






DUET:双向聚类增强的多变量时间序列预测
| 标题 | DUET:Dual Clustering Enhanced Multivariate TimeSeries Forecasting |
|---|---|
| 作者 | Xiangfei Qiu, Xingjian Wu, Yan Lin, Chenjuan Guo, Jilin Hu, Bin Yang |
| 期刊 | SIGKDD|2025,(ACM SIGKDD Conference on Knowledge Discovery and Data Mining) |
| 机构 | East China Normal University,Aalborg University |
| 论文 | DUET: Dual Clustering Enhanced Multivariate Time Series Forecasting |
| 代码 | https://github.com/decisionintelligence/DUET |

摘要
本文提出了一种名为DUET(Dual Clustering Enhanced Multivariate Time Series Forecasting)的框架,用于提升多变量时间序列预测的性能。DUET通过在时间维度和通道维度引入双重聚类机制,分别建模时间异质性和通道间复杂关系,从而有效应对多变量时间序列预测中的两大挑战:时间分布偏移(Temporal Distribution Shift, TDS)和通道间复杂关联。主要由以下三个模块组成:
- 时间聚类模块(TCM):通过将时间序列划分为不同的分布类别并为每个类别设计特定的模式提取器,捕捉时间序列的异质性。
- 通道聚类模块(CCM):则通过频域中的度量学习和稀疏化处理通道间关系,生成通道掩码矩阵,使每个通道能够专注于对其预测有益的其他通道,同时减少噪声通道的干扰。
- 融合模块(FM):基于掩码注意力机制将两者结合,实现精准预测。
实验表明,DUET在25个真实世界的数据集上均优于现有的最先进方法,尤其是在处理时间异质性和通道间复杂关系方面表现出色。
1 研究背景与动机
多变量时间序列预测(MTSF)在金融投资、能源管理、天气预测和交通优化等领域具有重要应用。然而,现实中的时间序列通常面临两大挑战:
- 时间分布漂移(Temporal Distribution Shift, TDS):现实世界中的时间序列常因外部因素影响而表现出非平稳性,导致不同时间段的数据分布不同,从而产生异质性的时间模式。
- 通道间复杂关联:多变量时间序列中的通道(变量)之间存在复杂的相互关系,难以精确建模。传统方法要么假设通道独立,要么假设所有通道都相关,但这些假设都存在局限性。
1.1 由时序漂移引起的异质性时间模式难以建模
在实际应用中,描述不稳定系统的时间序列往往容易受到外部因素的影响。这种时间序列的非平稳性意味着数据分布会随着时间的推移发生变化,这一现象被称为时间分布漂移(Temporal Distribution Shift, TDS)。TDS 会导致时间序列呈现出不同的时间模式,这种现象正式被称为时间模式的异质性。
例如,图1(a) 展示了一个经济领域的时间序列,反映了随国际环境变化而产生的波动。
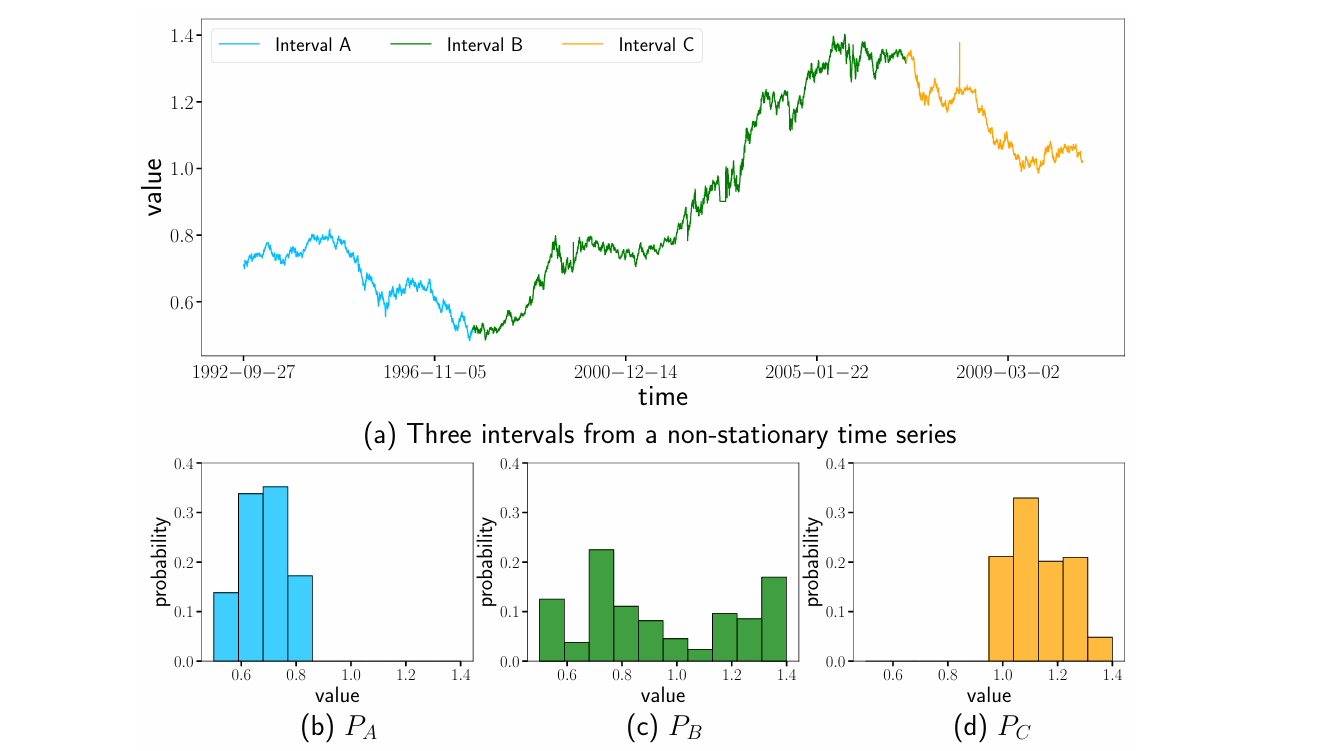
图1:一个非平稳时间序列,有三个间隔A、B和C,表现出不同的值分布( P A ≠ P B ≠ P C P_{A}\neq P_{B}\neq P_{C} PA=PB=PC)和时间模式。
可以观察到,三个时间区间 A、B 和 C 遵循不同的时间分布,这一点可以通过图1 (b)、图1(c)和图1 (d) 所示的值直方图得到证明。这种分布的变化伴随着时间模式的差异。正如图1 (a) 所示,蓝色区间 A 呈现下降趋势,绿色区间 B 呈现上升趋势,而黄色区间 C 则表现为更陡峭的下降趋势。
考虑到这些模式在时间序列中的普遍存在,将其纳入建模过程显得尤为重要。然而,近期的研究大多以隐式方式处理时间模式的异质性,这在很大程度上削弱了预测的准确性。
1.2 复杂的通道间关系难以灵活建模
多变量时间序列预测任务中,建模不同通道之间的相关性至关重要,因为利用其他相关通道的信息往往可以提升特定通道的预测精度。
例如,在天气预测中,温度的预测可以通过结合湿度、风速和气压等数据得到改进,因为这些因素之间相互关联,可以提供更全面的天气状况信息。
研究人员探索了多种通道策略,包括:将每个通道独立对待 (Channel-Independent, CI);假设每个通道与其他所有通道相关(Channel-Dependent, CD);以及将通道分组为若干簇 (Channel-Hard-Clustering, CHC)。
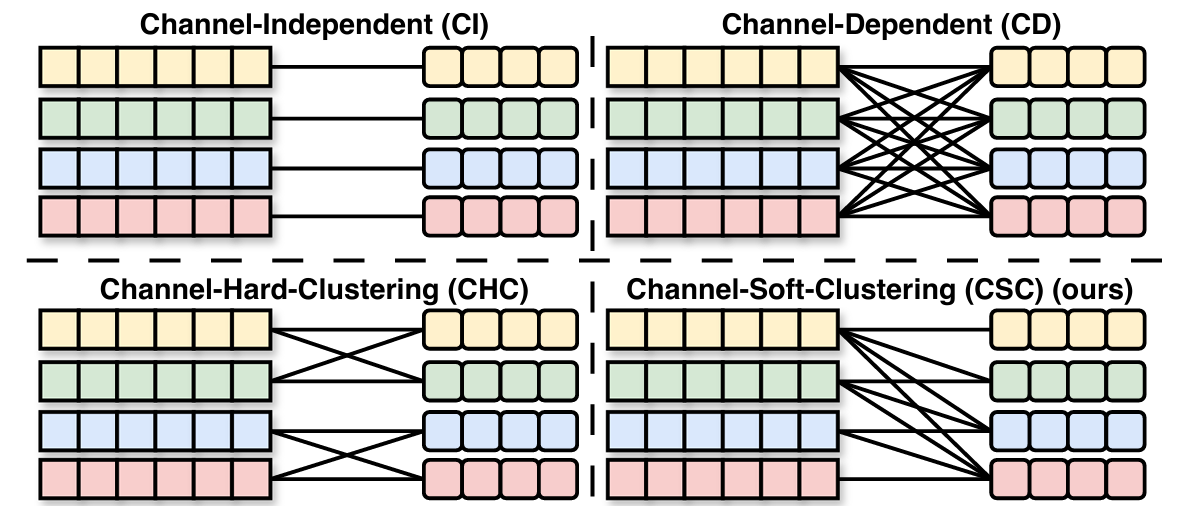
图2:通道策略。不同的颜色代表不同的通道,方形代表不同通道策略处理前的特征,圆角方形代表处理后的特征。
- CI强制对不同通道使用相同的模型。尽管这一策略具有一定的鲁棒性,但它忽略了通道之间的潜在交互,可能在未见通道的泛化能力和建模容量上受到限制;
- CD 则同时考虑所有通道,并生成用于解码的联合表示,但可能受到无关通道噪声的干扰,从而降低模型的鲁棒性;
- CHC 通过硬聚类将多变量时间序列划分为互不相交的簇,在每个簇内使用 CD 建模方法,而在簇之间使用CI方法。然而,该方法仅考虑同一簇内的关系,限制了其灵活性和通用性。
- 目前尚未有一种方法能够精确且灵活地建模通道之间的复杂交互关系。
1.3 核心贡献
为了解决多变量时间序列预测(MTSF)问题,论文提出了一个通用框架——DUET。该框架通过时间维度和通道维度的双向聚类,学习准确且自适应的预测模型。
- 研究人员设计了时间聚类模块(TCM),将时间序列划分为细粒度的分布簇。针对不同的分布簇设计了多种模式提取器,以捕捉其独特的时间模式,从而建模时间模式的异质性。
- 通道聚类模块(CCM),通过度量学习在频率域中灵活捕捉通道间的关系,并进行稀疏化处理以抑制噪声通道的影响,从而实现灵活且高效的通道关系建模。
最后,在TFB的25个数据集上进行了广泛实验,实验结果表明,DUET优于现有的最先进基线。此外,所有数据集和代码已公开。
1.4 问题表述
定义3.1(Time series):时间序列 X ∈ R N × T X\in\mathbb{R}^{N\times T} X∈RN×T 维时间点的面向时间的序列,其中 T {T} T 为时间戳的数量, N {N} N 为通道的数量。如果一个时间序列的二进制数为1,则称为单变量,如果一个时间序列的二进制数大于1,则称为多变量。为方便起见,我们用逗号分隔维度。具体来说,我们将 X i , j ∈ R X_{i,j}\in\mathbb{R} Xi,j∈R 表示为 j {j} j 时间戳处的 i {i} i 通道, X n , : ∈ R T X_{n,:}\in\mathbb{R}^T Xn,:∈RT 表示第 n {n} n 个通道的时间序列,其中 n {n} n = 1,··· , N {N} N。
定义3.2 (Temporal Distribution Shift):给定一个时间序列 X ∈ R N × L \mathcal{X}\in\mathbb{R}^{N\times L} X∈RN×L ,通过滑动窗口,我们得到一组长度为 T {T} T 的时间序列,表示为 D = { X n , i : i + T ∣ n ∈ [ 1 , N ] & i ∈ [ 1 , L − T ] } \mathcal{D}=\{\mathcal{X}_{n,i:i+T}|n\in[1,N]\&i\in[1,L-T]\} D={Xn,i:i+T∣n∈[1,N]&i∈[1,L−T]} ,其中每个 X n , i : i + T X_{n,i:i+T} Xn,i:i+T 等于这样的 X n , : X_{n,:} Xn,: 。然后,时间分布移位指的是 D \mathcal{D} D 可以聚类为 D \mathcal{D} D 数据集,即 D = ∪ i = 1 K D i \mathcal{D}=\cup_{i=1}^{K}\mathcal{D}_{i} D=∪i=1KDi ,其中每个 D i \mathcal{D}_{i} Di 表示具有数据分布的集合 P D i ( x ) P_{\mathcal{D}_{i}}(x) PDi(x) ,其中 P D i ( x ) ≠ P D j ( x ) , ∀ i ≠ j P_{\mathcal{D}_i}(x)\neq P_{\mathcal{D}_j}(x),\forall i\neq j PDi(x)=PDj(x),∀i=j , 1 ≤ i , j ≤ k 1\leq i,j\leq k 1≤i,j≤k。
多元时间序列预测旨在预测下一个 F {F} F 未来时间戳,基于历史时间序列 X = ⟨ X : , 1 , ⋯ , X : , T ⟩ ∈ R N × T X=\langle X_{:,1},\cdots,X_{:,T}\rangle\in\mathbb{R}^{N\times T} X=⟨X:,1,⋯,X:,T⟩∈RN×T 具有 N {N} N 通道和 T {T} T 时间戳,其公式为 Y = ⟨ X : , T + 1 , ⋯ , X : , T + F ⟩ ∈ R N × F Y=\langle X_{:,T+1},\cdots,X_{:,T+F}\rangle\in\mathbb{R}^{N\times F} Y=⟨X:,T+1,⋯,X:,T+F⟩∈RN×F。
2 DUET框架概述
DUET框架的核心思想是通过**时间聚类模块(TCM)和通道聚类模块(CCM)来分别处理时间异质性和通道间关系,最后通过融合模块(FM)**将两者结合,实现精准预测。
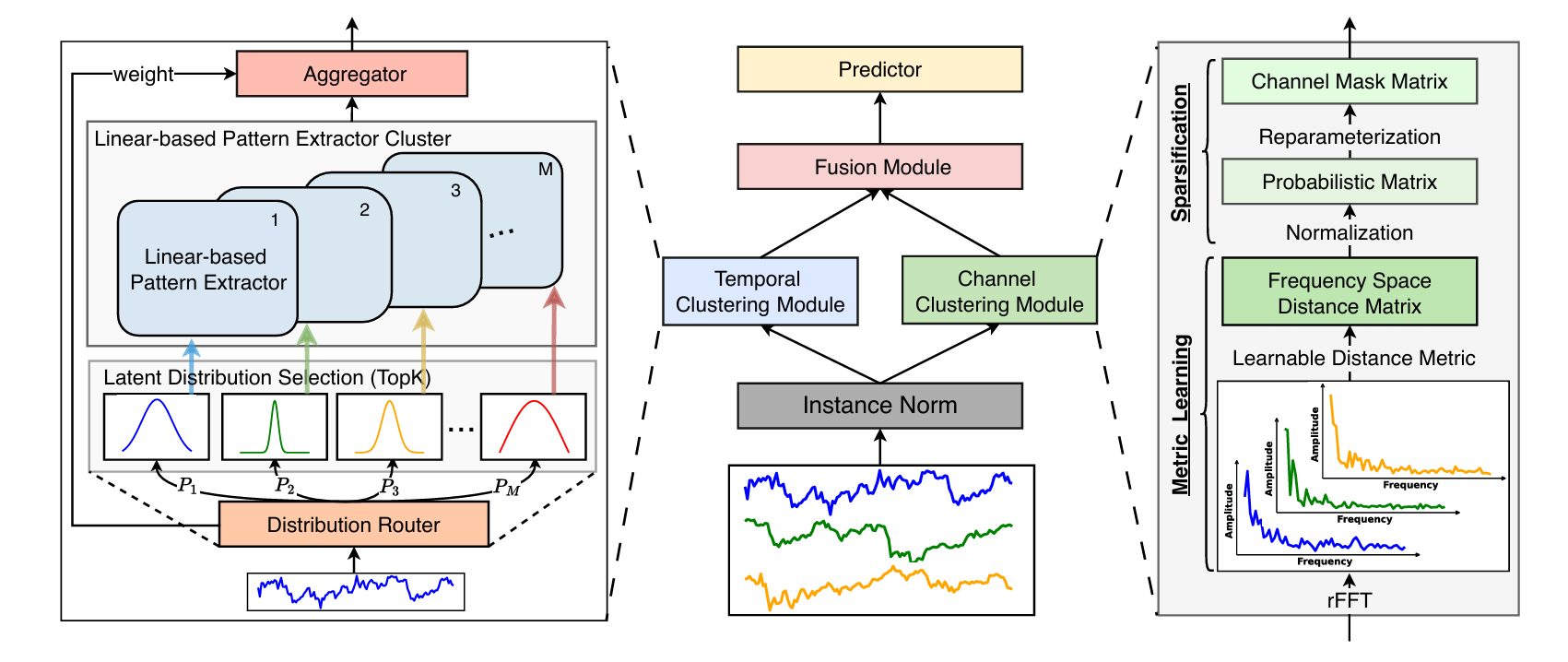
图3:DUET的架构。时间聚类模块将时间序列聚为细粒度分布。对于不同的分布簇,设计了各种模式提取器来捕获其固有的时间模式。信道聚类模块通过度量学习灵活地捕捉频域空间中信道间的关系,并进行稀疏化处理。融合模块结合了时间特征和信道掩码矩阵。
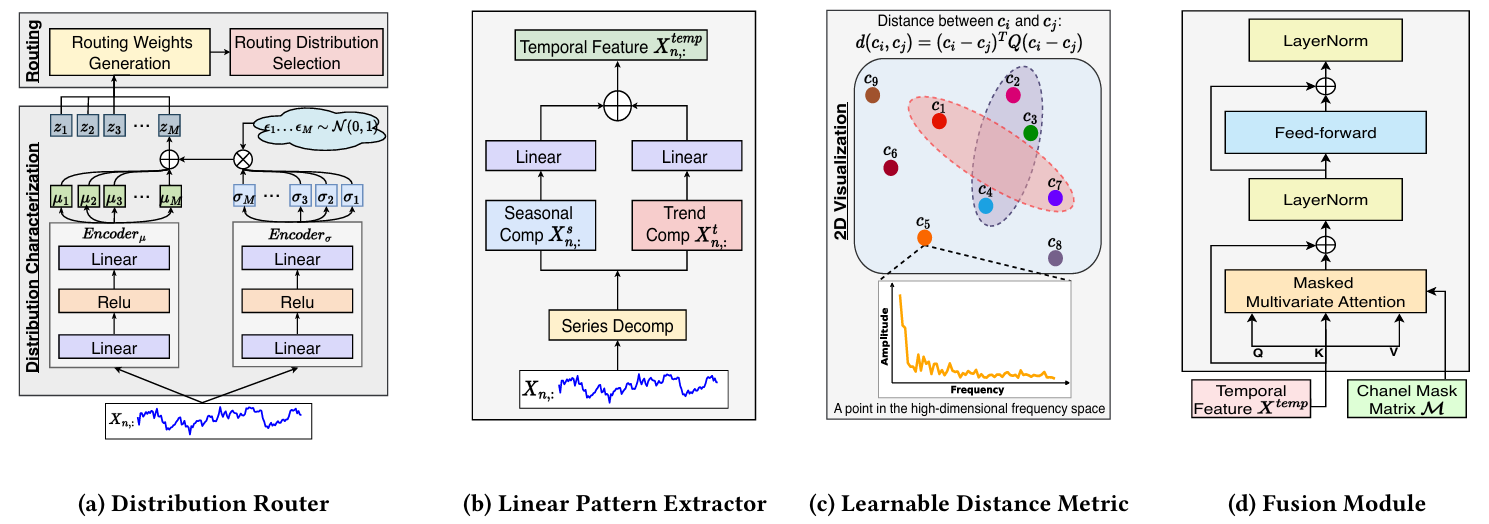
图4 :(a)分布路由器的结构,由分布表征和路由组成。(b)基于线性的模式提取器(linear -based Pattern Extractor)的结构,将序列分解为季节和趋势部分,分别用线性模型提取时间特征并读取。©可学距离度量是捕捉通道之间的关系。(d)融合模块(Fusion Module)是将时序特征和信道掩码矩阵结合起来。
图3显示了DUET的架构,它在时间和通道维度上采用双聚类,同时挖掘内在时间模式和动态通道相关性。具体来说,我们首先使用实例规范来统一训练和测试数据的分布。然后,时间聚类模块(TCM)利用专门设计的分布路由器(图4a)捕获每个时间序列的潜在分布 X n , : ∈ R T X_{n,:}\in\mathbb{R}^T Xn,:∈RT 一种与通道无关的方式,然后通过将具有相似潜在分布的时间序列分配给同一组基于线性的模式提取器(图4b)来聚类它们。通过这种方式,我们可以缓解由于时间模式的异质性,即使有数百万个参数,单一结构也不能完全提取时间特征的问题。同时,信道聚类模块(CCM)捕获了通道间的相关性信道在频率空间中以信道软聚类的方式进行。通过利用自适应度量学习技术并应用稀疏化,CCM输出一个学习到的信道掩码矩阵,因此每个信道可以专注于那些有利于下游预测的信道,并以稀疏连接的方式隔离无关信道的不利影响。最后,基于掩码注意机制的融合模块(FM)(图4d)有效地将TCM提取的时间特征与CCM生成的信道掩码矩阵相结合。然后使用线性预测器来预测我们框架结束时的未来值。
根据上述描述,DUET工艺流程可表述如下:
X n o r m = I n s t a n c e N o r m ( X ) ( 1 ) X t e m p = T C M ( X n o r m ) ( 2 ) M = C C M ( X n o r m ) ( 3 ) X m i x = F M ( X t e m p , M ) , Y ^ = P r e d i c t o r ( X m i x ) , ( 4 ) \begin{aligned}X^{norm}&=InstanceNorm(X)&&\left(1\right)\\X^{temp}&=TCM(X^{norm})&&\mathrm{(2)}\\\mathrm{M}&=CCM(X^{norm})&&\left(3\right)\\X^{mix}=FM(&X^{temp},\mathcal{M}),\hat{Y}=Predictor(X^{mix}),&&\left(4\right)\end{aligned} XnormXtempMXmix=FM(=InstanceNorm(X)=TCM(Xnorm)=CCM(Xnorm)Xtemp,M),Y^=Predictor(Xmix),(1)(2)(3)(4)
其中, X t e m p , X m i x ∈ R N × d , M ∈ R N × N X^{temp},X^{mix}\in\mathbb{R}^{N\times d},\mathcal{M}\in\mathbb{R}^{N\times N} Xtemp,Xmix∈RN×d,M∈RN×N ,步骤2和3可以同时计算,效率更高。下面,我们将介绍我们框架中每个模块的详细信息。
2.1 时间聚类模块(TCM)
TCM旨在通过聚类将时间序列划分为不同的分布类别,然后为每个类别设计特定的模式提取器来捕捉其内在的时间模式。具体步骤如下:
- 分布路由器(Distribution Router):通过编码器提取时间序列的潜在分布特征,并使用Noisy Gating技术选择最可能的分布类别。
- 线性模式提取器(Linear-based Pattern Extractor):对每个分布类别,使用基于线性的模型分别提取季节性和趋势性特征,并将它们融合以建模时间模式。
- 聚合器(Aggregator):将不同分布类别的特征聚合起来,形成最终的时间特征表示。
2.1.1 分布路由器
分布路由器的目标是提取时间序列的潜在分布特征,并为每个时间序列分配到最合适的分布类别。具体实现步骤如下:
通过两个全连接层(FC layers)提取每个时间序列的潜在分布特征:
-
均值编码器(Mean Encoder):计算时间序列的均值向量。
E n c o d e r μ ( X n , : ) = R e L U ( X n , : ⋅ W 0 μ ) ⋅ W 1 μ ( 5 ) Encoder_{\mu}(X_{n,:})=ReLU(X_{n,:}\cdot W_{0}^{\mu})\cdot W_{1}^{\mu}\qquad(5) Encoderμ(Xn,:)=ReLU(Xn,:⋅W0μ)⋅W1μ(5)
-
方差编码器(Variance Encoder):计算时间序列的方差向量。
E n c o d e r σ ( X n , : ) = R e L U ( X n , : ⋅ W 0 σ ) ⋅ W 1 σ ( 6 ) Encoder_{\sigma}(X_{n,:})=ReLU(X_{n,:}\cdot W_{0}^{\sigma})\cdot W_{1}^{\sigma} \qquad(6) Encoderσ(Xn,:)=ReLU(Xn,:⋅W0σ)⋅W1σ(6)
其中, W 0 μ , W 0 σ ∈ R T × d 0 , W 1 μ , W 1 σ ∈ R d 0 × M W_{0}^{\mu},W_{0}^{\sigma}\in\mathbb{R}^{T\times d_{0}},W_{1}^{\mu},W_{1}^{\sigma}\in\mathbb{R}^{d_{0}\times M} W0μ,W0σ∈RT×d0,W1μ,W1σ∈Rd0×M ,然后,利用噪声门控技术选择 X n , : X_{n,:} Xn,: 可能属于的 k {k} k 种最可能的分布并计算相应的权重。
我们可以观察到,用于测量正态分布的重参数化技巧与噪声门控中的噪声添加技术有相似之处,因此我们将它们优雅地结合为统一的形式:
Z n = E n c o d e r μ ( X n , : ) + ϵ ⊙ S o f t p l u s ( E n c o d e r σ ( X n , : ) ) ( 7 ) H ( X n , : ) = W H ⋅ Z n ( 8 ) Z_{n}=Encoder_{\mu}(X_{n,:})+\epsilon\odot Softplus(Encoder_{\sigma}(X_{n,:}))\qquad(7)\\ H(X_{n,:})=W^{H}\cdot Z_{n}\qquad(8) Zn=Encoderμ(Xn,:)+ϵ⊙Softplus(Encoderσ(Xn,:))(7)H(Xn,:)=WH⋅Zn(8)
其中, H ( X n , : ) , ϵ ∈ R M , ϵ i ∼ N ( 0 , 1 ) , W H ∈ R M × M H(X_{n,:}),\epsilon\in\mathbb{R}^{M},\epsilon_{i}\sim\mathcal{N}(0,1),W^{H}\in\mathbb{R}^{M\times M} H(Xn,:),ϵ∈RM,ϵi∼N(0,1),WH∈RM×M , ϵ \epsilon ϵ 的引入不仅有利于从正态分布中恢复,而且稳定了噪声门控的训练过程。激活函数Softplus有助于保持方差为正, H ( X n , : ) H(X_{n,:}) H(Xn,:) 表示分布的投影权重。
随后,我们选择K(K ≤ M)最可能的潜在分布并计算权重:
G ( X n , : ) = S o f t m a x ( K e e p T o p K ( H ( X n , : ) , k ) ) ( 9 ) K e e p T o p K ( H ( X n , : ) , k ) i = { H ( X n , : ) i i f i ∈ A r g T o p k ( H ( X n , : ) ) − ∞ o t h e r w i s e , ( 10 ) G(X_{n,:})=Softmax(KeepTopK(H(X_{n,:}),k))\qquad(9)\\KeepTopK(H(X_{n,:}),k)_i=\begin{cases}H(X_{n,:})_i&\mathrm{if~}i\in ArgTopk(H(X_{n,:}))\\-\infty&\mathrm{otherwise}&\end{cases},\qquad(10) G(Xn,:)=Softmax(KeepTopK(H(Xn,:),k))(9)KeepTopK(H(Xn,:),k)i={H(Xn,:)i−∞if i∈ArgTopk(H(Xn,:))otherwise,(10)
其中, G ( X n , : ) ∈ R k G(X_{n,:})\in\mathbb{R}^k G(Xn,:)∈Rk 表示每个候选分布的概率。从聚类的角度来看,在 k 个潜在分布中,属于相同潜在分布的单变量时间序列 X n , : ∈ R T , n = 1 , ⋯ , N X_{n,:}\in\mathbb{R}^{T},n=1,\cdots,N Xn,:∈RT,n=1,⋯,N 倾向于被同一组基于线性的模式提取器处理。
2.1.2 线性模式提取器
通过上述分布路由器确定潜在分布。然后,将上述分布路由器确定了潜在分布。然后, X n , : X_{n,:} Xn,: 被传递给相应的 k {k} k 个选定的基于线性模式的提取器,以进行时序特征提取。对于第 i {i} i 个基于线性的模式提取器(参见图4b),我们首先使用移动平均技术将 X n , : X_{n,:} Xn,: 分解为季节和趋势部分,然后分别提取特征,最后融合它们,以便更好地捕获同一分布的时间序列模式:
X n , : t = A ν g P o o l ( p a d d i n g ( X n , : ) ) ( 11 ) X n , : s = X n , : − X n , : t ( 12 ) X n , : t e m p i = X n , : t ⋅ W t i + X n , : s ⋅ W s i ( 13 ) \begin{gathered}X_{n,:}^{t}=A\nu gPool(padding(X_{n,:}))&&\left(11\right)\\X_{n,:}^{s}=X_{n,:}-X_{n,:}^{t}&&\left(12\right)\\X_{n,:}^{temp^{i}}=X_{n,:}^{t}\cdot W_{t}^{i}+X_{n,:}^{s}\cdot W_{s}^{i}&&\left(13\right)\end{gathered} Xn,:t=AνgPool(padding(Xn,:))Xn,:s=Xn,:−Xn,:tXn,:tempi=Xn,:t⋅Wti+Xn,:s⋅Wsi(11)(12)(13)
其中, X n , : t , X n , : s ∈ R T X_{n,:}^t,X_{n,:}^s\in\mathbb{R}^T Xn,:t,Xn,:s∈RT 是分解的趋势和季节部分, W t i , W s i ∈ R T × d W_{t}^{i},W_{s}^{i}\in\mathbb{R}^{T\times d} Wti,Wsi∈RT×d 是线性变换中的可学习参数。 X n , : t e m p i ∈ R d X_{n,:}^{temp^{i}}\in\mathbb{R}^{d} Xn,:tempi∈Rd 是由第 i {i} i 个提取器生成的时间特征, d {d} d 是隐藏维度。
2.1.3 聚合器
在选定的 𝑘 个线性模式提取器输出相应的特征后,聚合器基于之前计算的加权门收集时间特征:
X n , : t e m p = ∑ i = 1 k G ( X n , : ) i ⋅ X n , : t e m p i ( 14 ) X_{n,:}^{temp}=\sum_{i=1}^kG(X_{n,:})_i\cdot X_{n,:}^{temp^i}\qquad(14) Xn,:temp=∑i=1kG(Xn,:)i⋅Xn,:tempi(14)
其中, G ( X n , : ) i G(X_{n,:})_i G(Xn,:)i 表示第 i {i} i 个基于线性的模式提取器的权重, X n , : t e m p ∈ R d X_{n,:}^{temp}\in\mathbb{R}^{d} Xn,:temp∈Rd 表示由基于线性的模式提取器聚类提取的 X n , : ( n = 1 , ⋯ , N ) X_{n,:}\left(n=1,\cdots,N\right) Xn,:(n=1,⋯,N) 的时间模式,通过与通道无关的方式获取每个 X n , : ( n = 1 , ⋯ , N ) X_{n,:}\left(n=1,\cdots,N\right) Xn,:(n=1,⋯,N) 的时间特征后,最终聚集成 X t e m p ∈ R N × d X^{temp}\in\mathbb{R}^{N\times d} Xtemp∈RN×d 。
2.2 通道聚类模块(CCM)
为了减轻在预测过程中考虑跨信道关系所带来的不利影响,我们设计了一种有效的度量学习方法,在频率空间中
对信道进行软聚类,并生成相应的学习信道掩码矩阵来实现稀疏连接。具体步骤如下:
- 可学习距离度量(Learnable Distance Metric):使用Mahalanobis距离度量通道在频域中的关系。
- 归一化与重参数化:将通道关系矩阵归一化,并通过Gumbel Softmax重参数化技术生成二值通道掩码矩阵。
2.2.1 可学习距离度量
“频域空间”描述了在傅里叶基下的函数,它们的坐标来自于通过对 L 2 {L^2} L2 空间中的积分计算进行傅里叶变换。具体而言,给定第 n {n} n 个通道的离散时间序列 X n , : ∈ R T X_{n,:}\in{\mathbb{R}^{T}} Xn,:∈RT,我们首先使用实数快速傅里叶变换(rFFT)将其投影到一个有限的 T 2 \frac{T}{2} 2T 维频域空间中,该空间具有相同的 T 2 \frac{T}{2} 2T 个傅里叶基(以复数形式表示)。然后,我们需要找到一个合适的距离度量,以精确评估频域空间中的通道关系。
我们提出了这样一个距离度量,它可以精确地评估频率空间中的信道关系,并使每个信道在预测任务中获得最大的邻居增益。具体地说,我们取范数(或幅度)得到 X n , : c h a n ∈ R T 2 X_{n,:}^{chan}\in\mathbb{R}^{\frac{T}{2}} Xn,:chan∈R2T ,并采用可学习的马氏距离度量自适应地发现通道之间的相互关系:
d ( X i , : , X j , : ) = ( X i , : c h a n − X j , : c h a n ) T ⋅ Q ⋅ ( X i , : c h a n − X j , : c h a n ) ( 15 ) X i , : c h a n = n o r m ( r F F T ( X i , : ) ) , X j , : c h a n = n o r m ( r F F T ( X j , : ) ) ( 16 ) d(X_{i,:},X_{j,:})=(X_{i,:}^{chan}-X_{j,:}^{chan})^{T}\cdot Q\cdot(X_{i,:}^{chan}-X_{j,:}^{chan})\qquad(15)\\ X_{i,:}^{chan}=norm(rFFT(X_{i,:})),X_{j,:}^{chan}=norm(rFFT(X_{j,:}))\qquad(16) d(Xi,:,Xj,:)=(Xi,:chan−Xj,:chan)T⋅Q⋅(Xi,:chan−Xj,:chan)(15)Xi,:chan=norm(rFFT(Xi,:)),Xj,:chan=norm(rFFT(Xj,:))(16)
**马氏距离(Mahalanobis Distance)**是一种度量两点之间距离的方式,它考虑了数据的协方差结构和变量间的相关性,因此与欧几里得距离相比,能够更好地处理高维数据以及特征之间的相关性。公式定义如下:
D M ( x , y ) = ( x − y ) T Σ − 1 ( x − y ) D_M(\mathbf{x},\mathbf{y})=\sqrt{(\mathbf{x}-\mathbf{y})^T\Sigma^{-1}(\mathbf{x}-\mathbf{y})} DM(x,y)=(x−y)TΣ−1(x−y)
其中, Q ∈ R T 2 × T 2 Q\in\mathbb{R}^{\frac{T}{2}\times\frac{T}{2}} Q∈R2T×2T 是可学习的半正定矩阵。它实际上可以通过 Q = A T ⋅ A Q=A^{T}\cdot A Q=AT⋅A 来构造,其中 A {A} A 也是一个可学习的矩阵。这个过程从度量空间的角度引入了一种更通用和轻量级的方法,并自适应地探索了一种距离度量来测量信道相关性,以获得更好的预测精度。
2.2.2 归一化与重参数化
归一化
使用可学习的通道距离度量,我们首先计算通道的关系矩阵,并将其归一化到[0,1]的范围内:
D i j = d ( X i , : , X j , : ) ( 17 ) C i j = { 1 D i j i f i ≠ j 0 i f i = j , P i j = { C i j ⋅ γ max j ( C i j ) i f i ≠ j 1 i f i = j , ( 18 ) \begin{aligned}D_{ij}&=d(X_{i,:},X_{j,:})&\mathrm{(17)}\\C_{ij}&=\begin{cases}\frac{1}{D_{ij}}&\mathrm{if}i\neq j\\0&\mathrm{if}i=j&\end{cases},P_{ij}=\begin{cases}\frac{C_{ij}\cdot\gamma}{\max_j(C_{ij})}&\mathrm{if}i\neq j\\1&\mathrm{if}i=j&\end{cases},&\mathrm{(18)}\end{aligned} DijCij=d(Xi,:,Xj,:)={Dij10ifi=jifi=j,Pij={maxj(Cij)Cij⋅γ1ifi=jifi=j,(17)(18)
其中, D , C , P ∈ R N × N D,C,P\in\mathbb{R}^{N\times N} D,C,P∈RN×N 是距离、关系和概率矩阵, γ ∈ ( 0 , 1 ) \gamma\in(0,1) γ∈(0,1) 是避免绝对连接的折现因子。以上过程对通道之间的关系进行了概率化,其中 P i j P_{ij} Pij 表示通道 j {j} j 对通道 i {i} i 的预测任务有用的概率。
重新参数化
由于我们的目标是滤除不相关信道的不利影响,并保留相关信道的有利影响,因此我们进一步对概率矩阵进行Bernoulli重采样,以获得二进制信道掩码矩阵 M ∈ R N × N \mathcal{M}\in\mathbb{R}^{N\times N} M∈RN×N ,其中 M i j ≈ B e r n o u l l i ( P i j ) \mathcal{M}_{ij}\approx\mathrm{Bernoulli}(P_{ij}) Mij≈Bernoulli(Pij) 。 P i j P_{ij} Pij 较高的概率导致 M i j \mathcal{M}_{ij} Mij 更接近1,表明通道和通道之间存在关系。由于 P i j P_{ij} Pij 包含可学习的参数,我们在伯努利重采样过程中使用Gumbel Softmax重参数化技巧来确保梯度的传播。
2.3 融合模块(FM)
通过时间维度和信道维度的双重聚类,框架提取每个时间序列 X ∈ R N × T X\in\mathbb{R}^{N\times T} X∈RN×T 的时间特征 X t e m p ∈ R N × d X^{temp}\in\mathbb{R}^{N\times d} Xtemp∈RN×d 和信道掩码矩阵 M ∈ R N × N \mathcal{M}\in\mathbb{R}^{N\times N} M∈RN×N 。随后,我们利用掩码注意力机制进一步融合它们。这个过程可以形式化如下:
Q = X t e m p ⋅ W Q , K = X t e m p ⋅ W K , V = X t e m p ⋅ W V ( 19 ) MaskedScores = Q ⋅ K T d ⊙ M + ( 1 − M ) ⊙ ( − ∞ ) ( 20 ) X m i x = S o f t m a x ( M a s k e d S c o r e s ) ⋅ V ( 21 ) \begin{aligned}Q=X^{temp}\cdot W^{Q},K&=X^{temp}\cdot W^{K},V=X^{temp}\cdot W^{V}&&\left(19\right)\\\text{MaskedScores}&=\frac{Q\cdot K^T}{\sqrt{d}}\odot\mathcal{M}+(1-\mathcal{M})\odot(-\infty)&&\left(20\right)\\X^{mix}&=Softmax(MaskedScores)\cdot V&&\left(21\right)\end{aligned} Q=Xtemp⋅WQ,KMaskedScoresXmix=Xtemp⋅WK,V=Xtemp⋅WV=dQ⋅KT⊙M+(1−M)⊙(−∞)=Softmax(MaskedScores)⋅V(19)(20)(21)
其中, W Q , W K , W V ∈ R d × d W^{Q},W^{K},W^{V}\in\mathbb{R}^{d\times d} WQ,WK,WV∈Rd×d 为注意块中的投影矩阵, M a s k e d S c o r e s ∈ R N × N ˉ MaskedScores\in\mathbb{R}^{N\times\bar{N}} MaskedScores∈RN×Nˉ 为注意得分矩阵, X m i x ∈ R N × d X^{mix}\in\mathbb{R}^{N\times d} Xmix∈RN×d 为融合特征。
融合模块基于掩码注意力机制,将TCM提取的时间特征和CCM生成的通道掩码矩阵结合起来,通过进一步优化特征表示,采用LayerNorm、前馈和跳过连接,就像一个经典的Transform块一样,确保了融合模块的稳定性和鲁棒性,而前馈层使融合模块能够捕获复杂的特征。最后,我们采用线性投影来预测未来值,公式如下。
Y ^ = X m i x ⋅ W O ( 22 ) \hat{Y}=X^{mix}\cdot W^O \qquad(22) Y^=Xmix⋅WO(22)
其中, W O ∈ R d × F , Y ^ ∈ R N × F W^O\in\mathbb{R}^{d\times F},\hat{Y}\in\mathbb{R}^{N\times F} WO∈Rd×F,Y^∈RN×F 。
3 实验与结果
文章使用了25个真实世界的数据集,涵盖10个不同的应用领域,验证了DUET的性能。实验结果表明,DUET在多个数据集上均优于现有的最先进方法,尤其是在处理时间异质性和通道间复杂关系方面表现出色。
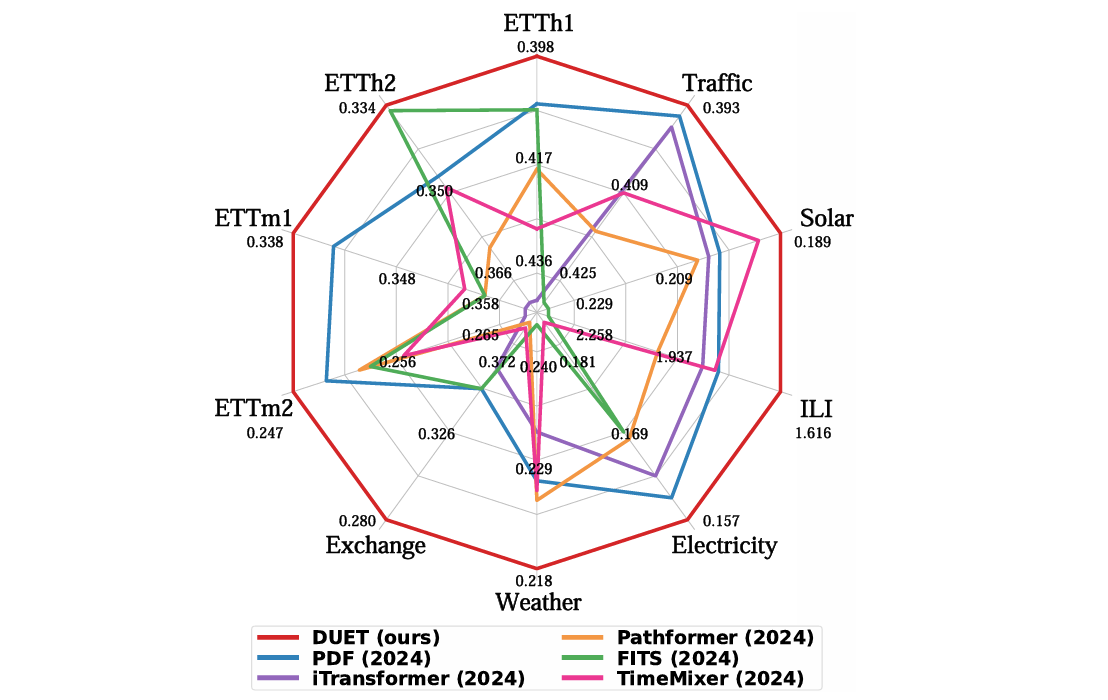
图5:DUET的性能。结果(MSE)是所有预测窗口的平均值。DUET在10个常用数据集中优于强基线。
3.1 关键结论
- 时间异质性建模:DUET通过时间聚类模块有效处理了时间分布偏移问题,与非平稳时间序列建模的最新方法相比,MSE降低了32.4%,MAE降低了21.7%。
- 通道间关系建模:DUET采用的通道软聚类策略(CSC)优于传统的通道独立(CI)和通道依赖(CD)策略,尤其在通道相关性强的数据集(如交通和太阳能数据集)上表现突出。
- 整体性能:DUET在10个常用数据集上的平均MSE和MAE分别比第二名降低了7.1%和6.5%,显示出其在多变量时间序列预测中的优越性能。
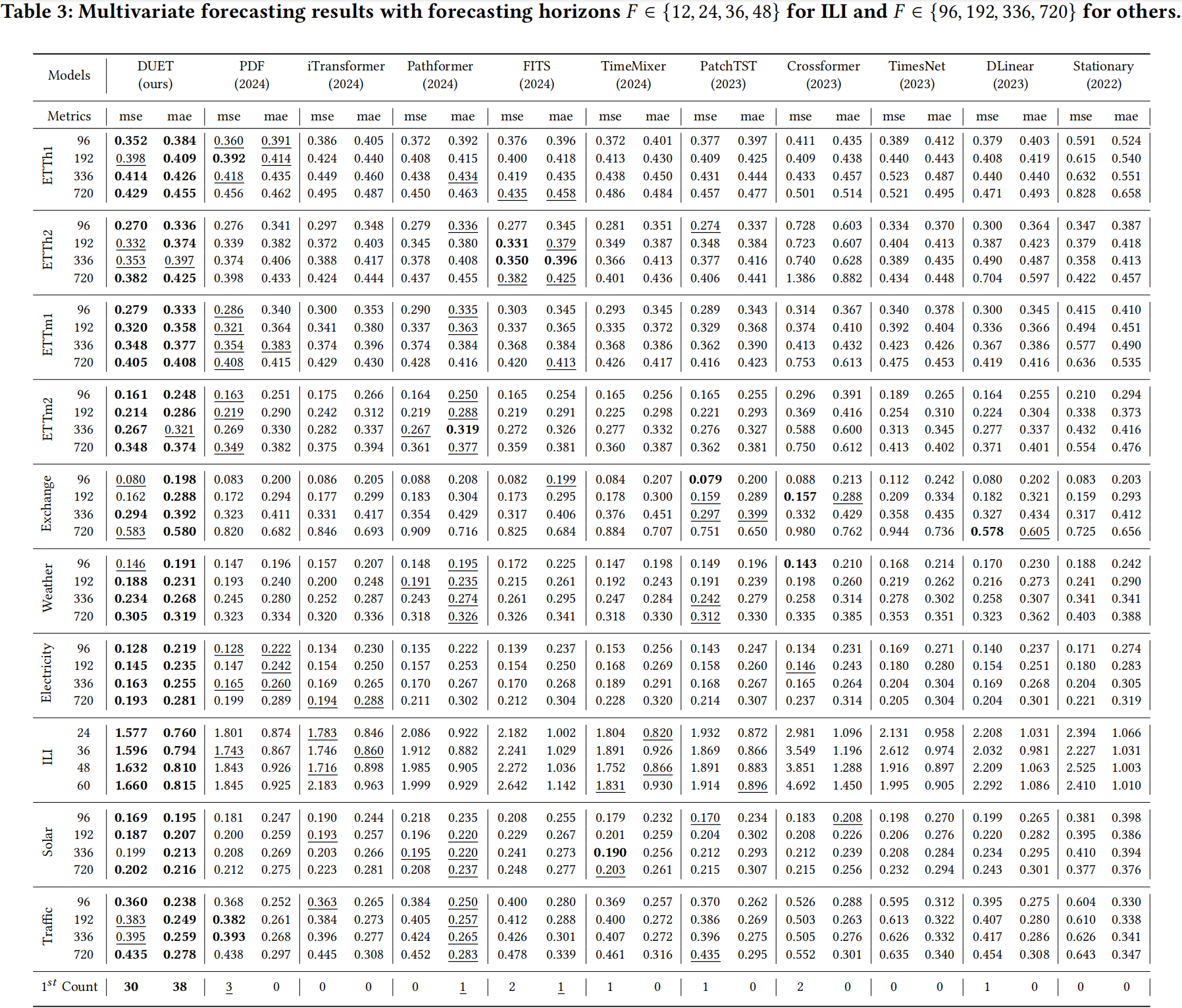
3.2 消融研究
- 移除时间聚类模块(TCM)会导致在时间分布变化较大的数据集(如ETTh2)上性能显著下降,证明了TCM的有效性。
- 移除通道聚类模块(CCM)会使模型退化为通道独立策略,导致在通道相关性强的数据集(如交通)上性能下降。
- 使用全注意力机制(而非掩码注意力)会使模型退化为通道依赖策略,导致在通道相关性弱的数据集(如ETTh2)上性能下降。
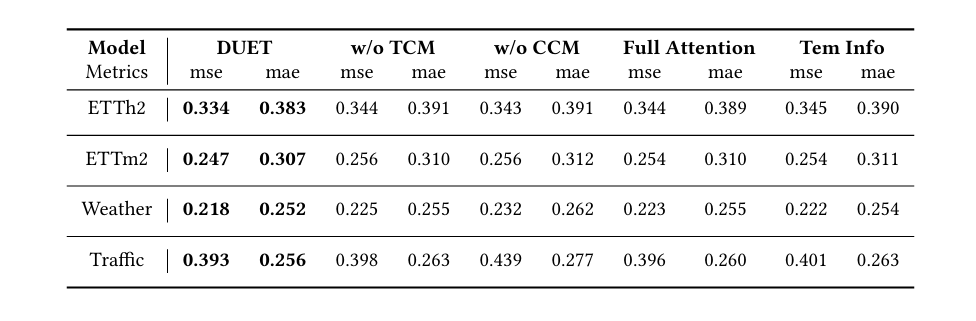
我们证明了可学习的马氏体距离度量优于其他相似度量方法。我们选择用不可学习的相似性度量方法替代可学习度量:欧几里得距离、余弦相似性和DTW。如表4所示,使用这些方法会导致模型性能下降,这充分证明了可学习度量的有效性。此外,我们还将学习到的掩模矩阵替换为随机掩模矩阵,并证明其性能远不如学习到的掩模矩阵。
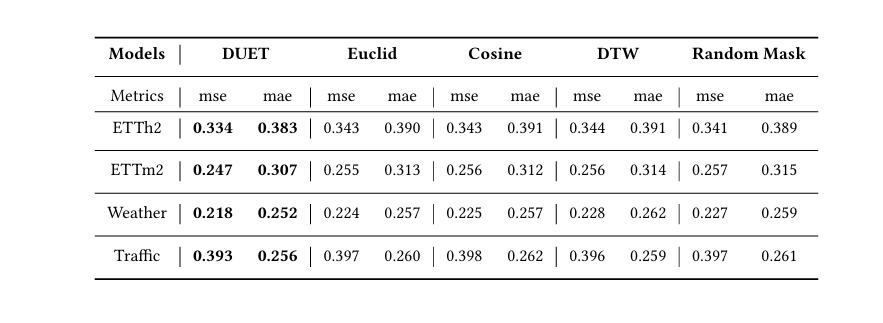
表4:不同距离指标之间的比较。结果取所有预测视界的平均值。
4 方法分析
从距离度量的比较到参数灵敏度分析,再到各种可视化,全面地评估了DUET的各个方面。这些分析不仅验证了DUET设计选择的有效性,还提供了对模型在不同情况下如何表现的深入理解。特别是双重聚类机制,通过处理时间异质性和通道关系的复杂性,证明了其优越性。
4.1 不同距离度量的比较
在这一部分,作者比较了在CCM中用于聚类通道的几种不同距离度量方法,包括欧几里得距离、余弦相似度、动态时间弯曲(DTW)和随机掩码。结果表明,可学习的马氏距离度量在所有预测范围内都优于其他方法,证实了其在频率域中适应性评估通道关系的有效性。使用非可学习的相似度度量方法会导致模型性能下降,突显了频率域中可学习度量的优势。
4.2 参数灵敏度
接下来,分析研究了在TCM中使用的线性模式提取器数量(M)对DUET性能的影响。结果表明,最佳的 M 值因数据集而异,但同一领域的数据集通常具有相同的最佳 M 值。例如,电力领域的ETTh1和ETTh2数据集的最佳 M 值都是4,而健康和经济领域的ILI和Exchange数据集的最佳 M 值分别是2和5。此外,使用最合适的 M 的DUET在大多数情况下都优于其他变体,证明了从时间角度进行聚类的有效性,并暗示不同领域的数据集通常具有不同的时间分布。
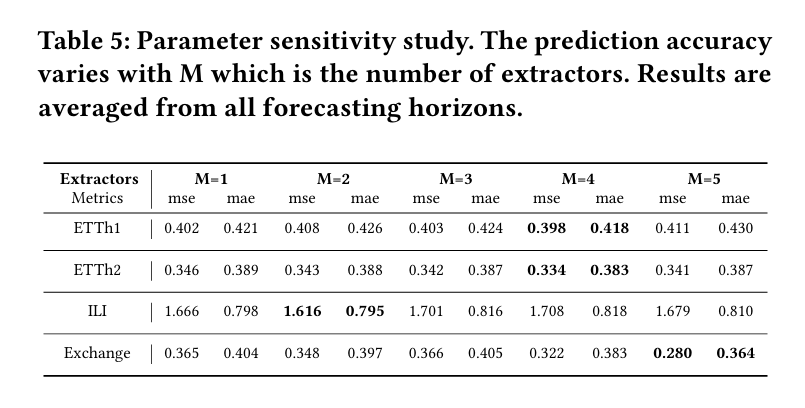
4.3 可视化分布权重
在这部分,通过展示来自ETTh1和Weather数据集的四个时间序列样本的分布权重,来说明TCM中的分布路由器如何工作。结果表明,具有相似季节性模式的样本具有相似的分布权重,而分布不同的样本则具有不同的权重。这强调了DUET区分不同分布样本的能力,突显了其适应性。
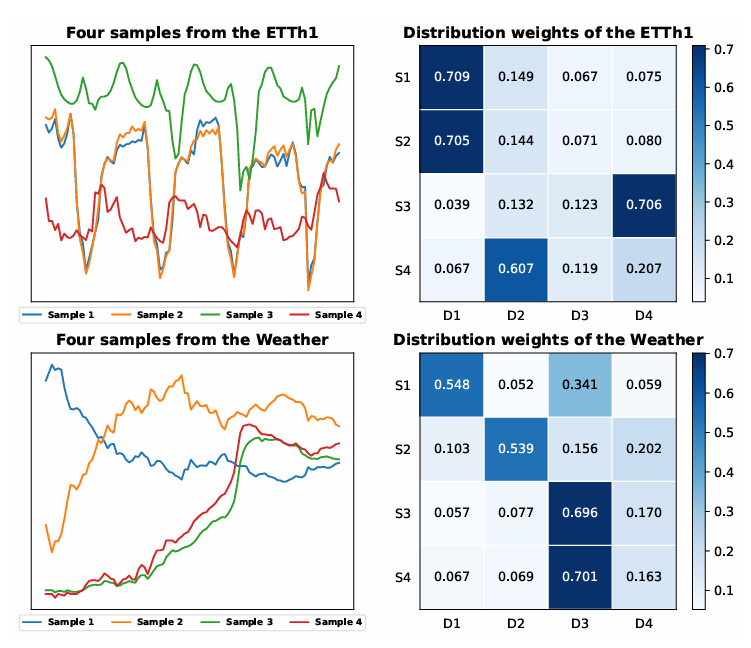
图6:来自ETTh1和Weather的不同时间序列样本的分布权重。S1-S4表示不同的样本,D1-D4表示不同的分布。
4.4 可视化通道权重
在这一部分,通过ETTh2数据集中七个通道之间的相互注意权重,评估了CCM的有效性。CCM通过在频率空间中测量同一时间间隔内通道之间的相关性,并生成相应的掩码矩阵,来实现聚类效果。可视化显示,具有相似频率成分组合的通道可能会被聚成一个软组,同时保持跨组的相关性,以最大化预测任务的邻域信息增益。
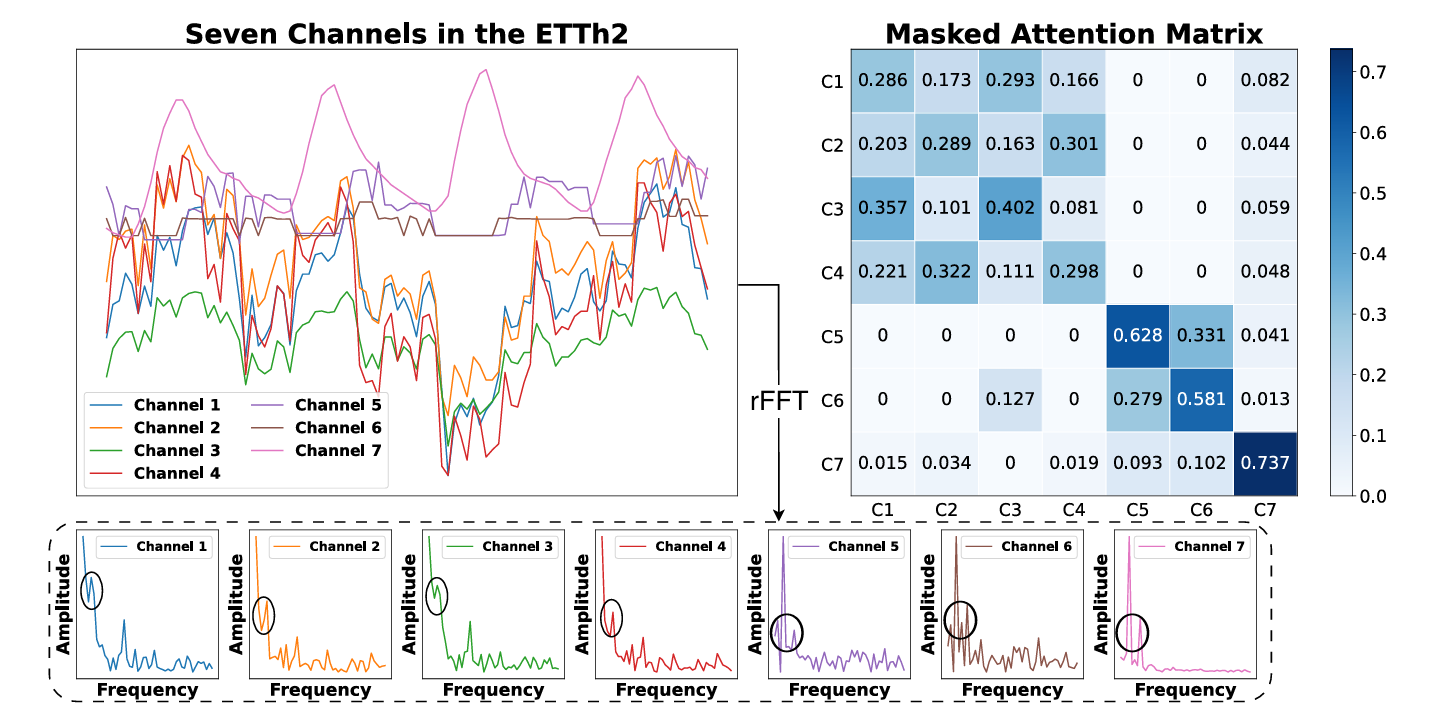
图7:来自ETTh2的不同频道的注意力得分。C1-C7表示不同的通道。
5 总结
在本文中,我们提出了一个通用的框架,DUET,它在时间和通道维度上引入了双重聚类来增强多元时间序列预测。它集成了一个时间聚类模块(TCM),将时间序列聚类成细粒度分布。然后为不同的分布集群设计各种模式提取器,以捕获其独特的时间模式,模拟时间模式的异质性。此外,我们还介绍了使用信道软聚类策略的信道聚类模块(CCM)。这通过度量学习捕获频域中信道之间的关系,并应用稀疏化。最后,基于掩码注意机制的融合模块(FM)将TCM提取的时序特征与CCM生成的信道掩模矩阵有效地结合在一起。这些创新机制共同使DUET能够实现出色的预测性能。

















 1791
1791

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









