







我自己的原文哦~ https://blog.51cto.com/whaosoft/13768944
#2024上的AIGC扩散模型
一、扩散模型改进
1、∞-Brush : Controllable Large Image Synthesis with Diffusion Models in Infinite Dimensions
从错综复杂的领域特定信息中合成高分辨率图像仍是生成建模中的一个重大挑战,尤其适用于大图像域(如数字组织病理学和遥感)中的应用。现有方法面临着关键限制:像素空间或潜在空间中的条件扩散模型在超出它们训练的分辨率时就会失去保真度,并且对于更大的图像尺寸,计算需求会显著增加。
基于patch方法提供了计算效率,但由于过度依赖局部信息,无法捕捉长距离空间关系。本文引入一种新无限维条件扩散模型,∞-Brush,用于可控大图像合成。提出交叉注意力神经操作器,以实现函数空间中的条件化。模型克服了传统有限维扩散模型和基于patch方法的约束,提供可扩展性和在保持全局图像结构的前提下保持细节的卓越能力。∞-Brush 可控合成高达 4096 × 4096 像素分辨率图像的条件扩散模型。https://github.com/cvlab-stonybrook/infinity-brush

2、AccDiffusion: An Accurate Method for Higher-Resolution Image Generation
本文试图解决基于patch更高分辨率图像生成中的对象重复(object repetition)问题。提出AccDiffusion,无需训练,深入分析揭示了重复的对象生成,而没有提示会损害图像的细节。因此,AccDiffusion首次提出将图像内容感知提示解耦为一组分区内容感知提示,每个提示作为对图像分区的更准确描述。
AccDiffusion还引入了带窗口交互的dilated sampling,以更好提高更高分辨率图像生成中的全局一致性。与现有方法的实验比较表明,AccDiffusion有效解决了重复对象生成的问题,并在更高分辨率图像生成方面表现更好。

3、Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators
本文指出扩散Transformer模型的自注意机制中存在与查询-键交互的显著冗余,特别是在去噪扩散步骤的早期阶段。针对这一观察结果,提出一个新的扩散Transformer框架,包括一个额外的中介token集,用于分开处理查询和键。通过在去噪生成阶段调节中介token的数量,模型通过准确、明确的阶段开始去噪过程,并逐渐过渡到丰富细节的阶段。同时,整合中介token简化了注意模块的复杂度至线性尺度,增强了全局注意过程的效率。
此外,提出一个时间步动态中介token调整机制,进一步减少了生成所需的计算 FLOPs,同时促进了在各种推断预算的约束下生成高质量图像。实验证明,方法改善生成图像的质量,同时降低推断成本。与最近的 SiT 工作集成后,方法实现了 2.01 的最先进 FID 分数。等待开源在:https://github.com/LeapLabTHU/Attention-Mediators

4、Enhancing Diffusion Models with Text-Encoder Reinforcement Learning
文生图扩散模型通常被训练以优化对数似然目标,这在满足下游任务的特定要求,如图像美学和图像-文本对齐方面存在挑战。最近的研究通过强化学习或直接反向传播优化扩散 U-Net,利用人类奖励来解决这一问题。然而,许多研究忽视了文本编码器的重要性,该编码器通常在训练期间是预训练的且固定的。
本文证明通过强化学习微调文本编码器,可增强结果的文本-图像对齐,从而提高视觉质量。主要动机来自于观察到当前文本编码器并不是最佳的,通常需要仔细的提示调整。虽然微调 U-Net 可以部分改善性能,但仍受制于次优的文本编码器。因此,提出用低秩调整的强化学习来微调文本编码器,基于任务特定的奖励进行微调,称为 TexForce。首先展示微调文本编码器可以提高扩散模型的性能。然后,说明 TexForce 可简单地与现有微调模型结合,以获得更好的结果,无需额外训练。最后,展示了方法在各种应用中的适应性,包括生成高质量的人脸和手部图像。https://github.com/chaofengc/TexForce

5、Lost in Translation: Latent Concept Misalignment in Text-to-Image Diffusion Models
文生图扩散模型拓展了下游实际应用,但这些模型常在文本和图像之间遇到对齐问题。以生成两个解耦概念的组合为例,比如给定提示“一杯冰可乐”,现有模型通常会生成一个玻璃杯中的冰可乐,因为冰可乐通常在模型训练中与玻璃杯共现,而不是茶杯。这种对齐问题的根源在于文本到图像扩散模型在潜在语义空间中存在混淆,因此将“一杯冰可乐”现象称为潜在概念对齐失误(LC-Mis)。
利用大型语言模型(LLMs)彻底调查 LC-Mis 的范围,并开发一个自动化流程,用于将扩散模型的潜在语义与文本提示对齐。实证评估证实方法有效性,显著减少 LC-Mis 错误,增强了文本到图像扩散模型的韧性和通用性。https://github.com/RossoneriZhao/iced_coke

6、Navigating Text-to-Image Generative Bias across Indic Languages
本研究调查了针对印度广泛使用的印地语言的文生图(TTI)模型中的偏见。它评估并比较了这些语言中领先的 TTI 模型在生成性能和文化相关性方面与其在英语中的表现。利用提出的 IndicTTI 基准测试,全面评估了30种印地语言的两个开源扩散模型和两个商业生成 API 的性能。
该基准测试的主要目标是评估这些模型在这些语言中支持的程度,并确定需要改进的领域。鉴于印度使用的30种语言被14亿人口说着,该基准测试旨在提供对 TTI 模型在印地语言环境中效果的详细而独到的分析。IndicTTI 基准测试的数据和代码:https://iab-rubric.org/resources/other-databases/indictti

7、Post-training Quantization with Progressive Calibration and Activation Relaxing for Text-to-Image Diffusion Models
高计算负担是扩散模型面临的一个棘手问题。最近研究利用后训练量化(PTQ)来压缩扩散模型。然而,大多数研究仅集中在无条件模型上,未探索广泛使用的预训练文本到图像模型,如 Stable Diffusion 的量化。
本文提出一种扩散模型后训练量化方法 PCR(Progressive Calibration and Relaxing),该方法包括一个考虑跨时间步积累的量化误差的渐进校准策略,以及一个通过激活放松策略来提高性能而成本微乎其微的传动。此外,证明先前用于文本到图像扩散模型量化的指标并不准确,因为存在分布差异。为解决这个问题,提出一个新的 QDiffBench 基准测试,该基准测试利用相同领域的数据进行更准确的评估。

8、PreciseControl: Enhancing Text-To-Image Diffusion Models with Fine-Grained Attribute Control
文生图(T2I)扩散模型个性化方法的激增,用少量图像学习概念。现有方法在面部个性化领域受到困扰,很难实现带有身份保留的令人信服的逆映射生成,并依赖于生成的面部的基于语义文本的编辑。然而,对于面部属性编辑,更精细的控制是需要的,仅仅通过文本提示是具有挑战性的。
StyleGAN 模型学习了丰富的面部先验,并通过潜在操纵实现了朝着精细特征编辑的平滑控制。本文使用 StyleGAN 的 W+ 空间来对 T2I 模型进行条件设置。这种方法精确操纵面部属性,例如平滑地引入微笑,同时保留 T2I 模型中固有的基于文本的粗略控制。为使 T2I 模型在 W+ 空间上具有条件设置,训练了一个潜在映射器,将 W+ 空间的潜在代码转换为 T2I 模型的token嵌入空间。
方法在面部图像的inversion和属性保留方面表现出色,并有助于实现对精细特征编辑的持续控制。此外,方法可以方便地扩展到生成涉及多个个体的组合。大量实验证明方法对于面部个性化和精细特征编辑的验证。https://rishubhpar.github.io/PreciseControl.home/

9、Memory-Efficient Fine-Tuning for Quantized Diffusion Model
十亿参数扩散模型,如Stable Diffusion XL,Imagen和DALL-E 3,推动生成式人工智能领域。然而,大规模架构在微调和部署中存在挑战,因为资源需求高,推断速度慢。本文探讨相对未被探索但极具潜力的量化扩散模型微调领域。
分析显示,基线忽略了模型权重中的不同模式以及在微调扩散模型时各个时间步骤的不同角色。为解决这些限制,引入一种专门为量化扩散模型设计的新型内存高效微调方法,称为TuneQDM。方法引入量化比例作为可分离函数,以考虑通道间的权重模式。然后,它以时间步特定的方式优化这些比例,以有效反映每个时间步骤的作用。TuneQDM在与其全精度对应物相媲美的性能同时,还提供显著的内存效率。
实验结果表明,方法在单个/多个主体生成方面始终优于基线,表现出高主体忠实度和与全精度模型相媲prompt忠实度。

10、Reliable and Efficient Concept Erasure of Text-to-Image Diffusion Models
文生图模型面临安全问题,包括与版权和NSFW(不安全内容)相关的担忧。尽管已提出几种方法来从扩散模型中消除不合适的概念,但它们往往表现出不完全消除、消耗大量计算资源,并无意中损害了生成能力。
这项工作介绍一种名为可靠高效概念消除(RECE)的新方法,可在3秒内修改模型而无需额外微调。具体而言,RECE高效利用闭合形式解来推导出新的目标嵌入,能够在未学习的模型中重新生成已消除的概念。为了缓解由推导出的嵌入表示可能具有的不当内容,RECE进一步将它们与交叉注意力层中的无害概念对齐。为了保留模型的生成能力,RECE在推导过程中引入了额外的正则化项,从而最小化了消除过程中对不相关概念的影响。
保证仅需3秒极其高效的消除。与之前的方法进行基准测试,方法实现更高效和彻底的消除。https://github.com/CharlesGong12/RECE
11、Unmasking Bias in Diffusion Model Training
去噪扩散模型已成为图像生成的主要方法,然而它们在训练中收敛速度缓慢,采样中存在颜色偏移问题。这项工作发现这些障碍主要归因于扩散模型默认训练范式中固有的偏差和次优性。具体而言,提供理论见解,即扩散模型Ɛ-预测中普遍存在的恒定损失权重策略导致训练阶段估计偏见,阻碍了对原始图像的准确估计。
为解决这个问题,提出一个简单有效的加权策略,从解锁的偏置部分中推导而来。此外,进行了全面系统的探究,揭示了偏差问题在存在、影响和潜在原因方面的内在原因。这些分析有助于推动对扩散模型的理解。实证结果表明,方法显著提高样本质量,并且在训练和采样过程中提高了效率,仅通过调整损失加权策略。https://github.com/yuhuUSTC/Debias

12、SlimFlow: Training Smaller One-Step Diffusion Models with Rectified Flow
扩散模型在生成高质量方面表现出色,但由于迭代采样而导致推断速度缓慢。尽管最近的方法已成功将扩散模型转化为一步生成器,但它们忽略了模型尺寸的缩减,限制了在计算受限场景中的适用性。
本文旨在基于强大的矫正流框架,通过探索推断步骤和模型尺寸的联合压缩,开发小而高效的一步扩散模型。矫正流框架使用回流和蒸馏两种操作来训练一步生成模型。与原始框架相比,缩小模型尺寸带来了两个新挑战:(1)在回流过程中大型教师和小型学生之间的初始化不匹配;(2)小型学生模型上天真蒸馏的表现不佳。为克服这些问题,提出渐变回流和流引导蒸馏,二者共同构成我们的SlimFlow框架。
新框架训练了一个具有FID为5.02和15.7M参数的一步扩散模型,在CIFAR10上胜过了以前的最先进一步扩散模型(FID=6.47,19.4M参数)。在ImageNet 64×64和FFHQ 64×64上,方法得到了小型一步扩散模型,与较大模型相媲美,展示方法在创建紧凑、高效的一步扩散模型方面的有效性。

13、Optimizing Resource Consumption in Diffusion Models through Hallucination Early Detection

扩散模型在生成AI方面取得显著进展,但在生成多个对象的复杂组合时遇到困难。由于最终结果严重依赖于初始种子,在确保所需输出准确性方面可能需要生成过程的多次迭代。这种重复不仅会导致时间浪费,还会增加能源消耗,反映出在复杂生成任务中效率和准确性的挑战。
为解决这个问题,引入 HEaD(幻觉早期检测),一种旨在在扩散过程开始时迅速检测不正确生成的新范例。HEaD流水线结合了交叉注意力图和预测的最终图像这一新指标,通过利用生成过程早期阶段可用信息来预测最终结果。
证明用HEaD可以节省计算资源并加速生成过程以获取完整图像,即所有请求的物体都准确呈现在图像中。研究结果显示,HEaD可在双物体情景下节约高达12%的生成时间,并强调生成模型中早期检测机制的重要性。
14、Adaptive Multi-Modal Control of Digital Human Hand Synthesis Using a Region-Aware Cycle Loss

扩散模型已证明了其合成图像的能力,包括在特定姿势中生成人物。然而,当前模型在为详细的手部姿势生成提供条件控制方面面临挑战,导致手部区域的显著失真。为解决这个问题,首先整理了How2Sign数据集,提供更丰富和准确的手部姿势标注。此外,引入自适应多模态融合,以整合在骨架、深度和表面法线等不同模态中表达的字符物理特征。
提出了一种新的区域感知循环损失(RACL),使扩散模型训练着重于改进手部区域,从而提高生成手势的质量。具体而言,RACL计算生成图像中全身姿势关键点与真值之间的加权关键点距离,以在平衡整体姿势准确性的同时生成更高质量的手部姿势。此外用两个手部区域度量标准,分别为手部PSNR和手部距离,用于手部姿势生成评估。实验展示方法在利用扩散模型改善数字人体姿势生成质量方面的有效性,尤其是手部区域的质量。https://github.com/fuqifan/Region-Aware-Cycle-Loss
15、Improving Text-guided Object Inpainting with Semantic Pre-inpainting

图像可编辑性引发了对下游任务的极大兴趣,即在图像中指定区域内通过文本提示绘制一个新对象。然而,从两个方面来看,问题并不简单:1)仅仅依靠一个单一的U-Net在所有去噪时间步上对齐文本提示和视觉对象不足以生成期望的对象;2)在扩散模型复杂的采样空间中,不能保证目标生成的可控性。
本文提出将对象绘制分解为两个级联过程:1)语义预绘制 semantic pre-inpainting,在多模态特征空间中推断目标的语义特征;2)在扩散潜在空间中生成high-fieldity目标,该空间以这些嵌入的语义特征为中心。为实现这一点,级联了一个基于transformer的语义inpainter和一个对象绘制扩散模型,构成一个新的级联Transformer-Diffusion (CAT-Diffusion)框架。
从技术上讲,训练语义inpainter来预测目标对象在未屏蔽上下文和文本提示条件下的语义特征。然后,语义inpainter的输出作为信息性视觉提示,通过参考适配器层指导对象生成,从而实现可控制的对象inpainter。
对OpenImages-V6和MSCOCO的广泛评估验证了CAT-Diffusion相对于最先进方法的优越性。https://github.com/Nnn-s/CATdiffusion
16、Towards Reliable Advertising Image Generation Using Human Feedback
在电子商务领域,引人注目的广告形象是吸引顾客注意力的关键。生成模型自动生成图像,但经常生成不合格的图像,可能会误导客户,并且需要大量的劳动力成本来检查。
本文探讨如何提高可用生成图像。首先引入一个多模态可靠反馈网络(RFNet)来自动检查生成的图像。将RFNet结合到一个循环过程中,即循环生成,会产生更多可用的广告图像。为进一步提高生产效率,利用来自RFNet (RFFT)的反馈,利用创新的一致条件正则化对扩散模型进行微调。这显著增加可用率,减少了循环生成中的尝试次数,并在不牺牲视觉吸引力的情况下提供了高效的生产过程。
还构建一个100万(RF1M)数据集,包含100多万张人工标注的生成广告图像,这有助于训练RFNet准确评估生成图像的可用性并忠实地反映人类的反馈。总的来说,方法为广告形象生成提供了可靠的解决方案。https://github.com/ZhenbangDu/Reliable_AD
17、Distilling Diffusion Models into Conditional GANs

提出一种方法,将复杂的multistep扩散模型蒸馏为single-step条件GAN学生模型,可显著加速推理,同时保持图像质量。方法将扩散蒸馏解释为一项成对的图像到图像转换任务,使用扩散模型 ODE 轨迹的噪声到图像对。
为进行高效的回归损失计算,提出E-LatentLPIPS,一种在扩散模型潜在空间中直接操作的感知损失,利用了一组增强技术。此外,适应一个扩散模型,构建一个带有文本对齐损失的多尺度鉴别器,以构建一个有效的基于条件 GAN 的公式。即使考虑到数据集构建成本,E-LatentLPIPS 的收敛速度也比许多现有的蒸馏方法更高。展示一步生成器在零样本 COCO 基准测试中优于尖端的一步扩散蒸馏模型 - DMD、SDXL-Turbo 和 SDXL-Lightning。
二、数据增广18、InstructGIE: Towards Generalizable Image Editing

最近的图像编辑方法的泛化能力仍受到限制。为应对这一挑战,引入了一种新的图像编辑框架,通过增强上下文学习能力和统一语言指令来提高泛化鲁棒性。
该框架包括一个专门针对图像编辑任务进行优化的模块,利用VMamba模块和编辑位移匹配策略来增强上下文学习。此外,揭示一个特别设计用于纠正生成图像中的损坏细节(如人脸特征)的选择性区域匹配技术,以进一步提高质量。方法的另一个关键创新是整合语言统一技术,该技术将语言嵌入与编辑语义对齐,提升图像编辑的质量。
此外,编制了第一个用于带有视觉提示和编辑说明的图像编辑的数据集,可用于增强上下文能力。在此数据集上训练,方法不仅在训练任务的合成质量方面表现出色,而且通过定制提示展示了对未知视觉任务的稳健泛化能力。https://github.com/cr8br0ze/InstructGIE-Code
19、Photorealistic Object Insertion with Diffusion-Guided Inverse Rendering

对真实场景图像中虚拟对象的正确插入需要深入理解场景的光照、几何和材质以及图像形成过程。尽管最近的大规模扩散模型展示出强大的生成和修补能力,但当前模型不足以在单个图片中足够“理解”场景以生成一致的光照效果(阴影、明亮反射等),同时保留合成对象的身份和细节。
提出使用个性化的大规模扩散模型作为物理反渲染过程的指导。方法恢复场景光照和色调映射参数,允许在室内或室外场景的单帧或视频中逼真地组合任意虚拟对象。基于物理的流水线进一步实现了自动材质和色调映射的细化。https://research.nvidia.com/labs/toronto-ai/DiPIR/
20、RegionDrag: Fast Region-Based Image Editing with Diffusion Models

基于点拖动的图像编辑方法,如DragDiffusion,吸引了相当多的关注。然而,点拖动方法存在计算开销大和对用户意图的错误解释问题,这是由于基于点的编辑指令的稀疏性所致。
本文提出一种基于区域的复制粘贴拖动方法RegionDrag,以克服这些局限性。RegionDrag允许用户以处理和目标区域的形式表达其编辑指令,实现更精确的控制并减轻歧义。此外,基于区域的操作可以在一次迭代中完成编辑,比基于点拖动的方法要快得多。
还结合了注意力交换技术,以提高编辑过程的稳定性。为验证方法,用基于区域拖动指令扩展了现有的基于点拖动的数据集。实验证明,RegionDrag在速度、准确性和与用户意图的一致性方面优于现有的基于点拖动的方法。值得注意的是,RegionDrag在512×512分辨率的图像上完成编辑的时间少于2秒,比DragDiffusion快100多倍,并且表现更好。https://github.com/Visual-AI/RegionDrag
21、TurboEdit: Instant text-based image editing

本文在少步扩散模型的背景下解决了精确图像inversion和解耦图像编辑的挑战。引入了一种基于编码器的迭代inversion技术。inversion网络以输入图像和上一步重建图像为条件,允许纠正下一个重建朝向输入图像。演示了在少步扩散模型中如何通过条件生成(自动生成的)详细文本提示轻松实现解耦控制。
为了操纵inversion图像,固定噪声图并修改文本提示中的一个属性(手动或通过基于LLM驱动的指令编辑),产生一个类似于输入图像但只改变一个属性的新图像。它还可以进一步控制编辑强度并接受指导性文本提示。方法实现了实时逼真的基于文本引导的图像编辑,不仅速度快,而且在多步扩散编辑技术上明显优于现有技术。
22、Data Augmentation via Latent Diffusion for Saliency Prediction

显著性预测模型受限于有限多样性和标注数据的数量。诸如旋转和裁剪等标准数据增强技术改变了场景构成。提出一种新的用于深度显著性预测的数据增强方法,编辑自然图像同时保持真实世界场景的复杂性和变化性。由于显著性取决于高级和低级特征,方法结合学习两者,包括颜色、对比度、亮度和类别等光度和语义属性。为此,引入一种显著性引导的交叉注意力机制,用于在光度特性上进行有针对性的编辑,从而增强特定图像区域内的显著性。
实验结果表明,数据增强方法始终提高各种显著性模型的性能。此外,利用增强特性进行显著性预测在公开可用的显著性基准测试中表现出更出色的性能。预测结果与经用户研究验证的编辑图像中的人类视觉注意模式紧密吻合。https://github.com/IVRL/Augsal
23、MacDiff: Unified Skeleton Modeling with Masked Conditional Diffusion

自监督学习已被证明对基于骨架的人体动作理解非常有效。然而,先前研究要么依赖于对比学习,存在错误负问题,要么基于重建,学习了太多不必要的低层线索,导致下游任务的表示受限。
最近,在生成学习方面取得巨大进展,这自然是一个具有挑战性但有意义的预训练任务,以建模一般性的潜在数据分布。然而,生成模型对具有空间稀疏性和时间冗余的骨架的表示学习能力尚未得到充分探索。因此,提出蒙蔽条件扩散(MacDiff)作为人体骨架建模的统一框架。首次利用扩散模型作为有效的骨架表示学习器。
具体而言,训练一个扩散解码器,其以语义编码器提取的表示为条件。对编码器输入进行随机屏蔽,引入信息瓶颈并消除骨架的冗余。此外在理论上证明,生成目标涉及对比学习目标,对齐了屏蔽和嘈杂视图。同时,它还强制表示来补充嘈杂视图,从而提高了泛化性能。MacDiff在表示学习基准上取得了最先进的性能,同时保持了生成任务的竞争力。此外用扩散模型进行数据增强,在数据稀缺的情况下显着增强微调性能。https://lehongwu.github.io/ECCV24MacDiff/
三、数据挖掘24、Diffusion Models as Data Mining Tools

本文展示如何用经过图像合成训练的生成模型作为视觉数据挖掘的工具。本文认为,既然生成模型学习了其训练数据的准确表示,就可以通过挖掘视觉模式来总结数据。具体而言,展示了在对条件扩散模型进行微调以合成特定数据集的图像后,可以利用这些模型为该数据集定义一个典型性测量。该测量评估不同数据标签(如地理位置、时间戳、语义标签或甚至疾病存在)的视觉元素的典型程度。
这种通过合成进行的数据挖掘方法有两个主要优点。首先,它比传统的基于对应的方法具有更好的扩展性,因为它不需要显式比较所有视觉元素对。其次,尽管大多数以往的视觉数据挖掘研究集中于单一数据集,方法适用于内容和规模多样的数据集,包括历史汽车数据集、历史人脸数据集、大型全球街景数据集以及更大的场景数据集
四、数据蒸馏25、Generative Dataset Distillation Based on Diffusion Model

本文介绍在2024 ECCV首届数据集蒸馏挑战中的生成轨道方法。由于扩散模型因其高质量的生成效果而成为生成模型的主流,本文专注于基于扩散模型的蒸馏方法。考虑到该轨道在10分钟内只能使用生成模型为CIFAR100和Tiny-ImageNet数据集生成固定数量的图像,需要使用能够快速生成图像的生成模型。
本研究提出一种基于扩散的生成数据集蒸馏新方法。具体来说,用可以快速生成图像的SDXL-Turbo模型。与其他只能生成每类图像(IPC = 1)的扩散模型相比,方法可以实现Tiny-ImageNet的IPC = 10和CIFAR-100的IPC = 20。
此外,为为CIFAR-100和Tiny-ImageNet生成高质量的蒸馏数据集,将类信息用作文本提示,并在SDXL-Turbo模型上进行了数据增广。实验结果表明所提出方法的有效性,并且在ECCV 2024 DD挑战的生成轨道中获得第三名。https://github.com/Guang000/Generative-Dataset-Distillation-Based-on-Diffusion-Model
五、图像增强与恢复26、LightenDiffusion: Unsupervised Low-Light Image Enhancement with Latent-Retinex Diffusion Models

本文提出一种基于扩散的无监督框架,将可解释的Retinex理论与扩散模型结合应用于低光照图像增强,命名为LightenDiffusion。具体地,提出一个内容迁移的分解网络,该网络在潜变量空间中执行Retinex分解,而不像之前的方法在图像空间中执行,使得非配对的低光照和正常光照图像的编码特征能够被分解为富含内容的反射图和无内容的照明图。随后,采用低光照特征的指导,将低光照图像的反射图和正常光照图像的照明图作为扩散模型的输入进行无监督恢复,进一步提出了自约束一致性损失来消除正常光照内容对恢复结果的干扰,从而提高整体视觉质量。
在公开可用的真实世界基准测试上进行的广泛实验表明,LightenDiffusion胜过现有的无监督竞争对手,并且与受监督方法相媲美,同时更具有适用于各种场景的泛化能力。https://github.com/JianghaiSCU/LightenDiffusion
27、MoE-DiffIR: Task-customized Diffusion Priors for Universal Compressed Image Restoration

提出MoE-DiffIR,一种新的通用压缩图像恢复(CIR)方法,以任务定制的扩散先验。这旨在解决现有CIR方法面临的两个关键挑战:(一)缺乏适应性和普适性,适用于不同图像编解码器,例如JPEG和WebP;(二)在低比特率下,纹理生成能力较差。
具体来说,MoE-DiffIR开发了强大的专家混合(MoE)提示模块,其中一些基本提示合作,从扩散(SD)中挖掘出任务定制的扩散先验。此外,提出考虑退化的路由机制,使得基本提示的灵活分配成为可能。为激活并重复使用SD的跨模态生成先验,为MoE-DiffIR设计了视觉到文本适配器,旨在将来自视觉域的低质量图像的嵌入适应为SD的文本引导,从而实现更一致和合理的纹理生成。
还构建了一个通用CIR的全面基准数据集,涵盖来自7种流行的传统和学习编解码器的21种降质类型。对通用CIR的广泛实验已经证明了MoE-DiffIR具有出色的鲁棒性和纹理恢复能力。https://renyulin-f.github.io/MoE-DiffIR.github.io/
六、布局生成28、COHO: Context-Sensitive City-Scale Hierarchical Urban Layout Generation

大规模城市布局的生成,引起各个学科的广泛关注。以往方法使用程序化生成,需要手动编码规则,或者深度学习需要大量数据。以前方法并未考虑城市布局生成的上下文敏感性质。本文方法通过利用整个城市的规范图表示,弥补这一空白,这有助于扩展性和捕捉城市布局固有的多层语义。
为城市规模的城市布局生成引入了一种新的基于图的掩蔽自编码器(GMAE)。该方法将属性建筑物、城市街区、社区和城市编码到统一的图结构中,实现了图自编码器的自监督掩蔽训练。此外,采用调度迭代采样来生成2.5D布局,优先生成重要的城市街区和建筑物。方法实现了良好的逼真度、语义一致性和正确性,在美国330个城市的异构城市风格中展示出了优秀的性能。https://github.com/Arking1995/COHO
七、动作预测29、Gated Temporal Diffusion for Stochastic Long-Term Dense Anticipation

长动作预测已成为许多应用的重要任务,如自动驾驶和人机交互。与短预测不同,预测更多未来的动作在更长时间内带来挑战。虽然在预测更多未来动作方面取得了重大进展,但大多数提出的方法都是在确定性设置中解决这个任务,忽略了潜在的不确定性。
本文提出一种新的门控时间扩散(GTD)网络,用于建模观测和未来预测的不确定性。作为生成器,引入了一个门控预测网络(GTAN),用于在相互表示中建模视频的观察和未观察帧。一方面,对过去和未来使用共同表示能共同建模观察和未来的歧义,另一方面,GTAN可以通过设计区分观察和未观察部分,并控制它们之间的信息流。
模型在Breakfast、Assembly101和50Salads数据集上在随机和确定性设置中均取得了最先进的结果。https://github.com/olga-zats/GTDA
八、深度估计30、Diffusion Models for Monocular Depth Estimation: Overcoming Challenging Conditions

提出一种新方法,旨在解决单图深度估计任务中由具有挑战性的、超出分布数据引起的复杂性。从易于深度预测的图像开始,因为不存在不利因素,系统生成新的、用户定义的场景,包括一套全面的挑战和相关深度信息。
通过利用以深度感知控制而闻名的文生图扩散模型,以生成和源图像之间的3D结构的一致性为特点,合成高质量图像内容。通过自蒸馏协议对任何单眼深度网络进行后续微调,考虑用策略生成的图像以及其在简单的、不具挑战性的场景上的深度预测。针对目的定制的基准实验证明了有效性和多功能性。https://diffusion4robustdepth.github.io/
九、自动驾驶31、Safe-Sim: Safety-Critical Closed-Loop Traffic Simulation with Diffusion-Controllable Adversaries

评估自动车规划算法的性能需要模拟长尾安全关键交通场景。然而,用于生成这种场景的传统方法通常在可控性和现实性方面存在不足,还忽视代理间互动的动态。为克服这些限制,提出Safe-Sim,一种基于扩散的可控闭环安全关键仿真框架。
方法具有两个显著优势:1)生成实际反映现实世界条件的逼真长尾安全关键场景,以及2)为更全面和交互性评估提供可控的对抗行为。通过在扩散模型的去噪过程中引入对抗项的新方法,使得一个对抗代理可以对规划器提出合理的动作,同时场景中的所有代理都展现出反应迅速和现实性的行为。此外,提出新的引导目标和部分扩散过程,使用户能够控制场景的关键方面,如对抗代理的碰撞类型和侵略性,同时保持行为的逼真性。
通过在 nuScenes 和 nuPlan 数据集上对多个规划器进行实证验证,验证了框架在现实性和可控性方面的改进。这些发现证实扩散模型为安全关键、交互式交通仿真提供了坚实和多功能的基础,扩展了它们在更广泛的自动驾驶领域的实用性。https://safe-sim.github.io/
十、可解释性32、DEPICT: Diffusion-Enabled Permutation Importance for Image Classification Tasks

提出一种基于排列的图像分类器解释方法。当前图像模型解释(如激活图)局限于像素空间中的基于实例的解释,这使得理解全局模型行为变得困难。相比之下,针对表格数据分类,基于排列的解释方法对数据进行排列前后,比较模型性能的变化来测量特征重要性。
提出一种针对基于图像模型的解释方法,该方法通过在数据集图像上对可解释概念进行排列来度量特征重要性。给定带有特定概念标签的图像数据集(如标题),在文本空间中对示例进行概念排列,然后通过文本条件的扩散模型生成图像。特征重要性通过与未排列数据相比的模型性能变化来反映。当应用于一组概念时,该方法生成特征重要性的排名。展示这种方法在合成和现实世界图像分类任务中恢复底层模型特征重要性。https://mld3.github.io/depict/
十一、对抗攻击33、T2IShield: Defending Against Backdoors on Text-to-Image Diffusion Models

文生图扩散模型展示了令人印象深刻的生成能力,但也表现出对后门攻击(backdoor attacks)的脆弱性,后门攻击涉及通过恶意触发控制模型输出。
本文首次提出一种名为T2IShield的全面防御方法,用于检测、定位和减轻此类攻击。具体而言,发现由后门触发引起的交叉注意力图中的“同化现象”。基于这一关键洞察,提出两种有效的后门检测方法:Frobenius范数阈值截断和协方差判别分析。此外,引入了一种二分搜索方法来定位后门样本中的触发器,并评估现有概念编辑方法在减轻后门攻击方面的有效性。对两种先进的后门攻击情景进行的实证评估显示防御方法的有效性。针对后门样本检测,T2IShield实现了88.9%的检测F1分数,并具有低计算成本。
此外,T2IShield实现了86.4%的定位F1分数,并使99%的恶意样本无效。https://github.com/Robin-WZQ/T2IShield
十二、增量学习持续学习34、DiffClass: Diffusion-Based Class Incremental Learning

类增量学习(CIL)由于灾难性遗忘而具有挑战性。除此之外,无范例的CIL由于无法访问先前任务数据而更具挑战性。最近的无范例CIL方法试图通过合成先前任务数据来缓解灾难性遗忘。然而,它们未能解决由于无法处理真实数据和合成数据之间显著域差异而导致的灾难性遗忘。
为解决这些问题,提出一种新的无范例CIL方法。用多分布匹配(MDM)扩散模型来对齐合成数据的质量,并消除训练数据所有域之间的域差异。此外,方法整合了选择性合成图像增强(SSIA)以扩展训练数据的分布,从而提高模型的可塑性,并加强多域适应(MDA)技术的性能。
通过提出的集成方法,方法将无范例CIL重塑为一个多域适应问题,以隐式解决域差异问题,并在增量训练过程中增强模型稳定性。在基准CIL数据集和设置上实验表明,方法在不明显改进的同时优于以往的无范例CIL方法。https://cr8br0ze.github.io/DiffClass/
35、Diffusion-Driven Data Replay: A Novel Approach to Combat Forgetting in Federated Class Continual Learning

联邦类连续学习(FCCL,Federated Class Continual Learning)将分布式客户端学习(distributed client learning)的挑战与无需遗忘旧类便实现对新类的无缝适应需求相结合。FCCL中的关键挑战是灾难性遗忘,这在连续学习(CL)中一定程度上进行了探索的问题。然而,由于隐私保护需求,一些传统方法如经验回放等并不直接适用于FCCL。现有的FCCL方法通过生成通过GANs进行联邦训练的历史数据或无数据知识蒸馏来缓解遗忘问题。然而,这些方法往往遭遇到生成器训练不稳定或生成数据质量低的问题,限制了它们对模型的引导。
为解决这一挑战,提出一种基于扩散模型的数据重放方法。不是训练扩散模型,而是用预训练的条件扩散模型对每个类进行逆向工程,搜索模型输入空间内每个类的相应输入条件,显著减少计算资源和时间消耗,同时确保有效的生成。此外,通过对比学习增强分类器在生成和真实数据上的领域泛化能力,间接提高了生成数据对真实数据的表征能力。实验表明方法明显优于现有基线。https://github.com/jinglin-liang/DDDR
十三、虚拟试衣36、Improving Virtual Try-On with Garment-focused Diffusion Models

直接应用扩散模型来合成目标人穿着给定服装的图像,即基于图像虚拟试穿(VTON)任务,并非易事。难点在于扩散过程既要产生目标人物的整体高保真逼真图像,又要局部保留给定服装的每一个外观和纹理细节。
为解决这个问题,塑造一个新的扩散模型GarDiff,以服装为中心扩散过程,同时放大来自给定服装的基本视觉外观和细节纹理(即高频细节)的指导。GarDiff首先用参考服装的CLIP和VAE编码衍生的附加外观先验重新构建了一个预训练的潜在扩散模型。同时,在扩散模型的UNet中集成了一种新颖的以服装为中心的适配器,追求与参考服装的视觉外观和人体姿势的局部细粒度对齐。
在合成服装上特别设计了一个外观损失来增强关键的高频细节。在VITON-HD和DressCode数据集上进行的大量实验表明,与最先进的VTON方法相比,GarDiff具有优势。https://github.com/siqi0905/GarDiff/tree/master
37、D4-VTON: Dynamic Semantics Disentangling for Differential Diffusion based Virtual Try-On

本文介绍一种新解决方案D4-VTON,用于图像虚拟试衣。以前研究中存在的挑战,例如在服装拉伸之前后语义不一致以及对静态、基于标注的服装解析器的依赖。此外,解决扩散基于VTON模型在处理同时执行的任务(如修补和去噪)时遇到的复杂性。
方法利用两项关键技术:第一,动态语义分解模块(DSDMs)从服装中提取抽象语义信息,创建不同的局部流,以自发方式改善准确的服装拉伸。第二,通过整合差分信息跟踪路径(DITP),建立一种新的基于扩散的VTON范式。该路径捕获了不完整试穿输入和完整版本之间的差分信息,使网络能够独立处理多重降解,从而减少学习模糊和实现具有最小开销的实际结果。
实验表明,D4-VTON在定量指标和定性评估方面明显优于现有方法,展示了其在生成逼真图像并确保语义一致性方面的能力。https://github.com/Jerome-Young/D4-VTON
十四、虚拟试鞋38、ShoeModel: Learning to Wear on the User-specified Shoes via Diffusion Model
本文专注于将AIGC技术应用于电子商务营销领域的一个领域,即为展示用户指定的鞋子生成逼真的广告图片。具体而言,提出一种名为ShoeModel的虚拟穿鞋系统,用于生成与给定鞋子互动的人腿的合理图像。
由三个模块组成:(1)鞋可穿戴区检测模块(WD),(2)腿姿势合成模块(LpS)和(3)鞋穿戴图像生成模块(SW)。这三个模块按顺序执行。与基准方法相比,ShoeModel表现出更好地适应不同类型鞋子的能力,并具有保持给定鞋子的ID一致性的能力,以及自动生成与人的合理互动。大量实验展示有效性。
十五、分布外检测39、Diffusion for Out-of-Distribution Detection on Road Scenes and Beyond

近年来,关于语义分割外分布(OoD)检测的研究主要集中在道路场景,这是一个具有受限语义多样性的领域。这项工作挑战这一限制,将此任务领域扩展到一般自然图像。
为此,引入基于ADE20k数据集的ADE-OoD基准,其中包括来自不同领域且具有高语义多样性的图像,以及一种使用扩散分数匹配用于OoD检测(DOoD)的新方法,该方法对增加的语义多样性具有鲁棒性。ADE-OoD包括室内和室外图像,将150个语义类别定义为内分布,并包含各种OoD对象。对于DOoD,在语义内分布嵌入上使用MLP架构训练扩散模型,并建立了基于得分匹配解释的推断时间像素级OoD得分计算方法。
在常见的道路场景OoD基准上,DOoD的性能与或优于最先进的方法,而不使用异常值进行训练或对数据域进行假设。在ADE-OoD上,DOoD优于先前的方法,但在未来改进方面仍有很大空间。https://github.com/lmb-freiburg/diffusion-for-ood
十六、强化学习40、Diffusion Models as Optimizers for Efficient Planning in Offline RL

扩散模型通过将决策制定为顺序生成,已在离线强化学习任务中展现出强大的竞争力。然而,由于它们需要漫长的推理过程,这些方法的实用性受到限制。
本文通过将扩散模型的抽样过程分解为两个解耦的子过程来解决这一问题:1)生成可行轨迹,这是一个耗时的过程;2)优化轨迹。通过这种分解方法,能够部分分离效率和质量因素,从而同时获取效率优势并确保质量保障。提出Trajectory Diffuser,它利用更快的自回归模型处理生成可行轨迹的过程,同时保留扩散模型的轨迹优化过程。这能够实现更高效的规划,而不牺牲能力。
为评估Trajectory Diffuser的有效性和效率,在D4RL基准上进行实验。结果表明比以前的序列建模方法快3-10倍,同时在整体性能方面更优。https://github.com/RenMing-Huang/TrajectoryDiffuser
十七、deepfake41、Contrasting Deepfakes Diffusion via Contrastive Learning and Global-Local Similarities

区分AI方法生成的真实内容和真实内容变得越来越具有挑战性。这促使最近探索了采用基于视觉和语言的基础模型(如CLIP)的解决方案。然而,CLIP嵌入空间被优化用于全局图像到文本的对齐,并不是专门为深度伪造检测而设计的,忽略了定制训练和本地图像特征的潜在好处。
这项研究提出CoDE(对比深伪嵌入),一个专门为深度伪造检测设计的新型嵌入空间。通过对比学习来训练CoDE,另外还要强化全局-局部相似性。为模型训练,生成一个包括使用四种不同生成器产生的920万张图像的全面数据集。实验结果表明,CoDE在新收集的数据集上实现了最先进的准确性,同时还表现出对未知图像生成器的优秀泛化能力。https://github.com/aimagelab/CoDE
42、DiffFAS: Face Anti-Spoofing via Generative Diffusion Models

人脸活体检测/反欺骗(Face anti-spoofing,FAS)在防止人脸识别系统受到表示攻击方面起着至关重要的作用。目前,FAS系统面临着域漂移domain shift的挑战,影响了现有FAS方法的泛化性能。
本文重新思考域移的内在性,并将其解构为两个因素:图像风格和图像质量。质量影响着欺骗信息呈现的纯度,而风格影响着欺骗信息呈现的方式。在此基础上,提出DiffFAS框架,该框架将质量量化为输入到网络中的先验信息来对抗图像质量偏移,并执行基于扩散的高保真跨域和跨攻击类型生成来对抗图像风格偏移。
DiffFAS将易于收集的现场人脸转换为具有精确标签的高保真攻击人脸,同时保持了现场人脸和恶搞人脸身份的一致性,这也可以缓解目前FAS系统所面临的标记数据的稀缺性和新型攻击。展示了框架在挑战跨域和跨攻击FAS数据集上的有效性,实现了最先进的性能。https://github.com/murphytju/DiffFAS
十八、医学图像43、A Diffusion Model for Simulation Ready Coronary Anatomy with Morpho-skeletal Control

虚拟干预(Virtual interventions),使得可以对冠状动脉内进行基于物理的设备部署模拟。这个框架允许通过在不同动脉解剖中部署相同设备来进行反事实推理。然而,目前创建此类反事实动脉的方法面临可控性和真实性之间的权衡。这项研究探讨潜在扩散模型(LDMs)如何根据中级解剖约束(如拓扑有效性、局部形态形状和全局骨骼结构)为虚拟干预研究定制合成冠状动脉。
还将扩散模型指导策略扩展到形态 - 骨骼条件的背景,并提出一种新的引导方法,用于连续属性,该方法在采样过程中自适应更新负向引导条件。框架以可控方式生成和编辑冠状动脉解剖。
44、fMRI-3D: A Comprehensive Dataset for Enhancing fMRI-based 3D Reconstruction

从功能性磁共振成像(fMRI)数据重建3D视觉,对认知神经科学和计算机视觉都具有重要意义。为了推进这一任务,提出 fMRI-3D 数据集,其中包含来自15名参与者的数据,展示了共计 4,768 个3D物体。该数据集包括两个组成部分:fMRI-Shape(https://huggingface.co/datasets/Fudan-fMRI/fMRI-Shape),以及本文提出的 fMRI-Objaverse(https://huggingface.co/datasets/Fudan-fMRI/fMRI-Objaverse)。
fMRI-Objaverse 包括来自5名受试者的数据,其中4名也是 fMRI-Shape 的核心集的一部分,每名受试者观看了来自117个类别的3,142个3D物体,所有物体均附带文本说明。这显著增加了数据集的多样性和潜在应用。此外,提出 MinD-3D,一个新框架,旨在从fMRI信号中解码3D视觉信息。该框架首先利用神经融合编码器从fMRI数据中提取和聚合特征,然后利用特征桥扩散模型生成视觉特征,最后使用生成式transformer解码器重建3D物体。通过设计语义和结构水平的新基准指标评估模型性能,建立了新的基准。
此外,评估了模型在分布外环境中的有效性,并分析了从fMRI信号中提取的特征和视觉 ROIs 的归因。实验表明,MinD-3D 不仅能以高语义和空间精度重建3D物体,还加深对人脑如何处理3D视觉信息的理解。https://jianxgao.github.io/MinD-3D/
45、Co-synthesis of Histopathology Nuclei Image-Label Pairs using a Context-Conditioned Joint Diffusion Model

在多类组织病理细胞核分析任务中,缺乏训练数据成为基于学习的方法性能的主要瓶颈。为解决这一挑战,先前方法用生成模型通过生成合成样本来增加数据。然而,现有方法常常忽视考虑合成数据中生物组织的上下文(例如形状、空间布局和组织类型)的重要性。
此外,虽然生成模型在合成逼真的组织病理学图像方面表现出优越性能,但目前没有任何现有方法能够同时生成图像-标签对。本文引入一个新框架,用上下文条件联合扩散模型来共同合成组织病理细胞核图像和配对语义标签。提出用细胞核质心布局结构相关的文本提示来调节扩散模型,以将空间和结构上下文信息整合到生成目标中。此外,通过同时生成实例级细胞核标签的距离图来增强合成语义标签的细粒度。
框架在生成多机构、多器官和多模态数据集上的高质量样本方面的有效性。合成数据在细胞核分割和分类的下游任务中始终优于现有的增强方法。
十九、超分46、Arbitrary-Scale Video Super-Resolution with Structural and Textural Priors

任意尺度视频超分辨率(Arbitrary-scale video super-resolution,AVSR)旨在提高视频帧的分辨率,可能在各种缩放因子上进行,这提出了关于空间细节再现、时间一致性和计算复杂性的几个挑战。
本文首先描述AVSR的一个强劲基线,将三种基本构建块组合在一起:1)一个由流引导的循环单元,聚合来自先前帧的时空信息,2)一个流精炼的交叉注意力单元,选择来自未来帧的时空信息,3)一个超级采样单元,生成具有规模感知性和内容独立性的上采样核。然后,通过为基线配备从预训练的VGG网络计算得到的多尺度结构和纹理先验,引入了ST-AVSR。这个先验已被证明能有效区分不同位置和尺度上的结构和纹理,这对于AVSR是有益的。
实验表明,ST-AVSR显著提高了超分辨率质量、泛化能力和推断速度,超过了现有技术。https://github.com/shangwei5/ST-AVSR
二十、去模糊47、Rethinking Video Deblurring with Wavelet-Aware Dynamic Transformer and Diffusion Model

目前的视频去模糊方法在恢复高频信息方面存在局限,因为回归损失保守地处理高频细节。由于扩散模型(DMs)在生成高频细节方面具有强大的能力,考虑将扩散模型引入视频去模糊任务中。然而发现直接将扩散模型应用于视频去模糊任务存在以下问题:(1)DMs需要多个迭代步骤从高斯噪声生成视频,这消耗了很多计算资源。(2)DMs很容易被视频中的模糊伪影误导,导致去模糊视频内容的不合理和失真。
为解决上述问题,提出一个新视频去模糊框架VD-Diff,将扩散模型整合到Wavelet-Aware Dynamic Transformer(WADT)中。具体来说,在高度紧凑的潜在空间中执行扩散模型,以生成包含高频信息并符合真实分布的先验特征。设计WADT以保留和恢复视频中的低频信息,同时利用扩散模型生成的高频信息。
实验表明VD-Diff在GoPro、DVD、BSD和真实世界视频数据集上表现优越,远超现有方法。https://github.com/Chen-Rao/VD-Diff
二十一、人像生成48、HumanRefiner: Benchmarking Abnormal Human Generation and Refining with Coarse-to-fine Pose-Reversible Guidance

文生图扩散模型在有条件的图像生成方面取得进展。然而,这些模型通常在准确渲染具有人类特征的图像方面遇到困难,导致肢体等变形和其他生成异常。这个问题主要源于扩散模型在识别和评估肢体质量方面不足。
为了解决这个问题,提出AbHuman,第一个着重于解剖生成异常的大规模合成人类基准。该基准包含56K个合成人类图像,每个图像都用详细的边界框级标签标注,识别了18个不同类别共计147K的人类异常。基于此,可以建立人类异常的识别,进而通过传统技术(如负面提示和引导)改进图像生成。
为进一步提升改进效果,提出HumanRefiner,一个用于粗到精细改进文本到图像生成中人类异常的新型即插即用方法。具体来说,HumanRefiner利用自诊断程序检测和纠正粗粒度异常人体姿势和细粒度异常级别方面的问题,促进姿势可逆扩散生成。对AbHuman基准的实验结果表明,HumanRefiner显著减少了生成差异,肢体质量比开源生成器SDXL提高了2.9倍,比DALL-E 3提高了1.4倍。https://github.com/Enderfga/HumanRefiner
49、IDOL: Unified Dual-Modal Latent Diffusion for Human-Centric Joint Video-Depth Generation

在人类为中心的视频生成方面取得进展,但联合视频深度生成问题仍未得到充分探讨。大多数现有的单目深度估计方法可能无法很好地推广到合成图像或视频,并且基于多视角的方法难以控制人类外观和动作。
这项工作提出用于高质量人类为中心联合视频深度生成的IDOL(unIfied Dual-mOdal Latent diffusion)。IDOL包括两个新设计。首先,为实现双模态生成并最大化视频和深度生成之间的信息交流,提出统一的双模态U-Net,一个参数共享框架用于联合视频和深度去噪,其中模态标签指导了去噪目标,交叉模态注意力实现了信息流动。其次,为确保视频深度的精确空间对齐,提出一个运动一致性损失,强制视频和深度特征运动场之间的一致性,从而产生协调的输出。
此外,应用一个跨注意力映射一致性损失,将视频去噪的跨注意力映射与深度去噪的映射对齐,进一步促进空间对齐。在TikTok和NTU120数据集上的广泛实验显示了卓越表现,超越现有方法在视频FVD和深度准确性方面。https://github.com/yhZhai/idol
二十二、视频生成50、MoVideo: Motion-Aware Video Generation with Diffusion Models

近年来,使用扩散模型进行视频生成取得了巨大进展,但其中大多数方法仅仅是图像生成框架的简单扩展,没有明确考虑视频和图像之间的一个关键区别,即动态。本文提出一种新的基于运动感知的视频生成框架(MoVideo),从两个方面考虑动态:视频深度和光流。前者通过逐帧对象距离和空间布局规范运动,而后者通过描述通过帧对应来保留细节和提高时间一致性。
更具体地,给定一个存在或从文本提示生成的关键帧,首先设计一个具有时空模块的扩散模型来生成视频深度和相应的光流。然后,在另一个空间中模型的指导下,通过深度、基于光流变形的潜在视频和计算的遮挡蒙版生成视频。最后,再次使用光流来对齐和优化不同帧,以更好地从潜在空间解码视频到像素空间。
在文本到视频和图像到视频生成方面的实验中,MoVideo达到了最先进的结果,显示有前途的提示一致性、帧一致性和视觉质量。https://jingyunliang.github.io/MoVideo/
二十三、视图生成51、PanoFree: Tuning-Free Holistic Multi-view Image Generation with Cross-view Self-Guidance

沉浸式场景生成,尤其是全景图的创建,在多视图图像生成方面从大型预训练文本到图像(T2I)模型的适应中受益良多。由于获得多视图图像的成本很高,无需微调的生成更为可取。然而,现有方法要么仅限于简单的对应,要么需要进行广泛的微调才能捕捉复杂的对应。
提出PanoFree,一种用于无需微调的多视图图像生成的新方法,支持广泛的对应。PanoFree使用迭代的扭曲和修复逐步生成多视图图像,解决由于误差累积引起的不一致性和伪影的关键问题,而无需进行微调。通过增强不同视角的感知和通过视图引导、风险区域估计和擦除、对称双向引导生成等提升扭曲和修复过程,改善错误积累。在Planar、360°和全球全景实验中,PanoFree展示出显著的误差减少,提高全局一致性,提升了图像质量,而无需额外微调。
与现有方法相比,PanoFree在时间上更有效率(节省多达5倍时间)和GPU内存使用上更高效(节省多达3倍),并且在结果多样性方面(在用户研究中更好2倍)保持卓越。PanoFree为昂贵的微调或使用额外预训练模型提供了可行的选择。https://github.com/zxcvfd13502/PanoFree
二十四、图像编辑52、COMPOSE: Comprehensive Portrait Shadow Editing

现有的肖像重照明方法在精确控制面部阴影方面存在困难,特别是当面临来自定向光源的强硬阴影或在调整阴影时仍保持与现有照明条件和谐的挑战时。在许多情况下,完全改变输入照明对于肖像修饰应用是不可取的:人们可能希望保留捕获环境的某些真实性。
现有的阴影编辑方法通常将其应用限制仅在脸部区域,通常提供有限的照明控制选项,如阴影软化或旋转。本文介绍COMPOSE:用于人像的新阴影编辑管道,可精确控制阴影属性,例如形状、强度和位置,同时保持肖像的原始环境照明。得益于将环境图表示分解为环境光和可编辑的高斯主光源,得到了这种解耦和可控性水平。
COMPOSE是一个包含光估计和编辑、光扩散、阴影合成和阴影编辑四个阶段的管道。将面部阴影定义为由主光源产生的结果,用新型高斯环境图表示进行编码。利用OLAT数据集,已训练模型来:(1)从图像中预测该光源表示,以及(2)使用该表示生成现实阴影。还通过定量和定性评估展示系统在阴影编辑中的稳健能力。
53、InstructGIE: Towards Generalizable Image Editing

最近的图像编辑方法的泛化能力仍受到限制。为应对这一挑战,引入了一种新的图像编辑框架,通过增强上下文学习能力和统一语言指令来提高泛化鲁棒性。
该框架包括一个专门针对图像编辑任务进行优化的模块,利用VMamba模块和编辑位移匹配策略来增强上下文学习。此外,揭示一个特别设计用于纠正生成图像中的损坏细节(如人脸特征)的选择性区域匹配技术,以进一步提高质量。方法的另一个关键创新是整合语言统一技术,该技术将语言嵌入与编辑语义对齐,提升图像编辑的质量。
此外,编制了第一个用于带有视觉提示和编辑说明的图像编辑的数据集,可用于增强上下文能力。在此数据集上训练,方法不仅在训练任务的合成质量方面表现出色,而且通过定制提示展示了对未知视觉任务的稳健泛化能力。https://github.com/cr8br0ze/InstructGIE-Code
54、LogoSticker: Inserting Logos into Diffusion Models for Customized Generation

文生图模型定制的进展很大程度上局限于广泛常见的目标对象,这些对象可以通过模型充分的共享先验知识相对容易地学习。相反,以独特图案和文本元素为特征的logo很难在扩散模型中建立共享知识。
为弥补这一差距,引入了logo insertion任务。目标是将logo插入扩散模型,并使其在不同的环境中无缝合成。提出LogoSticker来解决这个问题。
首先,提出了行动者-评论家关系预训练算法,解决模型在理解logo的潜在空间定位和与其他对象的交互方面的重要差距。其次,提出一种解耦的logo特征学习算法,实现logo的精确定位和特征提取。
LogoSticker可以在不同的语境下准确和谐地生成logo。全面验证了LogoSticker在定制方法和大型模型(如DALLE 3)上的有效性。https://mingkangz.github.io/logosticker/
55、Photorealistic Object Insertion with Diffusion-Guided Inverse Rendering

对真实场景图像中虚拟对象的正确插入需要深入理解场景的光照、几何和材质以及图像形成过程。尽管最近的大规模扩散模型展示出强大的生成和修补能力,但当前模型不足以在单个图片中足够“理解”场景以生成一致的光照效果(阴影、明亮反射等),同时保留合成对象的身份和细节。
提出使用个性化的大规模扩散模型作为物理反渲染过程的指导。方法恢复场景光照和色调映射参数,允许在室内或室外场景的单帧或视频中逼真地组合任意虚拟对象。基于物理的流水线进一步实现了自动材质和色调映射的细化。https://research.nvidia.com/labs/toronto-ai/DiPIR/
56、RegionDrag: Fast Region-Based Image Editing with Diffusion Models

基于点拖动的图像编辑方法,如DragDiffusion,吸引了相当多的关注。然而,点拖动方法存在计算开销大和对用户意图的错误解释问题,这是由于基于点的编辑指令的稀疏性所致。
本文提出一种基于区域的复制粘贴拖动方法RegionDrag,以克服这些局限性。RegionDrag允许用户以处理和目标区域的形式表达其编辑指令,实现更精确的控制并减轻歧义。此外,基于区域的操作可以在一次迭代中完成编辑,比基于点拖动的方法要快得多。
还结合了注意力交换技术,以提高编辑过程的稳定性。为验证方法,用基于区域拖动指令扩展了现有的基于点拖动的数据集。实验证明,RegionDrag在速度、准确性和与用户意图的一致性方面优于现有的基于点拖动的方法。值得注意的是,RegionDrag在512×512分辨率的图像上完成编辑的时间少于2秒,比DragDiffusion快100多倍,并且表现更好。https://github.com/Visual-AI/RegionDrag
57、TurboEdit: Instant text-based image editing

本文在少步扩散模型的背景下解决了精确图像inversion和解耦图像编辑的挑战。引入了一种基于编码器的迭代inversion技术。inversion网络以输入图像和上一步重建图像为条件,允许纠正下一个重建朝向输入图像。演示了在少步扩散模型中如何通过条件生成(自动生成的)详细文本提示轻松实现解耦控制。
为了操纵inversion图像,固定噪声图并修改文本提示中的一个属性(手动或通过基于LLM驱动的指令编辑),产生一个类似于输入图像但只改变一个属性的新图像。它还可以进一步控制编辑强度并接受指导性文本提示。方法实现了实时逼真的基于文本引导的图像编辑,不仅速度快,而且在多步扩散编辑技术上明显优于现有技术。
二十五、图像分割58、Exploring Phrase-Level Grounding with Text-to-Image Diffusion Model

最近,扩散模型在视觉理解上表现出越来越强大的能力。通过利用基于提示的学习构建句子,这些模型在分类和视觉grounding任务中展示了出色的能力。然而,现有方法主要展示了它们执行句子级定位的能力,而未充分探索利用语境信息进行短语级理解的潜力。
本文利用Panoptic Narrative Grounding(PNG)作为代理任务进一步研究这一能力。PNG旨在根据给定文本中提到的多个名词短语来分割物体实例。具体来说,DiffPNG框架充分利用扩散体系结构通过将过程分解为一系列定位、分割和细化步骤来进行分割。该框架首先使用交叉注意机制识别锚点,随后利用自注意进行分割以实现零样本PNG。此外,引入了一个基于SAM的细化模块,以提高分割质量。
在PNG数据集上进行的大量实验表明,DiffPNG在零样本PNG任务设置中取得了强大的表现,从而确切证明了扩散模型在具有上下文感知的短语级理解方面的能力。https://github.com/nini0919/DiffPNG
二十六、图像组合59、Training-free Composite Scene Generation for Layout-to-Image Synthesis

文本到图像扩散模型的突破已显著推动了从文本描述生成高保真、逼真图像的进展。然而这些模型难以从文本中解释空间布局,从而阻碍了它们生成具有精确空间配置的图像的能力。
为弥合这一差距,布局到图像生成已经成为一个有前途的方向。然而,基于训练的方法受限于对大量标注数据集的需求,导致了高昂的数据获取成本和局限性概念范围。相反,基于无训练的方法面临着在复杂构图中准确定位和生成语义相似对象的挑战。
本文介绍了一种新的无训练方法,旨在在扩散条件化阶段解决对抗语义交叉。通过利用选择性采样改进intra-token loss,以及通过关注力重新分配增强扩散过程,提出两个新约束:1) 解决token之间冲突的inter-token约束,以确保准确的概念合成;和2) 改善像素到像素关系的自注意约束。
评估证实了利用布局信息指导扩散过程的有效性,生成内容丰富、具有增强保真度和复杂性的图像。https://github.com/Papple-F/csg
二十七、异常检测60、R3D-AD: Reconstruction via Diffusion for 3D Anomaly Detection

在精密制造中,3D异常检测在监测零部件的局部固有缺陷中起着至关重要的作用。基于嵌入和基于重建的方法是最流行和最成功的方法之一。然而,当前方法的实际应用存在两个主要挑战:1)嵌入模型由于内存结构而遭受严重的计算和存储限制;2)基于MAE机制的重建模型无法检测未掩盖区域中的异常。
本文提出R3D-AD,用扩散模型重建异常点云进行精准的3D异常检测。方法利用扩散过程的数据分布转换来完全模糊输入的异常几何结构。它逐步学习严格的点级位移行为,系统地纠正异常点。为增加模型的泛化能力,进一步提出一种名为Patch-Gen的新的3D异常模拟策略,生成逼真且多样的缺陷形状,减小了训练和测试之间的领域差距。
R3D-AD确保均匀的空间变换,通过距离比较直接生成异常结果。大量实验证明,R3D-AD胜过先前现有的最先进方法,在Real3D-AD数据集上实现了73.4%的图像级AUROC,以及在Anomaly-ShapeNet数据集上实现了74.9%的图像级AUROC,并具有异常的出色效率。https://zhouzheyuan.github.io/r3d-ad
61、TransFusion – A Transparency-Based Diffusion Model for Anomaly Detection

在制造检查中,表面异常检测是一个至关重要的组成部分。当前的判别方法采用了由重构网络和依赖重构输出的判别网络组成的两阶段体系。目前使用的重建网络经常产生质量较差的重建,要么仍然包含异常,要么在无异常区域缺乏细节。判别方法对于一些重建网络失败都是健壮的,这表明判别网络学习到了重构网络忽略的强正常外观信号。
本文将两阶段架构重新构造为允许重建和定位之间信息交换的单阶段迭代流程。提出了一种新的基于透明度的扩散过程,其中异类区域的透明度逐步增加,准确恢复其正常外观,同时利用先前步骤的局部线索保持无异常区域的外观。将所提出的过程实现为TRANSparency DifFUSION(TransFusion),一种新的判别性异常检测方法,在VisA和MVTec AD数据集上均取得了最先进的性能,分别为98.5%和99.2%的图像级AUROC。https://github.com/MaticFuc/ECCV_TransFusion
二十八、字体生成62、One-DM: One-Shot Diffusion Mimicker for Handwritten Text Generation

现有的手写文本生成方法,通常需要超过十个手写样本作为样式参考。然而,在实际应用中,用户倾向于更喜欢仅使用单个参考样本操作的手写生成模型,因其便利性和高效性。这种被称为“单样本生成”的方法极大简化了流程,但由于从单个样本准确捕捉写手风格的困难性,尤其是在提取字符边缘的细节时,面对稀疏前景和不必要背景噪音。
为解决这个问题,提出一种单样本生成模拟扩散器(One-DM),以仅一个参考样本生成可以模仿任何书法风格的手写文本。受到个别样本的高频信息通常包含独特的风格模式(例如,字符倾斜和字母连接),开发一个新的风格增强模块,通过合并单个样本的高频成分来改进风格提取。然后,将风格特征与文本内容融合为扩散模型的融合条件,以引导生成高质量的手写文本图像。
实验表明方法可成功生成多种语言的手写脚本,甚至在使用超过十个样本的先前方法的情况下也可以胜过这些方法。https://github.com/dailenson/One-DM
63、Kinetic Typography Diffusion Model

本文介绍一种用于生成用户喜爱的可动态排版的“文本内容”的逼真动态排版方法。借鉴最新的引导视频扩散模型的进展,以实现视觉上令人愉悦的文本外观。
为此,首先构建了一个动态排版数据集,包括约60万个视频。数据集由专业动态图形设计师设计的584个模板的各种组合组成,并涉及更改每个字母的位置、字形和大小(例如,飞行、毛刺、色差、反射效果等)。接下来,为动态排版提出了一个视频扩散模型。为此,有三个要求:美学外观、动态效果和可读文本。本文确定这些要求。为此,提出用作视频扩散模型的空间和时间指导的静态和动态字幕。静态字幕描述视频的整体外观,如颜色、纹理和字形,代表每个字母的形状。动态字幕考虑字母和背景的移动。通过零卷积增加了一种额外的指导,以确定视频中应该可见哪些文本内容。将零卷积应用于文本内容,并将其施加在扩散模型上。最后,字形损失仅最小化预测文字与实际文字间的差异,以使预测的文字可读。
实验证明模型根据文本提示生成具有可读性和艺术性的动态排版视频。https://github.com/SeonmiP/KineTy
二十九、3D64、3DEgo: 3D Editing on the Go!

提出3DEgo,解决一个新问题,即通过文本提示指导从单目视频直接合成逼真的3D场景。传统方法通过一个三阶段过程构建一个文本条件的3D场景,涉及使用诸如COLMAP的Structure-from-Motion(SfM)库进行姿态估计,使用未编辑的图像初始化3D模型,并通过迭代地使用编辑后的图像更新数据集,以实现文本保真度的3D场景。
通过克服对COLMAP的依赖和消除模型初始化的成本,将传统的多阶段3D编辑过程简化为单阶段工作流程。采用扩散模型在创建3D场景之前编辑视频帧,包括设计的噪声融合模块,以增强多视图编辑的一致性,这一步骤不需要额外训练或微调T2I扩散模型。3DEgo利用3D高斯扩散来从多视角一致的编辑帧创建3D场景,利用固有的时间连续性和显式点云数据。
3DEgo在各种视频来源上的编辑精度、速度和适应性,通过对六个数据集进行全面评估来验证,包括自建的GS25数据集。https://3dego.github.io/
65、COIN: Control-Inpainting Diffusion Prior for Human and Camera Motion Estimation

从移动相机中估计全局人类运动,由于人类运动和相机运动的耦合而具有挑战性。为减轻这种模糊,现有方法利用学习的人类运动先验,然而这经常导致运动过度平滑和不对齐的2D投影。为解决这一问题,提出COIN,一种控制-修补运动扩散先验,使得可以对人类和相机运动进行细粒度控制以解耦。
尽管预训练的运动扩散模型编码了丰富的运动先验,但难以利用此类知识来指导从RGB视频中对全局运动的估计。COIN引入一种新的控制-修补评分蒸馏抽样方法,以确保扩散先验中的控制-修补分数对齐、一致和高质量,同时在一个联合优化框架中。此外引入一个新的人类-场景关系损失,通过在人类、相机和场景之间强制一致性,减轻尺度模糊。
针对三个具有挑战性的基准测试,实验证明COIN有效性,在全局人类运动估计和相机运动估计方面优于最先进方法。https://nvlabs.github.io/COIN/
66、Diff3DETR: Agent-based Diffusion Model for Semi-supervised 3D Object Detection

三维物体检测对于理解三维场景至关重要。通常需要大量标注的训练数据,然而为点云获取逐点标注是耗时且劳动密集的。最近半监督方法通过用教师-学生框架为未标注的点云生成伪标签来缓解这一问题。然而,这些伪标签经常缺乏足够的多样性和较低质量。
为了克服这些障碍,引入一种基于代理的半监督三维物体检测模型(Diff3DETR)。具体来说,设计一个基于代理对象的查询生成器,用于生成能够有效适应动态场景的对象查询,同时在采样位置与内容嵌入之间取得平衡。此外,一个基于框的去噪模块利用了DDIM去噪过程和transformer解码器中的远程注意力,逐步精化边界框。
在ScanNet和SUN RGB-D数据集上进行的广泛实验表明,Diff3DETR优于现有半监督三维物体检测方法。
67、DiffSurf: A Transformer-based Diffusion Model for Generating and Reconstructing 3D Surfaces in Pose

本文提出DiffSurf,基于transformer的去噪扩散模型,用于生成和重建三维表面。具体来说,设计了一个扩散transformer架构,用于从嘈杂的三维表面顶点和法线预测噪声。借助这种架构,DiffSurf能够生成各种姿势和形状的三维表面,例如人体、手部、动物和人造物体。
此外,DiffSurf具有通用性,可以解决包括变形、体形变化和将三维人体网格拟合到二维关键点在内的各种三维下游任务。在三维人体模型基准上的实验结果表明,DiffSurf可以生成具有更大多样性和更高质量的形状,优于先前的生成模型。此外,当应用于单图像三维人体网格恢复任务时,DiffSurf以接近实时的速率达到可与先前技术相媲美的精度。https://github.com/yusukey03012/DiffSurf
68、CloudFixer: Test-Time Adaptation for 3D Point Clouds via Diffusion-Guided Geometric Transformation

由于各种障碍(如遮挡、有限分辨率和尺度变化)导致的实际传感器捕获的3D点云经常包含嘈杂点。虽然在 2D 领域中的测试时适应(TTA)策略已经在该问题上显示出有希望的结果,但是将这些方法应用于 3D 点云的情况仍未得到充分探讨。
在 TTA 方法中,一种输入适应方法直接将测试实例通过预训练扩散模型转换为源领域,在 2D 领域已被提出。尽管在实际情况下其对 TTA 的性能表现鲁棒,但是简单地将其应用到 3D 领域可能并不是最佳选择,因为忽略了点云的固有特性,以及其高昂的计算成本。
受到这些限制的启发,提出CloudFixer,一种专为 3D 点云量身定制的测试时输入适应方法,采用预训练扩散模型。具体来说,CloudFixer 通过优化几何转换参数,利用点云的几何属性精心设计的目标来提高计算效率。此外,通过避免通过扩散模型进行反向传播和耗时的生成过程,显著提高计算效率。此外,提出了一个在线模型适应策略,通过将原始模型预测与经过调整的输入的预测进行对齐。实验展示 CloudFixer 在各种 TTA 基线上的优越性。https://github.com/shimazing/CloudFixer
69、DreamDissector: Learning Disentangled Text-to-3D Generation from 2D Diffusion Priors

最近,文本到三维生成取得显著进展。为增强其在现实应用中的实用性,关键是生成具有相互作用的多个独立对象,类似于2D图像编辑中的图层合成。然而,现有的文本到三维方法在这一任务上存在困难,因为它们旨在生成非独立对象或缺乏空间合理互动的独立对象。
为解决这个问题,提出DreamDissector,一种能够生成具有交互作用的多个独立对象的文本到三维方法。DreamDissector接受一个多对象文本到三维NeRF作为输入,并生成独立的有纹理的网格。为实现这一点,引入神经类别场(NeCF)来解耦输入NeRF。此外,提出Category Score Distillation Sampling (CSDS),通过深度概念挖掘(DCM)模块实现,以解决扩散模型中的概念差距问题。通过利用NeCF和CSDS,可有效从原始场景中导出子NeRF。进一步细化增强几何和纹理。
70、DreamMesh: Jointly Manipulating and Texturing Triangle Meshes for Text-to-3D Generation

用强大的2D扩散模型学习Radiance Fields(NeRF)在文本到3D生成方面变得流行起来。然而,NeRF的隐式3D表示缺乏对网格和表面上的纹理的显式建模,这种表面未定义的方式可能会导致问题,例如具有模糊纹理细节或交叉视图不一致的嘈杂表面。
为缓解这一问题,提出DreamMesh,一种新的文本到3D架构,侧重于定义良好的表面来生成高保真的显式3D模型。在技术上,DreamMesh利用独特的由粗到精的方案。实验证明,DreamMesh在忠实生成具有更丰富文本细节和增强几何的3D内容方面明显优于当前文本到3D方法。https://dreammesh.github.io/
71、JointDreamer: Ensuring Geometry Consistency and Text Congruence in Text-to-3D Generation via Joint Score Distillation

经过良好训练的2D扩散模型在文本到三维生成中显示出巨大潜力。然而,这种范式将视角不可知的2D图像分布蒸馏为每个视角独立的3D表示的渲染分布,忽略了视角之间的一致性,导致生成中的3D不一致性。
本文提出Joint Score Distillation (JSD),一个确保一致3D生成的新范式。具体而言,建立了联合图像分布,引入能量函数来捕捉扩散模型中去噪图像之间的一致性。然后,在渲染的多个视角上推导联合分数蒸馏,而不是SDS中的单个视角。此外,实例化了三个通用的视角感知模型作为能量函数,展示了与JSD的兼容性。从经验上看,JSD明显缓解了SDS中的3D不一致性问题,同时保持文本的一致性。
JointDreamer在文本到三维生成中建立了一个新的基准,具有88.5%的CLIP R-Precision和27.7%的CLIP分数。https://jointdreamer.github.io/
72、Length-Aware Motion Synthesis via Latent Diffusion

合成人类动作的目标持续时间是一个关键属性,需要对动作动态和风格进行建模控制。加快动作表现并不仅仅是加速它。然而,针对人类行为合成的现有技术在目标序列长度控制上存在局限。
从文本描述生成长度感知的3D人体运动序列的问题,提出一个新的模型来生成可变目标长度的动作,将其称为“Length-Aware Latent Diffusion”(LADiff)。LADiff包括两个新模块:1)一个长度感知变分自编码器,用于学习具有长度相关潜在码的运动表示;2)一个符合长度的潜在扩散模型,用于生成随着所需目标序列长度增加而增加细节丰富度的动作。在HumanML3D和KIT-ML两个建立的动作合成基准上,LADiff在大多数现有动作合成指标上显著优于现有技术。https://github.com/AlessioSam/LADiff
73、Local Action-Guided Motion Diffusion Model for Text-to-Motion Generation

文本到动作生成,不仅需要将局部动作与语言进行基础接触,还需要无缝地融合这些个别动作来综合多样且逼真的整体动作。然而,现有的动作生成方法主要集中于直接合成全局动作,却忽视了生成和控制局部动作的重要性。
本文提出局部动作引导的动作扩散模型,通过利用局部动作作为细粒度控制信号促进全局动作生成。具体而言,提供一种自动化的参考局部动作采样方法,并利用图注意力网络评估每个局部动作在整体动作合成中的引导权重。在合成全局动作的扩散过程中,计算局部动作梯度以提供条件指导。这种由局部到全局的范式减少了直接全局动作生成所带来的复杂性,并通过采样多样动作作为条件促进动作多样性。
在两个人类动作数据集(HumanML3D 和 KIT)上进行的大量实验表明了我们方法的有效性。此外,方法提供了在无缝组合各种局部动作和连续引导权重调整方面的灵活性,适应了各种用户偏好,可能对社区具有潜在的重要意义。https://jpthu17.github.io/GuidedMotion-project/
74、MonoWAD: Weather-Adaptive Diffusion Model for Robust Monocular 3D Object Detection

单目三维物体检测,是自动驾驶中一项重要而具有挑战性的任务。现有方法主要集中在理想天气条件下进行3D检测,这些情景具有清晰和最佳的可见性。然而,自动驾驶的挑战在于需要处理天气条件的变化,如有雾的天气,而不仅仅是晴天。
引入MonoWAD,一个具有天气自适应扩散模型的新型抗天气单目3D物体检测器。它包含两个组件:(1)天气codebook用于记忆晴天的知识并为任意输入生成一个天气参考特征,以及(2)天气自适应扩散模型,通过整合一个天气参考特征来增强输入特征的表示。这在指示根据天气条件需要对输入特征进行多少改进方面起着注意力作用。为了实现这一目标,引入了天气自适应增强损失,以增强特征在晴天和有雾天气条件下的表示。在各种天气条件下的大量实验表明,MonoWAD实现了抗天气的单目3D物体检测。https://github.com/VisualAIKHU/MonoWAD
75、NL2Contact: Natural Language Guided 3D Hand-Object Contact Modeling withDiffusion Model

对于调整不准确的手部姿势并生成三维手-物体重建中的新型人类抓取,建模手部与物体之间的物理接触是标准的。然而,现有方法依赖于无法指定或控制的几何约束。本文引入了一种新的可控3D手-物体接触建模任务与自然语言描述。挑战包括:i)从语言到接触的跨模态建模复杂性,以及ii)缺乏用于接触模式的描述性文本。
为解决这些问题,提出NL2Contact,一个通过利用分层扩散模型生成可控接触的模型。给定手部和接触的语言描述,NL2Contact生成逼真和忠实的3D手-物体接触。为训练模型,构建 ContactDescribe,这是第一个带有以手为中心的接触描述的数据集。它包含由基于精心设计的提示(如抓取动作、抓取类型、接触位置、自由手指状态)的大型语言模型生成的多层次且多样化的描述。展示了模型在抓取姿势优化和新型人类抓取生成方面的应用,这两者都基于文本接触描述。
76、NVS-Adapter: Plug-and-Play Novel View Synthesis from a Single Image

最近关于单一图像的新视角合成(NVS)已经通过利用预训练文本到图像(T2I)模型的生成能力取得令人印象深刻的结果。然而,先前NVS方法需要额外优化才能使用其他即插即用的图像生成模块,如ControlNet和LoRA,因为它们微调了T2I参数。
本研究提出一个高效的即插即用适配模块 NVS-Adapter,它与现有的即插即用模块兼容而无需进行大量微调。引入目标视图和参考视图对齐,以提高多视角预测的几何一致性。实验结果表明NVS-Adapter与现有即插即用模块兼容。此外,尽管没有对预训练的T2I模型的数十亿参数进行微调,NVS-Adapter在NVS基准测试中表现优越。https://postech-cvlab.github.io/nvsadapter/
77、Open-Vocabulary 3D Semantic Segmentation with Text-to-Image Diffusion Models
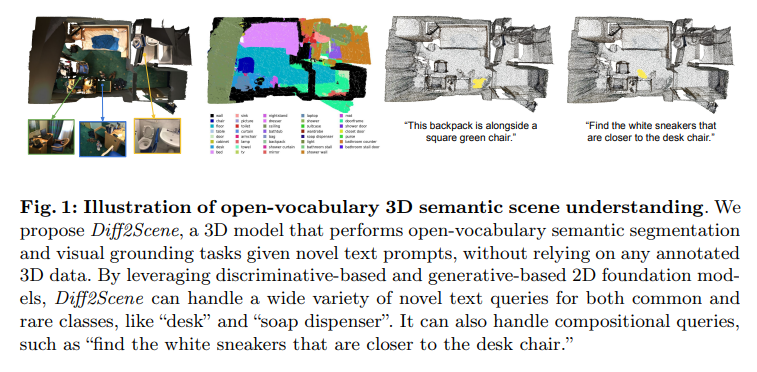
这篇论文研究预先在大规模图像-文本对上进行预训练的扩散模型在开放词汇三维语义理解中的使用。提出一种新方法,即 Diff2Scene,利用文本-图像生成模型的冻结表示以及敏锐感知和几何感知蒙版,用于开放词汇三维语义细分和视觉定位任务。
Diff2Scene 摆脱了任何标注的3D数据,并有效识别了三维场景中的对象、外观、材料、位置及其组合。展示它优于竞争基线,并且较现有的方法取得了显著提升。特别是,在 ScanNet200 数据集上,Diff2Scene 将现有方法的准确率提高了12%。
78、Realistic Human Motion Generation with Cross-Diffusion Models

这项工作介绍一种基于文本描述生成高质量人类动作的 Cross Human Motion Diffusion Model(CrossDiff3)。方法在扩散模型的训练中使用共享transformer整合了3D和2D信息,将运动噪音统一到一个特征空间中。这使得 CrossDiff 能够将特征解码为3D和2D运动表示,不管它们的原始维度如何。
CrossDiff 的主要优势在于其交叉扩散机制,允许模型在训练期间将2D或3D噪音反转为干净的运动。这种能力利用了两种运动表示中的互补信息,捕捉了仅仅依赖3D信息的模型常常错过的复杂人体运动细节。因此,CrossDiff 有效地结合了这两种表示的优势,生成更加逼真的运动序列。
在实验中,模型展示了竞争性的最先进性能,适用于文本到动作基准。此外,方法始终提供增强的运动生成质量,捕捉复杂全身运动细节。方法还适应使用在野外收集的2D运动数据而不需3D运动地面真相进行训练来生成3D运动,突显了其更广泛应用的潜力以及对现有数据资源的高效利用。https://wonderno.github.io/CrossDiff-webpage/
79、SMooDi: Stylized Motion Diffusion Model

引入一种新风格化运动扩散模型,名为 SMooDi,用于根据内容文字和风格运动序列生成风格化运动。与现有方法不同,现有方法要么生成多样内容的运动,要么从一个序列转移风格到另一个序列,SMooDi 可以快速地生成跨多样内容和不同风格的运动。
为此,为风格定制了一个预训练文本到动作模型。具体而言,提出风格引导来确保生成的动作与参考风格密切匹配,同时还提出了一个轻量级风格适配器,将运动引导到所需的风格,同时确保逼真性。在各种应用程序中的实验表明,框架在风格化运动生成方面优于现有方法。https://neu-vi.github.io/SMooDi/
80、TexGen: Text-Guided 3D Texture Generation with Multi-view Sampling and Resampling

给定3D mesh,如何生成对应文本描述的3D纹理外观?本文提出TexGen,一个全新的多视图抽样和重新抽样框架,用于纹理生成,利用预训练的文本到图像扩散模型。为解决这些问题,提出一种关注引导的多视图抽样策略,以在视图之间广播外观信息。为保留纹理细节,开发一种噪声重新抽样技术,用于估算噪声,生成用于后续去噪步骤的输入,由文本提示和当前纹理地图指导。
通过大量的定性和定量评估,展示了方法为具有高度视图一致性和丰富外观细节的各种3D对象产生了更好的纹理质量,优于当前最先进的方法。此外,提出的纹理生成技术还可以应用于保留原始身份的纹理编辑。https://dong-huo.github.io/TexGen/
81、Connecting Consistency Distillation to Score Distillation for Text-to-3D Generation

尽管最近文本到3D生成的质量已有提高,细节级别问题和低保真度仍然存在,需进一步改进。为理解这些问题本质,通过将一致性蒸馏理论连接到评分蒸馏,对当前的评分蒸馏方法进行了彻底分析。基于通过分析获得的见解,提出一个优化框架,引导一致性抽样(GCS),并结合3DGS以减轻这些问题。
此外,观察到生成的3D资产渲染视图中持续存在的过度饱和现象。通过实验,发现这是由于在优化过程中3DGS中不必要的累积亮度引起的。为减轻这一问题,在3DGS渲染中引入了一种亮度均衡生成(BEG)方案。实验结果表明,方法生成了更多细节和更高保真度的3D资产,优于目前最先进的方法。https://github.com/LMozart/ECCV2024-GCS-BEG
82、TPA3D: Triplane Attention for Fast Text-to-3D Generation

由于缺乏大规模文本-3D对应数据,最近的文本到3D生成方法主要依赖于利用2D扩散模型合成3D数据。由于基于扩散的方法通常需要大量的优化时间进行训练和推断,因此仍希望使用基于GAN的模型进行快速3D生成。
这项工作提出Triplane Attention用于文本引导的3D生成(TPA3D),一个端到端可训练的基于GAN的深度学习模型,用于快速文本到3D生成。通过训练观察的仅为3D形状数据及其渲染的2D图像,TPA3D旨在检索详细的视觉描述,以合成相应的3D网格数据。这是通过在提取的句子和词级文本特征上提出的注意机制实现的。
实验展示了TPA3D生成与精细描述对齐的高质量3D纹理形状,同时还能观察到令人印象深刻的计算效率。
83、Transferable 3D Adversarial Shape Completion using Diffusion Models

最近的研究将几何特征和transformers纳入3D点云特征学习中,显著提高3D深度学习模型的性能。然而,它们对抗性攻击的韧性尚未得到彻底探索。现有的攻击方法主要集中在白盒场景,很难迁移到最近提出的3D深度学习模型。更糟糕的是,这些攻击引入了对3D坐标的扰动,生成不太现实的对抗性示例,并导致对3D对抗性防御的性能不佳。
为增强攻击的可转移性,深入研究3D点云的特征并利用模型的不确定性来更好地推断通过对点云进行随机降采样实现模型分类的不确定性。采用集成对抗引导的方法,以改善跨不同网络架构的可转移性。为了保持生成质量,仅针对点云的关键点采用对抗引导,通过计算显著性分数。
大量实验证明,提出的攻击方法在黑盒模型和防御方面优于最先进的对抗攻击方法。黑盒攻击为评估各种3D点云分类模型的韧性建立了一个新的基准。
84、VividDreamer: Invariant Score Distillation For Hyper-Realistic Text-to-3D Generation

本文介绍不变分数蒸馏(ISD),一种用于高保真度文本到3D生成的新方法。ISD旨在解决得分蒸馏抽样(SDS)中的过度饱和和过度平滑问题。通过将SDS拆分为两个组件的加权和以此来解决这些问题。实验发现,过度饱和源于大的无分类器引导比例,过度平滑来自重构项。
为克服这些问题,ISD利用从DDIM抽样中派生的不变分数项来替代SDS中的重构项。这个操作允许利用一个中等的无分类器引导比例,并减轻与重构相关的错误,从而防止结果的过度平滑和过度饱和。
大量实验证明,方法极大地增强了SDS,并通过单阶优化产生了现实的3D物体。https://github.com/SupstarZh/VividDreamer
三十、风格迁移85、StyleTokenizer: Defining Image Style by a Single Instance for Controlling Diffusion Models

尽管控制扩散过程的新方法不断涌现,但在文生图中有效控制图像风格仍是一项具有挑战性的任务。许多基于适配器的方法在去噪过程中对图像表示条件进行约束,以实现图像控制。然而这些条件与词嵌入空间不对齐,导致图像和文本控制条件之间的干扰,可能会导致来自文本提示的语义信息丢失。
解决这个问题涉及两个关键挑战。首先,如何在不影响控制中文本表示的有效性的情况下注入风格表示。其次,如何从单个参考图像中获取准确的风格表示。为解决这些挑战,引入 StyleTokenizer,一种零样本风格控制图像生成方法,用风格tokenizer将风格样式表示与文本表示对齐。这种对齐有效地减小了对文本提示有效性的影响。
此外,收集了一个名为 Style30k 的标注好的风格数据集,训练一个能够准确表示风格的特征提取器,同时排除其他内容信息。实验结果表明,方法把握了参考图像的风格特征,生成与目标图像风格和文本提示一致且吸引人的图像。https://github.com/alipay/style-tokenizer
三十一、图像插值86、DreamMover: Leveraging the Prior of Diffusion Models for Image Interpolation with Large Motion
研究从带有大运动的图像对生成中间图像的问题,同时保持语义一致性。由于存在大运动,输入图像中可能缺少中间语义信息。现有方法要么局限于小运动,要么专注于拓扑相似的对象,导致内插结果中出现伪像和不一致性。
为克服这一挑战,深入研究预训练的图像扩散模型,因为它们在语义认知和表示方面具有优势,确保了与输入的缺失中间语义表示的一致表达。因此提出DreamMover,一个新的图像插值框架,具有三个主要组件:1)基于扩散模型的自然流估计器,可以隐式推理出两个图像之间的语义对应关系。2)为避免在融合过程中丢失详细信息,关键思路是在高级空间和低级空间中的两部分融合信息。3)为增强生成图像与输入之间的一致性,提出自注意力串联和替换方法。
最后提出一个具有挑战性的基准数据集InterpBench,用于评估生成结果的语义一致性。https://dreamm0ver.github.io/
#Neural Network Diffusion
由新加坡国立大学尤洋团队、加州大学伯克利分校以及Meta AI Research联手发布的一项名为“Neural Network Diffusion”的研究,已经实现了利用扩散模型来生成神经网络,这意味着扩散模型不再局限于生成表面的产品或物体结构,而是直接进行底层革新,开始拿神经网络做文章了,颇有种用魔法来打败魔法的意味。
Neural Network Diffusion,开始用魔法打败魔法了。如果你有被 Sora 生成的视频震撼到,那你就已经见识过扩散模型在视觉生成方面的巨大潜力。当然,扩散模型的潜力并不止步于此,它在许多其它不同领域也有着让人期待的应用前景
- 论文地址:https://arxiv.org/pdf/2402.13144.pdf
- 项目地址:https://github.com/NUS-HPC-AI-Lab/Neural-Network-Diffusion
- 论文标题:Neural Network Diffusion
这样一来,似乎就可以使用现有的神经网络来轻松生成新的神经网络了!这一点让 Yann LeCun 也忍不住点赞分享。不仅如此,生成的模型的性能表现甚至还能超越原始模型。
扩散模型的起源可以追溯到非平衡热力学。2015 年时,Jascha Sohl-Dickstein 等在论文《Deep Unsupervised Learning using Nonequilibrium Thermodynamics》中最早使用扩散过程来渐进式地移除输入中的噪声,进而生成清晰的图像。
说起扩散模型生成的东西,你会立刻想到什么?
是OpenAI的经典牛油果椅子?

是英伟达Magic3D生成的蓝色箭毒蛙?

还是斯坦福大学和微软Folding Diffusion生成的蛋白质结构?
这些都是扩散模型的魔法展示,而近期,关于扩散模型的研究又进行了一次全新的升级。
由新加坡国立大学尤洋团队、加州大学伯克利分校以及Meta AI Research联手发布的一项名为“Neural Network Diffusion”的研究,已经实现了利用扩散模型来生成神经网络,这意味着扩散模型不再局限于生成表面的产品或物体结构,而是直接进行底层革新,开始拿神经网络做文章了,颇有种用魔法来打败魔法的意味。
论文地址:https://arxiv.org/pdf/2402.13144.pdf
该研究一出,迅速在国际AI社区引起了热烈反响,登上了各大模型开发平台的热搜榜单,在业界内收获了极高赞誉。
这项工作中,研究团队创新性地应用扩散模型来生成高性能神经网络的参数配置。他们结合了自动编码器框架和标准潜在扩散模型(LDM)设计了一种新颖的方法,即“参数扩散”(p-diff),通过训练LDM从随机噪声中合成有效的神经网络参数latent representations。
此方法具有以下特点:1)它始终达到与训练数据相似的性能,甚至能在多数据集和架构中增强性能;2)生成的模型与训练的模型有很大的不同,这表明此方法可以合成新参数,而不是记忆训练样本。
1 扩散模型如何生成“神经网络”?
尽管扩散模型已经在视觉内容生成任务上取得了显著成就,然而在其他众多领域的应用潜力仍有待深入挖掘。
在此之前,学术界和工业界的研究重心主要在于如何通过传统的学习策略来获得针对特定任务表现优异的神经网络参数,而不是直接利用扩散模型进行参数生成。学者们普遍从统计学先验和概率模型的角度出发,例如探索随机神经网络架构及贝叶斯神经网络方法,以优化模型性能。
而在深度学习这个大框架下,虽然监督学习和自监督学习一直是训练神经网络的核心机制,并且在很多实际应用中取得了巨大成功。但为了更好地展示扩散模型在生成高效能模型架构与参数方面的卓越能力,研究团队大胆地将目光投向了尚未被充分探索的领域,尝试利用扩散模型来创造并优化高性能、结构新颖的神经网络参数。
简而言之,“Neural Network Diffusion”项目所采用的是一种名为“神经网络扩散”的方法(p-diff,p代表参数),使用标准的LDM来合成新参数。
该团队经过深入研究神经网络的训练机制以及扩散模型的工作原理后,敏锐地洞察到:基于扩散原理的图像生成过程与随机梯度下降(SGD)等常用学习方法之间存在着两种相似性。这意味着扩散模型或许能够借鉴并革新现有的训练范式,从而为构建更加智能且高效的神经网络提供新的视角与工具。
首先,神经网络训练和扩散模型的逆过程都可以被视为从随机噪声/初始化到特定分布的转变。其次,高质量图像和高性能参数也可以通过多次噪声的添加来降级为简单分布,例如高斯分布。
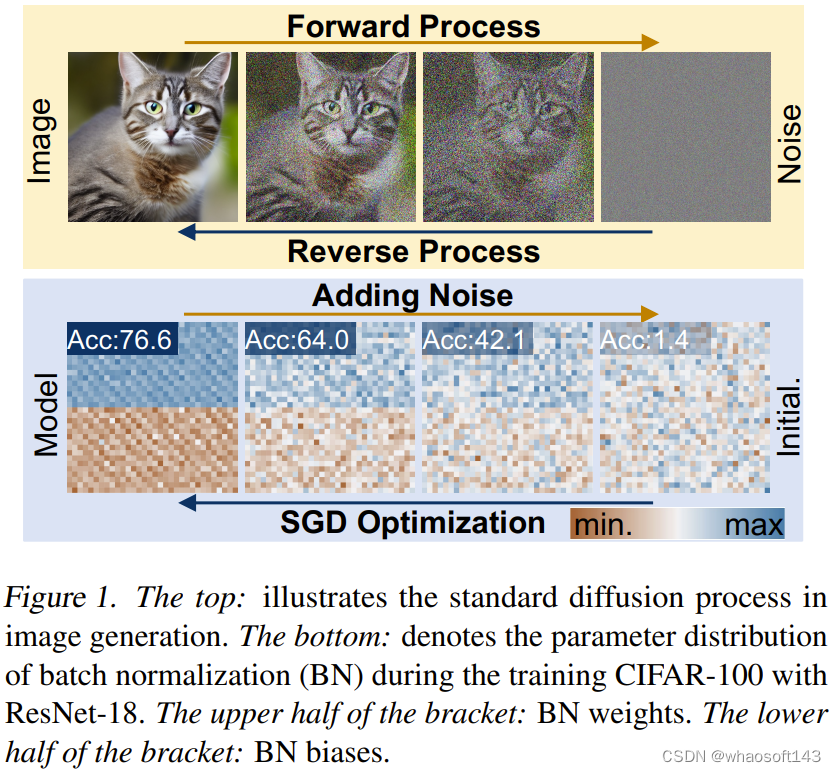
基于这些观察,研究团队引入了一种新的参数生成方法,称之为“神经网络扩散”(p-diff,p代表参数),它采用标准的LDM来合成一组新的参数。
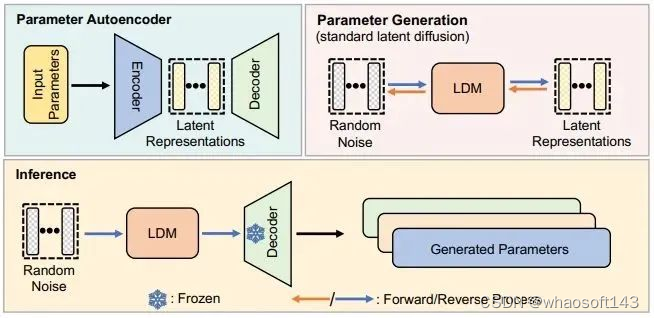
扩散模型能够将给定的随机分布转换为特定的随机分布,因此研究人员使用了一个自动编码器和一个标准的LDM来学习高性能参数的分布。
该研究方法整合了参数自动编码器和扩散模型来实现神经网络参数的创新生成。首先,研究人员选取一组经过充分训练且表现出色的模型作为基础,从中抽取一部分关键或有代表性的参数子集,并将这些多维结构的参数展平为一维向量形式。
接下来,他们构建了一个参数自动编码器架构,其中包含一个编码器模块,用于从所提取的一维参数向量中学习潜在的低维表示(latent representations),这一过程能够捕捉到原有参数的关键特征和模式。同时配备一个解码器模块,其任务是根据这些潜在表示恢复出原始的高维参数结构。
在此基础上,团队进一步训练一个标准的扩散模型(LDM,Latent Diffusion Model)以适应参数生成场景,使其能够在随机噪声输入下逐步迭代并生成与目标参数对应的高质量潜在表示。
训练完成后,研究人员利用一个逆扩散过程(p-diffusion process)来生成新的神经网络参数。这个过程始于一个随机噪声向量,通过逆向递归地应用扩散模型的反变换,将其一步步转化为有意义的潜在表示。最后,将这些合成的潜在表示输入训练好的解码器中,解码器会将其转换为全新的、有望保持高性能的神经网络参数。这种方法不仅拓展了扩散模型的应用领域,还可能挖掘出之前未被发现的有效网络结构和参数配置。
训练后,研究团队利用 p-diff 通过以下链条生成新的参数:随机噪声 → 逆过程 → 训练好的解码器 → 生成的参数。
介绍扩散模型
扩散模型通常由前向和反向过程构成,这些过程组成一个多步骤的链式过程并且可通过时间步骤索引。
前向过程。给定一个样本 x_0 ∼ q(x),前向过程是在 T 个步骤中逐渐添加高斯噪声,得到 x_1、x_2……x_T。
反向过程。不同于前向过程,反向过程的目标是训练一个能递归地移除 x_t 中的噪声的去噪网络。该过程是多个步骤的反向过程,此时 t 从 T 一路降至 0。
神经网络扩散方法概述
神经网络扩散(p-diff)这种新方法的目标是基于随机噪声生成高性能参数。如图 2 所示,该方法包含两个过程:参数自动编码器和参数生成。
2 记忆训练样本?不,真能合成新参数!
为了验证该方法的有效性,研究团队紧接着还在MNIST、CIFAR-10/100、ImageNet-1K、STL-10等广泛的数据集上进行了评估实验,实验主要在神经网络ResNet-18/50、ViT-Tiny/Base 和 onvNeXt-T/B 上进行。
研究团队详细阐述了具体的训练细节。在实验中,自动编码器和LDM均包含了一个基于 4 层 1D CNN 的编码器和解码器。研究人员默认收集所有架构的200 个训练数据。在神经网络 ResNet-18/50 上,他们从头开始训练模型。到了最后一个 epoch中,他们则继续训练最后两个归一化层并修复其他参数。在大多数情况下,自动编码器和潜在扩散训练可以在单个英伟达的 A100 40G GPU 上于 1~3 小时内完成。
实验过后,研究人员发现,在大多数情况下,p-diff的方法取得了与两个基线相似或更好的结果,这表明了此方法可以有效地学习高性能参数的分布,并从随机噪声中生成优异的模型。而且,该方法在各种数据集上始终表现良好,也证明了它具有良好的通用性。

那么如何进一步确认p-diff是否真正可以合成新参数,而不只是在记忆训练样本呢?
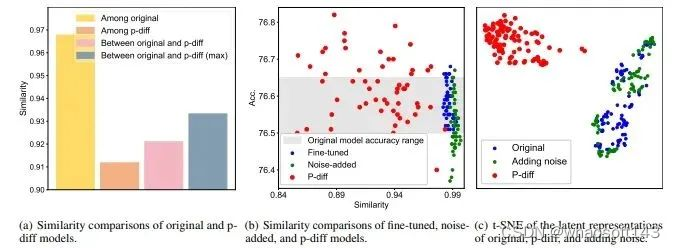
为了验证p-diff能够生成一些与原始模型表现不同的新参数,研究团队设计了另一个实验,通过比较原始模型、添加噪声模型、微调模型和 p-diff 模型的预测和可视化来研究它们之间的差异。
他们进行了四组对比:1)原始模型之间的相似性;2)p-diff模型之间的相似性;3)原始模型和p-diff模型之间的相似性;4) 原始模型和 p-diff 模型之间的最大相似度(最近邻)。
可以发现,在不同情况下,生成的模型之间的差异远大于原始模型之间的差异。另外,即使是原始模型和生成模型之间的最大相似度,也低于原始模型之间的相似度。这表明,p-diff 的确可以生成与其训练数据表现不同的新参数。
3 结语
Sora的平地一声惊雷,让本就火爆的文生图、文生视频的领域又增添了好几分热度,也让在图像和视频生成方面取得了显著成功的扩散模型获得了更多的关注。
而无论是Sora、DALL·E 、Midjourney,还是Stable Diffusion等已经拥有众多用户的模型,它们背后的魔法都是扩散模型。在已有的例子中,扩散模型总是被运用在生成图片或视频上,而这一次,扩散模型居然直接渗入更深层,直接生成神经网络,这堪称机器学习中“用魔法打败魔法”的神操作。
今日,研究团队中的共同指导作者 Zhuang Liu 还在社交媒体上答复了网友的疑惑,解释了“Neural Network Diffusion”和Sora 负责人 William Peebles 此前发布的研究“Learning to Learn with Generative Models of Neural Network Checkpoints”之间的区别:
William Peebles的研究工作是逐步生成参数,更像是优化器,将先前的检查点作为输入。“Neural Network Diffusion”则是直接生成整套参数,无需之前的权重作为输入。
尽管研究团队目前尚未解决内存限制、结构设计效率和性能稳定性等问题,但使用扩散模型生成神经网络的创新尝试,让大模型领域的技术边界又向外开拓了一面。
实验
该团队在论文中给出了详细的实验设置,可帮助其他研究者复现其结果,详见原论文,我们这里更关注其结果和消融研究。
结果
表 1 是在 8 个数据集和 6 种架构上与两种基准方法的结果比较。

基于这些结果,可以得到以下观察:1)在大多数实验案例中,新方法能取得与两种基准方法媲美或更优的结果。这表明新提出的方法可以高效地学习高性能参数的分布,并能基于随机噪声生成更优的模型。2)新方法在多个不同数据集上的表现都很好,这说明这种方法具有很好的泛化性能。
消融研究和分析
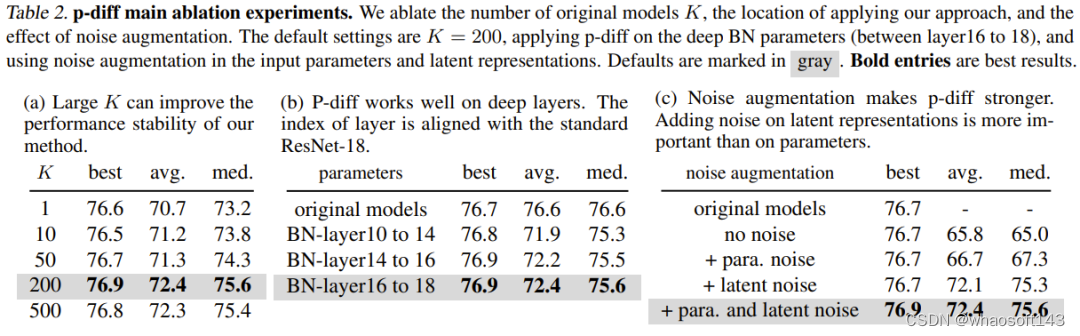
表 2(a) 展示了不同训练数据规模(即原始模型的数量)的影响。可以看到,不同数量的原始模型的最佳结果之间的性能差异其实不大。
为了研究 p-diff 在其它归一化层深度上的有效性,该团队还探索了新方法合成其它浅层参数的性能。为了保证 BN 参数的数量相等,该团队为三组 BN 层(它们位于不同深度的层之间)实现了新提出的方法。实验结果见表 2(b),可以看到在所有深度的 BN 层设置上,新方法的表现(最佳准确度)都优于原始模型。
噪声增强的目的是提升训练自动编码器的稳健性和泛化能力。该团队对噪声增强在输入参数和隐含表征方面的应用进行了消融研究。结果见表 2(c)。
此前,实验评估的都是新方法在合成模型参数子集(即批归一化参数)方面的效果。那么我们不禁要问:能否使用此方法合成模型的整体参数?
为了解答这个问题,该团队使用两个小型架构进行了实验:MLP-3 和 ConvNet-3。其中 MLP-3 包含三个线性层和 ReLU 激活函数,ConvNet-3 则包含三个卷积层和一个线性层。不同于之前提到的训练数据收集策略,该团队基于 200 个不同的随机种子从头开始训练了这些架构。
表 3 给出了实验结果,其中将新方法与两种基准方法(原始方法和集成方法)进行了比较。其中报告了 ConvNet-3 在 CIFAR-10/100 以及 MLP-3 在 CIFAR-10 和 MNIST 上的结果比较和参数数量。

这些实验表明新方法在合成整体模型参数方面的有效性和泛化能力,也就是说新方法实现了与基准方法相当或更优的性能。这些结果也能体现新方法的实际应用潜力。
但该团队也在论文中表明目前还无法合成 ResNet、ViT 和 ConvNeXt 等大型架构的整体参数。这主要是受限于 GPU 内存的极限。
至于为什么这种新方法能够有效地生成神经网络参数,该团队也尝试探索分析了原因。他们使用 3 个随机种子从头开始训练了 ResNet-18 并对其参数进行了可视化,如图 3 所示。
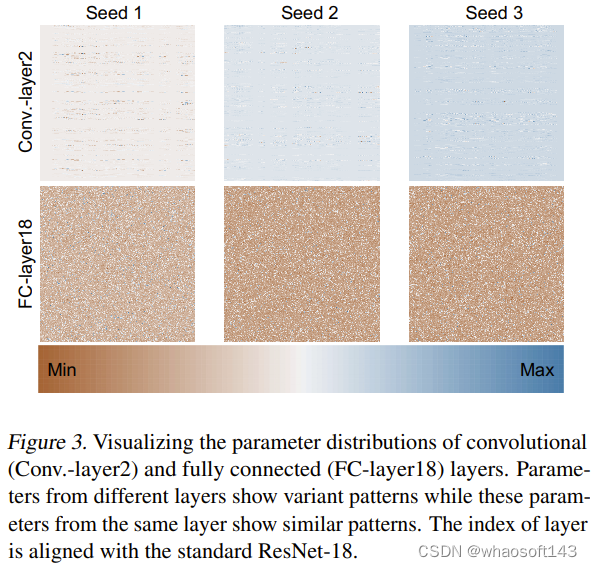
他们通过 min-max 归一化方法,分别得到了不同层的参数分布的热力图。基于卷积层(Conv.-layer2)和全连接层(FC-layer18)的可视化结果,可以看到这些层中确实存在一定的参数模式。通过学习这些模式,新方法就能生成高性能的神经网络参数。
p-diff 是单纯靠记忆吗?
p-diff 看起来能生成神经网络参数,但它究竟是生成参数还是仅仅记住了参数呢?该团队就此做了一番研究,比较了原始模型和生成模型的差异。
为了进行量化比较,他们提出了一个相似度指标。简单来说,这个指标就是通过计算两个模型在错误预测结果上的交并比(IoU)来确定它们的相似度。然后他们基于此进行了一些比较研究和可视化。
可以看到,生成的模型之间的差异比原始模型之间的差异大得多。另外,原始模型和生成的模型之间的最大相似度也低于原始模型之间的相似度。这足以表明,p-diff 可以生成与其训练数据(即原始模型)不同的新参数。
该团队也将新方法与微调模型和添加噪声的模型进行了比较。结果见图 4(b)。
可以看到,微调模型和添加噪声的模型很难超过原始模型。此外,微调模型或添加噪声的模型与原始模型之间的相似度非常高,这表明这两种操作方法无法获得全新且高性能的模型。但是,新方法生成的模型则表现出了多样的相似度以及优于原始模型的性能。
该团队也比较了隐含表征。结果见图 4(c)。可以看到,p-diff 可以生成全新的隐含表征,而添加噪声方法只会在原始模型的隐含表征周围进行插值。
该团队也可视化了 p-diff 过程的轨迹。具体而言,他们绘出了在推理阶段的不同时间步骤生成的参数轨迹。图 5(a) 给出了 5 条轨迹(使用了 5 种不同的随机噪声初始化)。图中红心是原始模型的平均参数,灰色区域是其标准差(std)。
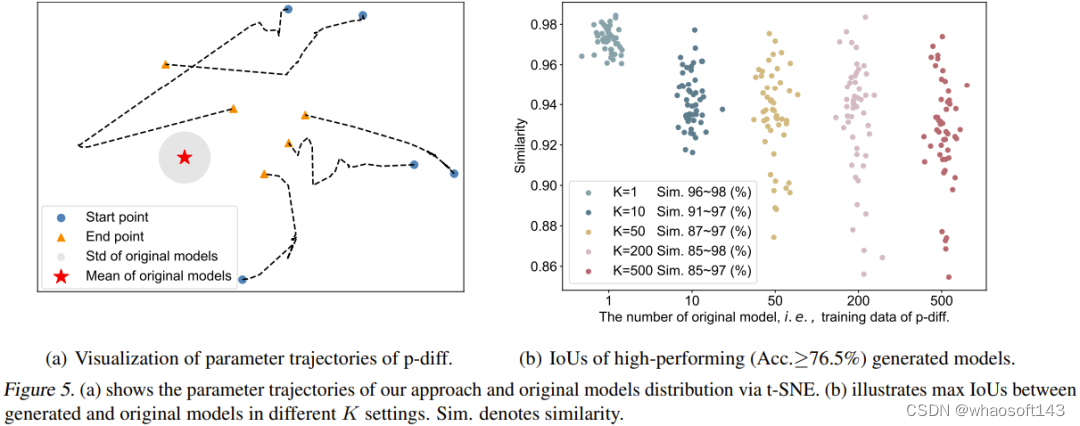
随着时间步骤增加,生成的参数整体上会更接近原始模型。但是也能看出,这些轨迹的终点(橙色三角形)与平均参数仍然有些距离。另外,这五条轨迹的形状也很多样化。
最后,该团队研究了原始模型的数量(K)对生成的模型的多样性的影响。图 5(b) 可视化地展示了不同 K 时原始模型与生成的模型之间的最大相似度。具体来说,他们的做法是生成 50 个模型,通过持续生成参数,直到生成的 50 个模型在所有情况下的表现均优于 76.5%。
可以看到,当 K=1 时,相似度很高且范围窄,说明这时候生成的模型基本是记忆了原始模型的参数。随着 K 增大,相似度范围也变大了,这表明新方法可以生成与原始模型不同的参数。
#PDPP~~
这里将教学视频过程规划任务转化为一个分布的拟合与采样问题,并使用条件投影扩散模型完成了这一任务。PDPP在三个不同规模的数据集以及不同的预测长度设置下都达到了最好的性能,能够生成兼具多样性与准确性的动作规划。
本文介绍我们媒体计算课题组近期被CVPR 2023接受的工作:PDPP: Projected Diffusion for Procedure Planning in Instructional Videos。针对教学视频过程规划任务的特点,PDPP将需要预测的所有动作视为一个整体的序列进行拟合,从而将该任务建模为一个特征空间分布拟合与采样问题。考虑到教学视频过程规划任务中存在的规划多样性特点,我们利用一个条件投影扩散模型来完成动作序列特征分布的拟合,通过在学习和采样阶段引入噪声实现预测的多样性。同时,我们还利用任务类别标签代替以往方法中需要的监督信息,减少了完成此任务需要的标注成本。相比于之前的SOTA方法,PDPP利用更简单的训练策略和更易获得的监督信息,在CrossTask,NIV和COIN三个数据集的指标上都取得了大幅度的提升。
论文链接:
https://arxiv.org/abs/2303.14676
教学视频过程规划任务(Procedure Planning in Instructional Videos)通过提供一段教学视频开始以及结束的视频片段,要求模型预测出这之间发生的一系列动作。之前的方法可以分为自回归式预测[1][2][3]与并行预测[4]两种。自回归式预测方法将每一个中间动作发生时对应的视频片段作为监督信号,一步步地预测接下来发生的动作和场景,从而完成整个动作序列的预测。这种方法的缺点在于预测慢,训练复杂,而且前期预测发生错误将会导致之后的预测全部失败。并行预测方法则利用一个transformer模型直接预测所有的动作。为了获得好的结果,该方法利用中间动作的文本标签作为监督信号,并引入了可学习的memory bank,GAN以及后处理策略来完成该预测任务,从而带来了复杂的训练策略与冗杂的推理过程。
过去的方法都着重于如何准确地预测每一个单独的动作,忽视了这些动作之间的关联性。因此,我们将学习目标由每一个离散的动作转化为整个动作序列,即将需要预测的动作视为一个完整的特征分布,从而将这个序列预测问题转化为一个特征拟合以及采样的问题。这样就可以直接利用MSE loss完成训练,避免了之前方法中复杂的训练策略,还可以一次预测所有的中间动作。此外,我们还注意到预测动作序列与要执行任务的类别相关度很高,例如在 "jacking up a car" 任务中,是不会出现 "add sugar" 这种动作的。因此我们提出使用任务类别标签作为监督信息,进一步减少数据标注的成本。
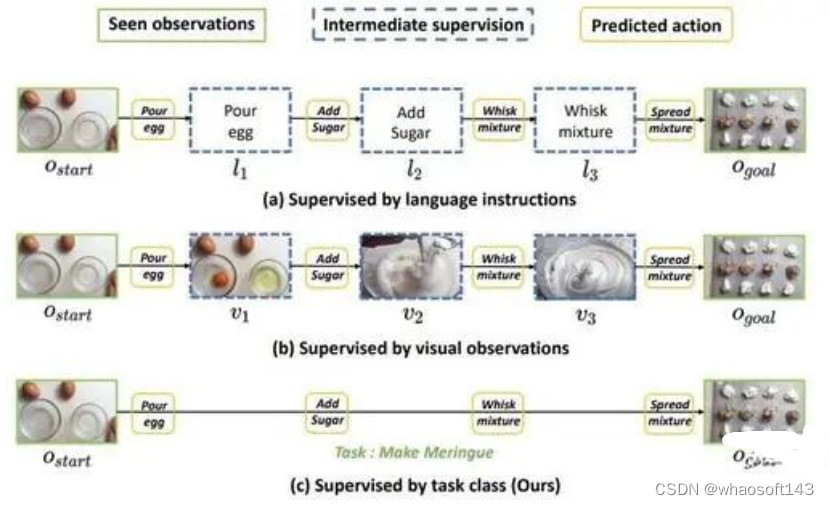
教学视频过程规划任务方法示意图
教学视频过程规划任务中还存在着规划多样性的特点,即给定教学视频开始以及结束的片段,合理的中间动作序列可以有很多。例如,在 "makingcake" 任务中,"add sugar" 与 "add butter" 两个动作发生的顺序是完全可以调换的。因此需要考虑如何实现预测的多样性。考虑到扩散模型在训练与采样过程中都会引入随机噪声,因此非常合适用来完成多样性的预测。由此,我们将教学视频过程规划任务建模为一个条件引导的分布拟合问题,并通过一个条件投影扩散模型来完成该任务。
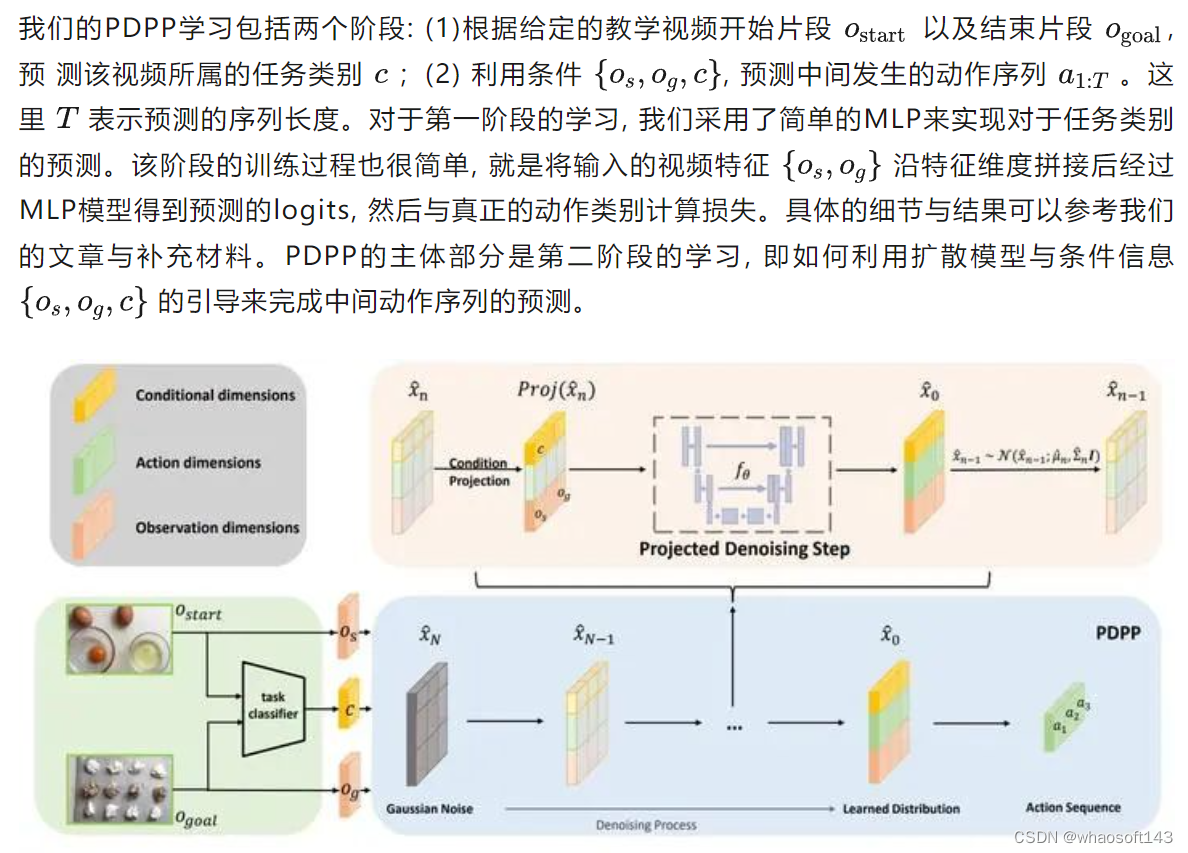
扩散模型DDPM
在正式介绍PDPP之前,先简单回顾一下扩散模型DDPM[5]。DDPM包含前向加噪与反向去噪两个过程,分别表示为:

PDPP介绍

此外,在实验中我们发现直接预测每一步添加的噪声会导致训练失败,这与将diffusion应用到NLP任务[6]中的现象是一致的。可能的原因就是我们预测的特征分布具有很强的语义性,在去噪初期预测的噪声并不是很准确的情况下,去噪后的特征分布不具备要求的强语义性,从而导致后面的一系列去噪操作偏离正确的方向。因此,我们采用了预测初始分布 x_0x_0 的训练策略,为模型的去噪学习提供一个强的锚点。
基于以上改进思路,我们得到了PDPP的训练策略以及采样过程:

实验结果
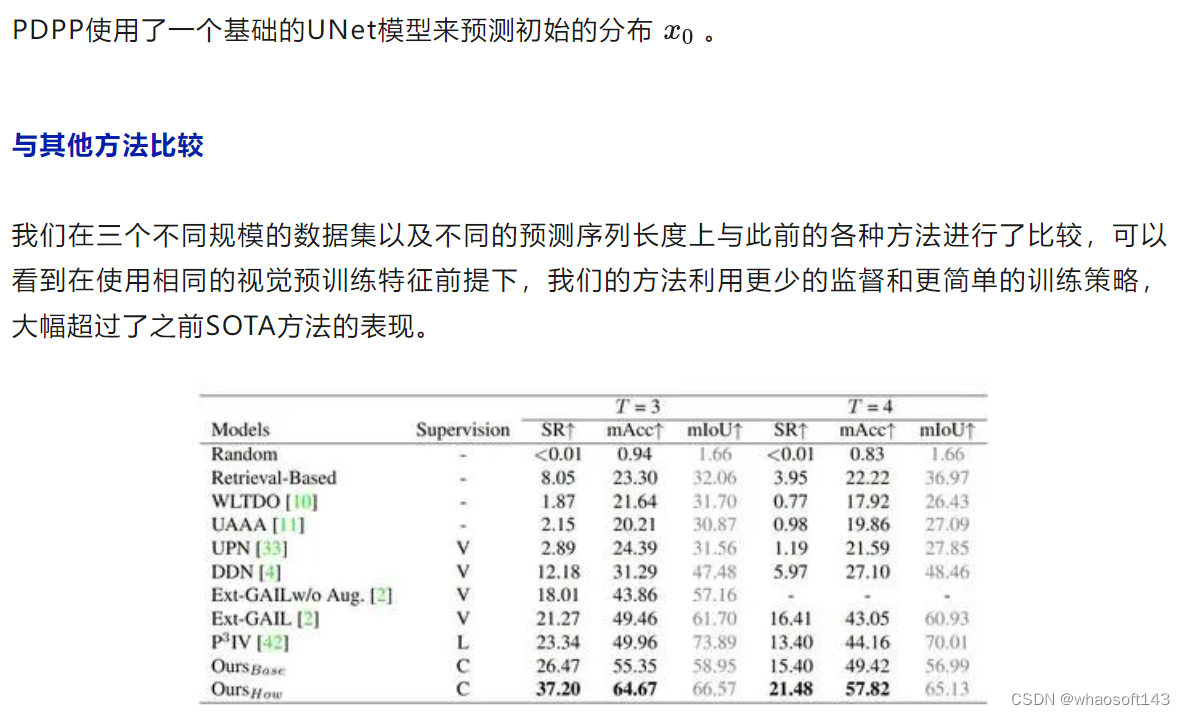

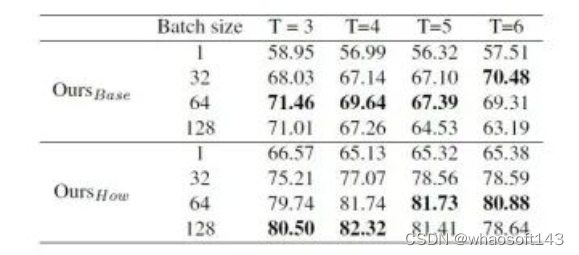
这里关于mIoU指标表现不佳的原因是因为我们在测试时选取了batch size=1,之前的方法则是在整个batch上计算得到mIoU。为了验证batch size对mIoU指标的影响,我们选取了不同的batch size对相同的模型进行了测试,发现batch size确实会大幅度影响mIoU的结果:
任务类别条件引导的作用
我们进一步验证了任务类别条件 c 对于预测结果的作用:
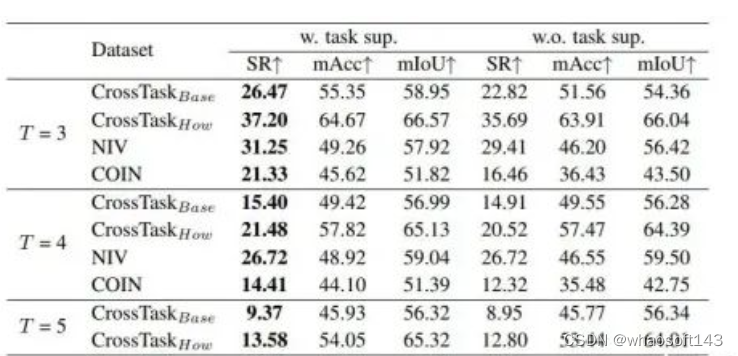
可以看到,任务类别条件能够帮助模型完成更加准确的动作规划,尤其是对于COIN这种任务类别众多、数据量大的数据集,类别条件可以大幅提高预测的准确性。同时也可以看到,即使没有类别条件的引导,我们的方法也在多个指标上达到了SOTA,进一步证明了我们方法的有效性。
规划多样性测试
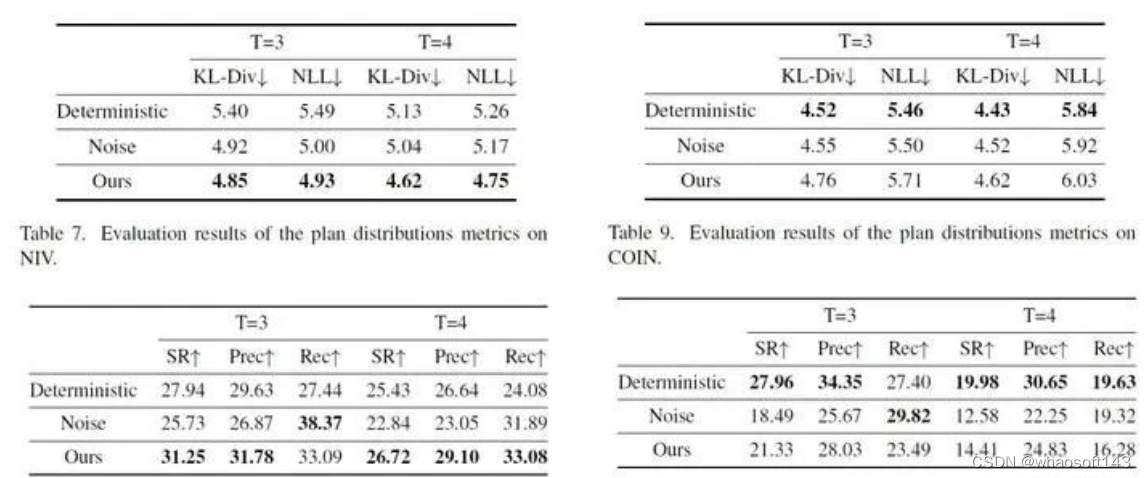
我们利用扩散模型来完成教学视频过程规划任务,希望能够适应该任务中规划多样性的特点,因此我们对于PDPP生成规划的多样性进行了测试。为了进行对比,我们提出了Noise和Deterministic两个基线方法:
- Noise:在PDPP的基础上移除diffusion过程,即学习如何从一个随机高斯噪声中根据条件信息通过一次采样得到动作序列;
- Deterministic:在Noise的基础上将采样的起始点由高斯随机噪声改为0,即直接利用条件信息生成预测的动作序列
这样,对于Noise方法,预测多样性的来源只有初始高斯噪声的随机性;而对于Deterministic方法,则完全没有预测的多样性。
我们首先统计了三个数据集拥有相同起始动作、不同中间动作的序列数目,统计结果如下:
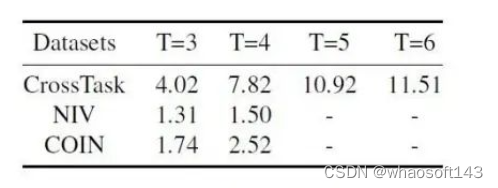
由此可以看出,CrossTask中的规划多样性是最强的,相对来说NIV与COIN的多样性就没有那么明显。
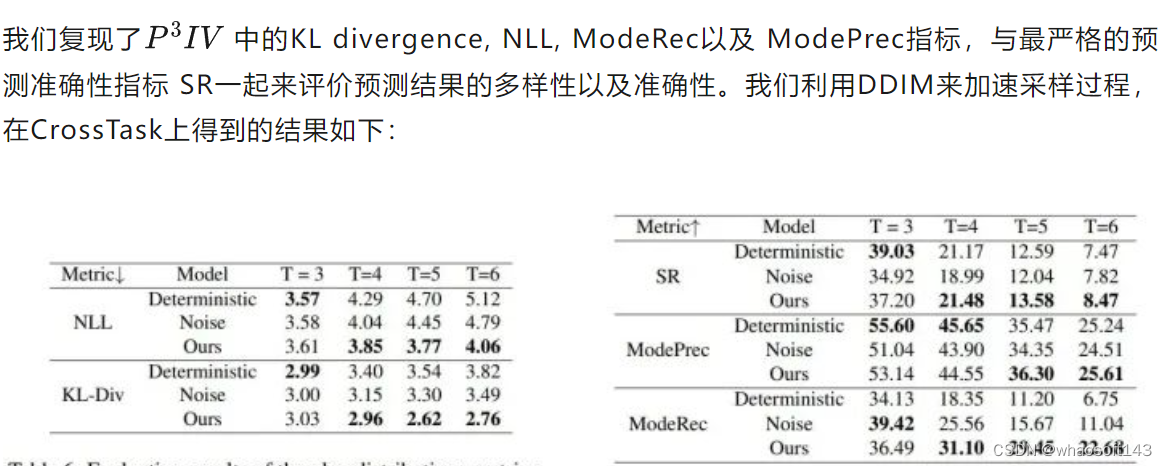
可以看到,对于CrossTask数据集,在预测长度较长时(T>3),PDPP能够给出既准确又多样的动作序列规划,其中反映预测结果多样性的指标 ModeRec 的提升最为明显。在T=3时,不添加噪声的 Deterministic 方法可以得到更准确的预测结果,这是因为在预测长度较小时,相应动作序列的多样性也会减少。
对于COIN与NIV两个多样性并不太明显的数据集,PDPP的表现完全相反:对于NIV数据集,PDPP能够兼顾预测的准确性和多样性,很好地完成动作序列的预测;而对于COIN数据集,PDPP的表现则不如不添加噪声的 Deterministic 方法。我们认为造成这种差异的原因是数据集的规模不同。对于小的数据集NIV,我们的模型能够很好地对其进行拟合,这时引入噪声起到了一种防止过拟合的作用,配合扩散模型采样的过程,就可以得到多样且准确的结果;但是对于数据量很大的COIN数据集,我们的模型还没能实现充分的拟合,这时加入噪声反而会对模型的训练起到反作用。
规划多样性可视化
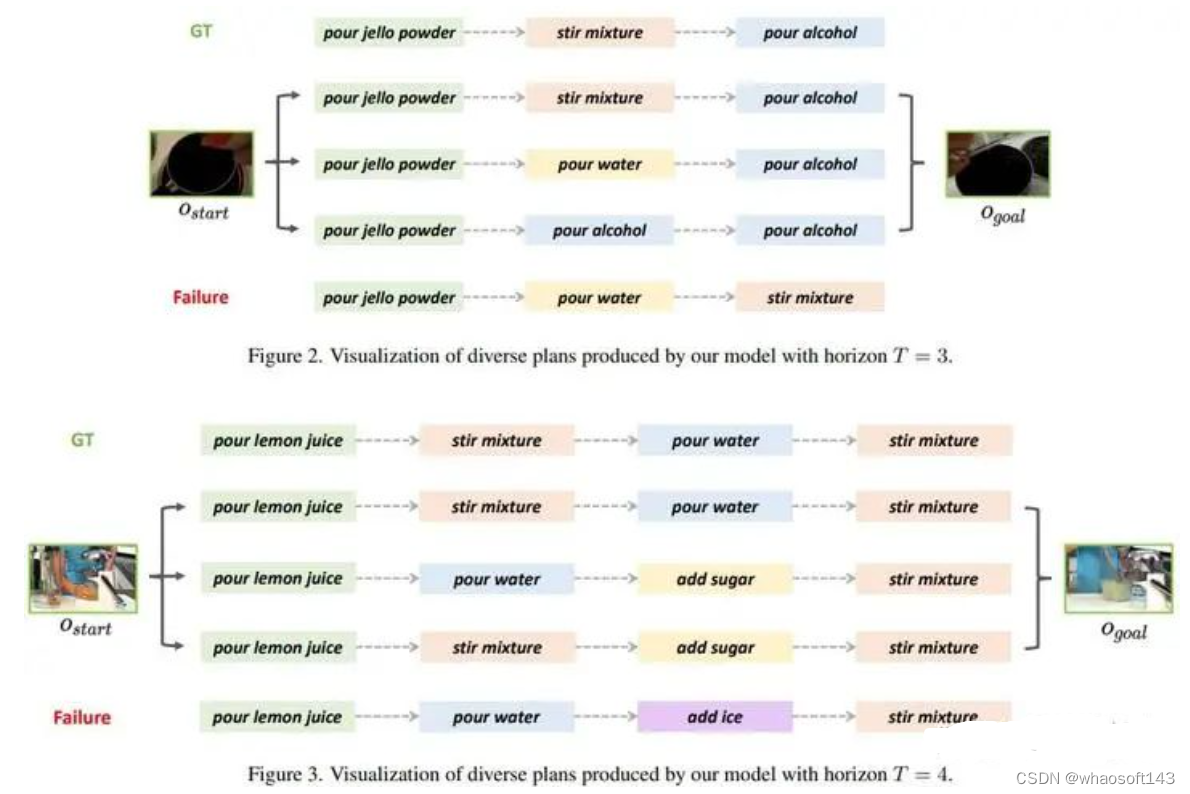
我们将不同预测长度下的动作序列生成结果进行了可视化,可以看到PDPP能够基于给定的视频开始和结束片段生成多种合理的动作规划序列。这里的Failure结果指的只是相应的动作序列没有在测试集中出现过,但仍有一定的合理性,例如T=4时的 Failure 结果,"add ice"也是一种比较合理的中间动作。

总结
在这篇文章中,我们将教学视频过程规划任务转化为一个分布的拟合与采样问题,并使用条件投影扩散模型完成了这一任务。和之前的工作相比,PDPP需要的监督信息更少,训练的策略也简单了很多。PDPP在三个不同规模的数据集以及不同的预测长度设置下都达到了最好的性能,能够生成兼具多样性与准确性的动作规划。对于大多数指标,即使不使用任何额外的监督信息,我们的方法也能够超过之前的SOTA。我们的工作证明了对于教学视频过程规划任务,将动作序列预测问题转化为分布拟合问题是一种有效且便捷的解决方法。
参考
- ^[1]: Jing Bi, Jiebo Luo, and Chenliang Xu. Procedure planning in instructional videos via contextual modeling and modelbased policy learning. In ICCV, pages 15591–15600. IEEE, 2021.
- ^[2]: Chien-Yi Chang, De-An Huang, Danfei Xu, Ehsan Adeli, Li Fei-Fei, and Juan Carlos Niebles. Procedure planning in instructional videos. In ECCV (11), volume 12356 of Lecture Notes in Computer Science, pages 334–350. Springer, 2020.
- ^[3]: Jiankai Sun, De-An Huang, Bo Lu, Yun-Hui Liu, Bolei Zhou, and Animesh Garg. Plate: Visually-grounded planning with transformers in procedural tasks. IEEE Robotics Autom. Lett., 7(2):4924–4930, 2022.
- ^[4]: He Zhao, Isma Hadji, Nikita Dvornik, Konstantinos G. Derpanis, Richard P. Wildes, and Allan D. Jepson. P3iv: Probabilistic procedure planning from instructional videos with weak supervision. In CVPR, pages 2928–2938. IEEE, 2022.
- ^[5]: Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising diffusion probabilistic models. In NeurIPS, 2020.
- ^[6]: Xiang Lisa Li, John Thickstun, Ishaan Gulrajani, Percy Liang, and Tatsunori B. Hashimoto. Diffusion-lm improves controllable text generation. CoRR, abs/2205.14217, 2022.
#BELM
浙大、微信提出精确反演采样器新范式,彻底解决扩散模型反演问题
浙江大学和微信视觉团队合作提出的基于双向显式线性多步法(BELM)的扩散模型精确反演采样器,这一新范式能够彻底解决扩散模型反演问题,同时提升生成样本的质量,对图像和视频编辑等下游任务具有广泛的应用前景。研究成果已被NeurIPS 2024会议接收。
随着扩散生成模型的发展,人工智能步入了属于 AIGC 的新纪元。扩散生成模型可以对初始高斯噪声进行逐步去噪而得到高质量的采样。当前,许多应用都涉及扩散模型的反演,即找到一个生成样本对应的初始噪声。当前的采样器不能兼顾反演的准确性和采样的质量。
为彻底解决这一问题,微信视觉团队与浙江大学和清华大学联手提出了基于双向显式线性多步法的扩散模型精确反演采样器(BELM)这一通用算法,并通过截断误差分析确定了最优的 BELM 采样器系数。
此方法在确保精确反演的同时还提升了生成样本的质量,在图像与视频的编辑、插值等下游任务中有广泛的应用前景。这一研究成果已被 NeurIPS 2024 会议接收。
当前,扩散模型在图像生成、文字生成、音频生成等多个领域得到了广泛应用,表现出了卓越的性能。扩散模型的反演操作,即找到一个生成样本对应的初始噪声,对若干下游任务起到关键的作用。传统的 DDIM 反演会造成严重的不一致问题,即原始图片加噪再去噪的结果与原图相差甚远。
近期,研究者们提出了多种启发式的精确反演采样器来解决 DDIM 反演的不一致问题。然而,这些启发式的精确反演采样器的理论特性尚不明确,且采样质量常常不尽如人意,这在一定程度上限制了它们的应用。
为此,本研究引入了一种通用的精确反演采样器范式 —— 双向显式线性多步(BELM)采样器,该范式包含了上文提到的启发式精确反演采样器。该团队在 BELM 范式内系统地研究了局部截断误差(LTE),发现现有的精确反演采样器的 LTE 并非最优。
因此,研究团队通过 LTE 最小化方法提出了最优的 BELM(Optimal-BELM,O-BELM)采样器。实验表明,O-BELM 采样器在实现精确反演的同时,也提升了采样的质量。
论文题目:
BELM: Bidirectional Explicit Linear Multi-step Sampler for Exact Inversion in Diffusion Models
论文链接:https://arxiv.org/abs/2410.07273
项目链接:https://github.com/zituitui/BELM
01 背景:DDIM反演造成的不一致问题
由于 DDIM 的正向过程和反演过程使用的迭代式并不相同,所以 DDIM 的反演重构样本与初始的样本存在较大差别。
实际使用中,DDIM 的反演有显著的不一致问题:


02 现有精确反演方法Null-text-inversion
以 Null-tex-inversion 为代表的方法对 unconditional 占位符进行 fine-tune,以达到精确反演。
问题:这类方法局限于 text-classifier-free-guidance 场景下的扩散模型;需要额外训练,低效。

EDICT
EDICT 是基于 DDIM 的启发式算法,借鉴了可逆网络的做法,有两个相互糅合的采样链。

其逆过程如下,精确可逆:

问题:需要两倍计算量;超参数 p 不鲁棒,导致采样质量不可控。
BDIA
BDIA 改进了 EDICT,使用 x_i 的速度,x_i 和 x_{i+1} 的位置,通过下述公式实现精确可逆:

问题:超参数 gamma 不鲁棒,导致采样质量不佳。
EDICT 和 BDIA 参数的不鲁棒:
EDICT 和 BDIA 超参数的意义不明,没有理论指导如何调整,导致不同情形下超参数的选择差别巨大。使用起来极为不便。


03 双向显式线性多步法(BELM)框架
思路起源:DDIM 的正向过程(由蓝线表示)与反演过程(由红线表示)是两种不同的关系,这导致了 DDIM 的反演不准确。如果强制正过程与反过程使用相同关系,又会引入隐式方法,大大增加计算复杂度。如果多引入一个点,不用隐式方法也可逆(由绿线表示)。

该论文中的算法,正向和反演过程都服从相同的关系,因此能够精确反演。具体来说,为了系统地设计这种采样器,首先要将扩散模型的采样过程建模为一个 IVP(Initial Value Problem,初值问题):

以下是 IVP 的一般形式,这实际上是一个变步长变公式线性多步方法(VSVFM):

为了避免隐式方法的复杂计算,上式需要在正向和反向都是显式的,该团队称这一性质为双向显性(bidirectional explicit)。

代入双向显性条件,可以得到一般的 k 步 BELM 采样器:

最简单的形式是 k=2,称为 2-BELM,其表达式如下:

据此很容易证明,一个满足双向显性性质的线性多步法采样器拥有精确反演性质:

研究团队还发现,前文提到的 EDICT 和 BDIA 都是 BELM 框架的特例:

这也解释了 EDICT 和 BDIA 能够精确反演的原因。
04 最优双向显式线性多步(O-BELM)采样器
研究团队在推导 BELM 框架暂时没有给出具体的系数选择,而启发式的系数选择(如 EDICT 和 BDIA)会造成采样质量的退化。因此,他们提出使用局部截断误差(LTE)来获取最优系数。
首先分析 BELM 的局部截断误差:

通过对局部截断误差的最小化,我们得到了最优的 BELM 系数,我们称此系数下的 BELM 采样器为最优 BELM(O-BELM):

O-BELM 的正向过程表达式如下:

O-BELM 的反演过程表达式如下:

此外,研究团队还证明了 O-BELM 满足稳定性和全局收敛性:

至此,可以对比几种不同反演采样器的性质:

可见,O-BELM 是第一种在严格的理论保证下兼顾精确反演性质和采样质量的采样器。
05 实验
重建实验(验证O-BELM精确反演性质)
latent 空间上的 O-BELM 的重建误差为 0,这表明 O-BELM 具有精确反演的性质:


采样实验(验证O-BELM的高质量采样性质)
不论在无条件生成还是条件生成中,O-BELM 都表现出了高于 DDIM,EDICT 和 BDIA 的采样质量:

下游任务 —— 图像编辑
图像编辑实验体现了:
1. 由于 DDIM 不具有精确反演性质,编辑的结果中存在不一致问题(红色框);
2. 由于 EDICT 和 BDIA 具有较大的采样误差,编辑的结果出现了不真实区域(黄色框);
3.O-BELM 在保持图像一致的条件下完成了高质量的编辑。


由于 O-BELM 是一个采样方法,因此可以无缝地与 controlNet 结合,编辑效果也优于其他方法:

下游任务 —— 图像插值
由于 O-BELM 精确地建立了噪声和生成样本的对应关系,这个关系是 probability flow ODE 的近似,因此 O-BELM 也使得图像插值更符合人的直觉:

06 结语
本研究提出的双向显式线性多步法采样器从理论上分析并彻底解决了现有扩散生成模型中的反演问题,进一步拓宽了扩散模型在计算机视觉领域的能力边界。在图像和视频的编辑任务上有巨大的应用前景。
#NaturalSpeech
基于扩散模型的语音合成,
文本到语音合成(Text to Speech,TTS)作为生成式人工智能(Generative AI 或 AIGC)的重要课题,在近年来取得了飞速发展。多年来,微软亚洲研究院机器学习组和微软 Azure 语音团队持续关注语音合成领域的研究与相关产品的研发。为了合成既自然又高质量的人类语音,NaturalSpeech 研究项目(https://aka.ms/speechresearch)应运而生。
NaturalSpeech 的研究分为以下几个阶段:
1)第一阶段,在单个说话人上取得媲美人类的语音质量。为此,研究团队在2022年推出了 NaturalSpeech 1 ,在 LJSpeech 语音合成数据集上达到了人类录音水平的音质
2)第二阶段,高效地实现多样化的语音合成,包含不同的说话人、韵律、风格等。为此,该联合研究团队在2023年推出了 NaturalSpeech 2,利用扩散模型(diffusion model)实现了 zero-shot 的语音合成,只需要几秒钟的示例语音(speech prompt)模型就能合成任何说话人、韵律、风格的语音,实现了零样本语音合成的重要突破,为语音合成技术的未来发展带来了无限可能。
3)当前,研究团队正在开展第三阶段的研究,为达到高自然度(高质量且多样化)的语音合成这一目标,乘势而上,开创新局面。
三大创新设计,让NaturalSpeech 2脱颖而出
于近期发布的新一代语音合成大模型 NaturalSpeech 2,经历了上万小时、多说话人的语音数据集训练,并采用了 zero-shot(预测时只提供几秒钟的目标示例语音)的方式合成新的说话人、韵律、风格的语音,以实现多样化的语音合成。
论文链接:
https://arxiv.org/abs/2304.09116
项目演示:
https://speechresearch.github.io/naturalspeech2/
要想达到良好的 zero-shot 训练效果,面临极大挑战。先前的方法是将语音量化成离散 token,并用自回归语言模型进行建模(例如 AudioLM)。但这种方法存在很大的局限性:自回归模型面临严重的错误传播(error-propagation)问题,导致生成语音质量低下、鲁棒性差,韵律失调以及重复、漏词等问题。同时还容易陷入离散 token 量化和自回归建模的两难困境(如表1所示),即要么离散 token 难以以较高质量还原语音,要么离散 token 难以预测。

NaturalSpeech 2 提出了一系列创新设计,如图1所示,完美地有效规避了先前的局限,实现了零样本语音合成的重要突破。考虑到语音波形的复杂性和高维度,微软亚洲研究院机器学习组与 Yoshua Bengio 共同提出的 Regeneration Learning 范式,为这个问题提供了创新的参考答案。
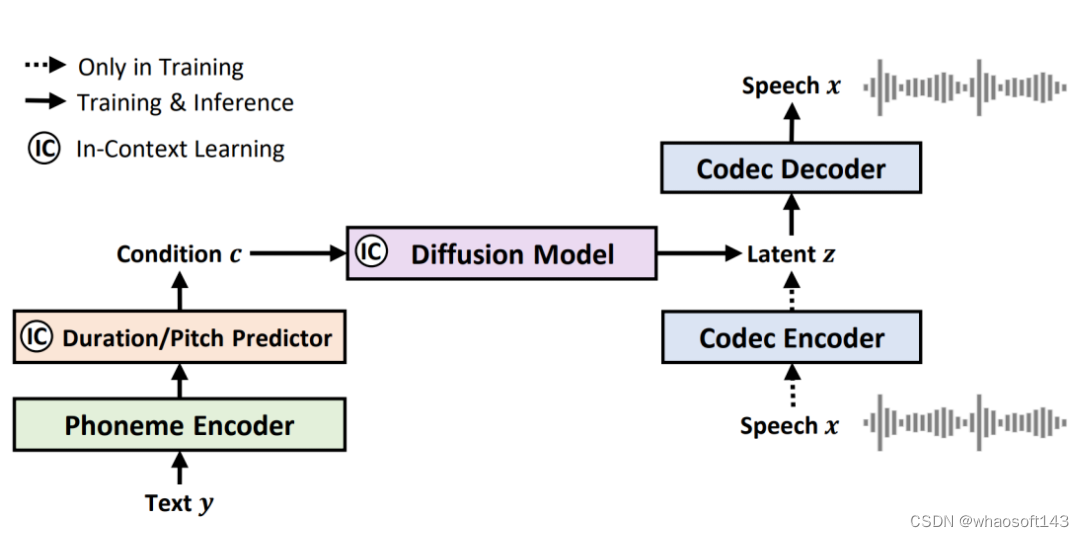
图1:NaturalSpeech 2 系统概览
NaturalSpeech 2 首先利用神经语音编解码器(Neural Audio Codec,如图2所示)的编码器(encoder),将语音波形转换为连续向量并用解码器(decoder)重建语音波形,再运用潜在扩散模型(Latent Diffusion Model)以非自回归的方式从文本预测连续向量。在推理时,利用潜在扩散模型和神经语音解码器从文本生成语音的波形。
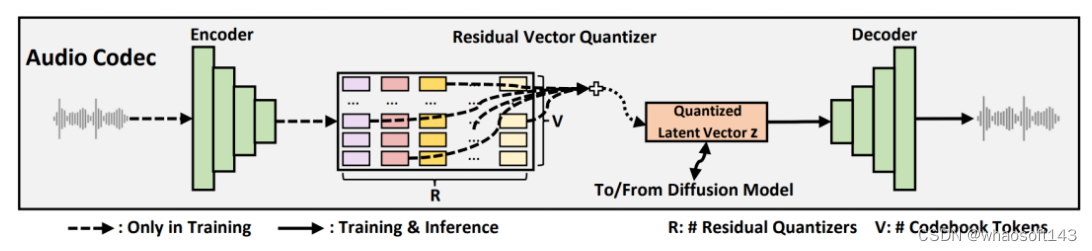
图2:NaturalSpeech 2 中的 Neural Audio Codec 概览
相比先前的语音合成系统,NaturalSpeech 2 有以下几大优势,如表2所示:

表2:NaturalSpeech 2 相比先前语音合成系统的优势
1. 使用连续向量替代离散 token。离散 token 会导致序列长度过长(例如,使用8个残差向量量化器,序列长度会增加8倍),增加了预测的难度。而连续向量可以缩短序列长度,同时增加细粒度重建语音所需要的细节信息。
2. 采用扩散模型替代自回归语言模型。通过非自回归的生成方式,能避免自回归模型中的错误累积所导致的韵律不稳定、重复吐次漏词等问题。
3. 引入语音提示机制,激发上下文学习能力。研究员们创新设计的语音提示机制(如图3所示),让扩散模型和时长/音高预测模块能够更高效地学习语音上下文,从而提升了零样本的预测能力。
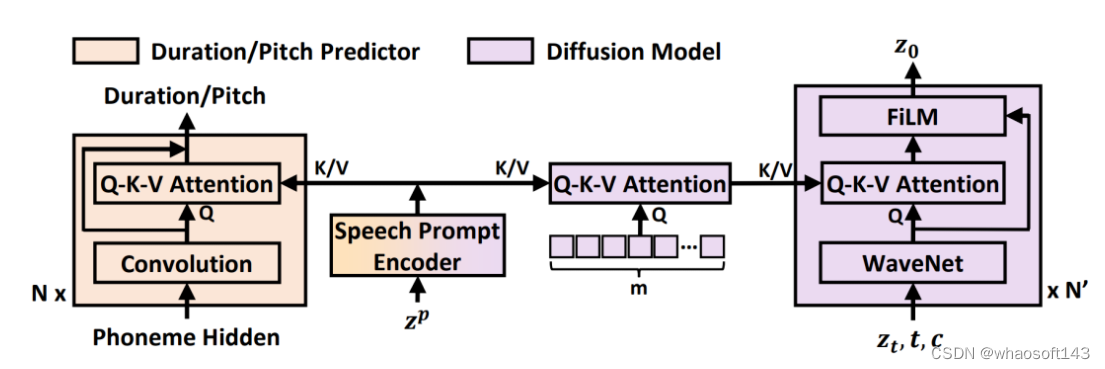
图3:NaturalSpeech 2 中的语音提示机制
得益于以上设计,NaturalSpeech 2 生成的语音非常稳定、鲁棒,无需要复杂的两阶段模型来预测中间表征序列。同时,非自回归的方式和音高时长预测机制也赋予了 NaturalSpeech 2 扩展到语音之外的风格(例如歌声)的能力。
微软亚洲研究院高级研究员谭旭表示,语音合成是人工智能内容生成的一个非常重要的领域,该研究团队一直致力于构建高自然度的语音合成系统。NaturalSpeech 2 是继去年推出的 NaturalSpeech 后跨越的又一里程碑,利用大数据、大模型和零样本合成技术,极大地丰富了语音合成的音色、韵律、风格的多样性,使语音合成更自然更像人类。
NaturalSpeech 2的语音合成性能大检测
研究团队将 NaturalSpeech 2 的模型大小扩展到了400M,并基于4.4万小时的语音数据进行了训练。值得一提的是,即使 NaturalSpeech 2 与被模仿人“素昧平生”,只需几秒的语音提示, NaturalSpeech 2 输出的结果也可以在韵律/音色相似度、鲁棒性和音质方面都更优于先前的 TTS 系统。这一成果使得 NaturalSpeech 2 的性能达到了新高度,并有望为未来的 TTS 研究提供基础性参考。
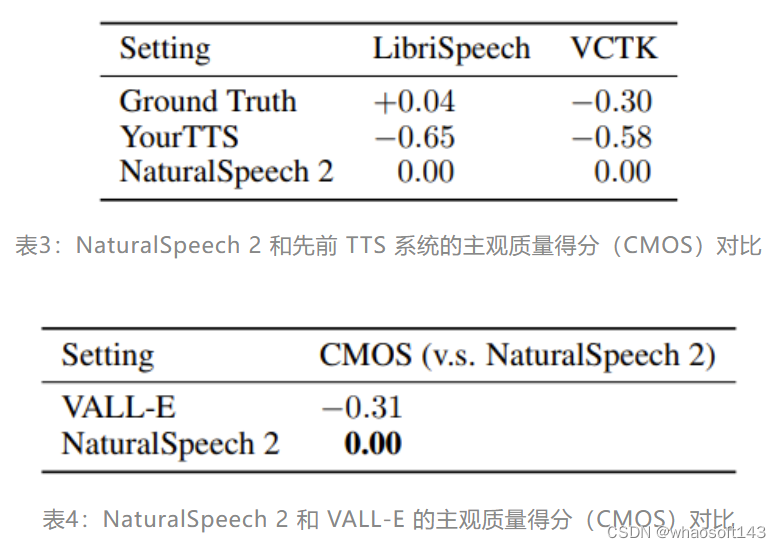
首先,在音质方面,NaturalSpeech 2 在 zero-shot 条件合成的语音显著优于先前的 TTS 系统,如表3和表4所示。
同时,在相似度方面,NaturalSpeech 2 也能更好地生成和语音提示相似的语音,如表5和表6所示(评估指标详细介绍参见论文)。
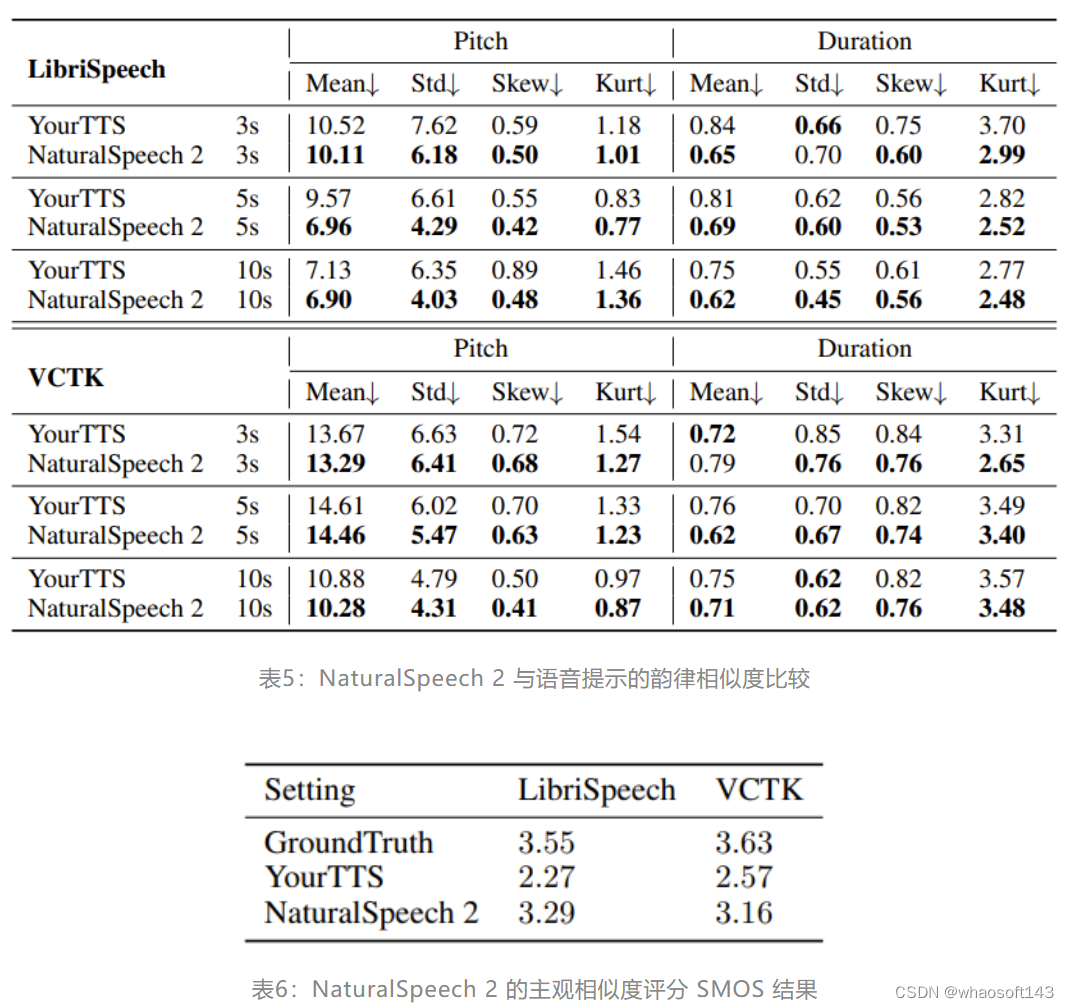
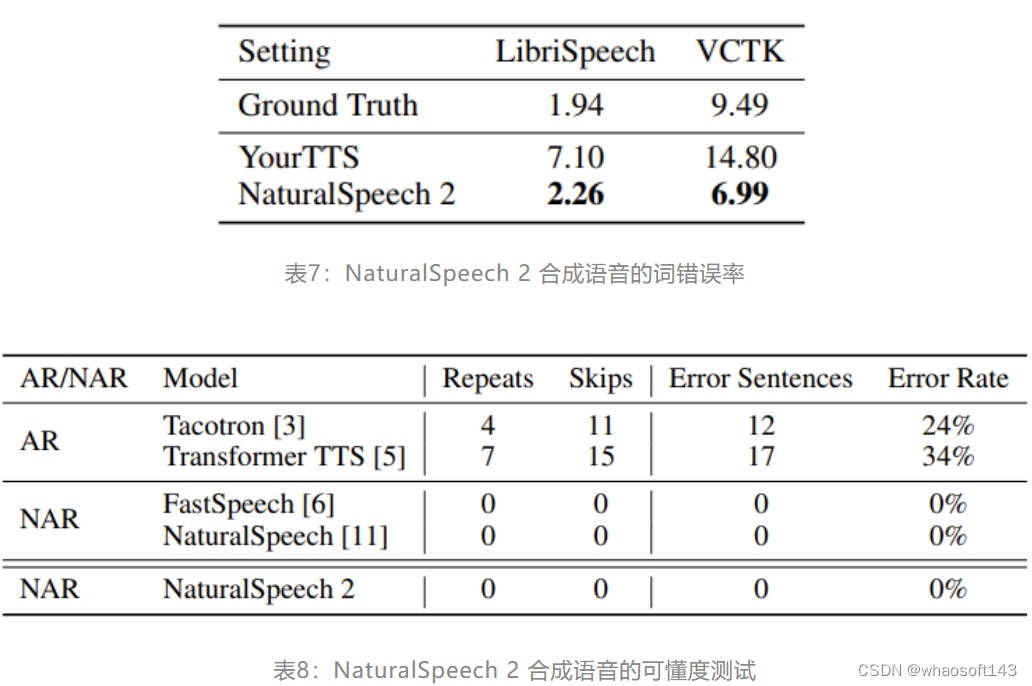
在稳定度方面,相较于既有的 TTS 模型,NaturalSpeech 2 的表现也更为优异,如表7和表8所示。
以下是零样本语音合成的示例:
输入文本:His death in this conjuncture was a public misfortune.
声音发不了.....
研究员们还从互联网上收集了歌声数据,并将其与语音数据混合起来,共同训练模型。令人惊喜的是,无论是语音还是歌声提示,NaturalSpeech 2 都可以进行零样本歌声合成。欢迎点击链接:https://speechresearch.github.io/naturalspeech2/,一起听一听更多 AI 合成的语音和歌声吧!
#One-Step Diffusion Distillation through Score Implicit Matching
单步生成:让扩散模型实现高速无损的内容生成
本篇分享 NeurIPS 2024 论文One-Step Diffusion Distillation through Score Implicit Matching,单步生成:让扩散模型实现高速无损的内容生成。
- 团队成员:Weijian Luo, Zemin Huang, Zhengyang Geng, J. Zico Kolter, Guo-jun Qi
- 相关论文:https://arxiv.org/abs/2410.16794
- 项目网站:https://github.com/maple-research-lab/SIM
引言
扩散模型(Diffusion Models, DMs)是一类通过逐步添加噪声来破坏数据分布并逆向生成数据的模型。这类模型在图像生成、文本到图像生成等领域表现出色,但其生成过程往往需要几十步的采样步骤,造成高昂的计算成本和较长的响应时间。这在实际应用中,尤其是在实时生成或移动设备上,是一个重要的限制。
随着对生成模型效率的需求不断增加,研究人员开始探索如何将预训练的扩散模型转化为高效的单步或少步生成模型。我们的研究聚焦于扩散模型蒸馏(Diffusion Distillation),通过优化策略实现单步生成图像,同时尽量保留与原始模型相近的生成能力。
单步扩散算法
我们提出的隐式得分匹配算法可以将多步推理的扩散模型蒸馏为单步推理的生成模型,并且在蒸馏后没有任何图像生成质量上的损失。这一算法的关键思想是推导出一个可优化的训练目标,同时其梯度与不可直接优化的基于得分函数的散度相同。一般的基于得分函数的散度定义如下,它可以用于将单步生成器的分布和预训练教师模型的分布进行匹配以优化单步生成器:

但实际由于这个损失函数很难直接优化,因此我们通过推导出得分散度梯度定理获得了一种等效但易于处理的训练目标,用于优化单步生成器,这一等效的训练目标可以表示为:
![]()
我们最终的训练算法包含了如下两个阶段的交替训练:
- 在线扩散模型更新:在这一阶段,我们固定单步生成模型的参数,利用扩散模型的损失来优化在线模型。
- 学生模型参数更新:在这一阶段,我们固定在线扩散模型的参数,通过上文提出的损失函数来优化单步生成器。
实验结果
为了验证隐式得分匹配这一蒸馏算法的有效性,我们在多个设置上进行了大量实验,包括小规模的CIFAR10 数据集和开放数据集上训练的文生图模型 PixArt-α 实验结果显示,我们的单步生成模型在无条件和有条件的生成中均显著优于其他蒸馏模型,达到2.06/1.96的 FID 值,显著优于其他蒸馏方法。

在文本到图像生成的实验中,我们选择了 DiT 架构的 PixArt-α 模型作为教师模型,应用我们的算法蒸馏出了 SIM-DiT-600M。与其他经过少步蒸馏的扩散模型相比,我们只需一步就能生成高质量的图像,并在多个基准测试中取得了优异的性能。这些结果展示了我们的蒸馏算法在快速生成和高质量样本方面的潜力。

下图我们对比了 SIM-DIT-600M 和其他单步与少步生成的蒸馏工作,最左侧是我们生成的图像,可以看出我们的蒸馏模型与其他的模型相比具有更强的生成质量以及美学效果。

下图最右侧是 LCM-PixArt-α生成的结果,左边两侧的图由教师模型 PixArt-α和我们蒸馏后的模型生成并打乱排列顺序。我们的蒸馏后的模型有几乎和原模型相当的生成质量,并且将推理步数从几十步降低到只需要单步推理。

结论
本文介绍了 Score Implicit Matching(SIM) 方法在扩散模型蒸馏中的应用,展示了如何通过新颖的基于得分函数的散度训练来实现单步生成。实验结果验证了 SIM 在多个生成任务 中的优越性能,标志着在快速生成和高质量样本方面的一个重要进展。未来,随着对 SIM 方法的进一步研究和优化,我们相信其将在更多领域展现出更大的应用潜力,推动生成模型的发展。
#THE FLOW MAP OF THE FOKKER-PLANCK EQUATION DOES NOT PROVIDE OPTIMAL TRANSPORT
扩散模型、最优传输存在什么关系?法国数学家4页论文引网友围观
扩散模型和最优传输之间到底存在怎样的联系?对很多人来说还是一个未解之谜。
但有一点很清楚的是:在相似的数据集上训练的不同扩散模型倾向于恢复出相似的映射关系。
这就提出一个问题:如果这些映射关系不是最优传输(OT,Optimal Transport )映射,那么它们到底在什么意义上是最优呢?
2022 年,博科尼大学助理教授 Hugo Lavenant 与里昂第一大学教授 Filippo Santambrogio 合作,在论文《 THE FLOW MAP OF THE FOKKER-PLANCK EQUATION DOES NOT PROVIDE OPTIMAL TRANSPORT 》中探讨了流模型在最优传输框架中的应用,并提供了一个反例,表明在某些情况下,流模型并不能实现最优传输。
论文地址:https://cvgmt.sns.it/media/doc/paper/5469/counterexample_flow_v3.pdf
在这篇文章的摘要部分,作者表示,Khrulkov 和 Oseledets 在先前研究中(论文:Understanding DDPM Latent Codes Through Optimal Transport)提出了一个猜想,该猜想认为通过积分 Fokker-Planck 方程的 Wasserstein 速度得到的 ODE 流,可以获得一个最优传输映射。
然而,在 Kim 和 Milman 的论文中《A generalization of Caffarelli’s contraction theorem via (reverse) heat flow》,这一结果被认为是错误的,但没有提供证明。Hugo Lavenant、Filippo Santambrogio 的这篇论文正好展示了 Khrulkov 和 Oseledets 所声称的结果不能成立。
但这篇文章过于晦涩难懂,全篇论文看下来几乎都是推导公式且篇幅又长。
为此,法国数学家 Gabriel Peyré 在论文《 Diffusion models and Optimal Transport 》中给出了一个很好的概括,文章重述了 Hugo Lavenant 和 Filippo Santambrogio 关于简洁证明的主要内容,即一般情况下,扩散模型不能定义最优传输映射。


地址:https://github.com/mathematical-tours/mathematical-tours.github.io/blob/971ddb3aab5803c7a4abef122f878292f6a6c25d/book-sources/diffusion-models/note-diffusion-ot.pdf
接下来,我们看看这篇文章讲了什么内容。
生成模型旨在在参考分布 α(通常是各向同性高斯分布)和数据分布 β 之间构建传输映射 T。用 T♯α 表示 α 被 T 向前推进(如果 α 是由 Dirac 质量在 x_i 处构成的,那么 T♯α 是由 Dirac 质量在 T(x_i)处构成的)。
因此,目标是找到 T,使得 T♯α = β 。很明显,对于任何 β,这样的映射总是存在的,但找到 T 的明确构造方法却出奇地困难。
这里有两种标准方法,分别是最优传输和集成扩散过程的逆向积分伴随的平流场。
最优传输
最优传输通过求解 Monge 问题求出 T:

1991 年,Brenier 著名定理表明这个映射是存在的,且是唯一的,并且可以写成一个凸函数 T =∇φ 的梯度。根据质量守恒定律,即 T♯α = β ,等价于说 φ 解决了 Monge-Ampère 方程:

逆向 Flow Map
扩散模型需要考虑 β_0 = β 和 β_∞= α =N (0,Id) 之间的差值 β_t ,求解过程定义如下:

请注意,使用 y 来表示空间变量,因为演化是逆向进行的,即从数据 β 到后一个变量 α,它收敛于 β_∞= α。

将方程写成离散形式:

这表明,如果已经计算出了 β_t,那么这种演化可以根据向量场 v 演化粒子来获得。

映射 S_t 就是 flow map :

逆向 Flow Map 不是最优传输
人们很自然地想知道逆向 Flow Map

是否是 (1) 的解。在一维情况下,S_t 定义微分同胚( diffeomorphism),因此

是单调的,

也是单调的。因此,它是凸函数的梯度,根据 Brenier 定理使其最优。如果 β 是高斯分布,直到空间旋转以使协方差对角化,则扩散映射由沿每个轴的单调映射定义,并且也是最优传输。
Lavenant 和 Santambrogio 通过矛盾证明,一般来说,逆向 flow map 并不是最优传输。他们构造了一个接近各向同性高斯 α 的 β,但他们没有证明 β 的猜想是错误的,而是证明存在一些 t ≥ 0,使得从 α 到 β_t 的逆向 Flow Map T_t 不是最优传输。他们实际上表明,对于某些 t_0 > 0,T_t 并不是所有 t ∈ (0, t_0] 的最优传输。
用 S_t 表示从 β_0 = β 到 β_t 的 Flow Map。如果猜想成立,则从 α 到 β_t 的逆向 Flow Map T_t 是所有 t 的最优传输。根据 Flow Map 的构成规则,该 Map 为:

并且

目标是证明:如果 β 选择得当(具体来说,非常接近 α,且特定的二阶和四阶对数密度导数为 0),那么 T_t 是所有 t 的最优传输会导致矛盾。根据 Brenier 定理,T_t 是最优传输意味着它是凸函数的梯度,这相当于:
![]()
结合:
- 对 (7) 对 t 求微分
- 对流 ODE (4) 对 x 求微分
然后在 t = 0 时评估所获得的方程,Hugo 和 Filippo 通过显式计算表明,这会导致:

利用基本性质:A、B 对称且 AB 对称

则 (8) 意味着:
![]()
为了达到矛盾,假设 G (y) 和 H (y) 对于所有 y 都是可交换的。由于

并且 T 和 S 是逆最优传输映射,因此将

表示为 ψ 凸。Monge-Amp`ere 方程 (2) 意味着:

为了使 β 接近 α,请考虑:对于较小的 ε,

在泰勒级数中展开,经过一些计算:

着眼于 y = 0,目标是通过设计 h 来达到矛盾,使得

和

不能交换。在 0 附近,h 必须至少是 4 次多项式。二维情况下的一个示例是:

产生:

#SVDQuant
扩散模型部署有新解,直接量化为4bit?韩松团队等提出:16GB笔记本上加速8.7 倍
在 12B FLUX.1-dev 上,与 BF16 模型相比,它减少了 3.6 倍的 memory。通过消除 CPU offloading,在 16GB 笔记本电脑 4090 GPU 上时,它比 16 bit 模型提供了 8.7 倍的加速,比 NF4 W4A16 基线快 3 倍
量化文生图扩散模型的成功范式。
Diffusion Model 的部署一直都是个很大的问题,因为随着这种模型越做越大就需要更多的 memory 造成更大的时延,而这些对于部署而言都是不利的。
本文给出了一个很激进的量化方案:把扩散模型的 weight 和 activation 都量化为 4 bit。 在如此激进的量化层面上,weight 和 activation 都高度敏感,传统 LLM 的 post-training quantization 方法,如 smoothing 就不好使了。
因此,本文提出了一种 4-bit 量化算法:SVDQuant。SVDQuant 的核心操作不像 smoothing 那样在 weight 和 activation 之间重新分配异常值 (Outlier),而是使用一个 low-rank 分支来吸收这些异常值。SVDQuant 首先通过将异常值从 activation 转移到 weight 来巩固异常值,然后使用高精度的 low-rank 分支通过奇异值分解 (SVD) 获取权重异常值。这个过程使得 weight 和 activation 的量化都得到了简化。但由于激活的额外数据移动,简单地独立运行 low-rank 分支会产生显著的额外开销,使得量化很难获得实际加速。
为了解决这个问题,本文 co-design 了推理引擎 Nunchaku,把 low-rank 分支的 kernel 吸收到 low-bit 分支中,切断冗余的内存访问。它也可以无缝支持现成的低秩适配器 (LoRA),而无需重新量化。作者在 SDXL, PixArt-Σ, 和 FLUX.1 上都进行了实验。12B FLUX.1 模型的内存使用量减少了 3.5 倍,在 16GB 笔记本电脑 4090 GPU 上的 4-bit权重量化基线上实现了 3.0 倍的加速。

图1:SVDQuant 是一种训练后量化,用于 4 bit 权重和激活,可以很好地保持视觉保真度。在 12B FLUX.1-dev 上,与 BF16 模型相比,它减少了 3.6 倍的 memory。通过消除 CPU offloading,在 16GB 笔记本电脑 4090 GPU 上时,它比 16 bit 模型提供了 8.7 倍的加速,比 NF4 W4A16 基线快 3 倍
下面是对本文的详细介绍。
本文目录
1 SVDQuant:吸收异常值量化 4-bit 扩散模型
(来自 MIT 韩松团队,NVIDIA)
1 SVDQuant 论文解读
1.1 SVDQuant 研究背景
1.2 量化过程介绍
1.3 问题定义
1.4 SVDQuant 方法介绍
1.5 推理引擎 Nunchaku
1.6 SVDQuant 支持的模型数据集和评价指标
1.7 实验结果
1 SVDQuant:吸收异常值量化 4-bit 扩散模型
论文名称:SVDQuant: Absorbing Outliers by Low-Rank Components for 4-Bit Diffusion Models
论文地址:
http://arxiv.org/pdf/2411.05007
Quantization Library:
http://github.com/mit-han-lab/deepcompressor
Inference Engine:
http://github.com/mit-han-lab/nunchaku
1.1 SVDQuant 研究背景
扩散模型通过在海量数据上进行训练,可以从简单的文本提示生成令人惊叹的图像。为了追求更高的图像质量和更精确的文本到图像对齐,研究者开始扩大扩散模型。Stable Diffusion 1.4 只有 800M 参数,而 SDXL 扩展到 2.6B 参数。AuraFlow v0.1[1]进一步扩展为 6B 参数,最新模型 FLUX.1[2]扩展到了 12B 参数。如图2所示,与大语言模型 (LLM) 相比,扩散模型的计算量要大得多。它们的计算成本随模型大小的增加而迅速增加,给现实世界的模型部署带来了令人望而却步的内存和时延障碍,特别是对于需要低延迟的交互用例。

图2:LLM 和扩散模型的计算量 vs. 参数量。LLM 的计算是用 512 的 context 和 256 输出 tokens 来衡量的,扩散模型的计算是针对单步的
由于摩尔定律放缓,硬件供应商转向低精度推理以维持性能提升。例如,NVIDIA 的 Blackwell Tensor Cores 引入了一个新的 4-bit floating point (FP4) 精度,与 FP8 相比,性能翻倍。因此,使用 4-bit 推理来加速扩散模型很有吸引力。在 LLM 领域,研究人员利用量化来压缩模型大小并提高推理速度。
但是,扩散模型与 LLM 不同,LLM 的时延主要受权重加载的限制,对于小 Batch size 的扩散模型计算量仍然很大。仅仅量化权重不可以加速扩散模型。为了实现加速,weight 和 activation 必须量化为同等位宽。否则,较低精度的计算性能优势将被抹除。
因此,本文专注于将扩散模型的 weight 和 activation 量化为 4 bits。这种具有挑战性和激进的方案往往容易出现严重的质量下降。本文提出了一种新的通用量化范式 SVDQuant。
其可以用下图3概括。SVDQuant 的核心思想是引入一个低成本的分支来吸收两边的异常值。为了实现这一点, 首先通过平滑将它们从激活 迁移到权重 来聚合异常值。然后将奇异值分解 (SVD) 应用于更新的权重 , 将其分解为低秩分支 和残差 。low-rank 分支以 16-bit 运行, 允许仅将残差量化为 4 位, 这显着减少了异常值幅度。

图3:SVDQuant 方案。(a) 最初,激活 X 和权重 W 都包含异常值,这使得 4 位量化具有挑战性。(b) 将异常值从激活迁移到权重,从而得到新的激活和权重。虽然新的激活更容易量化,但新的权重现在变得更加困难。(c) SVDQuant 进一步将权重分解为低秩分支和残差分支。低秩分支 16 位运行,减轻了量化难度
但是直接运行 low-rank 分支会产生大量的内存访问开销,抵消了 4-bit 推理加速。为了克服这个问题,我们一起设计了一个专门的推理引擎 Nunchaku,将低秩分支计算融合到 4-bit 量化和计算 Kernel 中。这种设计能够在有额外的分支的情况下实现推理加速。
1.2 量化过程介绍
量化是加速网络中线性层的有效方法。给定一个张量 ,量化过程定义为:

式中, 是 的 low-bit 表示, 是比例因子, 是最大量化值。对于有符号的 位整数量化, 。对于 1 位尾数和 2 位指数的 4 位浮点量化, 。因此,去量化张量可以表述为 。对于输入 和权重 的线性层, 其计算可以近似为:

相同的近似适用于卷积层。为了加快计算速度, 现代算术逻辑单元需要具有相同位宽的 和 。
本文专注于用于加速的 W4A4 量化,其中权重和激活的异常值都有很大的障碍。抑制这些异常值的传统方法包括量化感知训练 (QAT)[3]和 Rotation[4][5][6]。QAT 需要大量的计算资源,特别是对于超过 10B 参数的模型 (例如,FLUX.1)。由于扩散模型中使用自适应归一化层,Rotation 不适用。归一化权重由于需要运行时候在线生成,所以没办法离线集成到投影层权重里。所以,在线生成的激活和权重都会产生显著的计算开销。
1.3 问题定义
SVDQuant 的核心思想是引入额外的 low-rank 分支,可以吸收 weight 和 activation 中的量化困难。最后,作者提供了一个具有 Kernel 融合的协同设计推理引擎 Nunchaku,以最小化 4 bit 模型中 low-rank 分支的开销。
设线性层为 , 权重为 , 则量化误差为:

式中, 是 Frobenius 范数。
Proposition 1 (误差分解): 量化误差可以分解为:

从命题中可以看出, 误差受权重和输入的大小 以及它们各自的量化误差 的限制。为了最小化整体量化误差, 目标是优化这4项。
1.4 SVDQuant 方法介绍
Smoothing 是减少异常值的有效方法。可以通过缩小输入 并使用每通道平滑因子 相应地调整权重矩阵 来平滑激活中的异常值。如图 4(a)(c) 所示, 平滑输入 表现出减小的幅度和更少的异常值,从而导致较低的输入量化误差。然而,在图 4(b)(d) 中,转换后的权重 在幅度和异常值的存在方面都显着增加,这反过来又提高了权重量化误差。因此,整体误差减少有限。

图4:PixArt-Σ 中输入和权重的示例值分布,λ 是平滑因子,红色表示异常值。最初,权重和激活值都包含大量异常值。Smoothing 之后,激活的异常值减少,权重展示出更多异常值。减去 SVD low-rank 分支之后,剩下的部分的范围更窄,并且不受异常值的影响
用 low-rank 分支吸收增加的权重异常值。 本文核心的做法是引入一个 16-bit low-rank 分支, 并进一步将权重量化难度迁移到该分支。具体来说,将转换后的权重分解为 ,其中 和 是秩 的两个低秩因子, 是残差。那么 可以近似为:

与直接进行 4-bit 量化, 即 相比, 本文的方法首先以 16-bit 精度计算 low-rank 分支 , 然后用 4-bit 量化逼近残差 。实践中, 一般设置 , 通常为 16 或者 32。因此, low-rank 分支的附加参数和计算可以忽略不计。现在, 仍然需要仔细的系统设计来消除冗余内存访问。
根据上式5,量化误差可以写成:

根据命题 4.1, 由于 已经没有异常值, 因此只需要专注于优化 及其量化误差 。
Proposition 2 (量化误差界): 对于式1 中描述的任何张量 和量化方法,如 。假设 的元素服从正态分布, 则有:

其中 表示 中的元素数。
因此,量化误差 受残差 大小的限制。
因此,本文目标是找到使 最小化的最优 ,这可以通过简单的奇异值分解 (SVD) 来解决。给定 的 SVD,最优解为
图5 绘制了原始权重 、转换后的权重 和残差 的奇异值分布。原始权重 的奇异值高度不平衡。平滑后,转换后的权重 的奇异值分布更加陡峭,前几个值明显更大了。

图5:不同变量的前 64 个奇异值分布。转换后的矩阵的前 32 个奇异值表现出陡峭的下降,而其余的值更渐进
通过去除这些主导值, Eckart-Young-Mirsky 定理表明残差 的大小显着降低。因为有 , 原始的幅值为 , 其中 为 的第 个奇异值。
此外, 实践表明, 与 相比, 表现出更少的异常值, 具有显着压缩的值范围, 如图 4(d) (e)所示。在实践中,可以通过分解 并相应地调整 多次迭代来进一步减少量化误差,然后选择误差最小的结果。
因此,SVDQuant 的思路:
- 原始模型中,根据 Proposition 1 得到的误差分为 4 项,都要考虑。

- 使用了 Smoothing 操作之后, 此时 已经基本没有异常值了, 但是此时 中的异常值加剧。还是不好。

- 使用了本文提出的 low-rank 分支之后,将误差表达式变为了 5 式,继而将量化误差等效为 7 式 (由于此时 已经基本没有异常值了)。

- 根据 Proposition 2 得到 7 式的量化误差相当于以残差 为上界。
- Eckart-Young-Mirsky 定理表明残差 大小相比原始的幅值 显著降低。
因此,使用 Smoothing 操作和 Low-Rank 分支以后,得到的量化误差显著降低了。
1.5 推理引擎 Nunchaku
尽管 low-rank 分支理论上引入的计算可以忽略, 但它作为一个单独的分支运行会产生显著的延时一大约 的 4-bit 分支延迟, 如图 6 所示。这是因为, 对于一个小的秩 , 即使计算成本大大降低,输入和输出激活的数据大小保持不变,把瓶颈从 Computation 转移到 Memory Access。这种情况, 当 GPU 的 L2 缓存装不下激活值的时候情况会更严重。比如, QKV 投影的 low-rank 分支中向上投影要慢很多, 因为其输出超过了可用的 L2 缓存, 并导致额外的加载和存储操作到 DRAM。
幸运的是,作者观察到低秩分支中向下投影 与低位分支中的量化内核共享相同的输入,而向上投影 与 4-bit 计算 Kernel 共享相同的输出, 如图 7 所示。通过将下投影与量化 Kernel 融合,将上投影与4位计算 Kernel 融合, low-rank 分支可以与低 bit 分支共享激活, 消除额外的内存访问, 并将内核调用的数量减半。因此, 低秩分支仅增加了 5 10% 的延迟, 使其几乎免成本。

图6:直接运行 rank 为 32 的 low-rank 分支会引入 57% 的延时开销,因为在 Down Project 中额外读取 16 位输入和 Up Projection 中额外写入 16 位输出。本文的 Nunchaku 引擎通过内核融合优化了这种开销

图7:向下投影和量化 Kernel 使用相同的输入,而向上投影和 4-bit 计算 Kernel 共享相同的输出。为了减少数据移动开销,我们将前两个内核和后两个 Kernel 融合在一起
1.6 SVDQuant 支持的模型数据集和评价指标
模型
1) FLUX.1
FLUX.1[7]是基于 SoTA 开源 DiT 的扩散模型。它由 19 个 joint attention block[8]和 38 个 parallel attention block [9]组成,总共 12B 参数。作者评估了两个模型,分别是 50 步引导蒸馏 (FLUX.1-dev) 和 4 步时间步蒸馏 (FLUX.1-schnell) 变体。
2) PixArt-Σ
PixArt-Σ[10]是另一个基于 DiT 的模型。它不是使用联合注意力,而是堆叠由 self-attention、cross-attention 和 FFN 组成的 28 个 attention block,相当于 600M 参数。作者在默认的 20 步设置中对其进行评估。
3) SDXL
Stable Diffusion XL (SDXL)[11]是一种广泛使用的基于 U-Net 的模型,具有 2.6B 参数。它预测具有 3 个分辨率尺度的噪声。最高分辨率阶段完全由 ResBlocks 处理,而其他 2 个阶段联合使用 ResBlocks 和 attention 层。与 PixArt-Σ 一样,SDXL 使用 cross attention 进行文本调节。作者评估其 30 步变体以及它的 4 步蒸馏变体 SDXL-Turbo[12]。
数据集
继之前的工作[13][14][15]之后,作者随机抽取 COCO Captions 2024[16]中的提示进行校准。为了评估本文方法的泛化能力,作者采用了两种不同的提示集,具有不同的样式进行基准测试:MJHQ-30K[17]和 Densely Captioned Images (DCI)[18]的 summarized 版本 (sDCI)。
作者将 SVDQuant 与以下 Post-Training Quantization (PTQ) 方法进行比较:
- 4 位 NormalFloat (NF4) 是仅权重量化的数据类型[19]。它假设权重服从正态分布,并且是信息论最优的 4-bit 表示。作者使用社区量化的 NF4 FLUX.1 模型[20]作为基线。
- ViDiT-Q[15]使用 per-token 量化和 smoothing 缓解不同 batch 和 token 的异常值,并在 PixArt-Σ 上实现无损 8-bit 量化。
- MixDQ[14]识别 text embedding 的句首标记中的异常值,并通过 16-bit 预计算保护它们。这种方法最多可实现 W4A8 量化,SDXL-Turbo 的性能退化可以忽略不计。
- TensorRT[21]包含一个行业级别的 PTQ 工具包,用于将扩散模型量化为 8-bit。它使用 smoothing,并且仅使用百分位数方案在选定的时间步长范围内校准激活。
评价指标
- 对于图像质量评估,使用 FID[22]来衡量生成的图像和真实图像之间的分布距离。
- 使用 Image Reward 来近似生成图像的人工评分[23]。
- 使用 LPIPS (越低越好) 来衡量感知相似度[24]和峰值信噪比 PSNR 来衡量 16-bit 模型中图像的数值相似度。
实现细节。对于 8-bit 设置,作者对 activation 使用 per-token dynamic 量化,对 weight 使用 per-channel 的量化,low-rank 分支为 16。对于 4-bit 的设置,作者对 weight 和 activation 都采用 per-group 对称量化,low-rank 分支为 32。对于 FLUX.1 模型,自适应归一化中线性层的输入保持在 16-bit (即 W4A16)。对于其他模型,交叉注意中的键和值投影保持在 16-bit,因为它们的延迟仅占总运行时间的 5% 以上。
1.7 实验结果
作者在图 8 中报告了各种模型和精度级别的定量结果,并在图 9 中展示了相应的 4-bit 的定性比较。在所有的模型中,本文的 8-bit 结果可以完美地反映 16-bit 结果,实现了高于 21 的 PSNR,击败了所有其他 8-bit 基线。在 FLUX.1-dev 上,本文的 INT8 PSNR 在 MJHQ 上甚至达到了 27。
对于 4-bit 量化,在 FLUX.1 上,本文的 SVDQuant 在 Image Reward 上超过了 NF4 W4A16 基线。在 schnell 变体上,Image Reward 甚至超过了原始 BF16 模型,这表明人类偏好更强。
在 PixArt-Σ 上,虽然本文 INT4 Image Reward 显示出轻微的退化,但 FP4 模型获得了比 FP16 模型更高的分数。这可能是因为 PixArt-Σ 的小尺寸 (600M 参数),它已经高度紧凑,并且受益于较小的 group size。值得注意的是,本文的 INT4 和 FP4 结果在所有指标上都始终优于 ViDiT-Q 的 W4A8 结果。
对于基于 UNet 的模型,在 SDXL-Turbo 上,本文的 4-bit 模型显着优于 MixDQ 的 W4A8 结果,本文的 FID 分数与 FP16 模型相当,表明性能没有损失。在 SDXL 上,本文的 INT4 和 FP4 结果都实现了与代表了 8 位 SoTA 的 TensorRT 的 W8A8 性能相当。

图8:不同模型的定量质量比较。IR 表示 ImageReward。8-bit 结果与 16-bit 模型的质量密切相关。此外,本文 4-bit 结果优于其他 4-bit 基线,有效地保留了 16-bit 模型的视觉质量

图9:MJHQ 的定性视觉结果。Image Reward 是在整个数据集上计算的
显存节省和加速
在图 10 中,作者报告了 FLUX.1 的测量模型大小、内存节省和加速。

图10:SVDQuant 将 12B FLUX.1 的模型大小减少了 3.6 倍。引擎 Nunchaku 进一步将 16-bit 模型的显存使用量减少了 3.5 倍,并在桌面和笔记本电脑 NVIDIA RTX 4090 GPU 上都比 NF4 W4A16 提供了 3.0 倍的加速。在笔记本电脑 4090 上,通过消除 CPU offloading,它总共实现了 10.1 倍的加速
本文的 INT4 量化将原始 Transformer 大小从 22.2 GiB 降低到 6.1 GiB,包括 0.3 GiB 的 low-rank 分支,整体减少了 3.6 倍。
由于 weight 和 activation 都被量化,与仅 NF4 权重量化的变体相比,本文的推理引擎 Nunchaku 甚至节省了更多的内存占用,并且在桌面级和笔记本电脑级 NVIDIA RTX 4090 GPU 上提供了 3.0 倍的加速。
值得注意的是,虽然原始的 BF16 模型需要 16GB 笔记本电脑 4090 上的每层 CPU offloading,但本文的 INT4 模型完全适合 GPU 内存,通过避免 offloading,带来了 10.1 倍的加速。作者预计 NVIDIA 的下一代 Blackwell GPU 上 FP4 量化模型的加速比更大,因为它们固有地支持组量化的微缩放,而不需要专门的 GPU Kernel。
集成 LoRA
之前的量化方法需要融合 LoRA 分支并在集成 LoRA 时重新量化模型。相比之下,本文的 Nunchaku 消除了冗余内存访问,允许添加单独的 LoRA 分支。在实践中,可以通过稍微增加 rank 将 LoRA 分支融合到本文的 low-rank 分支中,进一步提高效率。图 11 展示了一些可视化示例,将 5 种不同风格的 LoRA (现实主义、Ghibsky 插图、动漫、儿童草图和 Yarn Art)应用于本文的 INT4 FLUX.1-dev 模型。INT4 模型成功地适应了每种风格,同时保留了 16-bit 版本的图像质量。

图11:本文的 INT4 模型与现成的 LoRA 无缝集成,无需重新量化。在应用 LoRA 时,它与原始 16 位 FLUX.1-dev 的图像质量相匹配
增加 rank 的影响
图 12 显示了 PixArt-Σ 上 SVDQuant 中不同 rank r 的结果。将 rank 从 16 增加到 64 可以显着提高图像质量,但会增加参数和延迟开销。在本文的实验中,作者选择了 32 的 rank,它提供了不错的质量,开销很小。

图12:在 SVDQuant 中增加低秩分支的秩 r 可以提高图像质量,但它也会导致更高的参数和延时开销
#l-DAE
扩散模型也可以作为优秀的特征提取器,CV大神何恺明,也来搞扩散模型(Diffusion Model)了!
大神最新论文刚刚挂上arXiv,还是热乎的:解构扩散模型,提出一个高度简化的新架构l-DAE(小写的L)。
并且通过与何恺明在视觉自监督学习领域的代表作MAE(Masked Autoencoder)对比,更好地理解了扩散模型内部的工作原理。
不仅如此,这篇论文还发现在扩散模型中,去噪过程比扩散过程更重要。
这项工作阵容非常豪华,不仅有何恺明坐镇,合著作者中还有纽约大学计算机科学助理教授、CV大牛谢赛宁。
以及曾和他共同发表ConvNeXT工作的刘壮——他同时是DenseNet的共同一作。
给扩散模型开刀
团队认为,尽管去噪扩散模型在生成任务上表现出色,但它们在表示学习方面的能力尚未得到充分探索。
为此,他们找到一个新颖的研究方法:
希望通过解构扩散模型,将其逐步转化为类似于MAE的架构,以更深入地理解其在自监督学习中的表示学习能力。
先来一图概括解构过程:
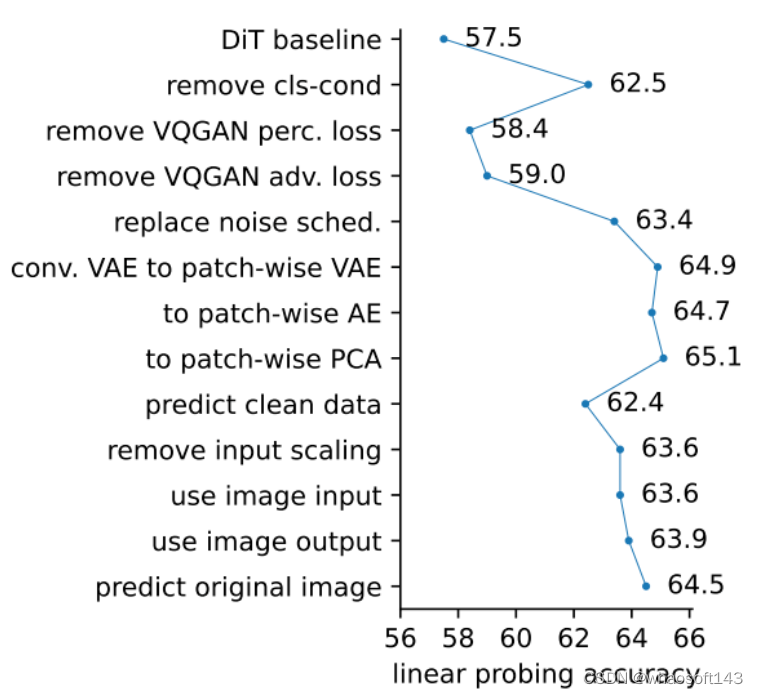
(如果你也觉得这个图很眼熟,没错,就是谢赛宁在代表作ConvNeXT中使用的同款。)
以使用了VQGAN tokenizer的DiT模型作为基线,接下来介绍团队如何一刀一刀把它改造成更简化版本的。
- 移除类别条件
首先移除扩散模型中基于类别标签的条件,很显然,有条件标签与自监督学习的目标不符。
这一步骤显著提高了线性探测(linear probing)的准确率。
- 解构VQGAN
接下来移除原本采用的VQGan感知损失和对抗损失,在自监督学习中,这两种损失函数都不是必须的。
感知损失涉及到对类别标签的依赖,这与自监督学习的目标不符;对抗损失涉及对生成过程的优化,而不是直接学习数据的表示。移除两种损失函数后,模型表现受到影响下降,但下一步又一把拉了回来。
- 替换噪声调度器
在原始扩散模型中,噪声调度通常遵循一个复杂的时间步序列。团队采用了一种更简单的线性衰减策略,让噪声水平在训练过程中线性地从最大值衰减到零,而不是遵循复杂的非线性衰减路径。
这种简化的噪声调度策略使得模型在训练过程中更多地关注于较干净的数据,而不是在高度噪声的数据上花费太多计算资源。

- 简化tokenizer
作者进一步改造了扩散模型中的tokenizer,这是将输入图像映射到潜在空间的关键组件。
他们比较了几种不同的方法,包括卷积变分自编码器(conv. VAE)、基于块的变分自编码器(patch-wise VAE)、基于块的自编码器(patch-wise AE)和基于块的主成分分析(patch-wis PCA)。

最终发现,即使是简单的PCA也能有效地工作。
通过逆PCA(inverse PCA)将输入图像投影到潜在空间,添加噪声,然后再将噪声图像投影回图像空间。这种方法允许模型直接在图像上进行操作,而不需要tokenizer。
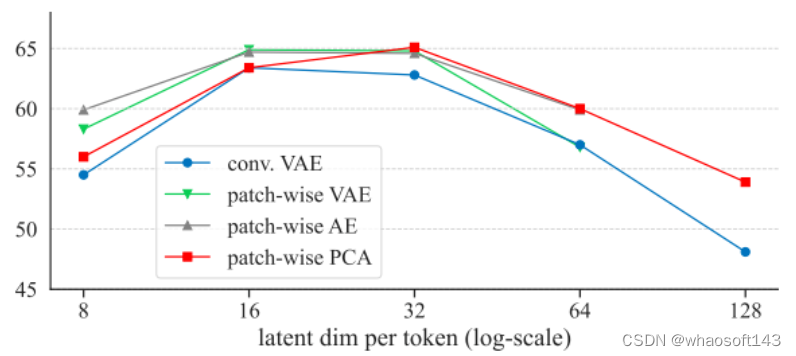
- 改变预测目标
与现代扩散模型通常预测噪声不同,团队让模型预测干净的数据,通过调整损失函数实现。
最后一步,作者又让模型直接预测原始图像,而不是经过PCA编码的潜空间。这涉及到在PCA空间中计算残差,并在损失函数中对PCA重建误差进行加权。
最终,整个模型的工作流程就非常简单了:
输入是一张有噪声的图片,噪声添加在PCA潜空间里。输出是原始的干净图片。
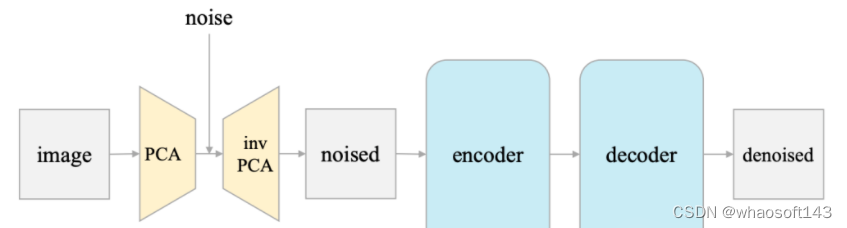

经过这一系列改造,团队发现:
- 模型的表示能力主要来源于去噪过程,而非扩散过程。
- 低维潜在空间非常关键,允许模型学习到数据的压缩表示。
并且提出只有很少的现代组件对学习良好的表示至关重要,而许多其他组件是非必要的。
经过改造简化后的模型称为l-DAE,在自监督学习任务中表现出竞争力,同时在结构上更接近于传统的DAE(去噪自编码器)。
在实验中,MAE和l-DAE两种自编码器方法表现都超过了MoCo v3,在ViT-B(86m参数)上,l-DAE表现与MAE相当,但在更大规模的ViT-L(304M)上还所有落后。
最后,团队在简短的结论中提出:
希望我们的发现能够重新激发对基于去噪方法在当今自监督学习研究领域的兴趣。
两位作者已离开Meta
论文一经公布,几位作者就激情当起了自个儿的首批自来水(doge)。
谢赛宁在推特上转发了别人对I-DAE的分享和讨论,并表示:
越来越多研究表明,扩散模型也可以作为效果优秀的特征提取器来使用。
作者刘壮也在一旁开麦,表示扩散模型这东西,不仅仅能做生成相关的工作:
还有开发者惊讶地发现,居然还有人使用主成分分析,可有一阵子不见了。
不过,大神们的工作刚放出来嘛,还有待大家多多传播和具体感知。除这项最新研究涉及了MAE外,何恺明在提出代表作MAE后,还在此基础上还发表了一系列研究。
例如,提出了一个用来训练CLIP的快速、简单且有效的方法FLIP(Fast Language-Image Pre-training),对CLIP架构引入类似于MAE的思路。
只在模型的极简结构上,施加了一个简单的mask,就让新模型的速度快了3.7倍,同时,性能还可以做到不降反升。
此外,还提出了不对ViT引入分层设计,只用普通ViT就能搞定目标检测的ViTDet。
他们使用普通ViT作为骨干网络,基于MAE方法进行预训练,由此得到的ViTDet能与之前所有基于分层骨干网络的先进方法竞争。
其他学者同样将MAE方法用在了众多项目之中,MAE开山论文目前谷歌学术引用量达4174次。
论文地址:
https://arxiv.org/pdf/2401.14404.pdf
参考链接:
https://twitter.com/sainingxie/status/1750741794080407893
#qvpo
打破扩散模型与在线强化学习结合的瓶颈!引入Q变分训练的在线扩散强化学习算法
该工作引入Q变分训练, 打破了扩散模型与在线强化学习结合的瓶颈,更好地利用了扩散模型强大的多模生成能力和探索性,极大提高了强化学习算法的样本效率和最终表现。
Arxiv地址:https://arxiv.org/pdf/2405.16173
项目主页:https://dingsht.tech/qvpo-webpage/
代码链接:https://github.com/wadx2019/qvpo
本文介绍上科大YesAI Lab 发表在NeurIPS 2024关于在线强化学习的工作《Diffusion-based Reinforcement Learning via Q-weighted Variational Policy Optimization》。该工作引入Q变分训练, 打破了扩散模型与在线强化学习结合的瓶颈,更好地利用了扩散模型强大的多模生成能力和探索性,极大提高了强化学习算法的样本效率和最终表现。该工作上海科技大学2021级研究生丁枢桐为第一作者,由石野教授指导完成。
研究背景:
扩散模型因其强大的表达能力和多模态性而在强化学习领域中引起了广泛关注。实践证明,利用扩散策略可以显著提高强化学习算法在连续控制任务中的性能,克服单模态策略(如高斯策略)的局限性,以此来为智能体提供更强的探索能力。但是,现有使用扩散策略的研究主要集中在离线强化学习和模仿学习领域,而将扩散策略扩展到在线强化学习领域仍存在几个问题:
- 如果使用扩散模型损失训练,应该如何拿到好的动作样本进行策略提高?
- 如果将扩散模型当做一个黑盒模型,直接对生成的动作做确定性策略梯度,如何避免过长的反向传播链以及训练的不稳定性?

为了解决这些,研究者提出了一种基于扩散模型的在线强化学习算法,称为Q加权变分策略优化。具体来说,研究者引入了与强化学习策略目标等价的Q加权变分损失。此外,为了进一步提高扩散策略的探索能力,研究者设计了一个专用于扩散模型的熵正则化项。研究者还开发了一种高效的行为策略,通过减少在线交互期间扩散策略的方差来提高样本效率。
Q加权变分损失:
如上文所说,在线强化学习中优化扩散策略并非易事,这主要有两个原因。一方面,如果研究者将确定性策略梯度直接应用于扩散策略(如 Diffusion-QL [1]),则通过扩散模型的去噪过程的反向传播链会变得非常长。这会导致训练期间计算成本高且不稳定,严重限制了在线强化学习中扩散策略的性能。另一方面,直接使用变分界限目标来训练扩散策略时,需要来自最优策略的动作样本。然而,这些优秀的动作样本通常在在线强化学习中不可得到。
在此背景下,研究者重新审视了扩散模型的变分下界目标和策略梯度目标。研究者发现通过为扩散模型的变分下降目标添加对应的Q值作为权重,在这些权重都大于0的情况下,它会成为策略梯度目标的紧下限。研究者将其成为Q-weighted变分下界损失

尽管研究者现在可以使用该损失来优化扩散策略,仍有两个问题需要解决。
- 存在负的Q值。在现实世界的决策任务中,很难确保返回的奖励始终为非负数,这意味着 Q 值对于某些状态动作对可能为负。因此,要在实际任务中应用QVPO,研究者必须解决Q值对于某些状态和动作为负的情况。
- 如何获得高质量的训练样本。根据上述目标,实现显着的策略改进需要获得某些具有高Q值的稀有状态动作样本。考虑到在线强化学习和环境有限的交互次数,这一点颇具挑战性。
针对问题1,研究者将原始的Q值权重改成了A值权重,并对负的A值权重进行截断处理,从而避免了权重为负的问题。

针对问题2,研究者使用当前的扩散策略针对同一个状态生成大量动作样本,并从中根据Q值选取一个最好的作为训练样本进行策略提高。
扩散熵正则:
尽管扩散策略可以在在线强化学习中通过Q加权VLO损失获得较好的表现,但其强大的探索能力实际尚未得到充分利用。如Diffusion-QL [1]中所述,扩散模型的策略表达能力随着扩散步骤的减少而降低。在实验中,研究者发现,当扩散步骤的数量减少时,不仅策略表达能力下降,而且扩散模型的探索能力也会降低。然而,限制扩散步骤的数量是至关重要的,以避免在实际应用中产生过多的训练和评估成本。因此,研究如何在有限数量的扩散步骤下增强扩散模型的探索能力是必要的。
在这种情况下,在策略损失中添加额外的熵正则化项是一个很好的解决方案,因为它已在离散动作空间中的分类策略和连续动作空间中的高斯策略中得到验证。然而,由于无法获得动作样本的对数似然,估计扩散策略的熵并非易事。另一方面,最大化策略的熵在某种意义上可以看作是缩小策略与最大熵分布(即均匀分布)之间的距离。因此,可以使用来自均匀分布的训练样本来增加扩散模型的熵。基于这个想法,研究者提出了一个用于扩散策略的熵正则化项

有效的行为策略:
尽管扩散模型允许在线强化学习寻求更好的策略,但它也引入了较大的策略方差。这导致行为策略与环境的在线交互效率较为低下。为了解决这个问题,研究者提出了一种通过动作选择来降低行为策略的方差,从而得到更高的样本效率

最后,QVPO算法的整体流程为

实验证明,QVPO算法充分利用了扩散策略的探索能力和多模态性,防止强化学习策略收敛到次优解。下图为QVPO与其他强化学习算法在Mujoco机器人任务上的表现对比

在Humanoid-v3任务上,qvpo和sac收敛后的可视化:
QVPO:

SAC:

#Z-Sampling
让扩散模型在反思中提升采样
从理论角度证明了扩散采样中的每一次反思都可以提供额外的语义信息。
xLeaF Lab作品。
本文由论文一作同学 Lichen Bai @爱吃糖果 主笔,Lab PI编辑、修改。
亮点总结
我们发现扩散模型中去噪过程和反演过程之间引导(CFG)强度的差距能够捕捉潜在空间中的语义信息,这对图像生成质量以及与生成条件的对齐具有重要影响。
我们把一个扩散模型在一步采样后重新反演到上一步的操作叫做扩散反思。我们的工作从理论角度证明了扩散采样中的每一次反思都可以提供额外的语义信息。
基于此,我们提出了Zigzag Diffusion Sampling(Z-Sampling),一种让扩散模型在一步步的自我反思中提高生成质量。 看下面的示意图就很容易理解,为什么叫Z采样,因为它的采样轨迹变成了“之”字型。

Z-Sampling采样轨迹示意图

多类有挑战性的prompt上,Z-Sampling均能取得明显受益。
Z-Sampling实际上是xLeaF Lab上一篇文章介绍的工作“Golden Noise”的姐妹篇 xLeaF Lab | 扩散模型的“黄金噪声”:随机噪声并不生而平等(https://zhuanlan.zhihu.com/p/15259944648)。
Golden Noise只考虑第一步反思操作对于初始噪音的影响,并用一个小网络来学习第一步反思。而Z-Sampling考虑了扩散反思在整个采样路径的累计收益。所以Z-Sampling大部分时候在生成质量上甚至会更高于Golden Noise,大大提高了扩散反思能提供的受益上限。当然,代价是会出多几步扩散反思的成本。
Z-Sampling方法利用反思过程中CFG强度的差距,通过每一步自反思操作积累语义信息,从而生成更理想的结果。Z-Sampling能够灵活控制语义信息的注入,适用于多种扩散架构,特别是作为一种无训练方法,Z-Sampling在限制推理时间的情况下,依然能够显著超越基准性能 。
我们的实验里,Z-Sampling在DrawBench上可以让DreamShaper上相对于标准采样的HPS胜率winning rate提高到94%!
Z-Sampling已被ICLR2025接收,代码已经开源,欢迎大家使用!
Code: https://github.com/xie-lab-ml/Zigzag-Diffusion-Sampling
Paper: Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection(https://openreview.net/pdf?id=MKvQH1ekeY)
知识储备
这项研究聚焦于扩散模型的推理采样上,扩散模型通过逐渐给数据添加噪声直到变成随机,然后再通过反向去噪来恢复或生成新数据。我们分析的关键工具是扩散模型的去噪和反演过程,具体来说:
Denoising Process (去噪过程)

上面这张图可以说是对扩散模型最经典的解释之一:从随机采样的高斯隐变量出发, 经过去噪网络,迭代地生成干净的结果——这也是扩散模型的去噪过程。在这个过程中,纯噪声x_t经过T步去噪,得到了生成数据x_0。
Inversion Process (反演过程)
相反地,如果有一个干净数据x_0,我们如何得到对应生成它的高斯噪声呢?这时便需要利用扩散模型的反演过程,反演操作在图像和视频编辑领域中得到了广泛应用。值得注意的是,在忽略反演带来的误差前提下,并且假设两个过程的去噪网络参数以及生成条件(例如条件引导强度)一致的情况下,去噪过程与反演过程可视为一对互逆的映射。

DDIM 和 DDIM Inversion 示意图
研究动机&观察
在扩散模型的采样过程中,什么才算是一个“好的隐变量”?或者说,一个好的隐变量需要具备哪些与众不同的属性?
我们的方法受到了两个关键insight启发。
1. Latent空间有隐含语义信息
作为Z-Sampling的姊妹篇,第一个观察实验其实已经在扩散模型的“黄金噪声”:随机噪声并不生而平等(https://zhuanlan.zhihu.com/p/15259944648)中阐述过了,这里我们再简要说明一下:
这个实验的结论可以用一句话概括:“对于特定的条件提示,如果一个随机采样的初始噪声能够在没有任何额外条件的情况下,就能生成与提示相关的结果,那么可以认为这个初始噪声天然地携带了与提示相关的语义信息。在这种情况下,这个噪声就是一个好的初始隐变量。
举个例子,下图(左)中,考虑在 seed 为 21 时采样的初始噪声。从第一列可以看出,即使在无条件下 ,seed 21也能生成和“Flower”相关的图像。因此,可以认为seed 21天然地携带了与“Flower”相关的语义信息。接着,在给定提示 prompt= "Flower"时,相比于其他初始噪声(例如 seed = 41),是一个更好的初始隐变量(对Flow而言),从这个初始噪音出发,可以得到更符合提示的生成结果。
而下图(右)形象地展示了这一实验得出的结论:绿色的隐变量(带有语义信息)要比红色的隐变量(不带有语义信息)更好。这意味着带有语义信息的隐变量能更好地对齐给定的提示,从而生成更加符合预期的结果。

2.扩散反思(Inversion)注入语义信息
我已经知道了从无条件生成可以看出来,有的latent和prompt是天生一对,能提高生成质量。
而第二个实验的insight是,“Inversion促使隐变量变得更好”。
考虑两张自然照片(左边的猫咪,和右边的蜘蛛),按照DDIM Inversion的操作,我们将它们反转得到与猫咪和蜘蛛对应的初始噪声。

接着神奇的事情发生了。猫咪反转得到的latent就是更擅长生成猫咪,蜘蛛反转得到的latent就是更擅长生成蜘蛛。

扩散反思机制的秘诀
到底是什么导致Inversion操作有如此魔力呢。答案就是此前提到的伏笔,在 Inversion 操作中,条件的引导非常弱(CFG scale很小), 而在对应的 Denoising 过程中,我们通常设置较高的引导尺度(e.g. 5.5),也就是说,Inversion 和 Denoising 之间存在一个 guidance gap, 这个 gap 的存在使得隐变量能够注入与提示有关的语义信息,使之成为一个good latent(即第一个观察实验中的latent with semantic information)。
其实,这个实验的核心概念很容易理解。我们可以将其想象成两个阶段:第一个阶段是去噪过程(绿色箭头),第二个阶段是反演过程(棕色箭头)。

上式可以推导出(由于去噪过程和反演过程的可逆性):

我们如果仅考虑当前时刻和前一时刻的关系,先在强条件下去噪,然后在弱条件下反演,从而是隐变量包含更多的语义信息。

同样有

这也说明了,去噪与反演操作之间的引导差距(即引导强度的差异)能够有效地捕捉和注入提示相关的语义信息,从而优化生成结果的质量。
至此,得到了本文的核心结论:
Denoising与Inversion操作之间的guidance gap能够捕捉latent空间中和prompt 相关联的语义信息,并将这些语义信息注入到隐变量中,优化扩散模型的采样质量。
Z-Sampling算法
接下来的部分就顺理成章了。既然每次反思都有新的信息注入,那么我们就每步都进行反思,具体算法如下所示:

我们只需要关注这个gap,就能随意控制采样轨迹中语义信息注入的大小和方向了,我们称之为Z-Sampling。同样的,Z-Sampling 的采样轨迹呈现出一个之字形(PS:我们的后续工作在实验中还原了这种 zigzag 的采样轨迹)。
理论分析

同时,我们进行了一些推导,表示Z-Sampling的效果可以由两项决定:
- 语义增益项:由guidance gap带来的语义信息增益
- 反演误差项:由inversion process带来的不可避免的近似误差
我们在论文里做了更详细的说明,表明应该尽可能增大语义增益项,而缩小反演误差项,从而带来更好的生成效果增益。

特别的,如果反演误差为0的话,那么Z-Sampling带来的效果则完全由guidance scale在去噪和反演过程里的差值决定。

可以看到guidance gap控制着语义增益项的强度和方向,精细地调节模型如何以及多大程度上将提示中的语义信息融入到生成过程中,这也为之前的两个观察实验提供了理论上的解释。
实验结果
由于篇幅限制,此处仅展示部分实验结果;更多详细的实验结果请参见论文 。
- 实验一比较直观,主要比较了 winning rate的结果, Z-Sampling 在四个指标上均取得了领先,特别是在 HPS v2 指标上(这是一个用于评估人类偏好的指标),其 winning rate 可以超过了 90%。

- 实验二是主实验, 为了证明 Z-Sampling 在不同类型的扩散模型中均具有普适性,我们选用了以下几类模型:基于U-Net架构(SD-2.1,SDXL)、蒸馏模型(DreamShaper-xl-v2-turbo),基于DiT架构(Hunyuan-DiT),并在两个Benchmark中表现均比较出色。

- 实验三的目的是证明 Z-Sampling 与其他多种扩散模型提升方法之间是正交的,其提升效果可以相互叠加。无论是基于训练的方法(例如 Diffusion DPO),还是免训练的方法(例如 AYS),都能与 Z-Sampling 协同工作,进一步提升生成效果。我们认为这一特性蛮nice的,使得 Z-Sampling 具备即插即用的优势,展现出比较大的应用潜力。

定性实验
- 总体来说,Z-Sampling 带来了一些令人满意的改进——无论是在图像对比度的提升上,还是在更好契合 prompt 方面,都有一定进步。在风格、位置、颜色、数量等多个维度上,也展现出了相应的提升效果。
- 同时,我们也对Attention Map做了一些可视化分析,Z-Sampling可以让去噪网络对entity token的注意力响应更加清晰明了一些。

消融实验
限于篇幅,更多实验分析请参见论文
- Guidance Gap:第一个消融实验想证明,guidance gap 是怎么影响Z-Sampling的效果的。下图可以看到,当gGuidance Gap为正时,会呈现正增益;而Guidance Gap为0时,则近似为标准采样;当Guidance Gap为负的话,Z-Sampling反而会带来负增益。实验完全如理论预言。


- Time Efficiency:另一个重要的消融分析关注的是时间效率问题。尽管 Z-Sampling 会引入额外的去噪和反转操作,但实验证明,这种“之字形”(zigzag)操作带来的性能提升远远超过了其额外的时间开销。我们通过调整超参数,使得 Z-Sampling 与标准采样在生成同一张图片时所用的时间保持一致(具体表现为score network推理次数一致), 在相同的时间消耗下,Z-Sampling 始终优于标准采样,且大大提升了性能上限。这一实验结果为 Z-Sampling 的实际应用提供了有力支撑。

展望
最后再来总结展望一下,我们提出了一种新的扩散采样算法Z-Sampling——通过让扩散模型在采样时反思走出一种Zigzag的采样轨迹。参考LLM推理的术语,我们把扩散模型采样中每一步进行反演这个操作称之为“扩散反思”。
我们的理论分析(Theorem 3)很清楚地指出了,扩散反思操作的价值就是为latent空间提供语义增益,而步步反思可以累计这种增益;而motivation实验里end2end的反演会让不同step的语义增益互相抵消。
我们的实验结果也证明了,Z-Sampling既可以提高扩散模型生成质量的上限,也可以在相同的生成时间下超过标准方法。
甚至这种扩散反思操作还能推广到视频生成领域,用图像生成模型帮助视频生成模型“反思”,突破视频生成模型采样质量的上限——这也就得到了我们另一篇ICLR2025工作的方法:图像-视频混合采样器(IV mixed Sampler)。
这里先做个预告,后续撰文介绍。
Code: https://github.com/xie-lab-ml/IV-mixed-Sampler
Paper: IV-mixed Sampler: Leveraging Image Diffusion Models for Enhanced Video Synthesis(https://openreview.net/pdf?id=ImpeMDJfVL)
Website page: https://klayand.github.io/IVmixedSampler/
#Attentive Eraser
扩散模型新突破!无需微调,就能高效稳定移除目标物体
本文的共同第一作者为浙江工商大学统计与数学学院硕士生孙文灏和阿里巴巴算法工程师崔奔雷,本文的通讯作者为浙江工商大学统计与数学学院董雪梅教授。
最近,扩散模型在生成模型领域异军突起,凭借其独特的生成机制在图像生成方面大放异彩,尤其在处理高维复杂数据时优势明显。然而,尽管扩散模型在图像生成任务中表现优异,但在图像目标移除任务中仍然面临诸多挑战。现有方法在移除前景目标后,可能会留下残影或伪影,难以实现与背景的自然融合。
为了解决这些问题,本文提出了一种基于扩散模型且无需微调的方法 ——Attentive Eraser,以增强预训练扩散模型目标移除的能力,从而实现稳定有效的目标移除。实验结果表明,该方法在多种预训练扩散模型中均表现出优异的目标移除能力,甚至优于基于训练的方法,且无需微调,具有很强的可扩展性。
该研究论文已被人工智能顶会 AAAI 2025 录用并选为 Oral Presentation。
- 论文标题:Attentive Eraser: Unleashing Diffusion Model's Object Removal Potential via Self-Attention Redirection Guidance
- 论文链接:https://arxiv.org/pdf/2412.12974
- Github 地址:https://github.com/Anonym0u3/AttentiveEraser
- Diffusers Pipeline:https://github.com/huggingface/diffusers/tree/main/examples/community#stable-diffusion-xl-attentive-eraser-pipeline
- Model Scope Demo:https://www.modelscope.cn/studios/Anonymou3/AttentiveEraser
- Hugging Face Demo:https://huggingface.co/spaces/nuwandaa/AttentiveEraser
问题背景
目前,扩散模型的广泛应用使得生成与真实照片质量相媲美的高质量图像成为可能,并能够根据用户的需求提供逼真的视觉呈现。这引发了一个自然的问题:这些模型的图像生成能力是否可以被用于从图像中移除特定目标。这个被称为 “目标移除” 的任务是图像重绘(Image Inpainting)的一种特殊形式,并需要解决两个关键问题。首先,用户指定的目标必须能够被成功且有效地从图像中移除。其次,被移除的区域需要填充内容,这些内容必须真实、合理,并与图像整体保持一致性以确保视觉上的连贯性。
近年来扩散模型中最具代表性的开源预训练模型是 Stable Diffusion(SD),其作为一种隐变量扩散模型在多种图像生成任务中表现优异。然而,直接将其应用在重绘 pipeline 上进行目标移除时效果却不尽人意,往往会出现伪影导致目标移除不成功,如图 1(SD w/o SARG)所示:

图 1 Stable Diffusion 模型应用 SARG 前后目标移除效果对比图
为了将 SD 应用于目标移除任务,SD-inpainting 通过在模型中引入掩码作为附加条件并进行微调,构建成了一个端到端的图像重绘模型。然而,即使付出了大量资源成本,SD-inpainting 在目标移除任务中的性能依然不够稳定,经常无法完全移除目标,还是会生成随机伪影。除了基于模型微调的方法外,还有一种通过提示工程(prompt engineering)引导扩散模型完成目标移除的技术。尽管这类方法在某些场景下可以取得令人满意的结果,但其显著缺点在于,需要投入大量精力进行提示构建,同时难以与前景目标区域实现精确交互。此外,这类方法同样需要耗费大量资源进行模型微调,进一步限制了其实用性。
为了解决上述问题,本文提出了一种基于扩散模型且无需微调的目标移除方法,具体贡献如下:
(1)本文提出了一种无需微调的方法 ——Attentive Eraser,旨在激发预训练扩散模型的目标移除潜能。该方法由两个关键组成部分构成:1)注意力激活和抑制(Attention Activation and Suppression,AAS),这是一种专门设计用于修改预训练扩散模型中自注意力机制的方法,可在生成图像时增强模型对背景的注意力,同时降低对前景目标物体的注意力。同时针对生成过程中自注意力本身带来的对相似物体的高依赖性问题,本文提出了相似性抑制(Similarity Suppression,SS),有效地解决了该问题。2)自注意力重定向引导(Self-Attention Redirection Guidance,SARG),这是一种新颖的逆向扩散采样过程引导方法,利用所提出的 AAS 将采样过程引导到目标移除的方向,进一步提升了目标移除的效果。
(2)通过一系列实验和用户偏好研究,本文验证了所提出方法的有效性、鲁棒性和可扩展性。实验结果表明,本文的方法在目标移除的质量和稳定性方面均超越了现有的最先进方法。
AttentiveEraser 核心创新
本文提出的 Attentive Eraser 免微调目标移除方法的总体框架图如图 2 所示,其中有两个主要部分:(a)AAS,这是一种专为目标移除任务设计的自注意力机制修改操作,针对目标移除任务中固有的挑战,AAS 通过对自注意力机制进行精细调整,使得模型在生成前景目标区域时能够更加关注背景内容,而非前景目标,进而在生成结果图中消除目标的外观信息。此外,SS 可抑制由于自注意力的固有特性而可能导致的对相似物体的过度关注;(b)SARG,这是一种应用于逆向扩散采样过程的引导方法,它利用通过 AAS 重定向的自注意力来引导采样过程指向目标移除的方向。在这种引导下,扩散模型能够更好地消除掩码区域内的前景目标,并生成与背景自然融洽的图像内容。

图 2 Attentive Eraser 的总体框架图
创新一:注意力抑制与激活(AAS)
动机分析

图 3 去噪网络不同层在所有时间步上的平均自注意力图的可视化图
图 3 中,在输入图像经过 DDIM inversion 后,利用主成分分析和聚类技术,对逆向扩散去噪过程中去噪网络的不同层在所有时间步上的平均自注意力图进行了可视化。通过这些可视化结果,可以观察到自注意力图显示出类似于图像各个组成部分的语义布局。这种布局清晰地展示了前景物体和背景在生成过程中所对应的自注意力的显著差异,表明它们在模型中的处理方式存在明确的区分。这种语义布局为目标移除任务提供了重要的启示,为了在生成过程中有效地去除前景目标,一个直观的方法是在生成过程中将前景物体的自注意力逐渐 “融合” 到背景中,使其与背景区域的注意力更加趋同。换句话说,在生成过程中与前景目标相关的区域应更关注背景区域,同时减少对自身的关注。前景目标的自注意力逐渐向背景转移有助于消除前景物体,使其自然地消隐于背景之中。此外,考虑到目标移除任务的特殊性,前景目标是处理的核心,背景区域应在生成过程中保持固定不变,且不受前景区域变化的影响。因此,为了实现更自然的生成效果,背景区域对前景区域的关注度也应适当地降低,从而避免生成过程中背景被不必要地干扰。这一策略确保了生成结果与背景的自然融合,使生成图像显得更加和谐、真实。
专为目标移除设计的自注意力机制修改方法
结合上述分析,本文提出了一种针对目标移除任务设计的简单而有效的方法 ——AAS,如图 2(a)所示,AAS 方法的核心在于通过调整自注意力机制,灵活控制前景目标区域与背景区域之间的关系,从而实现更为自然的目标移除效果。
注意力激活的目的是通过增加前景目标区域生成内容对背景区域的注意力,即增加
![]()
,从而确保前景目标被移除后,生成的内容能够与背景自然融合。这一过程的关键在于增强前景区域生成内容对背景的关注度,使得前景区域在生成过程中更多地参考背景的特征信息,进而生成与背景风格一致的图像内容。这种增强能够有效地避免前景移除后出现与背景不协调的情况,确保生成图像的整体连贯性和视觉一致性。
与此相反,注意力抑制是指抑制前景目标区域关于其外观及其对背景影响的信息,即减少
![]()
,达到抹除前景目标的效果。降低
![]()
的目的是抑制前景区域对自身外观信息的关注,逐步抹除前景目标的原始语义信息。这意味着在逆向扩散去噪过程中,前景目标的特征信息将被逐步削弱直至完全消失而背景区域的生成过程则保持不变,以确保背景的完整性。此外,降低
![]()
的作用在于减少背景区域对前景区域的依赖,避免背景区域在前景移除过程中受到不必要的影响。
相似性抑制
尽管上述理论在目标移除任务中展现了显著的效果,但其仍存在一个重要的局限性。具体而言,当背景中包含与前景目标相似的内容时,由于自注意力机制的固有特性,在生成过程中这些相似部分的注意力可能会高于其他区域。这种情况会导致扩散模型在去除前景目标时,误将背景中相似的部分保留,从而无法彻底去除目标(见图 2(a)右侧的一个例子)。这一问题的存在表明,单纯依靠上述理论可能不足以应对复杂场景中具有相似特征的前景和背景目标的区分与处理。
因此,为了减少对相似目标的关注并将其分散到其他区域,本文提出了一种较为直接且有效的扩展策略引入到 AAS 中来解决上述问题:通过简单地引入一个小于 1 的相似性抑制系数
![]()
来降低相似性矩阵
![]()
方差。本文将该方法称为相似性抑制(SS)。基于 SoftMax 函数的权重计算机制,减少
![]()
方差可以在一定程度上削弱生成过程过度关注高相似度区域的倾向,同时增加对背景其他区域的注意力,由此来抑制生成过程中可能出现的相似物体,从而减少目标去除不彻底的情况。
创新二:自注意力重定向引导(SARG)
为了进一步提高目标去除能力以及生成图像的整体质量,本文受 Ahn 等人提出的 PAG(PAG:Ahn D, Cho H, Min J, et al. Self-rectifying diffusion sampling with perturbed-attention guidance [C]. European Conference on Computer Vision. Springer, Cham, 2025: 1-17.)启发,将经过 AAS 处理后的去噪网络
![]()
看作是噪声
![]()
预测过程中的一种扰动形式,通过这种扰动来引导采样过程朝向理想方向。因此,修正后的扩散模型的预测噪声可以定义如下:

这种引导过程的优势在于,通过调整自注意力机制,SARG 能够在生成过程中不断优化生成策略,使模型更加灵活地适应不同场景下的目标移除需求。同时,通过优化生成过程的各个时间步,SARG 还提高了最终生成图像的质量,通过合理地控制生成过程中的注意力分配,SARG 确保了最终生成图像与背景之间的自然融合,减少了它们之间的突兀感,从而提高了图像的视觉一致性和自然度,确保了高质量的目标移除效果。
实验亮点:AttentiveEraser 的稳定目标擦除能力及高拓展性
对比实验的定量和定性结果
表 1 对比实验定量结果表

从定量分析的结果来看,尽管在全局质量指标 FID 和 LPIPS 上,本文的方法表现处于平均水平,但这两个指标并不能充分反映目标去除的效果。进一步分析 Local-FID 指标,该指标评估生成区域的视觉质量与背景的真实分布的吻合程度,可以看到我们的方法在局部移除方面展现出色的表现,显著优于其他方法,说明在局部区域细节上我们方法生成的内容与真实图像分布更接近。同时,CLIP consensus 指标通过计算多次生成结果的标准偏差,揭示了方法在不同随机种子下生成结果的一致性。从结果可以明显看到其他基于扩散模型的方法的标准偏差较大,说明了它们应用在目标移除任务时的不稳定性,而我们的结果展现了显著更低的标准偏差,说明我们方法的稳定性显著优于对比方法,更倾向于生成一致性高的图像。而 CLIP Score 指标直接反映目标是否被有效去除且背景是否被合理重建,实验结果表明我们的方法能够高效地去除目标,并在重绘前景区域时与背景高度一致。在 CLIP Score 指标上,我们的方法与当前领先的基于快速傅立叶卷积的重绘模型 LAMA 达到了相当的竞争水平,并在特定场景中表现出更强的背景适配能力。

图 4 对比实验定性结果图

图 5 目标移除稳定性实验结果对比图
对比实验的定性结果如图 4 所示,其中输入图像中的掩码以红色高亮显示,本文的方法以粗体标出。从图中可以观察到本文的方法与其他方法之间的显著差异。LAMA 由于缺乏生成能力,虽然能成功去除目标,但生成的内容显得模糊且不清晰。相比之下,其他基于扩散模型的方法都存在一个普遍的问题,即目标移除的不稳定性,这种不稳定性往往导致随机伪影的出现,无法生成与背景连贯一致的内容。为了进一步证实这一问题,本文进行了目标移除稳定性实验,结果如图 5 所示。图中展示了每种方法在使用三种不同随机种子下的目标移除结果。可以清楚地看到,本文的方法在各个版本的 SD 模型中都能实现稳定的目标移除,生成的内容一致且连贯。而其他方法则难以保持这种稳定性,目标移除效果因随机性而产生较大的波动,难以实现与背景一致的生成效果。
用户偏好研究和 GPT-4o 评估
表 2 用户偏好研究和 GPT-4o 评估结果表

由于缺乏针对目标移除任务的有效指标,上述指标可能不足以证明本文方法的优越性。因此,本文进一步进行了用户偏好研究(User Study)以验证本文方法的实际效果。表 2 列出了用户对各种方法的偏好百分比,结果表明本文的方法比其他方法更受用户青睐。这一发现与对比试验的结果一致,进一步验证了本文方法在目标移除任务中的有效性和优越性,突出表明该方法在实际应用中的表现优于其他现有方法。
此外为了进一步表明本文提出方法的优越性,我们还利用 GPT-4o 对本文的方法和用户偏好研究中排名第二方法 LAMA 之间的目标移除性能进行了进一步评估。在该对比实验中,我们要求 GPT-4o 根据设计好的公平合理的文本提示选择目标移除效果最佳的图像。具体的文本提示如下:“你是一个生成图像评估专家。现有两张图和对应的掩码,请从以下方面进行评估:1. 生成图像是否有效移除了掩码内目标且在掩码区域内生成和背景一致的内容,2. 掩码内目标的生成内容的真实感。根据以上标准,请告诉我哪张图片更好。” 最终,计算了本文的方法和 LAMA 被选择的频率,以此衡量各自的目标移除性能。评估结果在表 2 中,结果也表明本文的方法明显优于 LAMA,表现出卓越的性能。通过这些实验,本文的方法不仅在生成图像的整体质量上优于 LAMA,还在目标移除的准确性和生成内容的真实感方面展现了显著的优势。
鲁棒性和可拓展性分析

图 6 Attentive Eraser 对输入掩码的鲁棒性实验结果图

图 7 在 solarsync 模型上应用 Attentive Eraser 去除卡通图像目标的结果图
由于 Attentive Eraser 是一个基于掩码的方法,因此我们在实验中进一步证明了其对输入掩码的鲁棒性,并展示了其在其他预训练扩散模型上的可拓展性。
如图 6 所示,我们通过三种不同精细度的掩码类型来评估该方法的鲁棒性,按从细致到粗糙可以将掩码分为:实例分割掩码、分割边界框掩码和手绘掩码。可以看出,即使使用较为粗糙的手绘掩码,我们的方法依然能够有效去除目标并生成合理的前景内容。这表明,Attentive Eraser 的性能并不依赖于掩码的精细程度,具有极高的鲁棒性。同时,这种鲁棒性也为用户提供了更多的灵活性和便捷性,无论是使用精细的自动生成的分割掩码,还是手工绘制的粗略掩码,用户都能够获得理想的目标移除效果。
此外,如图 7 所示,我们的方法不仅适用于生成自然图像的预训练扩散模型(例如 SD1.5、SD2.1 等),还可以扩展到生成动漫图像的模型,如 Civital 平台上的 solarsync 模型,体现出了 Attentive Eraser 在不同预训练扩散模型和架构上的可拓展性和广泛适用性,无论是用于自然图像还是动漫图像的目标移除任务,均能发挥出色的效果。
通过这些实验,我们充分展示了 Attentive Eraser 的鲁棒性和可拓展性,为其在实际应用中的广泛应用提供了坚实的理论与实验支持。
Demo 演示
- Demo 已发布在魔搭社区创空间及 Hugging Face spaces:
- https://www.modelscope.cn/studios/Anonymou3/AttentiveEraser
- https://huggingface.co/spaces/nuwandaa/AttentiveEraser


更多详情,请参阅论文原文。
#Alias-Free LDM
让模型告别“神经质”,从本质上提升潜扩散模型生成稳定性
本文提出了一种新型的无混叠潜扩散模型(Alias-Free LDM,AF-LDM),通过引入抗混叠模块和同变损失函数,显著提升了潜扩散模型在分数平移同变性方面的性能,从而增强了生成图像和视频编辑的稳定性和一致性。
潜扩散模型 (Latent Diffusion Models, LDM) 常因生成过程不稳定而备受诟病:哪怕模型的输入只是受到了一点微小的扰动,模型的最终输出也会截然不同。以视频逐帧风格化任务为例,哪怕对每帧使用同样的 Stable Diffusion ControlNet 图生图编辑方法,同样的随机种子,生成的风格化视频会有明显的闪烁现象。
为了找出这一现象的原因,我们设计了一种配置简单的扩散模型编辑实验:平移扩散模型的初始噪声,观察去噪输出。理想情况下,平移输入噪声,输出图片也应该会平滑地平移。然而,实验结果却显示,直接平移输入噪声会大幅改变输出图片;使用了提升内容一致性的 Cross-frame Attention (CFA) 技术后,虽然图片的主体内容不再变化,可是输出图像在平移时还是有不自然的「抖动」现象。
为什么 LDM 的生成过程这么不稳定呢?为什么 CFA 技术又能提升生成的一致性呢?在我们团队近期发表于 CVPR 2025 的论文 Alias-Free Latent Diffusion Models: sImproving Fractional Shift Equivariance of Diffusion Latent Space 中,我们从平移同变性 (shift equivariance) 的角度分析了 LDM 的生成稳定性,并提出了一种能够提升平移同变性的 Alias-Free LDM (AF-LDM) 模型。我们在无约束人脸生成、视频编辑、超分辨率、法向量估计等多个任务上验证了该模型的有效性。
在这篇博文中,我将系统性地介绍一下这篇论文。我会先简单回顾背景知识,让对信号处理不太熟悉的读者也能读懂本文;再介绍论文的方法、实验、贡献;最后从本工作出发,探讨新的科研方向。
项目网站:https://zhouyifan.net/AF-LDM-Page/
背景知识回顾
本节我会先回顾 LDM,再回顾对平移同变性做了深入研究的 StyleGAN3。由于理解 StyleGAN3 需要了解信号处理的基本概念,我会在尽量不用公式的前提下讲清楚图像频率、混叠等概念。为了简化文字,我会省略理论推导,并使用一些易懂却不见得严谨的叙述。对这些原理感兴趣的读者可以系统性地学习一下 StyleGAN3 论文。
潜扩散模型
扩散模型是一种图像生成模型。生成算法的输入是一张纯噪声图,输出是一张清晰图像。算法执行步,每一步都会调用一个去噪网络来去除图像中的部分噪声。

由于扩散模型运算较慢,我们可以借助一个变分自编码器 (VAE) 来压缩要生成的图像,减少要计算的像素数。简单来讲,VAE 由一个编码器 (encoder) 和一个解码器 (decoder) 组成。编码器负责压缩图像,解码器负责将压缩图像重建。网络的学习目标是让重建图像和输入图像尽可能相似。训练结束后,我们可以单独使用编码器或解码器,实现压缩图像和真实图像之间的相互转换。论文里通常会把压缩图像称为潜图像 (latent image 或者 latent)。

潜扩散模型 (Latent Diffusion Models, LDM) 是一种借助 VAE 加速的两阶段扩散模型。普通的像素级扩散模型会生成一张同样大小的清晰图像。而 LDM 会先生成一张潜图像,再用解码器把潜图像还原成真实图像。我们可以把解码操作简单看成一个特殊的上采样。比如在 Stable Diffusion 中,潜图像的边长被压缩了 8 倍,即解码器会对潜图像上采样 8 倍。

训练 LDM 时,我们需要获取训练图像的潜图像。因此,为了构建训练集,我们会用编码器把训练图像转换为潜空间的图像。

图像的频域表示
在计算机中,图像有很多种表示形式。最常见的形式是空域图像:图像由一个像素矩阵表示,每个像素存储了图像在某个位置的颜色值。此外,还可以把图像表示为频域图像:我们认为图像是由许多不同频率的正弦函数叠加而成的,频域图像的每个像素存储每个频率的正弦函数的振幅和相位。直观来看,图像在空域和频域的可视化结果如下所示:

具体来说,我们可以把空域图像和频域图像都看成二维数组。对于空域图像来说,数组的索引是二维位置坐标,值是此位置的颜色值;对于频域图像来说,数组的索引是横向和纵向的一对频率,值是该频率下的正弦函数的振幅和相位。

为什么我们要大费周章地在频域里表示一张图像呢?这是因为图像的各个频率分量从另一个维度拆分了图像中的信息,这种拆分方式有助于我们分析图像。一张空域图像可以通过 FFT 操作变换成频域图像,而频域图像又可以通过 IFFT 操作变回空域图像。那么,我们可以用如下操作可视化不同频率分量的作用:
- 把输入空域图像用 FFT 转换到频域
- 对频域图像滤波,分别得到低频、中频、高频三张频域图像
- 用 IFFT 在空域中可视化三张频域图像
该操作的结果如下所示。可以看出,图像的低频分量描述了图像的全局结构,而中频分量和高频分量进一步完善了图像的细节。

混叠
假设有一根时针在顺时针匀速旋转。现在,我每秒拍一次照片,一共拍下了时针的三张照片。请问,时针的旋转速度是每秒多少度呢?

从照片中可以看出,时针每秒都旋转了 90 度。因此,你可能会说,时针的旋转速度是 90 度每秒。
下面让我揭晓答案。其实,时针的旋转速度非常非常快。每次拍照时,时针都转了一圈多。也就是说,时针每次旋转了 90 + 360 = 450 度,它的速度是 450 度每秒。如果我们拍照的频率更高的话,将会得到下面的结果。

你可能会觉得这很赖皮:「只给三张照片,谁看得出时针已经多转了一圈啊?」这话确实没错。在相邻两次拍照之间,时针可能已经多转了一圈、两圈……。时针的速度究竟是多少?这其实可以有无数个答案。只有我们强行规定两次拍照之间,时针不能转一圈以上,我们才能得到唯一一种答案。在这种规定之下,如果要表示更快的时针,只能通过增加拍照的频率了。
让我们总结一下从这个示例中学到的规律。在现实中,时针是连续旋转的。而由于存储空间有限,我们往往只能对时针的状态拍照(采样),得到离散的指针状态。采样数相同的情况下,能够表达的信息量是等同的,或者说能够记录的时针最大旋转速度(最大频率)是等同的。要表示更快的时针(更高的频率),就必须要增加采样频率。反过来说,由于采样频率有限,我们有时会错判时针(周期信号)的频率。这种错判现象被称为混叠 (aliasing)。比如把速度 450 度每秒的时针看成 90 度每秒就是一种混叠现象。
类似地,我们可以把图像看成空间中的信号。在现实中,我们眼中看到的图像是处处连续的。为了用计算机显示图像,我们只好在空间中对图像采样,记录有限个位置处的颜色值。如果采样的频率过低,也就是在空间中采样的步长过大,就可能会漏掉某些关键信息,从而造成图像信号的混叠。
而在图像处理中,混叠现象一般出现在高分辨率图像的下采样中。我们来用 matplotlib 中的一个示例复现混叠现象。对于一个包含密集纹理的输入图像,如果我们简单地使用最近邻插值,就会在下采样图像中得到不自然的纹理;而换用抗混叠插值后,混叠现象被大大缓解。

抗混叠的原理是什么呢?我们知道,混叠现象是由于某种采样后,图像的采样率(正比于图像尺寸)过低,导致原图像的高频分量无法正确地在采样后图像中显示。既然如此,我们就先用一个低通滤波器,过滤掉原图像中的高频分量,再做采样。也就是说,抗混叠下采样,等于低通滤波+最近邻下采样。
平移同变性与混叠
通常,我们会为图像处理网络引入一些归纳偏置 (inductive bias),以降低网络的学习难度。CNN (卷积神经网络)就是利用归纳偏置的一个经典示例。由于 CNN 主要由卷积操作构成,而卷积操作在某像素处的输出只取决于邻近像素,因此 CNN 满足平移同变性:平移输入图像,CNN 的输出特征也应该对应地平移。而对于基于 CNN + Softmax 的图像分类网络,按理来说,它满足平移不变性:平移输入图像,输出的类别分布不变。
可是,我们训练出来的 CNN 分类网络真的满足平移不变性吗?在经典论文 Making Convolutional Networks Shift-Invariant Again [2] 中,作者发现,平移输入图像时,普通的 CNN 分类网络的输出概率会发现很大的变化。而这背后的罪魁祸首正是混叠现象。而一个抗混叠的神经网络有着更好的平移不变性。

为什么混叠会和平移不变性关联起来呢?为了方便说明,我们先用公式正式地表示一个简化版 CNN。在一个 CNN 分类网络中,输入 x 会经过若干个由卷积和下采样构成的模块,最后得到二维特征图 f。随后,f 会被展平成一维,并经过 MLP 和 Softmax,输出一个概率分布。
f = down(conv(x))
prob = softmax(mlp(flatten(f)))在这个过程中,我们希望 f 对 x 是平移同变的。严谨地说,对于输入 ,如果函数 满足
其中 是平移操作,那么操作 是平移同变的。在分类网络中,我们希望分类网络的卷积部分 down 是平移同变的。一旦这个操作满足平移同变性,后面的 softmax latten(f)))操作都不会考虑输入像素的先后顺序,整个网络就满足了平移不变性。
那么,这么多步骤中,是哪一步出错了呢?论文指出,通常 CNN 都使用最近邻下采样。这种下采样操作会导致图像出现混叠现象。解决方法也很简单,如上一节所述,我们可以将最近邻下采样换成先低通滤波再最近邻下采样,以缓解网络的混叠。果不其然,换用了抗混叠下采样后,CNN 的平移同变性大大提升,最后输出的概率分布的平移不变性也相应地大大提升。
无混叠的 StyleGAN3
经典图像生成网络 StyleGAN2 可以把一张 的特征图像不断上采样并转换成一张 的高清图像。由于该生成网络也是一个 CNN,我们希望它满足平移同变性。这样,移动输入特征图像,就能对应地移动输出高清图像。但是,在平移 StyleGAN2 的特征图像时,我们能在输出图像中观察到纹理滞留(texture sticking)现象:人物的胡须和头发好像停留在了原地,并没有随着输入移动而移动。而 StyleGAN3 的目标正是解决这一问题。
StyleGAN3 同样指出,混叠现象是造成纹理滞留的主要原因。为了彻底解决这一问题,StyleGAN3 系统性地用信号处理知识分析并改进了 StyleGAN2 的模块。如前文所述,一张图像能够表示的频率分量是有限的。图像尺寸越大,能表示的最大频率越大,图像的细节也就越多。而在对图像重采样(改变图像尺寸)前后,如果我们不能正确地调整图像的最大频率,就有可能产生造成图像内容错乱的混叠现象。所以,要系统性地调整每个模块以防止其出现混叠,其实就是要让每个模块正确地处理图像的最大频率。
经分析,StyleGAN3 主要对 CNN 的以下模块做出了改进以去除混叠:
- 上/下采样层:早期工作设计抗混叠采样时,只是简单地用同一个模糊卷积来近似低通滤波。而 StyleGAN3 精确地为采样率(边长)不同的特征算出了不同的最大频率,并根据此最大频率设计了不同的低通滤波器,用以修正采样前后的信号频率。
- 非线性函数(激活函数):StyleGAN3 指出,非线性函数会在信号中引入新的高频分量,从而引起混叠。为此,StyleGAN3 的解决方法是,先临时把信号上采样 倍,再让信号过非线性函数,最后将信号下采样 倍以使其复原。这是因为,采样率越高,能表示的最大频率越高,引起混叠的可能越小。实验中发现,令 就有不错的效果。这一模块被 StyleGAN3 称为经过滤的非线性函数(filtered nonlinearities)。
除此之外,StyleGAN3 还从抗混叠以外的角度提升了 CNN 的平移同变性:
- 傅里叶特征输入:为了让生成网络的输入平滑移动,即能够移动非整数个像素,StyleGAN3 将输入的离散特征图像修改成了一个在空间上可以任意采样的傅里叶特征。
- 边缘像素裁剪:此前研究表明,CNN 会从图像边缘处的 0 填充卷积中学习到绝对位置信息,这违反了 CNN 平移同变性的假设。因此,StyleGAN3 在同一尺度的特征图像外都填充了一些额外像素,并在每次上采样后丢弃这些边缘像素。
Alias-free Latent Diffusion Models设计动机
回顾了潜扩散模型理论基础以及神经网络的平移同变性与混叠的关系后,我们来正式学习 AF-LDM 论文。
如本文开头所述,为了分析 LDM 的生成稳定性为什么那么差,我们用一个更简单的平移任务来定位问题的根源。实验结果显示,LDM 网络的平移同变性也很差。更准确地说,LDM 只对整数平移有较好的同变性。
这里先补充介绍一下整数平移和分数平移。假设我们有一个能把图像 2 倍上采样的平移同变的网络。如果我们对输入移动 个像素,那么输出就应该平移 个像素。然而,如果只对输入平移整数个像素,那么输出只能平移偶数个像素。为了平滑地让输出平移 个像素,我们有时需要令输入图像平移分数个像素。
在分数平移时,我们要通过插值获得图像在非整数位置处的值。后文我们会详细讨论该如何选取插值方法。

回到 LDM 的平移同变性上。实验显示,尽管神经网络主干都是理论上应该平移同变的 CNN,LDM 的 VAE 和去噪 U-Net 都只对整数平移有同变性,而在分数平移时同变性较差。如下图所示,我们测试了潜空间下采样 8 倍的 VAE 和去噪 U-Net 的同变性,每一个平移步数表示平移 1/8 个像素。仅当平移步数是 8 的倍数时,网络的同变性指标(以 PSNR 表示)才比较高。

参考了之前工作后,我们认为 CNN 平移同变性下降是由于混叠现象导致的。如果我们去除了 LDM 的 VAE 和 U-Net 中的混叠,那么 LDM 就会有更好的同变性。总结下来,论文的整套思维链如下:
- Stable Diffusion 等 LDM 编辑稳定性差。
- 在较简单的输入平移任务上,LDM 的稳定性依然很差。
- LDM 的分数平移同变性差。
- 混叠现象降低了网络同变性。
为了提升 LDM 的稳定性,我们需要倒着解决问题:
- 设计抗混叠模块,去除网络中的混叠。
- 验证无混叠 LDM (AF-LDM) 的平移同变性确实有所提升。
- 验证提升平移同变性的 LDM 在编辑时稳定性更好。
在这一大节里,我们主要会学习 AF-LDM 论文的方法部分,即如何开发一个无混叠的 LDM。在下一大节里,我们再浏览论文里的实验结果,以验证 AF-LDM 确实能提升 LDM 的稳定性。
引入 StyleGAN3 抗混叠模块
我们希望设计一种无混叠的 LDM。同时,为了尽可能利用预训练 LDM (比如 Stable Diffusion)的权重,我们希望对 LDM 模型结构上的改动尽可能小。因此,我们仅将前文所述的 StyleGAN3 的两个抗混叠模块引入了 LDM 的 VAE 和 U-Net 中:
- 上/下采样层:让上采样层能够正确处理图像频率。和 StyleGAN3 不同的是,StyleGAN3 使用 Kaiser 卷积来近似低通滤波,而我们参考之前的 AF Convnet [3] 工作,使用了基于 FFT 操作的滤波操作以实现理想滤波(恰到好处地过滤图像中的频率)。
- 非线性函数:我们也使用了同样的经过滤的非线性函数,以抑制高频分量造成的混叠。
当然,仅做这些改动还不足以实现无混叠的 LDM。还需要解决的问题有:
- 如何定义分数平移。StyleGAN3 将输入特征图像定义成了傅里叶特征,它可以在任意位置采样,天生支持分数平移。而在 LDM 中,我们往往需要分数平移潜图像。而潜图像是离散的,它在分数平移中的插值方式需要慎重定义。
- 使用同变损失进一步提升同变性。我们在实验中发现,仅靠抗混叠模块还不足以提升模型的平移同变性,我们通过增加损失函数的方式强制让模型在训练中学习平移同变性。
- 改进自注意力模块。由于自注意力输入是全局操作,其输出对输入的变化非常敏感,平移同变性差。我们分析并缓解了此问题。
连续潜图像表示
对图像做分数平移,其实就是在图像分数位置处重新采样。比如,假设一维信号原来的采样坐标为 0, 1, 2, ...,将其向左平移 0.5 个单位后,采样的坐标变为 0.5, 1.5, 2.5, ...。为了求解这些新坐标下的像素值,我们需要使用某种插值方法。
在这个工作中,我们假设 LDM 的 VAE 中的潜图像是一种连续图像,即它可以无损被傅里叶变换转换成连续信号。那么,对这种连续图像做分数平移时,就可以使用理想插值:先用 FFT 把图像转到频域,再将分数平移转换成信号的相位变动,最后用 IFFT 把平移后的信号复原回空域。
值得注意的是,将潜图像假设成连续信号,只是规定了我们在分数平移潜图像时用到的算法。模型在训练时并不知道潜图像满足这种表示。在下一节中,我们会学习如何用损失函数让模型学到这种表示。
同变损失
加入了 StyleGAN3 中的抗混叠模块后,一个随机初始化的 VAE 确实有了更好的同变性。然而,我们发现了一个奇怪的现象:随着 VAE 训练的不断进行,VAE 的同变性开始不断下降(稍后我们会在实验部分看到这些结果)。相同的现象在去噪 U-Net 也可以观察到。我们猜测这是因为我们的网络中一些不够完美的设计让模型始终会产生轻微的混叠现象,而这些混叠现象能够帮助网络的学习。因此,随着训练的进行,网络会倾向于放大混叠现象。这些不完美的设计可能包括:
- 未使用傅里叶特征:StyleGAN3 将输入定义为连续的傅里叶特征,天生支持连续平移。而我们只是假设 VAE 的潜图像可以由连续信号表示,而没有在训练中让模型感知到这一点。
- 未使用边缘像素裁剪:边缘像素的卷积会泄露绝对位置信息。我们没有像 StyleGAN3 一样使用这个技术。
StyleGAN3 可以简单看成一个不断上采样低分辨率图像的网络,它在结构设计上有很大的自由。而在由 VAE 和 U-Net 组成的 LDM 里,实现上述两种技术的方法并不是很直观。且由于我们想尽可能减少新设计,并通过微调预训练模型来使之具有同变性,我们没有在 AF-LDM 里加入上述技术。
为了防止 LDM 在训练中同变性下降,我们根据同变性的定义,提出了一个额外的同变损失来规范网络模块的学习。对于不同的模块,我们根据其输入输出设置不同的同变损失。比如,对于 VAE 编码器 ,我们定义以下损失:
其中, 表示将 平移 个单位, 表示编码器下采样倍数。由于潜图像 的边长缩小了 倍,编码器输入平移 对应输出平移 。除了直接做差以对齐同变性的定义外,我们还设置了掩码 以表示需要计算损失的有效区域。之所以平移时存在「有效区域」,是因为我们将平移定义为裁剪平移(cropped shift),即最右的像素移出图像边界后,最左侧只会填充全零像素。这些全零像素就属于无效区域,我们应该只在另外的有效区域计算同变损失。
VAE 解码器和 U-Net 的同变损失有着类似的形式。欢迎大家阅读论文以了解细节。
由于在计算同变损失时,我们将平移操作中的插值设置成了理想插值,因此模型能够学到我们在上一节定义的连续潜图像表示。
同变注意力
LDM 的去噪 U-Net 一般会使用自注意力操作:
其中,矩阵 是 个长度为 的特征,三个参数矩阵 为可学习参数。
自注意力会严重降低模型的平移同变性。如文本开头的视频所示,原版 Stable Diffusion 在输入噪声平移后,输出会发生极大的改变。而使用 Cross-frame Attention (CFA) 这种提升自注意力稳定性的操作后,模型的输出才稳定起来。
为什么自注意力的平移同步性较差呢?为什么 CFA 能提升同变性呢?在这篇文章中,我们深入地研究了自注意力的平移同变性。准确来说,我们考虑的是裁剪平移下的同变性。
根据同变性的定义,自注意力满足以下条件时才是同变的:
由于此时 ,即 不是一张图像,而是一个特征序列,图像里的每一个像素是一个行向量,因此这里的平移操作 其实是修改 的行向量的排序。我们先记住这个性质。
观察上面等式的右边,我们可以将它看成先有输入 ,再做了两次矩阵右乘,再做了一次 Softmax,再做了一次矩阵右乘,最后平移。而矩阵右乘和 Softmax 对行向量都是独立的,所以上面的右式可以化简成 。
现在,要让自注意力操作满足平移同变性,只需要满足下面两个式子:
然而,由于此时的平移操作为裁剪平移,上面两个式子无法成立,且随着平移的推进误差会越来越大。通过上述分析,我们得出结论:自注意力对裁剪平移不具有平移同变性。这也符合我们直觉上的理解:自注意力是一种全局操作,一旦输入某处发生了一些微小的改变,输出就会出现较大的变动。
想要重新设计一种同变性更好的自注意力操作并不简单。不过,我们可以采取一种权宜之策来提升现有自注意力的相对平移同变性。假设有参考帧 和平移后的帧 ,我们将计算 时的自注意力定义为同变注意力(Equivariant Attention):
在实现时,我们先正常算所有注意力特征 ,并将其缓存下来;而在计算某一层的 的自注意力时,我们再取出对应的 。这样,含 和 的那两项不随输入 而变化,整个注意力操作就是一定是平移同变的了。注意,这里的平移同变是 相对参考帧 而言的,我们不能保证其他帧之间,如两个平移后的帧之间,仍然具有平移同变性。
这一操作其实就是之前 Stable Diffusion 视频编辑工作 (如 Text2Video-Zero [4]) 里常用的 CFA 操作。而之前工作并没有对 CFA 做深入分析,只是简单解释成「将参考帧的 K, V 注入其他帧能够提升其他帧的风格一致性」。而在我们这篇论文中,我们发现 CFA 有用的原因是它提升了其他帧对参考帧的平移同变性,这其实是一种同变注意力。为了方便其他研究者的理解,我们在后文还是把这种同变注意力称为 CFA。为了把 CFA 加入模型中,我们在两处使用了 CFA:
- 计算同变损失时
- 训练结束后,生成平移后的图片时
方法小结
我们的方法可以用下面的示意图概括。除了像 StyleGAN3 一样加入抗混叠模块外,我们的主要改进是在训练时加入同变损失。而在计算此损失时,需要将平移后图像的自注意力运算改成同变注意力。

实验
做完上述所有改进后,我们将这种同变性更好,无混叠的 LDM 称为 AF-LDM。参照这一简称方式,我们会把改进后的 VAE, Stable Diffusion 简称为 AF-VAE, AF-SD。在实验环节,我们会验证改进后模型的有效性,并展示它的一些应用。
同变性消融实验
根据同变性的定义,我们用先平移、再操作和先操作、再平移的图像之间的重建误差来反映同变性的高低。参考之前的工作,我们用 PSNR 来计算重建误差。这种反映同变性的 PSNR 在论文中被简称成 SPSNR。我们看一下消融实验的结果。Latent PSNR 表示 U-Net 输出的潜图像的同变性,Image PSNR 表示 U-Net + VAE 解码器的同变性。这个表展示了非常多的结论:
- 比较第一栏和第二栏的结果,使用 SD VAE 看起来 Latent PSNR 还不错,但由于 VAE 不是同变的,最后的 Image PSNR 还是很差。我们必须把 VAE 和 U-Net 都变成无混叠的。
- AF-LDM random weights 表示做了模块上的改进 (Ideal Sampling, Filtered Nonlinearity) 之后仅随机初始化参数,不训练模型。将它的同变性和训练过的模型做对比,可以发现模型的同变性在训练中下降。
- 为了防止同变性在训练中下降,我们需要加入同变损失。
- 在计算同变损失时,我们需要在自注意力中使用 CFA。
- 比较不做模块上的改进只加同变损失(倒数第二行)和 AF-LDM (倒数第三行)的结果,可以发现同变损失单独是不起作用的,不仅 FID 差了很多,SPSNR 也变差了。因此,同变损失必须和抗混叠模块一起使用。
上表的结果表明,我们在论文中介绍的所有设计都是有效的。最终的 AF-LDM 可以在几乎不降低生成质量的前提下大幅提升模型同变性。除表格外,我们在项目网站上分享了更直观的消融实验结果。
我们还用一个简单的实验说明,此前模型仅在整数平移(潜图像移动 1 个单位,真实图像移动 8 个单位)时具有较好的同变性。而为了实现平滑的图像编辑,我们最大的收获是提升了模型的分数平移同变性。

仅用光流变换的视频编辑
尽管我们在方法设计中仅考虑了裁剪平移的同变性,但在实验中,我们发现模型对更复杂的不规则变换,如光流变换,也具有更好的同变性。这一性质拓宽了 AF-LDM 的应用场景。为此,我们在 AF-VAE 的潜空间里重新训练了加入了抗混叠模块的 Stable Diffusion 1.5 (AF-SD),并在 AF-SD 上做了光流变换同变性的相关实验。
先简单补充一下光流的相关知识:光流描述了视频两帧之间每个像素的平移。因此,光流是一张的图片,两个通道分别表示每个像素在横向和纵向上的平移。根据光流,我们能够把视频的前一帧变换到后一帧。当然,这种变换是存在误差的。
在实验中,我们主要观察两张图片在扩散模型的 DDIM 反演 (将真实图片变回纯噪声)和 DDIM 重建阶段对光流变换的同变性(以 SPSNR 来评估)。另外,为了知道在光流变换中「较好的」 SPSNR 应该是多少,我们计算了输入帧之间的光流变换误差,用以提供参考。

结果显示,AF-SD 在反演和生成时的光流变换同变性都有所提升。惊人的是,AF-SD 在生成时的重建效果竟然比直接对输入图像做光流变换还要好。也就是说,在用 AF-SD 时,只要对初始噪声做光流变换,输出视频就会自然做对应的光流变换,且比直接在图像上做更加准确。

受到上述实验结果启发,得益于 AF-SD 在反演和生成过程中的同变性,我们设计了一种非常简单的视频编辑方法:对一个视频的每一帧进行 DDIM 反演和再生成(改变生成时 prompt)。我们做的唯一改动是同时在反演和生成的时候都启用后续帧对第一帧的 CFA。
这种简单的视频编辑方法能够为内容变化不大(相对第一帧而言)的视频输出平滑的编辑结果。由于我们的改进主要体现在分数平移同变性上,输入视频的变化越是细微、平缓,我们的编辑方法的优势就越明显。比如,以下是同一个编辑方法下,SD 和 AF-SD 的结果对比。
小声说一句,由于 AF-SD 需要重新训练所有模型,而我们的数据和计算资源都不够,所以 AF-SD 的生成质量较差。当然,它还是可以完成一些简单的编辑任务的。我们主要用这个模型来验证 AF-LDM 的应用潜力。
其他应用
我们还在其他一些任务上简单验证了 AF-LDM 的通用性。在实现所有任务时,我们都采用了基于扩散模型的方法。欲知细节欢迎阅读原论文和访问项目网站。
贡献总结与未来展望
读完论文的主要内容后,我们可以总结论文的贡献:
- 我们追溯了潜扩散模型编辑不稳定的主要原因:缺乏分数平移同变性。
- 我们设计了一种无混叠的潜扩散模型 (AF-LDM),它能够有效提升 LDM 的平移同变性。
- 从技术贡献上看,我们提出了简明有效的同变损失,以防止加入了抗混叠模块的模型在训练中损失同变性。此外,我们分析了自注意力运算不够稳定的原因,并通过在同变损失里加入同变注意力来提升模型对参考帧的相对同变性。
- 我们在多项任务中展示了 AF-LDM 广泛的应用前景。
其中,我认为第一项贡献是最重要的。潜扩散模型的不稳定性是一个老生常谈的问题,但很少有工作对其做深入分析。而我们提供了一个分析此问题的新视角,并且证明此前常见的 CFA 技术其实和同变性密切相关。第四项贡献也很有趣,我们发现 AF-LDM 也能提升不规则平移的同变性,可能可以拓展到更多任务上。剩下两项技术贡献倒相对来说没有那么重要。
按惯例,我也给论文挑挑刺,列举它的几项不足:
- 社区用户很多时候会关注一项工作的方法能否直接用起来,能否用预训练模型实现一些好玩的应用。但我们在这个项目中训练的文生图模型 AF-SD 生成质量较差,只能做一些简单的应用。
- 论文没有进一步分析为什么训练时模型的同变性会逐渐下降,只给了解决方法。
- 我们并没有完美解决自注意力的低同变性问题,目前的同变注意力必须要给一个参考帧。
总体上来,我个人比较喜欢能够深入解释某一问题的工作,我对这个工作的贡献十分满意。
从这个工作出发,我能想到的未来探索方向有:
- 帮助视频生成和多视角 3D 生成。平移同变性好,意味着模型能够用同样的形式表达不同位置的同一物体。这一性质在图像生成中难以体现,而在视频生成和多视角 3D 生成中比较重要。
- 更稳定的视频编辑和图像插值方法。我们在论文仅仅展示了简单的视频编辑和图像插值算法。如果将 AF-SD 和之前的方法结合,再稍微加一点新的设计,就能实现一套不错的方法。当然,由于我们提供的预训练 AF-SD 质量较差,开发图像插值应用更可行一点。
- 获取像素级精确特征。潜图像的一个像素代表了 个真实像素。而如本工作所示,目前多数 LDM 的 VAE 存在混叠现象。这会导致我们难以准确获取每个真实像素处的特征,只能大概获取其邻域的特征。而 AF-LDM 可以改善这一点。当然,为了验证 AF-LDM 在这方面的优越性,我们需要找到一个合适的任务去测试。我简单测试了像素级匹配任务 (pixel correspondence),但似乎 AF-LDM 在这个任务上没有明显提升。
除了最直接的应用外,这篇论文还能给我们更宏观的一些启示。比如,现在的神经网络在处理图像时并不是完美的。神经网络的上下采样操作一般是固定的,不管网络的其他参数学得有多么好,不够合理的上下采样总会导致一些问题(比如混叠)。我们不能希望靠加数据来解决一切问题,有时候要从更底层的神经网络设计来解决问题。希望这篇论文能够引发大家在科研上的更多思考。
参考文献
[1] StyleGAN3: Alias-Free Generative Adversarial Networks
[2] Making Convolutional Networks Shift-Invariant Again
[3] AF Convnet: Alias-Free Convnets: Fractional Shift Invariance via Polynomial Activations
[4] Text2Video-Zero: Text-to-Image Diffusion Models are Zero-Shot Video Generators
[5] I2SB: Image-to-Image Schrödinger Bridge
#DDT
解决Diffusion Transformers优化困境!南京大学与字节等提出:解耦扩散模型
解耦 Encoder-Decoder Transformer 能否加速收敛并增强样本质量?
一个类似 MAR+REPA 的技术。
本文研究的是 Diffusion Transformers。Diffusion Transformers 在每个去噪步骤中,输入是带有噪声的图片,会对其进行编码 (Encode),以提取低频语义分量。编码之后,再通过解码 (Decode) 恢复高频预测的噪声。
本文认为,这个过程带来了一个优化的困境:Encode 的过程需要减少高频分量,而 Decode 过程又需要增加高频分量,就会带来优化的难度。
因此,本文的解耦扩散模型 (DDT) 就可以应对这个问题:把 condition encoder 和 velocity decoder 解耦。condition encoder 用于提取语义信息,velocity decoder 用于解码。
DDT 的结果:对于 ImageNet 256×256,DDT-XL/2 实现了 1.31 FID 的 SOTA 性能。对于 ImageNet 512×512,DDT-XL/2 实现了 1.28 的 SOTA FID。
DDT 还有一个额外的好处:可以增加推理速度。原因是对不同 denosing steps 可以共享 condition。还专门提出了一种基于统计动态规划的方法来识别出最佳的共享策略。

图1:DDT-XL/2 在 256 Epoch 实现了 SoTA 1.31 的 FID

图2:在 ImageNet 256×256 分辨率和 ImageNet 512 × 512 分辨率下训练的 DDT-XL/2 在 CFG = 4.0 的生成结果
专栏目录:https://zhuanlan.zhihu.com/p/687092760
1 DDT:解耦扩散模型
论文名称:DDT: Decoupled Diffusion Transformer
论文地址:http://arxiv.org/pdf/2504.05741
代码链接:http://github.com/MCG-NJU/DDT
1.1 DDT 研究背景
图像生成是计算机视觉研究的一项基本任务,其目的是捕捉原始图像数据集的固有数据分布,并通过采样合适的分布来生成高质量的图像。
Diffusion 的前向过程按照 SDE 前向过程逐渐向原始数据添加高斯噪声。去噪过程从这个损坏过程中学习分数估计。一旦准确地学习了得分函数,就可以通过数值求解反向 SDE 来合成数据样本。
Diffusion Transformer 将 Transformer 架构引入扩散模型中,以取代传统的主流的基于 UNet 的模型。在给定足够的训练迭代的情况下,即使在不依赖长残差连接的情况下,Diffusion Transformer 也优于传统方法。然而,由于成本高,它们的收敛速度慢仍然给开发新的模型带来了巨大的挑战。
本文希望从模型设计的角度解决上述缺点。传统模型常使用 Encoder-Decoder 架构,本文探索的是解耦 Encoder-Decoder Transformer 能否解锁加速收敛和增强样本质量,希望回答这个问题:解耦 Encoder-Decoder Transformer 能否加速收敛并增强样本质量?
本文的结论是:Diffusion Transformer 在 "提取抽象结构信息" 以及 "恢复详细细节信息" 之间存在优化的困境。此外,由于原始像素监督,DiT 在提取语义表征方面受限。
本文的解决方案:解耦 Encoder 和 Decoder,即解耦低频语义编码和高频细节解码。将此 Encoder-Decoder DiT 模型称为 Decoupled Diffusion Transformer (DDT)。DDT 包含一个 condition encoder 来提取语义特征。提取的自条件和 noised latent 一起被送入 velocity decoder 来计算速度场。为了保持相邻步骤的 Self Condition 特征的局部一致性,对解码器的速度回归损失进行间接监督,对表征对齐进行直接监督。
1.2 Diffusion Transformer 困境:低频语义编码能力有限
本文分析的主题是 Flow-based Model。 代表纯噪声。如图 3 所示,扩散模型其实相当于是对谱分量 Autoregressive 的细化[1]。Diffusion Transformer 对 noisy latent 进行编码,以捕获低频语义,然后再解码高频细节。然而,这种语义编码过程不可避免地会衰减高频信息,造成优化困境。
因此,DDT 觉得应该将传统的 Decoder-Only 的扩散模型架构解耦为显式的 Encoder-Decoder 架构。

图3:SiT-XL/2 的 reverse-SDE (生成) 过程。生成过程中一个很明显的趋势是从低频到高频,大多数时间都花在生成高频细节上 (从 t = 0.4 到 t = 1.0)
引理1: 对于一个第 步的 flow-matching noise scheduler,定义 为干净数据 的最高频率。noisy latent 的最大保持频率为:

代表纯噪声。当 增加,噪声降低,此时语义编码变得更容易了(因为噪声降低),而解码变得更加困难(因为从低频的输入预测高频输出,这步需要预测的频率差大了)。
考虑第 去噪步骤的最坏情况,Diffusion Transformer 将频率编码为 ,直到第 步,它需要解码至少 的残差频率。如果没能在第 步解码此残差频率,就会为后续步骤创造瓶颈。
- 如果将更多的计算分配给噪声较大的时间步能够获得提升,意味着 Diffusion Transformer 难以编码低频信息,以提供语义信息。
- 如果将更多的计算分配给噪声较小的时间步能够获得提升,意味着 Flow-matching Transformer 难以解码出更高的频率,来提供更精细的细节。
如下图 4 所示,证明了与 uniform scheduling 相比,将更多的计算分配给早期时间步可以提高最终性能。这表明扩散模型面对的挑战,更多的是在比较 noisy 的时间步。

图4:SiT-XL/2 在不同 timeshift 的 FID50K。在 noisy 步骤中分配更多的计算可以显著提高性能
这就引出了一个关键的结论:Diffusion Transformer 从根本上受到低频语义编码能力的限制。 因此,本文探索了 Encoder-Decoder 的架构。
之前的研究 MAR 中,轻量级的 diffusion MLP head 的解码能力受限,因此 MAR 通过 Backbone 得到的语义 latent 做辅助,以完成高质量图像生成。
之前的研究 REPA 中,通过预训练的 vision foundations 的表征对齐,来增强低频编码。
1.3 DDT 方法:解耦编解码器
Decoupled Diffusion Transformer 包括一个 condition encoder 和一个 velocity decoder。
DDT 的整个框架是 linear flow diffusion。
Condition Encoder
condition encoder 的输入包括 noisy input ,时间步 ,以及 class label 。它提取的低频分量 self-condition 作为 velocity decoder 的输入条件。
其结构按照 DiT 和 SiT 设计,一系列 Attention 和 FFN 的堆叠。

其中,noisy input 被 patchfied 为连续 token,然后通过 Condition Encoder 提取 self- condition 。时间步长 和类标签 作为额外的 condition 信息输入。这些外部 condition embedding 在每个 Block 中通过 AdaLN-Zero 逐渐注入到 noisy input 的编码特征中。
为了在相邻时间步中保持 的局部一致性,还采用了 REPA 的表征对齐技术。如式 3 所示,该方法将 Encoder 第 层的中间特征 与 DINOv2 表征 对齐。 是可学习投影 MLP:

这种简单的正则化加速了训练收敛,促进了相邻步骤之间 的局部一致性。它允许在相邻步骤之间共享编码器的输出 。实验表明,这种编码器共享策略显着提高了推理效率,且性能下降可忽略不计。
Velocity Decoder
Velocity Decoder 采用与 Condition Encoder 相同的架构设计,由堆叠的 Attention 和 FFN 组成,类似于DiT/SiT。
Velocity Decoder 的输入包括 noisy input ,时间步 ,以及 Condition Encoder 提供的 condition ,目标是估计出高频速度 。Decoder 的额外输入只有时间步 ,以及 self- condition 。

为了提高相邻步骤之间 condition 的一致性,通过 AdaLN-Zero 把 condition 引入 Decoder 特征。
Decoder 使用 Flow-matching 损失进行训练,如式 5 所示:

1.4 采样加速
通过将显式表示对齐合并到 Encoder 中,并将隐式 Self-condition 注入 Decoder 中,在训练期间跨相邻步骤实现 的局部一致性。这使我们能够在适当的局部范围内共享 ,从而减少 Encoder 的计算量。

图5:不同时间步之间来自 Encoder 的特征 z_t 的余弦相似度。相邻步骤之间存在很强的相关性,有冗余
给定总推理步骤 和 Encoder 的计算预算 ,共享率为 ,定义 为计算 Self- condition 的时间步,如式 6 所示。如果当前时间步 不在 中,将先前计算的 重用为 。否则,使用 Encoder 和当前 noise latent 重新计算 :

一种简单的方法 Uniform Encoder Sharing 是每 步计算一次 。以前的工作,例如 DeepCache,使用这种范式来加速 UNet 模型。
本文还提出一种统计动态规划的方法计算最优 集。具体细节不展开了。
1.5 实验结果
首先是 ImageNet 256×256 实验。batch size 是 256,使用的 VAE 是 VAE-ft-EMA,下采样 8 倍,channel 为 4 (SDf8d4)。
架构改善:SwiGLU, RoPE 和 RMSNorm。
训练加速:lognorm sampling。
通过结合这些先进技术开发了改进的基线模型。
这些改进基线的性能如图 6 所示。为了验证我们实现的可靠性,作者还复现了 REPA-B/2 的结果,实现了略高于 REPA 中最初报告的指标。
图 6 中本文方法的结果,在没有 REPA 的情况下始终优于之前方法。但在使用 REPA 时,性能迅速接近饱和点。这在 XL 模型大小中尤为明显,其中这些增加的技术带来的收益逐渐下降了。

图6:不同模型大小的 400K 训练步骤的结果。灰色结果来自之前论文,DDT† 表示不使用架构优化和 lognorm sampling 的结果。DDT 模型始终优于其他模型。所有结果不使用 CFG
作者在图 6 中展示了不同大小的模型在 400K 训练步骤的性能。DDT 在各种模型大小上表现出一致且显着的改进。DDT-B/2(8En4De) 模型超过 Improved-REPA-B/2 2.8 的 FID。DDT-XL/2(22En6De) 超过 REPA-XL/2 1.3 的 FID。虽然 decoder-only 的 DiT 使用 REPA 接近性能饱和,但 DDT 继续提供更好的结果。架构改进以及其他训练技术在模型尺寸增加时的收益递减,但 DDT 模型保持了显著的性能优势。
ImageNet 256×256 结果
图 7 报告了 DDTXL/2 (22En6De) 和 DDT-L/2 (20En4De) 的最终指标。
DDT 展示了卓越的效率,与 REPA 和其他 DiT 模型相比,使用近 1/4 的 Epochs 即实现收敛。
为了与 REPA 保持方法的一致性,DDT 在区间 [0.3,1] 中使用了 2.0 的 CFG,结果是 DDT-L/2 达到了 1.64 的 FID,DDT-XL/2 在 80 个 Epochs 获得了 1.52 的 FID。通过将训练扩展到 256 Epoch,DDT-XL/2 在 ImageNet 256×256 上实现了 1.31 的 FID,优于以前的 DiT。在将训练扩展到 400 个 Epoch 后,DDT-XL/2 (22En6De) 实现了 1.26 的 FID,几乎达到了 SD-VAE-ft-EMA-f8d4 的上限,在 ImageNet256 上有一个 1.20 rFID。

图7:ImageNet 256×256 class-conditioned generation 性能比较。灰色块意味着该算法使用了在 ImageNet 上训练或微调的 VAE,而不是现成的 SD-VAE-f8d4-ft-ema
图 8 是 512×512 分辨率的结果。为了验证 DDT 模型的优越性,作者在 256 Epoch 下在 ImageNet 256×256 上训练的 DDT-XL/2 作为初始化,在 ImageNet 512×512 上微调 DDT-XL/2 100K 步。本文实现了 1.90 的 FID ,比 REPA 高出 0.28。在将更多的训练步骤分配给 DDT-XL/2 时,在 500K 步上实现了 1.28 个 FID,时间间隔为 CFG 3.0 [0.3, 1.0]。

图8:ImageNet 512×512 class-conditional generation 性能比较。DDT-XL/2 (512×512) 是从 1.28M 步的 256×256 训练的相同模型微调过来的
Encoder sharing 加速效果
如图 5 所示,Condition Encoder 中得到的 condition 具有很强的局部一致性。即使 与 的相似度高于 0.8 。这种一致性提供了一个机会,通过共享相邻步骤之间的 Encoder 来加速推理。
作者采用 uniform encoder sharing 策略和统计动态规划策略。具体来说,对于 uniform 策略,每 步重新计算 。对于统计动态规划,通过动态规划求解相似度矩阵上的最小求和路径,并根据求解的策略重新计算 。如图 9 所示,当 小于 6 时,可以在实现显著推理加速的情况下,几乎没有视觉质量损失。如图 10 所示,指标损失微不足道,推理却显著加速。新提的统计动态规划策略略微优于原始的 uniform encoder sharing 策略。

图9:在相邻步骤中共享 condition z_t 可以显著提高推理速度

图10:不同模型尺寸 400K 训练步骤的指标对比。所有结果不使用 CFG
消融实验:Encoder-Decoder 比例
作者系统地探索了 不同模型大小下从 2:1 到 5:1 的 Encoder-Decoder 比例。图 11 和图 12 显示了对架构优化的关键见解。
作者观察到,随着模型尺寸的增加,更大的 Encoder 有利于进一步提高性能。对于图 11 中的基本模型,最佳配置显示为 8 Encoder+ 4 Decoder,提供卓越的性能和收敛速度。值得注意的是,图 12 中更大的模型表现出明显的偏好,使用 20 Encoder+ 4 Decoder 实现了峰值性能,这个 Encoder-Decoder 的比例更激进。这种意想不到的发现促使作者将 DDT-XL/2 比例缩放到 22 Encoder+ 6 Decoder 来探索 DiT 架构的性能上限。

图11:DDT-B/2,Improved-baselines,不同 Encoder-Decoder 比例的结果对比。DDT-B/2(8En4De) 实现了更快的收敛速度和更好的性能

图12:DDT-L/2,Improved-baselines,不同 Encoder-Decoder 比例的结果对比。DDT-L/2(20En4De) 实现了更快的收敛速度和更好的性能
参考
- ^Diffusion is spectral autoregression

















 4412
4412

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









