







Data Management For Large Language Models: A Survey论文精读
如标题所见,精读的论文是Data Management For Large Language Models: A Survey,这里有它的下载链接:[2312.01700] Data Management For Large Language Models: A Survey (arxiv.org)
是一篇关于大型语言模型(LLMs)在预训练和监督微调阶段数据管理策略的综述文章。作者主要来自两个机构:北京大学和华为诺亚方舟实验室。
背景介绍
随着人工智能技术的飞速发展,大型语言模型(LLMs)已经成为自然语言处理(NLP)领域的一项突破性进展。这些模型通过在海量文本数据上进行预训练,展现出了强大的语言理解和生成能力,从而在多种NLP任务中取得了令人瞩目的成果。然而,LLMs的成功不仅依赖于其复杂的模型架构,更关键的是它们所依赖的高质量、大规模的数据集。数据管理,即如何有效地组织和处理这些数据,对于LLMs的性能提升和训练效率至关重要。
在预训练阶段,构建包含高质量数据的数据集对于模型的高效训练至关重要。为了赋予LLMs多样化和全面的能力,需要混合不同领域的数据,形成异构数据集。然而,许多知名的LLMs在构建预训练数据集时,并没有公开其数据管理策略的选择理由和效果,这使得研究者难以理解某些策略背后的逻辑和影响。
在监督微调(Supervised Fine-Tuning, SFT)阶段,LLMs的性能和遵循指令的能力很大程度上取决于精心构建的指令数据集。尽管已有一些通过人类众包、自指导或现有数据集收集方法提出的指令数据集/基准,但实践者在LLM SFT实践中仍面临选择合适数据管理策略的困惑,这直接影响了微调后模型的性能。
为了应对这些挑战,有必要对LLM数据管理进行全面的系统分析,包括管理策略选择的逻辑、其对训练数据集的评估方法,以及持续改进策略的追求。本文旨在为那些致力于通过有效数据管理实践构建强大LLMs的实践者提供一个指导资源。
整个文章对数据管理的陈述基于两种情景,一种是大语言模型的预训练过程,另一种是在使用大语言模型的下游任务的有监督微调阶段。也正是基于这两大场景,提出了LLM数据管理的几个研究方向,如下图所示:
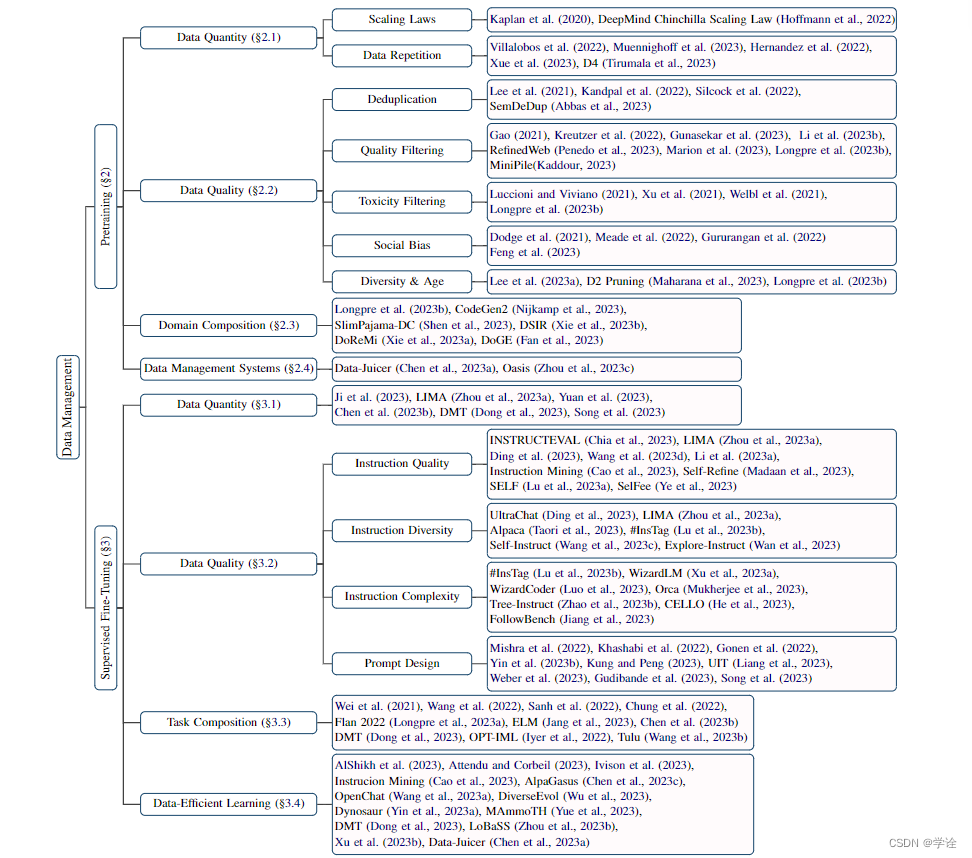
作者整理了两个场景数据管理大大小小几个方向,当然也有一个repo是上面图片的总结:
ZigeW/data_management_LLM: Collection of training data management explorations for large language models (github.com)
Pretraining of LLM
正如上文提到的,在大语言模型训练过程中的数据没有给出他们使用的数据管理方法,下面会对训练过程数据管理的研究方向进行简述:
Data Quantity
大模型只是简称,其全名是大规模语言模型。名字中的大规模指的有两个方面,一个是数据量大,另一个是模型规模大。在数据量上目前有以下两个可研究的点:
Scaling Laws
Scaling Laws中文翻译过来是缩放定律,该定律表明模型性能与训练数据集大小和模型参数数量之间存在幂律关系。随着模型大小的增加,对训练数据的需求也会增加。当模型大小和数据集大小同时增加时,模型性能会得到提升,但如果其中任何一个在另一个增加时保持不变,就可能导致过拟合。Kaplan的研究使用了以下两个公式来描述这种关系:
其中,L 是测试损失,D 是训练标记的数量,N 是模型参数的数量,αD 和 αN 分别是 D 和 N 的幂律成分,Dc 和 Nc 是常数,表示训练标记和非嵌入参数的数量。这些公式是Kaplan经验性得到的,也就是说,这两个公式中的一些量是经过多次实验得出的。而经验性的整合上面两个公式,可以得出下面这个公式:
这个公式就说明上面提到的N和D其中任何一个在另一个增加时保持不变,就可能导致过拟合。基于上述缩放定律,研究者们分析了在固定计算预算下,最优的数据集大小(Dopt)和模型大小(Nopt)的分配策略。他们发现:模型大小应该比训练数据集大小增长得更快。
当Kaplan发布这个研究两年后,Hoffmann在更大的语言模型上进行了实验,提出了一个新的缩放定律,这个定律考虑了计算预算(C)的限制,并得出了以下公式:
其中,E、A、B、α 和 β 是通过实验得到的常数。这个定律表明,在有限的计算预算下,模型大小和训练数据集大小应该以大致相同的速率增长,以达到最优的性能。
至此,两组科学家在不同实验中得到两种不同的结论,一个认为模型大小应该增长更快,另一个认为两者应该同步增长更好。
Data Repetition
上面两组研究者对缩放定律的研究是使用没有重复的数据并且在一轮训练的情况下得出的结果。但现实中很多数据都是重复的,或者说对于文本数据来说,有相当一部分是重叠的。Hernandez在使用重复数据训练时发现一个“双下降现象”,随着重复数据频率的增加,模型的测试损失会出现一个双峰现象。这意味着在某个重复频率下,模型性能会达到一个峰值,然后随着重复数据的进一步增加而下降。
在上面缩放原则得出的结果是当模型大小增长时,数据的大小也需要增长。但自然界高质量的数据却是有限的,毕竟数据标注人员不能标完所有数据。一个直接的方法去克服这个困难是将这些高质量的数据去重复几遍来增大数据量,但是就像上面说的重复数据会导致损失的增加。所幸,一个研究表明在数据受限和计算资源有限的情况下,使用重复数据训练多训练4个epoch只会造成轻微的影响。Tirumala则展示了一种智能重复训练的方法,即在精心选择的数据上进行重复训练,这种方法可以优于在随机选择的新数据上进行训练。他们指出,通过这种方式,即使在数据量有限的情况下,也可以通过重复训练来提高模型性能。
综合这一部分内容,主要考虑数据量的问题,随着模型参数的不断增大,数据量也需要增大。但现在数据量,尤其是优质数据的数量非常缺失,这里提到将数据增加重复的方法,适度的数据重复可以提高模型性能,但过度重复可能会导致性能下降。此外,通过智能选择数据进行重复训练,可以在资源有限的情况下有效利用数据,进一步提升模型的性能。
Data Quality
说完数量就是质量的问题,下面就是介绍如何提高数据质量的几个方法。
Deduplication
在构建预训练数据集时,去重是一个关键步骤。这是因为公开可用的数据集,通常包含大量重复内容,这可能会影响模型的训练效率和性能。重复的数据可能会导致模型过度记忆某些信息,而不是学习更广泛的语言模式。
这里介绍了几个去重技术:
- N-gram和Hash技术:去重的常见技术包括基于N-gram相似度的去重,这通常使用MinHash算法来检测重复项。这种方法通过计算文本片段的哈希值来识别重复内容。
- 神经网络方法:对比训练的双编码器和结合了双编码器和交叉编码器的“重新排序”方法,发现神经网络方法在去重性能上显著优于传统方法。
- 语义去重:SemDeDup,这是一种专门针对预训练模型嵌入空间中紧密相似的语义重复项的去重方法。他们使用聚类技术来减少搜索计算量
去重通常被证明对模型性能有积极影响,尽管这可能会减少训练数据的数量和多样性。
Quality Filtering
在构建用于预训练LLMs的高质量数据集时,质量过滤是一个至关重要的步骤。为了提高数据质量,研究者们采用了多种方法,包括使用分类器、基于规则的启发式方法,以及基于困惑度等指标的阈值过滤。
- 分类器:研究者们通常使用分类器来执行质量过滤,这些分类器可以基于模型的预测来评估数据的质量。
- 启发式规则:除了分类器,研究者们还采用手工制作的启发式规则来识别和过滤低质量数据。
- 阈值过滤:另一种方法是使用阈值过滤,例如基于困惑度(Perplexity)等标准来决定数据的保留与否。
Kaddour通过过滤掉低质量的嵌入聚类,从Pile数据集中构建了一个名为MiniPile的子集,这是一个质量过滤的实际应用案例。质量过滤通常被证明对模型性能有积极影响,即使这可能会减少训练数据的数量和多样性。但是经过研究发现,过于激进的质量过滤可能会导致模型在多种任务上的性能下降,因为过滤的目标可能无法充分代表模型的真实训练目标。
Marion通过综合考虑困惑度、Error L2-Norm(EL2N)和记忆因子等数据质量估计器,以及通过数据修剪保留不同比例的数据,发现基于困惑度的修剪方法在保留中间比例数据时表现最佳。
Social Bias
数据净化过程中可能会无意中加剧对少数群体的边缘化。这种边缘化是由于在清洗数据以去除有害内容时,可能会同时排除那些代表少数群体的声音和身份。这些偏见不仅影响模型的预训练,还可能进一步传播到下游任务,影响模型在实际应用中的公正性和准确性。
Diversity & Age
在构建LLMs预训练数据集时,除了关注数据质量,还需要考虑数据的多样性和时效性。多样性对于提高模型的泛化能力和适应性至关重要,而时效性则确保模型能够反映最新的语言使用和文化趋势。
数据多样性(Diversity):
- Task2Vec多样性系数:Lee使用Task2Vec多样性系数来衡量公开可用预训练数据集的格式多样性。他们发现,这些数据集在多样性方面表现良好,并且这种多样性与文本中潜在概念的数量有良好的对应关系。这表明多样性系数是一个有效的工具,可以帮助构建更加多样化的数据集,从而提高模型的泛化能力。
- D2 Pruning方法:Maharana提出了一种名为D2 Pruning的新方法,旨在平衡数据多样性和难度。他们将数据集视为一个无向图,其中样本作为节点,难度分数作为节点属性。通过前向和反向消息传递策略,选择包含多样化和困难数据样本的子图,以确保数据集在多样性和难度上的平衡。
数据时效性(Age):
- 评估数据集的时效性:Longpre等人(2023b)研究了评估数据集的时效性对模型性能的影响。他们发现,评估数据与预训练数据之间的时间差异(即数据时效性)可能导致性能估计不准确。这种时间错位在大型模型中尤为明显,并且可能无法通过微调来完全解决。
Domain Composition
研究者们发现,包含多样化领域的数据集通常能够提高模型的泛化能力,即使这些领域与最终任务不直接相关。并且,包含所有领域的数据集通常比精心选择的领域组合表现更好,尤其是在进行全局去重以消除不同领域数据集之间的重叠后。此外,研究者们提出了多种方法来确定最佳的领域权重,以便在预训练过程中更有效地利用不同领域的数据。
领域权重的确定方法:
- DSIR方法:Xie提出了DSIR方法,将问题定义为一个分布匹配问题,通过重要性重采样和KL散度来估计领域权重。
- DoReMi和DoGE方法:Xie的DoReMi方法和Fan等人(2023)的DoGE方法都是通过训练代理模型来确定领域权重,以便在所有领域或特定未见过的领域上最小化平均验证损失。这些方法通过衡量每个领域对其他领域的贡献来调整权重,从而优化模型性能。
Data Management Systems
由于预训练数据集的规模庞大且复杂,管理这些数据集是一个挑战。为了帮助LLM实践者更有效地处理这些数据,集成的数据管理系统应运而生。
Data-Juicer系统:
- 功能与特点:Chen开发的Data-Juicer系统提供了多样化的数据管理功能,包括超过50种灵活的数据管理操作符,以及针对零代码数据处理、低代码定制和现成数据处理组件的工具。这些工具旨在简化数据管理流程,支持数据配方的生成,并在数据配方和LLMs的多个开发阶段提供及时反馈。
Oasis系统:
- 模块化设计:Zhou的Oasis系统包含多个交互式模块,如模块化规则过滤模块、去偏见的神经质量过滤模块、自适应文档去重模块和全面的数据分析模块。这些模块共同工作,以提高数据集的质量和多样性,同时减少偏见和提高数据的代表性。
Supervised Fine-Tuning of LLM
在LLMs的有监督微调(SFT)阶段,研究者们基于模型在预训练阶段获得的知识和能力,旨在进一步提升模型遵循指令的能力和与人类期望的一致性。为了实现这一目标,研究者们通过多种方式构建指令数据,包括利用人类众包、自我指导或收集现有数据集。尽管这些方法已经在多种自然语言处理(NLP)任务中取得了显著的性能提升,但关于如何通过管理指令数据来进一步提升微调模型性能的问题,研究界仍在探讨中。
Data Quantity
作者们探讨了在大型语言模型(LLMs)的有监督微调(SFT)阶段,指令数据量对模型性能的影响。研究者们在这一问题上有两种不同的观点:一种观点是减少指令数据量可以提高训练效率,另一种观点是增加指令数据量对于提升模型性能至关重要。接下来列举几个研究:
- Ji等人的实证研究表明,增加指令数据量在某些任务上(如提取、分类、封闭问答和摘要)可以持续提升性能,但在数学、编码和链式推理等任务上的提升有限。
- Dong等人的研究则发现,一般能力的提升在达到一定数据量后会变得缓慢,而数学推理和代码生成能力则随着数据量的增加而持续提升。
- Yuan等人的研究观察到,模型的数学推理性能与指令数据量之间存在对数线性关系,但预训练模型在更大的微调数据集上提升有限。
- Song等人的实验涵盖了多种能力和任务,发现大多数能力与数据扩展一致,但每种能力的发展速度和模式各不相同。
研究结果表明,不同任务和模型能力对数据量的需求不同,这要求在实际应用中需要根据具体情况来确定合适的数据量。
Data Quality
Instruction Quality
许多研究者已经发现,指令数据的质量是提高模型性能的关键因素。高质量的指令数据可以帮助模型更好地理解和执行任务。在构建指令数据集时,通常会有一个筛选过程,以选择由模型生成的高质量指令。
- Wang使用困惑度作为标准来筛选最合适的指令。
- Cao等人(2023)提出了InstructionMining,这是一个自动数据选择器,它能够评估指令数据的质量,而无需人工专家的干预。他们假设微调模型在评估集上的推理损失可以作为数据质量的代理,并使用一系列自然语言指标来预测推理损失。
为了评估指令质量,研究者们采用了多种自然语言处理指标,如输入和输出中的标记数量、奖励分数、困惑度、文本词汇多样性、句子嵌入空间中的最近邻距离,以及对话模型提供的自然性、连贯性和可理解性分数。
此外,一些研究利用微调后的LLM自身的能力来评估指令质量,Li通过为增强指令分配质量分数并迭代改进模型预测,而SELF和Self-Refine则让LLM对自己的响应提供自我反馈。
Instruction Diversity
研究表明,指令的多样性对于提高模型性能具有积极影响。多样性可以帮助模型学习到更广泛的任务执行方式,从而在实际应用中表现出更好的泛化能力。评估和增强指令多样性的方法:
- Self-Instruct:Wang等人提出的Self-Instruct项目使用ROUGE-L相似度来过滤掉与现有指令过于相似的新生成指令,以确保指令集的多样性。
- #InsTag:Lu等人提出了#InsTag,这是一个基于ChatGPT 2的开放集细粒度标记器。它首先为给定的查询生成标签,然后通过一系列归一化步骤处理原始标签中的噪声,包括低频过滤、规则聚合、基于嵌入聚类的语义聚合和关联聚合。通过这些标签,研究者们量化了指令多样性,并发现更大的数据集通常具有更高的多样性,这与更高的模型性能相关。
Wan等人提出了Explore-Instruct方法,以解决在特定领域任务中实现指令多样性的挑战。该方法从代表性的领域用户案例出发,通过前瞻潜在的细粒度子任务和在搜索空间中回溯替代路径来探索变化和可能性,从而扩大数据集的覆盖范围。
Instruction Complexity
随着LLMs在复杂任务执行和推理能力方面的应用日益增多,研究者们开始关注如何量化和评估指令的复杂性。
量化和评估指令复杂性的方法:
- #InsTag:Lu等人提出了#InsTag,这是一个基于ChatGPT 2的开放集细粒度标记器,它通过计算数据集中查询被分配的平均标签数量来量化指令的复杂性。
- 复杂指令评估:He等人提出了一个包含八个特征的评估框架,用以评估复杂指令,这些特征包括多轮对话、指令长度、输入文本的异质性、多任务处理、语义理解、格式要求和任务描述的数量约束。
探索和控制指令复杂性:
- Tree-Instruct:Zhao等人提出了Tree-Instruct方法,它将指令视为一个语义树,并通过对树结构添加节点来构建新的复杂指令。这种方法允许研究者通过调整添加节点的数量来控制指令的复杂性,并通过实验发现,适当增加复杂性可以持续提升模型性能。
- Evol-Instruct:Xu等人和Luo等人提出了Evol-Instruct方法,通过逐步增加推理深度、添加约束、扩展和深化指令内容,以及使用代码和表格来复杂化输入,来重写指令。这种方法有助于模型学习更复杂的任务。
- FollowBench:Jiang等人提出了FollowBench,这是一个评估LLMs遵循约束能力的工具,通过逐步增加对内容、情境、格式和示例的约束来增强指令的复杂性。
Prompt Design
在有监督微调(SFT)过程中,指令提示(prompts)的设计对于大型语言模型(LLMs)性能的影响。当前的指令提示通常由人类基于启发式设计,或者由知名模型(如GPT系列)合成生成。这些提示的设计对于模型性能有显著影响,因为即使是相同的目的和语义,不同的表述方式也可能导致模型性能的显著变化。Khashabi等人发现,连续提示的离散化解释并不总是与预期一致,这表明在设计提示时需要考虑提示的精确性和一致性。
Yin等人和Kung、Peng通过消融分析研究了任务定义中哪些部分对LLMs的微调最为关键。他们发现,移除任务输出的描述,尤其是标签信息,可能是性能下降的主要原因。Yin等人还提出了一种自动任务定义压缩算法,可以在不牺牲性能的情况下减少标记数量。
此外,Liang等人提出了一个格式转换框架,以解决不同数据集中指令格式不一致的问题。Gudibande等人则探讨了在更强模型的输出上微调较弱模型的挑战,以及人类设计数据与合成数据在性能上的差异。
Task Composition
LLMs在处理多种NLP任务时展现出了强大的涌现能力,这使得多任务微调成为了提升模型泛化性能的有效方法。研究已经证明,无论是小型还是大型模型,增加SFT中的任务数量都能带来性能提升。但是,不同任务指令基准的混合比例和任务平衡对于有效的指令微调至关重要。这意味着在设计SFT策略时,需要考虑如何平衡不同任务的数据量,以达到最佳训练效果。
Dong等人专注于数学推理、代码生成和一般人类对齐能力的任务组合。他们的研究发现,当混合数据量适中时,模型的能力得到提升,但当混合数据量过大时,能力反而下降。这表明在不同任务之间可能存在能力冲突,需要通过调整数据比例来解决。
Jang等人提出,通过训练专家LLMs并形成一个专家库,可以避免负面任务转移,持续学习新任务而不发生灾难性遗忘,并提高模型的组合能力。这种方法可能优于传统的多任务微调,因为它专注于特定任务的深入学习。
Chen等人的研究也表明,针对单一任务数据进行微调的LLM在某些情况下可能优于针对多个任务进行微调的LLM。这可能是因为单一任务微调可以更专注于特定任务,从而在该任务上达到更高的性能。
Data-Efficient Learning
作者们探讨了如何通过不同的策略和方法来提高大型语言模型(LLMs)在有监督微调(SFT)过程中的数据效率。以下是该部分的具体内容:
数据量策略:
- 指令跟随得分(IFS):AlShikh等人提出了一种新的度量标准,即指令跟随得分(IFS),用于评估LLMs对指令的响应质量。IFS是通过一个二元分类器来预测响应是否为“答案类”,然后计算整个指令数据集中“答案类”响应的比例。这个度量可以作为早期停止微调的依据,从而避免在全尺寸数据集上进行不必要的微调。
- 双阶段混合微调(DMT):Dong等人基于对不同能力不同缩放模式的观察,提出了DMT策略。这种策略允许模型顺序学习专业能力和一般能力,同时保持一小部分专业数据以防止遗忘。
数据质量策略:
- 高质量数据子集选择:Cao等人采用BlendSearch方法自动选择最佳数据子集。AlpaGasus则利用强大的LLMs作为评分员,从Alpaca数据集中选择得分高于阈值的数据。这些方法旨在通过选择高质量的数据来提高微调效率。
- 动态数据修剪:Attendu和Corbeil提出了一种动态数据修剪方法,该方法在SFT过程中使用扩展版本的EL2N度量定期过滤不重要的示例,以减少计算开销。
任务组合策略:
- 多任务子集选择:Ivison等人根据预训练模型表示之间的相似性来找到相关的多任务子集进行微调。Dynosaur则将任务选择视为持续学习场景中的重放策略,以减轻灾难性遗忘并提高对未见任务的泛化能力。
其他策略:
- 学习性数据选择:Zhou等人引入了学习性作为SFT数据选择的新维度,认为模型能更有效地学习的数据是首选。他们提出了LoBaSS,这是一个基于学习性选择SFT数据的方法,通过比较微调和预训练模型之间的损失差异来衡量数据的学习性。
- 对比后训练技术:Xu等人提出了一种通过来自不同能力水平LLMs的对比对进行对比后训练的技术,并使用数据课程方案,使模型从“较容易的部分”逐步学习到“较难的部分”。
Challenges and Future Directions
全面和细粒度理解(Comprehensive and Fine-grained Understanding):
- 挑战:尽管已有研究在理解数据管理对LLMs训练各阶段的影响方面做出了贡献,但对整个数据管理过程的全面理解仍然不足。不同研究可能会得出相互矛盾的结论,例如在数据质量与毒性过滤、数据量与任务组合、以及专家模型与多任务学习之间的权衡。
- 未来方向:需要更深入的研究来解决这些冲突,以便更全面地理解数据管理对LLMs性能的影响。
通用数据管理框架(General Data Management Framework):
- 挑战:尽管已有如Data-Juicer和Oasis这样的数据管理系统,但实践者在寻找适合的数据集方面仍需付出努力。
- 未来方向:构建一个适用于广泛应用的通用数据管理框架,以降低数据管理成本,是未来的一个重要研究方向。
通过数据管理提高数据效率(Data Efficiency Through Data Management):
- 挑战:训练更强大的LLMs需要更少但更有效的训练数据。
- 未来方向:进一步探索数据管理策略,以实现更高效的数据使用,特别是在SFT阶段。
数据课程(Data Curriculum):
- 挑战:数据学习顺序的安排是数据管理的重要组成部分,但目前对数据课程策略的分析不足。
- 未来方向:需要更多研究来理解如何有效地安排数据学习顺序,以优化LLMs的训练过程。
冲突数据分离(Conflict Data Separation):
- 挑战:在训练数据收集过程中,同一查询可能产生冲突的响应,这可能对模型性能产生负面影响。
- 未来方向:研究如何分离和有效利用这些冲突数据,以提高模型性能。
多模态数据管理(Multimodal Data Management):
- 挑战:随着LLMs应用到视觉、音频等多模态领域,如何构建和管理多模态数据集变得重要。
- 未来方向:研究多模态数据集的构建、质量控制、任务平衡等,以及这些因素如何影响微调后的多模态LLMs的性能。
幻觉(Hallucinations):
- 挑战:LLMs在生成内容时可能出现与输入、上下文或事实相冲突的幻觉。
- 未来方向:研究如何通过预训练和SFT阶段的数据管理来减轻幻觉问题。
社会偏见和公平性(Social Biases and Fairness):
- 挑战:当前LLMs在预训练数据集中存在社会偏见问题,这影响了模型的公平性。
- 未来方向:探索如何减轻预训练数据集中的潜在偏见,以及是否可以通过SFT减少社会偏见。
以上就是Data Management For Large Language Models: A Survey的主要内容的介绍。文章首先介绍了LLMs在自然语言处理(NLP)领域的强大性能和潜力,强调了数据管理在提升模型性能和训练效率中的关键作用。在预训练阶段,文章讨论了数据量、数据质量、领域组成和数据管理系统的重要性,并提出了相应的挑战和未来发展方向。在SFT阶段,文章探讨了数据量、数据质量(包括指令质量、多样性、复杂性和提示设计)、任务组合以及数据高效学习的方法。
总的来说,这篇文章为LLMs的数据管理实践者和研究人员提供了宝贵的指导资源,帮助他们理解当前的研究进展,并为未来的研究和实践指明了方向。通过有效的数据管理,可以构建更强大的LLMs,推动NLP领域的发展。

















 570
570

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









