






💥💥💞💞欢迎来到本博客❤️❤️💥💥
🏆博主优势:🌞🌞🌞博客内容尽量做到思维缜密,逻辑清晰,为了方便读者。
⛳️座右铭:行百里者,半于九十。
📋📋📋本文目录如下:🎁🎁🎁
目录
💥1 概述
您好!您的描述涉及到统计学和概率论中的一些重要概念,让我帮您解释一下。
1. **边际分布(Marginal Distribution)**:指多维随机变量中每个单独变量的概率分布。如果有一个包含多个随机变量的联合分布,边际分布描述了每个变量单独的分布特征,而忽略其他变量。
2. **Copula**:Copula 是用于描述多维随机变量间依赖关系的函数。Copula 的基本思想是将多元分布的联合分布函数分解为边际分布和一个用于描述依赖结构的 Copula 函数的乘积。
3. **多元变量(Multivariate Variables)**:指多个随机变量之间相关的情况,通常需要考虑它们的联合分布及其相互关系。
4. **采样的Copula**:指从一个给定的 Copula 模型中生成具有特定相关性质的随机样本,通常这些样本可以用于研究多元变量的特性和行为,而不必关心具体的边际分布。
将边际分布和 Copula 结合起来,可以通过以下步骤来生成多元变量:
- **选择边际分布**:首先确定每个随机变量的边际分布,例如正态分布、指数分布等。
- **选择 Copula 模型**:根据所需的依赖结构选择合适的 Copula 模型,如高斯 Copula、t-Copula 等。
- **生成 Copula 随机样本**:使用选定的 Copula 模型生成具有所需相关性的随机样本。这些样本反映了变量之间的依赖关系,但不包括具体的边际分布。
这样的方法可以用于研究不同变量之间的相关性、联合分布以及它们的性质,而不需要考虑具体的边际分布。这种技术在金融学、风险管理和信用评估等领域有广泛的应用,用于模拟复杂的多变量关系和风险情景。
📚2 运行结果
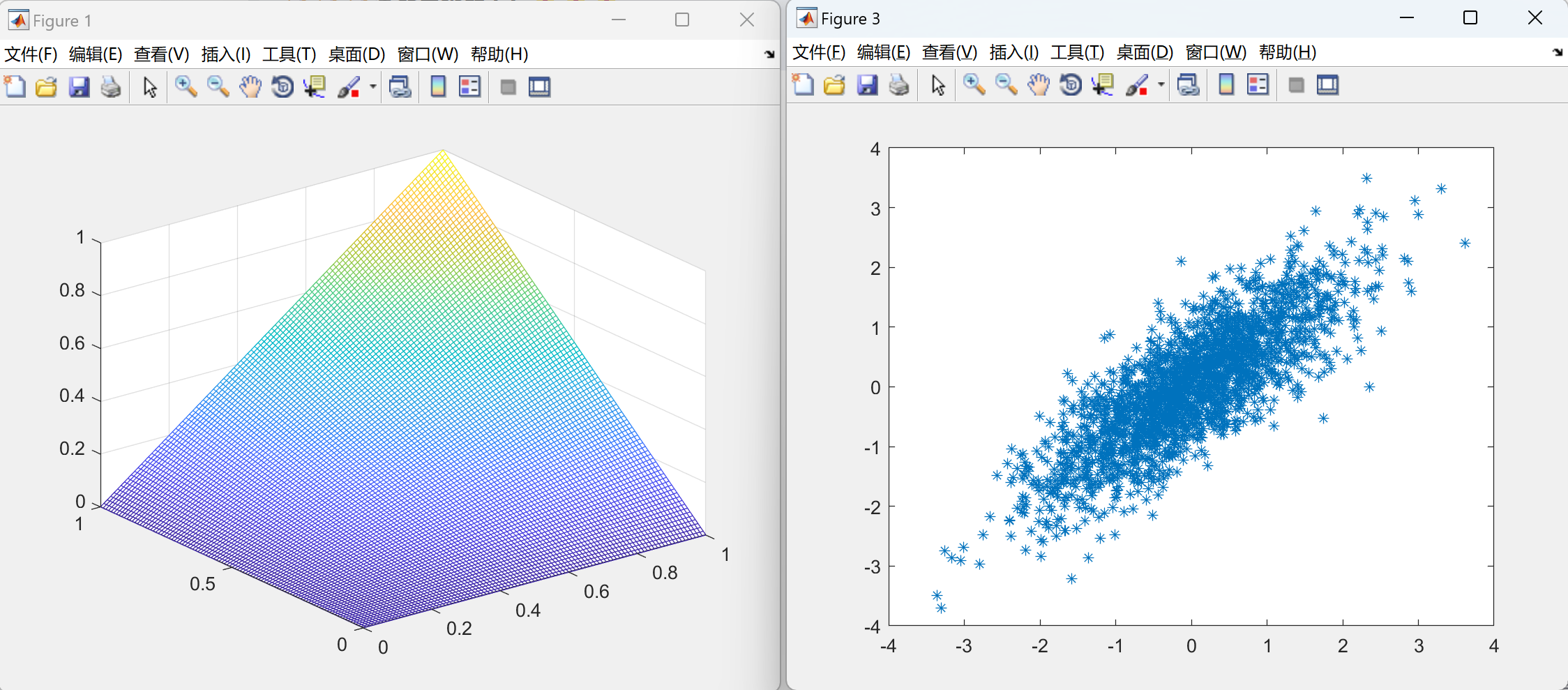
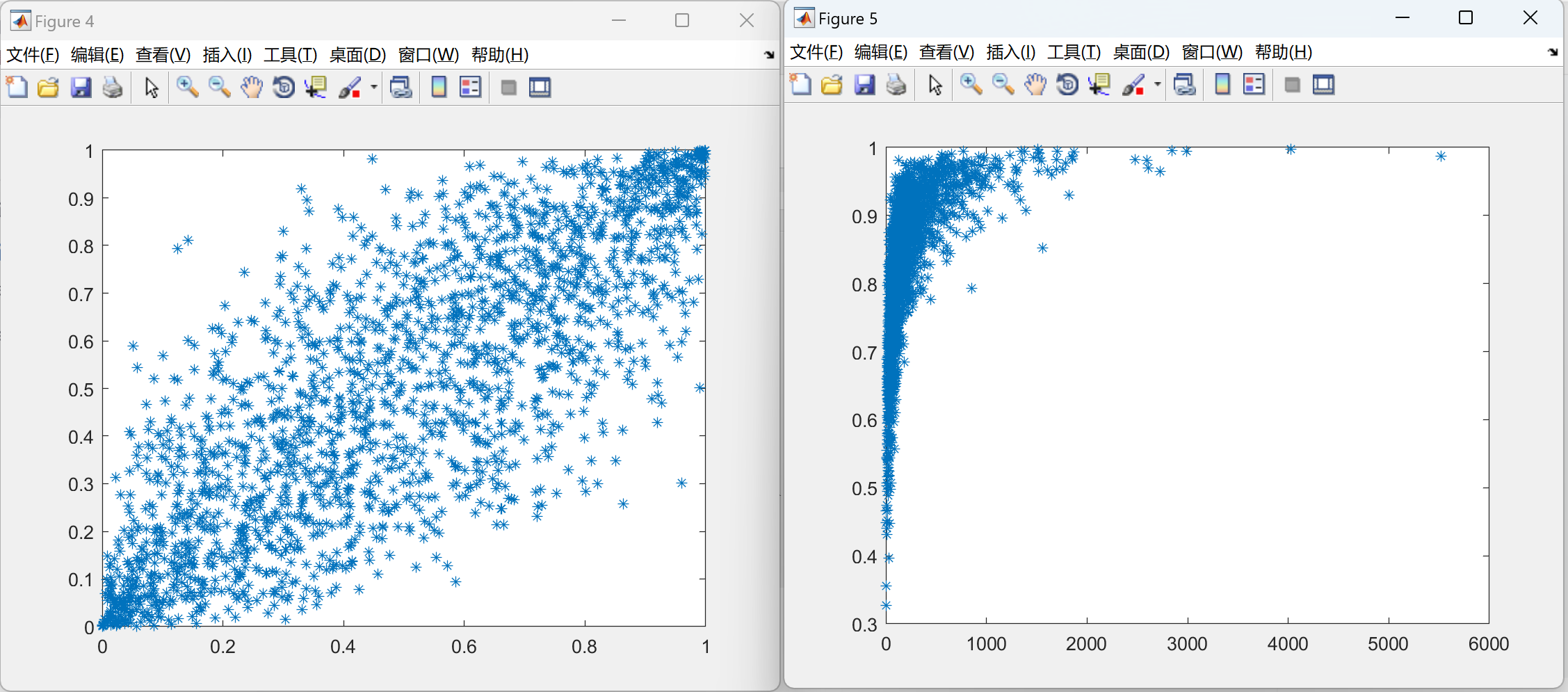
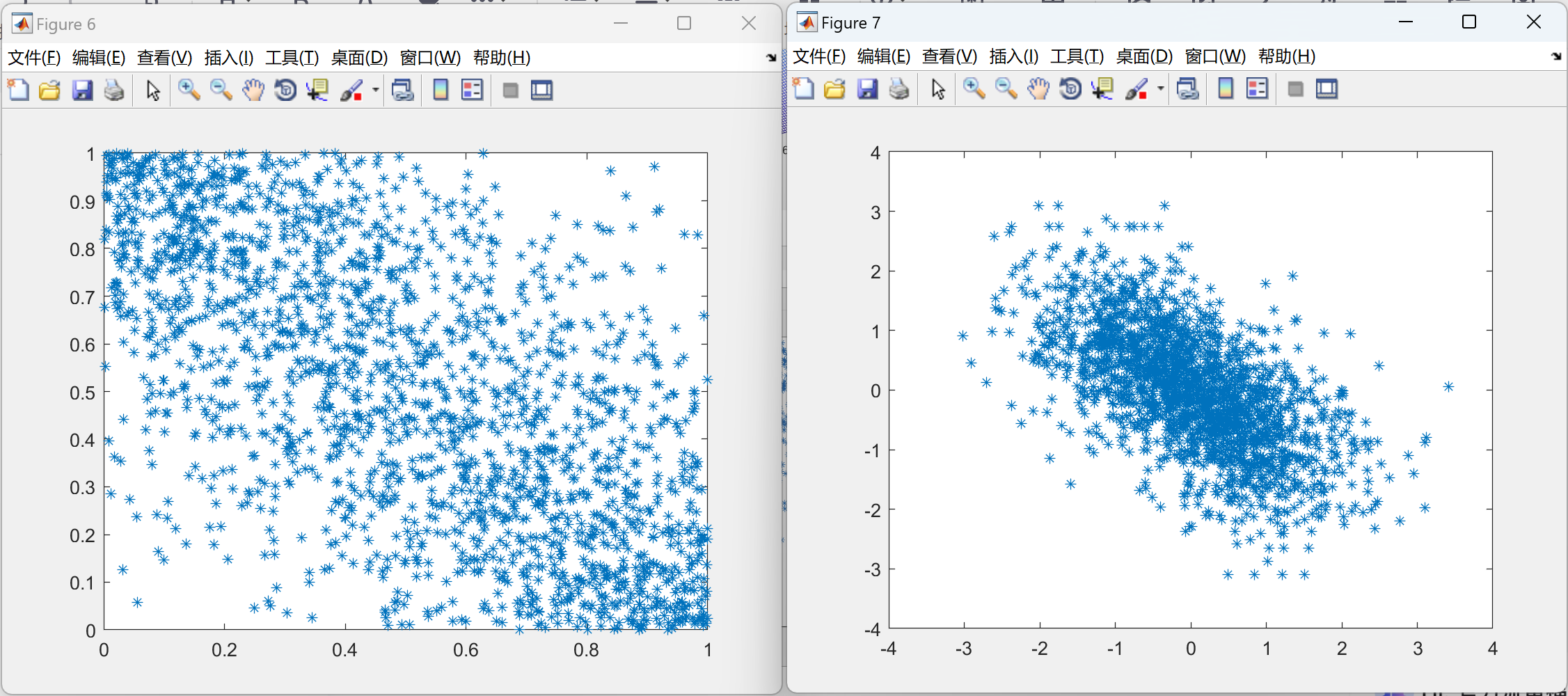
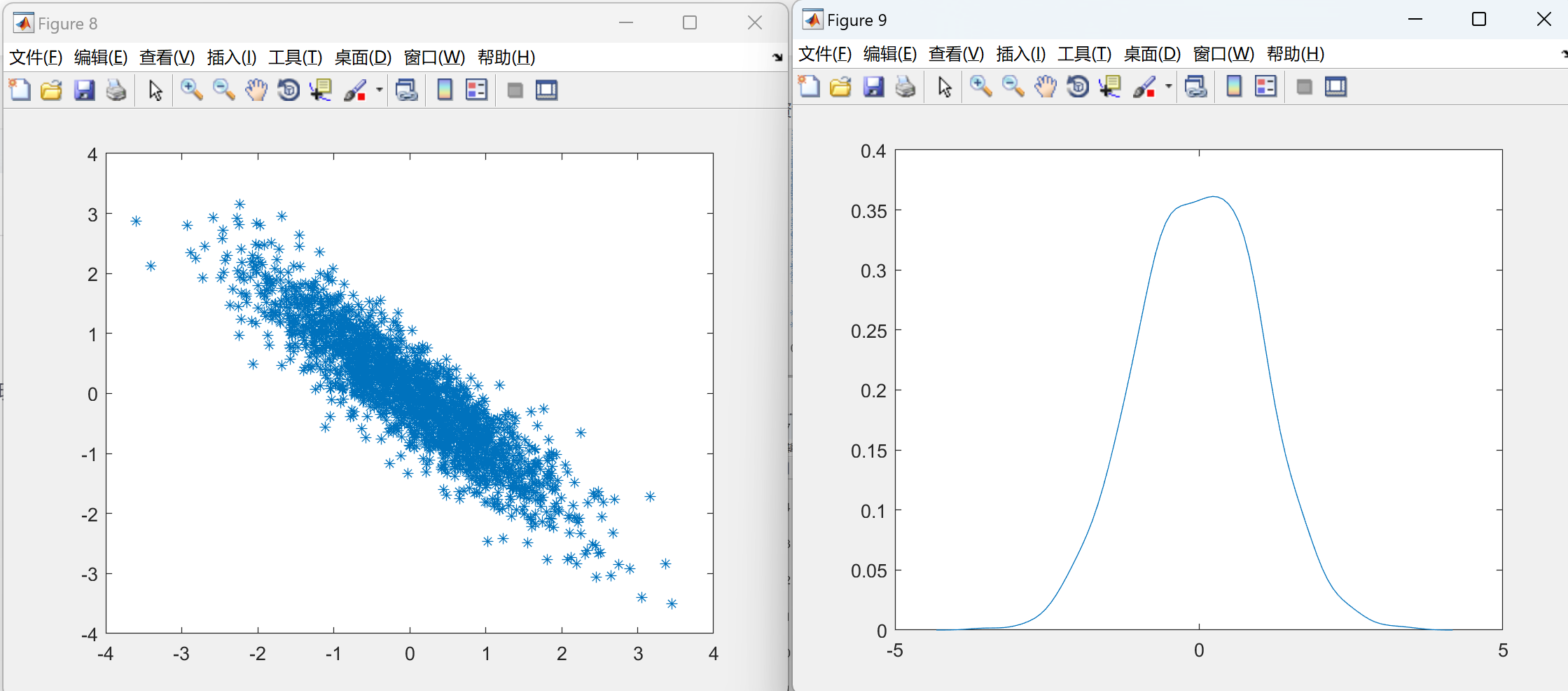
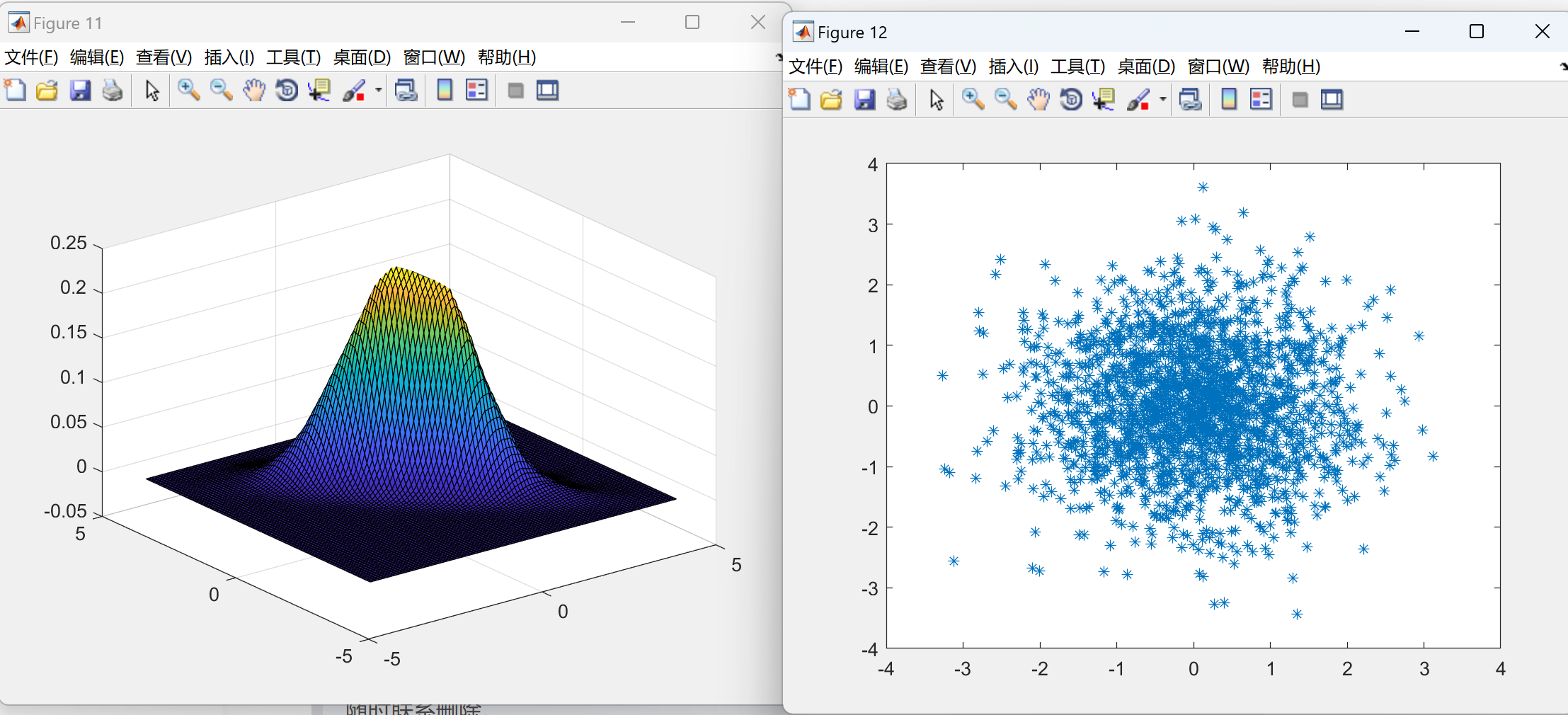
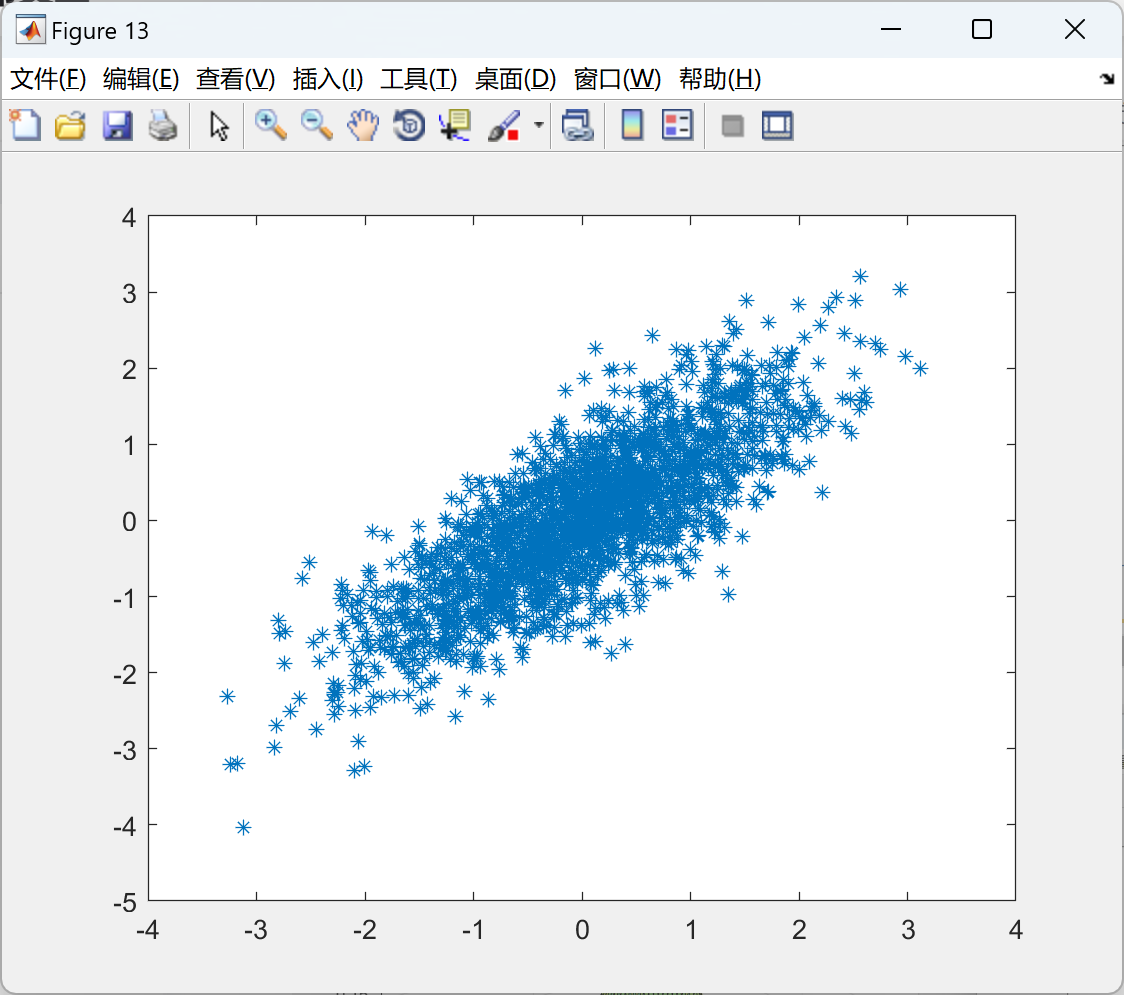
部分代码:
% Frank copula
% s>0; 0 for perfect, 1 for indep, inf for oposite
s =200;
C = @(x,y) log(1+(s.^x-1).*(s.^y-1)./(s-1))/log(s);
Z = C(X,Y);
%figure;
%meshc(X,Y,Z);
%% Clayton Copula
% t>-1; -1 for opisite, 0 for indep and inf for perfect
t = -1;
Cla = @(x,y) max((x.^(-t)+y.^(-t)-1).^(-1/t),0);
Z2 = Cla(X,Y);
%figure
%meshc(X,Y,Z2);
%% Generating joint distribution using marginals a copula
a = [-5:0.01:5];
b = [-5:0.01:5];
[X,Y]=meshgrid(a,b);
Marginal1 = @(x) normcdf(x,0,1);
Marginal2 = @(x) normcdf(x,0,1);
Joint = @ (x,y) op(Marginal1(x),Marginal2(y));
Z3 = Joint(X,Y);
%figure;
%meshc(X,Y,Z3);
%% Generated correlated samples of arbitrary marginals using normal coupla
% family. Applies to higher dimensions
corr = 0.8; %Select a Pearson correlation
% If spearmans correlation is give transformation is:
🎉3 参考文献
文章中一些内容引自网络,会注明出处或引用为参考文献,难免有未尽之处,如有不妥,请随时联系删除。
[1]吴娟.Copula理论与相关性分析[D].华中科技大学,2009.DOI:10.7666/d.d088238.
[2]李茂.基于Vine-copula的金融市场波动关联性影响分析[D].西南交通大学[2024-04-16].
[3]严忠权.二维随机变量的分布与Copula函数[J].黔南民族师范学院学报, 2008, 28(3):5.DOI:10.3969/j.issn.1674-2389.2008.03.007.















 905
905











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









