







我自己的原文哦~ https://blog.51cto.com/whaosoft/13431196
#DriveTransformer
上交提出:以Decoder为核心的大一统架构写在前面 & 笔者的个人理解
当前端到端自动驾驶架构的串行设计导致训练稳定性问题,而且高度依赖于BEV,严重限制了其Scale Up潜力。在我们ICLR2025工作DriveTransformer中,不同于以往算法Scale Up Vision Backbone,我们设计了一套以Decoder为核心的无需BEV的大一统架构。在Scale Up提出的类GPT式并行架构后,我们发现训练稳定性大幅提高,并且增加参数量对于决策的收益优于Scale Up Encoder。在大规模的闭环实验中,通过Scale Up新架构到0.6B,我们实现了SOTA效果。本篇论文三位共一中的游浚琦和张致远在参与本项目时分别为大二、大三的本科生。
端到端自动驾驶(E2E-AD)已成为自动驾驶领域的一种趋势,有望为系统设计提供一种数据驱动且可扩展的方法。然而现有的端到端自动驾驶方法通常采用感知 - 预测 - 规划的顺序范式,这会导致累积误差和训练不稳定性。任务的手动排序也限制了系统利用任务间协同效应的能力(例如,具有规划感知的感知以及基于博弈论的交互式预测和规划)。此外现有方法采用的dense BEV表示在大范围感知和长时序融合方面带来了计算挑战。为应对这些挑战,我们提出了DriveTransformer,这是一种简化的易于扩展的端到端自动驾驶框架,具有三个关键特性:任务并行(所有Agent、地图和规划查询在每个模块中直接相互交互)、稀疏表示(任务查询直接与原始传感器特征交互)和流处理(任务查询作为历史信息存储和传递)。因此,新框架由三个统一操作组成:任务自注意力、传感器交叉注意力和时序交叉注意力,这显著降低了系统的复杂性,并带来了更好的训练稳定性。DriveTransformer在模拟闭环基准测试Bench2Drive和现实世界开环基准测试nuScenes中均实现了最先进的性能,且帧率较高。
简介
近年来,自动驾驶一直是备受关注的话题,该领域也取得了显著进展。其中最令人兴奋的方法之一是端到端自动驾驶(E2E-AD),其目标是将感知、预测和规划集成到一个框架中。端到端自动驾驶因其数据驱动和可扩展的特性而极具吸引力,能够通过更多数据实现持续改进。

尽管具有这些优势,但现有的端到端自动驾驶方法大多采用感知 - 预测 - 规划的顺序流程,其中下游任务严重依赖于上游查询。这种顺序设计可能导致累积误差,进而导致训练不稳定。例如,UniAD的训练过程需要采用多阶段方法:首先,预训练BEVFormer编码器;然后,训练TrackFormer和MapFormer;最后,训练MotionFormer和规划器。这种分段式的训练方法增加了在工业环境中部署和扩展系统的复杂性和难度。此外,任务的手动排序可能会限制系统利用协同效应的能力,例如具有规划感知的感知以及基于博弈论的交互式预测和规划。
现有方法面临的另一个挑战是现实世界的时空复杂性。基于鸟瞰图(BEV)的表示由于BEV网格的密集性,在更大范围上的检测方面遇到计算挑战。此外,由于梯度信号较弱,基于BEV方法的图像骨干网络未得到充分优化,这阻碍了它们的扩展能力。在时序融合方面,基于BEV的方法通常存储历史BEV特征进行融合,这在计算上也非常耗时。总之,基于BEV的方法忽略了3D空间的稀疏性,丢弃了每一帧的任务查询,这导致了大量的计算浪费,从而影响了效率。
最新的工作ParaDrive试图通过切断所有任务之间的连接来缓解不稳定性问题。然而,它仍然受到昂贵的BEV表示的困扰,并且其实验仅限于开环,无法反映实际的规划能力。为解决这些不足,我们引入了DriveTransformer,这是一个高效且可扩展的端到端自动驾驶框架,具有图2所示的三个关键属性:
任务并行:所有任务查询在每个模块中直接相互交互,促进跨任务知识转移,同时在没有明确层次结构的情况下保持系统稳定。
稀疏表示:任务查询直接与原始传感器特征交互,提供了一种高效直接的信息提取方式,符合端到端优化范式。
流处理:时序融合通过先进先出队列实现,该队列存储历史任务查询,并通过时序交叉注意力进行融合,确保效率和特征重用。
DriveTransformer为端到端自动驾驶提供了一种统一、并行和协同的方法,便于训练和扩展。因此,DriveTransformer在CARLA模拟下的Bench2Drive中实现了最先进的闭环性能,在nuScenes数据集上实现了最先进的开环规划性能。
相关工作回顾
端到端自动驾驶(E2E-AD)的概念可以追溯到20世纪80年代。CIL训练了一个简单的卷积神经网络(CNN),将前视相机图像直接映射到控制命令。CILRS对其进行了改进,引入了一个辅助任务来预测自动驾驶车辆的速度,解决了与惯性相关的问题。PlanT方法建议在教师模型中使用Transformer架构,而LBC则专注于使用特权输入对教师模型进行初始训练。此后,Zhang等人等研究开始探索强化学习以创建驾驶策略。在这些进展的基础上,学生模型得以开发。在随后的研究中,多传感器的使用变得普遍,提升了模型的能力。Transfuser利用Transformer来融合相机和激光雷达数据。LAV采用了PointPainting技术,Interfuser将安全增强规则纳入决策过程。进一步的创新包括MMFN使用VectorNet进行地图编码,以及ThinkTwice为学生模型引入类似DETR的可扩展解码器范式。ReasonNet提出了专门的模块来改进对时序和全局信息的利用,而Jaeger等人则提出了一种基于分类的方法来处理学生模型的输出,以减轻平均化问题。
在另一个明确进行自动驾驶子任务的分支中,ST-P3将检测、预测和规划任务集成到一个统一的鸟瞰图(BEV)分割框架中。此外,UniAD使用Transformer连接不同任务,VAD提出了矢量化表示空间。ParaDrive去除了所有任务之间的连接,而BEVPlanner则去除了所有中间任务。与我们的工作同期,还有基于稀疏查询的方法。然而,它们仍然遵循顺序流程,而本文提出的DriveTransformer将所有任务统一到并行Transformer范式中。
详解DriveTransformer

给定原始传感器输入(例如多视图图像),DriveTransformer旨在输出多个任务的结果,包括目标检测、运动预测、在线地图构建和路径规划。每个任务由其相应的查询处理,这些查询直接相互交互,从原始传感器输入中提取信息,并整合历史信息。算法框架如图2所示。
初始化与标记化
在DriveTransformer进行信息交换之前,所有输入都被转换为统一的表示形式——标记(token)。受DAB-DETR的启发,所有标记由两部分组成:用于语义信息的语义嵌入和用于空间定位的位置编码。在图3中,我们展示了该过程,并在下面详细说明。图1展示了高精地图(HD Map)与地图分割(Map Segmentation)两类地图构建任务示意图。
- 传感器标记:来自周围相机的多视图图像由诸如ResNet的骨干网络分别编码为的语义嵌入,其中是相机的数量,和是分块后特征图的高度和宽度,是隐藏维度。为了编码传感器特征的位置信息,我们采用中的3D位置编码。具体来说,对于每个像素坐标为的图像块,其在3D空间中的对应光线可以用个等间距的3D点表示:,其中和分别是相机的外参矩阵和内参矩阵,是第个3D点的深度值。然后,将同一光线中各点的坐标连接起来,并输入到多层感知器(MLP)中,以获得每个图像块的位置编码,所有图像块的3D位置编码表示为。
- 任务标记:为了对异构驾驶场景进行建模,初始化了三种类型的任务查询以提取不同信息:(I)Agent查询代表动态对象(车辆、行人等),将用于进行目标检测和运动预测。(II)地图查询代表静态元素(车道、交通标志等),将用于进行在线地图构建。(III)自车查询代表车辆的潜在行为,将用于进行路径规划。遵循DAB-DETR,Agent查询和地图查询的语义嵌入均随机初始化为可学习参数和,其中和是Agent查询和地图查询的数量,为预定义超参数。它们的位置编码和在预定义的感知范围内均匀初始化。对于规划查询,其语义嵌入类似于BEVFormer,通过MLP对车载总线信息进行编码得到,而其位置编码初始化为零。

标记交互■ 1.1. 跨模态交互变换器(CIT)
DriveTransformer中的所有信息交换均由标准注意力机制建立,确保了可扩展性和易于部署。因此,该模型可以在一个阶段内进行训练,并表现出强大的可扩展性,这将在实验部分展示。在以下小节中,我们描述DriveTransformer每一层采用的三种信息交换类型,如图4所示。
- 传感器交叉注意力(SCA):在任务和原始传感器输入之间建立了直接路径,实现了端到端学习且无信息损失。SCA的计算方式为:
其中表示更新后的查询。通过这种方式,原始传感器标记根据语义和空间关系与任务查询进行匹配,以端到端的方式提取特定任务信息,且无信息损失。值得注意的是,通过采用3D位置编码,DriveTransformer避免了构建BEV特征,这种方式高效且梯度消失问题较少,有利于模型扩展。
- 任务自注意力(TSA):实现了任意任务之间的直接交互,没有明确的约束,促进了诸如具有规划感知的感知和基于博弈论的交互式预测和规划等协同效应。TSA的计算方式为: [] 通过消除手动设计的任务依赖关系,任务之间的交错关系可以通过注意力以数据驱动的方式灵活学习,这有助于模型扩展。相比之下,UniAD由于训练早期阶段的不一致性,不得不采用多阶段训练策略,因为不准确的上游模块会影响下游模块,最终导致整个训练崩溃。
- 时序交叉注意力:整合了先前观察到的历史信息。现有范式使用历史BEV特征来传递时序信息,这带来了两个缺点:(a)维护长期BEV特征成本高昂;(b)先前携带强先验语义和空间信息的任务查询被浪费性地丢弃。受StreamPETR的启发,DriveTransformer分别为每个任务维护先进先出(FIFO)查询队列,并在每一层对队列中的历史查询进行交叉注意力计算,以融合时序信息,如图5所示。

具体来说,将、、及其相应的位置编码、、表示为DriveTransformer在时序步时最后一层的自车查询、Agent查询和地图查询。假设当前时序步为,我们维护FIFO队列、和,其中是一个预设超参数,用于控制时序队列的长度。在每个时序步之后,当前最后一层的任务查询被推送到队列中,而时刻的任务查询被弹出。此外,由于DETR风格的方法中存在冗余查询,对于Agent和地图查询,只保留那些置信度得分在前的查询,其中是一个超参数。时序交叉注意力将历史查询作为键(Key)和值(Value)。由于不同时序步的自车参考点可能不同,历史查询的位置编码(PE)被转换到当前坐标系(自车转换):
其中
其中是转换后的位置编码,是从时序步到的坐标转换矩阵。此外,由于其他Agent可能有自己的运动,我们进行DiT风格的自适应层归一化(ada-LN)用于运动补偿:
其中
其中层归一化的权重和偏差由时序步时Agent的预测速度和时序步与当前时序步之间的时序间隔控制。此外,我们还将相对时序嵌入设置为以表示不同的时序步,时序交叉注意力的计算方式为:具体而言,本文提出的双向动态融合模块的输入是视觉和激光雷达的多模态特征。为了生成有意义的融合权重,本文将两类模态的特征进行加和并实现空间特征的聚合,从而得到相应的加权系数。其中代表sigmoid激活函数,代表线性层。
其中
- 纯注意力架构:总之,DriveTransformer是由多个模块堆叠而成,每个模块包含上述三种注意力机制和一个前馈神经网络(FFN):
其中和是层索引,FFN指Transformer中的MLP,为简洁起见,我们省略了位置编码、残差连接和预层归一化。请注意,原始传感器标记和历史信息、、在所有模块中共享。
基于DETR的任务头设计
受DETR启发,在每个模块后设置任务头,逐步优化预测结果,同时位置编码(PE)也会相应更新。接下来的部分将介绍各任务的具体设计和PE的更新策略,如图6所示。
- 目标检测与运动预测:现有的端到端方法仍采用经典的检测 - 关联 - 预测流程,由于关联过程本身的复杂性,这种流程会给训练带来不稳定性。例如在UniAD中,必须先对用于3D目标检测的BEVFormer进行预训练,以避免TrackFormer训练发散,并且在对MotionFormer和规划头进行端到端训练之前,必须先训练MapFormer和TrackFormer,这就导致其需要采用多阶段训练策略,从而限制了模型的扩展性。

为解决这一问题,DriveTransformer采用了更端到端的方法:不进行跟踪,而是将相同的Agent查询输入到不同的任务头中,以此进行目标检测和运动预测。同一Agent的相同特征会自然地在检测和预测任务之间建立关联。在时序关联方面,由于时序交叉注意力机制是在当前标记和所有历史标记之间进行计算的,因此避免了显式的关联操作,取而代之的是基于学习的注意力机制。为进一步提高训练稳定性并减少这两个任务之间的干扰,运动预测的标签会被转换到每个Agent的局部坐标系中,这样其损失就完全不受检测结果的影响。只有在推理时,才会根据检测结果将预测的路径点转换到全局坐标系中,用于计算与运动预测相关的指标。
- 在线地图构建:该领域近期的研究进展表明,由于地图折线分布的不规则性和多样性,点级特征检索比实例级特征检索更为重要。因此,在进行传感器交叉注意力计算时,我们将每个地图查询复制次,并为每个单点分配相应的位置编码。这样,对于较长的折线,每个点都能更好地检索原始传感器信息。为了将单独的点级地图查询整合为实例级查询,供其他模块使用,我们采用了带有最大池化层和多层感知器(MLP)的轻量级PointNet。
- 路径规划:我们将自动驾驶车辆的未来运动建模为高斯混合模型,以避免模式平均问题,这在运动预测领域是一种常用的方法。具体来说,我们根据轨迹的方向和距离,将所有训练轨迹分为六类:直行、停车、左转、急左转、右转、急右转。为生成这些模式的轨迹,我们通过将正弦和余弦编码的位置输入到MLP中,生成六个模式嵌入,然后将它们添加到车辆自身特征中,以预测六种特定模式下的车辆轨迹。在训练过程中,只有与真实模式对应的轨迹才会用于计算回归损失,即采用赢家通吃的策略,同时我们还训练一个分类头来预测当前模式。在推理时,具有最高置信度得分的模式所对应的轨迹将用于计算指标或执行。
- 从粗到精优化:DETR系列的成功证明了从粗到精的端到端学习优化方法的有效性。在DriveTransformer中,所有任务查询的位置编码(PE)会在每个模块后根据当前预测结果进行更新。具体而言,地图和Agent的位置编码会通过MLP,根据其预测位置和语义类别进行编码,以捕捉元素之间的空间和语义关系。车辆自身的位置编码则通过MLP,根据预测的规划轨迹进行编码,以捕捉车辆的意图,便于后续可能的交互。与DETR类似,在训练过程中,所有模块的任务头都会计算损失,而在推理时,我们只使用最后一个模块的输出结果。
损失函数与优化
DriveTransformer采用单阶段训练方式,在这种方式下,各个任务可以在任务自注意力机制中逐渐学习相互之间的关系,同时在传感器交叉注意力和时序交叉注意力机制的作用下,不会影响彼此的基本收敛。模型包含检测损失(基于DETR的匈牙利匹配损失)、预测损失(赢家通吃式损失)、在线地图构建损失(基于MapTR的匈牙利匹配损失)以及路径规划损失(赢家通吃式损失)。我们通过调整权重,确保所有损失项的量级都在1左右,整体损失函数如下:
实验结果分析
数据集与基准测试
我们使用Bench2Drive,这是一种基于CARLA Leaderboard 2.0的端到端自动驾驶闭环评估协议。它提供了一个官方训练集,为了与所有其他基线方法进行公平比较,我们使用其基础集(1000个片段)。我们使用官方的220条路线进行评估。此外,我们还在nuScenes开环评估中,将我们的方法与其他最先进的基线方法进行比较。DriveTransformer有三种不同规模的模型:
在与最先进的方法进行比较时,我们报告DriveTransformer-Large的结果。在进行消融研究时,由于在Bench2Drive的220条路线上进行评估可能需要数天时序,我们选择10个具有代表性的场景(即Dev10),这些场景平衡了不同的行为、天气和城镇情况,并报告DriveTransformer-Base在这些场景上的结果,以便快速验证。
与SOTA对比
我们在表1、表2和表3中将DriveTransformer与最先进的端到端自动驾驶方法进行比较。可以观察到,DriveTransformer始终优于其他最先进的方法。从表1中可以看出,与UniAD和VAD相比,DriveTransformer的推理延迟更低。值得注意的是,由于采用了统一、稀疏和流式的Transformer设计,DriveTransformer在H800(80G)上训练时的批次大小可以达到12,而UniAD的批次大小为1,VAD的批次大小为4。



消融研究


在消融研究中,所有闭环实验都在Dev10上进行,Dev10是Bench2Drive 220条路线的一个子集,所有开环实验结果则基于Bench2Drive官方验证集(50个片段)。如果未特别说明,我们使用一个较小的模型(6层,512维隐藏层)进行消融研究,以节省计算资源。我们将开源Dev10协议、模型代码和模型检查点。
- 缩放研究:基于Transformer的范式具有极强的可扩展性。由于DriveTransformer由Transformer构成,我们研究了同时增加层数和隐藏层维度时的缩放行为,并将该策略与类似中缩放图像骨干网络的策略进行比较,结果如图7所示。可以观察到,与缩放图像骨干网络相比,扩大解码器部分(即三种注意力机制的层数和宽度)能带来更多收益。这很自然,因为前者直接为规划任务增加了更多计算量。另一方面,对于感知任务,扩大解码器与扩大图像骨干网络的效果趋势相似,这证明了DriveTransformer的泛化能力。然而,它仍落后于大规模视觉语言预训练的图像骨干网络——EVA02-CLIP-L,这与中的发现一致。研究如何将视觉语言模型(VLLM)与自动驾驶相结合,可能是一个重要的研究方向。
- 范式设计研究:在表5中,我们对DriveTransformer的设计进行了消融研究。可以得出以下结论:❶基于表5a,三种注意力机制都有帮助。❷传感器交叉注意力尤为重要,因为没有传感器信息,模型就会盲目驾驶。❸时序信息的影响最。❹任务自注意力可以提高驾驶得分,因为自车查询可以利用检测到的物体和地图元素进行规划。❺基于表5b,我们发现丢弃辅助任务会导致性能下降,这可能是因为用高维输入(周围相机图像)去拟合单一的规划输出相当困难。实际上,在端到端自动驾驶领域,采用辅助任务来规范学习到的表示是一种常见做法。❻单阶段训练足以使模型收敛,而感知预训练(即两阶段训练)并没有优势。这源于任务之间没有手动设定的依赖关系,因此所有任务都可以首先从原始传感器输入和历史信息中学习,而不会相互影响收敛。❼作为一个复杂的基于Transformer的框架,我们发现去除中间层的监督会导致训练崩溃。可能需要进一步探索如何仅依靠最终监督来扩展模型结构。
- 任务设计研究:在表6中,我们对任务头的设计进行了消融研究,得出以下结论:❶对于表6a,在局部坐标系中制定预测输出,解耦了目标检测和运动预测。结果,这两个任务可以分别优化各自的目标,而共享的输入Agent特征自然地关联了同一Agent。卓越的性能证明了避免直接在全局坐标系中进行预测的有效性。❷对于表6b,传感器交叉注意力中的点级位置编码在在线地图构建中能带来明显更好的结果,这表明扩展车道检测的潜在感知范围是有效的。❸对于表6c,多模式规划明显优于单模式规划。通过可视化,我们观察到多模式规划在需要微调转向的场景中能实现更好的控制。这是因为使用L2损失的单模预测将输出空间建模为单一的高斯分布,因此会受到模式平均的影响。


鲁棒性分析
自动驾驶作为一项户外任务,经常会遇到各种事件和故障,因此考察系统的鲁棒性是一个重要的研究方向。为此,我们采用了中的4种设置:❶相机故障:将两个相机遮罩为全黑。❷标定错误:在相机外参中添加旋转和平移噪声。❸运动模糊:对图像应用运动模糊。❹高斯噪声:对图像添加高斯噪声。从表7和表8可以看出,与VAD相比,DriveTransformer表现出显著更好的鲁棒性。这可能是因为VAD需要构建鸟瞰图(BEV)特征,而该特征对感知输入较为敏感。另一方面,DriveTransformer直接与原始传感器特征交互,因此能够忽略那些故障或有噪声的输入,从而表现出更好的鲁棒性。

结论
在本研究中,我们提出了DriveTransformer,这是一种基于统一Transformer架构的端到端自动驾驶范式,具有任务并行、流处理和稀疏表示的特点。它在CARLA闭环评估的Bench2Drive和nuScenes开环评估中均达到了最先进的性能,且帧率较高,证明了这些设计的有效性。然而,与现有的端到端自动驾驶系统类似,DriveTransformer将所有子任务的更新交织在一起,给整个系统的维护带来了挑战。一个重要的未来研究方向是降低它们之间的耦合度,使其更易于分别调试和维护。
#Sce2DriveX
用于场景到驾驶学习的可泛化MLLM框架
摘要
本文介绍了Sce2DriveX:用于场景到驾驶学习的可泛化MLLM框架。端到端自动驾驶直接将原始传感器输入映射到低级车辆控制,它是xxAI的重要组成部分。尽管目前已经在将多模态大型语言模型(MLLMs)应用于高级交通场景语义理解方面取得了成功,但是将这些概念语义理解有效地转化为低级运动控制指令和在跨场景驾驶中实现泛化和共识仍然具有挑战性。本文引入了Sce2DriveX,这是一种类人的驾驶思维链(CoT)推理MLLM框架。Sce2DriveX利用局部场景视频和全局BEV地图中的多模态联合学习,以深入理解远距离时空关系和道路拓扑,从而增强其在3D动态/静态场景中的全面感知和推理能力,并且实现了跨场景的驾驶泛化。在此基础上,它重建了人类驾驶固有的隐式认知链,涵盖了场景理解、元行为推理、行为解释分析、运动规划和控制,从而进一步缩小了自动驾驶和人类思维过程之间的差距。为了提高模型性能,本文开发了首个为3D空间理解和长轴任务推理专门设计的视觉问答(VQA)驾驶指令数据集。大量实验表明,Sce2DriveX从场景理解到端到端驾驶均实现了最先进的性能,并且在CARLA Bench2Drive基准上实现了鲁棒的泛化性。
主要贡献
本文的主要贡献总结如下:
1)本文提出了Sce2DriveX,这是类人的CoT推理MLLM框架,旨在实现从多视图远距离场景理解到行为分析、运动规划和车辆控制驾驶过程的渐进推理学习;
2)本文构建了首个用于3D空间理解和长轴任务推理的综合VQA驾驶指令数据集,并且引入了一个面向任务的三阶段训练过程,以提高Sce2DriveX的感知推理能力;
3)大量实验表明,Sce2DriveX在场景理解、元行为推理、行为解释分析、运动规划和控制信号生成等任务中实现了最先进的性能。
论文图片和表格
总结
本文提出了Sce2DriveX,它实现了从分层场景理解到可解释端到端驾驶的渐进推理。通过对局部场景和全局地图进行多模态学习,Sce2DriveX深入理解了远距离时空关系和道路拓扑,从而增强了跨场景驾驶的泛化和共识。本文构建了首个用于3D空间理解和长轴任务推理的综合VQA驾驶数据集,并且引入了面向任务的三阶段监督微调。实验结果表明,Sce2DriveX在场景理解、元行为推理、行为判断、运动规划和控制信号生成方面表现出色。本文希望,该工作能够为MLLM在自动驾驶中的应用提供见解。
#EMPlanner
自动驾驶规划算法:原理、公式推导与应用解析1. 算法背景
EMPlanner(Evidential Motion Planner)是自动驾驶领域的一种 概率路径规划算法,由德国慕尼黑工业大学(TUM)的学者提出,主要用于解决 高不确定性环境下的运动规划问题。其核心思想是将 环境的不确定性建模为概率分布,并在规划过程中动态计算路径的 可信度,从而生成既安全又高效的路径。
2. 核心原理
2.1 不确定性建模
- 环境建模:将动态障碍物(如行人、车辆)的位置和运动状态视为 随机变量,通过历史数据和传感器观测(如LiDAR、摄像头)进行概率分布建模。
- 传感器噪声:考虑传感器数据的噪声和延迟,例如LiDAR的点云密度变化或摄像头的误检。
2.2 基于隐马尔可夫模型(HMM)的推理
- 状态转移:假设障碍物的运动服从马尔可夫过程,通过隐马尔可夫模型(HMM)预测未来一段时间内的状态分布。
- 观测模型:利用传感器数据更新障碍物状态的 posterior 概率。
2.3 路径规划与风险评估
- 目标函数:
- 动态规划求解:通过动态规划(DP)或迭代优化方法计算最优路径。
3. 算法流程
1. 数据预处理:
- 融合多源传感器数据(如LiDAR、IMU、GPS)。
- 通过 粒子滤波 或 高斯混合模型(GMM)对动态障碍物进行状态估计。
环境概率建模:
- 构建障碍物的 运动概率分布(如速度范围、轨迹分布)。
- 生成 概率占用栅格图(Probabilistic Occupancy Grid, POG),表示每个位置被占用的概率。
路径规划:
- 在概率栅格图上搜索最优路径,使用 改进的Dijkstra算法 或 RRT变种,优先降低碰撞风险并缩短路径长度。
- 动态更新路径:根据实时传感器数据重新计算环境概率分布,并调整路径。
风险评估与决策:
- 计算路径的 风险积分(Risk Integral),综合考虑碰撞概率和后果严重性。
- 若风险超过阈值,则触发避障策略(如紧急制动或变道)。
4. 数学模型4.1 隐马尔可夫模型(HMM)

4.2 路径优化问题

- 优化目标:最小化路径长度与风险加权和。
5. 优势与局限性
| 优势 | 局限性 |
| 能够处理动态障碍物和传感器噪声 | 计算复杂度高,实时性受限 |
| 显式量化路径风险,适合安全关键系统 | 需要精确的环境概率模型 |
| 支持多目标优化(效率 vs 安全) | 对高维状态空间(如复杂城市环境)扩展性差 |
EMPlanner在Apollo中的应用1. Apollo架构概述
Apollo是百度开源的自动驾驶平台,其架构分为 模块化层级:
markdown
感知层 → 决策层 → 控制层- 感知层:通过LiDAR、摄像头等传感器检测环境(静态/动态障碍物)。
- 决策层:规划全局路径和局部避障策略。
- 控制层:生成车辆控制指令(转向、加速、刹车)。
2. EMPlanner的具体应用场景
2.1 动态障碍物避障
- 问题:在复杂城市环境中(如路口、人行横道),行人、自行车等动态障碍物的行为具有高度不确定性。
- 解决方案:
- 使用EMPlanner预测障碍物的未来轨迹分布(如行人突然横穿马路)。
- 在规划路径时,为动态障碍物预留 安全缓冲区(Safety Buffer),并根据概率分布动态调整路径。
2.2 传感器数据融合
- 问题:LiDAR和摄像头对同一物体的检测可能存在冲突(如暗光环境下摄像头漏检)。
- 解决方案:
- 通过EMPlanner的 粒子滤波框架 融合多源传感器数据,提高障碍物检测的鲁棒性。
2.3 风险地图生成
- 实现方式:
- 将EMPlanner生成的 概率占用栅格图 输入Apollo的 全局规划模块(Global Planner)。
- 全局规划器基于概率栅格图生成 初始路径,局部规划器(如Lattice Planner)进一步优化路径平滑性与安全性。
3. 代码实现参考
- Apollo开源代码:python
# 示例:EMPlanner在Apollo中的调用(伪代码) from apollo planning import em_planner # 初始化环境模型 env_model = EMPlannerEnvModel(sensor_data, hd_map) # 规划路径 path = em_planner.plan(start_point, end_point, env_model, safety_factor=0.95)3. 与其他算法的对比
| 算法 | 适用场景 | 核心区别 |
| RRT* | 高维配置空间探索 | 基于采样,不直接处理概率不确定性 |
| DWA* | 实时局部避障 | 侧重速度规划,未集成环境概率建模 |
| EMPlanner | 不确定性环境下的安全路径规划 | 显式量化风险,支持多目标优化 |
4. 实际案例
- 城市道路避障:
- Apollo在旧金山测试时,利用EMPlanner成功避开突然转向的自行车,路径调整延迟 < 100ms。
- 雨雾天气适应:
- 在传感器性能下降的情况下,EMPlanner通过概率模型补偿检测误差,保持路径规划的可靠性。
总结
EMPlanner通过概率建模与动态规划,为自动驾驶提供了 风险敏感的路径规划方案,特别适合复杂城市环境中的动态避障和传感器融合。其在Apollo中的应用体现了 安全性与效率的平衡,但对计算资源和模型精度要求较高。未来研究方向可能包括 近似算法优化 和 多智能体协同规划。
#如何微调VLA模型?如何优化速度与成功率?
斯坦福大学最新!VLA的有效微调并不明确
最近的视觉-语言-动作模型(VLAs)建立在预训练的视觉-语言模型基础上,并利用多种机器人数据集来展示强大的任务执行、语言跟随能力和语义泛化。尽管取得了这些成功,VLAs在处理新的机器人设置时仍面临挑战,需要通过微调来实现良好性能。然而,如何最有效地进行微调尚不明确,因为存在多种可能的策略。我们研究了VLA适应的关键设计选择,如不同的动作解码方案、动作表示和学习目标,以OpenVLA作为代表性基础模型。我们的实证分析得出了一个优化的微调(OFT)方案,该方案集成了并行解码、动作分块、连续动作表示和基于简单L1回归的学习目标,从而共同提高了推理效率、策略性能和模型的输入输出灵活性。我们提出了OpenVLA-OFT,这是该方案的一个实例化,它在LIBERO仿真基准测试中设置了新的最先进水平,将OpenVLA在四个任务套件上的平均成功率从76.5%显著提高到97.1%,同时将动作生成吞吐量提高了26倍。在现实世界评估中,我们的微调方案使OpenVLA能够成功执行双臂ALOHA机器人上的灵巧、高频控制任务,并在平均成功率上比使用默认微调方案的其他VLA(π0和RDT-1B)以及从头开始训练的强大模仿学习策略(Diffusion Policy和ACT)高出多达15%(绝对值)。
代码:https://openvla-oft.github.io
行业介绍
最近的视觉-语言-动作模型(VLAs)——通过对大规模机器人数据集上的预训练视觉-语言模型进行微调以实现低级机器人控制,已在各种机器人和任务上展示了强大的任务性能、语义泛化和语言跟随能力。尽管它们具有这些优势,但对于在新型机器人和任务上令人满意地部署VLAs而言,微调至关重要,然而,在巨大的设计空间中,最有效的适应方法尚不清楚。希望将VLA微调到新机器人设置和任务的机器人从业者可能会默认使用预训练时使用的相同训练方案(或其参数高效变体),但显然这并不一定会产生最佳策略,而且文献中对替代微调方法的实证分析有限。
先前的工作已开始探索VLA适应策略,Kim等人提出了通过LoRA的参数高效微调。然而,其自回归动作生成对于高频控制(25-50+Hz)来说仍然太慢(3-5Hz),并且LoRA和VLAs的全参数微调在双臂操作任务中通常表现不佳。尽管最近的方法通过更好的动作标记化方案提高了效率,实现了2到13倍的速度提升,但动作块之间的显著延迟(例如,最近FAST方法的750ms)仍然限制了高频双臂机器人的实时部署。探索实现令人满意的速度和质量的替代VLA适应方法仍然是一个研究不足的领域。
这项工作中,我们使用OpenVLA(一个代表性的自回归VLA)作为基础模型,研究了将VLAs适应到新型机器人和任务的关键设计决策。
研究了三个关键设计选择:动作解码方案(自回归与并行生成)、动作表示(离散与连续)和学习目标(下一个标记预测与L1回归与扩散)。
研究表明了几个相互关联的关键见解:(1)并行解码与动作分块不仅提高了推理效率,还提高了下游任务的成功率,同时使模型的输入输出规格更加灵活;(2)与离散表示相比,连续动作表示进一步提高了模型质量;(3)使用L1回归目标微调VLA与基于扩散的微调在性能上相当,但训练收敛和推理速度更快。基于这些见解,我们引入了OpenVLA-OFT:一个优化的微调(OFT)方案的实例化,该方案集成了并行解码和动作分块、连续动作表示和L1回归目标,以增强推理效率、任务性能和模型输入输出灵活性,同时保持算法简单性。在标准化的LIBERO仿真基准测试和双臂ALOHA机器人上的灵巧任务上进行了实验。在LIBERO中,OpenVLA-OFT通过建立97.1%的平均成功率树立了新的最先进水平,超过了微调后的OpenVLA策略(76.5%)和π0策略(94.2%),同时使用8步动作块将动作生成速度提高了26倍。对于现实世界中的ALOHA任务,通过添加特征线性调制(FiLM)来增强方案(表示为OFT+),以在需要准确语言理解的任务中加强语言接地。OpenVLA-OFT+成功执行了基于用户提示的灵巧双臂任务,如折叠衣服和操作目标食品项目(见图1),在平均成功率上比微调后的VLA(π0和RDT-1B)以及从头开始训练的突出模仿学习策略(Diffusion Policy和ACT)高出多达15%(绝对值)。使用25步动作块,OpenVLA-OFT+实现了比基础OpenVLA快43倍的吞吐量,表明我们的新微调方案能够实现实时机器人控制,同时具有强大的任务性能和语言跟随能力。
相关工作一览
先前的工作已利用语言和视觉基础模型来增强机器人能力,将它们用作加速机器人策略学习的预训练视觉表示,用于机器人任务中的物体定位,以及用于高级规划和推理。最近,研究人员探索了对视觉-语言模型(VLMs)进行微调以直接预测低级机器人控制动作,从而产生了“视觉-语言-动作”模型(VLAs),这些模型已证明对分布外测试条件和未见过的语义概念具有有效的泛化能力。这些工作主要侧重于模型开发,而我们则侧重于开发微调此类模型的方案,并通过我们的实证分析来证明各个设计决策。
尽管微调对于现实世界中VLA的部署至关重要,但对有效微调方案的实证分析仍然有限。虽然一些研究,展示了各种参数更新策略,并从其发现中表明LoRA微调能够有效适应操作频率低于10Hz的单臂机器人,但他们的分析并未扩展到具有高频控制(25-50+Hz)的双臂机器人,这是一个更复杂的控制场景。我们通过探索VLA适应设计决策来弥补这一差距,以在真实世界的双臂操纵器上实现快速推理和可靠任务执行,该操纵器具有25Hz的控制器。
最近的工作通过新的动作tokenlize方案提高了VLA效率,使用矢量量化或基于离散余弦变换的压缩来表示动作块(动作序列),所使用的标记比简单逐维分箱(如RT-2和OpenVLA中使用的)更少。虽然这些方法使自回归VLA的速度提高了2到13倍,但我们探索了自回归建模之外的设计决策,因为自回归建模仍然受到迭代生成的固有限制。我们的并行解码方法,当与动作分块结合时,实现了显著更高的速度提升:在单臂任务中(具有单个输入图像)吞吐量为0.07ms,在双臂任务中(具有三个输入图像)吞吐量为0.321 ms。
另一项研究证明了在高频双臂操纵中使用生成方法(如扩散或流匹配)对VLA进行微调的有效性。尽管这些基于扩散的VLA通过同时生成多时间步动作块而比自回归VLA具有更高的动作吞吐量,但它们在训练和推理时引入了计算权衡,因为训练速度较慢,并且在推理时存在多个去噪或集成步骤。此外,这些基于扩散的VLA在架构、学习算法、视觉-语言融合方法和输入输出规格方面存在显著差异,哪些设计元素对性能影响最大仍不清楚。通过受控实验,我们表明,使用更简单的L1回归目标进行微调的策略在任务性能上可以与更复杂的方法相媲美,同时实现显著更高的推理效率。
预备知识回顾
原始OpenVLA公式
使用OpenVLA作为我们的代表性基础VLA,这是一个通过对Prismatic VLM在Open X-Embodiment数据集的100万个片段上进行微调而创建的70亿参数操纵策略。OpenVLA的原始训练公式使用每时间步7个离散机器人动作标记的自回归预测:3个用于位置控制,3个用于方向控制,1个用于夹持器控制。它采用下一个标记预测和交叉熵损失作为学习目标,类似于语言模型。
动作分块
先前的工作表明,动作分块(即预测和执行一系列未来动作而不进行中间重新规划)提高了许多操纵任务上的策略成功率。然而,OpenVLA的自回归生成方案使得动作分块不切实际,因为即使在NVIDIA A100 GPU上生成单个时间步的动作也需要0.33秒。对于大小为K的时间步和动作维度D,OpenVLA需要KD个顺序解码器前向传递,而没有分块则只需要D个传递。这种K倍增加的延迟使得动作分块对于高频机器人来说在原始公式下不切实际。
研究VLA微调关键设计决策
VLA微调设计决策
使用基础模型的自回归训练配方对VLAs进行微调的方法面临两个主要限制:推理速度慢(3-5Hz),不适合高频控制;在双臂操纵器上任务执行不可靠。

为了解决这些挑战,我们研究了VLA微调的三个关键设计组件:
(a)动作生成策略(图2,左):我们将自回归生成(需要顺序逐标记处理)与并行解码(能够同时生成所有动作并启用高效动作分块)进行比较。
(b)动作表示(图2,右):检查离散动作(归一化动作的256箱离散化),这些动作通过基于softmax的标记预测进行处理,与通过MLP动作头直接生成的连续动作进行比较。对于离散动作,语言模型解码器的最终隐藏状态被线性投影到logits中,这些logits通过softmax操作形成动作标记的概率分布。对于连续动作,最终隐藏状态而是被映射到归一化连续动作,由一个单独的动作头MLP完成。
(c)学习目标(图2,右):将使用下一个标记预测进行离散动作微调的策略与使用L1回归进行连续动作微调的策略以及使用条件去噪扩散进行比较。
我们使用OpenVLA作为基础模型进行研究,通过LoRA微调对其进行适应,因为训练数据集相对较小(500个演示,而预训练为100万个演示)。
实现替代设计组件
基础OpenVLA模型最初采用离散动作标记的自回归生成,通过下一个标记预测进行优化。我们在实现微调替代设计决策的同时保持原始预训练不变。
1)并行解码和动作分块
与需要顺序标记预测的自回归生成不同,并行解码使模型能够在单个前向传递中将输入嵌入映射到预测的输出序列。修改模型以接收空动作嵌入作为输入,并用双向注意力替换因果注意力掩码,允许解码器同时预测所有动作。这将动作生成从D个顺序传递减少到单个传递,其中D是动作维度。
并行解码自然地扩展到动作分块:为了预测多个未来时间步的动作,只需在解码器的输入中插入额外的空动作嵌入,这些嵌入随后被映射到动作块。对于大小为K的块,模型在单个前向传递中预测KD个动作,将吞吐量提高K倍,对延迟影响最小。虽然并行解码在理论上可能不如自回归方法具有表现力,但实验表明,在各种任务上性能没有下降。
2)连续动作表示
OpenVLA最初使用离散动作标记,其中每个动作维度被归一化到[-1,+1]并均匀离散化为256个箱。虽然这种方法很方便,因为它不需要对底层VLM进行架构修改,但离散化过程可能会牺牲精细的动作细节。我们研究了连续动作表示,并借鉴了两种来自主流模仿学习方法的学习目标:
首先,通过用MLP动作头替换解码器的输出嵌入层来实现L1回归,该动作头直接将最终解码器层隐藏状态映射到连续动作值。该模型被训练以最小化预测动作和真实动作之间的平均L1差异,同时保持并行解码的效率优势,并可能提高动作精度。
其次,实现了条件去噪扩散建模,其中模型学习预测在正向扩散过程中添加到动作样本中的噪声。在推理期间,策略通过反向扩散逐渐对嘈杂的动作样本进行去噪以产生真实动作。虽然这种方法提供了可能更具表现力的动作建模,但它要求在推理期间进行多次前向传递(在我们的实现中为50个扩散步骤),从而影响部署延迟,即使使用并行解码也是如此。
3)附加模型输入和输出
虽然原始OpenVLA处理单个相机视图,但一些机器人设置包括多个视角和附加的机器人状态信息。我们实现了一个灵活的输入处理管道:对于相机图像,使用OpenVLA的双视觉编码器从每个视图提取256个patch embedding,这些embedding通过共享投影仪网络投影到语言嵌入空间中。对于低维机器人状态输入(例如,关节角度和夹持器状态),使用单独的投影网络将其映射到与语言embedding相同的embedding空间作为附加输入embedding。
所有输入embedding(视觉特征、机器人状态和语言标记)在序列维度上连接,然后传递给解码器。这种统一的潜在表示使模型能够在生成动作时关注所有可用信息。结合并行解码和动作分块,该架构可以高效地处理丰富的多模态输入,同时生成多个时间步的动作,如图1所示。
通过FiLM增强OpenVLA-OFT以实现增强的语言接地
1)语言跟随的挑战
在部署到具有多个视角(包括腕部安装相机)的ALOHA机器人设置时,我们观察到策略可能会因视觉输入中的虚假相关性而难以跟随语言。在训练期间,策略可能会在学习预测动作时学会关注这些虚假相关性,而不是适当地关注语言指令,从而在测试时导致对用户命令的遵守情况不佳。此外,语言输入可能仅在任务中的特定时刻至关重要——例如,在用勺子舀取食材后决定舀取哪种食材的“将X舀入碗中”任务中。因此,如果没有特殊技术,训练模型以适当关注语言输入可能特别具有挑战性。
2)FiLM
为了增强语言跟随,采用特征线性调制(FiLM),它将语言embedding注入视觉表示中,以便模型更关注语言输入。计算任务描述语言embedding x的平均值,并将其投影以获得缩放和移位向量γ和β。这些向量通过仿射变换调制视觉特征F:

一个重要的实现细节是选择视觉transformer中要进行调制的“特征”。虽然人们可能会自然地考虑将每个patch embedding视为要调制的特征,但我们发现这种方法会导致较差的语言跟随。相反,从FiLM在卷积网络中的操作方式中汲取灵感,其中调制以空间无关的方式应用于整个特征图的缩放和移位,我们将γ和β的每个元素应用于跨所有视觉patch embedding的相应隐藏单元,以便γ和β影响所有patch embedding。这使得γ和β成为DViT维向量,其中DViT是视觉patch embedding中的隐藏维度数。
在每个视觉transformer block的自注意力层之后和前馈层之前应用FiLM,每个块使用单独的投影仪(见图8)。
实验:评估VLA微调设计决策
LIBERO实验设置
在LIBERO仿真基准上进行了评估,该基准以Franka Emika Panda机器人为特征,包含相机图像、机器人状态、任务注释和末端执行器姿态动作增量的演示。使用了四个任务套件:LIBERO-Spatial、LIBERO-Object、LIBERO-Goal和LIBERO-Long,每个套件提供500个专家演示,涵盖10项任务,以评估策略对不同空间布局、对象、目标和长期任务的泛化能力。遵循Kim等人的方法,过滤掉不成功的演示,并通过LoRA对每个任务套件独立微调OpenVLA。我们训练了50,000到150,000个梯度步骤(非扩散方法)和100,000到250,000个梯度步骤(扩散方法),使用64到128的批量大小,跨越8个A100/H100 GPU。每50,000步测试一次模型,并报告每次运行的最佳性能。除非另有说明,否则策略接收一张第三人称图像和语言指令作为输入。对于使用动作分块的方法,将分块大小设置为K=8,以匹配Diffusion Policy基线,并在重新规划之前执行完整的分块,我们发现这可以提高速度和性能。
LIBERO任务性能比较
对于令人满意的部署,机器人策略必须展示可靠的任务执行。我们首先评估不同的VLA微调设计决策对LIBERO基准上成功率的影响。
效率分析表明,并行解码(PD)和动作分块(AC)一起对于高频控制(25-50+Hz)是必要的,特别是对于具有两倍动作维度的双臂机器人。因此,我们评估了同时使用这两种技术的OpenVLA策略,比较了使用离散动作、连续动作(使用L1回归)和连续动作(使用扩散)的变体。
表I中的结果显示,并行解码和动作分块不仅提高了吞吐量,还显著提高了下游任务的成功率,与自回归OpenVLA策略相比,平均成功率提高了14%(绝对值)。这种改进在LIBERO-Long中尤为明显,表明动作分块有助于捕捉时间依赖性并减少累积误差,从而导致更平滑和更可靠的任务执行。
此外发现使用连续动作变体比离散动作变体进一步提高了5%(绝对值)的成功率,这可能是由于动作预测的精度更高。L1回归和扩散变体实现了可比的性能,表明高容量的OpenVLA模型可以有效地建模多任务动作分布,即使使用简单的L1回归也是如此。
LIBERO推理效率比较
高效推理对于在高频控制机器人上部署VLA至关重要。现在评估并行解码(PD)、动作分块(AC)和连续动作表示如何影响模型的推理速度。我们通过在一个NVIDIA A100 GPU上对每个模型变体进行100次查询来测量平均延迟(生成一个机器人动作或动作分块所需的时间)和吞吐量(每秒生成的总动作数)。每个查询处理一张224x224像素的图像和一个LIBERO语言指令(“拿起字母汤并放入篮子”)。
表II中的结果显示,并行解码通过将解码器部分的策略中的7个连续前向传递替换为单次传递,将延迟降低了4倍,吞吐量提高了4倍。添加动作分块(K=8)由于解码器中更长的注意力序列而增加了17%的延迟,但与并行解码结合使用时,它显著提高了吞吐量,实现了比基线OpenVLA快26倍的加速。使用L1回归的连续动作变体在效率方面与基线模型相差无几,因为额外的MLP动作头增加的计算成本可忽略不计。而扩散变体需要50个去噪步骤,因此延迟是基线模型的3倍。然而,由于并行解码和分块,它仍然比原始自回归变体快2倍的吞吐量。这意味着尽管动作分块之间存在显著的延迟,但扩散变体仍然比原始自回归变体更快地完成机器人情节。
模型输入输出灵活性
并行解码使OpenVLA能够以最小的延迟增加生成动作分块,从而增强了模型输出的灵活性。并行解码和动作分块实现的显著加速为处理额外的模型输入提供了空间。我们通过微调OpenVLA以包括额外的输入(如机器人本体感觉状态和手腕安装相机图像),验证了这一点,这将传递给语言模型解码器的视觉patch embedding数量从256增加到512。尽管输入序列长度显著增加,但微调后的OpenVLA策略仍保持了高吞吐量(71.4Hz)和低延迟(0.112秒),如表II所示。
在LIBERO基准上评估这些具有额外输入的策略,结果显示在所有任务套件上的平均成功率进一步提高。值得注意的是,我们增强的微调OpenVLA策略甚至超过了表现最好的π0策略(通过更大规模的预训练和更复杂的学习目标(流匹配)受益),以及多模态扩散转换器(MDT)。即使我们的基础模型预训练数据较少,但发现替代的VLA适应设计决策使微调后的OpenVLA策略能够在LIBERO基准上建立新的最先进的性能。
优化微调配方
基于在任务性能、推理效率和模型输入输出灵活性方面的改进,提出了一种优化微调(OFT)配方,用于VLA适应,该配方结合了三个关键组件:
- 并行解码与动作分块
- 连续动作表示
- L1回归目标
这些设计选择协同工作,产生强大的策略,可以在高频下部署,同时保持算法的简单性。我们将使用OFT配方从OpenVLA基础模型微调的策略称为OpenVLA-OFT。
将OpenVLA适应到现实世界中的ALOHA机器人
虽然前面的实验结果证明了OpenVLA-OFT在仿真中的有效性,但在机器人平台上成功部署,这些平台与预训练期间看到的平台有很大不同,对于展示广泛的适用性至关重要。因此,我们评估了优化微调配方在ALOHA机器人设置上的效果,这是一个操作频率为25Hz的真实双臂操作平台。在OpenVLA预训练期间从未遇到过的新颖灵巧操作任务上进行了评估(其预训练仅涉及单臂机器人数据)。
先前的工作表明,使用自回归VLAs的LoRA微调对于此类任务是不切实际的,因为其吞吐量(对于单臂机器人为3-5Hz,对于双臂任务甚至更低)远低于实时部署所需的25-50Hz。因此,在实验中排除了这个基线,并比较了更有效的方法。
ALOHA实验设置
ALOHA平台由两个ViperX300S机械臂、三个相机视角(一个俯视图,两个手腕安装)和机器人状态输入(14维关节角度)组成。它以25Hz(从原始的50Hz降低,以加快训练速度,同时仍保持平滑的机器人控制)运行,动作表示目标绝对关节角度。该设置与OpenVLA的预训练存在显著差异,后者的预训练包括仅单臂机器人数据、来自第三人称相机的单个相机视角、无机器人状态输入、低频控制(3-10Hz)和相对末端执行器姿态动作。这种分布偏移对模型的适应构成了挑战。
我们设计了四个代表性任务,测试可变形物体操作、长期技能、工具使用和语言驱动控制:
- “折叠短裤”:在桌子上用两次连续的双臂折叠折叠白色短裤。训练:20次演示。评估:10次试验。
- “折叠衬衫”:通过多次同步双臂折叠折叠白色T恤,测试接触丰富的长期操作。训练:30次演示。评估:10次试验。
- “用勺子舀X到碗里”:用左手臂将碗移到桌子中央,用右手臂用金属勺子舀指定的配料(“葡萄干”、“杏仁和绿色M&M”或“椒盐脆饼”)。训练:45次演示(每种配料15次)。评估:12次试验(每种配料4次)。
- “把X放进锅里”:用左手臂打开锅,用右手臂放入指定物品(“青椒”、“红椒”或“黄玉米”),然后盖上锅盖。训练:300次演示(每种物品100次)。评估:24次试验(12次在分布内,12次在分布外)。
使用OFT+在每个任务上独立微调OpenVLA,进行50,000到150,000个梯度步骤(总批量大小为32,使用8个A100/H100-80GB GPU),动作分块大小为K=25。在推理时,在重新查询模型以获取下一个分块之前执行完整的动作分块。
比较方法
ALOHA任务对OpenVLA构成了显著的适应挑战,因为基础模型在控制频率、动作空间和输入模式方面与其预训练平台存在显著差异。出于这个原因,我们将OpenVLA-OFT+与最近的VLA(RDT-1B和π0)进行比较,这些VLA在双臂操作数据上进行了预训练,并可能合理地预期在这些下游任务上表现更好。在作者推荐的配方下对这些模型进行微调,并将这些方法作为重要的比较点。此外,为了提供与计算上有效的替代方案的比较,评估了两种流行的模仿学习基线:ACT和Diffusion Policy,这些基线是从头开始在每个任务上训练的。
为了使这些基线方法能够进行语言跟随,我们使用语言条件实现。对于ACT,修改EfficientNet-B0以处理通过FiLM的CLIP语言嵌入。对于Diffusion Policy,使用DROID数据集的实现,该实现根据DistilBERT语言嵌入对动作去噪进行条件设置,并修改为支持双臂控制和多个图像输入。
仅对语言依赖任务(“用勺子舀X到碗里”和“把X放进锅里”)使用此FiLM-EfficientNet实现。对于衣服折叠任务,我们使用原始的ResNet-18骨干网络。
ALOHA任务性能结果
在所有方法(ACT、Diffusion Policy、RDT-1B、π0和OpenVLA-OFT+)上评估了我们的四个ALOHA任务。为了提供细致的评估,我们使用一个预定义的评分细则,该细则对部分任务完成分配分数。图4显示了汇总性能分数,而图5特别跟踪了语言依赖任务的语言跟随能力。
非VLA基线的性能。从头开始训练的基线方法显示出不同程度的成功。ACT虽然能够完成基本任务,但产生的动作不够精确,整体性能最低。Diffusion Policy表现出更强的能力,在衣服折叠和舀取任务上的可靠性匹配或超过RDT-1B。然而,它在“把X放进锅里”任务上表现挣扎,该任务拥有更大的训练数据集,这表明与基于VLA的方法相比,其可扩展性有限。
微调VLAs的性能。微调VLA策略在任务执行和语言跟随方面普遍优于从头开始训练的基线,这与先前的研究结果一致。在VLAs中,我们观察到不同的特性:RDT-1B通过其“交替条件注入”方案实现了良好的语言跟随,但在处理闭环反馈方面存在局限。如图7所示,它经常在“用勺子舀X到碗里”任务中犯错——例如,在错过实际碗后继续将配料倒入想象中的碗,这表明过度依赖本体感觉状态而非视觉反馈。另一方面,π0展示了更稳健的执行,动作更平滑,对反馈的反应更好,经常能够从初始失败中成功恢复(如图7所示)。虽然其语言跟随能力略逊于RDT-1B,但π0在整体任务完成方面表现更好,成为最强的基线。最后,OpenVLA-OFT+在任务执行和语言跟随方面实现了最高性能(图6显示了OpenVLA-OFT+成功任务展开的示例)。这尤其值得注意,因为基础OpenVLA模型仅在单臂数据上进行了预训练,而RDT-1B和π0分别在大量双臂数据集(6000个情节和8000小时双臂数据)上进行了预训练。这表明微调技术在下游性能方面可能比预训练数据覆盖范围更重要。
FiLM的消融研究。通过消融FiLM并评估策略在语言依赖任务上的语言跟随能力,来评估FiLM在我们OpenVLA-OFT+方法中的重要性。如图5所示,去除FiLM后,语言跟随能力下降到33%,这相当于随机选择正确指令的成功率。这表明FiLM对于防止模型过度拟合到虚假视觉特征并确保对语言输入的适当关注至关重要。
ALOHA推理效率比较
通过测量每个方法100次查询的动作生成吞吐量和延迟来评估推理效率。我们在表III中报告了结果。即使仅添加了手腕相机输入,原始OpenVLA公式也显示出较差的效率,吞吐量为1.8Hz,延迟为0.543秒。相比之下,OpenVLA-OFT+实现了77.9Hz的吞吐量,尽管其延迟与先前LIBERO实验中的方法相比更高,因为它必须处理两个额外的输入图像。
其他方法由于架构较小,显示出比OpenVLA-OFT+更高的吞吐量:ACT(84M参数)、Diffusion Policy(157M)、RDT-1B(12亿参数)和π0(33亿参数)。而OpenVLA有75亿参数。ACT通过结合基于L1回归的单通道动作生成(如OpenVLA-OFT+)与其紧凑架构,实现了最高速度。此外,尽管规模更大,但π0由于其优化的JAX实现(所有其他方法均使用PyTorch),在速度上超过了RDT-1B和Diffusion Policy。
值得注意的是,OpenVLA-OFT+的吞吐量(77.9Hz)接近RDT-1B的吞吐量(84.1Hz),尽管其规模大了7倍,因为它在单次前向传递中生成动作,而不需要像RDT-1B那样进行多次去噪步骤。
#PreWorld
清华:半监督3D Occ世界模型新突破~
在自动驾驶领域,理解 3D 动态场景对于规划至关重要,当前自动驾驶场景理解任务中,3D 占用预测和 4D 占用预测面临诸多挑战,如标注成本高、信息易损失等。本文创新性地提出半监督以视觉为中心的 3D 占用世界模型 PreWorld,通过独特的两阶段训练范式,有效利用 2D 标签,大幅降低标注成本。其简单且高效的状态条件预测模块,避免了信息损失,增强了模型性能。实验结果表明,PreWorld 在多项任务中表现卓越,如在 3D 占用预测任务上超越先前最优方法,在 4D 占用预测中达到新的 SOTA 性能。
笔者的个人理解
3D场景理解构成了自动驾驶系统的基石,对规划和导航等下游任务产生了直接的影响。在各种 3D 场景理解任务中,3D占用预测任务在自动驾驶系统中发挥着至关重要的作用。它的目标是从有限的观察中预测整个场景中每个体素的语义占用。考虑到激光雷达在准确的几何信息捕获方面的强大性能,在之前的一些方法中激光雷达点云被作为优先的输入模态。由于其造价比较昂贵,近年来转向以视觉为中心的解决方案。
尽管基于以视觉为中心的方法取得了重大进展,但它们主要集中在增强对当前场景的更好感知。对于路径规划而言,自动驾驶汽车不仅需要理解当前的场景,还需要基于对世界动态特性的理解来预测未来场景的演变。因此,4D占用预测被引入来预测给定历史观测的未来3D占用率。
最近的一些研究旨在通过学习 3D 占用世界模型来实现这一目标。然而,在处理图像输入时,这些方法遵循一条迂回的路径,如下图(b)所示。通常,采用预先训练的 3D 占用模型来获得当前占用,然后将其输入到预测模块以生成未来占用。预测模块包括将占用编码为离散标记的标记器、生成未来标记的自回归架构和获得未来占用的解码器。在这种重复的编码和解码过程中很容易发生信息丢失。因此,现有方法严重依赖 3D 占用标签作为监督来产生有意义的结果,导致显著的标注成本。

与 3D 占用标签相比,2D 标签相对容易获取。最近,使用纯 2D 标签进行自监督学习在 3D 占用预测任务中显示出一些有希望的结果,如上图(a)所示。通过利用体积渲染,使用 2D 深度图和语义标签来训练模型。然而,在 4D 占用预测任务中还没有类似的尝试。
基于以上观察,我们提出了 PreWorld,一种半监督的以视觉为中心的 3D 占用世界模型,旨在满足训练期间 2D 标签的利用率,同时在 3D 占用预测和 4D 占用预测任务中实现具有竞争力的性能,如上图(c)所示。
在nuScenes数据集上的大量实验验证了我们的方法的有效性和可扩展性,并证明了PreWorld在3D占用率预测、4D占用率预测和运动规划任务中实现了具有竞争力的性能。
文章链接:https://arxiv.org/abs/2502.07309
网络模型结构&细节梳理
4D Occupancy预测任务的回顾
对于在时刻,以视觉为中心的3D占用预测任务采用张环视图像作为输入,然后预测当前时刻的3D占用结果。一个3D占用模型通常会包含一个栅格网络以及一个占用预测头。占用预测任务可以用下述的方式进行表述。
![]()
另一方面,以视觉为中心的4D占用预测任务利用过去帧的图像序列作为输入,用于预测未来帧的3D占用结果。3D占用世界模型通过自回归的方式实现这一过程。

为了实现上述所描述的4D占用预测任务,我们采用了一个3D占用模型来预测过去帧的3D占用结果,然后使用一个场景标记器,一个自回归的架构和一个解码器来预测未来的3D占用结果。再获得历史占用结果之后,4D占用预测模型通过场景标记器将3D占用编码到离散的标记。随后,被使用基于现有的这些标记来预测未来的标记,生成的结果被喂入到解码器中生成未来的占用结果。整个过程可以用下式进行表示。

状态条件预测模块
在本文中,我们更倾向于采用直接的方式,这使我们能够同时优化 3D 占用模型和预测模块。具体而言,我们采用了状态条件预测模块代替了场景标记器、自回归架构以及解码器。提出的状态条件预测模块的整体网络结构如下图所示。

不失一般性,我们的预测模块仅由两个 MLP 组成。我们证明,即使没有复杂的设计,这种简单的架构仍然可以实现与最先进方法相当甚至更好的结果。这种设计表明,以前在训练期间单独优化预测模块的做法有其局限性。通过同时优化占用网络和预测模块,3D 占用世界模型可以实现更强大的性能。此外,我们的模块可以选择性地将速度、加速度和历史轨迹等自车状态信息纳入网络当中。
此外,这种架构还为我们带来了额外的好处。鉴于之前的预测模块将场景编码为离散标记,它们无法像自监督的 3D 占用模型那样通过体积渲染直接监督带有 2D 标签的未来预测。由于我们的模块保留了未来场景的体积特征,因此它提供了以自监督方式训练 3D 占用世界模型的机会。
时间二维渲染自监督
- Attribute Projection:我们利用一个属性映射头模块将当前和未来的时序体特征序列进行变换到时序属性场当中。

- Ray Generation:给定在时刻的第个相机的内参和外参,我们可以提取一组3D射线。此外,我们可以利用自车位姿矩阵将来自相邻帧的射线转换为当前帧,从而更好地捕捉周围信息。这些射线共同构成了集合。
- Volume Rendering:对于每一条射线,我们沿着这条射线采样个点。然后每个采样点的渲染权重可以按照下式计算出来。

- Temporal 2D Rendering Supervision:在利用3D射线集合获得2D渲染预测后,时间2D渲染损失看可以表示为如下的形式

两阶段训练范式

通过上述PreWorld算法模型的整体流程图可以看出,我们的PreWorld训练方案包括两个阶段。具体而言,在自监督的预训练阶段,我们使用属性映射头模块来实现具有2D标签的时序监督。这种方法使我们能够利用丰富且易于获取的2D标签,同时预先优化占用网络和预测模块。在随后的微调阶段,我们利用占用头生成占用结果,并使用 3D 占用标签进行进一步优化。
实验结果&评价指标
3D占用预测实验结果
我们首先将 PreWorld 模型的 3D 占用预测性能与 Occ3D-nuScenes 数据集上的最新方法进行比较。如下表所示,PreWorld 实现了 34.69 的 mIoU,超过了之前最先进的方法 OccFlowNet,其 mIoU 为 33.86,以及使用 2D、3D 或组合监督的其他方法。这凸显了 PreWorld 在感知当前场景方面的有效性。此外,所提出的2D预训练阶段将性能提高了0.74mIoU,几乎所有类别(包括静态和动态)都有所改善。这些结果强调了所提出的 2D 预训练阶段对于增强场景理解的重要性。

此外,我们进一步将 PreWorld 的定性结果与最新的全监督方法 SparseOcc 和自监督方法 RenderOcc进行了比较,如下图所示。RenderOcc 可以将场景体素投影到多视图图像上,以从各个射线方向获得全面的监督,从而从 2D 标签中捕获丰富的几何和语义信息。然而,如最后一栏所示,它在预测看不见的区域和理解整体场景结构方面遇到了困难。另一方面,SparseOcc 在预测场景结构方面表现出色。

然而,由于对 3D 占用标签中的小物体和长尾物体的监督不足,它在预测电线杆和摩托车等物体时经常会遇到信息丢失的情况,如第二行和最后一行所示。相比之下,我们的模型最初是用 2D 标签进行预训练的,从而对场景的几何和语义有了足够的理解。在微调阶段,使用 3D 占用标签进一步优化模型,使 PreWorld 能够更好地预测场景结构。因此,PreWorld 在整体结构预测方面的表现与 SparseOcc 相当,但在预测细粒度局部细节方面表现出明显的优势,凸显了我们训练范式的优越性。
4D占用预测实验结果
下表展示了PreWorld算法模型与现有基线模型OccWorld和OccLLaMA相比的 4D 占用预测性能。当仅使用 3D 占用监督时,我们的方法在未来 3 秒间隔内实现了最高的 mIoU,优于基线。这证明了我们的训练方法在端到端占用特征提取和预测模块中的有效性。与 3D 占用预测的结果类似,结合 2D 预训练阶段可进一步改善所有未来时间戳的 mIoU 和 IoU。鉴于 2D 标签比昂贵的 3D 占用标记更容易获得,PreWorld 的两阶段训练范式带来的性能提升是值得注意的。

运动规划实验结果
下表进一步比较了运动规划任务的结果。在不纳入自车状态信息的情况下,我们的模型的表现与占用世界模型甚至一些精心设计的规划模型相当。当使用与 OccWorld 和 OccLLaMA 相同的配置(以灰色表示)时,我们的方法实现了 SOTA 性能并获得了显着改进,并通过预训练阶段进一步增强。由于 PreWorld 遵循直接训练范式,以原始图像作为输入并产生规划结果,因此自车状态的影响与世界模型基线的影响明显不同。我们将这种差异归因于先前工作中观察到的“捷径”效应。

消融实验分析
接下来,本文分析了2D预训练阶段不同监督属性的有效性。预训练的好处在 3D 占用预测和 4D 占用预测中都是一致的。因此,为了节省计算资源,我们对 3D 占用预测任务进行了消融实验。如下表所示,随着 RGB、深度和语义属性在预训练阶段逐步添加,最终的 mIoU 结果稳步提高。这证明了三个 2D 监督属性的有效性,即使是最简单的 RGB 属性也能提高性能。

为了验证我们方法的可扩展性,我们对预训练和微调阶段使用的数据规模进行了消融研究,如下表所示。首先,引入预训练阶段可以持续提高所有微调数据规模的性能,其中更大的预训练规模可带来更好的结果。其次,当微调数据集较小(150 个场景)时,这意味着昂贵的 3D 占用标签有限,预训练阶段显着将 mIoU 从 18.66 提升到 25.02。通过预训练,在较小数据集(450 个场景)上微调的模型实现了与没有预训练但在较大数据集(700 个场景)上微调的模型相当的性能,mIoU 分别为 33.37 和 33.95。这些结果凸显了我们的两阶段训练范式的有效性和可扩展性。

结论
在本文中,我们提出了PreWorld算法模型,一种用于自动驾驶的半监督以视觉为中心的 3D 占用世界模型。我们提出了一种新颖的两阶段训练范式,使我们的方法能够利用丰富且易于访问的 2D 标签进行自监督预训练。通过大量实验,我们证明了 PreWorld 在 3D 占用预测、4D 占用预测和运动规划任务中的鲁棒性。
#2025图像/视频/3D生成论文汇总
Awesome-CVPR2025-AIGC
A Collection of Papers and Codes for CVPR2025 AIGC
整理汇总下2025年CVPR AIGC相关的论文和代码,具体如下。
最新修改版本会首先更新在Github,欢迎star,fork和PR~
也欢迎对AIGC相关任务感兴趣的朋友一块更新~
github.com/Kobaayyy/Awesome-CVPR2025-CVPR2024-ECCV2024-AIGC/blob/main/CVPR2025.md
论文接收公布时间:2025年2月27日
【Contents】
- 图像生成(Image Generation/Image Synthesis)
- 图像编辑(Image Editing)
- 视频生成(Video Generation/Image Synthesis)
- 视频编辑(Video Editing)
- 3D生成(3D Generation/3D Synthesis)
- 3D编辑(3D Editing)
- 多模态大语言模型(Multi-Modal Large Language Model)
- 其他多任务(Others)
1.图像生成(Image Generation/Image Synthesis)
Collaborative Decoding Makes Visual Auto-Regressive Modeling Efficient
- Paper: https://arxiv.org/abs/2411.17787
- Code: https://github.com/czg1225/CoDe
Inversion Circle Interpolation: Diffusion-based Image Augmentation for Data-scarce Classification
- Paper: https://arxiv.org/abs/2408.16266
- Code: https://github.com/scuwyh2000/Diff-II
Parallelized Autoregressive Visual Generation
- Paper: https://arxiv.org/abs/2412.15119
- Code: https://github.com/Epiphqny/PAR
PatchDPO: Patch-level DPO for Finetuning-free Personalized Image Generation
- Paper: https://arxiv.org/abs/2412.03177
- Code: https://github.com/hqhQAQ/PatchDPO
Reconstruction vs. Generation: Taming Optimization Dilemma in Latent Diffusion Models
- Paper: https://arxiv.org/abs/2501.01423
- Code: https://github.com/hustvl/LightningDiT
Rectified Diffusion Guidance for Conditional Generation
- Paper: https://arxiv.org/abs/2410.18737
- Code: https://github.com/thuxmf/recfg
SemanticDraw: Towards Real-Time Interactive Content Creation from Image Diffusion Models
- Paper: https://arxiv.org/abs/2403.09055
- Code: https://github.com/ironjr/semantic-draw
SleeperMark: Towards Robust Watermark against Fine-Tuning Text-to-image Diffusion Models
- Paper: https://arxiv.org/abs/2412.04852
- Code: https://github.com/taco-group/SleeperMark
TokenFlow: Unified Image Tokenizer for Multimodal Understanding and Generation
- Paper: https://arxiv.org/abs/2412.03069
- Code: https://github.com/ByteFlow-AI/TokenFlow
2.图像编辑(Image Editing)
Attention Distillation: A Unified Approach to Visual Characteristics Transfer
- Paper: https://arxiv.org/abs/2502.20235
- Code: https://github.com/xugao97/AttentionDistillation
Edit Away and My Face Will not Stay: Personal Biometric Defense against Malicious Generative Editing
- Paper: https://arxiv.org/abs/2411.16832
- Code: https://github.com/taco-group/FaceLock
EmoEdit: Evoking Emotions through Image Manipulation
- Paper: https://arxiv.org/abs/2405.12661
- Code: https://github.com/JingyuanYY/EmoEdit
K-LoRA: Unlocking Training-Free Fusion of Any Subject and Style LoRAs
- Paper: https://arxiv.org/abs/2502.18461
- Code: https://github.com/HVision-NKU/K-LoRA
StyleStudio: Text-Driven Style Transfer with Selective Control of Style Elements
- Paper: https://arxiv.org/abs/2412.08503
- Code: https://github.com/Westlake-AGI-Lab/StyleStudio
3.视频生成(Video Generation/Video Synthesis)
ByTheWay: Boost Your Text-to-Video Generation Model to Higher Quality in a Training-free Way
- Paper: https://arxiv.org/abs/2410.06241
- Code: https://github.com/Bujiazi/ByTheWay
Identity-Preserving Text-to-Video Generation by Frequency Decomposition
- Paper: https://arxiv.org/abs/2411.17440
- Code: https://github.com/PKU-YuanGroup/ConsisID
InstanceCap: Improving Text-to-Video Generation via Instance-aware Structured Caption
- Paper: https://arxiv.org/abs/2412.09283
- Code: https://github.com/NJU-PCALab/InstanceCap
WF-VAE: Enhancing Video VAE by Wavelet-Driven Energy Flow for Latent Video Diffusion Model
- Paper: https://arxiv.org/abs/2411.17459
- Code: https://github.com/PKU-YuanGroup/WF-VAE
4.视频编辑(Video Editing)
Cinemo: Consistent and Controllable Image Animation with Motion Diffusion Models
- Paper: https://arxiv.org/abs/2407.15642
- Code: https://github.com/maxin-cn/Cinemo
Generative Inbetweening through Frame-wise Conditions-Driven Video Generation
- Paper: https://arxiv.org/abs/2412.11755
- Code: https://github.com/Tian-one/FCVG
X-Dyna: Expressive Dynamic Human Image Animation
- Paper: https://arxiv.org/abs/2501.10021
- Code: https://github.com/bytedance/X-Dyna
5.3D生成(3D Generation/3D Synthesis)
Fancy123: One Image to High-Quality 3D Mesh Generation via Plug-and-Play Deformation
- Paper: https://arxiv.org/abs/2411.16185
- Code: https://github.com/YuQiao0303/Fancy123
Fast3R: Towards 3D Reconstruction of 1000+ Images in One Forward Pass
- Paper: https://arxiv.org/abs/2501.13928
- Code: https://github.com/facebookresearch/fast3r
GaussianCity: Generative Gaussian Splatting for Unbounded 3D City Generation
- Paper: https://arxiv.org/abs/2406.06526
- Code: https://github.com/hzxie/GaussianCity
LT3SD: Latent Trees for 3D Scene Diffusion
- Paper: https://arxiv.org/abs/2409.08215
- Code: https://github.com/quan-meng/lt3sd
Towards High-fidelity 3D Talking Avatar with Personalized Dynamic Texture
- Paper: https://arxiv.org/abs/2503.00495
- Code: https://github.com/XuanchenLi/TexTalk
You See it, You Got it: Learning 3D Creation on Pose-Free Videos at Scale
- Paper: https://arxiv.org/abs/2412.06699
- Code: https://github.com/baaivision/See3D
6.3D编辑(3D Editing)
DRiVE: Diffusion-based Rigging Empowers Generation of Versatile and Expressive Characters
- Paper: https://arxiv.org/abs/2411.17423
- Code: https://github.com/yisuanwang/DRiVE
FATE: Full-head Gaussian Avatar with Textural Editing from Monocular Video
- Paper: https://arxiv.org/abs/2411.15604
- Code: https://github.com/zjwfufu/FateAvatar
Make-It-Animatable: An Efficient Framework for Authoring Animation-Ready 3D Characters
- Paper: https://arxiv.org/abs/2411.18197
- Code: https://github.com/jasongzy/Make-It-Animatable
7.多模态大语言模型(Multi-Modal Large Language Models)
Automated Generation of Challenging Multiple Choice Questions for Vision Language Model Evaluation
- Paper: https://arxiv.org/abs/2501.03225
- Code: https://github.com/yuhui-zh15/AutoConverter
RAP-MLLM: Retrieval-Augmented Personalization for Multimodal Large Language Model
- Paper: https://arxiv.org/abs/2410.13360
- Code: https://github.com/Hoar012/RAP-MLLM
SeqAfford: Sequential 3D Affordance Reasoning via Multimodal Large Language Model
- Paper: https://arxiv.org/abs/2412.01550
- Code: https://github.com/hq-King/SeqAfford
ShowUI: One Vision-Language-Action Model for GUI Visual Agent
- Paper: https://arxiv.org/abs/2411.17465
- Code: https://github.com/showlab/ShowUI
8.其他任务(Others)
Continuous and Locomotive Crowd Behavior Generation
- Paper:
- Code: https://github.com/InhwanBae/Crowd-Behavior-Generation
Taming Multimodal Joint Training for High-Quality Video-to-Audio Synthesis
- Paper: https://arxiv.org/abs/2412.15322
- Code: https://github.com/hkchengrex/MMAudio
持续更新~
#DexGraspVLA
成功率极高!北大最新:首个灵巧抓取的分层VLA
灵巧抓取仍然困难
灵巧抓取在机器人领域中仍是一个基础且具有挑战性的问题。通用机器人必须能够在任意场景中抓取各种物体。然而,现有研究通常依赖特定假设,如单物体设置或有限环境,导致泛化能力受限。我们提出的解决方案是DexGraspVLA,一个分层框架,它将预训练的视觉-语言模型用作高级任务规划器,并学习基于扩散的策略作为低级动作控制器。其核心在于迭代地将多样的语言和视觉输入转换为域不变表示,由于域转移问题得到缓解,模仿学习可在此基础上有效应用。因此,它能够在广泛的现实场景中实现强大的泛化。值得注意的是,方法在 “零样本 ”环境下,面对数千种未见过的物体、光照和背景组合时,成功率超过90%。
实证分析进一步证实了模型内部行为在环境变化中的一致性,从而验证了设计并解释了其泛化性能。希望这项工作能为实现通用灵巧抓取迈出一步。演示和代码链接:https://dexgraspvla.github.io/。
行业介绍
灵巧的多指手作为多功能机器人末端执行器,在各种操作任务中展现出了卓越的能力。在这些能力中,抓取是最基本的前提条件,但它仍然是最具挑战性的问题之一。现有的灵巧抓取方法主要在孤立物体或简化设置下进行评估。然而,实际应用需要机器人具备更通用的抓取能力,以便在工业制造和家庭环境等各种场景中可靠地发挥作用。然而,开发通用的灵巧抓取能力面临着多方面的挑战。在物体层面,策略必须能够泛化到具有不同几何形状、质量、纹理和方向的物体上。除了物体特征外,系统还必须对各种环境因素(如光照条件、背景复杂度和潜在干扰)具有鲁棒性。更具挑战性的是,多物体场景引入了额外的复杂性,需要复杂的推理能力。例如,在杂乱或堆叠的环境中,规划抓取所有物体的最佳顺序成为一项关键的认知任务,这远远超出了简单的抓取执行范畴。
传统的灵巧抓取方法遵循两阶段流程:首先从单帧感知中预测目标抓取姿态,然后执行开环运动规划以达到该姿态。然而,这种方法受到精确相机校准和机械精度要求的严重限制。端到端方法,如模仿学习和强化学习,通过根据实时感知反馈不断调整动作,实现闭环抓取,提供了更强大和自适应的解决方案。近年来,强化学习在机器人系统中的应用取得了显著进展。借助大规模并行模拟,强化学习使机器人能够在模拟环境中进行广泛训练,然后将学习到的策略部署到现实世界中。尽管取得了这些进展,但现实世界物理参数的复杂性在模拟建模中带来了巨大挑战,导致了不可避免的模拟到现实的差距。同时,研究人员探索了模仿学习方法来学习操作技能。这些方法通过远程操作收集人类演示数据,并使用监督学习直接学习从原始感知输入到机器人控制命令的映射。然而,这种方法在演示数据之外的泛化能力往往较差。由于通用抓取需要处理各种物体和环境,收集所有情况的演示数据并不现实。因此,关键挑战在于如何有效地利用演示数据实现更广泛的泛化。
视觉和语言基础模型的迅速出现为机器人操作带来了有前景的机遇。这些模型在预训练过程中利用了大量互联网规模的数据,对视觉和语言输入表现出卓越的场景理解和泛化能力。虽然直接让这些模型生成机器人控制命令看似直观,但这种简单策略面临着根本性的限制。由于在训练过程中缺乏物理交互数据,这些模型的空间智能有限。另一种方法是将视觉-语言模型(VLMs)集成到机器人控制策略中,以端到端的方式对它们进行训练。然而,这种范式通常需要大量手动收集的演示数据,试图涵盖现实世界的所有多样性和复杂性。即便如此,这些模型在未见过的场景中性能仍会显著下降,并且仍然需要进一步收集数据和微调才能处理新的情况。此外,机器人数据集与大规模预训练语料库之间的巨大差异会导致灾难性遗忘,损害模型宝贵的长程推理能力。有效地利用基础模型的世界知识来增强机器人策略的泛化能力仍然是一个挑战。
DexGraspVLA是第一个用于通用灵巧抓取的分层视觉-语言-动作(VLA)框架,它整合了基础模型和模仿学习的互补优势。在高层,它利用预训练的VLM作为任务规划器,用于解释和推理语言指令、规划整体抓取任务并提供监督信号。在这些信号和多模态输入的引导下,基于扩散的低级模块化控制器生成闭环动作序列。DexGraspVLA的核心在于利用基础模型迭代地将多样的视觉和语言输入转换为域不变表示,然后在此基础上高效且有效地应用基于扩散的模仿学习,以捕捉灵巧抓取数据集中的动作分布。因此,训练集之外的新场景不再会导致失败,因为基础模型将它们转换为与训练期间遇到的表示相似的形式,从而使这些场景仍在学习到的策略的域内。这种方法将基础模型广泛的世界知识与模仿学习强大的动作建模能力相结合,从而在实际应用中实现强大的泛化性能。
值得注意的是,DexGraspVLA在杂乱场景中抓取的成功率达到了前所未有的90.8%,涵盖了1287种未见过的物体、光照和背景组合,所有测试均在 “零样本 ”环境下进行。在单物体抓取基准测试中的系统评估表明,DexGraspVLA的综合成功率达到98.6%,比直接从原始视觉输入中学习的现有基线控制器高出至少48%。此外,实证分析表明,DexGraspVLA内部的表示和注意力图在不同环境中保持一致,从而证实了其框架设计的合理性并解释了其性能。这些结果证实,DexGraspVLA可以从少量单领域的人类演示中有效学习,同时可靠地泛化到广泛的现实场景中,这标志着在迈向通用灵巧抓取的道路上迈出了有前景的一步。
相关工作介绍
1)灵巧抓取
灵巧抓取通常分为两类:两阶段方法和端到端方法。两阶段方法首先生成抓取姿态,然后控制灵巧手朝着该姿态运动。主要挑战在于基于视觉观察生成高质量的抓取姿态。目前的方法采用基于采样、基于优化或基于回归的方法来生成目标抓取姿态,随后进行机器人执行的运动规划。例如,SpringGrasp使用基于优化的方法对部分观察中的不确定性进行建模,以提高抓取姿态生成的质量。UGG提出了一种基于扩散的方法,用于统一抓取姿态和物体几何形状的生成。虽然这些方法受益于解耦的感知和控制以及模拟数据生成,但它们通常缺乏闭环反馈,并且对干扰和校准误差较为敏感。
端到端方法直接使用模仿学习或强化学习对抓取轨迹进行建模。最近的研究探索了在模拟环境中使用强化学习训练灵巧操作,并将其转移到现实世界中。DexVIP和GRAFF使用计算机视觉方法生成可供性提示,并基于这些特征使用强化学习训练策略。DextrAH-G和DextrAH-RGB通过在模拟中进行大规模并行训练,在现实世界中展示了一定的泛化能力。然而,这种对模拟的依赖不可避免地引入了模拟到现实的差距,而在现实世界中直接训练则样本效率较低。最近,使用人类演示的模仿学习在复杂任务中取得了显著成果。这些方法需要人类通过远程操作收集演示数据,并直接学习数据集中的分布。虽然这种方法更容易训练,但它限制了其泛化能力。SparseDFF和Neural Attention Field探索了如何通过3D蒸馏特征场来增强泛化能力。
2)机器人领域的基础模型
近年来,在大规模数据集上预训练的基础模型取得了显著进展。视觉基础模型表现出强大的分布外泛化能力,而包括GPT-4o和Qwen2.5-VL在内的视觉-语言模型则展示了复杂的多模态推理能力。有效利用这些基础模型已成为机器人研究中有前景的方向。一种突出的方法,以RT-X、OpenVLA、Pi0等为代表,涉及在机器人数据上直接微调视觉-语言模型。然而,这种策略需要大量涵盖各种现实条件的演示数据才能实现泛化。即使是目前可用的最大机器人数据集也无法覆盖所有场景;在这些数据集上训练的模型在未见过的领域中仍难以达到在已见过领域中的性能,并且通常需要为新环境收集额外数据并进行微调。此外,由于机器人操作任务的复杂性和专业数据的稀缺性,这些模型往往会牺牲一些先进的推理能力。另一项研究,以VoxPoser和Rekep为代表,利用视觉-语言模型生成特定任务的输出,如可供性图或约束点,然后将其与传统运动规划相结合。虽然这种分层策略通常保留了视觉-语言模型固有的推理能力,但它依赖于足够强大的低级控制器来执行高级命令,这使得有效接口的设计至关重要。我们的工作利用预训练的基础模型生成域不变表示,这有助于学习灵巧抓取策略。通过将现实世界的大部分复杂性转移到基础模型上,我们可以显著减少所需的演示数据量,同时实现强大的零样本泛化能力。
问题公式化
我们的目标是开发一种基于视觉的控制策略,用于语言引导的灵巧抓取,并将其公式化为一个顺序决策问题。最初,会给出一个语言指令l,例如 “抓住玩具”,以直接指定目标物体。在每个时间步t,策略会从手腕摄像头接收第一视角图像(H和W分别表示图像的高度和宽度)、从头部相机接收第三视角图像,以及机器人的本体感受信息,其中包括七个手臂关节角度和六个手部关节角度 。基于这些观察,机器人通过从动作分布中采样,产生一个动作,其中和分别表示手臂和手部的目标关节角度。这个过程一直持续到达到终止条件。机器人会收到一个二进制奖励,用于指示它是否成功完成了指令l。策略π的目标是最大化预期奖励。
更一般地,我们考虑用户提示P可能是一个涉及多个抓取过程的长期任务的情况,例如 “清理桌子”。这就要求策略π对提示进行推理,将其分解为单个的抓取指令,并按顺序完成这些指令。
DexGraspVLA方法
1)DexGraspVLA框架
如图2所示,DexGraspVLA采用分层模块化架构,由一个规划器和一个控制器组成。下面我们将解释各部分的设计。
规划器:为实现通用灵巧抓取,模型需要能够处理多模态输入、进行视觉定位,并对用户提示进行推理。基于视觉语言模型(VLMs)的最新进展,采用现成的预训练Qwen-VL-Chat作为高级规划器,来规划和监控灵巧抓取工作流程。给定用户提示P,规划器根据头部摄像头的观测结果对执行计划进行推理。具体而言,如果P是一个涉及多个抓取步骤的长周期任务描述,比如 “清理桌子”,规划器会考虑桌子上物体的位置和方向,并提出一个合适的抓取指令作为第一步,例如 “抓取饼干”。否则,如果P直接针对一个物体进行抓取,规划器就将其视为指令l。
对于每个指令l,规划器在初始时刻,通过在头部摄像头图像中标记目标物体的边界框来引导低级控制器。虽然语言指令的表述和内容因用户和情况而异,即表现出领域差异性,但边界框是一种一致的物体定位格式,无论语言和视觉输入如何变化,都能实现领域不变性。因此,这种转换减轻了控制器的学习难度。
在接收到边界框后,控制器开始执行任务。在此过程中,规划器以1Hz的频率查询当前头部图像,以监控进展情况。如果发现机器人成功抓取物体,规划器会执行预设的放置动作,将物体放入袋子中,然后将机械臂和手重置为初始状态。之后,规划器根据提示和视野中剩余的物体推理,提出新的抓取指令,直到提示P完全完成。另一方面,如果控制器未能抓取目标物体,规划器会重置机器人,并根据当前物体状态用新指令重新初始化抓取循环。
控制器:基于目标边界框 ,控制器旨在在杂乱环境中抓取目标物体。我们将这个边界框作为输入,输入到SAM中,以获得目标物体的初始二进制掩码,然后使用Cutie随时间连续跟踪该掩码,在每个时刻t生成。这确保了在整个过程中,在杂乱场景中都能准确识别物体。问题在于学习能有效对动作分布进行建模的策略。
为实现通用灵巧抓取能力,系统必须在各种真实场景中有效泛化。然而,原始视觉输入、的高度可变性给学习关键任务表示带来了根本性挑战。传统的模仿学习方法,即使在物体或环境条件稍有变化的情况下,也往往会惨败。为解决这个问题,我们的解决方案是将可能随领域变化的输入转换为适合模仿学习的领域不变表示。我们认识到,虽然像素级感知可能差异很大,但大型基础模型提取的细粒度语义特征往往更稳健、更一致。因此,我们利用在互联网规模数据上预训练的特征提取器(如DINOv2)从原始图像中获取特征。在每个时刻t,我们获得头部摄像头图像特征:
和腕部摄像头图像特征:
其中,、、、分别表示头部和腕部特征序列的长度和隐藏维度。这些提取的特征对干扰视觉因素的变化相对不变。
到目前为止,通过利用基础模型,原始的语言和视觉输入,包括指令l和图像、,已被迭代转换为领域不变表示,包括掩码和特征、。这为模仿学习奠定了基础。现在,我们要学习基于这些表示预测H步长动作块的策略。为将物体掩码与头部摄像头特征融合,我们使用随机初始化的ViT将投影到头部图像特征空间,生成。然后,我们将和按补丁拼接,形成:
随后,使用单独的多层感知器(MLP)将、腕部摄像头特征和机器人状态映射到一个公共嵌入空间,得到、和。然后将这些嵌入连接起来,形成完整的观测特征序列:
对于动作预测,我们采用扩散transformer(DiT),遵循扩散策略范式来生成多步动作。在每个时刻t,将接下来的H个动作捆绑成一个块 。在训练过程中,随机采样一个扩散步骤,并向中添加高斯噪声,得到带噪动作令牌。形式上:
其中,和是标准的DDPM系数。然后,将与观测特征序列一起输入到DiT中。每个DiT层对动作令牌执行双向自注意力机制,对执行交叉注意力机制,并进行MLP变换,最终预测原始噪声。通过最小化预测噪声与真实噪声之间的差异,模型学习重建真实的动作块。在推理时,通过迭代去噪步骤,从学习到的分布中恢复预期的多步动作序列,从而能够稳健地模仿复杂的长周期行为。还采用滚动时域控制策略,即仅执行预测动作块中的前个动作,然后再生成新的动作块预测,以提高实时响应性。
DexGraspVLA对通过基础模型从领域变化输入中导出的领域不变表示进行模仿学习。这种方法不仅利用了基础模型的世界知识和泛化能力,还有效地捕捉了从这些抽象表示到最终动作输出的映射。
2)数据收集
为训练我们的灵巧抓取策略,手动收集了一个数据集,其中包含2094个在杂乱场景中成功抓取的片段。该数据集涉及36种家用物品,涵盖了广泛的尺寸、重量、几何形状、纹理、材料和类别。每个片段记录了每个时刻t的原始摄像头图像、、机器人本体感受、物体掩码和动作。掩码的标注方式与控制器中的标注方式相同。对于每个物体,将其放置在3×3网格排列的九个位置上,并在每个位置收集多个抓取演示。杂乱场景中的其他物体在不同片段之间随机化。这些演示以典型的人类运动速度进行,每个演示大约需要3.5秒。它们经过严格的人工检查,以确保质量和可靠性。DexGraspVLA控制器在这个数据集上通过模仿学习进行训练。
实验分析
这里全面评估DexGraspVLA的性能。所有实验均在与演示设置不同的机器人和环境上进行。这种 “零样本” 设置比大多数先前依赖少样本学习来实现高性能的模仿学习研究更具挑战性。实验旨在解决以下问题:
- DexGraspVLA在杂乱场景中对数千种不同的、以前未见过的物体、光照和背景组合的泛化效果如何?
- 与不使用固定特征提取器、直接从原始视觉输入中学习的基线方法相比,DexGraspVLA的泛化优势如何?
- DexGraspVLA高级规划器在不同场景下的边界框预测准确性如何?
- DexGraspVLA在不同环境下的内部模型行为是否一致?
1)实验设置
硬件平台:如图3所示,我们用于灵巧抓取的机器人是一个7自由度的Realman RM75-6F机械臂,搭配一个6自由度的PsiBot G0-R手。安装在机械臂腕部的Realsense D405C摄像头提供第一人称视角,而机器人头部的Realsense D435摄像头提供第三人称视角。待抓取的物体放置在机器人前方的桌子上。机器人的控制频率为20Hz。
- 基线方法:据我们所知,目前没有现有工作可直接作为比较的基线。大多数灵巧抓取方法无法处理杂乱场景中的语言输入,而现有的接受语言输入的VLA框架与灵巧手不兼容。因此,我们比较以下方法:(1)DexGraspVLA(我们的方法):DexGraspVLA的完整实现。(2)DexGraspVLA(DINOv2-train):与我们的方法设计相同,除了两个DINOv2模型是可训练的,而不是固定的。(3)DexGraspVLA(ViT-small):与我们的方法设计相同,除了两个DINOv2模型被两个小型可训练的预训练ViT(来自Steiner等人的R26-S-32 ResNet-ViT混合模型)取代。根据经验,DexGraspVLA(ViT-small)代表了扩散策略的增强版本。这些方法的实现细节在附录A中提供。在初步实验中,我们发现策略推理中的随机性可能导致失败,通过额外尝试可以克服这些失败。因此,在5.2节中,我们比较DexGraspVLA(Ours@k),k的取值范围为1到3。这些方法与我们的方法相同,只是每个测试分别允许k次尝试。Ours@1等同于我们的方法。请注意,策略在单次尝试中初始失败后的重新抓取是允许的,并且不被视为单独的尝试。
2)大规模泛化评估
- 任务:我们挑选了360个以前未见过的物体、6种未见过的背景和3种未见过的光照条件。精心选择这些物体,以确保它们涵盖广泛的尺寸、重量、几何形状、纹理、材料和类别,同时也能被我们的灵巧手抓取。图4展示了这种多样性。背景和光照条件也被选择为差异很大的类型。基于此设置,在杂乱场景中设计了三种类型的抓取任务,每个杂乱场景包含大约六个物体:(1)未见物体:在白色桌子上的随机场景中,在白光下抓取一个未见物体。360个未见物体中的每个物体都被抓取一次,总计360次测试。(2)未见背景:我们首先随机选择103个未见物体作为物体子集s。对于每个背景,我们在白光下用子集中的物体随机排列103个杂乱场景。103个物体中的每个物体都被抓取一次,总共进行618次测试。(3)未见光照:对于每种未见光照,我们在白色桌子上用子集中的物体构建103个杂乱场景。我们对103个物体中的每个物体抓取一次,总计309次测试。
- 指标:如果机器人将物体在桌子上方10厘米处保持20秒,我们认为一次抓取尝试成功。我们将成功率作为评估指标,其定义为成功测试的次数除以总测试次数。我们还报告综合性能,即根据各个成功率的比例进行加权求和。
- 结果:在表1中展示定量结果。从第一行(“Ours@1”)可以看出,DexGraspVLA在360个未见物体上的单次尝试成功率达到91.1%,在6种未见背景上达到90.5%,在3种未见光照条件下达到90.9%,综合成功率为90.8%。这些结果表明,DexGraspVLA能够准确控制灵巧手从杂乱场景中抓取指定物体,同时对环境变化具有鲁棒性。值得注意的是,尽管评估环境是全新的,任务也是以前未见过的,但DexGraspVLA在没有任何特定领域微调的情况下,始终保持高成功率,突出了其强大的泛化能力。这表明我们的框架大大缓解了模仿学习中长期存在的挑战,即过度拟合单一领域并依赖微调来获得令人满意的性能,这对于广泛的应用可能具有重要意义。我们将在5.5节中进一步分析这种泛化能力的来源。


定性地说,DexGraspVLA学会了灵巧地调整机械臂和手,以适应不同的物体几何形状、大小和位置。虽然物理干扰或不理想的动作偶尔会导致抓取失败,但我们策略的闭环性质有助于根据更新的观测进行重新抓取,从而增强了鲁棒性。该方法还能容忍人为干扰,因为机器人可以跟踪重新定位的物体,直到成功抓取。
从第二行和第三行(“Ours@2”和“Ours@3”)可以观察到,虽然单次尝试中可能会出现随机性和偶然失败,但多次尝试通常会成功,三次尝试时整体性能可提高到96.9%。这表明我们的方法有能力达到更高的成功率。最后,我们的模型平均大约需要6秒来抓取一个物体,这与人类的抓取时间相近,确保了在现实场景中的实际可用性。
我们的大规模评估证实,DexGraspVLA能够稳健地处理各种未见场景,朝着通用灵巧抓取迈出了有意义的一步,并有望在更广泛的现实世界中部署。
3)与未使用固定视觉编码器的基线方法的比较
- 任务:为系统地比较DexGraspVLA与未使用固定视觉编码器、直接从原始视觉输入中学习的基线方法,我们使用训练数据集中的13个已见物体和8个未见物体进行单物体抓取实验。在桌子上选择五个位置,这些位置既覆盖操作空间,又在机器人的可达范围和头部摄像头的视野内。每个物体放置在这些点上,在每个点上,我们让策略抓取该物体两次。请注意,同一物体在同一点的两次抓取被视为两次单独的测试,而不是同一测试的重复尝试。这种方法定量地考虑了实验中的随机性。总共进行210次测试。这些实验的环境条件是白色桌面和白光。
- 指标:报告每种方法的成功率。
- 结果:图5表明,DexGraspVLA在已见和未见物体抓取实验中始终保持超过98%的成功率,显著优于DexGraspVLA(DINOv2-train)和DexGraspVLA(ViT-small)。我们的方法在 “零样本” 测试环境中的综合性能接近完美,这表明DexGraspVLA(我们的方法)不受视觉输入领域转移的影响。我们还注意到,未见物体上的性能甚至略优于已见物体,这再次证实我们的模型学会了完成抓取任务,而不是过度拟合训练集中的已见数据。相比之下,替代设计在新环境中无法正常工作,因为它们直接将原始输入映射到动作,而感知变化很容易使它们超出分布范围。
4)规划器的边界框预测准确性
任务。规划器的边界框预测精度对于抓取操作的成功与否至关重要,因为它决定了控制器的目标。为了评估这一精度,设计了三种类型的任务,这些任务具有不同的环境干扰因素:(1)无干扰(1 种场景):杂乱的场景布置在白色灯光下的白色桌子上;(2)背景干扰(2 种场景):杂乱的场景放置在标定板或色彩鲜艳的桌布上,且均处于白色灯光下;(3)光照干扰(2 种场景):场景设置在一个黑暗的房间里,由台灯或迪斯科灯照明。对于每种场景,我们随机布置五个杂乱场景,每个场景包含六个随机选择的物体,然后记录前置摄像头拍摄的图像。对于每个物体,我们提供一个文本提示,描述其外观和位置,并检查规划器的边界框预测是否准确地标定了目标。总的来说,无干扰任务包含 30 次测试,而背景干扰和光照干扰任务各有 60 次测试,总计 150 次测试。
度量标准。如果一个边界框能够紧密包围目标物体,我们就将其定义为准确的边界框。然后,精度被衡量为准确边界框在所有测试物体中所占的比例。
结果。精度报告见表 2,对于 150 个提示,规划器仅错误标记了一个边界框,而在其他 149 次测试中均取得成功,综合精度超过了 99%。这证明了我们的规划器能够可靠地对用户提示进行视觉定位,并且能够在不同复杂程度的背景和光照条件下为控制器标记出正确的边界框。
5)内部模型行为分析
为了进一步验证我们的设计,通过实证证明了内部模型的行为在各种视觉变化情况下是一致的,并将结果展示在图6中。由于篇幅限制,我们仅展示了每张包含桌面工作空间的图像的相关部分。我们设计了四种截然不同的环境条件:白色桌子、标定板、彩色桌布以及在迪斯科灯光照射下的彩色桌布。在每种环境中,构建了相同的杂乱场景,其中包含九个物体,并让DexGraspVLA执行“抓取中间的蓝色酸奶”这一任务。
尽管图6第一行中的前置摄像头图像看起来差异明显,但第二行中DINOv2的特征却相当一致。这些特征通过将主成分映射到RGB通道来进行可视化,方法与Oquab等人所做的相同。在不同环境下,物体的属性都能稳健地保持并匹配,这从根本上使得在单一数据域上训练的DexGraspVLA具备了泛化能力。 第三行展示了Cutie能够准确地追踪物体,为控制器提供正确的引导。基于域不变掩码和DINOv2特征,DiT动作头现在可以预测后续动作。在第四行中,我们对DiT针对前置摄像头图像的所有交叉注意力进行了平均和归一化处理。我们发现,所有的注意力图都表现出相同的行为,即聚焦于目标物体,而不会受到环境的干扰。第五行将注意力图叠加在原始图像上,以确认注意力模式的合理性。 因此,我们证实了DexGraspVLA确实将在感知上多样的原始输入转换为不变的表征,在此基础上,它有效地应用模仿学习对数据分布进行建模,这就解释了其卓越的泛化性能。不出所料,它在所有四种环境中都成功抓取到了酸奶。
#VLA较E2E-VLM的3个提升点
原作者:大懒货
原文链接:https://weibo.com/2062985282/PgmxNm2rL
以下为原文:
【技术向】自动驾驶 领域能工程落地【VLA】视觉语言动作模型的贡献价值
~不亚于我们成功搞定千T算力的自动驾驶芯片~
VLA可能是目前从高阶驾驶辅助【L2】走向真正自动驾驶【L3及更高】的关键敲门砖
基于目前学术研究探讨:AD领域 的VLA可能的工作流
可以拿Open-VLA 这个参考图作为举例
1️⃣:信息感知:
多颗摄像头视频流、导航需求、自车定位、其他传感器信息通过统一编码、对齐
进入 基于基座模型蒸馏后应对驾驶领域专一的LLM模型【参量数B至数十B?或者更高】
2️⃣:决策输出
通过驾驶领域专一的LLM模型直接输出决策、决策转换为轨迹并直接输出控制细节
VLA相较于现在的E2E-VLM 有以下几个差异【或者直接说提升的点吧】:
1️⃣:如果全局直接用VLA来控制驾驶领域,首先不需要考虑端到端模型和VLM模型握手的问题,不太可能出现在VLM告知端到端模型该怎么做,但是端到端模型不太清楚该怎么做【因为现在这个信息握手仍然是通过人工定义的方式处理】
2️⃣:VLA的模型参量相较于现在VLM有大幅度的提升,因此非常有可能在驾驶领域涌现出弱的人工智能处理能力。换句话说,针对于没有针对性训练过的场景,VLA也能通过多步骤逻辑推理、分析等方式处理。针对于复杂场景的能力会明显变强。
我们都知道现在VLM更多是通过语言模型去做场景的感知联动元动作,存在一定的弱智能和推理能力【like 有车打灯要小心、复杂路口要小心】,但是特别复杂场景的、需要长上下文背景信息的推理能力还是比较弱的,而VLA通过增加参量、基座模型专一训练成驾驶领域都可以在有限算力【OrinX/Thor】下尽可能提升驾驶领域的通用理解和思考能力,就像拥堵场景用VLA去解会比现在E2E-VLM解的表现好的多的。
3️⃣:针对于基于LLM去探索AD,针对模型的幻觉。这个肯定要用类似模型化的主动安全或者用其他强化学习的方式去兜底。既然@刘杰-理想 大王已经官宣OrinX/Thor 都可以跑通VLA。那么大概率模型化的安全兜底应该也是跑通了。
再简单总结一下⭐⭐:
通过工程落地VLA,在2025年AD Max车主能看到在驾驶场景中,车辆会具备一定深度思考、复杂推理的一套智能驾驶。通过模型推理的方式让车辆更好应对复杂场景和那些可能没有见过的场景。
因为这个世界的变量太多了,我们很难通过数据训练实现模型应对100%的场景,因为能力泛化可能就需要基于模型分析、推理、乃至涌现的方式去实现~
#BEVDriver
基于多模态BEV表征的自动驾驶决策新范式,暴力提升35%个人理解
自动驾驶技术有望为未来出行效率奠定基础,但其研究领域需通过安全、可靠且透明的驾驶能力建立信任。大型语言模型(LLMs)凭借其推理能力和自然语言理解潜力,可作为通用决策者进行自车运动规划,并与人类交互及适应为人设计的驾驶环境。尽管这一方向前景广阔,当前自动驾驶方法在结合3D空间表征与LLMs的推理及语言能力方面仍面临挑战。本文提出BEVDriver,一种基于LLM的端到端闭环驾驶模型,在CARLA模拟器中利用潜在BEV(鸟瞰图)特征作为感知输入。
BEVDriver通过BEV编码器高效处理多视角图像与3D LiDAR点云数据。在共享的潜在空间中,BEV特征通过Q-Former与自然语言指令对齐,并传递至LLM以预测精确的未来轨迹,同时考虑导航指令与关键场景。在LangAuto基准测试中,我们的模型在驾驶得分(Driving Score)上较最先进方法(SoTA)提升高达18.9%。
- 论文链接:https://arxiv.org/abs/2503.03074
简介
在复杂且安全至上的自动驾驶领域,生成式端到端方法是基于规则或模块化预测与运动规划方案的有力替代方案。后者的泛化能力存在不足,而生成式方法则能通过更多训练数据提升性能,并高效优化最终驾驶任务。LLMs凭借其推理能力与自然语言理解,被视为高效且可解释的决策者。其内在的世界知识增强了上下文理解与推理能力,同时生成自然语言解释的潜力为解决生成模型的“黑箱”问题提供了途径。然而,LLMs在绝对空间理解上的局限性成为安全关键场景中的主要挑战,因为精确运动预测与轨迹规划至关重要。
基于Transformer的运动规划方法利用鸟瞰图(BEV)特征图,将单模态或多模态传感器数据转换为自车周围环境的俯视特征表示,为轨迹规划等任务提供鲁棒的空间输入。LMDrive首次实现了基于语言指令的CARLA模拟器端到端导航。该方法通过BEV编码器处理LiDAR与多视角相机数据,结合目标检测与交通灯状态等感知标记及未来路径点预测,验证了BEV编码器在LLM驱动的运动规划研究中的潜力。
基于此,本文进一步拓展LLMs的能力,证明其不仅能完成高层决策或路径点优化,还可直接通过BEV特征(包括3D LiDAR点云与多视角图像)端到端预测轨迹,融合自然语言指令,弥合高层决策与底层规划的鸿沟。与依赖预预测路径点作为输入的LMDrive不同,我们的方法直接使用感知训练的编解码器生成的原始潜在BEV特征,避免了轨迹特定预处理的依赖。这一设计通过LLM对高维特征的直接解释,提升了泛化能力,并支持自监督运动学习。
总结来说,本文的主要贡献如下:
- 提出BEVDriver,一种基于LLM的端到端闭环轨迹预测与规划模型,直接利用LiDAR与相机生成的原始BEV特征(图1),消除对预预测路径点的依赖,提升鲁棒性与自监督学习能力。
- 在LangAuto基准测试中,BEVDriver的驾驶得分较现有最佳方法提升高达18.9%,并开源模型权重、训练代码与数据集扩展,以推动语言引导自动驾驶研究。

第二章 相关工作回顾
a) BEV特征图
BEV特征图通过单模态或多模态输入数据生成自车周围环境的俯视表示。这种空间表征通过提供无遮挡的环境视角,增强了对复杂场景的鲁棒性。此外,统一的BEV表示为下游预测与规划模块的推理提供了便利。BEVDepth专注于基于相机输入的3D深度估计以实现目标检测。多模态BEV融合通过整合语义图像信息(如BEVFusion)提升传感器失效时的鲁棒性,这对安全关键场景至关重要。BEVFormer利用基于网格的空间查询与时间查询,实现LiDAR-图像融合与序列推理;而BEVFusion]则通过共享BEV表示保留语义信息。
b) 闭环驾驶
闭环评估根据环境反馈动态调整自车行为,而开环评估仅测量与真实轨迹的偏差。当前多数端到端方法聚焦于优化开环规划,但开环性能无法保证闭环场景的有效性,突显动态交互评估的必要性。CARLA模拟器提供闭环评估环境,其中BEV方法表现优异。InterFuser通过LiDAR与多视角图像的BEV投影增强场景理解;ReasonNet则在BEV地图中集成时序与全局推理模块以捕捉动态交互。
c) 基于LLM的驾驶
LLM凭借其世界知识与推理能力,被用于生成上下文感知的驾驶决策,如DriveLM、DriveVLM和EMMA等先进方法。自然语言处理通过生成解释性文本(如DriveGPT4、RAG-Driver、DriveMLM)提升模型可解释性。然而,LLM的空间理解能力仍受限。现有方法如OmniDrive通过3D标记化解码空间信息,CarLLaVA则利用视觉编码保留空间特征。BEV地图因其高效清晰的表示成为理想解决方案,如Talk2BEV结合BEV与视觉语言模型(VLM)实现感知与推理的统一。
BEVDriver详解
图2展示了BEVDriver的整体架构。多视角RGB图像与3D LiDAR点云通过BEV编码器融合为BEV特征图。该特征图通过Q-Former与导航指令对齐后输入LLM,LLM输出未来路径点并生成驾驶指令,最终由PID控制器执行。以下详细描述各模块设计。

A. 感知模块
为生成BEV特征嵌入,我们基于InterFuser的编码器架构实现BEV编码器。该架构采用ResNet-50处理图像数据,ResNet-18处理LiDAR数据,确保高效的多模态特征提取。提取的特征通过基于Transformer的编码器映射至256维嵌入空间。
解码器部分复用InterFuser的交通检测头、交通灯状态预测头,并新增前视语义分割头。语义分割头采用金字塔场景解析网络,通过多尺度自适应平均池化(1、2、3、6尺度)捕获全局上下文,并通过投影层融合池化特征与输入特征以保留空间细节,最终输出精确的分割结果。
BEV编码器通过四类损失函数预训练:
- L1交通检测损失:优化目标检测精度;
- 交叉熵交通灯状态损失:预测交通灯状态;
- 焦点损失(Focal Loss):加权交叉熵(α=0.9,γ=5)优化语义分割;
- 对比损失(Contrastive Loss):增强时序一致性,使相邻帧特征相似,远距离帧特征差异显著。
推理阶段,仅保留编码器部分,生成紧凑的BEV特征表示。编码器参数量为5.37M,推理频率达18Hz。
B. 端到端流程
端到端驾驶流程包含以下组件:
- BEV编码器:融合多视角图像(前、左、右、后视)与LiDAR点云,生成BEV潜在特征。编码器可处理最多40帧历史数据以捕捉时序依赖。
- Q-Former对齐模块:
- 采用改进的BLIP-2 Q-Former,将BEV特征与导航指令在自然语言潜在空间对齐;
- 使用32个可学习查询向量(768维),将BEV特征与指令语义关联。
- LLM推理模块:
- 通过LoRA适配器(秩16,丢弃率32.5%)调整LLM参数,生成导航动作标记;
- GRU网络基于LLM最后一层隐藏状态预测5个未来路径点;
- 2层MLP判断导航指令是否完成(布尔标志)。
- 控制执行:
- 纵向与横向PID控制器分别调节油门/刹车与转向,跟踪预测路径点。
实验结果分析
A. 实验设置
我们采用LLM模型Llama-7b和指令微调模型Llama-3.1 8B-Instruct,将BEVDriver与LMDrive和AD-H进行闭环评估对比。主要实验中,预训练的BEV编码器参数保持冻结。输入帧采样率为1,PID控制器的积分误差项设为20以增强控制稳定性。所有实验均在每场景重复3次取平均值。
B. 数据集与基准测试
a) LMDrive数据集:使用LMDrive提供的数据集,包含15k条序列,涵盖CARLA 8个城镇(Town 1-7、10)的路线数据,采样频率为10Hz,包含导航指令、控制信号、多视角RGB图像、LiDAR数据及元数据(如交通灯状态、地面真实路径点)。训练数据包含所有8个城镇,验证集保留3种天气-时段条件(soft rain午间、soft rain黄昏、hard rain夜间)。
b) BEVDriver语义数据集:在LMDrive的8个城镇中额外采集2k条序列,包含前、左、右视角的语义分割标注(涵盖行人、车辆、道路、交通标志等CARLA语义类别)。数据集与生成代码将公开。
c) CARLA基准测试:CARLA提供闭环基准测试Leaderboard 1.0。LangAuto基准将其适配为LLM评估,将7种离散导航指令映射为自然语言指令。测试场景包含多样的环境、天气、时段及复杂交互(如交叉路口、行人/骑行者突然穿行、多车道环岛)。路线分为短程(<150m)、中程(150-500m)、长程(>500m),并插入不可行任务以测试鲁棒性。
C. 评估指标
闭环规划采用三项指标:
- 驾驶得分(DS):路线完成率(RC)与违规得分(IS,含碰撞、闯红灯等)的乘积。
- 开放环路基线:使用平均位移误差(ADE)和最终位移误差(FDE),计算预测路径点与真实值的L2距离。
D. 训练细节
- LLM训练:使用AdamW优化器(权重衰减0.06),余弦学习率调度器(初始学习率1e-4,最小1e-5,预热步数2000)。Llama-7b和Llama-3.1模型训练15轮(72小时),8块Nvidia A100 GPU,批量大小4。
- BEV编码器训练:8块Nvidia A40 GPU,批量大小16,AdamW优化器(学习率5e-4,权重衰减0.05)。
E. 定性结果
图3展示BEVDriver在CARLA中的导航示例,模型能处理复杂场景(如环岛)并提前规划车道变换。图4显示语义分割与BEV检测结果,模型能准确识别远距离行人/交通标志,但对道路细节(如斑马线)存在局限。


F. 定量结果
a) 闭环规划:表I对比BEVDriver与现有方法在LangAuto基准的表现。BEVDriver在驾驶得分(DS)和路线完成率(RC)上优于最先进方法。例如,在LangAuto长程测试中,Llama-7b版本DS较AD-H提升11.1%,RC提升12.2%。
b) 开环规划:BEVDriver在ADE和FDE指标上表现最佳(Llama-7b:ADE 0.04,FDE 0.07),优于LMDrive的LLaVA-7B(ADE 0.09,FDE 0.18)。


G. 消融实验
a) Town 5泛化测试:在未训练的CARLA Town 5长程测试中,BEVDriver(Llama-7b)DS为28.4%,RC为38.9%,优于其他模型。
b) 端到端训练:解冻BEV编码器后,RC提升5%,但IS下降(表III),可能因交通灯状态监督缺失导致初期性能下降。
c) 无误导指令测试:移除误导指令后,BEVDriver DS降至70.2%(表IV),表明频繁指令可提升模型表现。

讨论
BEVDriver通过融合低层BEV特征与高层自然语言指令,实现了端到端的轨迹预测与规划,在LangAuto基准测试中较最先进方法(AD-H)的驾驶得分提升高达18.9%。与LMDrive的Llama-7b模型相比,BEVDriver在相同骨干网络下性能提升35.1%-56.2%,验证了BEV特征与LLM结合的有效性。
主要发现与局限性:
- 距离指令的执行挑战:模型对“x米后左转”等基于距离的指令存在误执行问题(如立即变道)。未来需通过时空注意力机制或增强距离指令与BEV表示的对齐解决。
- 闭环评估的重要性:CARLA与LangAuto框架虽提供闭环测试能力,但场景多样性不足和交通阻塞问题仍限制泛化性与指标可靠性。
- 端到端训练的潜力:消融实验表明,解冻BEV编码器可提升路线完成率(RC),但可能因交通灯状态监督不足导致初期违规增加,需进一步优化训练策略。
跨领域扩展性:
BEVDriver的架构可迁移至其他需自然语言交互的复杂环境导航任务(如服务机器人、辅助机器人),其核心思想——通过统一BEV表示融合感知与语言推理——具有广泛适用性。
未来工作:
- 增强时空推理能力(如自回归预测)以提升动态场景适应性;
- 通过生成场景描述语言标记提高模型可解释性(已开展初步实验);
- 开源代码库以推动语言引导自动驾驶研究。
结论
我们提出了BEVDriver,一种基于LLM的端到端运动规划器,通过统一的潜在BEV表示从自然语言指令中预测低层路径点并规划高层机动动作。通过融合相机与LiDAR数据,BEVDriver能够生成精确的未来轨迹,同时结合上下文驱动的决策(如转向与让行)。我们的模型性能优于最先进方法,驾驶得分(DS)提升高达18.9%,在相同Llama-7b骨干网络下较LMDrive的最佳模型提升35.1%,并在LangAuto基准测试中实现56.2%的性能改进。未来工作将聚焦于增强BEVDriver的鲁棒性、时序感知能力与可解释性。
#NVIDIA自动驾驶技术解析
近年来,随着人工智能、深度学习及高性能计算的突破,传统驾驶模式正逐步向智能驾驶、无人驾驶转型,自动驾驶技术正以惊人的速度改变大家的出行方式。NVIDIA作为全球领先的加速计算和AI平台提供商,在自动驾驶安全领域投入了巨额资源和研发力量,旨在构建一套既安全又高效的自动驾驶生态系统。
NVIDIA AV 2.0平台
当自动驾驶汽车从概念走向现实,自动驾驶系统需要在复杂、多变的现实环境中实现精确感知、实时决策和安全控制。传统的模块化方法虽然在部分场景下能够满足需求,但在面对复杂交通状况和突发异常时,难以全面兼顾安全与效率。
在NVIDIA的技术体系中,安全性始终被置于首位。通过软硬件协同设计、冗余架构、深度神经网络 (DNN) 多帧检测以及多传感器融合等技术手段,在自动驾驶系统出现故障或传感器异常时能够迅速切换到安全模式,确保驾驶员和行人的安全。可以说,NVIDIA不仅仅是在追求自动驾驶的智能化,更是在为整个交通系统提供一套完备的安全保障方案。
NVIDIA构建了AV 2.0平台,与AV 1.0专注于使用多个深度神经网络改进车辆感知能力不同,AV 2.0引入了端到端的驾驶思路。该技术通过一个大规模、统一的 AI 模型,从传感器输入直接生成车辆轨迹,有效避免了传统流水线中信息传递失误和延迟带来的风险。
在AV 2.0平台中,NVIDIA利用先进的深度学习算法对异常情况进行预测和应对。通过仿真与现实数据的不断融合,系统能在面对罕见或极端场景时自动评估风险,并实施故障安全行为。端到端驾驶不仅简化了算法流程,还大大提升了系统整体响应速度和鲁棒性,为未来全面无人驾驶奠定了坚实的技术基础。
安全架构的设计与实践
自动驾驶系统作为一种高度复杂的软件定义系统,其安全架构设计需覆盖硬件、固件、操作系统、应用软件等各个层面。NVIDIA采用的V模型开发流程,对每一个环节进行详细的功能和安全性分析。在系统开发初期,通过故障模式及影响分析(FMEA)、故障树分析(FTA) 等方法,识别潜在安全隐患,并制定对应的安全目标和风险缓解措施。
在实际设计中,NVIDIA将功能安全要求分解到各个子系统,并通过冗余设计、多样化算法以及实时监控机制,确保在任一单点发生故障时,系统仍能迅速切换至最小风险状态。如当车辆传感器因恶劣天气失效时,系统会自动调整控制策略或将控制权交还给驾驶员,从而最大限度降低事故风险。此外,通过不断更新的无线升级机制,NVIDIA自动驾驶系统能够及时响应新威胁和新标准,保持系统的长期安全性和可靠性。
NVIDIA自动驾驶技术架构
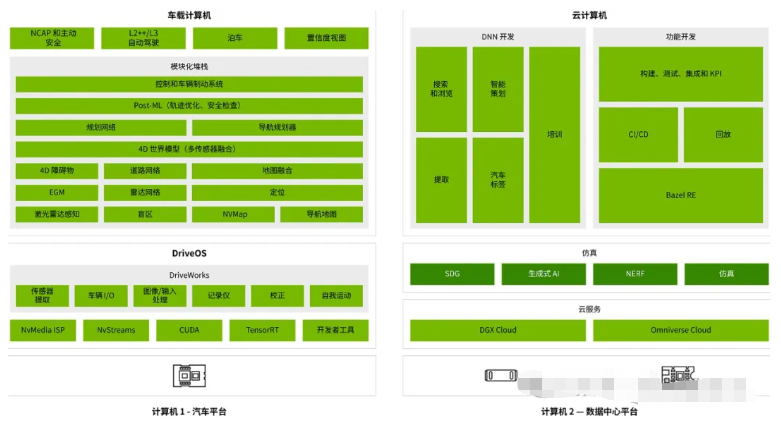
3.1 高性能硬件平台的支撑
硬件是自动驾驶系统的基石,直接决定了系统处理速度和实时响应能力。NVIDIA DRIVE AGX系列平台在硬件设计上实现了从L2+辅助驾驶到L5完全自动驾驶的跨越。以最新一代的DRIVE AGX Orin为例,其芯片支持高达254 TOPS(每秒万亿次运算)的计算性能,为复杂的深度神经网络和多传感器数据融合提供了强大算力。DRIVE AGX Thor则整合了最新的NVIDIA Blackwell GPU架构,不仅支持高精度的计算任务,还兼顾了能耗和系统成本,为未来大规模商用自动驾驶系统奠定了坚实基础。
NVIDIA DRIVE AGX Orin
NVIDIA DRIVE AGX Thor
硬件平台的另一大亮点在于其模块化设计和开放的API支持。开发者可以通过CUDA、TensorRT等工具,充分利用底层硬件的算力,实现自定义算法和多样化应用。这种开放、灵活的平台架构不仅延长了产品生命周期,也为汽车制造商提供了从入门级到高端自动驾驶解决方案的多层次选择。
3.2 软件平台与AI算法的深度融合
在自动驾驶系统中,软件层面承载着感知、定位、规划和控制等核心功能。NVIDIA DRIVE SDK提供了一整套完善的软件开发工具,涵盖了传感器数据处理、深度学习推理、实时控制以及驾驶员监控等各个方面。其核心操作系统DriveOS是首个面向车载加速计算的安全操作系统,整合了NVIDIA CUDA库和TensorRT推理引擎,能够在毫秒级时间内完成复杂的AI计算任务。
通过利用20多个同时运行的深度神经网络模型,NVIDIA DRIVE SDK能够实现对障碍物检测、目标跟踪、多帧数据融合以及动态环境预测等功能。这些模型不仅在单一传感器数据上进行判断,更通过多传感器数据的交叉验证,确保检测结果的准确性和鲁棒性。同时,DRIVE SDK采用嵌入式模块化设计,支持不同车辆和场景下的自适应调整,为系统的高可用性和安全性提供了多重保障。
软件平台与硬件平台之间的无缝协同使得自动驾驶系统能够快速响应外部变化。无论是在高峰城市道路中的复杂交通场景,还是在高速公路上进行高速行驶,软件平台都能够及时调度系统资源,执行精细化的路径规划和实时控制,从而确保车辆始终处于安全运行状态。
3.3 深度学习开发基础设施与大数据支撑
自动驾驶汽车每年可产生数百万亿字节(PB)级别的数据,这对数据处理、存储和分析提出了前所未有的挑战。NVIDIA在数据中心层面构建了一整套AI训练和数据管理基础设施,涵盖了从数据采集、标注、存储到深度神经网络训练与验证的全流程。利用NVIDIA DGX系统,开发者能够在庞大的数据集上训练出应对各种复杂驾驶场景的AI模型,并不断迭代优化模型性能。
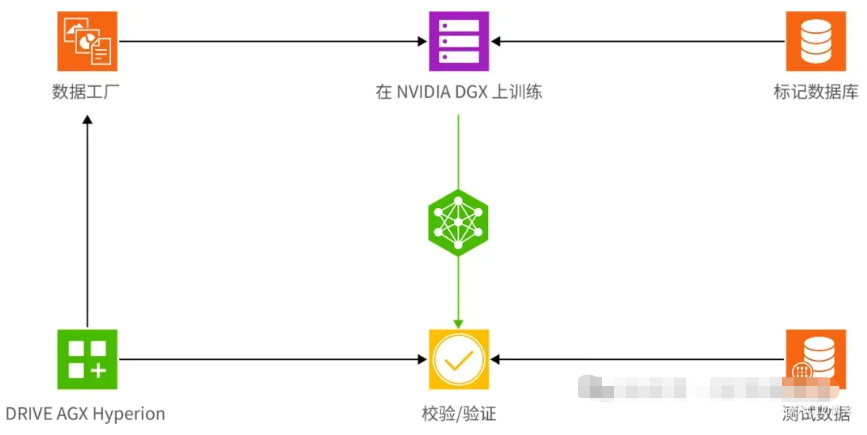
在数据标注和管理中,NVIDIA通过“数据工厂”流程,将海量传感器数据进行系统化整理,并利用自动标注技术为图像、视频序列及场景条件生成详细标签。这些数据不仅为深度学习训练提供了丰富的样本,也为系统在实际道路测试前的仿真和验证奠定了坚实基础。同时,借助NVIDIA Omniverse Replicator等工具,开发者能够生成高保真合成数据,补充现实世界中难以采集的极端场景,进一步提升模型的泛化能力和鲁棒性。
数据中心与云服务的无缝整合使得整个自动驾驶研发流程从数据采集、AI训练到仿真验证形成了闭环管理体系。通过持续监控和数据反馈,系统能够在迭代更新中不断进步,实现安全性、准确性和实时性的三重提升。
3.4 物理精准传感器仿真技术
在自动驾驶研发过程中,真实道路测试虽然至关重要,但其成本高昂且存在不可控风险。为了弥补现实测试的局限性,NVIDIA借助高保真物理仿真平台,通过基于OpenUSD的虚拟环境重现真实世界中的传感器数据。利用 NVIDIA Omniverse Cloud Sensor RTX平台,开发者可以在虚拟空间中构建逼真的交通场景、光照条件、天气变化等复杂环境,并利用物理引擎对传感器(如摄像头、激光雷达、雷达和超声波传感器)进行精确模拟。
这种传感器仿真技术不仅使开发者能够在安全、受控的环境中测试系统反应,还可以通过生成合成数据进一步丰富AI模型的训练样本。通过仿真数据与现实数据的对比验证,能够在正式上路之前识别并修正潜在的安全隐患,从而大大降低实际测试中的风险。借助fVDB等开源深度学习框架,自动驾驶系统还可以快速构建出基于真实3D数据的高保真虚拟环境,为自动驾驶算法提供更多可能性和扩展空间。
3.5 网络安全与系统整体安全保障
随着自动驾驶系统逐步向商业化推广,其面临的网络攻击和数据泄露风险也日益严峻。NVIDIA在系统设计和开发过程中,严格遵循国际和国内的安全标准,如ISO 26262、ISO 21448(SOTIF)、ISO/SAE 21434、NIST指南以及GDPR等,构建了一套全方位的安全和网络安全保障体系。其安全策略不仅涵盖硬件、软件和数据传输等各个环节,还特别注重系统在长期使用过程中的安全更新和风险监测。
在具体实现上,NVIDIA采用了多层防御机制,包括静态与动态代码分析、渗透测试和实时监控等手段,以检测系统内部潜在的安全漏洞。安全事件响应团队则与汽车信息共享、工业安全局以及相关标准化组织保持密切合作,一旦出现安全事件,能够迅速采取应急措施,防止风险蔓延。与此同时,通过无线升级机制,系统能够在不间断运行的情况下及时修复漏洞,保持最新的安全防护能力。
这种全链条、跨部门的安全保障体系确保了自动驾驶系统在各种网络攻击和硬件故障情况下仍能维持安全运行,从而为消费者和合作伙伴提供了高度信任的产品和服务。
3.6 道路测试与验证流程
在理论设计与仿真验证的基础上,实际道路测试仍然是检验自动驾驶系统安全性的重要环节。NVIDIA 制定了详细的《DRIVE 道路测试操作手册》,确保每一次上路测试都严格按照既定的安全流程执行。测试前,车辆必须经过单元测试、集成测试和系统仿真等多个阶段的验证,确保软件和硬件在各种极端条件下都能保持稳定运行。
道路测试过程中,训练有素的安全驾驶员和测试操作员全程监控车辆表现,通过对比车辆检测到的物体与真实路况,实时调整系统参数。同时,借助远程监控系统和虚拟测试平台,部分测试可以在远程操控下进行,以降低现场人员风险。通过多维度、多场景的数据采集,系统不断反馈并优化算法,为最终实现大规模商业化部署提供了坚实的技术保障。
3.7 开发者培训与生态系统建设
为了推动自动驾驶技术的快速普及和持续创新,NVIDIA同时十分重视开发者教育和生态系统建设。通过NVIDIA深度学习培训中心(DLI)以及全球GTC大会,NVIDIA向数以百万计的开发者提供了系统化的培训课程,涵盖从基础深度学习原理到自动驾驶系统的实际开发技术。NVIDIA还积极与全球各大高校、研究机构和产业联盟合作,共同推动自动驾驶相关标准的制定和技术交流。
这种开放且合作的生态系统不仅为行业提供了大量高素质技术人才,也使得不同厂商和供应商能够共享资源和最佳实践,共同应对自动驾驶技术在研发和应用过程中遇到的各种挑战。通过不断的技术培训、标准推广和实际案例分享,NVIDIA正在为整个自动驾驶产业构建一个开放、互联且充满活力的生态圈。
结语
在自动驾驶技术逐步走向商业化和大规模应用的背景下,安全始终是最不可妥协的底线。NVIDIA通过融合深度学习、物理仿真、高性能硬件以及严格的安全认证流程,构建了一个端到端安全、可靠的自动驾驶平台。正是凭借这一整套完备的技术体系和不断迭代优化的研发流程,NVIDIA才得以在全球自动驾驶领域树立起坚实的技术标杆,并持续引领行业发展。
#MapFusion
分割性能暴涨6%!最新多模态地图BEV融合网络
自动驾驶系统包括感知、预测、决策、规划等不同的功能模块。对于其中的自动驾驶规划模块而言,要想实现准确安全的路径规划,就需要利用自动驾驶车辆上配置的传感器采集周围的环境信息构建地图。
本文介绍了MapFusion:一种用于多模态地图构建的新型BEV特征融合网络。
论文标题:MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
论文作者:Xiaoshuai Hao, Yunfeng Diao, Mengchuan Wei, Yifan Yang, Peng Hao, Rong Yin, Hui Zhang, Weiming Li, Shu Zhao, Yu Liu
论文地址:https://arxiv.org/abs/2502.04377

▲图1| 自动驾驶系统中地图构建任务示意图
现有的地图构建算法根据所使用的传感器数据进行划分,大体可以分成三种。分别是基于纯视觉的、基于纯激光雷达的以及基于相机和激光雷达融合的。在这三类方法当中,由于多模态融合算法可以充分利用不同模态数据之间的信息互补优势,其性能明显高于其他两类单模态的地图构建算法。
近年来,学术界已经提出了不少采用多模态的地图构建算法,比如,X-Align采用基于元素相加的方式进行多模态BEV特征的融合过程;BEVFusion采用两种模态加权平均的BEV特征融合方式;HDMapNet采用两种不同模态通道拼接的方式完成BEV特征的融合。尽管上述融合方式取得了不错的性能,但是这些方法通常忽略了不同模态特征之间的交互过程,影响了最终的地图构建效果。
在本文中,提出了跨模态交互变换器(CIT)模块,通过采用自注意力的方式实现了两种模态BEV特征之间的更加有效交互。同时,文中还进一步提出了双向动态融合(DDF)模块实现自适应的从不同模态之间选择有价值的信息构建最终的BEV融合特征。
本文的主要贡献总结如下:
- 提出了一种名为MapFusion的多模态地图构建算法,实现对于不同模态之间的更加高效的交互和集成,提高最终的高精地图和地图分割任务的效果。
- 为了解决视觉和点云模态语义特征不对齐问题,设计了名为跨模态交互变换器模块,通过自注意力的方式实现两类模态特征的有效交互。
- 为了更好的解决两类模态的特征融合问题,提出了名为双向动态融合模块,自适应的从两类特征中选择有价值的信息完成融合特征的构建。
- 大量实验表明,提出的MapFusion算法模型高于nuScenes数据集中高精地图和BEV地图分割任务的SOTA算法3.6%和6.2%。
MapFusion算法模型的网络结构如图2所示。具体而言,给定传感器采集的环视图像和点云数据,分别利用2D编码器和3D编码器完成各自模态的特征提取和BEV特征构建;然后将两个模态的BEV特征喂入提出的跨模态交互变换器中实现两类特征的交互,接下来利用双向动态融合模块实现两类特征的融合,最后接Map Decoder输出地图的构建结果。

▲图2| MapFusion算法模型的整体框架图
在上文中提到,由于不同模态之间存在语义不对齐问题,本文采用了跨模态交互变换器来缓解这一问题的发生。具体而言,CIT模块的整体流程可以总结为以下几步。
1.将相机分支和雷达分支输出的BEV特征进行展平,并按照矩阵的顺序进行排列,从而得到和。
2.为了能够让不同模态的token在训练的过程中进行区分,本文添加了PE位置编码。
3.由于跨模态交互变换器采用了Transformer中自注意力的思想,所以将添加了位置编码后的多模态数据利用线性层进行转换,得到矩阵。
4.按照Transformer中自注意力的计算公式,计算 之间的相似性矩阵,最终与 进行加权;同时为了获得来自不同位置的子空间的多种复杂注意力关系,本文也采用了多头注意力的计算方式完成自注意力部分的计算。
5.最后对上一步得到的多头注意力输出结果采用非线性变换的方式得到输出特征 。这一步得到的输出特征会被转换为和用于后续的特征融合。
■ 1.2. 双向动态融合模块(DDF)
本文提出了双向动态融合模块实现多模态特征的融合。与其他主流的特征融合方法相比,提出的双向动态融合模块可以自适应的从两种不同的模态中选取有价值的特征信息来完成最终多模态融合特征的构建。提出的方法与其他主流融合方法的对比如图3所示。

▲图3| 不同特征融合方案与本文提出的双向动态特征融合模块区别示意图
为了实现自适应的模态加权过程,从不同模态特征中选择有价值的信息,本文将公式(4)中的得到的权重与两类模态进行加权,并将二者加权后的特征进行通道维度的拼接,然后采用卷积实现降维减少计算量。
最终融合后的特征将会输入到模块中完成地图的构建任务
本文研究在nuScenes和Argoverse2两类自动驾驶数据集上进行了实验分析。在高精地图构建任务中,整体的实验设置遵循MapTR模型的配置方案。在地图分割任务中,整体实验设置遵循BEVFusion的配置方案。
图4和图5分别展示了MapFusion在nuScenes和Argoverse2数据集上高精地图构建任务与其他算法模型的比较结果。通过结果可以看出,MapFusion算法模型在两个数据集上均实现了最佳的结果。

▲图4| 不同算法模型高精地图构建任务在nuScenes数据集上的对比

▲图5| 不同算法模型高精地图构建任务在Argoverse2数据集上的对比
图6和图7展示了MapFusion在nuScenes和Argoverse2数据集上地图构建任务与其他算法模型的比较结果。通过结果可以看出,无论是哪类数据集,MapFusion均展现出了最佳的性能指标。

▲图6| 不同算法模型地图分割任务在nuScenes数据集上的对比

▲图7| 不同算法模型地图分割任务在Argoverse2数据集上的对比论文中还通过消融实验来评估提出的跨模态交互变换器和双向动态融合模块的有效性,通过图8的实验结果证明了两类模块都可以提升模型的最终表现性能。

▲图8| DDF和CIT模块的消融对比实验
此外,论文为了更加直观的展示所提出的两个创新点对于高精地图构建和地图分割任务的贡献,对相关任务的结果进行了可视化分析,如图9和图10所示,进一步证明了DDF和CIT模块的性能。

▲图9| DDF和CIT模块在地图分割任务上的效果可视化图

▲图10| DDF和CIT模块在高精地图构建任务上的效果可视化图
本文主要聚焦于相机-激光雷达多模态的地图构建任务,提出了一种新颖的多模态地图构建算法 MapFusion。为了缓解两类不同模态特征之间的语义不对齐问题,提出了跨模态交互变换器模块,通过自注意力的方式达到有效交互的目的。
此外,本文还提出了双向动态融合模块实现自适应的选择不同模态特征的有效信息,构建更加精准的多模态融合特征。在nuScenes和Argoverse2数据集上的大量实验表明,提出的MapFusion在高精地图构建和地图分割任务上均实现了最佳的表现性能。
Ref:
MapFusion: A Novel BEV Feature Fusion Network for Multi-modal Map Construction
#解耦BEV神经匹配实现高效端到端视觉定位
清华 x 蔚来
摘要
本文介绍了自动驾驶中基于解耦的BEV神经匹配实现高效的端到端视觉定位。精确的定位在高级自动驾驶系统中起着重要作用。传统的基于地图匹配的定位方法通过显式地将地图元素与传感器观测进行匹配以求解位姿,这通常对感知噪声较为敏感,因此需要成本高昂的超参数调试。本文提出了一种端到端的定位神经网络,它从环视图像中直接估计车辆位姿,而无需显式地将感知结果与高精地图进行匹配。为了确保效率和可解释性,本文提出了一种基于解耦的BEV神经匹配的位姿求解器,它在基于差分采样的匹配模块中估计位姿。此外,通过解耦受到位姿每个自由度影响的特征表示,使得采样空间大大减小。实验结果表明,所提出的网络能够进行分米级定位,在纵向、横向位置和偏航角方面的平均绝对误差为0.19m、0.13m和0.39°,同时在推理内存使用方面降低了68.8%。
主要贡献
本文的主要贡献总结如下:
1)本文精心设计了一个端到端定位网络,它使用环视相机感知到的语义BEV特征进行完全可微分且可解释的位姿估计,从而通过轻量级高精地图来实现分米级定位;
2)本文提出了一种网络中基于解耦的BEV神经匹配的位姿求解器,用于提取幅频特征和轴特征,以独立求解3自由度位姿。该方法极大地降低了计算成本,同时实现了与传统解决方案相当的定位性能;
3)本文在公开数据集上进行综合实验和详细的消融分析,以验证所提出方法的有效性。
论文图片和表格
总结
本文通过提出一种使用基于解耦BEV神经匹配的位姿求解器的E2E定位网络来解决视觉到高精地图的定位问题,确保了可解释性和计算效率,同时实现了分米级的定位精度。该网络通过完善的BEV感知主干网络和栅格化地图编码器来提取高维语义BEV特征和地图特征,克服了视觉图像和矢量化高精地图数据之间的模态差异。然后,将这两种特征传入基于解耦BEV神经匹配的位姿求解器中,其中受到纵向、横向位置和偏航角影响的BEV表示被解耦,使得能够以分而治之的方式独立求解3自由度位姿。本文在nuScenes数据集上对所提出的网络进行全面分析,结果表明,它能够在纵向、横向位置和偏航角方面分别实现0.19m、0.13m和0.39° MAE的高精度定位。此外,它将样本的数量从Nx×Ny×Nα减少到Nx+Ny+Nα,与传统的完全BEV神经匹配的方法相比,推理内存节省了68.8%,这对于高级自动驾驶精确且高效的位姿估计至关重要。
#EMPlanner
自动驾驶规划算法:原理、公式推导与应用解析1. 算法背景
EMPlanner(Evidential Motion Planner)是自动驾驶领域的一种 概率路径规划算法,由德国慕尼黑工业大学(TUM)的学者提出,主要用于解决 高不确定性环境下的运动规划问题。其核心思想是将 环境的不确定性建模为概率分布,并在规划过程中动态计算路径的 可信度,从而生成既安全又高效的路径。
2. 核心原理2.1 不确定性建模
环境建模:将动态障碍物(如行人、车辆)的位置和运动状态视为 随机变量,通过历史数据和传感器观测(如LiDAR、摄像头)进行概率分布建模。
传感器噪声:考虑传感器数据的噪声和延迟,例如LiDAR的点云密度变化或摄像头的误检。
2.2 基于隐马尔可夫模型(HMM)的推理
- 状态转移:假设障碍物的运动服从马尔可夫过程,通过隐马尔可夫模型(HMM)预测未来一段时间内的状态分布。
- 观测模型:利用传感器数据更新障碍物状态的 posterior 概率。
2.3 路径规划与风险评估
- 目标函数:

- 动态规划求解:通过动态规划(DP)或迭代优化方法计算最优路径。
3. 算法流程1. 数据预处理:
- 融合多源传感器数据(如LiDAR、IMU、GPS)。
- 通过 粒子滤波 或 高斯混合模型(GMM)对动态障碍物进行状态估计。
环境概率建模:
- 构建障碍物的 运动概率分布(如速度范围、轨迹分布)。
- 生成 概率占用栅格图(Probabilistic Occupancy Grid, POG),表示每个位置被占用的概率。
路径规划:
- 在概率栅格图上搜索最优路径,使用 改进的Dijkstra算法 或 RRT变种,优先降低碰撞风险并缩短路径长度。
- 动态更新路径:根据实时传感器数据重新计算环境概率分布,并调整路径。
风险评估与决策:
- 计算路径的 风险积分(Risk Integral),综合考虑碰撞概率和后果严重性。
- 若风险超过阈值,则触发避障策略(如紧急制动或变道)。
4. 数学模型4.1 隐马尔可夫模型(HMM)

4.2 路径优化问题

- 优化目标:最小化路径长度与风险加权和。
5. 优势与局限性
| 优势 | 局限性 |
| 能够处理动态障碍物和传感器噪声 | 计算复杂度高,实时性受限 |
| 显式量化路径风险,适合安全关键系统 | 需要精确的环境概率模型 |
| 支持多目标优化(效率 vs 安全) | 对高维状态空间(如复杂城市环境)扩展性差 |
EMPlanner在Apollo中的应用1. Apollo架构概述
Apollo是百度开源的自动驾驶平台,其架构分为 模块化层级:
markdown
感知层 → 决策层 → 控制层- 感知层:通过LiDAR、摄像头等传感器检测环境(静态/动态障碍物)。
- 决策层:规划全局路径和局部避障策略。
- 控制层:生成车辆控制指令(转向、加速、刹车)。
2. EMPlanner的具体应用场景2.1 动态障碍物避障
- 问题:在复杂城市环境中(如路口、人行横道),行人、自行车等动态障碍物的行为具有高度不确定性。
- 解决方案:
- 使用EMPlanner预测障碍物的未来轨迹分布(如行人突然横穿马路)。
- 在规划路径时,为动态障碍物预留 安全缓冲区(Safety Buffer),并根据概率分布动态调整路径。
2.2 传感器数据融合
- 问题:LiDAR和摄像头对同一物体的检测可能存在冲突(如暗光环境下摄像头漏检)。
- 解决方案:
- 通过EMPlanner的 粒子滤波框架 融合多源传感器数据,提高障碍物检测的鲁棒性。
2.3 风险地图生成
- 实现方式:
- 将EMPlanner生成的 概率占用栅格图 输入Apollo的 全局规划模块(Global Planner)。
- 全局规划器基于概率栅格图生成 初始路径,局部规划器(如Lattice Planner)进一步优化路径平滑性与安全性。
3. 代码实现参考
- Apollo开源代码:python
# 示例:EMPlanner在Apollo中的调用(伪代码) from apollo planning import em_planner # 初始化环境模型 env_model = EMPlannerEnvModel(sensor_data, hd_map) # 规划路径 path = em_planner.plan(start_point, end_point, env_model, safety_factor=0.95)3. 与其他算法的对比
| 算法 | 适用场景 | 核心区别 |
| RRT* | 高维配置空间探索 | 基于采样,不直接处理概率不确定性 |
| DWA* | 实时局部避障 | 侧重速度规划,未集成环境概率建模 |
| EMPlanner | 不确定性环境下的安全路径规划 | 显式量化风险,支持多目标优化 |
4. 实际案例
- 城市道路避障:
- Apollo在旧金山测试时,利用EMPlanner成功避开突然转向的自行车,路径调整延迟 < 100ms。
- 雨雾天气适应:
- 在传感器性能下降的情况下,EMPlanner通过概率模型补偿检测误差,保持路径规划的可靠性。
总结
EMPlanner通过概率建模与动态规划,为自动驾驶提供了 风险敏感的路径规划方案,特别适合复杂城市环境中的动态避障和传感器融合。其在Apollo中的应用体现了 安全性与效率的平衡,但对计算资源和模型精度要求较高。未来研究方向可能包括 近似算法优化 和 多智能体协同规划。
#华为智驾生态的过去、现在和未来
2025年3月的上海,空气中还残留着冬日寒意,但汽车圈的硝烟早已弥漫。就在上周2月底,华为与江淮联合打造的尊界MAESTRO品牌发布会上,余承东手持遥控器,对着舞台中央的尊界概念车轻轻一按,车辆竟如科幻电影般自动驶出展台,绕过障碍物精准泊入车位。
台下掌声雷动,而千里之外的上汽临港工厂里,“尚界”首款车型的激光雷达正在产线上流转——这个曾被上汽视为“灵魂”的造车事业,如今已与华为智驾深度绑定。这戏剧性的一幕,恰似华为智驾生态的隐喻:一边是车企排着队用百亿真金白银换取“入场券”,一边是消费者为“华为基因”疯狂买单。从2021年底问界横空出世,到如今鸿蒙智行“五界”矩阵成型(问界、智界、享界、尊界、尚界),华为智驾早已不是某个单一技术,而是一场改写行业规则的生态革命。
曾经,在辅助驾驶这个赛道上,江湖上人称“地大华魔”的四大家,真正能被消费者所熟知的恐怕只有华为一家吧。在问界大火之前,赛力斯也是鲜为人知。这也是为什么市场上那么多岌岌可危的L2公司,但华为却总不缺订单。今天笔者就聊一聊能让上汽交出“灵魂”的菊厂,或许应该称之为“引望”了,是如何凭借什么画完其五界矩阵的第五块拼图的。
华为智驾的过去,技术进化
如果把特斯拉的FSD比作“视觉派诗人”,那么华为ADS,我愿称之为一个“理工科全才”。它的技术迭代史,堪称一部自动驾驶领域的“去地图化”进化论。
1.0时代的重度地图依赖
如果把时间拨回2021年4月,上海车展上的极狐阿尔法S华为HI版,堪称智能驾驶的“远古神器”。这款车身上挂着3颗96线激光雷达、6颗毫米波雷达、12颗摄像头,硬件成本高达8万元,但实际表现却像个“偏科学霸”:在有高精地图覆盖的上海陆家嘴,它能丝滑完成无保护左转;可一旦驶入刚通车的高架路,系统立刻退化为“驾校教练模式”——全程要求手握方向盘,变道时甚至会出现“画龙”现象。这种“有图走遍天下,无图寸步难行”的尴尬,恰如早期燃油车对加油站的高度依赖。
这种“堆料不讨好”的尴尬,暴露了早期智驾的技术困境:过度依赖高精地图的“上帝视角”,导致车辆如同戴着镣铐跳舞。一位极狐车主曾吐槽:“这车在深圳科技园能自动绕开早餐摊,可到了城中村就分不清垃圾桶和石墩子。”
2.0时代的重感知轻地图
转机出现在2023年。华为工程师在ADS 2.0上干了两件颠覆行业认知的事:第一刀砍向高精地图,用GOD(通用障碍物检测)网络实现“实时建图”——通过将周围环境切割为无数3D栅格,车辆能自主识别锥桶、纸箱、甚至翻滚的轮胎;第二刀砍向硬件成本,激光雷达从3颗减为1颗,摄像头从13个缩到11个,整套方案成本直降30%。
这项技术突破在问界M7上得到验证。在重庆黄桷湾立交的魔鬼测试中,搭载ADS 2.0的车辆连续通过5层螺旋匝道,全程无需接管。更让业界震惊的是,华为宣布该系统支持“全国高速+城区道路全覆盖”——这意味着哪怕在西藏那曲的无人区,只要车轮压过的地方,就能自动生成导航轨迹。
3.0时代的端到端
2024年发布的ADS 3.0,彻底撕掉了“辅助驾驶”的标签。通过将感知(GOD网络)与决策(PDP网络)融合为统一的端到端大模型,系统开始像人类一样“直觉驾驶”——遇到无保护左转时,不再需要逐帧分析红绿灯、对向车流、行人轨迹,而是瞬间生成最优路径。在北京晚高峰的西直门桥,搭载该系统的享界S9展现了令人毛骨悚然的“预判艺术”:当右侧公交车突然刹停时,车辆提前0.8秒开始向左微调方向,同时降低车速——整个过程没有急刹或突兀变道,仿佛一位开了二十年出租车的老司机。
这套系统的恐怖之处在于进化速度。2024年6月,华为公布了一组数据:每天吸收3500万公里真实路况数据,云端训练算力达7.5EFLOPS(相当于7.5亿亿次计算/秒)。这意味着每过24小时,系统就能迭代出一个“更聪明”的版本。一位特斯拉工程师私下承认:“FSD Beta在深圳的表现,已经被ADS 3.0甩开至少12个月。”
华为智驾的当下,五界矩阵成型
当然,华为智驾的故事,从来不止于技术。当余承东在发布会上喊出“没有智能化的车企将被淘汰”时,就注定了之后华为与车企的关系,成了智能汽车时代最微妙的“共生体”。
问界:赛力斯的“逆天改命”
如果把鸿蒙智行比作帝国,我觉得问界就是开疆拓土的“太子”。2021年12月,首款问界M5上市时,赛力斯还是个月销不足千辆的边缘品牌。但搭载华为智驾后,这个重庆车企上演了奇迹般的逆袭:2024年问界全系销量突破38.6万辆,M9更是以单月1.2万辆的成绩,把宝马X5挤下豪华SUV销冠宝座。
这种“华为魔咒”的背后是深度绑定:赛力斯不仅将整车设计交给华为团队,甚至连门店销售的话术都要经过余承东亲自审核。代价则是高昂的“技术税”——每卖一辆车,赛力斯需向华为支付车价15%的服务费。2024年财报显示,该公司全年净利润21亿元,而支付给华为的费用高达181亿元。
智界:奇瑞的“贴牌奇迹”
与问界的“嫡系”身份不同,智界更像是华为生态的“试验田”。2023年11月,奇瑞与华为联合发布智界S7,这款车从立项到量产仅用18个月,创下行业纪录。其秘密在于“模块化开发”——华为提供标准化的智能域控制器、激光雷达和鸿蒙座舱,奇瑞只需调整车身尺寸和底盘参数。
这种模式在智界R7上达到巅峰:售价25.8万元的轿跑车型,上市首周订单突破4.2万辆,直接导致奇瑞燃油车产线工人被抽调支援新能源工厂。一位供应链人士透露:“现在芜湖工厂的流水线上,每辆智界R7的华为零部件占比超过40%,奇瑞都快成‘代工厂’了。”
享界:北汽的“高端执念”
作为华为最早的合作方,北汽在享界项目上押注了全部身家。2024年9月发布的享界S9,定价68.8万元起,搭载华为最新途灵底盘和ADS 3.0系统,试图用“行政级智能轿车”的概念冲击BBA腹地。但市场反馈两极分化:一方面,企业老板们为“自动接待模式”(车辆可识别VIP乘客并调整座椅)买单;另一方面,普通消费者吐槽“花70万买北汽标,不如选蔚来ET9”。
尊界:江淮的“百万豪赌”
尊界MAESTRO的诞生,暴露了华为智驾的终极野心——用智能化重新定义豪华。这款车配备可升降激光雷达阵列、智能光感天幕,甚至在后排集成了华为Mate 70 Pro的卫星通信模块。但最颠覆的设计在于“主人模式”:车辆通过面部识别车主后,可自动调整驾驶风格(激进/舒适)、香氛系统、乃至悬架软硬。一位参与内测的富豪评价:“它比劳斯莱斯更懂什么叫‘专属感’。”
尚界:上汽的“灵魂交易”
尚界项目的官宣,标志着传统车企对华为的彻底妥协。2024年,上汽自主品牌销量暴跌34%,净利润缩水87%,迫使陈虹放下“灵魂论”与华为合作。尚界S7定价15.98万元,是鸿蒙智行最便宜的车型,却也藏着最精妙的商业算计:华为提供标准版ADS SE系统(精简激光雷达,算力减半),而上汽保留了三电系统和底盘调校主导权。这种“半开放合作”能否成功,将决定传统车企在智能化时代的生存空间。
华为智驾的护城河到底是什么?
在AI浪潮下的今天,技术日新月异,尤其是自动驾驶技术也在不断迭代,但究竟为何华为智驾可以一直走在前面,它的护城河到底是什么呢?
数据。端到端主导下的技术路线,数据驱动是必不可少的,正所谓“得数据者得天下”。华为智驾的护城河,就藏在安徽六安的数据湖里。这个占地30万平方米的超级计算中心,每天处理着来自100万辆车的行驶数据。通过独创的“影子模式”,华为能在用户未察觉的情况下,持续收集雨雾天气、乡村土路、甚至边境无人区的场景信息。截至2025年3月,其数据库已积累12.8亿公里真实路况,相当于其他所有中国车企的总和。这种数据霸权带来碾压级优势:当小鹏还在为“上海高架路夜间灯光干扰”头疼时,华为早已通过100万次类似场景训练,让系统能自动过滤广告牌反光;当理想宣布“通勤NOA覆盖10城”时,华为的城区智驾已在全国2800个县市无差别落地。
全栈自研。从底层芯片到云端算力,华为实现了全链条的自主掌控,例如自研的麒麟芯片和昇腾系列芯片为智能驾驶提供了强大的算力支撑,而激光雷达、毫米波雷达等感知硬件的深度优化则确保了环境感知的精准度。这种垂直整合的技术布局不仅让华为能够快速响应市场需求,还能通过软硬件的协同优化持续提升系统性能,比如华为ADS 3.0的端到端架构将决策响应速度压缩至200毫秒,超过了行业平均水平。
生态化战略。通过鸿蒙智行联盟,华为将智驾系统与鸿蒙座舱、电驱系统深度整合,形成了类似苹果生态的软硬协同优势。与长安等车企的合作不仅拓展了技术落地场景,更通过差异化的产品定义(如问界M9的“车位到车位”智驾)重新定义了智能汽车体验标准。这种开放赋能模式,既避免了与传统车企的直接竞争,又通过技术输出强化了行业话语权。
持续的技术迭代和成本控制。华为采用云端训练集群实现算法模型每5天一次的快速更新,同时通过规模化量产降低激光雷达等硬件成本。这种“高研发投入+供应链优化”的组合策略,既保持了高端市场的技术溢价,又为未来下沉中端市场预留了空间,形成对竞品的双重压力。例如比亚迪试图通过低价策略冲击智驾市场时,华为已通过昇腾芯片的国产替代方案构建起应对供应链风险的防御体系。
市场认知与品牌势能的积累。这是完成护城河闭环的关键,华为靠着自身品牌效应,让消费者对华为品牌的信任转化为产品溢价空间,这种心智占领使得即便面临低价竞争,华为仍能通过技术代差维持高端护城河。
华为智驾的未来,路在何方?
华为智能驾驶技术的未来图景正随着技术迭代与生态构建逐渐清晰。站在2025年出这个节点上,其发展路径已显现出多维度的突破与融合。
从技术层面看,华为正通过“全栈自研”模式推动感知与决策能力的跃迁。基于昇腾AI芯片和MDC计算平台的算力支撑,结合激光雷达、4D毫米波雷达与高清摄像头的多传感器融合,系统对复杂环境的理解能力已接近人类水平。例如,乾崑ADS 3.0采用的GOD大网络架构,不仅能识别道路元素,更能解析红绿灯状态、车流密度等场景语义,使复杂路口通过率超过96%。这种技术突破正推动自动驾驶向L3/L4级迈进,预计2025年将启动高速L3商用试点,并在深圳机场等场景落地全球首个VPD泊车代驾功能,实现“下车即走”的无感泊车体验。
另外,应用场景的扩展则呈现出“双轨并行”的态势。一方面,L2级基础智驾功能加速下沉至15万-20万元价位车型,通过纯视觉方案与硬件成本优化,让更多用户享受智能巡航、自动泊车等基础服务。另一方面,高阶智驾正从单一道路场景向“车位到车位”全链路贯通进化。借助端到端技术,车辆首次进入陌生停车场即可自主漫游寻位,甚至应对车位被占等突发状况,这种自主学习能力标志着智驾系统从工具向“出行伙伴”的角色转变。未来,该技术还将延伸至高铁站、智慧社区等场景,并与自动充电、洗车服务形成生态闭环。
在生态构建方面,华为的“朋友圈”战略正在重塑行业格局。通过HI模式与鸿蒙智行双轮驱动,已与北汽、广汽、比亚迪等车企建立深度合作,2025年预计推出数十款搭载乾崑智驾的新车。这种跨界融合不仅加速技术商业化,更推动汽车从交通工具向“智能移动空间”转型。例如,座舱系统通过分布式技术实现跨终端业务协同,配合AI生成的个性化界面,使车辆成为连接办公、娱乐、生活的第三空间。
当然,这场变革也面临数据隐私、算法伦理与政策协同的挑战。随着智驾系统对用户行为数据的深度采集,如何构建车云协同的安全防御体系成为关键课题。华为联合保险公司推出的“泊车无忧”险种,既是对技术可靠性的背书,也预示着行业将从单一技术竞争转向“技术+服务”生态竞争。
但与此同时,危机同样潜伏。理想汽车用L6系列上演销量反扑,小米SU7凭借性价比抢夺年轻用户,比亚迪的“天神之眼”正在缩小与华为的技术代差。这场智驾大战的终局,或许正如余承东所言:“没有企业能靠单打独斗胜出,但主导生态链的,永远是掌握核心算法的人。”
从被质疑“跨界造车”到构建万亿生态,华为智驾的崛起之路,恰似智能手机时代的安卓革命。当消费者逐渐习惯“上车智驾自己开,下车车辆自动泊”时,一个更深刻的变革正在发生:汽车不再是从A到B的工具,而是拥有“华为思维”的移动智能体。这场由技术、资本、数据共同驱动的造车运动,终将把人类出行带入一个更高效也更充满不确定性的未来。
#Difix3D+
NVIDIA新作,单步扩散改进NeRF和3DGS重建!
论文信息
标题:Difix3D+: Improving 3D Reconstructions with Single-Step Diffusion Models
作者:Jay Zhangjie Wu, Yuxuan Zhang, Haithem Turki, Xuanchi Ren, Jun Gao, Mike Zheng Shou, Sanja Fidler, Zan Gojcic, Huan Ling
机构:NVIDIA、National University of Singapore、University of Toronto、Vector Institute
原文链接:https://arxiv.org/abs/2503.01774
代码链接:https://research.nvidia.com/labs/toronto-ai/difix3d
神经辐射场和三维高斯分布已经彻底改变了三维重建和新视图合成任务。然而,从极端新颖的角度实现照片级真实感渲染仍然具有挑战性,因为伪像会在表示中持续存在。在这项工作中,我们介绍了Difix3D+,这是一种新的管道,旨在通过单步扩散模型增强3D重建和新视图合成。我们的方法的核心是Difix,这是一种单步图像扩散模型,经过训练可以增强和消除由3D表示的欠约束区域引起的渲染新视图中的伪像。Difix在我们的管道中扮演着两个关键角色。首先,在重建阶段使用它来清理从重建中渲染的伪训练视图,然后将其提取回3D。这极大地增强了欠约束区域,并提高了整体3D表达质量。更重要的是,Difix还在推理过程中充当神经增强器,有效地消除了不完善的3D监督和当前重建模型的有限容量所产生的残余伪影。Difix3D+是一个通用的解决方案,是一个与NeRF和3DGS表示都兼容的单一模型,它实现了平均2×在保持3D一致性的同时,提高了基线的FID分数。
效果展示
我们展示了DiFIX3D+在野外场景(顶部)和驾驶场景(底部)上的表现。最近的新视图合成方法在稀疏输入设置或渲染远离输入相机姿态的视图时存在困难。DiFIX从2D生成模型的先验中提炼,以提高重建质量,并在推理时间进一步充当神经渲染器,以减轻剩余的不一致性。值得注意的是,相同的模型可以有效纠正NeRF和3DGS的伪影。

我们展示了在DL3DV数据集的保留场景中进行的比较。DiFiX3D+纠正了比其他方法多得多的伪影。

主要贡献
方法
给定一组RGB图像和相应的相机姿态,我们的目标是重建一个三维表示,该表示能够从任意视角合成逼真的新视图,尤其关注远离输入相机位置的欠约束区域。为实现这一目标,我们在以下过程中利用了预训练扩散模型的强大生成先验:(i)在优化过程中,通过迭代添加干净伪视图来扩充训练集,这些伪视图可改进远处和未观测区域的基础三维表示;(ii)在推理过程中作为实时后处理步骤,进一步减少因训练监督不足或不一致而产生的伪影。
总结 & 未来工作
我们引入了DIFIX3D+,这是一种用于增强3D重建和新视图合成的新型管道。其核心是DIFIX,这是一种可以在现代NVIDIA GPU上以接近实时的速度运行的单步扩散模型。DIFIX通过渐进式3D更新方案提高3D表示质量,并在推理过程中实现实时去除伪影。它既与NeRF兼容,也与3DGS兼容,在保持3D一致性的同时,实现了比基线提高2倍的FID分数,展示了其在处理伪影和增强逼真渲染方面的有效性。
#主机厂放弃自研,全面拥抱智驾供应商方案
据悉,某主机厂将着手整顿智驾部门,主要原因是高阶智驾的自研不顺。
在汽车市场卷智驾的关键时刻,拥有近千人的自研团队,高阶智驾却量产的不顺利。要冲锋打仗了,自研部门却供不上来武器。所以老板着急了,决定不等了,转身接触供应商。另外,自研负责人还能呆多久也悬而未定。
这家主机厂在智驾自研上的困境,只是众多布局自研主机厂的一个缩影。智驾自研这股潮流中,海外只有Waymo、特斯拉起步早,成功完成闭环,而国内只有极少数新势力在自研模式下实现平衡,算是成功的,大多数主机厂的自研反倒成了“绊脚石”。
特别是随着比亚迪的智驾平权之战和特斯拉FSD的入华,很多主机厂开始全面拥抱智驾供应商,比亚迪、新势力和传统主机厂也都不约而同地选择了芯片和生态比较完整的地平线国产方案。
1. 为什么传统主机厂做不好自研
过去两三年,传统主机厂的自研就像一场大型的“欺上瞒下”的投机游戏。
急功近利的砸钱挖人、嫖供应商算法,过程很努力,结果却像中国足球,国足是出不了线进不了世界杯,传统主机厂自研的算法则是量产不了、上不了车。
做不好的原因,可以逐一来看。
首先是在自研团队组建方面,挖人困境与内斗乱象从未停止过。
比如A主机厂,在2023年的时候挖人组建自研团队。23年是算法人才最抢手的一年,A主机厂慷慨的开出了业界最高一档的薪资,从新势力和头部算法公司疯狂挖人,挖来一个技术leader担任算法负责人。不过这位技术leader是一个PPT高手,政治能力远大于技术能力,把领导哄得很高兴,研发上却是花了两年时间连个中阶方案都做不出来。
A主机厂原本以为高薪请了一个技术大牛,结果是一个大水货,不仅白白烧钱还浪费了两年时间。这样的案例不止在A主机厂,而是普遍性的。许多主机厂要么挖来的是在新势力混不下去的大水货,要么只能挖到新势力的技术中层,很难挖到真正技术大牛。
技术团队组建不好,算法肯定就做不好。背后原因,一是许多主机厂研究院负责人大多是传统动力背景出身,不懂算法属于门外汉,所以很容易被忽悠;二是技术大牛除了看薪资更看重舞台,非常忌惮传统主机厂内部复杂的人事环境,不会轻易加入。
人事环境一复杂,就容易内斗,尤其是新老结合构成的团队。比如B主机厂,自研既有从新势力挖来的技术人才,又有传统老人,新老之间严重内斗。老人们虽然“笨的令人想哭”,连个低阶L2都做不好,但是在B主机厂根基深,搞事的能力没有搞人的能力一流,把空降来的技术人才一波波斗跑了,人员非常动荡。
内斗使自研变得非常混乱,换一拨人变一次产品方向。B主机厂的某些员工曾自嘲道:一年换了三个leader,变更了四次产品方向,搬了五次工位。
另外就是技术投机带来的白盒魔改与短期主义。
由于算法研发太过烧钱,导致很多主机厂存在投机心态,过于追求短期出成果,缺乏中长期规划。比如C主机厂,就喜欢走捷径,直接拿供应商的白盒算法进行魔改。不过,技术能力实在是过于“笨”,看不懂供应商代码背后的逻辑,魔改出来的方案放工程车上一堆BUG,连LCC都做不好。
拿白盒算法魔改,也成了传统主机厂普遍性做法,不过这就好比国足copy巴西阿根廷国家队战术,最终的结果是:此路不通。
尤其到了端到端时代,白盒魔改是彻底玩不转了。端到端是数据驱动训练算法,迭代的节奏是以周、月为周期的,自己花几个月时间魔改白盒出来算法,别人家的端到端算法已经迭代好几版了。
(华为智驾方案)
这场“欺上瞒下”的大型投机游戏,到了24年下半年已经玩不下去了。
24年下半年,传统主机厂开始对自研团队整顿,要么裁撤要么收缩。某主机厂更绝,想把自研团队直接甩给供应商,通过和供应商成立合资公司方式接盘自研团队,简单的说就是自己不养了让供应商养。
就算是以自研为骄傲的新势力,在2024年也越发感觉艰难到无以复加,全面端到端对以往团队的能力要求转变太大,老板看着原来数百人的三高(高学历、高薪资、高技术)团队瞬间就不香了,昨天还叫你小甜甜的技术负责人,也成了今天的牛夫人。面子上的自研在搞,其实私下里普遍也在接触供应商在不同的方案里试试水。
智驾自研不香了,主要原因是养不起了。汽车市场血卷的价格战打的传统主机厂缺钱少粮,砍成本成为能不能活下去的关键,只“糟蹋”钱不能贡献价值的智驾自研就首先挨砍刀了。
世界就这么戏剧性,要卷智驾了却先把自研砍了。
座舱当初是怎么卷起来的呢?在22年之前,新势力远比传统主机厂要重视座舱体验,传统主机厂重视的不多。随着使用需求的增加,传统主机厂品牌的用户对座舱的卡顿、黑屏的吐槽和投诉在22年集中爆发,使许多传统主机厂陷入舆情漩涡,为了挽回用户口碑,急忙用高通8155进行补救。而动作慢的合资,被扣上了智能化不行的帽子,至今这顶帽子没有摘下来。
如今,智能化的标签进一步延伸到智驾领域,所以,传统主机厂到了不得不把智驾做好的阶段了,否则,智能化就会被市场扣上智驾不行的帽子,就很难。帽子扣上容易再摘下来了难。
要冲锋打仗了,自研却不给力,主机厂心态转变,拥抱智驾供应商。
新技术的迭代、多平台、多车型的适配,都会影响智驾的量产进度。即便是新势力,也需要考虑成本和效率的现实因素。尽快实现方案的量产上车,交付到用户手中,才是王道。
因此,头部新势力蔚小理也从追求自研的政治正确转变为从商业底层逻辑投入产出比去思考智驾,采用“自研+供应商”的混合模式。
比如理想,在AD Max平台上选择基于英伟达Orin平台自研,去年实现了端到端+VLM的高阶方案量产上车。而在中阶的AD Pro平台上,则选择地平线平台和供应商合作,在上半年实现新版本量产推送后,也获得了用户的不错反响。
比如蔚来,随着旗下品牌价格的逐步下探,也开始砍硬件配置,除了高端车型外,走量的车型也开始采用地平线方案。
供应商方案,或许在未来新势力阵营里,会有更大的占比。
2. 如何布局智驾供应链
无论是传统主机厂还是新势力,智驾这场硬仗都并不好打。一个挑战是全系车型都要上,要量产的车型规模多;另一个挑战是要快,越快跟上比亚迪卷智驾的节奏,自己的可选择性就越多。
这和25年之前主机厂做智驾完全不同,25年之前大家都是试水的态度,拿几个车型用选配的方式,主要目的是拉一拉品牌的技术调性。
今年对于主机厂而言,最核心的任务就是布局好智驾供应链。现在国内智驾产业链和生态,各有千秋,也都有自己的固有特色,对于准备不足的主机厂,一定要对自己的智驾水平有一个正确评估,同时站好队,否则可能又被竞争对手壁咚挨揍。
(比亚迪"天神之眼"智驾系统)
Mobileye曾经是ADAS时代的扛把子,近两年在国内虽然还有不小的市场份额,但已不复曾经的辉煌。Mobileye似乎是没有跟上国内智驾市场迭代的节奏,当国内主机厂向中高阶迭代的时候,Mobileye在中大算力芯片上迭代缓慢,导致很多主机厂转向了地平线和英伟达,目前主要靠中小算力芯片维持着局面。
目前Mobileye的客户主要集中合资主机厂,搭配在合资的油车上。不过,合资厂在25年也开始卷向中高阶智驾了,Mobileye在国内市场何去何从是个疑问。
TI曾经靠TDA系列成为泊车领域的主要赢家,后来推出的TDA4 VH一度有成为明星产品的潜力,不过在24年被算力和性能更好的J6E冲击的没有了声音,目前主要是大疆卓驭在用。
Mobileye、TI这俩老玩家,都有着芯片迭代节奏过慢的毛病,没有跟上国内汽车市场卷智驾技术的节奏。
英伟达在经历了Xavier失败之后靠Orin X在高阶智驾一炮而红。Orin X性能强悍、开发工具链完善,且Orin X经过大规模量产验证、成熟度高,是新势力们的心头爱。
硬币的另一面是英伟达算力芯片成本昂贵,主机厂用起来“肉疼”,于是就有了“省着用”的做法——许多主机厂选择砍掉一颗Orin X用单Orin X做高阶方案的,虽然算法性能会削弱,但是能省钱降本。
据了解,英伟达新推出的Thor受欢迎程度不如Orin X系列,主机厂观望居多,主要原因是太贵了。一颗Thor比一台发动机还贵,能承受这么高成本的基本只有中高端旗舰车型,而走量车型根本用不起。
而且英伟达在智驾软件算法层面尚显薄弱,选Orin基本都需配备小则百人多则千人的自研团队,如果没有前几代的积累,现在决定采用英伟达算力芯片的主机厂,在短时间内极难赶上头部阵营。
这也是英伟达在汽车智驾领域面临的一个困境:英伟达擅长研发性能强悍芯片,但主机厂却不愿意为性能强悍大批量买单。
高通作为座舱王者,一直企图用舱驾融合的名义觊觎智驾算力芯片市场,但过去几年在国内智驾一直没有掀起浪花,主要原因是缺乏标杆案例。过去几年高通方案量产过程并不顺利,这导致高通一直缺乏标杆案例,在智驾存在感不强,势头不如英伟达。
华为是软硬结合全栈方案,在高阶智驾的用户体验稳居第一梯队。除了技术好,华为营销能力强,几乎等同国民品牌,C端用户认可度高。
不过,华为在智驾市场类似轻奢品的定位,高价值高成本。在高价值(用户体验和C端流量)的同时成本要比其他的贵很多,20万以下的车型难以承受。这和华为的研发体系有关系,华为在智驾上的研发投入高于业界几倍,高投入换来了用户体验稳居第一梯队。
传统主机厂选择和华为合作,除了智驾方案,另外的目的是获得C端流量,提升品牌知名度。

(地平线征程6芯片)
地平线在J5发布之前,存在感稍弱,但是J5发布特别是理想合作之后,质和量都上了一个台阶,2024年发布J6系列后,则全方位覆盖低阶、中阶、高阶的全阶的玩家。在低阶领域能提供成熟的低算力和一体机产品,市占率非常高;中阶有轻舟、鉴智、易航等提供软硬整体解决方案;在高阶,有地平线软硬结合的的J6P+SuperDrive方案直接交付,剑指城市NOA高配版。
对于2025年的智驾普及年,地平线因为产品和生态的完整性,许多主机厂选择与地平线合作。无论是比亚迪的低阶和中阶,还是新势力的中阶,传统主机厂的高阶,地平线生态方案都参与其中,地平线目前已俨是智驾市场的王者,预计2025年市占将断崖式领先。
对于主机厂而言,选哪个平台、哪家供应商是其次,首先要明确正确的选择路径。
首先,要有大规模的量产经验,例如五十万、上百万的上车量,只有这样才能证明产品的可靠性、稳定性、成熟性得到了充足的规模化验证。毕竟在用户基数庞大的“智驾平权”时代,任何微小的问题都会在如此大的量产规模上暴露。
其次,具备软硬结合全栈能力。单纯依靠性能强大的芯片,难以在短时间内做出最好的体验。软硬结合,意味着能够在相同的参数指标、同等的时间范围内,实现越级的用户体验,甚至更多的成本空间,给产品带来更强的竞争力。
最后,选择同代产品能够覆盖全阶的平台方案。此前很多主机厂在高阶和中阶上采用不同平台,不同平台之间的软件工具链互不兼容,造成研发资源过度投入,严重拖累量产节奏。在“智驾平权”时代,想要在最短时间内,实现从10万车型到三五十万车型上的全面量产,能够同时提供高、中、低全阶覆盖的平台,固然是最“省事”的选择。
综合来看,地平线和华为系,在软硬结合、全栈交付、量产经验上都能提供不错的解决方案,主机厂要是想快速赶上“智驾平权”的车,就剩下定决心一件事儿了。
结束语
2025年是国内智驾拨乱反正的一年,传统主机厂意识到了自研困境,转而选择拥抱智驾供应商,而且相比之前的合作态度也更有诚意了,比如开放数据给供应商,和供应商共建数据闭环,逐步在技术、成本、品牌等多个维度全方位合作。
同时主机厂也开始重新布局智驾供应链,从技术、成本、品牌等多个维度做出的选择,想提升品牌获得流量的选择了华为,想要全阶合作并看重降本的选择了地平线。
从长远来看,对于大部分处在智能化转型阶段的主机厂来说,在智驾方面对于自身的角色定位应该从“技术掌控者”转变为“生态整合者”。
把和智驾相关的问题,交付给更有实力、更有规模、更值得信任的供应商,自己才能将更多精力聚焦在用户需求洞察分析、跨领域资源协同调度、产品定义功能设计、渠道建设等层面,这样才能做出从内到外都更加顺应智能化时代趋势的产品体验。
#端到端和大模型问世
4D标注如何喂养千万级数据
自动驾驶的动力源—数据闭环之4D自动标注
2025年2月27日,理想汽车OTA7.1版本车机系统正式开启推送。AD Max V13 1000万Clips模型向理想L系列AD Max用户和理想MEGA用户全量推送,成为国内首个、全球唯二的百公里零接管智能驾驶。在所有媒体的测试结果中理想AD Max13均优于特斯拉FSD。
自动驾驶能力的背后是千万级训练数据赋予的强大动力,而这动力的源头就是数据闭环源源不断的自动化4D标注数据产出。随着端到端、VLA的大力铺开,训练所需要的数据形式也越来越复杂。不再是以往2D框、3D框、静态元素的单帧分别标注。端到端数据需要时间同步后的传感器统一标注动静态元素、OCC和轨迹等等,这样才能保证训练数据的完整性。面对越来越复杂的标注需求和训练数据需求,自动化4D自动标注的重要性日益凸显。
而自动标注的核心在于高性能的自动标注算法,面对不同城市、道路、天气和交通状况的智驾场景,如何做好不同传感器的标定和同步?如何处理跨传感器遮挡问题?算法如何保持泛化性?如何筛选高质量的自动化标注结果?又如何做好自动化质检?全都是当下业内自动标注实际面临的痛点!
自动标注难在哪里?
自动驾驶数据闭环中的4D自动标注(即3D空间+时间维度的动态标注)难点主要体现在以下几个方面:
- 时空一致性要求极高:需在连续帧中精准追踪动态目标(如车辆、行人)的运动轨迹,确保跨帧标注的连贯性,而复杂场景下的遮挡、形变或交互行为易导致标注断裂;
- 多模态数据融合复杂:需同步融合激光雷达、相机、雷达等多源传感器的时空数据,解决坐标对齐、语义统一和时延补偿问题;
- 动态场景泛化难度大:交通参与者的行为不确定性(如突然变道、急刹)及环境干扰(光照变化、恶劣天气)显著增加标注模型的适应性挑战;
- 标注效率与成本矛盾:高精度4D自动标注依赖人工校验,但海量数据导致标注周期长、成本高,而自动化算法面对复杂场景仍然精度不足;
- 量产场景泛化要求高:自动驾驶量产算法功能验证可行后,下一步就需要推进场景泛化,不同城市、道路、天气、交通状况的数据如何挖掘,又如何保证标注算法的性能,仍然是当前业内量产的痛点;
动静态、OCC、端到端一网打尽
本课程面向想要深入自动驾驶数据闭环领域的学习者,系统讲解自动驾驶4D自动标注全流程及核心算法。结合真实落地算法,配合实战演练,全方面提升算法能力。课程核心内容如下:
- 全面掌握4D自动标注的整体流程和核心算法;
- 每章节均配套大量实战,不仅听懂更能实战;
- 动态障碍物检测&跟踪&问题优化&数据质检;
- 激光&视觉SLAM重建原理和实战演练;
- 基于重建图的静态元素标注;
- 通用障碍物OCC的标注全流程;
- 端到端标注的主流范式和实战教学;
- 数据闭环的核心痛点及未来趋势。
第一章 4D自动标注的基础
第一章主要介绍4D自动标注的相关基础。作为自动驾驶数据闭环的算法核心,这一章先从整体上帮助同学们了解4D自动标注是做什么的,有哪些应用场景。下一步延伸到课程所需要的数据及相关环境。然后重点介绍4D标出的交付物和涉及的诸多算法,从更高的层级认识4D自动标注。我们为什么需要这些算法,他们的作用究竟是什么。最后则重点介绍系统时空同步,传感器标定怎么做,时间同步如何保证精度。都会在第一章得到答案!
第二章 动态障碍物标注
第二章正式进入到动态障碍物标注的相关内容。首先介绍动态障碍物标注的整体流程。然后重点讲解离线3D目标检测算法,常用检测算法的Image/Lidar数据增广怎么做、Backbone/检测头有哪些、BEV/多帧时序融合方案是哪些,老师都会一一介绍!之后实战聚焦在CVPR 2024的SAFDNet算法,让大家实际感受下3D检测算法的输出是什么,以及面对工程上最常见的误漏检问题我们都有哪些解决方法!下一步则展开讲解3D多目标跟踪算法,数据匹配怎么做、速度模型如何实现、轨迹的生命周期如何管理、ID跳变如何解决,全都是问题!全都有答案!!!进一步老师会展开时序后处理算法DetZero的实战讲解,以及实际工程中遇到传感器遮挡时如何优化。最后则是数据质检部分,结果好不好,质检来把关。
第三章 激光&视觉SLAM重建
第三章的内容聚焦在激光&视觉SLAM重建。我们首先回答一个问题:为什么要做重建?在4D自动标注中都有哪些用途?先把这个问题搞清楚,咱们在进一步介绍重建算法的基本模块和评价指标。然后讲解Graph-based的常用激光SLAM算法。
第四章 基于重建图的静态元素标注
第四章承上启下关注静态元素的自动化标注。静态元素和动态标注不同,动态元素需要单帧检测再通过跟踪把时序的结果串起来。如果静态元素也采用单帧感知,投影得到的整条道路则可能会存在偏差。所以基于第三章SLAM的重建输出,我们就可以得到全局clip的道路信息,进而基于重建图的得到静态元素的自动化标注结果。
第五章 通用障碍物OCC标注
第五章聚焦在通用障碍物OCC标注上。自从2022年特斯拉宣布Occupancy Network量产以来,OCC基本上成为了自动驾驶感知的标配。所以第五章我们聚焦在通用障碍物OCC标注上。我们首先解析通用障碍物算法的输入输出和标注需求。再进一步讲解OCC真值的生成流程,基于lidar的方案怎么做、基于视觉的方案怎么做、工程上如何稠密化点云和优化噪声、跨传感器遮挡的场景如何优化。都会在这一章得到答案!
第六章 端到端真值标注
第六章则是咱们课程最重要的章节:端到端真值生成!首先明确下端到端的数据需求,然后进一步展开讲解业内应用最广泛的一段式和两段式端到端如何实现?最后则是把端到端真值生成的流程整体串起来:动态障碍物、静态元素、可行驶区域、自车轨迹全部打通!老师还特别准备了闭环仿真DrivingGaussian算法的讲解,闭环仿真是端到端自动驾驶的刚需,在4D自动标注的基础上,进一步扩展同学们的视野。总结来说第六章三大实战,全面搞定端到端真值生成!
第七章 数据闭环专题
有了前面六个章节的算法基础,第七章我们聚焦在更高层面的经验输出,这一章都是实打实老师工作多年的经验积累。自动驾驶数据的scaling law还奏效么?业内主流公司的数据驱动架构是怎样的?数据闭环当前面临哪些痛点?跨传感器/跨感知系统又存在什么问题?我们又如何准备相关岗位的面试,什么内容是公司真正关注的?在这一章都会有答案!

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









