









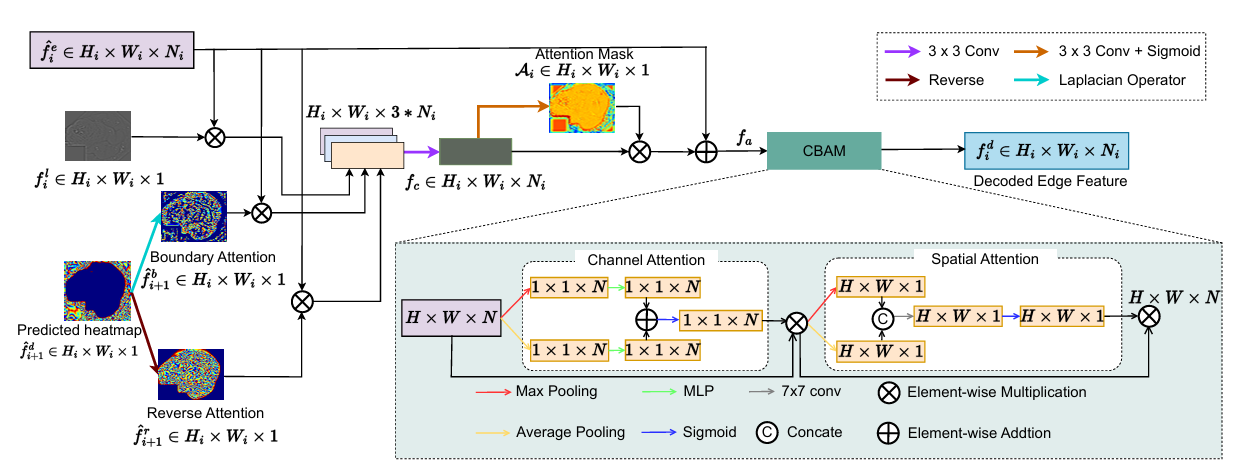
EGA边缘引导注意力模块
标题:MEGANet: Multi-Scale Edge-Guided Attention Network for Weak Boundary Polyp Segmentation
期刊:WACV2024
代码: https://github.com/UARK-AICV/MEGANet
简介:
任务是在息肉分割领域,解决前景背景分割难的问题。使用多尺度边缘引导网络实现更好的分割效果。多尺度捕捉不同分辨率特征,边缘细化特征提取于恢复,注意力机制聚焦关键区域。适用于伪装目标、阴影去除等任务。
模型结构
拉普拉斯金字塔得到不同尺度高频特征
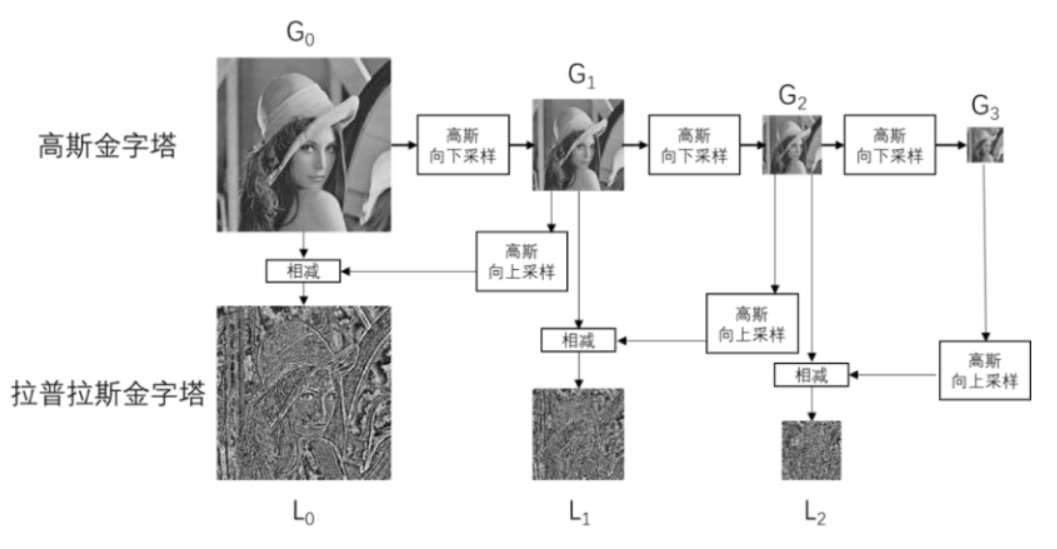
整体架构
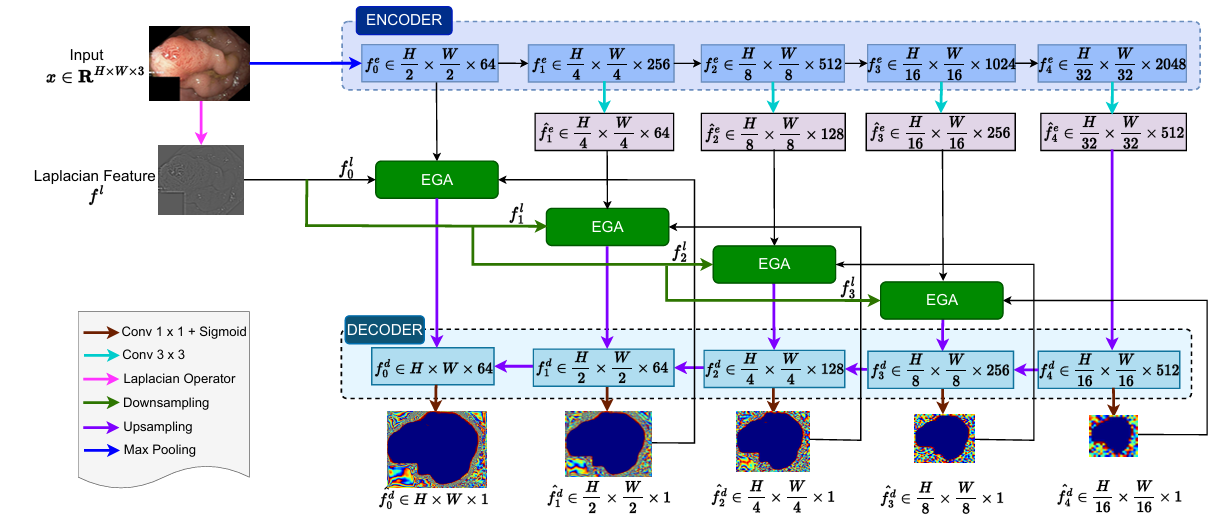
EGA边缘引导注意力模块
模型代码
import torch
import torch.nn.functional as F
import torch.nn as nn
# Github地址:https://github.com/UARK-AICV/MEGANet
# 论文:MEGANet: Multi-Scale Edge-Guided Attention Network for Weak Boundary Polyp Segmentation, WACV 2024
# 论文地址:https://arxiv.org/abs/2309.03329
# 高斯卷积核
def gauss_kernel(channels=3, cuda=True):
# 定义一个5x5的高斯权重矩阵
kernel = torch.tensor([[1., 4., 6., 4., 1],
[4., 16., 24., 16., 4.],
[6., 24., 36., 24., 6.],
[4., 16., 24., 16., 4.],
[1., 4., 6., 4., 1.]])
# 归一化
kernel /= 256.
# 重复权重矩阵,使其与输入通道数相匹配
# 将核进行拓展
kernel = kernel.repeat(channels, 1, 1, 1)
# 如果cuda可用,则将核移动到GPU上
if cuda:
kernel = kernel.cuda()
return kernel
# 下采样
def downsample(x):
return x[:, :, ::2, ::2]
# 高斯卷积,输入为图像以及高斯卷积核,尺寸维度输入输出保持不变
def conv_gauss(img, kernel):
img = F.pad(img, (2, 2, 2, 2), mode='reflect') # 四周各填充2像素(反射模式),类似于膨胀操作
out = F.conv2d(img, kernel, groups=img.shape[1]) # 分组卷积(每组对应一个通道)
return out
# 高斯上采样,该函数通过零填充和维度变换来实现2倍上采样,然后使用高斯卷积进行平滑处理。
# 宽高都变为原来的两倍
def upsample(x, channels):# 输入为x,以及通道数
# 1. 宽度方向插零:在特征图宽度维度插入零值
cc = torch.cat([x, torch.zeros(x.shape[0], x.shape[1], x.shape[2], x.shape[3], device=x.device)], dim=3)
# 2. 调整形状实现宽度的2倍上采样
cc = cc.view(x.shape[0], x.shape[1], x.shape[2] * 2, x.shape[3])
# 3. 交换宽高维度,为高度方向插零做准备
cc = cc.permute(0, 1, 3, 2)
# 4. 高度方向插零
cc = torch.cat([cc, torch.zeros(x.shape[0], x.shape[1], x.shape[3], x.shape[2] * 2, device=x.device)], dim=3)
# 5. 调整形状实现高度的2倍上采样
cc = cc.view(x.shape[0], x.shape[1], x.shape[3] * 2, x.shape[2] * 2)
# 6. 恢复原始维度顺序
x_up = cc.permute(0, 1, 3, 2)
# 7. 使用4倍高斯核进行卷积平滑(保持能量守恒)
return conv_gauss(x_up, 4 * gauss_kernel(channels))
#拉普拉斯金字塔的构建,主要用于提取图像的高频细节(边缘信息)
def make_laplace(img, channels):
filtered = conv_gauss(img, gauss_kernel(channels)) # 高斯模糊
down = downsample(filtered) # 下采样
up = upsample(down, channels) # 上采样
# 尺寸对齐(防止奇数次尺寸问题)
if up.shape[2] != img.shape[2] or up.shape[3] != img.shape[3]:
up = nn.functional.interpolate(up, size=(img.shape[2], img.shape[3]))
diff = img - up # 计算高频残差
return diff
# 构建图像的拉普拉斯金字塔
# 通过多尺度分解提取图像的高频细节信息(边缘、纹理等),常用于多尺度特征分析。
def make_laplace_pyramid(img, level, channels):# 输入参数,图像,金字塔层数,通道数
current = img # 初始化当前处理层
pyr = [] # 金字塔存储列表
# 逐层构建金字塔
for _ in range(level):
filtered = conv_gauss(current, gauss_kernel(channels)) # 高斯滤波
down = downsample(filtered) # 下采样(尺寸减半)
up = upsample(down, channels) # 上采样(恢复原尺寸)
# 尺寸对齐(处理奇数尺寸问题)
if up.shape[2] != current.shape[2] or up.shape[3] != current.shape[3]:
up = nn.functional.interpolate(up, size=(current.shape[2], current.shape[3]))
diff = current - up # 计算高频残差(拉普拉斯层)
pyr.append(diff) # 保存当前层
current = down # 更新当前层为下采样结果
pyr.append(current) # 添加最后的低频残差
# 返回金字塔列表,包含多层高频残差和最后一层低频残差
return pyr
class ChannelGate(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16):
super(ChannelGate, self).__init__()
self.gate_channels = gate_channels
self.mlp = nn.Sequential(
nn.Flatten(),
nn.Linear(gate_channels, gate_channels // reduction_ratio), # 通道压缩
nn.ReLU(), # 非线性激活
nn.Linear(gate_channels // reduction_ratio, gate_channels) # 通道恢复
)
def forward(self, x):
# 平均池化路径
avg_out = self.mlp(F.avg_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3))))
# 最大池化路径
max_out = self.mlp(F.max_pool2d(x, (x.size(2), x.size(3)), stride=(x.size(2), x.size(3))))
# 双路径特征融合
channel_att_sum = avg_out + max_out
# 生成注意力权重 (0-1范围)
scale = torch.sigmoid(channel_att_sum).unsqueeze(2).unsqueeze(3).expand_as(x)
# 特征重标定
return x * scale
class SpatialGate(nn.Module):
def __init__(self):
super(SpatialGate, self).__init__()
kernel_size = 7
self.spatial = nn.Conv2d(2, 1, kernel_size, stride=1, padding=(kernel_size - 1) // 2)
def forward(self, x):
# 通道压缩:取最大和平均值(空间维度保留)
x_compress = torch.cat((torch.max(x, 1)[0].unsqueeze(1), # 最大池化 [B,1,H,W]
torch.mean(x, 1).unsqueeze(1)), dim=1) # 平均池化 [B,1,H,W]
# 空间卷积生成注意力图
x_out = self.spatial(x_compress) # [B,1,H,W]
scale = torch.sigmoid(x_out) # 归一化到0-1
# 空间注意力加权
return x * scale
# 通道空间注意力模块
class CBAM(nn.Module):
def __init__(self, gate_channels, reduction_ratio=16):
super(CBAM, self).__init__()
self.ChannelGate = ChannelGate(gate_channels, reduction_ratio)
self.SpatialGate = SpatialGate()
def forward(self, x):
x_out = self.ChannelGate(x)
x_out = self.SpatialGate(x_out)
return x_out
# Edge-Guided Attention Module(EGA)
class EGA(nn.Module):
def __init__(self, in_channels):
super(EGA, self).__init__()
# 融合卷积层,包含卷积、归一化以及非线性激活
self.fusion_conv = nn.Sequential(
nn.Conv2d(in_channels * 3, in_channels, 3, 1, 1),
nn.BatchNorm2d(in_channels),
nn.ReLU(inplace=True))
# 注意力机制,通过卷积归一化以及sigmoid来生成权重
self.attention = nn.Sequential(
nn.Conv2d(in_channels, 1, 3, 1, 1),
nn.BatchNorm2d(1),
nn.Sigmoid())
# 通道空间注意力模块
self.cbam = CBAM(in_channels)
# 输入为边缘特征[1, 1, 256, 256],输入特征[1, 64, 256, 256],预测特征[1, 1, 256, 256]
def forward(self, edge_feature, x, pred):
residual = x # [1, 64, 256, 256]
xsize = x.size()[2:] # 获取空间维度大小[256, 256]
pred = torch.sigmoid(pred)# [1, 1, 256, 256]-->[1, 1, 256, 256]
# reverse attention
# 反向注意力(背景区域)
background_att = 1 - pred # [1, 1, 256, 256]-->[1, 1, 256, 256]
background_x = x * background_att # [1, 64, 256, 256]-->[1, 64, 256, 256]
# boudary attention
# 边界注意力(预测边缘)
edge_pred = make_laplace(pred, 1)# 拉普拉斯边缘提取 [1, 1, 256, 256]-->[1, 1, 256, 256]
pred_feature = x * edge_pred #通道广播相乘 [1, 64, 256, 256]-->[1, 64, 256, 256]
# high-frequency feature
# 高频特征(输入边缘)
edge_input = F.interpolate(edge_feature, size=xsize, mode='bilinear', align_corners=True)
input_feature = x * edge_input # [1, 64, 256, 256]-->[1, 64, 256, 256]
# [1, 64, 256, 256]-->[1, 192, 256, 256]
fusion_feature = torch.cat([background_x, pred_feature, input_feature], dim=1)
fusion_feature = self.fusion_conv(fusion_feature)# [1, 192, 256, 256]-->[1, 64, 256, 256]
attention_map = self.attention(fusion_feature) # [1, 1, 256, 256]
fusion_feature = fusion_feature * attention_map # [1, 64, 256, 256]
out = fusion_feature + residual # [1, 64, 256, 256]
out = self.cbam(out) # [1, 64, 256, 256]
return out
if __name__ == '__main__':
# 模拟输入张量
edge_feature = torch.randn(1, 1, 256, 256).cuda()
x = torch.randn(1, 64, 256, 256).cuda()
pred = torch.randn(1, 1, 256, 256).cuda() # pred 通常是1通道
# 实例化 EGA 类
model = EGA(64).cuda()
# 传递输入张量通过 EGA 实例
output = model(edge_feature, x, pred)
print('input_size:', x.size())
print('output_size:', output.size())
print("最大内存占用:", torch.cuda.max_memory_allocated() // 1024 // 1024, "MB")


















 129
129

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











