







–https://stuartlab.org/signac/articles/pbmc_multiomic
看文章看累了来看看代码,换换口味。本章主要涉及peaks to genes的联动。
留意更多内容,欢迎关注微信公众号:组学之心
数据下载:
wget https://cf.10xgenomics.com/samples/cell-arc/1.0.0/pbmc_granulocyte_sorted_10k/pbmc_granulocyte_sorted_10k_filtered_feature_bc_matrix.h5
wget https://cf.10xgenomics.com/samples/cell-arc/1.0.0/pbmc_granulocyte_sorted_10k/pbmc_granulocyte_sorted_10k_atac_fragments.tsv.gz
wget https://cf.10xgenomics.com/samples/cell-arc/1.0.0/pbmc_granulocyte_sorted_10k/pbmc_granulocyte_sorted_10k_atac_fragments.tsv.gz.tbi
1.导入scATCA-seq和scRNA-seq数据
library(Signac)
library(Seurat)
library(EnsDb.Hsapiens.v86)
library(BSgenome.Hsapiens.UCSC.hg38)
counts <- Read10X_h5("../vignette_data/multiomic/pbmc_granulocyte_sorted_10k_filtered_feature_bc_matrix.h5")
fragpath <- "../vignette_data/multiomic/pbmc_granulocyte_sorted_10k_atac_fragments.tsv.gz"
从hg38中获取细胞注释
下载获取基因注释文件,包含有关基因组位置的信息,例如染色体、起始和结束位置,以及相关的meta数据。
annotation <- GetGRangesFromEnsDb(ensdb = EnsDb.Hsapiens.v86)
#给染色体加上前缀“chr”
seqlevels(annotation) <- paste0('chr', seqlevels(annotation))
先创建scRNA-seq seurat项目
pbmc <- CreateSeuratObject(
counts = counts$`Gene Expression`,
assay = "RNA"
)
再创建scATAC-seq assay,然后把它加入到seurat项目中
pbmc[["ATAC"]] <- CreateChromatinAssay(
counts = counts$Peaks,
sep = c(":", "-"),
fragments = fragpath,
annotation = annotation
)
pbmc
## An object of class Seurat
## 144978 features across 11909 samples within 2 assays
## Active assay: RNA (36601 features, 0 variable features)
## 1 layer present: counts
## 1 other assay present: ATAC
2.计算质控指标
我们可以使用 DNA 可及性数据计算每个细胞的质量控制指标,并去除这些指标的异常细胞,以及 RNA 或 ATAC 测序中count低或异常高的细胞。
DefaultAssay(pbmc) <- "ATAC"
# 计算每个细胞的nucleosome signal值
pbmc <- NucleosomeSignal(pbmc)
# 计算每个细胞的TSS enrichment值
pbmc <- TSSEnrichment(pbmc)
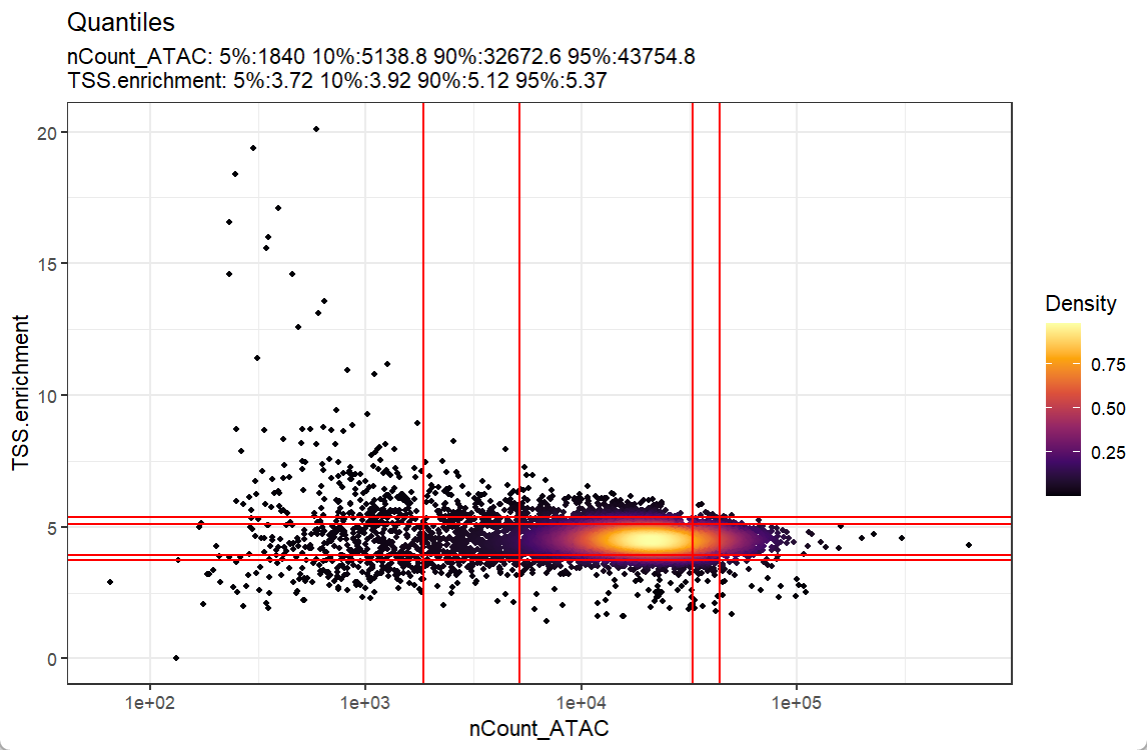
可以使用 DensityScatter() 函数可视化存储在项目中metadata中的变量之间的关系。通过设置 quantiles=TRUE,还可以快速找到不同 QC 指标的合适截止值:
DensityScatter(pbmc, x = 'nCount_peaks', y = 'TSS.enrichment', log_x = TRUE, quantiles = TRUE)
VlnPlot(
object = pbmc,
features = c("nCount_RNA", "nCount_ATAC", "TSS.enrichment", "nucleosome_signal"),
ncol = 4,
pt.size = 0
)
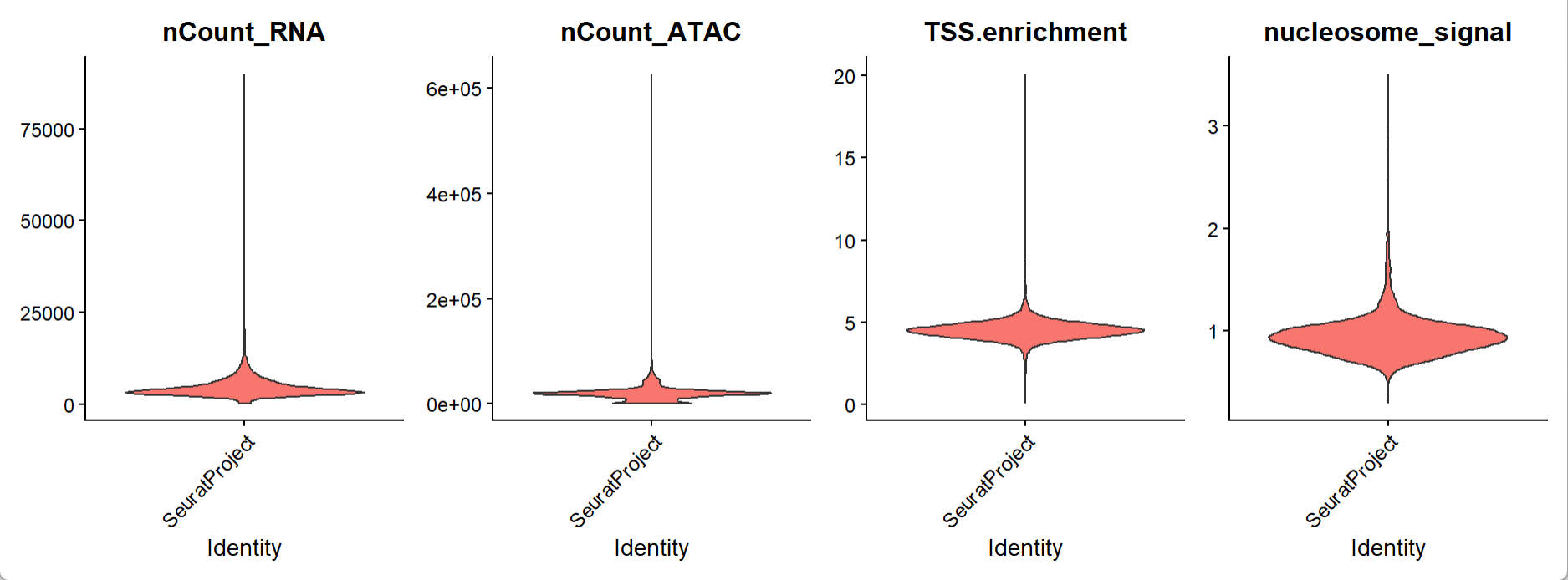
小提琴图指控指标的统计分布。用以下阈值来筛选(没有最优解,只有适合与否):
pbmc <- subset(
x = pbmc,
subset = nCount_ATAC < 100000 &
nCount_RNA < 25000 &
nCount_ATAC > 1800 &
nCount_RNA > 1000 &
nucleosome_signal < 2 &
TSS.enrichment > 1
)
pbmc
## An object of class Seurat
## 144978 features across 11070 samples within 2 assays
## Active assay: ATAC (108377 features, 0 variable features)
## 2 layers present: counts, data
## 1 other assay present: RNA
3.基因表达数据预处理
可以使用 SCTransform 对基因表达数据进行归一化,并使用 PCA 降低维数
DefaultAssay(pbmc) <- "RNA"
pbmc <- SCTransform(pbmc)
pbmc <- RunPCA(pbmc)
4.染色质可及性数据处理
TF-IDF 和 SVD 的组合步骤称为潜在语义索引 (LSI)。通过LSI,以与处理 scATAC-seq 数据集相同的方式处理 DNA 可及性。
DefaultAssay(pbmc) <- "ATAC"
pbmc <- FindTopFeatures(pbmc, min.cutoff = 5)
pbmc <- RunTFIDF(pbmc)
pbmc <- RunSVD(pbmc)
5.注释细胞类型
将使用 Hao 等人 (2020) 的带注释的 PBMC 参考数据集,可以从这里下载:https://atlas.fredhutch.org/data/nygc/multimodal/pbmc_multimodal.h5seurat
加载PBMC的参考数据
reference <- LoadH5Seurat("00practice/PBMC10K_scATAC_scRNA/pbmc_multimodal.h5seurat", assays = list("SCT" = "counts"), reductions = 'spca')
reference <- UpdateSeuratObject(reference)
DefaultAssay(pbmc) <- "SCT"
细胞类型注释转移
transfer_anchors <- FindTransferAnchors(
reference = reference,
query = pbmc,
normalization.method = "SCT",
reference.reduction = "spca",
recompute.residuals = FALSE,
dims = 1:50
)
predictions <- TransferData(
anchorset = transfer_anchors,
refdata = reference$celltype.l2,
weight.reduction = pbmc[['pca']],
dims = 1:50
)
pbmc <- AddMetaData(
object = pbmc,
metadata = predictions
)
设置细胞类型为预测值,并去除低质量的预测
Idents(pbmc) <- "predicted.id"
pbmc <- pbmc[, pbmc$prediction.score.max > 0.5]
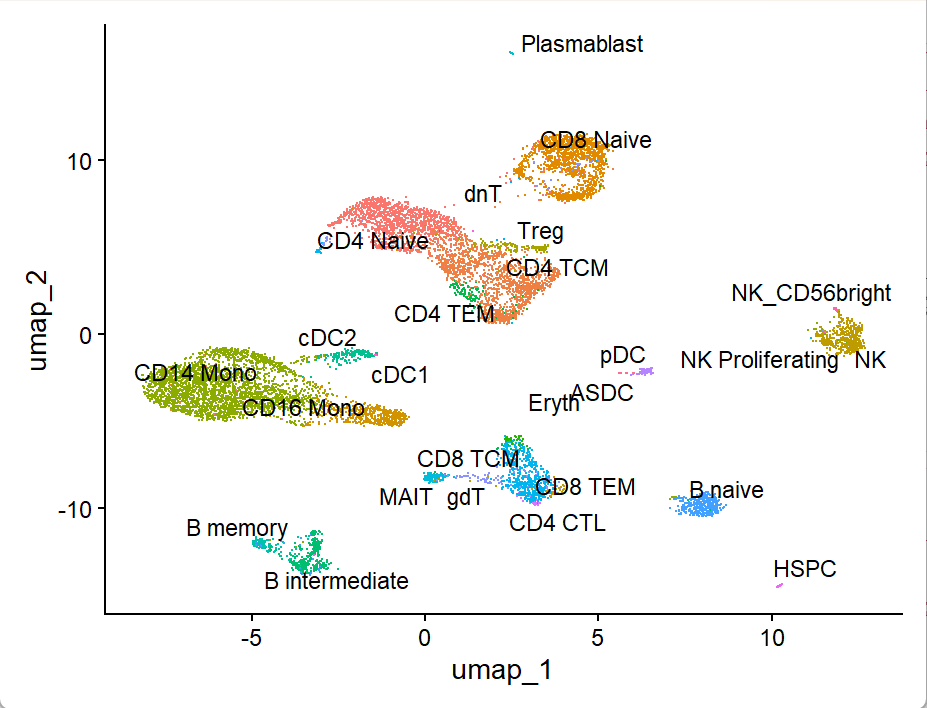
6.联合UMAP图展示
pbmc <- FindMultiModalNeighbors(
object = pbmc,
reduction.list = list("pca", "lsi"),
dims.list = list(1:50, 2:40),
modality.weight.name = "RNA.weight",
verbose = TRUE
)
注意的是ATAC数据dims.list从第2个开始,第一个 LSI component 通常捕获测序深度(技术变化)而不是生物变化。
#构建联合UMAP图
pbmc <- RunUMAP(
object = pbmc,
nn.name = "weighted.nn",
assay = "RNA",
verbose = TRUE
)
DimPlot(pbmc, label = TRUE, repel = TRUE, reduction = "umap") + NoLegend()
7.将峰值与基因联系起来
对于每个基因,signac可以通过计算基因表达与附近峰值的可及性之间的相关性,并校正由于 GC 含量、总体可及性和峰值大小而导致的偏差,来找到可能调节该基因的峰值。
在整个基因组上运行此步骤会非常耗时,在这里用部分基因的峰值基因关联为例进行演示。通过省略 genes.use 参数,使用相同的函数来查找所有基因的关联:
# 首先计算每个峰的 GC 含量
pbmc <- RegionStats(pbmc, genome = BSgenome.Hsapiens.UCSC.hg38)
# 将峰值与基因联系起来
pbmc <- LinkPeaks(
object = pbmc,
peak.assay = "ATAC",
expression.assay = "SCT",
genes.use = c("LYZ", "MS4A1")
)
idents.plot <- c("B naive", "B intermediate", "B memory",
"CD14 Mono", "CD16 Mono", "CD8 TEM", "CD8 Naive")
作图展示
p1 <- CoveragePlot(
object = pbmc,
region = "MS4A1",
features = "MS4A1",
expression.assay = "SCT",
idents = idents.plot,
extend.upstream = 500,
extend.downstream = 10000
)
p2 <- CoveragePlot(
object = pbmc,
region = "LYZ",
features = "LYZ",
expression.assay = "SCT",
idents = idents.plot,
extend.upstream = 8000,
extend.downstream = 5000
)
patchwork::wrap_plots(p1, p2, ncol = 1)
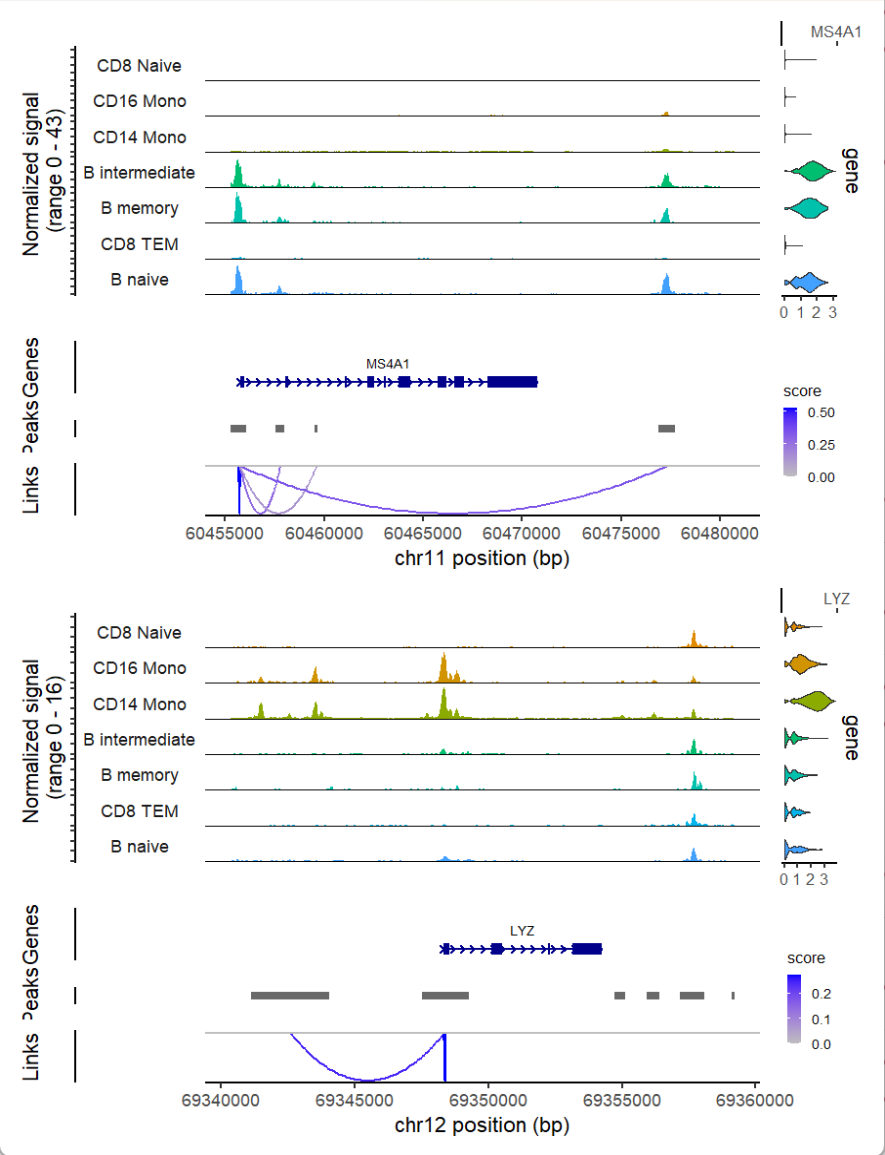
图展示了7种细胞类型种MS4A1和LYZ两个基因的ATAC-seq和RNA-seq情况,中间的小山峰是ATAC-seq数据的展示,代表了染色质开放的位置区域,每个基因名字下的深蓝色条带显示该基因的结构和转录方向。深蓝色粗矩形代表外显子;深蓝色细线代表内含子;箭头表示转录方向(RNA聚合酶的运动方向)。
连线部分是小山峰之间的相关性预测,代表它们之间相互作用的强度,score越高,互作越强。后续可以进一步做FIMO分析,来给小山峰注释上调控元件,进一步探究调控元件互作的内容/方式。
右侧的小提琴图展示该基因在不同细胞亚群中的表达情况(RNA)。




















 5462
5462

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











