






摘要:随着人工智能大模型的快速发展,开源模式在推动技术创新的同时,也面临知识产权、伦理风险与合规治理等新挑战。本文系统梳理了大模型领域的开源许可协议体系,从通用开源软件许可协议、知识共享许可协议到专为大模型设计的协议,分析其特点与适用场景。新型协议在保持开放共享的同时,增加了对伦理、安全与使用场景的限制条款。文章为开发者和企业提供了协议选择与合规风险管理的实践指南,以促进大模型开源生态的健康发展。
关键词:人工智能 开源许可协议 知识产权 伦理合规
一、引言
随着人工智能技术迅猛发展,大模型已成为当前科技创新的重要引擎。在这一浪潮中,开源模式正以其独特的协作机制推动着AI技术的普及与进步。然而,大模型开源涉及复杂的知识产权问题,选择合适的开源许可协议对于开发者、企业以及整个行业的健康发展至关重要。本文旨在系统梳理人工智能大模型领域的开源许可协议体系,分析不同协议的特点与适用场景,为相关主体提供指引。
二、开源许可协议的AI适应性演进及实践
(一)开源许可协议的定义
2021年,“开源”被首次写入国家“十四五”规划,开源依靠其公开、合作、互享的特性,现已演变为全球软件研发与行业革新进步的核心协同范式,开源体系借由降低革新壁垒、促进学识扩散、推动规范标准确立,为数字科技优质增长提供了坚实支撑。
开源许可协议(Open Source License,与“开源许可证”概念基本相同,以下又称“开源许可协议”)是规范开源软件使用、修改和分发的法律文件,旨在平衡开发者权益与开放共享理念。开源许可协议舍弃了某些传统著作权限制,在特定情境下容许他方运用、调整并发布其源码层级创作,以推进协同与共享。
(二)开源许可协议的AI适应性演进
多元化的版权限制规定和使用条款,衍生出了多样化的开源许可协议类别。传统的通用开源许可协议(如MIT、GPL、Apache协议等)以代码为中心,旨在通过明确代码使用、修改和分发的权限规则,推动技术开放共享。这类协议的约束范围仅限于代码本身,既不涉及数据来源的合规性,也不限制代码运行后的输出结果,更未针对AI模型部署场景设定责任边界,因此在应对AI技术的复杂性时存在显著局限性。
近年来随着AI模型的发展,一批AI模型专用协议应运而生,如OpenRAIL、Llama系列协议等,这些协议在开源精神的基础上,加入了针对AI特定场景的条款,这些条款多为用途和生成内容的输出限制。
(三)DeepSeeek的开源策略演进
2025年1月20日,DeepSeek-R1发布。该模型性能与OpenAI-o1持平,并且完全开源,其不仅受到了科技界的高度关注,也引发了资本市场的剧烈反应,打破了美国在AI领域长期依赖的垄断局面。
在DeepSeek-R1发布前,DeepSeek模型采用差异化许可策略,其开源许可协议体系针对代码库和模型采用了差异化设计,结合了传统开源许可协议与AI领域新型责任约束条款,其代码库使用了MIT协议(通用开源许可协议),而其模型采用了修改版的OpenRAIL协议(AI模型专用协议)。例如,DeepSeek-V3在发布之初即采用上述开源策略。
自DeepSeek-R1发布起,DeepSeek模型开始全面转向统一许可策略,即代码库和模型均采用MIT协议,目的是降低使用者的理解难度和开发者合规成本。例如,DeepSeek-R1代码库和模型均采用了MIT协议;DeepSeek-V3在2025年3月的更新中,也调整了其开源许可协议体系,全面采用了MIT协议,与DeepSeek-R1保持了一致。
基于上述,笔者认为,AI开源许可协议的演化路径既受技术透明度需求驱动,也因商业利益与公共安全的冲突而充满变数,本文将仅基于现有的各种协议进行分析介绍。
三、开源许可体系:从传统软件到AI模型的权益平衡
人工智能开源实践早有先例,如Meta于2023年推出的LLaMA系列采用了限制性开源许可协议、阿里云通义千问采用Apache 2.0开源许可协议等。据Hugging Face平台统计,截至2025年3月,其开源模型库已收录超百万个AI模型,其涉及的开源许可协议类型众多,大致可以分为三类:通用开源许可协议、知识共享许可协议、AI模型专用协议。这三类协议之间并非泾渭分明,其核心条款在内涵上往往存在诸多相似之处。开发者在开源过程中,也可能会同时适用多种协议,此处的分类仅为便于理解与阐释之便。
(一)通用开源许可协议
通用开源许可协议是软件开发和分发的基础法律工具,它们为代码共享、协作开发和软件分发提供了明确的法律框架。这些协议的核心目的是促进知识共享和技术创新,同时保护创作者的某些权利。通过明确定义使用者可以如何使用、修改和分发软件,这些协议在保障软件自由的同时,也为开发者提供了法律保护。
不同类型的通用开源许可协议反映了开源社区内部对“自由”定义的不同理解——从强调最大使用自由的宽松协议,到强调代码持续开放的强传染性协议,再到寻求平衡的混合型协议。这些协议在商业使用、源代码公开、专利授权等方面的差异,构成了开源软件生态系统的多样性基础。开源许可协议框架详见图1。
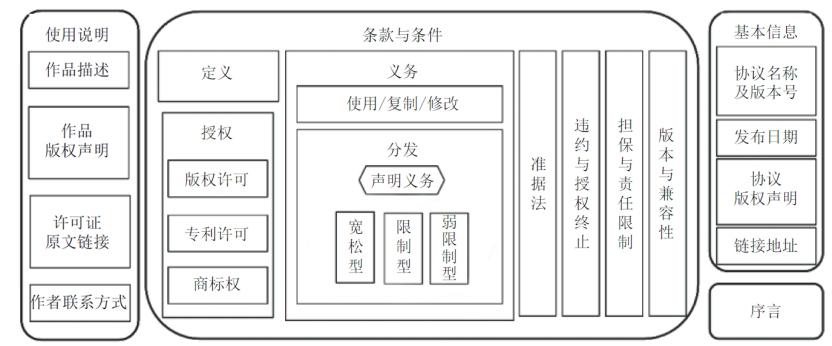
图1 开源许可协议框架
1.宽松型协议(Permissive Licenses)
宽松型协议允许使用者自由使用、修改、分发代码,对衍生作品的限制极少,不强制要求衍生作品开源,商业友好性高。
(1)MIT 协议
MIT协议因其极简的设计和宽松的条款而备受欢迎,是目前最广泛使用的开源许可协议之一。其核心特点在于几乎不对使用者施加任何限制,只要保留版权声明。
自由使用与分发:基于MIT协议授权的材料(包括模型输出、衍生代码及修改后的权重,以下统称为“材料”)可以被自由地使用、复制、修改和发布。无论是个人还是商业项目,都可以对其进行使用、复制、修改和发布,并且无需支付费用。
版权声明与许可声明:使用、复制、修改和发布基于MIT协议授权的材料需要保留原始版权声明和许可声明。
免责条款:MIT协议包含免责声明,指出该软件是“按现状(AS IS)”提供的,即不附带任何明示或暗示的保证,也不对因使用该软件导致的任何损害负责。
其他特点:MIT协议没有对使用场景、专利权或数据处理设置任何限制,同时与几乎所有其他开源许可协议高度兼容。MIT协议没有专利相关条款,法律保护相对有限。
(2)Apache协议
Apache协议由Apache软件基金会(ASF)维护,目前最新版本为Apache 2.0协议。相比MIT协议,Apache协议显得更“严谨”,它不仅允许使用者自由使用代码,还提供了额外的法律保护,比如专利授权。
商用授权条款:完全允许在任何商业环境中使用,无论使用者规模或收入多少,都不需要支付费用。从初创公司到大型企业,均可自由将任何基于Apache协议授权的材料整合到商业产品中。
修改与分发限制:允许自由修改和闭源使用,但要求如果分发修改版本,必须明确指出修改内容。具体来说,需要在修改的文件中添加显著通知,说明文件已被更改,但不需要详细列出所有修改或提供完整源代码。
版权声明:使用者在使用、修改或分发软件时,必须保留原始的版权声明和许可声明。
专利条款:Apache协议的一个显著优势是其明确的专利授权条款,自动授予使用者使用相关专利的权利,同时包含防御条款,保护生态系统免受专利诉讼的威胁。
商标使用限制:未经许可方书面授权,使用者不得使用与项目相关的商标、服务标志、商品名称来背书或推广衍生作品。
免责条款:Apache协议包含免责声明,指出该软件同样是“按现状(AS IS)”提供的,即不附带任何明示或暗示的保证,也不对因使用该软件导致的任何损害负责。
2. 强传染性协议(Copyleft Licenses)
强传染性协议是开源许可协议中约束最严格的一类,其核心特征在于要求任何使用或修改协议代码的衍生作品必须使用相同协议并且开源,从而确保代码的开放性和共享性。
GPL 协议
GPL协议是自由软件基金会(FSF)制定的开源许可协议,旨在保障软件的“自由”属性,确保使用者对软件的复制、修改和分发的权利。自1989年发布以来,共有3个版本(GPL v1/v2/v3),著名的Linux中就使用了GPL v2协议。
商用授权条款:使用者可以免费使用、复制和分发使用基于GPL协议授权的材料,并且允许商业使用。
修改与分发限制:有着极为严格的“传染性”要求。任何包含使用基于GPL协议授权的材料在分发时必须:1)同样以GPL协议发布;2)提供完整源代码;3)允许他人以相同条件再分发。而衍生代码是否需要开源的司法判断规则为:专有代码与使用GPL协议的代码通过共享数据结构或深度交互(如动态链接)结合,可能被认定为“衍生作品”,需整体开源;若代码间仅通过简单接口通信,且技术栈独立,可视为“聚合作品”,从而避免传染。
版权与专利保护:为避免开源软件贡献者通过开源许可协议授予使用者著作权许可,但转而又针对使用者提起专利侵权诉讼,GPL协议规定:“每个贡献者就‘必要专利权利要求’授予使用者非独占的、全球范围的、免费的‘专利许可’”,其中“‘必要专利权利要求’是指贡献者已经获取或将会获取的,可能会被他人在遵守GPL协议条款的前提下,因制造、使用或销售本软件而侵犯的所有专利权利要求”,强制开源软件贡献者同时授予使用者专利许可,以保障使用者对开源软件的自由使用不会受到专利的限制。
3. 混合型协议
混合型协议介于宽松与强传染性之间,部分条款限制开源范围,允许一定程度的闭源。
MPL 协议
MPL协议是在1998年初Netscape的Mozilla小组为其开源软件项目设计的软件许可证。MPL协议出现的最重要原因就是,Netscape公司认为GPL协议没有很好地平衡开发者对源代码的需求和他们利用源代码获得的利益。MPL协议代表了一种平衡的开源许可方式,在保持核心开源精神的同时,为商业集成提供了更大灵活性。目前使用最广泛的MPL协议是2012年发行的MPL2.0版本。
商用授权条款:完全允许商业使用,无需支付费用。企业可以在商业产品中使用、销售基于MPL协议授权的材料,没有公司规模或收入限制。
修改与分发限制:采用“文件级”传染性,比GPL协议更温和。修改基于MPL协议授权的材料必须以MPL协议分享,但新创建的文件可以使用任何协议,包括专有许可。这种灵活性使MPL成为商业与开源结合的理想选择,允许闭源组件与开源部分共存。即在使用基于MPL协议授权的材料时,后续只需要继续开源这部分特定代码即可,新研发的部分不用完全被该协议控制。
版权条款:开发人员在发布新软件时,必须附带一个专门用于说明该程序的文件,内容要有原始代码的修改时间和修改方式。
专利条款:MPL协议包含明确的专利授权条款,提供重要的法律保障,防止专利纠纷。
其他特点:MPL协议具有良好兼容性,开发者可以将使用MPL协议的代码与多种协议的代码一起混合使用,使其成为不同许可生态系统间的桥梁。
(二)知识共享(Creative Commons,CC)许可协议
随着数据资产化,开放数据和数据流通成为一种新“开源”典范。数据通常体现为事实和信息,而著作权一般应用于具备独创性的数据表现模式,著作权通常无法覆盖全部数据资产。开放数据许可聚焦于数据的访问、共享和再利用,不一定涉及数据的修改和编程。开放数据许可因法律法规、隐私保护和数据质量保证等原因,一般会根据法律法规、数据性质和共享方式等来制定专属的知识共享许可协议(以下简称“CC协议”)。
CC协议种类繁多,CC协议通过署名(BY)、非商业用途(NC)、禁止衍生作品(ND)、相同方式共享(SA)四个基本部分,形成不同授权模式。这几个部分可以单独起作用,也可以组合起来。以下是这四部分的简介:
1.署名(BY):作品上必须附有作品的归属。如此之后,作品可以被修改,分发,复制和其它用途。
2.非商业用途(NC):作品可以被修改、分发等等,但不能用于商业目的。然而,CC协议对“商业用途”的界定相当模糊,缺乏精确定义,这就要求项目开发者在使用时主动提供明确说明。例如,有些人简单的解释“非商业”为不能出售这个作品。而另外一些人认为你甚至不能在有广告的网站上使用它们。还有些人认为“商业”仅仅指你用它获取利益。
3.禁止衍生作品(ND):禁止使用者对原作品进行任何形式的修改、转换或构建。使用者只能以原始形式使用作品,而不能对其进行任何改编或创作新作品。
4.相同方式共享(SA):作品可以被修改、分发或其它操作,但所有的衍生品都要置于CC协议下。
CC协议的这些条款可以自由组合使用。比较严格的CC协议会使用“署名权,非商业用途,禁止衍生”条款,这意味着可以自由地分享这个作品,但不能改变它和用于商业用途,并且需要声明作品的归属。这种严格的CC协议可以让作品传播,但又可以对作品的使用保留部分或完全的控制。而最少限制的CC协议类型当属 “CC0”协议,这是一种开放授权协议,旨在将作品完全置于公共领域,放弃其在全球范围内的所有版权和相关邻接权。
(三)AI模型专用协议
AI模型专用协议是为了规范模型的使用、分发和研究而设计的法律框架。这些协议在传统开源许可协议的基础上,增加了针对AI模型伦理、安全和合规的特殊约束。以下是主要协议及其特点的详细介绍:
1.OpenRAIL协议
OpenRAIL协议源自 RAIL(Responsible AI Licenses,负责任人工智能许可协议)倡议。RAIL倡议组织成立于2019年,旨在倡导在许可和合同中采用基于行为的使用限制,以降低开源人工智能技术带来的危害风险。OpenRAIL协议要求允许免版税使用、修改和再分发基于OpenRAIL协议授权的材料,同时通过“使用限制”条款约束下游应用场景。这种“开放但受控”的模式与传统开源许可协议(如Apache 2.0)有本质区别。
开放性与传染性:允许自由访问、使用、修改模型、再分发模型/代码,并且允许用于商业用途,但所有衍生模型必须继承OpenRAIL协议,确保责任条款延续。
禁止用途:不得用于监控、军事行动、种族歧视、制造生物武器等;禁止生成儿童虐待、暴力、深度伪造(Deepfake)等非法内容。
透明度义务:鼓励使用者披露模型使用场景,并评估潜在社会影响。部分协议要求公开模型训练数据的来源。
2.Llama 3协议
Llama 3协议是Meta公司于2024年4月18日发布的一项专为开源大型语言模型设计的开源许可协议,旨在推动AI研究的同时限制高风险应用。
许可范围:使用者被授予非独占、全球、不可转移和非排他的有限许可,允许使用、复制、分发、修改和创建衍生作品。
许可限制:使用者在分发或使用Llama3协议的软件时,必须提供一份许可副本,并确保衍生作品名称开头包含“基于Meta Llama构建”。
商业限制:若产品或服务的月活跃使用者数超过7亿,需单独向Meta申请商业授权,否则无权行使协议权利。
用途限制:任何基于Llama 3协议授权的材料不得用于优化其他模型(Llama 3的衍生品除外)。
商标许可限制:仅在遵守命名规则时允许使用,禁止使用Meta及其关联公司的其他商标或标识。
涉诉即终止许可:若使用者对Meta发起知识产权诉讼,协议自动终止,且使用者需赔偿Meta相关损失。
免责条款:Llama 3协议包含免责声明,指出该软件“按现状(AS IS)”提供的,即不附带任何明示或暗示的保证,也不对因使用该软件导致的任何损害负责。
禁止用途包括:暴力、恐怖主义、儿童剥削、人口贩卖、非法药物等;军事、核工业、关键基础设施、医疗诊断、金融建议(需资质);生成虚假信息、冒充他人、垃圾信息、伪造在线互动;收集敏感个人信息(如健康数据)未经授权等。
三、开源实践指南:协议选择与合规使用
AI项目的各组成部分可采用不同类型的开源许可协议:代码部分通常依托于成熟的通用开源许可协议;数据集则多采用CC协议,它们为不同程度的数据共享提供了灵活选择;而考虑到AI技术的特殊性和潜在的伦理影响,越来越多地使用专为AI定制的协议。
在选择合适的开源许可协议时,开发者与使用者需要从各自角度出发,权衡不同协议的特点与自身需求,以实现权益保护与技术共享的平衡。
(一)开发者视角
作为AI项目的开发者,使用合适的开源许可协议需要考虑以下几点:
1、项目定位:开源许可协议直接影响项目的传播路径和商业化可能性。如果项目的核心价值在于广泛采用和社区贡献,那么宽松协议可能更为适合;而如果项目包含具有显著竞争优势的创新,更严格的协议可以保护这些价值不被竞争对手直接利用。
2、生态系统构建:在人工智能领域,单个项目很难独立存在,往往需要与其他工具、框架和模型组合使用。选择兼容性好的协议有助于项目融入更大的生态系统。开发者应当考虑目标使用者群体常用的其他组件所采用的协议类型,评估协议间的兼容性。
3、社区面向考虑:不同类型的开源许可协议会吸引不同类型的贡献者,协议选择应与项目的社区的模式相匹配。更宽松的协议通常能吸引企业使用者和贡献者,而强传染性协议则可能吸引更注重知识共享的个人和学术团体。
4、项目所处阶段考虑:根据项目所处阶段的不同,开发者也应选择相应的开源许可协议,具体包括:
(1)项目起步阶段:在项目初期,吸引使用者和建立基础社区是开发者的主要目标,宽松协议通)常更有优势:1)降低采用门槛,最大化潜在使用者;2)简化法律复杂性,专注技术开发;3)建立项目声誉和初始使用者基础。
(2)增长扩展阶段:当项目获得一定关注后,可能需要更精细的协议策略:1)引入商业友好条款以支持可持续发展;2)设置适当边界,防止价值过度流失;3)构建差异化协议结构,支持多元化应用场景。
(3)成熟稳定阶段:成熟项目通常已形成独特的协议生态:1)建立完整的许可体系;2)发展特定领域的定制协议;3)通过协议创新推动行业标准发展。
作为开发者,可以考虑为项目的不同部分采用不同协议,实现更精细的权限控制。例如应用接口可以设计商业友好的条款促进集成、模型架构可以使用包含专利条款的协议等。前文所介绍的是目前比较常见的几种协议,开发者可以根据项目的需求在常见开源许可协议的基础上定制协议,增加或删除部分条款,以适应项目发展。
(二)使用者视角
作为AI开源项目的使用者,需要了解所使用的材料是基于何种开源许可协议所授权的,并系统性地评估风险,以下是需要注意的条款:
1、场景限制条款:某些协议可能明确禁止在特定领域应用,使用者需要结合自身业务场景进行匹配度分析,确保合规使用。
2、传染性条款:如果要选择传染性协议,使用者需要分析:1)计划如何整合开源组件(链接、修改、衍生);2)传染性协议对商业代码的影响范围;3)隔离策略的可行性和实施成本。
3、专利条款:不同协议对专利权的处理各不相同,使用者应关注:1)协议是否包含明确的专利授权条款;2)协议中隐含的专利许可范围和限制。
4、变更与终止条款:使用者需要注意协议中是否有终止或撤销的触发条件,如上文所述的“OpenRAIL规定发起专利诉讼将终止授权”。
5、商业化限制条款:部分开源许可协议可能对商业应用设置特定限制,使用前应充分评估这些限制对商业计划的影响。例如Llama 3协议规定了“若产品或服务的月活跃用户数超过7亿,需单独向Meta申请商业授权,否则无权行使协议权利”。
四、结语
AI模型领域的开源许可协议体系正在迅速演进,从传统软件开源许可协议向专门面向AI模型的协议发展。这一转变不仅反映了技术本身的特殊性,也体现了业界对AI伦理、安全与合规的日益关注。
未来,随着AI监管政策的不断完善和技术的持续演进,模型开源许可协议将面临新的挑战与机遇。可以预见的是,针对AI特性的专用开源许可协议将更加细化和多元化,在平衡开放与安全、创新与责任方面发挥更大作用。
对于开发者和使用者而言,深入理解各类开源许可协议的内涵与边界,选择符合自身需求和发展战略的协议类型,将成为参与AI开源生态的基础能力。同时,积极参与开源社区建设,共同探索人工智能治理的新模式,也是推动行业健康发展的重要途径。
附:主要开源许可协议链接
1.MIT协议:https://opensource.org/license/MIT
2.Apache 2.0协议:https://opensource.org/license/apache-2-0
3.GPL协议:https://www.gnu.org/licenses/gpl-3.0.html
4.MPL协议:https://opensource.org/license/MPL-2.0
5.Creative Commons (CC) 协议:https://creativecommons.org/licenses/
6.OpenRAIL协议:https://www.openrail.org/
7.Llama 3协议:https://ai.meta.com/llama

















 1344
1344

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









