







Keywords: GSConv; object detection; design paradigm; lightweight; autonomous driving
Q: 对于一个车载边缘计算平台,庞大的模型很难达到一个实时检测的要求,且大量深度可分离的卷积层建立的轻量级模型不能达到足够的精度。
A: 本文提出GSConv,在模型的速度与精度之间可以达到平衡,轻量化模块,并且保持精度。
Dateset: WiderPerson, PASCAL VOC, SODA10M and DOTA1.0 .
Xception , MobileNets and ShuffleNets是通过DSC来提升检测速度,但精度低。
MobileNets用大量的1*1密集卷积来融合独立计算的信道信息, 反而占用了更多的计算资源;ShuffleNets使用“channel shuffle”来实现通道信息的交互,该效果仍然没有影响到SC的结果;Ghostnet使用“减半”SC操作来保留信道间的交互信息 但或多或少又回到了SC的道路上,影响可能来自多方面。
DSC的缺陷在主干网络中被直接放大,无论是用于图像分类还是检测。
 图1,GSConv是SC, DSC and a shuffle的混合卷积。具体来讲,用shuffle将SC运算生成的信息渗透到DSC生成的信息的各个部分。该方法通过在不同的通道上均匀地交换局部特征信息,使得来自SC的信息完全混合到DSC的输出中。
图1,GSConv是SC, DSC and a shuffle的混合卷积。具体来讲,用shuffle将SC运算生成的信息渗透到DSC生成的信息的各个部分。该方法通过在不同的通道上均匀地交换局部特征信息,使得来自SC的信息完全混合到DSC的输出中。
GSConv替代SC有了更明显的accuracy提升,在其他模型上,在骨干中使用SC,在neck中使用GSConv时,模型的accuracy非常接近原始。采用GSConv方法的slim-neck最大限度地减少了DSC缺陷对模型的负面影响,并有效地利用了DSC的优点。
本文贡献:
1.提出的GSConv使卷积计算的输出尽可能接近SC的输出,减少了计算量;
2. 为自动驾驶汽车的检测器架构提供了一个设计范例,即带标准backbone的slim-neck;
3. 在GSCONV-Slim-Neck探测器上验证了各种常用技巧的有效性,为该领域的研究提供了参考。
2.Related work:
Backbone: Alexnet验证了CNNs强有力的特征提取能力,之后检测器或分类器的Backbone开始被设计,用于SC,如VGG,Resnet,Darknet.
neck:用于分配和合并特征更好地与头部,
对于neck,FPN[20]通过在不同尺度的特征图层上独立地执行预测操作,提高了目标检测模型的速度和精度。
对于head,主要区别在于该模型采用基于锚点的或无锚点的方法来完成对象定位任务。前者对设计者和用户来说可能更可控,但必须使用NMS过滤出IOU阈值得分最高的预测框,后者更加灵活,没有更多的参数可以手动控制,但会增加模型的不稳定性。虽然基于锚点的或无锚点的方法并非本文的核心,但值得注意的是,SOTA模型仍然使用基于锚点的方法。More,注意力机制,如SPP,SE,CBAM,CA都可以提升检测器的性能和效率,特别是对于轻量级的检测器,合理使用这些模块可以获得较好的性价比。
3.1Why GSConv
空间信息一步步转移到通道,每次空间(width和height)的压缩和通道特征图的扩展,都会引起部分分割信息的丢失。Channnel-dense(SC)卷积计算最大化的保留了每个通道间的隐藏连接,而channel-sparse(DSC)卷积则完全切断了这些联系。GSConv保留了这些连接。FLOPs计算:
SC: W*H*K1*K2*C1*C2
DSC: W*H*K1*K2*1*C2
GSConv: W*H*K1*K2*C2/2*(C1+1)
W - 输出特征图的宽
H - 输出特征图的高
K1*K2 -卷积核的大小
C1、C2分别为输入、输出特征图的通道数量。

表3 ,实验部分比较了SC, DSC, ShuffleNet 方法, GhostNet 方法 和 GSConv 方法。
在GSConv上以一种简单的方式完成shuffle且没有额外的参数。第一种选择是通过换位操作融合特征,并且重构原始尺寸,虽没有额外的参数,但是是一种非标准化操作,可能在一些设备上不支持。
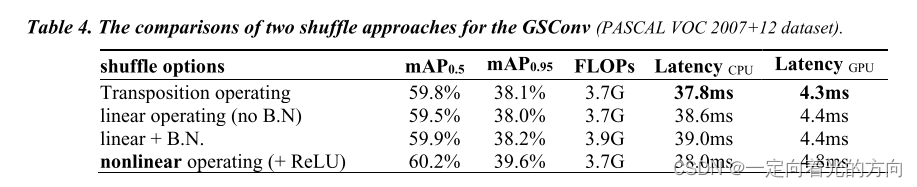
表4消融实验的对比,是第二种选择通过线性操作,成本低,卷积计算的表现能力支持在所有的设备上。
GSConv的优点是通过DSC和shuffle,可以增强非线性的表达能力。但如果GSConv用于模型的所有阶段,模型的网络层会加深,深层会加重抵制数据的流通,显著的增强推理时间。
因此,较好的选择是仅在neck用GSConv连接特征图,冗余重复的信息是少的,且并不需要压缩。
3.2.1 The element modules of the slim-neck
增强CNNs学习能力的方法如DensNet, Vovnet, CSPNet,在这些方法的理论上设计了slim-neck。slim-neck可以降低计算的复杂性和检测器的推理时间,同时维持accuracy。GSConv可以降低计算的复杂性,减少推理时间和维持accuracy需要新的模型。
GSConv的计算成本是SC的50%,但对于模型学习能力的贡献后者更好,在GSConv基础上,引入了GS bottleneck,图4a。之后用一次性聚合方法设计出GSCSP,Vov-GSCSP

3.2.2 The slim-neck for the YOLO family
由于高效的检测,YOLO系列更多的用于工业,对于Scaled-YOLOv4l 和YOLOV5l,用slim-neck 的元素模块来改进neck层,如表1表2
3.3 The improvement tricks for free
在CNNs-based detectors,用local特征增强的方法来降低计算的成本。注意力机制,增强方法可以明显提升模型accuracy,但是比neck低。这些方法包括采用通道信息和空间信息。SPP集中在空间信息,通常解决物体尺度过大,融合局部或全局输入的特征。
SE通道包括squeeze和excitation,该模块允许网络更多地关注信息更丰富的特征通道,而否定信息更少的特征通道。
CBAM为空间通道注意力机制。CA是为避免由全局池化操作引起位置信息损失的新的解决方案。对于输入特征空间融合信息的高效利用,把注意力分别放到width和height两个维度上。

图6a,b,c分别为SE, CBAM, CA的模型结构。
3.4 损失函数
基于深度学习,Iou损失关注检测器的极大值,使得预测框抑制值得位置更加准确。更先进的Iou损失函数已经提出,如GIoU,DIoU,CIoU, EIoU

表7,消融实验的对比。在更深的网络上,Mish比Swish的accuracy更好,尽管这两个损失函数的曲线很接近。相较于Swish,Mish花费了更长的训练时间(由于计算成本的增加)。
4.2 Ablation Studies
为测试YOLOv5n detectors的accuracy,在PASCAL VOC 2007+12
dataset构建了5种不同的卷积方法,分别是SC, the DSC, the ShuffleNet , the GhostNet method and the GSConv。 为了更清楚地验证这五种方法的有效性,我们分别在1/8、1/16和1/32的下样本尺度下使用了不同的方法。 GSCONV最终以较小的时间复杂度获得最佳结果。

在表4中,我们比较了GSCONV的两种shuffle方法在CPU(Intel Xeon Gold5118)和GPU(T4)上的性能,包括精度、复杂度和一个批量大小的推理时间。 结果表明,转换法在比较项目中更具竞争力,而在某些设备不支持换位的情况下,线性融合法可以替代转换法。
在表6中,比较了YOLOV5n使用不同注意模块的实验结果。 第一部分中的所有模型都使用slim-backbone + slim-neck,第二部分中的模型只使用 slim-neck。 实验数据集是WiderPerson和VOC2007+12。 在此表中,“SE*3 640”表示在Yolov5n的结构中使用了三次SE模块和一次SPPF,训练图像大小为640×640像素。

表6表明:在VOC2007+12和WiderPerson数据集上,“CA*3+SPPF*1”模型在相同的参数数下获得了最好的结果。 此外,在推断时间非常接近的情况下, slim-neck的精确度远优于slim-backbone。 如果我们强制关闭 slim-neck和slim-backbone的精度,后者需要花费3.5%以上的推断时间。
此外,对MISH和SWISH激活函数以及CIOU和EIOU损失函数对准确性和速度的影响进行了对比实验。

在表7中,我们报告了VOC2007+12数据集上的实验结果。 使用带EIOU的MISH的网络具有更高的平均准确率,而使用SWISH的网络具有更快的速度(使用MISH的训练时间比使用SWISH的训练时间增加约29.26%)。
为了对比直观,我们以YOLOV5N为基线验证了我们方法的有效性,表8报告了相关的实验结果。

4.3 Comparisons between the Slim-neck detectors and the Originals

表9,slim-neck YOLO检测器与原始检测器的性能比较。slim-neck 探测器以较小的尺寸实现了最佳的精度。 slim-neck 和小技巧的结合使测量精度有了很大的提高,尤其是对YOLOV3/V4-TINY这样的轻量级探测器。

图7,SODA10M的无人驾驶数据集上比较五个SOTA探测器的速度和精度。 我们使用一个20秒的现场视频来测试我们的方法的有效性,该视频是在夜间微光下由仪表板摄像头捕捉的。
5. Discussion
目前基于深度学习的物体检测器主要有两类,基于Transformer的和基于CNNS的。 基于变压器的探测器由于延时较差,其应用面临困难,而基于CNNS的探测器仍然是业界的首选。 研究人员已经提出了许多方法来进一步优化基于CNNS的模型的性能。 我们提出的GSCONV为研究人员提供了一种新的基于CNNS的检测器或分类器的设计选择。 对于轻量级模型,设计者可以直接用GSCONV层替换原始卷积层,以获得显著的精度增益,而无需额外操作。 事实上,我们已经在一些基于视觉的特定辅助驾驶系统中测试了GSCONV,比如针对卡车的限高碰撞监测和预警系统,结果是可以的。 但随着平台计算能力的增长,GSCONV的优势变得不那么明显。 GSCONV具有计算量小、内存占用少等优点,更适合于边缘计算设备。 总之,如果综合考虑模型的成本和性能,采用GSCONV将是一个明智的选择。















 4177
4177











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









