






Informer:超越Transformer的长序列时序预测模型
| 标题 | Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting |
|---|---|
| 作者 | Haoyi Zhou, Shanghang Zhang, Jieqi Peng, Shuai Zhang, Jianxin Li, Hui Xiong, Wancai Zhang |
| 期刊 | 来自CCF-A会议(AAAI 2021, AAAl Conference on Artificial Intelligence) |
| 机构 | Beihang University,UC Berkeley,Rutgers University,SEDD Company |
| 论文 | Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting |
| 代码 | https://github.com/zhouhaoyi/Informer2020 |
摘要
许多实际应用都需要对长序列时间序列进行预测,如电力消费规划。长序列时间序列预测(LSTF)要求模型具有较高的预测能力,即能够有效地捕捉输出与输入之间的长期依赖性耦合。最近的研究表明,Transformer 具有提高预测能力的潜力。然而,Transformer 有几个严重的问题使其不能直接应用于 LSTF,包括二次时间复杂度、高内存使用率和编码器-解码器架构的固有限制。
为了解决这些问题,我们设计了一个高效的基于 的 LSTF 模型 Informer,该模型具有三个显著的特点:
- P r o b S p a r s e ProbSparse ProbSparse 自注意机制,该机制在时间复杂度和内存占用上达到O(L log L),并且在序列依赖比对上具有相当的性能。
- 自注意力提取通过将级联层输入减半来突出主要注意力,并有效地处理超长输入序列。
- 虽然概念上简单,但是生成式解码器以一个前向操作而不是逐步方式来预测长时间序列序列,这极大地提高了长序列预测的推断速度。
在4个大规模数据集上的实验结果表明,Informer 算法在保持快速、无训练等优点的同时,检测性能优于目前主流算法,为 LSTF 问题提供了一种新的解决方案。
1 Informer研究背景
1.1 研究背景
对于该论文的研究背景,我们可以知道是针对长序列的预测问题。这些问题会出现在哪些地方呢?
-
股票预测(数据、规则都在变,模型都是无法预测的)
-
机器人动作的预测
-
人体行为识别(视频前后帧的关系)
-
气温的预测、疫情下的确诊人数
-
流水线每一时刻的材料消耗,预测下一时刻原材料需要多少…

那么以上需要时间线来进行实现的,无疑会想到使用 Transformer 来解决这些问题,Transformer 的最大特点就是利用了 attention 进行时序信息传递。每次进行一次信息传递,我们需要执行两次矩阵乘积,也就是 QKV 的计算。并且我们需要思考一下,我们每次所执行的 attention 计算所保留下来的值是否是真的有效的吗?我们有没有必要去计算这么多 attention ?
那么对于现在的时间预测可以大致分为下面三种:
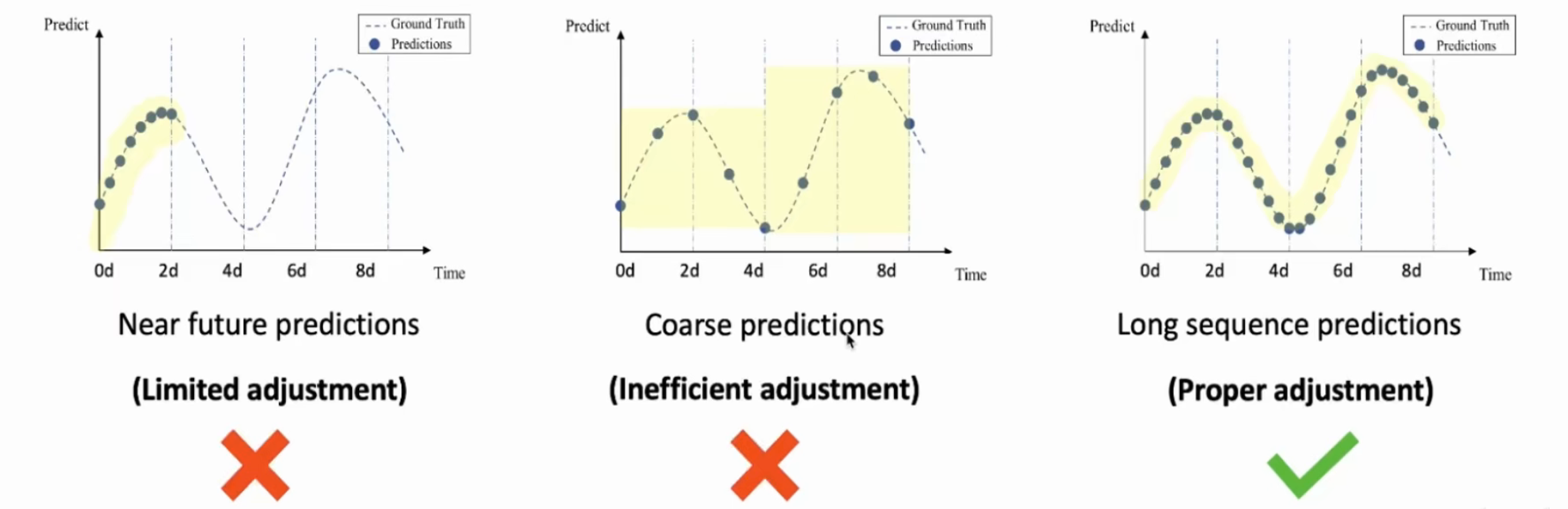
短序列预测 趋势预测 精准长序列预测
很多算法都是基于短序列进行预测的,先得知前一部分的数据,之后去预测短时间的情况。想要预测一个长序列,就不可以使用短预测,预测未来半年或一年,很难预测很准。长序列其实像是滑动窗口,不断地往后滑动,一步一步走,但是越滑越后的时候,他一直在使用预测好的值进行预测,长时间的序列预测是有难度的。
1.2 时间序列预测的现有方法概述
现有的时间序列预测方法主要可以分为两大类:经典模型和基于深度学习的方法。
经典模型
经典时间序列模型以其可解释性和理论保证而著称,例如自回归移动平均(ARMA)模型、自回归积分滑动平均(ARIMA)模型等。这些模型适用于线性或非线性的时间序列数据,并且能够处理缺失数据和多种数据类型。它们通常具有较好的统计性质和理论基础,但在处理长序列和复杂模式方面可能存在局限性。
深度学习方法
基于深度学习的方法主要通过循环神经网络(RNN)及其变体(如长短期记忆网络LSTM和门控循环单元GRU)来开发序列到序列的预测范式。这些方法在处理非线性模式和长期依赖关系方面取得了突破性进展,但是在进行长序列预测时,它们通常存在累积误差和梯度消失或爆炸的问题。
2 Transformer的时间序列预测模型及其局限性
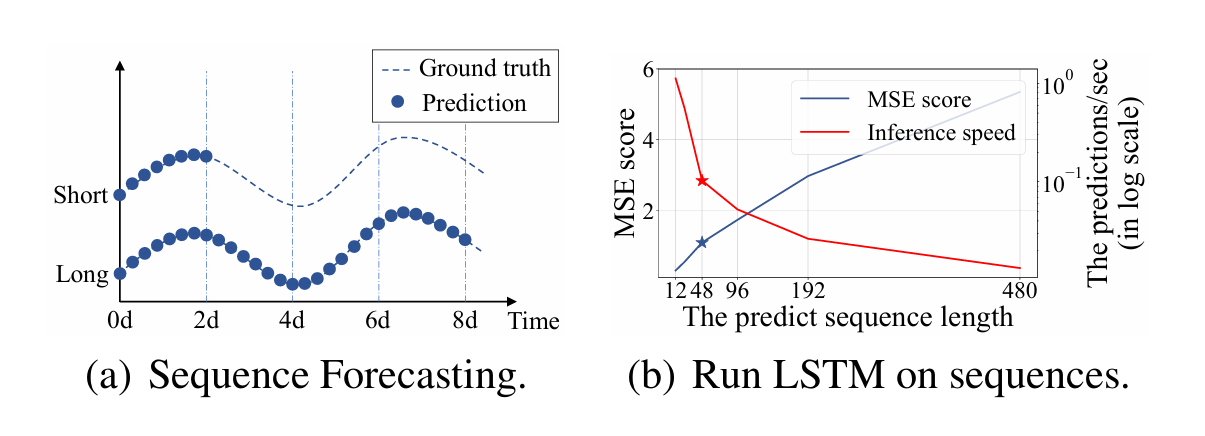
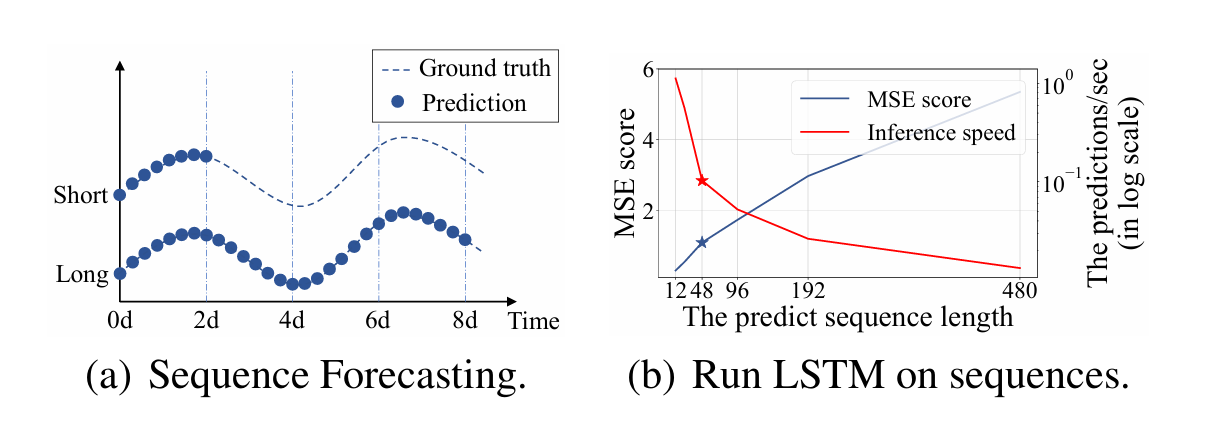
在深度学习的方法中,长短期记忆网络LSTM也会用于序列预测。在长序列预测中,如果序列越长,那速度肯定越慢,效果也越差。LSTM使用的是串行结构,效率很低,也会基于前面的特征来预测下一个特征,其损失函数的值也会越来越大。在下图(b)中,LSTM网络预测了某变电站从短期周期(12点,0.5天)到长期周期(480点,20天)的时温。随着数据序列长度的增加,LSTM的推理速度急剧下降,导致在有限的计算能力和时间下无法成功预测长序列。同时,误差的连续积累导致MSE的值逐渐增大。
因此 Transformer 中提及了改进 LSTM 的方法,其优势和问题在于:
-
万能模型,可直接套用,代码实现简单。
-
并行的,比 LSTM 快,全局信息丰富,注意力机制效果好。
-
长序列中 attention 需要每一个点跟其他点计算,如果序列太长,其效率很低。
-
Decoder 输出很麻烦,都要基于上一个预测结果来推断当前的预测结果,这对于一个长序列的预测中最好是不要出现这样的情况。
Transformer模型:
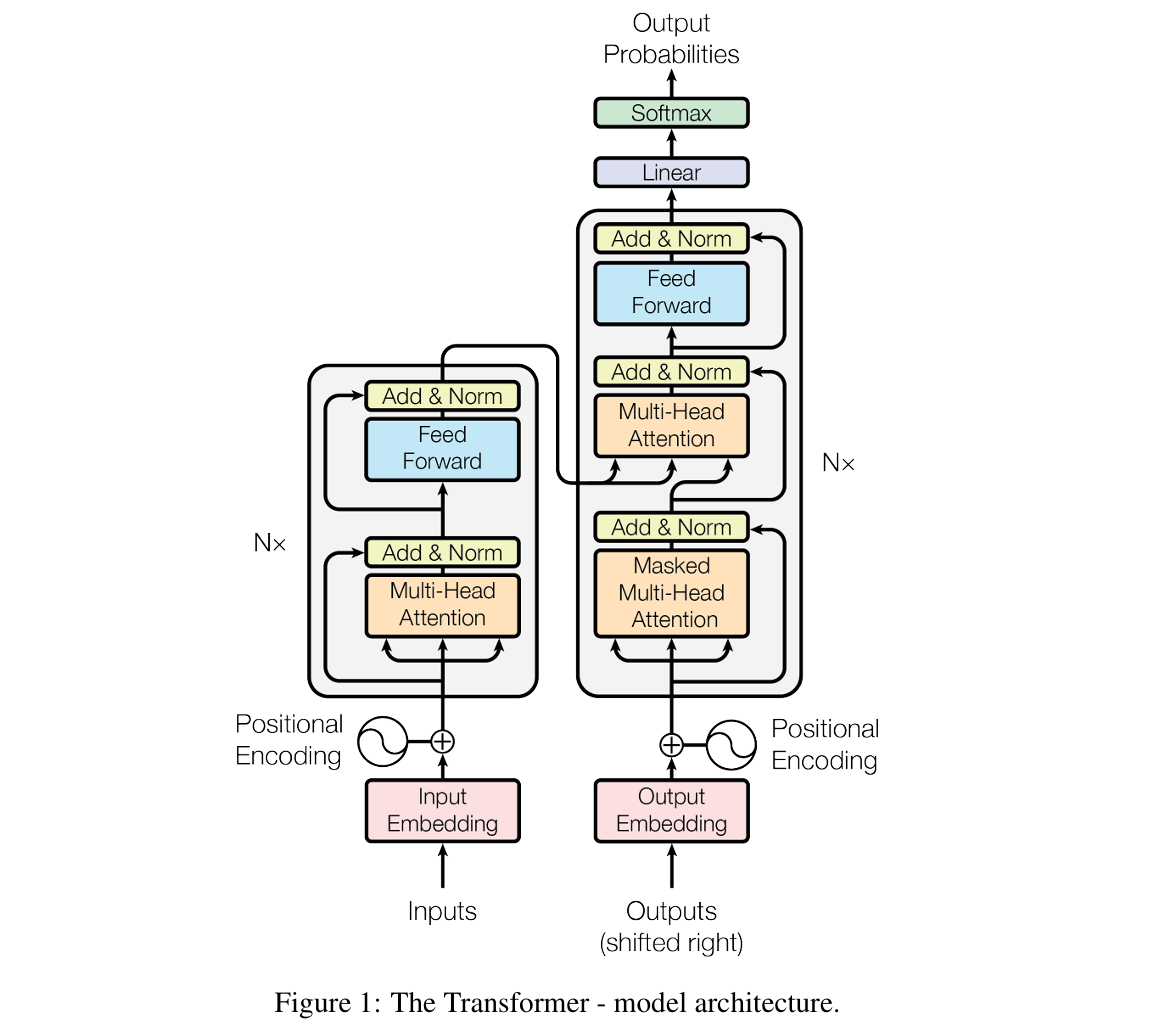
但是当 Transformer 应用于时间序列预测时,尤其是长序列时间序列预测(LSTF)时,存在几个主要局限性:
-
self-attention的平方复杂度。self-attention的时间和空间复杂度是O(L2),L为序列长度。
-
对长输入进行堆叠(stack)时的内存瓶颈。多个encoder-decoder堆叠起来就会形成复杂的空间复杂度,这会限制模型接受较长的序列输入。
-
预测长输出时速度骤降。对于Tansformer的输出,使用的是step-by-step推理得像RNN模型一样慢,难以满足实时预测的需求,并且动态解码还存在错误传递的问题。
为了解决这些问题,研究者们提出了各种改进的自注意力机制,如稀疏Transformer、LogSparse Transformer和Longformer等,它们通过启发式方法减少自注意力机制的复杂度至O(L log L),但这些方法在理论上的效率增益有限,且在实际应用中可能存在信息丢失的问题。因此,如何改进Transformer模型以适应LSTF问题,成为了一个重要的研究方向。那么Informer就需要解决如下的问题:
| Transformer的缺点 | Informer的改进 |
|---|---|
| self-attention平方级的计算复杂度 | 提出ProbSparse Self-attention筛选出最重要的Q,降低计算复杂度 |
| 堆叠多层网络,内存占用瓶颈 | 提出Self-attention Distilling进行下采样操作,减少维度和网络参数的数量 |
| step-by-step解码预测,速度较慢 | 提出Generative Style Decoder,一步可以得到所有预测的 |
基于以上,Informer提出了LSTF(Long sequence time-series forecasting)长时间序列预测。
3 Informer模型
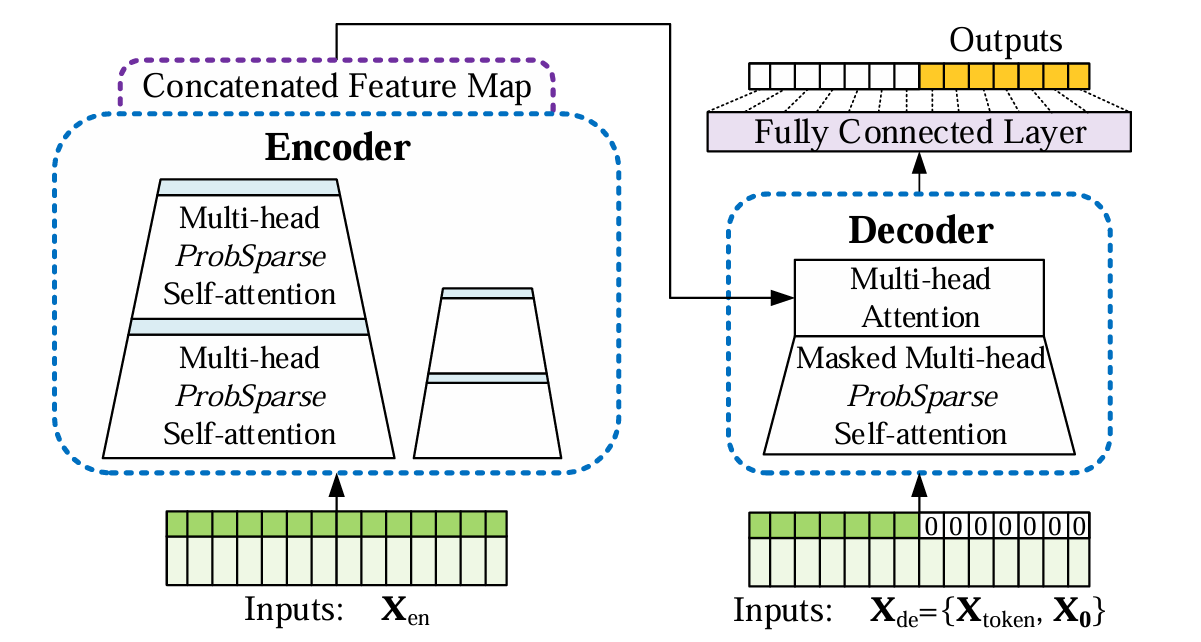
Informer模型概述:
- 左图:编码器接收大量长序列输入(绿色系列)。我们用提出的 P r o b S p a r s e ProbSparse ProbSparse 自注意替换正则自注意。蓝色梯形是提取支配性注意的自注意蒸馏操作,大幅减小网络规模。层堆叠副本增加鲁棒性。
- 右图:解码器接收长序列输入,将目标元素填充为零,测量特征图的加权注意力组成,并以生成式的方式即时预测输出元素(橙色系列)。
3.1 ProbSparse Self-attention
算法思想
对self-attention平方级的计算复杂度问题,最基本的一个思路就是降低 Attention 的计算量,仅计算一些非常重要的或者说有代表性的 Attention 即可,一些相近的思路在近期不断的提出,比如 Sparse-Attention,这个方法涉及了稀疏化 Attention 的操作,来减少 Attention 计算量,然后涉及的呈 log 分布的稀疏化方法, LogSparse-Attention 更大程度上减小 Attention 计算量,再比如说 Restart+LogSparse。但是它们都具有随机局限性,是一类启发式方法,在多头视角下,这些注意力为每个头生成相同的稀疏的“查询-键对”(query-key pairs),可能会造成严重的信息丢失。
启发式假设也就是说计算那些 Attention 是用规则决定的,这种方法的缺点就是不能自适应的。
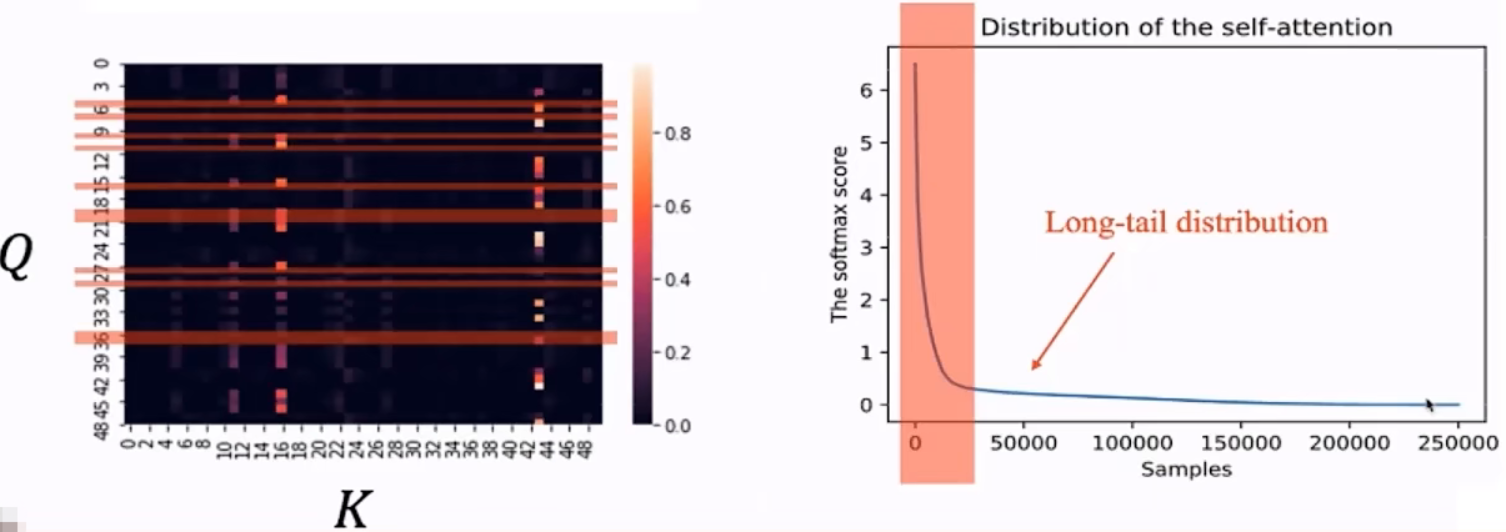
根据具体的情况去计算那些 Attention,经过研究发现 Attention_map 的高激活值,在很多情况下都是较为稀疏的,如果我们把 query,key,score,这些 pairs 排一个序,然后画出一个统计图来(右图所示),然后我们会发现它是服从一个 Long-Tail 分布的,也就是说大部分的 Attention 仅仅起了一个很微弱的作用。
也就是说并不是每个QK的点积都是有效值,我们也不需要花很多时间在处理这些数据上。
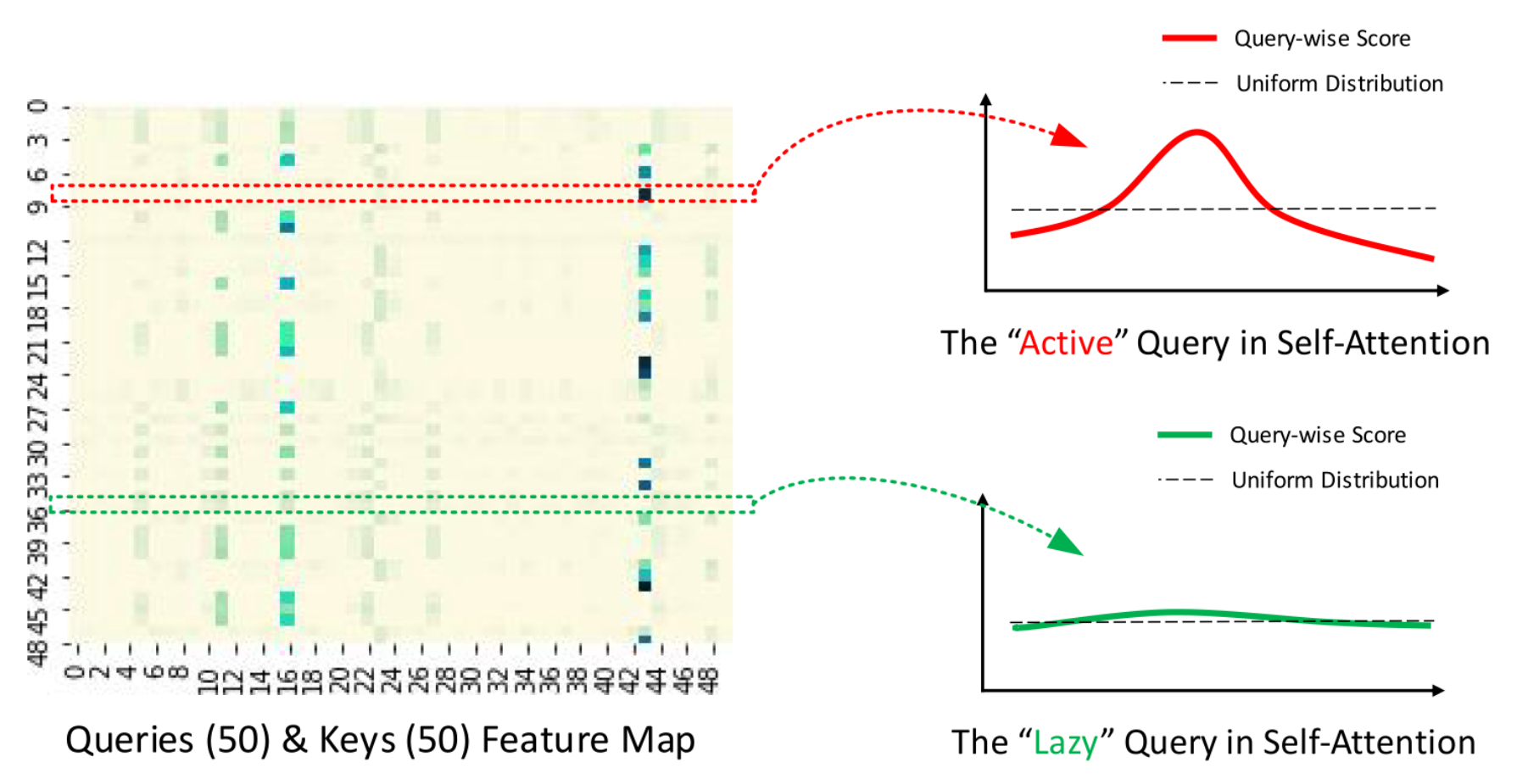
通过对 Attention_map 随机抽取一些Query-wise Score(按行抽取),我们抽象出比较典型的 Attention score 的两种代表,一个是"Active",一个是"Lazy",Active Query 特征是有一个或者多个较大的峰值,而其他的 Atten_score 较小,然后另一种是 Lazy Query 整个统计曲线没有过大的起伏与均匀分布相差不大,我们称之为 Lazy Query,然后希望根据这种发现重新定义一种计算和选取 Attention 的方法——衡量Query稀疏性,即 probability sparse – 概率分布稀疏。目的是尽量保证不遗漏重要的 Attention,又能尽量的较小计算量,降低开销。
公式
首先,我们需要进行一次Query稀疏性的衡量:
从概率角度看待自注意力,定义 p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) p(\mathbf{k}_j|\mathbf{q}_i)=\frac{k(\mathbf{q}_i,\mathbf{k}_j)}{\sum_lk(\mathbf{q}_i,\mathbf{k}_l)} p(kj∣qi)=∑lk(qi,kl)k(qi,kj)是概率的形式,即在给定第 ${i} $ 个 query 的条件下 Key 的分布。
作者认为,如果算出来的这个结果接近于均匀分布 q ( k j ∣ q i ) = 1 L K q(k_j|q_i)=\frac{1}{L_K} q(kj∣qi)=LK1 ,那么就说明这个 query 是在偷懒,没办法选中那些重要的 Key,如果反之,就说明这个 query 为积极的,活跃的。
其计算公式如下:
A ( q i , K , V ) = ∑ j k ( q i , k j ) ∑ l k ( q i , k l ) v j = E p ( k j ∣ q i ) [ v j ] ( 1 ) p ( k j ∣ q i ) = k ( q i , k j ) ∑ l k ( q i , k l ) k ( q i , k j ) = exp ( q i k j T d ) \mathcal{A}\left(q_{i},K,V\right)=\sum_{j}\frac{k\left(q_{i},k_{j}\right)}{\sum_{l}k\left(q_{i},k_{l}\right)}v_{j}=\mathbb{E}_{p\left(k_{j}|q_{i}\right)}\left[v_{j}\right] \qquad(1) \\p\left(k_{j}\mid q_{i}\right)=\frac{k\left(q_{i},k_{j}\right)}{\sum_{l}k\left(q_{i},k_{l}\right)}\\k\left(q_{i},k_{j}\right)=\exp\left(\frac{q_{i}k_{j}^{T}}{\sqrt{d}}\right) A(qi,K,V)=∑j∑lk(qi,kl)k(qi,kj)vj=Ep(kj∣qi)[vj](1)p(kj∣qi)=∑lk(qi,kl)k(qi,kj)k(qi,kj)=exp(dqikjT)
之后我们进行比较:
KL divergence: K L ( q ∥ p ) = ln ∑ l = 1 L k e q i k l T / d − 1 L k ∑ j = 1 L q i k j T / d − ln L k \text{KL divergence: }KL(q\|p)=\ln\sum_{l=1}^{L_k}e^{q_ik_l^T/\sqrt d}-\frac{1}{L_k}\sum_{j=1}^Lq_ik_j^T/\sqrt d-\ln L_k KL divergence: KL(q∥p)=ln∑l=1LkeqiklT/d−Lk1∑j=1LqikjT/d−lnLk
sparsity measurement:
M ( q i , K ) = ln ∑ j = 1 L K e q i k j ⊤ d − 1 L K ∑ j = 1 L K q i k j ⊤ d ( 2 ) M(\mathbf{q}_i,\mathbf{K})=\ln\sum_{j=1}^{L_K}e^{\frac{\mathbf{q}_i\mathbf{k}_j^\top}{\sqrt{d}}}-\frac{1}{L_K}\sum_{j=1}^{L_K}\frac{\mathbf{q}_i\mathbf{k}_j^\top}{\sqrt{d}}\qquad (2) M(qi,K)=ln∑j=1LKedqikj⊤−LK1∑j=1LKdqikj⊤(2)
其中,第一项是所有键 q i \mathbf{q}_{i} qi 的 Log-Sum-Exp (LSE),第二项是它们的算术平均值。如果第 i i i 个查询获得更大的 M ( q i , K ) M\left(q_i,K\right) M(qi,K),则其关注概率 p {p} p 更“多样化”,并且有很高的机会包含长尾自关注分布的头部字段中的主导点积对。
P r o b S p a r s e S e l f − a t t e n t i o n ProbSparse\quad Self-attention ProbSparseSelf−attention :基于提出的度量,我们通过允许每个键只关注 u u u 个主导查询来获得ProbSparse自关注:
A ( Q , K , V ) = S o f t m a x ( Q ‾ K ⊤ d ) V ( 3 ) \mathcal{A}(\mathbf{Q},\mathbf{K},\mathbf{V})=\mathrm{Softmax}(\frac{\overline{\mathbf{Q}}\mathbf{K}^{\top}}{\sqrt{d}})\mathbf{V}\qquad(3) A(Q,K,V)=Softmax(dQK⊤)V(3)
其中, Q ˉ \bar{\mathbf{Q}} Qˉ 是一个与 q \mathbf{q} q 大小相同的稀疏矩阵,它只包含稀疏度度量 M ( q , K ) M\mathbf{\left(q,K\right)} M(q,K) 下的 Top-u 查询。
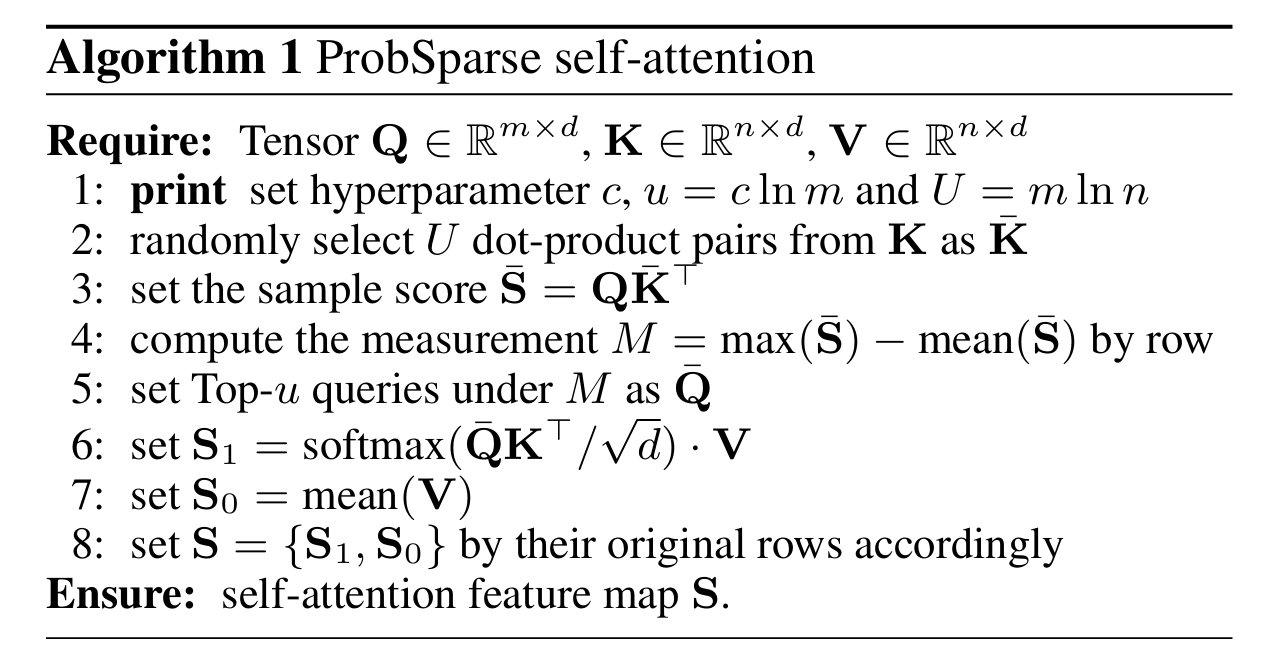
我们算出了其概率以及与均匀分布的差异,如果差异越大,那么这个Q就有机会去被关注、说明其起到了作用。那么其计算方法到底是怎么样进行的,我们要取哪些Q哪些K进行计算:
(1)输入序列长度为96,首先在 K中进行采样,随机选取25个K。
(2)计算每个Q与25个K的点积,可以得到 M ( q i , K ) M\left(q_i,K\right) M(qi,K),现在一个Q一共有25个得分
(3)在25个得分中,选取最高分的那个Q与均值算差异。
M ‾ ( q i , K ) = max j { q i k j ⊤ d } − 1 L K ∑ j = 1 L K q i k j ⊤ d ( 4 ) \overline{M}(\mathbf{q}_i,\mathbf{K})=\max_j\{\frac{\mathbf{q}_i\mathbf{k}_j^\top}{\sqrt{d}}\}-\frac{1}{L_K}\sum_{j=1}^{L_K}\frac{\mathbf{q}_i\mathbf{k}_j^\top}{\sqrt{d}}\qquad(4) M(qi,K)=maxj{dqikj⊤}−LK1∑j=1LKdqikj⊤(4)
(4)这样我们输入的96个Q都有对应的差异得分,我们将差异从大到小排列,选出差异前25大的Q。
(5)那么传进去参数例如:[32,8,25,96],代表的意思为输入96个序列长度,32个batch,8个特征,25个Q进行处理。
(6)其他位置淘汰掉的Q使用均匀方差代替,不可以因为其不好用则不处理,需要进行更新,保证输入对着有输出。
以上的时间复杂度为O(L ln L):
P r o b S p a r s e ProbSparse ProbSparse Attention 在为每个Q随机采样K时,每个 head 的采样结果是相同的,也就是采样的K是相同的。但是由于每一层self-attention都会对QKV做线性转换,这使得序列中同一个位置上不同的 head 对应的 QK 都不同,那么每一个head对于Q的差异都不同,这就使得每个head中的得到的前25个Q也是不同的。这样也等价于每个head都采取了不同的优化策略。
伪代码
3.2 Self-attention Distilling
受扩张卷积的启发(Yu,Koltun和Funkhouser 2017; Gupta和Rush 2017),我们的“蒸馏”过程从第 j 层向前到第(j + 1)层为:
X j + 1 t = M a x P o o l ( E L U ( C o n v 1 d ( [ X j t ] A B ) ) ) ( 5 ) \mathbf{X}_{j+1}^{t}=\mathrm{MaxPool}\left(\mathrm{ELU(Conv}1\mathrm{d}([\mathbf{X}_{j}^{t}]_{\mathrm{AB}}))\right)\qquad(5) Xj+1t=MaxPool(ELU(Conv1d([Xjt]AB)))(5)
其中 [·]AB 代表注意力块。它包含多头 ProbSparse 自关注和基本运算,其中 Conv1d(·) 在时间维度上使用 ELU(·) 激活函数执行1-D卷积滤波器(核宽度=3)
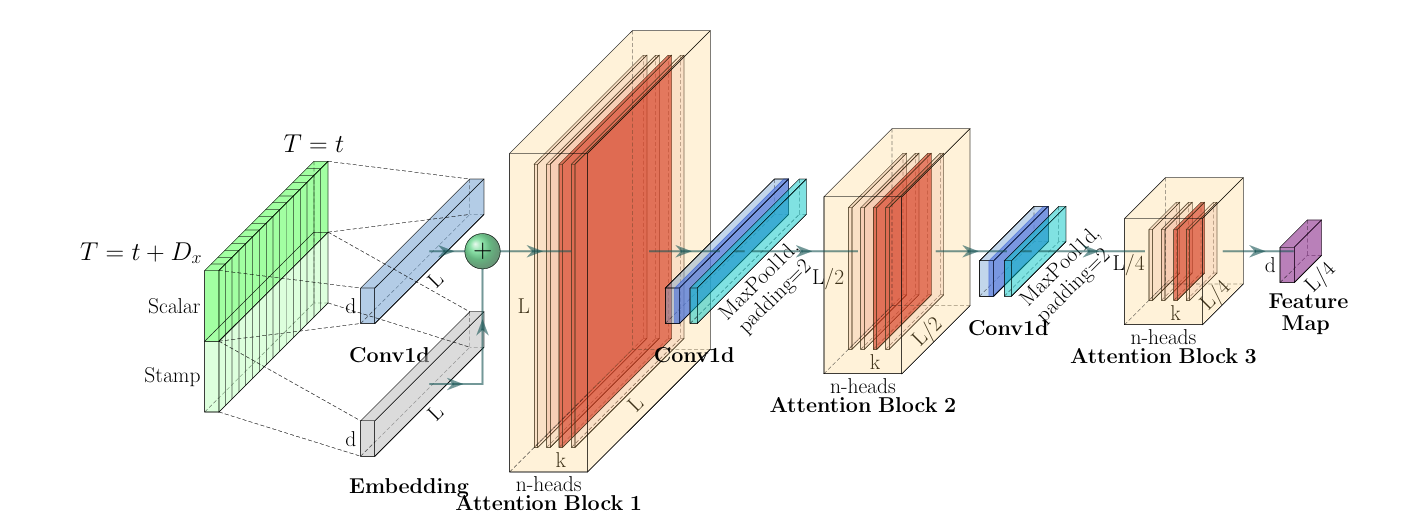
Informer编码器中的单栈:
- 水平堆栈代表图(2)中编码器副本中的单个堆栈。
- 所呈现的堆栈是接收整个输入序列的主堆栈。然后第二个堆栈获取输入的一半切片,随后的堆栈重复。
- 红色层是点积矩阵,它们通过在每一层上应用自注意蒸馏得到级联减少。
- 串联所有堆栈的特征映射作为编码器的输出。
这一层类似于下采样。将我们输入的序列缩小为原来的二分之一。作者在这里提出了自注意力蒸馏的操作,具体是在相邻的的 Attention Block 之间加入卷积池化操作,来对特征进行降采样。之所以可以这么做,是因为在上面的ProbSparse Attention 中只选出了前25个Q做点积运算,形成 Q-K 对,其他 Q-K 对则填充为mean,所以当与value相乘时,会有很多冗余项,因此应用卷积与池化来进行减半操作,是一个合情合理的过程(逐层减半,参数融合,feature map 融合)。这样也可以突出其主要特征,也降低了长序列输入的空间复杂度,也不会损失很多信息,大大提高了效率。
3.3 Generative Style Decoder
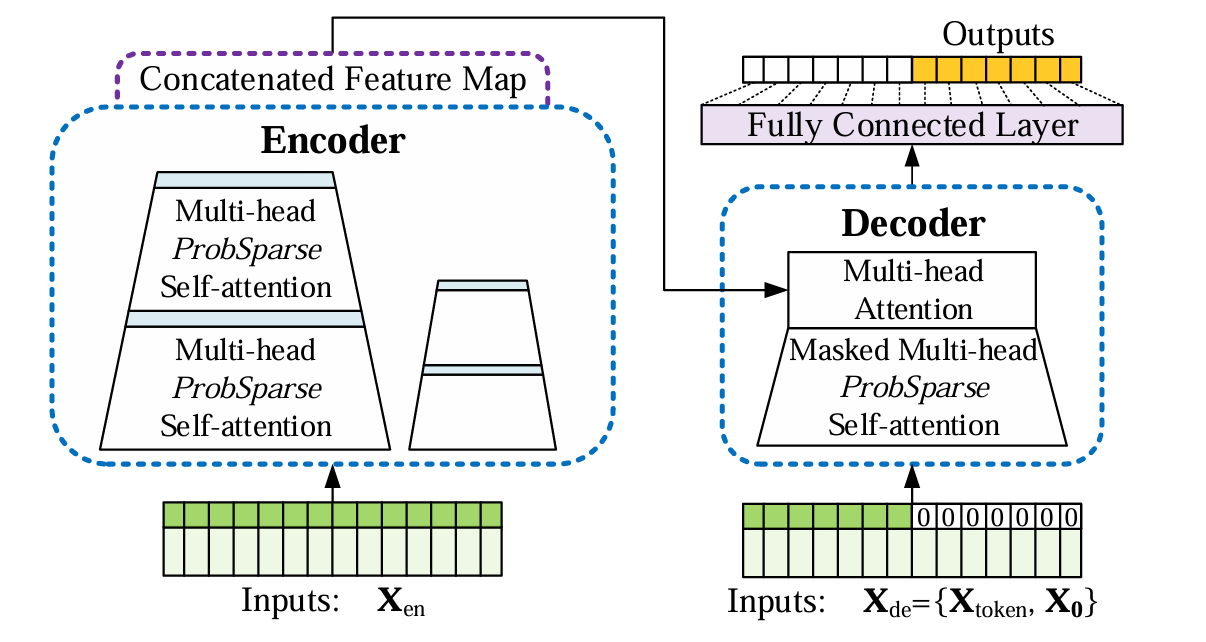
对于原始的Transformer而言,没办法解决 Long output 的问题,也是跟 rnn-based model一样属于动态输出的级联输出,无法处理长序列的推理。这样子效率慢并且精度不高。看看总的架构图可以发现,decoder由两部分组成:第一部分为 encoder 的输出,第二部分为 embedding 后的 decoder 输入,即用0掩盖了后半部分的输入。
看看Embedding的操作:
-
Scalar是采用conv1d将1维转换为512维向量。
-
Local Time Stamp采用Transformer中的Positional Embedding。
-
Gloabal Time Stamp则是上述处理后的时间戳经过Embedding。可以添加上我们的年月日时。
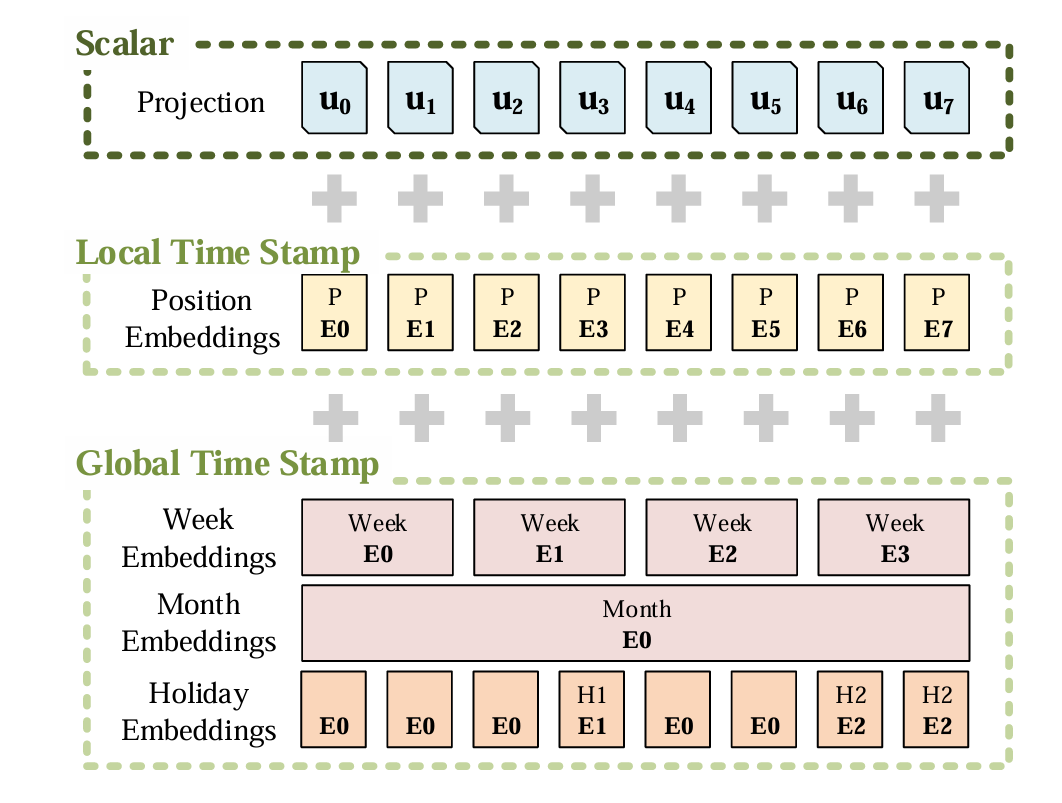
这种位置编码信息有比较丰富的返回,不仅有绝对位置编码,还包括了跟时间相关的各种编码。
最后,使用三者相加得到相加得到最后的输入(shape:[batch_size,seq_len,d_model])。
我们在图(2)中使用了一个标准的解码器结构(Vaswani etal. 2017),它由两个相同的多头注意层堆叠而成。然而,我们采用了生成推理来缓解长预测中的速度暴跌。我们为解码器提供以下向量为:
X d e t = C o n c a t ( X t o k e n t , X 0 t ) ∈ R ( L t o k e n + L y ) × d m o d e l ( 6 ) \mathbf{X}_{\mathrm{de}}^{t}=\mathrm{Concat}(\mathbf{X}_{\mathrm{token}}^{t},\mathbf{X}_{\mathbf{0}}^{t})\in\mathbb{R}^{(L_{\mathrm{token}}+L_{y})\times d_{\mathrm{model}}}\qquad(6) Xdet=Concat(Xtokent,X0t)∈R(Ltoken+Ly)×dmodel(6)
其中, X t o k e n t ∈ R L t o k e n × d m o d e l \mathbf{X}_{\mathrm{token}}^t\in\mathbb{R}^{L_{\mathrm{token}}\times d_{\mathrm{model}}} Xtokent∈RLtoken×dmodel 为起始token, X 0 t ∈ R L y × d m o d e l \mathbf{X_{0}^{t}}\in \mathbb{R}^{L_y\times d_{\mathrm{model}}} X0t∈RLy×dmodel 为目标序列的占位符(标量设为0)。通过将掩码点积设置为 − ∞ -\infty −∞ ,在 P r o b S p a r s e ProbSparse ProbSparse 自关注计算中应用掩码多头关注。它防止了每个位置对即将到来的位置的关注,从而避免了自回归。
Start token 是NLP“动态解码”中的一种有效技术,特别是对于每个训练模型,并扩展为生成方式。我们在输入序列中请求“较短”的长序列,即输出序列之前的较早的切片,而不是选择特定的标志作为标记。以预测168点为例(实验部分的7天温度预测),我们将把目标序列之前已知的5天作为“start-token”,并以 X d e = { X 5 d , X 0 } \mathbf{X_{de}}=\{\mathbf{X_{5d}},\mathbf{X_{0}}\} Xde={X5d,X0} 为生成式推理解码器提供数据。 X 0 \mathbf{X_{0}} X0 包含目标序列的时间戳,即目标周的上下文。然后我们提出的解码器通过一个前向过程预测输出,而不是传统编码器-解码器架构中耗时的“动态解码”。在计算效率部分给出了详细的性能比较。
4 实验
实验:多数据集上单变量多变量模型预测
我们在四个数据集上进行了广泛的实验,包括2个收集的 LSTF 真实数据集和2个公共基准数据集。
( I n f o r m e r † \mathrm{Informer}^{\dagger} Informer† 表示的是一个使用规范自注意力机制(canonical self-attention)的 Informer 模型变体)
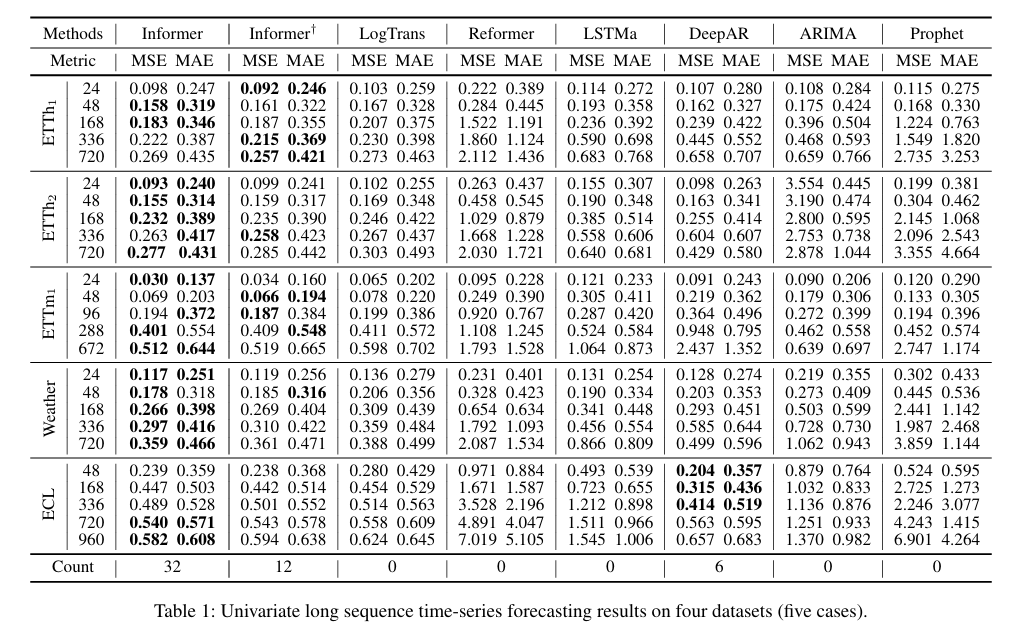
表1:4个数据集(5例)的单变量长序列时间序列预测结果。
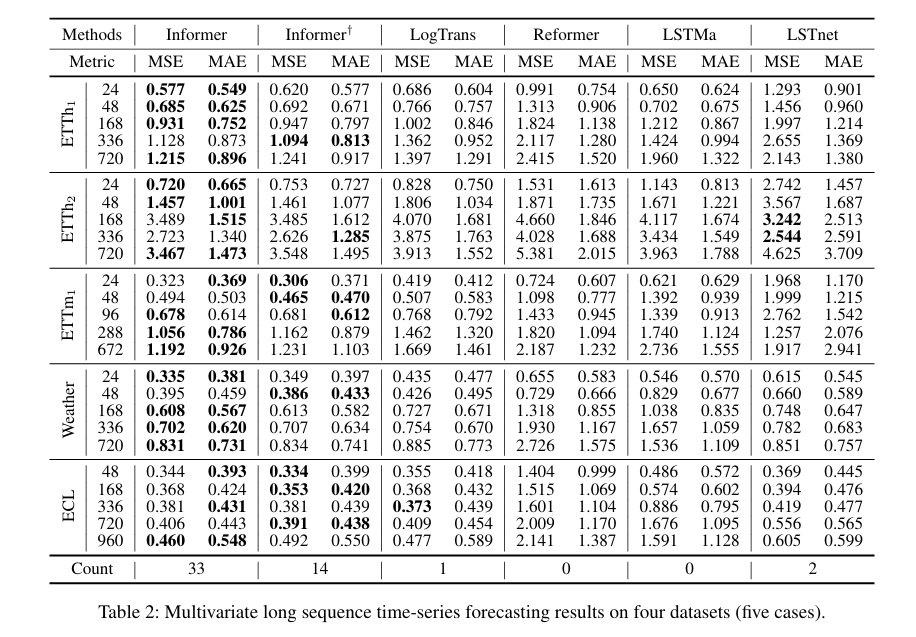
表2:4个数据集(5例)的多元变量长序列时间序列预测结果。
Dataset
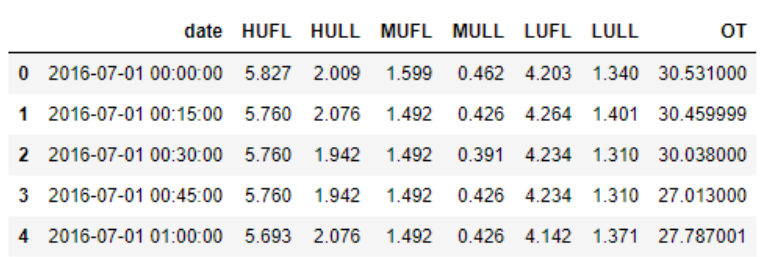
The ETT dataset used in the paper can be downloaded in the repo ETDataset. A demo slice of the ETT data is illustrated in the following figure. Note that the input of each dataset is zero-mean normalized in this implementation.
Figure 3. An example of the ETT data.
The ECL data and Weather data can be downloaded here.
- Google Drive
- BaiduPan, password: 6gan
实验:计算效率
使用多元设置和所有方法当前的最佳实现,我们在图中执行了严格的运行时比较。在训练阶段,Informer(红线)在基于Transformer的方法中获得了最好的训练效率。
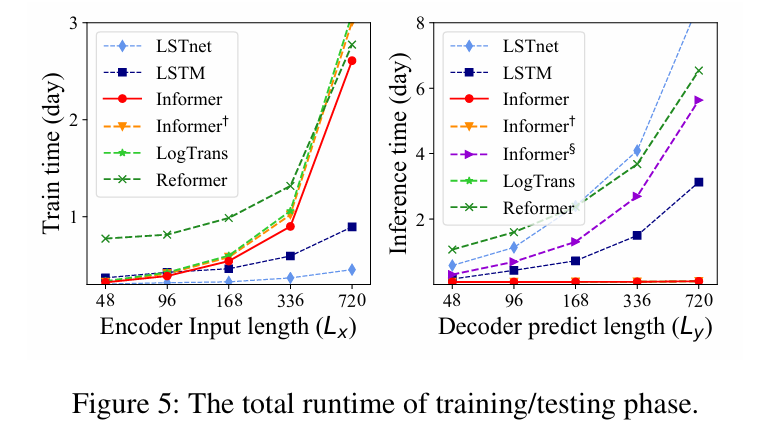
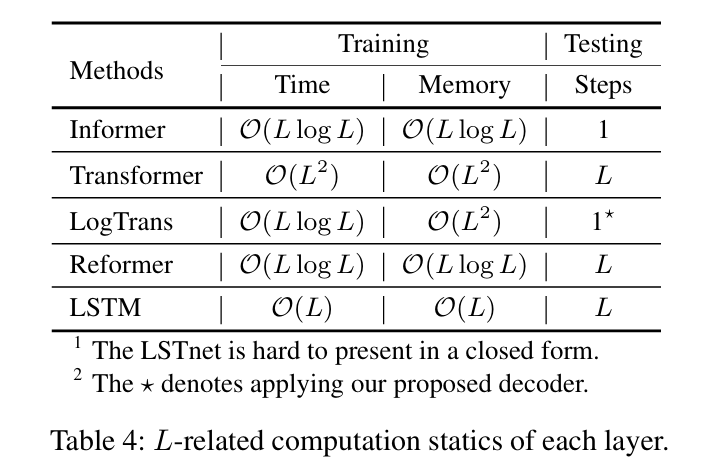
在测试阶段,我们的方法在生成式解码方面比其他方法要快得多。理论时间复杂度和内存使用的比较总结如表所示。Informer的性能与运行时实验结果一致。请注意,LogTrans专注于改进自注意机制,我们在LogTrans中应用我们提出的解码器进行公平比较。
实验:模型拟合效果切片
图中给出了8个模型的预测切片。最相关的工作 LogTrans 和 Reformer 显示了可接受的结果。LSTMa 模型不适用于长序列预测任务。ARIMA 和 DeepAR 可以捕捉长序列的长趋势。与 ARIMA 和 DeepAR 相比,Prophet 可以更好地检测到变化点并将其与平滑曲线拟合。我们提出的模型 Informer 和 I n f o r m e r † \mathrm{Informer}^{\dagger} Informer† 的拟合效果明显好于上述方法。
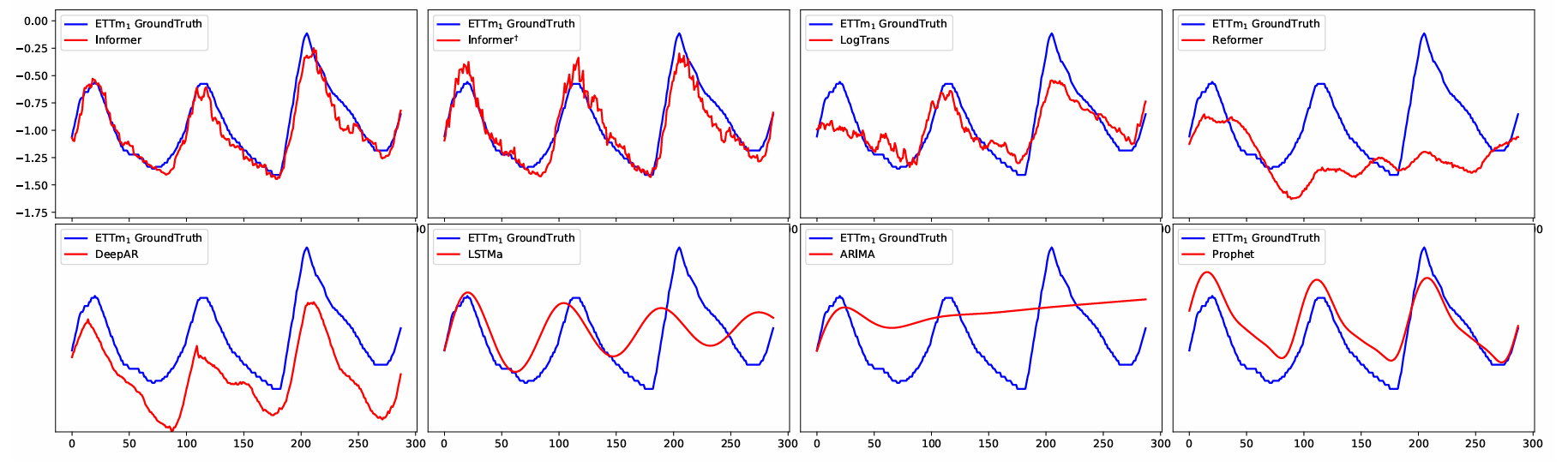
图9:Informer、 I n f o r m e r † \mathrm{Informer}^{\dagger} Informer† 、LogTrans、Reformer、DeepAR、LSTMa、ARIMA和Prophet对ETTm数据集的预测(len=336)。红色/蓝色曲线代表预测/真实值的切片。
5 结论
在本文中,我们研究了长序列时间序列预测问题,并提出了Informer来预测长序列。具体来说,我们设计了 P r o b S p a r s e ProbSparse ProbSparse 自关注机制和蒸馏操作来处理原始 Transformer 中二次时间复杂度和二次内存使用的挑战。此外,精心设计的生成式解码器缓解了传统编码器-解码器架构的局限性。在实际数据上的实验证明了 Informer 在提高 LSTF 问题的预测能力方面的有效性。
6 参考文献以及链接
Informer: Beyond Efficient Transformer for Long Sequence Time-Series Forecasting
Informer讲解PPT介绍【超详细】–AAAI 2021最佳论文:比Transformer更有效的长时间序列预测_informer详解-CSDN博客

















 3642
3642

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









