






编者按
本文系『OR青年计划』成果,是郭德真同学在覃含章和朱睿豪教授指导下完成。由『运筹OR帷幄』社区主办的『OR青年计划』,旨在帮助对运筹学应用有理想和追求的同学,近距离与学界、业界导师交流课题,深入了解运筹学的细分方向,为后续的深造、就业生涯打下坚实的基础。关于第二届『OR青年计划』的详细情况,请参考成果汇报来啦!第二届OR青年计划之学界实验室结营直播预告!!!
云计算的快速发展使得资源分配问题成为需要解决的关键问题。计算资源的分配需要考虑用户的多种需求,本文首先总结了Mao et al. (2016)利用深度强化学习进行资源分配的方法以及Mondal et al. (2021)考虑用户资源使用时变因素的资源分配方法。其次对阿里巴巴和谷歌的开源数据集进行简单介绍,并总结目前业界关心的问题。
一、引言
近年来,云计算在得到广泛应用。云计算是指将计算资源集中起来,用户通过对集中资源的访问完成计算,云计算中心将程序处理的结果返回给用户。云计算不仅适用于个人用户,同时适用于企业用户。通过购买云服务器,用户不必购买大量的计算机,节约计算成本。云服务商可以根据用户的访问需求动态调度计算资源,使计算资源利用效率达到最大。根据中国经济新闻网的报道,我国云计算规模已经达到2091亿元。目前,国内较为成熟的云服务商有阿里云、百度云、华为云等。
资源合理分配在云计算中起到至关重要的作用。在云计算的资源分配中,云计算中心拥有有限的云资源,用户依次到达,每个用户向云计算中心请求使用特定时间的一定数量的云资源。云计算服务中心需要决定是否接受用户的请求,或者暂时搁置用户的请求。合理的云资源分配能够实现在有限资源下最大限度提高服务用户的质量,提高用户满意度。现有资源分配大多采用启发式算法进行资源分配,但是启发式算法很难在复杂的情景下取得良好的效果。
云计算的资源分配需要考虑用户的多种需求。不同用户对云资源的需求是不同的,云计算中心需要根据用户需求进行资源分配。用户对云资源的需求可以分为两类约束,即硬约束和软约束。硬约束是指必须满足的约束,例如用户请求一组虚拟机而不是单个虚拟机,为了确保高可用性,每个虚拟机需要放置在一个单独的故障域(共享单点故障的服务器),这样能够避免云计算中心的故障导致用户服务不可用而造成经济损失。软约束是指可以满足也可以不满足的约束,但满足约束能够显著提升服务质量。例如在神经网络训练的过程中,在网络结构中将云虚拟机靠近放置,能够减少网络延迟并加快计算速度;在用户请求的处理过程中,分配地理位置上离用户较近的虚拟机能够提升云计算中心与用户的通信速度,提升用户的体验。
本研究主要提出一种考虑用户需求的基于深度强化学习的云资源分配方法。本研究主要考虑将用户分配到距离较近的服务器以提升用户的服务质量,但是如果保持将用户分配到较近的服务器可能会导致部分位置服务器拥堵,等待时间较长。因此本研究考虑一种基于深度强化学习的云资源分配方法。深度强化学习能够根据系统目前的状态决定资源的动态分配,从而最大化云资源的利用效率,减少用户等待时间。
二、相关研究
2.1 研究1——利用深度强化学习进行资源调度
Mao et al. (2016)利用深度学习方法研究了资源分配问题,主要使用策略梯度方法进行资源动态分配。
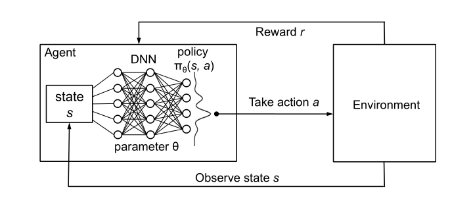
图1 策略网络的强化学习方法(图源: Mao et al. (2016))
如图1所示,神经网络输入为系统目前的状态,输出为动作,当系统采用动作之后,环境会返回相应的奖励,系统优化的目标是最小化用户的等待时间,即最大化
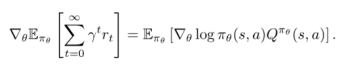

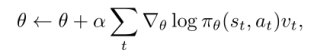
2.2 研究 2——考虑时变特征的资源调度
Mondal et al. (2021)主要考虑了用户长时间使用云计算资源时,不同时间的计算资源的使用量是不同的,尤其是在诸如神经网络训练等长时间的云计算任务中。考虑用户不同时间使用计算能力的不同来分配资源能够减轻服务器高峰时期的使用压力,减少服务器宕机的风险。
此研究主要通过构造一个利用用户历史资源使用特征来学习用户资源时变特征的学习器,主要采用一种非监督的学习方法。同时,本研究提出了诸多新型的奖励评估机制。本研究的框架如下:
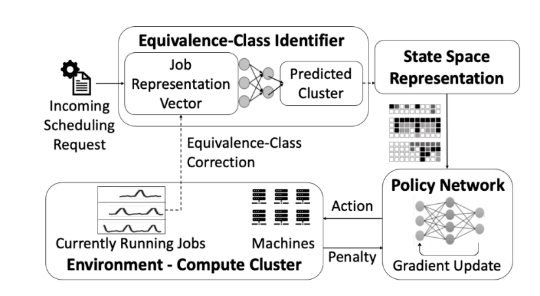
图2 考虑时变特征的深度强化学习方法(图源:Mondal et al. (2021))
如图2所示,相较于研究1,此研究首先利用聚类的方法预测用户在云资源使用时的时变特征,从而避免不同用户使用的高峰期相互重叠,给服务器造成巨大的压力。在聚类方法部分,主要是使用了自回归方法、线性趋势、加和线性趋势,同时加入动态时间距离(Dynamic Time Warping)的方法并且进行K均值聚类来识别具有相似时间利用曲线的用户。
在深度强化学习部分,本研究与研究1的思路大致类似。研究2提出了诸多对于奖励的定义值得借鉴。主要包含以下几个部分:


三、相关数据
阿里云和谷歌云分别开源了数据帮助研究者研究云计算相关问题。阿里巴巴集团公开了实际工作中计算群的使用轨迹,包括2017-2022年的诸多数据,研究者可以任意使用阿里巴巴公开的数据进行研究,相关数据可以在github通过脚注网站获得。
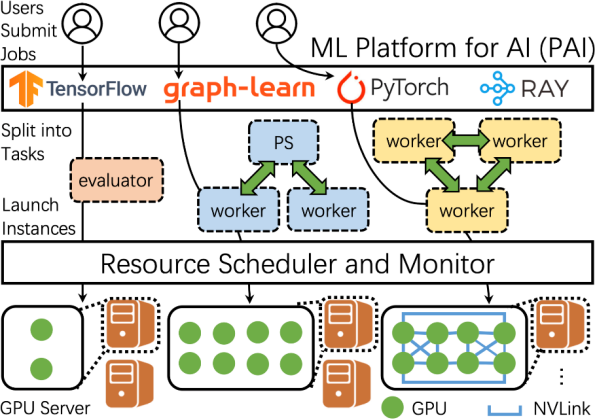
图3 阿里巴巴数据生成过程
阿里巴巴数据生成过程主要如图3所示,用户提交神经网络训练的需求,这些需求会被划分为诸多任务,任务主要由实例完成,云资源的调度中心为不同的实例调度不同的资源,将这些实例划分到不同服务器上,从而满足用户不同的服务需求。阿里巴巴对用户资源的使用和实际分配的资源之间进行分析,并分析用户的等待时间以及工作实际完成的时间等。同时,阿里巴巴提出在以下三个问题方面面临挑战:
1. 负载特征化问题。如何描述工作负载,从而能够以一种代表性的方式模拟各种生产工作负载,用于调度和资源管理策略研究。
2. 分配工作负载到相应机器的算法。如何分配工作负载来获得较高的资源使用量并且保证不同应用表现的服务水平协议。
3. 在线服务调度器和批处理作业调度器之间的协作。如何适应在线服务和批处理工作之间的资源分配是值得解决的问题。在云计算资源分配中,要同时保证批处理工作的吞吐量以及对在线服务的服务质量。在规模不断扩大的过程中,协作机制的设计变得越来越重要。
谷歌通过谷歌云公开了谷歌云的使用数据。谷歌云主要公开了谷歌2019年5月在谷歌八个服务器上运行的工作,描述了每个工作的提交、分配决定以及在工作集群上的使用数据。对比于2019年的数据集,新的数据集包含了每5分钟用户的资源使用量而不只是点数据,分配集合的信息以及任务的母任务信息。相关数据集可以通过谷歌的bigquery数据库获得。此数据集较大,且国内注册谷歌云相对难度较大,对数据集的一个取样可以通过kaggle获得。相较于阿里巴巴数据,谷歌数据提供了较为丰富的时序特征,能够监控到用户在使用过程中对资源动态利用的变化。数据字段内动较多,诸多开源项目给出了字段内容的解释,具体解释可见github google cluster data。
此外,阿里巴巴曾举办阿里云天池云基础设施比赛。阿里云供应链大赛主要提供了云计算资源的日期级使用资源,数据的颗粒度较大。字段的内容主要包括单元、日期、资源使用量、地理信息、地理聚合维度、产品信息以及产品聚合维度、库存量、地理拓扑数据等。主要的目标是根据需求来预测不同地理位置资源的使用,从而进行云资源的补货(即购买新的云计算资源)。可见,地理位置信息在企业的云资源补货决策中发挥着重要作用。
同时,华为云在ICPC竞赛中也提出考虑拓扑结构的云资源分配方法。华为云的比赛场景主要是考虑虚拟机请求动态到达的一种在线算法。主要目标是最大化虚拟机的放置数量,需要满足用户对资源放置的硬约束(如一组虚拟机放置在不同的故障域)以及软约束,即尽量达到云资源放置的资源约束、高效率以及高可用性约束等,如何平衡大规格虚拟机发放能力钰拓扑资源可用性是算法面临的主要挑战。
参考文献
Mao, H., Alizadeh, M., Menache, I., & Kandula, S. (2016). Resource management with deep reinforcement learning. Proceedings of the 15th ACM workshop on hot topics in networks,
Mondal, S. S., Sheoran, N., & Mitra, S. (2021). Scheduling of time-varying workloads using reinforcement learning. Proceedings of the AAAI Conference on Artificial Intelligence,

















 1006
1006

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









