







1.低光照补偿模型的简单介绍

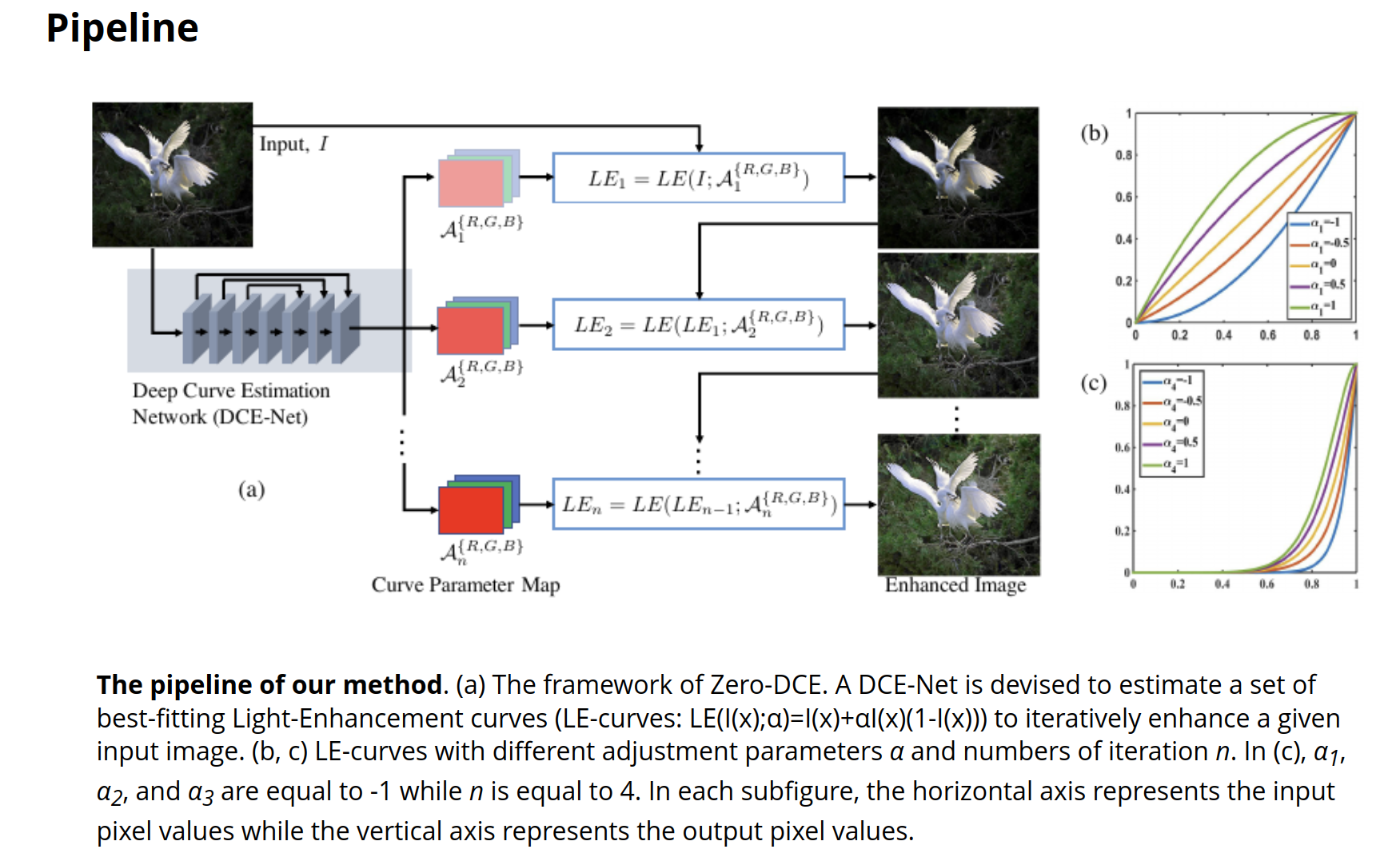
作者介绍一种Zero-Reference Deep Curve Estimation (Zero-DCE)的方法用于在没有参考图像的情况下增强低光照图像的效果。
具体来说,它将低光照图像增强问题转化为通过深度网络进行图像特定曲线估计的任务。训练了一个轻量级的深度网络 DCE-Net,来估计像素级和高阶曲线,以对给定图像进行动态范围调整。这种曲线估计考虑了像素值范围、单调性和可微性等因素。
Zero-DCE 的优点在于它不需要任何成对或不成对的数据进行训练,它通过一系列精心设计的非参考损失函数来实现这一点,这些函数能隐式地衡量增强质量并驱动网络学习。该方法通过直观且简单的非线性曲线映射实现图像增强,并且在多种照明条件下都具有很好的适用性。
文章还通过大量的实验来证明 Zero-DCE 在亮度、色彩、对比度和自然度等方面的视觉效果优于现有的先进方法,而其他方法在处理极暗背光或生成彩色伪影方面可能会失败。相比之下,Zero-DCE 的训练方式也与其他深度学习方法不同,并且它在黑暗环境下的面部检测方面也具有潜在优势。
这篇论文的方案以及低光照补偿结果如下:


文章源码地址:https://github.com/Li-Chongyi/Zero-DCE.git
2. zero_dce源码的简单介绍
2.1模型设计
模型设计比较简单,常规常见的算子
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
#import pytorch_colors as colors
import numpy as np
class enhance_net_nopool(nn.Module):
def __init__(self):
super(enhance_net_nopool, self).__init__()
self.relu = nn.ReLU(inplace=True)
number_f = 32
self.e_conv1 = nn.Conv2d(3,number_f,3,1,1,bias=True)
self.e_conv2 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv3 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv4 = nn.Conv2d(number_f,number_f,3,1,1,bias=True)
self.e_conv5 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv6 = nn.Conv2d(number_f*2,number_f,3,1,1,bias=True)
self.e_conv7 = nn.Conv2d(number_f*2,24,3,1,1,bias=True)
self.maxpool = nn.MaxPool2d(2, stride=2, return_indices=False, ceil_mode=False)
self.upsample = nn.UpsamplingBilinear2d(scale_factor=2)
def forward(self, x):
x1 = self.relu(self.e_conv1(x))
# p1 = self.maxpool(x1)
x2 = self.relu(self.e_conv2(x1))
# p2 = self.maxpool(x2)
x3 = self.relu(self.e_conv3(x2))
# p3 = self.maxpool(x3)
x4 = self.relu(self.e_conv4(x3))
x5 = self.relu(self.e_conv5(torch.cat([x3,x4],1)))
# x5 = self.upsample(x5)
x6 = self.relu(self.e_conv6(torch.cat([x2,x5],1)))
x_r = F.tanh(self.e_conv7(torch.cat([x1,x6],1)))
r1,r2,r3,r4,r5,r6,r7,r8 = torch.split(x_r, 3, dim=1)
x = x + r1*(torch.pow(x,2)-x)
x = x + r2*(torch.pow(x,2)-x)
x = x + r3*(torch.pow(x,2)-x)
enhance_image_1 = x + r4*(torch.pow(x,2)-x)
x = enhance_image_1 + r5*(torch.pow(enhance_image_1,2)-enhance_image_1)
x = x + r6*(torch.pow(x,2)-x)
x = x + r7*(torch.pow(x,2)-x)
enhance_image = x + r8*(torch.pow(x,2)-x)
r = torch.cat([r1,r2,r3,r4,r5,r6,r7,r8],1)
return enhance_image_1,enhance_image,r
2.2模型训练和损失函数
模型的损失函数设计部分比较复杂,在训练过程中使用
L_color = Myloss.L_color()
L_spa = Myloss.L_spa()
L_exp = Myloss.L_exp(16,0.6)
L_TV = Myloss.L_TV()而这里的损失函数全都在文件中间的Myloss.py文件中,在训练的过程中:
for epoch in range(config.num_epochs):
for iteration, img_lowlight in enumerate(train_loader):
img_lowlight = img_lowlight.cuda()
enhanced_image_1,enhanced_image,A = DCE_net(img_lowlight)
Loss_TV = 200*L_TV(A)
loss_spa = torch.mean(L_spa(enhanced_image, img_lowlight))
loss_col = 5*torch.mean(L_color(enhanced_image))
loss_exp = 10*torch.mean(L_exp(enhanced_image))
# best_loss
loss = Loss_TV + loss_spa + loss_col + loss_exp
2.3 图像的前处理
源码中的图像前处理部分如下:
def __getitem__(self, index):
data_lowlight_path = self.data_list[index]
data_lowlight = Image.open(data_lowlight_path)
data_lowlight = data_lowlight.resize((self.size,self.size), Image.ANTIALIAS)
data_lowlight = (np.asarray(data_lowlight)/255.0)
data_lowlight = torch.from_numpy(data_lowlight).float()
return data_lowlight.permute(2,0,1)在源码的lowlight_test中也可以看到图像的这个模型的前处理的代码:
data_lowlight = Image.open(image_path)
data_lowlight = (np.asarray(data_lowlight)/255.0)
data_lowlight = torch.from_numpy(data_lowlight).float()
data_lowlight = data_lowlight.permute(2,0,1)
data_lowlight = data_lowlight.cuda().unsqueeze(0)
2.4 源码的后处理代码
源码直接使用torchvisopn.utils.save_image()方法保存了推理的结果
_,enhanced_image,_ = DCE_net(data_lowlight)
end_time = (time.time() - start)
print(end_time)
image_path = image_path.replace('test_data','result')
result_path = image_path
if not os.path.exists(image_path.replace('/'+image_path.split("/")[-1],'')):
os.makedirs(image_path.replace('/'+image_path.split("/")[-1],''))
torchvision.utils.save_image(enhanced_image, result_path)点开save_image()方法
def save_image(
tensor: Union[torch.Tensor, List[torch.Tensor]],
fp: Union[str, pathlib.Path, BinaryIO],
format: Optional[str] = None,
**kwargs,
) -> None:
"""
Save a given Tensor into an image file.
Args:
tensor (Tensor or list): Image to be saved. If given a mini-batch tensor,
saves the tensor as a grid of images by calling ``make_grid``.
fp (string or file object): A filename or a file object
format(Optional): If omitted, the format to use is determined from the filename extension.
If a file object was used instead of a filename, this parameter should always be used.
**kwargs: Other arguments are documented in ``make_grid``.
"""
if not torch.jit.is_scripting() and not torch.jit.is_tracing():
_log_api_usage_once(save_image)
grid = make_grid(tensor, **kwargs)
# Add 0.5 after unnormalizing to [0, 255] to round to the nearest integer
ndarr = grid.mul(255).add_(0.5).clamp_(0, 255).permute(1, 2, 0).to("cpu", torch.uint8).numpy()
im = Image.fromarray(ndarr)
im.save(fp, format=format)
3. 导出模型
由于这个代码本身没有复杂的算子和其他恶心的操作,我这边直接使用yolov5的环境测试这个lowlight_test.py的文件,发现可以直接运行。这里需要需要注意
DCE_net.load_state_dict(torch.load('/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/snapshots/Epoch99.pth'))
filePath = '/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/data/test_data/'
这里使用完整的路径。
在Zero-DCE_code文件夹下面创建export_onnx.py的文件,写如下的导出代码
import torch
import model
def convert_to_static_onnx():
# 设备配置
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# 加载预训练模型
DCE_net = model.enhance_net_nopool().to(device)
DCE_net.load_state_dict(torch.load('/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/snapshots/Epoch99.pth', map_location=device))
DCE_net.eval()
static_height = 640
static_width = 640
# 创建固定尺寸的虚拟输入
dummy_input = torch.randn(1, 3, static_height, static_width).to(device)
# 导出为静态模型
torch.onnx.export(
DCE_net,
dummy_input,
"ZeroDCE_static640.onnx",
verbose=True,
input_names=["input"],
output_names=["output1","output2","output3"],
opset_version=12,
)
if __name__ == "__main__":
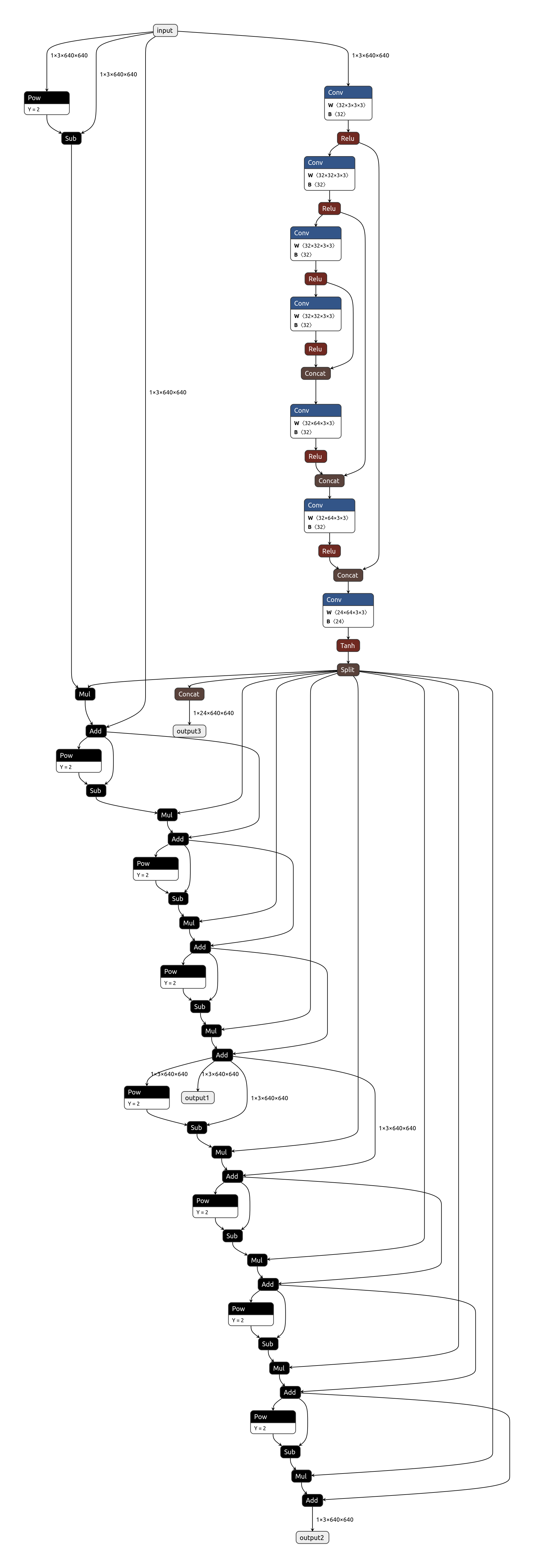
convert_to_static_onnx()运行即可生成对应模型的onnx文件,onnx文件可视化如下:

4. 使用onnx加载推理模型试验
这里加载python版本的onnxruntime来试验推理模型,完整的推理代码如下:
import onnxruntime as ort
import numpy as np
import cv2
def preprocess_image_cv2(image_path, input_shape):
# 读取图像
img = cv2.imread(image_path)
# 转换为 RGB 格式
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
# 调整大小
img = cv2.resize(img, (input_shape[2], input_shape[1]))
# 归一化
img = img / 255.0
# 转换为通道优先格式 (C, H, W)
img = img.transpose(2, 0, 1)
# 添加批次维度 (1, C, H, W)
img = np.expand_dims(img, axis=0).astype(np.float32)
return img
def postprocess_image_cv2(output, output_shape):
# 去除批次维度
output = np.squeeze(output, axis=0)
# 转换为 HWC 格式
output = output.transpose(1, 2, 0)
# 调整大小到原始图像大小
output = cv2.resize(output, output_shape)
# 转换为 BGR 格式
output = cv2.cvtColor(output, cv2.COLOR_RGB2BGR)
return output
# 示例用法
if __name__ == '__main__':
# 示例图像路径
image_path = '/home/zpec/workspace/source-cnn/Zero-DCE-master/Zero-DCE_code/data/test_data/DICM/06.jpg'
# 模型输入形状 (例如: [3, 640, 640])
input_shape = [3, 640, 640]
# 预处理图像
input_image = preprocess_image_cv2(image_path, input_shape)
ort_session = ort.InferenceSession('ZeroDCE_static640.onnx')
# 运行推理
input_name = ort_session.get_inputs()[0].name
output_name = ort_session.get_outputs()[1].name
# 检查模型的输入和输出的节点
# 获取所有输入节点的信息
inputs_info = ort_session.get_inputs()
# 获取所有输出节点的信息
outputs_info = ort_session.get_outputs()
# 打印输入节点的信息
print("Input nodes:")
for idx, input_info in enumerate(inputs_info):
print(f"Input node {idx}:")
print(f" Name: {input_info.name}")
print(f" Shape: {input_info.shape}")
print(f" Type: {input_info.type}")
print()
# 打印输出节点的信息
print("Output nodes:")
for idx, output_info in enumerate(outputs_info):
print(f"Output node {idx}:")
print(f" Name: {output_info.name}")
print(f" Shape: {output_info.shape}")
print(f" Type: {output_info.type}")
print()
outputs = ort_session.run([output_name], {input_name: input_image})
# 后处理输出
# output_image = postprocess_image_cv2(outputs[0], (input_shape[2], input_shape[1]))
output_image = postprocess_image_cv2(outputs[0], (640, 480))
# 保存结果
output_image_path = 'enhanced_image.jpg'
cv2.imwrite(output_image_path, (output_image * 255).astype(np.uint8))
print(f"Output image saved to {output_image_path}")推理效果展示如下:

说明我们的前处理和后处理没有任何问题。现在开始tensorRT的模型部署和推理吧。
5. 使用tensorRT10部署模型
项目地址:GitHub - YLXA321/ZERO_DCE_model-tensorRT10: 基于tensorRT10部署低光照补偿代码
图像前处理的代码
void preprocess_cpu(cv::Mat &srcImg, float* dstDevData, const int width, const int height) {
if (srcImg.data == nullptr) {
std::cerr << "ERROR: Image file not found! Program terminated" << std::endl;
return;
}
cv::Mat dstimg;
if (srcImg.rows != height || srcImg.cols != width) {
cv::resize(srcImg, dstimg, cv::Size(width, height), cv::INTER_AREA);
} else {
dstimg = srcImg.clone();
}
// BGR→RGB转换 + HWC→CHW转换
int index = 0;
int offset_ch0 = width * height * 0; // R通道
int offset_ch1 = width * height * 1; // G通道
int offset_ch2 = width * height * 2; // B通道
for (int i = 0; i < height; i++) {
for (int j = 0; j < width; j++) {
index = i * width * 3 + j * 3;
// 从BGR数据中提取并赋值到目标通道
dstDevData[offset_ch0++] = dstimg.data[index + 2] / 255.0f; // R
dstDevData[offset_ch1++] = dstimg.data[index + 1] / 255.0f; // G
dstDevData[offset_ch2++] = dstimg.data[index + 0] / 255.0f; // B
}
}
}图像后处理的代码:
cv::Mat decode_cpu(const float* model_output, const int KInputW, const int KInputH,
const int src_width, const int src_height) {
cv::Mat src_image;
if (model_output == nullptr) {
std::cerr << "ERROR: Model output is null." << std::endl;
return cv::Mat();
}
// 创建临时浮点图像(HWC格式,RGB顺序)
cv::Mat temp_image(KInputH, KInputW, CV_32FC3);
float* temp_data = reinterpret_cast<float*>(temp_image.data); // 直接操作内存
// 计算各通道的起始指针
const int channel_size = KInputH * KInputW;
const float* r_channel = model_output + 0; // R通道起始地址
const float* g_channel = model_output + channel_size; // G通道起始地址
const float* b_channel = model_output + 2 * channel_size; // B通道起始地址
// 并行化填充(OpenCV自动优化)
for (int i = 0; i < KInputH; ++i) {
for (int j = 0; j < KInputW; ++j) {
const int pixel_idx = (i * KInputW + j) * 3; // HWC中每个像素的起始位置
const int ch_idx = i * KInputW + j; // CHW中当前像素的通道内索引
temp_data[pixel_idx] = r_channel[ch_idx]; // R
temp_data[pixel_idx + 1] = g_channel[ch_idx]; // G
temp_data[pixel_idx + 2] = b_channel[ch_idx]; // B
}
}
// 反归一化并转为8UC3(与Python一致)
temp_image.convertTo(temp_image, CV_8UC3, 255.0);
// Resize到目标尺寸(使用INTER_LINEAR)
if (KInputW != src_width || KInputH != src_height) {
cv::resize(temp_image, src_image, cv::Size(src_width, src_height), cv::INTER_LINEAR);
} else {
src_image = temp_image.clone();
}
// RGB转BGR(与Python的cv2.COLOR_RGB2BGR一致)
cv::cvtColor(src_image, src_image, cv::COLOR_RGB2BGR);
return src_image;
}构建模型的推理引擎:
bool genEngine(std::string onnx_file_path, std::string save_engine_path, trtlogger::Logger level, int maxbatch){
auto logger = std::make_shared<trtlogger::Logger>(level);
// 创建builder
auto builder = std::unique_ptr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(*logger));
if(!builder){
std::cout<<" (T_T)~~~, Failed to create builder."<<std::endl;
return false;
}
auto network = std::unique_ptr<nvinfer1::INetworkDefinition>(builder->createNetworkV2(0U));
if(!network){
std::cout<<" (T_T)~~~, Failed to create network."<<std::endl;
return false;
}
// 创建 config
auto config = std::unique_ptr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig());
if(!config){
std::cout<<" (T_T)~~~, Failed to create config."<<std::endl;
return false;
}
// 创建parser 从onnx自动构建模型,否则需要自己构建每个算子
auto parser = std::unique_ptr<nvonnxparser::IParser>(nvonnxparser::createParser(*network, *logger));
if(!parser){
std::cout<<" (T_T)~~~, Failed to create parser."<<std::endl;
return false;
}
// 读取onnx模型文件开始构建模型
auto parsed = parser->parseFromFile(onnx_file_path.c_str(), 1);
if(!parsed){
std::cout<<" (T_T)~~~ ,Failed to parse onnx file."<<std::endl;
return false;
}
{
auto input = network->getInput(0);
auto input_dims = input->getDimensions();
auto profile = builder->createOptimizationProfile();
// 配置最小、最优、最大范围
input_dims.d[0] = 1;
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMIN, input_dims);
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kOPT, input_dims);
input_dims.d[0] = maxbatch;
profile->setDimensions(input->getName(), nvinfer1::OptProfileSelector::kMAX, input_dims);
config->addOptimizationProfile(profile);
// 判断是否使用半精度优化模型
// if(FP16)
config->setFlag(nvinfer1::BuilderFlag::kFP16);
config->setFlag(nvinfer1::BuilderFlag::kGPU_FALLBACK);
config->setDefaultDeviceType(nvinfer1::DeviceType::kDLA);
// 设置默认设备类型为 DLA
config->setDefaultDeviceType(nvinfer1::DeviceType::kDLA);
// 获取 DLA 核心支持情况
int numDLACores = builder->getNbDLACores();
if (numDLACores > 0) {
std::cout << "DLA is available. Number of DLA cores: " << numDLACores << std::endl;
// 设置 DLA 核心
int coreToUse = 0; // 选择第一个 DLA 核心(可以根据实际需求修改)
config->setDLACore(coreToUse);
std::cout << "Using DLA core: " << coreToUse << std::endl;
} else {
std::cerr << "DLA not available on this platform, falling back to GPU." << std::endl;
// 如果 DLA 不可用,则设置 GPU 回退
config->setFlag(nvinfer1::BuilderFlag::kGPU_FALLBACK);
config->setDefaultDeviceType(nvinfer1::DeviceType::kGPU);
}
};
config->setMemoryPoolLimit(nvinfer1::MemoryPoolType::kWORKSPACE, 1 << 28); /*在新的版本中被使用*/
// 创建序列化引擎文件
auto plan = std::unique_ptr<nvinfer1::IHostMemory>(builder->buildSerializedNetwork(*network, *config));
if(!plan){
std::cout<<" (T_T)~~~, Failed to SerializedNetwork."<<std::endl;
return false;
}
//! 检查输入部分是否符合要求
auto numInput = network->getNbInputs();
std::cout<<"模型的输入个数是:"<<numInput<<std::endl;
for(auto i = 0; i<numInput; ++i){
std::cout<<" 模型的第"<<i<<"个输入:";
auto mInputDims = network->getInput(i)->getDimensions();
std::cout<<" ✨~ model input dims: "<<mInputDims.nbDims <<std::endl;
for(size_t ii=0; ii<mInputDims.nbDims; ++ii){
std::cout<<" ✨^_^ model input dim"<<ii<<": "<<mInputDims.d[ii] <<std::endl;
}
}
auto numOutput = network->getNbOutputs();
std::cout<<"模型的输出个数是:"<<numOutput<<std::endl;
for(auto i=0; i<numOutput; ++i){
std::cout<<" 模型的第"<<i<<"个输出:";
auto mOutputDims = network->getOutput(i)->getDimensions();
std::cout<<" ✨~ model output dims: "<<mOutputDims.nbDims <<std::endl;
for(size_t jj=0; jj<mOutputDims.nbDims; ++jj){
std::cout<<" ✨^_^ model output dim"<<jj<<": "<<mOutputDims.d[jj] <<std::endl;
}
}
// 序列化保存推理引擎文件文件
std::ofstream engine_file(save_engine_path, std::ios::binary);
if(!engine_file.good()){
std::cout<<" (T_T)~~~, Failed to open engine file"<<std::endl;
return false;
}
engine_file.write((char *)plan->data(), plan->size());
engine_file.close();
std::cout << " ~~Congratulations! 🎉🎉🎉~ Engine build success!!! ✨✨✨~~ " << std::endl;
return true;
}创建runtime部分:
bool ZeroDCEModel::Runtime(std::string engine_file_path, trtlogger::Logger level,int maxBatch){
auto logger = std::make_shared<trtlogger::Logger>(level);
// 初始化trt插件
// initLibNvInferPlugins(&logger, "");
std::ifstream engineFile(engine_file_path, std::ios::binary);
long int fsize = 0;
engineFile.seekg(0, engineFile.end);
fsize = engineFile.tellg();
engineFile.seekg(0, engineFile.beg);
std::vector<char> engineString(fsize);
engineFile.read(engineString.data(), fsize);
if (engineString.size() == 0) { std::cout << "Failed getting serialized engine!" << std::endl; return false; }
// 创建推理引擎
m_runtime.reset(nvinfer1::createInferRuntime(*logger));
if(!m_runtime){
std::cout<<" (T_T)~~~, Failed to create runtime."<<std::endl;
return false;
}
// 反序列化推理引擎
m_engine.reset(m_runtime->deserializeCudaEngine(engineString.data(), fsize));
if(!m_engine){
std::cout<<" (T_T)~~~, Failed to deserialize."<<std::endl;
return false;
}
// 获取优化后的模型的输入维度和输出维度
// int nbBindings = m_engine->getNbBindings(); // trt8.5 以前版本
int nbBindings = m_engine->getNbIOTensors(); // trt8.5 以后版本
// 推理执行上下文
m_context.reset(m_engine->createExecutionContext());
if(!m_context){
std::cout<<" (T_T)~~~, Failed to create ExecutionContext."<<std::endl;
return false;
}
auto input_dims = m_context->getTensorShape("input");
input_dims.d[0] = maxBatch;
m_context->setInputShape("input", input_dims);
std::cout << " ~~Congratulations! 🎉🎉🎉~ create execution context success!!! ✨✨✨~~ " << std::endl;
return true;
}申请内存,并且绑定模型输入输出:
bool ZeroDCEModel::trtIOMemory() {
m_inputDims = m_context->getTensorShape("input"); // 模型输入
m_outputDims[0] = m_context->getTensorShape("output1"); //第一个输出
m_outputDims[1] = m_context->getTensorShape("output2"); //第二个输出
m_outputDims[2] = m_context->getTensorShape("output3"); //第三个输出
this->kInputH = m_inputDims.d[2];
this->kInputW = m_inputDims.d[3];
m_inputSize = m_inputDims.d[0] * m_inputDims.d[1] * m_inputDims.d[2] * m_inputDims.d[3] * sizeof(float);
m_outputSize[0] = m_outputDims[0].d[0] * m_outputDims[0].d[1] * m_outputDims[0].d[2] * m_outputDims[0].d[3] * sizeof(float);
m_outputSize[1] = m_outputDims[1].d[0] * m_outputDims[1].d[1] * m_outputDims[1].d[2] * m_outputDims[1].d[3] * sizeof(float);
m_outputSize[2] = m_outputDims[2].d[0] * m_outputDims[2].d[1] * m_outputDims[2].d[2] * m_outputDims[2].d[3] * sizeof(float);
// 声明cuda的内存大小
checkRuntime(cudaMalloc(&buffers[0], m_inputSize));
checkRuntime(cudaMalloc(&buffers[1], m_outputSize[0]));
checkRuntime(cudaMalloc(&buffers[2], m_outputSize[1]));
checkRuntime(cudaMalloc(&buffers[3], m_outputSize[2]));
// 声明cpu内存大小
checkRuntime(cudaMallocHost(&cpu_buffers[0], m_inputSize));
checkRuntime(cudaMallocHost(&cpu_buffers[1], m_outputSize[0]));
checkRuntime(cudaMallocHost(&cpu_buffers[2], m_outputSize[1]));
checkRuntime(cudaMallocHost(&cpu_buffers[3], m_outputSize[2]));
m_context->setTensorAddress("input", buffers[0]);
m_context->setTensorAddress("output1", buffers[1]);
m_context->setTensorAddress("output2", buffers[2]);
m_context->setTensorAddress("output3", buffers[3]);
checkRuntime(cudaStreamCreate(&m_stream));
return true;
}推理模型:
cv::Mat ZeroDCEModel::doInference(cv::Mat& frame) {
if(useGPU){
zero_dce_preprocess::preprocess_gpu(frame, (float*)buffers[0], kInputH, kInputW, m_stream);
}else{
zero_dce_preprocess::preprocess_cpu(frame, cpu_buffers[0], kInputW, kInputH);
// Preprocess -- 将host的数据移动到device上
checkRuntime(cudaMemcpyAsync(buffers[0], cpu_buffers[0], m_inputSize, cudaMemcpyHostToDevice, m_stream));
}
bool status = this->m_context->enqueueV3(m_stream);
if (!status) std::cerr << "(T_T)~~~, Failed to create ExecutionContext." << std::endl;
// 将gpu推理的结果返回到cpu上面处理
checkRuntime(cudaMemcpyAsync(cpu_buffers[1], buffers[1], m_outputSize[0], cudaMemcpyDeviceToHost, m_stream));
checkRuntime(cudaMemcpyAsync(cpu_buffers[2], buffers[2], m_outputSize[1], cudaMemcpyDeviceToHost, m_stream));
checkRuntime(cudaMemcpyAsync(cpu_buffers[3], buffers[3], m_outputSize[2], cudaMemcpyDeviceToHost, m_stream));
checkRuntime(cudaStreamSynchronize(m_stream));
int height = frame.rows;
int width = frame.cols;
cv::Mat enhance_image;
if(useGPU){
enhance_image = zero_dce_postprocess::decode_gpu(buffers[2],kInputW,kInputH,width,height);
}else{
// cv::Mat enhance_image_1 = zero_dce_postprocess::decode_cpu(cpu_buffers[1],kInputW,kInputH,height,width);
enhance_image = zero_dce_postprocess::decode_cpu(cpu_buffers[2],kInputW,kInputH,width,height);
// cv::Mat r = zero_dce_postprocess::decode_cpu(cpu_buffers[3],kInputW,kInputH,height,width);
}
return enhance_image;
}部署代码的增强图展示:

至此,完成模型zero_dce_model模型的部署代码。
6. 低光照补偿代码的使用
这是一个低光照补偿的模型部署,一般情况下需要配合其他模型使用。比如在检测模型中,发现实际检测场景比较暗,这个时候可以先配合检查图像的暗亮程度,如果过暗的话,可以使用这个模型先增加图像的亮度,然后再次输入到检测模型中开始检测。
检测图像的暗亮程度,对这个图像灰度化,然后求取图像的平均亮度作为判断条件,然后再使用其他模型。
int main(){
cv::VideoCapture cap("media/6.mp4");
// 检查视频是否成功打开
if (!cap.isOpened()) {
std::cerr << "无法打开视频文件或摄像头!" << std::endl;
return -1;
}
// 创建一个窗口用于显示视频
cv::namedWindow("Video", cv::WINDOW_NORMAL);
cv::Mat frame;
while (true) {
// 读取一帧
if (!cap.read(frame)) {
std::cerr << "无法读取视频帧!" << std::endl;
break;
}
//----------------判断的亮度------------------------
cv::Mat gray;
// 将彩色图转换为灰度图
cv::cvtColor(frame, gray, cv::COLOR_BGR2GRAY);
cv::Scalar mean_value = cv::mean(gray);
std::cout << "[OpenCV] Average: " << mean_value[0] << std::endl;
if (mean_value[0]< 30)
{
frame = zero_model.doInference(frame);
}
//----------------判断的亮度------------------------
auto detections = model.doInference(frame);
model.draw(frame,detections);
// 显示这一帧
cv::imshow("Video", frame);
// 按下 'q' 键退出循环
if (cv::waitKey(30) == 'q') {
break;
}
}
// 释放资源并关闭窗口
cap.release();
cv::destroyAllWindows();
return 0;
}
















 1193
1193

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









