






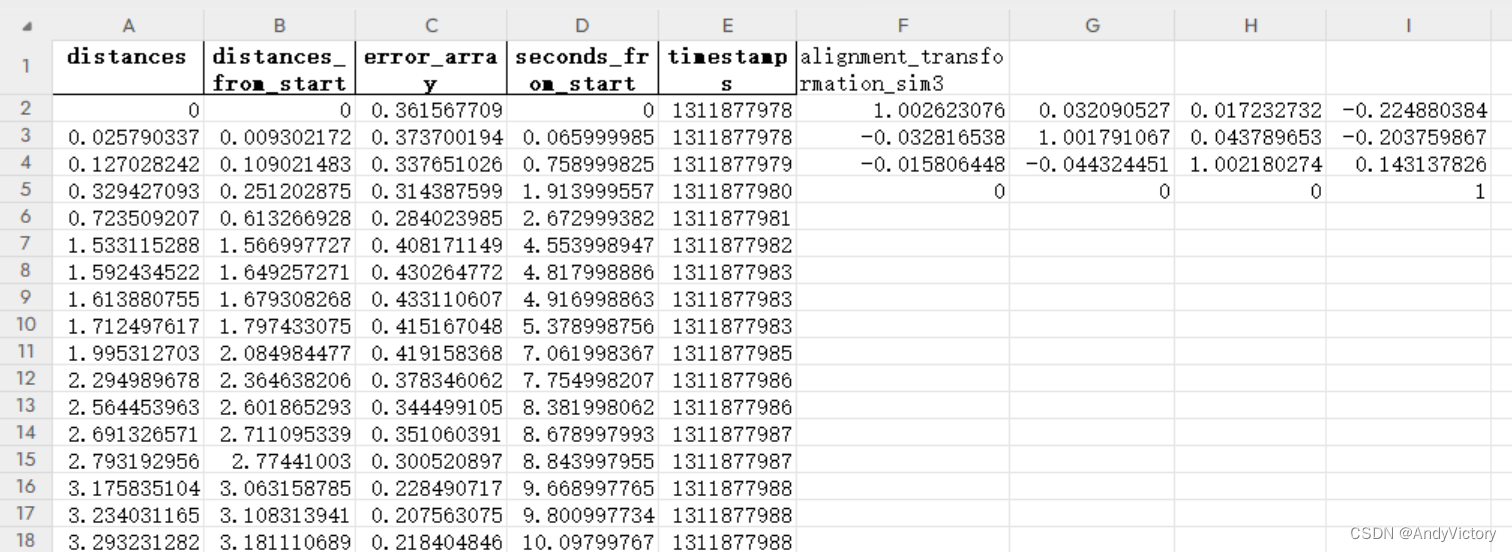
输出结果示意:
代码:
import numpy as np
import pandas as pd
from openpyxl import load_workbook
import os
"""
本函数作用:读取evo输出的zip文件
info.json: 这个JSON文件包含了运行评估时使用的参数和配置的信息,可能还包括了评估的总结。
stats.json: 这个JSON文件可能包含了统计数据,比如均方误差(RMSE)、平均误差、中位数误差、标准差、最小和最大误差值等。
"""
# TODO 替换为你的文件夹的路径
pathName = 'ape_1-ORB'
file_paths = []
file_path1 = '.\\' + pathName + '\\alignment_transformation_sim3.npy' # 用于对齐真实轨迹和估计轨迹的变换矩阵
file_paths.append(file_path1)
file_path2 = '.\\' + pathName + '\\distances.npy' # 累计距离
file_paths.append(file_path2)
file_path3 = '.\\' + pathName + '\\distances_from_start.npy'
file_paths.append(file_path3)
file_path4 = '.\\' + pathName + '\\error_array.npy'
file_paths.append(file_path4)
file_path5 = '.\\' + pathName + '\\seconds_from_start.npy' # 从轨迹开始到每个时间戳的秒数
file_paths.append(file_path5)
file_path6 = '.\\' + pathName + '\\timestamps.npy'
file_paths.append(file_path6)
# 加载.npy文件
data = []
for path in file_paths:
n = np.load(path)
print(f"{n}\n")
data.append(n)
# 检查error.xlsx文件是否存在
if not os.path.exists('.//errors.xlsx'):
print(f"\n.\\errors.xlsx 不存在,正在创建一个新文件...")
df = pd.DataFrame() # 创建一个空的 DataFrame
# # index=False:这个参数告诉 pandas 在保存到 Excel 文件时不包括行索引。
# 如果省略或设置为 True,则每行数据前会有一个额外的列显示行索引(通常是从0开始的整数)。
df.to_excel('errors.xlsx', index=False)
else:
print(f"\n.\\errors.xlsx 已存在,将进行数据覆盖 !")
# 将数组转换为 DataFrame
dataNeed = pd.DataFrame({'distances': data[1],
'distances_from_start': data[2],
'error_array': data[3],
'seconds_from_start': data[4],
'timestamps': data[5]})
# 注意:如果工作表名称已存在,它将被覆盖
dataNeed.to_excel('errors.xlsx', sheet_name=pathName, index=False, engine='openpyxl')
# alignment_transformation_sim3 是一个矩阵,单独保存
wb = load_workbook('errors.xlsx')
ws = wb.active
ws.title = pathName
# 将矩阵添加到指定位置
ws.cell(row=1, column=6, value='alignment_transformation_sim3')
for i in range(len(data[0])):
for j in range(len(data[0][i])):
ws.cell(row=i+2, column=j+6, value=data[0][i][j])
# 保存对Excel文件的修改
wb.save('errors.xlsx')
print(f"\n写入到文件 error.xlsx 的 {pathName} 工作表成功 !")

















 3277
3277











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











