依然会接近原始曲线,此时平滑性误差最小。

显然,该指标并非越小越好,因为通过越平滑则相应就会越滞后,故该指标需要结合速度滞后性误差一起使用。如下图所示:红色曲线为gt,蓝色和绿色曲线分别表示两种方法求得的速度曲线,显然,蓝色曲线非常平滑,但是滞后,而绿色曲线尽管抖动较大但相应较快。平滑性误差不依赖于真实值(gt)。首先,我们对原始的滤波速度使用SG滤波器(Savitzky-Golay)进行平滑处理,然后计算平滑后的滤波速度与原始滤波速度 之间的差值并进行求和。理论上,如果一条曲线足够平滑,那么将其输入滤波器进行再次平滑的效果就不会明显,结果仍然会接近原始曲线,此时平滑性误差达到最小。

5. 实验
5.1 定量实验
正如前言所述,我们希望提供一套统一的ppl,因此,我们在当前常用的3D MOT数据集上(如KITTI、nuScenes和Waymo)进行了测试。总体而言,我们在KITTI和nuScenes数据集中取得了第一名,而在Waymo数据集中获得了第二名。值得一提的是,Waymo第一名所采用的检测方法在mAP等指标上比本文使用的检测器高出两个点,因此我们认为这两者之间并不具备可比性。

nuScenes跟踪榜单第一

KITTI跟踪榜单第一

Waymo跟踪榜单第二
与SOTA方法对比
****



5.2 运动指标评估在本文中,我们提出了多种速度计算方法,包括差分法、卡尔曼滤波和曲线拟合等。这三种方法各有优缺点。此外,速度的计算并不限于上述几种方式。我们希望能够提供一个完善的评估指标,鼓励大家不仅关注轨迹连接的准确性,还要关注在正确连接后,如何更好地输出下游控制所需的速度等信息。

5.3 消融实验将本文提出的Ro_GDIoU分别融合到当前KITTI和nuScenes的SOTA方法中,其中PolyMOT在当时的nuScenes排名中位居第一。我们发现,将Ro_GDIoU应用于该方法时,MOTA指标提升了1.1个点,同时nuScenes的主要评价指标AMOTA也提升了0.4个点。此外,在另一个数据集KITTI上,使用当时的SOTA方法结合Ro_GDIoU也实现了不同程度的提升。

对于二次匹配,在公开数据集上的提升非常有限。这是因为我们所使用的检测器均基于点云,虽然这类方法在深度方向上相对准确,但值得注意的是,检测器性能较差时,基于RV的二次匹配所带来的提升会更加明显。

6. 总结
在本文中,我们提出了一种简洁且统一适用于自动驾驶领域的3D多目标跟踪方法。我们的方法在多个数据集上均取得了SOTA性能。此外,我们对不同数据集的感知格式进行了标准化处理,这样大家能够专注于多目标跟踪算法的研究,而无需由于数据集格式差异而引发的繁琐预处理工作。最后,我们引入了一组全新的运动评估指标,希望大家关注对下游应用至关重要的运动属性。
#MambaBEV
MambaBEV成功将Mamba2引入BEV目标检测
MambaBEV是一个专为自动驾驶系统设计的基于Mamba2的高效3D检测模型。该模型利用了鸟瞰图(BEV)范式,并整合了时序信息,同时提高了检测的稳定性和准确性。在nuScences数据集上,该模型具有出色的表现。
对于自动驾驶系统而言,更安全、准确地进行3D目标检测至关重要。历史上,这些感知系统主要依赖霍夫变换和关键点提取等技术构建基础框架。然而,深度学习的兴起使得感知精度的重大飞跃。
然而,单目相机的感知方法仍面临诸多挑战,尤其是距离感知误差大和盲区范围广,这些问题对驾驶安全构成了显著威胁。为了解决距离误差问题,研究人员提出了双目立体匹配技术,通过利用一对相机捕获图像之间的视差,在一定程度上改善了距离估计的准确性。然而,这些系统仍然存在关键的局限性:它们无法感知车辆侧面和后部的物体及车道标记,从而在自动驾驶系统的安全范围内留下空白。
为了应对这些局限性,最新的研究探索了使用环视相机系统进行感知,该系统通常包括六个相机。这种方法为每个相机输入部署独立的深度学习模型,并依赖后处理技术将各个输出整合为对环境的一致感知。尽管这种方法克服了单目和双目系统的局限性,但也引入了一系列新挑战,包括大量的GPU内存消耗、感知冗余、跨相机视图的目标重新识别,以及缺乏跨相机的信息交互。这些因素共同影响了感知系统的效率和有效性。

图1 MambaBEV的框架。
为了解决这些障碍,基于鸟瞰图(BEV)的范式作为一种有前景的解决方案应运而生。这种方法将多个相机的输入整合到一个统一的BEV表示中,从而使车辆周围环境的全面理解成为可能。通过直接将图像数据映射到环境的俯视图,BEV方法促进了更准确的距离估计和障碍物检测,同时有效解决了盲区问题。此外,这种方法还促进了不同相机视图之间的信息高效共享,从而增强了感知系统的整体鲁棒性和可靠性。
另一个关键方面是处理时序数据。单帧检测虽然简单,但常常因为帧间目标遮挡和特征不明显而错过检测。为了解决这些问题,整合时序融合技术,利用历史特征来增强当前特征,已被证明可以显著提高模型性能。然而,传统的时序融合范式主要依赖自注意力机制,导致高内存消耗、有限的全局感受野,以及较慢的训练和推理速度。因此,开发一种新的时序融合方法以克服这些缺点具有重要的工程意义。
最近,一个专门处理序列的新模型mamba在多个下游任务中展现出巨大的潜力。Mamba2是mamba的改进版本,在多个任务上显示了更优的性能。这种新方法采用基于块分解的矩阵乘法,并利用GPU的存储层次结构,从而提高了训练速度。将mamba2引入3D自动驾驶感知是一个值得探索的方向。为了解决时序融合模块面临的问题,作者提出了MambaBEV,这是一个基于BEV的3D感知模型,使用了mamba2。据作者所知,这是首次将Mamba2整合到基于相机的3D目标检测网络中。
作者提出了一种基于mamba2的3D目标检测范式,命名为MambaBEV。该方法采用了一个基于mamba-CNN的模块,名为TemporalMamba,用于融合不同帧中的BEV特征。此外,作者在解码器层设计了一种mamba-detr头部,以进一步优化检测效果。
A.预备知识
结构化状态空间模型(SSMs)是一类深度学习模型,特别适用于序列建模任务。通过利用这些结构化公式,SSMs在表达性与计算效率之间提供了一种权衡,成为与基于注意力的模型(如Transformer)的一种有效替代。SSMs的公式代表了推进深度学习中序列建模的一个有前景的方向。作者使用的基模型称为Mamba2,它基于结构化状态空间(S4)序列模型,这些模型根植于连续系统。这些模型通过采取1-D输入序列或函数和一个中间隐藏状态, ,如下所示:
它结合了一个可学习的步长,并采用零阶保持将连续系统转换为离散系统。注意,如果设置D为0,则可以忽略Du(t)。因此,方程(1)可以重写为:
通过应用数学归纳法,的最终输出可以表示为:
其中M定义为:
表示从到的矩阵乘积,索引j和i分别表示第j个和第i个A,B,C矩阵。Mamba2中的变换矩阵M也符合N-序半可分离(SSS)表示的定义。因此,在Mamba2框架内,SSM和SSS的表示是等价的。这种等价性允许在涉及SSM的计算中高效利用结构化矩阵乘法进行SSS。为了实现这种方法,参数矩阵M被分解为对角块和低秩块,分别使用结构化掩码注意力(SMA)二次模式算法和SMA线性模式算法。此外,多头注意力(MHA)被集成以增强模型的性能。

图2 TemporalMamba的总体框架。
B.总体架构
MambaBEV的主要结构在图1中展示。该模型可以总结为四个主要模块:图像特征编码器、后向投影(SCA)、TemporalMamba和Mamba-DETR头部。MambaBEV以六个相机图像为输入,并通过图像特征编码器生成六个多尺度特征图。这些特征图随后被送入名为空间交叉注意力(SCA)的后向投影模块,以生成BEV特征图。
接下来,历史BEV特征与当前BEV特征进行融合,用于指导生成新的当前BEV特征。此过程由作者提出的TemporalMamba块执行。经过多层处理后,最终使用mamba-DETR头部作为3D目标检测的输出模块。
C. 图像特征编码器
图像特征编码器由两部分组成:高效的主干和经典的颈部。针对场景中不同视图的六张图片,作者使用在ImageNet上预训练的经典ResNet-50、从FCOS3D检查点初始化的ResNet-101-DCN,以及非常有效的VoV-99(同样来自FCOS3D检查点)作为主干,以提取每张图片的高级特征。Vmamba也可以作为主干。为了更好地提取特征并提升性能,作者采用经典的特征金字塔网络(FPN)生成多尺度特征。

图3 Query重组。
D. TemporalMamba块
对于传统的基于注意力的时序融合块,作者采用了可变形自注意力。Temporal Self-Attention(TSA)主要遵循以下流程:首先,给定历史BEV特征图和当前特征图,TSA将它们连接,并通过线性层生成注意力权重和偏移量。然后,每个查询(代表BEV特征)根据权重进行并行计算。然而,作者认为这种方法存在一些副作用。尽管可变形注意力可以降低计算成本,但由于每个参考查询仅允许与三个查询交互,导致大尺寸物体特征在跨帧交互中受到限制。
模型使用了mamba以增强全局交互能力。首先,两种模态的特征通过自我旋转角度进行变换,并通过一个卷积块将维度从512压缩到256,如图2所示。
在处理历史BEV特征图和当前特征图(每个维度为256)时,首先在第三维度将它们连接,连接后的特征分别经过两次带有批归一化的3x3卷积层和一次带有批归一化的1x1卷积层,然后将它们相加。
然后,作者对特征图Z进行离散重排,并通过mamba2块处理。典型的mamba2块是为自然语言处理设计的,旨在处理序列,但在应用于视觉数据时面临重大挑战。因此,设计合适的离散重排方法至关重要。基于实验并受到Vmamba的启发,作者设计了四种不同方向的重排方法,并讨论了这些方法在消融研究中的影响。
作者创新性地提出了一种多方向特征序列扫描机制,其中特征图Z被离散序列化,并以四个方向:向前左、向前上、向后左和向后上重新组合,如图3所示,形成新的序列作为Mamba2模型的输入。值得注意的是,作者没有采用蛇形螺旋重组合方法,因为他们认为这种方法会导致相邻特征之间的交互不平衡,一些相邻特征可能过于接近,而其他特征则相距甚远。mamba输出增强的序列特征,然后重新组合并恢复图4中显示的原始顺序。接着,作者计算四个张量的平均值,并将以0.9的dropout率生成的增强融合BEV特征图作为跳跃连接添加到当前BEV特征图中。

图4 Query融合。
E. Mamba-DETR头部
如图1所示,作者重新设计了一个结合mamba和传统DETR编码器的mamba-DETR头部。在此结构中,900个目标查询首先在mamba2块中进行预处理,并相互之间进行交互,承担与自注意力相同的职责。随后,mamba块的输出将像传统的CustomMSDeformableAttention那样,通过可变形注意力进行处理。
在实验中,MambaBEV在nuScenes数据集上表现出色,其基础版本实现了51.7%的NDS(nuScenes Detection Score)。此外,MambaBEV还在端到端自动驾驶范式中进行了测试,展现了良好的性能。在3D对象检测任务中,MambaBEV-base相较于仅使用单帧的BEVFormer-S,在mAP和NDS上分别提高了3.51%和5.97%,充分显示了TemporalMamba块的有效性。当添加TemporalMamba块时,平均速度误差降低了37%,表明历史信息,特别是经过TemporalMamba块处理的信息,可以显著改善速度估计,因为它提供了宝贵的历史位置信息。

表1 在nuScenes验证集上的3D目标检测结果。

表2 开环规划性能。

表3 动态预测。

表4 拼接方法与卷积方法的消融对比。

表5 不同窗口大小造成的影响。

表6 不同重排方法的比较

表7 BEV特征不同分辨率的影响
MambaBEV是一种基于BEV范式和mamba2结构的创新3D目标检测模型,充分利用时序信息以处理动态场景。在nuScenes数据集上实现51.7%的NDS,突出了其有效性和准确性。通过引入TemporalMamba块,MambaBEV有效整合历史信息,改善速度估计和目标检测性能。与传统卷积层和可变形自注意力相比,该模型在全局信息交换上更具优势,并且优化了计算成本。为适应端到端的自动驾驶范式,MambaBEV结合了mamba和传统DETR编码器的特性,展现出良好的潜力,尤其在自动驾驶应用中具有可观的发展前景。
#RAG实战全解析
1. 背景介绍
RAG(Retrieval Augmented Generation,检索增强生成 )方法是指结合了基于检索的模型和生成模型的能力,以提高生成文本的质量和相关性。该方法是Meta在2020年发表的文章《Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks》中提出的,该方法让LM(Language Model,语言模型)能够获取内化知识之外的信息,并允许LM在专业知识库的基础上,以更准确的方式回答问题。而在大模型时代,它更是用于解决幻觉问题、知识时效问题、超长文本问题等各种大模型本身制约或不足的必要技术。
2. RAG的挑战
RAG主要面临三个方面的挑战:检索质量、增强过程和生成质量。
2.1 检索质量
语义歧义:向量表示(例如词嵌入)可能无法捕捉概念之间的细微差别。例如,“苹果”一词可能指的是水果或科技公司。嵌入可能会混淆这些含义,导致不相关的结果。
用户输入变复杂:与传统关键词或者短语搜索逻辑不太一致,用户输入问题不再是词或者短句,而是转变成自然对话声知识多轮对话数据,问题形式更加多元,紧密关联上下文,输入风格更加口语化。
文档切分:文档切分主要有两种方式:一种是基于形式的切分,比如利用标点和段落的结束;另一种是基于文档内容的意义进行切分。如何将这些文档块转换成电脑能够理解和比较的形式(即“嵌入”),进而影响这些块与用户搜索内容的匹配程度。
多模内容的提取及表征(例如表格、图表、公式等):如何对多模内容进行提取及动态表征,是目前面临的现实问题,尤其是处理那些含糊或负面的查询,对 RAG 系统的性能有显著影响。
2.2 增强过程
上下文的集成:这里的挑战是将检索到的段落的上下文与当前的生成任务顺利地集成。如果做得不好,输出可能会显得脱节或缺乏连贯性。
冗余和重复:如果多个检索到的段落包含相似的信息,则生成步骤可能会产生重复的内容。
排名和优先级:确定多个检索到的段落对于生成任务的重要性或相关性可能具有挑战性。增强过程必须适当权衡每个段落的价值。
2.3 生成质量
- 过度依赖检索内容:生成模型可能过于依赖增强信息,导致幻觉问题突出,而不是增加价值或提供合成。
- 无关性:这是另一个令人担忧的问题,即模型生成的答案无法解决查询问题。
- 毒性或偏见:这也是另一个问题,即模型生成的答案有害或令人反感。
3. 整体架构3.1 产品架构
从图上可以清晰的看出,整个产品架构包含如下四层:
- 最底层是模型层。在模型层屏蔽掉了模型的差异,不仅可以支持自研的序列猴子,也可以支持开源的大模型,第三方的模型。此外,为了优化embedding的效果,提出一种跨语言Embedding模型,有效的解决跨语言检索问题,同时提高了模型的效果。
- 离线理解层。在该层,主要围绕智能知识库和搜索增强两个模块设计的。关于智能知识库主要负责将非结构化的文本进行处理,从而转化为检索知识库,主要包括文本解析,表格识别,OCR识别等。搜索增强通过引入问句改写、重排等模块,保证检索的精准度。
- 在线问答层,为了满足产品设计需要,这里支持多文档、多轮次、多模态及安全性与拒识等,在一定程度上提高了产品的竞争力,同时也满足了不同场景的用户需求。
- 场景层,针对不同行业的特点,预制多种场景类角色,降低产品使用门槛。
3.2 技术架构
为了理解检索增强生成框架,我们将其分为三个主要组成部分:query理解、检索模型和生成模型。
- query理解:该模块旨在对用户的query进行理解或者将用户的query生成结构化的查询,既可以查询结构化的数据库也可以查询非结构化的数据,进而提高召回率。该模块包括四部分,他们分别是query改写,query扩写和意图识别等。各个模块的介绍我们将在之后的章节进行详细介绍。
- 检索模型:该模型旨在从给定的文档集或知识库中检索相关信息。他们通常使用信息检索或语义搜索等技术来根据给定的查询识别最相关的信息。基于检索的模型擅长查找准确且具体的信息,但缺乏生成创意或新颖内容的能力。从技术上来讲, 检索模型主要包括文档加载、文本转换、Embedding等模块。我们将在之后的章节中详细介绍。
- 生成模型:该模型旨在根据给定的Prompt或上下文生成新内容。目前,生成模型可以生成富有创意且连贯的文本,但它们可能会在事实准确性或与特定上下文的相关性方面遇到困难。在RAG框架中,生成模型主要包括chat系统(长期记忆和短期记忆)、Prompt优化等。这些内容在之后的章节中也会介绍。
总之,检索增强生成结合了检索模型和生成模型优势,克服它们各自的局限性。在此框架中,基于检索的模型用于根据给定的查询或上下文从知识库或一组文档中检索相关信息。然后,检索到的信息将用作生成模型的输入或附加上下文。通过整合检索到的信息,生成模型可以利用基于检索的模型的准确性和特异性来生成更相关、更准确的文本。这有助于生成模型立足于现有知识,生成与检索信息一致的文本。
4. Query理解
目前,RAG系统可能会遇到从知识库中检索到与用户query不相关的内容。这是由于如下问题:(1)用户问题的措辞可能不利于检索,(2)可能需要从用户问题生成结构化查询。为了解决上述问题,我们引入query理解模块。
4.1 意图识别
意图识别是指接收用户的query和一组"选择"(由元数据定义)并返回一个或多个选定的"选择模块"。它既可以单独使用(作为 "选择器模块"),也可以作为查询引擎或检索器使用(例如,在其他查询引擎/检索器之上)。它是原理简单但功能强大的模块,目前主要利用 LLM 实现决策功能。它可以应用于如下场景:
- 在各种数据源中选择正确的数据源;
- 决定是进行摘要(如使用摘要索引查询引擎)还是进行语义搜索(如使用矢量索引查询引擎);
- 决定是否一次 "尝试 "多种选择并将结果合并(使用多路由功能)。
核心模块有以下几种形式:
- LLM 选择器将选择作为文本转储到提示中,并使用 LLM 做出决定;
- 构建传统的分类模型,包括基于语义匹配的分类模型、Bert意图分类模型等。
4.2 Query改写
该模块主要利用LLM重新措辞用户query,而不是直接使用原始的用户query进行检索。这是因为对于RAG系统来说,在现实世界中原始query不可能总是最佳的检索条件。
4.2.1 HyDE
Hypothetical Document Embeddings(HyDE)是一种生成文档嵌入以检索相关文档而不需要实际训练数据的技术。首先,LLM创建一个假设答案来响应query。虽然这个答案反映了与query相关的模式,但它包含的信息可能在事实上并不准确。接下来,query和生成的答案都被转换为嵌入。然后,系统从预定义的数据库中识别并检索在向量空间中最接近这些嵌入的实际文档。
4.2.2 Rewrite-Retrieve-Read
这项工作引入了一个新的框架--Rewrite-Retrieve-Read,从query改写的角度改进了检索增强方法。之前的研究主要是调整检索器或LLM。与之不同的是,该方法注重query的适应性。因为对于 LLM 来说,原始query并不总是最佳检索结果,尤其是在现实世界中。首先利用LLM 进行改写query,然后进行检索增强。同时,为了进一步提高改写的效果,应用小语言模型(T5)作为可训练的改写器,改写搜索query以满足冻结检索器和 LLM的需要。为了对改写器进行微调,该方法还使用伪数据进行有监督的热身训练。然后,将 "先检索后生成 "管道建模为强化学习环境。通过最大化管道性能的奖励,改写器被进一步训练为策略模型。
4.3 Query扩写
该模块主要是为了将复杂问题拆解为子问题。该技术使用分而治之的方法来处理复杂的问题。它首先分析问题,并将其分解为更简单的子问题,每个子问题会从提供部分答案的相关文件检索答案。然后,收集这些中间结果,并将所有部分结果合成为最终响应。
4.3.1 Step-Back Prompting
该工作探索了LLM如何通过抽象和推理两个步骤来处理涉及许多低级细节的复杂任务。第一步先是使用 LLM "后退一步"生成高层次的抽象概念,将推理建立在抽象概念的基础上,以减少在中间推理步骤中出错的概率。这种方法即可以在有检索的情况下使用,也可以在无检索的情况下使用。当在有检索情况下使用时,抽象的概念和原始问题都用来进行检索,然后这两个结果都用来作为LLM响应的基础。
4.3.2 CoVe
Chain of Verification (CoVe) 旨在通过系统地验证和完善回答以尽量减少不准确性,从而提高大型语言模型所提供答案的可靠性,特别是在事实性问题和回答场景中。它背后的概念是基于这样一种理念,即大型语言模型(LLM)生成的响应可以用来验证自身。这种自我验证过程可用于评估初始响应的准确性,并使其更加精确。
在RAG系统中,针对用户实际场景中日益复杂的问题,借鉴了 CoVe技术,将复杂 Prompt 拆分为多个独立且能并行检索的搜索友好型query,让LLM对每个子查询进行定向知识库搜索,最终提供更准确详实答案的同时减少幻觉输出。
4.3.3 RAG-Fusion
在这种方法中,原始query经过LLM 生成多个query。然后可以并行执行这些搜索查询,并将检索到的结果一并传递。当一个问题可能依赖于多个子问题时,这种方法就非常有用。RAG-Fusion便是这种方法的代表,它是一种搜索方法,旨在弥合传统搜索范式与人类查询的多面性之间的差距。这种方法先是采用LLM生成多重查询,之后使用倒数排名融合(Reciprocal Rank Fusion,RRF)来重新排序。
4.3.4 ReAct
最近,在RAG系统中,使用ReAct思想,将复杂查询分解成更简单的"子查询",知识库的不同部分可能会围绕整个查询回答不同的 "子查询"。这对组合图尤其有用。在组成图中,一个查询可以路由到多个子索引,每个子索引代表整个知识语料库的一个子集。通过查询分解,我们可以在任何给定的索引中将查询转化为更合适的问题。
ReAct的模式如上图所示,它是将思维链提示(Chain of Thoughts,简写为CoT)和Action计划生成结合起来,相互补充增强,提升大模型解决问题的能力。其中CoT的Reasoning推理跟踪有助于模型诱导、跟踪和更新行动计划以及处理异常。Action操作允许它与知识库或环境等外部来源接口并收集其他信息。
4.4 Query重构
考虑Query理解模块整体pipeline的效率,参考Query改写和Query扩写核心思想,自研了Query重构模块,该模块强调了通过一次请求,实现对原始用户输入的复杂问题进行改写、拆解和拓展,挖掘用户更深层次的子问题,从而借助子问题检索效果更高的特点来解决复杂问题检索质量偏差的问题,旨在提高查询的准确性和效率。
- 检索模型
5.1 检索模型的挑战
- 依赖于Embedding模型的向量化是否准确
- 依赖于外部数据是否有合理的分割(不能所有的知识转化成一个向量,而是需要分割数据后转化再存入向量数据库)
- 依赖于Prompt拼接,当我们将返回的最相似的文档进行排序后,与用户的问题一起送给大模型,实际上是想让大模型在长上下文中准确识别定位到合适的内容进行回答。
《Lost in the Middle: How Language Models Use Long Contexts》文章指出,当相关信息出现在输入上下文的开头或结尾时,性能往往最高,而当模型必须在长上下文中间获取相关信息时,性能会明显下降,即使对于明确的长上下文模型也是如此。
5.2 架构5.3 文档加载器
文档加载器提供了一种 "加载 "方法,用于从配置源加载文档数据。文档数据是一段文本和相关元数据。文档加载器可从多种不同来源加载文档。例如,有一些文档加载器可以加载简单的 .txt 文件或者加载任何网页的文本内容,甚至加载 YouTube 视频的副本。此外,文档加载器还可以选择实现 "懒加载",以便将数据懒加载到内存中。
5.4 文本转换器
检索的一个关键部分是只获取文档的相关部分。当加载文档后,通常需要对其进行转换,以便更好地适应应用程序。这涉及几个转换步骤,以便为检索文档做好准备。其中一个主要步骤是将大型文档分割(或分块)成较小的块,即文本转换器。最简单的例子是,当需要处理长篇文本时,有必要将文本分割成若干块,以便能放入模型的上下文窗口中。理想情况下,希望将语义相关的文本片段放在一起。这听起来很简单,但潜在的复杂性却很大。
5.4.1 工作原理
- 将文本分割成语义上有意义的小块(通常是句子)。
- 开始将这些小块组合成一个大块,直到达到一定的大小(用某个函数来衡量)。
- 一旦达到一定大小,就将该语块作为自己的文本,然后开始创建有一定重叠的新语块(以保持语块之间的上下文)。
5.4.2 常见如下文本转换器类型5.4.3 评估文本转换器
你可以使用 Greg Kamradt 创建的 Chunkviz 工具来评估文本转换器。Chunkviz 是可视化文本转换器工作情况的工具。它可以向你展示文本的分割情况,并帮助你调整分割参数。
5.5 文本嵌入模型
检索的另一个关键部分是文档嵌入模型。文档嵌入模型会创建一段文本的向量表示。它可以捕捉文本的语义,让你快速有效地找到文本中相似的其他片段。这非常有用,因为它意味着我们可以在向量空间中思考文本,并进行语义搜索等操作。
理想情况下,检索器应该具备将不同语种的翻译文本做关联的能力(跨语种检索能力),具备将长原文和短摘要进行关联的能力,具备将不同表述但相同语义的文本做关联的能力,具备将不同问题但相同意图的问题进行关联的能力,具备将问题和可能的答案文本进行关联的能力。此外,为了给大模型尽可能高质量的知识片段,检索器还应该给出尽可能多的相关片段,并且真正有用的片段应该在更靠前的位置,可以过滤掉低质量文本片段。最后,期望我们的模型可以覆盖尽可能多的领域和场景,可以实现一个模型打通多个业务场景,让用户获得开箱即用的模型,不需要再做微调。
关于文档嵌入模型,这里向大家推荐看一下《从MTEB看RAG:深入理解embedding评估,让AI更懂你!》文章。
5.6 向量数据库
随着嵌入式的兴起,人们开始需要向量数据库来支持这些嵌入式的高效存储和搜索。存储和搜索非结构化数据的最常见方法之一是嵌入数据并存储由此产生的嵌入向量,然后在查询时嵌入非结构化查询并检索与嵌入查询 "最相似 "的嵌入向量。向量数据库负责存储嵌入数据并执行向量搜索。
关于向量数据库,这里向大家推荐看一下《大模型引发爆发增长的向量数据库》文章。如果对向量数据库已经有认知了,可以直接跳过本节进行阅读。
5.7 索引
经过前面的数据读取和文本分块操作后,接着就需要对处理好的数据进行索引。索引是一种数据结构,用于快速检索出与用户查询相关的文本内容。它是检索增强 LLM 的核心基础组件之一。
下面介绍几种常见的索引结构。为了说明不同的索引结构,引入节点(Node)的概念。在这里,节点就是前面步骤中对文档切分后生成的文本块(Chunk)。下面的索引结构图来自 LlamaIndex 的《 How Each Index Works》。
5.7.1 摘要索引(以前称为链式索引)
摘要索引只是将节点存储为顺序链。在后续的检索和生成阶段,可以简单地顺序遍历所有节点,也可以基于关键词进行过滤。
5.7.2 树索引
树索引将一组节点 ( 文本块 ) 构建成具有层级的树状索引结构,其从叶节点 (原始文本块) 向上构建,每个父节点都是子节点的摘要。在检索阶段,既可以从根节点向下进行遍历,也可以直接利用根节点的信息。树索引提供了一种更高效地查询长文本块的方式,它还可以用于从文本的不同部分提取信息。与链式索引不同,树索引无需按顺序查询。
5.7.3 关键词表索引
关键词表索引从每个节点中提取关键词,构建了每个关键词到相应节点的多对多映射,意味着每个关键词可能指向多个节点,每个节点也可能包含多个关键词。在检索阶段,可以基于用户查询中的关键词对节点进行筛选。
5.7.4 向量索引
向量索引是当前最流行的一种索引方法。这种方法一般利用文本嵌入模型将文本块映射成一个固定长度的向量,然后存储在向量数据库中。检索的时候,对用户查询文本采用同样的Embedding模型映射成向量,然后基于向量相似度计算获取最相似的一个或者多个节点。
5.8 排序和后处理
经过前面的检索过程可能会得到很多相关文档,就需要进行筛选和排序。常用的筛选和排序策略包括:
- 基于相似度分数进行过滤和排序
- 基于关键词进行过滤,比如限定包含或者不包含某些关键词
- 让 LLM 基于返回的相关文档及其相关性得分来重新排序
- 基于时间进行过滤和排序,比如只筛选最新的相关文档
- 基于时间对相似度进行加权,然后进行排序和筛选
6. 生成模型6.1 回复生成策略
检索模块基于用户查询检索出相关的文本块,回复生成模块让 LLM 利用检索出的相关信息来生成对原始查询的回复。这里给出一些不同的回复生成策略。
- 一种策略是依次结合每个检索出的相关文本块,每次不断修正生成的回复。这样的话,有多少个独立的相关文本块,就会产生多少次的 LLM 调用。
- 一种策略是在每次 LLM 调用时,尽可能多地在 Prompt 中填充文本块。如果一个 Prompt 中填充不下,则采用类似的操作构建多个 Prompt,多个 Prompt 的调用可以采用和前一种相同的回复修正策略。
6.2 prompt拼接策略
用于将提示的不同部分组合在一起。您可以使用字符串提示或聊天提示来执行此操作。以这种方式构建提示可以轻松地重用组件。
6.2.1 字符串提示
使用字符串提示时,每个模板都会连接在一起。您可以直接使用提示或字符串(列表中的第一个元素必须是提示)。例如,langchain提供的prompttemplate。
6.2.2 聊天提示
聊天提示由消息列表组成。纯粹为了开发人员体验,我们添加了一种便捷的方式来创建这些提示。在此管道中,每个新元素都是最终提示中的一条新消息。例如,langchain提供的AIMessage, HumanMessage, SystemMessage。
7. 插件(Demonstration Retriever for In-Context Learning,基于演示检索的上下文学习)
上下文学习(In-Context learning)是一种新兴的范式,它是指通过给定一些示范性的输入-输出对(示例),在不更新模型参数的情况下实现对给定测试输入的预测。它独特的无需更新参数能力使得上下文学习的方法可以通过一个语言模型的推理,来统一各种自然语言处理任务,这使其成为监督式微调的一个有前途的替代方案。
虽然,这种方法在各种自然语言处理的任务中都表现不错,但它的表现依赖给定的示范性输入-输出对。在模型的prompt中为每个任务都指定示范性示例会影响prompt的长度,这导致每次调用大语言模型的成本增加,甚至超出模型的输入长度。因此,这带来一个全新的研究方向——基于演示检索的上下文学习。这类方法主要是通过文本(或语义)检索与测试输入在文本或语义上相似的候选示范性示例,将用户的输入与获得相似的示范性示例加入到模型prompt中作为模型的输入,则模型就可以给出正确的预测结果。然而,上述单一的检索策略使得召回率不高,造成示范性示例无法精准召回,致使模型的效果不佳。
为了解决上述问题,我们提出了一种基于混合演示检索的上下文学习方法。该方法充分考虑不同检索模型的优劣,提出一种融合算法,通过利用文本检索(例如,BM25和TF-IDF)和语义检索(例如,OpenAI embedding-ada和sentence-bert)进行多路召回,解决单路召回率不高的问题。然而,这带来全新的挑战,即如何将不同的召回结果进行融合。这是由于不同检索算法分数范围不匹配,例如,文本检索分数通常在 0 和某个最大值之间(这具体取决于查询的相关性);而语义搜索(例如,余弦相似度)生成 0 到 1 之间的分数,这使得直接对召回结果进行排序变得很棘手。因此,我们又提出一种基于倒序排序融合算法(Reciprocal Rank fusion)的重排方法,该算法在不需要调整模型的情况下,利用位置来组合不同检索算法的结果,同时,考虑到大模型对相关信息出现在输入上下文的开头或结尾时,性能往往最高,设计重排算法,从获得高质量的融合结果。
具体的模型架构如下图所示,它包括检索模块、重排模块和生成模块。
7.1 检索模块
检索模块又分为文本检索和语义检索。
语义检索采用双塔模型,用OpenAI的embedding-ada作为表征模型,分别对用户的输入和每个任务的候选示例进行表征,获取语义向量,之后利用k-近邻算法(K-Nearest Neighbor,KNN)计算语义相似度,并依据相似度对候选结果进行排序。其中,对于每个任务的候选示例我们采用离线表征,并将其存入向量数据库中,这是因为一旦任务确认,每个任务的候选示例是固定不变的。而对于用户的输入,我们采用实时表征,提高计算效率,这是因为用户的输入是多样的、不固定的。
文本检索,我们先是对每个任务的候选示例进行文本预处理,去除掉停用词、特殊符号等。同时,在文本检索中采用倒排索引的技术加速查询,并利用BM25计算文本相似度,最后按相似度进行排序。
7.2 重排模块
对于重排模块,我们提出了一种基于倒序排序融合的重排算法。该方法先是为了解决不同召回算法的分数范围不匹配的问题,我们引入倒序排序融合算法,对多路的召回结果进行融合排序。虽然倒序排序融合算法可以很好将多路召回进行融合排序,但是这种排序无法满足大模型具有对相关信息出现在输入上下文的开头或结尾时性能最高的特性。这使得简简单单的利用倒序排序融合进行输出,效果不好。因此,我们在此基础之上对融合排序后的结果进行重排,排序策略是依据融合排序后的结果进行两端填充排序。例如,原本的顺序为[1,2,3,4,5],进行重排后的顺序为[1,3,5,4,2]。
7.3 生成模块
生成模块可以生成富有创意且连贯的文本,它旨在根据给定的Prompt或上下文生成新内容,这里我们设计了prompt组装模块,通过将系统prompt与检索到相关信息进行组合。此外,还在组装模块中融入长期对话记录和短期对话记录进行prompt封装。
- 引用或归因(attribution)生成
8.1 什么是引用或归因
在RAG 的知识问答场景下,随着越来越多的文档、网页等信息被注入应用中,越来越多开发者意识到信息来源的重要性,它可以让模型生成的内容能够与参考信息的内容作出对齐,提供证据来源,确保信息准确性,使得大模型的回答更加真实。
这里为了统一,在之后的文章中用“归因”特指“引用或归因”。
8.2 归因的作用
用户角度:能够验证模型的回答是否靠谱。模型角度:提高准确性并减少幻觉。
8.3 如何实现归因
8.3.1 模型生成
直接让模型生成归因信息。可在Prompt 添加类似“每个生成的证据都需在参考信息中进行引用”的话。这种方法最简单,但也对模型的指令遵循能力要求较高,一般会采用GPT-4 回答,或者微调模型让模型学习在生成时附带引用的回答方式。缺点也很明显,极度依赖模型的能力(甚至可能引用也是编的),且针对实际场景中出现的badcase 修复周期长,干预能力弱。
8.3.2 动态计算
在模型生成的过程中进行引用信息的附加。具体的操作为在流式生成的场景下,对生成的文本进行语义单元的判断(比如句号,换行段落等),当出现一个完整的语义单元时,将该语义单元和参考信息中的每个参考源进行匹配(关键字,embedding等),通过卡阈值的办法找到Top-N 的参考源,从而将参考源进行附加返回。这种方法的实现相比方法一简单了很多,badcase 修复周期也短,但受限于匹配方式和阈值,且存在一个前提假设:模型的生成文本来源于参考信息。
更多关于归因研究的工作可以参考:A Survey of Large Language Models Attribution 或 LLM+RAG 中关于回答片段归因的讨论
9. 评估
做开发的同学不管用没用过,对 TDD(Test-Driven Development)的大名总归是听过的,类似的,开发大模型应用的时候也应该有个对应的 MDD(Metrics-Driven Development) 的概念,最舒服的姿势肯定是预先定义好业务的场景、用到的数据、设定的指标以及需要达到的分值,然后按部就班的实现既定目标,员工士气高老板也开心!
但理想和现实之间总是如此纠缠,对大部分的大模型开发任务来讲,更常见的情况是场景定义不清楚,数据光清洗就累死三军,至于需要的指标和目标?想都没想过!这一次,我们来补上本应该在最最开始的就考虑的,大模型应用如何量化业务指标,具体的,如何量化的证明,你的 RAG 就是比隔壁老王他们组的牛?到底该拿哪些量化的指标去说服同行?
影响RAG系统性能的几个方面:
- 位置偏见:LLMs 有可能对文本中特定位置的内容给予更高的关注,比如位于段落开头和结尾的内容更容易被采纳。
- 检索内容相关性:由于query的表达多样性,使得RAG系统可能检索到不相关的内容,这种不相关的内容为LLMs理解带来噪音,增加模型的负担。
9.1 评测指标
- Faithfulness是指用于评测生成的回答是否忠实于contexts,这对于避免幻觉并确保检索到的上下文可以作为生成答案的理由非常重要。
- Answer Relevance是指的生成的答案应解决所提供的实际问题。
- Context Relevance是指检索的上下文应重点突出,尽可能少地包含无关信息。理想情况下,检索到的上下文应该只包含处理所提供查询的基本信息。包含的冗余信息越少,context_relevancy越高。
9.2 评测方法
9.2.1 RGB(Benchmarking Large Language Models in Retrieval-Augmented Generation)
这一工作系统地研究了检索增强生成对大型语言模型的影响。它分析了不同大型语言模型在RAG所需的4项基本能力方面的表现,包括噪声鲁棒性、拒答、信息整合和反事实鲁棒性,并建立了检索增强生成基准。此外,现在做RAG都是做的pipeline,涉及到切块、相关性召回、拒答等多个环节,每个环节都可以单独做评测,文中提到的4个能力其实可以影射到每个环节当中。
9.2.2 RAGAS(RAGAS: Automated Evaluation of Retrieval Augmented Generation)
该工作提出了一种对检索增强生成(RAG)pipeline进行无参考评估的框架。该框架考虑检索系统识别相关和重点上下文段落的能力, LLM以忠实方式利用这些段落的能力,以及生成本身的质量。目前,该方法已经开源,具体可以参见github:GitHub - exploding gradients/ragas: Evaluation framework for your Retrieval Augmented Generation (RAG) pipelines
9.2.3 Llamalindex-Evaluating
LlamaIndex提供了衡量生成结果质量的关键模块。同时,还提供关键模块来衡量检索质量。
10. 总结
LLM这一波,催生的技术真的很多,每一个环节,要真正做好,符合企业应用,都可以让我们研究好长一段时间,并需要不断去实践,才能打磨出精品。本文总结了过去一年在RAG实践的关键模块,希望本文总结对大家有一定的帮助。此外,本文还属于大模型应用——RAG的一个大纲式的技术普及文章,这里面的很多技术细节,我们会在后面一篇篇专门来写。可以让我们研究好长一段时间,并需要不断去实践,才能打磨出精品。但是如果打磨出精品,你肯定可以摘取新技术带来的果实。本文可能还是属于大模型应用——RAG的一个大纲式的技术普及文章,这里面的很多技术细节,我们会在后面一篇篇专门来写。
#EMMA
Waymo玩明白了!全新多模态端到端算法EMMA:规划、感知、静态元素一网打尽~
本文介绍了EMMA,一种用于自动驾驶的端到端多模态模型。EMMA建立在多模态大型语言模型的基础上,将原始摄像头传感器数据直接映射到各种特定于驾驶的输出中,包括规划者轨迹、感知目标和道路图元素。EMMA通过将所有非传感器输入(如导航指令和自车状态)和输出(如轨迹和3D位置)表示为自然语言文本,最大限度地利用了预训练的大型语言模型中的世界知识。这种方法允许EMMA在统一的语言空间中联合处理各种驾驶任务,并使用任务特定的提示为每个任务生成输出。根据经验,我们通过在nuScenes上实现最先进的运动规划性能以及在Waymo开放运动数据集(WOMD)上取得有竞争力的结果来证明EMMA的有效性。EMMA还为Waymo开放数据集(WOD)上的相机主3D目标检测提供了有竞争力的结果。我们表明,将EMMA与规划器轨迹、目标检测和道路图任务联合训练,可以在所有三个领域取得进步,突显了EMMA作为自动驾驶应用的通用模型的潜力。然而,EMMA也表现出一定的局限性:它只能处理少量的图像帧,不包含激光雷达或雷达等精确的3D传感方式,计算成本很高。我们希望我们的研究结果能够激发进一步的研究,以缓解这些问题,并进一步发展自动驾驶模型架构的最新技术。
总结来说,本文的主要贡献如下:
- EMMA在端到端运动规划方面表现出色,在公共基准nuScenes上实现了最先进的性能,在Waymo开放运动数据集(WOMD)上取得了有竞争力的结果。我们还表明,通过更多的内部训练数据和思维链推理,我们可以进一步提高运动规划质量。
- EMMA展示了各种感知任务的竞争结果,包括3D目标检测、道路图估计和场景理解。在相机主Waymo开放数据集(WOD)上,EMMA在3D物体检测方面比最先进的方法具有更好的精度和召回率。
- 我们证明了EMMA可以作为自动驾驶领域的多面手模型,为多个与驾驶相关的任务联合生成输出。特别是,当EMMA与运动规划、目标检测和道路图任务共同训练时,它的性能可以与单独训练的模型相匹配,甚至超过单独训练模型的性能。
- 最后,我们展示了EMMA在复杂的长尾驾驶场景中推理和决策的能力。
尽管有这些SOTA的结果,但EMMA并非没有局限性。特别是,它面临着现实世界部署的挑战,原因是:(1)由于无法将相机输入与LiDAR或雷达融合,3D空间推理受到限制,(2)需要真实且计算昂贵的传感器仿真来为其闭环评估提供动力,以及(3)相较于传统模型,计算要求增加。我们计划在未来的工作中更好地理解和应对这些挑战。
详解EMMA

EMMA建立在Gemini之上,Gemini是谷歌开发的MLLM家族。我们利用经过训练的自回归Gemini模型来处理交错的文本和视觉输入,以产生文本输出:
![]()
如图1所示,我们将自动驾驶任务映射到基于Gemini的EMMA公式中。所有传感器数据都表示为拼接图像或视频V;所有路由器命令、驱动上下文和任务特定提示都表示为T;所有输出任务都以语言输出O的形式呈现。一个挑战是,许多输入和输出需要捕获3D世界坐标,例如用于运动规划的航路点BEV(鸟瞰图)位置(x,y)以及3D框的位置和大小。我们考虑两种表示方式:第一种是直接将文本转换为浮点数,表示为。RT-2在机器人控制中举例说明了这种方法。第二种方法使用特殊的标记来表示每个位置或动作,表示为,分辨率由学习或手动定义的离散化方案确定。MotionLM利用这种方法进行运动预测。我们注意到,这两种方法各有优缺点。我们选择文本表示,这样所有任务都可以共享相同的统一语言表示空间,并且它们可以最大限度地重用预训练权重中的知识,即使文本表示可能比专门的标记化产生更多的标记。
End-to-End Motion Planning
EMMA采用统一的端到端训练模型,直接从传感器数据生成自动驾驶汽车的未来轨迹。然后,这些生成的轨迹被转化为特定于车辆的控制动作,如自动驾驶车辆的加速和转弯。EMMA的端到端方法旨在仿真人类驾驶行为,重点关注两个关键方面:(1)第一,使用导航系统(如谷歌地图)进行路线规划和意图确定;(2)第二,利用过去的行动来确保平稳、一致的驾驶。
们的模型结合了三个关键输入,以与这些人类驾驶行为保持一致:
- 环视视频(V):提供全面的环境信息。
- 高级意图命令(Tintent):源自路由器,包括“直行”、“左转”、“右转”等指令。
- 历史自车状态集(Tego):表示为鸟瞰图(BEV)空间中的一组航路点坐标。所有航路点坐标都表示为纯文本,没有专门的标记。这也可以扩展到包括更高阶的自我状态,如速度和加速度。
该模型为运动规划生成未来轨迹,表示为同一BEV空间中自车的一组未来轨迹航路点:表示未来Tf时间戳,其中所有输出航路点也表示为纯文本。将所有内容放在一起,完整的公式表示为:
![]()
然后,我们使用此公式对Gemini进行微调,以生成端到端的规划器轨迹,如图1所示。我们强调了这种配方的三个特点:
- 自监督:唯一需要的监督是自车的未来位置。不需要专门的人类标签。
- 仅限摄像头:所需的唯一传感器输入是全景摄像头。
- 无高清地图:除了谷歌地图等导航系统的高级路线信息外,不需要高清地图。
2.2 Planning with Chain-of-Thought Reasoning
思维链提示是MLLM中的一个强大工具,可以增强推理能力并提高可解释性。在EMMA中,我们通过要求模型在预测最终未来轨迹航路点Otrajectory的同时阐明其决策原理Orationale,将思维链推理纳入端到端规划器轨迹生成中。
我们按层次结构构建驱动原理,从4种粗粒度信息到细粒度信息:
- R1:场景描述广泛地描述了驾驶场景,包括天气、时间、交通状况和道路状况。例如:天气晴朗,阳光明媚,现在是白天。这条路是四车道不可分割的街道,在中间有人行横道。街道两边都停着汽车。
- R2:关键目标是可能影响自车驾驶行为的道路代理,我们要求模型识别其精确的3D/BEV坐标。例如:行人位于[9.01,3.22],车辆位于[11.58,0.35]。
- R3:关键目标的行为描述描述了已识别关键目标的当前状态和意图。一个具体的例子如下:行人目前正站在人行道上,朝着路看,也许正准备过马路。这辆车目前在我前方,朝着同一个方向行驶,它的未来轨迹表明它将继续笔直行驶。
- R4:元驾驶决策包括12类高级驾驶决策,总结了之前观察到的驾驶计划。一个例子是,我应该保持目前的低速。
我们强调,驱动原理说明是使用自动化工具生成的,没有任何额外的人工标签,确保了数据生成管道的可扩展性。具体来说,我们利用现成的感知和预测专家模型来识别关键代理,然后使用精心设计的视觉和文本提示的Gemini模型来生成全面的场景和代理行为描述。元驾驶决策是使用分析自车地面真实轨迹的启发式算法计算的。
在训练和推理过程中,该模型在预测未来的航路点之前预测了驾驶原理的所有四个组成部分,即:
![]()
EMMA Generalist
虽然端到端的运动规划是最终的核心任务,但全面的自动驾驶系统需要额外的功能。具体来说,它必须感知3D世界,识别周围的物体、道路图和交通状况。为了实现这一目标,我们将EMMA制定为一种多面手模型,能够通过混合训练来处理多种驾驶任务。
我们的视觉语言框架将所有非传感器输入和输出表示为纯文本,提供了整合许多其他驾驶任务所需的灵活性。我们采用指令调优(LLM中一种成熟的方法)来联合训练所有任务以及方程1的输入T中包含的任务特定提示。我们将这些任务分为三大类:空间推理、道路图估计和场景理解。图2显示了整个EMMA概化图。

空间推理是理解、推理和得出关于物体及其在空间中的关系的结论的能力。这使得自动驾驶系统能够解释周围环境并与之交互,以实现安全导航。
我们空间推理的主要重点是3D目标检测。我们遵循Pix2Seq,将输出的3D边界框表示为Oboxes。我们通过写两位小数的浮点数将7D框转换为文本,每个维度之间用空格隔开。然后,我们使用固定提示Tdetect_3D表示检测任务,例如“检测3D中的每个目标”,如下所示:
![]()
道路图估计侧重于识别安全驾驶的关键道路元素,包括语义元素(如车道标记、标志)和物理属性(如车道曲率)。这些道路元素的集合形成了一个道路图。例如,车道段由(a)节点表示,其中车道遇到交叉口、合并或分割,以及(b)这些节点之间沿交通方向的边缘。完整的道路图由许多这样的折线段组成。
虽然每条折线内的边是有方向的,但每条折线相对于其他元素不一定有唯一的顺序。这与目标检测相似,其中每个框由有序属性(左上角、右下角)定义,但框之间不一定存在相对顺序。已有数篇研究使用Transformers对折线图进行建模,与语言模型有相似之处。
我们在EMMA中的一般建模公式如下:
![]()
本文特别关注预测可行驶车道,即自车在场景中可以行驶的车道。这些是同一交通方向上的相邻车道和从当前自我车道分叉的车道。为了构建Oroadgraph,我们(a)将车道转换为有序的航路点集,(b)将这些航路点集转换为文本。使用样本排序的航路点来表示交通方向和曲率是有益的。与检测一样,我们还发现按近似距离对车道进行排序可以提高预测质量。我们的折线文本编码的一个例子是:“(x1,y1和…以及xn,yn);…”其中“x,y”是精度为小数点后2位的浮点航点,“;”分隔折线实例。
场景理解任务测试模型对整个场景上下文的理解,这可能与驾驶有关。例如,道路可能会因施工、紧急情况或其他事件而暂时受阻。及时检测这些障碍物并安全绕过它们对于确保自动驾驶汽车的平稳安全运行至关重要;然而,需要场景中的多个线索来确定是否存在堵塞。我们使用以下公式重点研究我们的模型在这个临时堵塞检测任务中的表现:
![]()
Generalist Training
我们统一的视觉语言公式能够使用单个模型同时训练多个任务,允许在推理时通过任务提示Ttask的简单变化进行特定任务的预测。训练方式既简单又灵活。
实验结果表明,在多个任务中训练的通才模型明显优于在单个任务上训练的每个专家模型。这突出了通才方法的优势:增强了知识转移,提高了泛化能力,提高了效率。
实验结果






我们在图8、9和10中展示了12个不同的视觉示例,每个示例都是为了突出EMMA模型在一系列场景中的通用性。在所有场景中,我们显示模型的预测(从左到右):端到端运动规划、3D目标检测和道路图估计。
我们按场景类型对视觉示例进行分组:示例(a)-(d)展示了EMMA如何安全地与路上罕见、看不见的物体或动物互动。示例(e)-(f)的特点是EMMA在施工区域导航。示例(g)-(j)展示了EMMA在有交通信号灯或交通管制员的十字路口遵守交通规则的情况。示例(k)-(l)强调了EMMA尊重摩托车手等弱势道路使用者。
鉴于这些示例,我们展示了EMMA的以下功能:
- 泛化能力:能够很好地适应不同环境中的各种现实驾驶场景,并关注其微调类别之外的目标,如松鼠。
- 预测性驾驶:主动适应其他道路使用者的行为,实现安全平稳的驾驶。
- 避障:持续调整轨迹,避开障碍物、碎片和堵塞的车道。
- 适应性行为:安全地处理复杂的情况,如屈服、施工区和遵循交通管制信号。
- 精确的3D检测:有效识别和跟踪道路代理人,包括车辆、骑自行车的人、摩托车手和行人。
- 可靠的道路图估计:准确捕捉道路布局,并将其整合到安全轨迹规划中。
总之,这些场景突出了EMMA在各种具有挑战性和多样性的驾驶场景和环境中安全高效运行的能力。



限制、风险和缓解措施
在前面的部分中,我们在nuScenes规划基准上展示了最先进的端到端运动规划。我们还在WOD规划基准上实现了端到端的运动规划和WOD上的相机主3D检测的竞争性能。此外,我们的通才设置通过联合训练提高了多项任务的质量。尽管取得了这些有希望的结果,但我们承认我们工作的局限性,并提出了在此基础上进一步发展和在未来研究中应对这些挑战的方向。
内存和视频功能:目前,我们的模型只处理有限数量的帧(最多4帧),这限制了它捕获驾驶任务所必需的长期依赖关系的能力。有效的驾驶不仅需要实时决策,还需要在更长的时间范围内进行推理,依靠长期记忆来预测和应对不断变化的场景。增强模型执行长期推理的能力是未来研究的一个有前景的领域。这可以通过集成存储模块或扩展其高效处理较长视频序列的能力来实现,从而实现更全面的时间理解。
扩展到激光雷达和雷达输入:我们的方法严重依赖于预训练的MLLM,这些MLLM通常不包含激光雷达或雷达输入。扩展我们的模型以集成这些3D传感模式带来了两个关键挑战:1)可用相机和3D传感数据量之间存在显著不平衡,导致与基于相机的编码器相比,3D传感编码器的通用性较差。2) 3D传感编码器的发展尚未达到基于相机的编码器的规模和复杂程度。解决这些挑战的一个潜在解决方案是使用与相机输入仔细对齐的数据对大规模3D传感编码器进行预训练。这种方法可以促进更好的跨模态协同作用,并大大提高3D传感编码器的泛化能力。
预测驾驶信号的验证:我们的模型可以直接预测驾驶信号,而不依赖于中间输出,如物体检测或道路图估计。这种方法给实时和事后验证带来了挑战。我们已经证明,我们的多面手模型可以联合预测额外的人类可读输出,如目标和道路图元素,并且可以用思维链驱动原理进一步解释驾驶决策。然而,尽管经验观察表明这些输出通常确实是一致的,但不能保证它们总是一致的。此外,额外的输出会给部署带来巨大的运行时延迟开销。
闭环评估的传感器仿真:人们普遍认为,开环评估可能与闭环性能没有很强的相关性。为了在闭环环境中准确评估端到端的自动驾驶系统,需要一个全面的传感器仿真解决方案。然而,传感器仿真的计算成本通常比行为仿真器高几倍。除非进行大量优化,否则这种巨大的成本负担可能会阻碍端到端模型的彻底测试和验证。
车载部署的挑战:自动驾驶需要实时决策,由于推理延迟增加,在部署大型模型时面临重大挑战。这就需要优化模型或将其提炼成适合部署的更紧凑的形式,同时保持性能和安全标准。实现模型尺寸、效率和质量之间的微妙平衡对于自动驾驶系统在现实世界中的成功部署至关重要,也是未来研究的关键领域。
结论
在本文中,我们提出了EMMA,一种基于Gemini的自动驾驶端到端多模式模型。它将双子座视为一等公民,并将自动驾驶任务重新定义为视觉问答问题,以适应MLLM的范式,旨在最大限度地利用双子座的世界知识及其配备思维链工具的推理能力。与具有专门组件的历史级联系统不同,EMMA直接将原始摄像头传感器数据映射到各种特定于驾驶的输出中,包括规划轨迹、感知目标和道路图元素。所有任务输出都表示为纯文本,因此可以通过任务特定的提示在统一的语言空间中联合处理。实证结果表明,EMMA在多个公共和内部基准和任务上取得了最先进或具有竞争力的结果,包括端到端的规划轨迹预测、相机主要3D目标检测、道路图估计和场景理解。我们还证明,单个联合训练的EMMA可以联合生成多个任务的输出,同时匹配甚至超越单独训练的模型的性能,突出了其作为许多自动驾驶应用的多面手模型的潜力。
虽然EMMA显示出有希望的结果,但它仍处于早期阶段,在机载部署、空间推理能力、可解释性和闭环仿真方面存在挑战和局限性。尽管如此,我们相信我们的EMMA发现将激发该领域的进一步研究和进展。
#MVGS
3DGS优化神器 | 理想汽车提出MVGS:利用多视图一致性暴力涨点!
最近在体渲染方面的工作,例如NeRF和3GS,在学习到的隐式神经辐射场或3D高斯分布的帮助下,显著提高了渲染质量和效率。在演示表示的基础上进行渲染,vanilla 3DGS及其变体通过优化参数模型,在训练过程中每次迭代都进行单视图监督,从而提供实时效率,这是NeRF采用的。因此某些视图过拟合,导致新视角合成和不精确的3D几何中的外观不令人满意。为了解决上述问题,我们提出了一种新的3DGS优化方法,该方法体现了四个关键的新贡献:1)我们将传统的单视图训练范式转化为多视图训练策略。通过我们提出的多视图调节,3D高斯属性得到了进一步优化,而不会过拟合某些训练视图。作为通用解决方案,我们提高了各种场景和不同高斯变体的整体精度。2)受其他视角带来的好处的启发,我们进一步提出了一种跨内参指导方法,从而针对不同分辨率进行了从粗到细的训练过程。3)基于我们的多视图训练,进一步提出了一种交叉射线高斯split&clone策略,从一系列视图中在射线交叉区域优化高斯核。4) 通过进一步研究致密化策略,我们发现当某些视角明显不同时,densification的效果应该得到增强。作为一种解决方案,我们提出了一种新的多视图增强致密化策略,其中鼓励3D高斯模型相应地被致密化到足够的数量,从而提高了重建精度。我们进行了广泛的实验,以证明我们提出的方法能够改进基于高斯的显式表示方法的新视图合成,其峰值信噪比约为1 dB,适用于各种任务。
- 项目主页:https://xiaobiaodu.github.io/mvgs-project/
总结来说,本文的主要贡献如下:
- 首先提出了一种多视图调节训练策略,该策略可以很容易地适应现有的单视图监督3DGS框架及其变体,这些变体针对各种任务进行了优化,可以持续提高NVS和几何精度。
- 受不同外参下的多视图监督带来的好处的启发,提出了一种交叉内参指导方法,以从粗到细的方式训练3D高斯人。因此3D高斯分布可以与像素局部特征保持更高的一致性。
- 由于致密化策略对3DGS至关重要,我们进一步提出了一种交叉射线致密化策略,在2D loss图引导下发射射线,并对重叠的3D区域进行致密化。这些重叠区域中的致密三维高斯分布有助于多个视图的拟合,提高了新型视图合成的性能。
- 最后但同样重要的是,我们提出了一种多视图增强致密化策略,在多视图差异显著的情况下加强致密化。它确保了3D高斯分布可以被充分稠密,以很好地适应急剧变化的多视图监督信息。
- 总之大量实验表明,我们的方法是现有基于高斯的方法的通用优化解决方案,可以将各种任务的新视图合成性能提高约1 dB PSNR,包括静态对象或场景重建和动态4D重建。
MVGS方法介绍
高斯散射最近被提出用于实时新颖的视图合成和高保真3D几何重建。高斯散射不是使用NeRF中的密度场和NeuS中的SDF等隐式表示,而是利用一组由其位置、颜色、协方差和不透明度组成的各向异性3D高斯来参数化场景。与NeRF和NeuS等先前的方法相比,这种显式表示显著提高了训练和推理效率。在渲染过程中,高斯散斑还采用了NeRF之后的基于点的体绘制技术。如图2(a)所示,由于其点采样策略和隐式表示,NeRF在训练迭代中无法接收多视图监督。通过沿光线r(p,E,K)混合一组3D高斯分布,计算具有相机外部函数E和内部函数K的图像中每个像素p的视图相关辐射C。虽然NeRF与辐射场中采样器指定的点近似混合,但3DGS通过沿光线r用N个参数化内核进行光栅化来精确渲染。

多视角调节训练
给定T对GT图像I及其相应的相机外部函数E和内部函数K,3DGS的目标是重建由多视图立体数据描述的3D模型。在训练策略方面,3DGS遵循NeR的惯例,通过每次迭代的单视图监督来优化参数模型。关于训练,3DGS通常通过每次迭代的单一信息视图进行监督来优化,其中一次迭代中的监督被随机选择为(Ii,Ei,Ki)。因此,原始3DGS的损失函数可以相应地公式化为:

考虑到隐式表示(如NeRF)依赖于预训练的采样器来近似最自信的混合点,每次迭代的多视图监督并不能确保对单视图训练的改进,特别是当采样器没有如图2(a)所示经过训练时。另一方面,明确定义的高斯核不依赖于采样器来分配,如图2(b)所示,这使得我们提出的多视图训练策略适用于图2(c)所示的情况,其中G中的大多数混合核可以用多视图加权梯度反向传播,以克服某些视角的过拟合问题。
与原始的单视图迭代训练不同,我们提出了一种多视图调节训练方法,以多视图监督的方式优化3D高斯分布。特别是,我们在迭代中对M对监督图像和相机参数进行采样。请注意,M组匹配的图像和相机参数被采样并且彼此不同。因此,我们提出的梯度积分单次迭代中的多视图调节学习可以表示为:

与原始3DGS损失的唯一区别是,我们提出的方法为优化一组3D高斯G提供了梯度的多视图约束。这样优化每个高斯核gi可能会受到多视图信息的调节,从而克服某些视图的过拟合问题。此外,多视图约束使3D高斯人能够学习和推断与视图相关的信息,如图4左侧突出显示的反射,因此我们的方法可以在反射场景的新颖视图合成中表现良好。
跨内参指导
如图2底部所示,受图像金字塔带来的好处的启发,我们提出了一种从粗到细的训练方案,通过简单地补充更多的光栅化平面,使用不同的相机设置,即内在参数K。具体而言,如图2(d)所示,通过简单地重新配置焦距fk和K中的主点ck,可以构建具有下采样因子S的4层图像金字塔。根据经验,设置sk为8足以容纳足够的训练图像进行多视图训练,因子sk等于1意味着不应用下采样操作。对于每一层,我们都匹配了多视图设置。特别是,较大的下采样因子能够容纳更多的视图,从而提供更强的多视图约束。在最初的三个训练阶段,我们每个阶段只运行几千次迭代,而没有完全训练模型。由于目标图像是降采样的,因此模型在这些早期阶段无法捕捉到精细的细节。因此,我们将前三个训练阶段视为粗训练。在粗略训练期间,合并更多的多视图信息会对整个3D高斯模型施加更强大的约束。在这种情况下,丰富的多视图信息为整个3DGS提供了全面的监控,并鼓励快速拟合粗糙的纹理和结构。一旦粗略的训练结束,精细的训练就开始了。由于之前的粗略训练阶段提供了3DGS的粗略架构,精细训练阶段只需要为每个3D高斯模型细化和雕刻精细细节。特别是,粗训练阶段提供了大量的多视图约束。它将学习到的多视图约束传递给下一次精细训练。该方案有效地增强了多视图约束,进一步提高了新颖的视图合成性能。
跨射线稠密化
由于体渲染的性质和3DGS的显式表示,某些区域的3D高斯分布在渲染时对不同的视图有重大影响。例如在以不同姿态拍摄中心的相机进行渲染时,中心3D高斯分布至关重要。然而找到这些区域并非易事,尤其是在3D空间中。如图2所示,我们提出了一种交叉射线致密化策略,从2D空间开始,然后在3D中自适应搜索。具体来说,我们首先计算多个视图的损失图,然后使用大小为(h,w)的滑动窗口定位包含最大平均损失值的区域。之后,我们从这些区域的顶点投射光线,每个窗口有四条光线。然后,我们计算不同视角光线的交点。由于我们每个视角投射四条光线,交点可以形成几个长方体。这些长方体是包含重要3D高斯分布的重叠区域,在渲染多个视图时起着重要作用。因此,我们在这些重叠区域中加密了更多的3D高斯分布,以促进多视图监督的训练。该策略依赖于对包含对多个视图具有高意义的3D高斯分布的重叠区域的精确搜索。首先,我们选择损失指导,因为它突出了每个视图应该改进的最低质量区域。其次,光线投射技术使我们能够定位包含一组对这些视图有重大贡献的3D高斯分布的3D区域。基于精确的位置,这些区域中的3D高斯分布可以被视为多视图联合优化的关键。通过这种方式,我们将这些3D高斯图像加密到一定程度,以共同提高这些视图的重建性能。
多视图增强稠密化
为了在不同视图之间的差异显著时获得快速收敛、避免局部最小值并学习细粒度高斯核,我们提出了一种多视图增强致密化策略。具体来说,我们的策略建立在原始3DGS的致密化策略的基础上,使用预定义的阈值β来确定哪些3D高斯应被致密化。如图2所示,我们首先确定训练视图是否非常不同。我们没有直接使用原始的相机平移,而是将采样视图的相机平移归一化为一个单位球体。这种方法使我们的策略能够适应各种场景。然后,计算每个相机和另一个相机之间的相对平移距离,其中距离n的数量为,假设我们有M个训练视图。在我们的多视图增强致密化中,我们有一个自适应标准,可以公式化为:

实验结果
结论
在这项工作中,我们提出了MVGS,这是一种新颖而通用的方法,可以提高现有基于高斯的方法的新颖视图合成性能。MVGS的核心在于提出的多视图调节学习,约束了具有多视图信息的3D高斯优化。我们表明,我们的方法可以集成到现有的方法中,以实现最先进的渲染性能。我们进一步证明了我们提出的跨内禀制导方案引入了强大的多视图约束,以获得更好的结果。我们还证明了所提出的多视图增强致密化和交叉射线致密化在增强致密化以促进3D高斯优化方面的有效性。大量实验证明了我们方法的有效性,并表明我们的方法取得了最先进的新颖视图合成结果。
#DINOv2
计算机视觉领域的基础模型终于出现
使用 DINOv2 进行语义分割的示例(图1-1)
DINOv2 是 Meta AI 推出的一款计算机视觉模型,旨在提供一个基础模型,类似于自然语言处理领域已经普遍存在的基础模型。
在这篇文章中,我们将解释在计算机视觉中成为基础模型的意义,以及为什么 DINOv2 能够被视为这样的模型。
DINOv2 是一个非常大的模型(相对于计算机视觉领域),拥有十亿个参数,因此在训练和使用时会面临一些严峻的挑战。本文将回顾这些挑战,并介绍 Meta AI 的研究人员如何通过自监督学习和蒸馏技术克服这些问题。即使你不熟悉这些术语,也不用担心,我们会在后面解释。首先,让我们了解 DINOv2 提供了什么,使它成为计算机视觉领域的基础模型。
什么是基础模型?
在没有基础模型的时代,必须先找到或创建一个数据集,然后选择一种模型架构,并在该数据集上训练模型。你所需的模型可能非常复杂,训练过程可能很长或很困难。
基础模型出现之前的生活。适用于任何任务的专用模型。可能很复杂。(图2-1)
于是,DINOv2 出现了,这是一种预训练的大型视觉Transformer(ViT)模型,这是计算机视觉领域中一种已知的架构。它表明你可能不再需要一个复杂的专用模型。
例如,假设我们有一张猫的图片(下图左侧的那张)。我们可以将这张图片作为输入提供给 DINOv2。DINOv2 会生成一个数字向量,通常称为嵌入或视觉特征。这些嵌入包含对输入猫图片的深层理解,一旦我们获得这些嵌入,就可以将它们用于处理特定任务的小型模型中。例如,我们可以使用一个模型进行语义分割(即对图像中的相关部分进行分类),另一个模型估计图中物体的深度。这些输出示例来自 Meta AI 对 DINOv2 的演示。
DINOv2 作为基础模型(图2-2)
DINOv2 的另一个重要特性是,在训练这些任务特定的模型时,DINOv2 可以被冻结,换句话说,不需要进行微调。这大大简化了简单模型的训练和使用,因为 DINOv2 可以在图像上执行一次,输出结果可以被多个模型使用。与需要微调的情况不同,那样每个任务特定的模型都需要重新运行微调后的 DINOv2。此外,微调这样的大型模型并不容易,需要特定的硬件,而这种硬件并非人人都能使用。
训练下游任务模型时,DINOv2 可能会被冻结(图2-3)
如何使用DINOv2?
我们不会深入探讨代码,但如果你想使用 DINOv2,可以通过 PyTorch 代码简单加载它。以下代码来自 DINOv2 的 GitHub 页面。我们可以看到,有几种不同大小的模型版本可供加载,因此你可以根据自己的需求和资源选择合适的版本。即使使用较小版本,准确率的下降也不明显,尤其是使用中等大小的版本时,这非常有用。
如何生成不同版本的 DINOv2 模型,答案是通过蒸馏技术实现。(图3-1)
模型蒸馏
蒸馏指的是将一个大型训练模型的知识转移到一个新的小型模型中。令人有趣的是,在 DINOv2 中,研究人员通过这种方式得到了比直接训练小型模型更好的结果。具体方法是使用预训练的 DINOv2 教授新的小型模型,例如给定一张猫的图片,DINOv2 和小型模型都会生成嵌入,蒸馏过程会尽量减少两者生成嵌入的差异。需要注意的是,DINOv2 保持冻结,只有右侧的小型模型在发生变化。
这种方法通常被称为师生蒸馏,因为这里的左侧充当老师,右侧充当学生
DINOv2 师生蒸馏(图4-1)
在实践中,为了从蒸馏过程中获得更好的结果,我们不会只使用一个学生模型,而是同时使用多个学生模型。每个学生模型会接收相同的输入并输出结果。在训练过程中,所有学生模型的结果会进行平均,最终形成一个经过蒸馏的毕业模型。
最终的蒸馏模型是多个学生模型的平均值(图4-2)
在 DINOv2 中,模型的规模相比之前版本大幅增加,这就需要更多的训练数据。这引出了一个话题,即使用大规模精心整理的数据进行自监督学习。这种方法帮助模型无需大量的人工标注数据,依靠数据本身进行有效的学习,尤其适合像 DINOv2 这样的大模型训练需求。
利用大量精选数据进行自我监督学习
首先,什么是自监督学习?简单来说,它指的是我们的训练数据没有标签,模型只从图像中学习。第一版 DINO 也使用了自监督学习技术。没有数据标注是否会更容易增加训练数据的规模?然而,以前尝试通过自监督学习增加未经整理的数据规模,反而导致了质量下降。
在 DINOv2 中,研究人员构建了一个自动化流程,用来创建精心整理的数据集,帮助他们取得了相较其他自监督学习模型的最新成果。他们从 25 个数据来源中收集了 12 亿张图像,最终从中提取了 1.42 亿张图像用于训练。这种数据筛选策略提升了模型性能。
因此,这个流程包含多个过滤步骤。例如,在未经整理的数据集中,我们可能会找到大量猫的图片以及其他图像。如果直接在这些数据上训练,可能会导致模型在理解猫方面表现优异,但在泛化到其他领域时表现不佳。
因此,这个流程的其中一步是使用聚类技术,将图像根据相似性进行分组。然后,他们可以从每个组中抽取相似数量的图像,创建一个规模更小但更多样化的数据集。这种方法确保了数据的广泛代表性,避免模型过度专注于某些特定类别如猫的图像。
无标签数据管理(图5-1)
更好的像素级理解
使用自监督学习的另一个好处是对像素级别的理解更强。目前计算机视觉中常见的方法是使用文本引导的预训练。例如,一张猫的图片可能会附带类似“草地上一只白色小猫”的描述。这种方法结合了图像和文本信息,但自监督学习能够更深入地理解图像本身,而无需依赖文本标签。
然而,这类模型会将图像和文本一起作为输入,但描述文本可能会遗漏一些信息,例如猫在走路或图片中的小白花,这可能会限制模型的学习能力。
常见方法 - 文本引导图像(图6-1)
通过 DINOv2 和自监督学习,模型在像素级别信息的学习上展现了惊人的能力。例如,图片中的多个马匹,即使在不同图片中,或者图片中的马很小,DINOv2 都能将相同身体部位标注为相似的颜色,非常令人印象深刻。这展示了 DINOv2 对细节的深度理解能力。
通过自我监督学习对 DINOv2 进行像素级理解(图7-1)
#Mapper(建图)系列论文总结
文总结了自动驾驶Mapper(建图)系列论文,包含:矢量地图、先验地图、MapLess、HDMap、SDMap、众包建图、BEV、多视图、蒸馏、融合等领域,总计40篇论文,可作为科研、开发的参考资料。
1.Efficient/高效
MapLite
题目:MapLite: Autonomous Intersection Navigation Without a Detailed Prior Map
名称:MapLite:无需详细先验地图的自动交叉口导航
论文:https://ieeexplore.ieee.org/document/8936918
代码:
单位:MIT
MapLite2.0
题目:MapLite 2.0: Online HD Map Inference Using a Prior SD Map
名称:MapLite 2.0:基于先前SD地图的在线高清地图推断
论文:https://ieeexplore.ieee.org/document/9807400
代码:
单位:MIT
RoadMap
题目:RoadMap: A Light-Weight Semantic Map for Visual Localization towards Autonomous Driving
名称:RoadMap:面向自动驾驶视觉定位的轻量级语义图
论文:https://arxiv.org/abs/2106.02527
代码:
单位:华为
2.Priors/先验地图
P-MapNet
题目:P-MapNet: Far-seeing Map Generator Enhanced by both SDMap and HDMap Priors
名称:P-MapNet:SDMap和HDMap先验增强的远视图生成器
论文:https://arxiv.org/abs/2403.10521
代码:https://jike5.github.io/P-MapNet
单位:北京理工大学、清华
PriorMapNet
题目:PriorMapNet: Enhancing Online Vectorized HD Map Construction with Priors
名称:PriorMapNet:利用Priors增强在线矢量化高清地图构建
论文:https://arxiv.org/abs/2408.08802
代码:
单位:北京理工大学、元戎启行
MapNeRF
题目:MapNeRF: Incorporating Map Priors into Neural Radiance Fields for Driving View Simulation
名称:MapNeRF:将地图先验结合到神经辐射场中用于驱动视图模拟
论文:https://arxiv.org/abs/2307.14981
代码:
单位:百度
NPN
题目:Neural Map Prior for Autonomous Driving
名称:自动驾驶的神经映射先验
论文:https://arxiv.org/abs/2304.08481
代码:
单位:清华&MIT&理想
HPQuery
题目:Driving with Prior Maps: Unified Vector Prior Encoding for Autonomous Vehicle Mapping
名称:使用先验地图驾驶:自动驾驶汽车地图的统一矢量先验编码
论文:https://arxiv.org/abs/2409.05352
代码:
单位:阿里巴巴、西安交通大学
3.Vector/矢量地图
VectorMapNet
题目:VectorMapNet: End-to-end Vectorized HD Map Learning
名称:VectorMapNet:端到端矢量化高精地图学习
论文:https://arxiv.org/abs/2206.08920
代码:https://github.com/yuantianyuan01/streammapnet
单位:清华大学
MapTR
题目:MapTR: Structured Modeling and Learning for Online Vectorized HD Map Construction
名称:MapTR:在线矢量化高精地图构建的结构化建模和学习
论文:https://arxiv.org/abs/2208.14437
代码:https://github.com/hustvl/MapTR
单位:华中科技大学、地平线
MapTRv2
题目:MapTRv2: An End-to-End Framework for Online Vectorized HD Map Construction
名称:MapTRv2:在线矢量化高精地图构建的端到端框架
论文:https://arxiv.org/abs/2308.05736
代码:https://github.com/hustvl/MapTR
单位:华中科技大学、地平线
题目:InstaGraM: Instance-level Graph Modeling for Vectorized HD Map Learning
名称:InstaGraM:用于矢量化高精地图学习的实例级图建模
论文:https://arxiv.org/abs/2301.04470
代码:
单位:韩国科学技术院
VAD
题目:VAD: Vectorized Scene Representation for Efficient Autonomous Driving
名称:VAD:用于高效自动驾驶的矢量化场景表示
论文:https://arxiv.org/abs/2303.12077
代码:https://github.com/hustvl/VAD
单位:华中科技大学、地平线
BeMapNet
题目:End-to-End Vectorized HD-map Construction with Piecewise Bezier Curve
名称:使用分段贝塞尔曲线构建端到端矢量化高清地图
论文:https://arxiv.org/abs/2306.09700
代码:https://github.com/er-muyue/BeMapNet
单位:旷视科技
MachMap
题目:MachMap: End-to-End Vectorized Solution for Compact HD-Map Construction
名称:MachMap:用于紧凑型高精地图构建的端到端矢量化解决方案
论文:https://arxiv.org/abs/2306.10301
代码:
单位:迈驰智行、西安交通大学
MapVR
题目:Online Map Vectorization for Autonomous Driving: A Rasterization Perspective
名称:自动驾驶在线地图矢量化:光栅化视角
论文:https://arxiv.org/abs/2306.10502
代码:https://github.com/ZhangGongjie/MapVR
单位:黑芝麻
InsightMapper
题目:InsightMapper: A Closer Look at Inner-instance Information for Vectorized High-Definition Mapping
名称:InsightMapper:仔细查看矢量化高清映射的内部实例信息
论文:https://arxiv.org/abs/2308.08543
代码:https://github.com/TonyXuQAQ/InsightMapper
单位:香港大学
PivoNet
题目:PivotNet: Vectorized Pivot Learning for End-to-end HD Map Construction
名称:PivotNet:用于端到端高精地图构建的矢量化枢轴学习
论文:https://arxiv.org/abs/2308.16477
代码:
单位:旷视科技
StreamMapNet
题目:StreamMapNet: Streaming Mapping Network for Vectorized Online HD Map Construction
名称:StreamMapNet:用于矢量化在线高精地图构建的流式测绘网络
论文:https://arxiv.org/abs/2308.12570
代码:https://github.com/yuantianyuan01/StreamMapNet
单位:清华大学
GlobalMapNet
题目:GlobalMapNet: An Online Framework for Vectorized Global HD Map Construction
名称:GlobalMapNet:矢量化全球高清地图构建的在线框架
论文:https://arxiv.org/abs/2409.10063
代码:
单位:复旦大学
SQD-MapNet
题目:Stream Query Denoising for Vectorized HD Map Construction
名称:矢量化高清地图构建中的流查询去噪
论文:https://arxiv.org/abs/2401.09112
代码:
单位:中科大、旷视科技
MapQR
题目:Leveraging Enhanced Queries of Point Sets for Vectorized Map Construction
名称:利用点集的增强查询进行矢量化地图构建
论文:https://arxiv.org/abs/2402.17430
代码:https://github.com/HXMap/MapQR
单位:上海交大、香港中文大学、辉羲智能
HRMapNet
题目:Enhancing Vectorized Map Perception with Historical Rasterized Maps
名称:利用历史栅格化地图增强矢量化地图感知
论文:https://arxiv.org/abs/2409.00620
代码:
单位:香港中文大学、辉羲智能
ADMap
题目:ADMap: Anti-disturbance framework for vectorized HD map construction
名称:ADMap:矢量化高清地图构建的抗干扰框架
论文:https://arxiv.org/abs/2401.13172
代码:https://github.com/hht1996ok/ADMap
单位:零跑汽车、浙江大学
4.HDMap/高精地图
ExelMap
题目:ExelMap: Explainable Element-based HD-Map Change Detection and Update
名称:ExelMap:基于可解释元素的高清地图变化检测与更新
论文:https://arxiv.org/abs/2409.10178
代码:
单位:瑞典皇家理工学院
HDMapNet
题目:HDMapNet: An Online HD Map Construction and Evaluation Framework
名称:HDMapNet:在线高精地图构建和评估框架
论文:https://arxiv.org/abs/2107.06307
代码:
单位:清华大学
THMA
题目:THMA: Tencent HD Map AI System for Creating HD Map Annotations
名称:THMA:腾讯高精地图人工智能系统,用于创建高精地图标注
论文:https://dl.acm.org/doi/abs/10.1609/aaai.v37i13.26848
代码:
单位:腾讯
5.CSMap/众包建图
EdgeMap
题目:EdgeMap: CrowdSourcing High Definition Map in Automotive Edge Computing
名称:EdgeMap:汽车边缘计算中的众包高清地图
论文:https://arxiv.org/abs/2201.07973
代码:
单位:内布拉斯加林肯大学、西安电子科技大学
MRVF-HDMap
题目:HD Map Generation from Noisy Multi-Route Vehicle Fleet Data on Highways with Expectation Maximization
名称:利用期望最大化的高速公路上嘈杂的多路线车队数据生成高清地图
论文:https://arxiv.org/abs/2305.02080
代码:
单位:德国信息技术研究中心
CenterLineDet
题目:CenterLineDet: CenterLine Graph Detection for Road Lanes with Vehicle-mounted Sensors by Transformer for HD Map Generation
名称:CenterLineDet:利用车载传感器通过 Transformer 进行道路车道中心线图检测,生成高清地图
论文:https://arxiv.org/abs/2209.07734
代码:https://tonyxuqaq.github.io/projects/CenterLineDet/
单位:香港科技大学
6.MultiView/多视图
MV-Map
题目:MV-Map: Offboard HD-Map Generation with Multi-view Consistenc
名称:MV-Map:具有多视图一致性的非车载高清地图生成
论文:https://arxiv.org/abs/2305.08851
代码:
单位:复旦大学
7.BEV/鸟瞰图
Mask2Map
题目:Mask2Map: Vectorized HD Map Construction Using Bird's Eye View Segmentation Masks
名称:Mask2Map:使用鸟瞰分割掩模构建矢量化高清地图
论文:https://arxiv.org/abs/2407.13517
代码:https://github.com/SehwanChoi0307/Mask2Map
单位:汉阳大学
Talk2Bev
题目:Talk2BEV: Language-enhanced Bird's-eye View Maps for Autonomous Driving
名称:Talk2BEV:用于自动驾驶的语言增强鸟瞰图
论文:https://arxiv.org/abs/2310.02251
代码:https://llmbev.github.io/talk2bev/
单位:海得拉巴大学
Bi-Mapper
题目:Bi-Mapper: Holistic BEV Semantic Mapping for Autonomous Driving
名称:Bi-Mapper:用于自动驾驶的整体BEV语义映射
论文:https://arxiv.org/abs/2305.04205
代码:https://github.com/lynn-yu/Bi-Mapper
单位:湖南大学
8.Fusion/融合
MemFusionMap
题目:MemFusionMap: Working Memory Fusion for Online Vectorized HD Map Construction
名称:MemFusionMap:用于在线矢量化高清地图构建的工作Memory融合
论文:https://arxiv.org/abs/2409.18737
代码:
单位:密歇根大学、NVIDAI
MapTracker
题目:MapTracker: Tracking with Strided Memory Fusion for Consistent Vector HD Mapping
名称:MapTracker:使用分层记忆融合进行跟踪,以实现一致的矢量高清映射
论文:https://arxiv.org/abs/2403.15951
代码:https://map-tracker.github.io/
单位:西蒙菲莎大学、Wayve
SensorSatelliteMap
题目:Complementing Onboard Sensors with Satellite Map: A New Perspective for HD Map Construction
名称:车载传感器与卫星地图互补:高精地图构建新视角
论文:https://arxiv.org/abs/2308.15427
代码:
单位:西安交通大学
SuperFusion
题目:SuperFusion: Multilevel LiDAR-Camera Fusion for Long-Range HD Map Generation
名称:SuperFusion:用于远距离高清地图生成的多级激光雷达相机融合
论文:https://arxiv.org/abs/2211.15656
代码:https://github.com/haomo-ai/SuperFusion
单位:苏黎世联邦理工学院、毫末智行
9.Distill/蒸馏
MapDistill
题目:MapDistill: Boosting Efficient Camera-based HD Map Construction via Camera-LiDAR Fusion Model Distillation
名称:MapDistill:通过摄像头LiDAR融合模型蒸馏提高基于摄像头的高清地图构建效率
论文:https://arxiv.org/abs/2407.11682
代码:
单位:三星(中国)
#如何将规划引入预测
重新思考轨迹预测 | 复旦提出PIFM
传统的自动驾驶主要可以分为感知、预测、规控三个大的部分,其中预测模块承担着十分重要的角色,为下游规划路径提供重要的信息。然而,现实世界驾驶环境的复杂性,其中包括多个动态智能体(如车辆和行人)之间的相互作用,给预测造成了不小的挑战。这其中有一个重要任务就是轨迹预测,这涉及到基于它们当前的状态和环境来预测周围智能体的未来移动。
传统上,运动预测模型预测单个智能体的轨迹,而没有考虑它们之间的相互依赖性。在多智能体环境中,这种方法会导致次优的预测,因为它并不能捕捉到智能体之间的复杂交互。为了克服这些限制,最近的工作开始将规划信息纳入轨迹预测过程,允许系统做出更明智的决策。
- 论文链接:https://arxiv.org/pdf/2410.19639
在过去几年,自动驾驶的轨迹预测也有了显著的发展,许多方法利用多模态融合技术来提高准确性。比较早期模型依赖于历史轨迹和地图数据,通常将这些输入结合起来做预测。近期的工作会使用基于transformer的架构,引入了注意力机制以更好地整合这些不同的模态。这些模型大大提高了自动驾驶系统的预测能力,尤其是在智能体与其环境动态交互的场景中。另外,Planning-aware模型也作为提高轨迹预测的有效方法之一,比如:PiP和PRIME明确地将规划信息集成到预测框架中,允许系统在轨迹生成过程中考虑未来的目标。然而,这些方法通常因为处理数据所涉及的计算复杂性,在实时多智能体场景中表现并不理想。因此,基于扩散的模型最近被提出来解决这些问题,同时减少计算负担,同时保持高预测性能。
在这项工作中,作者提出了轨迹信息规划扩散(Trajectory-Informed Planning Diffusion,TIP-D)模型,该模型基于扩散框架的优势,并直接将规划特征集成到运动预测过程中,目的是结合规划信息来提高轨迹预测的准确性和可解释性。作者的方法能够通过利用交叉注意力机制动态融合规划特征与环境数据,同时预测多个智能体的轨迹。此外,TIP-D模型在计算复杂性上实现了显著降低,与现有的最先进方法相比降低了80%以上,同时在复杂的多智能体驾驶场景中保持了高准确性。
相关工作
多模态融合
在运动预测中,准确的轨迹预测依赖于不同信息模态的整合,例如智能体的历史轨迹和地图数据。为了更好地捕捉运动动态的复杂性,最近的研究扩展到包括规划轨迹、交通状态和车道方向等额外模态。这些增强旨在提供对动态环境更全面的理解,允许模型以更高的准确性预测轨迹。Wayformer优化注意力机制以提高计算效率,而Scene Transformer使用统一的架构有效管理多智能体交互。同样,LatentFormer采用基于Transformer的方法,结合潜在变量来提高预测精度。这些策略证明了整合多个信息模态对于更准确、更可靠的运动预测的有效性。
Planning-aware运动预测
Planning-aware轨迹预测是多模态预测方法的一个关键方面,其中包含动态车辆信息的规划特征被整合到高级编码特征中。例如,PiP引入了一个双模块系统,其中规划耦合模块将未来规划注入交互特征中,目标融合模块编码和解码智能体之间的未来交互。PRIME通过使用基于模型的场景上下文进一步优化这种方法,通过查询各种张量生成保证可行性的未来轨迹。TPP专注于通过整合来自自我运动采样器的树状结构规划结果来改进规划轨迹,尽管它仍然使用采样器的输出作为直接输入,而不是与地图交互。此外,像Multipath++这样的模型已经证明了这些技术在运动预测挑战中实现最先进的性能的有效性,特别是通过使用有效整合这些多模态信息源的先进注意力和基于扩散的模型。作者的方法进一步发展了这一概念,实现了与Multipath++几乎相当的性能,同时参数数量极少。
方法论
输入表示
模型使用多模态嵌入策略将各种数据源,如历史轨迹、高清地图和规划轨迹,转换为统一的高维空间。这确保了模型能够捕捉到准确轨迹预测所需的复杂的空间和时间关系。
历史轨迹数据由每个智能体随时间的空间坐标组成,表示为 ,其中 是历史时间步数, 表示智能体 在时间 的位置。为了将这些轨迹投影到高维空间,作者应用一个多层感知机(MLP),结果为 。这个转换通过一系列线性投影和非线性激活来执行,定义为 ,其中 和 是权重矩阵, 和 是偏置项, 是非线性激活函数,如 ReLU。处理后,所有智能体的历史轨迹嵌入表示为:
其中 是智能体的数量。
高清地图数据提供了环境的几何形状,由以自我智能体为中心的特定半径 内的一组车道节点表示。地图定义为 ,其中 是车道数量,每个车道 包含 个节点。为了从高清地图中提取有意义的特征,作者使用一维特征金字塔网络(FPN),将地图数据投影到高维空间为 ,其中 表示映射函数。最终的高清地图嵌入的维度为 ,所有金字塔级别的特征被连接以获得:
规划轨迹是使用Frenet框架生成的,该框架将路径分解为纵向和横向组件。对于每个规划轨迹,轨迹相对于参考路径 在纵向位置 处,并且具有横向位移 。轨迹由 给出,其中 是位置 处的法向量。规划轨迹集合表示为 ,其中 是规划轨迹的总数。轨迹的优化通过最小化成本函数 实现,其中 是急动度, 表示行驶时间, 是到中心线的距离。超参数 ,,和 分别控制急动度、行驶时间和距离的相对重要性。最后,规划轨迹使用FPN投影到高维特征空间,与高清地图嵌入类似,表示为:
模型架构和融合机制
模型处理四种输入数据源:(轨迹数据)、(轨迹提议数据)、(规划数据)和(地图数据)。最初,每个输入进行自注意力处理以捕获模态内依赖性。对于每种模态X,自注意力机制计算如下:
其中 和 表示从输入X派生的查询、键和值矩阵, 是键的维度。这允许每种模态独立提取其关键的空间时间特征。
一旦自注意力提炼了每个数据源的内部结构,就应用交叉注意力机制。第一个交叉注意力机制将自注意力处理过的轨迹嵌入与轨迹提议嵌入对齐。这产生了一个联合表示,捕获了历史运动和未来轨迹预测,将智能体动态与提议的轨迹对齐:
接下来,规划数据嵌入与地图数据嵌入进行交叉注意力,产生,将空间上下文与规划轨迹整合。这些融合的表示进一步通过最终的交叉注意力机制处理,其中与中间表示结合。这一步确保了过去的动态、环境上下文和规划轨迹都被对齐:
最终融合的表示被传递到预测头部进行未来轨迹估计,有效地利用了所有模态之间的时空关系,生成了具有上下文意识的预测。
模型的整体工作流程从使用LSTM编码历史轨迹开始,产生;使用LSTM编码规划轨迹,产生。然后对每个模态应用自注意力以增强特征表示。随后,交叉注意力整合这些不同模态的特征。最后,集成的特征被LSTM解码器解码成未来轨迹预测,最终的线性层输出预测位置:

训练目标
作者将损失函数制定为多项任务损失的总和,并使用辅助学习方法来平衡它们。在训练阶段,作者还使用了联合损失来平衡最终输出和预测头部的输出,遵循TrackFormer的方法。
其中每个任务损失的权重都是可学习的。
- 可行驶区域感知(Drivable-area-aware, DAA)回归损失:Huber损失是约束预测常用的损失函数。作者注入规划信息以增加预测的合理性,并利用可行驶区域信息使预测结果更符合交通规则。作者提出了一个可行驶区域感知回归损失,当预测轨迹点在可行驶区域内时,损失函数保持Huber损失的定义。然而,如果预测点在可行驶区域外,作者引入了一个额外的惩罚项 ,其中 是预测点与真实点之间的距离。
其中 , 是可行驶区域。
- 置信度损失:为了根据驾驶意图的概率对提议区域进行评分,作者使用Kullback-Leibler散度作为作者的损失函数。这个损失函数限制了基于预测轨迹和真实值之间距离的提议概率的贡献。
其中 是预测提议的分布, 是真实提议的分布。
- 分类损失:作者将所有端点坐标聚类到K个类别中,并用最近的聚类中心类别标签标记真实值和预测提议。作者采用交叉熵作为额外的损失函数,以增强预测车辆驾驶意图的能力。
其中 是预测提议的概率分布, 是真实提议的真实分布。
实验及结果
数据集
Argoverse 数据集包含 324,000 个场景,包括详细的轨迹序列、传感器数据(如 3D 激光雷达和摄像头图片)以及高清地图。数据集被划分为训练集、验证集和测试集,并支持轨迹预测的多模态融合。用于评估模型准确性和预测能力的指标包括最小平均位移误差(Minimum Average Displacement Error, minADE)、最小最终位移误差(Minimum Final Displacement Error, minFDE)、未命中率(Miss Rate, MR)和布里尔分数。
指标
作者使用 Argoverse 数据集提供的各种指标来评估和确定模型的性能。这些指标包括最小平均位移误差(Minimum Average Displacement Error, )、最小最终位移误差(Minimum Final Displacement Error, )、未命中率(Miss Rate, )、布里尔最小最终位移误差(Brier Minimum Final Displacement Error, )和布里尔最小平均位移误差(Brier Minimum Average Displacement Error, )。每个指标从不同的角度衡量模型的预测能力和准确性。
实验结果
作者将提出的方法与最先进的Planning-aware运动预测技术进行比较,包括 PIP 和 PRIME 。PRIME 作为基准,作者的方法显示出显著的改进:minFDE 提高了 14.10%,minADE 提高了 30.33%,p-minADE 提高了 2.59%。作者的方法还优于基于图神经网络的方法,如 LaneGCN 、VDC 和 HGO。与基于扩散的方法如 mmdiffusion 和 Scenediffusion 相比,作者的方法取得了更优越的结果,与 Multipath++ 相比参数数量减少了 84.43%。

总之,作者提出的方法在 Argoverse 数据集上表现出色,实现了更高的预测准确性和效率,同时显著减少了参数数量和计算开销。

消融研究
作者在 Argoverse 数据集上使用 minFDE、minADE、Brier-minFDE 和 Brier-minADE 进行了消融研究,以 mmdiffusion 作为基线。Planning-Aware Encoder,整合 PreFusion-D,改进了 minFDE、minADE、Brier-minFDE 和 Brier-minADE,分别提高了 7.81%、0.24%、1.87% 和 0.33%。扩展联合损失改进了 minFDE 0.24% 和 minADE 1.45%。为所有智能体添加回归导致了进一步的增益,分别为 0.82% 和 1.47%。

写在最后
本文提出了一个Planning-aware的堆叠扩散网络,这是运动预测中的一个新框架。Planning-aware扩散预测未来轨迹时会使用多模态特征,尤其是先前的规划特征。为了获得更好的融合性能,作者设计并探索了四个融合模块,将规划信息聚合到堆叠扩散中。作者还提出了一种新的损失函数,迫使网络关注可行驶区域。在 Argoverse 运动预测基准测试中进行的实验证明了作者模型的有效性。
#孪生Transformer如何破局
车道线再出发!
车道检测是自动驾驶系统中一项重要但具有挑战性的任务。基于Visual Transformer的发展,早期基于Transformer的车道检测研究在某些场景下取得了有前景的结果。然而,对于复杂的道路条件,如不均匀的光照强度和繁忙的交通,这些方法的性能仍然有限,甚至可能比同期基于CNN的方法更差。在本文中,我们提出了一种新的基于Transformer的端到端网络,称为SinLane,该网络获得了关注稀疏但有意义的位置的注意力权重,并提高了复杂环境中车道检测的准确性。SinLane由一种新颖的孪生视觉变换器结构和一种称为金字塔特征集成(PFI)的新型特征金字塔网络(FPN)结构组成。我们利用所提出的PFI来更好地整合全局语义和更精细的尺度特征,并促进Transformer的优化。此外,所设计的Siamese视觉变换器与多级PFI相结合,用于细化PFI输出的多尺度车道线特征。在三个车道检测基准数据集上进行的广泛实验表明,我们的SinLane以高精度和高效率实现了最先进的结果。具体来说,与目前性能最佳的基于Transformer的CULane车道检测方法相比,我们的SinLane将精度提高了3%以上。
总结来说,本文的主要贡献如下:
- 提出了一种新的FPN模块,金字塔特征集成(PFI),以完全集成全局语义和更精细的尺度特征。
- 设计了一个Siamese视觉变换器来从PFI中提炼多尺度车道线特征。
- 在三个基准数据集上取得了最先进的结果,与CULane上最著名的Transformer方法相比,准确率提高了3%以上。
相关工作回顾
早期的车道检测工作依赖于手工制作的特征,导致特征捕获有限,因此对于复杂条件下的车道检测任务无效。
为了应对复杂的环境,深度学习(DL)方法被引入到车道检测任务中。基于分割的方法首先应用于车道检测,其检测输出基于每像素的分割图。与传统方法相比,基于CNN的方法可以捕获更丰富的视觉特征和空间结构信息,因此基于DL的方法优于传统的检测方法。然而,基于每像素的分割方法计算成本高,实时性有限,并且难以学习车道线的细长特征。
为了解决这些问题,LaneNet引入了一种分支的多任务架构,将车道检测任务转化为实例分割问题。与之前的方法相比,这种方法对道路状况的变化更具鲁棒性,但更耗时。RESA被提出通过移动切片特征图来聚合空间信息,这可以获得良好的实时结果,但在复杂的道路条件下仍然失败。此外,上述大多数方法的输出车道线可能不连续。
为了以更高的效率获得更连续的车道线,在最近的研究中,基于曲线的方法将车道检测任务视为多项式回归问题,并利用参数曲线来拟合车道线。这些方法在很大程度上取决于曲线的参数(表示车道线像素的坐标,a、b、c和d是曲线的参数)。PloyLaneNet首次提出了一种直接输出参数的端到端深度多项式回归方法。为了提高稳定性和效率,BézierLaneNet提出了一种参数化的Bézier曲线来模拟车道线的几何形状。然而,即使效率很高,受全局信息学习能力的限制,这些基于曲线的方法在大型数据集上的准确性也不能令人满意,特别是在复杂的道路条件下。
Transformer引入计算机视觉领域后,在模型推理速度和全局信息获取方面取得了令人瞩目的成果。DETR在目标检测方面取得了令人满意的结果,优于一些基于CNN的方法。但是,在车道检测领域,基于Transformer的方法仍然难以产生令人满意的结果。基于DETR的方法LSTR推理速度快,但精度相对较低,特别是在一些复杂的道路环境中。与预训练和局部先验的LSTR相比,PriorLane提高了预测的准确性。然而,目前基于Transformer的方法和基于CNN的方法在准确性上仍存在差距。
在检测任务中,底层富含几何信息,但缺乏抽象的语义信息,而深层则相反。对于车道检测任务,车道线独特的细长形状和复杂的驾驶场景对本地和全局信息的集成提出了很高的要求。FPN提出了一种自上而下的特征金字塔架构,用于合并低级和高级特征。PANet中提出了一种自下而上的架构,用于更好地从低级到高级特征的聚合。Kong重新制定了FPN结构,并应用全局注意力和局部重构将低级表示与高级语义特征融合在一起。Nas-FPN和BiFPN提出了可学习的融合策略,从多尺度上提高了特征融合的效果。然而,所有这些方法都忽略了数据集的尺度分布,无法在复杂的自动驾驶场景中融合全局和局部信息。
方法详解
结构设计
SinLane网络的总体架构如图2所示。由于车道线具有明显的结构特征,因此可以用沿y轴等距采样的一系列关键点来表示,这些关键点可以表示为:
![]()
虽然车道检测任务可以被视为分割任务,但通过车道线的关键点表示,它可以被转换为与对象检测任务相似的序列预测任务。受DETR[3]的启发,我们提出了一种基于端到端变压器的方法SinLane,用于生成车道预测,而无需复杂的后处理步骤,如非最大抑制(NMS)[31]。我们网络的主要结构可分为四个部分,骨干网(ResNet或DLA34)、颈部、头部和训练目标。
Pyramid Feature Integration
我们开发了PFI来整合全局语义信息和更精细的特征。图3显示了PFI的详细结构。
![]()
![]()
在使用融合因子来平衡相邻高层和低层的特征后,我们采用了一种集成结构来进一步融合它们。对于基于FPN的信息集成,有一些已知的方法,如PANet和NAS-FPN。当应用于车道检测任务时,由于图像中的车道线通常又长又细,因此这些方法很难平衡全局信息和更精细的尺度特征。
因此,我们开发了一种新的集成结构来集成全局语义信息和更精细的尺度特征。首先,我们将多尺度特征(已被融合因子平衡)重塑为相同的尺度。请注意,特征形状是一个可调整的参数,取决于精度和效率的平衡。接下来,我们对重塑后的特征进行平均,可以表示为:
![]()
与之前的PANet等工作相比,我们的PFI具有两个优势:
(1)轻量级,即插即用,可以通过并行计算轻松实现,并应用于其他任务和网络;
(2)它适用于严重依赖全局和局部信息融合的任务,如车道检测任务。
Siamese Visual Transformer
我们提出了Siamese Visual Transformer来从多尺度特征图中提取丰富的信息。图4显示了详细的Siamese Visual Transformer结构。主结构由四个具有共享参数的暹罗视觉转换器组成。
由于车道线细长且具有独特的结构特征,我们使用对象序列(图2中的e0、…、e3)来表示它们,这有助于降低计算成本,并且易于对Transformer进行优化。对象序列可以表示为:
![]()
通过使用GT监督对象序列的生成,我们可以强制输出序列逐一对应图像中的实际车道,从而实现车道线的检测。
我们将PFI的输入特征图划分为block,以减轻Transformer计算的负担。然后将三维补丁展平为二维序列,并添加位置嵌入。与传统的Transformer编码器不同,我们利用Siamese结构使Transformer能够通过共享参数学习更丰富的多尺度信息。具体来说,我们在输入特征图的序列和上层Transformer的输出序列(或预生成的序列e0)之间应用注意力,而不是原始的自注意力。这个过程可以表示为:

Training and Inference Details


![]()
实验结果结论在本文中,我们提出了一种新的基于变压器的端到端网络,称为SinLane,用于车道线检测。SinLane由一种新颖的暹罗视觉变换器结构和一种称为金字塔特征集成(PFI)的新型FPN结构组成。我们证明,我们提出的PFI可以有效地整合全局语义和更精细的尺度特征,促进Transformer的优化。此外,所设计的Siamese Visual Transformer优化了我们的PFI输出的多尺度车道线特征。我们在三个基准数据集CULane、Tusimple和LLAMAS上评估了我们提出的方法。实验结果表明,我们提出的SinLane取得了最先进的结果,提高了复杂环境中车道线检测的准确性。具体来说,与已知的基于Transformer的CULane数据集车道线检测方法相比,它将准确率提高了3%以上。
#自动驾驶中的自动标注
有监督学习需要大量的标注数据。可以完全由人工标注,也可以由机器自动标注,也可以人机混合。这三种模式分别称为人工标注,自动标注和半自动标注。
自动驾驶中,感知系统对标注需求很大,尤其是障碍物感知。其自动标注主要可利用不同传感器之间的相互标注。
障碍物感知有三大主流传感器: 激光雷达(LiDAR),相机(Camera),毫米波雷达(Radar)。从自动标注的数据流向来看,一般是依靠激光雷达和毫米波雷达给相机标注, 因为感知系统输出给下游的障碍物都需要提供三维信息:3D位置和3D尺寸,最不济也需要给出障碍物在BEV上(缺少高度方向)的大小和位置。
激光雷达输出的点云及其检测模型输出的障碍物都具有完整的3D信息,即中心点位置和长宽高。
毫米波直接输出BEV上的障碍物信息,有2D BEV位置有速度,但缺少高度。
相机的分辨率很高,具有丰富的语义信息。2D的视觉障碍物检测也是一个很热门且比较成熟的研究方向。要相机独立给出具有3D信息的障碍物结果,通常可以通过以下几种途径进行3D恢复:
- 纯粹的2D检测结合一些先验几何假设。例如假设框的下边中心点为障碍物的地面接触点,且地面是平的,然后根据相机外参确定地面高度,以此即可估计出障碍物的3D位置。最后根据类别取一个先验长宽高,作为其大小。这类方法的缺点是鲁棒性差。
- 检测模型不仅预测障碍物的2D信息,还预测一些3D信息,例如角度,尺寸,深度,投影关键点等,然后通过一些几何约束及必要的先验恢复其3D信息。这类方法很多,预测对象非常多样,也是当前3D视觉检测的热门研究方向。
- Pseudo LiDAR。对相机图片进行深度估计,得到稠密的伪点云,然后用点云模型进行障碍物检测。这类方法的关键和难点在于准确的深度估计。
下面通过几个例子来说明可以尝试的自动标注方法。
激光雷达提供点云级别的深度信息
将激光雷达的点云投影到相机上,可以得到像素级别的稀疏深度图。这个深度图可以用来训练纯视觉的单目深度估计模型。基于无监督学习的纯视觉单目深度估计是一个很有潜力的研究方向。直觉上,结合激光雷达的数据理论上有助于模型正确收敛。
若同时使用双目和激光雷达,这个深度图也可以转换为视差的真值。
激光雷达点云投影相机主要存在的问题包括:
- 稀疏,且距离稍远就没有点云了。
- 遮挡。相机和激光雷达安装位置肯定有相互偏移,激光雷达能看到的相机不一定能看到。所以可能存在被遮挡的点,它本身虽然位于相机的FOV内,但投影到相机上却没有对应的像素,错误的像素深度就这样产生了。相机和激光雷达间的安装偏移越大,出现遮挡的概率和程度越高。
- 同步。理论上可以在激光雷达转到和相机相同角度时触发相机曝光,但在实践中并没想象的那样简单:设备状态、网络状况都会影响到同步的实际效果。而且,常用的机械式激光雷达转一圈需要100毫秒,而相机曝光时间通常只有数毫秒。低速场景受非理想同步的影响不大, 但高速场景受其影响严重。并且,这里的速度不是指自车的速度, 而是指自车相对于环境中其他物体的速度。
一些可供参的论文:
Deeper Depth Prediction with Fully Convolutional Residual Networks
Semi-Supervised Deep Learning for Monocular Depth Map Prediction
Unsupervised Learning of Depth and Ego-Motion from Video Unsupervised Learning of Depth and Ego-Motion from Monocular Video Using 3D Geometric Constraints
激光雷达提供障碍物的3D位置和尺寸
激光雷达障碍物检测模型输出的物体一般都具有完整3D信息:3D位置和3D尺寸。将其3D框投影到相机上后可以提供视觉障碍物的以下信息:
- 中心点及8个角点的2D位置
- 物体的实例深度和角度
- 2D框位置
这些信息可供上文提到过的第二种相机3D恢复方法需要的真值。不过也存在不少缺点:
- 激光雷达的障碍物检测模型可能漏检、误检,或检测结果不准确, 特别是高度方向:3D关键点的2D投影受高度方向的准确度影响极大。
- 激光雷达的障碍物检测距离一般比相机要短
- 可能将非误检但不存在于相机上的物体投影到相机上, 例如被遮挡物体
一些可供参考的论文:
MonoGRNet: A Geometric Reasoning Network for 3D Object Localization
3D Bounding Box Estimation Using Deep Learning and Geometry
RTM3D: Real-time Monocular 3D Detection from Object Keypoints for Autonomous Driving
毫米波雷达提供实例深度
毫米波可提供障碍物的BEV位置和速度。速度在单帧检测中很难用上。另外还需要注意的是,毫米波雷达输出的障碍物位置不一定是障碍物的中心点位置: 一般在障碍物体上,但不能确定是物体的哪一个点。
Tesla在2019的自动驾驶日视频[1]大概71分钟处中给了个应用举例:在图像上自动匹配radar和camera物体, 以radar的深度作为真值训练camera物体的实例深度估计。3D形状也由camera通过关键点的形式预测。
这种radar自动标注方法只能提供实例深度, 其投影关键点仍需要人工标注(Tesla没有LiDAR)。
结语
总的来说, 自动标注产生的数据普遍存在噪声,但胜在数据量近乎无限且不需要人工标注。使用海量有噪声的数据的弱监督训练的潜力也已经证实[2]。
从传感器融合的角度来看, 自动标注也是比前融合更前的融合。
值得探索的自动标注方向很多。对自动驾驶公司来说, 通过对自动标注的探索,更有效充分地利用采集的海量测试数据,也是一件很有价值的事情。
#明星飞行汽车破产,烧光100亿仍难载人试飞...
曾估值235亿的独角兽Lilium,扛不住了。
由于没能从德国政府获得紧急筹资的担保,这家电动飞机明星正式申请破产,关闭在即。
成立9年以来,Lilium累计筹集了14.5亿美元(约103亿元)的资金,腾讯是主要投资人之一。过去的十多轮融资,腾讯至少参与了七轮,其中由腾讯领投的三轮融资,为Lilium总共募集到5.7亿美元(约40亿元)。
2020年,Lilium借SPAC风光上市,最高市值曾达到100亿美元(约713亿元)。
如今宣告破产,股价暴跌超60%后,市值已经不到1亿美元。
怎一个惨字了得。
飞行汽车明星深陷危机
最近,德国电动垂直起降(eVTOL)明星公司Lilium向SEC递交了通告,宣布正式破产。
文件显示,Lilium今年试图向德国复兴信贷银行筹集1亿欧元(约7.7亿元)的紧急贷款,但由于联邦政府没有批准5000万欧元担保,这次融资以失败告终。
无异于压死骆驼的最后一根稻草。
因为这次融资失败,宣告着Lilium的资金链彻底断裂,Lilium无法再继续运营两家全资子公司,不得不申请破产,以及申请自我管理程序。
随之而来的是,Lilium的A类股票可能会被纳斯达克摘牌,面临暂停交易,甚至是退市。
目前,Lilium的股价暴跌超60%,已不足0.1美元,折合成人民币大概只有7毛钱,市值仅剩6199.9万美元(约4.4亿元)。
Lilium最后的希望,就是法院批准自我管理程序,保留和继续诉讼所涉及的业务,还能在托管人的监督下继续经营业务。
破产的消息在低空领域炸响,任谁都想不到,这家曾被称为低空领域“特斯拉”的公司,没落速度如此之快,甚至就在四个月之前,Lilium才刚刚在中国开了分公司。
Lilium在2015年成立时,受到非常广泛的看好,很快就获得了Freigeist Capital的种子轮融资,还拿到了欧洲航天局的支持。
2017年,Lilium完成无人驾驶双座原型机的飞行测试,并且在2019年,生产出世界上第一架全电动喷气式五座飞机原型机,首次试飞也很成功。
这些进展为Lilium拉来了更多投资者的支持,其中腾讯是最主要的投资者之一。
在此后的多轮融资中,总能看到腾讯的身影。据估计,腾讯至少参与了Lilium至少7轮的融资,其中有至少3轮是由腾讯领投,加起来约5.7亿美元(约40亿元)的资金。
其他投资者中,也不乏一些知名人物或机构,包括特斯拉股东Baillie Gifford、Skype联合创始人Niklas的风投机构Atomico、黑石集团、LGT等,估值达到33亿美元(约235亿元)。
直到2020年,Lilium通过的SPAC方式,登陆纳斯达克上市,市值最高达到约100亿美元(约713亿元)。
上市后,融资脚步也未停止,Lilium又获得了1.19亿美元(约8.5亿元)的融资,累计融资金额达到14.5亿美元(约103亿元)。
同时,Lilium也获得了一些客户的支持,其中包括来自沙特阿拉伯的100 架电动飞机订单。
今年6月,Lilium来到中国寻求机会,成立力翎(深圳)航空有限公司,由子公司Lilium GmbH全资持股,并且要在中国招聘员工。
就在宣告破产前夕,Lilium才刚刚宣布取得了革命性地进展:已完成全电动 Lilium Jet 的首次系统启动,这是一个里程碑式的时刻。
原本按照计划,明年春天Lilium将进行首次载人飞行,2026年向客户首次交付。
一夜之间,巨星何以陨落?
昔日明星为何资金耗尽?
其实,Lilium的危险处境,在此前公布的中期财报里就早有预兆。
上半年的研发费用、一般和管理费用以及销售费用分别为1.31亿欧元(约10亿元),0.49亿欧元(约3.8亿元),以及0.06亿欧元(约0.48亿元),相比去年同期分别增长了55%,22.7%以及49%。
由于没有商业化落地,Lilium并没有营收,主要通过股东的融资和贷款维持运营。
所以,Lilium整体亏损,今年上半年净亏损了8694.9万欧元(约6.7亿元),上市后累计亏损了近20亿欧元(约153亿元),融资来的现金基本已经消耗殆尽。
今年上半年,来自经营活动的现金流减少了1.59亿欧元(约12.2亿元),来自投资、融资活动的现金流分别增加0.81亿欧元(约6.2亿元),以及1.05亿欧元(约6.24亿元)。
截至今年上半年末,Lilium的现金及现金等价物只剩下1.09亿欧元(约8.4亿元),现金储备已经岌岌可危。
在管理层分析当中,管理层已明确透露了对公司持续经营的能力存在重大怀疑。他们表示,Lilium能否继续经营,在很大程度上取决于能否获得政府可转换贷款。
自成立以来,Lilium一直出现经常性亏损和运营现金流为负值,并且预计在未来这种情况还会继续。因此,根据融资计划,Lilium需要立即获得额外资金以持续运营。
但是,如果德国联邦政府不批准、没能及时批准政府可转换贷款的担保,管理层只能被迫大幅降本成本和缩小运营范围,甚至申报破产。
不幸的是,这种最坏的结果已经发生。由于联邦政府拒绝担保,这笔1亿欧元的“救命钱”最终打了水漂。
在10月24日的发布声明中,公司表示,Lilium有如今的局面,最大的原因在于政府没有大力支持。
其竞争对手正在美国、法国、中国、巴西和英国获得资助和贷款,只有德国的Volocopter和Lilium没有得到政府支持。
德国对Lilium,乃至对低空领域行业,始终兴致缺缺,这笔承诺的资金,已经推迟了好几个月而毫无进展。
创始人Daniel Wiegand千言万语,只汇成一句:如果重来一次,不会选择德国。
全球低空领域:冰火两重天
低空领域相当烧钱,早已达成共识,想要“飞得稳”必须迈过两道坎:一个是坚实的资金后盾,一个是强大的技术支撑。
如今全球低空领域,可谓冰火两重天。
同样是德国eVTOL公司的Volocopter,融资进程也不算顺利,今年四月被爆资金紧缺,濒临破产,最后是靠一笔没有公开的资金度过难关。
反观其他eVTOL参与者,有不少公司获得巨额资助,还活得很好。
美国的Joby背靠大树好乘凉,月初刚宣布,将获得丰田5亿美元(约38.5亿元)的投资。2020年,丰田已经为Joby投了3.94亿美元(约30.3亿元),加上这次将共计投入将近70亿元。
美国的Archer同样获得了巨额资金,其中包括美国联合航空公司签订的价值10亿美元(约77亿元)的200架eVTOL飞机订单,并且可选择再订购 100 架。
再看国内低空经济领域,发展也是蒸蒸日上,并且有越来越多其他赛道的领军者加入。
6月份,吉利旗下子公司沃飞长空,宣布完成B轮数亿元融资,策源资本领投,中科创星、华控资本等原股东继续追投,创下了近两年国内eVTOL行业单笔融资的最高纪录。
8月份电池巨头宁德时代也入局,给峰飞航空投资了数亿美元,合作研发eVTOL航空电池。
不久后,小鹏汇天也宣布完成了1.5亿美元(约11.3亿元)的B1轮融资,不过融资历程也并非一帆风顺,此前两度资金即将断裂,一直咬牙坚持,直到何小鹏的出现转变了局面。
如今小鹏汇天现金充裕,10月27日刚宣布,飞行汽车工厂开启动工,规划年产能一万台。
需要强调的是,中国低空领域迅速发展起来,不仅仅是靠企业获得现金资助,更关键的还有政策在推波助澜。
大到全国,今年两会首次把“低空经济”写进政府工作报告;由工业和信息化部、科学技术部、财政部、中国民用航空局联合印发《通用航空装备创新应用实施方案(2024—2030年)》,计划到2030年推动低空经济形成万亿级市场规模。
小到地方,超过30个省份把低空经济写入政府工作报告,发布相关的发展行动计划,提供基础设施建设、下游应用场景拓展等方面的支持。
如同鼓励新能源汽车一般,从上到下托举低空经济发展。
这也是为什么Lilium试图在中国寻找新机遇,只可惜停留太短暂,来不及施展拳脚,家里先“着火”了。
对于中国低空经济的入局者而言,Lilium的失利,也是重重敲响的一记警钟。
中国低空经济联盟执行理事长罗军认为,eVTOL需要强大的技术支撑,也需要时间的打磨,尤其是需要拿到民航部门的全部认证,还需要经受市场的洗礼。
Lilium破产,外因是没有得到当地足够的支持,内因还是在于本身技术方面还存在不足。
例如,Lilium使用小型管道“喷气”风扇来提供升力和推力,在悬停时,存在能源效率较低的问题,而所需的功率是采用较大倾斜转子的类似重量设计的两倍左右。
直白点说,就是在起飞和降落阶段,飞行器会消耗大量的能源,非常影响电池的续航能力,续航里程、测试时间也都相对有限。
在2020年,Lilium的一架原型机在维修时起火,最终烧毁无法修复,飞行测试由于这次失火事故而推迟,后续也没有给出失火原因。
至今没有完成载人飞行测试,也是一个问题。
罗军指出,目前行业的参与者有上千家,而真正具备技术实力的只有大约300多家,而国内有这个实力的只有不到10家。
全球低空经济热潮已至,未来将进入千家万户。
而在接下来的五年、十年,eVTOL行业将面临重新洗牌,最大的市场在中国。
欧美市场由于更早进入通用航空市场,对低空飞行器的需求非常有限。
而中国市场,除了有资金支持、产业链优势、以及政策扶持,市场的应用场景也更加广泛,包括城市客运、区域客运、城市物流配送、商务出行、紧急医疗服务等等。
因此,中国市场的未来,也具备更多可拓展的规模。
援引瑞银证券的分析,到2030年,中国eVTOL市场的空间预计将达到70亿元人民币,其中大部分市场将用于景区观光。预计到2030年,中国将占据全球市场超过50%的份额。
欧美市场目前存有的技术优势,随着当前人工智能等技术的快速发展、eVTOL技术的升级迭代,可能也会逐渐消磨。
但中国市场也仍需警醒,有Lilium的血泪在前,不管是技术路线,适航认可,还是商业化落地,争夺市场份额,都还有很长的路要走。
#ORION
闭环VLA暴涨20%!华科&小米联手打造:全新端到端VLA框架
近年来,端到端(End-to-End,E2E)自动驾驶技术不断进步,但在复杂的闭环交互环境中,由于其因果推理能力有限,仍然难以做出准确决策。虽然视觉 - 语言大模型(Vision-Language Model,VLM)凭借其卓越的理解和推理能力,为端到端自动驾驶带来了新的希望,但现有方法在 VLM 的语义推理空间和纯数值轨迹的行动空间之间仍然存在巨大鸿沟。
除此之外,现有的方法常常通过叠加多帧的图像信息完成时序建模,这会受到 VLM 的 Token 长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION,这是一个通过视觉语言指令指导轨迹生成的端到端自动驾驶框架。ORION 巧妙地引入了 QT-Former 用于聚合长期历史上下文信息,VLM 用于驾驶场景理解和推理,并启发式地利用生成模型对齐了推理空间与动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。

图 1:不同的端到端自动驾驶范式的对比
ORION 在具有挑战性的闭环评测 Bench2Drive 数据集上实现了优秀的性能,驾驶得分为 77.74 分,成功率为 54.62%,相比之前的 SOTA 方法分别高出 14.28分和 19.61% 的成功率。
此外,ORION 的代码、模型和数据集将很快开源。
- 论文标题:ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation
- 论文地址:https://arxiv.org/abs/2503.19755
- 项目地址:https://xiaomi-mlab.github.io/Orion/
- 代码地址:https://github.com/xiaomi-mlab/Orion
- 单位:华中科技大学、小米汽车
我们来看一下 ORION 框架下的闭环驾驶能力:
ORION 检测到骑自行车的人并向左变道避免了碰撞。
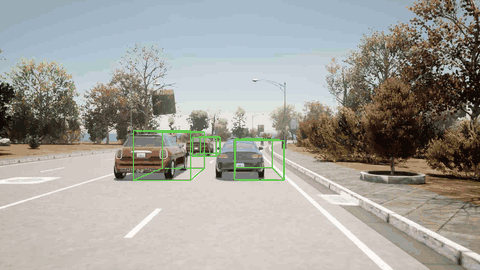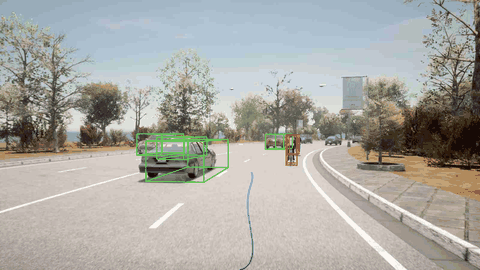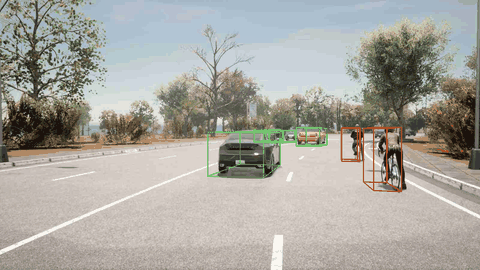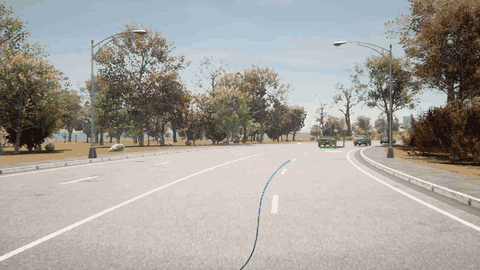
ORION 检测到右前方的车辆,先执行减速,然后再改变车道。
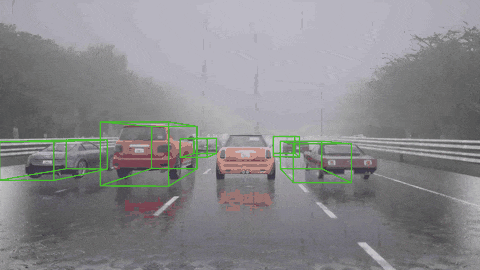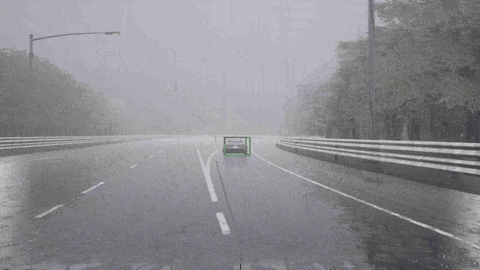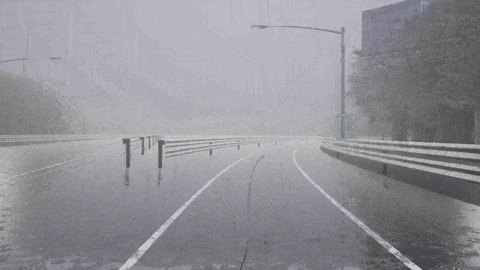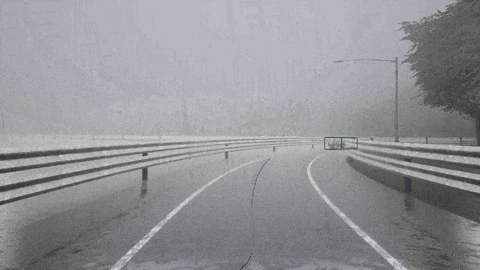
ORION 识别停车标志并停车,等待一段时间,然后重新启动成功通过十字路口。

主要贡献
本文提出了一个简单且有效的端到端自动驾驶框架 ORION,主要包含如下几方面的贡献:
- VLM + 生成模型:利用生成模型弥补了 VLM 的推理空间与轨迹的动作空间之间的差距,从而使 ORION 能够理解场景并指导轨迹生成。
- QT-Former:引入 QT-Former 聚合历史场景信息,使模型能够将历史信息整合到当前推理和动作空间中。
- 可扩展性:ORION 可以与多种生成模型兼容,实验证明了所提出框架的灵活性。
- 性能优异:在仿真数据集 Bench2drive 的闭环测试上取得 SOTA 的性能。
研究动机
经典的 E2E 自动驾驶方法通过多任务学习整合感知、预测和规划模块,在开环评估中表现出优秀的能力。然而,在需要自主决策和动态环境交互的闭环基准测试中,由于缺少因果推理能力,这些方法往往表现不佳。
近年来,VLM 凭借其强大的理解和推理能力,为 E2E 自动驾驶带来了新的解决思路。但直接使用 VLM 进行端到端自动驾驶也面临诸多挑战,例如,VLM 的能力主要集中在语义推理空间,而 E2E 方法的输出是动作空间中的数值规划结果。
一些方法尝试直接用 VLM 输出基于文本的规划结果,但 VLM 在处理数学计算和数值推理方面存在不足,且其自回归机制导致只能推断单一结果,无法适应复杂场景。还有些方法通过设计接口,利用 VLM 辅助经典 E2E 方法,但这种方式解耦了 VLM 的推理空间和输出轨迹的动作空间,阻碍了两者的协同优化。
除此之外,长期记忆对于端到端自动驾驶是必要的,因为历史信息通常会影响当前场景中的轨迹规划。现有使用 VLM 进行端到端自动驾驶的方法通常通过拼接多帧图像来进行时间建模。但这会受到 VLM 的输入 Token 的长度限制,并且会增加额外的计算开销。
为了解决上述问题,本文提出了 ORION。ORION 的结构包括 QT-Former、VLM 和生成模型。 ORION 通过 QT-Former 聚合长时间上下文信息,并巧妙地结合了生成模型和 VLM,有效对齐了推理空间和动作空间,实现了视觉问答(VQA)和规划任务的统一端到端优化。
方法概览
具体来说,ORION 通过以下三大核心模块,显著提升了自动驾驶系统的决策能力:
1. QT-Former:长时序上下文聚合
ORION 引入了 QT-Former,通过引入历史查询和记忆库,有效聚合长时视觉上下文信息,增强了模型对历史场景的理解能力。相比现有方法,QT-Former 不仅减少了计算开销,还能更好地捕捉静态交通元素和动态物体的运动状态。
2. VLM:场景推理与指令生成
ORION 利用 VLM 的强大推理能力,结合用户指令、长时和当前的视觉信息,能够对驾驶场景进行多维度分析,包括场景描述、关键物体行为分析、历史信息回顾和动作推理,并且利用自回归特性聚合整个场景信息以生成规划 token,用来指导生成模型进行轨迹预测。
3. 生成模型:推理与动作空间对齐
ORION 通过生成模型,将 VLM 的推理空间与预测轨迹的动作空间对齐。生成模型使用变分自编码器(VAE)或扩散模型,以规划 token 作为条件去控制多模态轨迹的生成,确保模型在复杂场景中做出合理的驾驶决策。

图 2:ORION 整体架构图
实验结果
本文在 Bench2Drive 数据集上进行闭环评估测试,如表 1 所示,ORION 取得了卓越的性能,其驾驶得分(DS)和成功率(SR)分别达到了 77.74 和 54.62%,相比现在的 SOTA 方法提升了 14.28 DS 和 19.61% SR,展现了 ORION 强大的驾驶能力。

表 1:Bench2Drive 上闭环评估和开环评估的性能对比
此外,如表 2 所示,ORION 还在 Bench2Drive 的多能力评估中表现优异,特别是在超车(71.11%)、紧急刹车(78.33%)和交通标志识别(69.15%)等场景中,ORION 的表现远超其他方法。这得益于 ORION 通过 VLM 对驾驶场景的理解,能够更好地捕捉驾驶场景之间的因果关系。

表 2:Bench2Drive 上多能力评估测试对比
可解释性结果
下图展示了 ORION 在 Bench2Drive 的闭环评估场景中的可解释性结果。ORION 可以理解场景中正确的因果关系,并做出准确的驾驶决策,然后根据推理信息指导规划轨迹预测。

图 3:可解释性结果图
总结
ORION 框架为端到端自动驾驶提供了一种全新的解决方案。ORION 通过生成模型实现语义与动作空间对齐,引入 QT-Former 模块聚合长时序场景上下文信息,并联合优化视觉理解与路径规划任务,在闭环仿真中取得了卓越的性能。
#模仿学习数据缺失?试试Diffusion Policy!
模仿学习是教机器人灵巧技能的有效方式,视觉模仿学习因采用图像或深度图等高维视觉观察,简化了特定任务状态估计需求而受到青睐。但视觉模仿学习的普遍性以大量演示为代价,如最先进的扩散策略方法,每个现实世界任务需要 100 - 200 次人类收集的演示,数据收集过程耗时且易失败。
虽然在线学习可作为一种解决方案,但在现实场景中存在安全、自动重置、人为干预和硬件成本等问题。因此,如何让离线模仿学习算法用尽可能少的演示学习强大且可泛化的技能,成为实际机器人学习中的一个关键问题,这也促使了diffusion policy 的诞生。
Diffusion policy(扩散策略)是一种基于扩散模型的机器人策略学习方法,将策略学习定义为对机器人动作空间的条件去噪扩散过程,以 2D 观测特征为条件 。其核心是通过正向扩散过程,从专家机器人轨迹开始,逐渐添加高斯噪声,直至信号近似为纯噪声;然后通过反向的去噪过程,将噪声转换为符合专家数据分布的轨迹,以此作为模型的训练信号。在训练时,通过最小化预测的去噪轨迹与原始干净轨迹之间的差异来优化模型。这种方法能够处理多模态动作分布,并直接预测长序列动作,但在生成动力学可行的机器人轨迹方面存在挑战,尤其是在欠驱动机器人系统中,容易生成不可行的状态序列。
Diffusion policy 通常以 2D 观测特征为条件进行策略学习,在处理机器人动力学可行性和多模态动作分布时存在一定局限性 。而 3D diffusion policy 则将条件输入扩展到 3D 视觉表示,能够更好地利用场景的三维结构信息,提升策略的泛化能力,更有效地处理复杂的机器人操作任务,如在不同的模拟和现实场景中,3D diffusion policy 可以凭借其对 3D 信息的处理能力,让机器人更好地完成任务,且所需演示次数更少,成功率更高。
今天总结了几篇关于Diffusion policy的论文:DDAT 模型引入生成动态可行机器人轨迹的扩散策略,通过投影方案让扩散模型生成的轨迹满足动力学约束,设计多种投影方法并将其融入训练和推理过程。ScaleDP 模型针对扩散策略在transformer架构中难以扩展的问题,提出可扩展的扩散transformer策略,通过引入因式分解观测特征嵌入的自适应层归一化(AdaLN)块和非因果注意力机制,改善训练动态以更好处理多模态动作分布。DP3 包含感知和决策两部分,感知部分处理点云数据为紧凑 3D 表示,决策部分以 3D 视觉特征和机器人姿态为条件转化随机噪声为连贯动作序列。改进后的 iDP3 模型框架采用以自我为中心的 3D 视觉表示,避免相机校准和点云分割问题,放大视觉输入增加采样点数量,用金字塔卷积编码器取代 MLP 视觉编码器提高准确性,延长预测范围缓解短预测范围受人类专家抖动和噪声传感器影响的问题,能更好地从人类演示中学习。ManiCM 模型提出实时 3D 扩散策略,把一致性约束应用于扩散过程,实现一步推理生成机器人动作,还设计操纵一致性蒸馏技术,直接预测动作样本,加快收敛且避免传统扩散模型预测噪声的不稳定问题。
一起看看吧~
DDAT:用于生成动态可行机器人轨迹的扩散策略
扩散模型凭借其多模态生成能力,在图像和视频生成领域取得了显著成果,在机器人研究中也备受关注,被广泛用于生成机器人运动轨迹。然而,其随机性质与机器人精确的动力学方程存在冲突,难以生成动力学上可行的轨迹,这一问题限制了扩散规划在欠驱动机器人系统中的应用。传统解决方法,如每几步重新生成轨迹或在推理后进行投影,都存在计算成本高、易发散等问题。因此,如何利用扩散模型生成满足机器人动力学约束的可行轨迹成为亟待解决的问题,这也是本文研究的出发点。
文章提出的 DDAT 模型架构旨在解决上述问题,将机器人动力学视为黑箱,通过从示例轨迹数据集中学习,利用正向扩散过程添加噪声,再训练神经网络反向去噪来生成轨迹。为确保生成轨迹的动力学可行性,采用了多种投影方案。如通过凸多面体对可达集进行下近似,将预测的下一状态投影到近似可达集上;引入参考投影,结合参考轨迹减少投影误差;利用动作预测来优化状态投影,缩小投影搜索空间;还设计了基于动作预测的直接获得可行状态的投影方法,并通过反馈校正提升效果 。在训练过程中,根据噪声水平设计投影课程,将投影融入训练和推理阶段,使模型更好地学习生成符合动力学约束的轨迹。
ScaleDP:将 Transformer 中的扩散策略扩展至十亿参数以用于机器人操作
扩散模型在图像、音频、视频和 3D 生成等众多领域取得了显著进展,在机器人学领域也作为模仿学习策略受到广泛关注,被应用于强化学习、奖励学习、抓取和运动规划等多个方面。在机器人操作任务中,研究人员期望模型具备可扩展性,即随着模型规模和训练数据的增加,性能和泛化能力能相应提升,就像语言建模和计算机视觉领域的大型模型那样。然而,现有基于 Transformer 架构的扩散策略(DP-T)在可扩展性方面存在问题,增加模型层数或头数并不能提升性能,甚至会导致训练结果恶化。经研究发现,这是由于观测融合模块中的大梯度问题导致训练不稳定。为解决该问题,文章提出了可扩展的扩散 Transformer 策略(ScaleDP) 。
ScaleDP 模型架构主要包含对神经架构的修改,具体有交叉注意力块、自适应层归一化(AdaLN)块和非因果注意力机制这几个关键部分。在交叉注意力块方面,传统方法在增加 DP-T 深度时会使梯度幅度变大,不利于训练,而 ScaleDP 通过改进结构来优化这一情况。自适应层归一化(AdaLN)块借鉴了图像生成中自适应归一化层的应用,通过从时间步 k 和观测 o 的嵌入向量之和回归尺度和偏移参数,让模型能根据条件改变噪声动作嵌入的分布,实现更稳定的训练和更好的推理性能。非因果注意力机制则是去除了传统 Transformer 架构中自注意力层的掩码,使每个动作能与前后动作更一致,解决了单向注意力机制隐藏动作表示的问题。通过这些改进,ScaleDP 能够有效扩大模型规模,从 1000 万参数扩展到 10 亿参数,在模拟实验和真实机器人实验中均表现出比基线模型更好的性能和泛化能力 。
3D Diffusion Policy:通过简单的3D表示进行可推广的视觉运动策略学习
3D Diffusion Policy(DP3)是一种新颖的视觉模仿学习算法,旨在解决机器人通过少量演示学习复杂技能的难题,它将3D视觉表示与扩散策略相结合,在多种模拟和现实任务中展现出高效性、泛化性和安全性。
3D Diffusion Policy由感知和决策两个关键部分组成。感知部分利用单目相机获取点云数据,将其处理为紧凑的3D表示;决策部分以3D视觉特征和机器人姿态为条件,通过扩散策略将随机噪声转化为连贯的动作序列。
感知模块:使用稀疏点云表示3D场景,通过裁剪和下采样处理点云数据,再用轻量级MLP网络(DP3 Encoder)将点云编码为64维的紧凑3D特征,该编码器结构简单却性能优异,优于多种复杂的预训练点编码器。
决策模块:基于条件去噪扩散模型构建,以3D视觉特征和机器人姿态为条件,从高斯噪声开始,通过去噪网络进行K次迭代,逐步将随机噪声转化为无噪声的动作。训练时,通过最小化预测噪声与真实噪声之间的均方误差来优化去噪网络。
基于 3D 扩散策略的通用人形机器人操作技术
3D Diffusion Policy(DP3)是一种将 3D 视觉表示与扩散策略相结合的视觉模仿学习算法,旨在让机器人通过少量演示学习复杂技能,并实现泛化。在此研究中,作者对其进行改进,提出了 Improved 3D Diffusion Policy(iDP3),以适应人形机器人的操作。
原始 DP3 模型框架的感知模块用稀疏点云表示 3D 场景,通过裁剪和下采样处理点云数据,再用轻量级 MLP 网络(DP3 Encoder)将点云编码为 64 维的紧凑 3D 特征,该编码器结构简单却性能优异,优于多种复杂的预训练点编码器。决策模块基于条件去噪扩散模型构建,以 3D 视觉特征和机器人姿态为条件,从高斯噪声开始,通过去噪网络进行 K 次迭代,逐步将随机噪声转化为无噪声的动作,训练时通过最小化预测噪声与真实噪声之间的均方误差来优化去噪网络。改进后的 iDP3 模型框架采用以自我为中心的 3D 视觉表示,直接使用相机坐标系下的 3D 表示,避免了相机校准和点云分割的问题。同时通过放大视觉输入,显著增加采样点数量来捕获整个场景,减少无关点云的影响。iDP3 还用金字塔卷积编码器取代了 DP3 中的 MLP 视觉编码器,卷积层结合金字塔特征提高了准确性。此外,iDP3 延长了预测范围,有效缓解了 DP3 在短预测范围内受人类专家抖动和噪声传感器影响的问题,使模型能更好地从人类演示中学习。
ManiCM:基于一致性模型的实时 3D 扩散策略用于机器人操作
在机器人研究领域,设计能够执行多样化操作任务的机器人一直是重要目标。随着技术发展,卷积网络、transformers 和扩散模型等多种架构被用于探索机器人操作,其中扩散模型凭借其在生成复杂高维机器人轨迹方面的能力,在机器人操作任务中受到越来越多关注,被广泛应用于高层次规划、低层次运动策略、教师模型和数据合成等领域。然而,扩散模型在推理阶段需要大量采样步骤来生成高质量动作,导致决策效率低下,尤其是在处理高维 3D 视觉输入时,这一问题严重阻碍了其在实时闭环控制中的应用。尽管有研究尝试通过分层采样等方法加速推理,但确定不同任务领域的分层结构存在困难,限制了这些方法在 3D 机器人操作中的实用性。
文章提出的 ManiCM 模型架构旨在解决扩散模型在 3D 机器人操作中决策效率低的问题。该模型以强大的 3D 扩散策略(DP3)为基础,通过一致性蒸馏技术将其知识提炼到单步采样器中,实现实时推理。在训练阶段,ManiCM 通过设计操纵一致性函数直接预测动作样本,而非像传统图像生成那样预测噪声,这使得模型能更快收敛到低维机器人动作流形。同时,采用一致性蒸馏方法,利用教师网络和目标网络确保动作能从 ODE 轨迹上的任意点直接去噪,通过最小化在线网络和目标网络输出的差异来优化模型。在评估阶段,ManiCM 能够在一步推理中解码高质量动作。此外,模型将点云表示作为条件注入扩散策略,通过下采样和 MLP 编码获取紧凑 3D 表示,使模型能够捕捉空间信息,更好地处理精细的机器人操作任务 。
上述研究成果都很好地解决了模仿学习数据缺失,借助 Diffusion policy 强大的生成能力,通过生成符合动力学约束的轨迹(如 DDAT 模型)、优化架构以更好处理多模态动作分布(如 ScaleDP 模型)、将随机噪声转化为连贯动作序列(如 DP3 及 iDP3 模型)以及实现一步推理生成动作(如 ManiCM 模型)等方式,为模仿学习提供了丰富且有效的数据补充与处理路径,极大地缓解了因数据不足给模仿学习带来的困境。
参考文献
DDAT: Diffusion Policies Enforcing Dynamically Admissible Robot Trajectories, https://arxiv.org/pdf/2502.15043
Scaling Diffusion Policy in Transformer to 1 Billion Parameters for Robotic Manipulation, https://arxiv.org/pdf/2409.14411
3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations, https://arxiv.org/pdf/2403.03954
Generalizable Humanoid Manipulation with 3D Diffusion Policies, https://arxiv.org/pdf/2410.10803
ManiCM: Real-time 3D Diffusion Policy via Consistency Model for Robotic Manipulation, https://arxiv.org/pdf/2406.01586
#从规则驱动到知识驱动~
近年来,智能驾驶行业在产业格局与技术范式层面经历了深刻变革。围绕L2与L4技术路线的博弈、传感器方案的路线之争(激光雷达vs纯视觉)、高精地图的战略价值争议、全栈自研与Tier 1合作模式的权衡,以及端到端架构与大模型技术的路径选择等议题,行业内外始终存在激烈的技术路线辩论。其中,部分争议已随着技术演进逐渐收敛,而诸如"端到端与大模型的必要性"等命题,仍处于持续演进的探索阶段,尚未形成定论。
过去数周,笔者系统梳理了智能驾驶技术相关的学术文献与产业动态,旨在通过知识整合厘清技术发展脉络。这一工作既服务于个人认知体系的构建,也期望通过观点碰撞推动技术认知的深化。然而,在当前技术范式加速迭代的背景下,许多关键问题仍处于"黑箱"状态——例如对端到端与大模型的路径选择,本质上属于尚无法通过实证完全验证的前沿命题,其答案可能需要更长时间维度的实践检验。
需要特别说明的是,本文的论述基于笔者当前的认知框架与有限的资料调研,相关判断必定存在片面性。文中观点仅代表笔者基于现有信息的阶段性思考,受限于个人认知局限,难免存在疏漏与偏颇之处,还望多指正。在技术路径的确定性与不确定性交织的当下,任何技术范式的探讨都应保持开放与审慎的态度,这或许正是行业持续创新的核心动力。
技术演进
智驾问题的定义早已明确,但其技术范式仍然处于持续演进中;对于智驾的技术范式及其发展,CVPR 2024相关专题进行了详细讨论(如下图),该演进路线可整理总结为规则驱动、数据驱动、知识驱动。
智驾发展演进路线(图源:CVPR 2024 | E2E AI Tutorial)
- 规则驱动范式(Rule-based)
该技术范式衍生于传统的机器人架构,由定位、感知、预测、规划、控制等子模块组成。该范式中各子模块研发独立,问题排查较便捷、可解释性较高;但由于人力规则驱动的原因,存在很多长尾问题难以发现并解决,且拓展性较差;比如高速/中低速(城区)/低速(地库/泊车)等不同场景变化、城市/国家等不同区域变化,均需要海量人力投入适配调整。当然,数据驱动的思想在部分子模块如感知模块已得到广泛应用;仅子模块的数据驱动在本文中归属于规则驱动范式。
典型的规则驱动范式(图源:Apollo 3.0)
- 数据驱动范式(Data-Driven)
规则驱动范式存在固有问题,比如各模块独立研发导致信息有损传递,进而系统难以达到全局最优;基于人力的规则驱动,导致系统的可规模化、可拓展性较差。基于此,基于数据驱动的端到端系统被提出且引发广泛关注。然而,行业内不同参与者对端到端系统却也有着不同定义;实用主义者甚至认为感知子模块模型化或决策规划模块模型化也是端到端,在此语境下端到端系统的常见分类如下图。
实用主义下的端到端系统(图源:端到端自动驾驶行业研究报告)
相较于上述实用主义定义,本文所关注、定义的端到端系统更为“狭义”,该系统定义有如下关键点:
- 输入信息:原始传感器数据,包括图像、定位、SD地图、导航、自车状态等;
- 输出信息:未来时刻,自车的轨迹点或自车控制命令;
- 可微性:该系统从输入到输出间全局可微,即输出端梯度可传导到输入端;
原始传感器信息无损传递、作用于规划输出端是该端到端系统的核心,也是本文关注的重点。上述特性使得端到端系统具有信息损失小、全局最优、可扩展性强、数据驱动等优势。需要强调的是,行业内常说的两段式端到端(即感知模型化+预测规划模型化,但两个模型之间的接口仍然采用人为定义),不属于本文讨论的端到端系统;但该两段式端到端在笔者看来是智驾系统端到端的中间态,但却是实现最终端到端的必要条件。本文后续提及的数据驱动范式特指“狭义”定义下的端到端系统。
- 知识驱动范式(Knowlodge-Driven/Principle-based)
在当前时间节点,尽管数据驱动范式下的端到端系统在工业界还没有大规模落地,但该范式的弊端行业内已有较多讨论。其中一个突出问题在于当前端到端系统大都采用模仿学习范式(更严格来说是行为克隆学习范式),但模仿学习范式具有固有问题,包括因果混淆(网络模型容易学到数据间的关联性、而非因果性)、对数据分布要求高(训练数据中未出现或少出现的场景表现差,模型推理过程中一旦遇到该场景,其表现会发散、不可控)等。因此,在智驾尤其端到端领域有不少关于"Imitatin Is Not Enough"的研究;为了缓解该问题,其他的模型学习范式在智驾领域也被广泛提出、研究,强化学习范式是其中的典型代表,但强化学习范式也存在对仿真环境要求高、稀疏监督等问题。近年来,大语言模型、多模态大模型、世界模型等取得了令人瞩目的成果;通过大模型将世界常识、思考推理能力、Zero-shot泛化能力注入到智驾系统或利用世界模型的what if能力,缓解数据驱动范式存在的问题、进而将智驾系统的驱动范式转移到知识驱动,在学术界得到了广泛的关注研究、在工业界也得到了尝试应用。然而知识驱动范式更偏前沿,大规模工业落地也还处于探索阶段。
上述对智驾的技术范式进行了简略介绍。由于规则驱动范式已经很成熟、在工业界也广泛落地,且由于其自身局限性,不是本文关注重点。后文主要对数据驱动范式(即端到端系统)、知识驱动范式进行探讨。
数据驱动的智驾
参照前文关于数据驱动范式的定义,关于数据驱动智驾的探讨收口在端到端智驾系统;端到端系统的定义及其优势,前文已进行阐述,此处不再赘言。一个略微反常识的点在于,尽管智驾行业发展才数十年,但端到端智驾概念的提出可追溯至上世纪80年代(ALVINN: An Autonomous Land Vehicle in a Neural Network)。端到端系统还处于快速发展、演进阶段,甚至端到端智驾系统的性能与规则驱动智驾系统性能之间还存在一定差距;另外由于端到端系统的数据驱动本质,该系统研发对于数据规模的需求也是极为惊人的(如下图所示)。端到端智驾系统仍处在大量研究中,根据网络模型是否显式划分为多个模块,端到端智驾系统可分为模块化端到端系统与One-Model端到端系统;由于One-Model方案在安全保障和可解释性方面是不够的(特别是对于高度动态的城市场景),本节重点关注模块化端到端系统方案。近期关于端到端智驾系统的文献、资料处于井喷之势,相应的解读博客也如雨后春笋、蓬勃发展。然而笔者在查阅相关文献、博客过程中,深感现有资料要么是对某经典框架的细节解读,要么草草罗列一大堆框架文献、缺乏分门别类的梳理,进而导致容易陷入只见树木不见森林、甚至迷失于森林的窘境。基于此,本节采用结构化思维模式,采用不同划分标准、从不同维度对相关端到端智驾系统进行梳理,然后基于划分标准对典型的端到端系统进行汇总对比;然而由于篇幅有限,本文难以对各框架细节进行深入探讨,仅期望能作为一个按迹循踪、抛砖引玉之物。
端到端发展轨迹(图源:CVPR 2024 | E2E AI Tutorial)
模块选择
根据模型架构是否显式划分为子模块,端到端系统可划分为模块化与非模块化(即One-Model)两大类;UniAD、VAD、OccNet等框架属于模块化端到端,该类框架模型结构中通常显式包含了感知、规划等模块,UniAD图中c.2、c.3均属于此类;TCP、TransFuser等框架属于非模块化端到端,该类框架直接将原始传感器输入转换为PnC输出,UniAD图中c.1属于此类。由于模块化框架通常会显式定义感知子网络模块,LAW论文也将模块化端到端称作perception-based approache,将非模块化端到端称作perception-free approache。本节后续探讨主要集中于模块化端到端系统。
基于模块化选择的端到端系统分类(图源:笔者)
UniAD对模块化端到端探讨(图源:UniAD)
模块排布
一旦选定采用模块化构建方式后,子模块的排布方式差异也能够带来不同模型框架。根据框架子模块位置的排列情况,可以将端到端智驾系统划分为序列式、并行式和混合式。上述划分主要参照感知(perception)、预测(prediction)、规划(planning)子模块的布局情况;PARA-Drive图中详细比对了序列式与并行式的差异(如下图所示)。UniAD、VAD、OccNet等框架属于典型的序列式框架,该类框架planning子模块前通常会有prediction子模块,当然由于各框架采用的具体子模块存在差异,各子模块布局也不尽相同。序列级联式框架存在级联带来累积误差进而训练不稳定、人为定义的任务顺序限制系统协同能力等问题;尤其序列级联式方案难以考虑他车预测与自车规划间的相互影响效应。基于此,并行式与混合式框架被提出;并行式与混合式框架相同点在于会同步进行预测、规划,并考虑二者间的相互影响;二者不同之处在于对感知等子模块的排列,并行式框架会同步考虑感知模块、甚至同步运行,而混合式框架则将感知(通常包括object detection、online mapping)前置于预测和规划模块之前。典型的并行式框架有PARA-Drive、DriveTransformer等,该类框架将感知、预测、规划模块进行并行联合训练,上述模块间不存在依赖关系、没有显式的信息传递,各模块间的信息交互隐式通过场景表征如BEV完成,在推理运行环节可以仅保留规划子模块分支以提升实时性。典型的混合式框架有SparseDrive、GenAD等,该类框架先通过感知操作进一步提炼环境动态、静态信息,然后同步进行预测与规划;相较于并行式框架,混合式框架预测与规划间的耦合程度通常更强,重点强调考虑预测与规划间的相互作用,实际推理运行过程中难以将预测与规划模块分拆。文献(The Integration of Prediction and Planning in Deep Learning Automated Driving Systems: A Review)具有类似的分类方法,根据prediction与planning间的关系,将智驾系统划分为Sequential、Undirected和Bidirectional集成组合范式;前述的序列式框架属于Sequential组合范式,并行式和混合式框架属于Bidirectional组合范式,One-Model类模型属于Undirected组合范式。
典型端到端系统的模块排列结构比对(图源:PARA-Drive)
基于模块排布的端到端系统分类(图源:笔者)
3D表征
对系统周围环境全面、可靠的3D表征是智驾系统的基础,一些常见的表征方法如下图所示。根据采用的不同3D表征形式,端到端智驾系统可划分为不同类别;考虑典型的3D场景表征形式,按照表征形式从稠密到稀疏,端到端系统可划分为Occupancy-based、BEV-based、Gaussian-based和Sparse-based(见下图)。OccWorld、OccNet是Occupancy-based范式的典型代表,除了感知模块、规划模块也使用Occupancy进行实现,进而实现更精细的感知、更好的规划,当然也带来更大的资源消耗。BEV-based范式是目前端到端系统使用最多的范式,通常将原始传感器输入映射至BEV空间,然后在BEV空间进行detection、online mapping等感知任务;对于预测和规划模块,不同框架有不同操作,比如UniAD中Motion/Occupancy prediction和planning均与原始BEV数据进行交互,而VAD则通过Vectorized Scene Learning环节学习到矢量化信息后,planning模块直接与矢量化query进行交互。Gaussian-based范式则直接使用3D GS对周围场景进行表征,Gaussian AD是其中的典型代表,该端到端系统基于3D GS的表征范式实现感知、预测、规划操作,理论上该方案也属于稀疏表达类别、且实时性较全模块基于Occupancy或BEV的框架更好,但该文献中并未看到实时性比对;考虑到3D GS的可微特性和渲染逼真性,笔者认为Gaussian-based范式框架在与闭环仿真、强化学习结合层面更具优势,但该范式端到端的研究及工业落地还处于探索中。算法落地过程中,通常会在效率与效果之间平衡考虑;前述Occupancy-based和BEV-based范式均属于稠密类型的3D场景表征,在保证表达效果的同时,也带来了较大资源消耗。Sparse-based范式旨在通过稀疏的表达方式减少资源消耗、使得更适用于端侧部署落地;SparseDrive、SparseAD、DriveTransformer、DiFSD等均是Sparse-based端到端智驾系统的典型代表,该类系统直接将地图要素、自车或他车表征编码为实例(instance/token),通过各种注意力机制的组合,直接将上述实例与提取的原始数据特征(如多相机的图像特征)进行交互,并且直接采用实例形式对历史信息进行缓存;没有将原始数据特征转换到某稠密空间、并缓存该稠密空间的操作,如此操作解决了缓存稠密特征对资源消耗大、原始稠密特征未充分利用更高层次的先验信息(语义/位置等)的问题。上述Sparse-based范式均能够取得不错的实时性,相较于UniAD,SparseDrive和DriveTransformer均有3~5倍的FPS提升。关于场景表征范式,VAD框架的确是值得单独拎出来分析讲解的一个类别,本质上VAD是属于稠密+稀疏表征的混合体,即感知模块(detection、online mapping等)基于BEV,但后续的planning模块则是基于矢量化的感知结果;就具体效果而言,VAD在实时性方面也具有竞争力,相比于UniAD,VAD的base版本FPS约有3倍提升,其实时性能与DriveTransformer相当,而VAD的tiny版本在NVIDIA 3090上可达16.8FPS、基本满足工业落地的实时性需求。
典型的3D表征方法(图源:GaussianAD)
基于3D场景表征的端到端系统分类(图源:笔者)
传感器输入
智驾系统通常会使用相机、激光雷达等传感器,用于感知并建模周围环境。关于激光雷达是否是智驾车辆的刚需,早年间引发过诸多争论;随着时间沉淀,各家车厂逐步默认激光雷达的非刚需地位,尤其中低端车型基本不再配置激光雷达。特斯拉作为纯视觉方案的领先者,一直宣称其智驾系统纯视觉方案的第一性原理,且通过算法提升来弥补视觉本身的空间感知弱势。就端到端智驾系统方案本身,在多相机基础上,根据输入是否包括激光雷达等其他传感器(定位、速度等车辆自身空间、状态信息相关传感器不在考虑范围内),可将系统划分为纯视觉范式和多传感器范式。纯视觉范式仅仅使用多个相机作为输入,大部分端到端系统均采用该范式,如UniAD、VAD、SparseDrive、PARA-Drive等。多传感器范式的端到端框架相对较少,与纯视觉范式的主要区别为是否支持激光雷达与相机融合,Transfuser及在此基础上的改进框架(如Hydra-MDP、DiffusionDrive、GoalFlow等)属于多传感器范式类别。
基于输入传感器的端到端系统分类(图源:笔者)
轨迹生成
端到端系统的输出通常为规划的自车轨迹,即未来时刻自车所处的位置、包括时间与空间位置信息。与网络模型的任务类别划分一样,轨迹的获取也可定义为生成式任务或判别式任务。使用生成式任务范式来获取自车轨迹相对更广泛,包括VAE、回归、GAN、Diffusion等,下图列举了各种方法的典型方案框架(PS:图中浅红标注的方案并非端到端方案);随着Diffusion技术的广泛且深入研究,且伴随在文生图、文生视频等AIGC领域的强势崛起、广泛应用,基于Diffusion的轨迹生成占据越来越重要位置,并使用Diffusion截断、锚点(Goal point/Anchor Gaussian Distribution)、Flow Matching等技术加速Diffusion去躁过程、提升轨迹生成效果。另外,受到NLP领域大语言模型对词库/词元的处理思路启发,VAD v2将轨迹生成问题建模为多分类问题,先构建多个轨迹的候选词库,最后输出词库中每个轨迹词元的概率。
基于轨迹生成方式的智驾系统分类(图源:笔者)
根据模型直接输出单条轨迹与否,端到端智驾系统可划分为单模轨迹范式和多模轨迹范式。单模轨迹范式直接输出单条轨迹,通常根据预设规划时间(如5秒)、单位时间内轨迹点数目(如每秒5个)等信息,轨迹输出头中使用全连接层直接回归出输出轨迹,较早期的端到端框架如UniAD、VAD、Transfuser均采用该范式。由于其他道路参与者的意图具有不可预测性,且不同的道路条件和人类驾驶员行为会引入的模糊性,最优轨迹预测本质上是随机的。单模轨迹范式具有环境和响应动作间存在确定性关系的假设,然而这种确定性假设与实际场景并不相符,尤其当场景复杂、以至于当可行解空间是非凸的时。基于此,多模轨迹范式最近受到了诸多关注,该范式的核心是模型并不输出确定性的单条轨迹,而是同时输出多条轨迹、及轨迹的概率分数;下游可综合轨迹概率分数、安全性、舒适性、效率等因素得出轨迹最终得分,选择分数最高轨迹作为控制模块输入。根据生成多条轨迹方式的差异,多模轨迹范式的端到端系统还可细分为基于词库、基于Diffusion、直接回归等类型。VAD v2、Hydra-MDP是基于词库类方法的典型代表,核心便是借鉴大语言模型领域的成功经验、将轨迹生成问题建模为多分类问题。GoalFlow、DiffusionDrive是基于Diffusion类方法的典型代表,这类框架主要是在如何减少去躁步骤、加速Diffusion去躁过程、高效生成轨迹等方面,结合车辆轨迹固有特性,对Diffusion方法进行研究、改进适配。而多模轨迹的直接回归生成,各框架则有较大差异,比如SparseDrive采用K-Means聚类来获取先验意图点,并将这些点转换为模式查询,再根据不同的驾驶意图生成不同查询query;DriveTransformer则根据方向和距离分为六种模式(直行、停止、左转、急左转、右转和急右转),为每种模式生成特定嵌入,将生成的模式嵌入添加到 ego 特征中,同步预测六种模式特定的 ego 轨迹。然而,之前的方法大都没有考虑时间一致性,这样会导致连续的轨迹可能缺乏相干性、导致车辆控制不稳定,甚至引入不希望的方向偏移和振荡(实车体验会出现画龙问题);为了提升生成的轨迹数据质量、保持更好的时间一致性,MomAD提出了动量规划(momentum planning)思路。
基于轨迹模态的端到端系统分类(图源:笔者)
典型端到端系统的轨迹生成方法对比(图源:DiffusionDrive)
实验评测
端到端智驾系统评测通常可分为开环评测与闭环评测。开环评测通常基于实车记录的数据以log-replay的方式进运行评估,使用原始传感器信息作为输入、预测自车的未来位置,然后评估预测轨迹与记录的专家轨迹间一致性;该方法智驾系统无法执行操作并观察其效果,因为该过程不会生成与原始记录不同的新传感器数据;常用的开环评测指标包括轨迹位置偏移量(L2 displacement error)、碰撞率( Collission Rate),典型的开环评测数据集包括nuScenes、Waymo、Argoverse。然而,由于采集的数据集分布有偏、因果混淆等原因,开环评测结果的有效性广受诟病。闭环评测通常是在模拟环境中评估系统整体驾驶能力的方法,在闭环评测中,系统需要在闭环环境中完成从起点到终点的完整驾驶任务,同时与环境交互、应对各种动态场景和挑战;与开环评测不同,闭环评测不仅关注系统的轨迹预测能力,还关注其在实际驾驶场景中的表现,包括决策、与环境的交互。常用的闭环评测指标包括任务成功率(Success Rate)、驾驶分数(Driving Score)、驾驶效率(Driving Efficiency)、平顺性(Smoothness)等;闭环评测的优势在于与环境的交互能力,但闭环评测通常基于仿真器生成输入数据,其数据的真实性存在较大挑战。一些典型的开环、闭环评测数据集如下图所示。基于实验评估过程中,采用的评测方式差异,端到端系统可分为开环与闭环两大类;学术界的相关文献中,大都基于nuScenes数据集使用开环评测进行对照分析,然而由于开环评测固有缺陷,相应系统的性能并不够solid。
典型的智驾评测系统比对(图源:CVPR 2024 | E2E AI Tutorial;Bench2Drive)
基于评测方式的端到端系统分类(图源:笔者)
关于闭环评测、闭环仿真还想多说几句。可以有这样的前提,强化学习依赖闭环仿真环境,但闭环仿真依赖任意视角3D渲染。但评价闭环仿真好坏的标准是,当智驾系统在仿真系统中的表现接近它在真实世界的表现时,这个仿真系统才更接近真实世界、这个闭环仿真才是好的,而不是智驾系统的指标越高就越好。构建与真实世界一致的仿真环境极具挑战,比如常用的闭环评测工具CARLA基于游戏引擎的创建虚拟世界,其渲染出来的图像如下图所示,能够明显看到与真实世界的差异;因此,基于真实数据的闭环数据生成,得到更具真实性、可扩展性、低成本、多样化的渲染数据吸引了诸多研究,比如UniSim。另外,还需要强调的是要实现智驾系统闭环仿真,至少需要Sensory data simulator与Driving policy simulator,二者在传感器数据高保真与驾驶交互策略高保真方面都存在较大挑战。
基于游戏引擎渲染的图像(图源:Bench2Drive)
训练范式
经典的端到端系统通常基于模仿学习(更准确来说是行为克隆)来进行系统训练,如UniAD、VAD等,这样的训练范式与当前开源数据集大都提供专家数据(如专家轨迹)有关。然而,模仿学习更易学到各因素间的关联关系,而非因果关系,这种范式主要捕捉的是观测和行动之间的相关性,而不是因果关系;这样的关联关系用来做预测是可以的,但它不是一个因果关系,对于决策会存在不足。譬如城区驾驶场景,在自车学习如何通过红绿灯场景路口时,可能会从他车的行驶轨迹学习到他车的行驶意图与自车驾驶意图的关联关系,而并非学习到红绿灯与自车驾驶意图的因果关系,因此当评测过程中,若自车周围没有他车,该智驾系统便可能崩溃。因此,通过模仿学习训练出的策略可能难以识别规划决策背后的真正因果因素,导致出现捷径学习、因果混淆、数据分布偏移等问题。适用于环境动态复杂、需自主探索任务的强化学习吸引了很多研究,该范式在大模型领域已经取得的瞩目效果(如RLHF、DeepSeek R1、QwQ等)更加速了强化学习在端到端智驾系统中的应用。比如,RAD基于3DGS、将强化学习与模仿学习结合使用;其中,强化学习通过处理因果关系和开环差距来增强模仿学习,而模仿学习通过确保更好的人类对齐来改善强化学习;具体来说,模仿学习用于初始化策略的概率分布,并作为强化学习的正则化项,以保持策略与人类驾驶行为的相似性;同时,强化学习用于探索状态空间并学习处理异常情况,从而提高自动驾驶策略的鲁棒性和可靠性。此处需要说明的是RAD论文更多的是对训练范式进行创新(比如如何结合使用强化/模仿学习、如何利用3DGS),该范式具有普适性,论文中使用的模型细节着墨不多、大概是VAD的改动版。DriveAdapter使用“Teacher-Student”范式,结合强化学习和模仿学习,通过分离感知和规划的学习过程,显著提高了端到端自动驾驶任务的效率和性能。然而,强化学习需要具备能够与驾驶策略交互的驾驶环境,在真实的驾驶环境进行闭环训练存在安全风险和运营成本问题,具有传感器数据模拟能力的模拟驾驶环境通常基于游戏引擎构建、无法提供真实的传感器模拟结果;这样也限制了强化学习在端到端训练中的直接应用。为了更好解决数据局限性问题,LAW利用隐式世界模型(latent world model)用于端到端系统中的场景表示和自车轨迹预测,进而构建了自监督学习范式(如下图所示);具体来说,该框架利用编码器从图像中提取隐式视觉特征,解码器根据这些隐式视觉特征预测waypoints,隐式世界模型则利用融合了动作信息的视觉特征预测未来隐式视觉特征,训练过程中则利用未来时间帧提取的隐式视觉特征进行监督;该范式同时适用于显示使用感知与不显示使用感知的端到端智驾框架。RAD也跳过了对仿真数据的需求,而是利用3DGS技术,基于真实数据构建了一个真实物理世界的孪生副本,进而实现大规模试错学习(见下图)。基于训练范式的不同,对典型的端到端智驾系统进行了分类(见下图);需要说明的是,该分类并不严谨,尤其划分到强化学习类别的系统(系统中只要使用了强化学习训练便被划分为该类别);比如笔者认为DriveAdapter本质还是模仿学习,只是利用了Teacher-Student范式,其中教师模型使用了强化学习训练范式。
基于隐式世界模型的自监督学习范式(图源:LAW)
不同端到端系统训练范式比对(图源:RAD)
基于训练范式的端到端系统分类(图源:笔者)
典型框架
前文已对端到端智能驾驶系统的关键考量维度及其划分标准进行了概述。近年来,随着端到端智能驾驶系统的迅猛发展,各类创新型模型框架层出不穷。为了更有效地辨识与比较这些模型的特性与创新点,笔者系统查阅了模块化端到端智能驾驶模型的相关资料,并选取了若干典型架构,依据前述划分标准进行分类整理。下表按时间顺序列出了这些代表性架构(更多典型框架详情参见前文),以期为读者提供一个清晰的技术演进脉络。
鉴于已有大量文献对各个框架进行了详细的单独解读,本文不再赘述单个框架的具体细节。然而,由于认知和资源的局限性,本文难免遗漏一些经典模型框架,且分类结果可能存在不准确之处,敬请批评指正。
模块化端到端智驾系统分类(表源:笔者)




知识驱动的智驾
数据驱动范式的工作机理是依赖大量数据,依赖数据中的统计规律进行学习和决策,模型通过大量数据训练获得泛化能力;其本质是归纳法,即从具体数据中总结一般规律,强调“数据即知识”。而基于原理或知识驱动范式则是依赖领域知识或基本原理(如物理定律、数学公式、因果逻辑)构建模型,强调对底层规律的建模和推理;本质是演绎法,即从一般原理推导具体结论,强调“知识先于数据”。
基于数据驱动范式的智驾系统已经取得了不错成果,且在工业界已有相关的探索、推动落地。然而,由于数据驱动本身的局限性,该范式的智驾系统的弊端已引起行业人员关注、讨论,包括:
- 数据驱动的特性,对数据数量、质量要求高,存在难以覆盖的长尾数据场景;
- 模仿学习范式存在因果混淆、数据分布偏移、稀疏监督等问题;
- 强化学习范式需要交互反馈,对仿真环境要求高、且存在稀疏监督等问题;
利用大模型的海量先验知识、环境理解、思考推理等能力,或利用世界模型对物理环境理解、内在机理推演、what if等能力,进而缓解数据驱动范式存在的问题,成为较热门的研究方向。本节主要从大模型和世界模型两个方向对知识驱动的智驾进行介绍。
大模型驱动
从GPT3开始引发的大模型浪潮,以及短短几年来大模型取得的各种颠覆式成果毋庸赘言。由于智驾的多模感知特性,将大模型与智驾结合的落脚点在于多模态大模型,更具体来说为视觉语言类大模型(VLx)。视觉语言大模型在智驾领域的应用面很广,包括交通环境感知与理解、开集物体检测、视觉语言导航、智驾数据生成、端到端智驾等。本节重点关注与端到端智驾的结合与使用。下图详细列举了VLx在端到端智驾系统(VLx-E2EAD)中的应用及分类,本节后续会围绕该图对典型方案进行介绍。
VLx在端到端智驾应用及分类(图源:笔者)
根据VLx在端到端智驾系统的推理环节使能与否,可将VLx-E2EAD分为辅助训练与融入推理两大类。由于大模型的参数量通常很大(B量级),直接用于推理,智驾系统的实时性难以保证;因此相关研究便提出直接将VLx用于模型训练过程,在训练阶段将知识注入模型,而推理环节去掉VLx,从而保证系统实时性;这类典型代表包括VLM-AD、DiMA和VLM-E2E。VLM-AD的框架如下图所示,由Cruise于2024年12月提出,该框架是一类VLM增强学习范式,能够适用于任意VLM和任意E2E-AD搭配;具体来说,是一种利用VLM 作为教师的方法,通过提供包含非结构化推理信息和结构化动作标签的额外监督来增强训练;这种监督增强了模型学习更丰富的特征表示的能力,这些表示捕获了驾驶模式背后的基本原理;重要的是,该方法在推理过程中不需要VLM,这使得它适用于实时部署;文章分别设计了三类非结构化推理信息和结构化动作标签,推理信息使用CLIP转换为特征编码,动作标签直接进行One-hot编码,并使用交叉熵作为监督loss。DiMA的框架如下图所示,由霍普金斯大学于2025年1月提出,图中绿色部分表示经典的端到端智驾系统,红色表示VLM模型;DiMA通过一组专门设计的代理任务从VLM中提取信息到基于视觉的端到端智驾系统;在联合训练策略下,两个网络公用的场景编码器产生语义一致的结构化表示,并与最终的规划目标对齐;而且,VLM在推理时是可选的,在不影响效率的情况下可实现了不错规划结果。VLM-E2E的框架如下图所示,由香港科技大学于2025年2月提出,该框架与VLM-AD很类似,只是监督信号作用于BEV空间;该方法通过将文本表示集成到BEV特征中进行语义监督,使模型能够学习到更丰富的特征表示,这些表示能够明确捕捉到司机的注意力语义。
VLM-AD框图(图源:VLM-AD)
DiMA框图(图源:DiMA)
VLM-E2E框图(图源:VLM-E2E)
VLx在推理环节使用的框架,可分为三大类别,包括纯VLx、VLx与经典端到端松耦合、VLx与轨迹规划紧耦合。纯VLx类别比较简单粗暴,输入环视图像、自车状态、导航命令等信息,经过多模态大模型映射后,输出相应轨迹规划结果,根据输出内容的差异大致可分为两大类:直接输出文本、输出action token。EMMA是直接输出文本这类方案的代表,直接以文本的形式输出自车未来轨迹点,其框图如下图所示,由Waymo于2024年10月提出,基于多模态大语言模型(MLLM)构建,通过将所有非传感器输入(如导航指令和车辆状态)和输出(如轨迹和3D位置)表示为自然语言文本,最大限度地利用了预训练的大语言模型中的世界知识,在实现端到端运动规划基础上,通过混合训练,还将EMMA构建为一个通才模型,实现3D 世界感知,识别周围物体/道路图/交通条件等功能。基于类似的思路,得克萨斯农工大学于2024年12月复刻了该模型得到OpenEMMA,并进行了开源。LINGO-2和CarLLaVA都是VLx直接输出action token的代表,LINGO-2由Wayve提出,其框图如下图所示;输出action token后,通过接入MLP等解码器,得到最终规划轨迹信息。尽管纯VLx这类方法理论上具有很大的潜力,但也存在一些局限性;例如,它只能处理少量的图像帧、无法准确合并3D传感模态(如LiDAR和雷达),计算成本高昂、实时性差,模型训练收敛存在挑战。为了解决VLx实时性差、难以端测部署问题,VLx与经典端到端松耦合方案被提出,这类方案会同步运行VLx、经典端到端两套网络,其中VLx运行速度较慢、不保证实时性,而经典端到端需实时运行,也就是大家熟知的快慢双系统。这类系统的典型代表便是清华与理想汽车于2024年2月提出的DriveVLM-Dual;其中,DriveVLM 包含一个 Chain-of-Though (CoT) 过程,具有三个关键模块:场景描述、场景分析和分层规划;场景描述模块在语言上描述了驾驶环境并识别场景中的关键对象,场景分析模块深入研究了关键对象的特征及其对自我车辆的影响,分层规划模块逐步制定计划,从元动作、决策描述到航路点;考虑DriveVLM实时性差、空间感知能力不足,进一步提出了 DriveVLM-Dual,这是一种结合了 DriveVLM 和传统端到端系统优势的混合系统;DriveVLM-Dual 可选地将 DriveVLM 与传统的 3D 感知和规划模块集成,使系统能够实现 3D 接地、高频规划能力;这种双系统设计,类似于人脑缓慢而快速的思维过程,有效地适应驾驶场景中不断变化的复杂性。基于类似的思路,华中科技大学与地平线机器人于2024年10月提出了Senna,该框架仍旧是一个快-慢双系统;该框架与DriveVLM-Dual的主要差异在于考虑大模型不擅长精确的数值计算,认为直接预测轨迹点会得到次优结果,Senna用元动作替换了低频轨迹预测,使用元动作指导经典端到端模型细化输出。然而,这种范式解耦了语义推理空间和轨迹动作空间,阻碍了轨迹优化和VLM推理过程之间的协同优化;上述框架没有充分利用VLM对端到端规划的能力,基于此相关研究提出了VLx与轨迹规划紧耦合思路,该思路的核心是紧耦合地考虑VLx的语义推理空间和motion planning的轨迹动作空间。华中科技大学与小米汽车于2025年3月联合提出了ORION框架,如下图所示;考虑到VLM的搜索空间和轨迹动作空间属于不同的域,引入了一个生成规划器来建立一个统一的潜在表示来对齐两个空间,在引入的模块的帮助下,利用VLM的推理信息构建轨迹,方便模型捕捉场景信息和驾驶行为之间的因果关系;该框架主要由三个关键部分组成:QT-Former(用于提取长期上下文、链接视觉编码器的视觉空间和LLM的推理空间)、LLM(用于执行推理任务和预测planning token)、生成规划器(连接推理空间和动作空间、生成由planning token为条件的多模态轨迹);此处的生成规划器参考了GenAD的实现思路,主要基于VAE+GRU实现。同一时期,理想汽车在2025年3月英伟达GTC大会上公布了其MindVLA架构,该架构整体思路差不多,但设计得更为精细,是理想汽车近期多项工作的集大成者,比如基于3D GS获取3D空间理解能力、MoE+SparseAtten提升端测推理速度、统一的快慢思考(是否有CoT)、基于双向注意力机制的action token输出、基于RLHF的人类偏好对齐等;需要说明的是MindVLA利用了基于常微分方程的ode采样器大幅加速的diffusion将action token解码成最终的轨迹信息(自车+其他交通参与者)。
EMMA框图(图源:EMMA)
LINGO-2框图(图源:https://wayve.ai/thinking/lingo-2-driving-with-language/)
DriveVLM-Dual框图(图源:DriveVLM)
ORION框图(图源:ORION)
MindVLA框图(图源:https://zhuanlan.zhihu.com/p/31040826884)
世界模型驱动
世界模型是人工智能中长期存在的概念,但笔者认为其概念并不明晰,不同人聊的世界模型可能并不是同一个事。本文暂且将其定义为以当前动作和过去观察为条件,对未来状态进行预测。世界模型在智驾领域已有较多研究,下图列举了不同智驾相关的世界模型比对。粗略来说,根据是否预测输出未来动作、轨迹,世界模型可分为两大类:纯粹生成未来场景、同步生成未来场景与预测未来动作。下图中的GAIA-1和WaabiWM属于前者,其余则属于后者。而根据未来场景的表征方式,世界模型又可分为三大类:2D图像、3D表征、隐式表达。2D图像视频是研究应用最广的类别,GAIA-1/2、DriveDreamer系列、ADriver-I等都属于该类别;3D表征通常采用占据栅格、点云等形式,典型代表包括OccWorld、MUVO、WaabiWM;隐式表达指的是不显式以2D或3D的形式输出未来场景的可视化结果,而是以隐式编码直接表达生成的未来场景,LAW是这类代表。
不同智驾相关世界模型比对(图源:Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities)
尽管已有智驾相关的世界模型被研究,但世界模型在智驾、尤其是端到端系统的应用却大有百家争鸣之态、并没形成统一的范式。
- 对于同步生成未来场景与预测未来动作这类世界模型(比如DriveDreamer,如下图所示),由于世界模型直接输出了车辆未来动作,理论上这类世界模型可以直接用于智驾,预测的未来动作直接驱动车辆行驶。这类范式与上一节介绍的纯VLx-E2EAD类似,输入原始传感器数据、自车历史状态等信息,然后通过生成或回归的方法,直接输出动作。该方案看着很美好、上限很高,但笔者认为这类方案监督信号较弱,模型较难收敛,直接输出的动作质量也难以保证;可能需要海量的数据才能得到可落地的效果。
DriveDreamer框架(图源:DriveDreamer)
- 将世界模型作为评判器,对端到端系统的输出结果进行评分,是世界模型与端到端结合的一种范式,Drive-WM是其中的典型代表(如下图所示)。Drive-WM首先利用多视图与时序帧联合建模、整合多个异构条件的统一接口等技术,实现高质量、条件可控、一致的多视图视频数据生成;然后,探索将世界模型与端到端系统结合,具体来说世界模型根据planner输出的多个action分别生成未来图像,然后使用基于图像的奖励函数,去评测、选择轨迹。整体来说,世界模型在其中的作用是利用生成的未来图像,对端到端系统生成的多条轨迹进行筛选、抉择。笔者认为这样的集成使用方法有些”大材小用“,一方面使用世界模型来选择轨迹、将轨迹选择环节做得过重,另一方面这样的使用方式并未充分挖掘世界模型的能力、既然已经建模构建出基于图像的奖励函数、更进一步将整个训练范式构建为强化学习收益可能更高。
Drive-WM流程图(图源:Drive-WM)
- 将世界模型模拟仿真器,对端到端系统进行强化学习、训练规控策略,是世界模型与端到端结合的另一种范式,理想汽车的MindVLA采用了这样的范式(如下图所示)。如何将世界模型与强化学习结合使用,理想汽车发表了一系列论文进行介绍,关于强化学习的细节可参考TrajHF论文,本节重点阐述世界模型在其中的作用。良好的交互环境是进行强化学习的前提;基于世界模型生成场景的优势在于其良好的泛化能力、能够根据输入条件可控地生成多变、不常见的场景,但这类方法也存在出现幻觉、不符合物理规律、缺乏时空相关性等问题,难以直接应用到智驾;基于真实数据、利用纯重建模型,构建出的3D场景,能够保证真实性,然而这类方法在输入图像重叠度低情况下效果不佳(如大视角变换下出现空洞、变形),而且纯重建方法难以渲染输入数据中未出现的新轨迹、难以准确表达更复杂的机动。为解决上述问题,理想汽车利用世界模型作为数据机器来合成新的轨迹视频,其中明确利用结构化条件来控制交通元素的时空一致性,还提出了大量训练策略来促进真实数据和合成数据的合并使用、以优化场景重建效果;具体详情可参照DriveDreamer 4D和ReconDreamer,其框架如下图所示。笔者认为这种将世界模型的生成能力与重建模型的真实重建能力结合的思路,能够增强场景重建效果、且能泛化到未知场景,尤其采用3D GS的3D场景表征方式,该范式能够更容易与端到端智驾系统结合使用;在当前技术发展水平下,是一种能加速世界模型的大规模落地、解决端到端系统模仿学习弊端的路径。
强化学习与世界模型结合(图源:https://zhuanlan.zhihu.com/p/31040826884)
世界模型与场景重建结合(图源:DriveDreamer 4D; ReconDreamer)v
- 将世界模型中场景采用隐式特征表达,并将世界模型建模为隐式特征预测;基于端到端系统输出的action,隐式世界模型预测输出隐式特征,使用未来时刻的图像特征对该预测特征进行监督,进而构建成自监督学习范式。这是另一类世界模型与端到端系统结合使用的范式,LAW是典型代表(框架如下图所示),前文在”训练范式“小节对LAW工作机理有过阐述,此处不再赘述。然而,笔者认为这样的范式其实存在较大的弊端,整个训练过程中缺乏端到端系统与环境的交互,尽管无需标注数据,但由于系统缺乏与环境交互,整体的学习链路、学习效果比较类似模仿学习;而且,整个系统的梯度传递链路较长,稀疏监督问题可能会更凸显。
LAW系统框图(图源:LAW)
探讨
前文分享了笔者对智能驾驶技术范式演进路径的认知与理解。值得注意的是,智能驾驶技术正处于持续发展和升级的阶段,这意味着我们需要不断更新个人的知识体系以跟上行业的步伐。目前在个人认知体系中有不少问题尚未明确,存在诸多值得探讨的空间。因此,笔者希望通过抛出一些个人还未理解深刻的问题,与各位同行共同探讨,以期集思广益。
- 智驾系统的模型架构会逐步统一?NLP领域过去几年经历了快速发展,并且快速完成了范式统一;大语言模型尽管可分为Encoder-only(如BERT)、Decoder-only(如GPT系列)、Encoder-Decoder(如T5、MT5)三大类别;然而,近期典型的大语言模型大都采用Decoder-only架构,且使用Next Token Prediction范式统一各类NLP任务;比如下图所示的GPT3、LLaMa 3、DeepSeek 3,其架构大面基本一致。VLM模型框架也在经历类似的发展路径,具体来说大都在Decoder-only类LLM模型基础上,对视觉adapter/connector进行调整(如下图)。然而,当前的智驾模型框架,无论是数据驱动范式,还是知识驱动范式,均还存在较大差异,甚至模型的输入输出形式也不尽相同。不禁疑问,智驾系统的模型架构是否会延续LLM/VLM的发展路径,走向模型架构大一统;最终模型效果的关键在于数据、训练方式?如果会,统一的智驾模型架构会是一种什么形式?
典型LLM框架(图源:数据技术课堂)
典型VLM框架(图源:A Survey on Multimodal Large Language Models)
- 评估结果是否真的有效?基本每篇文章基本都会说自己取得了SOTA的结果,但这些结论够solid?事实的确如此吗?
- 评测指标计算方法没有拉齐
- 评测场景有偏,场景数据不具有多样性
- 数据表征的分辨率有差异
- 开环评测方案的固有问题(因果混淆等)
- 仿真与实际间的隔阂
- 不要只看评估数值,评估结果具有欺骗性;导致评测差异的原因很多,如:
比如BEV-Planner/AD-MLP使用简单的MLP网络在nuScenes数据集即可达到E2E可比较的性能;PARA-Drive拉齐评测标准后,发现与UniAD对比,VAD的性能提升并没有文章中报告的那么大,参见下图
planning性能对比(图源:PARA-Drive)
- 实际业务场景中的很多case,当前的学术评测指标并不能予以正确全面评估,反应实际能力;比如
- 对于白实线/双黄线/导流线等交通法规不可行驶区域,压线行驶;
- 位于行人斑马线附近且有过马路意图的VRU,不予以让行;
- 前车长时间低速行驶或为"死车",未果断择机绕行;
- 面临多种抉择时,生成的轨迹不稳定/跳动;如临近路口选择车道迟疑,引发画龙问题;
常说是骡子是马拉出来遛一遛,然而如果"伯乐"本身就存在问题,怎么可能选出"千里马"?另外,说个题外话,在异构性更严重的具身智能/机器人领域,该问题愈发突出。
- 数据驱动范式、模仿学习范式的边界在哪里?还能支撑多久研发?小鹏汽车自动驾驶副总裁李力耘则认为,强化学习、世界模型和生成式仿真是实现L4不可或缺的技术支撑。“端到端技术可能不是实现无人驾驶的充分条件,但一定是必要条件。”暂且不论该论点是否正确,模仿学习的局限性在行业里已经得到了较多讨论(如Imitation Is Not Enough - 在运动规划中克服模仿学习的局限性 https://zhuanlan.zhihu.com/p/717288142),但对闭环环境要求高、稀疏监督等特性,强化学习可能也不是解决智驾问题的灵丹妙药。那模仿学习的能力边界到底在哪呢?如果模仿学习范式无法实现L4,是否可能实现L2+、L3?
- 世界模型对智驾系统的作用到底有多大?尽管在”知识驱动的智驾“板块,对世界模型进行了介绍,但相关认知大都来自学术文献;而且前文提到的那几种世界模型与端到端智驾结合的方式,个人感觉也稍显复杂,且各有弊端;比如,通过与强化学习结合,将世界模型应用到端到端智驾范式里面,世界模型是否也并非刚需,闭环仿真、3D场景构建是否已经能够解决较大部分问题?在智驾实际落地过程中,无论是直接输出动作,还是生成视频,世界模型到底能起到多大作用、是否是刚需,还需加强认知。
- 如何看待算法先进与落后,如何业务落地?
<The Bitter Lesson>提到在人工智能研究领域过去70年来最重要的经验教训是,只有通用计算方法最终是最有效的,并且优势巨大。将该理论套到智驾领域,越是先进的算法,比如大模型、世界模型加持的框架,上限理论上越高、也更具有前景。然而,在业务落地过程中,通常需要在眼前苟且、诗和远方间权衡折中。如何看待算法的先进、落后,因业务场景而适宜,很考验算法老大们的水平;先进技术范式上限高下限也低、其能力存在爬坡阶段的现实情况,更加剧了决策、迁移难度。在各家友商PR不断的大环境下,保持这份决策定力更难能可贵。 - "先进"算法 vs "落后"算法
- 大模型 vs 小模型
- 大算力芯片 vs 小算力芯片
后记
这是一个不断更新的时代,在智能驾驶技术领域,技术范式正以前所未有的速度迭代演进。从2021年BEV+Transformer架构的突破性应用,到2022年Occupancy占据网络的兴起,2023年端到端方案的全面崛起,2024年大模型的逐步渗透,直至2025年VLA的崭露头角,每年的技术焦点都在重新定义行业边界。这种指数级的技术革新不仅体现在学术研究的持续突破上,更在产业竞争维度催生出前所未有的内卷态势——不断刷新榜单的SOTA论文、各厂商对技术优势的激烈争夺,以及媒体对"遥遥领先"、"第0梯队"等表述的高频渲染,共同构成了复杂的技术叙事场域。 置身其中,从业者既面临技术认知的持续挑战,也遭遇信息甄别的现实困境。浮夸与务实交织的行业生态,使得技术真伪的辨识愈发困难。本文的创作初衷,正是希望通过系统梳理技术范式的演进脉络,为行业参与者提供穿透技术表象的认知工具。需要说明的是,受限于笔者当前的认知水平,文中对技术路线的分析可能仍存在局限性,恳请大家不吝指正。 特别需要强调的是,本文的论述重点聚焦于学术论文层面的技术范式变迁,对产业界具体技术方案的深度解析暂未展开。这一选择既基于避免对厂商技术路线做出可能失当的评价,也考虑到学术研究往往能更纯粹地反映技术发展的底层逻辑。通过这种学术视角的探讨,期望能为行业提供更具前瞻性的技术趋势研判,助力从业者在智能驾驶的技能图谱构建中把握关键节点。
参考资料
Survey
- Chen, Li, et al. End-to-End Autonomous Driving: Challenges and Frontiers. June 2023.
- The Integration of Prediction and Planning in Deep Learning Automated Driving Systems: A Review. Aug. 2023.
- Vision Language Models in Autonomous Driving: A Survey and Outlook. Oct. 2023.
- A Survey on Multimodal Large Language Models. June 2023.
- Choose Your Simulator Wisely: A Review on Open-Source Simulators for Autonomous Driving. Nov. 2023.
- Yang, Zhenjie, et al. LLM4Drive: A Survey of Large Language Models for Autonomous Driving. Oct. 2024.
- Minaee, Shervin, et al. Large Language Models: A Survey. Feb. 2024.
- Forging Vision Foundation Models for Autonomous Driving: Challenges, Methodologies, and Opportunities. Jan. 2024.
- CVPR 2024 | E2E AI Tutorial https://wayve.ai/cvpr-e2ead-tutorial/
- The Bitter Lesson http://www.incompleteideas.net/IncIdeas/BitterLesson.html
Data-Driven
- Hu, Yihan, et al. Planning-Oriented Autonomous Driving. Dec. 2022.
- Wu, Penghao, et al. Trajectory-Guided Control Prediction for End-to-End Autonomous Driving: A Simple yet Strong Baseline. June 2022.
- Chitta, Kashyap, et al. TransFuser: Imitation with Transformer-Based Sensor Fusion for Autonomous Driving. May 2022.
- Jia, Xiaosong, et al. DriveAdapter: Breaking the Coupling Barrier of Perception and Planning in End-to-End Autonomous Driving. Aug. 2023.
- Jiang, Bo, et al. VAD: Vectorized Scene Representation for Efficient Autonomous Driving. Mar. 2023.
- Chen, Shaoyu, et al. VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning. Feb. 2024.
- Tong, Wenwen, et al. Scene as Occupancy. June 2023.
- SparseDrive: End-to-End Autonomous Driving Via. May 2024.
- SparseAD: Sparse Query-Centric Paradigm for Efficient End-to-End Autonomous Driving. Apr. 2024.
- Liao, Bencheng, et al. DiffusionDrive: Truncated Diffusion Model for End-to-End Autonomous Driving. Nov. 2024.
- Weng, Xinshuo, et al. PARA-Drive: Parallelized Architecture for Real-Time Autonomous Driving. Mar. 2024.
- LAW:Enhancing End-to-End Autonomous Driving with Latent World Model. June 2024.
- DriveTransformer: Unified Transformer for Scalable End-to-End Autonomous Driving. Mar. 2025.
- Song, Ziying, et al. Don’t Shake the Wheel: Momentum-Aware Planning in End-to-End Autonomous Driving. Mar. 2025.
- GoalFlow: Goal-Driven Flow Matching for Multimodal Trajectories Generation in End-to-End Autonomous Driving. Mar. 2025.
- Zheng, Wenzhao, et al. GaussianAD: Gaussian-Centric End-to-End Autonomous Driving. Dec. 2024.
- UniSim: A Neural Closed-Loop Sensor Simulator. Aug. 2023.
- Jia, Xiaosong, et al. Bench2Drive: Towards Multi-Ability Benchmarking of Closed-Loop End-To-End Autonomous Driving. June 2024.
- Finetuning Generative Trajectory Model with Reinforcement Learning from Human Feedback. Mar. 2025.
- RAD: Training an End-to-End Driving Policy via Large-Scale 3DGS-Based Reinforcement Learning. Feb. 2025.
- Zhai, Jiang-Tian, et al. Rethinking the Open-Loop Evaluation of End-to-End Autonomous Driving in nuScenes. May 2023.
- Li, Zhiqi, et al. Is Ego Status All You Need for Open-Loop End-to-End Autonomous Driving? Dec. 2023.
Knowledge-Driven
- DriveVLM: The Convergence of Autonomous Driving and Large Vision-Language Models. Feb. 2024.
- Hwang, Jyh-Jing, et al. EMMA: End-to-End Multimodal Model for Autonomous Driving. Oct. 2024.
- OpenEMMA: Open-Source Multimodal Model for.Pdf. Dec. 2024.
- Senna: Bridging Large Vision-Language Models and End-to-End Autonomous Driving.Pdf. Oct. 2024.
- Tokenize the World into Object-Level Knowledge to Address Long-Tail Events in Autonomous Driving. July 2024.
- Zhang, Songyan, et al. WiseAD: Knowledge Augmented End-to-End Autonomous Driving with Vision-Language Model. Dec. 2024.
- Renz, Katrin, et al. CarLLaVA: Vision Language Models for Camera-Only Closed-Loop Driving. June 2024.
- Xu, Yi, et al. VLM-AD: End-to-End Autonomous Driving through Vision-Language Model Supervision. Dec. 2024.
- VLM-E2E: Enhancing End-to-End Autonomous Driving with Multimodal Driver Attention Fusion. Feb. 2025.
- Hegde, Deepti, et al. Distilling Multi-Modal Large Language Models for Autonomous Driving. Jan. 2025.
- DeepSeek-AI, DeepSeek-AI, et al. DeepSeek-V3 Technical Report. Dec. 2024.
- The Llama 3 Herd of Models. July 2024.
- Wang, Peng, et al. Qwen2-VL: Enhancing Vision-Language Model’s Perception of the World at Any Resolution. Sept. 2024.
- MindVLA https://zhuanlan.zhihu.com/p/31040826884
- LINGO-2: https://wayve.ai/thinking/lingo-2-driving-with-language/
- Fu, Haoyu, et al. ORION: A Holistic End-to-End Autonomous Driving Framework by Vision-Language Instructed Action Generation. Mar. 2025.
- Wang, Xiaofeng, et al. DriveDreamer: Towards Real-World-Driven World Models for Autonomous Driving. Sept. 2023.
- Wang, Yuqi, et al. Driving into the Future: Multiview Visual Forecasting and Planning with World Model for Autonomous Driving. Nov. 2023.
- Zhao, Guosheng, et al. DriveDreamer4D: World Models Are Effective Data Machines for 4D Driving Scene Representation. Oct. 2024.
- Ni, Chaojun, et al. ReconDreamer: Crafting World Models for Driving Scene Reconstruction via Online Restoration. Nov. 2024.
- GAIA-2: A Controllable Multi-View Generative World Model for Autonomous Driving. Mar. 2025.
#依据模糊指令寻找特定物体实例
Meta&佐治亚理工最新依据模糊指令寻找特定物体
在现实世界中,具身智能体面临解读模糊人类指令的挑战,比如家用机器人需识别指令模糊性并提问以准确理解用户意图来执行任务。为此,我们引入 ASK-TO-ACT 任务,让智能体在家庭环境里依据模糊指令找特定物体实例,并在部分可观测时策略性提问解决模糊性。同时,提出一种新方法,运用在线强化学习和大语言模型生成的奖励,微调多模态大语言模型成为视觉 - 语言 - 行动智能体,该方法无需大规模人类演示或手动设计奖励。经与强大零样本基线(如 GPT-4o)和监督微调的多模态大语言模型进行基准测试,此方法微调后的模型性能显著更优,在新场景和新任务中泛化能力良好,首次实现将多模态大语言模型适配为能通过在线强化学习和大语言模型生成奖励进行行动和寻求帮助的视觉 - 语言 - 行动智能体。
一些介绍
- 研究背景与问题提出:现实中具身智能体执行的人类指令常模糊、不明确或依赖上下文,如家用机器人执行 “拿杯子放咖啡桌” 任务(如图 1 所示)时面临诸多模糊性。提出 ASK-TO-ACT 任务,旨在让智能体通过提最少相关问题解决模糊性,但这需平衡探索、推理等多项目标。同时提出研究问题:如何构建能通过提问解决模糊性的具身智能体。
- 现有方法的局限:训练能交互并提问的智能体颇具挑战,传统依赖大规模人类演示结合模仿学习,或手动设计奖励的强化学习方法,存在不易实现和扩展的问题,尤其在涉及自然语言通信的智能体训练时更为突出。此前利用大语言模型零样本能力的方法,也存在需精心设计提示或依赖强假设(环境完全可观测且能无误差文本表示)的局限,与现实不符。
- 提出新方法:核心是利用大语言模型的上下文常识和演绎推理能力解决模糊性,通过大规模强化学习和大语言模型生成的奖励信号(大语言模型从模拟器获取特权信息),将多模态大语言模型适配为视觉 - 语言 - 行动模型。使用大语言模型生成的每步奖励评估智能体行动和问题,在正确表示任务和环境时,大语言模型生成奖励效果显著,该框架无需昂贵的人类演示或手动设计奖励。
- 实验验证:在更现实的设置中实例化 ASK-TO-ACT 任务,用 Habitat 3.0、ReplicaCAD 数据集和 Google Scanned Objects 的物体类别进行实验,从未见场景和未见任务两个维度评估智能体泛化能力。与强大零样本基线和基于监督微调的方法对比,新方法在未见场景和未见任务评估分割上成功率分别高出 40.3% 和 19.1%。还发现仅用任务子目标奖励训练效果差,且智能体提问数量增加有助于提升成功率和未见任务的泛化能力。
ASK-TO-ACT 任务介绍
- 任务提出与目标:为构建能处理模糊性并与用户交互获取澄清信息的具身智能体,提出 ASK-TO-ACT 任务。在该任务中,智能体需在未见室内环境里,依据不明确语言指令寻找特定物体实例并放置到指定容器上,且要提出最少澄清问题确定目标物体1。
- 任务模糊性维度:从物体属性、位置、大小,以及属性与空间推理、属性 / 空间推理和物体大小的组合这五个维度评估模糊性,涵盖了多模态大语言模型较难处理的能力,以此全面考察智能体对模糊性的推理能力。
- 评估方式
- 评估维度:从未见场景(考察智能体对新物体布局或物体类别新实例的任务执行能力)和未见任务(测试智能体在未见场景中处理新模糊实例的能力,要求其提出更多问题)两个维度评估智能体的泛化能力。
- 问题评估:利用大语言模型构建回答模块,输入任务指令、环境信息和目标物体元数据,回答智能体的问题。为降低难度和便于评估,将智能体的问题类型限制为查询物体属性、位置和大小三类(如表1所示),大语言模型以 “是 / 否” 响应,通过这种方式可离线计算回答和奖励,实现强化学习训练扩展。

- 任务设置与动作空间
- 任务设置:借助 Habitat 3.0,在 ReplicaCAD 数据集的 63 个训练场景和 20 个评估场景中开展任务,使用 Google Scanned Objects 的 42 个物体类别,采用 Spot 机器人实体,智能体每个时间步可获取多种信息。
- 动作空间:在 Habitat 3.0 中实现智能体动作空间,采用分层方法,高级策略从 116 个预定义技能或 “提问” 动作中选择,生成自然语言查询,技能包括拾取、放置和导航等操作。
方法介绍
我们的方法将预训练的多模态大语言模型(MLLM)适配为视觉 - 语言 - 行动(VLA)模型,该模型能够在多模态具身决策场景中同时采取行动并生成自然语言问题,以解决模糊性,而无需依赖人类注释或手动设计的奖励。我们使用带有大语言模型生成奖励的强化学习(RL)为 ASK-TO-ACT 任务训练视觉 - 语言 - 行动模型。
策略架构
我们将 LLaVA-OneVision 多模态大语言模型架构适配为用于任务规划和提问的视觉 - 语言 - 行动模型,如图 2 所示。多模态大语言模型策略将任务指令以及一系列过去的观察、行动、对所问问题的用户响应作为输入,并输出高级行动(即技能)或自然语言问题。如图 2 所示,任务指令首先被编码为语言令牌。传统的多模态大语言模型将单个视觉输入嵌入为大量视觉令牌,例如 LLaVA-OneVision 使用 729 个令牌。然而,在部分可观测的具身场景中,这些智能体需要对长时间的过去观察序列进行推理才能完成任务。为每个观察使用大量视觉令牌会迅速增加上下文长度(例如,32 个视觉观察 ×729 个令牌≈23k 个令牌)。为了使训练具有长观察历史的多模态大语言模型可行,我们采用 Perceiver 模型对每个观察的视觉令牌进行下采样,类似于 。具体来说,我们使用多模态大语言模型视觉编码器对每个视觉观察进行编码,然后将输出传递给 Perceiver 下采样器,该下采样器输出 k<729 个令牌(在我们的案例中 k = 4)。接下来,当前观察ot的这些下采样视觉令牌与任务指令令牌(,…,)、动作的文本表示令牌(,…,)以及在每个步骤被标记化的用户对所问问题给出的语言响应令牌(,…,)交错排列。

这些交错的语言和视觉令牌由多模态大语言模型处理,该模型自回归地预测与离散动作或自然语言问题相对应的语言令牌序列。每个智能体动作a∈A(一个技能或可能的问题q∈Q)被表示为自由形式的文本序列,并被标记化为(,…,)。例如,在一个高级技能被描述为 “pick red bowl” 的动作空间中,使用 Qwen - 2 分词器,该序列被标记化为 [29245, 2518, 19212]。多模态大语言模型必须先预测令牌 29245,然后是 2518,最后是 19212 才能执行该动作。对应无效动作的序列要么被过滤掉,要么被视为无操作以防止执行错误。
受限语法解码
使用语言动作通过强化学习训练多模态大语言模型会显著扩大动作空间,其中大多数动作是无效的,这使得强化学习训练变得困难 。例如,Qwen - 2 分词器有 151646 个令牌,导致每一步有种可能的动作预测,而这些动作中只有一小部分是有效的。为了解决这个问题,我们采用语法受限解码来将自回归采样限制为仅有效的动作令牌序列。语法受限解码被定义为一个函数M(,…,),它对所有令牌生成一个二进制掩码,指示哪些令牌在第 j 步解码时是有效的。这种限制确保模型只预测有效的动作,使强化学习训练易于处理。
使用大语言模型生成奖励的强化学习训练
为针对 ASK - TO - ACT 任务微调 LLaVA - OneVision 基础多模态大语言模型,采用带有大语言模型生成奖励的在线强化学习方法,具体内容如下:
- 方法提出的原因:手动用启发式方法定义密集奖励以生成子目标和评估问题较难,编写评估自然语言问题和智能体动作的程序也不可行。而当前先进大语言模型在获得正确的任务和环境信息时,具备在具身场景中推理模糊性的能力,可用于自动生成子目标和评估问题,作为强化学习训练的奖励信号。
- 具体操作:用特权环境状态、任务指令和目标对象元数据的文本表示提示大语言模型,让其生成解决每个 ASK - TO - ACT 任务的相关子目标和最优问题序列。
- 奖励函数:在每个时间步依据公式生成奖励,奖励函数包含完成任务的稀疏奖励、实现中间目标的子目标奖励、鼓励快速完成任务的松弛惩罚,以及有助于消除目标对象模糊性的澄清问题奖励。公式中各参数有明确含义,如表示任务是否成功完成、是否完成子目标、问题是否有效等。对于智能体提出的问题,奖励值会根据解决任务所需问题数量归一化。训练时若超出问题预算,会对智能体进行惩罚,默认预算为解决任务所需最少问题数量。
- 实现细节:我们使用 DD - PPO (一种用于分布式训练的 PPO 改编版本)在 8 个 A40 GPU 上对多模态大语言模型策略进行 5000 万步的训练。为了为我们的任务生成奖励,我们使用 Llama - 3 大语言模型。
实验分析实验
在本节中,我们将使用强化学习和大语言模型生成的奖励将多模态大语言模型适配为视觉 - 语言 - 行动模型的方法,与零样本设置下的专有多模态大语言模型,以及使用为我们的任务合成生成的监督微调数据训练的多模态大语言模型进行比较。
基线
对于涉及多模态大语言模型微调的方法,我们使用 LLaVA - OneVision 0.5B 作为我们的基础多模态大语言模型,并进行第 4.1 节中描述的修改。由于在 A40 GPU 上运行强化学习训练的计算限制,我们使用 0.5B 模型。以下是每个基线的详细信息:
- 完全可观测文本世界图 + ReAct(零样本):在这个基线中,我们为大语言模型(在我们的例子中是 GPT4o)提供一个基于文本的完全可观测世界图,描述环境,包括容器、物体及其位置(例如 “The apple is on the coffee table.”)。此外,大语言模型配备了一个用于执行动作的技能库、先前动作的历史记录以及任务指令。在每个时间步,大语言模型通过 ReAct 提示生成推理链,然后执行一个动作来完成任务。通过消除感知限制,这个基线评估了大语言模型在解决模糊具身任务时的零样本规划和推理能力。
- 完全可观测文本世界图 + ReAct(少样本):这个基线扩展了 (a),为大语言模型提供了一些上下文示例,展示了 ASK - TO - ACT 任务中的任务规划和模糊性解决策略。通过利用这些示例,这种方法评估了上下文学习是否能提高大语言模型在完全可观测情况下的任务规划和模糊性推理能力。
- 部分可观测文本世界图 + ReAct(少样本):虽然基线 (a) 和 (b) 假设可以获取完全可观测的世界图,但在现实世界场景中构建这样的表示通常是不可行的。这个基线放宽了这个假设,为大语言模型提供一个基于文本的部分可观测世界图。在一个情节开始时,智能体缺乏对物体位置的完整知识,必须积极探索以收集必要的信息。
- Vision GPT4o + SoM + ReAct:构建现实世界环境的无误差文本表示具有挑战性。这个基线评估现有的多模态大语言模型是否可以使用以自我为中心的视觉观察来解决 ASK - TO - ACT 任务。在每个时间步,多模态大语言模型接收机器人的视觉输入以及用于执行动作的技能库。为了增强基础,我们使用 Set - of - Marks (SoM) 对视觉观察进行标记,并通过为 GPT4o 提供过去观察和动作的文本历史来保持记忆。
- LLaVA - OneVision SFT:这个基线使用在合成生成的轨迹上进行监督微调(SFT)的方法,针对我们的任务对 LLaVA - OneVision 0.5B 多模态大语言模型进行微调。生成训练数据并非易事,因为智能体必须首先探索环境以定位相关物体,提出基于上下文的问题以消除目标物体的模糊性,最后在确定物体后执行指令。为了实现这一点,我们使用启发式探索和大语言模型设计了一个专家系统。智能体首先使用前沿探索 探索场景,直到看到所有容器,然后将其观察转换为基于文本的世界图。这个图与任务指令和关于目标对象的特权信息一起传递给大语言模型,大语言模型生成一系列澄清问题以识别物体。一旦确定了目标对象,启发式规划器执行重新布置任务。最终的轨迹包括探索过程中采取的动作、大语言模型生成的作为动作的问题,以及重新布置物体时采取的动作。只有成功的轨迹才包含在训练中。我们的监督微调数据集在 ReplicaCAD 数据集中的 63 个训练场景中包含约 40k 个轨迹。
指标
我们报告三个指标:1. 成功率(SR):衡量任务成功完成的比例;2. 模糊性解决效率得分(ARS):衡量智能体在成功完成任务的同时,提出最少数量的必要澄清问题并惩罚不相关问题的能力。3. 问题比率(QR):智能体提出的总问题数量与解决任务所需的最少问题数量的比率。
结果
在未见场景和未见任务分割上评估所有方法的结果:为了确定性能上限,我们首先评估具有特权信息的零样本大语言模型(表 2 的第 1 行和第 2 行)。当大语言模型获得基于文本的环境完全可观测表示并使用 ReAct 进行动作预测时,它们在未见场景和未见任务上的成功率分别达到 56.1% 和 47.3%,ARS 分别为 50.5% 和 37.4%。这凸显了大语言模型在零样本设置下进行任务规划和模糊性解决的固有困难。接下来,我们为大语言模型提供展示如何执行 ASK - TO - ACT 任务的特权上下文示例。这显著提高了性能,在未见场景和任务上的成功率分别提高到 96.2% 和 94.7%。这些有前景的结果促使我们探索将大语言模型用作 ASK - TO - ACT 任务的奖励生成器。然后,我们在部分可观测的情况下评估相同的基线(第 3 行),在这种情况下,智能体无法访问完全可观测的世界图,但仍然有上下文示例。这导致在两个分割上的成功率绝对下降 34.4% 和 45.5%(第 3 行与第 2 行相比),表明当智能体必须积极探索以收集信息时,任务规划和模糊性解决变得更加具有挑战性。如表 2 所示,我们的方法(第 6 行)使用强化学习和大语言模型生成的奖励对多模态大语言模型 进行微调,优于所有在部分可观测情况下运行的方法,在未见场景和未见任务分割上的成功率分别达到 89.8% 和 65.2%,ARS 分别为 63.2% 和 32.2%。我们的方法在成功率上比使用合成监督微调数据训练的策略(第 5 行与第 6 行相比)绝对高出 31.1 - 41.6%,在 ARS 上高出 6.3 - 16.3%。我们发现使用监督微调训练的智能体往往更加保守(如第 5 行所示,QR 低于 1),与使用强化学习训练的智能体相比,提问更少,这可能是性能差异的原因,更多分析见 5.4 节。此外,我们的方法在成功率上比使用带有 Set - of - Marks (SoM)提示和过去观察文本历史的 Vision GPT4o 的强大零样本基线(第 4 行)绝对高出 45.4 - 64.6%。这些结果表明,在线强化学习结合大语言模型生成的奖励是训练能够通过提问解决模糊性并与行动交织的具身智能体的有效方法。

强化学习训练的奖励选择:在表 3 中,我们对强化学习训练的奖励函数选择进行了消融实验,以证明使用大语言模型为 ASK - TO - ACT 任务生成奖励的有效性。我们考虑了两种可以为我们的任务通过编程定义的简单奖励:
- 成功奖励:一种简单的稀疏奖励设置,只有在情节结束时智能体成功完成任务才给予价值 10 的奖励,否则为 0。此外,智能体在每个时间步还会收到 0.01 的松弛惩罚,以鼓励更快地完成任务。
- 子目标奖励:在这种设置下,智能体完成完成整个任务所需的任何子目标都会获得奖励。例如,对于 “Bring me the cup and place it on the coffee table” 的任务,智能体应该导航到目标杯子,拿起目标杯子,然后导航到咖啡桌,最后放置杯子。在这种情况下,智能体将因导航到目标物体实例、拿起目标物体、导航到目标容器并放置它而获得奖励。这种奖励可以在训练情节中通过访问模拟器的特权信息和每个情节的目标对象元数据以编程方式生成。请注意,这种奖励并没有为探索或提出消除物体模糊性所需的一系列问题提供密集的逐步激励;相反,它隐含地奖励智能体提出导致其拿起正确物体的问题,这使得使用这种奖励进行强化学习训练变得困难。
如表 3 所示,这些奖励都不足以学习到针对我们任务的有效多模态大语言模型策略,这表明需要精确的每步奖励来激励智能体不仅采取行动,还提出有意义的问题。
在可变预算下训练:对于能够提问的具身智能体来说,一个理想的技能是遵循用户对于机器人提问频率的偏好。一些用户可能希望智能体尽可能少地提问,以通过牺牲任务成功率来获得更好的用户体验。相反,一些用户则希望智能体尽可能多地提问,以确保更高的任务成功率。受此启发,我们使用大语言模型生成的奖励通过强化学习训练多个多模态大语言模型策略,并对智能体可提问的最大数量设置可变上限。具体来说,我们训练的策略允许提问的预算为B∈{K,K+1,K+2,K+4},其中K是 ASK - TO - ACT 数据集中解决一个任务所需的最少问题数。在这种设置下,智能体在单个情节中最多可以问B个问题(无论相关与否)而不会受到任何惩罚。需要注意的是,在这个实验中,B要么等于K,即尽可能接近最少所需问题数提问,要么可以设置得相当高(K+4),即智能体在每个情节中比最少要求多问 4 个问题也不会受到惩罚。此外,智能体只会从其提出的所有问题中获得相关问题的奖励。我们只会对超出问题预算B后提出的每个问题惩罚智能体。图 3 展示了在奖励设置下,使用不同预算训练的各种策略的成功率。如图 3 (a) 所示,随着智能体可提问数量的增加,成功率也随之增加;然而,在成功率的增加和问题比率(即提问数量与最少所需数量的比率)之间存在明显的权衡,见图 3 (b)。
分析
智能体行为的定量分析:在图 4 (a) 中,我们展示了使用强化学习和监督微调训练的多模态大语言模型策略在未见任务分割上,与解决任务所需最少问题数之间的性能关系。这些结果表明,随着新任务所需问题数量的增加,两种方法的性能都会下降。在图 4 (b) 中,我们展示了这些策略与智能体提问数量之间的性能关系。结果显示,随着智能体提问数量的增加,性能开始下降(监督微调从 0 - 4 个问题,强化学习从 1 - 10 个问题),然而两种方法在某个转折点之后性能会提高(监督微调在 4 - 5 个问题之间,强化学习在 10 - 15 个问题之间)。这表明当这些智能体提出的问题远多于任务所需的最少问题时,它们能够解决模糊性。我们还观察到,使用监督微调训练的智能体比使用强化学习训练的智能体更保守,提问更少,这可以解释表 2 中性能的差异(第 5 行与第 6 行)。
定性示例:在图 5 中,我们展示了我们的方法在未见任务分割上的一个成功示例。智能体首先进行探索,直到找到所有 4 个杯子实例。然后它提出一系列问题。最后,根据用户的回答,它成功地将用户想要的绿色杯子拿到了浅色桌子上。
总结
在这项工作中,我们引入了 ASK - TO - ACT,这是一个新颖的任务,其中具身智能体被要求通过不明确的语言指令找到特定的物体实例。为了解决这个任务,智能体需要能够根据环境上下文对模糊性进行推理,并用自然语言提出澄清问题来解决模糊性。为了训练这样的智能体,我们提出了一种方法,即使用强化学习(RL)和大语言模型生成的奖励来适配多模态大语言模型(MLLMs)。我们的结果表明,这种方法显著提高了任务成功率和模糊性解决效率得分,优于使用 GPT4o 的强大零样本基线以及使用大语言模型生成的数据通过监督微调(SFT)进行微调的开源多模态大语言模型。我们在未见场景和未见任务上评估了我们的方法,结果表明,通过强化学习训练的视觉 - 语言 - 行动模型可以有效地泛化到新的物体排列和模糊的任务指令。我们的发现突出了密集的、上下文感知的大语言模型生成的奖励对于训练能够通过自然语言交互解决模糊性的具身智能体的有效性。
参考
[1] Grounding Multimodal LLMs to Embodied Agents that Ask for Help with Reinforcement Learning
#车企里第一个:因为智驾,把钱退还给车主
一辆带城区NOA,标配激光雷达的车,要卖多少钱?
“我觉着,怎么也得15万往上吧?”
15万?那是2024年!
11.98万起,五座家用SUV,还带冰箱彩电大沙发。
别急着惊讶,后续还能OTA车位到车位。
甚至之前花钱开通高阶智驾的用户,现在统统退钱,史上头一回。
零跑算是研究透了中国年轻用户的购车心理:
不求品牌溢价,但求六边全能。
高阶智驾“价格屠夫”,体验如何?
零跑新车B10,创造的第一个纪录就是高阶智驾车型的“史低”售价:11.98万。
比亚迪推的全民智驾,下探比零跑更深到了7万元车型,但是,天神之眼C功能只覆盖高速NOA和自主泊车。
业内争议颇多,有观点认为高速NOA根本不能算“高阶”…….各位观众老爷可以在评论区畅所欲言。
且不管“高阶”争议,零跑B10的确是目前带城区NOA以及后续OTA车位到车位功能售价最低的车型。
你说还有五菱宝骏?那还必须加一个前提:标配激光雷达。
零跑对高阶智驾的观点态度也就明确:高速NOA不算高阶,标配从城区NOA起。
反映到产品上,B10只有入门基础L2,和高阶智驾两个智驾SKU,不提供单独的高速NOA方案。
9.98万的入门款,是为了照顾预算的确有限的用户。
零跑B10的高阶智驾方案,总共27个传感器,包括1个激光雷达、11个摄像头、3个毫米波雷达、12个超声波雷达,底层高通8650智驾芯片。
其中激光雷达采用禾赛ATX,更强性能的同时,实现极致小巧和超低功耗:
高通8650芯片是零跑首发,4nm制程,具备200T稀疏算力,功耗较同级芯片低一半。
关键硬件选择上,可以看出零跑智驾体系的特征:轻。
算力轻、能耗轻、体积轻,自然,成本也就轻。
举个例子,零跑之前C系列采用的LEAP 3.0四叶草架构下,使用的是行业常见的英伟达Orin芯片,通常标注的是稠密算力200TOPS+。当然也能跑通端到端智驾模型。
多说一句,零跑官方向我们透露,和大多数玩家一样,零跑也在6-8个月时间内完成了端到端技术体系的切换。
所谓“端到端”,简单理解就是把驾驶全过程模型化、AI化,直接用人类成熟司机的驾驶数据去训练,理论上可以处理几乎所有复杂场景。而以往人工定义规则的系统靠“穷举法”,几乎无法应对庞大却复杂的博弈或异形障碍物。
体现在零跑B10上就是智驾体验更加“拟人”:
这个十字路场景下,有一块十分不规则的施工区域占据路口,零跑端到端高阶智驾不仅仅实现了绕行,而且巧妙地选择整个围栏区域外围绕行,符合交规,同时避免了对向盲区。
“拟人”还体现在避让动作上:
行人和电动车同时出现在转弯路口,但B10搭载的智驾系统刹车减速过程平缓顺滑,车内乘客没有丝毫“前俯后仰”。
规则主导的智驾系统也能避让,但有明确的“触发条件”,即目标进入车身周围某一范围内才会采取刹停措施,往往体验就很突兀。端到端的优势之一,就是系统会提前预判当前场景下各种目标的轨迹,然后不断实时修正自车的轨迹,避免条件反射式的驾驶行为。
这其实就是老司机常说的“防御性驾驶”。
紧急cut in场景,零跑端到端智驾也是在安全前提下尽量做到丝滑:
整套智能驾驶硬件系统,具备持续进化的能力,不仅可实现当前的城区智能领航,更可在未来升级到“车位到车位”的智驾功能。
以及,零跑端到端还有一个之前很少有玩家强调的优势:零接管之外,同时实现零违规:
特斯拉FSD落地中国后,这一点才引起大家重视。
因为端到端系统本质是通过数据“模仿”人类司机行为,能力上限高的同时,也代表着系统有可能为了通行效率学习错误的驾驶行为——下限也很低。
端到端体系下解决这个问题,只靠“大力出奇迹”喂数据是不行的。零跑给出的体验来看,在研发端至少已经深入到强化学习目标设置、高质量数据提炼等等颗粒度细致到代码级别的程度。
零跑这套端到端方案,有一个不同点:底层采用高通8650智驾芯片,稀疏算力200T,而非行业通用的英伟达Orin。
零跑自述在工程实践中发现:
“两款芯片真正参与运算的部分,能力是相当的,单颗的8650作为智驾算力足够应对端到端”。
零跑能够对智驾底层硬件的做出定性判断,前提无论对英伟达还是高通,或者是市场上任何其他类型的智驾芯片,都有深入到架构级的理解。
具体来说,是考察芯片架构对以Transformer结构为基础的模型优化支持是否足够、能耗是否经济、后续能否支持更进一步的VLM、VLA等新范式大模型。
零跑CEO朱江明总结为:
智能驾驶技术迭代到现在,已经不再是供应商给什么,主机厂就用什么,而是主机厂能理解多少,就能发挥多少。
所以,同样是端到端城区NOA,行业普遍需要数百TOPS以上、多个激光雷达的支持,搭载车型也止步15万以上。但零跑就可以在单激光雷达、算力200TOPS条件下左右落地,并且创造了13万内标配激光雷达加持下的城市NOA门槛新纪录。

而且转向高通智驾芯片,让零跑领先一步推进舱驾一体中央域控:LEAP 3.5在域控层面实现了一体化,智驾的8650和智舱的8295共用一块电路板、一套通信协议、一套电源冷却系统。
降本还在其次,真正的优势在于后续VLA模型上车,零跑在大语言模型和端到端融合、智驾可视化、人机交互层面具备了先发优势。
同时还是“冰箱彩电大沙发”的价格屠夫
零跑B10的第二个纪录,就是家用5座SUV的售价“史低”了,因为10万级售价,市场上普遍是A级小车。
4.5米左右车长,和2730mm的轴距达到紧凑级SUV天花板,这个尺寸其实和公认的“大车”坦克300相当,只是B10车身高度上符合常规家用SUV的惯例,显得没越野车那么大。
不同车型配置中,除了9.98万的入门版,其他所有车型都标配彩电——14.6英寸2.5K中控大屏,以及零跑自研的Leapmotor OS 4.0系统,以及大沙发——前排座椅通风加热,电动的后视镜、尾门、全景天幕等等。
冰箱据说能选配,但官方未透露详细方案。
10万级,零跑把能给的全给了,甚至别人给不了的,零跑也给了。
比如车机座舱接入了通义千问、DeepSeek,无论是说方言、多人下指令、还是离线控制,都是“信手拈来”。
再比如10万级别标配高通8295座舱芯片,零跑是行业首家。
之前大家调侃零跑的成功秘诀是“半价理想”,甚至老板朱江明也不避讳。
这次的B10,可以理解成“半价L6”:
外观上第一感觉确实如此,包括前后贯穿式灯组设计和下保险杠的U型区域都像是理想L系列的等比例缩小。
内饰上则不再走理想风格,更像smart的内饰,大量的圆角矩形,而且还做了内凹式的前IP台,并且包括中央扶手也是那种悬浮岛式的。整个内饰设计圆润可爱,更契合年轻人的需求:
续航方面,有510km和600km两种规格,都是磷酸铁锂电池包,最快支持19分钟30%-80%的快充能力。
B10整车所有的配置,都是在成本压力和家用实用之间去一个最大公约数。
9.98万入门版履行“代步车”职责,功能配置一项不多,但实用性一点不少,照顾预算有限的用户。
剩下所有车型,配置、体验都是越级下放。
只有在智能化这一项功能上,零跑不吝成本,8295、8650、端到端算法、激光雷达、城区NOA应上尽上,且没有任何额外收费订阅。
这样的策略年轻用户认可吗?零跑也给出了证明:
B10上市1小时大定超过10000台,70%用户选择激光雷达智驾版。
One more thing
出乎所有人预料,过去的3月零跑悄然登顶新势力销冠。
“半价理想”策略大获成功,理想汽车本尊反而屈居第二。
零跑的成功,可能还体现在这一点:
B10上市是零跑高阶智驾标配的开端,但也没忘老用户。
之前所有付费开通高阶智驾的车主用户,花多少钱零跑悉数奉还,即刻到账。
车企唯一。

















 676
676

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










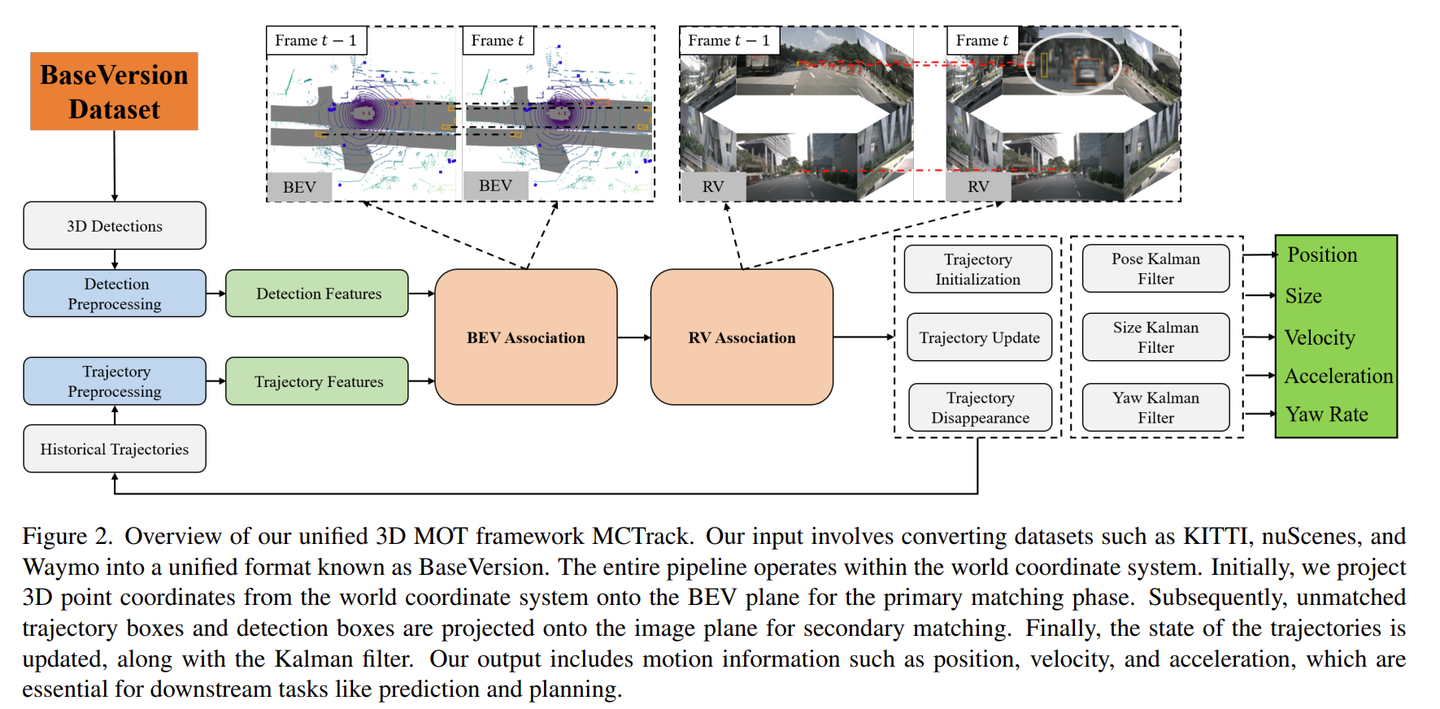{kind=link}