






下面这张图大家应该不陌生吧,细胞通讯分析得到的图
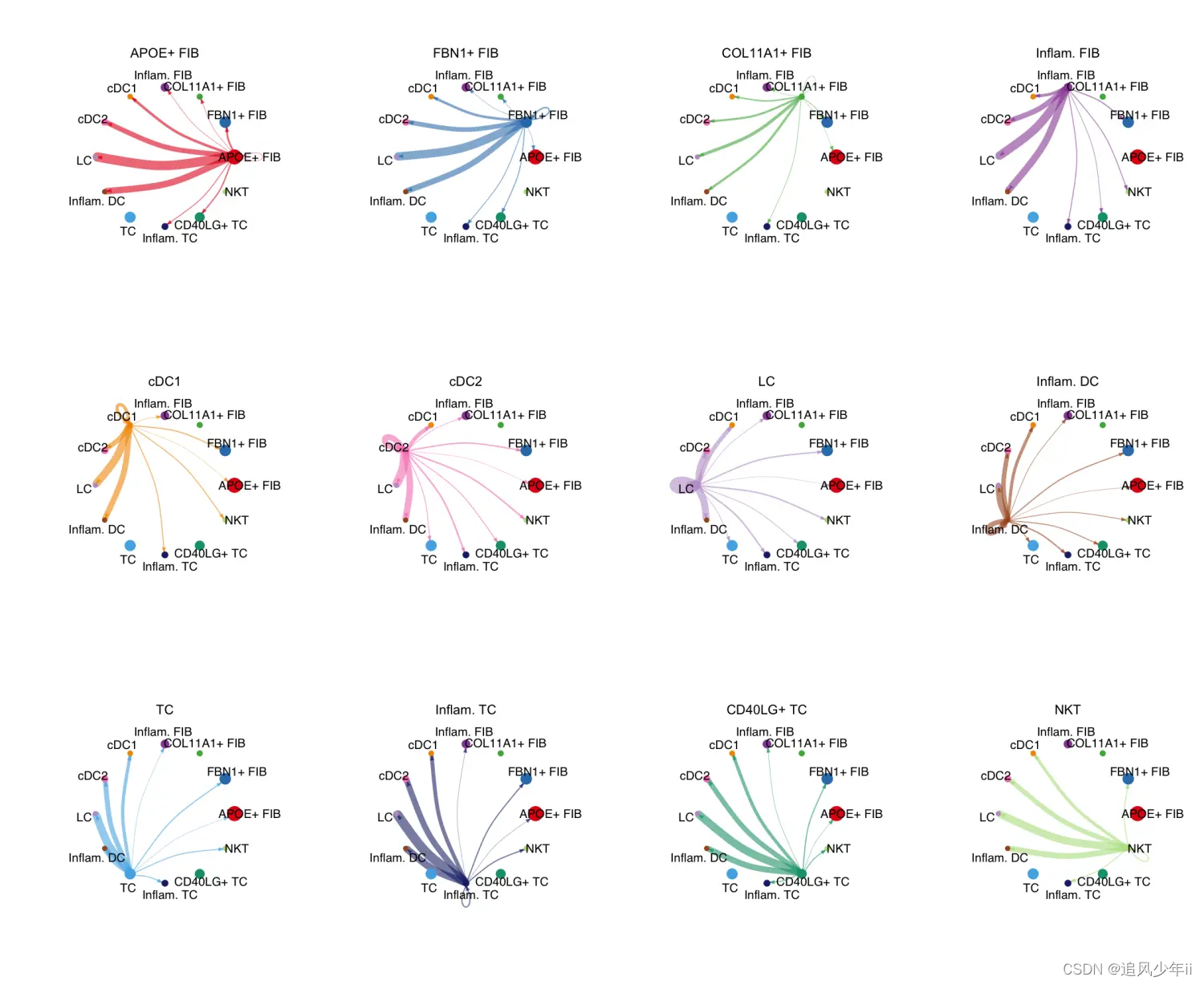
今天我们来实现一下,以下图为例,大同小异。

下面介绍绘图步骤与相应的代码。
第一步,数据存储。这里需要建立两个csv文件,命名为link.csv和node.csv,其中link里面存储节点之间的关系,node里面存储节点的信息。(对应我们分析得到的配受体对)
如下,在node这张表中,id是每一个节点的唯一身份码,name是节点的名称,size是节点的尺寸,name.type是节点的类型。(对应我们的细胞类型,细胞数量和细胞定义结果)。

如下,在link这张表中,from到to表示节点之间的关系,weight标识联系的强度,type标识联系类型。对应我们细胞通讯的配体细胞,受体细胞,配受体数量和通讯的类型。

第二步,读取数据。因为数据里面有中文,所以首先需要定义字体以及告诉R语言里面有中文,代码为(这个可选):
windowsFonts(
A=windowsFont("华文彩云"),
B=windowsFont("华文仿宋"),
C=windowsFont("华文行楷"),
D=windowsFont("华文楷体"),
E=windowsFont("华文隶书"),
F=windowsFont("华文中宋"),
G=windowsFont("华文细黑"),
H=windowsFont("微软雅黑"),
J=windowsFont("华文新魏"),
K=windowsFont("幼圆")
)
#下面一行代码解决不能显示中文
Sys.setlocale(category="LC_ALL",locale="en_US.UTF-8")
当然,我们还需要安装igraph包:
install.packages("igraph")
读取数据的代码为:
links<-read.csv("D:/network/data.csv",header = T,as.is=T)
nodes<-read.csv("D:/network/node.csv",header = T,as.is=T)
这里我们将读取的数据赋予两个新的变量links和nodes。还可以通过head()预览数据:
> head(links)
from to weight type
1 a1 s1 10 hyperlink
2 a2 s2 2 hyperlink
3 a3 s3 2 hyperlink
4 a4 s4 3 hyperlink
5 a5 s5 3 hyperlink
6 a6 s6 3 hyperlink
> head(nodes)
id name size name.type
1 a1 古月 10 1
2 a2 N2 3 1
3 a3 N3 8 1
4 a4 N4 7 1
5 a5 name5 6 1
6 a6 name6 5 1
第三步,生成网络分析的数据并绘图。代码如下:
library(igraph) #载入igraph包
(net<-graph.data.frame(links,nodes,directed = T)) #生成网络分析数据
colrs<- c("#87cefa","red") #定义两个颜色(因为节点有两个类型),可以用颜色代码,或者英文单词
V(net)$color<-colrs[V(net)$name.type] #设置节点的颜色
E(net)$width<-E(net)$weight/3 #设置边的宽度,这个宽度是weight除以3,也可以是别的数
E(net)$label<-E(net)$weight #设置边的标签
deg <- igraph::degree(net, mode="all")
V(net)$size <- deg*14 #和前面一行代码一起设置节点大小,扩大了14倍
plot(net,layout=layout.circle, #节点的布局
edge.arrow.size=0.5, #设置箭头大小
vertex.frame.color="transparent", #节点边框透明
vertex.label.color="black", #节点标签黑色
vertex.label.cex=1.25, #节点标签大小
vertex.label.family="B", #节点标签字体
edge.curved=0.5, #边是否弯曲,取值0-1,0为不弯曲
edge.color="pink" #边的颜色
)
plot(net)是绘图命令,后面的均是对图的定义修饰。layout定义图的布局,包括layout.circle圆形布局,即前述效果图,layout.random随机布局,以及layout.sphere/layout.drl/layout.star/layout.spring等等。
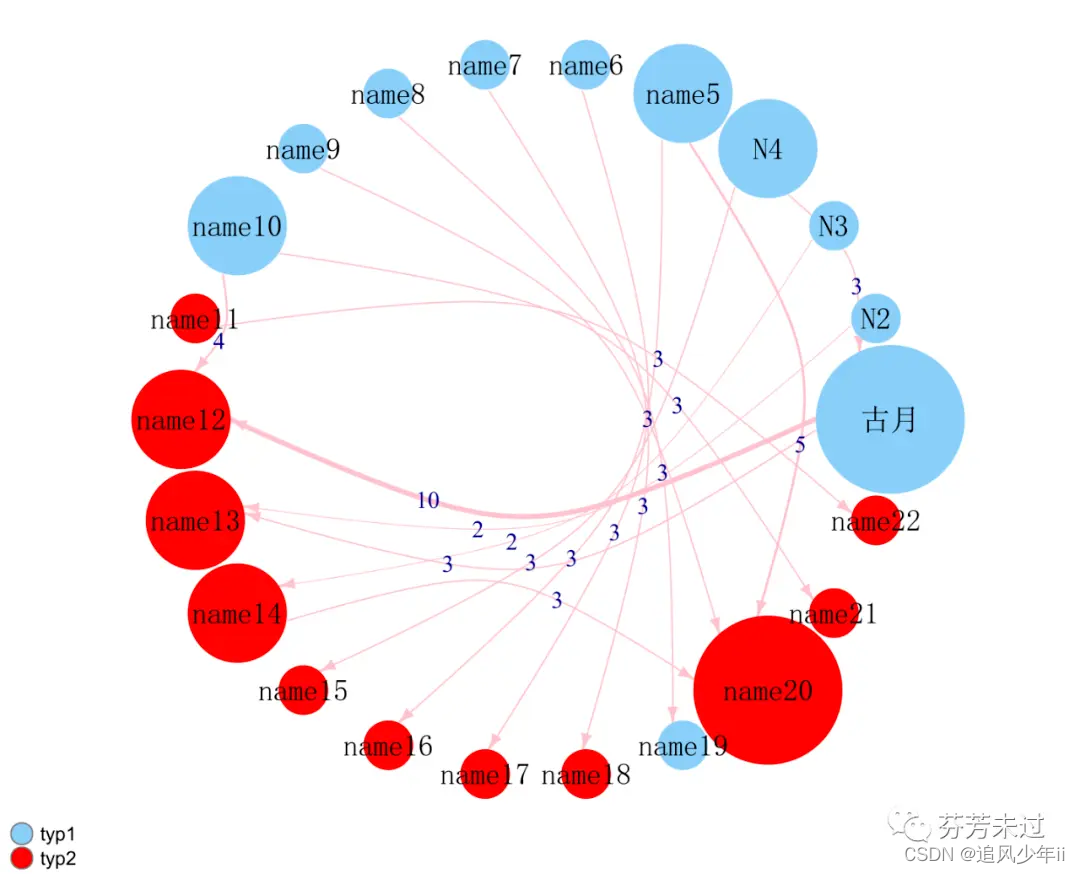
最后输出图例
legend(x=-1.5, y=-1.1, c("typ1","typ2"),
pch=21, col="#777777", pt.bg=colrs,
pt.cex=2, cex=.8, bty="n", ncol=1)
再来一个python版本的
import pandas as pd
import numpy as np
import os
import jieba
def my_cut(text):
#添加特定的词到jieba分词中,即不能分割的词
my_words = ['对口支援']
for i in my_words:
jieba.add_word(i)
# 加载停用词
stop_words = []
with open(r"meaningless.txt", 'r', encoding='utf-8') as f:
lines = f.readlines()
for line in lines:
stop_words.append(line.strip())
# stop_words[:10]
#返回结果:分词并且去除停用词
return [w for w in jieba.cut(text) if w not in stop_words and len(w) > 1]
def str2csv(filePath, s, x):
'''
将字符串写入到本地csv文件中
:param filePath: csv文件路径
:param s: 待写入字符串(逗号分隔格式)
'''
if x == 'node':
with open(filePath, 'w', encoding='utf-8') as f:
f.write("Label,Weight\r")
f.write(s)
print('写入文件成功,请在' + filePath + '中查看')
else:
with open(filePath, 'w', encoding='utf-8') as f:
f.write("Source,Target,Weight\r")
f.write(s)
print('写入文件成功,请在' + filePath + '中查看')
def sortDictValue(dict, is_reverse):
'''
将字典按照value排序
:param dict: 待排序的字典
:param is_reverse: 是否按照倒序排序
:return s: 符合csv逗号分隔格式的字符串
'''
# 对字典的值进行倒序排序,items()将字典的每个键值对转化为一个元组,key输入的是函数,item[1]表示元组的第二个元素,reverse为真表示倒序
tups = sorted(dict.items(), key=lambda item: item[1], reverse=is_reverse)
s = ''
for tup in tups: # 合并成csv需要的逗号分隔格式
s = s + tup[0] + ',' + str(tup[1]) + '\n'
return s
def build_matrix(co_authors_list, is_reverse):
'''
根据共同列表,构建共现矩阵(存储到字典中),并将该字典按照权值排序
:param co_authors_list: 共同列表
:param is_reverse: 排序是否倒序
:return node_str: 三元组形式的节点字符串(且符合csv逗号分隔格式)
:return edge_str: 三元组形式的边字符串(且符合csv逗号分隔格式)
'''
node_dict = {} # 节点字典,包含节点名+节点权值(频数)
edge_dict = {} # 边字典,包含起点+目标点+边权值(频数)
# 第1层循环,遍历整表的每行信息
for row_authors in co_authors_list:
row_authors_list = row_authors.split(' ') # 依据','分割每行,存储到列表中
# 第2层循环
for index, pre_au in enumerate(row_authors_list): # 使用enumerate()以获取遍历次数index
# 统计单个词出现的频次
if pre_au not in node_dict:
node_dict[pre_au] = 1
else:
node_dict[pre_au] += 1
# 若遍历到倒数第一个元素,则无需记录关系,结束循环即可
if pre_au == row_authors_list[-1]:
break
connect_list = row_authors_list[index + 1:]
# 第3层循环,遍历当前行词后面所有的词,以统计两两词出现的频次
for next_au in connect_list:
A, B = pre_au, next_au
# 固定两两词的顺序
# 仅计算上半个矩阵
if A == B:
continue
if A > B:
A, B = B, A
key = A + ',' + B # 格式化为逗号分隔A,B形式,作为字典的键
# 若该关系不在字典中,则初始化为1,表示词间的共同出现次数
if key not in edge_dict:
edge_dict[key] = 1
else:
edge_dict[key] += 1
# 对得到的字典按照value进行排序
node_str = sortDictValue(node_dict, is_reverse) # 节点
edge_str = sortDictValue(edge_dict, is_reverse) # 边
return node_str, edge_str
if __name__ == '__main__':
#工作文件夹路径
os.chdir(r'D:\university\my paper\Python_code')
filePath1 = r'node.csv'
filePath2 = r'edge.csv'
# 读取待分析csv文件获取数据并存储到列表中
df = pd.read_table("article.txt")
print(df)
df_ = [w for w in df['文章'] if len(w) > 20]
co_ist = [" ".join(my_cut(w)) for w in df_]
# 根据共同词列表, 构建共现矩阵(存储到字典中), 并将该字典按照权值排序
node_str, edge_str = build_matrix(co_ist, is_reverse=True)
# print(edge_str)
# 将字符串写入到本地csv文件中
str2csv(filePath1, node_str, 'node')
str2csv(filePath2, edge_str, 'edge')
上述代码运行完毕后,会在工作文件夹生成node.csv和edge.csv两个数据文件,下面就可以利用Gephi(软件下载【绘制关系网络图】Gephi 入门使用始于足下行千里致广大。-CSDN博客_gephi使用教程)可视化词语之间的网络关系。打开Gephi软件,在“文件”中“打开”之前生成的csv文件,这里直接打开边文件edge.csv,软件会自动识别节点。在“外观”和“布局”窗口可以对网络图进行定义,“图”周围的快捷按钮可以快速定义网络图。基本的设置完成之后,可以在“预览”窗口对网络图的整体风格进行定义。最后“文件”-“输出”为需要的格式文件。

来一张效果图

怎么样,很简单吧,赶紧试试吧















 2623
2623

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









