







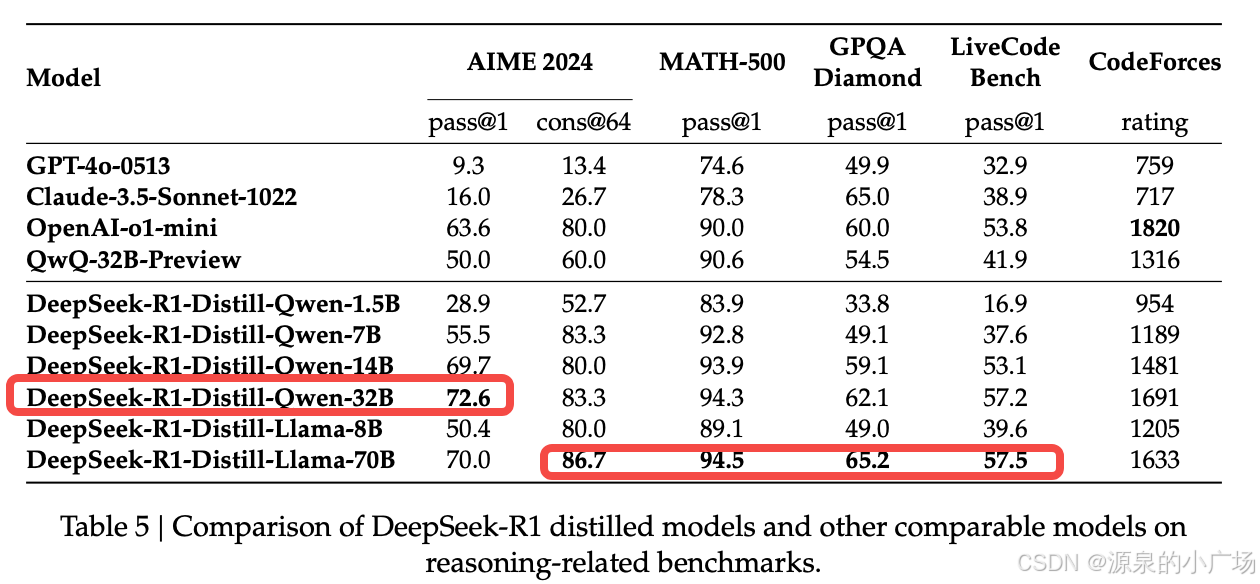
先说结论:R1数据蒸馏得到的ChatGLM32B模型效果远超GLM-Zero-Preview强化推理版本
1. 背景
在《DeepSeek V3/R1的局限性及行业微调方案》中,我们谈到客户反馈R1的不足,也介绍了一种针对v3/R1的lora模式的微调。但这类微调其实需要的计算资源还是比较大的。因此本文探索一种非常简单并且资源消耗极低的方案进行大模型微调,同样能够带来Aha moment。
再次回顾下R1的文章【1】,会发现其中提到的蒸馏技术,其实是 DeepSeek 的核心,在模型蒸馏中,DeepSeek 采用监督微调(SFT),利用教师模型生成的 80 万推理数据优化小型模型(如 Qwen、Llama),避免了强化学习的复杂性,大幅提升蒸馏效率。DeepSeek-R1-Distill-Qwen-7B 在 AIME 2024 取得 55.5% 的 Pass@1,超越 QwQ-32B-Preview,证明了该方法的优越性。
另外,李飞飞组近期公开了关于S1的一篇文章《s1: Simple test-time scaling》【2】,有异曲同工之妙。她们探索了一种最简单的方式来实现测试时扩展并提升推理能力。首先,构建了 s1K 数据集【3】,包含 1,000 道带推理过程的问题,并通过消融实验验证其难度、多样性和质量。其次,提出预算控制(Budget Forcing),通过强制终止或延长模型的思考过程(在模型生成终止时多次添加“Wait”)来调整计算量,从而促使模型复查答案并修正推理错误。在 Qwen2.5-32B-Instruct 经过 s1K 监督微调并结合预算控制后,s1-32B 模型在数学竞赛题上超越 o1-preview,MATH 和 AIME24 任务性能提升高达 27%。进一步扩展 s1-32B 后,其 AIME24 成绩从 50% 提升至 57%,无需额外推理干预,证明了测试时扩展的潜力。
因此,基于上述两篇论文的思想,针对行业垂直领域的业务问题,其实我们也可以通过对R1数据的蒸馏学习,让一般的大模型获得思考推理能力,能够带来Aha moment,并且效果确实很惊艳。
2. 业务应用及微调蒸馏实践
蒸馏得到的大模型,可以被应用于电商推荐与智能问答中。
- 电商推荐 —— 结合用户行为和商品特征,极速匹配个性化商品,提升购物体验和转化率。
- 智能问答 —— 快速理解问题,精准检索并生成专业解答,优化智能客服和搜索体验。
2.1 基座大模型选型
本文实验,基于智谱AI开放平台进行,选择规模比较小的模型GLM-4-Air,大概是32B的参数规模,token价格非常低,10亿token也只需要150元。

2.1 数据准备
最近liucong公开了Chinese-DeepSeek-R1-Distill-data-110k数据集,该数据集为中文开源蒸馏满血R1的数据集,数据集中不仅包含math数据,还包括大量的通用类型数据,总数量为110K。基于R1蒸馏数据SFT的小模型也能够展现出强大的效果。
该中文数据集中的数据分布如下:
Math:共计36987个样本,
Exam:共计2440个样本,
STEM:共计12000个样本,
General:共计58573,包含逻辑推理、小红书、知乎、Chat等。
对原始数据格式进行调整,整理成chatglm能够处理的格式,如下所示:

2.2 模型微调
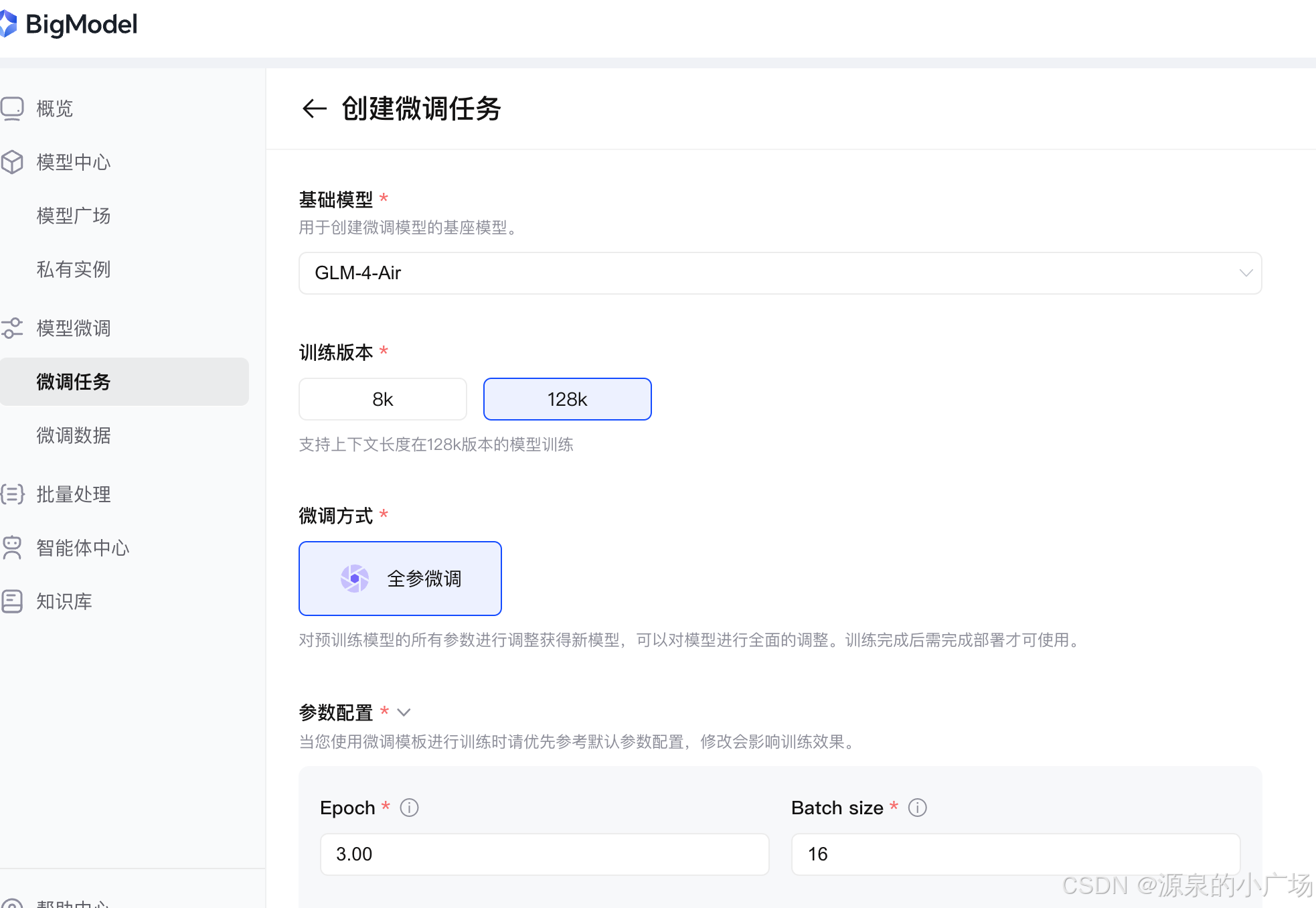
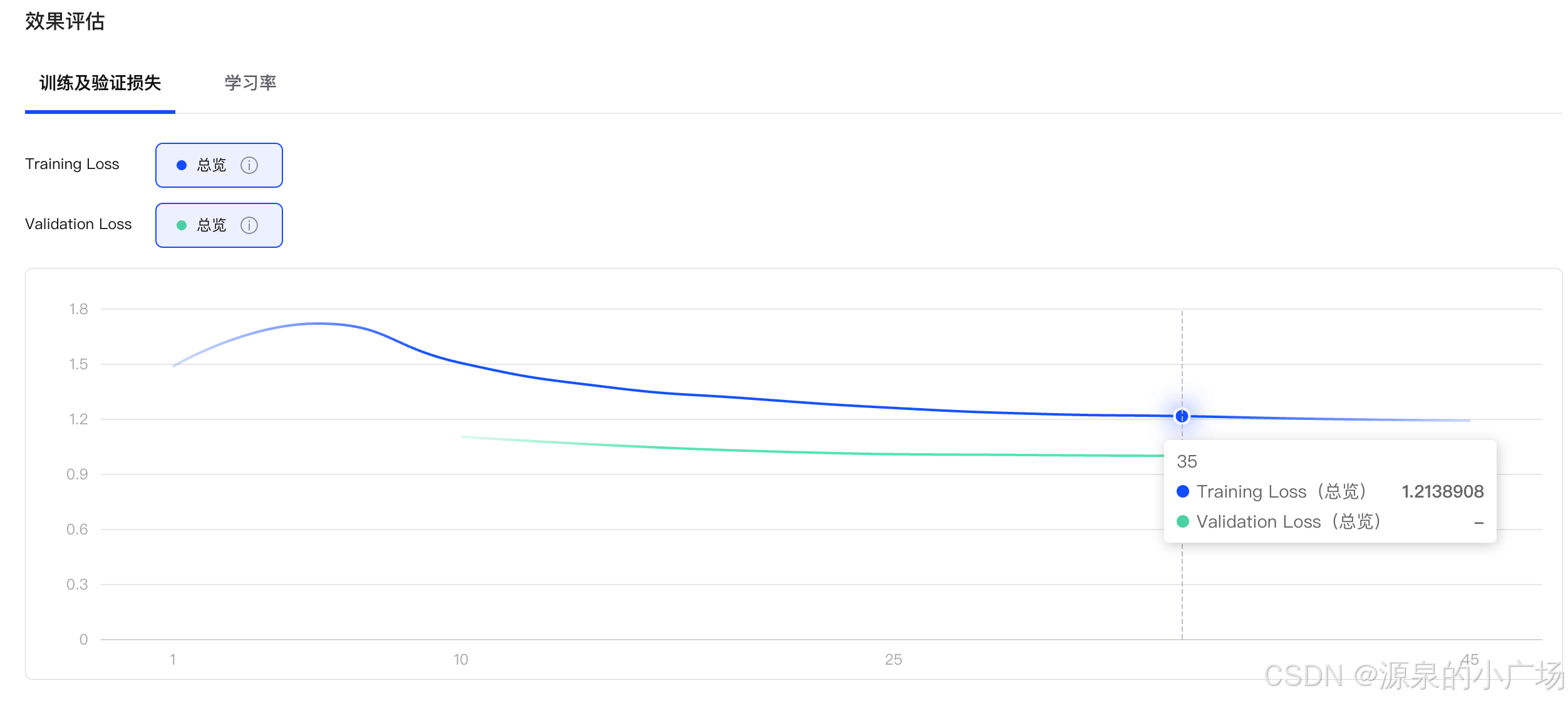
利用开放平台进行模型微调也很简单,创建微调任务即可。因为我们输入包含大段的think推理文本,因此选择128k全参微调,参数可以选择默认,epoch 3, batchsize 16,学习率1e-6。特别说明,batchsize比较敏感,设置64,发现训练loss直接飞了,后来降到16可以正常训练,loss降低到1.2。整个训练还是比较慢的,大概花了4.5小时。
2.3 模型部署及测试
部署8个算力单元,采用量化版本int8。


部署完之后就可以在模型体验中心测试效果了,问“怎么制作一本书”,蒸馏得到的glm-4-airR1版本,能够产生think思维链,进而得到很好的一个回复。
case1:“怎么制作一本书”

case2:怎么推销一款包包给一位年轻白领女性,目标是让她购买

对比智谱在12月推出的GLM-Zero-Preview强化推理版本,可以看到基于R1数据蒸馏的模型推理效果要好得多,也更有逻辑性。
同样一个问题,GLM-Zero-Preview强化推理版本的输出结果让人抓狂:没有逻辑性,而且洋洋洒洒输出了将近上万token,还没有停止think的过程,很难让人满意。

从上述实验可以看到,ChatGLM的32B小模型,其实已经具备很强的知识能力,通过输入高质量的推理链微调数据,可以得到非常惊艳的推理模型。
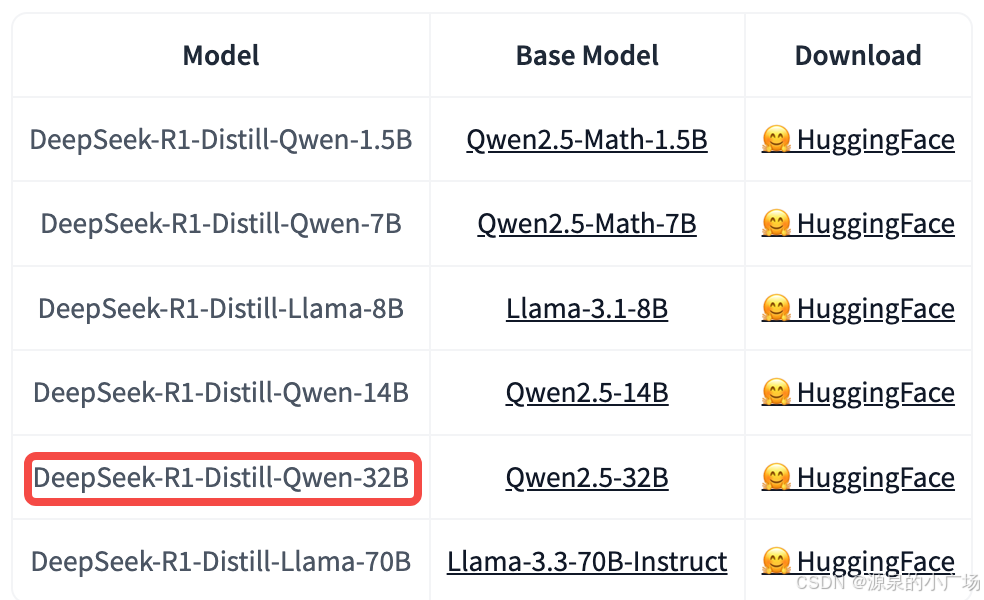
2.4 Distill版本的Qwen32B模型测试
另外我们也测试了Distill-R1-Qwen-32B【3】的效果,效果也很不错。测试也比较简单,可以直接利用modelscope提供的免费GPU notebook环境进行测试。
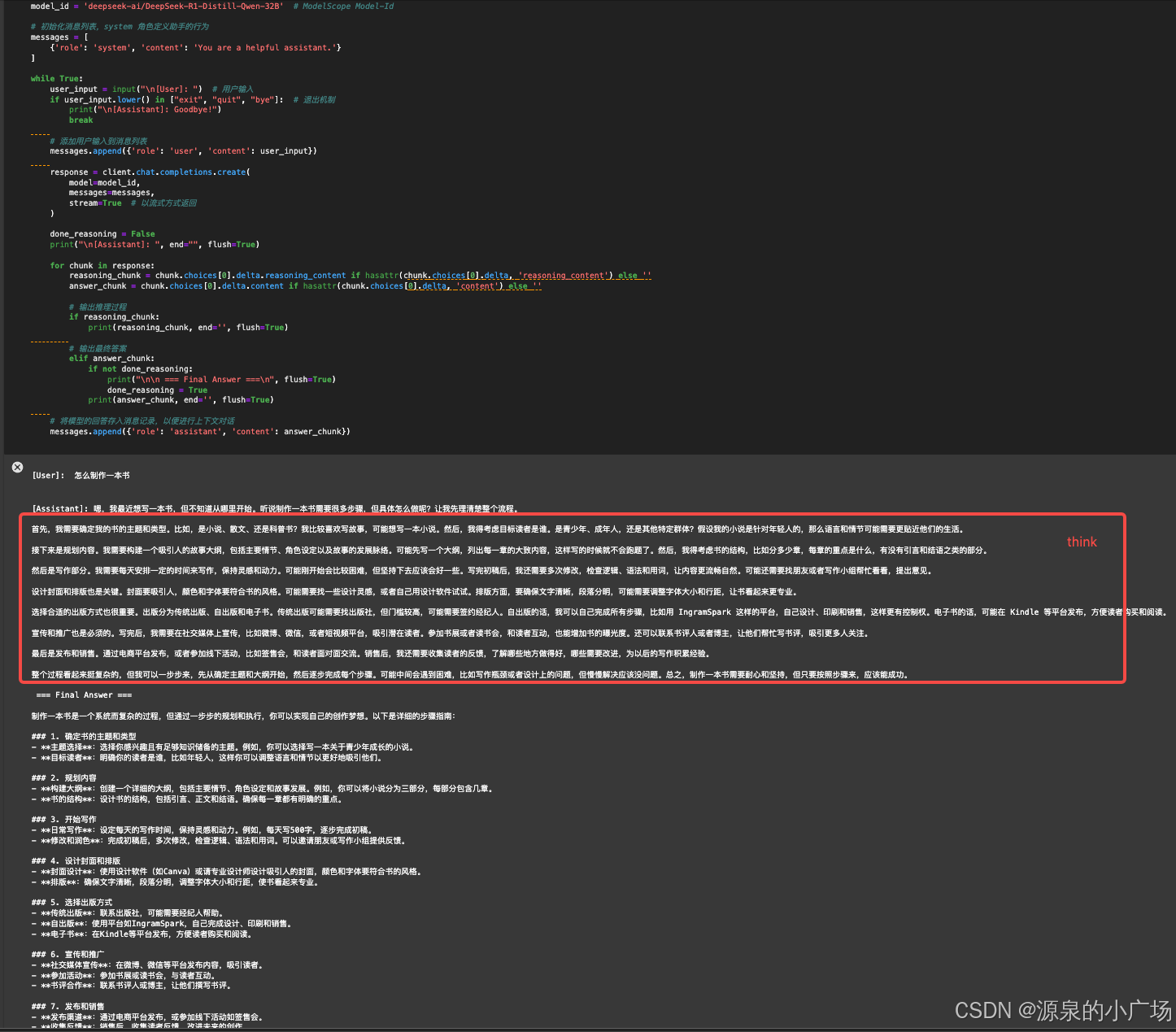
测试代码如下:
from openai import OpenAI
client = OpenAI(
base_url='https://api-inference.modelscope.cn/v1/',
api_key='输入你自己的key', # ModelScope Token
)
model_id = 'deepseek-ai/DeepSeek-R1-Distill-Qwen-32B' # ModelScope Model-Id
# 初始化消息列表,system 角色定义助手的行为
messages = [
{'role': 'system', 'content': 'You are a helpful assistant.'}
]
while True:
user_input = input("\n[User]: ") # 用户输入
if user_input.lower() in ["exit", "quit", "bye"]: # 退出机制
print("\n[Assistant]: Goodbye!")
break
# 添加用户输入到消息列表
messages.append({'role': 'user', 'content': user_input})
response = client.chat.completions.create(
model=model_id,
messages=messages,
stream=True # 以流式方式返回
)
done_reasoning = False
print("\n[Assistant]: ", end="", flush=True)
for chunk in response:
reasoning_chunk = chunk.choices[0].delta.reasoning_content if hasattr(chunk.choices[0].delta, 'reasoning_content') else ''
answer_chunk = chunk.choices[0].delta.content if hasattr(chunk.choices[0].delta, 'content') else ''
# 输出推理过程
if reasoning_chunk:
print(reasoning_chunk, end='', flush=True)
# 输出最终答案
elif answer_chunk:
if not done_reasoning:
print("\n\n === Final Answer ===\n", flush=True)
done_reasoning = True
print(answer_chunk, end='', flush=True)
# 将模型的回答存入消息记录,以便进行上下文对话
messages.append({'role': 'assistant', 'content': answer_chunk})
3. 参考材料
【1】DeepSeek-R1: Incentivizing Reasoning Capability in LLMs via Reinforcement Learning
【2】s1: Simple test-time scaling
【3】魔搭社区Qwen-32B-R1



















 1205
1205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











