







我自己的原文哦~ https://blog.51cto.com/whaosoft/13422809
#中科大统一内外参估计和3DGS训练
这下真的不用相机标定了?
同时优化相机的内外参和无序图像数据
在给定一组来自3D场景的图像及其相应的相机内参和外参的情况下,3D高斯喷溅(3DGS)能够使用一系列3D高斯来有效地表示场景,并从新视角生成高质量的图像。由于其高效的训练过程以及在测试阶段的卓越性能,3DGS已被广泛应用于场景重建、编辑以及增强现实(AR)/虚拟现实(VR)等多个领域。然而,3DGS的训练效果严重依赖于预先精确确定的相机姿态(即相机外参)和相机焦距(即相机内参)。这些参数通常需要使用COLMAP进行预处理。然而,该预处理步骤不仅耗时,还会影响3DGS的训练性能,尤其是在处理复杂的相机运动和场景时。
近期研究试图放宽对输入数据的要求。这些方法通常假设输入数据是按顺序排列的,并且已知相机的焦距。然而,与这些方法不同,我们的目标是同时优化相机的内参和外参,同时处理无序的图像数据,并探索相机参数与3DGS训练之间的关系。
为了解决这一问题,首次提出了一种联合优化方法[1],以在不依赖相机内参和外参的情况下,从一组图像中训练3DGS。具体而言,与以往仅在训练过程中更新相机姿态的方法不同,我们还从理论上推导出了焦距的梯度,以便通过反向传播同时优化相机内参,从而实现相机参数和3D高斯的统一学习。此外,为了提高训练的稳定性,我们进一步整合了全局轨迹信息,并选择与轨迹点对应的3D高斯。在训练过程中,这些跟踪的3D高斯会动态调整其大小,逐渐缩小至极小尺寸,并无限逼近真实的空间点,使其能够更精确地分布在实际表面附近。利用重投影损失,我们能够不断优化这些点的位置以及相机参数,以满足几何约束。此外,其余的3D高斯仍然保持原本的功能,并且所有3D高斯都会受到损失函数的约束。借助这种混合表示方法,我们无缝地将相机参数优化与3DGS训练结合在一起。
在公共基准数据集以及我们合成的虚拟数据集上进行了广泛的评估。与以往方法相比,我们的方法仅需一组图像作为输入,就能在相机参数估计和新视角合成方面取得最先进(SOTA)的性能。
主要贡献:
- 从理论上推导了焦距对3DGS训练的梯度,使得相机内参能够在训练过程中进行优化,从而彻底消除3DGS训练对相机参数的任何先验需求。
- 据我们所知,我们首次提出了一种相机参数与3DGS的联合优化方法。我们通过初始化一组3D高斯,并施加轨迹和尺度约束,使得我们能够应用多视角一致性和重投影损失来估计相机参数,从而实现更鲁棒的3DGS训练。
- 在公共数据集和合成数据集上,我们的方法超越了以往需要相机内参的方法,并在新视角合成任务上达到了当前最优(SOTA)性能。
具体方法
给定一组图像 ,其中每张图像 的相机外参表示为 ,相机内参矩阵表示为 。本方法的目标是同时获取相机的内参和外参,以及3D高斯喷溅(3DGS)模型,如图2所示。由于引入了额外的变量(即相机参数),我们对原始3DGS进行了多项关键改进。
首先,作为理论支撑,我们推导了相机内参的梯度,使得这些参数可以在训练的反向传播过程中进行更新。此外,我们结合全局轨迹信息,并选择与轨迹点对应的高斯核。利用重投影损失,我们进一步约束了3DGS和相机参数的优化,使其符合多视角几何一致性。为了确保计算重投影误差不会影响其余3D高斯的作用,我们要求跟踪的高斯核自动缩放至极小尺寸,并分布在场景的实际表面附近。接下来,我们提出了一种高效的联合优化方案来完成训练。
相机参数的梯度推导
要同时优化3D高斯的相机参数,我们需要计算损失函数 对相机参数的梯度。对于相机外参,梯度表示如下:
其中, ,而 。
进一步设 为投影到2D的中心点和协方差矩阵,那么焦距 的梯度可通过链式法则计算如下:
最终,损失函数 对相机内参 的梯度可表示为:
在推导梯度时不受特定损失函数的限制,只要损失函数是可微的即可。
初始化
为相机参数和3D高斯提供更好的初始值有助于加速收敛并避免陷入局部次优解。为了保证通用性,我们构建了一个最大生成树(MST),其边权表示两张图像之间的匹配点数量。利用MST,我们可以获得图像级匹配对及点级对应关系,从而提取全局轨迹信息(请参考补充材料获取详细信息)。随后,相机参数和3D高斯的初始化方法如下。
相机参数初始化
我们假设所有相机均采用标准的针孔模型、无畸变,且主点位于图像中心,则相机内参矩阵 定义为:
其中, 为主点坐标, 为焦距。经验上,我们用60°的视场角(FoV)来初始化焦距:
对于MST中的每条边 ,我们利用图像的单目深度信息(如DPT[17])来估计点云,并定义重投影损失来优化其相关变换矩阵:
通过最小化所有匹配对的重投影损失,我们可以初步获得相机的内参和外参。
3D高斯初始化
我们从MST提取一组轨迹点 ,其中每个轨迹点 由3D轨迹点 及其对应的像素匹配点 组成。轨迹点 的初始化方式如下:
值得注意的是,我们仅使用轨迹点来初始化3D高斯,而它们的具体位置会在后续的全局优化和约束中进一步调整,以准确表示物体表面。由于某些点的深度估计存在误差,其距离真实表面较远,因此不适合直接用于3D高斯初始化。
联合优化
由于我们需要同时优化相机的内参、外参以及3D高斯参数,训练的复杂度大幅增加。原始损失函数(公式4)仅依赖光度信息,在约束相机参数方面不足。为了解决这一问题,我们提出了一种多视角几何一致性约束的方法,通过跟踪匹配点轨迹来增强联合优化能力。值得注意的是,我们利用初始化的3D高斯质心来维护3D轨迹点,从而保证这些3D高斯在优化过程中得以保留,并可用于计算投影误差,以评估相机参数的准确性。为此,我们定义了两个额外的约束项。
轨迹损失
为了度量多视角几何一致性,我们将3D轨迹点 投影到所有对应的图像中,并计算投影误差:
总轨迹损失为:
尺度损失
3D轨迹点实际上位于场景中的物体表面。为了确保跟踪的3D高斯质心与实际物体表面对齐,并减少投影误差,我们引入了尺度损失:
总体目标
结合公式4,我们的联合优化目标可表示为:
此方法实现了相机参数优化与3DGS训练的无缝结合,有效提升了模型在新视角合成和相机参数估计方面的性能。
实验效果
总结一下
本文介绍一种新的联合优化方法,使得3DGS能够在无需相机内参和外参的情况下进行训练。为解决这一问题,我们首先推导出了相机内参的梯度,使得这些参数能够在反向传播过程中进行优化。此外,我们整合了全局轨迹信息,并选择与每个轨迹相关的高斯核进行训练。我们进一步将两种新的损失函数——轨迹损失和尺度损失,与原始3DGS的光度损失结合在一起。广泛的实验评估表明,我们的方法在公共数据集和复杂的合成数据集上均超越了以往需要相机内参的方法,并在新视角合成任务上达到了当前最优(SOTA)性能。
局限性:假设所有相机均遵循标准针孔模型,无畸变,并共享相同的内参。
参考
[1] No Parameters, No Problem: 3D Gaussian Splatting without Camera Intrinsics and Extrinsics
#DSPNet
探索3D场景推理问答新高度:双视觉感知网络
0.背景信息
在人工智能的前沿领域,3D场景问答(3D QA)正在成为视觉与语言理解的关键挑战。相比于传统的2D视觉问答(VQA),3D QA需要模型不仅能够感知复杂的三维空间结构,还要理解语言描述与场景之间的关系。然而,目前的3D QA方法大多依赖于3D点云数据,而忽视了多视角图像提供的丰富局部纹理信息,这使得模型在面对小型、扁平物体时表现受限。
在这一背景下, 研究人员提出了一种名为DSPNet(Dual-vision Scene Perception Network)的新型网络架构,它融合了点云与多视角图像信息,实现更鲁棒的3D场景问答推理。
1.论文信息
- 标题:DSPNet: Dual-vision Scene Perception for Robust 3D Question Answering
- 作者:Jingzhou Luo, Yang Liu, Weixing Chen, Zhen Li, Yaowei Wang, Guanbin Li,Liang Lin
- 机构:中山大学、香港中文大学(深圳)、鹏城实验室
- 原文链接:http://arxiv.org/abs/2503.03190
- 代码链接:https://github.com/LZ-CH/DSPNet
2. 挑战与解决方案
现有的多数3D QA方法主要依赖3D点云(比如ScanQA和3DGraphQA),通过检测和建模物体之间的关系来推理问题答案,而忽略了多视角图像对于全面 3D 场景感知和推理的关键作用。
例如,考虑图 1 中给出的问题“电视位于图画的哪一侧?”不仅需要识别几何场景中的实体,还需要理解场景实体和问题之间复杂的语义和空间关系。然而,现有的 3D QA 模型仅依靠点云信息很难准确识别一些扁平和小物体(例如电视、图片、地毯、手机等),而多视角图像可以通过丰富的局部纹理细节弥补这一点。
图 1 通过双视觉(点云和多视角图像)实现更全面的场景感知
由于相机位姿噪声、视角缺失和遮挡问题,简单采用多视角图像的反投影(back-projection)来融合特征,往往会导致特征退化,影响QA模型的稳定性。如图 2(a) 所示,在多视角特征聚合过程中,若对所有视图赋予相同的权重,可能无法充分考虑不同视图对特定任务的重要性。理想情况下,各视图的贡献应依据具体问题动态调整。此外,如图 2(b) 所示,由于相机位姿固有噪声、部分视角的缺失以及复杂的遮挡,在将多视角图像反投影到 3D 点云空间时,特征退化在所难免。
图 2 反投影的固有局限性。红色点表示反投影期间遗漏的点(即无效点),红色椭圆突出显示与原始点云特征相比明显退化的区域。
DSPNet旨在解决上述问题,通过双视角感知策略,使得3D QA模型能够同时利用点云与多视角图像信息:
- 基于文本引导的多视角融合(TGMF):融合多视角图像特征,在多视角特征融合过程中也能考虑文本上下文语境,促进挖掘更有利于回答问题的视角图像特征。
- 自适应双视觉感知(ADVP):逐点逐通道地自适应融合源于点云与图像的特征,缓解在多视角图像在反向投影过程中存在的特征退化问题
- 多模态上下文引导推理(MCGR):执行跨模态的高效交互与推理,综合利用较为密集的与下采样后的较为稀疏的视觉特征,在节省计算资源的同时,还能兼顾感知理解细致的场景信息。
3. 方法简介
3.1 网络架构
图 3 DSPNet的总体架构
DSPNet的整体架构如图 3所示,包括文本编码器、点云编码器、多视角图像编码器三大输入模块,以及TGMF、ADVP和MCGR等关键模块。
- 文本编码器:采用Sentence-BERT(SBERT)提取上下文信息,并对情景描述与问题进行编码。
- 点云编码器:使用PointNet++提取点云特征,保留空间结构信息。
- 图像编码器:利用Swin Transformer提取多视角图像特征,增强局部纹理感知能力。
3.2 核心模块解析
(1)基于文本引导的多视角融合(TGMF)模块
- 如图4,该模块执行反向投影,并通过计算文本内容与多视角图像的注意力,对不同视角在特征融合时赋予不同权重,从而使得多视角融合过程中能优先考虑与文本相关的视角。
- 步骤1:根据相机参数,将多视角图像特征反向投影到3D点云坐标空间。
- 步骤2:利用跨模态注意力机制根据文本与视角池化特征的相互注意力计算每个视角的权重,使得与问题相关的视角获得更高关注度。
- 步骤3:融合加权后的多视角特征,形成融合后的视觉信息。
图 4 文本引导的多视角融合(TGMF)模块旨在融合多视图特征。
(2)自适应双视觉感知(ADVP)模块
- 传统的点云与多视角图像融合方法难以应对特征退化问题,如图 5所示,ADVP模块通过逐点逐通道的注意力机制来动态调整特征的权重:
- 步骤1:拼接点云特征和回投后的多视角特征。
- 步骤2:使用MLP学习自适应权重。
- 步骤3:使用加权增强高置信度特征,同时抑制低置信度特征。并最终使用一层全连接层映射到统一的特征空间。
图 5 自适应双视觉感知(ADVP)模块旨在自适应地感知来自点云和多视角图像的视觉信息。
(3)多模态上下文引导推理(MCGR)模块
- MCGR模块旨在通过跨模态交互,综合利用密集与稀疏的视觉特征,在节省计算资源的同时,能兼顾感知理解细致的场景信息(见图 3的MCGR模块)。
- 步骤1:使用最远点采样(FPS)提取较为稀疏的关键点级别特征,减少计算量。引入位置编码,保持空间信息完整性。
- 步骤2:在MCGR子层中,稀疏的点特征通过cross-attention与密集点特征进行交互,并采用跨模态Transformer,与文本信息进行深度融合。这避免了密集点特征直接与文本进行交互,既降低了计算成本,又确保了空间视觉信息的完整性。
- 步骤3:通过堆叠L层的MCGR子层,来将视觉信息与文本信息进行深度融合,提高空间推理能力。
4. 实验部分
4.1 在SQA3D上的表现
如表 1所示,DSPNet在“What”、“How”和“Other”问题类型上取得最佳结果,并且在平均准确率方面优于其他方法,包括使用了外部3D-文本成对数据集预训练的方法。这证明了DSPNet具有强劲的多模态空间推理能力。
表 1 在SQA3D数据集上的问答准确率。测试集栏中:括号内表示各题型的样本数。最好结果以粗体显示,次好结果以下划线显示。
4.2 在ScanQA上的表现
如表 2所示,DSPNet在大多数评估指标上都优于现有的代表性方法,尤其是在 CIDEr、ROUGE 和 METEOR 中,它明显超越了其他方法。
表 2 ScanQA 上的答案准确率。每个条目表示“有对象测试”/“无对象测试”。最佳结果以粗体标记,次佳结果以下划线标记。
4.3 消融实验
如表 3所示,实验表明,TGMF、ADVP和MCGR这三个模块对提升DSPNet的3D空间推理能力至关重要。进一步验证了DSPNet的方法有效性。
表 3 各组件的消融研究。在 ScanQA 数据集的验证集和 SQA3D 数据集的测试集上进行,使用 EM@1 作为评测指标。
如表 4所示,去除DSPNet的2D模态,仅使用点云作为视觉信息来源,此时模型在两个评测集上的准确率大幅下降,这进一步验证了多视角图像在三维场景问答任务中的重要性。
表 4 使用 2D 模态的有效性消融研究
5. 定性研究
如图 6所示,DSPNet 在感知和推理一些具有挑战性的实体方面表现更好,例如那些具有平面形状和丰富局部纹理细节的实体,这些实体仅基于点云几何形状难以识别。此外,DSPNet 可以区分细微的颜色差异,例如白色和银色之间的差异,从而增强了其在识别细粒度视觉区别方面的鲁棒性。
图 6 DSPNet方法与 ScanQA 和 SQA 的定性比较
6. 结论
该论文提出了一种用于3D问答的双视觉感知网络 DSPNet。DSPNet 通过基于文本引导的多视角融合(TGMF) 模块融合多视角图像特征,并采用自适应双视角感知(ADVP)模块,将图像与点云特征融合为统一的表征。最终,引入多模态上下文引导推理(MCGR) 模块,实现对3D场景的综合推理。实验结果表明,DSPNet 在 3D问答任务中优于现有方法,预测答案与参考答案在语义结构上的对齐性更好,表现更加出色。
#PointVLA
如何将3D数据融入VLA模型?
三维数据增强预训练VLA模型
视觉-语言-动作(VLA)模型通过利用大规模二维视觉-语言预训练,在机器人任务中表现出色。但其对RGB图像的依赖限制了在真实世界交互中至关重要的空间推理能力。使用三维数据对这些模型进行重新训练在计算上是难以承受的,而丢弃现有的二维数据集则会浪费宝贵的资源。为了弥合这一差距,我们提出了PointVLA,这是一个无需重新训练,就能通过点云输入来增强预训练VLA模型的框架。我们的方法会冻结原始的动作专家模块,并通过一个轻量级的模块化块注入三维特征。为了确定集成点云表示的最有效方式,我们进行了skip block分析,以找出原始动作专家模块中不太有用的块,确保三维特征仅注入到这些块中,从而将对预训练表示的干扰降至最低。
大量实验表明,在模拟和真实世界的机器人任务中,PointVLA的表现优于最先进的二维模仿学习方法,如OpenVLA、Diffusion Policy和DexVLA。我们强调了通过点云集成实现的PointVLA的几个关键优势:(1)少样本多任务处理,PointVLA仅使用每个任务20个演示样本就能成功执行四种不同的任务;(2)真实物体与照片的判别,PointVLA利用三维世界知识区分真实物体与其图像,从而提高安全性和可靠性;(3)高度适应性,与传统的二维模仿学习方法不同,PointVLA使机器人能够适应训练数据中未见过的不同桌面高度的物体。此外,PointVLA在长视野任务中也取得了优异的性能,例如从移动的传送带上拾取和包装物体,展示了其在复杂、动态环境中的泛化能力。
领域介绍
机器人基础模型,尤其是视觉-语言-动作(VLA)模型,在使机器人能够感知、理解和与物理世界交互方面展现出了卓越的能力。这些模型利用预训练的视觉-语言模型(VLMs)作为处理视觉和语言信息的backbone,将它们embedding到一个共享的表示空间中,随后转化为机器人动作。这一过程让机器人能够以有意义的方式与环境进行交互。VLA模型的优势在很大程度上取决于其训练数据的规模和质量。例如,OpenVLA在4000小时的开源数据集上进行训练,而像这样更先进的模型则利用10000小时的专有数据,从而显著提高了性能。除了这些大规模基础模型外,许多项目还贡献了从真实世界中物理机器人上的人类演示中收集的大量数据集。比如,AgiBot-World发布了一个包含数百万条轨迹的大型数据集,展示了复杂的人形机器人交互。这些预训练的VLA模型,以及开源机器人数据集,通过提供丰富多样且高质量的训练数据,极大地推动了机器人学习的发展。
尽管取得了这些进展,但大多数现有的机器人基础模型都是在二维视觉输入上进行训练的。这是一个关键的限制,因为人类是在三维空间中感知和与世界交互的。训练数据中缺乏全面的三维空间信息,阻碍了机器人对其环境形成深入理解。对于那些需要精确空间感知、深度感知和物体操作的任务来说,这一点尤为关键。促使我们开展研究的是,许多机构已经在基础VLA模型和大规模二维机器人数据集上投入了大量资金。用三维数据从头开始重新训练这些模型在计算上是不可行的,而丢弃有价值的二维机器人数据也不切实际。因此,探索能够将额外的三维输入集成到现有的基础机器人模型中的新颖框架至关重要,而这一研究领域在以往的文献中尚未得到充分探索。
这里我们引入了PointVLA,这是一个将点云集成到预训练的视觉-语言-动作模型中的新颖框架。我们假设新的三维机器人数据比预训练的二维数据要小得多。在这种情况下,不破坏已经建立好的二维特征表示至关重要。为了解决这个问题,我们提出了一个三维模块化block,它可以将点云信息直接注入到动作专家模块中。通过保持视觉-语言骨干网络完好无损,我们确保二维视觉文本embedding得以保留,并仍然是可靠的信息来源。此外,我们旨在尽量减少对动作专家特征空间的干扰。通过skip-block分析,我们识别出在测试时不太关键的层。这些“不太有用”层的特征embedding对新模态的适应性更强。在确定了这些不太重要的block之后,通过相加的方式注入提取的三维特征。整体方法在保持预训练VLA完整性的同时,融入了点云输入的优势。
这里进行了大量实验来验证我们方法的有效性。例如,在RoboTwin模拟平台上,方法优于纯粹的三维模仿学习方法,如3D Diffusion Policy。此外,在两种双手机器人上进行了真实世界实验:类似人形的UR5e机械臂和类似于Aloha平台的AglieX机械臂。实验还突出了PointVLA的几个关键优势:
- 少样本多任务处理:PointVLA可以按照指令执行四项任务,每个任务仅在20个演示样本上进行训练。在如此小的数据集上进行多任务训练具有挑战性,而我们的方法明显优于基线方法。
- 真实物体与照片判别:真实物体及其照片在二维图像中可能看起来非常相似,这可能会给机器人带来混淆和安全隐患。PointVLA可以可靠地区分真实物体和它们的图像,避免被虚拟物体欺骗。
- 高度适应性:PointVLA可以根据桌面高度的变化调整机器人动作(例如,在高得多的桌子上抓取同一物品),而传统的二维VLA模型在这种情况下通常会失败。
此外,我们还处理了具有挑战性的长视野任务,如从移动的传送带上拾取多个物品并将它们包装到盒子中。这些实验展示了我们提出的PointVLA框架在各种场景下的强大性能和泛化能力,为将额外模态集成到预训练的VLA模型中指明了一个有前景的方向。
相关工作
视觉-语言-动作模型
最近的研究越来越关注开发在大规模机器人学习数据集上训练的通用机器人策略。视觉-语言-动作(VLA)模型已成为训练这类策略的一种有前景的方法。VLA模型扩展了在大规模互联网图像和文本数据集上预训练的视觉-语言模型(VLMs),将其应用于机器人控制。这种方法具有几个关键优势:利用具有数十亿参数的大规模视觉-语言模型骨干网络,能够从大量机器人数据中有效学习;同时,重用来自互联网规模数据的预训练权重,增强了VLA模型解释各种语言命令的能力,以及对新物体和环境的泛化能力,使其非常适合真实世界的机器人应用。
基于3D模态的机器人学习
在三维场景中学习强大的视觉运动策略是机器人学习的一个重要领域。像3DVLA这样的现有方法提出了全面的框架,将各种三维任务,如泛化、视觉问答(VQA)、三维场景理解和机器人控制,集成到统一的视觉-语言-动作模型中。然而,3DVLA的一个局限性是其在机器人控制实验中对模拟的依赖,这导致了显著的模拟到现实的差距。其他工作,如3D diffusion policies表明,使用外部三维输入(例如,来自外部相机)可以提高模型对不同光照条件和物体属性的泛化能力。iDP3进一步增强了三维视觉编码器,并将其应用于人形机器人,在具有以自我为中心和外部相机视角的各种环境中都实现了强大的性能。但是,丢弃现有的二维机器人数据,或者用添加的三维视觉输入完全重新训练基础模型,在计算上成本高昂且资源密集。一个更实际的解决方案是开发一种方法,将三维视觉输入作为补充知识源集成到预训练良好的基础模型中,从而在不影响训练模型性能的情况下,获得新模态带来的好处。
PointVLA方法
预备知识:视觉-语言-动作模型
视觉-语言-动作(VLA)模型正在推动真实世界机器人学习的重大变革。其能力源于底层的视觉-语言模型(VLM),这是一个在大量互联网数据集上训练的强大骨干网络。这种训练使得图像和文本表示能够在共享的embedding空间中有效对齐。VLM就像模型的“大脑”,处理指令和当前视觉输入以理解任务状态。随后,“动作专家”模块将VLM的状态信息转化为机器人动作。这项工作基于DexVLA展开,DexVLA采用具有20亿参数的Qwen2-VL VLM作为骨干网络,以及具有10亿参数的ScaleDP(一种扩散策略变体)作为动作专家模块。DexVLA经历三个训练阶段:100小时的跨实体训练阶段(阶段1),然后是特定实体训练(阶段2),对于复杂任务还有可选的特定任务训练(阶段3)。所有三个阶段都使用二维视觉输入。虽然这些VLA模型在各种操作任务中表现出令人印象深刻的能力,但它们对二维视觉的依赖限制了在需要三维理解的任务中的表现,例如通过照片进行物体欺骗或在不同桌面高度上的泛化。下一节将说明如何将三维世界注入到预训练的VLA中。整体框架如图2所示。
将点云注入VLA
动机
如前所述,视觉-语言-动作(VLA)模型通常在大规模二维机器人数据集上进行预训练。PointVLA方法基于一个关键观察:现有的二维预训练语料库和新兴的三维机器人数据集在数据规模上存在固有差异。我们认为与二维视觉-语言数据集相比,三维传感器数据(例如点云、深度图)在数量级上要小得多,这是由于机器人研究长期以来对二维感知的广泛关注。这种差异需要一种方法,既能保留从二维预训练中学到的丰富视觉表示,又能有效地集成稀疏的三维数据。
一种解决此挑战的简单策略是将三维视觉输入直接转换为三维视觉token,并将它们融合到大语言模型(LLM)中,这是许多3DVLM(如LLaVA-3D)采用的流行方法。然而,当前的视觉-语言模型在小规模三维数据集上进行微调时,三维理解能力有限,这一局限性受到两个因素的加剧:(1)二维像素和三维几何结构之间存在巨大的领域差距;(2)与丰富的图像文本和纯文本语料库相比,高质量的三维文本配对数据稀缺。为了避免这些问题,我们提出了一种范式,将三维点云数据视为补充调节信号,而不是主要输入模态。这种策略将三维处理与核心二维视觉编码器解耦,从而在保持预训练二维表示完整性的同时,使模型能够利用几何线索。通过设计,我们的方法减轻了对二维知识的灾难性遗忘,并降低了对有限三维数据过度拟合的风险。
点云注入器的模型架构
点云注入器的整体架构如图1(右)所示。对于输入的点云embedding,首先转换通道维度,使其与原始动作专家的通道维度匹配。由于根据block大小,来自点云的动作embedding可能会很大,这里设计了一个动作embedding bottleneck,用于压缩来自动作专家的信息,同时使其与三维点云embedding对齐。对于动作专家中选定的block,首先为每个块应用一个MLP层作为适配器,然后进行加法操作,将点云embedding注入到模型中。
值得注意的是,我们避免将三维特征注入到动作专家的每个block中,主要有两个原因。第一,由于需要条件block,计算成本会过高。第二,注入不可避免地会改变受影响块的模型表示。鉴于我们旨在尽量减少有限的三维视觉知识对从二维视觉输入导出的预训练动作embedding的干扰,我们进行了分析,以识别在推理过程中可以跳过而不影响性能的块。随后,仅将三维特征注入到这些不太关键的block中。
点云编码器
与DP3和iDP3中的观察结果一致,发现预训练的三维视觉编码器会阻碍性能,常常使机器人在新环境中难以成功学习行为。因此,我们采用了一种简化的分层卷积架构。上层卷积层提取低级特征,而下层卷积块学习高级场景表示。在层之间使用最大池化来逐步降低点云密度。最后,我们将每个卷积块的特征embedding连接成一个统一的embedding,封装了多层次的三维表示知识。提取的点云特征embedding将保留以供后续使用。这种架构与iDP3编码器类似。我们认为采用更先进的点云编码器可以进一步提高模型性能。
向哪些block注入点云?Skip Block分析
如前所述,将点云注入到动作专家的每个块中并不理想,因为这会增加计算成本,并破坏从大量基于二维视觉的机器人数据中学到的原始动作表示。因此,我们分析动作专家中哪些block不太关键,即在推理过程中可以跳过而不影响性能的block。这种方法在概念上与图像生成、视觉模型和大语言模型中使用的技术一致。我们以DexVLA中的衬衫折叠任务为例进行分析。回想一下,DexVLA配备了具有10亿参数的动作专家,其中包含32个扩散transformer block。评估遵循相同的指标:平均得分,这是长视野任务的标准度量方法,通过将任务划分为多个步骤并根据步骤完成情况评估性能。从每次跳过一个块开始,并在下图中总结我们的发现。
在图3(左)中展示了结果。实验表明,前11个块对模型至关重要,跳过其中任何一个都会导致性能显著下降。具体来说,当跳过第11层之前的块时,抓手无法紧密闭合,使得模型难以完成任务。然而,从第11个块开始,跳过单个块是可以接受的,直到最后一个块。这表明第11到31个块在训练后对性能的贡献较小。为了进一步研究哪些块适合注入点云,我们从第11个块开始进行多块跳跃分析,如图3(右)所示。发现在模型无法完成任务之前,可以连续跳过多达五个块。这表明可以通过特定块将三维表示选择性地注入到动作专家中,在不显著影响性能的情况下优化效率。因此,当引入新数据时,我们将所有三维条件块设置为可训练的。我们冻结原始动作专家中的所有模块,除了最后几层,最后几层会进行调整以适应实体的输出。最终,只训练五个额外的注入block,这些block在推理时轻量且快速,使我们的方法具有很高的成本效益。
实验分析
实现细节
我们在两种实体机器人上进行真实实验:
- 双手机器人UR5e:两台UR5e机器人,各自配备Robotiq平行夹爪和腕部摄像头。在两机械臂之间设有一个俯瞰摄像头。该设置共有三个摄像头视角,以及14维的配置和动作空间。数据采集频率为15Hz,使用RealSense D435i摄像头作为腕部摄像头。
- 双手机器人AgileX:两台6自由度的AgileX机械臂,每个机械臂都配有腕部摄像头和基座摄像头。此设置有14维的配置和动作空间,由三个摄像头共同支持。数据采集频率为30Hz,我们用RealSense D435i作为腕部摄像头,使用RealSense L515摄像头采集点云数据。
由于模型需要学习新的语言指令,将视觉语言模型(VLM)设置为可训练。在两个实验中,均采用DexVLA的第一阶段预训练权重,并针对我们的模型进行微调。训练超参数与DexVLA第二阶段训练时相同,且我们使用最后一个检查点进行评估,以避免数据筛选偏差。所有任务的块大小均设为50。
基线
在实验中,我们将方法与多个前沿模型进行对比,包括扩散策略(DP)、3D扩散策略(DP3)、ScaleDP-1B(将扩散策略扩展至10亿参数的变体)、Octo、OpenVLA和DexVLA。需注意,由于PointVLA基于DexVLA构建,DexVLA可视为我们提出的PointVLA在未融入3D点云数据时的简化版本。
少样本多任务处理
任务描述
如图5所示,为真实世界实验设计了四个少样本任务:手机充电、擦盘子、放面包和运输水果。物体随机放置在小范围内,我们记录每种方法的平均成功率。
- 手机充电:机器人拿起智能手机并放置在无线充电器上。手机的尺寸考验动作精度,其易碎性要求操作时需格外小心。
- 擦盘子:机器人同时拿起海绵和盘子,用海绵擦拭盘子,以此评估双手协作操作能力。
- 放面包:机器人拿起一片面包并放在盘子上。面包下方的薄泡沫层用于测试模型在不同高度下的泛化能力。
- 运输水果:机器人拿起随机放置的香蕉,并将其放入位于中央的盒子中。
由于我们旨在验证模型的少样本多任务处理能力,每个任务仅收集20个演示数据,共计80个演示数据。物体位置在小空间内随机分布。这些任务用于评估模型在不同场景下管理独立和协调机器人运动的能力。所有数据均以30Hz的频率采集。
实验结果
实验结果如表6所示,在该场景下我们的方法优于所有基线模型。值得注意的是,扩散策略在大多数情况下失败,可能是因为每个任务的样本量过小,导致动作表示空间混乱,这与先前文献中的发现一致。此外,即使增大模型规模(如ScaleDP-1B)也未带来显著改进。
DexVLA在数据有限的情况下仍展现出较强的少样本学习能力,但其性能与PointVLA相当或略逊一筹。PointVLA中融入的点云数据使其学习效率更高,凸显了将3D信息整合到模型中的必要性。更重要的是,实验结果证实我们的方法成功保留了从2D预训练VLA中学习的能力。
长视野任务:装配线上的包装
除传统多任务处理外,我们在长视野包装任务上进一步微调PointVLA,如图4所示。该任务极具挑战性,原因如下:首先,装配线处于运动状态,要求机器人快速精准地抓取物体;其次,此场景下的机器人实体与预训练数据中的不同,需要快速适应全新的设置;最后,作为长距离任务,机器人必须依次拾取并放置两袋洗衣液,然后才能密封包装盒。这些复杂性使得该任务要求极高。
如表1所示,PointVLA在长距离任务中实现了最高的平均完成长度,比强大的基线模型DexVLA高出0.64,同时也超越了其他多个基线模型。然而,下一节将重点介绍PointVLA更关键的一个方面——物体幻觉问题。
真实物体与照片判别
我们探索一种名为真实物体与照片判别的独特实验设置,用物体的图片替代真实物体。从2D视角看,屏幕上显示的“假”物体与真实物体几乎一模一样,但实际上它并不存在。人类能够轻易识别这种差异,并且不会伸手去拿,因为我们知道它不是真实的——那么机器人模型能做到吗?
为了验证这一点,我们使用双手机器人UR5e在包装任务中进行实验。将实验中的洗衣液替换为投影在屏幕上的洗衣液照片。实验设置如图7所示。从外部视角看,图片与真实物体差异明显。然而,从顶部摄像头的内部视角看,照片与实际洗衣液非常相似。我们发现,传统的基于2D的视觉语言动作模型,如OpenVLA和DexVLA,无法区分图片和真实物体。这些模型试图抓取物体,以DexVLA为例,它会反复尝试拾取并不存在的洗衣液。由于模型认为物体存在,但始终无法抓取,从而陷入重复抓取的循环。相比之下,PointVLA成功识别出传送带上没有真实物体。通过利用3D空间理解能力,它判断出物体应在的空间实际上是空的。这一关键优势凸显了我们方法的优势,证明了具有3D感知能力的模型在减少物体幻觉方面的优越性。
高度适应性
高度泛化指模型适应不同桌面高度的能力。这对机器人模型至关重要,因为大多数演示数据是在固定桌面高度下收集的。但是,当机器人部署在与训练时桌面高度差异显著的环境中会怎样呢?
为了研究这个问题,我们设计了如图8所示的实验。具体在“放面包”任务中,我们在面包下方放置了泡沫塑料层。训练时,泡沫层厚度为3mm,所有收集的数据均基于此高度。推理时,我们将泡沫厚度增加到52mm,以评估模型的高度泛化能力。观察结果显示,传统的基于2D的VLA模型,如OpenVLA、DP、ScaleDP-1B和DexVLA在这种情况下均失败。检测到面包后,这些模型试图按照训练数据中的高度下压并抓取面包,无法适应增加的高度。相比之下,PointVLA成功完成了任务。通过利用点云数据,它准确感知到面包的新高度,相应地调整了夹爪,并成功完成拾取动作。该实验表明,融入3D信息使VLA模型能够处理物体高度的变化,这是纯2D模型所不具备的能力。
模拟基准测试结果
在RoboTwin(一种广泛使用的配备14自由度机器人的移动双手机器人平台)上评估方法。该基准测试涵盖了一系列不同的任务。我们将方法与扩散策略和3D扩散策略(DP3)进行比较。扩散策略是视觉运动策略学习中成熟的基线模型,而DP3将其扩展到3D领域。原始的DP3仅使用点云数据作为输入。为确保公平对比,也将RGB图像融入DP3,实验由RoboTwin执行。我们将两种版本的DP3与原始扩散策略一同对比。在所有实验中,相机输入(包括L515和顶部摄像头)的标准图像分辨率设为320×180。
测试使用20和50个样本的数据集进行。根据RoboTwin的训练设置,每个实验使用三个随机种子(0、1、2)训练策略,且不进行数据筛选。每个策略测试100次,得出三个成功率。计算这些成功率的平均值和标准差,得到以下实验结果。
实验结果如表2所示。基线结果(包括3D扩散策略和扩散策略)由RoboTwin提供。值得注意的是,在所有任务和不同设置下,无论训练数据是20个还是50个演示样本,我们提出的PointVLA均获得了最高的平均成功率。这表明我们的方法即使在数据资源有限的情况下也有效,并且在有大量训练数据时性能依然出色。
此外,我们观察到对于像DP3这样的纯3D模型,直接融入RGB输入可能会对性能产生负面影响。相比之下,我们的方法强调了有条件地将3D点云数据集成到模型中的必要性,与仅依赖2D视觉输入的模型相比,这显著提升了性能。
最后,总结下
视觉-语言-动作(VLA)模型通过大规模2D预训练在机器人学习中表现出色,但其对RGB输入的依赖限制了3D空间推理能力。用3D数据重新训练成本高昂,丢弃2D数据集又会降低泛化能力。为解决这些问题,这里引入了PointVLA框架,它在保留2D表示的同时,通过3D点云输入增强预训练的VLA模型。通过集成模块化3D特征注入器并利用跳跃块分析,PointVLA无需完全重新训练就能高效融入空间信息。
在模拟和真实世界环境中的实验证明了PointVLA的有效性,它实现了少样本多任务学习(每个任务仅用20个演示样本完成4个任务),并在动态物品包装等长视野任务中表现卓越。在双手机器人(UR5e和AgileX机械臂)上的真实世界测试进一步验证了其实用性和安全性。我们的工作凸显了在无需昂贵重新训练的情况下,用新模态增强预训练机器人模型的可行性。未来的工作包括在更大的数据集上扩展3D感知预训练。
#TSP3D
清华提出:基于语言引导空间剪枝的高效3D视觉Grounding本文介绍了一种名为 TSP3D 的高效 3D 视觉定位框架,通过语言引导的空间剪枝和多层稀疏卷积架构,实现了高精度和快速推理,在 ScanRefer 和 ReferIt3D 数据集上达到了 SOTA 性能,同时显著提升了推理速度。
很开心我们最近的工作拿到了CVPR的满分,这也是继 DSPDet3D 之后三维空间剪枝在3DVG任务中的一次成功的尝试。在这篇文章中,我们提出了TSP3D,一个高效的3D视觉定位(3D Visual Grounding)框架,在性能和推理速度上均达到SOTA。此外,文中还包含了我们将三维稀疏卷积引入3D Visual Grounding任务中遇到的挑战,以及我们的探索和思考。

Text-guided Sparse Voxel Pruning for Efficient 3D Visual Grounding
论文:https://arxiv.org/abs/2502.10392
代码仓库:https://github.com/GWxuan/TSP3D
简介
3D视觉定位(3D Visual Grounding, 3DVG)任务旨在根据自然语言描述在三维场景中定位指定的目标对象。这一多模态任务具有很大挑战性,需要同时理解3D场景和语言描述。在实际应用(如机器人、AR/VR)中对模型的效率有着较高的要求,但现有方法在推理速度上受到了一定限制。早期的方法[1,2]大多采用两阶段框架:首先通过3D目标检测在场景中找到所有候选物体,然后结合文本信息在第二阶段选出与描述匹配的目标。这种方法虽然直观,但由于两个阶段分别提取特征,存在大量冗余计算,难以满足实际应用中的推理速度要求。为提升效率,随后出现了单阶段方法[3,4],直接从点云数据中定位目标物体,将目标检测与语言匹配一步完成。然而,现有单阶段方法大多同样基于点云处理架构(PointNet++[5]等),其特征提取需要耗时的最远点采样(FPS)和近邻搜索等操作。因此当前单阶段方法距离实时推理仍有差距(推理速度不足6 FPS)。
为了解决上述问题,本文提出了一种全新的单阶段3DVG框架——TSP3D,即“Text-guided Sparse voxel Pruning for 3DVG”。TSP3D放弃被现有方法广泛使用的点云处理架构,引入了多层稀疏卷积架构来同时实现高精度和高速推理。三维稀疏卷积架构提供了更高的分辨率和更精细的场景表示,同时在推理速度上具有显著优势。同时,为了有效融合多模态信息,TSP3D针对特征融合进行了一系列设计。如上面图一所示,TSP3D在精度和推理速度方面都超过了现有方法。
方法
我们将三维稀疏卷积引入3DVG任务时遇到了诸多挑战,我们在文中介绍了这些挑战以及我们的思考和分析,希望能够对研究社区有所帮助。

架构分析
点云处理架构:特征提取需要耗时的最远点采样(FPS)和近邻搜索等操作,同时受到场景表示的空间分辨率限制。
直接引入多层稀疏卷积(TSP3D-B):如上图(a)所示,场景特征和文本特征通过简单的拼接进行融合,推理速度快(14.58 FPS),但融合效果差,精度低。
改为attention机制的特征融合:如上图(b)所示,由于生成式稀疏卷积的作用,体素数量(场景表示的分辨率)极高,导致进行attention计算时显存溢出,在消费级显卡上难以训练和推理。
引入基于文本引导的体素剪枝(TSP3D):如上图(c)所示,根据语言描述逐步修剪对目标定位没有帮助的voxel,极大程度上减小了计算量,并提高推理速度。
简化的TSP3D(主推版):去掉了最远点采样和插值,将多个attention模块重新组合,进一步提高计算效率。
文本引导的体素剪枝(Text-guided Pruning, TGP)
TGP的核心思想是赋予模型两方面的能力:(1)在文本引导下修剪冗余体素来减少特征量;(2)引导网络将注意力逐渐集中到最终目标上。我们的TSP3D包含3 level的稀疏卷积和两次特征上采样,因此相应设置了两阶段的TGP模块:场景级TGP (level 3 to 2) 和目标级TGP (level 2 to 1)。场景级TGP旨在区分物体和背景,用来修剪背景上的体素。目标级TGP侧重于文本中提到的区域,保留目标对象和参考对象,同时修剪其他区域的体素。
TGP的作用分析:引入TGP后,level 1的体素数减少到原来的7%左右,并且精度得到了显著提高。这归功于TGP的多种功能:(1)通过attention机制促进多模态特征之间的交互;(2)通过剪枝减少特征数量;(3)基于文本特征逐渐引导网络集中注意力到最终目标上。
基于补全的场景特征融合(Completion-based Addition, CBA)

在剪枝过程中,一些目标体素可能会被错误地去除,尤其是对于较小或较窄的目标。因此,我们引入了基于补全的场景特征融合模块(CBA),它提供了一种更有针对性且更有效的方法来融合multi-level特征。CBA用于backbone特征和上采样的剪枝特征融合,基于完整性较好的backbone特征对剪枝特征进行补充。同时,CBA引入的额外计算开销可以忽略不计。方法细节请参见文章。
实验结果
我们在主流的3DVG数据集ScanRefer[1]和ReferIt3D[6]上进行了实验。我们是第一个全面评估3DVG方法的推理速度的工作,所有方法的推理速度在一个消费级的RTX 3090上测得。下面是两个主表的结果,左侧为ScanRefer数据集,右侧为ReferIt3D数据集。

我们进行了一些列消融实验,证明我们提出方法的有效性:

我们对文本引导的体素剪枝(TGP)进行了可视化。在每个示例中从上到下为:场景级TGP、目标级TGP和最后一个上采样层之后的体素特征。蓝框表示目标的ground truth,红框表示参考对象的bounding box。可以看出,TSP3D通过两个阶段的剪枝减少体素特征的数量,并逐步引导网络关注最终目标。

此外,我们对基于补全的场景特征融合(CBA)进行了可视化,展示了CBA自适应补全过度剪枝造成的目标体素缺失。图中蓝色点表示目标级TGP输出的体素特征,红色点表示CBA预测的补全特征,蓝色框表示ground truth。

下图展示了与其他方法的定性比较,TSP3D在定位相关目标、窄小目标、识别类别以及区分外观和属性方面表现出色。

更多实验、可视化可以参考我们的论文以及补充材料。如有问题欢迎大家在github上开issue讨论~
参考文献
[1] Dave Zhenyu Chen, Angel X Chang, and Matthias Nießner. Scanrefer: 3d object localization in rgb-d scans using natural language. In ECCV, pages 202–221. Springer, 2020.
[2] Pin-Hao Huang, Han-Hung Lee, Hwann-Tzong Chen, and Tyng-Luh Liu. Text-guided graph neural networks for referring 3d instance segmentation. In AAAI, pages 1610–1618, 2021.
[3] Junyu Luo, Jiahui Fu, Xianghao Kong, Chen Gao, Haibing Ren, HaoShen, HuaxiaXia, and SiLiu. 3d-sps: Single-stage 3d visual grounding via referred point progressive selection. In CVPR, pages 16454–16463, 2022.
[4] Yanmin Wu, Xinhua Cheng, Renrui Zhang, Zesen Cheng, and Jian Zhang. Eda: Explicit text-decoupling and dense alignment for 3d visual grounding. In CVPR, pages 19231-19242, 2023.
[5] Charles Ruizhongtai Qi, Li Yi, Hao Su, and Leonidas J Guibas. Pointnet++: Deep hierarchical feature learning on point sets in a metric space. In NeurIPS, 30, 2017.
[6] Panos Achlioptas, Ahmed Abdelreheem, Fei Xia, Mohamed Elhoseiny, and Leonidas Guibas. Referit3d: Neural listeners for fine-grained 3d object identification in real-world scenes. In ECCV, pages 422–440. Springer, 2020.
#Dora
开源三维生成框架Craftsman3D&Dora革新三维资产生成与编辑
香港科技大学谭平教授团队在 CVPR 2025 发表两项三维生成技术框架,核心代码全部开源,助力三维生成技术的开放与进步。其中 Craftman3D 获得三个评委一致满分,并被全球多家知名企业如全球最大的多人在线游戏创作平台 Roblox, 腾讯混元 Hunyuan3D-2,XR 实验室的 XR-3DGen 和海外初创公司 CSM 的 3D 创作平台等重量级项目的引用与认可。
相关技术已融入光影焕像的三维生成平台及产品,用户只需简单操作,就能开启专属三维创作之旅。
- 光影焕像 3D 生成平台(主站):https://triverse.ai/zh-cn/
- 光影焕像 3D 生成平台(国内备用):https://triverse.lightillusions.com/zh-cn/
本文中 Craftman3D 的共同一作李威宇、刘嘉瑞和阎鸿禹均为香港科技大学博士研究生。Dora 的第一作者为香港科技大学博士陈锐。均为香港科技大学谭平教授组的在读博士生。
,时长00:24
三维内容的创建对于游戏、影视、AR/VR 乃至具身智能的环境仿真中具备关键作用。不过,传统三维建模方式要求建模者掌握大量专业知识,且需投入大量人工操作,这使得建模过程极为耗时,极具挑战性,对于非专业用户而言更是如此。过高的时间与人力成本,已然成为限制这些领域发展的主要瓶颈。近年来,基于 AI 的三维内容生成技术逐步改变了这一局面。借助自动化生成技术,三维内容创建的门槛大幅降低,让更广泛的用户群体能够高效地构建三维数字内容。
当前原生三维生成模型主要由两部分构成:一是 3D-VAE(3D Variational Auto Encoder)变分自编码器,它通过 Encoder 网络将三维模型压缩编码至潜在空间(latent space),并通过 Decoder 网络解码重构出三维模型;二是基于 3D-VAE 构建的潜在扩散模型(latent diffusion model)用于处理文本或图像输入的三维模型生成。三维生成大模型所呈现的细节上限,在很大程度上取决于 3D-VAE 对三维几何的编码与重建能力。为提升三维模型编解码过程中的几何细节丰富度,香港科技大学谭平团队联合字节跳动豆包大模型团队与光影焕像团队,共同提出了 Dora 模型来改进三维原生 VAE。
在 3D-VAE 模型的基础上,香港科技大学与光影焕像团队进一步提出了 Craftsman3D 算法方案,该方案借鉴了传统建模流程,能够快速生成高质量的 3D 模型,以进一步生成满足设计师对高质量三维模型的生成要求。此方法在 CVPR 中获得审稿人一致满分评价,它融合了原生 3D 大模型以及实时几何细节优化两大部分:首先由原生三维大模型生成初始模型,随后通过实时可交互几何细化操作,短短几十秒内即可生成具备高质量几何细节的三维模型。
- Dora 开源代码:https://github.com/Seed3D/Dora/
- Dora 项目主页:https://aruichen.github.io/Dora/
本文提出的 Dora-VAE,创新性地将显著边缘采样算法与双交叉注意力机制相结合,极大地提升了三维变分自编码器(3D-VAE)的重建质量与压缩性能。在训练阶段,该方法能够精准识别出具有较高几何复杂性的区域,并对其优先处理,从而有效改善了对精细几何特征的保留情况,让变分自编码器能够着重关注那些传统均匀采样方式容易忽视的关键几何细节。在实现高质量重建的同时,相较于当前 SOTA 方法(Xcube),Dora-VAE 在 3D 形状压缩率方面实现了超过 8 倍的提升 。
当前,三维变分自编码器的运行机制是:通过在三维网格表面进行点采样来完成形状编码,而后利用解码器对原始三维网格进行重建。经过深入且细致的研究,研究人员察觉现有方法普遍采用均匀采样(uniform sampling)策略,从而导致重建性能受限。为了验证这一发现,研究人员选取了具有复杂几何细节的键盘(如下图 (a) 所示)作为实验对象,对其进行点云采样,并将不同采样策略在多种采样密度下的点云分布情况进行了可视化呈现(如下图 (b)(c) 所示)。实验结果清晰地显示:即便提升了采样率,采用均匀采样方式(如下图 (b) 所示)依旧无法有效地保留键盘按键等锐利特征(sharp feature)。这一简洁直观的实验有力地证实了,均匀采样在本质上对几何细节的捕捉能力形成了制约,而这种制约进一步对变分自编码器的重建精度以及所训练扩散模型的生成质量产生了不良影响。

受重要性采样理念的启发,研究人员设计了显著边缘采样(Sharp Edge Sampling, SES)算法,该算法能够基于几何显著性实现自适应点采样。具体而言,SES 算法首先识别网格中具有显著二面角的边缘(这些边缘所在区域往往对应高几何复杂度区域),并沿显著区域进行点采样。与此同时,为了保证三维模型表面的覆盖完整性,研究人员依旧会进行表面均匀点采样。因此,最终生成的采样点云

由表面均匀采样点

与显著区域采样点

联合构成:

。

显著边缘检测(Salient Edges Detection)
给定一个三维网格,研究人员通过计算相邻面间的二面角获得显著边缘集合

。对于每条由相邻面

和

共享的边

,研究人员通过下式计算其二面角

:

其中

和

分别表示面

和

的法向量。显著边缘集合

包含所有二面角超过预设阈值

的边:

,令

表示显著边缘的数量。
显著点采样(Salient Points Sampling)
针对每条显著边缘

,研究人员将其两个顶点

和

纳入显著顶点集合

,相连边缘产生的重复顶点仅保留一份:

。令

表示该集合中唯一几何顶点的数量。给定显著区域目标点数

,当显著顶点过多时,通过最远点采样法 (Farthest Point Sampling, FPS) 进行顶点下采样;当显著顶点不足,通过对显著边缘增加采样来补充数据,从而得到显著区域采样点

。

基于 SES 算法,研究人员提出 Dora-VAE,在保持紧凑潜在表征的同时实现了高保真度的三维重建。为充分利用 SES 采样获得的富含细节的点云数据,研究人员设计了双交叉注意力编码架构,该架构在特征编码过程中能有效融合显著区域与均匀区域的特征表达。具体而言,研究人员沿用 3DShape2VecSet 的做法,首先分别对均匀采样点云

和显著区域采样点云

进行最远点下采样:

其中

与

分别表示来自均匀采样点云

和显著区域采样点云

的下采样点云数量。研究人员随后分别计算均匀点与显著点的交叉注意力特征:

最终点云特征 C 通过融合双向注意力计算结果获得:

遵循 3DShape2VecSet,研究人员利用特征 C 通过自注意力模块预测占据区域

,整个模型

通过最小化均方误差损失进行优化:

研究人员通过三个指标评估重建质量:使用 1M 采样点对比输入网格与不同 3D VAEs 解码结果的差异,包括:1) F-score;2) 倒角距离 (CD);3) 尖锐法线误差 (SNE)。为公平比较,研究人员同时给出潜在编码长度 (LCL)。结果表明,Dora-VAE 在 Dora-bench 中所有的指标都达到了最佳。

- Craftman3d开源代码:https://github.com/wyysf-98/CraftsMan3D/
- Craftman3d项目主页:https://craftsman3d.github.io/
在训练 3D-VAE 的基础上,CraftsMan3D 通过汲取传统建模流程的经验,精心设计了两阶段的技术方案:第一阶段使用原生三维大模型进行初始模型生成。算法先使用 multi-view image diffusion 进行多视图生成,然后将多视图输入到 3D-DiT 扩散模型中来生成拓扑规则的几何和纹理。第二阶段为几何细化阶段,团队使用法向图超分的方案实现高质量法向估计,然后通过可微渲染实现法线图引导的几何细节优化。

阶段一:基于 DiT 的原生三维大模型
团队提出了将三维扩散模型与多视图扩散模型相结合的原生三维生成方案。具体来说,算法使用 3D-VAE 将几何压缩到潜在空间,然后使用 3D-DiT 扩散模型在潜在空间进行生成。对于单个参考图像或文本提示输入,首先将其输入到多视图扩散模型中以获得多视图图像作为三维扩散模型的输入,然后使用三维扩散模型从中学习生成三维几何图形。
团队设计了完善的数据筛选 - 几何水密化 - 渲染等数据处理流程,形成了强大的数据处理平台以支撑原生三维大模型的训练数据。

阶段二:高质量几何细节优化
受限于 3D 大模型常用的隐式表达方案和 VAE 的压缩特性,原生三维生成的物体往往难以具备很高频的几何细节。因此,论文提出了第二阶段交互式几何细节优化,通过法相贴图生成和反向 “烘焙” 优化的方式捕捉高频的几何细节,从而产生高质量的三维资产。

具体来说,该部分通过基于表面法线贴图的扩散模型来实现法线图细节增强,并通过显式三角网格优化增加三维几何细节。团队在原版 stable diffusion 的基础上使用法线数据集微调,并借助 tile 插件实现法相贴图的超分辨率生成。通过这种方式模型既拥有几何细节生成能力,还保留了原有的泛化能力。进一步基于法线贴图优化直接优化三维网格顶点,只需 10 秒,即可在用户绘制的区域添加几何细节,并完全保持其他区域的几何形状。

该技术还支持趣味扩展功能:以人物照片为输入,可生成与输入图像面部特征匹配的 3D 模型,实现 3D 资产快速换脸。

使用Craftman3D三维生成技术方案,普通用户无需复杂操作即可快速搭建出精美的三维模型和场景。无论是游戏开发、影视制作还是建筑室内设计、具身感知虚拟场景,各类创意都能轻松实现。如下图所示,场景中的所有物体均由 Craftman3D 自动生成。

#WonderTurbo
0.72秒生成3D世界!建模提速15倍!极佳&北大等的强势登场,可实时交互!
一种新型的实时交互式 3D 场景生成方法WonderTurbo,能够在 0.72 秒内生成高质量的 3D 场景,建模速度相比传统方法提升了 15 倍。
文章链接:https://arxiv.org/pdf/2504.02261
项目链接:https://wonderturbo.github.io/

从一幅图像开始,用户可以自由调整视角,交互式地控制 3D 场景的生成,每次交互只需 0.72 秒
亮点直击
- 提出了 WonderTurbo,首个实时(推理耗时:0.72 秒)的 3D 场景生成方法,支持用户交互式创建多样化且连贯连接的场景。
- 在几何效率优化方面,提出的 StepSplat 将前馈范式(feed-forward paradigm)扩展至交互式 3D 几何表示,可在 0.26 秒 内加速 3D 场景扩展。此外,引入 QuickDepth 以确保视角变化时的深度一致性。在外观建模效率方面,提出 FastPaint,仅需 2 步推理 即可完成图像修复。
- 通过全面实验验证,WonderTurbo 在实现 15 倍加速 的同时,在几何与外观方面均优于其他方法,可生成高质量的 3D 场景。
总结速览解决的问题
- 实时交互性不足:现有3D生成技术(如WonderWorld)更新单视角需近10秒,无法满足实时交互需求。
- 几何建模效率低:传统3D Gaussian Splattings(3DGS)等方法依赖迭代训练更新几何表示,耗时较长。
- 外观建模速度慢:基于扩散模型的图像修复方法需要大量推理步骤,计算开销大。
- 小视角局限性:现有单图像新视角生成方法仅支持小幅视角变化,难以适应动态交互需求。
提出的方案
- StepSplat:动态更新高效3D几何表示,单次更新仅需0.26秒,支持交互式几何建模。
- QuickDepth:轻量级深度补全模块,为StepSplat提供一致深度先验,提升几何准确性。
- FastPaint:两步扩散模型,专为实时外观修复设计,保持空间一致性,显著减少推理步骤。
应用的技术
- 几何建模:
- 基于前馈式推理(feed-forward)的3D Gaussian Splattings(3DGS)加速,避免迭代训练。
- 特征记忆模块动态构建cost volume,适应视角变化。
- 深度优化:轻量级深度补全网络(QuickDepth)提供稳定深度输入。
- 外观建模:高效扩散模型(FastPaint)仅需2步推理完成修复,兼顾质量与速度。
达到的效果
- 速度突破:
- 单视角生成仅需0.72秒,较基线方法(如WonderWorld)加速15倍。
- StepSplat几何更新仅0.26秒,FastPaint外观修复仅需2步推理。
- 质量与一致性:
- 在CLIP指标和用户评测中领先,保持高空间一致性和输出质量。
- 支持大幅视角变化(如全景相机路径和行走路径)。
- 应用场景:适用于实时3D内容创作、虚拟现实(VR)和交互式设计等场景。
效果展示


方法WonderTurbo 的整体框架
交互式 3D 场景生成受限于计算效率,主要由于几何与外观建模的耗时问题。WonderWorld 提出了 FLAGS 以加速几何建模,但仍需数百次迭代优化几何表示,且其外观建模依赖预训练扩散模型,需数十步推理完成修复。相比之下,WonderTurbo 通过同时加速几何与外观建模,实现实时交互式 3D 场景生成。具体而言,提出 StepSplat 加速几何建模,可在 0.26 秒 内直接推断 3DGS;在此框架下,QuickDepth 在 0.24 秒 内补全缺失深度信息;针对外观建模加速,引入 FastPaint,仅需 0.22 秒 完成图像修复。
下图 2 展示了 WonderTurbo 的流程。在第 次迭代时,给定用户指定位置,FastPaint 基于当前 3D 场景的渲染图像 和用户提供的文本描述,生成新场景外观 。随后,利用渲染深度图 和新生成的外观 生成深度图 ,确保新生成场景的几何结构与现有 3D 场景对齐。最后,StepSplat 以深度图 和新场景外观 为输入,将局部几何 增量融合至全局表示 。下文将详细阐述 StepSplat,QuickDepth 和 FastPaint。

StepSplat
为加速几何建模,本文提出 StepSplat。如下图 3 所示,StepSplat 以位姿 ,图像 及 QuickDepth 提供的对应深度 为输入,首先通过主干网络提取匹配特征 和图像特征 ;随后查询特征记忆模块中邻近视角的匹配特征以构建成本体积(cost volume)。成本体积与 拼接后预测高斯参数。同时,利用 QuickDepth 提供的稳定深度作为几何先验构建成本体积,确保高斯中心点的准确性。最终,通过增量融合策略将当前视角生成的局部几何 合并至全局几何 ,实现连续一致的 3D 表示。

特征记忆模块
本文引入特征记忆模块存储历史视角的匹配特征,用于构建后续成本体积。给定输入图像 和位姿 ,首先通过主干网络提取图像特征 和匹配特征 ,随后将元组 更新至特征记忆模块。为加速推理,采用 RepVGG 作为主干网络。
深度引导的成本体积构建
针对当前视角的成本体积构建,自适应地从特征记忆模块中选择 个邻近视角,并利用 QuickDepth提供的输入深度作为成本体积的深度候选。具体实现时,首先计算当前位姿 与特征记忆模块中所有历史位姿 的距离。

其中 表示 L2 范数。根据这些距离,选择 个最接近当前位姿的位姿,并从记忆模块中提取其对应的匹配特征 ,其中每个 对应 个最近位姿之一。
为确保 3D 表示的一致性,受多视图立体匹配(Multi-View Stereo)的启发,本文利用 指导成本体积的构建。从范围 中均匀采样 个深度候选 ,其计算公式为:

其中 是用于调整深度候选范围的偏移值。然后,使用平面扫描立体算法(plane-sweep stereo)将每个邻近视图的匹配特征 变换到当前视图的候选深度平面 上,特征变换公式表示为:

其中 表示可微分的warping操作。随后计算当前视角特征 与每个warped邻近特征 的归一化点积相关性,并对所有邻近视图的相关性图取平均:

其中 表示候选深度数量,各深度的相关性图被堆叠形成成本体积 。同时,采用额外的2D U-Net进一步精炼和上采样成本体积。对成本体积 进行归一化后,通过对所有深度候选进行加权平均得到预测深度图 :

在获得深度预测后,深度值被反投影作为3D高斯分布(3DGS)的中心点。随后对成本体积和图像特征进行解码以获取其他高斯参数,方法与MVSplat类似。
增量融合
为减少高斯分布的冗余,通过深度约束将局部几何 更新至全局几何 。具体而言,给定具有二维坐标 和深度 的 ,我们使用相机投影矩阵 将全局几何 中的所有高斯分布 投影至当前像素坐标系:

然后通过以下方式构建投影到相同离散像素位置的全局高斯候选集:

为保持几何连续性,从 中剔除违反深度一致性约束的冲突高斯分布。待剪枝的高斯分布定义为集合 中的元素:

其中 控制深度容差。随后通过选择性地将有效局部高斯(即未包含在 中的高斯)合并到现有全局模型中来完成全局模型更新,如以下公式所示:

StepSplat的训练
传统前馈式3DGS方法难以满足交互式3D场景生成的需求,部分原因是数据集的多样性有限(主要集中在自动驾驶或室内环境等特定场景),且这些数据集的视角变化与交互式3D场景生成的要求存在显著差距。本文利用3D生成模型创建包含模拟视角变化的数据集来训练StepSplat。训练时随机选取图像序列逐帧输入模型,生成全局高斯表示,并基于该表示渲染新视角图像,以RGB图像作为监督信号。

QuickDepth
现有深度补全方法虽取得显著进展,但主要针对稀疏深度补全任务,难以处理完全缺失深度信息的区域(交互式3D场景生成的关键需求)。WonderWorld提出免训练的引导深度扩散方法,但单张深度图需3秒以上;Invisible Stitch因缺乏真实数据而采用教师蒸馏与自训练策略,但训练数据有限导致部分场景性能下降。本文提出QuickDepth——基于自建数据集训练的轻量级深度补全模型,具有强泛化能力,可适应多样化场景。
为适配交互式3D场景生成,本文构建包含室内外环境、漫画与艺术作品等多样化场景的数据集。不同于使用随机掩码或投影模拟交互场景的掩码,本文设计了更符合交互需求的相机轨迹:
1.设计相机位姿 ,从数据集获取帧序列 及其对应深度图
2.利用相邻帧几何关系:将前一帧深度图 通过相对位姿 投影至当前帧 坐标系,生成不完整深度图 与二值有效掩码 (无效像素标识需补全区域)
训练时,输入构造方式为:
- 完全掩码目标帧真实深度
- 或选择经变换的深度-掩码对
QuickDepth以轻量预训练深度估计模型初始化,输入目标帧RGB图像、不完整深度图与二值掩码,通过损失监督预测深度与真实深度的差异。
FastPaint
在3D场景生成中,图像修复技术对3D外观建模至关重要。现有方法存在以下局限:
- 空间定位不足:如Pano2Room可从单输入生成全景图像,但难以在用户指定位置生成内容
- 效率瓶颈:WonderJourney和WonderWorld采用基于Stable Diffusion的微调修复模型,但存在:
- 微调时的修复区域与3D场景生成需求不匹配,需额外模型验证生成内容
- 扩散模型需多步推理(通常20+步)
本文提出FastPaint解决方案:
- 推理加速:通过知识蒸馏结合ODE轨迹保持与重构技术,将推理步骤压缩至2步
- 领域适配:构建专用训练数据集,其特点包括:
- 相机位姿模拟交互式3D生成过程
- 通过深度图投影获取掩码(与StepSplat/QuickDepth共享轨迹生成逻辑)
- 确保修复区域与实际应用场景对齐
交互式3D生成数据集
单张图像的交互式3D生成支持多样化风格图像作为输入,但现实数据往往局限于自动驾驶或室内环境等特定场景。这种局限性导致当前3D生成方法泛化能力不足。同时,部分方法直接采用预训练模型构建流程,这些模型可能并非专为交互式3D场景生成设计,因此需要借助视觉语言模型(VLM)来验证生成内容是否符合场景风格或文本要求。
为突破这一限制,本文基于现有3D场景生成方法构建数据集,并利用该数据集训练所有模块。采用多种3D场景生成方法来创建各方法擅长的3D场景,同时使用VLM模型验证生成数据是否符合预设场景。最终数据集包含通过模拟交互轨迹渲染的600多万帧画面,涵盖旋转路径、线性移动和混合轨迹三种运动模式,主要包含四大类场景:室内环境(32%)、城市景观(28%)、自然地形(25%)和风格化艺术场景(15%)。
训练StepSplat时,对相邻输入帧的间距施加约束,避免使用间隔过近的帧,从而更好地契合3D交互生成的实际应用需求。对于FastPaint和QuickDepth模块,则利用相邻帧的深度信息通过投影获取对应掩膜。
实验
本节将介绍实验设置(包括实现细节和评估指标),随后通过定量与定性结果证明WonderTurbo在性能和效率上的优越性,最后通过消融实验验证各模块的有效性。
实验设置
基线方法:在对比分析中,本文选取了具有代表性的离线与在线3D生成方法。离线方法包括通过多视角图像生成3D场景的LucidDreamer和Text2Room,以及直接生成全景图再提升至3D的Pano2Room和DreamScene360。在线方法则评估了WonderJourney和WonderWorld。所有对比均采用各方法的官方代码实现。
评估指标:遵循WonderWorld的设定,本文采用CLIP分数(CS)、CLIP一致性(CC)、CLIP-IQA+(CIQA)、Q-Align和CLIP美学分数(CA)作为评估指标,并辅以用户研究收集视觉质量的主观反馈(详见补充材料)。
实现细节:为确保全面评估,本文使用LucidDreamer、WonderJourney和WonderWorld的输入图像,针对4组测试案例各生成8个场景(总计32个场景)。评估采用固定全景相机视角,并以相同视域内场景生成时间作为效率对比指标。
主要结果
生成速度:交互式3D生成的时间成本至关重要。如下表1所示,即便采用FLAGS加速,对比方法中最快的WonderWorld仍需超过10秒生成场景。LucidDreamer和Text2Room需为每个新场景生成多视角,显著增加了外观建模时间;而Pano2Room和DreamScene360虽无需多视角生成,但全景图生成延迟和逐场景优化需求严重制约效率。值得注意的是,WonderTurbo在几何与外观建模上均表现优异,总体加速达15倍。

定量结果:下表2对比了WonderTurbo与多种3D生成方法。实验表明,在线生成方法因更贴合用户文本需求,其CLIP分数和一致性优于离线方法。WonderWorld在所有基线中领先,而WonderTurbo在加速15倍的同时仍保持与之相当的指标性能。此外,由于针对交互任务微调,WonderTurbo在CLIP分数、一致性、CLIP-IQA+和美学分数上均有提升。

用户研究:下表3,用户研究表明WonderTurbo在生成时间更低的情况下达到与WonderWorld相当的生成质量,并在用户偏好度上显著优于其他方法。

定性结果:下图5展示了相同设置下WonderTurbo与基线方法的生成效果对比。可见WonderTurbo在显著缩短生成时间的同时保持了竞争力:DreamScene360和Pano2Room因泛化能力有限出现几何失真且美学表现不足;LucidDreamer和Text2Room则存在内容错位与提示细节缺失问题;而WonderTurbo与WonderWorld的结果质量接近,均展现出优异性能。

消融实验
几何建模:本文对比了FreeSplat、DepthSplat等几何建模方法(均采用相同微调设置以确保公平)。如下表4所示,依赖无监督深度估计的FreeSplat和DepthSplat在Q-Align和CLIP美学分数上显著劣于StepSplat。而StepSplat通过一致性深度图指导代价体积构建,实现了自适应交互式3D场景生成。

StepSplat分析:针对深度引导代价体积(depth guided cost volume)与渐进融合(incremental infusion)的消融实验如下表5所示。结果表明:深度引导代价体积是精确几何建模与图像质量的关键;渐进融合则通过减少冗余高斯分布和避免浮点问题提升性能。

FastPaint验证:与预训练修复模型的对比显示,FastPaint显著增强了3D外观建模能力,各项指标均有提升。
讨论与结论
尽管单图像3D场景生成取得进展,但耗时的几何优化与视角细化仍制约效率。为此,提出实时交互框架WonderTurbo:
- 几何加速:StepSplat可在0.26秒内扩展3D场景并保持高视觉质量,QuickDepth为代价体积构建提供一致性深度先验
- 外观建模:FastPaint仅需2步推理即可完成空间一致的外观建模
实验表明,WonderTurbo能精准实现文本到3D的生成,在CLIP指标和用户偏好率上均优于基线方法,同时获得15倍加速。
参考文献
[1] WonderTurbo: Generating Interactive 3D World in 0.72 Seconds
#HiMoR
3D高斯还能这么表示?HiMoR实现高质量单目动态三维重建
单目实现动态重建
动态三维场景重建旨在从视频数据中恢复动态场景的几何、外观和运动信息。所重建的动态三维模型可以在任意时间点进行自由视角渲染,使其在虚拟现实、视频制作等方面具有实际应用价值,甚至为个人提供了一种创新方式,用于捕捉和重温他们的美好回忆。
随着三维高斯喷溅(3DGS)研究的兴起,一些方法尝试通过联合学习高斯及其变形,从多视角视频中重建动态三维场景。然而,由于信息受限,尤其是缺乏多视角一致性约束,从单目视频中进行重建仍然具有较大的挑战性。
近期的研究集中于为高斯设计更优的变形模型,以更好地整合跨帧的时间信息,从而克服单目视频中信息不足的问题。例如,Shape of Motion(SoM)提出了一组全局运动基底,为每个高斯分配决定其运动的系数,基于运动通常是平滑且简单的这一认识,换句话说是低秩的。由于整个场景只共享少量的全局运动基底,因此难以捕捉到细致的运动变化。
另一个代表性方法 MoSca 使用数百个三维节点建模运动,每个高斯从周围节点中插值得到其变形。这种大量的运动节点带来了极高的自由度,使得优化容易对训练视角产生过拟合。其他方法也面临类似的问题:要么难以捕捉精细细节,要么由于过拟合导致在空间和时间维度上无法实现平滑的高质量重建。
为了解决上述问题,本文介绍一种新颖的分层运动表示方法[1],能够在粗略与精细两个层面上同时建模运动。这种方法可以实现对动态三维场景的高质量单目重建,同时保持时空一致性并呈现细节。
具体来说,我们的分层运动表示采用树状结构实现,每个节点表示其相对于父节点的相对运动。在假设根节点固定在世界坐标原点的前提下,可以通过树状结构的层级关系迭代地推导出每个节点相对于世界坐标的全局运动。该设计允许不同层级的节点表达不同层次的运动细节,从而实现粗略与精细运动的有效分解。
核心思想是:在日常生活场景中,精细的运动通常与粗略的运动相关联。例如,手指的运动可以分解为手指相对于手腕的精细运动,再加上手臂的粗略运动。这种分解的优势在于,它不仅能简化复杂运动的学习过程,还能够提供更合理的运动表示:粗略运动有效捕捉时空平滑性,而精细运动则增强了细节的表达能力。
此外,从评估的角度来看,我们发现,由于单目动态场景重建任务本身高度不适定,常用的像素级指标(例如 PSNR)容易受到诸如深度模糊或摄像机参数估计不准确等因素的影响,因此在像素错位时难以准确反映重建质量。因此,我们提出采用感知指标来评估渲染质量。定量结果也表明,这种感知指标与人类主观感知更加一致。
我们在多个标准基准数据集上对所提出的方法进行了评估,结果在定性和定量上均优于现有方法。尤其值得注意的是,我们的方法在运动的时空平滑性以及细节还原方面实现了显著提升。
主要贡献:
- 提出了一种新颖的分层运动表示方法,将复杂的运动分解为平滑的粗略运动和细致的精细运动,为高斯提供了更具结构性的变形方式,从而提升了对动态三维场景的表达能力。
- 指出现有像素级指标在评估单目动态场景渲染质量方面存在的局限性,并提出采用更合适的感知指标进行评估。
- 在定性和定量评估中均达到了当前最先进的效果。
项目链接:https://pfnet-research.github.io/himor/
具体方法
给定一个具有已校准相机参数的单目视频,该视频表示一个动态场景,我们的目标是重建一个动态的三维高斯表示,其中包括规范帧中的高斯和用于对其进行变形的运动序列。
预备知识:三维高斯喷溅
三维高斯喷溅使用一组各向异性的三维高斯基元来表示静态场景,从而实现实时的真实感渲染。每个三维高斯基元 的参数包括:
- 均值
- 协方差矩阵
- 不透明度
- 通过球谐系数 所决定的视角相关颜色,其中 是球谐系数的阶数
从参数为 的相机进行渲染时,每个三维高斯首先被投影为图像平面上的二维高斯,其均值和协方差分别为:
然后,二维高斯按照深度排序,并通过高效的可微光栅化器使用 alpha 混合进行渲染,计算如下:
其中,
为像素位置, 为与该像素射线相交的高斯数量。
为了将三维高斯扩展至动态场景,可对高斯施加变形,将其从静态的规范帧变换至目标帧。设从规范帧到时间 的变换为 ,则变形后的高斯为:
其中 与 在时间上保持不变。
分层运动表示
我们方法的核心在于提出一种分层运动表示,用于对三维高斯进行变形,以实现动态三维场景重建。具体而言,分层运动表示是一个树状图结构,每个节点表示相对于其父节点的 运动序列。高斯的变形通过其在规范帧中附近叶子节点的运动加权计算得出。
表达形式
我们首先介绍分层运动表示的表达形式。树中的每个节点都表示一个随时间变化的 变换序列:
其中 表示该节点从规范帧到时间 的变换。虽然可以直接为每个节点分配一个独立的运动序列,但我们考虑到运动的低秩特性,提出使用共享的运动基底来建模节点的运动。
一个运动基底表示为一组随时间变化的 变换序列:
我们的目标是将目标运动序列表示为若干运动基底的加权和。设某父节点有 个子节点,使用 个运动基底 ,每个子节点有权重系数 ,则该子节点的运动为:
这种表达是递归定义的,其中根节点的运动固定为单位矩阵。作为父节点时,节点拥有一组运动基底;作为子节点时,节点拥有相应的加权系数。树结构中,根节点只作为父节点,叶子节点只作为子节点,中间节点既作为父节点也作为子节点。
由于该结构具有层级性,每个节点的运动表示其相对于父节点的相对运动,而非绝对运动。这种建模方式允许将运动分解为浅层节点表示的粗略部分和深层节点表示的精细部分,保留细节表达能力的同时简化了复杂运动的学习。每个节点相对于世界坐标的全局运动可以通过层层组合其上级节点的 变换获得。
我们提出分层结构的动机有两方面:一是日常生活中的运动通常可以分解为粗略、细致甚至更细致的部分,因此我们采用层次树结构以实现从粗到细的建模;二是运动具有低秩性质,且邻近区域的运动通常相似,因此我们仅使用有限的运动基底和节点进行建模。
高斯的变形
根据上述分层运动结构,我们可以计算所有节点的运动序列。对于非叶子节点(有子节点的节点),其运动表示为下一层更精细节点提供粗略的运动基础;而叶子节点则拥有最精细的运动,我们用它们来指导高斯的变形。
设高斯 的变形为 ,其由附近的叶子节点集合 中的 个最近邻节点的运动加权插值得出:
其中, 表示高斯 在规范帧中最接近的 个叶子节点的索引, 是权重,通过以下高斯函数计算:
其中 和 分别是第 个节点在规范帧中的位置和影响半径, 是归一化因子。我们使用双四元数进行插值以获得更好的插值效果。
与对每个高斯单独建模变形的方法不同,从运动节点插值得到的变形场在空间上更加平滑。同时,运动节点可以从更大范围内的高斯接收梯度,从而使变形优化更加稳定。
初始化
由于单目动态三维重建问题本身具有高度的不适定性,我们参考以往工作,使用预训练模型(如二维跟踪、深度估计)来初始化运动表示。
在优化初期,分层结构仅包含一层节点(即图中的橙色节点,其父节点为根节点)。随着优化进行,节点层级逐步扩展。
初始化阶段需确定第一层节点共享的运动基底及每个节点的系数。我们首先通过相对深度图对前景的二维轨迹进行反投影,获得三维轨迹。然后使用 K-Means 聚类得到 个聚类中心,从而定义 条三维轨迹。由于这些轨迹仅包含平移分量,我们通过时间序列上的 Procrustes 配准求解其旋转部分,获得 个完整的 序列作为运动基底。我们选择三维轨迹可见点最多的帧作为规范帧,从该帧中采样节点位置,并使用基于距离的反比加权方式初始化每个节点的运动基底系数。
更精细层级的节点在优化过程中迭代添加。操作过程与第一层节点初始化类似:对每个叶子节点,先选取一定范围内的高斯,并计算其相对于该节点的相对运动。再对这些相对运动使用 K-Means 聚类,聚类中心作为子节点共享的运动基底。子节点从这些高斯中下采样得到,并根据其位置与运动基底中心的距离初始化系数。与第一层节点不同的是,此处使用的是已配向的高斯,因此不再需要求解 Procrustes 问题。
节点加密
由于初始节点仅由规范帧中可见区域的三维轨迹构建,难以有效建模规范帧中不可见区域的运动。因此,我们采用逐步节点加密策略来覆盖整个场景中的运动。
类似于三维高斯密度增强的策略,可依据光度损失梯度添加新高斯。以往工作也采用了类似的基于梯度的节点添加策略。但我们发现,仅依赖该策略可能不足。例如,对于颜色较为均匀但初始节点稀疏的区域,仍可能无法生成新节点,导致运动无法被充分建模。
因此我们提出更直观的策略:对于每个高斯,若其附近的节点密度不足以提供有效的运动插值,则在其周围添加新节点。我们通过计算高斯与其 个最近邻节点之间的轨迹曲线距离来衡量节点密度:
其中 表示两个点随时间变化的轨迹, 为欧氏范数。对于曲线距离超过设定阈值的高斯,我们在其附近添加新节点。
我们在优化初期周期性地应用该策略,在若干步之后,再结合以往方法中提出的基于梯度的策略进一步添加或剪枝节点。
损失函数设计
刚性损失
刚性损失通过限制相邻区域中的位移、速度等变化,来对变形进行约束,从而实现局部刚性运动,并更好地保持几何结构。已有工作采用了类似的刚性损失来约束运动。
然而,这些方法常面临两难局面:约束过弱可能不起作用,导致运动发散;而约束过强则可能抑制对精细运动的表达。
得益于我们分层结构的设计,我们可以根据节点所在的层级,施加不同强度的约束。具体来说,对浅层节点施加更强的刚性约束,以强化其平滑、粗略的运动;对深层节点则施加更弱的约束,从而使其能灵活地捕捉精细运动。分层结构与层级约束强度的结合,使得我们能够以从粗到细的方式分解运动。
总体损失
为了缓解单目视频重建问题的病态性,我们在优化过程中引入了预训练模型的知识,并通过多项损失函数来约束学习过程。总损失包括以下项:
- 渲染损失
- 前景掩膜损失
- 深度损失
- 跟踪损失
- 刚性损失
其中,掩膜损失 使用预训练的分割模型生成的前景掩膜作为监督;深度损失 使用由单目深度估计模型预测的相对深度图作为监督,并与 Lidar 深度或 COLMAP 深度对齐。为了更好地恢复运动,我们引入了跟踪损失 ,该损失度量渲染出的点与预训练二维跟踪模型预测的点之间的误差。
将这些损失结合后,最终总损失函数表达如下:
其中各项的权重为经验设定。我们对规范帧中的高斯和分层运动表示(HiMoR)进行联合优化以最小化上述总损失。
实验效果
总结一下
HiMoR是一种结合3D高斯表示的全新分层运动表示方法,显著提升了单目动态三维重建的质量。HiMoR 利用树状结构,以由粗到细的方式表示运动,为高斯提供了更具结构性的变形方式。我们还指出了像素级指标在评估单目动态三维重建时的局限性,并提出使用更可靠的感知指标作为替代。
局限性:对于在规范帧中不存在的部分(例如新出现的物体或新暴露的场景区域),难以进行准确的建模。
未来方向:可以考虑为新出现的物体提供单独的分支,或设计一个自适应的规范空间。
参考
[1] HiMoR: Monocular Deformable Gaussian Reconstruction with Hierarchical Motion Representation
#三维部件编辑与自动绑定框架
D领域「源神」又开了两个新项目
在不久之前报道文章《3D领域DeepSeek「源神」启动!国产明星创业公司,一口气开源八大项目》中,我们曾介绍到,国内专注于构建通用 3D 大模型的创业公司 VAST 将持续开源一系列 3D 生成项目。
近日,新的开源项目它来了,包括针对任意三维模型生成完整可编辑部件的 HoloPart 与通用自动绑定框架 UniRig。
今天,就让我们一起围观下这两个新的3D开源项目。
- HoloPart:为任意三维模型生成完整、可编辑的部件
论文标题:HoloPart: Generative 3D Part Amodal Segmentation
论文地址: https://arxiv.org/abs/2504.07943
项目主页: https://vast-ai-research.github.io/HoloPart
代码地址: https://github.com/VAST-AI-Research/HoloPart
Demo: https://huggingface.co/spaces/VAST-AI/HoloPart
huggingface daily paper:https://huggingface.co/papers/2504.07943
3D 内容生产面临的一个关键痛点,是三维模型的部件及编辑挑战。
你是否曾尝试编辑网上下载的、扫描得到的、或是 AI 生成的三维模型?它们往往是「一整坨」的几何体,想要调整、驱动或重新赋予某个独立部件(比如椅子腿、角色眼镜)不同的材质都极其困难。

现有的三维部件分割技术能识别出属于不同部件的可见表面块,但往往得到的是破碎、不完整的碎片,这极大地限制了它们在实际内容创作中的应用价值。
HoloPart 引入了一项新任务:三维部件完整语义分割(3D Part Amodal Segmentation)——它不仅是将三维形状分解为可见的表面块,而是分解成其背后完整的、包含语义信息的部件,甚至能推断出被遮挡部分的几何结构,即使部分被遮挡也能生成完整部件。
,时长01:10
开发者可以在huggingface上试玩。
,时长01:46
「看见」完整部件
HoloPart 是一种新型扩散模型,由 VAST 和港大联合研发。受到非模式化感知(Amodal Perception,即人类即使在物体部分被遮挡时也能感知到完整物体的能力)的启发,研究团队通过一个实用的两阶段方法来实现:
- 初始分割:首先,利用现有的先进方法(如 SAMPart3D)获得初始的表面块(即不完整的部件)。
- HoloPart 部件补全:这是关键所在。将不完整的部件块,连同整个形状的上下文信息一起,输入到新颖的 HoloPart 模型中。HoloPart 基于强大的扩散变换器(Diffusion Transformer)架构,能够生成该部件完整且合理的 3D 几何形状。

HoloPart 工作原理
HoloPart 不仅仅是「填补空洞」。它基于 TripoSG 三维生成基础模型的生成先验构建,通过在大型数据集(如 Objaverse)上进行广泛预训练,并在部件 - 整体数据上进行专门微调,从而获得了对三维几何的深刻理解。
针对部件补全这一特定任务,HoloPart 对 TripoSG 的扩散变换器架构进行了适配。其关键创新在于双重注意力机制:
- 局部注意力(Local Attention):聚焦于输入表面块的精细几何细节,确保补全后的部件与可见几何无缝衔接。
- 上下文感知注意力(Context - Aware Attention):关注整体形状以及该部件在其中的位置。这一关键步骤确保补全的部件在全局上是合理的——保持比例、语义和整体形状的一致性。
这使得 HoloPart 能够智能地重建隐藏的几何细节,即使对于复杂部件或存在严重遮挡的情况,也能尊重物体的整体结构。
在该项目中,研究团队还利用 ABO 和 PartObjaverse - Tiny 数据集建立了新的基准测试来评估这项新任务。实验证明,在处理这种具有挑战性的部件补全任务时,HoloPart 的性能显著优于现有的各种先进形状补全方法。
从效果上看,差异是肉眼可见的:其他方法在处理复杂结构时常常失败或产生不连贯的结果,而 HoloPart 则能持续生成高质量、高保真的完整部件,并与原始形状完美契合。


解锁下游应用
通过生成完整的部件,HoloPart 解锁了一系列以前难以甚至无法自动实现的强大应用:
- 直观编辑:轻松抓取、缩放、移动或替换完整部件(如图中的戒指、图中的汽车编辑)。
- 便捷的材质分配:将纹理或材质清晰地赋予给完整的组件。
- 适用于动画的资产:生成适合绑定和动画制作的部件。
- 更智能的几何处理:通过处理连贯的部件,实现更鲁棒的网格重划分 (Remeshing) 等几何操作。
- 部件感知的生成:这项工作为未来能够在部件层面创建或操纵三维形状的生成模型奠定了基础。
- 几何超分辨率:HoloPart 甚至展示了通过用高数量的 token 来表征部件,从而提升部件细节的潜力。

- 统一模型绑定万物:UniRig 通用自动绑定框架

- 论文标题:One Model to Rig Them All: Diverse Skeleton Rigging with UniRig
- 论文链接:https://zjp-shadow.github.io/works/UniRig/static/supp/UniRig.pdf
- 代码地址:https://github.com/VAST-AI-Research/UniRig
- 项目主页:https://zjp-shadow.github.io/works/UniRig/
- HuggingFace 主页:https://huggingface.co/VAST-AI/UniRig
核心方法:自回归预测与创新的 Tokenization
UniRig 的核心在于借鉴了驱动语言和图像生成领域进步的大型自回归模型的力量。
但 UniRig 预测的不是像素或文字,而是 3D 骨骼的结构——逐个关节地进行预测。这种序列化的预测过程是确保生成拓扑结构有效骨骼的关键。
实现这一目标的关键创新是骨骼树 Tokenization (Skeleton Tree Tokenization) 方法。
将具有复杂关节相互依赖关系的层级化骨骼结构,表示为适合 Transformer 处理的线性序列并非易事。UniRig 的方案高效地编码了:
- 关节坐标:骨骼关节的离散化空间位置。
- 层级结构:明确的父子关系,确保生成有效的树状结构。
- 骨骼语义:使用特殊 Token 标识骨骼类型(例如,Mixamo 等标准模板骨骼,用于头发 / 布料模拟的动态弹簧骨骼),这对于下游任务和实现逼真动画至关重要。
这种优化的 Tokenization 方案,与朴素方法相比,序列长度减少约 30%,使得基于 OPT 架构的自回归模型能够有效地学习骨骼结构的内在模式,并以形状编码器处理后的输入模型几何信息作为条件。

不止骨骼:精准蒙皮与属性预测
在预测出有效的骨骼后,UniRig 采用骨骼 - 表面交叉注意力 (Bone - Point Cross Attention) 机制来预测每个顶点的蒙皮权重。该模块有效地捕捉了每根骨骼对其周围模型表面的复杂影响,融合了来自模型和骨骼的几何特征,并通过关键的测地线距离信息增强了空间感知能力。
此外,UniRig 还能预测骨骼特定属性(如弹簧骨骼的刚度和重力影响),使得基于学习参数的、更符合物理规律的次级运动成为可能。研究团队在训练中通过可微分的物理模拟对此进行了评估,以增强最终结果的真实感。

,时长00:16
Rig - XL 数据集:以数据驱动泛化能力
强大的模型离不开高质量数据的支撑。为了训练 UniRig 以获得广泛的适用性,研究团队还整理构建了 Rig-XL——一个全新的、包含超过 14000 个多样化已绑定 3D 模型的大规模数据集。
Rig - XL 源自 Objaverse - XL 等资源并经过精心清洗,涵盖多个类别(双足、四足、鸟类、昆虫、静态物体等),为训练一个真正具备泛化能力的绑定模型提供了必要的规模和多样性。研究团队还利用 VRoid 数据集进一步优化模型在处理包含弹簧骨骼的精细动漫风格角色上的性能。




业界最优的性能表现
UniRig 显著提升了自动绑定技术的现有水平:
- 高精度:在多个关键指标上远超现有学术界和商业方法,在具有挑战性数据集上,绑定精度(关节预测)提升 215%,动画精度(动画下的网格变形)提升 194%。
- 强通用性:在广泛的模型类别上展现出鲁棒性能——精细角色、动物、复杂的有机和无机形态——这些都是以往方法经常遇到困难的领域。
- 高鲁棒性:生成拓扑合理的骨骼和真实的蒙皮权重,在动画驱动下产生优于先前学术方法及常用商业工具的变形效果。
- 高效率:优化的 Tokenization 和模型架构带来了实用的推理速度(1-5 秒)。

#SLAM3R
基于单目视频的实时密集3D场景重建
北京大学陈宝权团队和香港大学等高校及业界机构联合推出实时三维重建系统 SLAM3R,首次实现从长视频(单目 RGB 序列)中实时且高质量地重建场景的稠密点云。SLAM3R 使用消费级显卡(如 4090D)即可达到 20+ FPS 的性能,重建点云的准确度和完整度达到当前最先进水平,同时兼顾了运行效率和重建质量。
该研究成果被 CVPR 2025 接收为 Highlight 论文,并在第四届中国三维视觉大会(China3DV 2025)上被评选为年度最佳论文,合作者为董思言博士(共同一作)、王书哲博士、尹英达博士、杨言超助理教授和樊庆楠博士,第一作者为北京大学本科生刘宇政。
- 论文标题:SLAM3R: Real-Time Dense Scene Reconstruction from Monocular RGB Videos
- 论文地址:https://arxiv.org/pdf/2412.09401
- 代码地址:https://github.com/PKU-VCL-3DV/SLAM3R
,时长00:22
SLAM3R 的交互界面(视频经过加速)。用户只需使用普通手机摄像头拍摄 RGB 视频,即可通过部署于服务器的 SLAM3R 系统实时重建出高质量的场景稠密点云,将二维视频转化为"可交互"、"可编辑"的三维世界。
在计算机视觉与机器人感知领域,基于单目摄像头的高质量三维环境感知与重建一直是个极具挑战性的课题——这主要是因为需要从有限的二维观测中恢复在相机投影过程中丢失的三维空间信息。过去的三十年间,研究者们建立了较为完善的多视角几何理论和计算框架,通常依赖多种算法的集成,包括运动恢复结构(Structure-from-Motion,简称 SfM)、同时定位和地图构建(Simultaneous Localization and Mapping,简称 SLAM)以及多视角立体视觉(Multi-View Stereo,简称 MVS)等。
由于拥有扎实的数学原理和优化算法作为"护城河",三维重建领域较少受到神经网络等深度学习方法的"入侵"。在传统方法中,神经网络主要作为算法流程的辅助模块,用于提升特征匹配的鲁棒性和深度估计的完整性。近年来,随着以 DUSt3R 为代表的大型神经网络模型出现,这一传统范式正在改变:通过端到端的前馈神经网络,可以直接从多视角 RGB 图像预测三维几何,避免了传统方法中迭代优化所带来的效率瓶颈。
SLAM3R(发音:/slæmər/)进一步革新了这一范式的演进,首次将大模型应用于长视频序列的稠密重建任务。该方案通过前馈神经网络,将局部多视角三维重建与全局增量式坐标配准无缝集成,为基于单目 RGB 视频输入的稠密点云重建提供了高效率解决方案,无需迭代优化相机参数或三维点云。实验结果表面,SLAM3R 不仅在多个数据集上展现出最先进的重建质量,还能在消费级显卡上保持 20+ FPS 的实时性能。更为重要的是,SLAM3R 的成功展示了纯数据驱动的方法在长视频序列三维几何感知任务中的潜力,为未来重建系统的研究提供了新思路。
,时长00:13
SLAM3R 渐进式重建过程展示。输入 RGB 图像序列(如左上图所示)后,SLAM3R 首先进行局部多视角三维重建(左下图),然后执行全局增量式坐标配准(右图),从而逐步构建完整场景的点云模型。
SLAM3R 渐进式重建过程展示。输入 RGB 图像序列(如左上图所示)后,SLAM3R 首先进行局部多视角三维重建(左下图),然后执行全局增量式坐标配准(右图),从而逐步构建完整场景的点云模型。
三位一体的挑战:准确、完整、高效
基于多视角几何理论的传统方法通常将三维重建分为两个阶段:首先通过 SLAM 或 SfM 算法估计相机参数和场景结构,然后使用 MVS 算法补充场景的几何细节。这类方法虽然能够获得高质量的重建结果,但是需要离线优化等处理,因此实时性能较差。
近年来,DROID-SLAM 和 NICER-SLAM 等集成了相机定位和稠密重建的 SLAM 系统相继问世。然而,这些系统或是重建质量不够理想,或是无法达到实时运行的要求。DUSt3R 开创性地提出端到端的高效点云重建,但其仅局限于图像对(双目),在视频场景下仍需全局迭代优化,因而影响了效率。同期工作 Spann3R 虽将 DUSt3R 扩展为增量重建方式并提高了效率,但也带来了明显的累积误差,降低了重建质量。
此外,重建的准确度和完整度之间存在着固有的权衡关系,导致当前重建系统难以同时实现准确、完整和高效这三个目标。因此,在单目视频稠密重建领域中,要同时达到高质量和高效率极具挑战性。
SLAM3R:大模型时代背景下的实时稠密重建系统
DUSt3R 首次证明了大型神经网络模型的 Scaling Law 在双目立体视觉中的可行性。SLAM3R 在此基础上更进一步,通过引入传统 SLAM 系统的经典设计理念,成功将大模型应用于长视频序列的稠密重建任务。这种端到端的方法不仅具有天然的高运行效率,而且经过大规模训练后能达到高质量的重建效果,从而实现了一个在准确度、完整读和效率方面都表现出色的三维重建系统。

SLAM3R 系统示意图。给定单目 RGB 视频,SLAM3R 使用滑动窗口机制将其转换为互有重叠的片段(称为窗口)。每个窗口输入至 Image-to-Points(I2P)网络,用于恢复局部坐标系中的稠密点云。随后,这些局部点逐步输入至 Local-to-World(L2W)网络,以创建全局一致的场景模型。I2P 网络选择一个关键帧作为参考建立局部坐标系,并利用窗口中的其余帧估计该窗口的稠密点云。第一个窗口用于建立世界坐标系,之后 L2W 网络逐步融合后续窗口。在增量融合过程中,系统检索最相关的已注册关键帧作为参考,并整合新的关键帧。通过这个迭代过程,最终完成整个场景的重建。
SLAM3R 主要由两个部分组成:Image-to-Points(I2P)网络和 Local-to-World(L2W)网络。I2P 网络负责从视频片段中恢复局部坐标系下的稠密点云,而 L2W 网络则将局部重建结果逐步注册到全局场景坐标系中。在整个点云重建过程中,系统直接使用网络在统一坐标系中预测 3D 点云,无需显式计算相机参数和三角化场景点云,从而避免了传统重建方法中迭代优化等耗时的操作。
窗口内的多视角三维重建(I2P 网络)。在每个窗口内,选择一帧作为关键帧来建立参考系,其余帧(称为支持帧)用于辅助该关键帧的重建。我们基于 DUSt3R 解码器设计了关键帧解码器,通过引入简单的最大值池化操作来聚合多个支持帧的交叉注意力特征,从而有效整合多视角信息。这一改进在保持模型结构简洁的同时具有多重优势:1)继承 DUSt3R 预训练权重,从而保证预测质量;2)未引入过多计算开销,保持实时性能;3)支持任意数量的图像输入,具有良好的扩展性。
窗口间的增量式点云注册(L2W 网络)。窗口间的注册与窗口内的重建相似,不同之处在于前者使用多帧重建结果作为参考系,用以辅助注册新的关键帧。因此,L2W 采用了 I2P 的整体架构。在此基础上,引入简单的坐标编码器来处理点云输入,并通过逐层特征叠加的方式注入解码器。这种机制让模型在解码过程中持续接收几何和坐标系的双重引导,既确保了信息传递的充分性,又避免了复杂特征交互设计带来的计算负担。这一设计巧妙地继承了 DUSt3R 的坐标转换能力,并将其转化为可控的注册过程。
场景帧检索模块。我们提出了一种前馈检索机制,用于确定 L2W 网络在注册新关键帧时所使用的参考帧。当 SLAM3R 系统需要调用 L2W 融合新窗口(关键帧)时,系统会先通过场景帧检索模块从已注册窗口中检索 K 个最优参考帧,再将这些参考帧与新帧一同输入 L2W 模型进行坐标系转换。这种设计既保持了全局一致性,又有效缓解了传统 SLAM 系统中的累积误差问题。检索模块通过在 I2P 网络中附加额外的轻量级 MLP 实现,完成前馈式快速检索。
大规模训练。SLAM3R 系统的各个模块均采用前馈式神经网络实现,最大程度地复用了 DUSt3R 大规模预训练的权重,并在大规模视频数据集上进行训练。具体来说,我们收集了约 85 万个来自 ScanNet++、Aria Synthetic Environments 和 CO3D-v2 数据集的视频片段,使用 8 张 4090D 显卡进行训练。训练完成后,该系统可在单张 4090D 显卡上实现实时推理。
单目视频稠密重建迈入高质高效新时代
我们在室内场景数据集 7-Scenes 和 Replica 上评估了 SLAM3R。在重建速度较快(FPS 大于 1)的方法中,SLAM3R 实现了最佳的准确度和完整度。


7-Scenes(上方表格)和 Replica(下方表格)数据集的重建结果评估。我们以厘米为单位报告重建的准确度和完整性。FPS 栏目的颜色渐变从红色变为黄色,再变为绿色,表示实时性能提升。
值得特别指出的是,即使没有进行任何后续全局优化,SLAM3R 的重建质量也达到了与需要复杂优化的离线方法相当的水平。这表明 SLAM3R 在准确度、完整度和运行效率三方面达到了理想的平衡。
,时长00:14
SLAM3R 基于公开数据集与日常视频的场景重建结果展示。
未来展望
SLAM3R 在保持 20+ FPS 实时性能的同时,其重建质量可达到离线方法相近的水平,旨在推动三维重建向高质量、高效率方向发展。通过将传统多阶段的三维重建流程简化为轻便的前馈网络,SLAM3R 降低了使用门槛,使三维重建有望从专业领域拓展至大众化应用。随着模型轻量化技术的突破,该方案未来有望进一步应用于移动终端,为三维资产快速获取、通用人工智能和具身智能的落地提供基础三维数据支持。
目前,SLAM3R 仍存在诸多局限性。由于跳过了相机参数预测和优化等环节,SLAM3R 无法执行显式的全局优化(Bundle Adjustment)。因此,在大规模场景中,系统仍会受到累积误差的影响。此外,基于场景重建推导出的相机参数的精度仍不如专门针对相机定位的 SLAM 系统。解决这些局限性是我们未来工作的重点。
#RealtimeDynamic
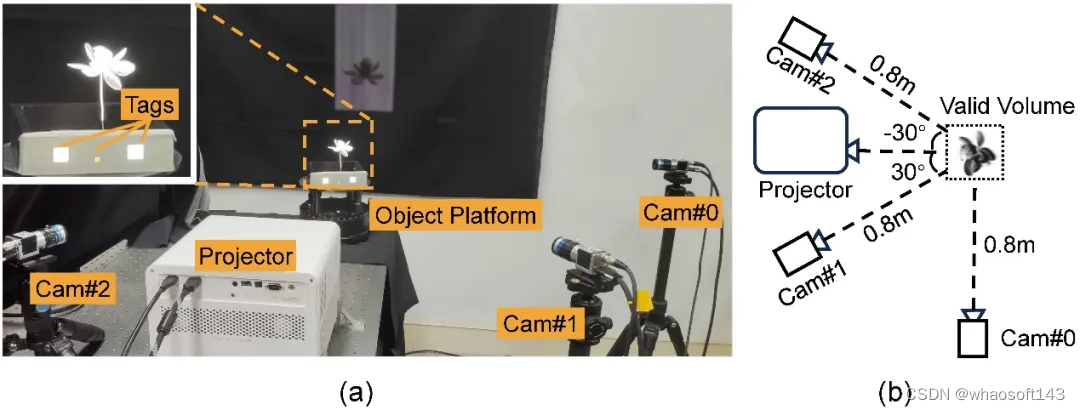
仅使用包含单投影仪和少量相机(1 或者 3 台)的轻量级硬件原型,把建模单个三维密度场(空间分辨率 128x128x128)的结构光图案数量降到 6 张,实现每秒 40 个三维密度场的高效采集。
对于烟雾等动态三维物理现象的高效高质量采集重建是相关科学研究中的重要问题,在空气动力学设计验证,气象三维观测等领域有着广泛的应用前景。通过采集重建随时间变化的三维密场度序列,可以帮助科学家更好地理解与验证真实世界中的各类复杂物理现象。

图 1:观测动态三维物理现象对科学研究至关重要。图为全球最大风洞 NFAC 对商用卡车实体开展空气动力学实验 [1]。
然而,从真实世界中快速获取并高质量重建出动态三维密度场相当困难。首先,三维信息难以通过常见的二维图像传感器(如相机)直接测量。此外,高速变化的动态现象对物理采集能力提出了很高的要求:需要在很短的时间内完成对单个三维密度场的完整采样,否则三维密度场本身将发生变化。这里的根本挑战是如何解决测量样本和动态三维密度场重建结果之间的信息量差距。
当前主流研究工作通过先验知识弥补测量样本信息量不足,计算代价高,且当先验条件不满足时重建质量不佳。与主流研究思路不同,浙江大学计算机辅助设计与图形系统全国重点实验室的研究团队认为解决难题的关键在于提高单位测量样本的信息量。
该研究团队不仅利用 AI 优化重建算法,还通过 AI 帮助设计物理采集方式,实现同一目标驱动的全自动软硬件联合优化,从本质上提高单位测量样本关于目标对象的信息量。通过对真实世界中的物理光学现象进行仿真,让人工智能自己决定如何投射结构光,如何采集对应的图像,以及如何从采样样本中重建出动态三维密度场。最终,研究团队仅使用包含单投影仪和少量相机(1 或者 3 台)的轻量级硬件原型,把建模单个三维密度场(空间分辨率 128x128x128)的结构光图案数量降到 6 张,实现每秒 40 个三维密度场的高效采集。
值得一提的是,团队在重建算法中创新性地提出轻量级一维解码器,将局部入射光作为解码器输入的一部分,在不同相机所拍摄的不同像素下共用了解码器参数,大幅降低网络的复杂程度,提高计算速度。为融合不同相机的解码结果,又设计结构简单的 3D U-Net 聚合网络。最终重建单个三维密度场仅需 9.2ms,相对于 SOTA 研究工作 [2,3],重建速度提升 2-3 个数量级,实现三维密度场的实时高质量重建。相关研究论文《Real-time Acquisition and Reconstruction of Dynamic Volumes with Neural Structured Illumination》已被计算机视觉顶级国际学术会议 CVPR 2024 接收。
- 论文链接:https://svbrdf.github.io/publications/realtimedynamic/realtimedynamic.pdf
- 研究主页:https://svbrdf.github.io/publications/realtimedynamic/project.html
相关工作
根据采集过程中是否控制光照可以把相关工作分为以下两大类。
第一类基于非可控光照的工作不需要专门的光源,在采集过程中不控制光照,因此对采集条件要求较宽松 [2,3]。由于单视角相机拍摄到的是三维结构的二维投影,因此难以高质量区分不同的三维结构。对此,一种思路是增加采集视角采样数,如使用密集相机阵列或光场相机,这会导致高昂的硬件成本。另一种思路仍然在视角域稀疏采样,通过各类先验信息来填补信息量缺口,如启发式先验、物理规则或从现有数据中学习的先验知识。一旦先验条件在实际中不满足,这类方法的重建结果会质量下降。此外,其计算开销过于昂贵,无法支持实时重建。
第二类工作采用可控光照,在采集过程中对光照条件进行主动控制 [4,5]。此类工作对光照进行编码以更主动地探测物理世界,还减少对先验的依赖,从而获得更高的重建质量。根据同时使用单灯还是多灯,相关工作可以进一步分类为扫描方法和光照多路复用方法。对于动态的物理对象,前者必须通过使用昂贵的硬件来达到高扫描速度,或者牺牲结果的完整性来减少采集负担。后者通过同时对多个光源进行编程,显著提高了采集效率。但是对于高质量的快速实时密度场,已有方法的采样效率仍然不足 [5]。
浙大团队的工作属于第二类。和大多数现有工作不同的是,本研究工作利用人工智能来联合优化物理采集(即神经结构光)与计算重建,从而实现高效高质量动态三维密度场建模。
硬件原型
研究团队搭建由单个商用投影仪(BenQ X3000:分辨率 1920×1080, 速度 240fps)和三个工业相机(Basler acA1440-220umQGR:分辨率 1440×1080, 速度 240fps)组成的简单硬件原型(如图 3 所示)。通过投影仪循环投射 6 个预训练得到的结构光图案,三个相机同步进行拍摄,并基于相机采集到的图像进行动态三维密度场重建。四个设备相对于采集对象的角度是由不同仿真实验模拟后所选出的最优排布。
软件处理
研发团队设计由编码器、解码器和聚合模块组成的深度神经网络。其编码器中的权重直接对应采集期间的结构光照亮度分布。解码器以单像素上测量样本为输入,预测一维密度分布并插值到三维密度场。聚合模块将每个相机所对应解码器预测的多个三维密度场组合成最终的结果。通过使用可训练结构光以及和轻量级一维解码器,本研究更容易学习到结构光图案,二维拍摄照片和三维密度场三者之间的本质联系,不容易过拟合到训练数据中。以下图 4 展示整体流水线,图 5 展示相关网络结构。
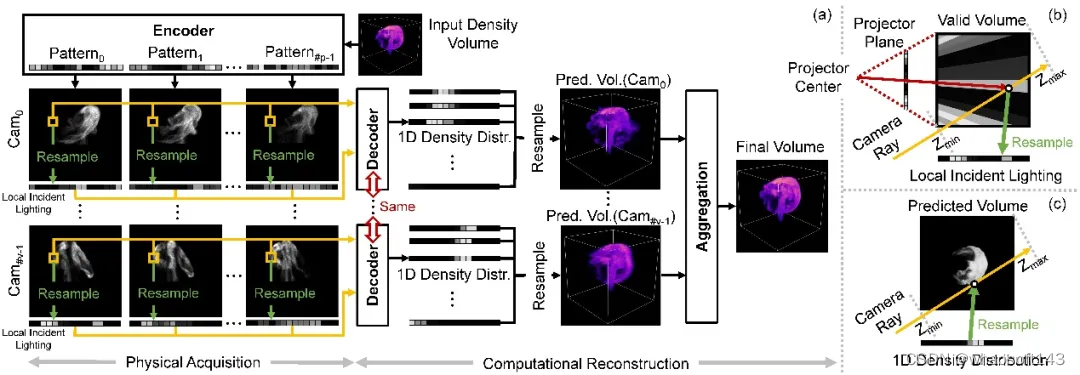
图 4:整体采集重建流水线 (a),以及从结构光图案到一维局部入射光 (b) 和从预测的一维密度分布回到三维密度场 (c) 的重采样过程。该研究从仿真 / 真实的三维密度场开始,首先将预先优化的结构光图案(即编码器中的权重)投影到该密度场。对于每个相机视图中的每个有效像素,将其所有测量值以及重采样的局部入射光送给解码器,以预测对应相机光线上的一维密度分布。然后收集一台相机的所有密度分布并将其重采样到单个三维密度场中。在多相机情况下,该研究融合每台相机的预测密度场以获得最终结果。
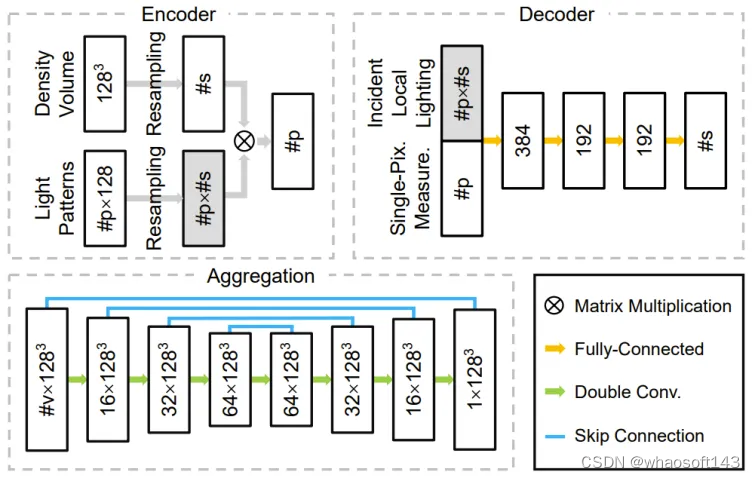
图 5:网络 3 个主要部件的架构:编码器、解码器和聚合模块。
结果展示
图 6 展示本方法对四个不同动态场景的部分重建结果。为生成动态水雾,研究人员将干冰添加到装有液态水的瓶子中制造水雾,并通过阀门控制流量,并使用橡胶管将其进一步引导至采集装置。
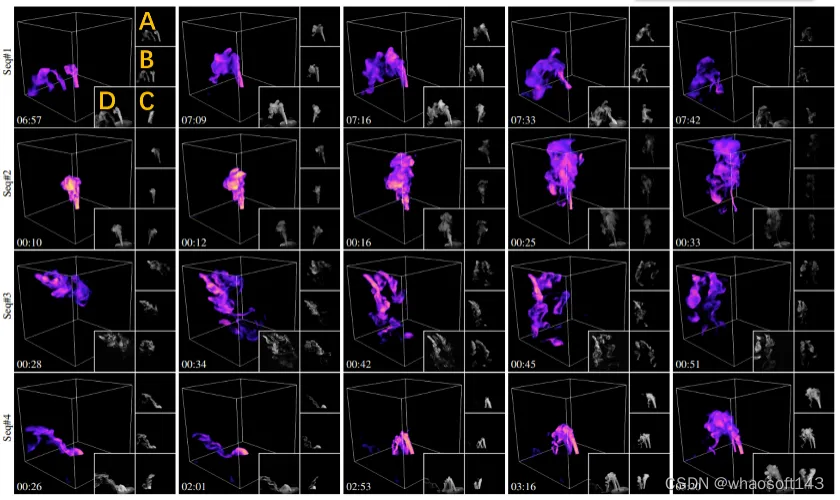
图 6:不同动态场景的重建结果。每一行是某水雾序列中选取部分重建帧的可视化结果,从上到下场景水雾源个数分别为:1,1,3 和 2。如左上方的橙色标注所示,A,B,C 分别对应三个输入相机所采集的图像,D 为和重建结果渲染视角类似的实拍参考图像。时间戳在左下角展示。详细的动态重建结果请参见论文视频。
为了验证本研究的正确性和质量,研究团队在真实静态物体上把本方法和相关 SOTA 方法进行对比(如图 7 所示)。图 7 也同时对不同相机数量下的重建质量进行对比。所有重建结果在相同的未采集过的新视角下绘制,并由三个评价指标进行定量评估。由图 7 可知,得益于对采集效率的优化,本方法的重建质量优于 SOTA 方法。

研究团队也在动态仿真数据上对不同方法的重建质量进行定量对比。图 8 展示仿真烟雾序列的重建质量对比。详细的逐帧重建结果请参见论文视频。

图 8:仿真烟雾序列上不同方法的比较。从左到右依次为真实值,本方法,PINF [3] 和 GlobalTrans [2] 重建结果。输入视图和新视图的渲染结果分别显示在第一行和第二行中。定量误差 SSIM/PSNR/RMSE (×0.01) 展示在相应图像的右下角。整个重建序列的误差平均值请参考论文补充材料。另外,整个序列的动态重建结果请参见论文视频。
未来展望
研究团队计划在更先进的采集设备(如光场投影仪 [6])上应用本方法开展动态采集重建。团队也期望通过采集更丰富的光学信息(如偏振状态),从而进一步减少采集所需的结构光图案数量和相机数量。除此之外,将本方法与神经表达(如 NeRF)结合也是团队感兴趣的未来发展方向之一。最后,让 AI 更主动地参与对物理采集与计算重建的设计,不局限于后期软件处理,这可能能为进一步提升物理感知能力提供新的思路,最终实现不同复杂物理现象的高效高质量建模。
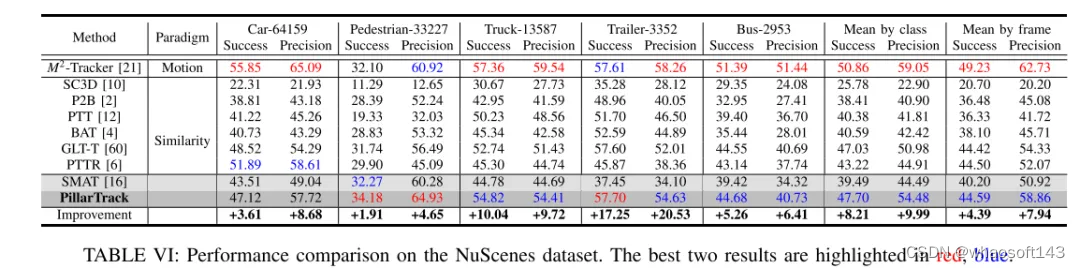
#PillarTrack
原标题:PillarTrack: Redesigning Pillar-based Transformer Network for Single Object Tracking on Point Clouds
论文链接:https://arxiv.org/pdf/2404.07495v1
代码链接:https://github.com/StiphyJay/PillarTrack
作者单位:南昌大学 东南大学 Houmo AI
重新思考基于Pillar的点云单目标跟踪网络
论文思路:
基于激光雷达的三维单目标跟踪(3D SOT)在机器人技术和自动驾驶领域是一个关键问题。它旨在基于相似性或运动从搜索区域获取精确的三维边界框(BBox)。然而,现有的3D SOT方法通常遵循基于点的流程,在这一流程中,采样操作不可避免地导致信息的冗余或丢失,从而导致意外的性能表现。为了解决这些问题,本文提出了PillarTrack,一个基于柱状结构的三维单目标跟踪框架。首先,本文将稀疏点云转化为密集的柱状结构以保留局部和全局的几何特征。其次,本文引入了金字塔式编码的柱状特征编码器(PE-PFE)设计来帮助每个柱状结构的特征表示。第三,本文从模态差异的角度出发,提出了一个高效的基于Transformer的主干网络。最后,本文基于上述设计构建了本文的PillarTrack跟踪器。在KITTI和nuScenes数据集上进行的广泛实验证明了本文所提方法的优越性。值得注意的是,本文的方法在KITTI和nuScenes数据集上均实现了最先进的性能,并且能够实现实时跟踪速度。本文希望本文的工作能够鼓励社区重新思考现有的3D SOT跟踪器设计。
主要贡献:
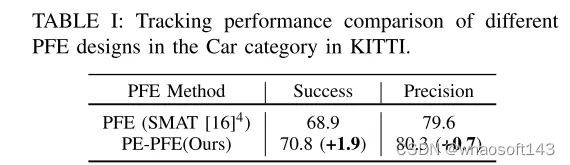
- PE-PFE:采用金字塔型编码的柱状特征编码器(Pyramid-type Encoding Pillar Feature Encoder, PE-PFE)设计,用以对每个柱状结构的点坐标进行金字塔型表示编码,并在不增加额外计算开销的情况下带来性能提升。
- 感知模态的基于Transformer的主干网络:更适合点云模态,旨在增强特征表征。这种设计涉及对主干网络前端计算资源的简单调整,允许捕获输入点云的更多语义细节。
- SOTA和开源:在KITTI和nuScenes数据集上的实验表明,本文的方法达到了最先进的性能。此外,本文将在 https://github.com/StiphyJay/PillarTrack 向研究社区开源本文的代码。
网络设计:
三维单目标跟踪(3D SOT)在自动驾驶和机器人技术中有着广泛的应用。给定第一帧中特定目标的初始状态(外观和位置),三维单目标跟踪旨在估计其在后续帧中的三维状态。现有基于激光雷达的三维单目标跟踪方法[1]–[7]通常遵循从二维视觉目标跟踪中借鉴的孪生范式,旨在实现运行时间和准确性之间的权衡。面对稀疏和不规则的输入点云,这些方法最初利用PointNet系列[8]、[9]学习逐点的区分性表征,然后通过特征聚合模块获得逐点的相似性。最后,他们基于这些相似性特征估计特定目标的状态。SC3D[10]作为首个基于激光雷达的三维孪生跟踪器,利用基于PointNet[11]的高效自编码器进行逐点特征编码。随后,像P2B[2]、3D-SiamRPN[1]、BAT[4]和PTT[3]、[12]这样的方法采用PointNet++[9]来提取更有效的逐点表征,并实现更优越的跟踪性能。然而,上述基于点的三维SOT方法的一个共同问题是需要将输入点重新采样为固定数量。例如,P2B[2]需要将搜索区域的输入点重新采样为1024个,模板点云(template point cloud)为512个,以对齐网络输入。这种重采样操作不可避免地引入了冗余或丢失信息的可能性,这可能会对性能产生不利影响。此外,依赖于三维空间中的点查询/检索(例如,PointNet++[9])进行重新采样过程可能不利于高效的硬件实现。
为此,受到基于柱状结构的三维目标检测器[13]–[15]近期取得的进展的启发,考虑到它们的实时速度和高性能,本文将稀疏不规则的点云转换为密集规则的柱状表示。值得注意的是,三维SOT任务可以被视为在局部搜索区域内的特定三维目标检测任务,附加了模板点先验信息。因此,利用来自三维点云检测的先进原理来改进点云跟踪任务是自然而然的选择。具体而言,基于柱状结构的点云表示具有以下优势:(1)柱状表示是密集有序的,便于无需太多修改就与先进的基于二维图像的技术无缝集成。(2)柱状表示的紧凑特性减少了计算开销,同时保持了性能和速度之间理想的权衡。(3)柱状表示对部署友好,非常适合资源有限的设备,如移动机器人或无人机。特别是,柱状表示自然符合三维跟踪器的高实时性要求,使其非常适合跟踪任务。
目前,很少有工作[16]、[17]致力于基于柱状结构的三维单目标跟踪(3D SOT)点云研究。SMAT[16]通过将稀疏的三维点云转换为密集的柱状结构,然后利用 transformer-based 编码器进行多尺度特征提取和交互来解决这一差距,取得了有希望的结果。然而,SMAT直接采用了来自PointPillars[18]的简单柱状编码模块,这限制了柱状表示的质量。此外,它们的主干网络直接遵循为RGB图像量身定制的 vision transformers 的设计原则,这对于点云模态可能并不是最优的。PTTR++[17]引入了逐点视图和柱状视图的融合,以进一步增强PTTR[6]的性能。尽管如此,PTTR++在其流程中仍然涉及重采样操作,这带来了实际部署上的挑战。
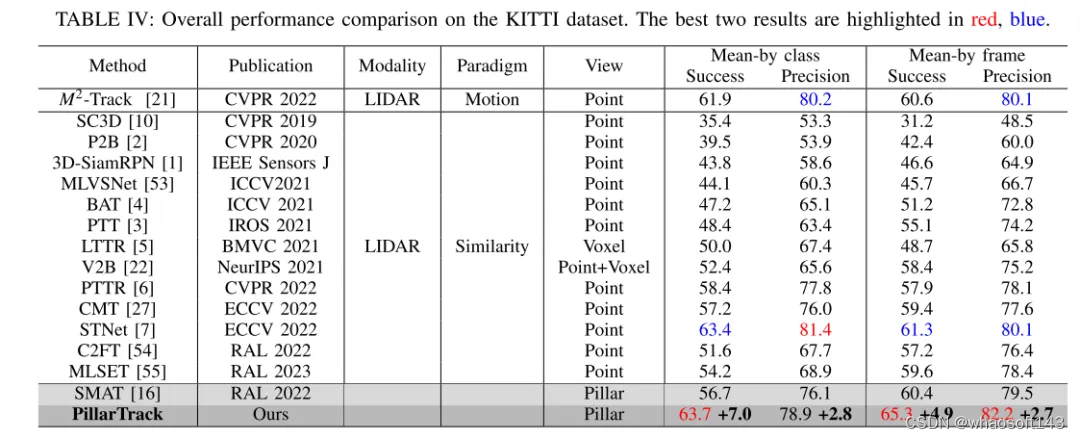
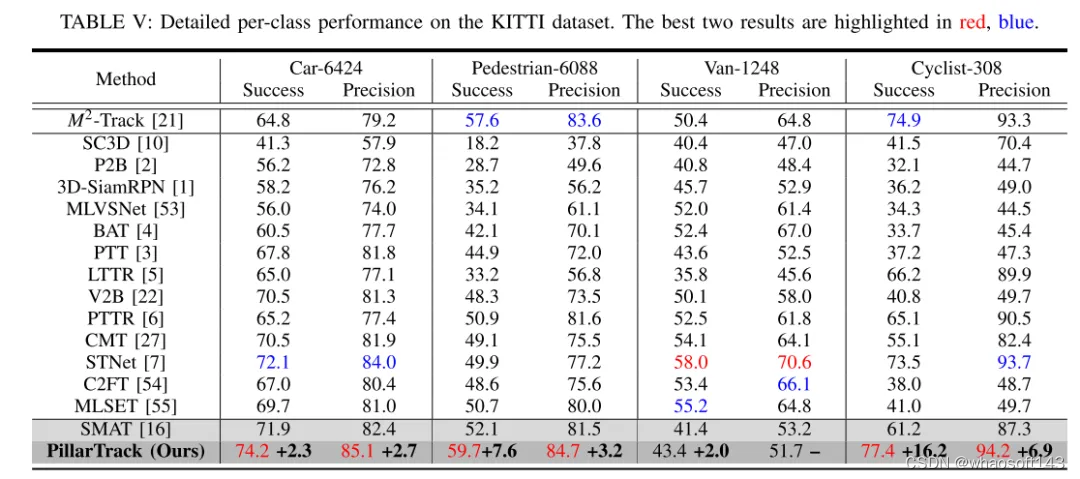
本文提出了PillarTrack,这是一个基于柱状结构的三维单目标跟踪框架,旨在在提高跟踪性能的同时增强推理速度。首先,本文将稀疏无序的点云转换为密集规则的柱状表示,以减少由重采样操作造成的信息丢失,并提出了金字塔型编码的柱状特征编码器(PE-PFE)设计,以帮助每个柱状结构的特征学习。其次,本文从模态差异的角度出发,针对现有 transformer-based 主干网络进行了设计,并提出了一种适用于点云模态的、感知模态的 transformer-based 主干网络,以较少的GFLOPs实现更高的性能。最后,本文构建了本文的PillarTrack网络。在KITTI和nuScenes数据集上进行的广泛实验证明了本文所提方法的优越性。如图1所示,本文的方法在KITTI和nuScenes数据集上实现了最先进的性能,更好地平衡了速度和准确性,并满足了多样的实际需求。
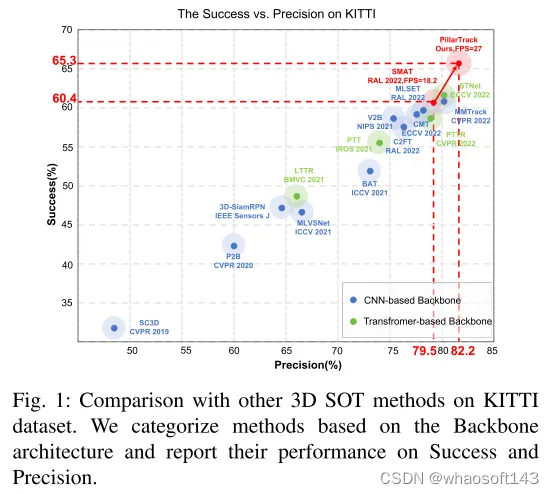
图 1:在KITTI数据集上与其他三维单目标跟踪(3D SOT)方法的比较。本文根据主干网络架构对方法进行了分类,并报告了它们在成功率和精确度上的性能。
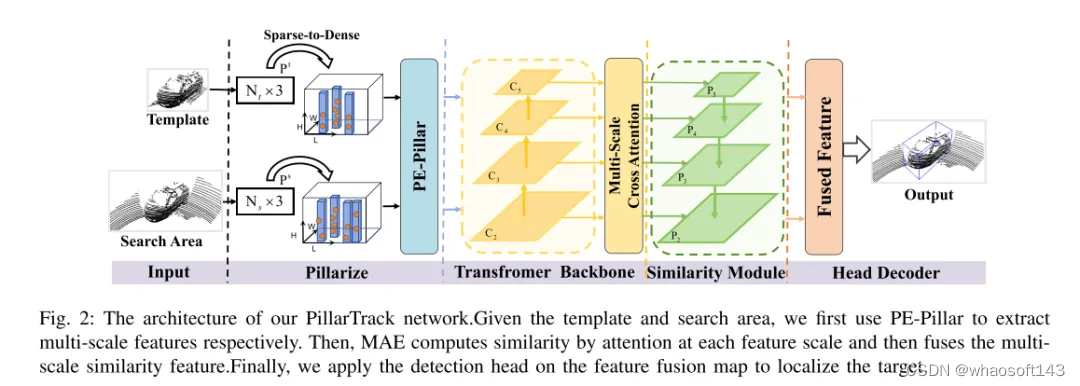
图 2:本文的PillarTrack网络架构。给定模板和搜索区域,本文首先使用PE-Pillar分别提取多尺度特征。然后,MAE通过在每个特征尺度上的注意力机制计算相似性,接着融合多尺度的相似性特征。最后,本文在特征融合图上应用检测头来定位目标。
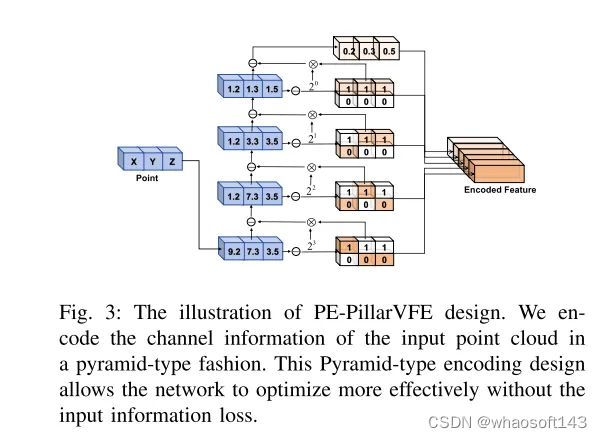
图 3:PE-PillarVFE设计的示意图。本文以金字塔型方式编码输入点云的通道信息。这种金字塔型编码设计使得网络能够在没有输入信息丢失的情况下更有效地进行优化。
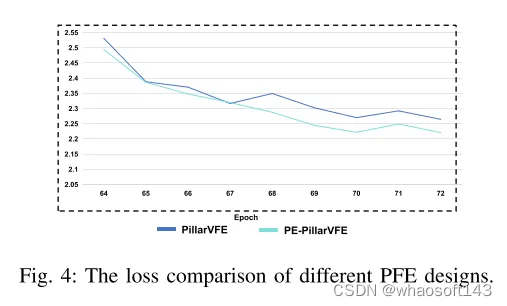
图 4:不同PFE设计的损失比较。
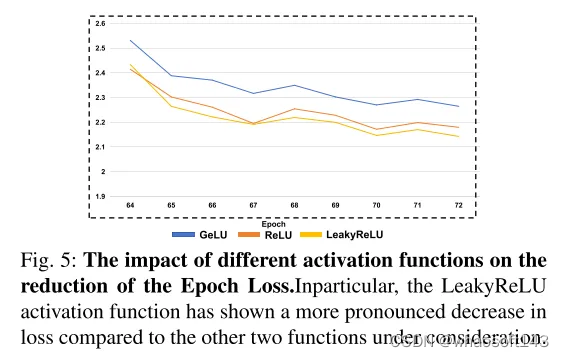
图 5:不同激活函数对降低Epoch损失的影响。特别是,LeakyReLU 激活函数与考虑中的其他两个函数相比,显示出更为明显的损失减少。
实验结果:
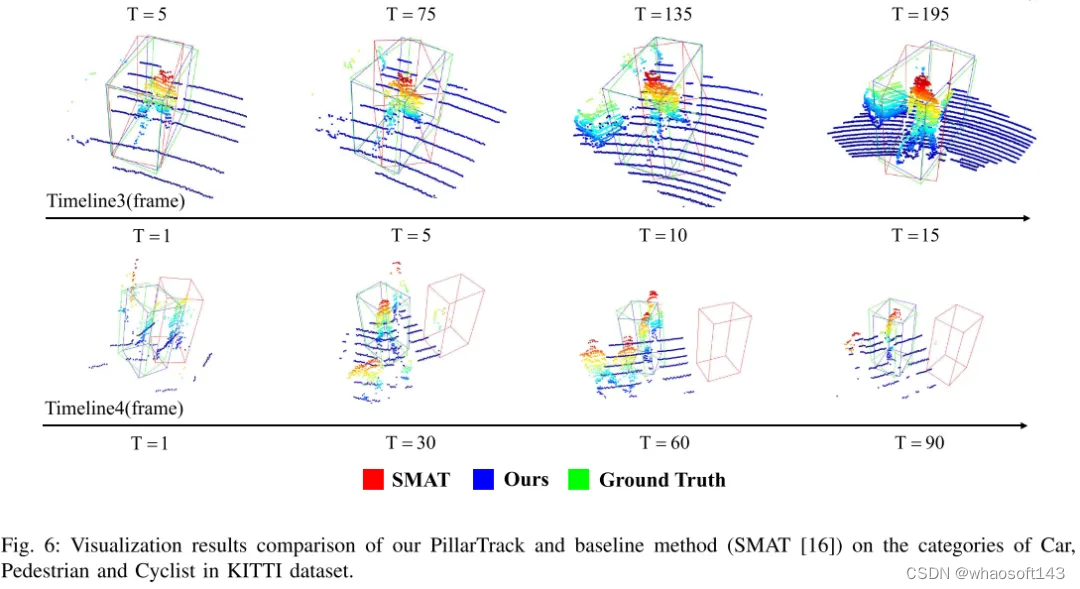
图 6:在KITTI数据集的汽车、行人和骑行者类别上,本文的PillarTrack与基准方法(SMAT [16])的可视化结果比较。
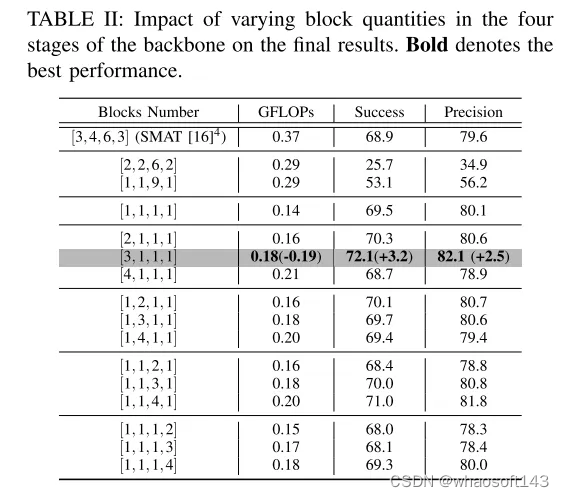
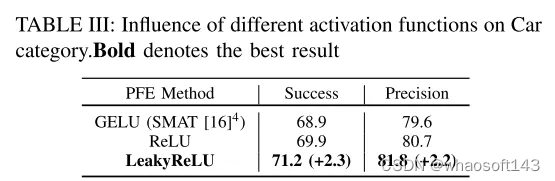
总结:
本文提出了PillarTrack,这是一个基于柱状结构的三维单目标跟踪框架,它在减少计算开销的同时提高了性能。该框架引入了金字塔型编码的柱状特征编码器(PE-PFE)、一个感知模态的基于Transformer的主干网络,以及一个简单的激活函数替换。本文在KITTI数据集上进行的广泛实验证明了PillarTrack的卓越性能,实现了速度和准确性之间更好的权衡。基于上述设计及其效率,本文希望激励社区重新思考基于点云的三维单目标跟踪网络的设计。
#CR3DT
本文介绍了一种用于3D目标检测和多目标跟踪的相机-毫米波雷达融合方法(CR3DT)。基于激光雷达的方法已经为这一领域奠定了一个高标准,但是其高算力、高成本的缺陷制约了该方案在自动驾驶领域的发展;基于相机的3D目标检测和跟踪方案由于它的成本较低,也吸引了许多学者的关注,但是检测效果较差。因此,将相机与毫米波雷达融合正在成为一个很有前景的方案。作者在现有的相机框架BEVDet下,融合毫米波雷达的空间和速度信息,结合CC-3DT++跟踪头,显著提高了3D目标检测和跟踪的精度,中和了性能和成本之间的矛盾。
主要贡献
传感器融合架构 提出的CR3DT在BEV编码器的前后均使用中间融合技术来集成毫米波雷达数据;而在跟踪上,采用一种准密集外观嵌入头,使用毫米波雷达的速度估计来进行目标关联。
检测性能评估 CR3DT在nuScenes 3D检测验证集上实现了35.1%的mAP和45.6%的nuScenes检测分数(NDS)。利用雷达数据中包含的丰富的速度信息,与SOTA相机检测器相比,检测器的平均速度误差(mAVE)降低了45.3%。
跟踪性能评估 CR3DT在nuScenes跟踪验证集上的跟踪性能为38.1% AMOTA,与仅使用相机的SOTA跟踪模型相比,AMOTA提高了14.9%,跟踪器中速度信息的明确使用和进一步改进显著减少了约43%IDS的数量。
模型架构
该方法基于BEVDet架构,融合RADAR的空间与速度信息,结合CC-3DT++跟踪头,该头在其数据关联中明确使用了改进的毫米波雷达增强检测器的速度估计,最终实现了3D目标检测和跟踪。
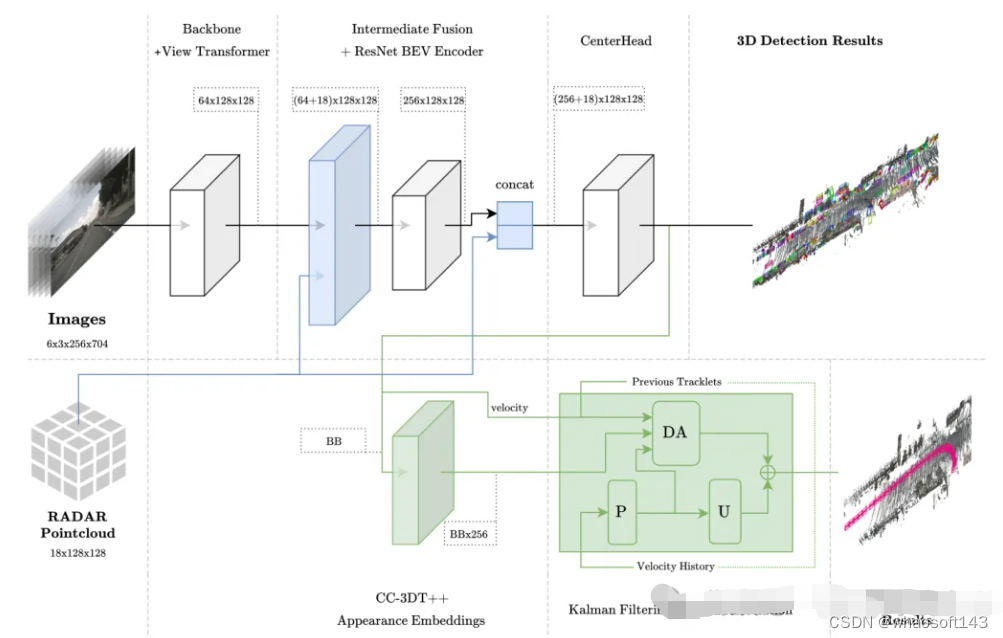
图1 整体架构。检测和跟踪分别以浅蓝色和绿色突出显示。
BEV 空间中的传感器融合
如图2所示是聚合到BEV空间以进行融合操作的Radar点云可视化结果,其中的LiDAR点云仅用于可视化对比。该模块采用类似PointPillars的融合方法,包括其中的聚合和连接,BEV网格设置为[-51.2, 51.2],分辨率为0.8,从而得到一个(128×128)的特征网格。将图像特征直接投射到BEV空间中,每个网格单元的通道数是64,继而得到图像BEV特征是(64×128×128);同样的,将Radar的18个维度信息都聚合到每个网格单元中,这其中包括了点的x,y,z坐标,并且不对Radar数据做任何增强。作者认为Radar点云已经包含比LiDAR点云更多的信息,因此得到了Radar BEV特征是(18×128×128)。最后将图像BEV特征(64×128×128)和Radar BEV特征(18×128×128)直接连接起来((64+18)×128×128)作为BEV特征编码层的输入。在后续的消融实验中发现,在维度为(256×128×128)的BEV特征编码层的输出中添加残量连接是有益的,从而使CenterPoint检测头的最终输入大小为((256+18)×128×128)。
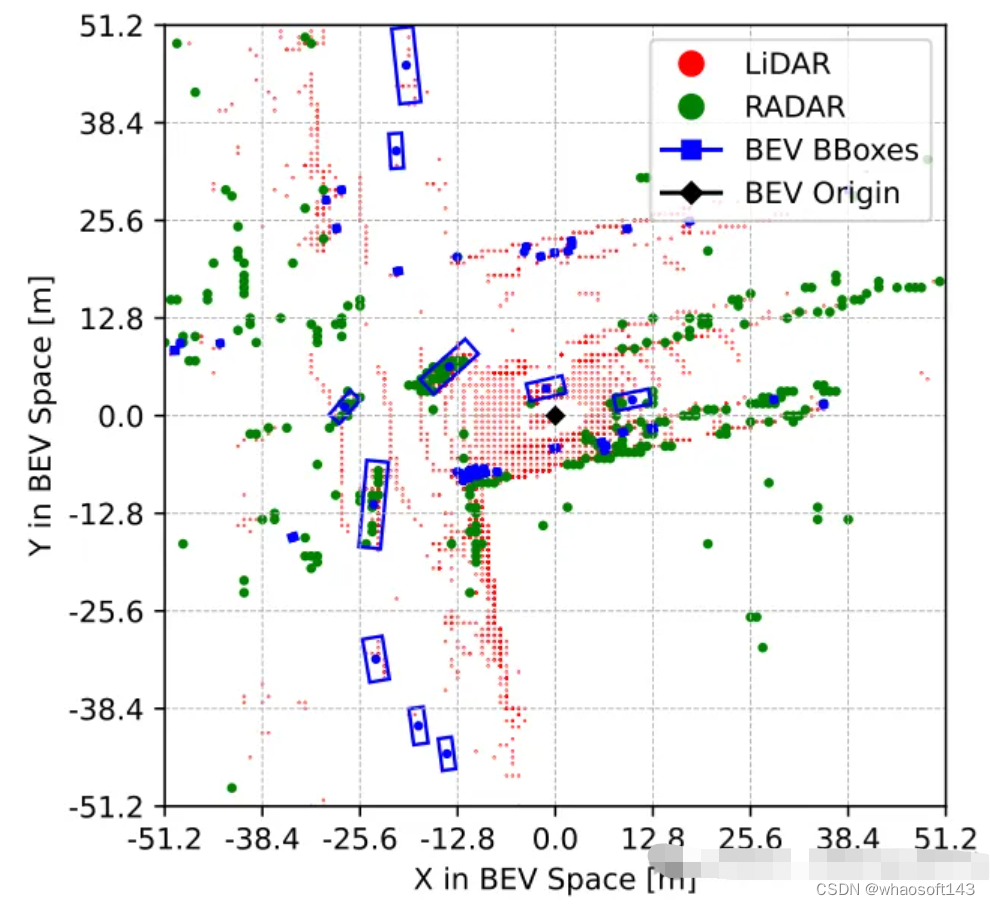
图2 聚合到BEV空间进行融合操作的Radar点云可视化
跟踪模块架构
跟踪就是基于运动相关性和视觉特征相似性将两个不同帧的目标关联起来。在训练过程中,通过准密集多元正对比学习获得一维视觉特征嵌入向量,然后在CC-3DT的跟踪阶段同时使用检测和特征嵌入。对数据关联步骤(图1中DA模块)进行了修改,以利用改进的CR3DT位置检测和速度估计。具体如下:

实验及结果
基于nuScenes数据集完成,且所有训练均没有使用CBGS。
受限制模型
因为作者整个模型是在一台3090显卡的电脑上进行的,所以称之为受限制模型。该模型的目标检测部分以BEVDet为检测基线,图像编码的backbone是ResNet50,并且将图像的输入设置为(3×256×704),在模型中不使用过去或者未来的时间图像信息,batchsize设置为8。为了缓解Radar数据的稀疏性,使用了五次扫描以增强数据。在融合模型中也没有使用额外的时间信息。
对于目标检测,采用mAP、NDS、mAVE的分数来评估;对于跟踪,使用AMOTA、AMOTP、IDS来评估。
目标检测结果
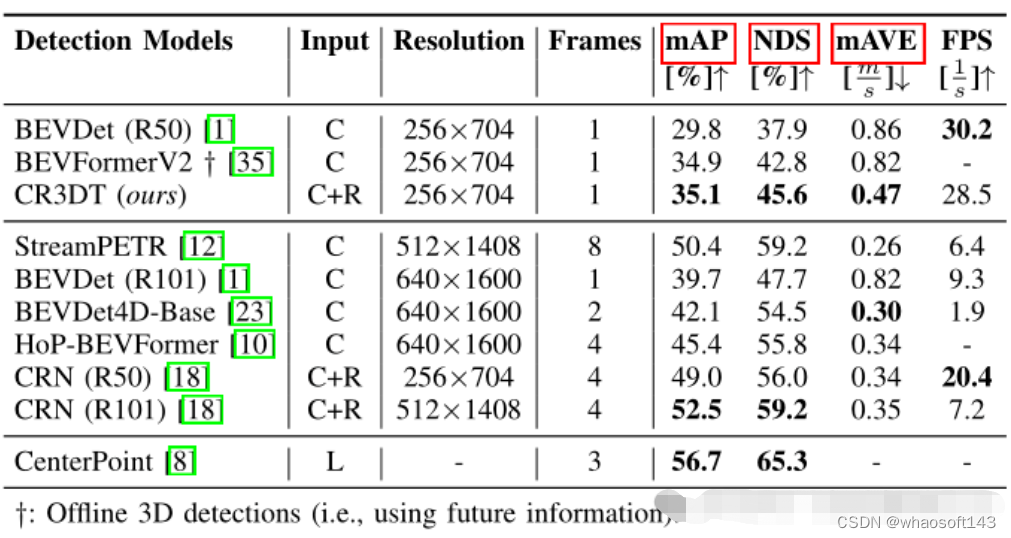
表1 在nuScenes验证集上的检测结果
表1显示了CR3DT与仅使用相机的基线BEVDet (R50)架构相比的检测性能。很明显,Radar的加入显著提高了检测性能。在小分辨率和时间帧的限制下,与仅使用相机的BEVDet相比,CR3DT成功地实现了5.3%的mAP和7.7%的NDS的改进。但是由于算力的限制,论文中并没有实现高分辨率、合并时间信息等的实验结果。此外在表1中最后一列还给出了推理时间。
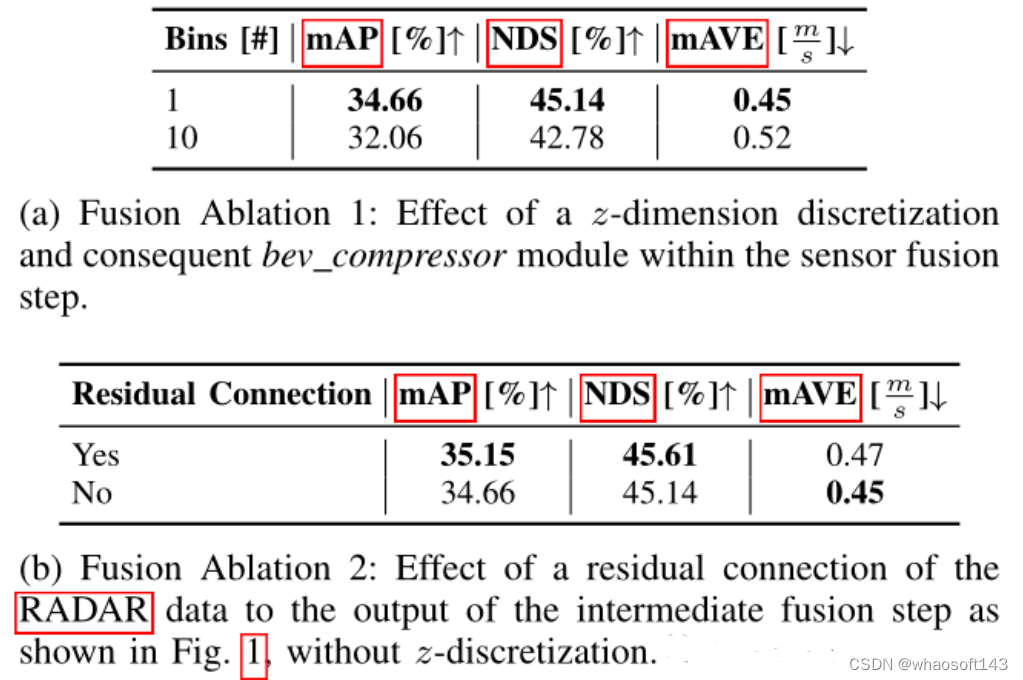
表2 检测框架的消融实验
在表2中比较了不同的融合架构对于检测指标的影响。这里的融合方法分为两种:第一种是论文中提到的,放弃了z维的体素化和随后的3D卷积,直接将提升的图像特征和纯RADAR数据聚合成柱,从而得到已知的特征尺寸为((64+18)×128×128);另一种是将提升的图像特征和纯RADAR数据体素化为尺寸为0.8×0.8×0.8 m的立方体,从而得到替代特征尺寸为((64+18)×10×128×128),因此需要以3D卷积的形式使用BEV压缩器模块。由表2(a)中可以看到,BEV压缩器数量的增加会导致性能下降,由此可以看到第一种方案表现得更为优越。而从表2(b)中也可以看到,加入了Radar数据的残差块同样能够提升性能,也印证了前面模型架构中提到的,在BEV特征编码层的输出中添加残量连接是有益的。
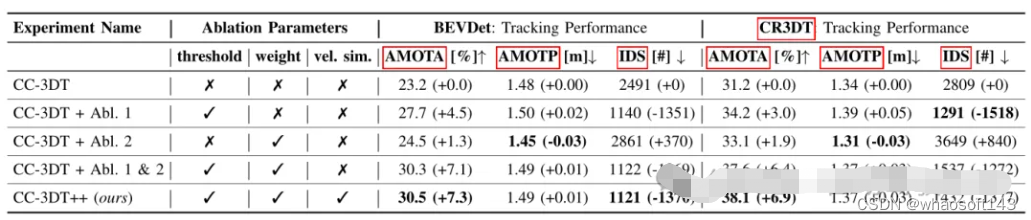
表3 基于基线BEVDet和CR3DT的不同配置在nuScenes验证集上的跟踪结果
表3给出了改进的CC3DT++跟踪模型在nuScenes验证集上的跟踪结果,给出了跟踪器在基线和在CR3DT检测模型上的性能。CR3DT模型使AMOTA的性能在基线上提高了14.9%,而在AMOTP中降低了0.11 m。此外,与基线相比,可以看到IDS降低了约43%。
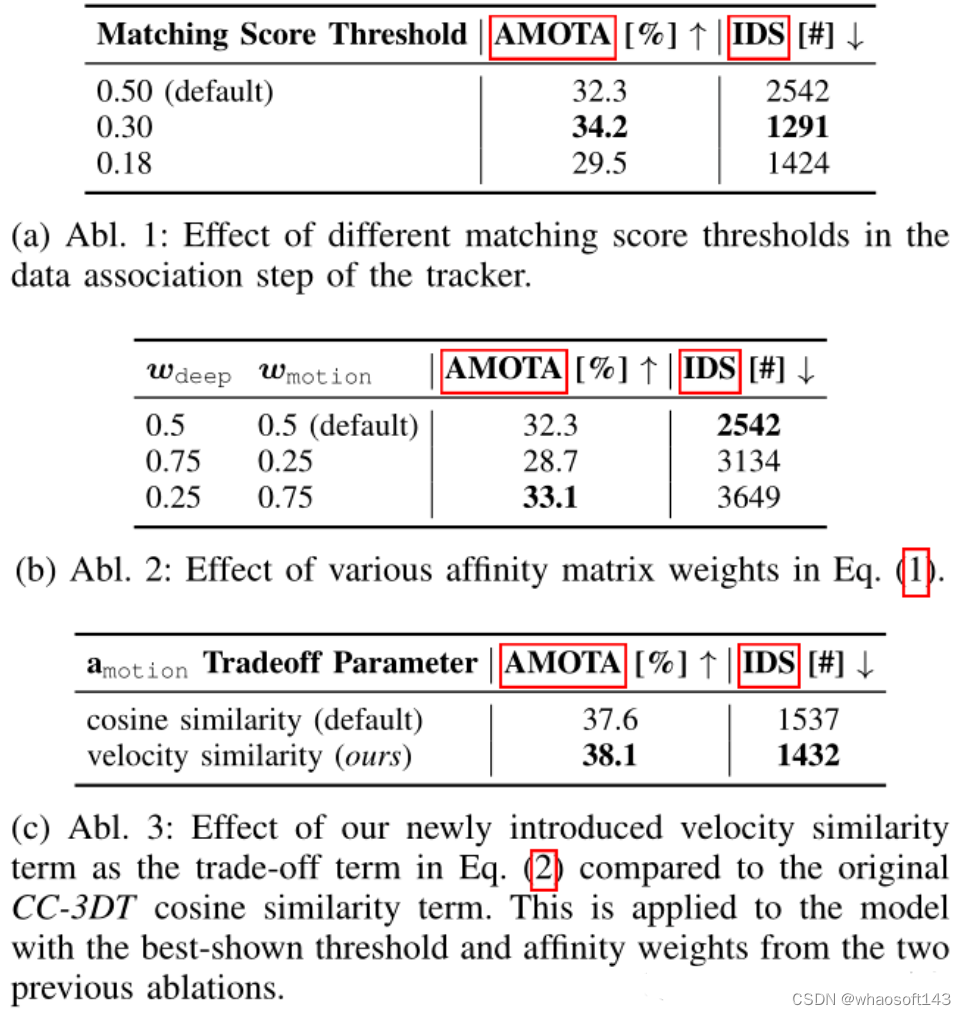
表4 在CR3DT检测骨干上进行了跟踪架构消融实验

结论
这项工作提出了一种高效的相机-雷达融合模型——CR3DT,专门用于3D目标检测和多目标跟踪。通过将Radar数据融合到只有相机的BEVDet架构中,并引入CC-3DT++跟踪架构,CR3DT在3D目标检测和跟踪精度方面都有了大幅提高,mAP和AMOTA分别提高了5.35%和14.9%。
相机和毫米波雷达融合的方案,相较于纯LiDAR或者是LiDAR和相机融合的方案,具有低成本的优势,贴近当前自动驾驶汽车的发展。另外毫米波雷达还有在恶劣天气下鲁棒的优势,能够面对多种多样的应用场景,当前比较大的问题就是毫米波雷达点云的稀疏性以及无法检测高度信息。但是随着4D毫米波雷达的不断发展,相信未来相机和毫米波雷达融合的方案会更上一层楼,取得更为优异的成果!
#VGGT
开创3D视觉新范式!
标题:VGGT: Visual Geometry Grounded Transformer
作者:Jianyuan Wang, Minghao Chen, Nikita Karaev, Andrea Vedaldi, Christian Rupprecht, David Novotny
机构:Visual Geometry Group, University of Oxford、Meta AI
原文链接:https://arxiv.org/abs/2503.11651
代码链接:https://vgg-t.github.io/
1. 导读
我们提出了VGGT,这是一个前馈神经网络,它可以从一个、几个或数百个视图中直接推断场景的所有关键3D属性,包括相机参数、点图、深度图和3D点轨迹。这种方法在3D计算机视觉中向前迈进了一步,在3D计算机视觉中,模型通常被约束并专门用于单一任务。它还简单高效,在不到一秒的时间内重建图像,仍然优于需要使用视觉几何优化技术进行后处理的替代方案。该网络在多个3D任务中实现了最先进的结果,包括相机参数估计、多视图深度估计、密集点云重建和3D点跟踪。我们还表明,使用预训练的VGGT作为特征主干显著增强了下游任务,如非刚性点跟踪和前馈新视图合成。
2. 效果展示
VGGT是一个个大型前馈Transformer,在大量 3D 标注数据上进行训练。它最多可以接受数百张图像,并在不到一秒的时间内同时预测所有图像的相机、点图、深度图和点轨迹,这通常优于未经进一步处理的基于优化的替代方案。
我们预测的3D点与DUSt3R的定性比较。正如第一行所示,我们的方法成功地预测了油画的几何结构,而DUSt3R预测了一个略有扭曲的平面。在第二行中,我们的方法正确地从两张没有重叠的图像中恢复了一个3D场景,而DUSt3R失败了。第三行提供了一个具有重复纹理的具有挑战性的例子,而我们的预测仍然是高质量的。我们不包括超过32帧的示例,因为DUSt3R在此限制之外会耗尽内存。
附加的点图估计可视化。相机剪裁框显示了估计的相机姿态。探索我们的交互式演示以获取更好的可视化质量。
3. 引言
我们研究了利用前馈神经网络从一组图像中估计场景3D属性的问题。传统上,3D重建主要通过视觉几何方法实现,采用束调整(BA)等迭代优化技术。机器学习通常扮演重要的辅助角色,用于解决仅凭几何方法无法完成的任务,例如特征匹配和单目深度预测。这种结合日益紧密,如今最先进的运动恢复结构(SfM)方法如VGGSfM已通过可微分BA将机器学习与视觉几何进行端到端融合。尽管如此,视觉几何仍在3D重建中占据主导地位,这增加了系统的复杂性和计算成本。
随着神经网络性能的不断提升,我们提出疑问:3D任务是否最终可以直接通过神经网络解决,而几乎完全摒弃几何后处理?近期工作如DUSt3R及其改进版MASt3R已在此方向展现出潜力,但这些网络一次只能处理两张图像,且需要依赖后处理来融合成对重建结果以重构更多图像。
本文进一步推进了这一方向,致力于消除对3D几何后处理优化的需求。为此,我们提出了视觉几何基础Transformer(VGGT),这是一种前馈神经网络,能够从单个、少量甚至数百个场景视图中进行3D重建。VGGT可在单次前向传递中(耗时数秒)预测完整的3D属性集合,包括相机参数、深度图、点云图和3D点轨迹。值得注意的是,即使不进行任何后处理,其性能也常优于基于优化的替代方案。这与仍需昂贵的迭代后优化才能获得可用结果的DUSt3R、MASt3R或VGGSfM形成了显著差异。
我们还表明,无需为3D重建设计专用网络。相反,VGGT基于一个相当标准的大型Transformer架构,除在帧级注意力与全局注意力之间交替外,未引入任何特定的3D或其他归纳偏置。该网络通过在大量带有3D标注的公开数据集上进行训练,其构建方式与自然语言处理和计算机视觉领域的大型模型(如GPT、CLIP、DINO和Stable Diffusion)一脉相承。这些模型已演变为通用的骨干网络,可通过微调解决新的特定任务。类似地,我们证明VGGT计算的特征可显著提升动态视频中的点追踪和新颖视角合成等下游任务性能。推荐课程:聊一聊经典三维点云方法,包括:点云拼接、聚类、表面重建、QT+VTK等。
近期已出现若干大型3D神经网络,例如DepthAnything、MoGe和LRM。然而,这些模型仅聚焦于单个3D任务,如单目深度估计或新颖视角合成。相比之下,VGGT通过共享主干网络联合预测所有相关3D属性。我们证明,尽管存在潜在冗余,但学习预测这些相互关联的3D属性可提升整体精度。
同时,我们展示了在推理阶段,可通过单独预测的深度和相机参数推导出点云图,相比直接使用专用点云图预测头,可获得更高的精度。
4. 主要贡献
综上所述,我们的贡献包括:(1)提出VGGT——一种大型前馈Transformer网络,给定单个、少量甚至数百张场景图像,可在数秒内预测包括相机内参外参、点云图、深度图和3D点轨迹在内的所有关键3D属性;(2)证明VGGT的预测结果可直接使用,其性能极具竞争力,通常优于使用缓慢后处理优化技术的现有最先进方法;(3)进一步表明,当与BA后处理结合时,VGGT在各项任务上均达到最先进水平,甚至优于专注于单一3D子任务的方法,并常能显著提升质量。
5. 方法
我们的模型首先通过DINO将输入图像分割成令牌,并为相机预测添加相机令牌。然后,它在帧级和全局自注意力层之间交替。一个相机头对相机外参和内参进行最终预测,一个DPT朝着任何密集输出前进。
6. 实验结果
7. 总结 & 未来工作
我们提出了可视化几何接地Transformer:(VisualGeometry Grounded Transformer, VGGT)个前馈神经网络,可以直接估计所有关键的三维场景的数百个输入视图的属性。它可以在多个三维任务中实现最先进的结果,包括相机参数估计、多视角深度估计、密集点云重建和三维点跟踪。我们简单的神经优先方法不同于传统的基于视觉几何的方法,后者依赖于优化和后处理来获得准确和特定任务的结果。我们方法的简单性和效率使其非常适合实时应用,这是与基于优化的方法相比的另一个优势。
#MultiGO
单图生成3D人体:港科广团队提出分层高斯建模框架
通过分层高斯建模从单张图片生成逼真的 3D 人体模型MultiGO。该方法采用三级几何学习策略,分别优化骨骼、关节和皱纹细节,显著提升了单图 3D 人体重建的精度和细节表现。
从一张照片重建出逼真的带纹理的人体 3D 模型一直是计算机视觉领域的难题。港科广团队提出的 MultiGO 创新方案,通过分层建模思路破解了这一挑战——将人体分解为不同精度层级,从基础体型到衣物褶皱逐级细化。
该方法类似乐高积木的搭建逻辑:先用大模块构建整体轮廓,再用小零件补充细节,最后用微型颗粒表现材质纹理。其核心技术在于采用高斯溅射点作为三维基元,这些数字化的"颜料滴"能自动形成光滑自然的物体表面。
这种分层建模方式与艺术家的创作过程异曲同工:先勾勒大体形态,再逐层深化细节,最终完善色彩质感。相关研究成果已入选 CVPR 2025,为单图三维人体重建提供了新的技术路径。相关论文入选 CVPR 2025,代码即将开源。
论文标题:MultiGO: Towards Multi-level Geometry Learning for Monocular 3D Textured Human Reconstruction
论文地址:https://arxiv.org/abs/2412.03103
项目地址:https://multigohuman.github.io/
01 技术痛点与突破
1.1 传统方法的瓶颈:
基于单目图像的三维人体重建存在固有深度歧义性,现有方法通常依赖 SMPL-X 等人体轮廓的预训练模板提供几何先验,但依然难以捕捉细节特征和特定解剖学结构。
这些方法往往聚焦于人体整体几何建模,而忽视了多层次结构(如骨骼、关节,以及手指、面部等部位的细密皱纹)。这种过度简化的建模方式导致骨骼重建不准确、关节位置偏差,以及衣物皱纹等细节模糊不清。
1.2 MultiGO 创新框架
该研究提出三级几何学习框架实现突破:
骨架增强模块:通过将 3D 傅里叶特征投影到 2D 空间,结合 SMPL-X 人体网格作为几何先验,增强人体骨架建模。傅里叶空间位置编码提升了 3D 模型与 2D 图像的语义对齐能力。
关节增强策略:在训练时对关节点位置施加扰动,提升模型对深度估计误差的鲁棒性。通过重点调整影响深度感知的参数,使模型能更好适应实际观测中的结构偏差。
皱纹优化模块:采用类似扩散模型去噪的方法,将表面皱纹视为可优化的噪声模式。从粗糙的人体网格中,恢复出更精细化的高频细节。

02 方法详解
MultiGO 方法的核心在于通过多层次几何学习框架全面提升单目纹理 3D 人体重建的质量。该方法基于现有物体高斯重建预训练模型,针对人体几何的不同粒度层级(骨骼、关节、皱纹)设计了协同优化的三重机制。
在骨骼层级,骨架增强模块通过将 3D 傅里叶特征投影到输入图像一样的 2D 空间,使高斯重建模型能够充分融合先验的人体形态知识,从而精准捕捉人体姿态特征。这种特征投影机制有效解决了单目视角下 3D 结构信息缺失的问题。

对于关节层级的深度估计,关节增强策略在训练阶段对真实的 SMPL(X) 模型的关节参数进行扰动。通过模拟深度不确定性,增强模型对推理过程中关节深度误差的鲁棒性。这种数据增强方式使模型能够学习更稳定的关节空间关系,避免因深度歧义导致的肢体位置重建不准。

在微观几何细节层面,皱纹优化模块创新性地借鉴扩散理论思想。该模块将粗糙网格视为高斯噪声,而以重建的高质量高斯纹理作为条件输入,通过类似扩散模型去噪的过程逐步优化皱纹等细微几何特征。这种纹理引导的细化机制实现了亚毫米级表面细节的生成,弥补了传统方法在衣物褶皱等高频细节上的不足。

三个层级模块并非孤立运作,而是形成从宏观姿态到微观特征的递进式优化链条:骨架增强模块建立的准确骨骼框架为关节定位提供基础,关节增强策略稳定的关节预测又为皱纹细化创造了低噪声的几何环境。
整个框架通过端到端训练实现多层次几何信号的联合优化,最终输出兼具准确拓扑结构和丰富表面细节的高保真 3D 人体模型。
03 方法效果
所提出的多层级几何学习框架在 CustomHuman 和 THuman3.0 两个测试集上实现了最先进的性能表现,在人体几何重建任务中显著优于其他现有技术。
在 CustomHuman 数据集上,倒角距离(CD)提升 0.180 / 0.406,法向一致性(NC)提高 0.034,f-score 增加 6.277;在 THuman3.0 数据集上,CD 指标提升 0.355 / 0.369,NC 提高 0.047,f-score 大幅提升 9.861。
这种性能突破源于我们提出的创新性解决方案——通过三级分层建模策略(而非传统单一层次建模)精细化处理人体几何特征,从多层次协同优化人体重建效果,从而实现了更精准的几何细节复原。



04 应用场景
MultiGO 的分层高斯建模技术通过将人体分解为不同精度层级(从基础体型到衣物褶皱和材质纹理逐级细化),并利用高斯溅射点作为 3D 基元实现高效、高保真的单图重建,使其在虚拟试衣与时尚电商(实时生成可动态调整的 3D 人体与服装模型)、游戏与元宇宙(快速创建个性化虚拟角色并支持细节编辑)以及影视特效(高精度动态人体重建与后期分层调整)等领域具有突出优势,尤其适合需要快速生成且对真实感和多尺度细节还原要求高的应用场景。
4.1 虚拟试衣与时尚电商
消费者上传一张全身照片即可生成高保真 3D 人体模型,系统能自动模拟不同服装的穿着效果(包括衣物褶皱和材质细节),支持 360 度查看,提升在线购物体验。结合分层建模能力,可区分用户体型(基础层)与服装细节(精细层),实现动态布料仿真。
4.2 游戏与元宇宙角色生成
通过单张照片快速创建个性化的 3D 虚拟形象,分层结构支持灵活调整(如更换发型、配饰等)。高斯溅射点的特性可保留皮肤纹理和光影细节,增强虚拟角色的真实感。适用于社交元宇宙、NPC 批量生成等场景,显著降低美术资源生产成本。
4.3 影视特效与虚拟制作
在特效制作中,仅需演员的单视角照片即可重建高精度 3D 模型,用于动作捕捉或替身合成。分层设计允许后期单独编辑特定层级(如调整肌肉线条或添加伤痕特效)。结合动态高斯溅射点技术,可进一步实现毛发、湿润皮肤等细微效果的实时渲染。
#3D图像形状的常见表示方法
现实世界中的物体大多数时候都是三维的。在我看来,大多数物体都存在于3D空间中,因此用三维图像来表示图像并训练模型非常重要。
3D 视觉是计算机视觉领域一个活跃的研究领域。如今,3D 视觉融合了传统算法和深度学习。在本文中,我将分享现有的 3D 形状表示方法。
1. 深度图(Depth Map)
深度图给出了现实世界中从相机到物体的距离。当深度图与源(输入)图像合并时,它会形成一个 3D 图像。某些类型的 3D 传感器也可以记录深度图数据。为了从 2D 图像创建深度图,可以使用全卷积网络进行预测。然而,深度图的主要问题是尺度模糊性,可以通过使用尺度不变损失来最小化。

2. 体素网格(Voxel Grid)
体素网格 (Voxel Grid) 表示具有 V x V x V 网格占用空间的形状。它类似于 Mask-R-CNN 中的分割掩膜,但形式为 3D。体素形状可以通过结合 2D 和 3D CNN 从 2D 输入图像生成。它也可以通过体素管表示模型生成。您还可以使用八叉树 (Oct-Trees)缩放体素。

3. 隐式曲面(Implicit Surface)
隐式曲面学习一种函数,将任意点分类为形状的内部或外部。 “隐式”一词意味着该方程无法求解任何变量。

4. 点云(Point Cloud)
点云表示三维空间中的一组 P 点。自动驾驶汽车使用点云来表示其周围世界。PointNet 是一个常用的神经网络应用。
5. 网格(Mesh)
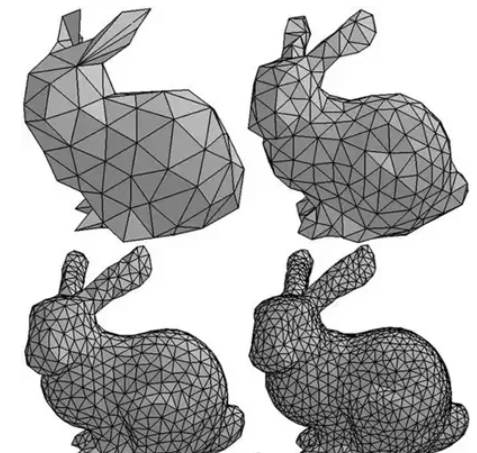
网格 (Mesh) 在计算机图形学中很常见。它将 3D 形状表示为一组三角形。一种流行的网格深度学习架构是Pixel2Mesh。图卷积 (Graph Convolutions) 可用于预测三角形网格。

















 1296
1296

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









