







top_de_exp<-dplyr::slice(de_result2,1:20)%>%#挑取差异最大的
select(-c(2:8))%>%#去掉2-8列
column_to_rownames(var="id")#列变行de_result2为上一篇转录组-火山图得到的数据!
#第一种做图方式
library(pheatmap)
pheatmap(log10(top_de_exp+1),
#cluster_rows = F,#顺序按照导入表一致且左侧不聚类,一般不用
#cluster_cols = F,#上面不聚类,一般不用
show_colnames = F)#去掉行名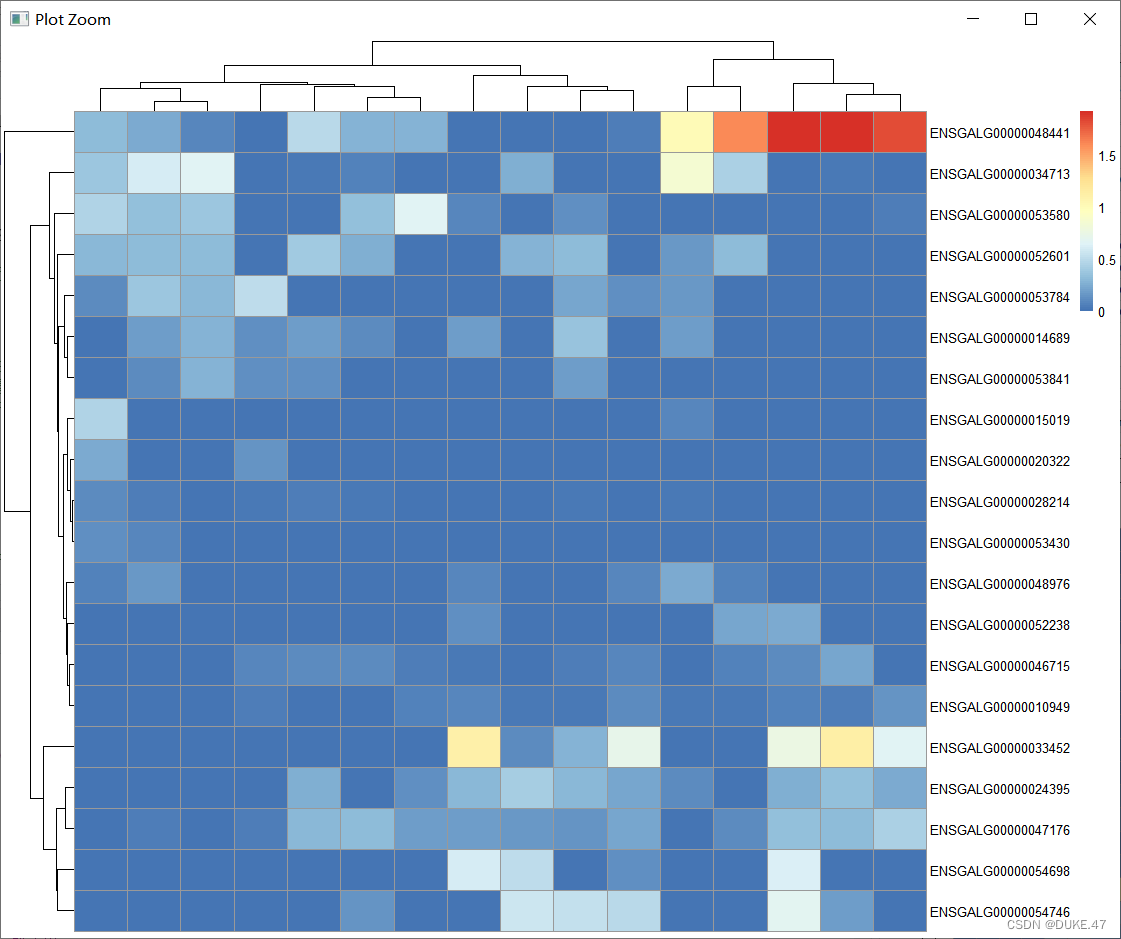
#第二种做图方式:标准化之后
pheatmap(top_de_exp,
scale = "row",
show_rownames = F)#不显示基因名字/列名 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 106
106











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









