






前面介绍了大语言模型(Large Language Models, LLMs)的技术原理和应用,LLM属于Foundation model一种,除了LLM外,Foundation model还包括视觉大模型(Large Vision Models),和多模态大模型(Large Multimodal Models)。
目前比较火的文生图大模型Stable Diffusion,DALL-E、文生视频大模型Sora,图文检索,视觉内容生成都属于多模态大模型范畴,今天给大家推荐一篇多模态大模型的综述论文,后续还会推出视觉大模型论文,请持续关注。

以下是文档内容的思维导图概括:
- 多模态基础模型
- 定义和背景
\- 多模态基础模型的重要性
\- 从专家模型到通用助手的过渡
- 研究领域
\- 视觉理解
\- 监督预训练
\- 对比学习
\- 自监督学习
\- 视觉生成
\- 文本到图像的生成
\- 空间可控生成
\- 文本提示遵循
\- 概念定制
\- 统一视觉模型
\- 从封闭集到开放集模型
\- 任务特定模型到通用模型
\- 从静态到可提示模型
- 大型多模态模型
\- 背景
\- 预训练指导
\- 多模态大型模型案例研究
\- 多模态代理的先进话题
- 多模态代理
\- 多模态代理的概述
\- 多模态代理的案例研究: MM-REACT
\- 多模态代理的先进话题
\- 多模态代理的评估
- 总结和研究趋势
\- 总结
\- 通用AI代理的构建
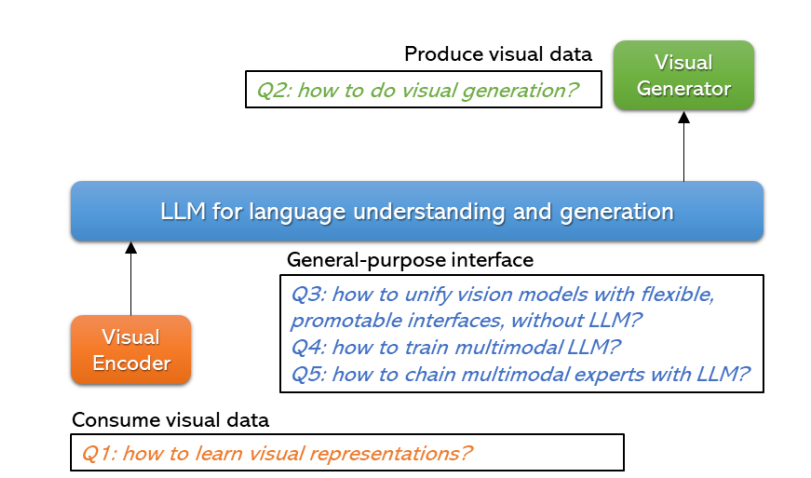
上图阐述了多模态大模型试图解决的三个代表性问题:视觉理解任务、视觉生成任务,以及具有语言理解和生成能力通用接口。
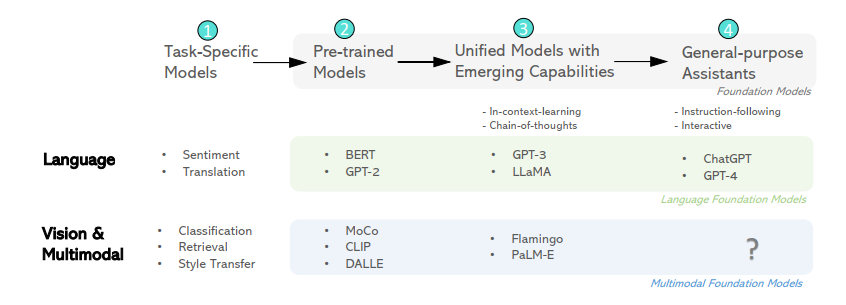
上图描述了基础模型在语言和视觉/多模态领域的发展趋势,指出了从专门模型向通用助手演进的趋势,并强调了需要进一步研究来确定如何最佳地实现这一转变。
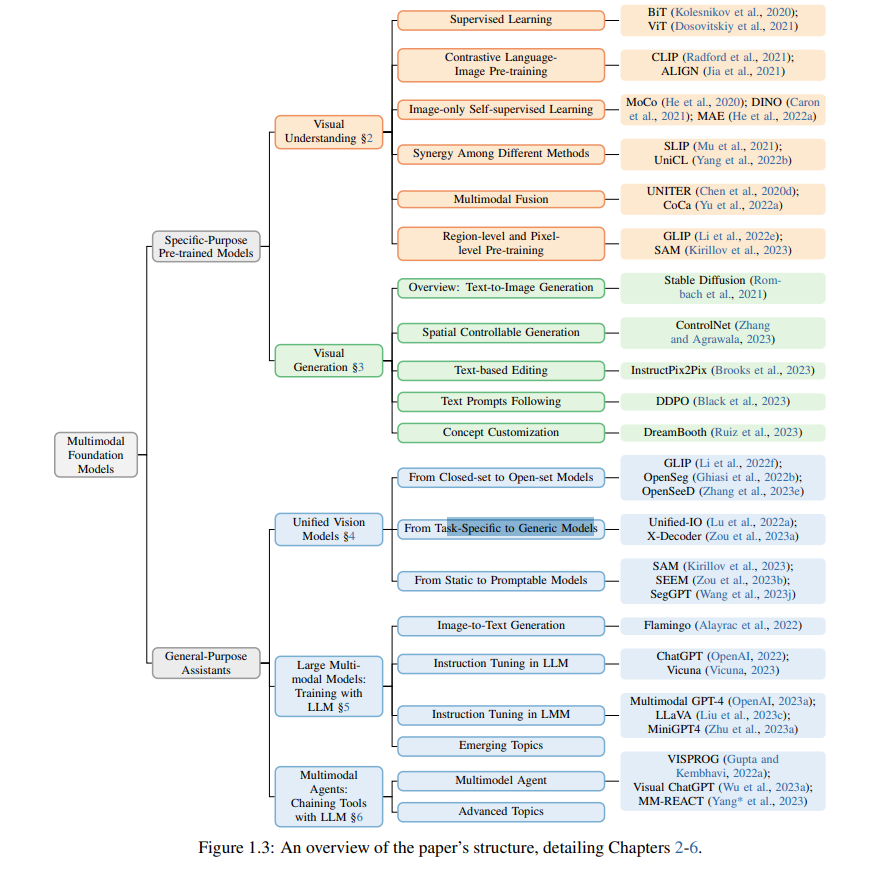
整篇论文章节内容结构
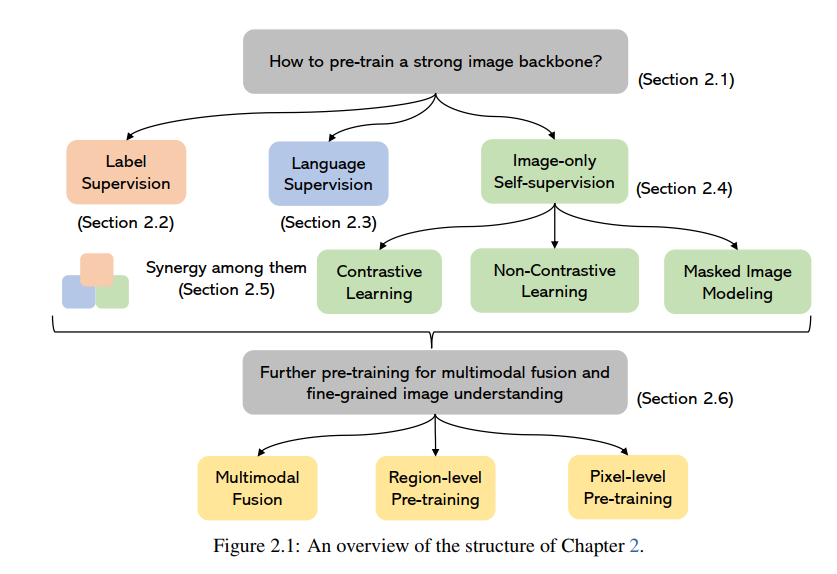
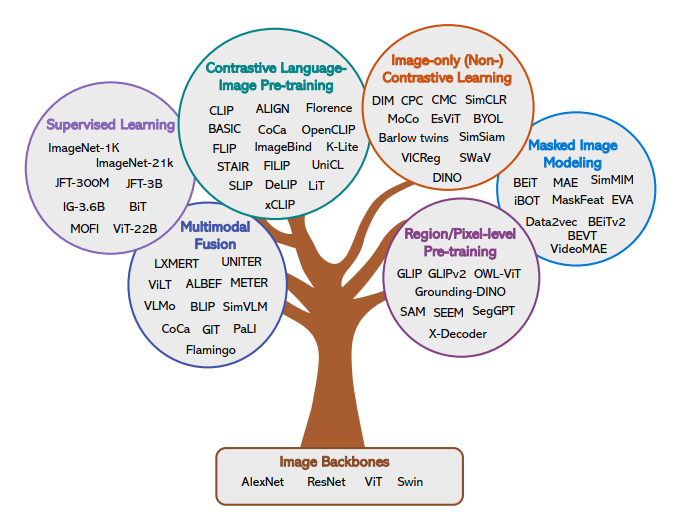
视觉理解总结
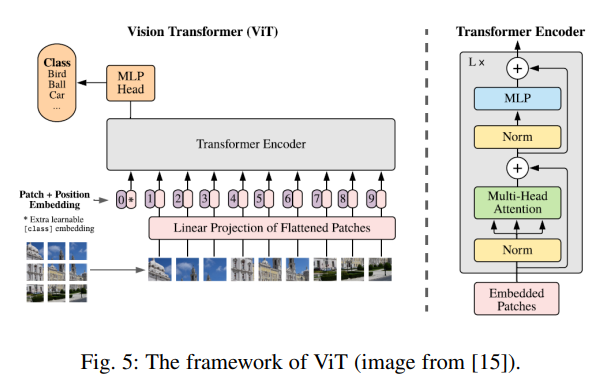
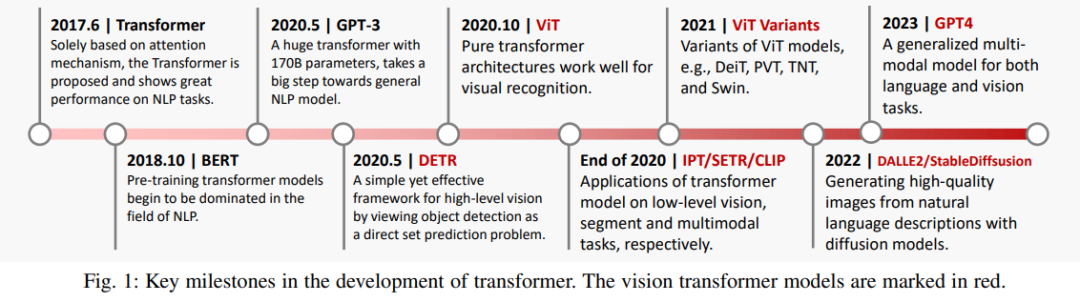
大语言模型的发展除了算力,数据因素外,也离不开模型架构的发展,Transformer是语言大模型的基础,在CV领域,ViT则是视觉大模型的基础。

视觉内容生成总结

图像生成大事件年表
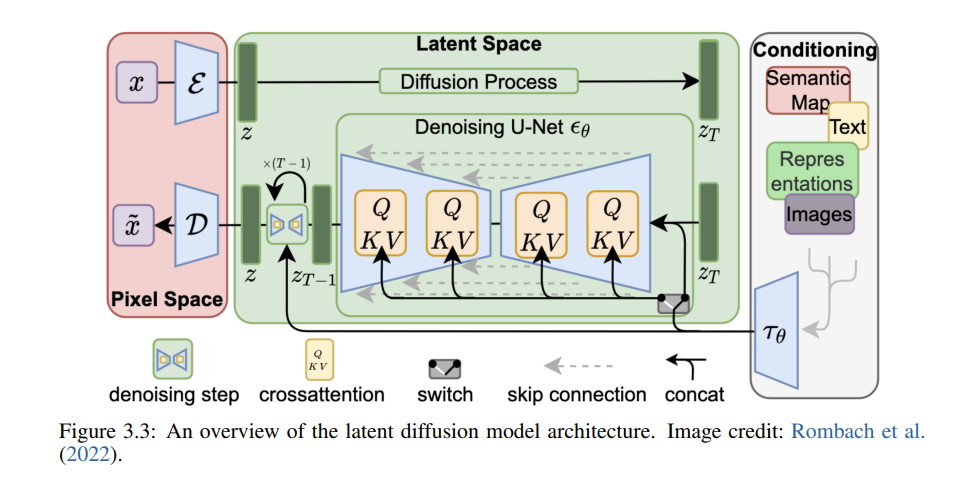
GANs擅长于生成与训练集中的图像非常相似的逼真图像,VAEs擅长于创建各种各样的图像,现有的模型还没有成功地将这两种功能结合起来,直到****Stable Diffusion的出现,它融合了GAN和VAE的优点,能生成真实且多样的图片。
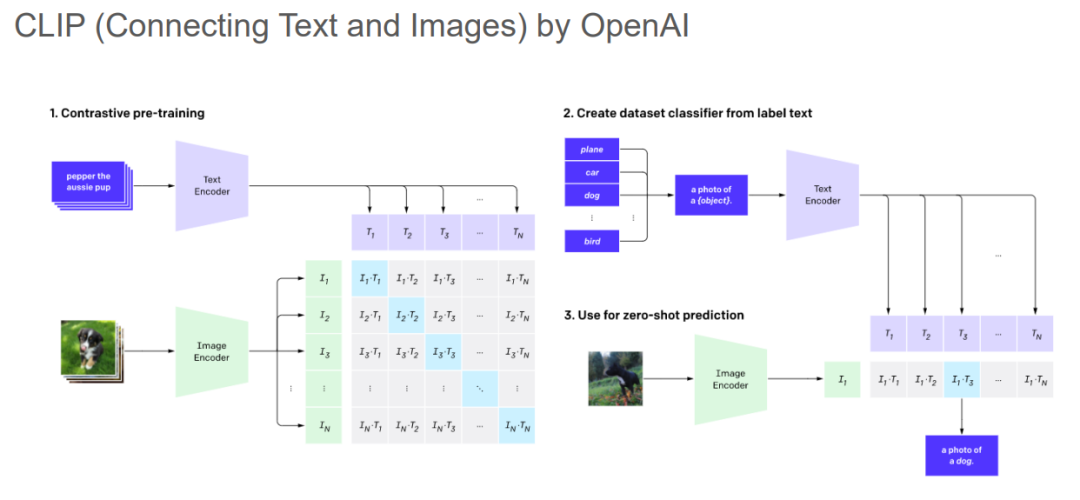
CLIP是将语言和图像映射到统一嵌入空间的开山之作,是多模态大模型的基础。
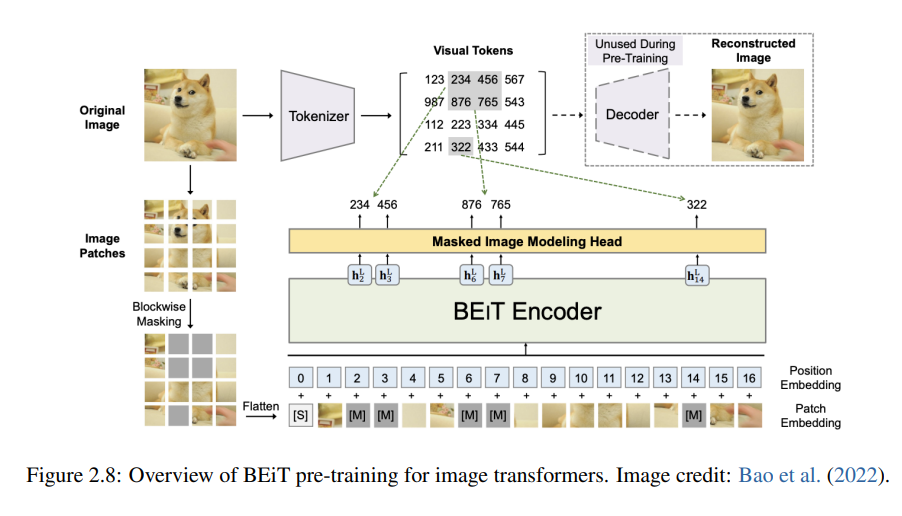

BeiT,MAE,IGPT开启了图像预训练时代,CV中的BERT。

















 1391
1391

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









